Nonlinear genomic selection index accelerates multi-trait crop improvement
J. Jesús Cerón-Rojas, Osval A. Montesinos-López, Abelardo Montesinos-López, Paolo Vitale, Paulino Pérez-Rodríguez, Samuel B. Fernandes, Rodomiro Ortiz, José Crossa

TL;DR
This paper introduces a new method for crop improvement that uses nonlinear relationships between traits to speed up breeding.
Contribution
The paper introduces the Quadratic Genomic Selection Index (QGSI) to capture nonlinear trait relationships in genomic selection.
Findings
QGSI outperforms linear and quadratic phenotypic and genomic indices in selection response and prediction accuracy.
QGSI integrates additive, squared, and cross-product terms of genomic estimated breeding values.
The method was validated using simulated and real maize and wheat datasets.
Abstract
Linear phenotypic and genomic selection indices assume additivity and linearity, limiting their ability to exploit nonlinear trait relationships. Here, we introduce the Quadratic Genomic Selection Index (QGSI), a genomic extension of the quadratic phenotypic selection index (QPSI) that integrates genomic estimated breeding values (GEBVs) within a unified quadratic framework. QGSI combines additive, squared, and cross-product terms of GEBVs, enabling phenotype-free, rapid-cycle multi-trait selection while capturing genome-wide nonlinear relationships. We evaluate QGSI using two genomic prediction strategies: (i) a maximum-likelihood additive genomic model, and (ii) a nonlinear multi-trait Gaussian kernel model that accommodates epistatic signals. Using 10 simulated maize selection cycles and two real maize and five wheat real datasets, QGSI achieves the highest selection response and the…
Genes, proteins, chemicals, diseases, species, mutations and cell lines named across the full text — each resolved to its canonical identifier and authoritative record.
Click any figure to enlarge with its caption.
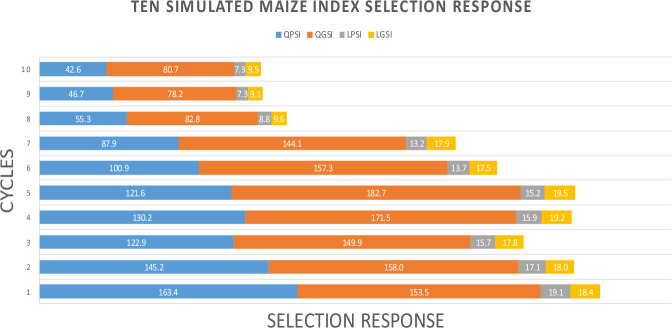 Figure 1
Figure 1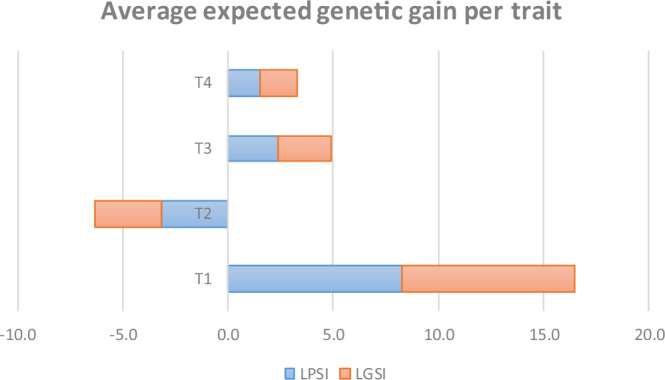 Figure 2
Figure 2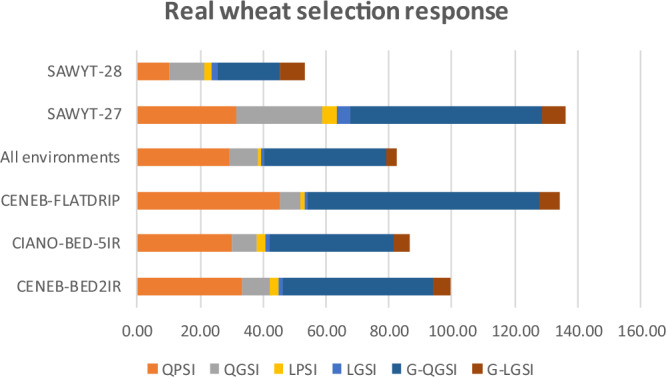 Figure 3
Figure 3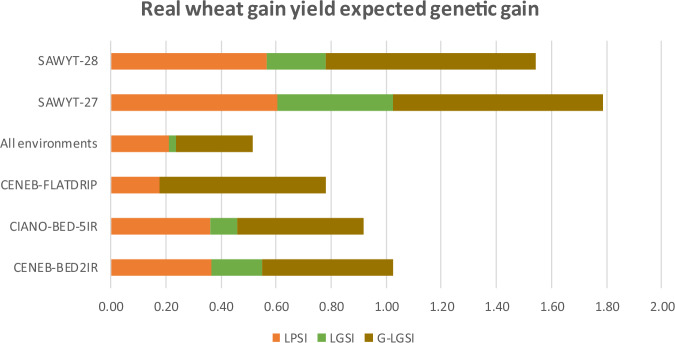 Figure 4
Figure 4Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsGenetic and phenotypic traits in livestock · Genetic Mapping and Diversity in Plants and Animals · Genetics and Plant Breeding
Introduction
Selection indices—linear or quadratic—have a central role in plant and animal breeding. They provide a formal framework to combine multiple traits into a single criterion for ranking individuals. The ratio indices^1^ and the Smith–Hazel linear phenotypic selection index (LPSI)^2,3^ offer a mathematically rigorous approach for optimizing multi-trait improvement. However, these indices rely on assumptions of linearity and additivity assumptions that are violated in biological systems where traits interact nonlinearly.
Genomic selection^4^ transformed index-based breeding by enabling genome-wide, marker-prediction of breeding values. This led to the development of the linear genomic selection index (LGSI)^5^, which accelerates genetic gain by shortening breeding cycles^6^. However, LGSI preserves the linear and additive structure of LPSI. Therefore, it cannot capture non-additive genetic effects, gene–gene interactions, trait–trait interactions, or intermediate trait optima^7^. The quadratic phenotypic selection index (QPSI)^8^ was introduced to overcome those limitations. This index incorporates squared and cross-product terms of traits, allowing the modeling of nonlinear relationships and stabilizing or disruptive selection patterns.
Here, we introduce the quadratic genomic selection index (QGSI), which extends QPSI by embedding genomic estimated breeding values (GEBVs)^9,10^ within a quadratic selection index framework. QGSI retains the desirable statistical properties of both QPSI and LGSI while enabling the modeling of nonlinear trait contributions and genome-wide interactions through quadratic and cross-product terms of GEBVs. This index enables phenotype-free and rapid-cycle multi-trait selection^11,12^. In addition, we derive the main parameters of QPSI and QGSI: the vectors and matrices of index coefficients, mean squared prediction error (MSPE), squared correlation between the quadratic net genetic merit and its predictors, selection response, and expected genetic gain per trait (Supplementary Methods 1 and 2). We evaluate QGSI using two estimation strategies: maximum likelihood (ML)⁷ and Bayesian Gaussian kernel methods¹³ (Supplementary Method 3). We assess empirical performance across 10 simulated maize selection cycles, two real maize datasets, and five real wheat datasets (Supplementary Method 4). Our results show that, by combining nonlinear genomic prediction with quadratic index theory, QGSI enables higher selection response and reduced prediction error variance. Recent study¹³ has demonstrated that epistatic architectures and genome-wide interaction effects can induce substantial nonlinear covariation among traits. In this context, we incorporate a multivariate Gaussian kernel (reproducing kernel Hilbert space, RKHS)^13^ framework to predict GEBVs for use in QGSI. This approach provides a flexible representation of nonlinear genomic relationships, including epistatic signals, while preserving the selection index structure.
Results
First, we present the theoretical results for QPSI and QGSI (Supplementary Eqs. 1–21). We then describe the simulated maize datasets (Tables 1 and 2; Figs. 1 and 2), followed by the real maize datasets (Tables 3 and 4) and the real wheat datasets (Tables 5 and 6; Figs. 3 and 4). Finally, we present Supplementary Table 1–3 and Supplementary Fig. 1, which report the univariate and multivariate normality tests, as well as the estimated broad-sense heritability of the real maize and wheat datasets (Supplementary Table 4).Fig. 1. Ten similated maize index selection response.QPSI (quadratic phenotypic), QGSI (quadratic genomic); LPSI (linear phenotypic), and LGSI (linear genomic) selection index.Fig. 2. Average genetic gain per trait.LPSI (linear phenotypic) and LGSI (linear genomic) selection index for four traits (T1, T2, T3, T4) in 10 maize simulated selection cycles.Fig. 3. Real wheat selection response.QPSI (quadratic phenotypic), QGSI (quadratic genomic); LPSI (linear phenotypic), LGSI (linear genomic); G-QGSI (Gauss quadratic genomic), and G-LGSI (Gauss linear genomic) selection index across five real wheat datasets in five environments (CENEB-BED2IR, CIANO-BED-5IR, CENEB-FLATDRIP, SAWYT-27, SAWYT-28) and all bottom three environments.Fig. 4. Real wheat grain yield expected genetic gain.LPSI (linear phenotypic), LGSI (linear genomic), and G-LGSI (Gauss linear genomic) selection index across five environments (CENEB-BED2IR, CIANO-BED-5IR, CENEB-FLATDRIP, SAWYT-27, SAWYT-28) and all bottom three environments.Table 1. Ten simulated maize selection cycles estimated selection response (R), square correlation (SCor), and square root of the mean square prediction error (SR-MSPE)CycleQuadratic selection indexLinear selection indexPhenotypicGenomicPhenotypicGenomicRSCorSR-MSPERSCorSR-MSPERSCorSR-MSPERSCorSR-MSPE1163.40.84440.0153.50.7454.019.10.9422.718.40.8744.02145.20.82338.3158.00.7304.017.10.9282.718.00.8664.03122.90.79835.2149.90.6704.615.70.9162.717.80.8324.64130.20.80136.9171.50.7913.615.90.9172.719.20.9003.65121.60.79535.2182.70.7963.615.20.9112.719.50.9073.66100.90.76132.2157.30.7244.313.70.8932.717.50.8424.3787.90.75028.9144.10.6954.013.20.8902.617.90.8664.0855.30.90310.382.80.9971.48.80.9421.29.60.9981.4946.70.8889.578.20.9981.27.30.9161.39.10.9961.21042.60.8828.980.70.9961.37.30.9201.29.50.9951.3Average101.70.82527.5135.90.7403.213.30.9172.315.60.9083.2Maximum likelihood estimation. Results are for four traits using quadratic (quadratic (QPSI) and linear (LPSI) phenotypic selection index and quadratic (QGSI) and linear (LGSI) genomic selection index) using ML parameters estimation. Selection intensity was 10% (k = 1.755).Table 2. Ten simulated maize selection cycles estimated expected genetic gain per trait for four traits (T1, T2, T3, T4) using phenotypic and genomic linear and quadratic indicesCycleLinear phenotypic selection indexLinear genomic selection indexT1T2T3T4T1T2T3T4110.4−5.53.82.08.6−4.73.31.8210.1−4.43.72.08.8−3.63.42.239.9−4.13.31.78.3−4.02.92.6410.9−4.32.61.49.7−4.63.11.8510.6−3.53.01.59.8−4.53.31.9610.0−3.52.51.49.0−3.23.22.175.0−2.01.71.47.9−4.72.92.485.6−1.61.21.66.5−0.80.81.595.2−1.50.81.46.5−0.50.91.2104.9−1.61.31.07.1−0.51.00.9Average8.3−3.22.41.58.2−3.12.51.8Maximum likelihood estimation. Results were obtained with quadratic (quadratic (QPSI) and linear (LPSI) phenotypic selection index and quadratic (QGSI) and linear (LGSI) genomic selection index) using ML parameters estimation. Selection intensity was of 10% (k = 1.755).Table 3. Estimated selection response (R), square correlation (SCor), and square root of the mean square prediction error (SR-MSPE) for two (JDMexico and JDZimbabwe in cycle 0) real maize datasets and two genomic selection cycles (cycle 1 and 2)DatasetMaximum likelihood parameters estimationGaussian kernel estimationQPSIQGSILPSILGSIQGSILGSICycleRSCorSR-MSPER**RSCorSR-MSPERRRJDMexico059.70.5034.15.90.553.0135.83.967.08.4237.04.169.08.3Average36.44.068.08.4JDZimbabwe046.70.3933.37.80.742.7134.16.995.84.6237.17.390.84.5Average35.67.193.34.6Non genomic results for that cycleResults were obtained using quadratic (QPSI = Quadratic phenotypic selection index and QGSI = Quadratic genomic selection index) and linear (LPSI = Linear phenotypic selection index and LGSI = Linear genomic selection index) indices for a phenotypic (Cycle 0) and two genomics selection cycles (Cycle 1 and 2) using two estimation parameters methods. Selection intensity was of 10% (k = 1.755).Table 4. Two real maize datasets estimated index expected genetic gain per trait for four traits (GY, EHT, PH, AD) using phenotypic and genomic linear and quadratic indicesIndexDatasetCycleEstimated expected genetic gain (ML)Estimated expected genetic gain (Gaussian)GYEHTPHADGYEHTPHADLPSI (QPSI)JDMexico01.418−8.622−3.303−0.0641.400.164.900.01LGSI (QGSI)10.828−0.6540.4460.2541.33−1.244.00−0.22LGSI (QGSI)20.845−0.7420.3980.2471.34−0.314.41−0.15LPSI (QPSI)JDZimbabwe0−0.004−17.501−12.518−1.5790.12−9.70-0.47−1.07LGSI (QGSI)10.049−9.813−8.996−1.0380.10−9.080.61−1.16LGSI (QGSI)20.049−10.284−9.394−1.1420.12−8.600.63−1.09This table summarizes estimated expected genetic gain per trait four traits (GY = Grain yield, PH = Plant height trait, EHT = Ear height trait, AD = Anthesis day) were obtained for two real maize datasets for phenotypic (at cycle 0) and genomic (at cycles 1 and 2) selection using two estimation methods: ML and Gaussian kernel. Selection intensity was of 10% (k = 1.755).Table 5. Wheat real datasets estimated selection response (R), square correlation (SCor), and square root of mean square prediction error (SR-MSPE)EnvironmentMaximum likelihood (ML) parameters estimationGaussian kernel estimationQPSIQGSILPSILGSIQGSILGSIRS-CorSR-MSPERRS-CorSR-MSPE*RRRCENEB-BED2IR33.50.55817.08.82.60.411.81.247.95.4CIANO-BED-5IR30.40.46818.47.53.20.442.01.239.44.9CENEB-FLATDRIP45.40.71716.36.51.50.940.20.8073.56.6All above environments29.30.52615.99.01.20.201.30.7038.83.3SAWYT-2731.60.68712.127.64.40.731.54.161.27.5SAWYT-2810.50.8822.611.02.20.391.62.219.77.6Results were obtained with quadratic (QPSI = Quadratic phenotypic selection index and QGSI = Quadratic genomic selection index) and linear (LPSI = Linear phenotypic selection index and LGSI = Linear genomic selection index) indices for a phenotypic (Cycle 0) and genomics selection cycles (Cycle 0) using two estimation parameters methods: ML and Gaussian kernel. Selection intensity was of 10% (k = 1.755).Table 6. Wheat traits estimated expected genetic gain per trait with two estimation parameter methodsEnvironmentsMaximum likelihood (ML) parameters estimationGaussian kernel estimationLPSI(QPSI)LGSI(QGSI)LGSI(QGSI)GYHDPHGYHDPHGYHDPHCENEB-BED2IR0.37−2.50−4.050.19−0.32−0.360.48−0.96−1.33CIANO-BED-5IR0.360.26−7.320.10−0.05−2.780.460.37−1.35CENEB-FLATDRIP0.18−3.908.72−0.01−0.57−0.580.60−0.34−1.50All above environments0.21−2.18-6.130.02-0.22−0.310.28-0.65−1.01SAWYT-270.611.373.210.421.242.950.761.584.07SAWYT-280.56−1.510.22−1.400.76−0.85*This table presents expected genetic gains per trait (GY = Grain yield, HD = Heading date, PH = Plant height trait) for quadratic (QPSI = Quadratic phenotypic selection index and QGSI = Quadratic genomic selection index) and linear (LPSI = Linear phenotypic selection index and LGSI=Linear genomic selection index) indices for a phenotypic (Cycle 0) and genomics selection cycle (Cycle 0) using two estimation parameters methods: ML and Gaussian kernel.
QPSI theoretical results
Supplementary Equations 1–8 show that the theoretical quadratic net genetic merit ( \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${H}_{q}$$\end{document} ) attains its best predictor under the ML estimator of the QPSI. This estimator is obtained by minimizing the MSPE with respect to the QPSI linear coefficient vector \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${{\bf{b}}}$$\end{document} and the quadratic and cross-product coefficient matrix \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${{\bf{B}}}$$\end{document} . These derivations yield closed-form expressions for the minimized MSPE, the squared correlation between \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${H}_{q}$$\end{document} and its QPSI predictor, the selection response, and the expected genetic gain per trait, which are the basis for evaluating QPSI and comparing it with alternative selection indices.
QGSI theoretical results
Supplementary Equations 9–16 describe the theoretical formulation of the QGSI and its main parameters. In the genomic context, QGSI is a predictor of \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${H}_{q}$$\end{document} and is derived by minimizing the MSPE with respect to the QGSI linear coefficient vector \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${{\boldsymbol{\theta }}}$$\end{document} and the quadratic and cross-product matrix \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${{\bf{D}}}$$\end{document} . These expressions yield the minimized MSPE, the squared correlation between \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${H}_{q}$$\end{document} and its QGSI predictor, the selection response, and the expected per-trait genetic gain.
Maximum-likelihood and Gaussian-kernel parameter estimation
Supplementary Equations 17–21 detail the estimation of the phenotypic ( \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${{\bf{P}}}$$\end{document} ) and genotypic ( \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${{\bf{G}}}$$\end{document} ) covariance matrices, the QPSI linear and quadratic coefficients ( \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${{\bf{b}}},{{\bf{B}}}$$\end{document} ), and the additive genomic covariance matrix \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${{\boldsymbol{\Gamma }}}$$\end{document} . These equations also describe the estimation of trait GEBVs, LPSI, and LGSI heritabilities for real datasets, and the Bayesian multi-trait Gaussian kernel (RKHS) model used to obtain the nonlinear genomic estimators required for QGSI. Because heritability definitions for quadratic indices have not yet been formalized, QPSI and QGSI heritabilities were not estimated.
Simulated maize selection response under maximum likelihood estimation
Across 10 simulated maize selection cycles, QPSI, QGSI, LPSI, and LGSI showed different abilities to predict \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${H}_{q}$$\end{document} and to generate selection response (Table 1). QPSI achieved a mean gain of 101.7, outperforming the LPSI (mean = 13.3). QGSI yielded the greatest overall response, with an average gain of 135.9 and a maximum of 182.7 in cycle C5. This advantage arises from QGSI’s capacity to exploit nonlinear and interaction-driven genetic variation through squared and cross-product terms. The LGSI mean (15.6) was consistent with the limitations of an additive linear genomic model. Across all cycles, QGSI systematically outperformed LPSI and LGSI. These results align with theoretical expectations that quadratic indices extract non-additive information unavailable to linear indices. Figure 1 illustrates these differences clearly: the QGSI selection response exceeded the QPSI, LPSI, and LGSI selection responses by 25.2%, 90.2%, and 88.5%, respectively. QPSI also surpassed both linear indices by more than 80%.
Squared correlation (predictive accuracy) between the indices and \documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${H}_{q}$$\end{document}Hq
LPSI and QPSI (Table 1) mean accuracy were \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${r}^{2}=0.917$$\end{document} and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${r}^{2}=0.825$$\end{document} , respectively. QGSI attained a mean accuracy of \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${r}^{2}=0.740$$\end{document} , striking a balance between nonlinear modeling and genomic information and maintained relatively uniform trait-specific correlations across cycles, benefiting from its ability to absorb interaction-driven signals. The LGSI mean accuracy \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${r}^{2}=0.908$$\end{document} was higher than QGSI. The QGSI stability explains why QGSI achieved higher realized selection responses even when LGSI exhibited similar or marginally higher accuracy estimates. It is important to note that the Pearson squared correlation is inherently linear and therefore does not perfectly capture the accuracy of indices predicting a nonlinear genetic merit.
Mean squared prediction error (MSPE)
Despite theoretical expectations of zero asymptotic MSPE (Table 1) for LGSI and QGSI under complete genomic information, QGSI consistently achieved lower empirical MSPE than QPSI across all cycles. This result is consistent with the analytical expressions presented in Supplementary Eqs. 5 and 13. QPSI produced the highest MSPE values. LPSI showed moderate MSPE values, but only describes the linear prediction part, contrary to QGSI, which explains linear and quadratic prediction. These results highlight the importance of incorporating nonlinear genomic components and reducing prediction error.
Expected genetic gains per trait
Table 2 summarizes the expected genetic gains for four traits (T1, T2, T3, T4) across 10 simulated cycles using linear (LPSI, LGSI) and quadratic (QPSI, QGSI) indices under ML estimation with 10% selection intensity ( \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$k=1.755$$\end{document} ). Average trait-wise gains were highly consistent between LPSI and LGSI, indicating that LGSI captured the major additive effects of the GEBVs like LPSI for predicting linear net merit. Traits with positive desired directions (T1, T3, T4) showed moderate to high gains, while T2 consistently exhibited negative correlated responses due to the imposed economic weights and covariance structure.
Figure 2 displays the average expected genetic gain across traits, highlighting the parallel behavior between phenotypic and genomic linear indices and reaffirming the robust estimation of trait-specific gains across cycles.
Maximum likelihood estimated selection response (real maize datasets)
Table 3 shows that for both real datasets (JMpop1 DTMA Mexico and JMpop1 DTMA Zimbabwe, hereafter JDMexico and JDZimbabwe, respectively), and across genomic selection cycles 1 and 2, QGSI outperformed LGSI in terms of selection response. The limited improvement of LGSI reflects the strictly additive nature of this index. On average, QGSI delivered 89% (JDMexico) and 80% (JDZimbabwe) greater gains than LGSI, demonstrating a clear advantage for quadratic genomic modeling when improving correlated traits.
QPSI also outperformed LPSI in Cycle 0 (Table 3). That is, even in the absence of genomic data, QPSI is more efficient for exploiting non-linear trait relationships. In JDMexico and JDZimbabwe, QPSI’s selection response exceeded that of LPSI by 90% and 87%, respectively. These results support a phased breeding strategy: (1) Use QPSI in early cycles, and (2) Transition to QGSI once genomic predictions become feasible. These patterns are illustrated in Supplementary Method 4 for JDMexico across cycles C0–C2, and are summarized for both datasets in Tables 3 and 4 for ML and Gaussian kernel.
Gaussian kernel estimated selection response
When \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${H}_{q}$$\end{document} was predicted using the multi-trait Gaussian kernel, QGSI achieved the highest and most stable selection responses across datasets. Average QGSI gains reached 68.0 in JDMexico and 93.3 in JDZimbabwe (Table 3). In contrast, when the same Gaussian kernel predictions were used within LGSI, average gains were only 8.4 (JDMexico) and 4.6 (JDZimbabwe). This striking contrast indicates that the benefit of the Gaussian kernel is maximized when combined with a quadratic index, which can exploit non-additive signals, local epistatic patterns, and complex multi-trait covariance structures. When these nonlinear predictions are forced into LGSI, the advantage disappears.
Maximum likelihood estimated expected genetic gain per trait (real maize datasets)
Table 4 presents expected genetic gains for GY, PH, EHT, and AD under 10% selection intensity (k = 1.755). LPSI and QPSI at Cycle 0 produced larger per-trait gains for EHT and PH relative to GY and AD. Across genomic cycles, QGSI and LGSI produced, in Cycles 1 and 2, patterns similar to those of QPSI and LPSI in Cycle 0, with moderate gains for GY but larger responses for height-related traits. In JDZimbabwe, genomic indices yielded more consistent and agronomically favorable gains for PH and AD in Cycles 1 and 2 while reducing the large negative correlated responses seen under phenotypic selection. In JDMexico, GY gains at Cycle 0 were relatively higher. Still, EHT and PH gains were smaller than in Zimbabwe, underscoring the difficulty of achieving balanced multi-trait improvement when relying solely on linear or phenotypic information.
Gaussian kernel estimated expected genetic gain per trait
Contrary to advantage of the Gaussian kernel for selection response (Table 3), its estimates of expected genetic gain per trait were surprisingly similar to those obtained under ML (Table 4). This pattern occurs because, in this case, QGSI and LGSI give the same results (Supplementary Eq. 16). These results indicate that the value of the Gaussian kernel emerges in the context of quadratic selection indices, not in linear ones. In both maize datasets, Gaussian kernel-based QGSI and LGSI produced: (1) Higher and more stable gains for GY, (2) Moderated changes for PH and EHT, reducing extreme negative correlated responses, and (3) Minimal fluctuations for AD. These results show that QGSI combined with the Gaussian kernel yield more multi-trait improvements than phenotypic indices or ML-based genomic indices.
Correlation between the QPSI and \documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${H}_{q}$$\end{document}Hq
The correlation between the QPSI and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${H}_{q}$$\end{document} could be evaluated only in phenotypic cycles. Across both datasets, QPSI and LPSI produced squared correlations comparable to those observed in the simulated maize dataset (Table 1). QPSI achieved correlations between 0.39 and 0.50, while LPSI ranged from 0.55 to 0.74 (Table 3). The larger improvements under LPSI occurred in traits with moderate heritability and known interaction effects, such as those present in JDZimbabwe.
Mean squared prediction error (MSPE)
In both the simulated (Table 1) and real (Table 3) datasets, during phenotypic cycles, LPSI exhibited lower MSPE than QPSI. This was particularly evident in traits subject to strong environmental fluctuations, where QPSI led to greater variation and larger error across cycles. This suggests that LPSI is more reliable when environmental variance dominates, which is the case in advanced testing stages.
Maximum likelihood estimated selection response (real wheat datasets)
Table 5 summarizes the selection response, squared correlation, and prediction error metrics for five wheat environments evaluated using LPSI, LGSI, QPSI, and QGSI under ML and Gaussian kernel estimation. QPSI produced moderate-to-high selection responses across environments (R = 10–45), but with relatively high SR-MSPE values and only intermediate squared correlations (SCor = 0.468–0.882). By contrast, LGSI (R = 0.7–4.1) and QGSI (R = 6.5–27.6) yielded much smaller gains, reflecting the limited capacity of LGSI to capture trait complexity in wheat.
Across CENEB-BED2IR, CIANO-BED-5IR and CENEB-FLATDRIP environments, QPSI consistently delivered strong selection responses (R = 30.4–45.4) accompanied by high predictive alignment (SCor = 0.468–0.882). In contrast, LPSI selection responses remained low (R = 1.2–3.2), although exhibited lower SR-MSPE values (0.2–2.0). This pattern replicates the behavior observed in the simulated maize datasets and is consistent with the theoretical properties shown in Supplementary Eq. 5: quadratic indices capture more signal but propagate more prediction variability. The two SAWYT environments showed similar tendencies: QPSI produced higher responses (R = 10–32) than LPSI (R = 2.2–4.4), but LPSI again obtained higher squared correlations (SCor = 0.39–0.73).
For the first top three environments individually, QGSI achieved selection responses between 6.5 and 9.0—capturing only about 14–26% of the gain observed for QPSI. LGSI produced the lowest responses (R = 0.8–1.2). For the two SAWYT environments, QGSI achieved much higher responses (R = 11–28), coming closer to the corresponding phenotypic QPSI values. When the three main environments were combined, both QPSI (R = 29.3; SCor = 0.526) and QGSI (R = 9.0) outperformed their linear counterparts—LPSI (R = 1.5; SCor = 0.20) and LGSI (R = 0.70). Yet, QPSI again showed the highest SR-MSPE (15.9), consistent with greater sensitivity to noise.
Gaussian kernel estimated selection response
The Gaussian kernel multi-trait increased the selection response for the QGSI, while improvements in LGSI remained modest (Table 5). Environments such as CENEB-FLATDRIP and SAWYT-27 displayed high QGSI responses (R = 73.5 and 61.2, respectively). Although Gaussian kernel improved LGSI relative to ML, the gains were consistently far lower than those obtained with QGSI. Across all environments combined, QGSI produced a selection response of 38.8; more than tripling the ML-based QGSI response (R = 9.0) and exceeding all linear indices. These consistent improvements across a broad range of wheat environments demonstrate that nonlinear genomic modeling substantially enhances the performance of quadratic indices.
Overall, the wheat results mirror the maize findings: quadratic indices deliver larger gains than linear indices, and the combination of QGSI + Gaussian kernel is the most effective strategy for capturing additive and non-additive variance. Although phenotypic indices occasionally outperform genomic ones in absolute response, genomic indices are essential for rapid-cycle breeding and for prediction in untested or future environments.
Figure 3 illustrates the estimated selection response (R) across six wheat environments: CENEB-BED2IR, CIANO-BED-5IR, CENEB-FLATDRIP, the combined dataset, SAWYT-27, and SAWYT-28. Figure 3 reinforce the patterns observed in Table 5: (1) Gaussian quadratic genomic indices (G-QGSI) consistently produced the highest selection responses across all environments, (2) QPSI ranked second in most environments, followed by QGSI, indicating the strong influence of quadratic modeling even without RKHS estimation, and (3) LPSI and LGSI produced lower responses in every environment.
Maximum likelihood estimated expected genetic gain per trait (real wheat datasets)
Table 6 reports expected genetic gains for grain yield (GY), heading date (HD), and plant height (PH) at a selection intensity of 10% (k = 1.755). QPSI and LPSI yield identical expected gains, as do QGSI and LGSI. Phenotypic indices produced moderate positive gains in GY, modest changes in HD, and often large negative or inconsistent shifts in PH. LGSI and QGSI tended to reduce the magnitude of these extreme correlated responses, but gains in GY remained small.
For the three top environments, phenotypic indices produced higher GY gains (0.18–0.37; combined = 0.21) than genomic indices (–0.01 to 0.10; combined = 0.02). In the two SAWYT environments, however, both phenotypic and genomic indices delivered larger gains in GY (LPSI = 0.56–0.61; LGSI = 0.22–0.42), likely reflecting the strong genotype × environment interactions typical of advanced yield trials. Across those three environments and their combined set, phenotypic indices generally yielded desirable reductions in HD (e.g., –2.50; –3.90) and moderate-to-strong reductions in PH (e.g., –7.32; –6.13), supporting improved lodging resistance and plant architecture. Genomic indices also reduced HD and PH, but to a far smaller extent. In SAWYT-27, phenotypic indices produced favorable gains for GY and HD but undesirable positive shifts in PH, reflecting environment-specific correlations.
Taken together, ML results show that phenotypic indices are effective for altering height and maturity traits, but genomic indices under ML produce more conservative and less variable per-trait gains, albeit with smaller improvements.
Gaussian kernel estimated expected genetic gain per trait
In contrast to ML, the Gaussian multitrait kernel produced more favorable and balanced expected gains across traits (Table 6). LGSI(QGSI) increased GY gains more than doubling ML-based genomic gains, while moderating negative correlated responses in HD and PH. For example: (1) CENEB-BED2IR: GY improved from 0.19 (ML) to 0.48 (RKHS), while negative shifts in HD and PH were reduced, (2) CIANO-BED-5IR: GY increased from 0.10 (ML) to 0.46 (Gaussian kernel), and undesirable decreases in PH were moderated, (3) SAWYT-27: All three traits improved under RKHS, with the largest gains observed for GY and favorable responses in HD and PH.
Across environments, the Gaussian kernel produced more stable, biologically desirable, and agronomically coherent responses than ML, highlighting the importance of modeling nonlinear genomic relationships when traits are polygenic and environments interact strongly with genotype performance. The wheat results confirm that while phenotypic indices often achieve the largest raw gains, genomic indices, under the Gaussian kernel, provide balance and stability across multiple traits, making them valuable tools for modern breeding.
Figure 4 illustrates the estimated expected genetic gain per trait across environments CENEB-BED2IR, CIANO-BED-5IR, CENEB-FLATDRIP, the combined dataset, SAWYT-27, and SAWYT-28. Figure 4 reinforce the patterns observed in Table 6. That is, due to the linear pattern of the estimated expected genetic gain per trait: (1) Gaussian QGSI, (2) QPSI, and (3) LPSI and LGSI produced similar results in every environment.
Distributional normality properties in simulated data
In the simulated maize datasets, Supplementary Tables 1 and 2 show that the joint distribution of (i) the true quadratic net genetic merit with QPSI and QGSI, (ii) univariate residuals, and (iii) the multivariate distributions of traits and GEBVs all produced p-values above conventional rejection thresholds. Average p-values for traits and GEBVs ranged from 0.15 to 0.58, indicating no evidence against multivariate normality. Visual diagnostics (Supplementary Fig. 1) also confirmed that QPSI and QGSI approximated normal distributions, with only minor deviations in the tails. These results support the validity of the analytical expressions for selection response, accuracy, expected genetic gain, and index variance in the simulated framework.
Real maize and wheat data
In the real maize datasets (Supplementary Table 3), phenotypic traits frequently deviated from multivariate normality, reflecting environmental variability and non-linear trait distributions. However, the corresponding GEBVs showed no evidence against joint multivariate normality, suggesting that genomic prediction smooths environmental noise and leads to more regular empirical distributions. In the wheat datasets (Supplementary Table 3), both traits and GEBVs conformed more closely to multivariate normality, with p-values generally above rejection thresholds across environments. This indicates that while raw phenotypic traits may deviate from normality—especially under stress—the genomic estimates tend to approximate normal distributions, supporting the application of parametric selection index theory.
Mild departures from normality did not materially affect the comparative performance of QPSI, QGSI, LPSI, or LGSI. Across species and environments, selection responses and predictive accuracies were stable, demonstrating that the quadratic genomic indices—particularly QGSI—are robust to modest violations of normality.
Heritability of real maize and wheat traits
Supplementary Table 4 reports broad-sense heritability estimates for all real maize and wheat traits, as well as the heritability of the LPSI. In maize, GY showed low-to-moderate heritability (0.16–0.73), consistent with strong environmental sensitivity. EHT and PH exhibited moderate heritabilities ( ≈ 0.46–0.62), while AD showed moderately high values (0.51–0.68). The heritability of LPSI averaged 0.64, indicating that the phenotypic index retained a meaningful proportion of genetic variance despite heterogeneity among individual traits.
In wheat, heritability patterns were generally higher and more stable. Heading date (HD) showed very high heritability (0.87–0.96), reflecting its strong genetic control; PH had moderate-to-high values (0.34–0.75); and GY ranged from low to moderate (0.02–0.73). The LPSI heritability (0.45–0.91) demonstrated that phenotypic indices captured substantial additive genetic signal even when individual traits varied widely across environments.
These heritability patterns help explain the observed index performance: (1) Traits with higher heritability (HD, PH) produced stable and predictable responses under both linear and quadratic indices. (2) Traits with lower heritability (GY) benefited more from genomic modeling and the non-linear structure of QGSI, which captures additional variance not accessible to linear indices. (3) The strong heritability of the LPSI clarifies why phenotypic selection remains competitive in early cycles, while the extra variance captured by QGSI explains its superiority once genomic information becomes available.
Discussion
We introduced and validated the QGSI, a nonlinear extension of QPSI and LGSI theory, where genomic data and non-additive genetic effects are simultaneously considered. Across simulated and real-world maize and wheat datasets, QGSI and QPSI outperformed LGSI and LPSI, delivering higher selection responses, stronger ranking fidelity, and more favorable genetic gains. These results reinforce the operational logic of deploying QPSI during early selection cycles when phenotypic data are still collected, and transitioning to QGSI in fully genomic pipelines.
Across both simulated datasets (Tables 1 and 2) and real maize and wheat datasets (Tables 3–6), QGSI demonstrated a unique advantage: it adapts to changing trait distributions, maintains balanced responses across multiple traits, and incorporates complex genomic patterns that LGSI cannot detect. Its capacity to account for non-additive effects, local epistatic interactions, and multi-trait genomic relationships makes QGSI a more dynamic and resilient tool than traditional LGSI.
The results from the real maize and wheat datasets (Tables 3–6) reinforce the complementary operational roles of the QPSI and QGSI. First, QPSI is the preferred index for early phenotypic cycles, where genotyping may still be limited. In these stages, QPSI delivered higher genetic gains, capturing non-linear relationships among traits and exploiting phenotypic covariance structures without requiring genomic information. Second, QGSI becomes the index of choice in later genomic cycles, where it outperforms LGSI in terms of selection response, prediction stability, and multi-trait coherence. This division of labor mirrors the trajectory of modern breeding programs, where early phenotypic selection transitions into rapid genomic cycles.
The combined empirical evidence clearly indicates that QPSI and QGSI represent a methodological advancement over their linear counterparts. While LPSI and LGSI offer stability under additive trait architectures, their predictive performance declines when genetic architectures involve non-linearities, epistasis, or strong trait interactions. In contrast, QPSI and QGSI extend the LPSI and LGSI, respectively, by incorporating squared terms and cross-product interactions, enabling them to exploit additional sources of genetic variance that linear indices cannot access.
Among these, QGSI stands out as the most powerful and adaptive tool. By integrating dense genome-wide marker data into a quadratic index formulation, QGSI identifies subtle multi-trait genomic patterns, captures non-additive genetic components, and remains robust to shifts in population structure and trait distributions across selection cycles. Unlike traditional indices with fixed weights, QGSI updates its coefficients in response to evolving data layers, making it inherently adaptive to dynamic breeding populations. From a practical breeding standpoint, the workflow distinctions are: (1) QPSI is most effective during early phenotypic stages, allowing breeders to maximize gains before genomic information becomes available or affordable, and (2) QGSI is the optimal tool in fully genomic pipelines, where prediction accuracy, rapid cycle turnover, and the integration of multiple traits are priorities. Its compatibility with Gaussian kernel estimation further amplifies its superiority in complex breeding scenarios.
The consistent of QGSI across both simulated and real datasets provides compelling justification for its adoption as a next-generation selection tool. In breeding programs involving multiple correlated traits, evolving genetic architectures, and potential non-additive effects, QGSI is poised to deliver greater and more sustained genetic gains than any linear index currently available. QPSI and QGSI are theoretical equivalents and confirm the robustness of the quadratic index framework. Computational demand increases with the number of traits, as quadratic indices require estimation of squared and interaction terms that may become unstable in small datasets. The closed-form derivations assume multivariate normality of breeding values—an assumption supported here by One-side (Shapiro-Wilk (SW), Henze-Wagner, Henze-Zirkler, and Royston) and two-side (Mardia) statistical tests^14–16^ and consistent with genomic selection theory under the infinitesimal model^17–19^—but potentially violated in real populations with strong structure or selection history. Noise in genotype information, limited sample sizes, or collinearity among traits may further complicate coefficient estimation.
Several promising extensions of QGSI could enhance its utility. Bayesian regularization^20^ or kernelized regression methods^21,22^ could improve estimation of quadratic weights in high-dimensional settings, especially when the number of traits or SNPs is large. Deep learning models^23^ could automatically discover nonlinearities and trait–trait interactions beyond the scope of explicit cross-product terms. The integration of environmental covariates into genomic prediction using reaction norms^24^, Gaussian kernels^13^, or machine learning approaches^23–25^ could enable G×E-informed QGSI for cross-environment predictions. QGSI may also be embedded in multi-layered prediction frameworks combining pedigree, markers, remote sensing data, and soil or climate information^26,27^. Incorporating dynamic economic weights or selection constraints within an index optimization framework^6^ could further align selection decisions with breeding goals. Lastly, the development of open-source tools to implement QGSI would facilitate broader adoption and reproducibility across breeding programs^28–30^.
Finally, the proposed QGSI framework directly addresses the growing recognition that epistasis and higher-order genetic interactions are fundamental components of complex trait architecture. Contemporary evidence from eco-evo-devo theory, omnigenic models, and multilayer interactome analyses shows that phenotypes emerge from dense networks of interacting loci whose effects are context-dependent and often nonlinear. Linear genomic selection indices can capture epistatic variance only indirectly through additive projections, whereas quadratic indices explicitly accommodate interaction-driven contributions via squared and cross-product terms. When combined with nonlinear genomic prediction methods—such as Gaussian kernel models that implicitly represent genome-wide epistasis—QGSI provides a biologically grounded and statistically coherent strategy for exploiting genetic networks without requiring explicit specification of interaction terms. This integration aligns with recent theoretical and empirical advances demonstrating that accounting for epistasis improves prediction accuracy, selection response, and long-term genetic gain in complex traits^31–34^. Thus, QGSI should be viewed not merely as an extension of classical index theory, but as a network-aware genomic selection framework consistent with modern views of genetic architecture.
We conclude that QGSI represents a significant advancement over traditional linear frameworks in both conceptual depth and operational impact. By explicitly modeling non-linear trait relationships and interaction effects, QGSI enables more accurate, stable, and biologically informed selection decisions in multi-trait genomic prediction. Unlike static linear indices, QGSI adapts to changes in population structure, trait distributions, and selection pressures across cycles. It leverages genomic data not only to predict additive effects, but also to uncover complex genetic architectures, including epistasis and pleiotropy^30^. From an operational standpoint, QPSI is most effective in early selection cycles when phenotypic data are available and genomic resources are limited. In contrast, QGSI is ideally suited for high-throughput genomic selection pipelines, where rapid cycle turnover and multi-trait optimization are essential. The empirical evidence presented here—across both controlled simulations and diverse real-world maize and wheat datasets—demonstrates that QGSI consistently delivers higher and more stable genetic gains than its linear analogues. As breeding programs increasingly aim to optimize multiple, sometimes antagonistic traits under variable conditions, QGSI provides a robust, adaptive, and forward-looking framework for accelerating genetic improvement.
Methods
Maize real dataset
We took two maize datasets from the published literature^5^. These datasets have been denoted as JMpop1 DTMA Mexico optimum environment and JMpop1 DTMA Zimbabwe optimum environment. We used these two datasets to perform phenotypic on a training population (C0), and genomic selection on two testing population: cycle 1 (C1) and cycle 2 (C2). For each data set, C0 contained genotypic (markers) data and four phenotypic traits: grain yield (GY, t/ha), plant height (PH, cm), ear height (EHT, cm), and anthesis days (AD, d), as well as three sets of markers corresponding to C0, C1, and C2. The numbers of individuals for the two datasets were 247, each one with two repetitions, and the numbers of molecular markers was 195 for C0, C1, and C2. Assuming that the breeding objective was to increase GY while decreasing PH, EHT, and AD, the vectors of economic weights in C0, C1, and C2 was \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${{{\bf{w}}}}^{{\prime} }=[\begin{array}{ccc}5 & -0.3 & \begin{array}{cc}-0.3 & -1\end{array}\end{array}]$$\end{document} , for all four indices and datasets. The QPSI and LPSI was applied only in C0 because there were no phenotypic data after that cycle, whereas QGSI and LGSI were applied in C1 and C2. The top 10% (k = 1.75) was selected in all cycles of the four data sets.
Wheat real datasets
One wheat data comprises two years of international nursery under high rainfall environments (High Rainfall Wheat Yield Trials, HRWYT), 27th and 28th, including 3 environments in Mexico, 2 at the Cd. Obregon CIMMYT experimental station (CENEB) and 1 at CIANO station. The environments included bed planting under 2 irrigations (BED2IR), bed planting under 5 irrigations (BED5IR), and flat planting under drip irrigation (FLATDRIP). The traits measured were grain yield (GY, t/h), heading date (HD, days), and plant height (PH, cm). The sample size of genotypes or individuals was of 50, each with two repetitions, whereas the number of markers was of 3111. The vector of economic weights for GY, HD, and PH was \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${{{\bf{w}}}}^{{\prime} }=[\begin{array}{ccc}10 & -0.3 & -0.1\end{array}]$$\end{document} .
The other real wheat data set used in this study is SAWYT-27 and SAWYT-28, which are consecutive cycles of CIMMYT’s Semi-Arid Wheat Yield Trials, designed to evaluate elite spring wheat lines under drought- and heat-prone environments. Each nursery contains approximately 40–50 advanced genotypes plus international checks, tested across diverse semi-arid locations in Mexico, South Asia, West Asia, North Africa, and Sub-Saharan Africa. Field trials typically follow an alpha-lattice design, with standardized management to impose moderate-to-severe water-limited conditions. Both crop seasons included GY, HD, and PH. Their multi-environment structure enables evaluation of yield stability, stress adaptation, and the transferability of predictive models across years. Also, this dataset included two locations at CENEB and one at CIANO with different planting systems and under drought and heat management.
Simulated datasets
The datasets were simulated with QU-GENE^5^ software using 2806 molecular markers and 315 quantitative trait loci (QTLs) for eleven phenotypic selection cycles (C0 to C10), each with four traits (T1, T2, T3, and T4), 500 genotypes, and four replicates for each genotype. The authors distributed the markers uniformly and the QTLs randomly across 10 chromosomes to simulate maize (Zea mays L.) populations. A different number of QTLs affected each of the four traits: 300, 100, 60, and 40, respectively. The common QTLs affecting the traits generated genotypic correlations of −0.5, 0.4, 0.3, −0.3, −0.2, and 0.1 between T1 and T2, T1 and T3, T1 and T4, T2 and T3, T2 and T4, T3 and T4, respectively. The economic weights used in the selection process for T1, T2, T3 and T4 were 1, −1, 1, and 1, respectively. We used 10 phenotypic and genomic selection cycles (C1-C10) with a proportion of selection of 10% (k = 1.755) in each cycle. We selected all four traits in each selection cycle.
The quadratic genomic selection index estimation
In the QGSI context, the total genetic merit of an individual is modeled as a quadratic function of true breeding values, where the coefficients assigned to squared trait values and cross-product terms reflect their relative economic importance. In this context, additive genetic values are estimated from SNP (Single Nucleotide Polymorphism) marker data using GBLUP (Genomic Best Linear Unbiased Prediction) and Bayesian prediction models, while the genomic relationship matrix ( \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${{\boldsymbol{\Phi }}}$$\end{document} , Supplementary Eqs. 9.1-9.3) is used to derive the index parameters. This generalization of the classical index framework enables breeders to construct selection indices that: (1) exploit both additive and non-additive genetic variance, (2) incorporate trait interactions, (3) operate without phenotypic records if necessary, and (4) remain flexible across changing populations and breeding cycles.
The quadratic net genetic merit of individuals (Supplementary Eq. 1) enables breeders to account for both additive contributions through \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${{\rm{t}}}({{\bf{w}}}){{\bf{g}}}$$\end{document} and interactions or nonlinearities among traits through \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${{\rm{t}}}({{\bf{g}}}){{\bf{Wg}}}$$\end{document} . In turn, the QGSI (Supplementary Eq. 10) is an extension of the QPSI, which predicts Supplementary Eq. 1 based on both linear and quadratic combinations of breeding values. In genomic contexts, true genomic breeding values are unknown and are replaced with GEBVs, which have been calculated using GBLUP or Bayesian prediction models ^5,6^. After the first selection cycle, each individual’s GEBVs for trait t is modeled as
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\hat{{{\rm{\gamma }}}}={{\rm{M}}}{{{\rm{\beta }}}}_{{{\rm{BLUP}}}}$$\end{document}where M = It \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\otimes$$\end{document} X is the matrix of standardized marker genotypes (2-2p, 1-2p and -2p for genotypes AA, Aa, and aa, respectively; p is the frequency of allele A, and 1-p is the frequency of allele a, respectively) in the testing population, where It is an identity matrix of size \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$t\times t$$\end{document} , \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\otimes$$\end{document} denotes the direct product, and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${{{\boldsymbol{\beta }}}}_{{{\rm{BLUP}}}}$$\end{document} is the vector of GBLUPs predictor of all estimated marker additive effects for t traits estimated in the training population, whereas matrix X was defined in Supplementary Eq. 9.1.
The estimated QGSI (Supplementary Eq. 10) integrates a linear and a quadratic component and is computed as:
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${\hat{\bf{I}}}_{{\bf{q}}{\bf{g}}}={\rm{t}} \left({\bf{w}}\right){\hat{\boldsymbol{\gamma }}}+{\rm{t}}\left({\hat{\boldsymbol{\gamma }}}\right){\bf{W}}{\hat{\boldsymbol{\gamma }}}$$\end{document}where \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${{\bf{w}}}$$\end{document} is the vector of linear weights and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${{\rm{t}}}\left({{\bf{w}}}\right)$$\end{document} its transpose; \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\hat{{{\boldsymbol{\gamma }}}}$$\end{document} is the vector of GEBVs and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${{\rm{t}}}\left(\hat{{{\boldsymbol{\gamma }}}}\right)$$\end{document} its transpose whereas \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${{\bf{W}}}$$\end{document} is a symmetric matrix of quadratic and cross products weights. The first term \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${{\rm{t}}}\left({{\bf{w}}}\right)\hat{{{\boldsymbol{\gamma }}}}$$\end{document} captures the linear additive genetic merit, while the second term \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${{\rm{t}}}\left(\hat{{{\boldsymbol{\gamma }}}}\right){{\bf{W}}}\hat{{{\boldsymbol{\gamma }}}}$$\end{document} model interactions or nonlinear trait GEBV contributions.
In Supplementary Eqs. 10-12, we derive the expected value and variance of the QGSI, which can be estimated as \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${{\rm{tr}}}({{\bf{W}}}\hat{{{\boldsymbol{\Gamma }}}})$$\end{document} and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${{\rm{t}}}\left(\hat{{{\boldsymbol{\gamma }}}}\right)\hat{{{\boldsymbol{\Gamma }}}}{{\bf{w}}}+2{{\rm{tr}}}[{{\bf{W}}}\hat{{{\boldsymbol{\Gamma }}}}{{\bf{W}}}\hat{{{\boldsymbol{\Gamma }}}}]$$\end{document} , respectively, where \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\hat{{{\boldsymbol{\Gamma }}}}$$\end{document} an estimator of the genomic covariance matrix \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${{\boldsymbol{\Gamma }}}$$\end{document} (Supplementary Eqs. 9.2, 9.3, 19.1, and 19.2). These derivations provide theoretical support for the formulation and comparison of QGSI with linear indices under various scenarios of trait correlation and heritability. Similar results can be finding for the QPSI.
R-software for testing the assumption of normality
We corroborated the residuals normality assumption using the stats R-package, whereas to corroborate the assumption of joint bivariate normality distribution of \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${{\rm{H}}}$$\end{document} and QPSI, and H and QGSI, we used the mvShapiroTest R-package (Supplementary Table 1). The stats R-package is part of the R-base software and includes the univariate one-side Shapiro–Wilk test through the shapiro.test() R-function, whereas the mvShapiroTest R-package contains the multivariate one-side Shapiro–Wilk test through the mshapiro.test() function. In addition, in Supplementary Table 2 and 3, we present the one-side (Shapiro-Wilk (SW), Henze-Wagner, Henze-Zirkler, and Royston) and two-side (Mardia) five test statistics^14–16^ and their p-values to test join multivariate normality of the simulated and real datasets trait and GEBVs, respectively. Those test statistics were implemented using the R package MVN^14^.
The \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$p-{{\rm{value}}}$$\end{document} was the decision criterion to accept or reject the null hypothesis \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$({H}_{0})$$\end{document} , e.g.,
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${{{\rm{H}}}}_{0}$$\end{document} : H_q_ and QPSI have joint bivariate normal distribution, vs.
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${{{\rm{H}}}}_{1}$$\end{document} : H_q_ and QPSI does not have a joint bivariate normal distribution.
The \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$p-{{\rm{value}}}$$\end{document} is an estimate of the probability that a particular value of the statistical test result, or a result more extreme than the statistical test value observed, could have occurred by chance if \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${{{\rm{H}}}}_{0}$$\end{document} were true. This is a measure of the credibility of \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${H}_{0}$$\end{document} and if this is large (e.g., p = 0.30) means that there is no evidence to reject \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${H}_{0}$$\end{document} for significance levels of 0.05, 0.10, or 0.20, for example ref. ^16^.
Reporting summary
Further information on research design is available in the Nature Portfolio Reporting Summary linked to this article.
Supplementary information
Supplementary Information Peer Review file Reporting Summary
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1Cerón-Rojas, J. J. & Crossa, J. Linear Selection Indices in Modern Plant Breeding Ch. 2 and 5 (Springer, 2018).
- 2Lynch, M. & Walsh, B. Genetics and Analysis of Quantitative Traits Ch. 26 and 27 (Sinauer, 1998).
- 3Erenstein, O., et al. Global trends in wheat production. In: Wheat Improvement & Food Security in a Changing Climate, pp.45–67, Reynolds, M. P., & Braun, H. J. (eds). (Springer, 2022).
- 4Zelterman, D. Applied Multivariate Statistics with R Chs. 5-7 (Springer, 2015).
- 5Crawley, M. J. The R book (2nd ed.) Ch. 8 (John Wiley & Sons, 2013).
- 6Hayes, B. & Daetwyler, H. Genomic selection. Armidale, Australia: Course (2015).
- 7Montesinos-López, A., Montesinos-López, O. & Crossa, J. Multivariate Statistical Machine Learning Methods for Genomic Prediction. (Springer, 2022).36103587 · pubmed ↗