Large Language Models in Infectious Diseases: A Systemic Review
Alon Gorenshtein, Eyal Klang, Jacob J. Smith, Richard Dzeng, Mark C. Poznansky, Girish N Nadkarni, Mahmud Omar

TL;DR
This review finds that large language models (LLMs) can help with infectious disease diagnosis and stewardship but are unreliable for autonomous use due to errors and fabricated content.
Contribution
The paper provides a systematic review of LLMs in infectious diseases, highlighting safety issues and performance gaps compared to experts.
Findings
LLMs show high diagnostic sensitivity for structured infections but have high error rates and fabricated content.
Retrieval-augmented systems improved specificity and reduced hallucinations compared to standard models.
Most studies had high risk of bias and used non-real clinical data, limiting reliability.
Abstract
Clinical reasoning in infectious diseases relies on validated evidence. LLMs are being introduced into diagnosis, antimicrobial stewardship, and guideline interpretation before their safety and reliability are established. This review, registered in PROSPERO (CRD420251155354), evaluated studies using GPT, Claude, Gemini, and retrieval-augmented or agentic systems for infectious disease decision-making. PubMed, CENTRAL, Scopus, and Web of Science were searched from January 2018 to September 2025. Two reviewers screened and extracted data. Risk of bias was assessed with QUADAS-AI. Thirty-one studies met inclusion criteria. Most were cross-sectional (61%) and vignette-based (68%). Only 32% used real clinical data; 23% had low risk of bias. Safety issues were reported in 90% of studies: incomplete responses (61%), unsafe advice (23–32%), and fabricated content (32%). In antimicrobial…
Genes, proteins, chemicals, diseases, species, mutations and cell lines named across the full text — each resolved to its canonical identifier and authoritative record.
Click any figure to enlarge with its caption.
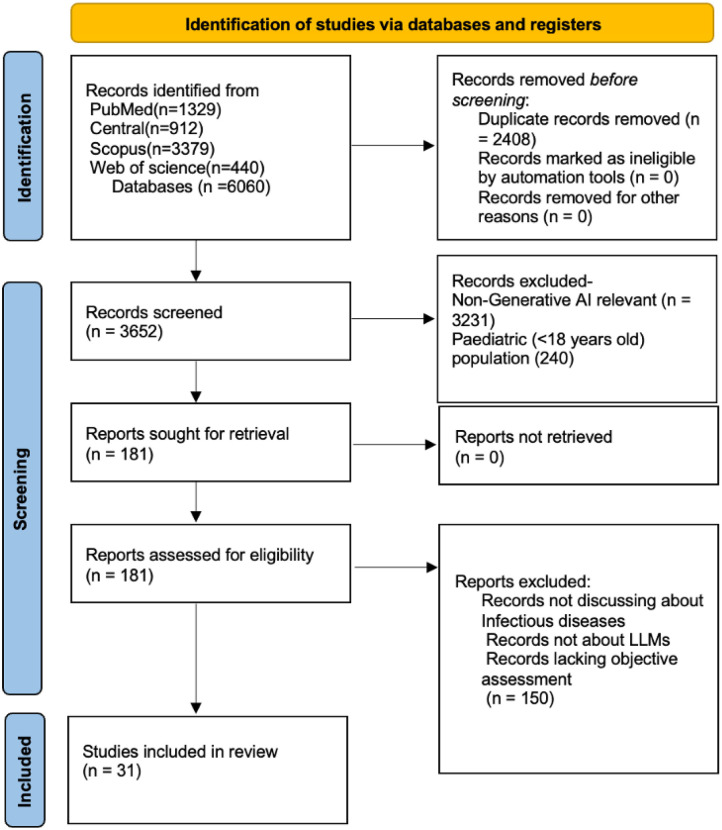 Figure 1
Figure 1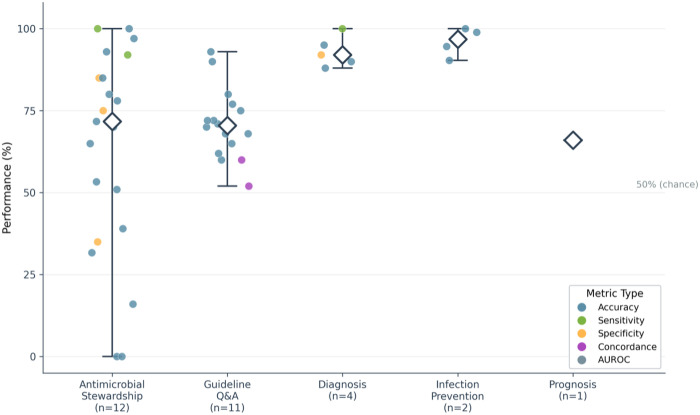 Figure 2
Figure 2 Figure 3
Figure 3Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsArtificial Intelligence in Healthcare and Education · Topic Modeling · Clinical Reasoning and Diagnostic Skills
Introduction
Clinical reasoning in infectious diseases (ID) depends on data, expertise, and judgment. Large language models (LLMs) now attempt to perform these tasks in text, generating diagnostic and therapeutic suggestions without task-specific training.^1–3^
ID present a natural testing ground. The specialty combines complex decision-making, workforce shortages, and rising antimicrobial resistance (AMR).^4,5^ The clinical burden is high across settings, with infections accounting for roughly 10% of ambulatory encounters in the USA (higher in paediatric care) and healthcare-associated infections affecting about 3% of hospitalized patients in point-prevalence surveys, yet specialist access is uneven, as over 80% of counties lack an ID physician and many fellowship positions go unfilled.^6–8^ Against this backdrop global AMR caused an estimated 4.95 million deaths in 2019, concentrated in respiratory and bloodstream infections.^9^
This environment invites automation. LLMs have been proposed for surveillance, guideline interpretation, and epidemic prediction.^10–15^ Yet early reports show instability—hallucinations, unsafe recommendations, and vulnerability to manipulation.^16–18^
This review examines whether recent advances have turned LLMs into reliable instruments for ID care.
Methods
Protocol and reporting
This systematic review was pre-registered with PROSPERO (CRD420251155354) and conducted according to PRISMA-2020 guidelines.^1^ Although quantitative pooling was pre-specified in the protocol, substantial heterogeneity in populations, interventions, and outcomes precluded meta-analysis.
Eligibility criteria
We included primary research studies evaluating LLMs-including general-purpose models (e.g. ChatGPT, Gemini etc.), fine-tuned LLMs, retrieval-augmented generation (RAG) systems, and agentic LLMs-applied to ID decision-making in human clinical or public-health contexts.
Eligible study designs were original research articles. Review papers, case reports, conference abstracts, editorials, preprints, and studies not conducted in English were excluded. Additionally, we excluded studies of classic machine learning or natural language processing methods without an LLM component, image-only models without LLM reasoning, non-ID applications, purely administrative or educational uses, and synthetic cases not traceable to real clinical scenarios. Studies focusing solely on user satisfaction without clinical correctness were also excluded.
Information sources and search
We searched PubMed, CENTRAL, Scopus, and Web of Science from 1 January 2018 to 30 September 2025. The search strategy combined index terms and free-text words for: (1) types of healthcare-associated infection and causative organisms; (2) LLM-based interventions, including IPC Core Components; (3) national or subnational context; and (4) outcome measures. No language restrictions were applied. Exact search strategies are provided in the appendix.
Study selection
Two independent reviewers screened titles (A.G., M.O.), abstracts, and full texts using pre-defined eligibility criteria. Disagreements were resolved by discussion or consultation with a third reviewer (E.K.).
Data extraction
Two reviewers (A.G. and M.O.) independently extracted key study details, including design, task type, disease focus, model used, data source, validation, comparator, and main outcomes. Unclear or missing information was clarified with authors or recorded as “not reported.”
Risk of bias and reporting quality
We assessed risk of bias using QUADAS-AI.^2^ Two reviewers (A.G.,M.O.) independently assessed each domain; disagreements were resolved by discussion.
Data synthesis
We synthesized findings narratively, stratified by task category, disease focus, and LLM family. Within task categories, we grouped studies by specific infections (e.g., pneumonia/respiratory, bloodstream infection [BSI]/sepsis, catheter-associated urinary tract infection [CAUTI], invasive fungal infection [IFI/IMD], HIV/sexually transmitted infections [STIs], tuberculosis [TB]). When three or more commensurable studies examined the same task, disease, and metric, we reported descriptive statistics (median [IQR]) without formal meta-analytic pooling.
Results
Study selection
The search retrieved 6,060 records from PubMed (1,329), CENTRAL (912), Scopus (3,379), and Web of Science (440). After removing 2,408 duplicates, 3,652 records were screened. Of these, 3,471 were excluded for irrelevance or pediatric focus. The remaining 181 full texts were reviewed, and 150 were excluded for not meeting inclusion criteria. Thirty-one studies, published between 2023 and 2025, were included in the final analysis (Figure 1).^3–33^
Risk of bias
QUADAS-AI assessment revealed low overall risk in 7/31 studies (23%) and high risk in 24/31 (77%) (Table Sup 1). Patient selection showed high risk in 24 studies (77%), primarily attributable to reliance on synthetic vignettes or curated guideline-based questions rather than consecutive real patient encounters. Meanwhile, the remaining domains exhibited predominantly low risk: index test (24/31 low risk, 77%), reference standard (27/31 low risk, 87%), and flow and timing (29/31 low risk, 94%).
Study characteristics
The 31 included studies evaluated LLM applications across diverse settings: inpatient wards (n=8), ICU (n=1), outpatient or primary care (n=1), mixed clinical settings (n=10), public health (n=2), laboratory (n=1), and comparative bench/question-based studies (n=8). Study designs comprised cross-sectional evaluations (n=19), prospective studies (n=5), retrospective analyses (n=4), and specialized accuracy/pilot studies (n=3).
Disease foci included sexually transmitted diseases (n=4), urinary tract infections (n=4), tuberculosis (n=2), sepsis (n=2), HIV (n=2), hepatitis (n=2), mixed ID (n=3), and single studies on bacteremia, osteoarticular infections, vertebral osteomyelitis, blood culture diagnosis, surgical site infection, pneumonia, antimicrobial resistance, Infection Prevention and Control(IPC) guidelines, infective endocarditis prophylaxis, and general ID topics. Sample sizes ranged from 6 vignettes to 4,786 patients.
LLM families included GPT-4/4o (n=20 studies), Claude 3/3.5 (n=7), Gemini (n=10), Mistral/Llama (n=3), custom chatbots (n=2), and specialized tools (n=6 studies using Consensus, OpenEvidence, Amboss, Perplexity, Microsoft Copilot). Retrieval-augmented generation or agentic architectures were explicitly implemented in 5 studies.
Data sources were vignettes/synthetic cases (n=21) and real EHR or clinical data (n=10). Comparators included infectious disease specialists (n=8), guidelines (n=8), other LLMs (n=13), or none (n=2) (Supplementary Table 2).
Safety and Clinical Applicability
Safety concerns were documented in 28/31 studies (90.3%). Clinically incomplete responses represented the most prevalent issue (19/31, 61.3%), with usefulness ratings of 42% and mean completeness scores of 40%. Unsafe recommendations occurred in 10/31 studies (32.3%), manifesting as substandard responses posing serious health risk in 10.3% of evaluated cases. Harmful or inadequate recommendations appeared in 7/31 studies (22.6%): 16% potentially hazardous bacteremia management plans (Maillard et al.)^32^, 71% incorrect isolation precautions in sepsis cases (Lorenzoni et al.)^3^, and 9% inadequate source-control recommendations rates significantly exceeding infectious disease expert benchmarks (1–4%, p<0.05).^32^
Hallucinations (fluent, confident response that presents incorrect information, akin to clinical confabulation), fabricated citations, contradictory statements, or artificial clinical details were documented in 10/31 studies (32.3%). Constraint-induced limitations (guardrail refusals, unanswered queries, token limits preventing processing of complete medical records) affected 9/31 studies (29%): 8% of interactions yielded no response and 65% experienced extraction errors from incomplete chart access. Context-dependent failures (errors mitigated by providing complete clinical data or external knowledge bases) in 3 studies, (3/31, 9.7%) demonstrated marked improvement with interventions: retrieval-augmented generation reduced hallucinations; providing complete clinical documentation improved central line-associated bloodstream infection detection specificity from 35% to 75% (Rodriguez-Nava et al.). These findings indicate requirements for expert oversight, structured validation protocols, and context-enrichment architectures before clinical deployment (Supplementary Table 2).
Antimicrobial Stewardship Performance
Twelve studies assessed LLMs in antimicrobial stewardship. Across tasks, concordance with infectious-disease specialists was moderate, averaging about 50%. Two bacteremia vignette studies (n=100 each) reported identical 51% agreement (κ=0.48). Agreement was higher for Gram-positive (70%, κ=0.68) than Gram-negative infections (46%, κ=0.43). In Maillard et al.’s prospective study using real patient data (n=44, GPT-4), diagnostic accuracy reached 59% and empiric therapy appropriateness 64%, but 16% of recommendations were potentially harmful, including inactive agents and missed source-control interventions.^32^ In a blood culture stewardship study (n = 84), LLMs produced 13% harmful or inadequate recommendations, significantly higher than experts (4%, p = 0.047). Most errors involved missing echocardiography for suspected endovascular infections.^24^
A 14-model comparison showed wide variation in antibiotic prescribing accuracy. Antibiotic selection ranged from 30% to 100%, while dose and duration accuracy fell to 0–92%. Citation accuracy ranged 0–100%, and several models produced fabricated references. ChatGPT-o1 performed best overall (71.7% correct, 43/60).^30^ In real-patient testing, Lorenzoni et al. (n = 7, GPT-4o) achieved perfect concordance for antibiotic selection but misjudged isolation precautions in 71% of cases.^3^ Rodriguez-Nava and colleagues reported initially low central line-associated bloodstream infection (CLABSI) detection specificity (35%), which improved to 75% when complete chart information was provided, highlighting the critical role of RAG in improving accuracy.^11^ In outpatient vignettes (n = 24, six models), Nguyen et al. found correct antibiotic selection between 59% and 100% and complete clinical advice between 25% and 96%, with proprietary models outperforming open-source ones.^29^
Diagnostic Accuracy and Guideline Concordance
Four studies evaluated LLM diagnostic accuracy for infectious conditions using sensitivity and specificity metrics. Diagnostic sensitivity ranged from 80% to 100% (median 91%), with high performance for catheter-associated urinary tract infection detection (91%), tuberculous pleural effusion diagnosis (89%), and surgical site infection screening (100%). Specificity varied substantially (range 35–100%, median 92%). Wu and colleagues demonstrated that a custom LLM for tuberculous pleural effusion diagnosis achieved AUROC 0·96 (sensitivity 76%, specificity 100%), matching or exceeding traditional machine learning models.^17^ Satheakeerthy and colleagues showed zero-shot Llama-3–70B could screen surgical site infections with 100% sensitivity and 86% specificity, flagging infections earlier than infection control staff in 50% of cases.^12^
Twelve studies evaluated LLMs in answering guideline-based questions, with accuracy ranging from 42% to 98% depending on topic and complexity. Borgonovo et al. found specialized RAG tools (Open Evidence, Microsoft Copilot) most accurate (94.4%), outperforming general-purpose models such as GPT-4o and Gemini 2.5 Pro (92.9%).^26^ Lin et al. showed OpenAI O1 performed best for pneumonia guidelines, achieving 55% “excellent” responses and effective self-correction, compared with GPT-4o, which produced 40% “poor” responses.^20^ Kufel et al. reported only 41.8% of GPT-3.5 outputs were rated “useful,” with low completeness (5.8/10) and safety (6.4/10).^28^ Accuracy also varied by disease: tuberculosis questions scored 3.6–4.4/5, viral hepatitis 71–78%, and infective endocarditis prophylaxis 69–80%, with GPT-4o highest (80%). Performance was consistently better for informal, social-media-style questions (92%) than for formal guideline queries (69%, p < 0.001) (Figure 2, Supplementary Table 3.).^9^
Limitations and Methodological Quality
Methodological quality was constrained by design and reporting deficiencies. More than two-thirds of studies (21/31, 68%) evaluated LLMs using synthetic vignettes or curated cases, potentially overestimating performance by avoiding complexity, ambiguity, and incomplete documentation characteristic of actual practice. Among studies using real patient data (32%), most were retrospective with attendant selection bias. Sample sizes were frequently inadequate (35%), yielding unstable estimates. Validation approaches were weak across the evidence base. 12 studies (39%) had no expert comparison, instead benchmarking LLMs against other LLMs or guideline text alone. 14 studies (45%) judged correctness by guideline concordance without clinical context. The predominant cross-sectional design (22/31, 71%) precluded assessment of performance stability over time, while lack of blinding in 24/31 (77%) introduced expectation bias that might favor novel technology. Reproducibility and transparency were deficient. Most studies queried each question only once without assessing response variability, potentially concealing inconsistency and raising concerns about selective reporting of optimal responses. Process measures were absent in 21/31 (68%), leaving intervention fidelity and implementation strategies unclear. Outcome definitions were universally heterogeneous, employing non-standardized custom scales for usefulness, appropriateness, or quality that precluded cross-study comparison or meta-analysis (Table 2).
Discussion
In this systematic review of 31 studies, we found wide variability in how LLMs perform across infectious disease medical practice. Their accuracy and reliability remain insufficient for autonomous clinical use. Across antimicrobial stewardship, diagnosis, guideline interpretation, and surveillance tasks, performance was inconsistent. Concordance with infectious-disease specialists for empiric therapy averaged about Taken together, the evidence suggests that LLM diagnostic performance is strongest for narrow, well-specified classification tasks, ranging from common syndromes such as CAUTI,SSI to rarer entities such as tuberculous pleural effusions. However, accuracy and calibration consistently decline when models must integrate context across comorbidities, timelines, devices, cultures, and competing diagnoses, which is where clinical reasoning is most vulnerable to error. According to current evidence, RAG can improve specificity by providing access to full clinical documentation. Yet safety remains a central limitation: most studies reported incomplete or unsafe recommendations and, in many cases, fabricated or contradictory content. Even the most advanced models (at time of evaluation), such as GPT-4o and Claude 3.5, performed better than open-source systems but still failed to reach expert reliability. Their stronger results on conversational or social-media-style questions compared with formal guideline queries suggest training data skewed toward lay information rather than specialist clinical knowledge.
Safety and clinical applicability
Safety has emerged as a significant barrier to the clinical deployment of LLMs in ID management. Rates of harmful or inadequate antimicrobial recommendations from these models ranged between 13% and 16%, sharply contrasting with the 1% to 4% error rates reported by infectious disease experts (Maillard et al.). Such harmful recommendations were described in Schwartz et al. document a paradigm case: when prompted to create a management plan for cryptococcal meningitis, GPT-3.5 recommended initiating antiretroviral therapy within 2 weeks-a recommendation^34^ directly contradicted by Boulware et al.’s randomized controlled trial proving this approach increases mortality.^35^ Such inaccuracies pose serious risks by jeopardizing patient safety and exacerbating the global issue of AMR.^36^ The underlying causes of these errors may mirror those observed in AMR challenges globally, primarily arising from various factors, such as wrong indication, selection, dosage, duration, lack of adherence to infection prevention and control (IPC) protocols.^37,38^ LLMs showed this issues when they were lacking a defined guidelines, leading to generate incorrect responses. This challenge is further compounded by geographic variability in treatment protocols (Nguyen et al.); as established LLMs often lack access to localized medical knowledge.^39^ This highlights the imperative for implementing RAG systems, which would enable LLMs to integrate context-specific information, thereby aligning with established protocols and mitigating the risk of adverse treatments. Another contributing factor to these inaccuracies is the inherent issue of hallucinations generated by LLMs.^40^ While not errors per se (byproduct of LLMs training)^41^, these hallucinations manifesting as spurious guideline citations, contradictory assertions within a single interaction, or fabricated clinical details were documented in approximately one-third of the studies reviewed, undermining clinical trust and introducing medico-legal risks. This phenomenon is linked to LLMs’ limited access to real-time resources.^42^ However, research indicates that providing web access significantly enhances their ability to generate accurate, high-quality scientific references.^43^ Given these considerations, LLMs should not be deployed in their unmodified form due to their potential threats in the field (Figure 3.). Instead, they should be utilized as part of AI agents that leverage LLM capabilities while planning tasks, accessing external tools, and coordinating with other agents. In contrast to standard LLMs, these agents can perform multi-step processes, access real-time clinical information, and synthesize data from diverse sources.^44^ This approach addresses the aforementioned safety concerns while also tackling additional issues such as verbosity, the need for expert-in-the-loop safety mechanisms, and iterative improvement. Due to the dearth of studies focusing specifically on ID, we cannot assertively conclude that such AI agents will resolve these challenges. However, this represents a critical area for future research as the next phase of LLM studies in infectious disease should aim to explore these innovations.
CAUTI and CLABSI exemplify both the promise and the ceiling for LLM-enabled hospital epidemiology. These endpoints are operational quality metrics defined by NHSN surveillance rules,^45,46^ not bedside diagnoses, so adjudication hinges on consistent application of standardized criteria to temporally ordered device, culture, and symptom data, often under substantial infection-prevention workload.^21^ In CAUTI, GPT-4 achieved high performance on curated case abstractions and improved further with iterative, criteria-aligned prompting, highlighting how structured inputs and explicit rule framing can materially shift reliability. In contrast, CLABSI identification from real clinical notes was strongly context dependent: when the model was constrained to partial chart excerpts, sensitivity remained high but specificity was limited, and performance improved when key missing chart elements were supplied, supporting the use of RAG to pull the relevant EHR fields and NHSN rule elements before generation. Near term, LLMs are best deployed as definition-aware tools for education and structured abstraction that priorities sensitivity and trigger escalation, while final CAUTI and CLABSI attribution remains with trained infection-prevention reviewers. Because surveillance labels can propagate to antimicrobial decisions, CAUTI workflows should include explicit stewardship safeguards that confirm symptoms and exclude asymptomatic bacteriuria before outputs are acted on.
Comparison with prior literature
Up until now the topic of AI in ID is residing in a controversial place. A stark example is the contradiction between Siddig et al. declaring AI “revolutionizing” ID control^47^ versus Schwartz’s et al. “Black Box Warning” arguing “existing LLMs are not safe for clinical consultation”.^34^
Our own group’s previous systematic review of 15 studies identified promise of NLP and LLM in areas like pathogen detection and surveillance but noted limited real-world validation.^48^ Our current findings extend beyond that review which included by the time of publications only two LLM studies. Be it as it may our current results show persistence of LLM limitation in literature, as evidenced by our observation that 58% of included studies relied on synthetic vignettes rather than real-world data.
Howard et al. highlighted similar challenges in data completeness and interoperability for AI in tackling AMR, advocating for support of UN General Assembly targets like antimicrobial stewardship programs and surveillance, though with less focus on LLM-specific safety risks.^49^ Despite this, our review found that LLMs may be useful in specific niches: diagnostics for urinary tract infections (UTIs), pneumonia, bloodstream infections (BSIs), and invasive fungal infections in defined populations (median AUROC 0.82, range 0.64–0.95); social media-based disease surveillance (accuracy 85–100%, with 92% for informal queries); antimicrobial stewardship (median appropriateness 71%, range 57–85%); and infection prevention/control with structured prompts (accuracy 98–100%). These successes share common features of well-defined diagnostic criteria, structured data sources, supplementary human verification, and consequences of errors that allow correction before patient harm.
Limitations
Our systematic review has several limitations. First, substantial heterogeneity in populations, interventions, and outcome measures precluded meta-analysis. Second, the overall risk of bias was high across included studies. Third, the rapidly evolving nature of LLM technology means newer models might show different performance characteristics than those evaluated in our included studies. Finally, the predominance of retrospective studies in our review indicates a need for more prospective studies to validate the findings.
Conclusions
The reviewed iterations of LLMs are not well-suited for clinical application in ID. Most studies highlight safety concerns despite the models demonstrating high performance in structured tasks (UTI, BSI and fungal infections). Issues such as hallucinations, missing guideline information, and lack of web search capabilities contribute to misinformation from LLMs. To mitigate these challenges, LLMs should be employed as AI agents before being utilized in future studies.
Supplementary Material
Supplementary Files
This is a list of supplementary files associated with this preprint. Click to download.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1Page MJ, Mc Kenzie JE, Bossuyt PM (2021) The PRISMA 2020 statement: an updated guideline for reporting systematic reviews. BMJ 372:n 71. 10.1136/bmj.n 7133782057 PMC 8005924 · doi ↗ · pubmed ↗
- 2Guni A, Sounderajah V, Whiting P, Bossuyt P, Darzi A, Ashrafian H (2024) Revised Tool for the Quality Assessment of Diagnostic Accuracy Studies Using AI (QUADAS-AI): Protocol for a Qualitative Study. JMIR Res Protoc 13:e 58202. 10.2196/5820239293047 PMC 11447435 · doi ↗ · pubmed ↗
- 3Lorenzoni G, Garbin A, Brigiari G, Papappicco CAM, Manfrin V, Gregori D (2025) Large Language Models in Action: Supporting Clinical Evaluation in an Infectious Disease Unit. Healthcare 13(8):879. 10.3390/healthcare 1308087940281830 PMC 12027404 · doi ↗ · pubmed ↗
- 4Evaluation of artificial intelligence (AI) chatbots for providing sexual health information: a consensus study using real-world clinical queries | BMC Public Health | Full Text. Accessed October 8 (2025) https://bmcpublichealth.biomedcentral.com/articles/10.1186/s 12889-025-22933-8
- 5De Vito A, Geremia N, Marino A (2025) Assessing Chat GPT’s theoretical knowledge and prescriptive accuracy in bacterial infections: a comparative study with infectious diseases residents and specialists. Infection 53(3):873–881. 10.1007/s 15010-024-02350-638995551 PMC 12137519 · doi ↗ · pubmed ↗
- 6AI Chatbots as Sources of STD Information: A Study on Reliability and Readability | Journal of Medical Systems. Accessed October 8 (2025) https://link.springer.com/article/10.1007/s 10916-025-02178-z
- 7Zhuo KY, Kim P, Kovacic J (2024) Can Artificial Intelligence Treat My Urinary Tract Infections?—Evaluation of Health Information Provided by Open AI™ Chat GPT on Urinary Tract Infections. Société Int D’Urologie J 5(2):104–107. 10.3390/siuj 5020018 · doi ↗
- 8Cakir H, Caglar U, Sekkeli S (2024) Evaluating Chat GPT ability to answer urinary tract Infection-Related questions. Infect Dis Now 54(4):104884. 10.1016/j.idnow.2024.10488438460761 · doi ↗ · pubmed ↗