Machine learning for medication error detection: a scoping review
Félicien Hêche, Sohrab Ferdowsi, Anthony Yazdani, Sara Sansaloni-Pastor, Douglas Teodoro

TL;DR
This review explores how machine learning can detect medication errors, highlighting current methods and gaps in real-world application.
Contribution
The paper provides a comprehensive scoping review of ML approaches for medication error detection, identifying key trends and limitations.
Findings
Most studies focus on prescription errors using structured data and tree-based models.
Fewer studies address medication-administration errors using multimodal data and neural networks.
Real-world evaluation and generalizability of ML methods remain limited.
Abstract
Medication errors remain a substantial public health concern, and existing measures, such as workforce training, have achieved only partial success. Advances in data availability and computational methods have led to increasing use of machine learning (ML) to support medication safety. This scoping review synthesizes and categorizes ML-based approaches to medication error detection or prediction. Following Preferred Reporting Items for Systematic Reviews and Meta-Analyses extension for Scoping Reviews (PRISMA-ScR) guidelines, PubMed, Embase, and Web of Science were searched for studies published between 2015 and April 2025. Two reviewers independently performed study selection using predefined eligibility criteria, and data extraction followed a structured extraction framework. Twenty-two studies met the inclusion criteria. Two dominant ML pipelines were identified. Most studies…
Click any figure to enlarge with its caption.
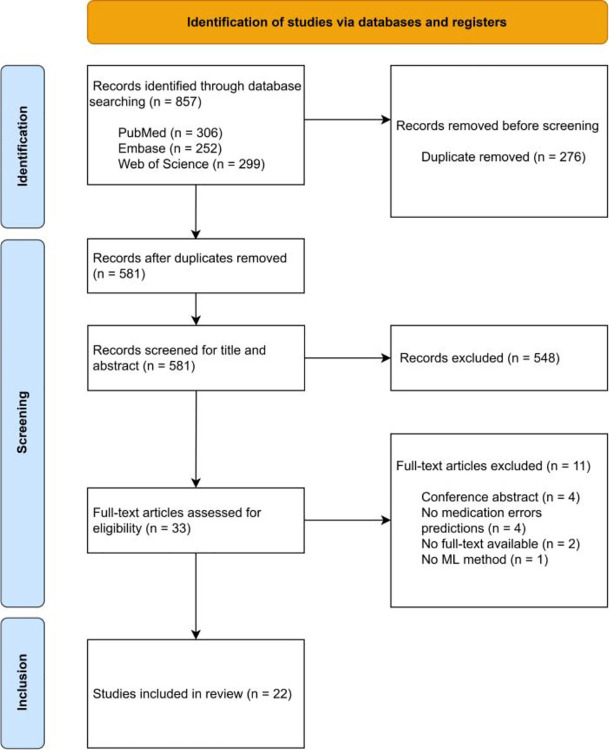 Figure 1
Figure 1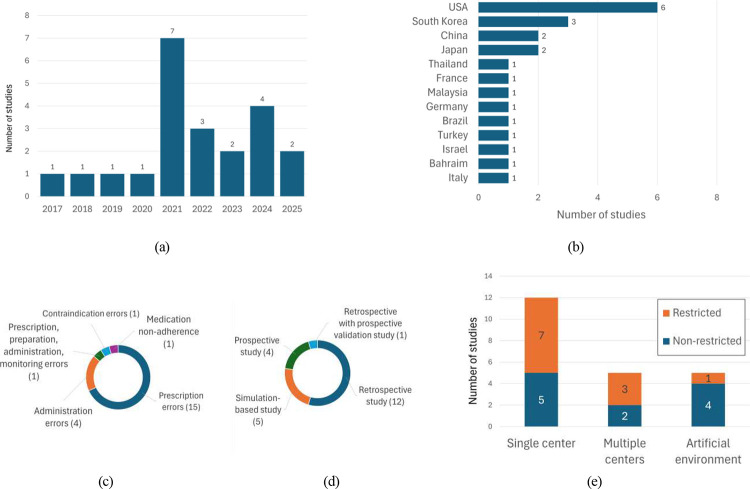 Figure 2
Figure 2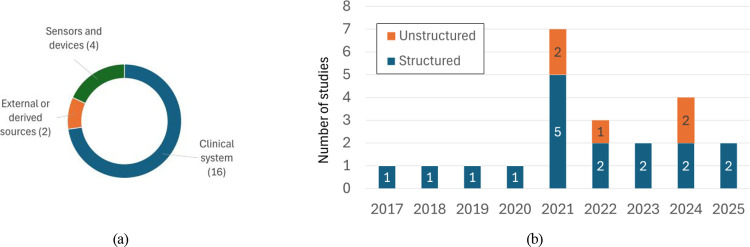 Figure 3
Figure 3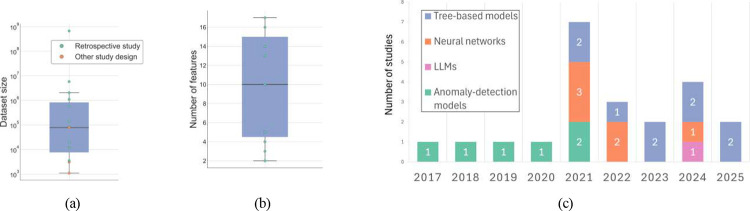 Figure 4
Figure 4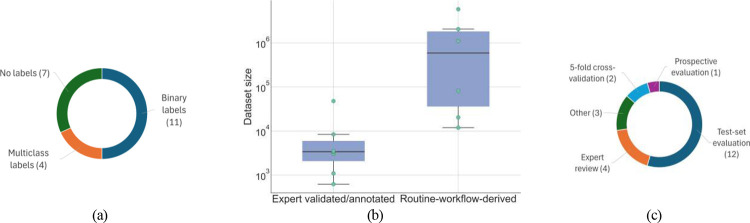 Figure 5
Figure 5Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsElectronic Health Records Systems · Artificial Intelligence in Healthcare and Education · Machine Learning in Healthcare
Introduction
1
Medication errors, defined as failures in the treatment process that lead to, or have the potential to lead to, patient harm [1], represent a major public health concern worldwide. These errors are frequent across healthcare systems, affecting a substantial proportion of patients and prescriptions [2, 3, 4], and may occur at any stage of the medication-use process, including prescribing, administration, and dispensing [5, 6, 7]. Their consequences range from minor harm to serious adverse drug events and fatal outcomes [8, 9, 10], while also contributing to increased healthcare costs and prolonged hospital stays [11, 12]. They arise not only in routine clinical care but also in clinical research settings, where complex protocols and investigational products introduce additional risk factors [13, 14].
In response to this critical issue, several health agencies have launched campaigns to promote safer medication practices. The World Health Organization (WHO) introduced the Medication Without Harm initiative [15] and recently issued a policy brief to support its ongoing execution [16]. At the national level, regulatory authorities have similarly prioritized medication safety, establishing dedicated strategies and organizational units to monitor, analyze, and prevent medication errors across clinical care and drug development processes [17, 18, 19, 20].
Various strategies have been implemented to mitigate medication errors, including medication reconciliation [21, 22], staff training [23], automated drug administration systems [24], and packaging or labeling guidelines designed to reduce confusion between look-alike and sound-alike products [25]. However, these interventions often face substantial practical limitations, such as high resource requirements, organizational complexity, training demands, and technical constraints, which can hinder their scalability and sustained implementation [26, 27, 28, 29, 30]. These challenges are particularly pronounced in clinical trials, where investigational products frequently lack finalized packaging or labeling, limiting the applicability of design-focused safety strategies.
In this context, machine learning (ML) has emerged as a promising approach for medication safety, offering the ability to model complex, high-dimensional, and potentially multimodal clinical data that challenge traditional rule-based systems [31, 32]. ML methods can identify subtle patterns associated with prescribing, dispensing, or administration errors and, when integrated into clinical workflows, support real-time decision making and risk prioritization. These capabilities have motivated a growing body of research on ML-based medication-error detection and prediction [33, 34, 35, 36].
A structured synthesis of this literature would be valuable for clinicians seeking to understand which ML tools have been evaluated in medication-safety workflows and for researchers aiming to identify methodological practices and remaining gaps. While prior reviews have examined AI for patient safety more broadly [37], clinical trial risk assessment [38], or medication alert optimization during prescribing [39], no review has yet synthesized ML applications across the full spectrum of medication errors, spanning both clinical care and research contexts.
This scoping review fills this gap by offering the first field-wide synthesis of ML-based medication-error detection, integrating structured and unstructured modalities, supervised and unsupervised methods, and both clinical and simulated environments. The review was conducted according to a pre-specified protocol developed prior to its initiation [40]. This protocol adheres to the Preferred Reporting Items for Systematic Reviews and Meta-Analyses extension for Scoping Reviews (PRISMA-ScR) guidelines [41]. Structured searches were performed across PubMedEmbase and Web of Science, applying predefined inclusion and exclusion criteria to identify relevant studies. Key information, including the type of model, data sources, evaluation methods, and clinical context, was extracted and analyzed through descriptive statistics, visualizations, thematic analysis, and narrative synthesis.
This scoping review is structured as follows. Section 2 describes the methodological protocol, Section 3 presents the main findings, and Section 4 synthesizes these results and discusses their clinical and research implications.
Methods
2
The protocol used to conduct our literature review, consists of five key stages: (i) formulation of the research questions; (ii) identification of relevant literature; (iii) study selection; (iv) data charting; and (v) synthesis and analysis of the results. This protocol was preregistered on the Open Science Framework prior to the start of the review (https://doi.org/10.17605/OSF.IO/38SFY).
Stage 1: formulation of the research questions
2.1
The aim of this review was to identify how ML methods have been applied to predict or detect medication errors across various medical settings. To achieve this objective, the following research questions were developed:
- What types of ML methods have been used to predict or detect medication errors?
- In which medical context have these approaches been applied?
- What kinds of data sources and modalities have been utilized in these applications?
- What are the main challenges, limitation, evaluation strategies, and reported outcomes?
Stage 2: identifying relevant literature
2.2
As detailed in the review protocol [40], PubMed, Embase, and Web of Science were selected as the primary databases. The search strategy was constructed using the following general query format:
where each Group_i_ corresponds to a predefined set of keywords listed in Table 1. All terms were searched exclusively within the title and abstract fields. The exact keyword search used for each database is provided in Appendix A.1. We considered articles published in English between January 1, 2015, and the date of the search (April 28, 2025).
Stage 3: study selection
2.3
Studies were eligible for inclusion if they (i) develop, apply, or evaluate ML methods to predict or detect medication errors; (ii) are related to clinical treatment or research involving human subjects; (iii) are basic research articles published in peer-reviewed journals or conference proceedings, available in full text, and written in English; and (iv) were published between 1 January 2015 and April 28, 2025.
As this review focuses on emerging ML methods capable of modeling complex, non-linear patterns and multimodal data (e.g., clinical text, images), we excluded traditional statistical approaches, such as linear and logistic regression or classical time-series models (e.g., ARIMA [42]), that rely on strong parametric assumptions and are not suited for high-dimensional or unstructured data. In addition, articles that address adverse drug events without explicitly focusing on medication errors were excluded. Works describing methods to prevent medication errors were excluded unless they involved the prediction of such incidents. These inclusion and exclusion criteria are presented in Table 2.
The selection procedure was carried out by two independent reviewers. First, titles and abstracts of the articles were screened to assess their compliance with the eligibility criteria. Studies deemed potentially relevant underwent full-text screening. Those that met the eligibility criteria upon full-text review were included in the final set of studies for the scoping review. For studies where eligibility was unclear or ambiguous, inclusion decisions were resolved through discussion and consensus between the two reviewers.
Stage 4: data charting
2.4
For data extraction, we followed the CHecklist for critical Appraisal and data extraction for systematic Reviews of prediction Modelling Studies (CHARMS) [43] framework, including metadata. In addition, data sources, types, features, labels, and dataset size, as well as the specific ML models employed, were extracted. The complete set of extracted information is described in Appendix A.2, Table 5.
Stage 5: synthesis and analysis of the results
2.5
The results of the scoping review were synthesized using complementary approaches to provide an overview of research topics and methodological practices across the included studies. The synthesis began with a descriptive summary, reporting numerical indicators such as publication trends, data types, ML models, and clinical contexts. Visualizations, including bar charts and summary tables, were used to present distributions across key categories and to concisely summarize use cases, model performance, and dataset characteristics.
Based on this exploratory synthesis, thematic analysis was conducted to identify recurring themes related to application contexts, methodological challenges, and validation strategies. Finally, a narrative synthesis was used to characterize the scope and nature of ML approaches for medication-error detection, highlighting major research trends, methodological patterns, and gaps in the literature.
Results
3
The initial search retrieved 306 records from PubMed, 252 from Embase, and 299 from Web of Science. Duplicate records were identified and removed from the initial set of 857 articles, using the reference management tool EndNote, resulting in a set of 581 studies. After title, abstract and full-text screening 22 studies met the eligibility criteria (Figure 1). The key characteristics extracted from these studies are summarized in Tables 3 and 4. To maintain clarity and comparability, only standardized elements are reported in the tables, while additional contextual details are synthesized narratively below.
The temporal distribution of publications (Figure 2a) shows an emergence of research activity from 2017, followed by a marked increase from 2021 onward. Notably, 82% of included studies were published after 2020.
Geographically, the included studies are dominated by Asia and North America (Figure 2b). The United States contributed the largest number of individual research (27.3%), whereas Asia was the most represented continent (54.5%), with contributions spanning South Korea [44, 45, 46], Japan [47, 48], China [49, 50], among other. Europe accounted for only three studies (13.6%) [51, 52, 53], and one investigation originated from South America (4.5%) [54]. No eligible studies were identified from other regions of the world.
Study characteristics and application areas
3.1
As shown in Figure 2c, most ML studies for medication errors detection focused on prescription errors (68.2%) [53, 44, 47, 45, 55, 56, 57, 58, 59, 54, 60]. Administration errors were addressed in 18.2% of the studies and typically within narrowly defined or specialized clinical settings [61, 62, 51, 63]. The remaining publications examined specific error types, including medication non-adherence [46], contraindication [50], or multiple error types within a single framework [64].
Retrospective analyses represented over half of the included literature and largely focused on developing ML models for predicting or detecting medication errors (Figure 2d). The remaining studies evaluated existing models or systems [57, 59, 60]. Simulation-based investigations (22.7%) primarily explored prototype systems in controlled or synthetic environments, such as medication-review scenarios [65], or home-based medication-taking simulations [51, 63, 46]. In contrast, prospective studies (18.2%) primarily aimed to develop ML models [61, 62, 64].
More than half of the studies (54.5%) were single-center (Figure 2e). These studies encompassed a wide range of clinical contexts, including general hospital populations [53, 44, 55, 56, 54], specific patient groups [49, 52, 45], or specific prescription categories [47, 48], and specific care units [64, 59]. Five investigations (22.7%) were multicenters, either within specialized environments, [62, 57, 61], or more general outpatient populations [58, 60]. The remaining five studies (22.7%) were conducted in simulated or artificial environments and primarily aimed to develop or test prototype systems, in generic clinical scenarios [65, 50, 51, 46], or specific administration procedures [63]. All identified studies focused on clinical care.
Data used for training and assessing ML
3.2
Most datasets (72.3%) were extracted from clinical information systems (Figure 3a) and consisted exclusively of structured variables. Several studies supplemented or replaced clinical data with unstructured inputs including videos [62, 46], images [51], and from radio-frequency signals [63]. Among the remaining works, only one processed free-text clinical scenarios using an LLM [65]. Overall, structured clinical data dominated the evidence base, while unstructured data modalities first appeared in studies published from 2021 onward (Figure 3b).
Dataset sizes of studies relying on structured data varied substantially (Figure 4a), with retrospective studies, ranging from several thousand records [49, 44] to several million [53, 56]. Prospective and simulation-based studies relied on smaller samples (1,093–82,553 observations) [61, 64]. Works leveraging alternative modalities operated on limited sample sizes [62, 46]. Some studies did not report dataset size, but only the cohort size [58, 60].
Feature dimensionality for structured tabular data was generally low, ranging from 2 [54] to 17 variables [49] (Figure 4b). Common features included patient demographics, clinical characteristics (e.g., diagnoses, laboratory values, vital signs), and prescription attributes such as drug name, dose, frequency, route, and temporal indicators.
In contrast, studies using unstructured data required richer representations: image-based models extracted visual embeddings [51], video-based systems derived object detections and spatiotemporal descriptors [62, 46], and radio-frequency sensors encoded human motion into high-dimensional tensors [63], while some processed free-text inputs directly with an LLM, thereby avoiding explicit feature engineering [65]. Several investigations did not report precise feature details [57, 58, 59, 60].
Model type, prediction outcome, and evaluations
3.3
From a modeling perspective, the choice of method most commonly followed the underlying data modality. In studies using structured clinical data, which represented the majority, tree-based ensemble models were the most common [49, 64, 53, 44, 61]. Deep learning applied to structured inputs was less frequent and generally limited to fully connected architectures embedded within hybrid rule–ML pipelines [45]. Studies using unstructured modalities applied neural-network architectures [62, 46, 63, 51], with only one employing LLMs [65]. As illustrated in Figure 4c, earlier work (pre-2021) relied almost exclusively on anomaly-detection paradigms, whereas the adoption of tree-based ensembles and deep neural architectures expanded substantially from 2021 onward.
Predictions outcome varied across studies (Figure 5a). While some investigations employed task-specific labels, such as contraindications [52], high-alert drug categories [48], drug-compatibility levels [50], or self-administration events [63], most used binary indicators denoting the presence or absence of a medication error [49, 53, 61, 44, 62, 64, 47, 51, 45, 46, 56]. A final group of studies did not use labels, either because they focused on evaluating existing systems [65, 57, 58, 59, 60] or adopted unsupervised methods [55, 57]. Except for [65], these investigations typically operated on large datasets. In addition, as shown in Figure 5b, relying on expert-annotated labels typically led to smaller datasets than the use of proxy-based or automated labeling strategies.
Most studies formulated the task as a supervised learning problem, predominantly binary classification, in which models separate correct from erroneous medication events [49, 53, 61, 44, 64, 47, 56]. A smaller subset addressed multi-class settings [50, 48]. Several studies combined data-driven learning with predefined clinical rules derived from guidelines or pharmacological knowledge [52, 45]. A number of investigations adopted multi-stage learning pipelines, particularly for unstructured data [62, 63]. These systems decomposed detection into sequential modules, for example, an object, recognition stage to localize medication-related entities or gestures, followed by a temporal classification stage to determine whether an error occurred. Several studies employed unsupervised anomaly-detection approaches [55, 57, 58, 59, 54, 60].
Evaluation strategies and reported outcomes
3.4
Evaluation practices varied across studies (Figure 5c), with most relying on a test set [53, 61, 44, 62, 64, 46, 56], and fewer using multiple test sets or cross-validation to assess robustness [47, 52, 63, 55]. Performance evaluation for multi-stage systems was often reported at the module level [62, 46], while anomaly-detection and LLM-based approaches primarily relied on expert review to assess system performance [57, 58, 60, 65]. Prospective or external validation was rare [49, 59, 45].
Reported outcomes mirrored the diversity of evaluation strategies. Supervised classification tasks predominantly rely on standard binary performance metrics such as AUROC or F1-score [49, 53, 61, 62, 64, 47, 56], with AUROC typically ranging from 0.71 to 0.92. Deep-learning systems reported high specificities (≥ 90%) [62, 63] and recalls exceeding 95% in controlled environments [46]. Among unsupervised approaches, precision was consistently high, often exceeding 75% [55, 58, 59, 60]. Recall was not systematically evaluated.
Discussion
4
The results reveal two distinct pipelines: one focusing on prescription errors and the other on administration errors. These differ in error type, data modality, modeling strategy, and evaluation context. The prescription pipeline, representing more than two-thirds of included studies, predominantly relies on structured EHR-derived data and tree-based models.
In contrast, administration-focused systems depend on unstructured multimodal inputs (e.g., video, image, or motion signals) and typically employ deep neural networks. Evaluations of administration systems have largely occurred in controlled or simulated environments.
Beyond these two pipelines, we also observe an evolution of training paradigms over time. Early studies relied primarily on anomaly-detection approaches, likely reflecting limited availability of high-quality labels. More recent work increasingly applies tree-based and deep-learning models, paralleling broader developments in clinical ML and expanded access to structured and multimodal data. Notably, LLMs appeared in only one proof-of-concept study [65], indicating that their integration into medication-safety workflows is still widely underexplored.
A recurrent challenge across the included studies was the construction of reliable labels, which often required balancing label quality against dataset size. Several studies derived labels from routine clinical processes, like routine pharmacist reviews [53], dose-related inquiries [44], prescription dose adjustments [47], or voided orders [56]. However, this process introduces inherent labeling inaccuracies. Routine clinical reviews may fail to detect certain errors, while proxy indicators can also be unreliable. For instance, [56] trained their model to predict voided orders, while explicitly noting that approximately 70 ± 10% of these orders correspond to true medication errors. To address these limitations, some investigations relied on expert assessment, with clinicians or pharmacists manually annotating errors through direct observation or detailed chart review. Although this strategy provides higher ground-truth reliability, it is resource-intensive and therefore typically limited to smaller datasets, as underlined in Section 3.3.
Evaluation practices also reflect structural constraints of medication-safety research. Most investigations relied on internal test sets from single-center datasets, limiting insight into cross-institutional performance under varying prescribing cultures and documentation standards. Prospective or external validation was rare, and only a few studies assessed integration within routine workflows. Although reported outcomes were often promising, including one prospective deployment that demonstrated tangible operational benefits, such as reductions in both cost and length of stay [49], the overall evidence base remains fragmented, and the generalizability of current ML approaches remains uncertain.
Implications for practice
4.1
ML-based systems for detecting prescription-related medication errors appear to be the most clinically actionable. Owing to the availability of standardized EHR-derived data and their natural alignment with existing medication-review processes, these approaches have received considerable research attention. Consequently, they have been evaluated across a wide range of settings, including several examples of early clinical integration, with consistently promising results.
In contrast, ML methods designed to detect administration errors remain at an earlier stage of development. These systems typically rely on complex multimodal pipelines capable of processing unstructured inputs with substantial associted challenges for dataset construction, scalability, and clinical deployment. These constraints likely explain why most evaluations have occurred in controlled or simulated environments rather than routine clinical practice. While initial findings are encouraging, their real-world feasibility and performance remain uncertain, and these systems should presently be considered experimental prototypes rather than deployable clinical tools.
Finally, most studies were conducted in single-center settings, often with restricted patient populations, limiting the generalizability of their findings. External validation, particularly across institutions with differing prescribing cultures, formularies, and documentation practices, remains scarce. For these reasons, sustained human oversight is essential. ML systems should be viewed not as stand-alone detectors of medication errors but as decision-support tools that augment clinical review, flag high-risk events, and help prioritize pharmacist workload. Institutions aiming for implementation should incorporate rigorous prospective evaluation and establish mechanisms for continuous human verification, feedback, and model updating.
Implications for research
4.2
This review identifies several priority areas for advancing research on ML-based medication-error detection.
A first gap concerns medication-administration errors, which remain underexplored and largely evaluated in controlled environments rather than routine workflows. Future work should prioritize close-to-deployment studies assessing workflow integration, human–AI interaction, and alert burden to determine real-world viability.
Research also remains heavily skewed toward structured tabular data. Although a small number of studies leveraged images or other unstructured sources, multimodal approaches remain limited. Notably, LLMs were evaluated in only one proof-of-concept study, underscoring the opportunity to explore their potential for extracting and reasoning over free-text clinical documentation.
A further implication concerns the difficulty of constructing reliable labels. Many studies relied on imperfect proxy indicators, introducing noise and inconsistency. To support real-world deployment, future research should consider methods robust to incomplete or noisy annotations, including noise-robust loss functions [66] and semi-supervised approaches [67].
Despite the well-established impact of hyperparameter optimization on model performance, several studies reported only limited, or in some cases, no, information on how hyperparameters were selected or tuned [33, 45, 63, 44, 55, 46]. In many instances, it was unclear whether any optimization procedure had been applied, and in one study[47] the authors explicitly stated that all models were trained using default settings without conducting hyperparameter tuning. Such incomplete reporting reduces methodological transparency, hinders reproducibility, and may result in inaccurate or biased assessments of model performance. Future research would therefore benefit from systematically documenting the hyperparameter-tuning procedures employed, including the search strategy, parameter ranges, and validation scheme, to support robust comparison across studies and ensure reliable interpretation of results.
Progress is also constrained by the absence of open, standardized benchmarks. Only one publicly available dataset was identified [54], originating from a single center and containing limited prescription attributes. As a result, most evaluations were conducted on isolated datasets under heterogeneous conditions. Developing multicenter, de-identified datasets supported by robust data-sharing frameworks would enable rigorous benchmarking and accelerate methodological advances.
Finally, none of the included studies addressed medication errors in clinical trials. Given the scale of global pharmaceutical research and development and the potential impact of medication errors on data integrity, participant safety, and regulatory compliance [68, 69], this absence is notable. Extending ML-based detection to clinical research settings represents an important opportunity to enhance trial quality and safety.
Strength and limitations of this scoping review
4.3
This scoping review has several strengths. It was conducted in accordance with a preregistered protocol and adhered to PRISMA-ScR guidelines, ensuring methodological transparency and reproducibility. A comprehensive search strategy was applied across three major scientific databases, capturing a broad range of ML applications for medication-error detection. Data charting was performed systematically using an extraction framework informed by the CHARMS checklist, enabling consistent assessment of model characteristics, data sources, error types, and evaluation strategies. The review also synthesizes findings across heterogeneous modalities, including structured EHR data, video, sensor signals, images, and free-text inputs, providing a uniquely wide overview of how ML has been applied across the medication-use process.
Despite these strengths, several limitations should be acknowledged. First, the search was restricted to English-language and peer-reviewed publications, which may have led to the omission of relevant studies, particularly emerging work disseminated through preprints or non-English sources. Second, the reporting quality of the included studies varied considerably; key details such as feature definitions, label construction procedures, and data modalities were often incomplete or inconsistently described, limiting direct comparison across studies. Finally, substantial heterogeneity in clinical contexts, data types, and evaluation strategies further constrained the possibility of quantitative synthesis. Consequently, the findings were primarily integrated through narrative synthesis. Despite these limitations, this review provides a comprehensive and structured overview of the current evidence base and highlights clear opportunities for advancing ML research in medication-error detection.
Conclusion
5
This scoping review identifies two dominant methodological pipelines for ML-based medication-error detection: a prescription-focused approach grounded in structured EHR data and tree-based models, and a smaller administration-focused paradigm relying on multimodal sensing and deep learning. While reported performance is often promising, the evidence base remains fragmented and largely confined to single-center retrospective evaluations. Label construction strategies vary substantially, external validation is rare, and no standardized benchmarks currently enable fair comparison across models. Beyond routine clinical workflows, no studies addressed medication errors in clinical research settings, despite their distinct operational complexity and safety implications.
Advancing the field will require multicenter datasets, transparent reporting of modeling and tuning procedures, and rigorous prospective evaluation embedded within real-world workflows. Emerging modalities, including free-text processing with large language models, remain underexplored and may offer opportunities to move beyond structured tabular paradigms.
ML systems should therefore be viewed not as autonomous error detectors, but as decision-support tools whose safe and effective deployment depends on robust validation, human oversight, and careful integration into clinical practice.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1Aronson Jeffrey K. Medication errors: definitions and classification. British journal of clinical pharmacology, 67(6):599–604, 2009.19594526 10.1111/j.1365-2125.2009.03415.x PMC 2723196 · doi ↗ · pubmed ↗
- 2Elliott Rachel Ann, Camacho Elizabeth, Jankovic Dina, Sculpher Mark J, and Faria Rita. Economic analysis of the prevalence and clinical and economic burden of medication error in england. BMJ Quality & Safety, 30(2):96–105, 2021.
- 3Rouhani Mahsa, Mousavi Maryam, Kooshyar Mohammad Mahdi, Shahidsales Soodabeh, Makhdoumi Yasha, Amirabadi Amir, and Elyasi Sepideh. Application of a chemotherapy standard form in patients with breast cancer: comparison of private and public centers. Jundishapur Journal of Natural Pharmaceutical Products, 13(3), 2018.
- 4Hodkinson Alexander, Tyler Natasha, Ashcroft Darren M, Keers Richard N, Khan Kanza, Phipps Denham, Abuzour Aseel, Bower Peter, Avery Anthony, Campbell Stephen, Preventable medication harm across health care settings: a systematic review and meta-analysis. BMC medicine, 18:1–13, 2020.31898501 10.1186/s 12916-019-1443-1PMC 6941399 · doi ↗ · pubmed ↗
- 5al Tehewy Mahi, Fahim Hoda, Gad Nanees Isamil, El Gafary Maha, and Rahman Shady Abdel. Medication administration errors in a university hospital. Journal of patient safety, 12(1):34–39, 2016.26895028 10.1097/PTS.0000000000000196 · doi ↗ · pubmed ↗
- 6Avery Anthony J, Ghaleb Maisoon, Barber Nick, Franklin Bryony Dean, Armstrong Sarah J, Serumaga Brian, Dhillon Soraya, Freyer Anette, Howard Rachel, Talabi Olanrewaju, The prevalence and nature of prescribing and monitoring errors in english general practice: a retrospective case note review. British Journal of General Practice, 63(613):e 543–e 553, 2013.
- 7Um Irene S, Clough Alexander, and Tan Edwin CK. Dispensing error rates in pharmacy: a systematic review and meta-analysis. Research in Social and Administrative Pharmacy, 20(1):1–9, 2024.
- 8Tansuwannarat Phantakan, Vichiensanth Piraya, Sivarak Ornlatcha, Tongpoo Achara, Promrungsri Puangpak, Sriapha Charuwan, Wananukul Winai, and Trakulsrichai Satariya. Characteristics and consequences of medication errors in pediatric patients reported to ramathibodi poison center: a 10-year retrospective study. Therapeutics and Clinical Risk Management, pages 669–681, 2022.35795851 10.2147/TCRM.S 363638 PMC 9252189 · doi ↗ · pubmed ↗