Will online behavioral research follow the fate of online survey research?
S. Van der Stigchel, C. Strauch, B. de Zwart, L. Van Maanen

Abstract
Genes, proteins, chemicals, diseases, species, mutations and cell lines named across the full text — each resolved to its canonical identifier and authoritative record.
Click any figure to enlarge with its caption.
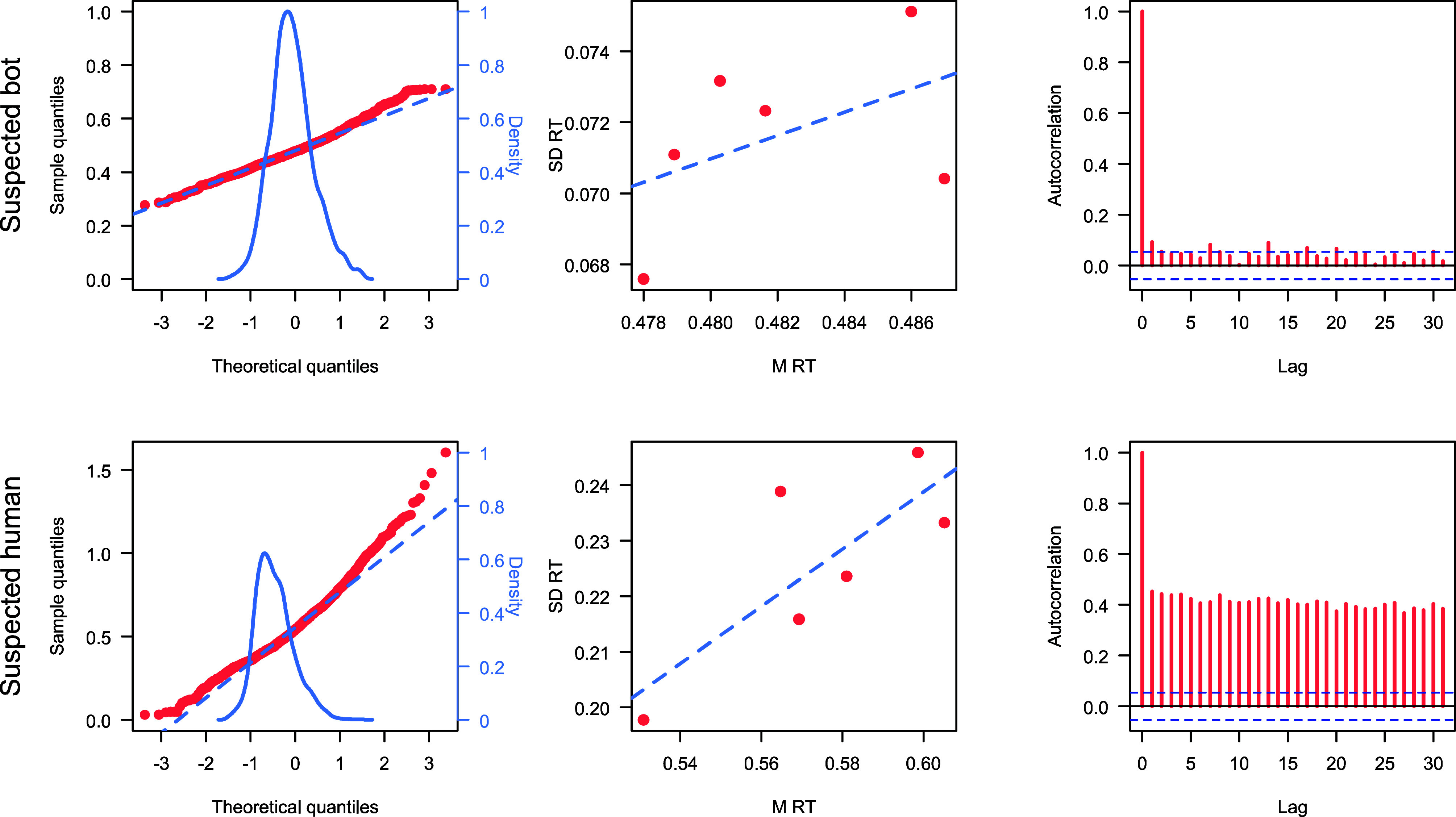 Figure 1
Figure 1Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsSurvey Methodology and Nonresponse · Focus Groups and Qualitative Methods · Social Media in Health Education
Westwood (1) convincingly shows that large language model-based agents can pass as human participants in online surveys, calling into question the reliability of self-report research. However, the threat may be considerably more pervasive than suggested. Using data from an online Posner cueing task, we find patterns consistent with AI-generated responding in reaction time (RT) datasets: a domain long thought to be safeguarded by perceptual-motor constraints. If bots can now mimic not only opinions but also millisecond-level behavior, the foundations of online experiments in cognitive science are equally at risk.
In a recent online Posner cueing experiment (39 participants on Prolific), we identified several participants whose response profiles were highly consistent with simulated, bot-generated data rather than human performance (details on the experiment and analysis can be found on Open Science Framework: https://osf.io/7mz9x). Using parameters derived from the real dataset (mean RT, SD), we simulated RT-distributions under simple Gaussian assumptions (200 trials/condition; no intertrial dependency). We then compared each participant to these simulations across three markers:
- 1.Distributional shape (Q–Q deviation): Suspected bots showed near-perfect normality; humans showed the expected rightward skew (2).
- 2.Mean-SD scaling: Typical human responders showed a positive mean-variance relationship; suspected bots showed no such trend (3).
- 3.Autocorrelation: Human RTs normally exhibit serial dependence; suspected bots showed near-zero autocorrelation across trials (4).
Several participants showed behavior that was close to the simulated bot profile (Fig. 1, Top). Importantly, not all suspicious signatures occurred in the same individuals, highlighting that bots may vary in sophistication and the most advanced cases may already mimic some properties of human-like RT structure.
We therefore call for routine screening of all online RT datasets (including those already published) for at the very least distributional shape, mean-variance scaling, and trial-wise autocorrelation. Until such checks are standard, our field cannot confidently assume that recently reported online cognitive effects reflect human data. As models improve, RT/behavior-aware bots may begin to mimic skew, variance, and even autocorrelation. Unfortunately, we see parallels to online survey data that until recently were deemed safe, using safeguards that are now shown to fail (1, 5). When that happens, statistical sanity checks will no longer be sufficient: Our field will need methods that verify the presence of a person, not of a plausible signal generator.
We hope this expands the discussion and accelerates development of methodological safeguards, as well as editorial and citation practice of inferences based on online behavioral experiments before automated respondents silently reshape the foundations of cognitive science.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1S. J. Westwood, The potential existential threat of large language models to online survey research. Proc. Natl. Acad. Sci. U.S.A. 122, e 2518075122 (2025).41264250 10.1073/pnas.2518075122 PMC 12663962 · doi ↗ · pubmed ↗
- 2R. D. Luce, Response Times (Oxford University Press, New York, NY, 1986).
- 3E.-J. Wagenmakers, S. Brown, On the linear relation between the mean and the standard deviation of a response time distribution. Psychol. Rev. 114, 830–841 (2007).17638508 10.1037/0033-295X.114.3.830 · doi ↗ · pubmed ↗
- 4D. Laming, Autocorrelation of choice-reaction times. Acta Psychol. 43, 381–412 (1979).10.1016/0001-6918(79)90032-5495175 · doi ↗ · pubmed ↗
- 5M. Simone, C. J. Cascalheira, B. G. Pierce, A quasi-experimental study examining the efficacy of multimodal bot screening tools and recommendations to preserve data integrity in online psychological research. Am. Psychol. 79, 956–969 (2024).37471008 10.1037/amp 0001183 PMC 10799166 · doi ↗ · pubmed ↗