Impact of tissue staining and scanner variation on the performance of pathology foundation models: a study of sarcomas and their mimics
Binghao Chai, Jianan Chen, Paul Cool, Fatine Oumlil, Anna Tollitt, David F Steiner, Tapabrata Chakraborti, Adrienne M Flanagan, Adrienne M Flanagan, Anna Tollit, Fatine Oumlil, Fernanda Amary, Roberto Tirabosco, Nischalan Pillay, Paul Cool, Adam Levine, Sebastian Brandner

TL;DR
This study examines how variations in tissue staining and scanners affect AI models in diagnosing soft tissue tumors, finding that some models are robust and adaptable.
Contribution
The study introduces a systematic evaluation of AI model robustness to staining and scanner variation in rare, morphologically diverse tumors.
Findings
Foundation models like UNI-v2, Virchow, and TITAN showed robustness to staining and scanner variation.
Including a small number of stain-varied slides improved model adaptability and data efficiency.
Soft tissue tumors served as a challenging test case for evaluating model generalizability.
Abstract
Histopathological analysis is considered the gold standard for the diagnosis and prognostication of cancer. Recent advances in AI, driven by large‐scale digitisation and pan‐cancer foundation models, are opening new opportunities for clinical integration. However, it remains unclear how robust these foundation models are to real‐world sources of variability, particularly in H&E staining and scanners produced by different manufacturers. In this study, we use soft tissue tumours, a rare and morphologically diverse tumour type, as a challenging test case to systematically investigate the colour‐related robustness and generalisability of seven AI models. Controlled staining and scanning experiments were utilised to assess model performance across diverse real‐world data sources. Foundation models, particularly UNI‐v2, Virchow and TITAN, demonstrated encouraging robustness to staining and…
Genes, proteins, chemicals, diseases, species, mutations and cell lines named across the full text — each resolved to its canonical identifier and authoritative record.
Click any figure to enlarge with its caption.
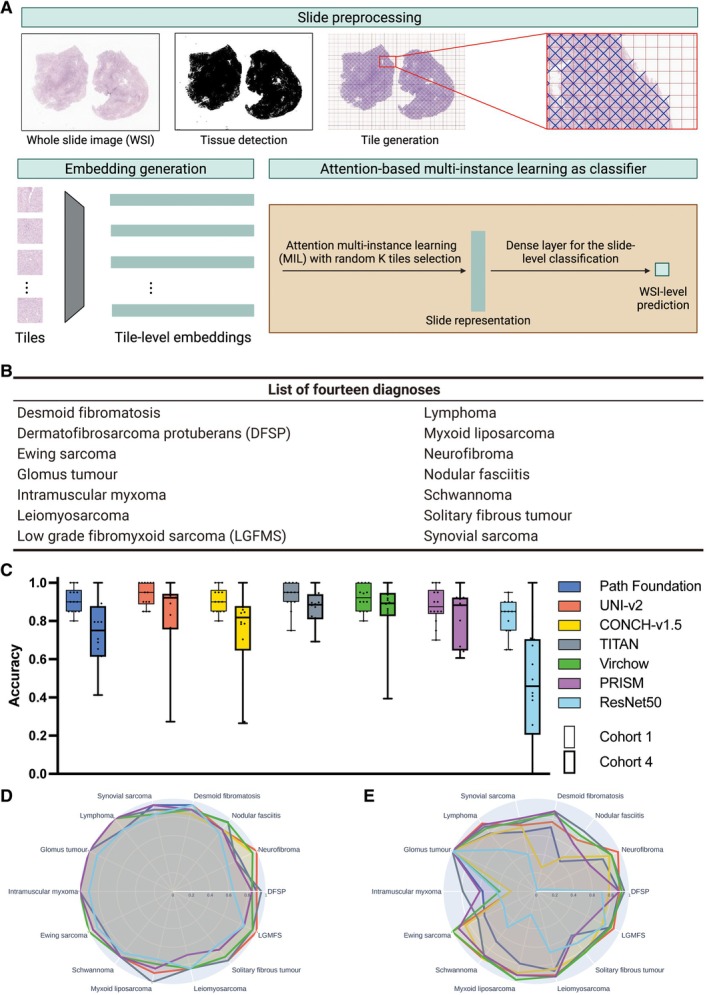 Figure 1
Figure 1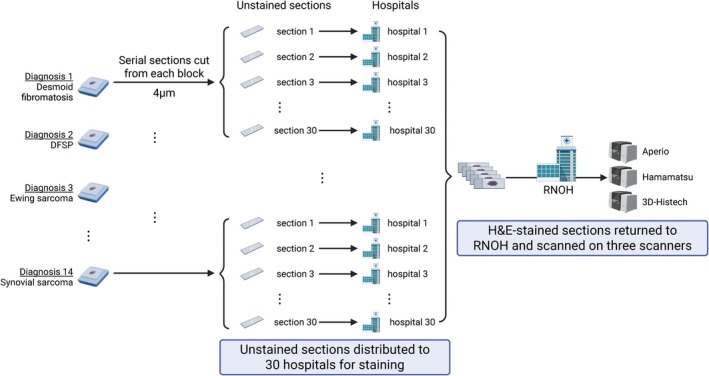 Figure 2
Figure 2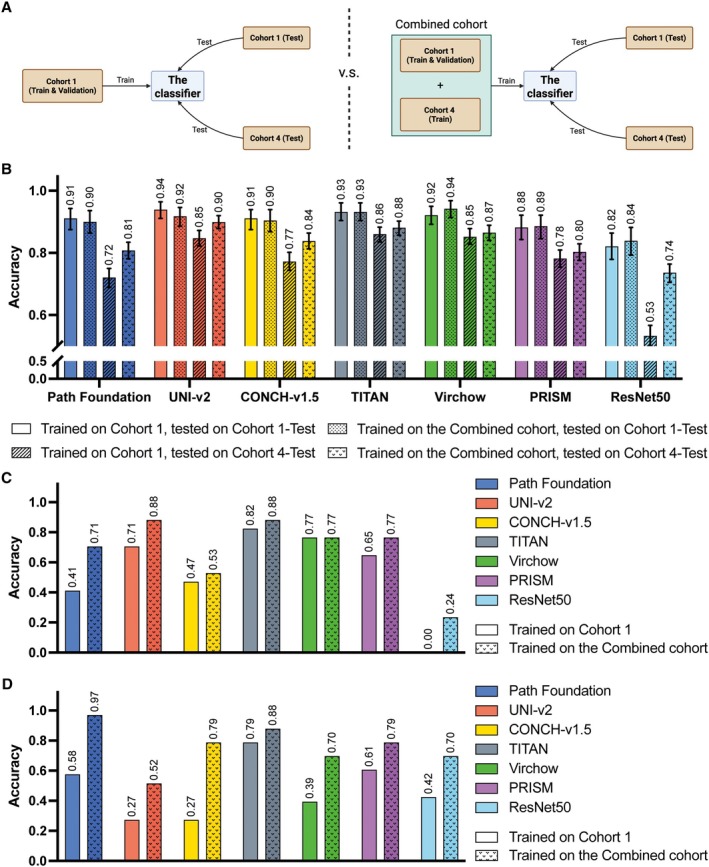 Figure 3
Figure 3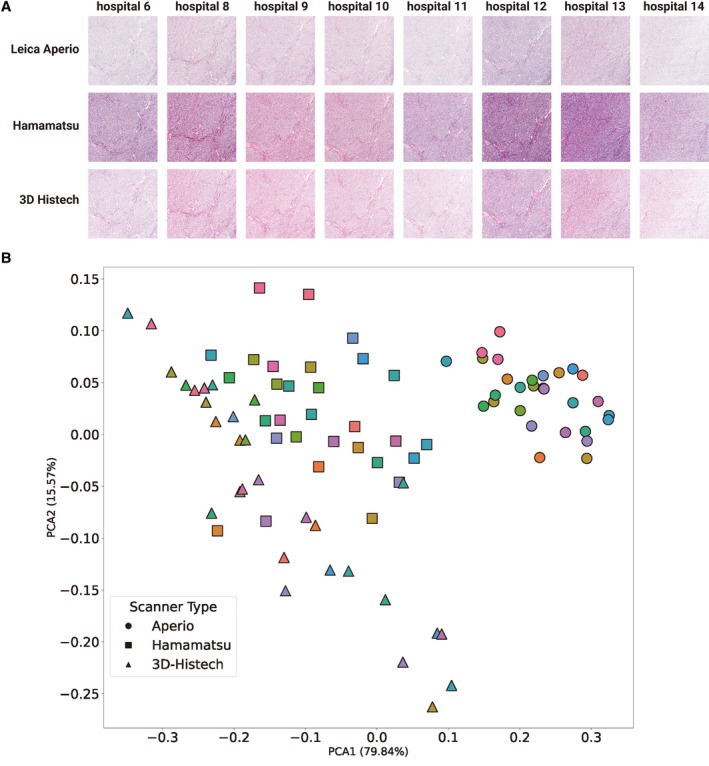 Figure 4
Figure 4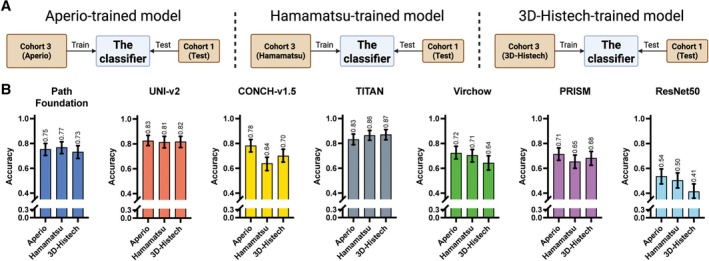 Figure 5
Figure 5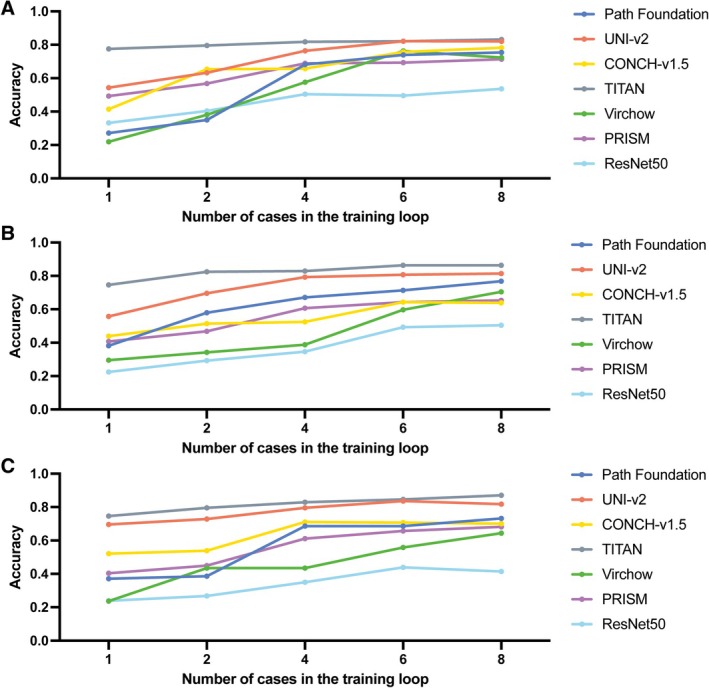 Figure 6
Figure 6| Dataset | Slides (Total) | Slides (Train) | Slides (Val) | Slides (Test) | Stain institute | Scan device |
|---|---|---|---|---|---|---|
| Cohort 1 | 1,394 | 835 | 279 | 280 | RNOH | Aperio |
| Cohort 2 | 1,243 | – | – | 1,243 | Multiple | Multiple |
| Cohort 3 | 335 | – | – | 335 | RNOH | Multiple |
| Cohort 4 | 934 | 121 | – | 813 | Multiple | Aperio |
| Total | 3,906 | 956 | 279 | 2,671 | – | – |
- —Sarcoma UK10.13039/100009756
- —Royal National Orthopaedic Hospital Research
- —Engineering and Physical Sciences Research Council10.13039/501100000266
- —Bone Cancer Research Trust10.13039/100011719
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsAI in cancer detection · Digital Imaging for Blood Diseases · Molecular Biology Techniques and Applications
Introduction
Digital pathology refers to the digitisation of whole slide images (WSIs) of stained tissue sections that can be used for diagnostic and research purposes. In recent years, there has been substantial development in the field, driven by advances in scanning technology, computational infrastructure, artificial intelligence (AI) and clinical need [1]. Moving from traditional light microscopy to digital workflows has enabled more scalable and reproducible image analysis, supporting remote consultations and real‐time diagnostic decision‐making and the use of AI to support pathologists in providing their clinical service. This transition has been accommodated by the widespread adoption of high‐speed, high‐resolution slide scanners, and improvements in image compression, cloud storage, and digital slide viewers [2]. Traditional AI models have been largely developed for narrowly defined problems, such as mitosis detection [3], nuclei segmentation [4], and Gleason grading in prostate cancer [5], which typically require large amounts of annotated data. In contrast, recent advances in deep learning, particularly the emergence of pathology foundation models, have expanded the scope and flexibility of AI applications [6, 7]. These large‐scale models, trained on up to millions of unlabelled image tiles across various tissue types, magnifications, and institutions, are capable of learning multiple general‐purpose representations that can be fine‐tuned for a variety of downstream tasks [6, 7].
Foundation models can reduce reliance on extensive task‐specific annotations, thereby accelerating the introduction of AI into clinical pathology. Such models include Google Path Foundation [8], Virchow [9, 10], and UNI [11] which are general‐purpose patch‐level encoders, while CONCH is a multimodal foundation model that integrates both image and text data [12]. Slide‐level foundation models such as TITAN [13] and PRISM [14] combine patch encoders with pretrained aggregation modules to generate slide‐level representations directly. Nevertheless, irrespective of the AI model employed, a consistent high level of performance across WSIs stained using different protocols and scanned on different devices is essential if they are to be introduced into clinical practice, as these two variables can substantially alter image appearance and model behaviour [15, 16, 17, 18, 19].
To address the challenges posed by stain variation, researchers have investigated a variety of strategies, including stain normalisation and more generalisable training designs. Stain normalisation (e.g., Reinhard et al [20], Macenko et al [21], and Vahadane et al [22]) aims to standardise colour distributions across slides prior to model training. However, these methods often underperform, particularly in preserving tissue morphology, compared to stain augmentation or deep learning‐based normalisation approaches [23, 24, 25]. Deep learning‐based stain variation correction methods, for example, those using generative adversarial networks (GANs), achieve better morphological preservation [26, 27, 28, 29, 30, 31]. However, these tools typically require large‐scale training datasets and tend to generalise poorly to slides from unseen sources. Foundation models have recently emerged as a promising solution to staining and scanning variability. Pretrained on large and diverse datasets, they offer a more robust and generalisable starting point for downstream task adaptation [8, 11, 12, 13]. In general, there has been a shift away from extensive stain preprocessing. Data are now often used in their original unnormalised form, due to the computational cost and practical challenges of applying stain normalisation on WSIs [23, 32]. However, the robustness of foundation models to stain and scanner variation remains relatively underexplored.
The aim of this study was to evaluate the extent to which pre‐trained foundation models remain robust to staining and scanning variation across real‐world images, thereby informing their utility in generalisable digital pathology workflows. We have employed sarcomas and their mimics, a rare and morphologically diverse tumour group [33], to investigate these questions.
Materials and methods
Ethical approval declarations
Ethical approval was given for undertaking the study ‘An Artificial Intelligence (AI) solution for diagnosing, prognosticating as well as predicting the outcome of sarcomas and their mimics: a multi‐centre study’. IRAS project ID: 328987 Protocol number: EDGE 161548. REC reference: 23/NI/0166. Sponsor University College London has been approved by HRA and Health and Care Research Wales (HCRW) (14 December 2023) and by Health and Social Care Research Ethics Committee B (HSC REC B) Office for Research Ethics Committees Northern Ireland (ORECNI) Lissue Industrial Estate West, 5 Rathdown Walk, LISBURN, BT28 2RF. REC reference: 23/NI/0166, Protocol number: EDGE 161548, IRAS project ID: 328987 (December 2023).
WSI datasets
We constructed four collections of haematoxylin and eosin (H&E)‐stained WSIs comprising 14 different diagnoses of sarcoma and their mimics. In total, 2,350 different WSIs were included in the study; each WSI was selected from a different case and only one image per patient. Diagnoses were based on the 2020 edition of the WHO series of soft tissue and bone tumour classification [33]. The tumours studied included desmoid fibromatosis, dermatofibrosarcoma protuberans (DFSP), Ewing sarcoma, glomus tumour, intramuscular myxoma, leiomyosarcoma, low‐grade fibromyxoid sarcoma (LGFMS), lymphoma, myxoid liposarcoma, neurofibroma, nodular fasciitis, schwannoma, solitary fibrous tumour, and synovial sarcoma (Figure 1B). Each case was reviewed by at least three expert soft tissue tumour pathologists, and the diagnoses were established using state‐of‐the‐art immunohistochemistry, molecular profiling and clinical context. The cohorts described below are found in Table 1 and all cases are listed in supplementary material, Table S1.
The computational pipeline and subtyping performance for soft tissue tumours. (A) WSIs were pre‐processed with tissue detection and tile generation on haematoxylin and eosin (H&E)‐stained slides using TRIDENT [34, 35]. Tile‐level embeddings were generated using six foundation models and ResNet50‐CNN before being sent to the attention‐based multi‐instance learning (MIL) classifier for training. (B) The list of 14 diagnoses containing sarcomas and their mimics in this study. (C) Class‐wise accuracy distribution for Cohort 1‐Test and Cohort 4‐Test sets across all seven models: Each pair of boxes represents the diagnostic accuracy of the 14 different diagnoses per model. Google Path Foundation (Cohort 1: 0.911±0.066, Cohort 4: 0.736±0.157), UNI‐v2 (Cohort 1: 0.939±0.063, Cohort 4: 0.842±0.189), CONCH‐v1.5 (Cohort 1: 0.911±0.066, Cohort 4: 0.737±0.233), TITAN (Cohort 1: 0.932±0.070, Cohort 4: 0.869±0.086), Virchow (Cohort 1: 0.921±0.067, Cohort 4: 0.859±0.152), PRISM (Cohort 1: 0.882±0.093, Cohort 4: 0.811±0.140) and ResNet50‐CNN (Cohort 1: 0.821±0.091, Cohort 4: 0.466±0.306). Each box represents the 14 subtype accuracies per model. (D, E) Radar plots showing the diagnosis‐level performance for all seven models on Cohort 1‐Test and Cohort 4‐Test, respectively. An interactive version of the radar plots is provided (see Data availability statement).
Cohort 1 serves as a controlled baseline for training and evaluation. It comprises 1,394 H&E‐stained WSI representing approximately 100 different cases per 14 diagnoses (one case per patient). All cases were sourced, processed, and stained at Royal National Orthopaedic Hospital (RNOH), and subsequently digitised using Leica Aperio GT 450 scanners at 40x equivalent magnification (0.2629μmpixel−1). The WSIs were split into training (60%), validation (20%), and hold‐out test (20%) sets. RNOH is UKAS‐accredited [36], and all tasks are undertaken according to standard operating procedures.
Cohort 2 was designed to investigate staining and scanning variability. See Figure 2 for details. It was made up of 1,243 WSI which were different to those cases in Cohort 1. For each of the 14 tumour subtypes studied, a case with representative histology for each was selected and serial sections (4μm) were cut from a single tissue block. One unstained slide per case was distributed to 30 different National Health Service (NHS) hospital laboratories, excluding RNOH (see list of members of Consortium), where local teams performed H&E staining using their clinical laboratory protocols. The stained slides were returned and digitised using three slide scanners: Leica Aperio GT 450, Hamamatsu NanoZoomer S360, and 3D‐Histech Pannoramic 1,000 (Figure 2).
Preparation of a unique multi‐institutional multi‐scanner collection of slides (Cohort 2, n=1,243 WSIs). This collection comprises a representative case from each of the 14 tumour subtypes, from which 30 serial sections (4 μm) were cut from one block and sent to different National Health Service (NHS) laboratories for H&E staining according to the local team's standard operating procedures. Stained slides were then returned to Royal National Orthopaedic Hospital and scanned on three different scanners (Leica Aperio GT 450, Hamamatsu NanoZoomer S360 and 3D‐Histech Pannoramic 1,000). DFSP, dermatofibrosarcoma protuberans; RNOH, Royal National Orthopaedic Hospital. Created with BioRender.com.
Cohort 3 was designed to assess the impact of scanning variation while controlling for staining variability (n=335 WSIs). For this cohort, eight cases per diagnosis were selected from Cohort 1 or Cohort 2 apart from eight new cases of synovial sarcoma which were added. All cases were stained at RNOH. Each stained slide was then scanned using the three scanners: Leica Aperio GT 450, Hamamatsu NanoZoomer S360, and 3D‐Histech Pannoramic 1,000. One WSI was not available from the 3D‐Histech batch.
Cohort 4 included all 14 diagnoses and serves as a ‘real‐world’ test set. A total of 934 WSIs were sourced from RNOH's clinical archives; 105 were stained at RNOH and the remaining 838 were stained in 73 different hospitals. These slides are different to those in Cohort 1, 2, and 3; details are found in supplementary material, Table S2. This cohort was divided into two groups: 813 slides were used exclusively to train Cohort 4 and the remaining 121 slides were used in combination with Cohort 1‐train to form a Combined cohort for the purpose of investigating if training on a limited number of images stained in different institutions improved the accuracy of the models.
Slides tiling
TRIDENT [34, 35] was used to preprocess the WSI (Figure 1A), during which all background tiles were efficiently discarded. Tiles can be generated under different magnification levels, at different sizes and with various levels of overlap between adjacent tiles. We used the default tiling settings for each of the models, which are: 224 × 224 at ×20 for Path Foundation, UNI‐v2, CONCH‐v1.5, Virchow, PRISM and ResNet50, and 512 × 512 at ×20 for TITAN.
Foundation models
We benchmarked the effectiveness of six foundation models for the sarcoma/sarcoma mimics subtyping task with staining and scanning variation. Path Foundation (Google Research) uses ViT‐S/B backbone [37] trained with Masked Siamese Networks [38] on 60 million H&E tiles from the Cancer Genome Atlas (TCGA) dataset [8], sampled at multiple magnifications to promote resolution robustness. UNI‐v2, CONCH‐v1.5, and TITAN (all from Mahmood Lab) are also ViT‐based models leveraging multi‐objective [11], contrastive learning [12], and end‐to‐end slide‐level pretraining [13], respectively. Virchow and PRISM (both from PaigeAI) are large‐scale models trained on over 1.5 million WSIs across diverse tissues [9, 10, 14]; PRISM uniquely integrates tile embeddings with clinical text using a multimodal generative approach. A ResNet50‐CNN [39], used as a benchmark model, was trained in a supervised manner directly on WSIs, without pretraining on external histopathology datasets or using self‐supervised learning. This provided a reference point on which to evaluate the benefits of using foundation model‐based feature extraction approaches in the presence of staining and scanning variation. Models were used either as tile encoders with Multi‐Instance Learning (MIL) or as end‐to‐end slide classifiers.
Slide‐level classification from tile‐ and slide‐based embeddings
To derive slide‐level diagnosis predictions, we adopted two strategies depending on the granularity of the feature representations. For models producing patch‐level embeddings (Google Path Foundation, UNI‐v2, CONCH‐v1.5, Virchow and ResNet50‐CNN), we adopted an attention‐based multi‐instance learning (MIL) framework [40]. Each slide was treated as a bag of instances (i.e., tiles/patches), and the MIL model learned to assign an attention weight to each tile, reflecting its relative importance for the slide‐level classification task. This attention mechanism could get those non‐informative or noisy tiles naturally filtered out and enable the classification model to focus on diagnostically relevant information. These weights are used to aggregate tile embeddings into a single slide‐level representation via a weighted sum z=∑i=1Kαixi. We randomly sampled K=500 tiles per slide during training, or used all tiles if fewer were available. Models were trained with cross‐entropy loss using the Adam optimiser and early stopping based on validation loss.
For slide‐level encoders such as TITAN and PRISM, which directly output a fixed‐length embedding per whole slide, we trained a logistic regression classifier using these slide‐level vectors. The classifier was implemented with scikit‐learn [41], trained on the slide embeddings and corresponding labels without regularisation or hyperparameter tuning. A maximum of 1,000 iterations and a fixed random seed ensured convergence and reproducibility.
Statistical analysis
To evaluate differences in classification performance, Pearson's chi‐squared test of independence was applied in two settings: (1) to assess whether each model's classification accuracy differed significantly between the internal (Cohort 1‐Test) and multi‐institutional (Cohort 4‐Test) test sets, and (2) to test whether if a small amount of multi‐institutional slides in training (i.e., trained with the Combined cohort; Figure 3A) significantly improved performance over training with only the internal slides (i.e., Cohort 1). For each comparison, the number of correctly and incorrectly classified slides was tabulated and used to compute the test statistic. All tests were two‐sided, with significance defined as p<0.05.
Improvement of the classification of 14 soft tissue tumour types by training on WSIs stained in more than one laboratory. (A) Experimental design to explore the impact of staining variation under two settings. In the original setting (left), the classifier was trained only on the internal cohort (Cohort 1‐Train), and then on a Combined cohort (right) containing an additional 121 WSIs from the multi‐institutional cohort (Cohort 4‐Train). Both versions of the classifier were evaluated independently on the internal (Cohort 1‐Test) and the ‘real world’ (Cohort 4‐Test) hold‐out set. (B) The analysis was conducted on Path Foundation, UNI‐v2, CONCH‐v1.5, TITAN, Virchow, PRISM and ResNet50‐CNN models. Models trained only on Cohort 1 revealed a statistically significant decline in classification performance when models were applied to the ‘real world’ test cohort (Cohort 4‐Test) compared to the internal cohort (Cohort 1‐Test): Google Path Foundation (p<0.001), UNI‐v2 (p<0.001), CONCH‐v1.5 (p<0.001), TITAN (p=0.004), Virchow (p=0.006), PRISM (p<0.001), and ResNet50 (p<0.001) with chi‐squared test. However, when the models were trained on the Combined cohort, a statistically significant improvement in Cohort 4‐Test classification performance was observed for Google Path Foundation (p<0.001), UNI‐v2 (p<0.002), CONCH‐v1.5 (p<0.001), and ResNet50 (p<0.001); while Virchow (p=0.478) and slide encoders (TITAN: p=0.238, PRISM: p=0.329), not significant. (C, D) Performance comparison between ‘trained on Cohort 1’ and trained on the Combined cohort’ on Cohort 4‐Test set for those failed subtypes (nodular fasciitis (C) and intramuscular myxoma (D), respectively) in the original training setting.
To quantify the uncertainty around classification performance, we estimated 95% confidence intervals for the accuracy using non‐parametric bootstrapping. Specifically, we resampled the test set with replacement 1,000 times, preserving its original size in each iteration. For each resampled set, accuracy was recalculated, yielding a distribution of accuracy estimates. The 2.5th and 97.5th percentiles of this distribution were taken as the lower and upper bounds of the confidence interval. This approach makes no assumptions about the underlying distribution of accuracy and provides a robust, data‐driven measure of variability.
Model evaluation
For each experiment, model performance was evaluated on the held‐out test set using standard metrics. These included micro‐averaged accuracy (i.e., the overall proportion of correctly predicted diagnoses across all test slides), top‐k accuracies (where k=1,3) and class‐wise (i.e., subtype‐level) accuracy breakdowns. To support interpretability and clinical transparency, each classifier also provided the top‐3 predicted classes along with their associated confidence scores for every test slide. These results were exported as structured CSV reports to facilitate downstream analysis and visualisation. This evaluation framework enables a lightweight and interpretable classifier to be applied on top of the rich representations extracted by foundation models, requiring significantly less annotated data and computational resources than training an end‐to‐end deep neural network.
Results
Evaluation of foundation models for slide‐level subtyping
All six foundation models (Google Path Foundation [8] UNI‐v2 [11], CONCH‐v1.5 [12], TITAN [13], Virchow [9, 10], and PRISM [14]) along with a ResNet50‐based convolutional neural network (CNN) [39] demonstrated a high level of diagnostic accuracy (i.e., the proportion of correctly predicted diagnoses) when trained and tested on an image collection stained in one laboratory and scanned on one device, Cohort 1 (Figure 1A). Foundation models, TITAN, UNI‐v2, and Virchow achieved the highest accuracy, and all models outperformed ResNet50. The performance of all foundation models dropped when tested on Cohort 4‐Test, a ‘real‐world’ dataset stained in multiple institutions and scanned on a single platform (Figure 3A, B). This diagnostic performance across 14 sarcomas and their mimics (Figure 1B) assessed on the seven models was reflected in the class‐wise accuracy, with Cohort 4‐Test showing a wider variance compared to Cohort 1 (Figure 1C). The radar plots of the 14 tumour types highlight the difference in performance between Cohorts 1 and 4. In Cohort 4, accuracy was retained for dermatofibrosarcoma protuberans (DFSP), desmoid fibromatosis, and synovial sarcoma, but was reduced moderately for solitary fibrous tumour. Nodular fasciitis and intramuscular myxoma were the lowest performing diagnoses. ResNet50‐CNN underperformed across all models when tested on both Cohorts 1 and 4 (Figure 1D, E).
To address the limitations of AI classification models when WSIs are stained in a single institution, we added a subset of externally stained WSIs from Cohort 4‐Train (n = 121; Table 1) to the Cohort 1‐Train (Combined cohort; Figure 3A). This resulted in all patch‐based foundation models exhibiting substantial overall accuracy improvements when tested on Cohort 4‐Test (Figure 3B and supplementary material, Table S3). This also led to improved class‐wise accuracy, and it is noteworthy that results for nodular fasciitis and intramuscular myxoma were better than in the previous experiments (Figure 3C, D). Interestingly, a minor decline in the performance of Google Path Foundation, UNI‐v2, and CONCH‐v1.5 was observed when the model was tested on Cohort 1‐Test but trained on the Combined cohort (Figure 3B). Full results are reported in supplementary material, Table S4.
Impact of staining and scanning variation
We next attempted to disentangle how differences in staining and scanning contribute to colour variation (Figure 2; Cohort 2; Table 1). Figure 4A illustrates the staining and scanning variations using a case of synovial sarcoma. We extracted stain vectors from randomly sampled 3,000×3,000 pixel tiles using the Vahadane method [22], which separates the optical density matrix into stain vectors and stain concentration maps. We then performed principal component analysis (PCA) to project the colour vectors in a two‐dimensional space (Figure 4B). Notably, the tile representations on PCA clustered largely by scanning device rather than staining institution. The Aperio‐scanned slides (circles) formed a tight cluster in the top right region of the plot, indicating relatively consistent colour vector characteristics, whereas 3D‐Histech‐scanned slides (triangles) were widely dispersed, reflecting higher intra‐scanner colour variability. Hamamatsu‐scanned slides (squares, top left region) showed clustering intermediate between the other two scanners (see supplementary material, Figure S1 for PCA plot with each scanner). These findings support our previous results, which showed that variation in staining reduces performance when classifying tumours using AI models, and that the addition of different scanning devices compounds the challenge. The wide distribution across the PCA does not allow quantitative assessment of the impact of staining and scanning of colour variation.
Visual and quantitative assessment of colour variation across staining institutes and scanners. (A) Representative images of a synovial sarcoma stained at 8 (out of 30) laboratories and scanned using three different WSI (Leica Aperio GT 450, Hamamatsu NanoZoomer S360, and 3D‐Histech Pannoramic 1,000), 3,000×3,000 pixel tiles extracted. (B) Principal component analysis (PCA) of stain vectors extracted from each 3,000×3,000 pixel tile. Each symbol represents a tile, where the colours correspond to the staining institute and the shape denotes the scanner used.
How robust are foundation models to scanning variation?
We next investigated how variability in colour induced by different scanning devices affects the generalisability of foundation models. Given our limited availability of non‐Aperio scanned slides, we aimed to isolate potential performance degradation introduced by mismatched scanner types during training (Figure 5A). For this experiment, we built a cohort (Cohort 3; Table 1) comprising eight cases randomly selected from each of the 14 diagnoses, stained at a single institution (Royal National Orthopaedic Hospital) and scanned on three scanners. These were used for training three classifiers for each foundation model: an Aperio‐trained model, a Hamamatsu‐trained model and a 3D‐Histech‐trained model (Figure 5A). The results (Figure 5B) showed that overall the models performed best when the training and testing WSIs were scanned using the same platform (Aperio). CONCH‐v1.5, Virchow, PRISM, and ResNet50 exhibited a noticeable drop in classification accuracy when trained on slides scanned with Hamamatsu or 3D‐Histech but tested on Aperio‐scanned slides. In contrast, TITAN and UNI‐v2 demonstrated greater consistent performance across scanner conditions: both remained high across all scanners, suggesting their robustness and generalisability to scanning variation.
Controlled scan variation experiments. (A) Schematic overview of the controlled scan variation experiment. A cohort of eight cases per diagnosis (Cohort 3), all stained at Royal National Orthopaedic Hospital, was scanned on three different devices. Three separate classifiers were trained on identical sets of slides scanned with different scanners (Aperio, Hamamatsu and 3D‐Histech scanners, respectively) and then evaluated on the same test set (Cohort 1‐Test, stained at RONH, scanned with Aperio). (B) Results of the controlled scan variation experiment for seven models.
Do foundation models enable few‐shot learning for rare tumour classification under stain variation?
To evaluate the data efficiency of foundation models in the context of rare tumours, and to assess their robustness to stain variation under limited data, we simulated low‐data settings using Cohort 3. Classifiers were trained using a small number of slides from each scanner type and evaluated on Cohort 1‐Test. Few‐shot training was conducted with increasing numbers of slides per diagnosis (1, 2, 4, 6, and 8).
TITAN demonstrated strong performance even when trained with one slide per diagnosis, while other models struggled with one slide for training (Figure 6). However, patch‐based encoders such as UNIv2 caught up quickly as the number of training slides increased. All foundation models outperformed ResNet50 in the few‐shot setting. All models perform better when trained with the slides scanned using the same scanner as the test slides (Aperio; Figure 6A). However, similar improved performance patterns were observed regardless of the scanner of the training slides.
Sample size sensitivity analysis using single‐institutionally stained, multiple‐device scanned slides; they are: (A) Royal National Orthopaedic Hospital (RNOH)‐stained Aperio‐scanned, (B) RNOH‐stained Hamamatsu‐scanned, and (C) RNOH‐stained 3D‐Histech‐scanned. Classifiers were trained using 1, 2, 4, 6, and 8 case(s) per diagnosis, and then evaluated on the same held‐out test set. Despite limited training data, most foundation models achieved strong performance (over 0.8 accuracy) with as few as eight cases per subtype, highlighting their sample efficiency in rare disease settings.
Extended data: embedding space exploration by visualising the features in two dimensions
One of the most visually apparent challenges in real‐world digital pathology is the substantial colour variation introduced by differing staining protocols across institutions. As illustrated in supplementary material, Figure S2, serial sections from a single leiomyosarcoma case were circulated to multiple NHS Trusts, each of which applied their routine haematoxylin and eosin (H&E) staining procedures. Despite being scanned using the same Aperio scanner under controlled imaging conditions, the resulting slides exhibited considerable variation in hue, contrast, and saturation. This example underscores the difficulty of achieving colour consistency in multi‐centre datasets and highlights the necessity for developing robust AI systems that can generalise across diverse staining conditions.
To qualitatively assess the types of staining and scanning information captured by foundation models, we visualised the feature/embedding space using two‐dimensional t‐distributed Stochastic Neighbour Embedding (t‐SNE) for the staining‐ and scanning‐controlled dataset (Cohort 2; Table 1 and Figure 2). The projection was performed on the two best‐performing models, UNI‐v2 and TITAN, using tile‐level embeddings and slide‐level embeddings, respectively. As UNI‐v2 is a tile‐level encoder, we randomly sampled three informative tiles (i.e., tiles from tumour areas) per slide and employed their tile‐level embeddings for the t‐SNE plot. This setting ensures consistent comparison across slides. In contrast, TITAN has a two‐stage architecture, containing a tile‐level encoder followed by a slide‐level aggregator, so a single slide‐level embedding vector was obtained per whole slide image. These slide‐level embeddings were employed to represent an entire slide on the t‐SNE plot. To facilitate interpretability, the dots in each of the t‐SNE plots were coloured by three distinct categorical schemes: (1) the diagnostic label as the slide‐level ground truth, (2) scan device, and (3) staining institute (supplementary material, Figure S3). These embedding space plots offered insights into how well the learned representations disentangle the relative contributions of biological, staining and scanning factors to model robustness and generalisability. An interactive tool, implemented with scikit‐learn [41] and Plotly [42], is provided to explore the t‐SNE outputs (see Data Availability).
Both UNI‐v2 and TITAN demonstrated strong class‐specific clustering when dots in t‐SNE plots were coloured by the slide‐level diagnosis: most tumour subtypes forming compact and well‐separated groups (supplementary material, Figure S3A, B). This pattern indicates that the embeddings encode meaningful biological information that reflects histological differences between tumour types. Even morphologically similar subtypes, such as lymphoma and Ewing sarcoma, appeared as distinct clusters, indicating that both models are sensitive to diagnostically relevant features. These results align with the strong subtype classification performance observed in earlier sections (Figures 1C, 3B and supplementary material, Table S4), reinforcing the view that foundation models offer robust feature extraction capabilities even in complex and heterogeneous diseases like sarcoma. Notably, the clustering observed in TITAN was more distinct and less noisy than that of UNI‐v2. The TITAN embeddings produced clearly delineated diagnostic groups with minimal overlap (supplementary material, Figure S3), reflecting the strength of its two‐stage architecture to a certain degree, particularly the slide‐level encoder. In contrast, while UNI‐v2 also exhibited meaningful clustering, some cases appeared more dispersed or intermixed (supplementary material, Figure S3A), which may stem from the fact that only three random tiles were sampled per slide. These sampled tiles may not always represent tumour‐rich regions, thereby introducing variability into the embedding space. Overall, these results highlight the added benefit of slide‐level modelling in enhancing representation quality and diagnostic separability.
When the same embeddings were coloured by scanner device, a different pattern emerged between the two models. In the UNI‐v2 t‐SNE plot (supplementary material, Figure S3C), three dominant sub‐clusters became visible within each diagnostic group, aligning with the scanner used. This suggests that despite capturing biologically meaningful features, the tile‐level embeddings from UNI‐v2 remain moderately sensitive to the image acquisition device. In contrast, the TITAN embeddings (supplementary material, Figure S3D) exhibited minimal separation by scanner, with diagnostic clusters forming coherent and compact groupings regardless of the scanning device. This indicates that TITAN's slide‐level encoder effectively mitigates scanner‐related artefacts in the embedding space. By contrast, when the embeddings were coloured by the staining institute (supplementary material, Figure S3E, F), neither model showed any consistent or interpretable clustering. Points from different centres were broadly interspersed without discernible grouping, suggesting that both models are comparatively robust to staining protocol variation across institutions.
These findings suggest that foundation models such as UNI‐v2 and TITAN prioritise biological signal over staining or scanning variations. While some scanner‐related structure remains in tile‐level models, slide‐level representations, such as those from TITAN, achieve greater invariance. This further supports the utility of foundation models, particularly those incorporating whole‐slide context, as robust and transferable embedding generators for multi‐institutional digital pathology applications.
Discussion
We systematically benchmarked seven deep learning models, including ResNet50, Google Path Foundation, UNI‐v2, CONCH‐v1.5, TITAN, Virchow, and PRISM, on 14 different types of soft tissue tumour. These models span conventional convolutional neural networks to recent foundation models, with TITAN and PRISM representing slide‐level encoders. Foundation models consistently outperformed traditional CNNs in both internal and external evaluations, demonstrating greater robustness to inter‐institutional variation. However, even the best‐performing models showed a 6–10% drop in accuracy on multi‐institutionally stained test sets. This performance gap was substantially reduced by incorporating a small number of externally stained slides into training the classifier, underscoring the value of including representative staining variation to improve generalisability. Additionally, we identified scanner‐related variation as a dominant source of performance degradation. Overall, while foundation models are not fully invariant to staining and scanning differences, fine‐tuned classifiers based on foundation models are strong candidates for real‐world pathology applications.
This study focuses on soft tissue tumour classification, but we have used these diagnoses as a proxy task to study stain variation and foundation models, and the findings and methodology presented here are broadly applicable to other types of tumour and computational pathological tasks. Sarcomas, a heterogeneous group of mesenchymal malignancies, represent less than 2% of all cancers [33]. They comprise numerous subtypes that often share overlapping histological features with benign lesions [43], making accurate diagnosis challenging, which can lead to delays in the diagnostic pathway [33, 44]. Given these challenges, patients with these tumours or their mimics could benefit from AI‐powered Clinical Diagnostic Support Systems. Multi‐instance learning (MIL) frameworks and self‐supervised pretraining algorithms [6, 40, 45] could be exploited to address intra‐tumoural heterogeneity and data scarcity.
Another key finding of this study is the strong data efficiency of the slide encoder TITAN. Unlike common cancers, where large training datasets are often available, sarcoma highlights the need for data‐efficient learning. In few‐shot experiments using only 1 to 8 cases per diagnosis, TITAN maintained stable performance, achieving over 0.75 accuracy even with a single case per class. This demonstrates TITAN's strong discriminative power in rare tumour settings, where large, well‐annotated datasets are difficult to obtain. These results underscore the potential of employing slide‐level foundation models for classifying rare diseases such as sarcoma. Nevertheless, it is noteworthy that as the training set size increased, patch‐based encoders showed rapid performance gains, suggesting that while slide encoders excel in low‐data regimes, patch encoders may match or surpass them when data are abundant.
To advance research in this field, we are releasing a unique multi‐institutional dataset comprising over 1,200 whole slide images covering 14 tumour types, stained in 30 institutions, and scanned with three scanners (Figure 2). This resource could facilitate further research into the generalisability of AI models in digital pathology, particularly in the context of staining and scanning variations.
This study has several limitations. First, only three scanner types (Aperio, Hamamatsu, and 3D‐Histech) were evaluated. While we believe these scanners represent common real‐world variation, the inclusion of additional devices, such as those from Philips and Roche, could further validate the generalisability of our findings. Second, we focused on a single task: soft‐tissue tumour classification; future work could expand this evaluation on stain variations to additional tumour types and tasks, such as mitosis detection and genomic marker prediction [46, 47].
Several avenues remain open for further exploration. Current stain normalisation and augmentation strategies are primarily image‐based and were originally developed for conventional CNNs. There is a notable lack of embedding‐space augmentation or normalisation techniques specifically tailored to foundation models, which is an open area with significant potential. Developing such methods could further stabilise downstream performance across diverse histological and technical conditions.
In summary, this study leverages sarcomas and their histological mimics as a testbed to evaluate the robustness of foundation models to real‐world variations in staining and scanning. Through benchmarking and controlled experiments, we demonstrate that foundation models exhibit promising resilience to such variability, when even a small number of training samples reflecting these differences are included. By releasing a curated, multi‐institutional dataset, we aim to support the development of more generalisable and robust AI models for digital pathology. While foundation models show significant promise, generalisation to external data remains a major challenge in building reliable AI‐based diagnostic systems. Increasing the diversity of training data continues to be a simple yet effective strategy for improving model generalisability.
Author contributions statement
BC: writing – original draft, writing – review and editing, validation, software, methodology, investigation, formal analysis. JC: writing – original draft, writing – review and editing, validation, software, methodology, investigation, formal analysis. PC: writing – review and editing, resources, investigation. FO: resources, investigation, data curation. AT: resources, data curation. DFS: writing – review and editing, validation, resources. TC: writing – review and editing, validation, supervision, methodology, conceptualisation. AMF: writing – review and editing, validation, supervision, project administration, methodology, funding acquisition, conceptualisation.
Consortia collaborators
The members of the AI Scope Consortium involved in this project are: Adrienne M Flanagan (UCL and Royal National Orthopaedic Hospital), Anna Tollit (UCL and Royal National Orthopaedic Hospital), Fatine Oumlil (UCL and Royal National Orthopaedic Hospital), Fernanda Amary (UCL and Royal National Orthopaedic Hospital), Roberto Tirabosco (UCL and Royal National Orthopaedic Hospital), Vahghelita Andrei (UCL and Royal National Orthopaedic Hospital), Nischalan Pillay (UCL and Royal National Orthopaedic Hospital), Paul Cool (The Robert Jones and Agnes Hunt Orthopaedic Hospital), Adam Levine (UCL and Royal Free London NHS Foundation Trust), Sebastian Brandner (UCL and University College London Hospital NHS Foundation Trust), Angela Richard‐Londt (UCL and University College London Hospital NHS Foundation Trust), Petra Balogh (University Hospitals Birmingham NHS Foundation Trust), Phillipe Taniere (University Hospitals Birmingham NHS Foundation Trust), Preethi Gopinath (Princess Alexandra Hospital NHS Trust), Neil Sebire (Great Ormond Street Hospital for Children NHS Foundation Trust and UCL), Luis Campos (Great Ormond Street Hospital for Children NHS Foundation Trust), Thomas Jacques (Great Ormond Street Hospital for Children NHS Foundation Trust and UCL), Sarah Coupland (Royal Liverpool University Hospital), Katalin Boros (Manchester University NHS Foundation Trust), Edmund Cheesman (Manchester University NHS Foundation Trust), Elizabeth Halloran (Manchester University NHS Foundation Trust), Caroline Glennie (Manchester University NHS Foundation Trust), Leona Doyle (University College Dublin, Ireland), Adrian Marino‐Enriquez (University College Dublin, Ireland), Jonathan Davey (NHS Lothian), Hannah Monaghan (NHS Lothian), Michael Toss (Sheffield Teaching Hospitals NHS Foundation Trust), David Hughes (Sheffield Teaching Hospitals NHS Foundation Trust), Malee Fernando (Sheffield Teaching Hospitals NHS Foundation Trust), David Leff (Sheffield Teaching Hospitals NHS Foundation Trust), Patrick Shenjere (The Christie NHS Foundation Trust), Oisin Houghton (Belfast Health and Social Care Trust), Tom McCulloch (Nottingham University Hospitals NHS Trust), Filomena Medeiros (Basildon University Hospital, Mid and South Essex NHS Foundation Trust), Ann Sandison (Guy's and St Thomas’ NHS Foundation Trust), Kalnisha Naidoo (King's College Hospital NHS Foundation Trust), Getnet Demissie (King's College Hospital NHS Foundation Trust), Heena Patel (King's College Hospital NHS Foundation Trust), Uchechi Igbokwe (Queen's Hospital, Barking, Havering and Redbridge University Hospitals), Graham Thwaites (Queen's Hospital, Barking, Havering and Redbridge University Hospitals), Keeley Thwaites (Queen's Hospital, Barking, Havering and Redbridge University Hospitals), Ann Fleming (Maidstone and Tunbridge Wells NHS Trust), Mercy Berin (Maidstone and Tunbridge Wells NHS Trust), Shyamala Fernandez (Ealing Hospital, London North West University Healthcare NHS Trust), Rajesh Nalluri (Northwick Park Hospital, London North West University Healthcare NHS Trust), Zahra Atiyyah (Northwick Park Hospital, London North West University Healthcare NHS Trust), Konrad Wolfe (Southend University Hospital, Mid and South Essex NHS Foundation Trust), Victoria Hills (Pathology First, SYNLAB UK & Ireland), Tomos Saunders (Pathology First, SYNLAB UK & Ireland), Matilda Ralph (Hemel Hempstead Hospital, West Hertfordshire Teaching Hospitals NHS Trust), Nicholas Southgate (Hemel Hempstead Hospital, West Hertfordshire Teaching Hospitals NHS Trust), Francesca Maggiani (North Bristol NHS Trust), Zsolt Orosz (Oxford University Hospitals NHS Trust), Jennifer Brown (Oxford University Hospitals NHS Trust), Nick Athanasou (Oxford University Hospitals NHS Trust), Ian Cook (Salisbury NHS Foundation Trust), Sarah Oliver (Salisbury NHS Foundation Trust), Peter Davis (Broomfield Hospital, Mid and South Essex NHS Foundation Trust), Shelley Brown (Broomfield Hospital, Mid and South Essex NHS Foundation Trust), Jasenka Mazibrada (Norfolk and Norwich University Hospitals NHS Foundation Trust), Nathan Asher (University College Hospital NHS Foundation Trust), Efren Quilala (Queen Elizabeth Hospital, Lewisham and Greenwich NHS Trust), Dalian Beaver (Queen Elizabeth Hospital, Lewisham and Greenwich NHS Trust), Izhar Bagwan (Royal Surrey County Hospital, Royal Surrey NHS Foundation Trust), Dawn Whyndham (Royal Surrey County Hospital, Royal Surrey NHS Foundation Trust), Khin Thway (Royal Marsden NHS Trust), Michael Hubank (Institute of Cancer Research), Janet Shipley (Institute of Cancer Research), and Anna Kelsey (Royal Manchester Children's Hospital).
Supporting information
Figure S1. Principal component analysis (PCA) of stain vectors extracted from each 3,000 × 3,000 pixel region of interest, showing the plot by each scanner Figure S2. Serial sections from a sample of a leiomyosarcoma stained at 30 different NHS Trusts show significant colour variation after digitisation with the same Aperio scanner Figure S3. Visualisation of the feature space using t‐SNE Table S1. Case IDs and diagnoses for all cohorts Table S2. Cohort 4 case distribution Table S3. Top‐1 and top‐3 classification accuracies on Cohort 4‐Test set for ‘trained with Cohort 1’ and ‘trained with the Combined cohort’ Table S4. Class‐wise accuracies for soft tissue tumours across internal and multi‐institutional test sets, using seven models
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1Mc Genity C , Clarke EL , Jennings C , et al. Artificial intelligence in digital pathology: a systematic review and meta‐analysis of diagnostic test accuracy. NPJ Digit Med 2024; 7: 144.38704465 10.1038/s 41746-024-01106-8PMC 11069583 · doi ↗ · pubmed ↗
- 2Shafi S , Parwani AV . Artificial intelligence in diagnostic pathology. Diagn Pathol 2023; 18: 109.37784122 10.1186/s 13000-023-01375-z PMC 10546747 · doi ↗ · pubmed ↗
- 3Shen Z , Simard M , Brand D , et al. A deep learning framework deploying segment anything to detect pan‐cancer mitotic figures from haematoxylin and eosin‐stained slides. Commun Biol 2024; 7: 1674.39702417 10.1038/s 42003-024-07398-6PMC 11659629 · doi ↗ · pubmed ↗
- 4Graham S , Vu QD , Raza SEA , et al. Hover‐Net: simultaneous segmentation and classification of nuclei in multi‐tissue histology images. Med Image Anal 2019; 58: 101563.31561183 10.1016/j.media.2019.101563 · doi ↗ · pubmed ↗
- 5Bulten W , Kartasalo K , Chen PHC , et al. Artificial intelligence for diagnosis and Gleason grading of prostate cancer: the PANDA challenge. Nat Med 2022; 28: 154–163.35027755 10.1038/s 41591-021-01620-2PMC 8799467 · doi ↗ · pubmed ↗
- 6Hassell LA , Forsythe ML , Bhalodia A , et al. Toward optimizing the impact of digital pathology and augmented intelligence on issues of diagnosis, grading, staging, and classification. Mod Pathol 2025; 38: 100765.40204094 10.1016/j.modpat.2025.100765 PMC 12272330 · doi ↗ · pubmed ↗
- 7Poalelungi DG , Neagu AI , Fulga A , et al. Revolutionizing pathology with artificial intelligence: innovations in immunohistochemistry. J Pers Med 2024; 14: 693.39063947 10.3390/jpm 14070693 PMC 11278211 · doi ↗ · pubmed ↗
- 8Lai J , Ahmed F , Vijay S , et al. Domain‐specific optimization and diverse evaluation of self‐supervised models for histopathology. ar Xiv preprint 2023; ar Xiv:2310.13259.