Operator-level quantum acceleration of non-logconcave sampling
Jiaqi Leng, Zhiyan Ding, Zherui Chen, Lin Lin

TL;DR
The paper introduces a quantum algorithm that accelerates sampling from non-logconcave distributions, offering a significant speedup over classical methods.
Contribution
A novel quantum framework is introduced that accelerates sampling processes without relying on classical discretization techniques.
Findings
The quantum algorithm provides up to a quartic speedup over classical Langevin-based methods for non-logconcave sampling.
A new quantum algorithm is developed for replica exchange Langevin diffusion, enabling efficient sampling from complex energy landscapes.
Abstract
Sampling from Gibbs distri-butions under continuous, often nonconvex, potentials is a fundamental challenge, which hinders classical methods such as the Langevin dynamics. Existing quantum approaches primarily rely on quantum walks to accelerate classical sampling algorithms, which limits the design space of quantum algorithms to the choice of classical counterparts and inherits technical difficulties in error analysis due to temporal discretization. We introduce a versatile framework for accelerating general sampling processes using quantum computers. In particular, our quantum algorithm is constructed at the operator level without relying on time discretization, thereby providing a path for quantizing continuous-time processes. Sampling from probability distributions of the form σ∝e−βV, where V is a continuous potential, is a fundamental task across physics, chemistry, biology,…
Genes, proteins, chemicals, diseases, species, mutations and cell lines named across the full text — each resolved to its canonical identifier and authoritative record.
Click any figure to enlarge with its caption.
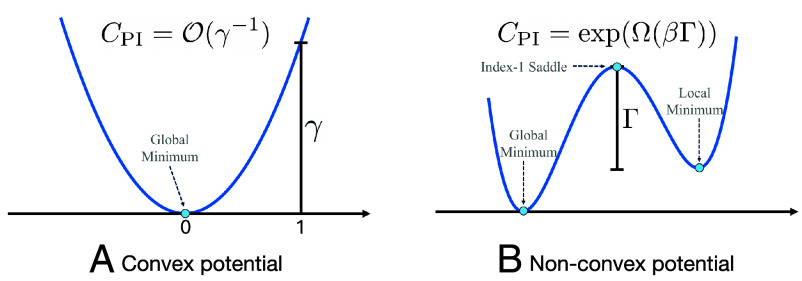 Fig. 2
Fig. 2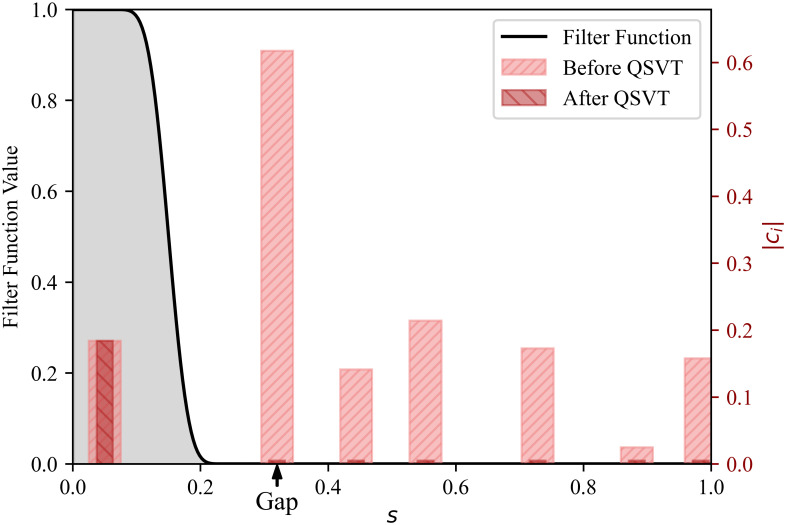 Fig. 3
Fig. 3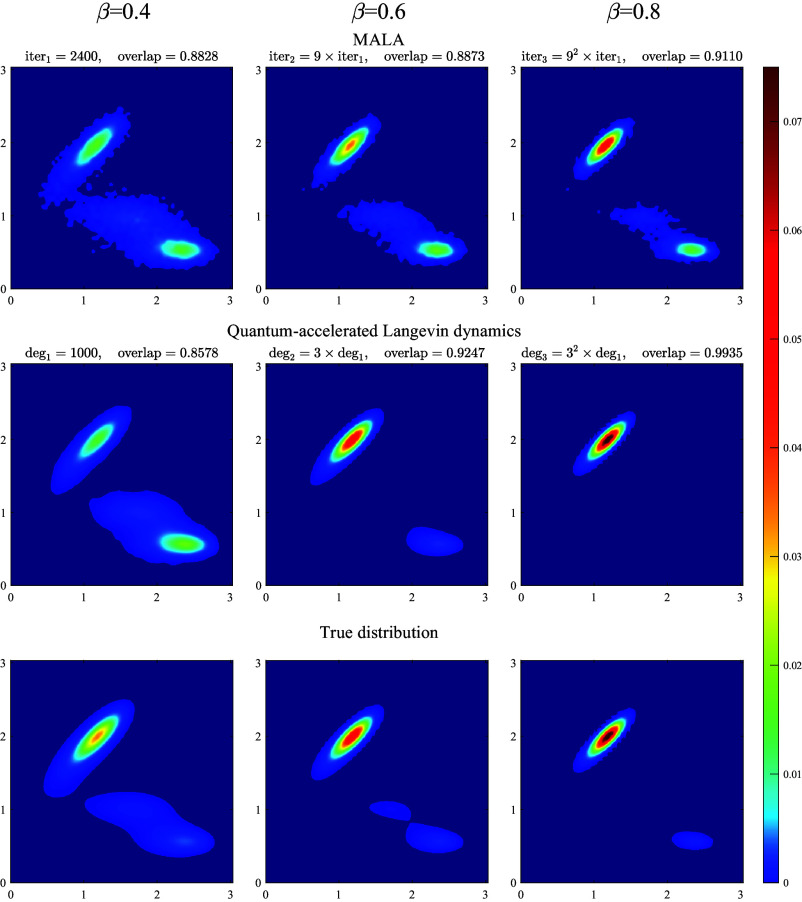 Fig. 4
Fig. 4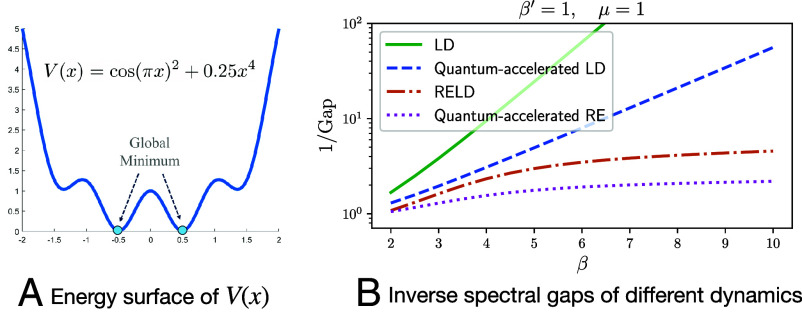 Fig. 5
Fig. 5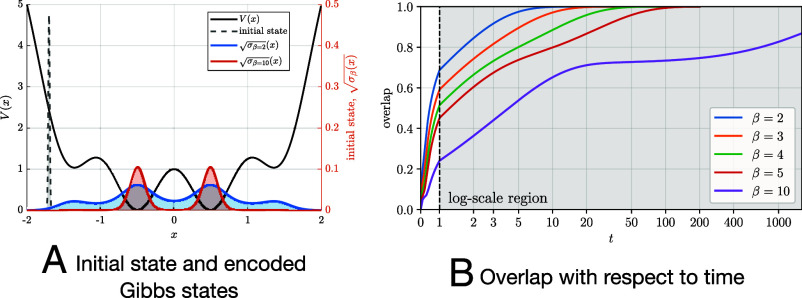 Fig. 6
Fig. 6- —Simons Foundation (SF)100000893
- —Heising-Simons Foundation (HSF)100014155
- —DOE | Office of Science (SC)100006132
- —DOE | Office of Science (SC)100006132
- —DOE | Office of Science (SC)100006132
- —DOE | Office of Science (SC)100006132
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsQuantum Computing Algorithms and Architecture · Quantum Information and Cryptography · Spectroscopy and Quantum Chemical Studies
Given a continuous potential function and an inverse temperature , sampling from the Gibbs distribution is an important task in computational sciences. Originally rooted in statistical physics, Gibbs sampling has found widespread applications in computational chemistry (1), statistics (2?–4), and learning theory (5, 6). Langevin dynamics is a standard continuous-time process for Gibbs sampling. The overdamped Langevin equation is given by
where is the standard -dimensional Brownian motion. The Gibbs measure is the stationary distribution of Eq. 1. This equation can be approximately solved using a simple scheme known as the Euler–Maruyama discretization, or the unadjusted Langevin algorithm (ULA):
where is a time step, and follows Gaussian distribution. While ULA approximates the continuous dynamics Eq. 1, its discretization can be unstable, which requires a careful choice of time steps to accurately approximate the target stationary distribution. Metropolis-Adjusted Langevin Algorithm (MALA), a variant of ULA, incorporates a Metropolis–Hastings correction step to ensure the correct equilibrium, yielding a high-accuracy, discrete-time Gibbs sampler (7, 8).
The performance of discretized dynamics (e.g., ULA, MALA, and variants) has been extensively studied (9???????????–21). Although the exponential convergence of the continuous dynamics Eq. 1 to the Gibbs measure can be established under the sole assumption that satisfies a Poincaré inequality, analyzing these discrete-time Markov chain Monte Carlo (MCMC) processes is often much more technical and relies on stronger assumptions (22).
In applications like molecular simulation and training generative models, the potential is often nonconvex, producing a non-logconcave distribution . Sampling such distributions is difficult for both continuous- and discrete-time Langevin dynamics: convergence can be exponentially slow in the barrier height of and the inverse temperature , a phenomenon known as metastability (10, 23, 24) and is closely related to rare event sampling (25???????–33). To overcome such challenges, advanced sampling algorithms such as replica exchange have been developed (34??????–41). They leverage more than one temperature level to facilitate transitions over barriers that are otherwise prohibitive at low temperatures. While nonasymptotic convergence results of replica-exchange-type algorithms exist for certain highly structured models [e.g., Gaussian mixture (42), mean-field spins (43), multimodal distributions (44, 45), etc.], a general understanding of theoretical efficiency guarantees remains largely open.
Quantum computers offer a promising alternative for accelerating classical sampling processes. The quantum walk algorithm, first developed by Szegedy (46) two decades ago, can be used to achieve a quadratic speedup over classical discrete-time MCMC processes in query complexity. To our knowledge, existing quantum algorithms for classical Gibbs sampling also apply the quantum walk to quantumly encode classical discrete-time MCMC processes, such as ULA, MALA, and their variants (47?–49). This restricts the design space of quantum algorithms to classical MCMC frameworks. In addition, the query complexity analysis highly relies on the complexity of the classical discrete-time MCMC process, which inherits the challenges of analyzing the convergence of these discrete-time schemes.
In this work, we propose a framework for achieving quantum acceleration of general sampling processes with the Gibbs measure as a stationary distribution. Our quantum algorithm is constructed at the operator level without relying on the dynamics generated by a discrete-time classical MCMC process. Take the Langevin dynamics Eq. 1 for example. Our method starts from the Fokker–Planck equation (for general Markov processes, it is called the Kolmogorov forward equation):
Here, represents the probability density associated with the random variable , and the Gibbs measure is a stationary point of the dynamics, satisfying . We refer the reader to SI Appendix, section A for the relevant mathematical preliminaries.
After a similarity transformation, the generator can be mapped to a quantum Hamiltonian , known as the Witten Laplacian operator (50), up to a constant scaling factor. The Gibbs measure is then encoded as the ground state of , denoted by . Measuring this ground state in the computational basis yields with a probability proportional to , thereby achieving Gibbs sampling (Fig. 1).
In order to efficiently prepare the ground state, a key structural property of is that it is frustration-free, meaning that it can be decomposed as a sum of operators: , and the encoded Gibbs state is a simultaneous singular vector of all ’s, satisfying . Each is a first-order differential operator free of time-discretization errors, and can be constructed directly from the gradient .
We will demonstrate that this frustration-free structure provides a simple mechanism to achieve quantum speedup with respect to the continuous-time Langevin dynamics in the non-logconcave setting, whose efficiency depends solely on the Poincaré constant (Theorem 1). Because of the broad applications of continuous sampling problems and the effectiveness of Langevin dynamics, extensive research has examined the complexity of Langevin-based sampling algorithms under various geometric assumptions on the target distribution-such as strong log-convexity (19, 47), log-Sobolev (48, 51), Cheeger (48, 51), and Poincaré typed inequalities (52)-in both quantum and classical settings. Table 1 compares the query complexities of our algorithms with existing quantum and classical algorithms. Although there is a vast body of literature on Langevin-based samplers, our algorithm is the first (classical or quantum) algorithm that provably achieves the scaling for a target distribution with a Poincaré constant . In contrast to previous quantum algorithms (47, 48), our operator-level formulation bypasses time-discretization error analysis and enables a direct continuous analysis via the Witten Laplacian. As a result, we obtain complexity bounds expressed directly in terms of the Poincaré constant of the invariant measure, without relying on additional geometric or isoperimetric assumptions such as Cheeger-type inequalities. We do not expect the geometric-constant dependence appearing in refs. 47 and 48 to admit substantial improvement, since in the strongly convex regime one has the identity . On the other hand, for a broad class of highly nonconvex potentials, , where is the Cheeger constant (defined in SI Appendix, section B), implying that our quantum algorithm can achieve a quartic speedup over MALA for non-logconcave sampling tasks.* Beyond Langevin-based sampling algorithms, the proximal method achieves a query complexity linear in by doubling the sampling space and employing a careful resampling process (52). Obtaining a comparable complexity analysis within the framework of Langevin dynamics, to the best of our knowledge, remains an open problem. A more detailed discussion and comparison can be found in SI Appendix,section B.
To ensure high success probability, our algorithm requires a good initial state, or a “warm start,” which has a constant -overlap with the target state . This is a standard assumption in the quantum sampling literature (47, 48), and strictly weaker than common warm-start assumptions (e.g, -divergence) in classical literature (19, 52). Several established strategies exist for preparing such states, including quantum simulated annealing (48, 53) and variational quantum circuits. In this work, we propose an approach to prepare this warm-start state based on Lindblad dynamics. Specifically, we observe that a Lindblad master equation employing the operators (i.e., factors of the Witten Laplacian) as jump operators naturally recovers the Fokker–Planck equation. For potential functions with moderately simple energy landscapes (for example, those with a constant number of local minima), short-time evolution under this Lindblad dynamics suffices to prepare a warm-start state.
The framework described above can be extended to a broad class of stochastic processes whose infinitesimal generators admit a similar quantization via a similarity transformation, thereby providing a natural and efficient means to accelerate the continuous-time sampling methods without introducing time-discretization error. In such cases, the quantum Hamiltonian is referred to as the generalized Witten Laplacian. As a concrete demonstration, we apply our method to accelerate the replica exchange Langevin diffusion (Theorem 2), which leads to the first provable quantum speedup of continuous-time enhanced sampling dynamics.
Poincaré Constant.
The generator of the Langevin dynamics Eq. 3 is detailed balanced, namely, the adjoint of the operator , denoted as , is self-adjoint with respect to an inner product related to the stationary distribution , defined as . The smallest positive eigenvalue of is called the spectral gap, denoted as . The inverse of the spectral gap, denoted as , is the Poincaré constant. A small spectral gap (or a large Poincaré constant) is a strong indicator that the mixing process can be slow.
The spectral gap and the Poincaré constant have direct geometric interpretations. If the potential is -strongly convex (in this case, sampling from is referred to as logconcave sampling), the smallest eigenvalue for the Hessian of is lower bounded by some constant , i.e., , then (54, Chapter 9] (55, Theorem 4.8.5]. Thus, the Poincaré constant decreases as the potential becomes more convex, causing the Gibbs distribution to concentrate more sharply around the global minimum (Fig. 2A).
For Langevin dynamics, the Poincaré constant CPI scales as O(γ−1) for the convex potential, but as exp(Ω(βΓ)) for the nonconvex potential. The mixing time of the continuous-time Langevin dynamics scales linearly in CPI.
Operator-Level Acceleration of Langevin Dynamics
Witten Laplacian.
From the generator in Eq. 3, we define a new operator ( act as multiplicative operators):
Since is self-adjoint with respect to the -weighted inner product, is self-adjoint with respect to the standard inner product. The operator is called the Witten Laplacian,† which was first proposed by Witten in his analytical proof of the Morse inequalities (50). Later, Witten Laplacian became a fundamental tool in the study of metastability (27, 56). We may readily check that when , the Witten Laplacian is the Hamiltonian of a quantum harmonic oscillator with a gap , which is independent of .
Due to the similarity transformation, the spectrum of is the same as that of (and thus of ), which belongs to the nonnegative real axis. The kernel of is given by the encoded Gibbs state with , which is a normalized state with respect to the standard inner product. In other words, if the Langevin dynamics is ergodic, then is the unique ground state of with a spectral gap . From the encoded Gibbs state we can readily evaluate any classical observable according to . Here, we extend the standard inner product to complex numbers and use the bra-ket notation , where is the complex conjugation of , and can be interpreted as unnormalized quantum states.
From a PDE perspective, the operators and are related as follows:
Since both operators have the same spectral gap, corresponding to SI Appendix, Eq. S25, we have
Here, we use the fact that is equal to the -divergence. Therefore, converges exponentially to the encoded Gibbs state in -divergence.
Quantum Algorithm.
The mapping from the generator of Langevin dynamics to the Witten Laplacian allows us to tackle the Gibbs sampling problem as a ground state preparation problem, which is a standard task in quantum computing (57??–60). However, such algorithms inevitably require querying the potential term, in Eq. 5, which depends on both the first- and second-order derivatives of the potential . This is undesirable since the classical Langevin dynamics only require first-order information.
The Witten Laplacian admits the following factorization (50) (for ):
The encoded Gibbs state is simultaneously annihilated by all ’s, i.e., . In other words, is the ground state of each individual Hamiltonian term . Such a Hamiltonian is called frustration-free.‡ By concatenating all operators together as
Eq. 7 can be compactly written as . Furthermore, constructing only requires the first-order information of the potential .
Based on this observation, we propose a quantum algorithm for the Gibbs sampling task without solving either the Fokker–Planck equation or the dynamics Eq. 5. The main idea is to prepare the encoded Gibbs state as the unique right singular vector of associated with the zero singular value. The singular value gap of is equal to . This provides a source for quantum speedup at the operator level, without either spatial or temporal discretization.
To implement this algorithm on the quantum computer, quantities such as and must be spatially discretized (SI Appendix, section D.2). With some abuse of notation, the spatially discretized quantities are still denoted by the same symbols. The spatial discretization error depends on the smoothness property of , which can be systematically controlled (SI Appendix, section D.1), and the discussion is omitted here for simplicity. We emphasize that, unlike classical MCMC processes, our algorithm does not require temporal discretization, which often presents significant challenges in the analysis.
Below, we briefly describe the major steps of our quantum algorithm.
- Prepare an initial state satisfying the warm start condition, i.e., .
- Block-encode the (spatially discretized) matrix using a quantum circuit.
- Apply a quantum singular value thresholding (SVT) algorithm to to filter out contributions in corresponding to nonzero singular values of . This succeeds in preparing a state with a constant success probability.
- Measure the resulting state in the computational basis§ to obtain a sample that approximately follows the Gibbs distribution .
We now discuss the singular value thresholding algorithm in more detail. The spatially discretized matrix is represented by its singular value decomposition (SVD) as , where is a unitary matrix, is a diagonal matrix with nonnegative diagonal entries, and is a rectangular matrix of orthogonal columns. This immediately gives the eigenvalue decomposition of , i.e., the right singular vectors of are the eigenvectors of , and we identify with the first column of corresponding to the unique zero singular value. With the warm start assumption, we can write with . Then, we can leverage the Quantum Singular Value Transformation (QSVT) algorithm (61) to implement singular value thresholding. Suppose we have access to a block-encoding of with a normalization factor . We can construct an even polynomial that is approximately equal to for , and approximately equal to for , see Fig. 3. Applying QSVT with this even polynomial to the block-encoded filters out all singular vectors with singular values greater than , thereby leaving only the encoded Gibbs state. The details of the quantum algorithm, including background on the quantum singular value thresholding algorithm, are provided in SI Appendix, section C.
Left y-axis: Value of the filter function p(s) that is approximately equal to 1 on [0,Gap/4], and approximately equal to 0 on [3Gap/4,1]. Right y-axis: Projection |ci| to each right singular vector before and after QSVT. Here, Gap=GapL/α, and α is the block encoding subnormalization factor for L.
Complexity Analysis.
Our quantum algorithm leverages two main subroutines: constructing the block-encoding of and implementing singular value thresholding. Each can be represented as a pseudodifferential operator and discretized into a finite-dimensional matrix. We first truncate the space into a finite-sized domain and discretize it using a uniform grid of points per dimension. Therefore, the dimension of each discretized operator is . For a smooth potential with certain growth conditions (e.g., for some large with ), to achieve a target sampling accuracy in the TV distance, we can choose and . Since the value of the Gibbs measure is very close to zero on the boundary of , we assume a periodic boundary condition to facilitate an efficient block-encoding of using Quantum Fourier Transforms, as detailed in SI Appendix, section D.1. It turns out that the discretized can be block-encoded using quantum queries to the gradient and ancilla qubits, see SI Appendix, Proposition 17. For , the normalization factor of the block-encoding of is equal to , where suppresses poly-logarithmic factors in and . Finally, we employ QSVT to implement singular value thresholding, which can be executed using queries to the block-encoded matrix . The overall complexity of our quantum algorithm is summarized as follows:
Theorem 1 (Informal).Assuming access to a warm start state , for a sufficiently large , there exists a quantum algorithm that outputs a random variable distributed according to such that using quantum queries to the gradient .
A rigorous statement and proof of the theorem above are provided in SI Appendix, Theorem 18. To the best of our knowledge, this is the first algorithm that provably achieves a query complexity of for general potentials. In the presence of metastability, will grow exponentially with , where denotes the barrier height of the potential . This implies that our quantum algorithm can be used to e.g., simulate systems at a lower temperature.
Operator-Level Acceleration of Replica Exchange
In this section, we extend the operator-level quantum algorithms to accelerate the replica exchange Langevin diffusion (RELD).
Replica Exchange Langevin Diffusion.
For rugged (nonconvex) energy landscapes, Langevin dynamics may require prohibitively long times to traverse energy barriers separating local minima. Replica exchange (or parallel tempering) is a widely adopted strategy to mitigate this difficulty. It involves simulating multiple replicas at different temperatures, where high-temperature replicas explore the global landscape and low-temperature replicas concentrate near local minima. Through carefully designed swap moves between replicas, replica exchange enables barrier-crossing events that are otherwise rare at low temperatures. Its ability to accelerate overdamped Langevin diffusion is well established numerically (40, 41, 62, 63) and supported to a lesser extent by theoretical results, for instance in the setting of Gaussian mixtures (64).
For clarity, we focus on the case of replica exchange with two temperatures. The continuous-time formulation, called the replica exchange Langevin diffusion (RELD), can be modeled by two correlated Langevin dynamics with inverse temperatures , respectively:
where and denote the positions of the particle undergoing the low- and high-temperature Langevin dynamics, respectively. and represent two independent standard Brownian motions. The invariant distribution of the variable is a joint Gibbs measure:
The marginal distribution of under recovers the target distribution .
Without correlation, the mixing time of Eq. 9 is governed by the low-temperature ( ) system, resulting in no acceleration. In RELD, an additional swap mechanism is introduced to accelerate convergence of Eq. 9 toward equilibrium. These swap events occur according to a Poisson clock and enable configuration exchange between replicas at different temperatures. Let denote a swapping intensity, and we assume the sequential swapping events take place according to an exponential clock with a rate . At a swapping event time, the two particles swap their positions with a Metropolis-Hasting type probability:
Note that the Metropolis-Hasting type swapping does not change the invariant Gibbs measure .
To obtain a continuous-time dynamics that includes the exchange mechanism, let denote the probability density of the random variables for time . The evolution of can be characterized by the forward Kolmogorov equation , where the generator captures both the Langevin dynamics and the swapping mechanism. In particular, takes the following form:
where and are the Fokker–Planck generators in Eq. 3 with inverse temperatures and , respectively. corresponds to the Metropolis-Hasting swapping described by Eq. 12 with intensity as
Under mild conditions, the dynamics can be shown to be ergodic, and the joint Gibbs measure is the unique invariant measure of the generator (65).
For non-logconcave sampling, low-temperature Langevin dynamics often become trapped near metastable configurations for an exponentially long time. Through the swapping process, well-explored configurations in the high-temperature system can be transferred to the low-temperature system, thereby significantly reducing the overall mixing time (see ref. 42 for an analysis of RELD for Gaussian mixture models).
While the swapping mechanism enables replica exchange to effectively overcome energy barriers in the potential landscape and thus achieve faster mixing, it could still suffer from the curse of dimensionality. For example, refs. 44 and 45 suggest that in the presence of multiple modes, the spectral gap of replica exchange can decay rapidly as the problem dimension increases. Thus it is desirable to design a quantum algorithm with provable speedup over RELD.
Generalized Witten Laplacian of RELD.
Now, we consider the operator transformation
which is referred to as the generalized Witten Laplacian of RELD. Due to the similarity transformation, the spectrum of is the same as that of , and the kernel of is given by the extended encoded Gibbs state with . Note that is a product state, and the Gibbs distribution can be recovered by measuring in the -variable register. Under this transformation, the two Fokker–Planck-type operators and are mapped to two Witten Laplacians, denoted by and . Similar to Eq. 7, each Witten Laplacian can be factorized as the sum of nonnegative operators of the form .
The transformation of the swap operator is more involved. First, we rewrite the operator , where is the identity operator, interchanges the and variables in a function, and represents the multiplication with the function . It can be readily verified that . In other words, commutes with , i.e., . Therefore, we can rewrite the transformed swap operator
Note that we use in the last step. It turns out that the generalized Witten Laplacian of RELD consists of three component operators . Moreover, admits a factorization of the form , where
where the block matrix encompasses operators: and correspond to the Langevin dynamics with inverse temperature and , respectively; corresponds to the swap mechanism. More details of can be found in SI Appendix, section E.1. We refer to as the generalized Witten Laplacian of RELD, and it enables us to apply our operator-level quantum sampling algorithm.
Quantum Algorithms and Complexity Analysis.
The encoded (joint) Gibbs state can be prepared as the ground state of the generalized Witten Laplacian Eq. 17, or equivalently, the right singular vector of associated with the zero singular value. This can be realized via the singular value thresholding algorithm as discussed before.
To construct a block-encoding of , we need to perform spatial discretization for the component operators in for each . Note that the component operator in acts on functions in . Similar to the previous section, we can first truncate the space into a finite-size numerical domain and discretize it using a uniform grid with points. The discretized operator is a matrix of dimension . For a smooth potential with certain growth conditions, to achieve a target sampling accuracy in the TV distance, we can choose and .
Since the first component operators in are essentially the same as in the Langevin dynamics case, they can be block-encoded using queries to through the same technique as mentioned before. The last operator can be implemented by concatenating two quantum circuits, one for and another for the scalar multiplication . The exchange operator can be realized by SWAP gates; the scalar multiplication operator can be directly implemented using an arithmetic circuit and queries to the function . Overall, we can build a block-encoding of with quantum queries to the gradient , quantum queries to the function value of , and ancilla qubits, as detailed in SI Appendix, Proposition 21. The normalization factor of this block-encoding is equal to (suppressing poly-logarithmic factors in and ). Finally, we can implement QSVT for singular value thresholding, which creates a projection onto the encoded Gibbs state using queries to the block-encoded matrix . Here, denotes the spectral gap of the generator of RELD, i.e., the smallest positive eigenvalue of . The overall complexity of the quantum algorithm is summarized below:
Theorem 2 (Informal).Assuming access to a warm start state , and let , be constant independent of and . For a sufficiently large , there exists a quantum algorithm that outputs a random variable distributed according to such that using quantum queries to the function value and the gradient , respectively. Consequently, the distribution of with a marginal law satisfies , where .
A rigorous statement and proof of the theorem above are provided in SI Appendix, Theorem 23. The complexity in the above theorem scales as , where denotes the spectral gap of the continuous-time RELD.
Lindblad Dynamics for Warm-Start Preparation
We consider a Lindblad master equation given by:
where is a time-dependent density operator and the jump operators are the same as in Eq. 7. Here, represents the anticommutator. It is straightforward to verify that the encoded Gibbs state is a fixed point of the Lindbladian , since for all . In general, is a mixed state. However, the evolution of its “diagonal elements” in the computational basis reduces to the Fokker–Planck equation in Eq. 3; see SI Appendix, Lemma 24.
Although the Lindblad dynamics is not asymptotically faster in convergence, it can rapidly prepare a quantum representation of a metastable state. This behavior arises because, while the spectral gaps between metastable states are typically small, which leads to a large Poincaré constant and hence slow overall convergence, the metastable subspace itself is often well separated from the rest of the Lindbladian spectrum. This can happen for potential functions with a relatively small number of local minima and for temperatures that are not too low. As a result, the system quickly relaxes into this low-lying subspace, yielding an intermediate state with a sufficiently large overlap with the target Gibbs state, which serves as an effective warm start for the subsequent quantum acceleration stage.
Therefore, by simulating the Lindblad equation on a quantum computer, which uses the same block-encoding of (66), we can efficiently obtain a warm-start state for our SVT-based quantum algorithm. A numerical demonstration of this two-phase behavior is presented in the next section, and further technical details are provided in SI Appendix, section F.
Numerical Experiments
In this section, we numerically demonstrate our quantum algorithms to accelerate Langevin dynamics (LD) and replica exchange Langevin diffusion (RELD) for non-logconcave sampling. Our results show that the quantum algorithms exhibit significant speedups over their classical counterparts. To simulate our quantum algorithms, we numerically implement singular value thresholding. The details of the numerical implementation can be found in SI Appendix, section G. Code and data supporting this study are available at (67)
Quantum-Accelerated Langevin Dynamics.
We compare the performance of our quantum-accelerated Langevin sampling with that of MALA using the Müller-Brown potential (68), which is often used as a proof of concept for rare event sampling in computational chemistry. The Müller-Brown potential is characterized by a highly nonconvex energy surface with three local minima. Details of this potential function, including its analytical expression and energy landscape, are provided in SI Appendix, section G.2.
To conduct a fair comparison, both algorithms start from the same Gaussian distribution (or the corresponding Gaussian state ) centered at one of the local minima of the potential function. We choose three inverse temperatures: for the experiment. For all tested inverse temperatures, the overlap between the initial distribution and the target Gibbs state , i.e., , is approximately 0.1, indicating a reasonable warm start.
To reflect the computational complexity of the algorithms, we report the number of MALA iterations and the polynomial degree of the filter function in QSVT, both of which directly determine the number of queries to . Due to the nonconvexity of the potential, the Arrhenius law predicts that the mixing time of MALA scales exponentially with the inverse temperature. For an ascending sequence , the numerical results show that MALA requires approximately 9 times more iterations for every increase in , as illustrated in the Top row of Fig. 4. On the other hand, the Middle row of Fig. 4 shows that our quantum algorithm outputs a sample distribution with a comparable (or even slightly better) accuracy by increasing the QSVT polynomial degrees by a factor of for the same increment in . This observation highlights the efficiency of our quantum algorithm and demonstrates the desired speedup in query complexity over classical MALA.
Quantum acceleration of Langevin dynamics. Each column corresponds to a different inverse temperature β. The overlap |〈σ||ϕ〉| measures the similarity between the sampled and true distribution, where 〈σ| is the encoded Gibbs state and |ϕ〉 represents either 1) the square root of the output probability density by MALA, or 2) the output pure state by our method. Note that the overlap definition can be generalized to accommodate mixed states; see Eq. 19. Top row: Sample distributions obtained using MALA with the number of iterations increasing by a factor of 9. Middle row: Distributions obtained by our quantum algorithm with the degree of polynomials increasing by a factor of 3. Bottom row: True distribution (Gibbs state).
Quantum-Accelerated Replica Exchange.
We numerically demonstrate the quantum-accelerated RELD using a 1-dimensional potential:
which is a nonconvex function with local minima, as illustrated in Fig. 5A. Even though this experiment is conducted on a one-dimensional example, we expect that similar behavior can be observed in a high dimensional setting, when the energy barrier can be identified along a “reaction coordinate” as is often the case in computational chemistry (69, 70).
Quantum acceleration of replica exchange. Left: a nonconvex 1D potential. Right: Inverse spectral gaps for LD, RELD, and their quantum counterparts as functions of β. The spectral gap of LD decays exponentially in β, while that of RELD shows a much milder decay. The quantum algorithms achieve square-root improvements in the gaps in both cases.
In Fig. 5B, we illustrate the inverse spectral gaps of two classical dynamics (LD and RELD) and their quantum counterparts. The inverse spectral gap indicates the scaling of the query complexity (for both quantum and classical algorithms) as grows. The spectral gaps of LD and RELD are computed based on the Witten Laplacians, i.e., Eqs. 4 and 15, respectively. For the two corresponding quantum algorithms, the singular value gaps are computed using Eqs. 8 and 17, respectively. For RELD, we set for all choices of .
We observe that the spectral gap of Langevin dynamics (LD) decays exponentially as increases, while RELD exhibits a much milder decay, illustrating the advantage of RELD for non-logconcave sampling. Furthermore, we find that the singular value gaps of the quantum-accelerated algorithms are approximately¶ the square root of the spectral gaps of their classical counterparts, consistent with our theoretical analysis and confirming that our quantum algorithms achieve a quadratic speedup as becomes large.
In Fig. 6, we demonstrate the effectiveness of the Lindbladian-based warm-start preparation method using the same 1D potential as in Fig. 5A. We evolve the Lindblad dynamics starting from an initial state with negligible overlap with the encoded Gibbs state (Fig. 6A). The overlap between the solution state and the encoded Gibbs state is defined as
Lindbladian-based warm-start generation. Left: Initial state for the Lindblad dynamics, and encoded Gibbs states at β=2 and β=10. Right: The overlap between the quantum state evolved under the Lindblad dynamics and the target Gibbs state, defined as in Eq. 19. A short evolution time (t≤1) is enough to prepare warm-start states with constant (≥0.2) overlap even at low temperatures.
and Fig. 6B illustrates how the overlap changes over time. We observe that a short-time Lindbladian evolution ( ) already yields a warm-start state with a constant ( 0.2) overlap. Beyond this point, the dynamics requires an evolution time at least an order of magnitude longer to fully converge to the target Gibbs state. This later stage can be significantly accelerated using our quantum-accelerated LD or RELD algorithms.
Discussion
In this work, we present a framework for accelerating probabilistic sampling using quantum computers. By associating the Gibbs sampling task with the preparation of the encoded Gibbs state, we leverage quantum singular value thresholding to accelerate classical sampling. Our method operates directly at the operator level, without requiring explicit time discretization of stochastic processes, thereby circumventing existing classical algorithms based on simulating discrete-time Markov chains. To the best of our knowledge, this provides the first provable quantum speedup for a broad class of sampling processes, directly in terms of the spectral gap of the infinitesimal generator, which is a type of speedup with no classical counterpart.
Our quantum algorithm relies on preparing the encoded Gibbs state , which corresponds to the stationary state of a Markov chain (i.e., a forward Kolmogorov equation). In the literature, the quantum state corresponding to the stationary distribution of a classical Markov chain is often referred to as a “qsample.” Generating a qsample is a long-standing challenge in quantum computing and is widely regarded as a significantly more powerful task than its classical counterpart (46, 71, 72). In our algorithm, the state is fully characterized as the ground state of the (generalized) Witten Laplacian . In fact, given any target probability distribution with density , as long as the quantum state can be characterized as an eigenstate of a linear operator, a similar singular value thresholding approach may apply to facilitate the sampling from . For example, the ground state of the index-1 Witten Laplacian (the standard Witten Laplacian is also called the index-0 Witten Laplacian) encodes a distribution that locates the metastable configurations over a nonconvex potential function (56, 73). In such cases, our framework may be extended to enable sampling from non-Gibbs distributions, for which few efficient classical algorithms are known.
Our construction of block-encodings for the factor operators relies on the quantum implementation of the Fourier transform in . Extending these techniques to more general manifolds or to nondifferentiable settings remains an open question and an interesting avenue for future research.
In the limit of zero temperature (i.e., ), non-logconcave sampling reduces to a nonconvex optimization problem. Recent works (74?–76) propose to leverage quantum dynamics (e.g., Hamiltonian or Lindbladian evolution) for solving nonconvex optimization problems. These dynamics-based quantum optimization algorithms operate independently of classical processes and can exhibit superpolynomial speedups over all classical algorithms for some problem classes (77). This raises a natural question: can certain quantum dynamics be harnessed to achieve large (i.e., superquadratic) acceleration for non-logconcave sampling? If such methods exist, they would greatly expand the design space of quantum algorithms with practical utility.
Quantum Gibbs sampling, which prepares a thermal state for a quantum Hamiltonian , has seen rapid progress in algorithmic developments and analysis in recent years (78???????–86). Since classical Gibbs sampling corresponds to the special case where is diagonal in the computational basis, we hope that the interplay between classical and quantum perspectives may help uncover further quantum advantages in Gibbs sampling tasks.
Supplementary Material
Appendix 01 (PDF)
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1D. Frenkel, B. Smit, Understanding Molecular Simulation: From Algorithms to Applications (Academic Press, 2002).
- 2S. Geman, D. Geman, “Stochastic relaxation, Gibbs distributions, and the Bayesian restoration of images” in IEEE Transactions on Pattern Analysis Machine Intelligence, T. Pavlidis, Ed. (The IEEE Computer Society, 1984), pp. 721–741.10.1109/tpami.1984.476759622499653 · doi ↗ · pubmed ↗
- 3J. K. Kruschke, Bayesian data analysis. Wiley Interdiscip. Rev. Cogn. Sci. 1, 658–676 (2010).26271651 10.1002/wcs.72 · doi ↗ · pubmed ↗
- 4C. P. Robert, G. Casella, G. Casella, Monte Carlo Statistical Methods (Springer, 1999), vol. 2.
- 5D. J. Mac Kay, Information Theory, Inference and Learning Algorithms (Cambridge Univ. Pr., 2003).
- 6R. M. Neal, Bayesian Learning for Neural Networks (Springer Science & Business Media, 2012), vol. 118.
- 7J. Besag, P. Green, D. Higdon, K. Mengersen, Bayesian computation and stochastic systems. Stat. Sci. 10, 3–41 (1995).
- 8G. O. Roberts, J. S. Rosenthal, Optimal scaling of discrete approximations to Langevin diffusions. J. R. Stat. Soc. Ser. B Stat. Methodol. 60, 255–268 (2002).