Neural Correlates of Dynamic Predictions and Prediction Errors in Response to Unexpected Silence and Sound
Fabian Aurich, Andreas Widmann, Tjerk T. Dercksen, Betina Korka, Anni Richter, Max‐Philipp Stenner, Nicole Wetzel

TL;DR
The study shows how the brain handles unexpected sounds and silences, revealing flexible predictions and error responses in dynamic environments.
Contribution
The research demonstrates that predictions of silence are represented categorically rather than at the sensory level.
Findings
Unexpected sounds and omissions trigger distinct brain responses like MMN and P3 complexes.
Predictions of silence lack explicit sensory representation at lower levels but emerge at higher stages.
Dynamic predictions are activated trial-by-trial in response to sound and silence mismatches.
Abstract
To interact efficiently with our environment, our brain predicts the sensory effects of our actions and compares them with the actual outcomes. This allows us to adapt our actions when predictions and sensory outcomes mismatch. While this process is generally well understood for action‐sound predictions, it is an open question whether these predictions can flexibly switch in frequently changing environments, as they occur in real life. To investigate the flexibility of top‐down predictions, we asked participants (N = 41) to press one of two buttons, a left‐hand and a right‐hand button, and switch hands autonomously. One button frequently produced a sound (80%) and rarely no sound. The other button frequently generated no sound (80%) and rarely produced a sound. In a third, separate condition, each button produced a sound in 50% of the trials. Unexpected sounds and unexpected sound…
Genes, proteins, chemicals, diseases, species, mutations and cell lines named across the full text — each resolved to its canonical identifier and authoritative record.
Click any figure to enlarge with its caption.
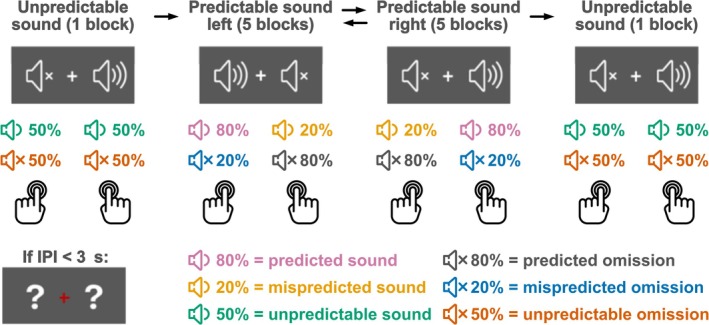 FIGURE 1
FIGURE 1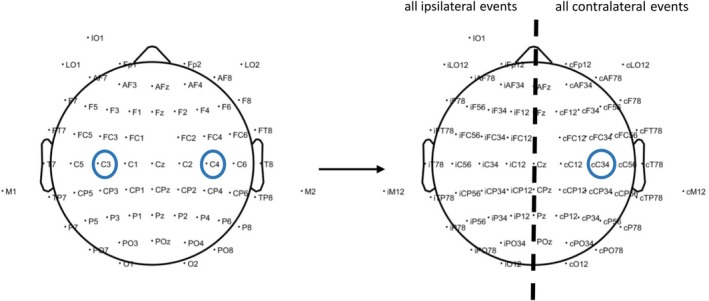 FIGURE 2
FIGURE 2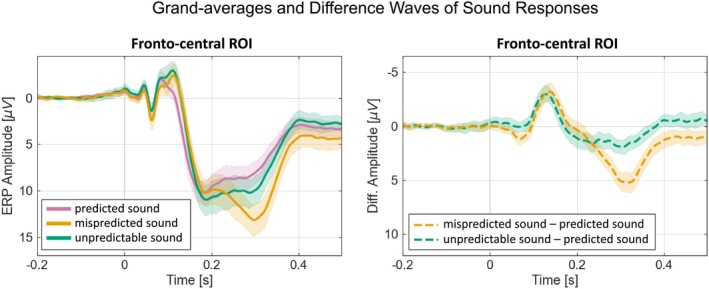 FIGURE 3
FIGURE 3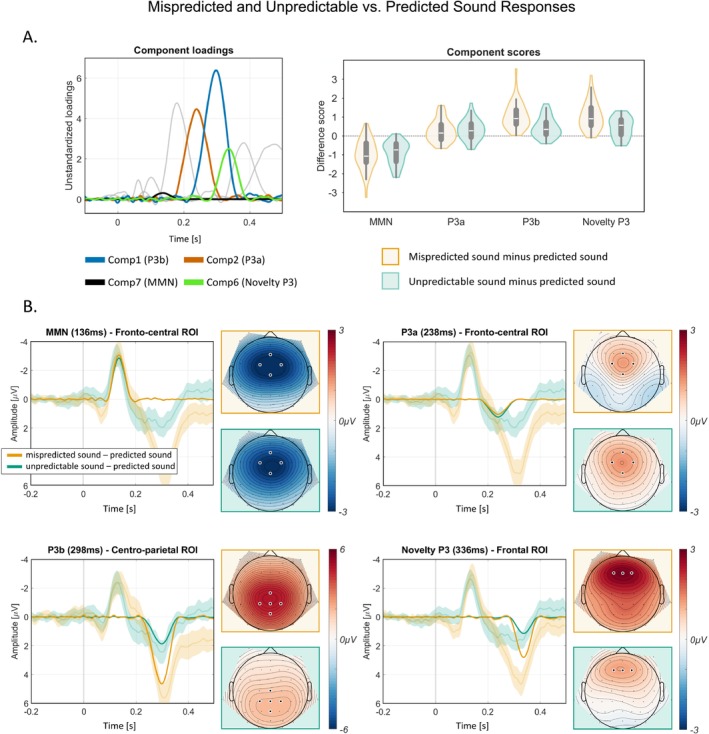 FIGURE 4
FIGURE 4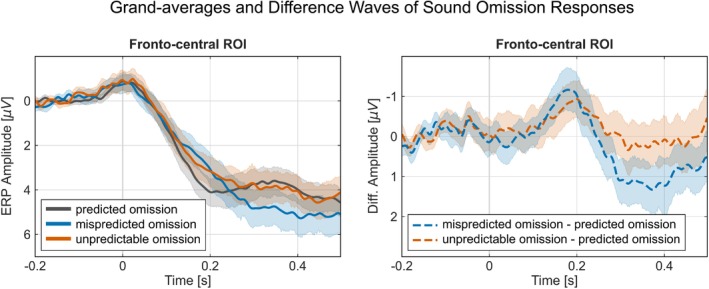 FIGURE 5
FIGURE 5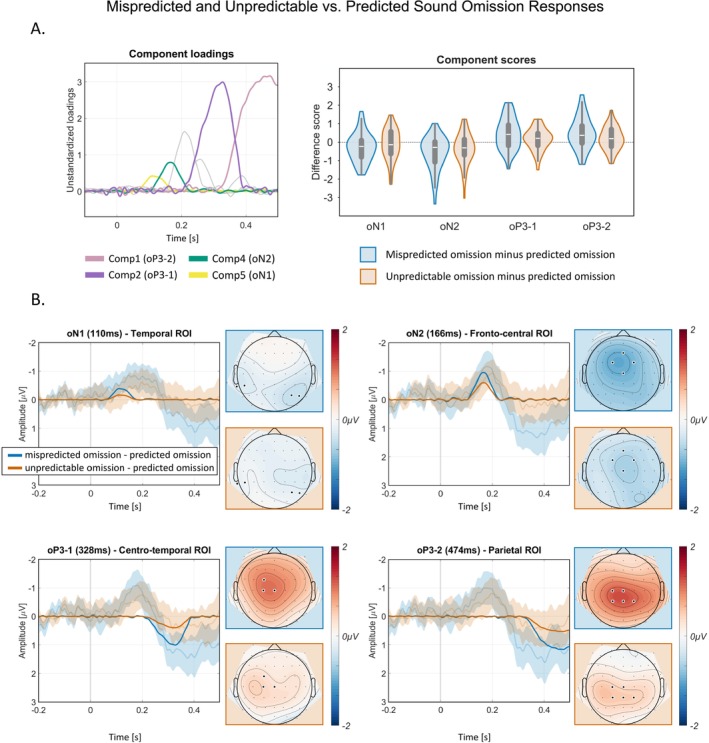 FIGURE 6
FIGURE 6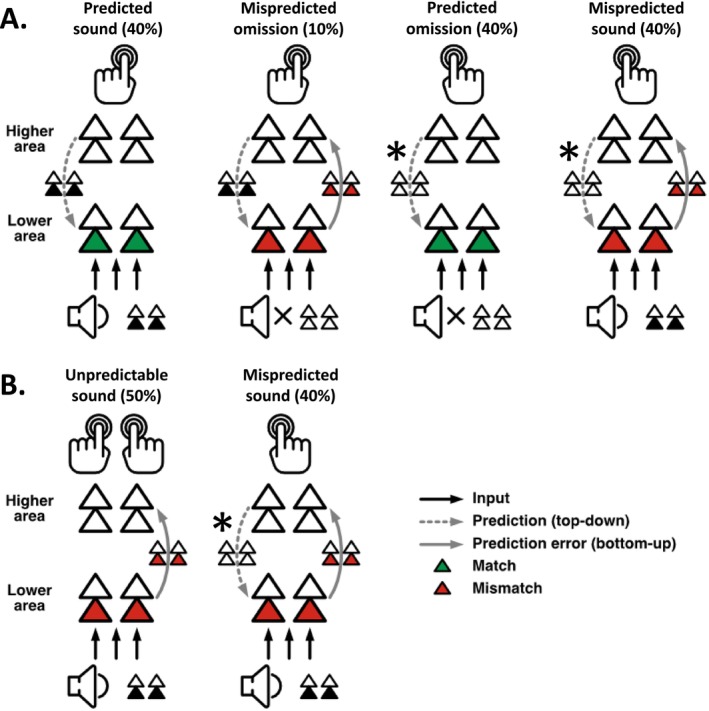 FIGURE 7
FIGURE 7| Contrast | Condition | Median | M | SD | Range |
|---|---|---|---|---|---|
| BPR | PSL | 1.022 | 1.048 | 0.185 | 0.681–1.801 |
| PSR | 0.996 | 0.992 | 0.164 | 0.673–1.363 | |
| US | 0.978 | 0.965 | 0.132 | 0.676–1.284 | |
| IPI (ms) | PSL | 3828 | 3862 | 284 | 3422–4622 |
| PSR | 3816 | 3888 | 312 | 3430–4624 | |
| US | 3848 | 3935 | 356 | 3365–4805 |
| Component (peak latency) | Contrast |
|
| Cohen's | BF10 |
|---|---|---|---|---|---|
| MMN (136 ms) | Mispredicted vs. predicted | −7.885 | < 0.001 | −1.231 | 1.010 × 107 |
| Unpredictable vs. predicted | −9.506 | < 0.001 | −1.485 | 1.111 × 109 | |
| Mispredicted vs. unpredictable | −0.707 | 0.484 | 0.110 | 0.213 | |
| P3a (238 ms) | Mispredicted vs. predicted | 2.978 | 0.010 | 0.465 | 7.454 |
| Unpredictable vs. predicted | 3.756 | < 0.001 | 0.587 | 51.652 | |
| Mispredicted vs. unpredictable | −0.639 | 0.526 | −0.100 | 0.204 | |
| P3b (298 ms) | Mispredicted vs. predicted | 10.024 | < 0.001 | 1.565 | 4.708 × 109 |
| Unpredictable vs. predicted | 5.297 | < 0.001 | 0.827 | 4121.168 | |
| Mispredicted vs. unpredictable | 6.070 | < 0.001 | 0.948 | 42268.951 | |
| Novelty P3 (336 ms) | Mispredicted vs. predicted | 9.126 | < 0.001 | 1.425 | 3.776 × 108 |
| Unpredictable vs. predicted | 5.027 | < 0.001 | 0.785 | 1853.471 | |
| Mispredicted vs. unpredictable | 5.548 | < 0.001 | 0.866 | 8729.815 |
| Component (peak latency) | Contrast |
|
| Cohen's | BF10 |
|---|---|---|---|---|---|
| oN1(110 ms) | Mispredicted vs. predicted | −2.335 | 0.075 | −0.365 | 1.888 |
| Unpredictable vs. predicted | −0.921 | 0.518 | −0.144 | 0.251 | |
| Mispredicted vs. unpredictable | −1.144 | 0.518 | −0.179 | 0.310 | |
| oN2 (166 ms) | Mispredicted vs. predicted | −4.134 | < 0.001 | −0.646 | 143.624 |
| Unpredictable vs. predicted | −2.765 | 0.009 | −0.432 | 4.610 | |
| Mispredicted vs. unpredictable | −1.254 | 0.217 | −0.196 | 0.349 | |
| oP3‐1 (328 ms) | Mispredicted vs. predicted | 3.475 | 0.003 | 0.543 | 24.985 |
| Unpredictable vs. predicted | 1.631 | 0.111 | 0.255 | 0.569 | |
| Mispredicted vs. unpredictable | 2.276 | 0.056 | 0.355 | 1.684 | |
| oP3‐2 (474 ms) | Mispredicted vs. predicted | 3.484 | 0.003 | 0.544 | 25.515 |
| Unpredictable vs. predicted | 1.940 | 0.106 | 0.303 | 0.922 | |
| Mispredicted vs. unpredictable | 1.990 | 0.106 | 0.311 | 1.003 |
- —Volkswagen Foundation
- —Deutsche Forschungsgemeinschaft10.13039/501100001659
- —Center for Behavioral Brain Sciences10.13039/100016839
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsNeuroscience and Music Perception · Free Will and Agency · Neural dynamics and brain function
Introduction
1
Our actions often lead to expectable sensory outcomes, which can help guide our behavior. Imagine typing a message on your smartphone. Each keystroke triggers an expected subtle “click” sound, giving you feedback that the input has been successful. In case of missing feedback, we are surprised and double check (e.g., Baragona et al. 2025). Contrary, when you silence your phone by putting it in “mute” mode, you expect silence (the absence of auditory feedback) after a keystroke and may be surprised otherwise. Each individual action results in a specific action effect. Consequently, expectations of action effects must be flexible, depending on action and context. This study examines the generation of flexible action‐based auditory predictions and the brain mechanisms involved. To this end, we violated auditory predictions in two ways: by presenting a sound when no sound was expected and by omitting an expected sound. We compared the elicited brain responses to physically identical events when they were expected versus unexpected. Furthermore, we examined the brain responses to the same events when no clear prediction can be formed, such as when typing on a new, unfamiliar phone.
Predictive coding suggests that higher and lower cortical levels of the brain communicate in a continuous loop to predict future events of our surroundings. In this loop, sensory predictions generated in predictive models at higher cortical levels are sent down to lower levels (Clark 2013; Feldman and Friston 2010). At lower levels, sensory inputs received from the environment are compared with the top‐down sensory predictions from the predictive model (Arnal and Giraud 2012; Clark 2013; Friston 2010). When mismatches occur, prediction errors are generated. These error signals can be sent back to the predictive model at higher levels to serve as feedback to refine sensory predictions and minimize future prediction errors (Feldman and Friston 2010).
An important source of predictions are our own actions, given that much of the sensory input we receive is self‐generated and therefore predictable. For example, typing on your phone generates a predictable sound. By comparing predicted and actual sensory input, you can verify whether the motor action fulfilled the intention to produce the correct input on your phone. Prediction is therefore central to theories of motor control. This includes ideomotor theory, which suggests that actions are guided by the expected sensory effects they aim to produce (Greenwald 1970; Hommel 2007, 2013). Initially, through repeated associations of motor actions with subsequent sensory inputs, a strong link between action and sensory effect develops. This is known as ideomotor learning, a prerequisite for motor control mechanisms to work. Once these action‐effect associations are established, we choose and evaluate our actions based on their desired effects and intention (Elsner and Hommel 2001). The Theory of Event Coding (TEC) extends this by proposing that actions and their sensory effects are neurally encoded as integrated representations, or event files, which are retrieved based on the agent's current goals (Hommel 2019; Hommel et al. 2001). In other words, a specific motor action and its associated sensory effect are bound together to form one event file, while a different action and its effect form another. The agent's intention to produce a desired sensory outcome then determines which event file is retrieved. This retrieval process serves both to select the appropriate motor action and to set a top‐down prediction of its sensory consequence.
Building on ideomotor theory, the extended Auditory Event Representation System (eAERS) described by Korka et al. (2022) integrates sensory and ideomotor information into a unified sensory predictive model at lower cortical levels to explain how the brain processes and predicts auditory stimuli. This predictive model combines information from bottom‐up sensory regularities with top‐down ideomotor expectations to form predictions about future auditory input. New incoming auditory input is then compared with these predictions and any mismatches elicit prediction error signals. These signals, along with auditory and relevant nonauditory information, are integrated to form auditory event representations and are propagated to predictive models in higher‐level cognitive systems for further evaluation to guide attention allocation and refine motor behavior. Unlike the general predictive coding theory, the eAERS specifically details how top‐down ideomotor expectations from the motor system are combined with bottom‐up auditory regularities to form prediction models that are unique to the auditory domain.
Previous research has demonstrated that humans can concurrently learn and maintain several different action‐effect associations within an experimental context. For instance, pianists continuously predict the auditory consequences of multiple finger movements across different keys, demonstrating the ability to integrate and select among multiple coexisting sensorimotor mappings (Drost et al. 2005; Huang et al. 2024). Other paradigms have similarly shown that participants can acquire and retrieve multiple learned contingencies, each linking a specific action to a particular sensory outcome (Dercksen et al. 2024; Dutzi and Hommel 2009; Harrison et al. 2023; Korka et al. 2020; J.‐Y. Lee and Schweighofer 2009; SanMiguel, Widmann, et al. 2013; Straube et al. 2017). Such findings suggest that predictive models can coexist and be switched depending on the currently intended action and contextual cues. However, these studies primarily focused on comparing action‐effect mappings between blocks of trials. These paradigms therefore fail to capture the flexible switching between predictions on a trial‐by‐trial level, which is more closely related to the dynamics of real‐world scenarios. Evidence of neural correlates that explicitly demonstrate this flexible switching between different prediction models on a trial‐by‐trial basis and throughout the auditory processing hierarchy is still missing. To address this, the present event‐related potential (ERP) study compares multiple concurrent action‐effect mappings within blocks of trials (on a trial‐by‐trial basis). We therefore employed a bimanual button press paradigm to establish multiple action‐effect contingencies simultaneously. For instance, Korka et al. (2019) examined action‐intention violations using left and right button presses to generate high and low frequency standard tones, with occasional unexpected deviant tones. They found that early auditory ERPs, such as the MMN and the P3a component, were elicited when participants' top‐down expectations, based on their intended actions, were contradicted (see also Widmann and Schröger 2022). The MMN, an early preattentive response to deviations from an established auditory pattern (Näätänen et al. 2007), is discussed to represent the mismatch between the predictive model and sensory representations (Garrido et al. 2009) in action‐based (Korka et al. 2019; Widmann and Schröger 2022) but also regularity‐based paradigms in auditory (Näätänen 1990; Näätänen et al. 2007), visual (Pazo‐Alvarez et al. 2003) and somatosensory (Näätänen 2009) domains. The MMN is often followed by a P3a component. The P3a component indicates an involuntary attention shift toward the deviant stimulus (Escera et al. 1998; Waszak and Herwig 2007), depending on its relevance to the listener's current goal (István Winkler and Schröger 2015). It has been shown that the P3a, like the MMN, is also sensitive to violations of action‐based predictions (Korka et al. 2019; Nittono 2006; Widmann and Schröger 2022). This component is thus considered the next stage in auditory distraction processing (Horváth et al. 2008). It is part of a broader P300 complex, including P3b and the Novelty P3 subcomponents (Barry and Rushby 2006; Barry et al. 2020) that presumably reflect higher cognitive evaluation tasks in auditory processing (Polich 2007) along the eAERS hierarchy (Korka et al. 2022). This makes the P300 complex, alongside the MMN, suitable for the current study to investigate the flexibility of intention‐based top‐down prediction control spanning from early sensory to higher cognitive levels along the auditory processing hierarchy.
However, a challenge in investigating auditory prediction error‐related mechanisms is the clear differentiation between bottom‐up and top‐down effects on the generation of prediction errors: “The informational content of the prediction error is in fact composed of two parts: that part of the sensory input that is encountered but was not predicted [bottom‐up], and that part of the sensory input that was predicted but is in fact absent [top‐down]” (Schröger et al. 2015, 647). Thus, the present study aims to separate the two types of prediction violation typically occurring concurrently: (a) a stimulus, which is not expected but presented (i.e., mispredicted sound) and (b) another stimulus, which is expected but not presented (i.e., mispredicted sound omission). The latter type of violation (b) hereby minimizes the influence of bottom‐up signals on the measured indicators of the prediction errors. Thus, the measured neural response in this case reflects the mismatch between the top‐down prediction of an auditory action effect and the unexpected absence of auditory input. It has been discussed that the brain's mismatch response in the time range of the N1 component represents this prediction error (“omission N1”—oN1), as there is no interfering sound information to overlay the prediction error signal (SanMiguel, Widmann, et al. 2013; Wacongne et al. 2011). Moreover, an increasing number of auditory omission studies investigated these prediction errors in humans and reported a sequence of brain omission responses consisting of oN1, oN2, and oP3 (Dercksen et al. 2020; SanMiguel, Saupe, and Schröger 2013; SanMiguel, Widmann, et al. 2013; van Laarhoven et al. 2017).
In sum, this study investigates whether and how flexible action‐based auditory predictions are generated on a trial‐by‐trial basis. Action‐based predictions were violated by the presentation of an unexpected sound or the unexpected omission of a sound. We asked participants to press one of two buttons with their left or right hand and change the hand from trial to trial. One button frequently produced a sound and rarely omitted the sound. The other button frequently generated no sound and rarely produced a sound. If flexible top‐down predictions are successfully switched on a trial‐by‐trial basis (based on changing between the left‐ and right‐hand button presses), the violation of predictions is expected to evoke MMN and P3 components when an unexpected sound is presented, and oN1, oN2, and oP3 components when a sound is unexpectedly omitted. Moreover, in a third condition, sounds were presented with a probability of 50% for each hand, so that participants could not form a reliable prediction whether or not a sound would be generated (SanMiguel, Widmann, et al. 2013; Tast et al. 2024).
Materials and Methods
2
Participants
2.1
A power analysis using G*Power (Faul et al. 2009) determined that a minimum of 34 participants was required for analysis to achieve a power of 0.8 for the planned paired‐samples t tests (Cohen's d = 0.5, α = 0.05) and 28 participants for the repeated measures ANOVA (f = 0.25, α = 0.05). To ensure a robust power across analyses, we aimed for a larger sample size. Therefore, 41 participants (31 female, 10 male) with a mean age of 25.3 years (range: 18–40, SD = 4.6) took part. Handedness, assessed via an adapted German Oldfield Scale (Oldfield 1971), identified 40 right‐handed participants and 1 left‐handed participant. Recruitment involved posters and social media. Exclusion criteria were an age outside 18–40, impaired hearing or diagnosed neurological or psychiatric disorders stated by participants. All participants signed written informed consent before the experiment. Ethical approval from the Ethics Committee of the Medical Faculty of the Otto‐von‐Guericke University Magdeburg was obtained via an amendment to the Project 189/18. Participants received either monetary compensation or course credits.
Stimulus and Apparatus
2.2
Participants were seated on a chair at a table in a dimly lit booth that provided both acoustic and electromagnetic shielding.
The experiment was created using Psychtoolbox (Brainard 1997) and ran on a Linux‐based system with GNU Octave (Version 4.0.0.). Participants responded via custom‐built infrared photoelectric buttons, one for each index finger. The buttons were covered with sound‐absorbing soft foam to minimize any button press related noise, as used in previous auditory omission studies (Dercksen et al. 2020; Korka et al. 2020). The buttons were linked to the stimulus computer via an RTbox (Li et al. 2010).
Visual stimuli were presented on a VIEWPixx/EEG Display (Resolution 1920(H) × 1080(V) – 23.6 in. display size), approximately 60 cm away from the participants. The stimuli included a white fixation cross (0.67° × 0.67° visual angle) displayed at the center of a grey background (RGB: 128, 128, 128) and additional versions of a speaker symbol (2.38° × 2.38° visual angle) or question mark (1.52° × 1.39° visual angle) symbols symmetrically placed on both sides of the cross (Figure 1). Binaural auditory stimuli were delivered simultaneously via two loudspeakers (Bose Companion 2 series III Multimedia speaker system) located on the left and right sides of the screen. The stimuli comprised a 100 ms, 1000 Hz low‐pass filtered (fourth‐order Butterworth filter; SanMiguel, Widmann, et al. 2013), click sound with a sound pressure level of 72 dB. The loudness was held constant for all participants.
Schematic description of the experimental design. A total of 12 blocks were conducted successively. The initial block was always an unpredictable sound block, followed by five predictable sound left blocks, five predictable sound right blocks and a concluding unpredictable sound block. The order of the predictable sound right and predictable sound left blocks was counterbalanced across participants. In the predictable sound left blocks, the predicted sound was presented on the left side in 80% of the button presses, whereas the mispredicted sound was presented on the right side in 20% of the button presses. The opposite was the case during the predictable sound right blocks.
Task and Procedure
2.3
Participants carried out self‐paced button presses with their left‐ and right‐index fingers. Each finger had a separate button. For any given press, participants decided for themselves which button to press. However, we asked participants to press each of the two buttons approximately equally often within any given block (of 90 presses each), and to refrain from any deliberate, fixed patterns in their choice (e.g., alternating between buttons, or higher‐level patterns).
Participants had to wait for at least 3 s between consecutive button presses (interpress interval [IPI]). If they pressed earlier than 3 s after the preceding press, the fixation cross turned red for 500 ms. After each block, we informed participants about the number of button presses that had been too early and the average IPI for that block.
Pressing a button generated an immediate click sound with a certain probability, which could differ between the two buttons depending on the block type. There were three block types. In predictable sound left blocks, pressing the left button generated a sound in 80% and no sound in 20%, while pressing the right button generated a sound in 20% and no sound in 80% of cases (Figure 1). In predictable sound right blocks, the right button generated a sound in 80% and no sound in 20%, while the left button generated a sound in 20% and no sound in 80% of cases. In unpredictable sound blocks, each button generated a sound in 50% and no sound in 50% of cases.
Across the three block types, this design yielded six event types. When a participant pressed a button that was associated with an 80% sound probability and actually generated a sound, this event defined a predicted sound trial. Generating no sound after pressing a button that was associated with an 80% sound probability defined a mispredicted omission trial. When a participant pressed a button that was associated with a 20% sound probability and generated no sound, that event defined a predicted omission trial, while generating a sound in response to that button press defined a mispredicted sound trial. Finally, generating a sound, or no sound, in unpredictable sound blocks defined unpredictable sound trials and unpredictable omission trials, respectively.
Throughout the predictable sound left and predictable sound right blocks, participants saw a speaker symbol on one side of the fixation cross and a muted speaker symbol on the other side, illustrating the probability of sound presentation for each button. This reinforced the unbalanced probability distribution of a predicted (higher probability of presentation) and a mispredicted (lower probability of presentation) sound following a button press. In the unpredictable sound blocks, two question marks were positioned on either side of the fixation cross (Figure 1). The experiment consisted of 12 blocks. All participants first completed an initial unpredictable sound block, followed by five consecutive blocks each for the predictable sound left and predictable sound right conditions, and a final unpredictable sound block. The unpredictable sound blocks were split in order to balance effects of attentional state, practice, and fatigue as much as possible (as done similarly for control conditions in preceding studies; e.g., Baragona et al. 2025; Dercksen et al. 2020; SanMiguel, Saupe, and Schröger 2013; SanMiguel, Widmann, et al. 2013). The order of the predictable sound left and predictable sound right conditions was counterbalanced across participants. Before the main experiment, all participants completed one training block of each block type, to get attuned to the task and the pace of button presses. Training started with a predictable sound left followed by a predictable sound right block and ended with an unpredictable sound block. Training blocks were shorter than experimental blocks and consisted of 30 trials each. Participants received feedback about the number of button presses that had been too early and the average IPI after each training block.
We defined each button press as a trial. Each block ideally consisted of 90 trials, resulting in a total of 1080 trials. For each block, the presentation of a sound after a given button press was pseudo‐randomized. The predictable sound left and predictable sound right blocks were designed to include 450 trials each, ideally comprising 360 predicted trials (180 sound and 180 omission trials) and 90 unpredicted trials (45 sound and 45 omission trials). In the unpredictable sound block, participants completed 180 trials, with a target distribution of 90 unpredictable sound and 90 omission trials. The first five trials of every predictable sound left/predictable sound right block were always predicted events. Following each mispredicted event in the predictable sound left/predictable sound right block, two consecutive predicted events followed. Although these numbers reflect the ideal event distributions, actual trial counts were likely to vary across participants due to differences in button press behavior, such as unequal left and right button press patterns. To minimize these deviations and maintain the target ratios, the stimulus presentation (sound or sound omission) was dynamically adjusted based on the monitored history of participants' button presses. This trial‐adaptive approach ensured that the target ratios were approximated.
EEG Recording
2.4
We recorded from 63 active electrodes placed according to the extended International 10–20 system. The active electrodes were placed at Fp1/Fp2, AFz, AF3/4, AF7/8, Fz, F1/2, F3/4, F5/6, F7/8, FC1/2, FC3/4, FC5/6, FT7/8, Cz, C1/2, C3/4, C5/6, T7/8, CPz, CP1/2, CP3/4, CP5/6, TP7/8, Pz, P1/2, P3/4, P5/6, P7/8, POz, PO3/4, PO7/8, O1/2 and at the left and right mastoids (M1/M2). Electrooculography (EOG) electrodes were positioned at the lateral canthi of both eyes and below the left eye. A reference electrode was placed at the tip of the nose. We recorded via an Actichamp amplifier (BrainProducts, Gilching, Germany) at a sampling frequency of 500 Hz using the Vision Recorder software (Version 1.21).
Data Analysis
2.5
EEG data preprocessing and analysis were performed using the MATLAB software (Version R2022b) and the EEGLAB toolbox (Delorme and Makeig 2004). Two datasets were prepared. For the analysis dataset, the raw EEG data were filtered using a 0.1 Hz high‐pass filter (Kaiser windowed sinc FIR filter, order = 8024, beta = 5, transition bandwidth = 0.2 Hz) and a 48 Hz low‐pass filter (Kaiser windowed sinc FIR filter, order = 402, beta = 5, transition bandwidth = 4 Hz). The data were then divided into epochs, with each epoch covering a period from 200 ms before the button press to 500 ms after. Trials were excluded if the IPI fell below 3000 ms or above 8000 ms. Channels with a robust z‐score of the robust standard deviation of their amplitudes over time larger than three were removed (Bigdely‐Shamlo et al. 2015). Epochs that exceeded a 500 μV signal change threshold were discarded. A second dataset was derived from the raw data to facilitate detection of artefacts associated with heart‐ and eye‐related activity using independent component analysis (ICA; Makeig et al. 1995). This dataset was identical to the analysis dataset (the same trials and channels were removed), with the difference that the raw data were high‐pass filtered at 1 Hz in order to improve ICA decomposition (Klug and Gramann 2021; Irene Winkler et al. 2015), using a Kaiser windowed sinc FIR filter (order = 1604, beta = 5, transition bandwidth = 1 Hz), followed by a low‐pass filter at 48 Hz using a Kaiser windowed sinc FIR filter (order = 402, beta = 5, transition bandwidth = 4 Hz). After ICA was performed on this dataset, the obtained demixing matrix was applied to the 0.1–48 Hz filtered data, which was then used for further analysis.
Independent components were classified with the support of the IClabel plugin (Pion‐Tonachini et al. 2019). Two independent evaluators (F.A. and T.D.) visually inspected the components for heart‐ and eye‐related artefacts and discussed the components that each evaluator had identified as artefacts to reach a consensus. These components were then removed from the dataset. Subsequently, channels that had been identified as bad channels and removed, were interpolated. Trials exceeding a 125 μV signal change threshold were excluded. Epochs were baseline corrected by subtracting the mean amplitude within the time interval between 200 ms and 100 ms prior to stimulus onset (to exclude motor execution potentials, as done similarly in previous studies, e.g., Dercksen et al. 2020, 2024). To account for potential contamination by motor‐related potentials, we used difference waveforms for statistical analysis (comparable to subtracting a so‐called “motor‐control” or “motor‐only” condition in preceding studies; e.g., Baragona et al. 2025; Dercksen et al. 2020; SanMiguel, Widmann, et al. 2013). Because the motor preparation and execution were identical across the compared event types (e.g., predicted vs. mispredicted), the subtraction of ERPs associated with identical motor actions isolates prediction‐related components from overlapping motor‐related activity. The initial five trials of each block, and the two trials following a mispredicted event, which were always predicted events, were excluded (Dercksen et al. 2020, 2024).
Lastly, we averaged data across trials to obtain an ERP for every participant and condition. Because of the bimanual design of the experiment, contralateral and ipsilateral events were recorded on electrodes of both hemispheres. For analysis, all contralateral data were merged onto the corresponding electrodes of the right hemisphere, and all ipsilateral data onto the corresponding electrodes of the left hemisphere, as illustrated in Figure 2.
Redefinition of channels as ipsilateral or contralateral to movement. When collapsing across trials, channels contralateral to movement were distributed across both hemispheres because participants moved the left‐ and right‐index fingers in different trials. To disentangle contralateral from ipsilateral signals, we defined contralateral channels (denoted with a small c, e.g., cC34) by collapsing data from left‐hemisphere channels during right‐hand movements (e.g., C3), and from right‐hemisphere channels during left‐hand movements (e.g., C4). Throughout the manuscript, contralateral channels are shown over the right hemisphere, and ipsilateral channels over the left hemisphere (denoted with a small i, e.g., iC34).
Behavioral Data
2.5.1
Participants were instructed to press the left and right buttons approximately equally often during all block types (predictable sound left, predictable sound right, unpredictable sound) to ensure a consistent probability distribution of sound presentation for both hands. This way, auditory adaptation, occurring in response to repeated sound, should remain constant throughout the experiment (i.e., 50% sound probability across trials in all conditions). To verify that the frequency of sound presentation was indeed balanced across block types, we calculated the ratio of left to right button presses for each block type. Furthermore, we compared median IPIs between block types after removing button presses with an IPI less than 3000 ms or greater than 8000 ms.
PCA
2.5.2
Temporal principal component analysis (PCA) was performed to investigate sound‐ and omission‐related ERPs, by decomposing them into individual components that collectively contribute to shaping the resulting ERP waveforms (Scharf et al. 2022). The number of components to be retained was determined using the Empirical Kaiser Criterion (Braeken and van Assen 2017; Scharf et al. 2022). A Geomin rotation (ε = 0.01), implemented in R (Version 4.1.2; R Core Team 2021), was applied to the initial PCA solution as described in the tutorial of Scharf et al. (2022).
Two separate PCAs were conducted in order to consider a potential different structure of components evoked by sound and omission trials (Dercksen et al. 2020). The sound PCA focused on the analysis of auditory stimulus responses and included per participant averaged ERPs for predicted sounds, mispredicted sounds, and unpredictable sounds. A second omission PCA focused on the omitted auditory stimulus responses and included per participant averaged ERPs for predicted omissions, mispredicted omissions, and unpredictable omissions.
We selected channels for statistical analysis by visual inspection of the topography of PCA components of interest. Regarding the sound components, the following channels of interest were selected: fronto‐central channels (Cz, Fz, iFC1/2, cFC1/2) for MMN and P3a, centro‐parietal channels (Cz, CPz, Pz, iCP1/2, cCP1/2) for P3b, and frontal channels (Fz, F1/2i, F1/2c) for Novelty P3. For the omission components, we selected temporo‐parietal channels (cP3/4, cP5/6, iTP7/8, iCP5/6) for oN1, fronto‐central channels for oN2 (Cz, Fz, iFC1/2, cFC1/2), central channels for oP3‐1 (Cz, iC1/2, iFC1/2), and centro‐parietal channels (Cz, CPz, iC1/2, iCP1/2, cCP1/2) for oP3‐2. From here on, the selected groups of channels will be referred to as regions of interest (ROI).
Statistical Analysis
2.6
Statistics combined Bayesian and frequentist tests of behavioral data and the PCA‐derived component scores. JASP was used for all statistical analyses (JASP Team ). Frequentist and Bayesian repeated‐measures ANOVAs compared the ratio of left to right button presses and the median IPI between block types (predictable sound left, predictable sound right, unpredictable sound). In cases where Mauchly's test indicated that the data violated the assumption of sphericity, degrees of freedom were adjusted using the Huynh‐Feldt estimates of sphericity.
Mean component scores were computed within channels of interest for each sound and sound omission component. Bayesian and frequentist two‐sided paired‐samples t tests then compared mean component scores between the predicted (80%), mispredicted (20%) and unpredictable (50%) sound trials (80% vs. 20%, 80% vs. 50%, 20% vs. 50%) for the sound PCA components. Similarly, Bayesian and frequentist two‐sided paired‐samples t tests compared between the predicted (80%), mispredicted (20%), and unpredictable (50%) sound omission trials for the omission PCA component scores. To control the family wise error rate in the multiple comparisons in the sound and sound omission PCA, all frequentist t tests underwent Bonferroni–Holm correction for a family of three (Holm 1979). In Bayesian statistics, the null hypothesis assumed a standardized effect size of δ = 0, while the alternative hypothesis employed a Cauchy prior distribution centered around 0. The scaling factor used was r = 0.707, reflecting the default setting for a “medium” effect size prior scaling in JASP. The standard priors for fixed effects (condition) and random effects (participant variability) were set to r = 0.5 and r = 1 for the Bayesian repeated‐measures ANOVA (Rouder et al. 2017). Bayes factors (BF_10_) were interpreted as per criteria (M. D. Lee and Wagenmakers 2013).
Results
3
Behavioral Results
3.1
Participants successfully pressed the left and right buttons with similar frequency and pace across all block types (Table 1). The ratio of left to right button presses did not differ significantly between block types (BF_10_ = 0.843, F(1.5, 60.0) = 2.983, p = 0.072), nor did the median IPIs (BF_10_ = 0.344, F(1.75, 69.84) = 1.83, p = 0.172).
Sound Responses
3.2
Grand‐average ERPs and difference waves over the fronto‐central ROI (Figure 3) revealed an early negativity of similar amplitude for both mispredicted and unpredictable sounds, followed by a later positivity that differed between these sound events. The early negativity is consistent with the MMN, while the later positivity presumably reflects a P300 complex. The subsequent sound‐related PCA extracted 20 components, explaining 99.8% of the variance. Components were categorized as reflecting MMN, P3a, P3b, and Novelty P3 based on their topographies and latencies (Figure 4). Component scores for mispredicted (20%), unpredictable (50%), and predicted (80%) sound trials were compared to test for prediction‐related differences. Statistical results confirmed equivalent MMN and P3a responses between mispredicted and unpredictable sounds and confirmed significantly more positive responses in later components (P3b, Novelty P3) for mispredicted compared to unpredictable sound events (Table 2).
Grand‐averages of predicted (80%), mispredicted (20%) and unpredictable (50%) sound responses over the fronto‐central ROI (left) and difference waves over the fronto‐central ROI of mispredicted minus predicted sounds (20%–80%), and unpredictable (50%–80%) minus predicted sounds (right). Both panels display a 95% confidence interval in transparent colors. ROI = region of interest.
Sound PCA component loadings and difference scores for components of interest. Difference waves of sound PCA components (MMN, P3a, P3b, Novelty P3) with difference waves of grand average ERPs (including 95% confidence interval) in transparent colors and corresponding difference component topographies. ROI = region of interest. (A) The left panel shows the sound stimulus PCA component loadings for the components of interest (MMN, P3a, P3b, Novelty P3). Non‐relevant component loadings are displayed in grey color. The right panel shows the difference component scores for mispredicted (20%) minus predicted sound (80%) and unpredictable (50%) minus predicted (80%) sound for components MMN, P3a, P3b, and Novelty P3 at fronto‐central (MMN and P3a), centro‐parietal (P3b) and frontal (Novelty P3) ROIs. (B) Difference waves (mispredicted [20%] sound minus predicted [80%] sound, unpredictable [50%] sound minus predicted [80%] sound) of sound PCA components over the regions of interest in opaque colors. Transparent colors represent grand‐average ERP difference waves including a 95% confidence interval. Component topographies on the right of each plot show the difference between mispredicted (20%) sound minus predicted (80%) sound conditions and between unpredictable (50%) minus predicted (80%) sound conditions at the latency shown.
MMN
3.2.1
The MMN is commonly derived from the difference between deviant and standard stimulus responses. Here, standard trials correspond to the predicted sound (80%) trials, and mispredicted (20%) sound trials correspond to deviants. In addition, we tested for the presence of an MMN component in unpredictable (50%) sound trials, relative to predicted (80%) sound trials. As shown in Figure 5, component 7 had a peak latency of 136 ms and a fronto‐central scalp distribution with a negative polarity. The component explained 5.7% of variance. Its topography, polarity, and latency were compatible with an MMN. Compared to the predicted sound trials (i.e., the standard), both mispredicted sound (20%; BF_10_ = 1.010 × 10^7^) and unpredictable sound (50%; BF_10_ = 1.111 × 10^9^) resulted in larger amplitudes of the MMN component (stronger negativity), while mispredicted sound trials did not differ from unpredictable sound trials (BF_10_ = 0.213).
Grand‐averages of predicted (80%), mispredicted (20%), and unpredictable (50%) sound omission responses over the fronto‐central ROI (left) and difference waves over the fronto‐central ROI of mispredicted minus predicted omissions (20%–80%), and unpredictable (50%–80%) minus predicted omissions (right). Both panels display a 95% confidence interval in transparent colors; ROI = region of interest.
P3a
3.2.2
Like the MMN, the P3a component is typically derived from the difference between deviant and standard stimulus responses. We therefore followed a similar approach as for the MMN, and compared predicted (80%) sound trials (i.e., the standard) to mispredicted (20%) and unpredictable (50%) sound trials. As shown in Figure 5, component 2 had a peak latency of 238 ms and a fronto‐central scalp distribution with a positive polarity, resembling typical features of a P3a. The component explained 17.4% of variance. The data provide moderate to strong evidence for more positive amplitudes elicited by both the mispredicted (BF_10_ = 7.454) and the unpredictable sound trials (BF_10_ = 51.652) in comparison to the predicted sound trials. Furthermore, the analysis reveals moderate evidence for the null model, that is, no difference between mispredicted sound trials and unpredictable sound trials (BF_10_ = 0.204).
P3b
3.2.3
Component 1 captured a component with more positive amplitudes in response to mispredicted and unpredictable compared to predicted sounds, presumably reflecting P3b with a centro‐parietal distribution and a peak latency of 298 ms. The component explained 22.2% of variance. The data provide extreme evidence for the alternative model, indicating a more positive amplitude for mispredicted sound trials versus predicted sound trials (BF_10_ = 4.708 × 10^9^), unpredictable sound trials versus predicted sound trials (BF_10_ = 4121.168) and mispredicted sound trials versus unpredictable sound trials (BF_10_ = 42268.951).
Novelty P3
3.2.4
Component 6 captured a component with more positive amplitudes in response to mispredicted and unpredictable compared to predicted sounds, presumably reflecting Novelty P3 with a frontal distribution and had a peak latency of 336 ms. The component explained 7.1% of variance. The data provides extreme evidence for the alternative model, indicating a more positive amplitude for mispredicted sound trials versus predicted sound trials (BF_10_ = 3.776 × 10^8^), unpredictable sound trials versus predicted sound trials (BF_10_ = 1853.471), and mispredicted sound trials versus unpredictable sound trials (BF_10_ = 8729.815).
In sum, mispredicted (20%) and unpredictable (50%) sounds evoked increased amplitudes compared to predicted (80%) sounds reflected by the ERP components MMN, P3a, P3b, and Novelty P3. While there was evidence for similar amplitudes of MMN and P3a in response to mispredicted and unpredictable sounds, amplitudes of P3b and Novelty P3 were increased in response to mispredicted compared to unpredictable sounds.
Sound Omission Responses
3.3
Similar to the sound responses, grand‐mean ERPs and difference waves at fronto‐central channels of interest show an early negativity after sound omission presentation followed by a positivity (Figure 5). The omission PCA extracted a total of 18 components (as determined by EKC), explaining a total of 97.6% of variance. Component loadings and difference scores for the components capturing oN1, oN2, oP3‐1, and oP3‐2 in mispredicted omission trials (20% omission probability) and unpredictable omission trials (50%), each relative to predicted omission trials (80%), were categorized based on their topographies and latencies (Figure 6).
Sound omission PCA component loadings and difference scores for components of interest. Difference waves of sound omission PCA components (oN1, oN2, oP3‐1, oP3‐2) with difference waves of grand average ERPs (including 95% confidence interval) in transparent colors and corresponding difference component topographies. ROI = region of interest. (A) The left panel shows the omission PCA component loadings for the components of interest oN1, oN2, oP3‐1, and oP3‐2. Non‐relevant component loadings are displayed in grey color. The right panel shows the component scores for mispredicted (20%) minus predicted omission (80%) and unpredictable (50%) minus predicted (80%) omission for components oN1, oN2, oP3‐1 and oP3‐2 at temporal (oN1), centro‐frontal (oN2), centro‐temporal (oP3‐1), and parietal (oP3‐2) ROIs. (B) Difference waves (mispredicted [20%] sound omission minus predicted [80%] sound omission, unpredictable [50%] sound omission minus predicted [80%] sound omission) of sound omission PCA components over the regions of interest in opaque colors. Transparent colors represent grand‐average ERP difference waves including a 95% confidence interval. Component topographies on the right of each plot show the difference between mispredicted (20%) minus predicted (80%) sound omission trials, and between unpredictable (50%) minus predicted (80%) sound omission trials, at the latency shown.
Component scores for mispredicted (20%), unpredictable (50%), and predicted (80%) omission trials were compared to test for prediction‐related differences (see Table 3 for statistical results). While we found convincing evidence that some of the omission responses differed between mispredicted omissions and predicted omissions (Table 3), evidence for differences between unpredictable and predicted omissions and between mispredicted and unpredictable omissions was anecdotal or moderate at most, and difficult to interpret for all omission responses. In the following paragraphs, we therefore focus on differences between mispredicted and predicted omissions.
oN1
3.3.1
Component 5, explaining 6.1% of variance, was identified as a candidate of the omission‐related N1 response with a mainly temporo‐occipital scalp distribution, and a peak latency of 110 ms. The data provide only anecdotal evidence for the alternative model, that is, the mispredicted omission trials elicited a more negative amplitude than the predicted omission trials (BF_10_ = 1.888).
oN2
3.3.2
Component 4, explaining 7.9% of variance, has a mainly fronto‐central scalp distribution and a peak latency of 166 ms. The data provide extreme evidence for the alternative model, that is, the mispredicted omission trials elicited a more negative amplitude than the predicted omission trials (BF_10_ = 143.624).
oP3‐1
3.3.3
PCA extracted two oP3 components which we labelled oP3‐1 and oP3‐2. Component 2 (oP3‐1), explaining 22.5% of variance, has a fronto‐central scalp distribution and a peak latency of 328 ms. The data provide strong evidence for the alternative model, that is, the mispredicted omission trials elicited a more negative amplitude than the predicted omission trials (BF_10_ = 24.985).
oP3‐2
3.3.4
Component 1, explaining 30.9% of variance, has a centro‐parietal scalp distribution and a peak latency of 474 ms. The data provide strong evidence for the alternative model, that is, the mispredicted omission trials elicited a more positive amplitude than the predicted omission trials (BF_10_ = 25.515).
In sum, most omission responses (oN2, oP3‐1, oP3‐2) showed increased amplitudes in response to mispredicted (20%) omissions compared to predicted (80%) omissions, except the oN1 component, for which we found only weak evidence for this effect.
Discussion
4
Predictions about the auditory effects of our actions help us determine whether our actions fulfil our intentions. However, it remains unclear whether these predictions can flexibly adapt when action‐effect contingencies change frequently, as they do in real‐world scenarios. We employed a dynamic button‐press paradigm that required participants to simultaneously manage multiple action‐sound contingencies. To clearly disentangle bottom‐up and top‐down effects on brain prediction error signals, we violated action‐based predictions by the presentation of unexpected sounds and unexpected omission of sounds. Both evoked a series of typical error‐related brain responses in the event‐related potential at different levels of auditory processing: MMN and P3 complex (sounds) and oN1, oN2, oP3 complex (omissions). This demonstrates the brain's ability to dynamically select action‐based predictions across the hierarchical structures of the auditory processing system. Moreover, we observed similar sound‐related MMN in the conditions predicting silence and the unpredictable condition while P3 components differed. This unexpected finding will be discussed as a possible inability of the brain to reliably predict silence at the early sensory level.
Flexible Top‐Down Control of Action‐Based Predictions of Sounds and Omissions
4.1
Self‐initiated actions that violated top‐down predictions evoked distinct prediction error‐related components. For mispredicted sounds (where silence was expected but a sound presented), these included MMN, P3a, P3b, and Novelty P3. For mispredicted omissions (where a sound was expected but omitted), components included oN1 (with weak evidence), oN2, oP3‐1, and oP3‐2. These findings add further evidence that self‐initiated actions cause the generation of predictions on sensory action effects (Darriba et al. 2021; Korka et al. 2019; Timm et al. 2014). Importantly, our results show that the generation of top‐down predictions through actions is highly flexible and can be observed even when participants frequently switch between actions on a trial‐by‐trial basis. This flexibility demonstrates that prediction generation mechanisms can dynamically switch between different effector‐specific (i.e., hand‐specific) action‐effect expectations based on the agent's current goals. Moreover, our findings align with the eAERS (Korka et al. 2022), supporting the idea that action‐effect expectations of top‐down prediction models from the motor system are selectively retrieved and transmitted to lower sensory predictive models in auditory processing (Hommel 2019; Hommel et al. 2001). On the sensory level, both sound and omission error responses (MMN, oN1 and oN2) to mispredicted events are evoked in the present study. This suggests that the predictive model dynamically adapts comparative processes between sensory representations and action‐effect expectations to the current task. Thus, we conclude that the retrieval and transmission of predictions from top‐down prediction models from motor systems to sensory predictive models occur flexibly. This flexible interaction between motor and sensory predictive models also aligns with the assumptions of TEC. Event files (action‐effect mappings) can be selectively retrieved and adapted according to the agent's current goals, allowing previously established top‐down sensorimotor bindings to guide sensory prediction generation. Together, these findings corroborate the close and dynamic interplay between the motor system and auditory perception processing. Later components, such as P3b and Novelty P3 for mispredicted sounds, and oP3‐1 and oP3‐2 for mispredicted omissions, are suggested to reflect the evaluation of discrepancies and integration of contextual information (Polich 2007) to form a comprehensive event representation (Korka et al. 2022). It is assumed that this representation is then used by higher‐level processes to adapt attention or motor behavior toward unexpected events (Korka et al. 2022; Ullsperger et al. 2014). As with early error responses, we found that later P3 components are evoked for mispredicted sound and omission events. This indicates a similarly high flexibility with regard to the current agent's task (Mars et al. 2008). These results highlight the flexibility of higher‐level cognitive systems (e.g., attention allocation) in response to violation of predictions.
In sum, our results provide strong evidence supporting the hypothesis that top‐down predictions can be flexibly switched. Moreover, they demonstrate that these top‐down predictions are applied downstream to modality specific areas on a trial‐by‐trial basis. A violation of these predictions evoked error signals in response to unexpected sounds and unexpected omissions on several levels of auditory processing. We suggest that auditory prediction is a highly flexible process within the hierarchically structured eAERS model, involving a close and dynamic interplay between high‐level motor systems and auditory perception.
Predictions of Silence in the Auditory Processing Hierarchy
4.2
We found that the MMN to mispredicted sounds (prediction of silence) was equivalent to the MMN to unpredictable sounds (50% unpredictable sound condition). This finding is surprising because we expected that the mispredicted sounds violated a prediction of silence (80% predicted omission trials), while no prediction could be formed in the unpredictable sound condition. According to the eAERS (Korka et al. 2022), the MMN responses are related to the early low‐level comparison of sensory input to top‐down predictions. This comparison appears straightforward for actual auditory stimuli, such as sounds following a button press. In this case, the sensory input has basic acoustic features (e.g., intensity, frequency) which, together with its acoustic context (e.g., sound patterns), can be the content of top‐down predictions. Resulting prediction errors and subsequent updating of the predictive model cause the observed MMN effects (István Winkler 2007). However, the representation of silence as an anticipated event is less straightforward. There are no actual features of silence a top‐down auditory prediction could anticipate, and it is therefore unclear how the prediction of silence—the absence of features—would be represented neurally (in a network dedicated to the processing of sound features). Furthermore, unlike silence, sound in our study corresponded to a change in sensory input at a discrete point in time. Thus, the comparative processes that involve top‐down predictions of expected silence, in particular as a continuous event without change in sensory input, pose a challenge in predictive coding.
On this notion, the present results reveal evidence for an equally strong activation of this early error detection system to different kinds of sound presentations: in a predictable condition when silence followed a button press in the majority of times (expected silence) and in an unpredictable condition when it was equally likely that a sound or an omission followed a button press (no clear expectation). Figure 7 provides a visualization of how prediction errors manifest under these conditions. In the predictable condition, predictions for sounds or omissions are formed based on the most probable motor action effects, and prediction errors arise when sensory input mismatches these predictions. In contrast, in the unpredictable condition, no reliable sensory‐level predictions can be formed due to the 50% probability of sound or omission. Here, the equivalent MMN‐related responses we observed for mispredicted sounds and unpredictable sounds demonstrate that despite the clear predictability of silence, an equally strong error response is triggered as in the unpredictable condition. Thus, if the prediction error for mispredicted sounds (silence predicted) and unpredictable sounds (i.e., no precise prediction possible) is equivalent, then we can conclude that also the predictions (or lack thereof) are equivalent. We suggest that the implementation of a prediction of silence, that is, the absence of stimulus features at sensory levels, has the same effect as the absence of a prediction. This indicates that encoding silence as a reliable prediction at sensory levels was not possible in our study. Therefore, the error signals observed in this study in response to mispredicted and unpredictable sounds can be interpreted as a prediction error at the sensory level inherent to the exogenous sound response in the absence of a prediction (Schröger et al. 2015). This exogenous prediction error is revealed by subtracting the ERP of a predicted sound that does not elicit a prediction error response.
(A) Prediction error in the predictable condition (based on Schröger et al. 2015, Figure 2, adapted): Depending on the button press a sound (left hand) or no sound (right hand) is expected. The expectation is transferred top‐down as prediction to sensory areas. For the expectation of silence, the asterisk () denotes our finding indicating that a prediction is possible at higher conceptual processing levels, but possibly not at the low sensory level. In case the sensory input mismatches the prediction, the prediction error is transferred bottom‐up to higher areas to update the generative model. The observed prediction error responses for mispredicted sounds and mispredicted omissions in this study demonstrate that predictions can be flexibly applied on a trial‐by‐trial basis. (B) Prediction error for unpredictable vs. mispredicted sounds: In the unpredictable condition, no reliable top‐down prediction can be established at sensory levels. We observed equivalent prediction error responses for unpredictable sounds and mispredicted sounds (in a strict sense, there can be no prediction error without prediction, which is why Schröger et al. 2015 also refer to it as “exogenous response” in the former case). We did not see an additional ERP signature of expectation violation for predicted silence by sounds compared to no prediction by sounds. Our interpretation of this surprising finding is that the representation of the prediction of an expected omission (i.e., silence) at sensory levels is equivalent to the absence of a prediction. As in Panel A, the asterisk () denotes that a prediction is possible at higher conceptual processing levels, but possibly not at the low sensory level. We consider the possible alternative interpretation that omissions (silence) are consistently predicted in the unpredictable condition as implausible because sounds were frequently encountered.
It could be argued that the equal error signals observed could instead reflect prediction violations which are based on similar top‐down predictions. That is, unpredictable sounds would violate a top‐down prediction of silence. Such an interpretation seems implausible. Silence conveys little informational content compared to a sound that possesses distinct features such as intensity, frequency, and onset. In an environment where sound and silence occur equally often and randomly, it is unlikely that an auditory system tuned toward the detection of acoustic onsets and salient auditory cues (e.g., Fitzgerald et al. 2018; Fitzgerald and Todd 2020) derives its predictions from the absence of sensory input rather than from the discrete auditory cues provided by sound stimuli. Moreover, if silence would be predicted on the sensory level, we would expect stronger error responses in the mispredicted (80% silence, 20% sound) than in the unpredictable (50% silence, 50% sound) condition.
In contrast to the early sensory‐level equivalence, later P3 components (P3b, Novelty P3), reflecting conceptual processing, reveal significant differences between the violation of expected silence (80% predicted omission) by sounds and the unpredictable condition (50%). According to the eAERS, responses at this stage represent the evaluation of resulting discrepancies and the integration of additional contextual information outside the auditory environment (i.e., motor action) with the sensory representation to form a comprehensive auditory event representation (Polich 2007). This representation is further fed into a higher‐level event predictive model which contains an abstract representation of the expected auditory event including its nonauditory context for further comparative processes (Korka et al. 2022). The significantly increased amplitudes of P3b and Novelty P3 components to unexpected sounds in the 80% predicted omission condition compared to the unpredictable condition indicate that expected silence is only adequately represented when additional contextual information (i.e., prior motor action or task requirements) has been integrated. This integration at later response stages underscores the hierarchical nature of auditory processing, where silence is represented conceptually only at higher cognitive levels within the eAERS framework.
On a broader level of implication, auditory information, omnipresent and complex, constitutes a fundamental aspect of our environment. The brain's proficiency in processing a diverse array of auditory cues at pre‐attentive stages, reflected by mechanisms such as the MMN (see Fitzgerald and Todd 2020; Kraus and Chandrasekaran 2010; Näätänen et al. 2007 for a comprehensive overview), underlines its fine‐tuned sensitivity to sound perception. Given that the brain is inherently designed to react to stimuli, the absence of stimuli (silence) may therefore not be encoded in the same way as sound. Traditionally, silence as an auditory event is considered to be derived from the absence of sound (Bregman and McAdams 1994; Kubovy and van Valkenburg 2001; István Winkler et al. 2009). However, in a recent study conducted by Goh et al. (2023), silence is described as not just the absence of sound but as a sound‐like entity, understanding silence to be an active element in the auditory environment. In a series of experiments, they showed that silences can substitute for sounds in event‐based auditory illusions. Their findings show that auditory perception handles moments of silence similarly to sounds at a behavioral level. One explanation by the authors, and in line with TEC (Hommel 2019), is that, similar to perceived sound, perceived silence can be understood as an empty event file (Hommel 2004; Hommel et al. 2001). This means that, despite the lack of explicit auditory cues, silence carries nonacoustic sensory information, such as temporal and contextual properties. According to the differences we found in later P3 components, the present results align well with this interpretation of silence as an “empty” auditory event file and the eAERS. It appears that an explicit representation can only be achieved when relevant nonauditory information has been integrated. This leads to the conclusion that a representation of silence is not solely derived from the absence of sound. However, because of the lack of actual auditory information at lower sensory levels, silence can only be perceived as an auditory event when relevant nonauditory information has been integrated at higher auditory processing levels. Together, these findings show that silence, much like sound, plays an active role in our sensory environment and, based on our findings, predictions of silence can be represented at conceptual but not necessarily at sensory levels. In other words, presumably silence can be represented as a concept depending on contextual information but not as explicit sensation in a strict sense.
This interpretation challenges traditional views of silence as merely the absence of sound, supporting its conceptualization as an “empty” event file within the TEC framework. This assumption accounts for the equal error response to mispredicted sounds when silence is expected and unpredictable silence at early response stages on the one hand, as depicted in Figure 4. On the other hand, the significantly different magnitudes at later response stages demonstrate that silence can be identified as a discrete auditory event in higher cognitive stages by the integration of additional contextual information.
Limitations
5
The ERPs in response to sound omissions presented a unique challenge due to the nature of silence as an auditory event. Unlike sound, silence has no actual auditory features and therefore no explicit onset or offset cue. To address this, silence and sound events were coupled to a button press. These button presses acted as onset cues for the sound and the sound omission. However, the IPI of 3 s was significantly longer than typically used in other omission studies (Dercksen et al. 2020; SanMiguel, Widmann, et al. 2013; Widmann and Schröger 2022). Moreover, the IPI consisted of silence only. In our study, this extended silent gap is combined with the inherent limitations of human temporal perception, which is context‐dependent (Ross and Balasubramaniam 2022) and thus possibly not accurate to the millisecond. Together, this likely contributed to a variability in the timing of when exactly participants perceived the (predicted) silence as an action effect within the stream of silence between button presses. This variability in perception may lead to a temporal distribution of oN1 responses. As event‐related potentials (ERPs) are averaged over multiple trials and participants, this distribution likely results in an attenuation or flattening of the oN1 signal, making it less pronounced compared to findings in studies with shorter IPIs.
Conclusion and Outlook
6
Our findings demonstrate the brain's ability to flexibly switch action‐based auditory predictions in dynamic environments, demonstrated by prediction error signals in sound and omission ERPs. Notably, the equivalent MMN responses to mispredicted and unpredictable sounds suggest that silence may not be explicitly represented at early sensory levels, requiring higher‐level contextual integration for processing. These results motivate future studies to explore the role of silence in auditory prediction and its integration into the eAERS model. For instance, how is silence as an action‐based prediction processed in complex auditory environments like speech or music? Such investigations could extend the understanding of sensory‐motor integration and refine predictive coding frameworks. Beyond basic research, our findings have broader implications for real‐world applications. The ability to dynamically adjust predictions is essential for navigating complex auditory environments, such as social interactions or noisy settings. Additionally, these insights may inform clinical research, particularly in disorders like schizophrenia or autism, where atypical responses to auditory prediction errors are common (Haigh et al. 2023; Kaser et al. 2013; M. Lee et al. 2017). Understanding how these populations process silence and unexpected sounds could lead to novel diagnostic or therapeutic approaches. In summary, this study highlights the flexibility of action‐based auditory predictions and raises important questions about the neural representation of silence, paving the way for future research and practical applications.
Author Contributions
Fabian Aurich: conceptualization, data curation, formal analysis, investigation, validation, visualization, writing – original draft, writing – review and editing. Andreas Widmann: conceptualization, methodology, software, visualization, writing – original draft, writing – review and editing. Tjerk T. Dercksen: data curation, formal analysis, software, validation, writing – review and editing. Betina Korka: conceptualization, methodology, writing – review and editing. Anni Richter: conceptualization, writing – review and editing. Max‐Philipp Stenner: conceptualization, funding acquisition, methodology, project administration, resources, supervision, validation, writing – review and editing. Nicole Wetzel: conceptualization, funding acquisition, methodology, project administration, resources, supervision, validation, writing – review and editing.
Funding
This work was supported by the Volkswagen Foundation (project‐ID 92977), the Deutsche Forschungsgemeinschaft (SFB‐1436, TPC03, project‐ID 425899996, WE5026/4‐1), and the Center for Behavioral Brain Sciences (ZS/2016/04/78120).
Conflicts of Interest
The authors declare no conflicts of interest.
Supporting information
Table A1: Descriptive statistics for included trials per trial type. M = mean, SD = standard deviation.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1Arnal, L. H. , and A.‐L. Giraud . 2012. “Cortical Oscillations and Sensory Predictions.” Trends in Cognitive Sciences 16, no. 7: 390–398. 10.1016/j.tics.2012.05.003.22682813 · doi ↗ · pubmed ↗
- 2Baragona, V. , E. Schröger , and A. Widmann . 2025. “Salient, Unexpected Omissions of Sounds Can Involuntarily Distract Attention.” Journal of Cognitive Neuroscience 1–16: 1–16. 10.1162/jocn_a_02307.39918914 · doi ↗ · pubmed ↗
- 3Barry, R. J. , and J. A. Rushby . 2006. “An Orienting Reflex Perspective on Anteriorisation of the P 3 of the Event‐Related Potential.” Experimental Brain Research 173, no. 3: 539–545. 10.1007/s 00221-006-0590-8.16850325 · doi ↗ · pubmed ↗
- 4Barry, R. J. , G. Z. Steiner , F. M. de Blasio , J. S. Fogarty , D. Karamacoska , and B. Mac Donald . 2020. “Components in the P 300: Do Not Forget the Novelty P 3!” Psychophysiology 57, no. 7: e 13371. 10.1111/psyp.13371.30920012 · doi ↗ · pubmed ↗
- 5Bigdely‐Shamlo, N. , T. Mullen , C. Kothe , K.‐M. Su , and K. A. Robbins . 2015. “The PREP Pipeline: Standardized Preprocessing for Large‐Scale EEG Analysis.” Frontiers in Neuroinformatics 9: 16. 10.3389/fninf.2015.00016.26150785 PMC 4471356 · doi ↗ · pubmed ↗
- 6Braeken, J. , and M. A. L. M. van Assen . 2017. “An Empirical Kaiser Criterion.” Psychological Methods 22, no. 3: 450–466. 10.1037/met 0000074.27031883 · doi ↗ · pubmed ↗
- 7Brainard, D. H. 1997. “The Psychophysics Toolbox.” Spatial Vision 10, no. 4: 433–436. 10.1163/156856897 X 00357.9176952 · doi ↗ · pubmed ↗
- 8Bregman, A. S. , and S. Mc Adams . 1994. “Auditory Scene Analysis: The Perceptual Organization of Sound.” Journal of the Acoustical Society of America 95, no. 2: 1177–1178. 10.1121/1.408434. · doi ↗