FedSCOPE: Federated cross-domain sequential recommendation with decoupled contrastive learning and privacy-preserving semantic enhancement
Lujin Zhao, Yi Lin, Sujuan Qin, Wenmin Li, Fei Gao, Yijie Shi, Zhengping Jin

TL;DR
FedSCOPE is a new framework for privacy-preserving cross-domain recommendations that improves accuracy and generalization using federated learning and semantic augmentation.
Contribution
FedSCOPE introduces a federated learning framework with decoupled contrastive learning and adaptive privacy strategies for cross-domain sequential recommendations.
Findings
FedSCOPE outperforms state-of-the-art methods in recommendation accuracy and cross-domain generalization.
The framework achieves a better privacy–utility trade-off through adaptive differential privacy strategies.
Semantic augmentation using offline LLMs improves representation quality without privacy risks.
Abstract
Cross-domain sequential recommendation (CDSR) models users’ dynamic preferences by exploiting behavioral signals from multiple domains, but it faces challenges in data sparsity, domain heterogeneity, and privacy protection. Although federated learning enables privacy-preserving CDSR by keeping raw data local, existing methods often suffer from sparse representations, unstable cross-domain alignment, and severe utility degradation under uniform differential privacy. In this work, we propose FedSCOPE, a novel federated CDSR framework that addresses these challenges through three tightly coupled and explicitly aligned components. First, FedSCOPE enriches user and item representations via offline large language model (LLM)-generated semantic augmentation, mitigating sparsity while avoiding online LLM inference and the associated privacy and deployment risks. Second, it introduces an Intra-…
Genes, proteins, chemicals, diseases, species, mutations and cell lines named across the full text — each resolved to its canonical identifier and authoritative record.
Click any figure to enlarge with its caption.
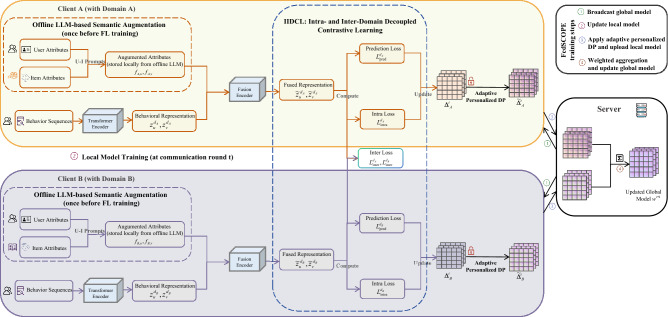 Figure 1
Figure 1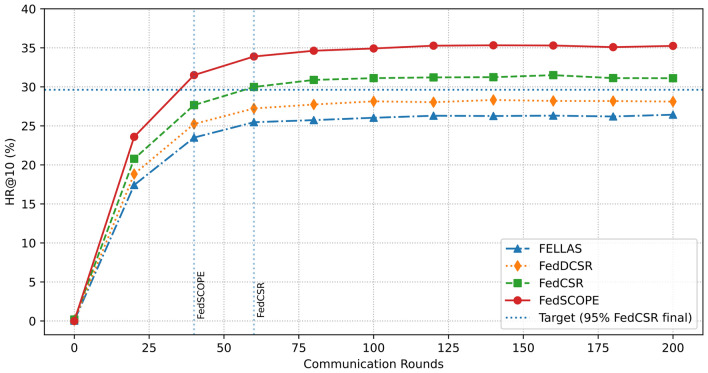 Figure 2
Figure 2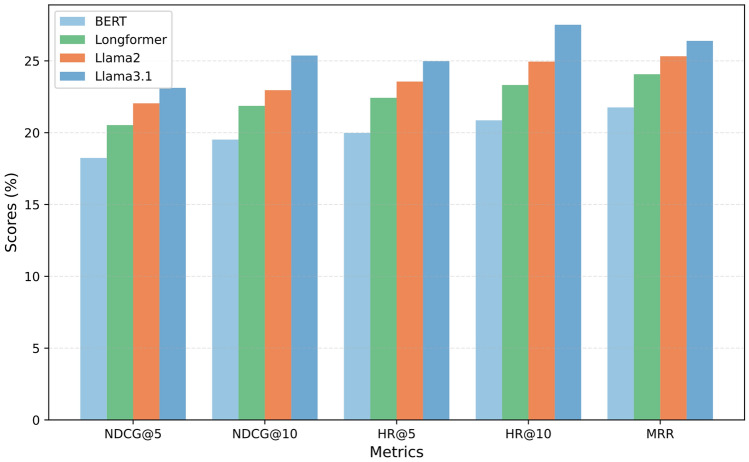 Figure 3
Figure 3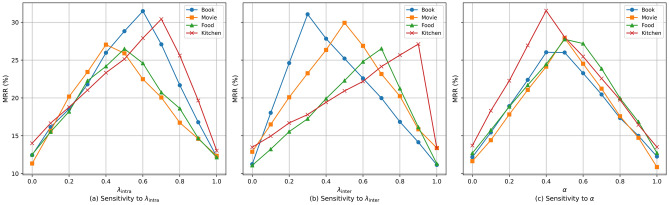 Figure 4
Figure 4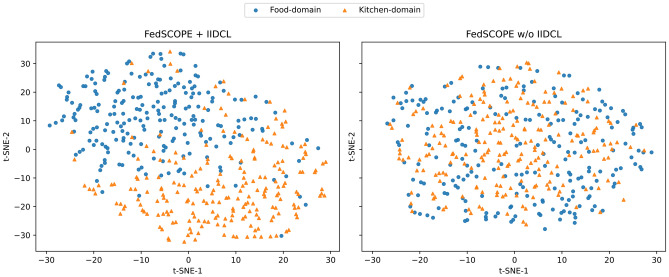 Figure 5
Figure 5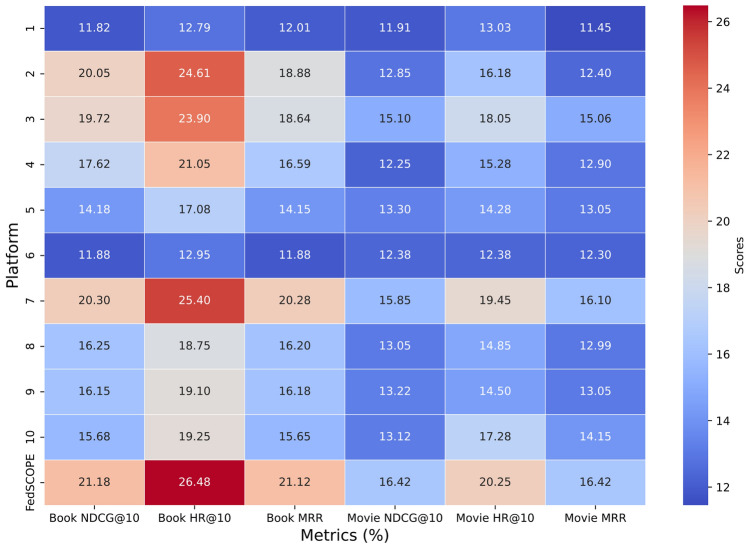 Figure 6
Figure 6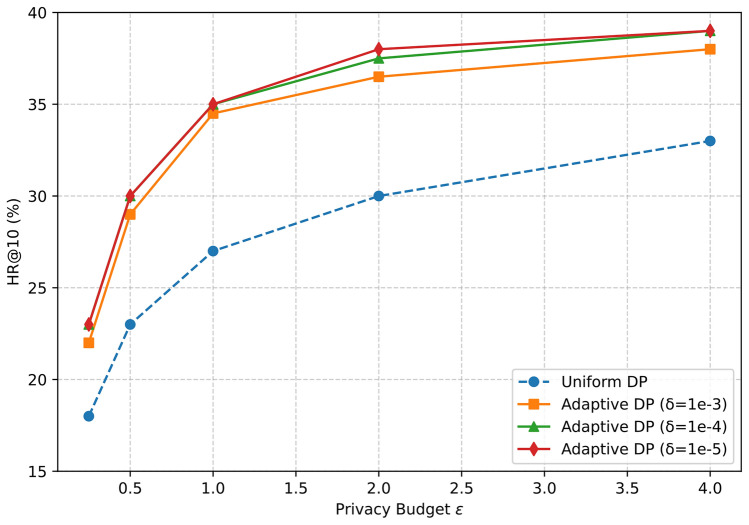 Figure 7
Figure 7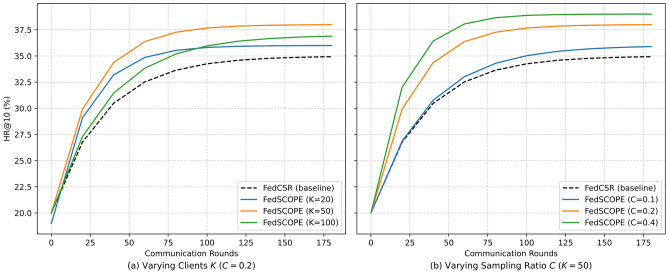 Figure 8
Figure 8- —https://doi.org/10.13039/501100001809National Natural Science Foundation of China
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsRecommender Systems and Techniques · Privacy-Preserving Technologies in Data · Advanced Graph Neural Networks
Introduction
Sequential recommendation (SR)^1^ has become a fundamental technique in modern personalization systems by modeling user–item interaction sequences to predict future user preferences. However, as users increasingly engage with multiple online services across different platforms, single-domain recommendation models^2,3^ struggle to capture users’ evolving interests across diverse contexts. To address this limitation, cross-domain sequential recommendation (CDSR)^4,5^ integrates user behaviors from multiple domains, enabling richer user representations and improved recommendation performance. CDSR has shown strong potential in real-world applications such as e-commerce, media platforms, and online content services.
The growing interconnection of digital ecosystems further amplifies the importance of CDSR. User behaviors are no longer isolated within a single application but instead span multiple services, forming complex and interdependent preference patterns. For example, interactions on a book-reading platform may reveal latent interests that are highly informative for video streaming or shopping recommendations. Effectively leveraging such cross-domain behavioral signals is crucial for building context-aware and proactive recommender systems. Without appropriate mechanisms to model these interactions, recommendation systems remain siloed and fail to fully exploit users’ behavioral histories.
Despite its effectiveness, most existing CDSR approaches rely on centralized data aggregation, which introduces serious privacy risks and raises compliance concerns under data protection regulations such as GDPR. To overcome these issues, federated cross-domain sequential recommendation (FedCDSR)^6,7^ has emerged as a promising paradigm. FedCDSR enables multiple platforms or clients to collaboratively learn cross-domain knowledge while keeping raw user data local, thereby providing a privacy-preserving solution for cross-domain personalization.
However, current FedCDSR methods still face three fundamental challenges. First, data sparsity is particularly severe in niche or long-tail domains, where limited interaction histories make it difficult to learn expressive user and item representations, leading to degraded recommendation accuracy and cold-start issues. Second, domain heterogeneity caused by imbalanced data distributions across clients often results in inconsistent local model updates, which slows global convergence and may even induce negative knowledge transfer across domains. Third, the trade-off between privacy protection and model utility remains challenging: conventional differential privacy (DP) mechanisms typically adopt uniform noise injection across all clients, which is poorly suited to heterogeneous federated environments and often causes unnecessary utility degradation.
Although several representative methods attempt to address subsets of these challenges, they still suffer from notable limitations. For example, FELLAS^8^ introduces large language models (LLMs) to enrich semantic representations in federated sequential recommendation. However, its reliance on remote LLM inference tightly couples the recommendation pipeline with external services, resulting in increased inference latency, additional computational and monetary costs, as well as potential exposure of user behavior data to third-party providers. These issues may significantly limit its deployability under strict privacy and compliance requirements. In contrast, FedCSR^9^ employs dual contrastive learning objectives to enhance cross-domain robustness but does not incorporate explicit semantic enrichment. Consequently, its performance can be severely limited in highly sparse or cold-start scenarios, where behavioral signals alone are insufficient to support expressive and stable representation learning.
These challenges indicate that an effective framework should simultaneously enrich sparse representations, align heterogeneous domain knowledge, and adapt privacy protection to client-specific characteristics. To jointly address these challenges, we propose FedSCOPE, a unified federated cross-domain sequential recommendation framework that explicitly aligns its core components with the three aforementioned challenges. To alleviate data sparsity, FedSCOPE incorporates an offline LLM-based semantic augmentation module that enriches user and item representations with high-level semantic attributes in a privacy-preserving manner, without relying on online LLM services during training or inference. To cope with domain heterogeneity, we design an Intra- and Inter-Domain Decoupled Contrastive Learning (IIDCL) mechanism, which disentangles intra-domain representation alignment from inter-domain uniformity, thereby improving personalization while preventing negative cross-domain interference. To address the privacy–utility trade-off, FedSCOPE adopts an adaptive personalized differential privacy mechanism that dynamically adjusts privacy budgets and clipping thresholds according to client-specific data characteristics, achieving a more favorable balance between privacy protection and model utility. These components are jointly optimized within a secure federated learning framework, enabling FedSCOPE to simultaneously enhance recommendation accuracy, robustness, and privacy.
The main contributions of this work are summarized as follows:
- We propose FedSCOPE, a federated cross-domain sequential recommendation framework that systematically addresses data sparsity, domain heterogeneity, and the trade-off between privacy and utility.
- We design three complementary components, namely an offline LLM-based semantic augmentation module, an Intra- and Inter-Domain Decoupled Contrastive Learning mechanism, and an adaptive personalized differential privacy strategy, and explicitly demonstrate how each component corresponds to a specific challenge in federated CDSR.
- Comprehensive experiments on multiple real-world datasets demonstrate that FedSCOPE consistently outperforms state-of-the-art methods, yielding improved recommendation accuracy, enhanced cross-domain generalization, and better privacy–utility trade-offs.
Related work
Cross-domain sequential recommendation
Cross-domain recommendation seeks to alleviate data sparsity by leveraging user–item interactions across multiple domains^10,11^. Early approaches such as NCF-MLP^12^ employed multilayer perceptrons to learn latent domain representations, while CoNet^13^ introduced cross-network connections for explicit knowledge transfer. However, these methods ignored temporal dynamics, limiting their effectiveness in sequential recommendation tasks. To overcome this, CDSR methods emerged: \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\pi$$\end{document} -Net^14^ utilized gated recurrent units to capture evolving user preferences; PSJNet^15^ designed a split–merge architecture to jointly model multi-domain knowledge and user intent; LEA-GCN^16^ exploited graph neural networks to encode rich item–item relationships across domains. Beyond CDSR, recent progress in self-supervised and diffusion-enhanced recommendation has further strengthened representation learning. MSRec^17^ introduces a multi-view self-supervised framework on heterogeneous graphs, where meta-path based structural views and local–global contrastive learning capture complex semantics in graph data. KMDCL^18^ employs a mask diffusion mechanism to generate adaptive knowledge views and uses user-intent–guided denoising to enhance robustness in knowledge-aware recommendation. FACLK^19^ mitigates feature distortion in high-order knowledge propagation through a feature decorrelation constraint and adaptive semantic refinement, enabling more reliable contrastive learning. SDMMR^20^ integrates masked prediction with diffusion-based perturbation and a smoothing mechanism to alleviate multimodal noise and improve semantic alignment. These advances inspire our design of decoupled contrastive learning and semantic enhancement in FedSCOPE. However, all such methods assume centralized data access and cannot be directly applied in federated cross-domain scenarios, where privacy constraints fundamentally restrict representation sharing.
Federated cross-domain recommendation
To overcome the limitations of centralized CDSR, federated learning (FL)^21^ has been explored as a privacy-preserving paradigm. Ammad et al.^22^ first introduced a federated collaborative filtering framework, inspiring subsequent works aimed at improving recommendation utility^23^ and enhancing privacy or security mechanisms^24,25^. Knowledge transfer under FL is particularly challenging due to non-IID data and restricted communication. FedCT^26^ employs variational autoencoders to exchange latent domain embeddings without exposing raw data; FedCTR^27^ builds a multi-platform training framework for CTR prediction; FedDCSR^7^ introduces decoupled representation learning to address feature heterogeneity and distribution shifts. More recent studies integrate advanced techniques. FELLAS^8^ incorporates large language models through online query services to enhance semantic transfer, but this approach raises additional privacy and operational concerns in FL settings. FedCSR^9^ applies contrastive learning to mitigate reliance on explicit cross-platform user alignment, yet its uniform differential privacy mechanism limits its effectiveness under heterogeneous client distributions. Compared with these methods, FedSCOPE adopts a different technical route by leveraging local offline LLM-based semantics to avoid exposure to external services, employing decoupled contrastive learning tailored for heterogeneous domains, and introducing an adaptive differential privacy mechanism that provides fine-grained protection. These distinctions further highlight that FedSCOPE is not a straightforward combination of existing centralized or federated techniques, but a federated-specific redesign that jointly considers semantic enrichment, domain heterogeneity, and privacy constraints. To better illustrate the distinctions, we provide a direct comparison of representative approaches in Table 1.Table 1. Comparison of FedSCOPE with representative federated CDSR methods.MethodOffline LLMDecoupled CLAdaptive DPFELLAS^8^ \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\times$$\end{document} (Online) \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\times$$\end{document} (Perturbation) \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\times$$\end{document} (Uniform)FedCSR^9^ \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\times$$\end{document} (None) \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\times$$\end{document} (Dual) \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\times$$\end{document} (Uniform)FedSCOPE (Ours) \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\checkmark$$\end{document} \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\checkmark$$\end{document} \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\checkmark$$\end{document}
Methodology
Problem definition
We consider a FL system with K clients and a central server, spanning m domains \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\mathcal {D}_{\text {total}}=\{d_1, \dots , d_m\}$$\end{document} . Each client may cover multiple domains and collaboratively trains a federated cross-domain sequential recommendation model with global parameters \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\textbf{w}$$\end{document} . At communication round t, the server broadcasts the current global model parameters \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\textbf{w}^t$$\end{document} to a subset of selected clients. Each client performs local optimization on its private dataset \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$D_k$$\end{document} and returns a privatized model update to the server for aggregation. For client k, the local dataset is denoted as \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$D_k=\{S_k^{(u)}\}_{u \in U_k}$$\end{document} , where \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$U_k$$\end{document} is the set of users on client k. Each user behavior sequence is truncated or padded to the most recent N interactions: \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$S_k^{(u)}=(s_u^1, \dots , s_u^N)$$\end{document} . Each domain \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$d_i \in \mathcal {D}_{\text {total}}$$\end{document} is associated with an item set \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$V_{d_i}$$\end{document} , and the unified item space is defined as \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$V^*=\bigcup _{i=1}^m V_{d_i}$$\end{document} . For each user, we maintain both domain-specific sequences \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$S_k^{d_i}$$\end{document} and an aggregated cross-domain sequence \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$S_k^*$$\end{document} . Compared with single-domain sequential recommendation, FedCDSR faces three key challenges: (i) domain sparsity and imbalance, (ii) heterogeneous user behavior distributions that induce inconsistent client updates, and (iii) strict privacy constraints that limit direct information sharing. The learning objective is to predict the next interacted item at step \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$N{+}1$$\end{document} either from a target domain \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$d_i$$\end{document} or from the unified item space \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$V^*$$\end{document} , where all users and items are embedded into a shared d-dimensional latent space. To address these challenges, we propose FedSCOPE, a federated cross-domain sequential recommendation framework as illustrated in Fig. 1. Here, Domain A and Domain B in Fig. 1 are used as representative examples of domains \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$d_i \in \mathcal {D}_{\text {total}}$$\end{document} to illustrate intra-domain modeling and inter-domain interaction, while FedSCOPE is generally applicable to an arbitrary number of domains.Fig. 1. Overview of the proposed FedSCOPE framework.
User-behavior sequence modeling and representation learning
To model user behavior sequences as the foundation for downstream semantic augmentation and contrastive objectives, we first encode historical interactions into latent representations using a Transformer-based encoder. This encoder captures long-range dependencies and enables efficient parallel computation, producing user representations \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\textbf{z}_u^{d_i}$$\end{document} that serve as the basis for cross-domain recommendation. For user u, the latest N interactions \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$S_k^{(u)}=(s_u^1,\dots ,s_u^N)$$\end{document} are mapped to embeddings \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\textbf{e}_{s_u^n}\in \mathbb {R}^d$$\end{document} , forming \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$E_k^{(u)}=(\textbf{e}_{s_u^1},\dots ,\textbf{e}_{s_u^N})$$\end{document} . To encode order, sinusoidal positions are added, i.e., \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\textbf{e}_{s_u^n}^p=\textbf{e}_{s_u^n}+\textbf{p}_n$$\end{document} . These position-aware embeddings are processed by L Transformer layers with multi-head self-attention and feed-forward networks (with residuals, normalization, and dropout). The final representation in domain \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$d_i$$\end{document} is:
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\begin{aligned} \textbf{z}_u^{d_i} = \text {TransformerEnc}\!\left( \textbf{e}_{s_u^1}^p,\dots ,\textbf{e}_{s_u^N}^p\right) \in \mathbb {R}^d. \end{aligned}$$\end{document}We denote the Transformer-only output as \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\textbf{z}$$\end{document} , the LLM-enhanced features as \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$f_A$$\end{document} , and the fused embedding as \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\tilde{\textbf{z}}$$\end{document} . While \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\textbf{z}_u^{d_i}$$\end{document} captures intra-domain sequential patterns, it remains incomplete under sparsity and heterogeneity, motivating the LLM-based augmentation module.
LLM-augmented user and item representations
Federated cross-domain data are often sparse and incomplete, especially under cold-start scenarios. To address this, we introduce an offline LLM-based augmentation module that enriches user profiles and item metadata via semantic reasoning (see Table 2).
User-side augmentation. For each client k, given a sequence \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$S_k^{(u)}$$\end{document} , prompts \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$P_u^U$$\end{document} query the LLM to infer attributes beyond demographics and genre, such as social tendencies, viewing environments, consumption patterns, and cross-domain interests. The generated vectors \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$f_{A,u} \in \mathbb {R}^{d_{LLM}}$$\end{document} are fused with sequential embeddings to form enriched user profiles.
Item-side augmentation. Many domains lack complete metadata. Given basic fields (title, category, year), prompts \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$P_v^I$$\end{document} guide the LLM to infer extended attributes, e.g., directors, actors, production company, sub-genres, awards, and ratings. Unavailable fields (e.g., subjective ratings) are set to N/A. The resulting \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$f_{A,v} \in \mathbb {R}^{d_{LLM}}$$\end{document} provides richer item representations, mitigating cold-start issues.
Offline usage. Unlike prior works relying on online LLM services, augmentation is done once before training. Clients sanitize prompts, query locally, and reuse generated attributes throughout training. Raw data never leaves the client, ensuring privacy-preserving enrichment without runtime dependency.
Robustness to noisy LLM-generated attributes. We acknowledge that LLM-generated attributes may contain noise or imperfect inferences. To mitigate their potential impact, we adopt several safeguards. First, all prompts enforce strict JSON schemas, and unavailable or uncertain attributes are explicitly marked as N/A, preventing the introduction of arbitrary or unstructured noise. Second, LLM-generated features are not used independently but are fused with behavior-driven representations through a lightweight MLP, allowing the model to learn appropriate weighting and downplay unreliable semantic signals. Third, the proposed IIDCL and federated training process further enhance robustness by emphasizing consistent behavioral patterns across users and domains, effectively regularizing noisy semantic features. As a result, occasional inaccuracies in LLM outputs do not dominate the learning process and have limited influence on final recommendations.
Feature fusion. Specifically, let \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\textbf{z}_u^{d_i}$$\end{document} and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\textbf{z}_v^{d_i}$$\end{document} denote the behavior-driven sequential embeddings of user u and item v in domain \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$d_i$$\end{document} , and let \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$f_{A,u}$$\end{document} and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$f_{A,v}$$\end{document} be their corresponding LLM-generated semantic features. To integrate behavioral and semantic information, we introduce a lightweight fusion encoder \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\text {Enc}(\cdot )$$\end{document} , implemented as a two-layer multi-layer perceptron (MLP), which projects the concatenated features into a shared latent space. The encoder produces fused representations \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\tilde{\textbf{z}}_u^{d_i}$$\end{document} and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\tilde{\textbf{z}}_v^{d_i}$$\end{document} as follows:
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\begin{aligned} \tilde{\textbf{z}}_u^{d_i} = \text {Enc}([\textbf{z}_u^{d_i}; f_{A,u}]), \quad \tilde{\textbf{z}}_v^{d_i} = \text {Enc}([\textbf{z}_v^{d_i}; f_{A,v}]), \end{aligned}$$\end{document}where \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\tilde{\textbf{z}}_u^{d_i}, \tilde{\textbf{z}}_v^{d_i} \in \mathbb {R}^d$$\end{document} . This fusion integrates sequential patterns with enriched semantics, improving accuracy, generalization, and robustness under cold-start scenarios.Table 2. Prompt templates for offline LLM-based augmentation.TaskPrompt TemplateUser ProfileSystem: You are a recommender data curator. User: Given the user’s movie history [title, year, genres], infer the following JSON fields: { ”age_range”: ””, ”gender”: ””, ”liked_genres”: [...], ”disliked_genres”: [...], ”social_tendencies”: ””, ”social_relationships”: ””, ”preferred_activities”: ””, ”viewing_environment”: ””, ”future_interests”: [...], ”language”: ”” } Rules: Follow schema; avoid PII; use concise and factual values.Item AttributeSystem: You complete missing metadata for movies. User: For the given movie [title, year, genres], output the following JSON fields: { ”director”: ””, ”country”: ””, ”language”: ””, ”main_actors”: [...], ”production_company”: ””, ”filming_locations”: [...], ”audience_ratings”: ”N/A” } Rules: Mark optional fields as ”N/A”; follow strict schema; provide short factual values.
Intra- and inter-domain decoupled contrastive learning
To enhance intra-domain consistency and inter-domain discriminability, we propose Intra- and Inter-Domain Decoupled Contrastive Learning. Unlike the standard InfoNCE loss that entangles attraction and repulsion within a single log-softmax term, IIDCL explicitly decouples alignment and uniformity components, thereby enabling finer-grained control over positive and negative forces. This design is particularly advantageous in federated settings with heterogeneous data distributions and limited local samples. Compared with FedCSR^9^, which applies dual contrastive objectives across clients, IIDCL directly targets intra-domain coherence and inter-domain separability within a unified framework.
Specifically, IIDCL consists of two complementary objectives. Intra-domain contrastive learning encourages an anchor user to attract a set of Top-K behaviorally similar users while repelling dissimilar ones, reinforcing preference consistency within each domain. Inter-domain contrastive learning aligns representations of the same user across different domains while pushing apart representations of different users, ensuring cross-domain separability. This decoupled design preserves personalized signals at the domain level while facilitating effective cross-domain knowledge transfer.
Formally, let \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\mathcal {U}_{d_i}$$\end{document} denote the user set of domain \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$d_i$$\end{document} . For a user \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$u \in \mathcal {U}_{d_i}$$\end{document} , we denote by \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\textbf{z}_u^{d_i} \in \mathbb {R}^d$$\end{document} the behavior-driven sequence representation obtained from the Transformer encoder, and by \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\tilde{\textbf{z}}_u^{d_i} \in \mathbb {R}^d$$\end{document} the fused representation after LLM-based semantic augmentation. Cosine similarity between two users \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$u_a$$\end{document} and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$u_b$$\end{document} in domain \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$d_i$$\end{document} is defined as \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\text {sim}(u_a,u_b) = \frac{\tilde{\textbf{z}}_{u_a}^{d_i} \cdot \tilde{\textbf{z}}_{u_b}^{d_i}}{\Vert \tilde{\textbf{z}}_{u_a}^{d_i}\Vert _2 \, \Vert \tilde{\textbf{z}}_{u_b}^{d_i}\Vert _2}$$\end{document} .
For each user u, the Top-K most similar users are treated as positive samples, and all remaining users are regarded as negatives:
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\begin{aligned} \mathcal {P}_u^{d_i} = \operatorname {TopK}_{u' \ne u}\big (\text {sim}(u,u'), K\big ), \quad \mathcal {N}_u^{d_i} = \mathcal {U}_{d_i} \setminus \big (\mathcal {P}_u^{d_i} \cup \{u\}\big ). \end{aligned}$$\end{document}The hyperparameter K controls the locality of the intra-domain neighborhood. A small K enforces strong local consistency but may be unstable under sparse data, while a large K risks introducing noisy positives. Following prior practice, we set \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$K = \min (K_{\max }, \lfloor \rho \cdot |\mathcal {U}_{d_i}| \rfloor )$$\end{document} with \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\rho = 0.02$$\end{document} and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$K_{\max } = 50$$\end{document} , and observe stable performance under moderate variations.
The intra-domain loss is defined as
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\begin{aligned} \begin{aligned} \mathcal {L}_{\text {intra}}^{d_i} = \tfrac{1}{|\mathcal {U}_{d_i}|} \sum _{u \in \mathcal {U}_{d_i}} \Big [&-\lambda ^{a}_{\text {intra}} \tfrac{1}{|\mathcal {P}_u^{d_i}|} \sum _{u^+\in \mathcal {P}_u^{d_i}} \tfrac{\text {sim}(\tilde{\textbf{z}}_u^{d_i},\tilde{\textbf{z}}_{u^+}^{d_i})}{\tau _{\text {intra}}} + \lambda ^{u}_{\text {intra}} \log \!\Big (\sum _{u^-\in \mathcal {N}_u^{d_i}} \exp (\tfrac{\text {sim}(\tilde{\textbf{z}}_u^{d_i},\tilde{\textbf{z}}_{u^-}^{d_i})}{\tau _{\text {intra}}})\Big ) \Big ], \end{aligned} \end{aligned}$$\end{document}where \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\mathcal {P}_u^{d_i}$$\end{document} and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\mathcal {N}_u^{d_i}$$\end{document} denote the positive and negative user sets for anchor user u in domain \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$d_i$$\end{document} , respectively. \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\lambda ^{a}_{\text {intra}}$$\end{document} and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\lambda ^{u}_{\text {intra}}$$\end{document} control the strengths of the alignment and uniformity terms, and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\tau _{\text {intra}}$$\end{document} is the temperature parameter. Although \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\mathcal {N}_u^{d_i}$$\end{document} is defined as the set of all non-positive users for notational clarity, in practice we randomly sample a fixed-size subset \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\tilde{\mathcal {N}}_u^{d_i} \subset \mathcal {N}_u^{d_i}$$\end{document} with \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$|\tilde{\mathcal {N}}_u^{d_i}| = M$$\end{document} to construct the intra-domain loss. This negative sampling strategy significantly reduces computational cost while preserving sufficient diversity among negative examples. Unless otherwise stated, we set \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$M=100$$\end{document} in all experiments.
For inter-domain contrastive learning, positive samples correspond to fused representations of the same user observed in different domains, while negative samples are fused representations of other users from those domains:
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\begin{aligned} \mathcal {P}_u^{\text {inter}, d_i} = \{ \tilde{\textbf{z}}_u^{d_j} \mid d_j \ne d_i \}, \quad \mathcal {N}_u^{\text {inter}, d_i} = \{ \tilde{\textbf{z}}_{u'}^{d_j} \mid d_j \ne d_i,\, u' \ne u \}. \end{aligned}$$\end{document}The inter-domain contrastive objective is given by
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\begin{aligned} \begin{aligned} \mathcal {L}_{\text {inter}}^{d_i} = \frac{1}{|\mathcal {U}_{d_i}|} \sum _{u \in \mathcal {U}_{d_i}} \Bigg [&-\lambda ^{a}_{\text {inter}} \frac{1}{|\mathcal {P}_u^{\text {inter}, d_i}|} \sum _{p \in \mathcal {P}_u^{\text {inter}, d_i}} \frac{\text {sim}(\tilde{\textbf{z}}_u^{d_i}, p)}{\tau _{\text {inter}}} + \lambda ^{u}_{\text {inter}} \log \!\Bigg ( \sum _{n \in \mathcal {N}_u^{\text {inter}, d_i}} \exp \!\left( \frac{\text {sim}(\tilde{\textbf{z}}_u^{d_i}, n)}{\tau _{\text {inter}}} \right) \Bigg ) \Bigg ], \end{aligned} \end{aligned}$$\end{document}where \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\lambda ^{a}_{\text {inter}}$$\end{document} and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\lambda ^{u}_{\text {inter}}$$\end{document} balance alignment and uniformity, and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\tau _{\text {inter}}$$\end{document} controls inter-domain smoothness.
The overall IIDCL objective is defined as
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\begin{aligned} \mathcal {L}_{\text {IIDCL}} = \sum _{d_i} \Big ( \lambda _{\text {intra}} \mathcal {L}_{\text {intra}}^{d_i} + \lambda _{\text {inter}} \mathcal {L}_{\text {inter}}^{d_i} \Big ). \end{aligned}$$\end{document}Privacy is preserved since all intra-domain contrastive signals are computed locally on each client without any cross-domain data exchange. For inter-domain representation alignment, FedSCOPE adopts a Private Set Intersection (PSI) protocol^28^, which enables the identification of anonymized user overlaps across domains while ensuring that no raw user identifiers are disclosed. Importantly, FedSCOPE does not assume globally shared or centralized user identities. When multiple domains reside on the same platform or share consistent pseudonymous user identifiers, inter-domain alignment can be performed directly. For cross-platform scenarios without explicit identifier sharing, privacy-preserving user matching mechanisms (e.g., PSI-based secure linkage) are employed to identify a partial set of overlapping users without revealing raw identities. Inter-domain user alignment is an optional component rather than a strict prerequisite of FedSCOPE. When no reliable inter-domain alignment is available, the inter-domain contrastive objective is disabled, and the training process naturally degrades to pure intra-domain learning. In this case, the framework remains fully functional and privacy-preserving, while the strength of cross-domain knowledge transfer is reduced accordingly.
Multi-task joint optimization and secure aggregation
For user \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$u \in \mathcal {U}_{d_i}$$\end{document} , the Transformer encoder produces a behavior-driven sequence representation \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\textbf{z}_u^{d_i}\in \mathbb {R}^d$$\end{document} , which is further enriched by the offline LLM-based semantic augmentation module into \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\tilde{\textbf{z}}_u^{d_i}$$\end{document} . Items in domain \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$d_i$$\end{document} are represented analogously as \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\tilde{\textbf{z}}_v^{d_i}$$\end{document} . Let \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\mathcal {V}_{d_i}$$\end{document} denote the candidate item set in domain \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$d_i$$\end{document} . Given \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\tilde{\textbf{z}}_u^{d_i}$$\end{document} and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\tilde{\textbf{z}}_v^{d_i}$$\end{document} , prediction scores \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\hat{y}_{u,v}^{d_i} = \tilde{\textbf{z}}_u^{d_i} \cdot \tilde{\textbf{z}}_v^{d_i}$$\end{document} are computed via inner product, and optimized using a binary cross-entropy objective. Formally, for each domain \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$d_i$$\end{document} , the next-item prediction loss is defined as
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\begin{aligned} \mathcal {L}_{\text {pred}}^{d_i} = - \sum _{u \in \mathcal {U}_{d_i}} \sum _{v \in \mathcal {V}_{d_i}} \Big [ y_{u,v}^{d_i} \log \sigma (\hat{y}_{u,v}^{d_i}) + (1 - y_{u,v}^{d_i}) \log \big (1 - \sigma (\hat{y}_{u,v}^{d_i})\big ) \Big ], \end{aligned}$$\end{document}where \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$y_{u,v}^{d_i}\in \{0,1\}$$\end{document} denotes the ground-truth interaction label and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\sigma (\cdot )$$\end{document} is the sigmoid function. In practice, negative sampling is applied to reduce computational cost.
To jointly exploit behavioral, semantic, and structural signals, we combine the prediction objective with intra- and inter-domain decoupled contrastive learning. The overall local training objective for each client is
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\begin{aligned} \mathcal {L} = \sum _{d_i} \Big ( \mathcal {L}_{\text {pred}}^{d_i} + \alpha \big ( \lambda _{\text {intra}} \mathcal {L}_{\text {intra}}^{d_i} + \lambda _{\text {inter}} \mathcal {L}_{\text {inter}}^{d_i} \big ) \Big ), \end{aligned}$$\end{document}where \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\alpha$$\end{document} balances the prediction loss and contrastive objectives, and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\lambda _{\text {intra}}$$\end{document} and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\lambda _{\text {inter}}$$\end{document} control the relative contributions of intra- and inter-domain contrastive learning, respectively. This joint objective yields three complementary effects: (i) \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\mathcal {L}_{\text {pred}}^{d_i}$$\end{document} drives accurate next-item recommendation; (ii) \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\mathcal {L}_{\text {intra}}^{d_i}$$\end{document} enhances domain-level personalization by encouraging consistency among behaviorally similar users; and (iii) \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\mathcal {L}_{\text {inter}}^{d_i}$$\end{document} aligns user representations across domains while preserving inter-user discrimination, thereby improving cross-domain generalization.
Privacy protection
While the multi-task objective jointly optimizes semantic, behavioral, and structural signals, federated training must also satisfy strict privacy constraints. To this end, we incorporate an adaptive personalized differential privacy mechanism into the federated optimization pipeline. The proposed mechanism is applied at the client side in each communication round, after local optimization and before transmitting updates to the server. Combined with secure aggregation, this design ensures that all communicated updates satisfy client-level DP while preventing the server from accessing raw data or exact gradients. This design choice provides a practical balance between strong privacy guarantees and learning utility, making it suitable for real-world federated recommendation deployments. In FedSCOPE, differential privacy is enforced at the client-update level. Each communicated update corresponds to an aggregation over all users on a client, and the applied DP mechanism provides formal client-level privacy guarantees, ensuring that the contribution of any individual user’s behavior cannot be inferred from the transmitted updates.
Formally, a randomized mechanism \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\mathcal {M}$$\end{document} satisfies \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$(\epsilon ,\delta )$$\end{document} -DP if, for any pair of neighboring datasets D and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$D'$$\end{document} , it holds that \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\Pr [\mathcal {M}(D)\!\in \!\mathcal {S}] \le e^\epsilon \Pr [\mathcal {M}(D')\!\in \!\mathcal {S}] + \delta$$\end{document} for all measurable sets \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\mathcal {S}$$\end{document} . Smaller values of \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\epsilon$$\end{document} correspond to stronger privacy guarantees.
Clipping and noise. After minimizing the local objective at communication round t, each client k clips its update \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\Delta _k^{t}$$\end{document} with threshold \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$C_k^{t}$$\end{document} and injects Gaussian noise. Specifically, the clipped update is computed as
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\begin{aligned} \Delta _k^{t,\text {clip}} = \Delta _k^{t} \cdot \min \!\Big (1,\tfrac{C_k^{t}}{\Vert \Delta _k^{t}\Vert _2}\Big ), \end{aligned}$$\end{document}and the privatized update is obtained by adding Gaussian noise,
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\begin{aligned} \tilde{\Delta }_k^{t} = \Delta _k^{t,\text {clip}} + \mathcal {N}(0,(\sigma _k^{t})^2 I), \end{aligned}$$\end{document}where the noise scale \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\sigma _k^{t}$$\end{document} is determined by the assigned privacy budget \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$(\epsilon _k,\delta _k)$$\end{document} and satisfies
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\begin{aligned} \sigma _k^{t} \ge \tfrac{\sqrt{2\ln (1.25/\delta _k)} \, C_k^{t}}{\epsilon _k}. \end{aligned}$$\end{document}Adaptive allocation. To account for client heterogeneity, privacy budgets are allocated proportionally to data size following \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\epsilon _k = \epsilon _{\text {total}} \frac{|U_k|^{\beta }}{\sum _j |U_j|^{\beta }}$$\end{document} and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\delta _k = \delta _{\text {total}}/K$$\end{document} , where \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\beta \in [0,1]$$\end{document} controls the degree of personalization. When \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\beta =0$$\end{document} , the mechanism reduces to uniform DP, while larger \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\beta$$\end{document} assigns relatively larger budgets to data-rich clients. Unless otherwise stated, we use \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\beta =0.5$$\end{document} , and observe stable behavior for \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\beta \in [0.3,0.7]$$\end{document} .
To further reduce excessive utility loss, clipping thresholds are adapted to client-specific update magnitudes according to
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\begin{aligned} C_k \leftarrow \gamma \cdot \operatorname {median}\!\left( \{\Vert \Delta _k^{(t')}\Vert _2\}_{t'=t-M}^{t-1}\right) , \end{aligned}$$\end{document}where M denotes the window size and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\gamma$$\end{document} is a scaling factor.
Privacy accounting. The cumulative privacy loss across T communication rounds is tracked using a Rényi/moments accountant under the subsampled Gaussian mechanism. Given the noise multiplier \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\mu _k=\sigma _k/C_k$$\end{document} and sampling rate \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$q_k$$\end{document} , the accountant computes the accumulated guarantee \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$(\epsilon _k^{(T)},\delta _k)$$\end{document} . If a client approaches its privacy budget limit, the noise scale is increased or the client is temporarily suspended.
Privacy protection in FedSCOPE is enforced entirely at the client side and seamlessly integrated into the federated optimization process, providing strong client-level guarantees without compromising cross-domain collaborative learning.
Federated cross-domain recommendation model training
The federated training procedure integrates the above privacy mechanism in a plug-and-play manner. Specifically, local optimization, privacy sanitization, and secure aggregation are sequentially performed within each communication round. In each communication round t, the server broadcasts the current global model parameters \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\textbf{w}^t$$\end{document} to a subset of selected clients. Each selected client performs local optimization by minimizing the joint objective \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\mathcal {L}$$\end{document} defined above, using only its private data.
After local training at communication round t, each client k computes a model update
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\begin{aligned} \Delta _k^{t} = \textbf{w}_k^{t+1} - \textbf{w}^{t}, \end{aligned}$$\end{document}where \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\textbf{w}_k^{t+1}$$\end{document} denotes the locally updated model on client k. To satisfy client-level privacy guarantees, the update \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\Delta _k^{t}$$\end{document} is clipped and perturbed by the proposed adaptive personalized differential privacy mechanism, resulting in a privatized update \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\tilde{\Delta }_k^{t}$$\end{document} . The server aggregates the privatized client updates via secure aggregation and updates the global model as
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\begin{aligned} \textbf{w}^{t+1} = \textbf{w}^{t} + \frac{1}{\sum _{k=1}^K |U_k|} \sum _{k=1}^{K} |U_k| \cdot \tilde{\Delta }_k^{t}, \end{aligned}$$\end{document}where \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$|U_k|$$\end{document} denotes the number of users on client k. Secure aggregation ensures that the server cannot access any individual client update, while the injected noise provides formal client-level \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$(\epsilon _k,\delta _k)$$\end{document} differential privacy guarantees. This federated optimization procedure enables FedSCOPE to collaboratively learn a global cross-domain recommendation model with formal privacy guarantees, while preserving robustness across multiple domains.
Experiments
To comprehensively evaluate the effectiveness and practicality of the proposed FedSCOPE framework, we design a series of experiments aimed at answering the following key research questions (RQs):
- RQ1: Does FedSCOPE consistently improve the performance of federated cross-domain sequential recommendation compared with representative baselines?
- RQ2: How much do LLM-based semantic enhancements of user and item representations contribute to the overall performance, and how sensitive is the model to different LLM choices?
- RQ3: How does the proposed IIDCL module influence performance and representation learning under different hyperparameter configurations?
- RQ4: How well does FedSCOPE handle cold-start scenarios where users have limited interaction histories?
- RQ5: Can federated training achieve better accuracy and generalization than standalone single-domain training?
- RQ6: Does the adaptive personalized differential privacy mechanism provide a better privacy–utility trade-off compared with conventional uniform DP?
- RQ7: Are the conclusions of FedSCOPE robust under varying federated configurations, such as the number of clients (K) and the per-round sampling ratio (C)? Before presenting the evaluation results, we first introduce the datasets, baselines, evaluation metrics, and implementation details used in our experiments.
Experimental settings
Datasets
We conduct experiments on the widely used Amazon e-commerce dataset^29^, which provides multi-domain user interaction histories and rich item metadata. This dataset is well suited for FedCDSR because it includes overlapping user behaviors across different domains. In our study, we focus on two domain pairs, namely Movie–Book and Food–Kitchen, which capture both complementary and heterogeneous user preferences, enabling a rigorous evaluation of cross-domain transfer. Following prior work^4,30^, we retain users who are active in both domains and exclude those with fewer than ten interactions. All interactions are chronologically ordered, with the last one used as the prediction target. The dataset is divided into training (80%), validation (10%), and test (10%) sets. Table 3 presents the statistics.Table 3. Statistics of the experimental datasets.Domain#Users#Items#Train#Test#ValidMovie15,35236,84559,0947,3977,376Book63,937Food16,57929,20740,5575,0805,059Kitchen34,886
Baselines
We compare FedSCOPE with four categories of representative baselines: (1) traditional recommendation methods (ItemKNN^31^, BPRMF^32^); (2) cross-domain general recommendation methods (CoNet^13^, CCDR^33^); (3) cross-domain sequential recommendation methods ( \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\pi$$\end{document} -Net^14^, PSJNet^15^, MIFN^30^, C2DSR^4^, LEAGCN^16^, TJAPL^34^); and (4) federated cross-domain recommendation methods (FELLAS^8^, FedDCSR^7^, FedCSR^9^, FFMSR^35^). Following prior federated cross-domain recommendation studies (e.g., FedDCSR^7^, FedCSR^9^), methods not originally designed for federated settings are adapted using the standard FedAvg framework. This ensures a consistent and neutral federated optimization protocol across all baselines, so that performance differences primarily reflect model architectures rather than optimization discrepancies. All baselines follow the same data splits and evaluation protocol as FedSCOPE.
In this work, FedAvg is employed as a commonly adopted federated optimization framework to establish a controlled and reproducible experimental setting. Notably, FedSCOPE itself is not inherently dependent on any specific federated optimizer. The proposed semantic augmentation, decoupled intra–inter domain contrastive learning, and adaptive privacy mechanisms are designed at the model and objective levels, and thus remain applicable under other federated optimization schemes, such as FedProx^36^ or SCAFFOLD^37^. An extensive comparison across different federated frameworks is beyond the scope of this study and is left for future investigation.
Evaluation metrics
We adopt the widely used leave-one-out evaluation protocol^10,38^, where the last item in each user’s interaction sequence is held out as the test instance and ranked among 999 randomly sampled negative items^39^. We report results using three complementary metrics: \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$NDCG@\{5,10\}$$\end{document} , MRR, and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$HR@\{5,10\}$$\end{document} . These metrics jointly assess ranking quality, recommendation precision, and hit accuracy at the top-K positions, where higher values indicate better recommendation performance.
Implementation details
All experiments are implemented in PyTorch and executed on machines equipped with NVIDIA GeForce RTX 4090 GPUs. For most baselines, hyperparameters are tuned via grid search on the validation set, and the optimal settings reported in their original papers are used when applicable. For our method, we set the embedding dimension to 64, mini-batch size to 256, and dropout rate to 0.3. The L2 regularization coefficient is searched from \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\{10^{-5}, 5 \times 10^{-5}, 10^{-4}, 5 \times 10^{-4}\}$$\end{document} , and the learning rate from \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\{10^{-4}, 5 \times 10^{-4}, 10^{-3}\}$$\end{document} . We train for 50 epochs with the Adam optimizer and apply early stopping if the validation loss does not improve for 10 epochs. The model with the highest validation MRR is selected for testing. Unless otherwise specified, we simulate \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$K=50$$\end{document} clients in each scenario. In every communication round, a fraction \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$C=0.2$$\end{document} of clients is sampled, each participating client performs \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$E=1$$\end{document} local epoch, and the total number of rounds is \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$T=200$$\end{document} . All reported results are averaged over five runs with different random seeds, and we report the mean and standard deviation to ensure robustness and reproducibility.
Experimental results and discussion
RQ1: Analysis of overall performance improvement
The overall performance comparison on the Movie–Book and Food–Kitchen datasets (Tables 4 and 5) reveals several important findings. First, cross-domain general recommendation methods (e.g., CoNet and CCDR) consistently outperform traditional methods (e.g., ItemKNN and BPRMF), highlighting the significance of domain adaptation and knowledge transfer in improving recommendation performance. Second, cross-domain sequential recommendation models further enhance accuracy by capturing temporal dependencies in user behavior, while attention-based approaches such as \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\pi$$\end{document} -Net and TJAPL achieve even stronger results by modeling fine-grained preference dynamics.Among federated approaches, FedCSR exhibits competitive performance and demonstrates effective collaborative learning across distributed client data. Moreover, the recently proposed FFMSR^35^, which enhances cross-domain recommendation by jointly encoding raw textual semantics, integrating ID–Text modalities, and filtering irrelevant semantic noise, achieves better performance than FedCSR across all evaluated domains, demonstrating the benefit of incorporating richer semantic learning into federated CDR. While these baselines show competitive results, FedSCOPE attains the best or near-best performance on most metrics and datasets. Its performance gains are largely attributed to two design elements: (1) the decoupled intra- and inter-domain contrastive learning strategy, which promotes more stable cross-domain alignment, and (2) the privacy-preserving semantic enhancement module, which enriches user and item representations through LLM-generated semantic priors without exposing sensitive data. These components collectively enable FedSCOPE to deliver more robust and personalized recommendations in heterogeneous federated environments. Figure 2 further shows HR@10 over communication rounds. FedSCOPE demonstrates faster convergence than representative baselines (FedCSR, FedDCSR, and FELLAS), suggesting improved training efficiency and reduced communication overhead in federated settings.Table 4. Experimental Results (%) on the Movie-Book Scenario.MethodsMovie-domain RecommendationBook-domain RecommendationNDCG@5NDCG@10HR@5HR@10MRRNDCG@5NDCG@10HR@5HR@10MRRTraditional Recommendation MethodsFedAvg+ItemKNN^31^4.364.985.217.135.143.033.353.414.433.32FedAvg+BPRMF^32^4.785.125.517.435.633.463.413.464.383.45Cross-domain General Recommendation MethodsFedAvg+CoNet^13^7.528.228.3910.568.316.326.526.657.446.69FedAvg+CCDR^33^7.688.278.7410.618.336.376.576.797.496.75Cross-domain Sequential Recommendation MethodsFedAvg+ \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\pi$$\end{document} -Net^14^11.4611.9112.4911.858.939.589.779.9910.589.91FedAvg+PSJNet^15^11.8812.5713.0415.2712.379.8110.0910.3211.0210.18FedAvg+MIFN^30^11.9512.9413.2516.0312.799.8610.0510.2510.8110.25FedAvg+C2DSR^4^12.5613.5114.2117.2913.289.9110.1910.5811.4910.29FedAvg+LEAGCN^16^12.9713.9115.2218.0313.8611.2111.3611.0111.9910.82FedAvg+TJAPL^34^14.2814.9916.3519.7514.9712.6312.7612.4913.4311.87Federated Cross-domain Recommendation MethodsFELLAS^8^22.7923.2323.8227.7123.2418.5319.3220.3722.5221.37FedDCSR^7^23.1823.6224.2128.0924.6318.9220.7121.7623.9122.76FedCSR^9^26.1326.5727.1631.0426.5821.8722.6623.7125.8624.71FFMSR^35^26.6227.3427.9532.0227.0122.3123.0824.1225.9625.09FedSCOPE (Ours)29.0731.6432.3236.1131.9525.9727.5528.4131.1529.06Table 5. Experimental Results (%) on the food-kitchen scenario.MethodsFood-domain RecommendationKitchen-domain RecommendationNDCG@5NDCG@10HR@5HR@10MRRNDCG@5NDCG@10HR@5HR@10MRRTraditional Recommendation MethodsFedAvg+ItemKNN^31^5.475.786.328.066.053.413.584.125.394.02FedAvg+BPRMF^32^5.686.166.948.546.233.583.984.315.564.24Cross-domain General Recommendation MethodsFedAvg+CoNet^13^8.859.3810.0111.599.376.747.357.318.957.41FedAvg+CCDR^33^9.189.7510.3412.149.736.817.277.479.347.65Cross-domain Sequential Recommendation MethodsFedAvg+ \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\pi$$\end{document} -Net^14^15.0615.8716.9919.4915.4210.7211.4712.0814.4111.27FedAvg+PSJNet^15^15.8116.5118.0220.1916.0711.4212.0612.9114.8911.84FedAvg+MIFN^30^16.0216.7518.1720.4516.2911.3112.0312.6014.8211.83FedAvg+C2DSR^4^16.3917.4518.9822.2816.6511.9812.6813.4815.9212.39FedAvg+LEAGCN^16^17.2318.2219.7323.1217.8613.4213.8114.7217.2413.46FedAvg+TJAPL^34^17.9818.9720.4223.7518.6913.8614.5215.1818.3314.59Federated Cross-domain Recommendation MethodsFELLAS^8^20.9421.5321.6926.1221.0416.5316.8817.8120.0415.72FedDCSR^7^22.3622.9523.1127.5422.4617.9518.3419.2321.4619.14FedCSR^9^25.4226.0126.1730.6323.5221.0121.3622.4324.5222.29FFMSR^35^25.7326.2626.3431.0124.0321.6822.1123.3625.1822.85FedSCOPE (Ours)30.5631.6232.4334.6427.5627.4928.5829.0230.1326.74
Fig. 2. Convergence comparison in the kitchen-domain.
RQ2: Contribution and sensitivity of LLM-based enhancement
To evaluate the contribution of LLM-based semantic augmentation, we conducted ablation experiments by selectively removing the user feature enhancement (UFE) and item attribute enhancement (IAE) modules. As shown in Table 6, removing both modules leads to the lowest performance, confirming the necessity of LLM-based augmentation. Retaining only UFE yields slightly better results than retaining only IAE, indicating that user-side enrichment plays a more critical role in modeling behavioral sequences, likely because user-level representations directly shape sequential preference modeling. Nevertheless, IAE also contributes by enriching item-level semantics, and combining UFE and IAE achieves the best results in both domains, demonstrating their complementary nature. We further analyzed the sensitivity of FedSCOPE to different LLMs by comparing BERT, Longformer, Llama2, and Llama3.1 on the Book domain. As shown in Fig. 3, FedSCOPE consistently outperforms the baseline FedSeqRec across all tested LLMs, highlighting its robustness in leveraging diverse semantic representations. BERT shows relatively weaker performance due to its limited capacity for long-context modeling, while Longformer better captures extended user sequences. More advanced models, such as Llama2 and Llama3.1, bring larger improvements, suggesting that model scale and the richness of pretraining data are positively correlated with recommendation quality. Importantly, these results demonstrate that FedSCOPE is not tied to a specific LLM and can effectively benefit from a wide range of language models. Beyond accuracy, we also examined the trade-off between computational overhead and performance gains. BERT offers the lowest computational cost and memory footprint, though its improvements are modest. Longformer requires moderately higher resources due to its extended attention mechanism but achieves noticeably better performance on long sequences. Llama2 and Llama3.1 demand the highest offline computational resources, yet deliver the most significant accuracy gains, especially in sparse and heterogeneous domains. Since FedSCOPE performs augmentation entirely offline and caches the generated features, these costs are incurred only once, avoiding repeated overhead during federated training and keeping the additional communication burden negligible. This design enables flexible choices: lightweight models are preferable in resource-limited scenarios, whereas larger models are more suitable when maximizing accuracy is the priority, making FedSCOPE adaptable to a wide range of real-world deployments.Table 6. Performance comparison (%) with user feature and item attribute enhancement.ComponentFood-domainKitchen-domainUFEIAENDCG@10HR@10MRRNDCG@10HR@10MRR \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\times$$\end{document} \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\times$$\end{document} 12.4513.059.1010.7311.0810.15 \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\times$$\end{document} ✓20.6920.2717.8618.4320.9819.86✓ \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\times$$\end{document} 21.4320.9618.5719.2122.1621.95✓✓31.5934.5827.4929.1231.47****27.32
Fig. 3. Performance comparison across different models in the Book-domain.
RQ3: Effectiveness and sensitivity analysis of IIDCL
To evaluate the effectiveness of the proposed IIDCL mechanism and analyze its key hyperparameters, we conduct a comprehensive sensitivity study on \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\lambda _{\text {intra}}$$\end{document} , \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\lambda _{\text {inter}}$$\end{document} , and the overall contrastive weight \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\alpha$$\end{document} in both the Book-Movie and Food-Kitchen scenarios.
**Sensitivity of ** \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\lambda _{\text {intra}}$$\end{document} . We first analyze the impact of the intra-domain contrastive weight \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\lambda _{\text {intra}}$$\end{document} by varying it from 0 to 1.0 with a step size of 0.1, while fixing \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\lambda _{\text {inter}}$$\end{document} and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\alpha$$\end{document} to their default values. As shown in Fig. 4, increasing \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\lambda _{\text {intra}}$$\end{document} initially leads to consistent performance improvements, indicating that stronger intra-domain contrastive regularization effectively enhances user aggregation and personalization within each domain. However, when \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\lambda _{\text {intra}}$$\end{document} becomes excessively large, performance starts to degrade, suggesting that overemphasizing intra-domain consistency may suppress cross-domain knowledge transfer and reduce generalization capability.
**Sensitivity of ** \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\lambda _{\text {inter}}$$\end{document} . Next, we examine the sensitivity of the inter-domain contrastive weight \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\lambda _{\text {inter}}$$\end{document} by varying it within the same range while fixing \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\lambda _{\text {intra}}$$\end{document} and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\alpha$$\end{document} . Moderate values of \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\lambda _{\text {inter}}$$\end{document} significantly improve cross-domain separability by encouraging representations of the same user across different domains to align while pushing apart different users. Nevertheless, overly large \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\lambda _{\text {inter}}$$\end{document} weakens domain-specific personalization, leading to performance degradation. These results confirm that excessive emphasis on inter-domain alignment may override fine-grained domain-level preferences.
**Sensitivity of ** \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\alpha$$\end{document} . Finally, we investigate the influence of the global contrastive weight \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\alpha$$\end{document} , which balances the prediction loss and the contrastive objectives. We observe that FedSCOPE achieves stable performance across a broad range of \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\alpha$$\end{document} values, indicating that IIDCL provides effective regularization without requiring precise tuning of the overall contrastive strength. Extremely small \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\alpha$$\end{document} values underutilize contrastive signals, while overly large values may dominate the prediction objective, slightly degrading accuracy. The sensitivity analysis demonstrates that \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\lambda _{\text {intra}}$$\end{document} , \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\lambda _{\text {inter}}$$\end{document} , and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\alpha$$\end{document} play complementary roles in IIDCL. Optimal performance emerges when these hyperparameters are properly balanced, validating the design motivation of decoupling intra-domain personalization and inter-domain generalization within the proposed framework.
Visualization and analysis. Beyond quantitative results, we further visualize user representations using t-SNE to provide intuitive insights into the role of IIDCL. As illustrated in Fig. 5, removing IIDCL results in scattered intra-domain representations with substantial inter-domain overlap, reflecting weak within-domain consistency and limited cross-domain discriminability. In contrast, FedSCOPE with IIDCL learns more compact intra-domain clusters and clearer inter-domain separation, where positive samples are pulled closer and negative samples are pushed farther apart. Such structured representations enable the model to simultaneously capture domain-specific behavioral patterns and preserve transferable knowledge across domains.Fig. 4. Sensitivity analysis of key hyperparameters in IIDCL. (a) Impact of \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\lambda _{\text {intra}}$$\end{document} . (b) Impact of \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\lambda _{\text {inter}}$$\end{document} . (c) Impact of the overall contrastive weight \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\alpha$$\end{document} .Fig. 5t-SNE visualization of user representations with and without IIDCL.
RQ4: Performance under cold-start scenarios
Table 7 reports the performance of different methods under cold-start scenarios, where users exhibit limited historical interactions. Compared with FedCSR, FedSCOPE consistently achieves better performance across all four domains, suggesting an improved ability to cope with data sparsity in federated cross-domain recommendation settings. When the LLM-based semantic augmentation module is removed, the performance generally decreases across domains, indicating that relying solely on behavioral signals may be less effective for representing cold-start users. This performance gap tends to be more noticeable in domains with sparser user interactions, highlighting the potential benefit of incorporating semantic information to complement limited behavioral data. By integrating LLM-generated user and item semantics, FedSCOPE can leverage additional contextual cues beyond short interaction histories, which helps mitigate the cold-start challenge to some extent.Table 7. Performance comparison under user cold-start scenarios (users with \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\le 5$$\end{document} interactions, %).MethodBook-domainMovie-domainFood-domainKitchen-domainHR@10NDCG@10HR@10NDCG@10HR@10NDCG@10HR@10****NDCG@10FedCSR17.8415.6218.3116.0515.2613.4814.9213.21FedSCOPE w/o LLM22.9720.8423.4121.3619.7317.9218.6616.85FedSCOPE27.9625.4128.8726.0224.1822.0323.0721.14
RQ5: Comparison of federated training and standalone training
To further evaluate the effectiveness of cross-platform collaboration, we compared FedSCOPE with independently trained models in the Movie–Book scenario. Independent training refers to a setting where each platform trains its own CSR model locally without any information exchange, whereas FedSCOPE collaboratively constructs a unified federated CSR model while keeping data decentralized. As shown in Fig. 6, FedSCOPE consistently outperforms independently trained models across all platforms, demonstrating the advantages of collaborative knowledge integration. This joint optimization allows FedSCOPE to capture complementary user behavior patterns and cross-domain correlations that isolated models fail to exploit. The results also highlight the strong impact of data sparsity on model performance. In independent training, platforms with larger amounts of data achieve relatively better results, while those with limited data suffer from lower accuracy due to insufficient behavioral signals. In contrast, FedSCOPE effectively mitigates these limitations by aggregating knowledge across platforms, enriching representation learning, and significantly improving overall recommendation performance even in sparse data conditions.Fig. 6. Comparison of recommendation performance between FedSCOPE and independent training in the Book-Movie scenario.
RQ6: Privacy–utility trade-off of adaptive DP
We next examine how Adaptive DP influences the privacy–utility trade-off compared with a standard Uniform DP mechanism. We evaluate both approaches under identical training protocols in the Kitchen domain across a range of privacy budgets \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\epsilon \in \{0.25, 0.5, 1, 2, 4\}$$\end{document} . As shown in Fig. 7, recommendation performance (HR@10) increases monotonically with larger \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\epsilon$$\end{document} for all methods, reflecting the expected reduction in injected noise. Importantly, every Adaptive DP variant consistently lies above the Uniform DP baseline across all privacy levels. The relative advantage is most pronounced under stricter privacy (smaller \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\epsilon$$\end{document} ) and gradually narrows as the constraint relaxes. This behavior can be attributed to two design factors: (i) personalized budget allocation, which avoids over-noising clients with abundant data while preventing under-protection for those with limited data; and (ii) adaptive clipping, which stabilizes per-client sensitivity and reduces the effective noise required by the Gaussian mechanism. Together, these mechanisms enable more efficient noise allocation while maintaining strong privacy guarantees. To further assess robustness, we vary the failure probability parameter \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\delta \in \{10^{-3}, 10^{-4}, 10^{-5}\}$$\end{document} . The three Adaptive DP curves in Fig. 7 almost overlap, indicating that performance is largely insensitive to \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\delta$$\end{document} . This aligns with theoretical expectations, since \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\delta$$\end{document} controls only a negligible failure probability rather than the dominant privacy–utility balance. This robustness also simplifies hyperparameter selection in practical deployments.Fig. 7. Kitchen domain: Adaptive vs. Uniform DP under different \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\delta$$\end{document} .
RQ7: Robustness to the federated configuration
We further evaluate the robustness and scalability of FedSCOPE under different federated configurations. Specifically, we vary the number of clients \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$K \in \{20, 50, 100\}$$\end{document} with a fixed sampling ratio \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$C = 0.2$$\end{document} , and vary the per-round sampling ratio \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$C \in \{0.1, 0.2, 0.4\}$$\end{document} with a fixed number of clients \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$K = 50$$\end{document} . All experiments use the same dataset, training protocol, and privacy parameters. As shown in Fig. 8, increasing K from 20 to 100 (panel a) leads to slightly slower convergence due to stronger client heterogeneity and reduced per-client data volume, resulting in a minor drop in the final HR@10. However, the performance degradation remains small, and the relative improvements of FedSCOPE over baseline methods are consistently preserved. When increasing C from 0.1 to 0.4 (panel b), convergence becomes noticeably faster and the final accuracy improves slightly, since more clients participate in each round. Although a larger C accelerates per-round privacy consumption in the privacy accountant, the overall privacy–utility balance remains stable under the same global budget. This trade-off allows practitioners to adjust C flexibly based on system constraints and application requirements.Fig. 8. Robustness to the federated configuration in the Kitchen domain. (a) Varying the number of clients K with \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$C{=}0.2$$\end{document} . (b) Varying the sampling ratio C with \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$K{=}50$$\end{document} .
Conclusion
In this work, we proposed FedSCOPE, a federated cross-domain sequential recommendation framework that addresses three practical challenges: data sparsity, domain heterogeneity, and the privacy–utility trade-off. FedSCOPE integrates three complementary components: an offline LLM-based semantic augmentation module to enrich sparse behavioral representations, an Intra- and Inter-Domain Decoupled Contrastive Learning mechanism to enhance both personalization and cross-domain alignment, and an adaptive personalized differential privacy strategy that tailors noise injection to client-specific data characteristics. Through joint optimization within a secure federated protocol, FedSCOPE achieves consistently superior performance on multiple real-world datasets, delivering higher accuracy, stronger generalization, and a more favorable privacy–utility balance, together with faster convergence. Future work will explore more advanced semantic enrichment, communication-efficient optimization, and adaptive privacy mechanisms to further improve scalability and robustness in federated cross-domain recommendation.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1Cao, J., Cong, X., Sheng, J., Liu, T. & Wang, B. Contrastive cross-domain sequential recommendation. In Proceedings of the 31st ACM international conference on information & knowledge management, 138–147 (2022).
- 2Zhang, H., Zheng, D., Yang, X., Feng, J. & Liao, Q. Feddcsr: Federated cross-domain sequential recommendation via disentangled representation learning. In Proceedings of the 2024 SIAM International Conference on Data Mining (SDM), 535–543 (SIAM, 2024).
- 3Yuan, W. et al. Fellas: Enhancing federated sequential recommendation with llm as external services. ACM Trans. Inf. Syst.43(6), 1–24 ACM New York, NY(2025).
- 4Zheng, D. et al. Fedcsr: A federated framework for multi-platform cross-domain sequential recommendation with dual contrastive learning. In Proceedings of the 31st International Conference on Computational Linguistics, 8699–8713 (2025).
- 5Xie, X. et al. Contrastive learning for sequential recommendation. In 2022 IEEE 38th international conference on data engineering (ICDE), 1259–1273 (IEEE, 2022).
- 6Zhang, W., Zhang, P., Zhang, B., Wang, X. & Wang, D. A collaborative transfer learning framework for cross-domain recommendation. In Proceedings of the 29th ACM SIGKDD Conference on Knowledge Discovery and Data Mining, 5576–5585 (2023).
- 7He, X. et al. Neural collaborative filtering. In Proceedings of the 26th international conference on world wide web, 173–182 (2017).
- 8Hu, G., Zhang, Y. & Yang, Q. Conet: Collaborative cross networks for cross-domain recommendation. In Proceedings of the 27th ACM international conference on information and knowledge management, 667–676 (2018).