A hybrid approach to large-scale systematic literature reviews: combining automated tools with text-mining techniques
Zhao Hui Koh, Armita Zarnegar, Jason Skues, Greg Murray

TL;DR
The paper introduces a hybrid method combining automated tools and text-mining to improve the efficiency and accuracy of large-scale systematic literature reviews.
Contribution
The novel hybrid approach enhances semi-automated tools by using text-mining to generate better seed articles, reducing biases and improving learning efficiency.
Findings
The hybrid approach effectively reduces and screens a large number of articles (N=90,871) for systematic reviews.
Simulations show the method can create comprehensive seed articles covering broad subject areas.
The approach increases transparency and reusability of keywords for future review updates.
Abstract
Semi-automated tools used during the preliminary screening of articles in systematic reviews can start with a small set of seed articles and actively learn from human decisions to prioritise more relevant articles for subsequent screening. However, given that these tools are vulnerable to biases and lack clear stopping criteria, their performance in large-scale systematic reviews remains uncertain, especially in reviews covering broad subject areas that require a substantial number of representative seed articles. This article presents a hybrid approach that uses text-mining techniques combined with a semi-automated tool to effectively reduce, screen, and validate a large cohort of articles (N = 90,871). A preliminary evaluation using simulations indicated that this approach has the potential to craft a comprehensive collection of seed articles that covers broad subject areas for…
Genes, proteins, chemicals, diseases, species, mutations and cell lines named across the full text — each resolved to its canonical identifier and authoritative record.
Click any figure to enlarge with its caption.
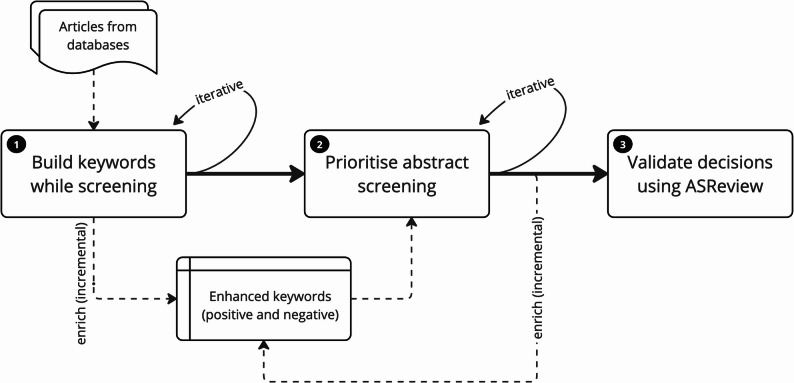 Figure 1
Figure 1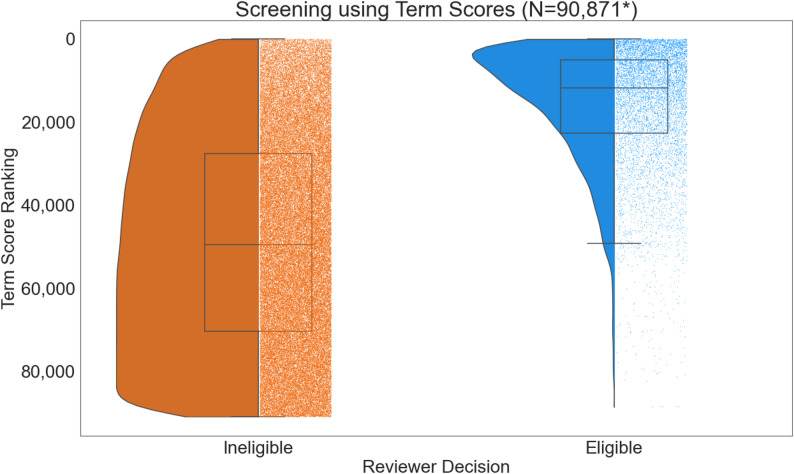 Figure 2
Figure 2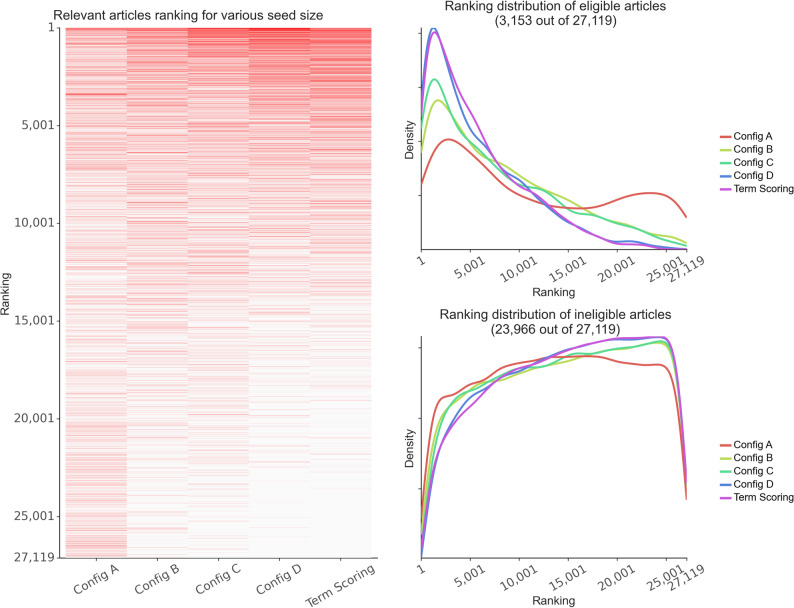 Figure 3
Figure 3- —https://doi.org/10.13039/501100024780Digital Health CRC
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsMeta-analysis and systematic reviews · Mental Health via Writing · Biomedical Text Mining and Ontologies
Introduction
Automation tools can reduce the screening effort in systematic reviews, a task previously deemed time-consuming [1–3], by 30%−50% with only a marginal precision loss (up to 5%) [4–6]. This promising performance could address concerns regarding the quality and reproducibility of research evidence [7, 8] while meeting the demand for faster and more extensive reviews. However, a fully automated tool must train with many articles and associated human decisions to reach an acceptable level of accuracy [9, 10]. This is impossible for a new systematic review with few screened articles.
Semi-automated tools (e.g., ASReview [11], Rayyan [12]) can start with limited seed articles, learn the decisions in vivo during screening and re-prioritise the relevance of the remaining articles [13]. Although their prospect seems promising [14], they are susceptible to the hasty generalisation problem, a bias in which a tool overgeneralises articles based on the information it has learned so far [4, 6, 15]. Furthermore, semi-automated tools typically require a stopping criterion for screening to be defined (e.g., the number of consecutive irrelevant articles screened) [16], which requires expert judgement. Stopping prematurely during screening could lead to missing a substantial number of eligible articles, which is a key drawback of relying solely on this approach [9]. Amidst these limitations, it is unclear how effective these tools are in large-scale reviews investigating broad subject areas, especially when a representative set of starting articles covering areas of interest is desirable.
This article outlines a hybrid approach combining text-mining and a semi-automated tool to undertake preliminary screening within a large-scale systematic review with broad subject areas (in press; see the protocol [17] for more details; PROSPERO ID: CRD42022306547). Our review [17] was designed to investigate empirical studies that administered mental health instruments in (1) the general population, (2) digital format, and (3) longitudinal designs. The database searches yielded approximately 95,000 unique articles, which were infeasible to screen serially. An early investigation using semi-automated tools to facilitate screening was unsatisfactory due to concerns about missing articles given the broad review.
Methods
In a systematic review focused on a broad topic, search results often return many irrelevant articles, making manual screening challenging. Using broad search terms in the database query resulted in numerous articles that included the target terms but were unrelated to the topic of interest (see Appendix 1 for some examples). Since it was impractical to screen all articles serially and include all permutations of negative keywords in the search query, we developed a method using text-mining techniques, such as keyword matching [18, 19], combined with domain knowledge and expert-weighted criteria to identify relevant articles (described below). We used this approach to screen all articles in our review.
In this section, Part 1 describes our approach in detail and Part 2 explains how the approach was provisionally evaluated. Based on the evaluation results, we highlighted the potential utility of our approach for identifying representative articles to use as input (seed) for semi-automated screening tools, thereby enhancing the tools’ capabilities.
Part 1: the term-scoring approach
Our approach was a two-step iterative method (see Fig. 1). In Step 1, we eliminated irrelevant articles by their titles using positive and negative keywords that we generated and refined iteratively. Step 1 (title-only screening) reduced noise from the additional text in the abstracts, enabling easy identification of irrelevant articles. In Step 2, we calculated a term score for each article using (i) the article’s title and abstract, (ii) keywords generated in Step 1 and (iii) weights assigned to the keywords (between 1 and 10) by an expert based on their assessment of Step 1 to reflect their importance. These weights were revised iteratively during the screening process. The term scores were then used to prioritise the order of the remaining articles for screening. We used a simple scoring formula to calculate the term score (TS):
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:TS=\sum\:_{p=1}^{P}{w}_{p}{m}_{p}-1.2\left(\sum\:_{n=1}^{N}{w}_{n}{m}_{n}\right)$$\end{document}where
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:P$$\end{document} is the count of positive keyword matches
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:N$$\end{document} is the count of negative keyword matches
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:{w}_{p}$$\end{document} is the \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:weighting/10$$\end{document} for the positive keyword
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:{w}_{n}$$\end{document} is the \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:weighting/10$$\end{document} for the negative keyword
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:{m}_{p}$$\end{document} is the product of the match count and the word count for the positive keyword, over the word count in the title and abstract
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:{m}_{n}$$\end{document} is the product of the match count and the word count for the negative keyword, over the word count in the title and abstract
The aforementioned approach combined semi-automated rapid screening with iterative scoring to improve accuracy and efficiency in article selection. Each iteration enriched the keyword list and weightings, which re-calculated the articles’ term scores and re-ranked them. The process continued until all articles were screened. Upon completion, we cross-validated the screening results with ASReview (version 1.0) [11]. The cross-validation used approximately 70% of all screened articles as seeds (input) for ASReview. Once ASReview processed (learnt from) these seed articles, the remaining 30% of the articles were ranked by ASReview. We expected that the ranking of these articles would be associated with human decisions using the term-scoring approach described above. Appendix 1 elaborates more on the cross-validation procedure.
Fig. 1. Approach in preliminary screening titles and abstracts. The screening process involved (1) building up a list of positive and negative keywords to eliminate irrelevant articles by their titles; (2) assigning weights iteratively to the positive and negative keywords and calculating term scores to prioritise abstract screening; and (3) comparing screening results with ASReview. Both Step 1 and Step 2 involved text-mining and manual review. Step 3 used ASReview.
Part 2: evaluation of the term-scoring approach
To demonstrate the validity of our approach, after the screening was completed, we ranked all articles by their term scores (called term score ranking) before analysing them. To compare our approach with using ASReview alone, multiple configuration profiles were set up in ASReview for simulations by varying the following parameters:
-
Starting seed: the number of seed articles provided to train ASReview, operationalised as the number of relevant and irrelevant articles.
-
Mode: could be either active-learning mode or rank-once mode. In the active-learning mode, a person actively screens the articles while ASReview actively learns about their decisions. In the rank-once mode, ASReview ranks the rest of the un-screened articles once, based on the seed articles.
The four configuration profiles were:
- *Config A: *This configuration emulated the active learning using ASReview with minimal seed (1 relevant and 1 irrelevant article). Once the seed was loaded, the reviewer screened approximately 20 articles using the ASReview user interface.
2.* Config B: *This configuration loaded 20 relevant and 20 irrelevant seed articles to ASReview before ASReview ranked the rest of the unscreened articles once.
-
Config C: This configuration loaded 50 relevant and 50 irrelevant seed articles to ASReview before ASReview ranked the rest of the unscreened articles once.
-
Config D: This configuration represented how we cross-validated our screening effort (see Appendix 1). We loaded approximately 5,332 relevant and 58,480 irrelevant seed articles to ASReview before ASReview ranked the rest of the unscreened articles (n = 27,119) once. After that, we compared the ASReview rankings of these unscreened articles with our screening decision.
Once the simulation for each configuration was completed, the article rankings from ASReview were extracted for analysis. Additional simulation analyses examining ASReview’s recall rates and stopping criteria are provided in Appendix 2.
Results
Part 1 - term score ranking between eligible and ineligible articles
To validate our term-scoring approach, first, we compared the ranking of term scores of articles grouped by their eligibility (see Fig. 2). In Fig. 2, the y-axis is inverted to represent ranking. A lower ranking implied a higher relevance of the article to the review. Our term-scoring approach yields a high percentage of true positives, with 75% of eligible articles appearing in the top quartile of ranked results. In contrast, ineligible articles showed a more dispersed ranking distribution. Manual inspection revealed that many ineligible articles contained a high number of positive terms but were excluded based on predefined criteria outlined in our systematic review (see [17]). Eligible articles that were missed in this screening stage will be picked up in full-text screening subsequently.
Fig. 2. The distribution of term score ranking between eligible and ineligible articles. The y-axis is inverted. Lower-ranked articles are more relevant to the review. *Any articles with no DOI, no abstract, ineligible article types or abstracts with fewer than 200 characters (approximately 5% of the total number of articles) were considered ineligible and were ranked last with higher term-score ranking values.
Part 2 - ranking across different configurations
To further validate the term-scoring approach, we cross-validated our screening effort by including 70% of randomly selected articles ( \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:n$$\end{document} = 63,752; 5,332 relevant, 58,420 irrelevant) as seed articles (as training data) in ASReview. The remaining 30% of articles ( \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:n$$\end{document} = 27,119) were used for testing. The results of this process are presented as Configuration D in Fig. 3. We compared this configuration to Configurations A, B and C, as well as to the term-score ranking alone (for details of each configuration, see Part 2 under Methods).
Fig. 3. Ranking comparison across different configurations and term scoring. The red lines in the left subplot represent eligible articles. Config A: active learning mode with minimal seed (1 relevant and 1 irrelevant articles) and manual screening for 20 articles using ASReview; Config B: rank-once mode (i.e., ASReview ranked the un-screened articles once based on the seed articles) with 20 relevant and 20 irrelevant articles; Config C: rank-once mode with 50 relevant and 50 irrelevant articles; Config D: rank-once mode with 5,332 relevant and 58,480 irrelevant articles (Step 3 in Fig. 1); Term Scoring: term-scoring approach described above. The top-right subplot in Fig. 3 shows that Configuration D and the term-scoring approach yielded the narrowest ranking distributions, indicating more consistent performance compared to other configurations. The bottom-right graph reveals that ineligible articles were generally ranked lower under both Configuration D and the term-scoring approach. Notably, Config D and the term-scoring approach produced more accurate and concise results compared to other methods. In Configuration A, relevant articles (represented by red lines) were dispersed across the entire spectrum, suggesting less effective prioritisation. The ranking distributions between Configuration D and our term-scoring approach were highly similar, further validating the effectiveness of our term-scoring approach. In both approaches, the majority of eligible articles had lower rankings (indicating more relevance). The Spearman rank-order correlation [20] between Configuration D and the term-scoring approach was moderate ( \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:\rho\:$$\end{document} = 0.587, \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:p$$\end{document} < 0.001), despite each using different mechanisms to screen the articles. Additional analyses of the ranked articles and a simulation-based evaluation of ASReview’s full-screening performance are detailed in Appendix 3 and Appendix 4 respectively.
Discussion
This article outlines a hybrid approach to preliminarily screen articles for a large-scale systematic review with broad subject areas and the provisional evaluation of this approach. One key distinction between our approach and the use of semi-automated tools alone is that our approach enables domain experts to directly influence the keywords and weightings, resulting in more accurate information early on (i.e., relevant seed articles) for subsequent prioritisation and, therefore, more efficient screening. Furthermore, by having a more representative set of seed articles for semi-automated tools, it has broader coverage and could prevent eligible articles being missed from premature stopping. In addition, should a decision is made to stop screening using a semi-automated tool, the keywords and term scores generated from this approach can be used to evaluate the relevancy of the unscreened articles. This is particularly crucial in a broad large-scale review. Our approach can be implemented as a standalone tool for abstract and title screening, or as a pre-screening tool to gauge the nature of the articles in broad-topic reviews and help tailor subsequent screening strategies, for example, integrating with a semi-automated tool (as demonstrated in this study).
For clarification, we do not claim that our approach is more efficient than using semi-automated tools in general. Rather, in a large-scale review covering broad subject areas, utilising the term-scoring approach to generate a set of relevant seed articles for semi-automated tools is more efficient than using a semi-automated tool alone. For instance, if the average number of titles and abstracts screenable daily is approximately 470 [21], then manually screening 60,000 seed articles in Configuration D would take approximately 128 days. The proposed hybrid approach can reduce the screening time.
The proposed approach has several limitations. Firstly, steps outlined here, such as weighted keywords, are domain-specific, so for each review an expert in the field needs to reassign the weights, which makes generalisability somewhat limited. Furthermore, in the present study, only one expert reviewer was involved in generating keywords and weightings, which could introduce biases during the screening process. Secondly, the iterative keyword refinement process in our approach is currently resource-intensive; a user-friendly interface should be developed to enable non-technical users, who may not be familiar with custom scripts, to perform it more easily. Future tool developers could consider providing a more generic approach that allows reviewers to identify domain-specific keywords and weightings to guide their review. Thirdly, although we screened all articles using the term-scoring approach, in hindsight, a potential improvement would be to incorporate the term-scoring approach at the start of the review for representative seed articles and integrate a semi-automated tool throughout the review process to guide the stopping criteria. Future studies could refine the hybrid approach introduced here, which harnesses the best of both worlds.
Amidst flourishing research in machine learning, it is not our intention in this article to devise a classification method to screen articles. We opted for a simple scoring mechanism that emerged from our real-world problem of screening articles for an otherwise overwhelming review task. We simply aim to demonstrate how text-mining techniques can be combined with automated tools to make screening decisions explicit (using keywords and weightings) for a large-scale review covering broad subject areas while improving both efficiency and transparency.
Supplementary Information
Supplementary Material 1.
The reference list from the paper itself. Each links out to its DOI / PubMed record.