A tutorial for software options to aid in assessing functional relations in single-case experimental designs
Rumen Manolov

TL;DR
This tutorial reviews free online tools to help researchers analyze data from single-case experiments and determine if an intervention has a causal effect.
Contribution
The paper introduces and evaluates freely accessible software tools for analyzing single-case experimental designs without requiring additional installations.
Findings
Free websites can provide graphical data representations and quantifications for single-case experimental designs.
The tutorial outlines data analytical steps for assessing functional relations and evaluating effect consistency.
Real data examples demonstrate how to interpret outputs from the reviewed software.
Abstract
Single-case experimental designs (SCEDs) can be used for identifying effective interventions via the intensive study of one or a few individuals in different conditions, actively manipulated by the researcher. The assessment of SCED data entails both judging whether there is sufficient evidence of a functional relation (i.e., a causal effect of the intervention on the target behavior) and quantifying the magnitude of the effect. In the current text, the focus is on assessing the presence of a functional relation, considering all the attempts to demonstrate an effect that SCEDs include. Specifically, the aim is to review several freely available websites, which require no additional software to be installed, and offer graphical representations of the data, visual aids, and quantifications. Several data analytical steps are outlined for performing the assessment, both dealing with each…
Genes, proteins, chemicals, diseases, species, mutations and cell lines named across the full text — each resolved to its canonical identifier and authoritative record.
Click any figure to enlarge with its caption.
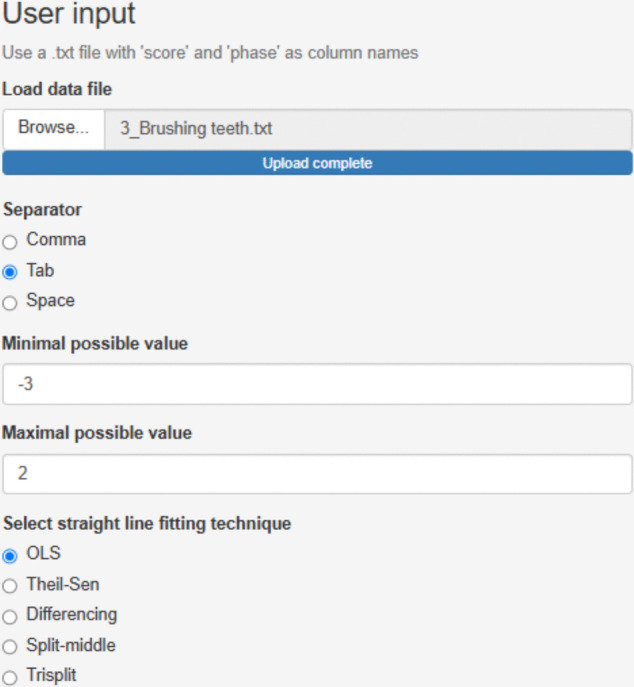 Figure 10
Figure 10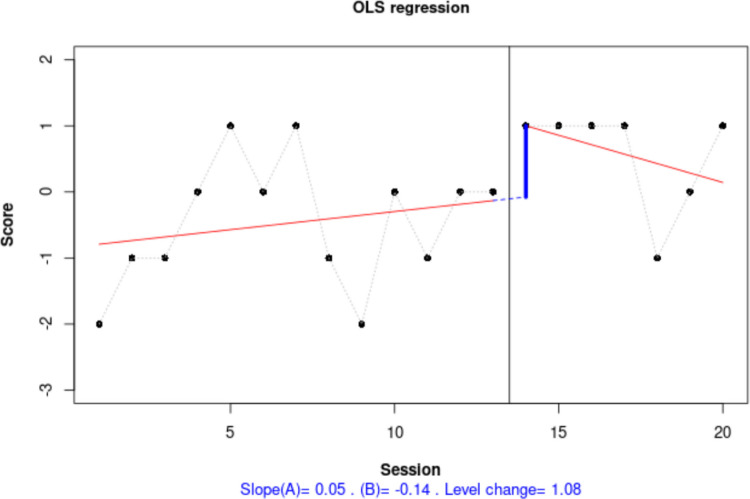 Figure 11
Figure 11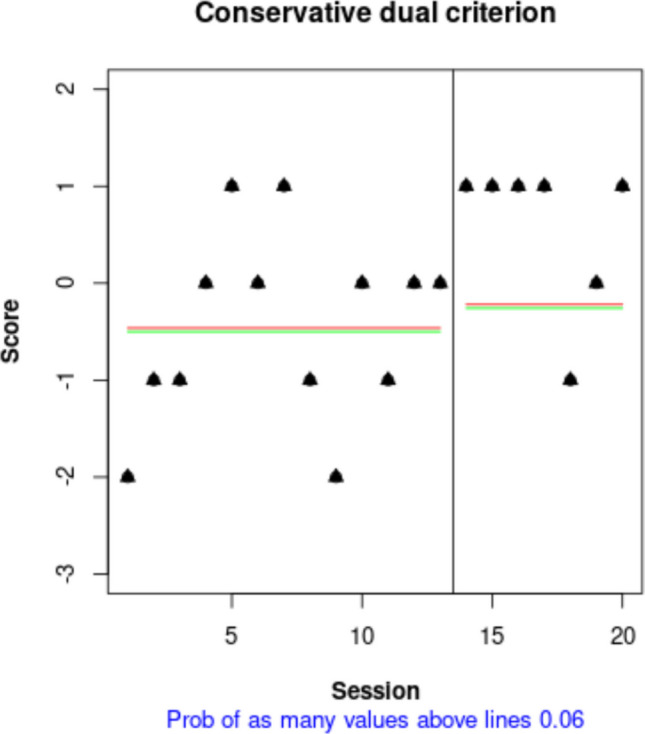 Figure 12
Figure 12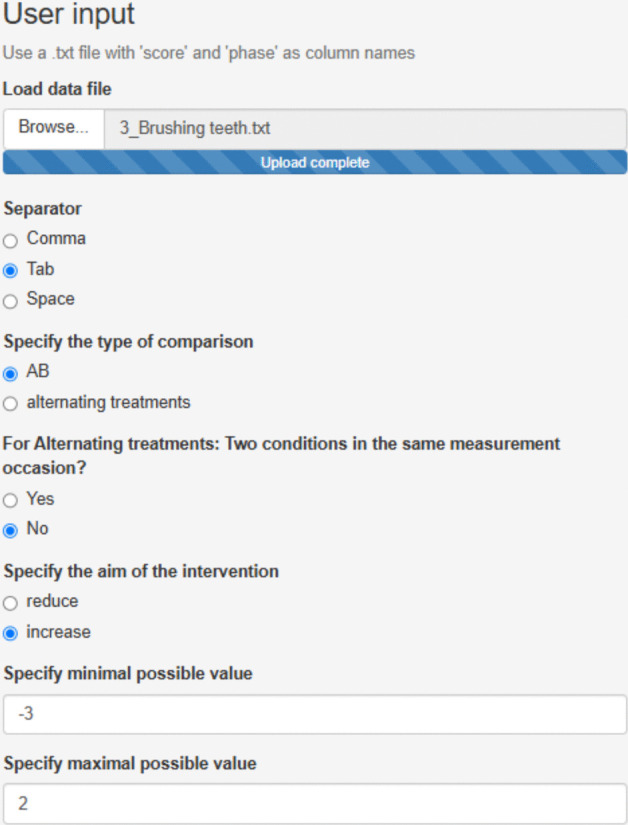 Figure 13
Figure 13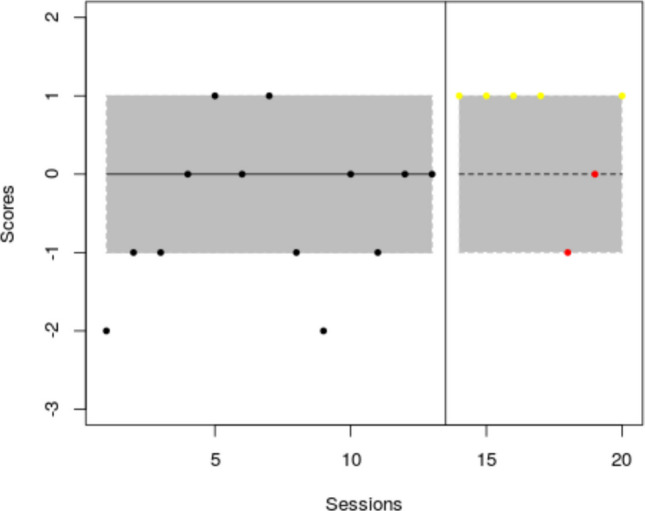 Figure 14
Figure 14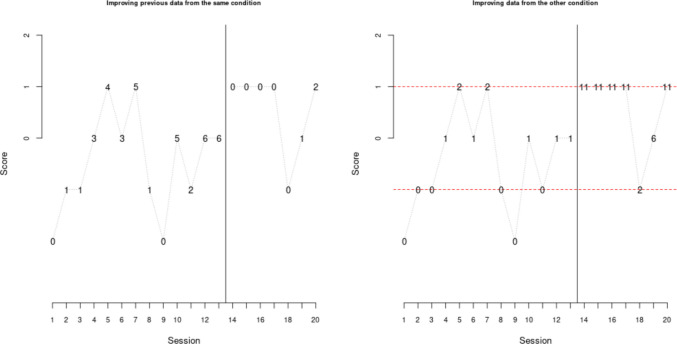 Figure 15
Figure 15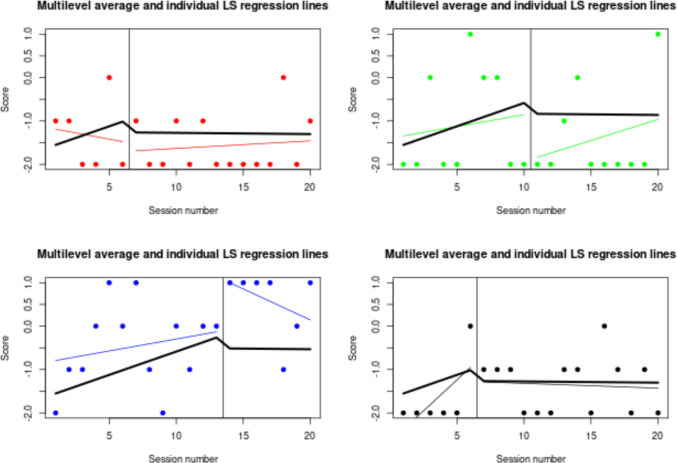 Figure 16
Figure 16 Figure 17
Figure 17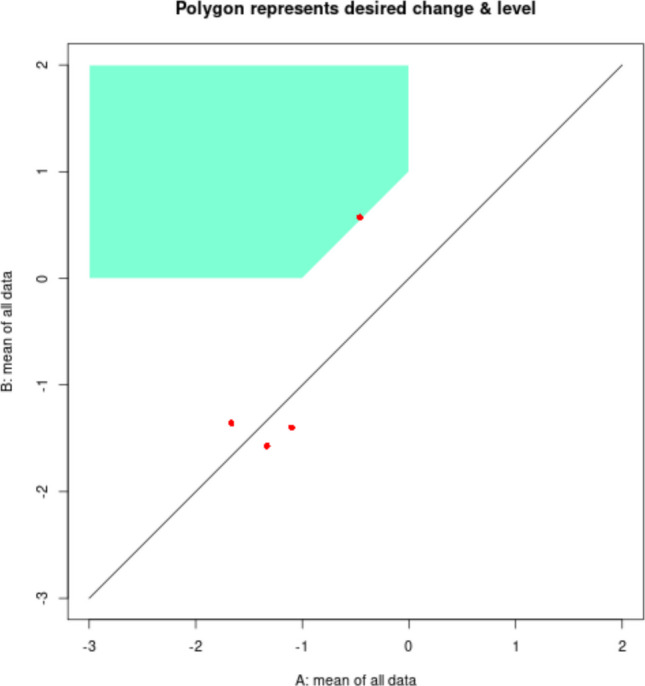 Figure 18
Figure 18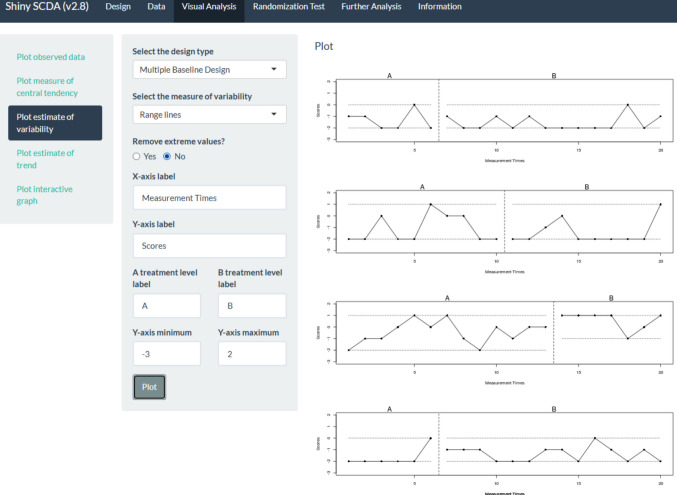 Figure 19
Figure 19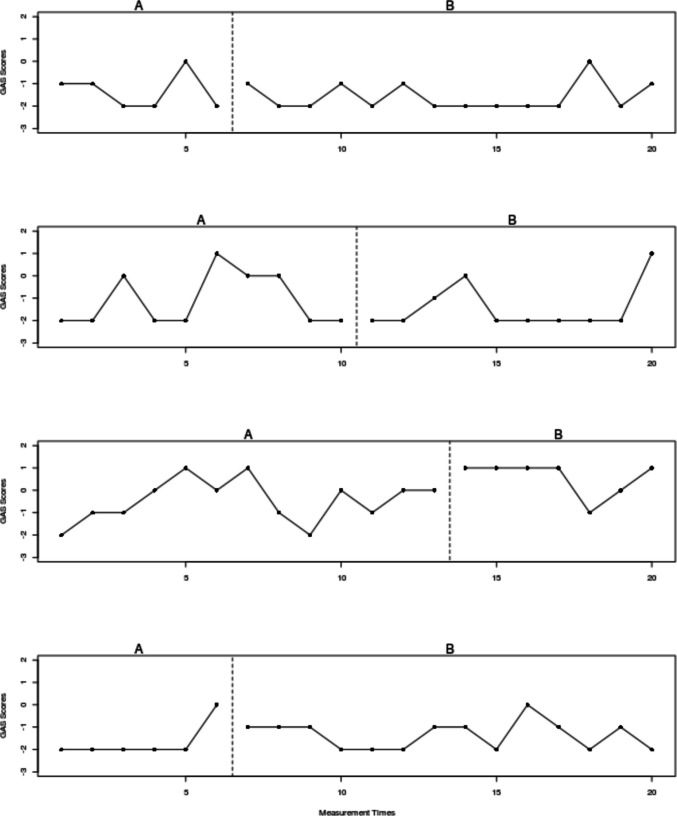 Figure 1
Figure 1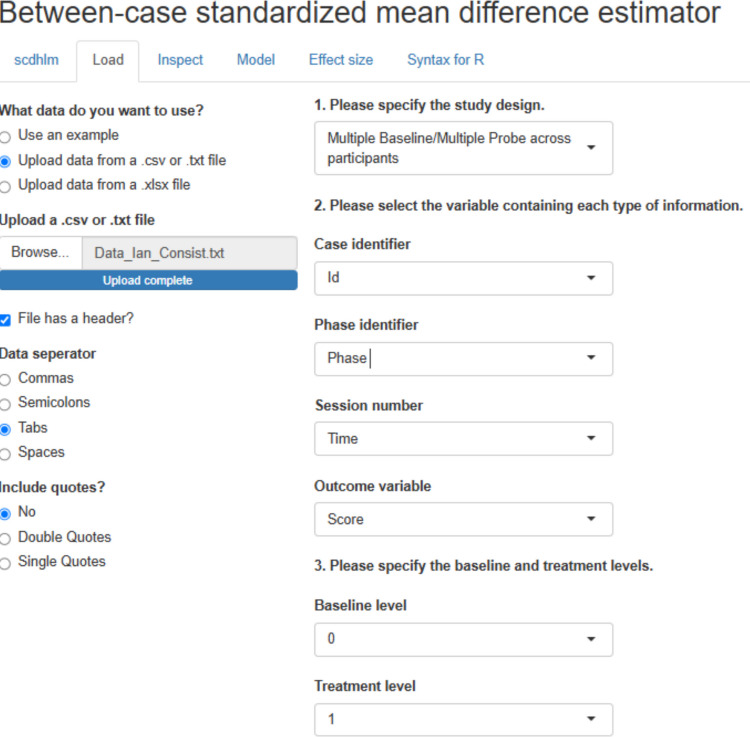 Figure 20
Figure 20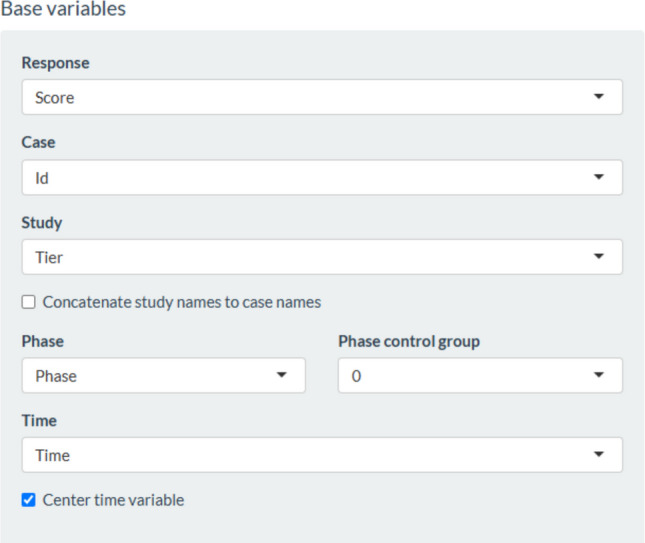 Figure 21
Figure 21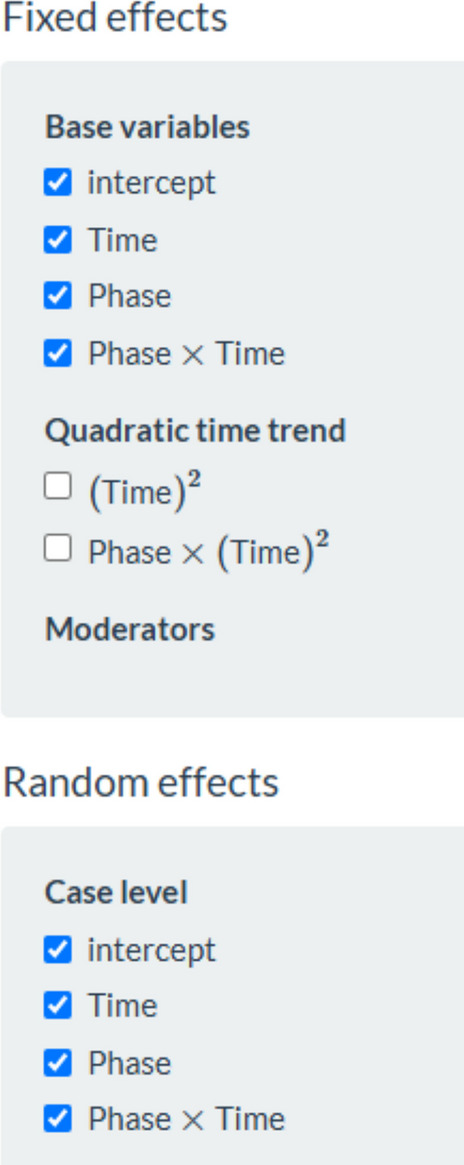 Figure 22
Figure 22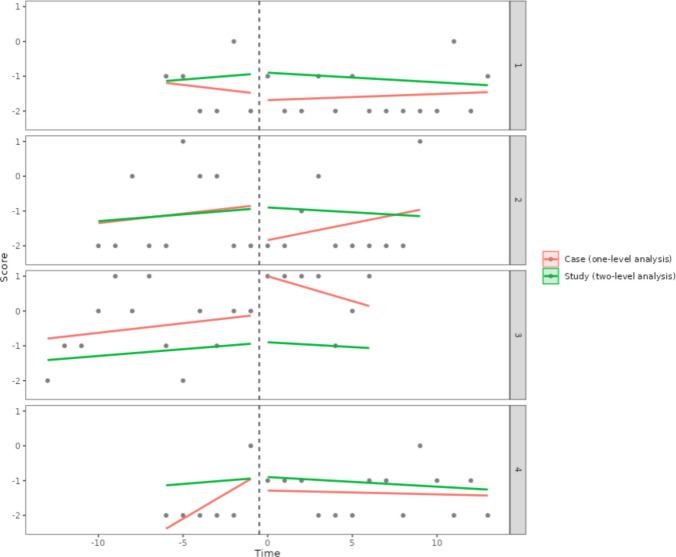 Figure 23
Figure 23 Figure 2
Figure 2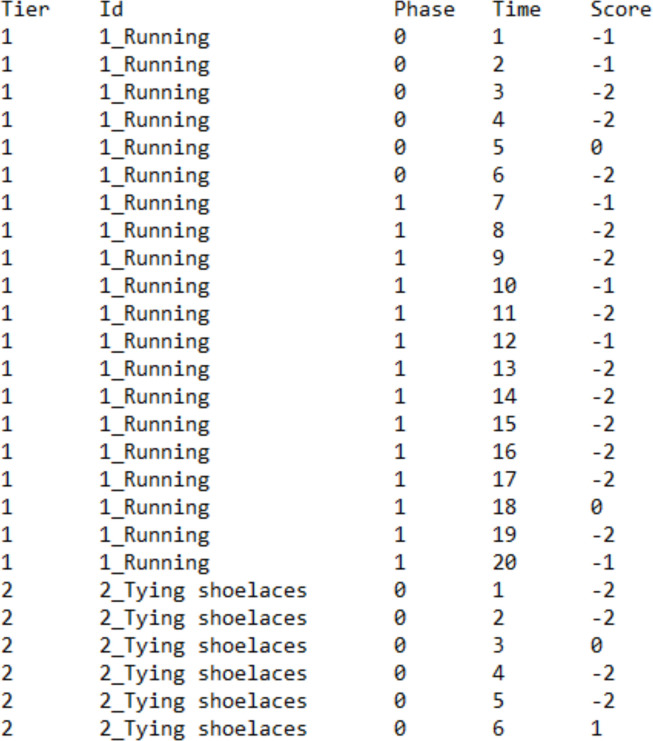 Figure 3
Figure 3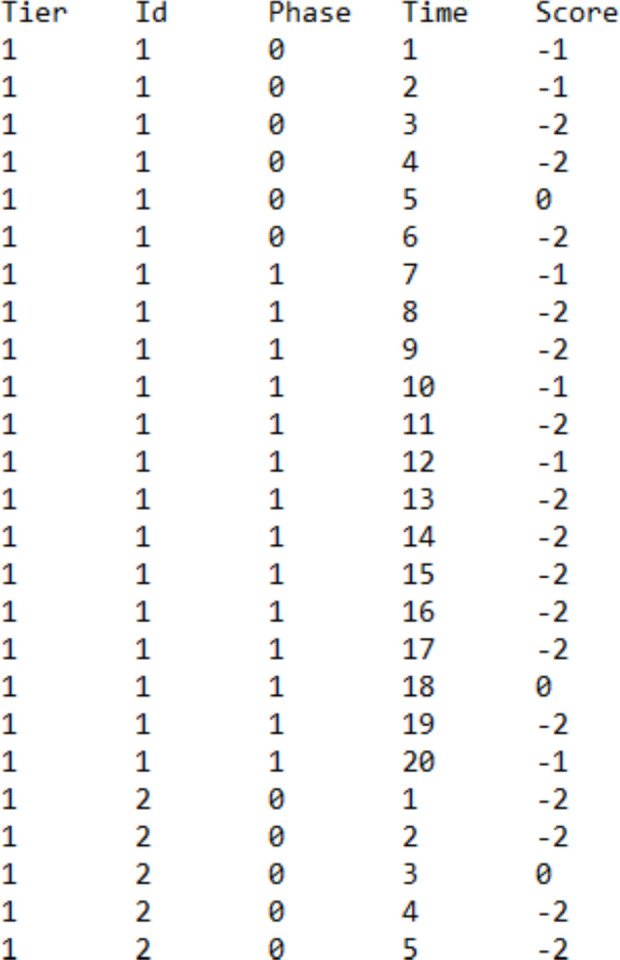 Figure 4
Figure 4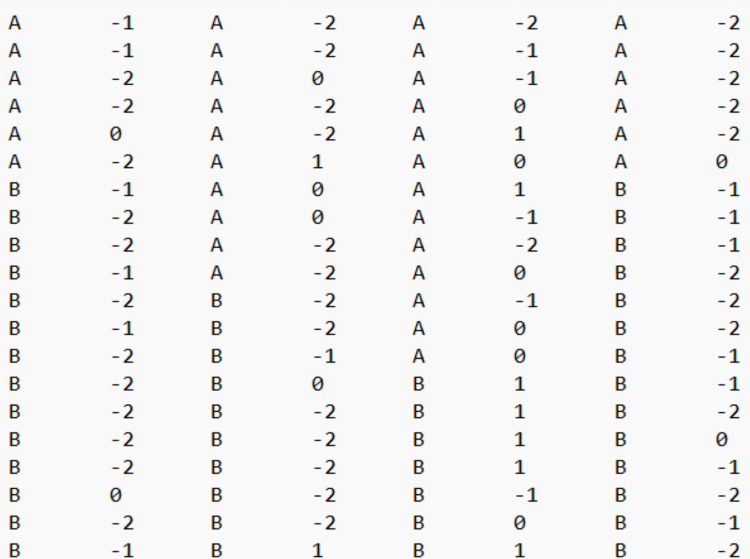 Figure 5
Figure 5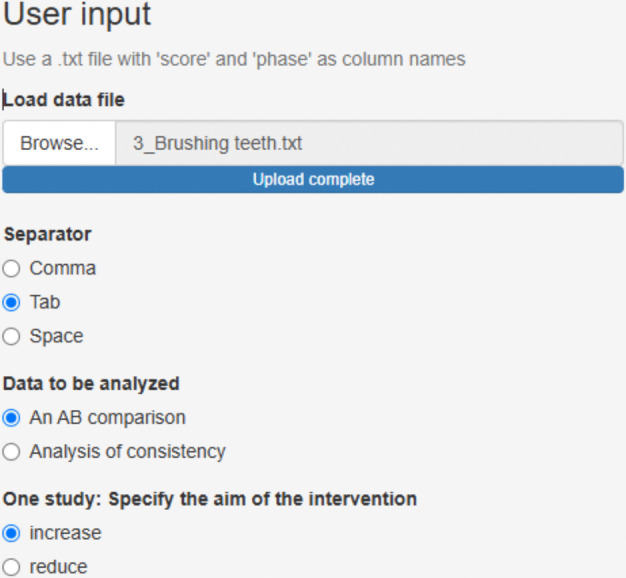 Figure 6
Figure 6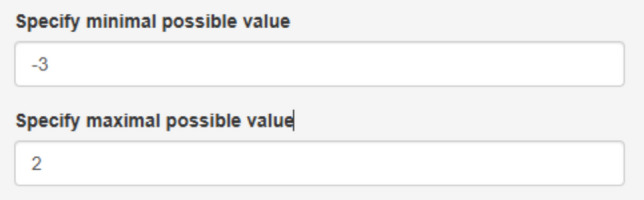 Figure 7
Figure 7 Figure 8
Figure 8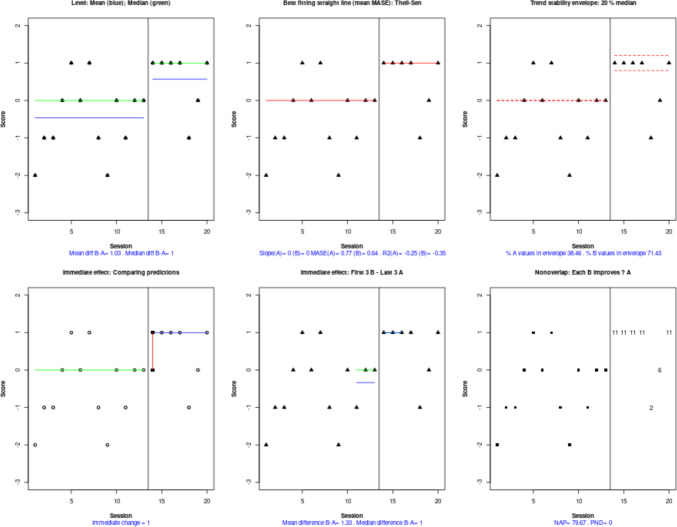 Figure 9
Figure 9- —Agència de Gestió d’Ajusts Universitaris i de Recerca
- —Universitat de Barcelona
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsBehavioral and Psychological Studies · Psychometric Methodologies and Testing · Optimal Experimental Design Methods
Single-case experimental designs (SCEDs) offer a valid means of providing evidence regarding the effect of interventions (Horner et al., 2005; Jenson et al., 2007; Schlosser, 2009), by meeting certain methodological requirements (Ganz & Ayres, 2018; Perdices et al., 2023; Tanious et al., 2024). One of these requirements is having several attempts to show an intervention effect, that is, several changes between conditions at different moments in time, either for the same unit or for different units (Perdices et al., 2023; What Works Clearinghouse, 2022). This can be understood as a within-study replication of the intervention effect, which can be performed within the same participant (e.g., in a reversal design, alternating-treatment design, or multiple-baseline design across settings or behaviors), or it may require having several participants available (e.g., in a multiple-baseline design across participants). It is common to require at least three attempts to demonstrate an intervention effect in order to consider a design methodologically strong (Tate et al., 2013; What Works Clearinghouse, 2022; but see Cariveau & Lewis, 2025).
Within-study replication enhances internal validity (Morley, 2018; Tate & Perdices, 2019), as the main aim of a single study is to provide evidence regarding a functional (causal) relation between the intervention and the changes in the outcome. This could also be referred to as “simultaneous replication,” to be distinguished from “sequential replication” more focused on generalizability (Michiels & Onghena, 2019). Similar to the latter, the main aim of a meta-analytical integration of several studies (i.e., cross-study replication) is to provide an overall quantification of the intervention effect and an assessment of the generality of the effect or external validity.
Regarding the assessment of intervention effectiveness in the SCED context, it can be performed from several complementary perspectives. While data collection is still ongoing, a formative analysis can be performed by continually plotting the measurements being obtained and making any necessary adaptations in the intervention or decisions regarding the change in phases (Barton et al., 2016). In contrast, a summative analysis is performed once data collection is over, and the aim is to document the intervention effect. For a formative analysis and for deciding whether there a functional relation is present (as an instance of summative analysis), visual analysis is important alongside considering the features of the design (Ledford et al., 2019; Kratochwill et al., 2021, 2023). The identification of the presence of an effect can be complemented by performing another kind of summative analysis, using quantifications of the magnitude of effect, which bring objectivity and the possibility of a quantitative research synthesis (Kratochwill et al., 2023; Pustejovsky & Ferron, 2017). Recent studies have also proposed a meta-analytical integration complemented by visual representations of the data (Kinney et al., 2025; Tanious & Manolov, 2022). Specifically, the proposal by Kinney and colleagues (2025) emphasizes the importance of not only computing an effect size when performing a meta-analysis but also using “structured criteria [in each study] to visually analyze the generated graphs and verify whether a functional relation had been demonstrated between the intervention and the dependent variable” (p. 348). Complementarily, also in the context of the quantitative integration of the results of several studies, Tanious and Manolov (2022) propose representing all data points via violin plots (one for the baseline condition and another for the intervention condition) in order to allow for comparisons beyond summary measures such as means.
Finally, beyond the use of visual analysis for identifying the presence of a functional relation and quantifying the magnitude of the effect, it is important to assess social validity. This assessment includes taking into account the importance of the target outcome for the individual, the acceptability and feasibility of the intervention, and the real-life impact and maintenance of the intervention effect (Kazdin, 1977; Snodgrass et al., 2023). As part of the evaluation of social validity, it can be considered whether and to what extent a pre-established goal (e.g., a mastery criterion) has been achieved (Ferron et al., 2020). A mastery criterion can be understood as a level of behavior that enables normal everyday life functioning, for instance, in comparison to typically developing peers. Thus, such a level would transcend labels such as “statistically significant” or “large” and would translate to a meaningful effect for the individual’s activities and/or well-being, outside the context of the research.
Aims, scope, and organization of this paper
The aim of the current text is to present how different freely accessible web-based applications can be used by applied researchers for the assessment of functional relations in SCED data. A structured approach to visual analysis is necessary (see proposals by Maggin et al., 2013; Wolfe et al., 2019) in order to overcome the insufficient interrater agreement (Bishara et al., 2021; Ninci et al., 2015; Wilbert et al., 2021). Moreover, it is crucial to improve reporting of how visual analysis is performed (Wolfe et al., 2024). A tutorial on software tools making possible a systematic visual analysis is a relevant step in this direction. The current tutorial is also necessary because, as it will be illustrated, there are multiple tools that can aid in the assessment of functional relations, scattered over several websites, each with its own characteristics.
It is important to note that the initial version of the What Works Clearinghouse standards (Kratochwill et al., 2010) clearly separated the assessment of the presence of a functional relation via visual analysis from the quantification of effects, with the latest version (What Works Clearinghouse, 2022) focusing only on the latter. Nonetheless, there were reactions against the omission of visual analysis (Kratochwill et al., 2021; Maggin et al., 2022) along with a recent emphasis on functional relations (Gilroy et al., 2025). For these reasons, the current text focuses on functional relations.
As it is beyond the scope of the current text, the reader interested in quantifying effects can consult several different sources, written as tutorials, as follows: (a) for the between-case standardized mean difference (Shadish et al., 2014), Valentine et al. (2016); (b) for the implementation of multilevel models (Ferron et al., 2009, 2010), Declercq et al. (2020) and Manolov and Moeyaert (2025); see also Li et al. (2025); (c) for randomization tests (Heyvaert & Onghena, 2014; Levin & Kratochwill, 2021), Bulté and Onghena (2013) and Levin et al. (2014); and (d) for Bayesian analysis, Natesan (2019) and Natesan Batley (2023).
Given that the assessment of overlap is usually part of visual analysis, in the current text we will refer to software implementations making possible the quantification and graphical representation of overlap. This is also well aligned with the idea that nonoverlap indices (see Parker, Vannest, & Davis, 2011a, 2011b, for a review, and for later proposals see Tarlow, 2017; Manolov & Tanious, 2025) may not be understood as “effect sizes” in the same way as a standardized mean difference or a log response ratio due to the presence of a ceiling effect (i.e., no quantification of distance once complete nonoverlap is achieved; Carter, 2013; Wolery et al., 2010).
Regarding the organization of the paper, first we provide a brief review of the assessment of functional relations. Second, we present the data that we will use for illustrating the software implementations reviewed here. Third, we refer to the software that will be useful for several data analytical steps and the required formats for the data files. Fourth, we present the results of the use of the websites for the illustrative data. Finally, we provide a discussion, referring to topics open to debate and to further readings on software for SCED data analysis.
Functional relations
To begin with, it should be noted that in certain situations, the two kinds of SCED data analysis (assessing functional relations and quantifying the magnitude of effect) may not coincide completely. For instance, in the context of a multiple-baseline design, the between-case standardized mean difference (Hedges et al., 2013) and multilevel models (Ferron et al., 2009) quantify the difference between the adjacent baseline and intervention phases within each tier, but pay no attention to the staggered introduction of the intervention unless a specific model is used (Ferron et al., 2014). Similarly, for reversal (ABAB) designs, the between-case standardized mean difference (Hedges et al., 2012) omits the comparison between the first intervention and the second baseline phase from the quantification, which may not be methodologically desirable (Tanious & Manolov, 2025). Specifically, in the case that there is a complete reversal in A_2_ relative to A_1_ (and thus a large difference between B_1_ and A_2_), omitting this information may underestimate the effect. Contrarily, in the case of a small or no reversal (apart from being a problem for the functional relation), omitting this small or null effect from the quantification may overestimate the effect. In contrast to the between-case standardized mean difference, when using a multilevel model, the researcher can select the coding in order to include or exclude this comparison (see Shadish et al., 2013).
Regarding the use of visual analysis for assessing functional relations (see Kratochwill et al., 2010; Lane & Gast, 2014; Ledford et al., 2019; Maggin et al., 2018), an initial step consists of focusing on within-phase data patterns in order to check whether there is a clear (predictable) pattern within each condition. Given that level, trend, and variability are assessed, the stability around a mean or a trend line is especially important (Lane & Gast, 2014). Subsequently, adjacent phases (baseline and intervention) are compared, with each two-phase comparison being considered a basic effect (Horner & Odom, 2014) and requiring at least three such basic effects to be present (What Works Clearinghouse, 2022). Specifically, it is possible to identify changes in level, trend, or variability, as well as the amount of overlap between measurements belonging to different conditions. Moreover, it is possible to assess whether the effect is immediate or not. Overall, the assessment performed via visual analysis can be understood as comparing the projection of the baseline data with the actual intervention phase measurements (Kratochwil et al., 2010). Several proposals reflect this latter idea (e.g., Fisher et al., 2003; Manolov & Vannest, 2023; Pfadt & Wheeler, 1995).
In relation to the five previously mentioned data features (level, trend, variability, overlap, and immediacy), it is important to determine, before data collection, which data feature is the focus of the analysis, according to the expectation (Manolov et al., 2022a, 2022b), as is common in the context of randomization tests (Heyvaert & Onghena, 2014; Levin et al., 2017, 2021). Such a practice is also well aligned with the recent calls for transparency (including preregistration; Cook et al., 2022; Johnson & Cook, 2019; Tincani et al., 2024) and the need to avoid questionable research practices (Tincani et al., 2025), potentially leading to confirmation bias (Laraway et al., 2019).
Once a focal data feature is chosen, it is important to consider, across all comparisons between a baseline and an intervention condition, whether there is enough evidence of an intervention effect. This entails considering all basic effects together and assessing their consistency (Kratochwill et al., 2010; Lane et al., 2017; Ledford, 2018; see also Tanious et al., 2020, 2021). Here we suggest following the logic of a “success rate” (Reichow & Volkmar, 2010; see also Hagopian, 2020), which is essentially equivalent to Speelman and McGann’s (2020) proposal to assess the “pervasiveness” of an effect as the proportion of people (here, A–B comparisons1) for whom a desirable effect is observed. Specifically, one proposal from the SCED context is the requirement for a ratio of at least 3:1 positive (desirable) effects for each null effect (Cook et al., 2015; Maggin et al., 2013), although each researcher can judge whether this ratio is sufficient for considering that the intervention is effective.
On the one hand, a positive effect can be understood as the one for which the difference is of the expected sign (Maggin et al., 2011), that is, the intervention is better than the baseline. On the other hand, it is possible to define a minimally relevant effect in relation to the importance of social validity. Apart from inspecting the typical time-series plots, the assessment of consistency can also benefit from the use of the modified Brinley plot (Blampied, 2017), in which the baseline and intervention phase means2 for several basic effects can be represented jointly, and it is possible to assess whether the sign and magnitude of the difference in means is consistent (Manolov & Tanious, 2022; Manolov et al., 2022a, 2022b).
Context
The current example is based on the data3 gathered by Lebrault et al. (2024), studying the effect of an intervention called “Cognitive Orientation to daily Occupational Performance” on occupational performance goals for children with executive function deficits after acquired brain injury. The authors report three multiple-baseline studies (an initial study and two replications), each with four participants and four goals per participant. The fourth goal for each participant was an untrained control goal not expected to change unless transfer occurred. The attainment of the different goals was measured via a Goal Attainment Scale, which is an ordinal measure with six possible values, following Steenbeek et al. (2010): −3, performance below the initial level; −2, initial level; −1, less improvement than expected; 0, expected goal; +1, somewhat more than expected; and +2, much more than expected. In the current illustration, we use the data for “Replication 2” for participant Ian (see Fig. 1).Fig. 1. Multiple-baseline data for Ian, representing three treated behaviors and a control behavior. Note. Graph obtained via https://tamalkd.shinyapps.io/scda/, using a datafile structured as depicted in Fig. 5. A represents baseline; B represents intervention phase
This dataset was chosen because it represents the most commonly used type of SCED (per reviews by Ledford et al., 2024; Shadish & Sullivan, 2011; Tanious & Onghena, 2021): the multiple-baseline design (Carr, 2005; Slocum et al., 2022). Moreover, the measurement scale of the main dependent variable is ordinal, which presents an analytical challenge to applied researchers that is worth noting. A quantification based on distances (e.g., a mean difference) would be less appropriate, as it requires the assumption of constant distance (i.e., a dependent variable measured in an interval or ratio scale). In contrast, a quantification of nonoverlap—one of the six visually assessed data features—only entails ordinal comparisons (i.e., which value is smaller and which value is larger, but not how much smaller or larger). Finally, out of all participants studied, participant Ian’s data (Fig. 1) show certain variability that makes the analysis more challenging. For illustrative purposes and for the assessment of consistency of effects, we will assume that 0 is the minimum desirable value for the intervention phase, as it represents the expected goal. We will also assume that a difference of at least 1 point on average is required for the intervention to be considered effective.
Software implementations reviewed
Data analysis plan and links to the websites
The following steps will be carried out:
- For each basic effect (i.e., each A–B comparison), assess the within-phase pattern, focusing on data variability in order to gauge whether the data show a predictable level or trend. It is possible to use any website (e.g., https://tamalkd.shinyapps.io/scda; https://jepusto.shinyapps.io/SCD-effect-sizes) or an Excel macro (https://ex-prt.weebly.com/) or Excel templates (https://osf.io/bt9hf/), allowing us to construct a time-series plot; https://manolov.shinyapps.io/Overlap/, for instance, includes a stability envelope (Lane & Gast, 2014).
- Again, for each basic effect, assess the focal data feature (level, trend, variability, overlap, immediacy) chosen according to a priori expectations. For the current illustration, we will suppose that variable data are expected, but no spontaneous improvement (i.e., problematic baseline trend). Therefore, summarizing the data by a mean or a trend line may not be reasonable in the case of lack of (trend) stability. We will focus on overlap and choose one specific operational definition: the one entailed in the Nonoverlap of All Pairs (NAP; Parker & Vannest, 2009), in which all baseline measurements are compared to all intervention phase measurements, obtaining a quantification equivalent to a probability of superiority (Grissom & Kim, 2001).
- For level, consider the mean or the median, according to the measurement scale and the presence of potential outlying values. https://manolov.shinyapps.io/Overlap/ and http://www.interventioncentral.org/teacher-resources/graph-maker-free-onlinecan be used. The median can also be represented via https://ansa.shinyapps.io/ansa/.
- For trend, consider different possible trend line fitting techniques. https://manolov.shinyapps.io/TrendMASE can be used. Further quantifications, specifically based on regression, can be obtained via several websites (https://manolov.shinyapps.io/Regression/, https://mirisola-unipa.shinyapps.io/unipa-scr-dev/, and http://www.interventioncentral.org/teacher-resources/graph-maker-free-online) and an R package (https://cran.r-project.org/web/packages/scan/index.html). Additionally, for monotonic trend, https://ansa.shinyapps.io/ansa/ can be used.
- For projecting level and trend, compare the results of the conservative dual criteria projecting the mean level and the split-middle trend (Fisher et al., 2003) with the projection of the Theil–Sen trend line (see Vannest et al., 2012, for an application to SCED data) considering the variability of the baseline data (Manolov & Vannest, 2023). For the former, use https://manolov.shinyapps.io/Overlap/; for the latter, use https://manolov.shinyapps.io/TrendMAD. The p value corresponding to the conservative dual criterion can be obtained via a binomial test (e.g., https://www.graphpad.com/quickcalcs/binomial1/), quantifying the probability of as many or more points from the intervention phase that fall above or below (according to the effect desired) the projected baseline split-middle trend.
- For immediacy,4 assess the difference between the final three baseline measurements and the initial three intervention phase measurements (Horner & Kratochwill, 2012). Following the logic of sensitivity analysis, assess immediacy in a different way as well: on the basis of the projection of the baseline trend to the first intervention phase measurement occasion, as defined in piecewise regression (Center et al., 1985; Moeyaert, Ugille, et al., 2014a, 2014b). Both options are implemented at https://manolov.shinyapps.io/Overlap/, with piecewise regression quantifications also available at https://manolov.shinyapps.io/Regression/.
- For overlap, consider whether baseline trend has to be taken into account or not (Manolov & Tanious, 2025; Parker, Vannest, Davis, & Sauber, 2011a, 2011b; Tarlow, 2017). Assess the amount of overlap and whether a ceiling effect is present. Multiple websites (e.g., https://singlecaseresearch.org/; https://ktarlow.com/stats/; https://jepusto.shinyapps.io/SCD-effect-sizes; http://www.interventioncentral.org/teacher-resources/graph-maker-free-online ) and R packages (e.g., https://cran.r-project.org/web/packages/scan/index.html) implement nonoverlap indices, but here we focus on the website that serves multiple purposes related to visual analysis (https://manolov.shinyapps.io/Overlap/).
- For all basic effects considered together, for assessing consistency:
- Compare the average baseline and intervention trend lines and the average intervention effects with the trends and effects for each tier (here, behavior for Ian). This can be achieved by visual inspection via the two-level model implemented in https://manolov.shinyapps.io/Overlap/, http://34.251.13.245/MultiSCED/, or https://manolov.shinyapps.io/SeveralAB/.
- Construct a modified Brinley plot (via https://manolov.shinyapps.io/Brinley/) for comparing the effects for the four tiers and check whether these effects meet the requirement (for the current example) of at least 1-point average improvement and at least an average of 0 in the Goal Attainment Scale after the intervention.
- Assess the consistency in variability using the visual aid from https://tamalkd.shinyapps.io/scda. There are different ways of representing within-phase variability in this website; here we use the range.
- Compute a success rate on the basis of an a priori criterion regarding what represents a positive result and the focal data feature. Focusing on overlap and NAP, it is possible to follow three criteria for a positive effect. The most lenient one is a NAP value of more than 50%, suggesting there is at least some difference between the conditions. An intermediate option is the NAP value of a moderate effect: 65% as per Parker and Vannest (2009). The most stringent option is to consider the maximum value5 (100%) as the threshold, since it is the value that represents complete separation (i.e., all intervention phase measurements show an improvement to all baseline phase measurements). Here we chose the threshold for a moderate effect (i.e., a value of 65%).
- Complement with quantifications of variability across A–B comparisons, such as variance estimates from a two-level model (http://34.251.13.245/MultiSCED/) or the intraclass correlation from the between-case standardized mean difference (https://jepusto.shinyapps.io/scdhlm/). It should be noted that while the variance (or standard deviation) of the effect, as quantified via a multilevel model, refers specifically to the variability of the intervention effect, the intraclass correlation from the between-case standardized mean difference does not. Instead, the latter provides a quantification of the data variability that is across participants, and this data variability can also be in terms of the level of the behavior in experimentally similar phases. In that sense, the intraclass correlation mixes the two kinds of consistency outlined by Kratochwill and colleagues (2010, 2013): consistency of data in similar phases and consistency of effects. Proposals regarding the former kind of consistency are made by Tanious et al. (2020, 2021).
Required data files
For the basic effect (i.e., each A–B comparison), the websites require a simple .txt file with two columns: one that includes the measurements and one that includes the condition, marked with either A (baseline) or B (intervention). For https://tamalkd.shinyapps.io/scda/, it is better that the two columns contain no headers. In contrast, for the remaining websites (https://manolov.shinyapps.io/Overlap/; https://manolov.shinyapps.io/TrendMASE/; https://manolov.shinyapps.io/Regression/ and https://manolov.shinyapps.io/TrendMAD/), it is important to use the headers “score” (for the measurements of the target behavior) and “phase” (for the A and B labels), both in small letters. See Fig. 2 as an example.Fig. 2. Data structure for using the websites for evaluating a basic effect (i.e., an A–B comparison)
For the assessment of consistency, the data files need to include more columns. Specifically, for https://manolov.shinyapps.io/Overlap/ (which allows superimposable one-level regression lines specific for each basic effect and two-level lines representing the average for all basic effects), the data file should be created as shown in Fig. 3. The first column (Tier) includes an integer identifying each of the A–B comparisons. The second column (Id) provides a more informative label on this comparison. The third column (Phase) marks the baseline condition with a 0 and the intervention with a 1. The fourth column (Time) marks the session number. The fifth column (Score) includes the measurement of the dependent variable.Fig. 3. Data structure for using the websites for evaluating consistency using a multilevel model (i.e., several A–B comparisons)
For using https://manolov.shinyapps.io/Brinley/, the structure is practically identical (see Fig. 4). Specifically, the columns with the headers Phase, Time, and Score are defined as previously. The definitions of the columns Tier and Id are different, because this website is designed to handle several comparisons (i.e., different integers in the Id column) for several participants (i.e., different integers in the Tier column). Regarding the example data from the Lebrault et al. (2024) study, we could have depicted the four behaviors studied for the four participants. Given that the current focus is on one of the participants (Ian), the column Tier will only contain the integer 1, whereas the column Id will contain integers from 1 to 4 for the four behaviors.Fig. 4. Data structure for using the website implementing the modified Brinley plot for evaluating consistency (i.e., several A–B comparisons)
For using https://tamalkd.shinyapps.io/scda, for representing all of Ian’s data (i.e., the four goals), the data structure is as represented in Fig. 5: each column with a phase label is followed by a column with the measurements of the dependent variable, without headers.Fig. 5. Data structure for using https://tamalkd.sninyapps.io/scda for visual analysis superimposing visual aids (or for randomization tests and computing quantifications of effect)
For quantifications using the between-case standardized mean difference (Shadish et al., 2014) or multilevel model (Ferron et al., 2009, 2010), the data structure represented in Fig. 3 or 4 can be used for the former (https://jepusto.shinyapps.io/scdhlm/) and the structure from Fig. 4 for the latter (http://34.251.13.245/MultiSCED/). These analytical options offer not only average effect sizes but also quantifications of variability useful for assessing consistency (potentially useful for the assessment of consistency as part of the evaluation of functional relations). All data files included in the current tutorial can be accessed via https://osf.io/8ngwc/overview?view_only=4f3ac8bfc86544d49abd25a351ac2623.
Results: Use of the software
Basic effect: Two-phase comparison
We focus on the third treated behavior for Ian, brushing teeth. After accessing https://manolov.shinyapps.io/Overlap/, the user has to browse the data file and specify that, in this case, the aim is to reduce the target behavior (Fig. 6). For optimal graphical representations, the lower and upper limits of the measure of the target behavior are specified (Fig. 7).Fig. 6. Menu from https://manolov.shinyapps.io/Overlap/, for locating the data file and defining the aim of the A–B comparisonFig. 7Menu from https://manolov.shinyapps.io/Overlap/, for defining the y-axis limits of the graphical representations, according to the way in which the dependent variable is measured
Level and trend: Overall, immediacy, and projection considering data variability
On this website, the different graphical representations, visual aids, and quantifications are accessed via tabs. An overall representation of five data features (level, trend, variability, immediacy, and overlap) is obtained by clicking on the “WWC Visual: Two phases” tab (Fig. 8).Fig. 8. Tabs from https://manolov.shinyapps.io/Overlap/, for choosing different graphical representations, visual aids, and quantifications
This overall representation (Fig. 9) suggests substantial within-phase variability; as shown in the top right panel, less than 80% of data are within each stability envelope (Lane & Gast, 2014). This precludes us from drawing conclusions related to level6 and trend. In any case, if there were interest in a deeper assessment of trend, it should be noted that the website selected the Theil–Sen method for fitting a trend line for these data, following the criterion of the mean absolute scaled error (Hyndman & Koehler, 2006; Manolov et al., 2019). According to the trend lines fitted, there is no change in the measurements with time in either of the phases. However, it is possible to compare different trend lines via another website (https://manolov.shinyapps.io/TrendMASE) using the same data file (see Fig. 10 for specifying the y-axis of the plot and selecting a trend line fitting technique). For instance, using ordinary least squares estimation (Fig. 11), the trend lines of the two phases are not flat. Instead, the baseline trend is increasing (improving), whereas the intervention phase trend is decreasing (deteriorating), suggesting an overall deterioration according to this data feature and disregarding the immediate increase in level.Fig. 9. Graphical representation of five data features (level, trend, variability, immediacy, and overlap) from https://manolov.shinyapps.io/Overlap/Fig. 10. Menu of https://manolov.shinyapps.io/TrendMASE/Fig. 11. Graphical representation of within-phase linear trend estimated via ordinary least squares, obtained from https://manolov.shinyapps.io/TrendMASE/
If the aim were to compare the projected baseline with the actual intervention phase measurements, the conservative dual criteria combining the mean level and the split-middle trend (Fisher et al., 2003) could be used via the “Dual Criterion” tab of https://manolov.shinyapps.io/Overlap/. The result is depicted in Fig. 12 and suggests that the probability of six out of seven intervention phase measurements being above both lines only by change is .06, which is almost at the .05 threshold suggesting the presence of an intervention effect.Fig. 12. Graphical representation of the conservative dual criteria from https://manolov.shinyapps.io/Overlap/
However, it is also possible to take the variability into account when projecting baseline trend (see Manolov & Vannest, 2023) via https://manolov.shinyapps.io/TrendMAD. The menu is represented in Fig. 13 and the output in Fig. 14. This option indicates that all intervention phase measurements fall within the expected variability band, indicating no change.Fig. 13. Menu of https://manolov.shinyapps.io/TrendMAD/Fig. 14. Graphical representation of projecting baseline trend with a variability band, obtained via https://manolov.shinyapps.io/TrendMAD/
Overlap
For the current example, we had established that the main interest lies in overlap due to the expected (and subsequently, actually observed) data variability. It can be considered that when data are highly variable, they may not be well represented by a straight line (such as a mean or a trend line), as would be indicated by a large error (bouncing) around such a line. In contrast, NAP compares the data points directly without reducing them to a summary line. In that sense, the preceding section is included only for illustrative purposes, and should not be the focus of the analysis. The https://manolov.shinyapps.io/Overlap/ website yields a NAP value of 80%, representing a moderate effect (between 65% and 92%, as per Parker and Vannest, 2009). Figure 15 provides further details on this quantification. Looking at the left plot, we see that there is no clear evidence for an improving monotonic baseline trend: although several measurements improve previous data points, this is not the case for all of them. Similarly, there is no clear monotonic trend in the intervention phase. Looking at the right plot, we see a large overlap area, but most of the intervention phase measurements represent improvements over (nonoverlaps with) most baseline data points. Thus, for this behavior, there seems to be an improvement in terms of overlap.Fig. 15. Result from https://manolov.shinyapps.io/Overlap/, for representing overlap
Consistency: Visual inspection via a two-level model (level and trend)
For comparing the one-level regression trend lines (fitted for each behavior separately) and the average trend lines (obtained via a two-level model), the https://manolov.shinyapps.io/Overlap/ website can easily7 be used, as it offers an automatic depiction. Once the data (as represented in Fig. 3) are loaded, the output is obtained in the “WWC Visual: Consistency” tab (see Fig. 16). There is a considerable difference between the thick black lines (averages) and the colored lines representing each behavior: three of the baseline trends are increasing, whereas one is decreasing; two of the intervention phase trends are increasing, one is decreasing, and one is practically zero; the immediate effect is not consistently an increase or a decrease for all behaviors. Thus, at least visually, there is no evidence for consistency in either the trend lines or in the effect of the intervention.Fig. 16. Result from https://manolov.shinyapps.io/Overlap/, for a visual inspection of consistency via a two-level model
Consistency: Visual inspection via a modified Brinley plot (level)
The data structured as shown in Fig. 4 are loaded in https://manolov.shinyapps.io/Brinley/. The menu is depicted in Fig. 17, including the definition of both axes according to the minimum and maximum values for the Goal Attainment Scale, the minimum required effect (1 point, in absolute terms) and the minimum required post-intervention mean (0, representing the desired goal). As per the “Main Brinley plot” tab (see Fig. 18), it can be seen that the dot is above the diagonal line for only two of the four tiers, representing an improvement (i.e., intervention phase mean higher than the baseline phase mean). Moreover, according to the colored polygon, only one of the dots (tiers) represents the desired amount of improvement. Clicking on the “Additional Brinley plots” tab, we can see that the improvements are the third behavior (brushing teeth) and the fourth one (i.e., the control behavior), with only the former presenting the desired amount of improvement. Thus, focusing on means, there is not enough evidence for a consistent effect.Fig. 17. Menu from https://manolov.shinyapps.io/Brinley/Fig. 18. Modified Brinley plot with polygon for desired effect, from https://manolov.shinyapps.io/Brinley/
Consistency: Variability
If we focus on variability, using https://tamalkd.shinyapps.io/scda, we can see from Fig. 19 that the overall variability is larger (including almost all possible values between −3 and 2) for two of the behaviors than for the other two. In three of the comparisons, there is no difference in variability (operationally defined as the range) between the baseline and the intervention phase, and only for one behavior is there a reduction. Thus, what is consistent (although not desirable) is the presence of considerable data variability and an overall lack of reduction in variability after the intervention.Fig. 19. Menu from https://tamalkd.sninyapps.io/scda, alongside Ian’s data with range lines
Consistency: Success rate (overlap)
As stated previously, the current focus is on the NAP, as a quantification of overlap, with a requirement for a value of at least 65% (moderate effect, according to Parker & Vannest, 2009) for considering the effect positive. Considering that there are four opportunities to show an effect (i.e., four A–B comparisons) and that one of the behaviors is not treated, the expected (and desired) success ratio is 3:1. The use of https://manolov.shinyapps.io/Overlap/ for all four behaviors (with a data structure as depicted in Fig. 2) yields the following values: 42%, 44%, 80%, and 66%. Thus, only two of the basic effects can be considered a success (i.e., a 2:2 ratio), but the fourth behavior (NAP value of 66%) was control and was not expected to produce an effect. Therefore, there is not enough evidence for a consistent intervention effect on the basis of overlap as a data feature, just as was the case for means, described previously.
Effect size calculation and quantifications of variability
Just for the sake of completeness, in addition to assessing the presence of a functional relation, we include the results of two possible quantifications: the between-case standardized mean difference (focusing on level via https://jepusto.shinyapps.io/scdhlm) and a two-level model incorporating trend and quantifying the change in slope and the immediate change in level (via https://34.251.13.245/MultiSCED/).
Regarding the between-case standardized mean difference, the data are loaded in https://jepusto.shinyapps.io/scdhlm, and the columns are identified as specified in Fig. 20. The moment estimation8 yields an estimate of 0.1789 with a standard error of 0.2182, leading to a 95% confidence interval ranging between −0.2783 and 0.6362, suggesting that any average effect is likely to be irrelevant. Excluding the fourth (control) behavior, the effect estimate is even lower: 0.1234. Regarding variability across tiers (here, the different behaviors studied for Ian), the intraclass correlation is equal to 0.3205, suggesting considerable variability.Fig. 20. Menu of https://jepusto.shinyapps.io/scdhlm
Regarding a two-level model including separate estimates of baseline and intervention phase trend, the data required by the website https://34.251.13.245/MultiSCED/ are as shown in Fig. 4 (for the modified Brinley plot). The columns representing the different variables are identified as shown in Fig. 21. This specification includes centering the time variable so that, when modeling trend, the change in level is quantified for the first intervention phase measurement occasion. The model is specified as in Fig. 22, including separate estimates of trend for the baseline and the intervention phase and a quantification of change in level and immediate change in trend. The fixed effects represent the averages for the four behaviors, and the random effects quantify the variability around these averages. All these estimates are in the same measurement units as the dependent variable (the Goal Attainment Scale ranging from −3 to 2) rather than being standardized.Fig. 21. Menu of https://34.251.13.245/MultiSCED/ for identifying the variablesFig. 22Menu of https://34.251.13.245/MultiSCED/ for specifying the model
The results suggest practically zero immediate effect on average and an average decrease in trend after the intervention of 0.06 (after an average positive baseline trend of 0.03). The variability estimates, expressed as standard deviations, are as follows: for baseline trend, 0.008 (suggesting similar baseline trends), for the immediate effect of the intervention, 0.697 (suggesting great variability across behaviors), and for the difference in trend, 0.090 (also suggesting considerable variability, when compared to the average value). A graphical representation of the ordinary least squares regression lines fitted separately for each behavior (in red) and the two-level averages (in green) is available in Fig. 23. Thus, the conclusion of this analysis is equivalent to the previous one: no evidence for a consistent effect, given (mainly) the variability observed across goals and (additionally) the small estimates of effect. A necessary subsequent step would be to study why the intervention was effective for some behaviors but not for others.Fig. 23. Graphical results from https://34.251.13.245/MultiSCED/
Discussion
Success rate
Identifying evidence-based practices has been strongly related to performing quantitative integrations of several studies on the same intervention and target behavior, even in the SCED context (Jenson et al., 2007). Such an integration can be performed by using multilevel models (Baek et al., 2023; Declercq et al., 2022; Moeyaert & Yang, 2021; Van den Noortgate & Onghena, 2003a, 2003b). Notwithstanding the importance of documenting the magnitude of effect, in the SCED context it is important to consider whether there is enough evidence that any difference observed (quantified) in the target behavior can be considered to be reliably (consistently) due to the intervention. This is where the assessment of functional relations becomes important.
As illustrated in the current text, such an assessment can be performed by visual analysis aided by several graphical aids and descriptive quantifications, and can also be summarized quantitatively via a success rate. It should be noted that counting favorable results resembles vote-counting as an integration procedure applicable for a meta-analysis of several studies (Bushman & Wang, 2009). Thus, just as with weighted means, there is a continuity with the common meta-analytical practice.
Regarding the need for further debate, the assessment of functional relations and the success rate both require us to define what a positive result is. We suggest that such a definition should not necessarily be completely automated by comparing a quantification to a universal (null, moderate, or maximum) cutoff point or benchmark. Instead, it is likely to require the researchers’ judgment (Branch, 2014; Hagopian, 2020; Imam, 2021) based on their knowledge of the participant and the issue studied.
Transparent reporting
Part of transparent reporting for avoiding questionable research practices (Tincani et al., 2025) is to mention all data analytical decisions made, beyond following the relevant reporting guidelines (Tate et al., 2016). Following a data analytical plan as described here can be useful for that purpose. Moreover, in relation to replicability and the current tutorial, it is also important to report the software used for visual representation, visual aids, and all quantifications obtained.
Similarly, reporting null or negative results is important, as long as they stem from methodologically sound studies, for at least two reasons (Kratochwill et al., 2018; Tincani & Travers, 2018). One the one hand, it is important to avoid publication bias and inflating effect estimates. On the other hand, it is relevant to identify what works (and does not work) for whom, and for that purpose, moderator analysis can be especially useful (Moeyaert & Yang, 2021).
Limitations and additional resources
The current text focuses on the classical features which are usually the object of visual analysis as performed by a human researcher, as described in several sources: Kratochwill et al. (2010), Lane and Gast (2014), Maggin et al. (2018), Ledford et al. (2019). In contrast, it does not include another option for reaching a conclusion regarding the presence or absence of an intervention effect: the more or less autonomous use of computer-intensive methods or the use of artificial intelligence (Mensah & Chen, 2025). The reader interested in the latter can consult Lanovaz and Bailey (2024) for the use of artificial neural networks and Turgeon and Lanovaz (2020) for machine learning (in terms of websites for implementing this analytical option, see https://labrl.shinyapps.io/MachineLearningQABF/; https://labrl.shinyapps.io/MachineLearningABGraphs/; https://labrl.shinyapps.io/singlecaseanalysis/). Although here we echo previous claims on the importance of human judgment (Imam, 2021), applied researchers are encouraged to consult as much information as possible in order to decide for themselves how to approach the task of assessing the presence of a functional relation in SCED data.
Regarding the data features which are the object of visual analysis, it is important to mention that the current text did not deal with certain complexities related to trend. On the one hand, when projecting baseline trend, it is important to consider whether some extrapolations may be unreasonable or even impossible (Manolov et al., 2019; Parker, Vannest, Davis, & Sauber, 2011a, 2011b). On the other hand, even though the focus was linear trend, nonlinear data patterns can take place and be modeled (see Cheng et al., 2025; Hembry et al., 2015; Swan & Pustejovsky, 2018; Verboon & Peters, 2020).
Another simplification introduced in the text refers to consistency. While Kratochwill et al. (2010, 2013) referred to two kinds of consistency (of data in similar phases and of effects), in the current text the focus is on the latter, as it may be of greater interest for researchers. Nevertheless, proposals regarding the quantification of the consistency of data in experimentally similar phases can be consulted in Tanious et al. (2020, 2021; see the website https://manolov.shinyapps.io/CONDAP/ implementing these proposals).
The fact that the current tutorial includes multiple steps in the data analytical process and multiple websites can also be viewed as a limitation. The underlying rationale was to try to provide a comprehensive guide for a complex process. In any case, if simplifying (excessively?) is required, an applied researcher using SCEDs could focus on (a) performing visual analysis including all six data features (Kratochwill et al., 2010; Lane & Gast, 2014; Ledford et al., 2019) using https://manolov.shinyapps.io/Overlap/, or (b) multilevel modeling for obtaining an average quantification of effect alongside its variability (Ferron et al., 2009; Moeyaert, Ferron, et al., 2014a, 2014b) via http://34.251.13.245/MultiSCED/ (website described in Declercq et al., 2020) and the quantification of individual effects for each A–B comparison (Ferron et al., 2010) via https://manolov.shinyapps.io/SeveralAB/ (website discussed in Manolov & Moeyaert, 2025).
Finally, the six data features that are the object of visual analysis are mainly useful for multiple-baseline and reversal (ABAB) designs. In contrast, alternating-treatment designs in which there are only one or two consecutive measurements in the same condition (Barlow & Hayes, 1979) are assessed differently (see Diller et al., 2016; Lanovaz et al., 2019; Manolov & Onghena, 2018; some analytical options are implemented at https://tamalkd.shinyapps.io/scda and https://manolov.shinyapps.io/ATDesign). Similarly, the changing criterion design entails a comparison of the measurements to predefined desired levels (Hartmann & Hall, 1976). These designs are accompanied by specific methodological recommendations (Klein et al., 2017) and data analytical approaches (Ferron et al., 2023; Manolov et al., 2020; Onghena et al., 2019). Some data plotting options for the changing criterion design are available at https://manolov.shinyapps.io/ChangingCriterion/). For both kinds of designs, the coding in multilevel modeling can be adapted (Shadish et al., 2013).
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1Bushman, B. J., & Wang, M. C. (2009). Vote-counting procedures in meta-analysis. In H. Cooper, L. V. Hedges, & J. C. Valentine (Eds.), The handbook of research synthesis and meta-analysis (2nd Ed., pp. 207−220). Russell Sage.
- 2Cariveau, T., & Lewis, T. K. (2025). Omne trium perfectum/Everything that comes in threes is perfect. Journal of Behavioral Education. Advance online publication. 10.1007/s 10864-025-09609-4
- 3Cheng, K., Yi, Z., Moeyaert, M., Beretvas, S. N., Van den Noortgate, W., & Ferron, J. (2025). Synthesizing single-case experimental designs: Modeling complex data structures. Journal of Behavioral Education. Advance online publication. 10.1007/s 10864-025-09602-x
- 4Horner, R. H., & Odom, S. L. (2014). Constructing single-case research designs: Logic and options. In T. R. Kratochwill & J. R. Levin (Eds.), Single-case intervention research: Methodological and statistical advances (pp. 27–51). American Psychological Association. 10.1037/14376-002
- 5Johnson, A. H., & Cook, B. G. (2019). Preregistration in single-case design research. Exceptional Children, 86(1), 95–112. ://doi.org/10.1177/0014402919868529
- 6Kratochwill, T. R., Hitchcock, J., Horner, R. H., Levin, J. R., Odom, S. L., Rindskopf, D. M. & Shadish, W. R. (2010). Single-case designs technical documentation. Retrieved from What Works Clearinghouse website: https://ies.ed.gov/ncee/wwc/Docs/Reference Resources/wwc_scd.pdf
- 7Levin, J. R., Evmenova, A. S., Gafurov, B. S. (2014). The single-case data-analysis Ex PRT (Excel Package of Randomization Tests). In T. R. Kratochwill & J. R. Levin (Eds.), Single-case intervention research: Methodological and statistical advances (pp. 185–219). American Psychological Association. 10.1037/14376-007
- 8Manolov, R., & Moeyaert, M. (2025). Multilevel model selection applied to single-case experimental design data. Journal of Behavioral Education. Advance online publication. 10.1007/s 10864-025-09593-9