Predicting EQ-5D-3L utility values from clinical data in a prospective cohort of kidney transplant recipients
V. Bonnemains, Y. Foucher, P. Tessier, C. David, M. Giral, E. Dantan

TL;DR
This study uses clinical data to predict quality-of-life scores in kidney transplant patients over time, helping assess long-term outcomes and resource allocation.
Contribution
A novel method for predicting health utility values using mixed models and clinical data in kidney transplant recipients.
Findings
Recipient age, female sex, BMI, comorbidities, and dialysis duration were linked to lower utility scores.
Predicted scores increased in the first year post-transplant and then slowly declined.
The LME model showed better calibration than other models for predicting utility values.
Abstract
Modelling health-state utility values (HSUVs) from clinical data offers a means to conduct retrospective cost-effectiveness analyses using clinical studies that did not collect direct HSUV measures. Such studies can support the efficient allocation of resources in kidney transplantation (KT). We aim to model KT recipients' EQ-5D-3L HSUVs using routinely collected clinical data. From a French observational multicentric prospective cohort, we included 2,787 adult recipients of a first or second single renal graft transplanted between January 2014 and December 2021 who completed 5,679 EQ-5D-3L questionnaires post-KT, from which the HSUVs were calculated. Considering two time periods before and after 1-year post-KT, we estimated a linear mixed effect model (LME), a mixed adjusted limited dependent variable mixture model, and beta and two-part beta mixed models. We compared their predictive…
Genes, proteins, chemicals, diseases, species, mutations and cell lines named across the full text — each resolved to its canonical identifier and authoritative record.
Click any figure to enlarge with its caption.
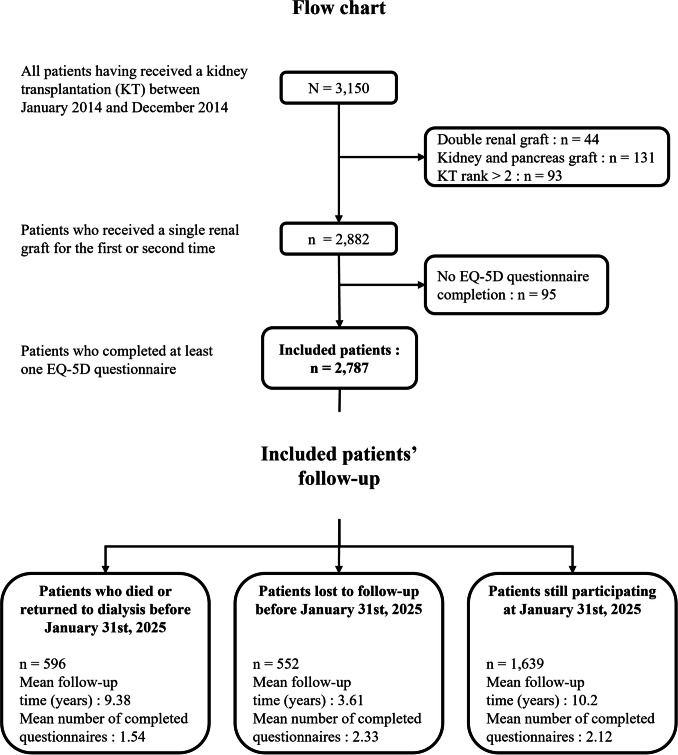 Figure 1
Figure 1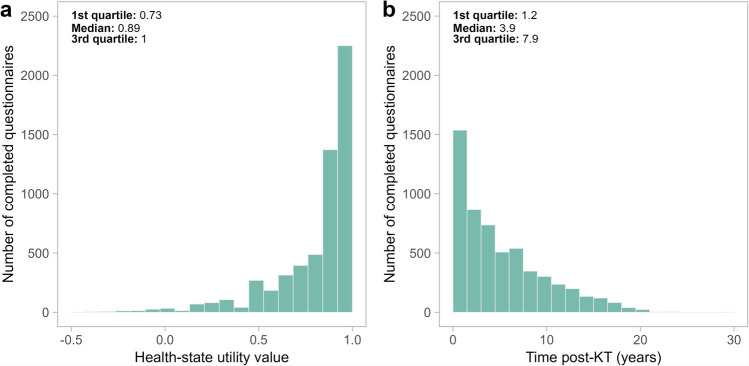 Figure 2
Figure 2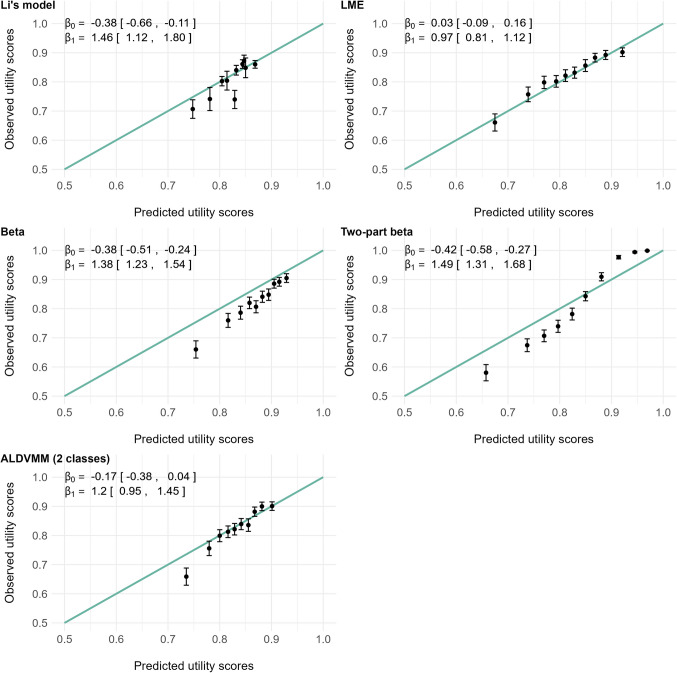 Figure 3
Figure 3- —http://dx.doi.org/10.13039/501100001665Agence Nationale de la Recherche
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsHealth Systems, Economic Evaluations, Quality of Life · Pharmaceutical Economics and Policy · Statistical Methods in Clinical Trials
Introduction
When possible, kidney transplantation (KT) is the preferred renal replacement therapy for end-stage renal disease (ESRD) in terms of morbidity, mortality, and quality of life [1, 2]. Associated with lower costs compared to peritoneal dialysis and haemodialysis [3], KT has been reported to be cost-effective in several studies [4, 5]. Nevertheless, the assessment of solutions aimed at improving transplantation procedures and patients’ management could benefit from further cost-effectiveness studies.
Such studies often rely on modelling approaches such as Markov models to represent costs and Quality-Adjusted Life-Years (QALYs) over a long time horizon [6–8]. This requires that published health states utility values (HSUVs) be available to estimate QALYs. However, model-based cost-effectiveness studies cannot always rely on longitudinal HSUVs, which are rarely collected in practice. Thus, the possibility to predict the evolution over time of KT recipients’ HSUVs from routinely collected clinical data could be helpful to provide more accurate estimates of QALYs in model-based cost-effectiveness studies and in studies that did not collect preference-based measures of Health-Related Quality of Life (HRQoL).
Li et al. recently proposed models to predict 6-month post-transplantation EQ-5D HSUVs for KT recipients from clinical variables, arguing that HSUV at this time offered a stable reflection of post-KT HRQoL [9]. This assumption of a stable health state and corresponding utility value is questionable. Indeed, answers to the EQ-5D questionnaire are characterized by an individual variability along the KT recipient follow-up, which makes the corresponding HSUVs time-dependent. Additionally, Galichon et al. considered two clinical phases in the post-KT follow-up: one phase associated with post-operation complications and acute rejection episodes, usually considered as the first year post-transplantation, followed by a chronic phase [10]. They reported a higher but decreasing graft failure rate during the first year post-KT, followed by a steadier rate thereafter. To the best of our knowledge, only Li et al. [9] proposed a predictive model of HSUVs in KT. Given the endogenous nature of HSUVs and the two clinical phases described by Galichon et al. [10], it appears relevant to consider the HSUV of KT recipients as a time-dependent outcome.
Kontodimopoulos et al. reported that the estimation of a prediction model using only baseline data could lead to biased QALY predictions [11]. Gonçalves et al. further stressed the importance of including all time points in the analysis [12]. Although linear models have commonly been employed to model HSUVs in cross sectional studies [13], linear mixed models enable the consideration of intra-class correlations, for example, those induced by individual repeated measures in longitudinal data [14]. However, this relies on several assumptions with theoretical limitations in the context of HSUV modelling: the unboundedness, unimodality and symmetry of the normal distribution [15]. More recently, beta regression models have been proposed to consider the bounded and skewed nature of the HSUV distribution [16, 17], as well as mixture models to account for possible bimodality [18]. Nevertheless, their random effect extensions for longitudinal data remain sparsely studied and have never been investigated in the specific context of kidney transplantation.
Using questionnaires collected longitudinally since 2014 for a French cohort of KT patients, the present study aims to propose a new model to predict the post-KT evolution of EQ-5D HSUVs until they returned to dialysis or died from clinical information, as well as an online calculator allowing investigators to apply this model to their data. For this purpose, we compare the performances of several models to predict time-dependent HSUVs. This would provide new insights on the model family that best fits such data. This study also provides an external validation of Li et al.’s model.
Materials and methods
Study population
Data were extracted from the French multicentric, observational and prospective DIVAT cohort (Données Informatisées et VAlidées en Transplantation, www.divat.fr, CNIL no. 914184, ClinicalTrials.gov recording NCT02900040). All participants gave informed consent. Since January 2014, patients have been encouraged to complete self-administered EQ-5D-3L questionnaires at each anniversary of the transplantation in 6 centres until they returned to dialysis or died, while being able to do so with no restrictions in the period of collection. We considered all the completed questionnaires regardless of the time of completion. The inclusion criteria for this study were: adult recipients of a first or second single renal graft and transplanted between January 2014 and December 2021. This led to 2,787 included patients (Fig. 1). Among them, 12 patients (0.4%) completed EQ-5D questionnaires during their first and second transplantations. This low number of occurrences did not allow the consideration of transplantation as a second grouping level in our analyses. Therefore, we chose to consider only the first transplantation for these 12 patients so that no patient was included more than once. There were no multiorgan transplant recipients in the study.Fig. 1. Flow chart of the cohort study design
Available data
HSUVs were obtained from the patients responses to the EQ-5D-3L questionnaire [19]. This questionnaire is made up of five questions, each exploring one dimension of the respondent’s quality of life: mobility, self-care, usual activities, pain/discomfort, and anxiety/depression. In the 3L version, each question can be given a 3-ordered-level answer (no problem, some problems and extreme problems) such that a higher level indicates more problem with the dimension under consideration. These questionnaires were converted into HSUVs using French published tariffs [20]. From expert background knowledge (M.G.) and considering the most frequent comorbidities occurring before kidney transplantation with ageing and chronic kidney insufficiency, the following baseline recipient characteristics were considered potential determinants of the HSUVs: age, sex, body mass index (BMI), history of comorbidities (diabetes, cardiovascular disease, neoplasia, hypertension), time spent on dialysis before transplantation, graft rank and cause of initial renal disease (recurrent nephropathy or not). Donor age was also included in the analysis.
Statistical analyses
Recipient and donor characteristics were reported as the mean and standard deviation for continuous variables and as count and percentage for categorical variables. For the longitudinal analysis of HSUVs, we compared four multivariate mixed regression models: linear mixed model, mixed adjusted limited dependent variable mixture model (mixed ALDVMM) [18], mixed beta regression [16, 17] and mixed two-part beta regression [17] (details of each approach are provided in Online Resource 1).
For the linear mixed model and the mixed ALDVMM, we modelled the raw HSUVs. For the mixed beta and two-part beta regressions, we transformed the HSUVs \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$u$$\end{document} so that they are restricted from 0 to 1 while the raw HSUVs resulting from the French EQ-5D-3L scoring system may range from −0.53 ( \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${u}_{min}$$\end{document} ) to 1.00 ( \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${u}_{max}$$\end{document} ): \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$y=({u}_{max}-u)/\left({u}_{max}-{u}_{min}\right)$$\end{document} , as suggested by Brazier et al. [21]. Note that in doing so, we thus modelled the rescaled decrement \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$y$$\end{document} in patients’ HSUVs \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$u$$\end{document} compared to perfect health. The two-part beta model corresponds to a zero-inflated beta-regression, possibly interesting to consider the mass of observations at the maximum value of 1, which correspond to a decrement \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$y$$\end{document} of 0. We compressed the \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$y$$\end{document} -values into \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${y}^{*}$$\end{document} so that they never reach the boundary values using the method suggested by Hunger et al. [16], i.e., \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${y}^{*}=\left[y\times \left(N-1\right)+0.5)\right]/N$$\end{document} where \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$N$$\end{document} denotes the total number of observations. We modelled the corresponding longitudinal decrements using the \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$logit$$\end{document} link function. The beta-based model predictions were then back-transformed to obtain HSUV predictions ranging from −0.53 to 1, comparable to those of the other models. Hence, predicted HSUVs are the outcome of each model, regardless of whether it belongs to a linear-based or beta-based family.
For each model, we first included the time effect considering two evolution slopes before and after 1-year post-KT [10]. Then, all the characteristics listed in Table 1 were considered possible baseline predictor and selected following the same procedure on the basis of likelihood-ratio tests: 1) univariate selection (p < 0.20), 2) and then a forward selection (p < 0.05). ALDVMMs including 1 and 2 classes were estimated using this procedure and the one with the lowest BIC was ultimately retained.Table 1. Characteristics of the recipients and donors in the cohort at the time of transplantation (n = 2,787)Quantitative characteristicsMissingMean (± SD) Recipient age (years)050.0 (± 14.2) Donor age (years)751.6 (± 15.7) Time spent on dialysis (years)122.5 (± 3.3)Categorical characteristicsMissingEffective (%) Recipient men01,757 (63.0) Recipient Body mass index2 Less than 18 kg/m^2^ In between 18 and 30 kg/m^2^ Higher than 30 kg/m^2^119 (4.3)2,331 (83.7)335 (12.0)First transplantation02,378 (85.3)Recipient history of diabetes0378 (13.6)Recipient history of cardiovascular disease0961 (34.5)Recipient history of neoplasia0320 (11.5)Recipient history of hypertension02,414 (86.6)Relapsing initial nephropathy0784 (28.1)Missing, number of missing values; SD, standard deviation
We assessed the goodness of fit as follows. Performances were reported with root mean squared error (RMSE) and mean absolute error (MAE). We also evaluated the models’ calibration, i.e., their ability to accurately predict HSUVs across the whole prediction range. The models’ calibrations were graphically evaluated by comparing the observed versus predicted HSUVs in subgroups corresponding to each decile of predictions [22]. The calibration curve was obtained by linearly regressing the observed HSUVs and the predicted deciles [23]. The closer the regression coefficients of this linear regression are to an intercept of 0 and a slope of 1, the more the calibration can be considered reasonable. We also evaluated the model proposed by Li et al. using the same metrics. We performed a sensitivity analysis by fitting the models only on first-time KT recipients (Online Resource 2).
All analyses were performed using R software version 4.3.1 [24]. We provide the complete R code enabling HSUVs prediction under a gitlab repository, as well as a user-friendly R Shiny application available at https://sphere-inserm.fr/en/jm-qalys.
Results
Description of baseline characteristics
The demographic and clinical characteristics of the KT recipients are reported in Table 1. Among the 2,789 patients, the mean age at transplantation was 50.0 (± 14.2) years and the mean BMI was 24.6 (± 4.4) kg/m^2^. The studied sample included 1,757 men (63.0%), 378 patients (13.6%) with history of diabetes, 961 (34.5%) with history of cardiovascular disease and 2,378 (85.3%) transplanted for the first time.
Description of the follow-up
In the whole studied sample, 5,679 completed EQ-5D-3L questionnaires were collected. The number of questionnaires per patient ranged from 1 to 10: 1,430 (51.3%) patients completed one questionnaire, 634 (22.7%) completed two and 723 (25.9%) completed at least three. HSUVs and completion time distributions are represented in Figs. 2a and b.Fig. 2. Distributions for EQ-5D-3L health-state utility values (part a) and EQ-5D-3L questionnaire completion time post-kidney transplantation (KT) (part b)
Among the 5,679 completed questionnaires, 1,132 (19.9%) were completed during the first year post-KT, while 4,547 (80.1%) were completed later, up to 29.5 years post-KT. Patients’ median latest questionnaire completion time was 5.0 years. The EQ-5D HSUVs ranged between −0.497 and 1.00 throughout the questionnaires, with a mean of 0.82 (± 0.23). Few patients reported low HSUVs (first decile = 0.487). As previously described [18], many patients (n = 2,250, 39.6%) reported the best possible health-state, which corresponds to a HSUV of 1. Online Resource 3 illustrates the longitudinal evolution of the observed HSUVs in four subgroups of patients according to sex and diabetes (Figure S1).
Selection of the models
Calibration plots (Fig. 3) revealed a good adequation between predicted and observed HSUVs for the linear mixed model, which outperformed the other models in this area.Fig. 3. Predicted versus observed health-state utility values (HSUVs) for the five models. The predicted HSUVs were grouped by deciles, and the black dots represent the means of the observed and predicted HSUVs for each group. The green lines represent perfect calibrations. \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${\beta }_{0}$$\end{document} and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${\beta }_{1}$$\end{document} are the intercept and slope, respectively, obtained by linearly regressing* the observed HSUVs and the ten predicted deciles (a perfect calibration corresponding to \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${\beta }_{0}=0$$\end{document} and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${\beta }_{1}=1$$\end{document} ). LME: linear mixed effect model; ALDVMM: adjusted limited dependent variable mixture model. * Li’s model’s 5th decile and the 2-class ALDVMM’s 1st decile were detected as outliers by analysing studentized residuals and Cook’s distance and excluded for \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${\beta }_{0}$$\end{document} and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${\beta }_{1}$$\end{document} estimation
The 2-class ALDVMM, which resulted in a lower BIC than the 1-class alternative, was selected as the candidate ALDVMM. It showed a good calibration across most of the prediction range, except the lowest decile which was overestimated. The beta and 2-part beta models both showed a poor calibration across the whole prediction range: the first consistently overestimated HSUVs, while the second overestimated low scores and underestimated high ones. The model proposed by Li et al. also substantially overestimated the HSUVs in our sample.
The RMSE, MAE and prediction range resulting of each model’s predictions are reported in Table 2. The inclusion of a larger set of covariates along with the consideration of questionnaires completed at different times of patients’ post-KT follow-up resulted in quite larger prediction ranges than those of the model proposed by Li et al. This was particularly the case for the two-part beta mixed model, which was able to predict both lower and higher HSUVs than the other models, and the closest HSUV prediction to 1 (prediction range from 0.357 to 0.990). This is further illustrated by Online Resource 3, in which the longitudinal predictions resulting from each model in four subgroups of patients according to sex and diabetes were represented along with the time spent since KT (Figure S2). Despite its poor calibration, the two-part beta model outperformed the other models both in terms of RMSE and MAE. Apart from this model, very little differences appeared from one model to another in terms of prediction errors.Table 2. Root mean squared error (RMSE), mean absolute error (MAE) and prediction range for each modelRMSEMAEPrediction rangeLinear mixed model0.2230.165[0.448, 0.975]Beta mixed model0.2280.154[0.415, 0.952]Two-part beta mixed model0.1920.127[0.357, 0.990]2-class mixed ALDVMM0.2250.162[0.625, 0.932]Model proposed by Li et al.^^0.2300.169[0.718, 0.883]^^Model 7 from Li et al.’s Table 3, including recipients’ age, diabetic status and sex as predictors
The linear mixed model for HSUV prediction
The linear mixed model, which showed the best calibration, is presented in Table 3. Being a woman, recipient age, history of diabetes, history of cardiovascular disease, a BMI greater than 30 kg/m^2^, and time in dialysis, were associated with lower baseline HSUVs. The most significant characteristics were diabetic status (−0.091 ± 0.013) and female sex (−0.074 ± 0.009), whereas recipient age (−0.002 ± 0.0003), time spent on dialysis (−0.009 ± 0.001), having a BMI greater than 30 kg/m^2^ (−0.037 ± 0.013) or the presence of cardiovascular comorbidities (0.036 ± 0.009) resulted in significant but lower decreases in HSUVs. Moreover, the HSUV increased during the first year (slope of the evolution (years) = + 0.059 ± 0.012), whereas it decreased afterwards (slope of the evolution (years) = −0.006 ± 0.001), suggesting a rapid increase of HSUV during the first year post-KT followed by a slow decrease thereafter.Table 3. Multivariate linear mixed model of patients’ health-state utility values (n = 2,774, 13 patients excluded due to missing data on adjustment covariates)Coefficients95% CIpBaseline predictors Age (years)−0.002[−0.003, −0.001] < 0.001 Sex (men versus women)0.074[0.057, 0.091] < 0.001 Body mass index (> 30 kg/m^2^, vs ≤ 30)−0.037[−0.063, −0.012]0.004 History of diabetes (yes versus no)−0.091[−0.116, −0.066] < 0.001 History of cardiovascular disease (yes versus no)−0.036[−0.054, −0.018] < 0.001 Time spent on dialysis (years)−0.009[−0.011, −0.006] < 0.001Slopes of the evolution (years) Before 1-year post-transplantation0.059[0.035, 0.083] < 0.001 After 1-year post-transplantation−0.006[−0.007, −0.004] < 0.001Intercept: 0.881 (95% CI [0.842, 0.921]), SD of the random intercept: 0.231 (95% CI [0.211, 0.252]), SD of the random slope in the first year post-KT: 0.213 (95% CI [0.186, 0.241]), SD of the residuals: 0.122 (95% CI [0.118, 0.125])CI, confidence interval; KT, kidney transplantation; SD, standard deviation
The two-part beta mixed model for HSUV prediction
The two-part beta mixed model, which showed the best precision, is presented in Table 4. Consistent with the linear mixed model outcome, being a woman, recipient age, history of diabetes, history of cardiovascular disease, having a BMI greater than 30 kg/m^2^ and time in dialysis, were associated with both lower probability of reporting the maximum HSUV at baseline and higher decrements from it, i.e., lower baseline HSUVs.Table 4. Multivariate two-part beta mixed model of patients rescaled decrement in health-state utility values (HSUVs) (n = 2,774, 13 patients excluded due to missing data on adjustment covariates). A greater decrement indicates a lower HSUVZero-inflation modelCoef95% CIpBaseline predictors Age (years)−0.025[−0.035, −0.016] < 0.001 Sex (men vs. women)1.055[0.799, 1.310] < 0.001 Body mass index (> 30 kg/m^2^, vs ≤ 30)−0.464[−0.837, −0.090]0.015 Recipient history of diabetes (yes vs. no)−0.534[−0.904, −0.164]0.005 Recipient history of cardiovascular disease (yes vs. no)−0.541[−0.807, −0.276] < 0.001 Time spent on dialysis (years)−0.079[−0.117, −0.041] < 0.001Slope of the evolution (years) ≤ 1-year post-KT0.993[0.631, 1.355] < 0.001 > 1-year post-KT−0.070[−0.096, −0.044] < 0.001 Intercept: −0.403 (95% CI [−0.982, 0.176]), SD of the random intercept: 2.112 (95% CI [1.895, 2.353])Conditional modelCoef95% CIpBaseline predictors Age (years)0.008[0.005, 0.010] < 0.001 Sex (men vs. women)−0.229[−0.304, −0.153] < 0.001 Body mass index (> 30 kg/m^2^, vs ≤ 30)0.120[0.012, 0.230]0.030 Recipient history of diabetes (yes vs. no)0.382[0.276, 0.488] < 0.001 Recipient history of cardiovascular disease (yes vs. no)0.107[0.026, 0.188]0.009 Time spent on dialysis (years)0.030[0.019, 0.040] < 0.001Slope of the evolution (years) ≤ 1-year post-KT−0.222[−0.340, −0.105] < 0.001 > 1-year post-KT0.022[0.014, 0.030] < 0.001Intercept: −1.919 (95% CI [−2.104, −1.734]), SD of the random intercept: 0.766 (95% CI [0.676, 0.868]), SD of the random slope in the first year post-KT: 0.872 (95% CI [0.740, 1.027])CI, confidence interval; KT, kidney transplantation; SD, standard deviation
Diabetic status and female sex were again the most significant characteristics on the conditional model (respectfully, 0.382 ± 0.054 and 0.229 ± 0.039), while female sex and recipient age were the most significant characteristics on the zero-inflation model (respectfully, 1.055 ± 0.130 and −0.025 ± 0.005).
Time since KT was also estimated to have consistent effects with the linear mixed model, i.e., an increase in HSUVs and the probability of reporting the maximum HSUV during the first year post-KT (slope of the evolution (years) = −0.222 ± 0.060 in the conditional model and 0.993 ± 0.185 in the zero-inflation model) followed by a slow decrease thereafter (slope of the evolution (years) 0.022 ± 0.004 in the conditional model and −0.070 ± 0.013 in the zero-inflation model). The other candidate models are presented in Online Resource 1.
Discussion
We found that the linear mixed model was overall better calibrated than the alternative models in predicting the post-KT evolution of patients’ EQ-5D-3L HSUVs until they returned to dialysis or died, although the two-part beta mixed model resulted in the most precise predictions. Carefully chosen, both models can be useful to predict HSUVs for future cost-effectiveness studies, especially because the model proposed by Li et al. was associated with an unsatisfactory calibration and less precise predictions.
Building regression models to predict HSUVs is challenging because their distributions typically exhibit particular features such as boundedness, right skewness, multimodality and a mass of observations at the maximum value [18]. The linear framework has been widely used but theoretically fails to account for these features, raising questions about its appropriateness [15]. ALDVMMs were developed to better account for HSUV properties [18, 25–29]. Beta regression provides another flexible framework able to handle bounded and skewed distributions [16, 17, 30]. In addition, modelling the longitudinal evolution of HSUVs requires the hierarchical structure of the data to be considered [12]. This can be done by considering random effects in the previous parametric regressions.
In our study, the linear mixed model resulted in predictions of HSUVs as precise as most concurrent models, despite the latter’s theoretically sounder properties. This is consistent with the existing literature, which often reports small differences between the different classes of models precision-wise, in both cross-sectional [17, 27–34] and longitudinal settings[26, 35–37]. The mixed 2-class ALDVMM predictions were well calibrated, except for the lowest HSUVs, which were overestimated. Although ALDVMMs have been reported to perform better, especially for low HSUVs [26, 37, 38], the linear mixed model showed good calibration in our application even for the lowest prediction decile. The KT context might explain this finding: in our data, the HSUV distribution was unimodal with only few extremely low HSUVs. Moreover, the linear mixed model predictions all lied inside the possible range of HSUVs, which cancels out the theoretical limitation due to their bounded nature. Our study also highlights the importance of providing disease-specific prediction algorithms, as no one-fits-all model seem to exist.
Both beta-based models showed calibration issues. These issues have been previously reported to varying degrees for both beta models [16, 17] and two-part beta models [39], despite some literature indicating better results for these types of models [30, 31]. Although the beta distribution seemed a promising framework due to its boundedness and the flexibility allowed by its two shape parameters, the assumption that HSUVs would be beta-distributed does not seem to fit our data. However, the addition of zero-inflation substantially enhanced the precision of the predictions, resulting in better RMSE and MAE than the concurrent models.
The discrepancy between the two-part beta mixed model’s poor calibration but good precision can be explained by the lower variance of its predictions, especially for high HSUVs, as shown in Fig. 3. Hence, the choice of whether using it or the linear mixed model comes down to a trade-off between bias and variance. While one can be tempted to retain the model with the lowest RMSE, which is a criterion that reflects both features, we rather advise using the linear mixed model. Indeed, the two-part beta mixed model’s overestimation of low HSUVs and underestimation of high ones would result in biased QALYs estimation, should the model be applied to populations at either end of the scale. Nevertheless, we propose the use of both models in an online calculator enabling HSUV predictions from KT recipients'clinical characteristics, available at https://sphere-inserm.fr/en/jm-qalys.
Several previous studies aimed to predict the post-KT HRQoL [9, 40–43]. However, most of them used non-preference-based HRQoL measures that are unsuitable to obtain HSUVs, which are necessary to estimate QALYs and perform cost-effectiveness analyses. To the best of our knowledge, Li et al. [9] is the only study that proposed such a predictive model. However, we reported a poor calibration from our French cohort. Moreover, it consists of time-fixed predictions, assuming that the 6-month post-KT HSUV adequately reflects the whole prediction time range, with a limited number of predictors. Despite these differences, our proposed models and Li et al.’s find consistent effects, i.e., a negative effect of age, diabetes and female sex on patients’ HSUVs. Our proposed models are also consistent with studies that reported the association between KT recipients’ clinical characteristics and non-preference-based HRQoL metrics [40–42]. Indeed, patient’s age, female sex, presence of comorbidities and time since dialysis were found to be associated with lower levels of various HRQoL dimensions. It is harder to compare the effect of time post-KT evaluated in our models to this literature, which reports different time effects depending on the HRQoL dimension, while not using the same modelling as us, i.e., two slopes before and after 1-year post-KT. However, our models’ estimates showing a substantial increase in HSUV during the first year post-KT followed by a steadier state thereafter matches the shape of graft failure rate over time reported by Galichon et al. [10], which arguably supports the clinical relevance of this modelling choice. The observed HSUVs in the DIVAT cohort were also consistent with the previously published results, although they concern non-French populations. Indeed, we reported a mean HSUV of 0.823 whereas Li et al. reported an average 6-month post-KT HSUV of 0.827, Liem et al. reported an average EQ-5D-3L HSUV of 0.81 and Wyld et al. reported an average HSUV of 0.82 [9, 44, 45].
Our study proposes models for the time-dependent prediction of HSUVs, which may be used in practice to address the limited availability of preference-based quality-of-life measures for KT patients. These models could help estimate QALYs [46] and facilitate retrospective cost-effectiveness analyses based on clinical trials, as well as quasiexperimental studies using observational datasets and cohorts that did not collect HSUVs. Predicting patients’ utility may also be useful for populating Markov models in economic evaluations. Model-based CEAs are frequently used in studies supporting reimbursement or pricing decisions, as seen in the UK and France, for instance, and inputs for these models may sometimes be difficult to obtain. Finally, predicted HSUVs could also be useful in developing tools that support clinical decision-making.
Our study suffers from several limitations. First, we encountered difficulties in estimating random slopes, 1,430 out of 2,787 (51.3%) patients having only one measure of HSUV. Updating the proposed models in a few years with a higher number of EQ-5D questionnaires per patient would be relevant, notably to increase the precision of the long-term evolution. Second, we could not evaluate the models’ performances using an external validation sample, which questions the generalization of our findings to other countries. Third, the HSUVs were measured with the EQ-5D-3L rather than the EQ-5D-5L, which results in a lower sensitivity and potential ceiling effects due to the lower number of distinguishable health states [47]. However, the EQ-5D-5L was not associated with a French value set before 2020 [48], hence the use of the three-level version in the DIVAT cohort. Fourth, we did not investigate every aspect of the ALDVMM framework. Notably, we did not consider the inclusion of covariates in the class membership probability, nor the existence of more than two latent classes in the population. We also did not consider beta-regression mixtures in our candidate models. Although its relative simplicity may explain the rather disappointing results of our mixed ALDVMM, fitting the latter was already quite a challenge, which dissuaded us to add further complexity. Investigating the relationship between disease-specific QoL measures and the EQ-5D-3L HSUVs in patients suffering from chronic kidney disease-associated pruritus, Hernandez Alava et al. reported the performance of two-class and three-class ALDVMMs [49]. They observed similar performances of the two models in terms of RMSE and MAE. Studying the existence of more than two latent classes in the mixed ALDVMM framework would be an interesting perspective for our work. We limited our results to two-class ALDVMM because of convergence issues noted for three-class ALDVMM. This may be due to the insufficient sample size and number of observations per patient with respect to model complexity. Moreover, studies having considered beta mixtures as an attempt to improve ALDVMMs did not report clear improvements [26–29]. Fifth, we considered the evolution of the HSUV in two time periods: before and after 1-year post-KT. Alternative time cut-offs could also be relevant. Additionally, the HSUV evolution could be decomposed into more than two phases. Considering two phases in the first year post-KT may be a modelling option since it could correspond to an acute risk of surgical complications in the very early posttransplantation times and a higher risk of acute graft rejection just after this initial phase. Distinguishing KT recipients’ medium-term and long-term HSUV evolution (e.g., from 1 to 10 years post-KT and after 10 years post-KT) could also be relevant, although it would require sufficient long-term follow-up. However, the considered time periods were consistent with both the graphical examination of the observed data and the clinical considerations reported by Galichon et al. [10]. Finally, we considered only baseline characteristics along with time since KT in our models. Considering post-KT variables such as graft function or the occurrence of events is an interesting perspective that may improve the calibration of HSUV predictions.
In conclusion, we propose two predictive models of the post-KT EQ-5D-3L HSUVs until they returned to dialysis or died based on routinely collected clinical data, and we report their goodness of fit compared to other regression methods. Both of them outperformed the model proposed by Li et al. [9] which was associated with a lack of calibration in our French cohort. Although we advertise for the use of the linear mixed model, both may constitute a useful tool to allow for future model-based cost-effectiveness studies or studies using information from clinical trials that did not directly collect HSUVs. Therefore, we provide an online application to predict KT recipients’ HSUVs using either model. Future studies applied to international cohorts are important to support the external validity of our results.
Supplementary Information
Below is the link to the electronic supplementary material.Supplementary file1 (PDF 157 KB)Supplementary file2 (PDF 379 KB)Supplementary file3 (PDF 561 KB)
The reference list from the paper itself. Each links out to its DOI / PubMed record.