Toward robust surgical phase recognition via deep ensemble learning
Flakë Bajraktari, Lina Hauser, Peter P. Pott

TL;DR
This paper explores using deep ensemble learning to improve the accuracy of recognizing surgical phases, showing that combining diverse models leads to better performance than individual models.
Contribution
The study introduces an ensemble learning approach that combines diverse deep learning models to enhance surgical phase recognition accuracy and reliability.
Findings
Ensemble learning significantly improved performance metrics like F1-score, accuracy, and Jaccard Index compared to individual models.
High model diversity in ensembles led to superior performance compared to less diverse ensembles.
Majority voting and the proposed StackingNet ensemble strategies achieved the best results.
Abstract
Automatic recognition of surgical workflows is a complex yet essential task of context-aware systems in the operating room. However, achieving high accuracy in phase recognition remains a challenge due to the complexity of surgical procedures. While recent deep learning models have made significant progress, individual models often exhibit limitations—some may excel at capturing spatial features, while others are better at modeling temporal dependencies or handling class imbalance. This study investigates the use of ensemble learning to combine the complementary strengths of diverse architectures, aiming to mitigate individual model weaknesses and improve performance in surgical phase recognition using the Cholec80 dataset. A variety of advanced deep learning architectures was integrated into a single ensemble. Models were carefully selected and tuned to ensure diversity, resulting in…
Genes, proteins, chemicals, diseases, species, mutations and cell lines named across the full text — each resolved to its canonical identifier and authoritative record.
Click any figure to enlarge with its caption.
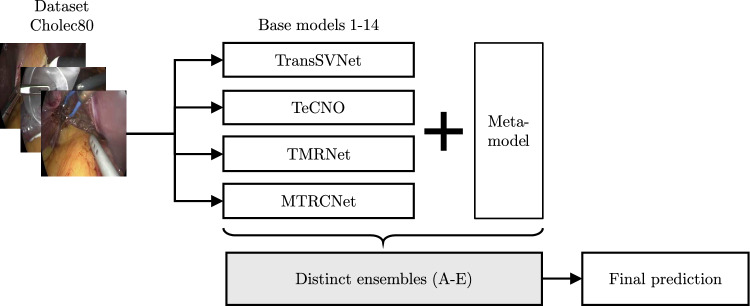 Figure 1
Figure 1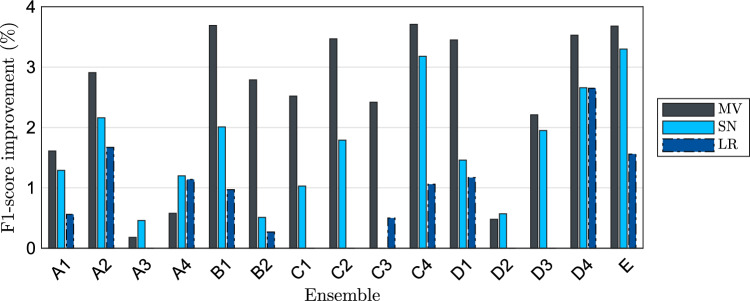 Figure 2
Figure 2- —Universität Stuttgart (1023)
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsSurgical Simulation and Training · Artificial Intelligence in Healthcare and Education · AI in cancer detection
Introduction
Fig. 1A schematic representation of the proposed process and components, which consists of four base models and their variations, accounting for a total of 14 models, all trained on Cholec80. One of 12 meta-models was applied to combine the models in each ensemble, resulting in 15 distinct ensembles (A–E) that ultimately produced the surgical phase predictions
The digital transformation of the operating room (OR) has become a focal point in contemporary medical research, with artificial intelligence (AI) playing a pivotal role in improving surgical workflows. Among the most impactful applications of AI in surgery is automated surgical phase recognition (SPR), which enhances intraoperative guidance and reduces the workload of OR personnel by automating tasks such as procedural documentation. Ultimately, this will lead to improved efficiency and patient safety [1–3].
In recent years, breakthroughs in machine learning, particularly in deep learning, have propelled the automation of SPR using datasets such as Cholec80 [3], a benchmark for SPR research. Sophisticated algorithms have demonstrated promising results in the automatic classification of surgical phases. Convolutional neural networks (CNNs), such as ResNet [4], serve as the backbone for many SPR architectures [3, 5–8]. Before passing individual frames to temporal models, spatial features are extracted through CNNs. Temporal models, including recurrent neural networks (RNNs), temporal convolutional networks (TCNs), and vision transformers (ViTs), model temporal dependencies in sequential data for SPR. RNNs process sequences step by step with memory cells to retain past information [9, 10], TCNs employ dilated convolutions to capture long-range dependencies efficiently [11–13], and Transformers leverage self-attention to analyze all time steps simultaneously [5, 14]. While these models have significantly advanced SPR, their effectiveness is often constrained by several challenges, including limited data availability due to privacy concerns and the difficulty of obtaining large-scale sets of annotated surgical videos [15]. Additionally, the variability in surgical techniques introduces challenges in model generalization, making it difficult to achieve consistent performance not only across different procedures and datasets but also between different models trained under varying conditions [16]. To address these challenges, ensemble learning offers a promising approach by combining multiple models to enhance prediction accuracy and robustness [17, 18]. By leveraging the strengths of different deep learning architectures, models can improve their prediction accuracy in image classification tasks such as cancer [18] and tool detection during surgery [19, 20]. This approach enhances consistency in predictions, making models more reliable in real-world surgical settings [21].
Although ensemble learning is a well-established strategy in machine learning, its potential in SPR remains underexplored. Most existing approaches rely on individual deep learning architectures, with limited investigation into ensemble methods that could exploit the complementary strengths of multiple models. This study addresses this gap by systematically applying and evaluating a range of ensemble techniques for SPR. While ensemble learning itself is not new, the proposed approach introduces domain-specific methodological innovations by combining architectures with complementary temporal and spatial modeling capabilities through a diversity-driven selection. The primary objectives were to evaluate different deep learning architectures on the Cholec80 dataset, compare the effectiveness of various meta-models, and analyze the impact of ensemble learning on phase recognition accuracy. This work aims to advance the development of more accurate and reliable AI-driven assistance systems in surgery.
Methods
The framework of this study followed a stacking ensemble approach as shown in Fig. 1, integrating state-of-the-art base models for SPR, which are trained on Cholec80, and combining their class probability vectors through various meta-models, ultimately classifying the surgical phases.
Dataset and base models
The Cholec80 dataset, a widely used benchmark for SPR, proposed by Twinanda et al. [3], was used for training and evaluation. It consists of a total of 80 videos of laparoscopic cholecystectomy procedures performed by 13 different surgeons. The recordings were captured at a frame rate of 25 frames per second (fps) with a resolution of either \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$1920 \times 1080$$\end{document} or \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$854 \times 480$$\end{document} pixels. Each video is annotated with seven distinct surgical phases, each varying in duration across different videos. For model training, the frame rate was reduced to 1 fps, and images were resized to \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$250 \times 250$$\end{document} pixels. Additionally, data augmentation was applied using basic transformations, including cropping, random horizontal flipping, and random color variations. The data was split into a ratio of 32:8:40 for training, validation, and testing, respectively. Four different state-of-the-art models were identified as base models. To evaluate the ensemble with models of the same architecture, two RNN models with long short-term memory (LSTM) cells were included. Otherwise, all models differ fundamentally in their model architecture. The set consisted of a TCN (TeCNO [11]), a transformer-based model (Trans-SVNet [5]), and two LSTM-based models (MTRCNet [10] and TMRNet [22]). The models were trained and tested individually in cases where no pre-trained models were available or they did not adhere to the 32:8:40 data split. Otherwise, the hyperparameters from the original studies were applied. The Trans-SVNet model was trained to optimize it using a 32:8:40 data split, differing from the original study. Since the model incorporates a TeCNO component, the pre-trained TeCNO models used in this study were adopted for the TeCNO evaluation. Similarly, the MTRCNet model was trained, as tool detection for SPR was not required, and only the phase recognition branch of the model was utilized. For TMRNet, the hyperparameters from the original study were retained, as the model was already trained on Cholec80 using the defined data split, eliminating the need for additional hyperparameter optimization.
Each model was trained in three independent runs, and the reported performance metrics were computed through the mean across these runs. For the final evaluation, the epoch with the highest validation accuracy was selected. Additionally, various model variants were trained to increase diversity within the ensemble. The backbones ResNet50 [4] and ResNeSt50 [23] were used, and the number of feature maps and the number of multistage TCN (MSTCN) layers in TeCNO and Trans-SVNet were varied. This resulted in 14 different models. Training was carried out on a workstation ( Core \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$^{\textrm{TM}}$$\end{document} i9-12900K, 5.2 GHz, HP Inc., CA, USA) equipped with a GeForce RTX 3080 Ti graphics card (NVIDIA Corp., CA, USA), running Ubuntu 20.04.01 (Focal Fossa). The PyTorch machine learning framework was used for model development, while Weights & Biases (W&B) [24] was employed for hyperparameter tuning.
The F1-score was used for metric comparison, as the Cholec80 dataset is imbalanced, making the F1-score a more suitable measure for evaluation. In line with established evaluation protocols for surgical workflow recognition [25], the metrics were computed without relaxed boundaries, meaning that no tolerance window was considered around phase transitions to account for minor temporal deviations in annotations.
Meta-models and ensembles
To combine the predictions of the base models, the following meta-models were used in this study:
- Majority voting (MV)
- Logistic regression (LR)
- Stochastic gradient descent (SGD)
- Random forest (RF)
- Decision tree (DT)
- AdaBoost (AB)
- Bagging classifier SVM (BSVM)
- Bagging classifier SGD (BSGD)
- Bagging classifier LR (BLR)
- Gaussian naïve Bayes (GNB)
- K-nearest neighbor (KNN)
- StackingNet (SN) Table 1. Summary of ensembles implemented and evaluated in this studyEnsembleModelsDescriptionA11, 2, 3, 4All Trans-SVNet modelsA25, 6, 7, 8, 9, 10All TeCNO modelsA311, 12All TMRNet modelsA413, 14All MTRCNet modelsB11, 2, 5, 6, 7, 11, 13All models based on ResNet50 backboneB23, 4, 8, 9, 10, 12, 14All models based on ResNeSt50 backboneC12, 6, 12, 14Models from each architecture with highest F1-scoreC22, 6, 11, 13Top models from each architecture using ResNet50C33, 9, 12, 14Top models from each architecture using ResNeSt50C42, 3, 6, 9, 11, 12, 13, 14Top models across all architectures and backbonesD11–10All Trans-SVNet and TeCNO modelsD211–14All TMRNet and MTRCNet modelsD31–4, 11, 12All Trans-SVNet and TMRNet modelsD45–10, 13, 14All TeCNO and MTRCNet modelsE1–14All 14 models
The meta-models employed in this study vary in complexity and decision mechanisms. To illustrate the diversity of approaches, the underlying functions of three representative models are presented: majority voting, logistic regression, and StackingNet. Other ensemble methods such as random forest, AdaBoost, and bagging classifiers follow standard implementations using Scikit-learn [26], and are therefore not detailed here. MajorityWhen using majority voting, the class label thatVotingreceives the highest number of votes among all base models is selected. Formally, for a classification problem with class set \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\mathcal {C}$$\end{document} , the final predicted label \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\hat{y}$$\end{document} is given by
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\begin{aligned} \hat{y} = \arg \max _{c \in \mathcal {C}} \sum _{i=1}^{M} \mathbb {1}(h_i(x) = c), \end{aligned}$$\end{document}where \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$M$$\end{document} denotes the number of base models, \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$h_i(x)$$\end{document} is the class label predicted by the \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$i$$\end{document} th base model for input sample \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$x$$\end{document} , and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\mathbb {1}(\cdot )$$\end{document} is the indicator function, which equals 1 if its argument is true and 0 otherwise. This method relies exclusively on the discrete predictions of the base models without considering confidence scores.StackingThe StackingNet meta-learner used in this studyNetwas previously introduced by Bajraktari et al. [27], where its architecture and training procedure are described in detail. StackingNet is a three-layer feedforward neural network with two hidden layers that takes as input the concatenated predicted class probabilities from all base models. Let \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\textbf{z} \in \mathbb {R}^M$$\end{document} denote this input vector. The network computes the output \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\hat{y}$$\end{document} through successive layers as follows:
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\begin{aligned} \begin{aligned} \textbf{h}^{(1)}&= \phi ^{(1)}\big (\textbf{W}^{(1)} \textbf{z} + \textbf{b}^{(1)}\big ), \\ \textbf{h}^{(2)}&= \phi ^{(2)}\big (\textbf{W}^{(2)} \textbf{h}^{(1)} + \textbf{b}^{(2)}\big ), \\ \hat{y}&= \phi ^{(3)}\big (\textbf{W}^{(3)} \textbf{h}^{(2)} + \textbf{b}^{(3)}\big ), \end{aligned} \end{aligned}$$\end{document}where \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\textbf{W}^{(l)}$$\end{document} and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\textbf{b}^{(l)}$$\end{document} are the weight matrices and bias vectors of layer \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$l$$\end{document} , \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\phi ^{(l)}(\cdot )$$\end{document} denotes the activation function at layer \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$l$$\end{document} , ReLU for hidden layers and softmax for the output layer, and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\textbf{h}^{(l)}$$\end{document} represents the activations of the \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$l$$\end{document} th layer. The output \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\hat{y}$$\end{document} corresponds to the predicted class probabilities.LogisticIn the meta-learning context, logistic regressionRegressionmodels the posterior probability of each class as a function of the concatenated predicted class probabilities from all base models. Let \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\textbf{z} \in \mathbb {R}^M$$\end{document} denote the feature vector formed by concatenating these predicted probabilities, where \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$M$$\end{document} is the total number of probability values across all base models. For multi-class classification, the class posterior probabilities, i.e., the probability that the true label is \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$c$$\end{document} after observing the aggregated outputs \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\textbf{z}$$\end{document} from the base models, are computed as
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\begin{aligned} P(y = c \mid \textbf{z}) = \frac{\exp (\textbf{w}_c^\top \textbf{z} + b_c)}{\sum _{k \in \mathcal {C}} \exp (\textbf{w}_k^\top \textbf{z} + b_k)}, \end{aligned}$$\end{document}where \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$c \in \mathcal {C}$$\end{document} is the class index, and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\textbf{w}_c \in \mathbb {R}^M$$\end{document} and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$b_c \in \mathbb {R}$$\end{document} are the weight vector and bias term corresponding to class \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$c$$\end{document} . The summation index \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$k$$\end{document} ranges over all classes in \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\mathcal {C}$$\end{document} , ensuring the posterior probabilities sum to one. The final predicted label is then
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\begin{aligned} \hat{y} = \arg \max _{c \in \mathcal {C}} P(y = c \mid \textbf{z}). \end{aligned}$$\end{document}For each meta-model, hyperparameter optimization was performed using grid search. The performance of each ensemble was assessed using the optimal hyperparameter set that achieved the best performance on the validation data.Table 2. Individual performance of each modelNr.ModelBackboneLayerFeature mapsMetrics in %AccuracyPrecisionRecallF1-scoreJaccard1Trans-SVNetResNet50832 \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$87.66 \pm 7.43$$\end{document} \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$83.89 \pm 9.75$$\end{document} \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$83.51 \pm 8.10$$\end{document} \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$80.91 \pm 7.24$$\end{document} \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$70.81 \pm 10.08$$\end{document} 2964 \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$88.62 \pm 8.54$$\end{document} \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$85.69 \pm 8.08$$\end{document} \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$85.19 \pm 5.76$$\end{document} \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$83.06 \pm 7.33$$\end{document} \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$73.88 \pm 9.59$$\end{document} 3ResNeSt50832 \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$89.41 \pm 7.71$$\end{document} \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\mathbf {87.26 \pm 6.80}$$\end{document} \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$82.36 \pm 12.16$$\end{document} \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$82.83 \pm 7.70$$\end{document} \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$72.89 \pm 11.11$$\end{document} 4964 \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\mathbf {89.93 \pm 6.04}$$\end{document} \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$86.73 \pm 9.86$$\end{document} \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$81.37 \pm 12.68$$\end{document} \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$82.78 \pm 7.79$$\end{document} \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$71.74 \pm 12.73$$\end{document} 5TeCNOResNet50832 \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$86.38 \pm 8.31$$\end{document} \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$80.76 \pm 10.49$$\end{document} \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$84.33 \pm 7.39$$\end{document} \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$79.40 \pm 7.34$$\end{document} \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$69.08 \pm 9.80$$\end{document} 6964 \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$87.50 \pm 8.73$$\end{document} \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$82.79 \pm 10.28$$\end{document} \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\mathbf {87.18 \pm 4.02}$$\end{document} \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$82.37 \pm 7.05$$\end{document} \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$72.86 \pm 9.65$$\end{document} 71064 \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$87.70 \pm 6.86$$\end{document} \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$84.21 \pm 10.00$$\end{document} \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$82.05 \pm 10.35$$\end{document} \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$81.26 \pm 6.70$$\end{document} \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$70.48 \pm 9.53$$\end{document} 8ResNeSt50832 \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$87.53 \pm 8.29$$\end{document} \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$82.82 \pm 10.16$$\end{document} \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$81.70 \pm 13.03$$\end{document} \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$79.40 \pm 9.47$$\end{document} \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$68.93 \pm 12.08$$\end{document} 9964 \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$89.28 \pm 6.21$$\end{document} \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$84.56 \pm 10.90$$\end{document} \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$84.15 \pm 7.09$$\end{document} \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$82.31 \pm 7.71$$\end{document} \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$72.74 \pm 10.88$$\end{document} 101064 \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$89.08 \pm 7.36$$\end{document} \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$84.52 \pm 10.20$$\end{document} \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$83.78 \pm 8.55$$\end{document} \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$82.21 \pm 7.62$$\end{document} \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$72.38 \pm 10.76$$\end{document} 11TMRNetResNet50–– \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$87.52 \pm 9.61$$\end{document} \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$84.59 \pm 5.60$$\end{document} \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$84.42 \pm 6.29$$\end{document} \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$82.25 \pm 6.37$$\end{document} \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$72.50 \pm 8.41$$\end{document} 12ResNeSt50–– \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$88.35 \pm 8.37$$\end{document} \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$85.04 \pm 5.97$$\end{document} \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$85.43 \pm 5.64$$\end{document} \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\mathbf {83.59 \pm 5.61}$$\end{document} \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\mathbf {73.89 \pm 8.63}$$\end{document} 13MTRCNetResNet50–– \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$85.11 \pm 8.05$$\end{document} \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$79.05 \pm 8.85$$\end{document} \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$82.04 \pm 6.64$$\end{document} \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$78.17 \pm 8.35$$\end{document} \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$66.83 \pm 10.70$$\end{document} 14ResNeSt50–– \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$85.76 \pm 7.87$$\end{document} \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$79.66 \pm 8.20$$\end{document} \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$83.35 \pm 6.43$$\end{document} \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$79.23 \pm 7.55$$\end{document} \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$68.21 \pm 9.71$$\end{document} Best values for each metric are highlighted
For the quantitative evaluation of the ensemble models, the F1-score of the best-performing base model within each combination was selected as the reference. Subsequently, the performance improvements achieved by the meta-models over the best individual model in each configuration group A–E were calculated, providing relative performance gains.
The ensemble configurations listed in Table 1 were designed to address key research questions regarding the effectiveness of ensemble learning for SPR as detailed below. The model numbers and their corresponding model architectures can be extracted from Table 2.
- Model architecture-based ensemble (A1–A4): Evaluation of whether ensembles, composed of variations of the same architecture, achieve higher performance compared to individual models.
- Backbone-based ensembles (B1–B2): Evaluation of whether ensembles, grouped by backbone architecture, lead to different classification performances.
- Performance-based ensembles (C1–C4): Evaluation of whether ensembles, built from the best-performing models based on the F1-score ranking, outperform ensembles that include all available models.
- Heterogeneous model architecture in ensembles (D1–D4): Evaluation of both homogeneous (D2) and heterogeneous (D1, D3, D4) ensembles to assess the effectiveness of combining similar models versus mixing different architectures.
- Full ensemble (E): Evaluation of the performance of a single ensemble containing all available models.
Results
The best-performing models based on the evaluation metrics are summarized in Table 2. The highest observed accuracy is 89.93 %, while the maximum precision, recall, F1-score, and Jaccard Index are 87.26 %, 87.18 %, 83.59 %, and 73.89 %, respectively.
The ensemble performances were assessed across all meta-models. Figure 2 illustrates the F1-score improvements in % for the meta-models relative to the best-performing model within its respective ensemble. For better visibility, only the three best-performing meta-models majority voting, StackingNet, and logistic regression are displayed.
Majority voting emerged as the most consistently high-performing meta-model, achieving the highest rank in 12 out of 15 configurations, including a 3.71 % improvement over the baseline in configuration C4. It also ranked second in two configurations and third in one. StackingNet followed, attaining the top rank in three configurations and second-highest performance in 11. Logistic regression showed competitive results, ranking second once and third in seven configurations. These three meta-models consistently demonstrated superior performance compared to the others, indicating their effectiveness in the ensemble learning framework for surgical phase recognition.Fig. 2F1-score improvements of each ensemble including the three best-performing meta-models, majority Vote (dark gray), StackingNet (light blue), and logistic regression (dark blue), relative to the best-performing base model within the respective ensemble
Discussion and outlook
The evaluation of the ensemble models reveals key insights into the impact of model diversity, backbone architectures, and meta-model selection on classification performance. The results indicate that ensembles consisting of multiple variations of the same network architecture can enhance classification performance compared to individual models. This effect is particularly evident in ensembles A1 and A2, where the use of different configurations of ResNet50 and ResNeSt50 led to improvements of 1.61 % and 2.91 %, respectively, with majority voting as the meta-model. The increased diversity in model configurations appears to contribute to higher performance, as the ensemble can capture a wider range of feature representations. In contrast, ensembles with only two networks, as in A3 and A4, show more modest improvements, with the best results achieved using StackingNet (0.46 % for A3 and 1.2 % for A4). This suggests that while integrating different backbone architectures within an ensemble can lead to performance gains, the limited number of networks may restrict the potential benefits. This pattern is further supported by D2, where only one architecture type is used. This combination also fails to show substantial performance improvements, reinforcing the idea that architectural diversity within an ensemble is a key factor for achieving higher performance.
The analysis reveals that ensemble C4 with majority voting achieves the highest F1-score of 87.27 %, making it the best-performing ensemble in this study. This ensemble achieves improvements, with particularly notable increases in F1-score (+3.68 %) and Jaccard Index (+5.43 %). The rise in Jaccard Index suggests that the ensemble improves the alignment between predicted and actual classes, leading to more precise classification. Interestingly, C1, which consists of the best-performing model from each architecture, does not surpass the performance of C4. This indicates that a diverse ensemble does not automatically yield the best results; rather, having a sufficient number of complementary models appears to be the key factor. The ability of the ensemble to learn from both strong and weaker individual models reinforces the benefits of aggregating multiple perspectives in the classification process. This pattern is supported by the marginal difference between C4 (87.27 %) and E (87.24 %), which suggests that ensemble performance improves primarily with the number of networks included, rather than solely relying on selecting the best individual models. This finding emphasizes that quantity, alongside quality, plays a crucial role in ensemble effectiveness.
Regarding meta-model performance, majority voting emerges as the most effective approach, ranking first in 12 of the 15 ensembles regarding F1-score improvements. StackingNet follows closely, ranking second in 11 cases. A key observation is that the effectiveness of majority voting increases with the number of models in the ensemble. This aligns with the idea that a larger ensemble benefits from greater model diversity, which helps mitigate biases and capture a broader spectrum of patterns in the data. The combination of multiple models with different configurations allows majority voting to leverage the strengths of each, leading to more robust predictions. Conversely, in smaller ensembles, where base models may generate highly similar predictions, a learned meta-model like StackingNet is better suited to identify nuanced decision patterns.
From a clinical perspective, improved phase recognition accuracy has tangible implications for intraoperative assistance systems. In particular, ensembles with high diversity reduce misclassifications during critical phase transitions, thereby supporting reliable context-aware decision-making. Even improvements of a few percentage points, which may appear modest in absolute terms, can substantially lower error rates in real surgical procedures. Clinically, this translates into more consistent workflow predictions, enhanced trust in AI-driven systems, and improved safety during surgery. For clinical deployment, the ensemble must also remain effective over time. A dynamic ensemble management framework could be implemented in which the ensemble configuration is updated regularly. In the process, performance metrics such as F1-score are automatically monitored using a continuously updated validation set derived from recent surgeries. Based on these metrics and pre-defined thresholds, the ensemble is then reassembled by selecting the top-performing models, while outdated or underperforming models are removed during regular software updates. Newly trained or fine-tuned models are integrated in the latest version, ensuring that only the best-performing models in the optimal combination remain active. This dynamic mechanism would enable continuous improvement of ensemble performance in clinical use.
While ensembles improve performance, it is important to note that they also increase computational and energy demands compared to single models. This trade-off highlights the need to balance accuracy gains with efficiency considerations, particularly for clinical applications where real-time deployment and sustainability are crucial.
Another aspect worth reflecting on is the choice of strict evaluation boundaries. Relaxed boundaries typically yield higher metric values, since small temporal shifts around phase transitions are tolerated. However, this can also blur the interpretation of how well a model truly captures phase boundaries. In line with recent findings in the field, a strict evaluation protocol was chosen. While this may result in more conservative performance values, it ensures that reported improvements more directly reflect genuine advances in recognition rather than artifacts of the evaluation setup.
The selection of ensemble strategies in this study was not intended to exhaust all possible combinations of the 14 base models, which would have resulted in an unmanageable number of ensembles. Instead, ensembles A–E were designed to systematically address specific research questions. This targeted approach enabled a structured evaluation while keeping the study scope tractable. Nevertheless, the design space of ensemble methods in SPR remains broad. Future work could extend the analysis to a wider range of combinations or incorporate alternative paradigms to further investigate their potential benefits. One possibility is to apply boosting strategies at the base model level, where models are trained sequentially and each model focuses on the errors of previous models. Such approaches could increase complementarity between base learners and potentially lead to more powerful ensembles. Another promising direction is Bayesian aggregation at the meta-model level. Instead of combining base model outputs through fixed or globally learned rules, Bayesian aggregation combines them probabilistically and infers weights that reflect each model’s confidence and reliability. This could improve robustness, particularly in uncertain or rare surgical situations.
Overall, the results demonstrate that ensembles effectively enhance classification performance, with model diversity, ensemble size, and meta-model selection being key factors influencing the outcome. While larger ensembles tend to perform better with statistical methods like majority voting, ensembles with fewer models may benefit more from meta-models that can learn complex relationships between predictions. The findings of this study provide a strong foundation for further research in SPR. Expanding the ensemble to include a wider range of architectures and model combinations could further increase diversity and capture complementary information, which may lead to higher robustness and accuracy. From a clinical perspective, such improvements translate into more reliable intraoperative assistance, fewer misclassifications during critical phases, and greater consistency in decision support. Ultimately, these developments could enhance surgeon trust in AI systems and contribute to improved patient safety in computer-assisted surgery.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1Farha YA, Gall J (2019) MS-TCN: multi-stage temporal convolutional network for action segmentation. In: 2019 IEEE/CVF conference on computer vision and pattern recognition (CVPR), pp 3570–3579. Doi: 10.1109/CVPR.2019.0036910.1109/TPAMI.2020.302175632886607 · doi ↗ · pubmed ↗
- 2Biewald L (2020) Experiment tracking with weights and biases. https://www.wandb.com/. Accessed 23 Feb 2025