Large Language Models in Clinical Neurology: A Systematic Review
Alon Gorenshtein, Kamel Shihada, Mahmud Omar, Yiftach Barash, Girish N Nadkarni, Eyal Klang

TL;DR
This paper reviews how large language models are being used in neurology, finding early promise but significant limitations in real-world applications.
Contribution
A systematic review of LLM applications in clinical neurology, identifying current uses, performance, and critical limitations.
Findings
LLMs show high performance in constrained tasks like diagnostic classification and information extraction.
Prospective validation is rare, and most studies have a high risk of bias.
Safety issues like hallucinations and overconfidence highlight the need for improved model architectures.
Abstract
Large language models (LLMs) are increasingly explored for clinical applications in neurology, yet their real-world utility, safety, and optimal implementation remain uncertain. We systematically reviewed the literature to characterize current applications, evaluate evidence quality, and identify knowledge gaps regarding LLM use in clinical neurology. Following PRISMA guidelines, we searched PubMed, Embase, Scopus, Web of Science, and CENTRAL from January 1, 2022 through February 1 2026. for peer-reviewed studies evaluating LLM applications in clinical neurology. We included studies using large language models for clinically relevant neurology tasks from text or multimodal inputs. Two independent reviewers screened records, extracted data, and assessed risk of bias using the QUADS-AI. We synthesized evidence narratively across application domains, validation approaches, and model…
Genes, proteins, chemicals, diseases, species, mutations and cell lines named across the full text — each resolved to its canonical identifier and authoritative record.
Click any figure to enlarge with its caption.
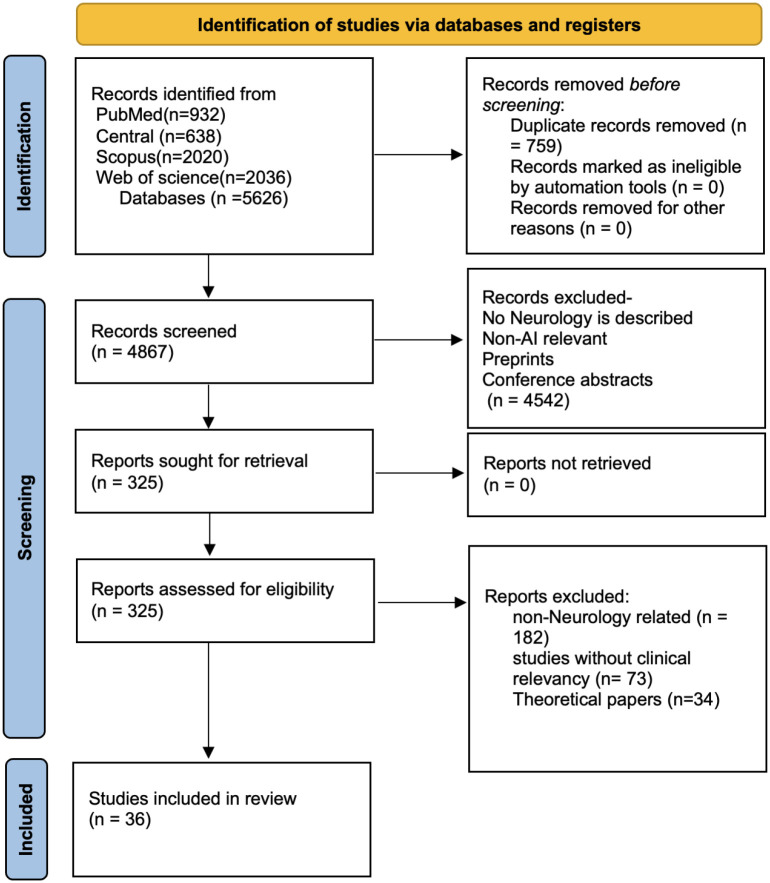 Figure 1
Figure 1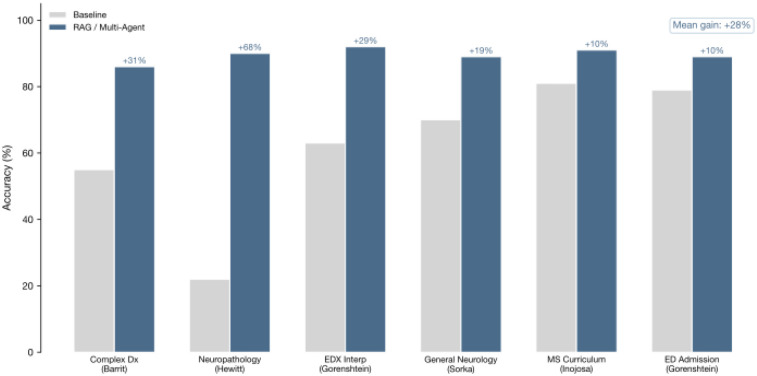 Figure 2
Figure 2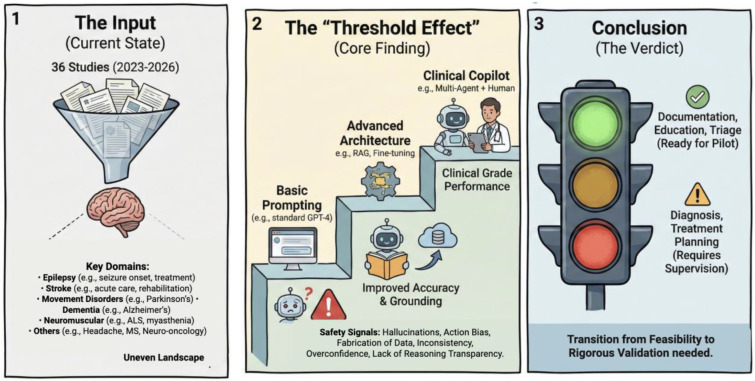 Figure 3
Figure 3Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsArtificial Intelligence in Healthcare and Education · Machine Learning in Healthcare · Topic Modeling
INTRODUCTION
The growing integration of artificial intelligence (AI) into medical practice is transforming healthcare delivery.^1^ Large language models (LLMs), such as Chat Generative Pre-trained Transformer (ChatGPT), can interpret and generate complex clinical text and are being explored for tasks including clinical decision support, documentation assistance.^2^
Neurology is a particularly demanding field for these tools.^3^ Neurological disorders are highly prevalent and contribute substantially to the global burden of disease, generating heavy workloads for physicians and healthcare systems.^4^ At the same time, neurological diagnosis often hinges on detailed linguistic descriptions of symptoms and examination findings that must be interpreted alongside multimodal data, e.g. neuroimaging and electrophysiology.^5^
Early studies nevertheless suggest that LLMs may add value in selected neurology-related applications.^6^ Be it as it may differences in task framing, prompting strategies, data sources (synthetic versus real-world clinical data), evaluation metrics, and clinical comparators make results difficult to compare across studies and limit generalizability.^7^ This variability is not only a methodological challenge but also a safety concern. In high stake field as neurology, these models pose risk as they may generate confident but incorrect or fabricated statements (“hallucinations”), propose misleading differential diagnoses, or suggest inappropriate management steps, including medication choices.^8^ Risks may be amplified when models are used outside well-defined use cases or without human oversight, and performance can further degrade in rare syndromes, atypical presentations, or multilingual documentation.^9,10^
Taken together, these factors highlight the need for a systematic review that synthesizes the current literature into a cohesive evidence map for neurologists. Such a review can clarify where LLMs perform reliably, where evidence is limited or inconsistent, how studies are being evaluated, and what safety risks and implementation gaps remain before broader clinical adoption.
METHODS
Protocol and reporting
We conducted this systematic review in accordance with PRISMA 2020. A protocol was prepared a priori and registered in PROSPERO (CRD420251082465).
Conceptual framework and operational definition
We evaluated large language model (LLM) applications in clinical neurology. An LLM application was defined as a generative transformer-based model used during inference to perform a clinically relevant neurology task from text and or multimodal inputs (for example clinical histories and physical examinations, imaging reports, free-text clinic letters, patient narratives, transcripts, paired imaging, or structured questions). We included both proprietary and open-weight models, and both standalone LLM pipelines and hybrid systems, including retrieval-augmented generation (RAG), multi-agent orchestration, and LLM plus conventional machine learning ensembles, provided the LLM materially contributed to the evaluated output. Systems focused solely on non-generative NLP without an LLM at inference, lack of clinical relevancy, benchmark studies without integration of models beyond Base LLM were excluded.
Data sources and search strategy
We searched PubMed, Scopus, Web of Science, and CENTRAL for peer-reviewed studies from January 1st, 2022 through Febubary 1st 2026. Searches were restricted to English-language records. The PubMed strategy used concept blocks capturing (1) LLMs and generative AI and (2) clinical neurology domains and tasks. Search terms included large language model, LLM, generative AI, ChatGPT, GPT, Claude, Gemini, Bard, Llama, Mistral, and neurology terms spanning stroke and vascular neurology, epilepsy, neuroimmunology, movement disorders, neuro-oncology, neuromuscular medicine, headache, and language disorders. The strategy was translated to other databases using database-specific field tags while preserving the concept structure. Reference lists of included studies and relevant reviews were screened to identify additional eligible articles. Full search startgery in supplementary appendix.
Eligibility criteria
We included peer-reviewed original studies that evaluated an LLM-based system on a clinical neurology task, including diagnostic classification, differential diagnosis generation, neuroanatomical localization or phenotyping, clinical decision support and guideline adherence, prognosis or monitoring, clinical documentation and summarization, and information extraction from clinical text. Studies were required to report an empirical evaluation using quantitative metrics, structured human evaluation, or both.
We excluded non-original publications (reviews, editorials, protocols), conference abstracts without a peer-reviewed full text, studies outside clinical neurology, studies that did not use an LLM during inference, and studies without evaluative outcomes.
Study selection
After deduplication, two reviewers independently screened titles and abstracts and then reviewed full texts for eligibility. Discrepancies were resolved by discussion and consensus.
Data extraction and data items
We used a standardized extraction template. Study-level variables included year, country, clinical domain, setting, study design, sample size, data source type (real-world clinical data, synthetic data, vignettes, benchmark questions), input modality (text-only vs multimodal), primary task, model name and version, and whether the system used augmentation (RAG, tools, agents, or hybrid ML).
Outcomes extracted included primary performance metrics (for example AUC, sensitivity and specificity, accuracy, F1, agreement statistics, or rubric-based grades), comparator performance when available (clinicians, conventional ML or NLP, rules, or LLM-only baselines), and implementation characteristics when reported (prompting approach, latency, cost, reproducibility). We also extracted explicitly reported safety considerations and failure modes, including hallucination risk, citation fabrication, over-calling or low specificity, semantic false positives, numerical reasoning failures, and performance gaps in rare clinical subgroups or anatomical regions.
Task taxonomy and classification
To support synthesis, we categorized each study into prespecified task categories aligned with clinical use: diagnostic classification, information extraction, patient education and communication, clinical decision support, localization or phenotyping, and prognosis or monitoring. When a study evaluated multiple tasks, it was assigned to each relevant category for qualitative synthesis, while preserving the primary task as reported by the authors.
Outcomes and synthesis
The primary outcome was task performance relative to the study-defined reference standard and comparator, where applicable. Secondary outcomes included safety signals and failure modes, auditability and traceability features (for example citations, guideline tethering, or structured outputs), and operational feasibility. Due to heterogeneity in tasks, datasets, metrics, and evaluation designs, we did not perform a meta-analysis. We conducted a structured narrative synthesis with descriptive statistics, summarizing performance ranges within task categories and highlighting consistent patterns of success and limitation across domains and study designs.
Risk of bias and applicability assessment
We adapted the QUADAS-AI tool^11^ (Quality Assessment of Diagnostic Accuracy Studies for AI) to assess risk of bias and applicability concerns. This modified instrument evaluated four domains: (1) Patient/Data Selection, (2) Index Test (AI system), (3) Reference Standard, and (4) Flow and Timing. Each domain was rated as low risk, high risk, or unclear risk of bias.34 Additionally, we assessed concerns regarding applicability for the first three domains. Specific high-risk indicators included: use of synthetic/simulated data only, single-center validation, sample size <100, lack of external validation, unclear ground truth establishment, and selective outcome reporting. Two reviewers independently assessed each study, with disagreements resolved through consensus discussion.
Results
Study Selection and Characteristics
We identified 5,626 records. After removing 759 duplicates, 4867 records were screened; 325 full texts were assessed; and 36 studies met inclusion criteria (Figure 1).^12–47^ Studies were published between 2023 and 2026, with 1/36 (2.8%) in 2023, 9/36 (25.0%) in 2024, 25/36 (69.4%) in 2025, and 1/36 (2.8%) in 2026, reflecting the rapid emergence of this field. Clinical domains spanned 8 neurological subspecialties: epilepsy (n=9, 25.0%), general neurology (n=9, 25.0%), stroke/vascular neurology (n=8, 22.2%), neuro-immunology (n=3, 8.3%), movement disorders (n=2, 5.6%), neuromuscular disease (n=2, 5.6%), neuro-oncology (n=2, 5.6%), and neurocritical care (n=1, 2.8%). Study designs varied in rigor: 13/36 (36.1%) were simulation/feasibility studies, 17/36 (47.2%) analyzed retrospective clinical data, and only 6/36 (16.7%) achieved prospective clinical validation, representing a critical translational gap (Table 1). GPT-4 variants (GPT-4, GPT-4o, GPT-4-Turbo, GPT-4-Vision) were the most frequently employed LLMs, appearing in at least 6/36 studies (16.7%) as primary models, with additional studies using GPT-4 alongside other models. Proprietary/closed-source models dominated (25/36, 69.4%). Retrieval-augmented generation (RAG) was employed in 7/36 studies (19.4%), multi-agent frameworks in 3/36 (8.3%), while open-source models, including Llama, Mistral, Gemma-2, and BERT variants were evaluated in 9/36 studies (25.0%). Retrieval-augmented generation (RAG) was employed in 7/36 studies (19.4%), and multi-agent frameworks in 3/36 (8.3%).
Risk of bias
Overall risk of bias was rated high in all 36 studies. This was driven extensively by participant selection, which was rated high risk in 36/36 (100%) studies. This high risk stems from the fact that the majority of evaluations relied on single-center cohorts without external validation, small sample sizes (<100), or synthetic/simulated data (e.g., vignettes, exam questions, or public datasets) rather than real-world clinical streams. These selection biases also generated high applicability concerns across the cohort. Analysis limitations remained a major driver of bias, with most studies failing to report calibration or clinical-utility metrics, relying instead on discrimination metrics (e.g., Accuracy, AUC) derived from internal validation alone. In contrast, the index test and reference standard domains were generally rated lower risk, although specific concerns regarding data leakage (e.g., models trained on public cases used for testing) and unclear ground truth were identified in a subset of studies (Supplementary Methods Section 4).
Clinical Domain Distribution
Task applications varied by domain. Epilepsy studies focused predominantly on diagnostic classification (3/9) and patient education (2/9), with additional work in information extraction for anti-seizure medication documentation and epileptogenic zone localization. General Neurology encompassed the broadest task diversity, including diagnostic reasoning, summarization, and clinical decision support. Stroke/Vascular Neurology studies addressed the full clinical pathway from screening and localization to prognostic prediction. The two Movement Disorders studies both leveraged LLM-derived features from speech transcripts for Parkinson’s disease staging, while Neuromuscular studies focused on electrodiagnostic report interpretation and generation. Validation rigor also varied by domain (Supplementary Figure X). Notably, Stroke/Vascular Neurology despite being among the most studied domains had no prospective clinical validation studies (0/8), with 5/8 retrospective and 3/8 simulation designs. In contrast, smaller domains achieved higher validation rates: Movement Disorders (1/2 prospective), Neuromuscular (1/2 prospective), and Neuro-oncology (1/2 prospective). The six prospective studies spanned epilepsy diagnosis (Brigo et al.), neurocritical care guideline adherence (Kliem et al.), patient education benchmarking (Li et al.), Parkinson’s motor state classification (Castelli), neuro-oncology decision support (Tini et al.), and EMG/NCS report generation (Gorenshtein 2025_a et al.).
Architectural Determinants of Performance
Model architecture substantially influenced outcomes (Figure 2, Table 3). RAG was employed in 7/36 studies (19.4%) and consistently outperformed standard prompting: neuropathology classification improved from 22% to 90% with RAG (Hewitt et al. 2024);^39^ complex differential diagnosis rose from 55% (neurologists) to 86% (RAG-GPT4) (Barrit et al.);^45^ MS curriculum performance increased from 81% to 91% (Inojosa et al.).^32^ Multi-agent frameworks (3/36, 8.3%) showed comparable gains: INSPIRE 3-agent improved EDX interpretation from 62.6% to 92.2% (Gorenshtein et al. 2025_d);^13^ CrewAI boosted LLaMA-3.3–70B from 69.5% to 89.2% on board exams (Sorka et al.).^12^ Mean improvement across enhanced architectures was +28 percentage points (Figure 4). Open-source models (9/36, 25.0%) approached proprietary performance for well-defined tasks: Llama-2–13B achieved F1 ~0.90 for ASM extraction (Fang et al.)^35^; Gemma-2/Llama-3.1 reached 98.4% for Parkinson’s classification (Castelli et al.).^29^
Safety Signals and Failure Modes
Five systematic failure patterns recurred across studies (Table 3). Epistemic failures (hallucination) were acknowledged in 7 studies, with citation fabrication documented: Wu (2024) noted “risk of fabricated citations” in patient education, while RAG-augmented systems with source attribution reported no unverifiable claims (Barrit et al.).^45^ Calibration deficits manifested as diagnostic over-calling: Brigo et al. reported 100% sensitivity but 26.7% specificity for epilepsy;^17^ Chen et al. noted “semantic false positives” flagging inactive history as active contraindications;^20^ Maiorana et al. found LLMs over-ordered investigations in 17–25% of cases.^40^ Action bias toward intervention was quantified: Shmilovitch (2025) found GPT-4 over-recommended tPA in 11/105 cases (10.5%); Tini et al documented radiotherapy mismatches in gray-zone glioma cases despite clinical equipoise.^18^ Numerical reasoning failures emerged: Acır et al. showed standalone GPT-4 had r=0.054 for NIHSS prediction, improving only with structured ML integration (r=0.513).^44^ Domain knowledge gaps: cerebellar localization was consistently less accurate than supratentorial (Lee et al.);^37^ epileptogenic zone identification failed for cingulate and insular regions (Luo et al.).^28^ Studies positioning LLMs as autonomous decision-makers consistently reported concerning safety signals, while working as a “copilot” showed improved outcomes. AI-alone achieved quality score 0.70 versus 0.94 for AI+physician, identical to physician-alone (Gorenshtein 2025_a^15^, Table 4).
Discussion
Our findings indicate that LLM architectures demonstrate promise in neurology; Be it as it may, the methodologies employed in most studies and identified safety concerns suggest these models are not yet suitable for clinical deployment. A total of 36 studies were identified, spanning eight neurological subspecialties. Performance was encouraging in diagnostic classification (AUC 0.75–0.92), information extraction (F1 0.85–0.90), and patient education (accuracy 68–97%). However, only 16.7% of studies achieved prospective validation, and just 5.6% demonstrated external generalizability. This disparity between technical potential and clinical readiness constitutes the pressing challenge in the field (Figure 3.).
The safety signals identified in this review are concerning espeically at high stake domain such as neurology. LLMs are trained to generate plausible, helpful responses, an optimization target that creates systematic bias toward action over appropriate restraint. In stroke care, this manifested as thrombolysis over-recommendation in cases where experts recognized contraindications; in neuro-oncology, radiotherapy was endorsed in gray-zone glioma scenarios where watchful waiting may be equally valid. These are not random errors but predictable consequences of training objectives that reward confident, interventional outputs.^48^ The clinical stakes are profound: hemorrhagic transformation from inappropriate thrombolysis and radiation necrosis from unnecessary treatment represent precisely the irreversible harms that neurological training teaches clinicians to prevent through careful equipoise. The calibration deficits we observed, 100% sensitivity paired with 27% specificity for epilepsy diagnosis reflect the same underlying asymmetry.^49^ LLMs appear optimized for recall at the expense of precision, generating false positives^50^ that translate directly into unnecessary antiepileptic drug exposure, patient anxiety from unwarranted diagnostic labels, and healthcare resource utilization from excessive testing. Perhaps most concerning, domain knowledge gaps followed an inverse relationship with clinical need: cerebellar localization was consistently less accurate than supratentorial lesions, and epileptogenic zone identification failed specifically for cingulate and insular regions. This pattern likely reflects training data imbalances where common presentations dominate the corpus while rare but clinically important entities remain underrepresented^51^ meaning current LLMs may reinforce rather than address the diagnostic challenges most difficult for neurologists. These vulnerabilities extend beyond our neurology-specific findings. Omar and colleagues demonstrated that LLMs are “highly vulnerable to adversarial hallucination attacks,” with 50–82% hallucination rates when fabricated clinical details were embedded in clinical vignettes and prompt-based mitigation failed to eliminate this risk.^52^ The implication is sobering: base LLMs lack the deep relational understanding necessary for the anatomical, syndromic, and prognostic reasoning that characterizes neurological expertise. This limitation is architectural, not addressable through prompt engineering or temperature adjustments, and demands fundamentally different approaches to clinical deployment.
A path forward for mitigating these safety issues lies in retrieval-augmented generation (RAG) and agentic systems. RAG is an architectural approach that augments LLM generation with retrieved documents from external knowledge bases, grounding model outputs in verifiable sources rather than relying solely on parametric knowledge embedded during training.^53^ This enables real-time access to current guidelines, institutional protocols, and domain-specific literature while providing source attribution that facilitates verification. AI agent systems extend this paradigm further, these are architectures that can plan multi-step tasks, invoke external tools (including RAG retrieval, calculators, and database queries), and in some cases coordinate reasoning across multiple specialized agents.^54^ The evidence from our included studies supports these architectural approaches. RAG-augmented systems reported no unverifiable claims while substantially improving diagnostic performance, neuropathology classification accuracy rose from 22% to 90% when LLMs were grounded in retrieved pathology literature. Multi-agent frameworks demonstrated comparable gains through orchestrated reasoning: the INSPIRE three-agent system (Validator, Knowledge Integrator, Synthesizer) improved electrodiagnostic interpretation from 62.6% to 92.2%, while multi-agent decomposition transformed LLaMA-3.3 from 69.5% to 89.2% on neurology board examinations, elevating a mid-tier model to near-expert performance. When baseline model knowledge is insufficient, agentic workflows use targeted retrieval of primary medical sources to close information gaps and ground outputs in evidence rather than parametric recall.^55^ For quantitative prediction, hybrid architectures that combine LLM reasoning with structured machine learning models improved NIHSS prognostication from r=0.054 (functionally no association) to r=0.513 (moderate predictive value). That all six prospective validation studies in our corpus employed these enhanced architectures rather than basic prompting suggests that architectural augmentation may be prerequisite rather than optional for neurological applications meeting clinical-grade standards (Figure 3.).
However, the agentic systems proposed to mitigate base LLM failures may introduce novel failure modes requiring independent evaluation. As AI agents gain tools they gain the capability of autonomy, such autonomy come with it’s own price. Klang et al. tested clinical agents in EHR workflows and found they demonstrated “indifference” to patient identity inconsistencies accurately coding encounters but writing them into incorrect patient records.^56^ Agents failed to detect subtle tampering that human verification would flag: single-digit MRN changes passed unnoticed in nearly all cases. In neurology, such misbinding failures could result in stroke protocols applied to wrong patients, seizure medications reconciled to incorrect records, or genetic testing results misattributed across families, errors with cascading consequences for treatment decisions and inherited disease counseling. Similarly Agentic LLMs treated patient tone as clinical input, altering triage, follow-up, prescribing, and sick-leave decisions despite identical symptoms.^57^ These findings suggest the field must evaluate autonomy, abstention appropriateness, alongside accuracy. Safe deployment of neurological AI agents will require explicit verification gates before treatment recommendations, deterministic upstream checks on patient identifiers, and continuous monitoring frameworks.
This review is limited by English-language restriction, heterogeneity precluding meta-analysis, and likely publication bias. QUADAS-AI assessment revealed pervasive methodological concerns: 94% of studies lacked external validation. Rapid model evolution means specific benchmarks require updating, though architectural and safety insights should remain durable.
LLMs represent transformative potential for clinical neurology, yet the gap between technical promise and clinical validation remains striking. The finding that all prospective validation studies employed enhanced architectures whcih none relied on basic prompting suggests a threshold effect: standard LLM deployment may be fundamentally insufficient for neurological applications regardless of model sophistication. Future implementation should prioritize RAG grounding in specialty guidelines, agentic verification systems, and hybrid architectures for quantitative prediction, while recognizing that this emerging infrastructure itself requires safety validation in neurology.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1Silcox C, Zimlichmann E, Huber K, The potential for artificial intelligence to transform healthcare: perspectives from international health leaders. Npj Digit Med. 2024;7(1):88. doi:10.1038/s 41746-024-01097-638594477 PMC 11004157 · doi ↗ · pubmed ↗
- 2Goh E, Gallo RJ, Strong E, GPT-4 assistance for improvement of physician performance on patient care tasks: a randomized controlled trial. Nat Med. Published online February 5, 2025:1–6. doi:10.1038/s 41591-024-03456-y · doi ↗
- 3Bassetti CLA, Accorroni A, Arnesen A, General neurology: Current challenges and future implications. Eur J Neurol. 2024;31(6):e 16237. doi:10.1111/ene.1623738545838 PMC 11236055 · doi ↗ · pubmed ↗
- 4Steinmetz JD, Seeher KM, Schiess N, Global, regional, and national burden of disorders affecting the nervous system, 1990–2021: a systematic analysis for the Global Burden of Disease Study 2021. Lancet Neurol. 2024;23(4):344–381. doi:10.1016/S 1474-4422(24)00038-338493795 PMC 10949203 · doi ↗ · pubmed ↗
- 5Nicholl DJ, Appleton JP. Clinical neurology: why this still matters in the 21st century. J Neurol Neurosurg Psychiatry. 2015;86(2):229–233. doi:10.1136/jnnp-2013-30688124879832 PMC 4316836 · doi ↗ · pubmed ↗
- 6Large language models in biomedicine and healthcare | npj Artificial Intelligence. Accessed February 8, 2026. https://www.nature.com/articles/s 44387-025-00047-1
- 7Gallifant J, Afshar M, Ameen S, The TRIPOD-LLM reporting guideline for studies using large language models. Nat Med. 2025;31(1):60–69. doi:10.1038/s 41591-024-03425-539779929 PMC 12104976 · doi ↗ · pubmed ↗
- 8Romano MF, Shih LC, Paschalidis IC, Au R, Kolachalama VB. Large Language Models in Neurology Research and Future Practice. Neurology. 2023;101(23):1058–1067. doi:10.1212/WNL.000000000020796737816646 PMC 10752640 · doi ↗ · pubmed ↗