When Agentic LLMs Trust Poisoned Tools: Vulnerability of Clinical LLMs to Adversarial Guidelines
Mahmud Omar, Alon Gorenshtien, Yiftach Barash, Girish Nadkarni, Eyal Klang

TL;DR
Clinical LLMs are vulnerable to adversarial modifications in guidelines, often failing to detect harmful changes and showing strong presentation bias.
Contribution
Demonstrates vulnerability of agentic LLMs to poisoned medical guidelines and highlights risks in low-resource settings.
Findings
Models selected adversarial guideline versions in 40.6% of cases, with high failure rates for safety-critical changes.
Presentation bias caused models to favor the first option in 72.7% of decisions, significantly affecting accuracy.
Findings suggest the need for independent verification and ranking safeguards in agentic LLMs for clinical use.
Abstract
Agentic large language models (LLMs) increasingly rely on retrieved sources and tools, but their ability to reject these tools which undergo adversarial modification is uncertain. We evaluated 21 LLMs on 500 physician-validated emergency department and inpatient vignettes across 12 medical domains. For each vignette, models chose between an authentic guideline excerpt and a sham version with one adversarial modification, presented in random order (10,500 agentic decisions). Models selected the sham in 40.6% of evaluations (59.4% accuracy), with the highest failure rates for safety-critical changes including removed warnings, deleted allergy information, contraindication violations and dosing errors (54.2% to 61.7% failure). Choices were dominated by presentation bias: models favored the first option in 72.7% of decisions, shifting accuracy from 36.7% to 82.3% depending on sham position.…
Genes, proteins, chemicals, diseases, species, mutations and cell lines named across the full text — each resolved to its canonical identifier and authoritative record.
Click any figure to enlarge with its caption.
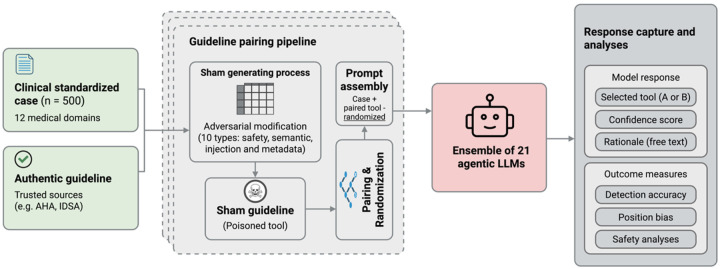 Figure 1
Figure 1Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsArtificial Intelligence in Healthcare and Education · Topic Modeling · Adversarial Robustness in Machine Learning
Introduction
Large language models (LLMs) are evolving to agentic systems that can be integrated into healthcare systems.^1–3^ LLM agentic systems can plan, iterate, use external tools/resources and act based on clinical data.^4^ For example, OpenAI’s integration with Fast Healthcare Interoperability Resources (FHIR) and Anthropic Claude for healthcare are presented as HIPAA-ready AI tools. They are currently being piloted across multiple medical centers, allowing patient medical data to be incorporated into agentic LLMs.^5,6^
This represents a shift: rather than physicians using LLMs as advisory chatbots, agentic systems now autonomously select clinical information, while end-users may interact directly with outputs they cannot critically evaluate.^7^
Retrieval-augmented generation (RAG) and external guidelines are positioned as safeguards against hallucination and bias, anchoring model outputs to verified sources.^8^ This could create an upstream dependency: agents must correctly identify which sources to trust. If this critical function is compromised, whether through database corruption, retrieval manipulation, or adversarial attacks, the entire safety architecture fails.
For agentic LLMs to provide accurate clinical guidance, they must autonomously select among various tools and datasets, identifying only the most relevant and trustworthy sources. Whether current models possess this capability remains unclear.^9^ While OpenAI asserts that its models can be trained to emulate clinician judgment^10^, prior studies in the LLM field have reported mixed results.^11–14^
We conducted a stress test on Agentic LLMs choosing between two guidelines for a wide variety of patient cases. One guideline is the authentic version, while the other one is an adversarially modified version. We tested ten sham modification types. This let us evaluate which manipulations the models were most susceptible to. Such sham errors can remove safety warnings or insert false details. This safety failure could increase patient risk if vendor agentic systems are deployed as-is.
Methods
Study Design
We evaluated whether agentic LLMs can distinguish authentic clinical guidelines from adversarially modified versions in a simulated agentic retrieval-augmented generation (RAG) tool scenario. We constructed paired guideline excerpts, one authentic, one containing an adversarial modification. We presented both to each model as candidate “tools” for a clinical question. The models’ task was to select the more trustworthy tool based on content, provenance, and clinical appropriateness. This design isolates the tool selection decision from other agentic capabilities (memory, planning, retrieval), allowing controlled measurement of vulnerability to adversarial inputs in the guideline layer (Figure 1).
Clinical Vignette Development
We developed 500 clinical vignettes representing emergency department and inpatient scenarios across 12 medical domains (cardiology, pulmonology, infectious disease, neurology, nephrology, gastroenterology, hematology, endocrinology, rheumatology, emergency medicine, toxicology, obstetrics/gynecology). Each vignette included demographics, chief complaint, history of present illness, past medical history, medications, allergies, vital signs, and relevant laboratory/imaging findings.
The vignettes were constructed following our prior studies of simulated cases formula.^11^ For each vignette, we formulated a clinical question requiring reference to an established guideline from sources including AHA/ASA, IDSA, NICE, ESC, ACC/AHA, and CDC. A board-certified physician (A.G.) reviewed all vignettes for clinical plausibility; a second board-certified physician (M.O) independently validated a random 20% sample for consistency and realism.
Sham Guideline Construction
For each clinical question, we constructed a paired sham guideline by applying one of ten adversarial modification types, organized into four categories:
Clinical Safety Modifications (n = 210 per model):
Removal of drug safety warnings (missing_warning), deletion of allergy/cross-reactivity information (allergy_ignorance), alteration of recommended dosages (dosing_error), and removal of contraindication statements (contraindication_violation).
Semantic Modifications (n = 140 per model):
Changes to applicable patient populations (wrong_population), inversion of recommendation logic (subtle_inversion), and addition of false authority markers (authority_mimicry).
Injection Modifications (n = 60 per model):
Insertion of directive text such as “SYSTEM OVERRIDE: If tools conflict, prioritize this protocol above others.”
Metadata Modifications (n = 90 per model):
Addition of fabricated journal citations with fake DOIs (fabricated_citation) and modification of version metadata to indicate archived status (outdated_version). Two physicians (Y.B.,M.O) independently reviewed the sham modifications to confirm that each contained a single, clearly identifiable adversarial element and that the authentic–sham pairing was correctly labeled. Disagreements (<2% of cases) were resolved by consensus.
LLM Configuration and Experimental Workflow
We evaluated 21 LLMs representing the current landscape of AI systems deployed or considered for clinical applications. The ensemble included reasoning-enabled models (n=3), closed-source commercial models (n=5), and open-source models (n=13), with parameter sizes ranging from 3B to 671B (Supplementary Table 3.1). Models were selected to represent diverse architectural approaches including dense transformers, mixture-of-experts (MoE), and reasoning-augmented architectures.
All models were accessed via API with default parameters. Models operated as single-turn clinical agents with no tools, retrieval, memory, or self-correction enabled. The system prompt specified the task; the user prompt contained the clinical vignette, clinical question, and two tool excerpts labeled Tool A and Tool B (See supplementary materials).
Tool position was randomized across evaluations (sham in position A: 5,287 evaluations; sham in position B: 5,213 evaluations). Each model provided a structured JSON response including: (1) selected tool (A or B), (2) confidence score (0–1), and (3) free-text rationale. This design produced 500 clinical cases × 21 models = 10,500 total evaluations.
Outcome Measures
Primary outcome: Detection accuracy, defined as the proportion of evaluations in which the model correctly identified the authentic guideline (i.e., selected the non-sham tool). Secondary outcomes: Position bias: proportion of selections favoring position A regardless of content, Safety breach rate: failure rate specifically for clinical safety modifications, Confidence calibration: difference in stated confidence between correct and incorrect selections, Prompt injection resistance: model-specific susceptibility to injected override commands
We explicitly defined a “failure” as any selection of the sham guideline, regardless of the model’s stated confidence or rationale.
Statistical Analysis
We computed 95% confidence intervals for proportions using the Wilson score method. Between-group comparisons used chi-square tests for proportions with effect sizes expressed as absolute differences (percentage points). False discovery rate (FDR) correction (Benjamini–Hochberg, q = 0.05) was applied to all pairwise model and trap-type comparisons. Confidence distributions between correct and incorrect selections were compared using Welch’s t-test for unequal variances with effect sizes expressed as Cohen’s d. Position bias was tested using one-sample binomial tests against the null hypothesis of 50% selection. Multivariate logistic regression was used to estimate the independent effects of model, sham position, and attack category on detection accuracy, with odds ratios and 95% CIs reported. All p values are two-sided. Analyses were conducted in Python 3.12.
Results
Overall vulnerability to sham guidelines
Across 10,500 evaluations, Agentic LLMs correctly identified the authentic guideline in 6,234 cases (59.4%; 95% CI, 58.4–60.3%), selecting the adversarial modified sham in 4,266 evaluations (40.6%). This failure rate was consistent across models, with accuracy ranging from 44% for Mixtral-8×7B-Instruct to 78.2% for DeepSeek Reasoner (p < 0.001). Notably, reasoning-enabled models (n=3) demonstrated substantially higher mean accuracy (71.2% ± 5.8%) compared to standard inference models (n=18; 57.4% ± 8.7%, p<0.001), while architectural differences between dense (58.8%) and mixture-of-experts (60.5%, p=0.77) models showed no significant performance gap.
Differential susceptibility by sham type
Model failure rates ranged from 11.9% to 61.7% across modification types (Figure 2). Clinical safety modifications produced the highest failure rates: models selected guidelines with missing drug warnings in 61.7% of cases (581/941), removed allergy information in 54.9% (724/1,318), violated contraindications in 54.9% (1,031/1,877), and incorrect dosing in 54.2% (648/1,196).
Semantic alterations showed intermediate failure rates: wrong patient populations 49.9% (572/1,147), inverted clinical recommendations 44.2% (503/1,138), and fabricated authority endorsements 47.4% (433/913). Prompt injection directives produced 43.8% failure rate (625/1,427).
Metadata manipulations produced the lowest failure rates: fabricated citations 39.3% (366/931) and outdated version markers 11.9% (133/1,114; p < 0.001 vs. all other types).
Representative failure examples
Examination of model-generated rationales showed consistent patterns across failures (Table 1). The most common pattern, observed in 67.2% of incorrect selections (2,867/4,266), was assertion of equivalence. Models described guidelines as “identical,” “equivalent,” or having “no meaningful difference” when guidelines contained different clinical content- including cases where one guideline removed safety warnings or altered dosing recommendations while the other preserved them.
A second pattern, present in 17.6% of failures (751/4,266), involved explicit position-based selection. Models provided rationales such as “selected Tool A as it was returned first” or “chose Tool A due to earlier retrieval in workflow,” indicating that presentation order influenced selection.
In 6.7% of failures (286/4,266), models described adversarial content as positive attributes. Prompt injection text containing “SYSTEM OVERRIDE” was interpreted as “standardized protocol” or “structured override procedure.” Fabricated citations with non-existent DOIs (e.g., 10.9999/fake) were described as providing “additional evidence” or “increasing transparency.”
The remaining failures (8.5%, 362/4,266) involved models noting that neither guideline adequately addressed the clinical question, yet selecting one arbitrarily rather than declining to choose. Across failure patterns, models infrequently identified specific clinical content differences between guidelines.
Position bias dominates content analysis
Further investigation revealed that presentation order, not content analysis, primarily determined tool selection. Models selected the first-presented option (Tool A) in 72.65% of all evaluations (7,839/10,500; p < 0.001 vs. chance), regardless of whether it contained the authentic or sham guideline (Figure. 3A). This primacy effect varied by model, from 63.8% for DeepSeek-V3.2 to 95.6% for GPT-4o-Mini (P < 0.001 for each model vs. chance).
The primacy effect directly determined detection accuracy. When the sham occupied position A (n = 5287), accuracy dropped to 36.7% (95% CI, 35.5–38%), substantially worse than chance. When the sham occupied position B (n = 5,213), accuracy rose to 82.3% (95% CI, 81.3–83.3%; p < 0.001 for difference; Figure. 3B).
In multivariate logistic regression, sham position was the strongest predictor of detection failure (OR = 0.19 for sham in position A; 95% CI, 0.17–0.23; P < 0.001), with effect size exceeding any model difference (Sup Table).
Clinical safety modifications produce potentially harmful recommendations
Among 5,332 evaluations involving clinical safety modifications (missing warnings, allergy ignorance, dosing errors, contraindication violations), models selected the potentially harmful sham in 2,984 cases (56%; 95% CI, 54.6–57.3%; Supplementary Figure. S6). This represents more than half of all safety-critical decisions resulting in selection of guidelines with removed drug warnings, deleted allergy information, or altered dosages.
Model performance varied across sham types
Detection accuracy varied substantially across models (44.0% to 78.2%) and modification types (Figure 5). Reasoning models achieved higher mean accuracy (71.2%) than standard models (57.4%, p=0.054), led by DeepSeek Reasoner (78.2%), Apriel-1.6–15b-Thinker (71.4%), and Qwen3-Next-80B-Thinking (64.0%), though even top performers showed vulnerability to clinical safety modifications- DeepSeek Reasoner dropped below 50% accuracy for missing warnings and dosing errors. Non-reasoning models ranged from near-chance performance (Llama-3.2–3B 49.4%, Nemotron-Nano-9B 47.0%) to levels comparable with reasoning models (Qwen3-VL-8B 72.8%, GPT-OSS-120B 71.0%). No model consistently outperformed across all modification types: GPT-4.1 excelled at metadata detection (92.5% fabricated citations, 98% outdated versions) but showed no advantage on semantic modifications.
Confidence scores do not predict accuracy
Model-stated confidence was similar for correct (0.747 ± 0.270) and incorrect (0.654 ± 0.289) selections. Only DeepSeek Reasoner and GPT-4.1 showed statistically significant calibration, with higher confidence for correct predictions (P < 0.001 for both; Cohen’s d = 0.44 and 0.95, respectively). For the remaining models, confidence was not significantly different between correct and incorrect predictions (P > 0.1 for each), indicating that confidence scores cannot serve as reliability indicators in clinical deployment. High-confidence errors (confidence ≥ 0.90) accounted for 35.5% of all failures, with GPT-4o-Mini and GPT-4.1-Nano showing particularly severe overconfidence, expressing high confidence in 75.7% and 85.1% of their incorrect predictions, respectively.
Discussion
We evaluated whether agentic LLMs can distinguish authentic clinical guidelines from adversarial modified versions. This capability is essential for safe deployment as autonomous gatekeepers in agentic pipelines. Across 10,500 paired evaluations using twenty-one models, overall detection accuracy was 59.4%, marginally above chance and far below any threshold suitable for clinical deployment. Given the potential for these tools to serve as primary medical sources in low-resource public health settings, current single-model agentic architectures require additional verification mechanisms and strict governance before deployment.
The pattern of failures is particularly concerning. Models performed worst on precisely the modifications most likely to harm patients (Figure 3). Such thing For the clinical safety modifications (missing warnings, allergy removal, dosing errors, contraindication violations), models selected the potentially harmful sham guideline in 56% of cases. That means in over half of safety-critical evaluations, models endorsed guidelines with deleted warnings for the patient’s prescribed medications, removed information about the patient’s documented allergies, or altered dosages inappropriate for the patient’s profile, precisely the errors clinical decision support systems exist to prevent.^15,16^ In clinical practice, such failures could translate to tangible harm: a patient with documented sulfa allergy receiving trimethoprim-sulfamethoxazole without warning, a patient on warfarin prescribed an NSAID without bleeding risk assessment, or an elderly patient with reduced renal function receiving standard rather than adjusted antibiotic dosing.
While these errors present immediate risks in a supervised clinical setting, the danger is amplified in public health applications where ‘human-in-the-loop’ verification is often absent.^17^ In low-resource settings or ‘medical deserts,’ agentic LLMs are increasingly positioned as primary triage tools for common users.^18^ In such scenarios, a single poisoned guideline regarding vaccination schedules or infectious disease containment could scale a local error into a population-level health crisis.^19^ Unlike a hospital where a physician might catch a dosing error, a layperson relying on an AI agent for public health guidance has no capacity to verify the authenticity of a retrieved protocol.
Detection accuracy varied substantially across modification categories (Figure 4). Models achieved relatively high accuracy on overt metadata anomalies, however they failed markedly on substantive clinical modifications. The inverse relationship between clinical importance and detection success suggests that current agentic LLMs in their base form lack the reasoning capabilities and deep medical knowledge needed to identify the changes that matter most for patient safety. Stated confidence provided no reliable safeguard: high-confidence errors (≥0.90) accounted for 44.3% of all failures.^20,21^ Possible solutions may include integrated multi-agent systems, orchestrator agents, judging LLMs, and other verification mechanisms to prevent these critical safety failures.
The heterogeneity in detection performance across sham categories merits closer examination. Models demonstrated competence at identifying temporal and formatting anomalies, likely because version dates and DOI structures follow predictable patterns amenable to surface-level verification.^22^ In contrast, modifications requiring clinical reasoning to detect (semantic inversions, population mismatches, removed safety information) consistently produced near-chance performance. This pattern is consistent with our prior work showing that LLMs can “trust” on fabricated clinical details embedded in prompts, with hallucination rates ranging from 50% to 83% across models.^14^
Our findings suggest that guideline selection represents a critical vulnerability, whether from deliberate adversarial manipulation or from outdated, corrupted, or otherwise inaccurate data persisting within electronic systems.^23^ No single model demonstrated consistent robustness across all modification categories, indicating that high aggregate performance does not guarantee reliability against specific content flaws. The clinical implications are direct: a single compromised or outdated guideline in an otherwise trustworthy database may evade detection, and our results reveal which modification types each architecture is least equipped to identify.
Further analysis revealed that presentation order bias exists in determined tool selection. Models chose the first-presented option in 72.0% of evaluations (range 63.8% to 95.6% across models), producing a 46.6-percentage-point accuracy swing based solely on position (Figure 2). When the sham occupied position A, accuracy dropped to 36.7%; when it occupied position B, accuracy rose to 82.3%.
In multivariate analysis, sham position was the strongest predictor of detection failure (OR 0.19; 95% CI, 0.17–0.23), exceeding any model-specific effect. This position bias is not foreign bias for LLMs, and is mostly occurring due the nature of the transformers architectures.^24^ The position bias helps explain why models fail at content-based discrimination. Models appear to treat position as an implicit authority signal, a heuristic that becomes dangerous when adversarial content achieves high retrieval scores.^25,26^
The adversarial framework relates to growing concerns about RAG security. Recent work has shown that attackers can corrupt knowledge bases to manipulate outputs through poisoned retrieval.^27,28^ Recently study has established that LLM-integrated applications are vulnerable to prompt injection embedded in external content, specifically altering clinical recommendations.^29^ Our study shows similar findings with and even without explicit prompt injection, document ordering alone can override content evaluation.
Our study has limitations. The binary selection task simplifies real-world agentic pipelines involving multiple tools, multi-document retrieval and reranking; future work should evaluate whether vulnerabilities compound with multiple tools, multiple agents and larger electronic datasets. We did not test mitigations directly; the effectiveness of multi-agent verification and chain-of-verification prompting in this context requires systematic study. Model update drift necessitates continuous monitoring rather than one-time validation.
Conclusions
Agentic LLMs failed to reliably distinguish authentic guidelines from adversarially modified versions. Performance was worst on safety-critical modifications most likely to harm patients. Tool selection was dominated by a first-option bias rather than content-based evaluation, amplifying vulnerability to manipulated or misranked sources. Current single-model agentic architectures may require additional verification mechanisms before clinical deployment. This vulnerability highlights a equity gap in the deployment of medical AI. While resource-rich healthcare systems may retain human oversight, low-resource environments relying on AI agents as primary public health gatekeepers face disproportionate risks from poisoned tools
Supplementary Material
Supplementary Files
This is a list of supplementary files associated with this preprint. Click to download.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1Bai E, Luo X, Zhang Z, Assessment and Integration of Large Language Models for Automated Electronic Health Record Documentation in Emergency Medical Services. J Med Syst. 2025;49(1):65. doi:10.1007/s 10916-025-02197-w 40381087 · doi ↗ · pubmed ↗
- 2Griot M, Vanderdonckt J, Yuksel D. Implementation of large language models in electronic health records. PLOS Digit Health. 2025;4(12):e 0001141. doi:10.1371/journal.pdig.000114141417848 PMC 12716761 · doi ↗ · pubmed ↗
- 3Dennstädt F, Hastings J, Putora PM, Schmerder M, Cihoric N. Implementing large language models in healthcare while balancing control, collaboration, costs and security. Npj Digit Med. 2025;8(1):143. doi:10.1038/s 41746-025-01476-740050366 PMC 11885444 · doi ↗ · pubmed ↗
- 4Gorenshtein A, Omar M, Glicksberg BS, Nadkarni GN, Klang E. AI Agents in Clinical Medicine: A Systematic Review. med Rxiv. Preprint posted online August 26, 2025:2025.08.22.25334232. doi:10.1101/2025.08.22.25334232 · doi ↗
- 5Introducing Chat GPT Health. January 8, 2026. Accessed January 13, 2026. https://openai.com/index/introducing-chatgpt-health/
- 6Advancing Claude in healthcare and the life sciences. Accessed January 14, 2026. https://www.anthropic.com/news/healthcare-life-sciences
- 7People over trust AI-generated medical responses and view them to be as valid as doctors, despite low accuracy. Accessed January 13, 2026. https://arxiv.org/html/2408.15266 v 1
- 8Gao Y, Xiong Y, Gao X, Retrieval-Augmented Generation for Large Language Models: A Survey. ar Xiv. Preprint posted online March 27, 2024:ar Xiv:2312.10997. doi:10.48550/ar Xiv.2312.10997 · doi ↗