Catheter detection and segmentation in X-ray images via multi-task learning
Lin Xi, Yingliang Ma, Ethan Koland, Sandra Howell, Aldo Rinaldi, Kawal S. Rhode

TL;DR
This paper introduces a deep learning model that detects and segments catheters in X-ray images, improving accuracy and efficiency for real-time surgical guidance.
Contribution
A novel multi-level dynamic resource prioritization method for multi-task learning in catheter detection and segmentation.
Findings
The proposed method achieves a mean J of 64.37/63.97 for detection and segmentation multi-task.
Average precision over all IoU thresholds reaches 84.15/83.13 on validation and test sets.
The model balances accuracy and efficiency, suitable for real-time surgical applications.
Abstract
Automated detection and segmentation of surgical devices, such as catheters or wires, in X-ray fluoroscopic images have the potential to enhance image guidance in minimally invasive heart surgeries. In this paper, we present a convolutional neural network model that integrates a resnet architecture with multiple prediction heads to achieve real-time, accurate localization of electrodes on catheters and catheter segmentation in an end-to-end deep learning framework. We also propose a multi-task learning strategy in which our model is trained to perform both accurate electrode detection and catheter segmentation simultaneously. A key challenge with this approach is achieving optimal performance for both tasks. To address this, we introduce a novel multi-level dynamic resource prioritization method. This method dynamically adjusts sample and task weights during training to effectively…
Genes, proteins, chemicals, diseases, species, mutations and cell lines named across the full text — each resolved to its canonical identifier and authoritative record.
Click any figure to enlarge with its caption.
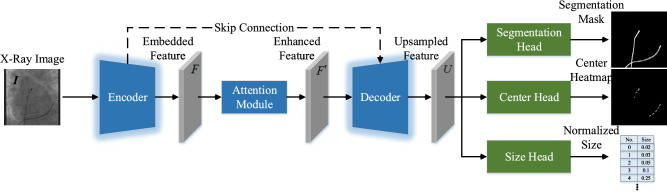 Figure 1
Figure 1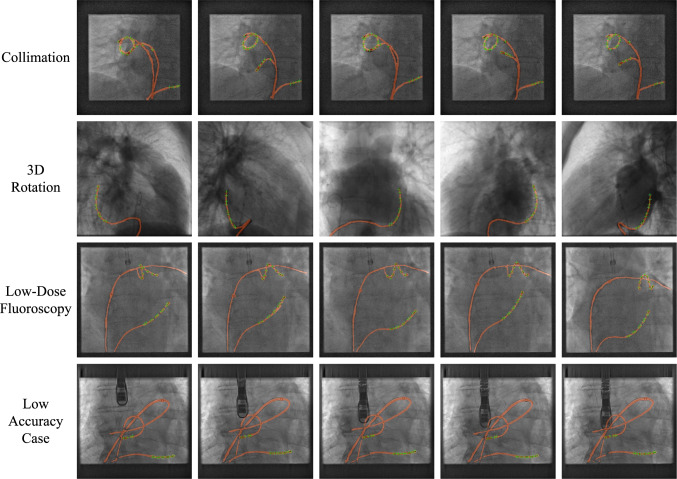 Figure 2
Figure 2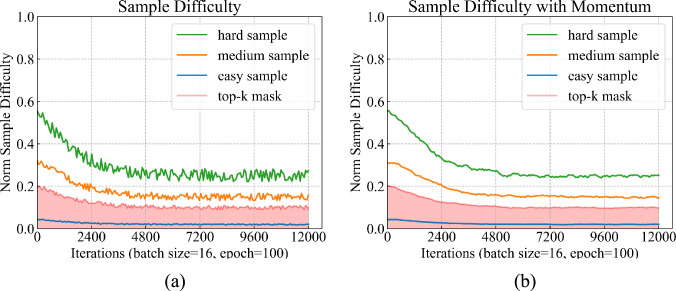 Figure 3
Figure 3- —http://dx.doi.org/10.13039/501100000266Engineering and Physical Sciences Research Council
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsAdvanced Neural Network Applications · Central Venous Catheters and Hemodialysis · Advanced X-ray and CT Imaging
Introduction
Minimally invasive heart surgeries are routinely carried out to treat heart diseases such as atrial fibrillation (AF), heart failure, congenital heart diseases, and more. The surgery is usually guided using X-ray fluoroscopy. Catheters and pacing leads in the form of wires are used as surgical devices to carry out the treatment and they are highly visible in X-ray images. However, heart chambers and blood vessels are hardly visible under X-ray. To enhance the procedure guidance, 3D models of heart chambers and blood vessels extracted from pre-procedural CT or MR scans can be overlaid on the top of X-ray images to add anatomical information [1]. To improve the accuracy of the enhanced guidance, motion compensation is added to the 3D models to allow them moving together with the patient’s cardiac and respiratory motions by tracking a stationary catheter or wire in X-ray images [2]. Furthermore, detecting catheters in X-ray images enables the automatic registration between 3D heart models and 2D X-ray images [3]. Finally, knowing the locations of catheters and wires may allow procedures with complete or shared autonomy with robots in the near future. For catheter detection, early work is focused on active contours and shape models [4, 5]. Recently, vessel enhancement filters were used to extract the body of catheters and identify the type of catheter [6, 7]. However, these methods are prone to errors due to image artifacts and the presence of other wire-like objects. Learning-based approaches have been developed to build a shape template to continuously track guidewires [8, 9]. They use manual feature extraction, and the methods are less robust when the image contains numerous wire-like structures and they only track one particular object.
Implementing a real-time unified model for both detection and segmentation tasks is essential for achieving a more accurate and streamlined integration approach in robotic systems. The most accurate two-stage object detection methods [10, 11] are not suitable for developing a unified model, and incorporating a one-stage object detection [12, 13] with a segmentation model [14–17] is challenging to achieve real-time speed. Our main goals are to determine the catheter location and region through more accurate and real-time catheter detection and segmentation algorithms, and then use post-processing algorithms to localize the electrode positions and wire centerline of the catheter.
The rise of deep learning (DL) for surgery instruments (i.e., catheter [18], ultrasound probes [19, 20]) detection and segmentation in X-ray images offers an opportunity for the development of robust catheter detection methods. DL-based methods, similar to humans, can perform multi-task learning by training on multiple tasks simultaneously, such as classification, detection, and segmentation [21–23]. Inspired by human learning processes [24], DL models allocate resources based on the complexity and difficulty of each sample and task, thereby improving the effectiveness and efficiency of the learning process [25–27]. Curriculum learning (CL) focuses on learning easy tasks first and harder ones later, distinguishing between basic and advanced tasks [25]. In the CL approach [28], tasks are broken down into subtasks that follow an easy-to-hard training strategy. However, CL can struggle in multi-task problems, as it assumes a consistent underlying distribution across tasks, which may not hold when dealing with different types, like segmentation and classification in medical imaging. Dynamic task prioritization (DTP) addresses this by encouraging the model to focus on difficult tasks [29] and embedding explicit task priorities into the neural network.
In this paper, we propose a multi-task framework with multi-level dynamic resource prioritization for medical image analysis. Inspired by CL [25, 28], our model is designed to prioritize difficult samples and tasks simultaneously, similar to the optimization of hard negative examples [30, 31] across different samples and tasks. This approach results in more generalizable features and improves object detection and segmentation, achieving performance that surpasses state-of-the-art (SoTA) methods on both public and private datasets. Our contributions are:
- A novel convolutional neural network architecture capable of object detection using a center heatmap and object segmentation.
- A novel multi-level dynamic resource prioritization training strategy for multi-task learning. It effectively allocates learning resources to difficult samples/tasks rather than easier samples/tasks at both a sample-level and task-level.
Methods
Network formulation
The model is designed in an encoder-decoder fashion since this kind of architecture is able to preserve low-level details to refine high-level global contexts. More specifically, our model comprises three key modules: encoder, attention module, and decoder. The overall framework of the model is shown in Fig. 1.
Fig. 1. The overview of our model. Given an X-ray image \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\boldsymbol{I}$$\end{document} , we utilize an encoder to embed it into a 512-dimensional embedding feature \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\boldsymbol{F}$$\end{document} and then fed into an attention module to produce enhanced feature \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\boldsymbol{F}'$$\end{document} . The enhanced features \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\boldsymbol{F}'$$\end{document} further fed into a decoder to recover resolution via a top-down manner with a skip connection. Finally, the output of the top-down decoder is passed to segmentation, center, and size prediction heads to obtain final results
The encoder takes the X-ray image \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\boldsymbol{I}$$\end{document} as the input. The encoder outputs an embedded feature map \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\boldsymbol{F}$$\end{document} attached to the backbone network. We take res4 features with stride 16 from the base ResNets as our backbone features and discard res5. A 3 \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\times $$\end{document} 3 convolutional layer without non-linearity is used as a projection head from the backbone feature to the latent feature space. We set latent feature dimensions to 512. The output of the embedding is a 2D map ( \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\boldsymbol{F}\in \mathbb {R}^{H\times W\times C}$$\end{document} ), where H is the height, W is the width, and C is the feature dimension of the backbone network output feature map.
Similar to attention map inference along two separate dimensions of CBAM [32], namely channel and spatial, we add an attention module \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$A(\cdot )$$\end{document} to apply temporal and spatial fusion for the embedding feature map \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\boldsymbol{F}$$\end{document} . The enhanced features \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\boldsymbol{F}'$$\end{document} are fed into a decoder. Features are processed and upsampled at a scale of two gradually with higher-resolution features from the attention module incorporated using skip-connections with an encoder. The final layer of the decoder produces a stride 4 feature \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\boldsymbol{U}$$\end{document} which is fed into the center, size, and segmentation heads and bilinearly upsampled to the original resolution.
Multi-level dynamic resource prioritization
We introduce a multi-level dynamic resource prioritization strategy for biomedical image analysis. Unlike the DTP in [29], which assigns different weights by the focal loss-like weighting strategy at the task level, our method directly adjusts the weights based on the performance metric across both samples and tasks. Additionally, unlike [33], our approach does not rely on task losses to determine the relative difficulty of tasks. Instead, we use more intuitive and realistic metrics for dynamically prioritizing tasks: task performance—also known as key performance metrics (KPIs) in [29]. To reasonably arrange resources, we define the notion of priority and discuss how we dynamically adjust it, based on training difficulty. There are two use cases: (i) sample-level priority and (ii) task-level priority.
Key Performance Indicators. For each task \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$T_{t}\ (t\in \{\texttt {d},\texttt {s}\})$$\end{document} , we select a key performance indicator (KPI) denoted by \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\kappa _{t}\in [0, 1]$$\end{document} and should be a meaningful metric such as accuracy or average precision, where \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\texttt {d}$$\end{document} and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\texttt {s}$$\end{document} represent the detection and segmentation task, respectively. For each task, we use mean absolute error (MAE) or root mean square error (RMSE) for the detection task and dice similarity coefficient (DSC) or intersection-over-union (IoU) for the segmentation task in the catheter dataset. We also define difficulty \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\mathcal {D}\propto \kappa ^{-1}$$\end{document} to sort samples and tasks ordered by the difficulty \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\mathcal {D}$$\end{document} .
In training process, we update \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\kappa $$\end{document} to be an exponential moving average \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\bar{\kappa }^{(\tau )}_{t}=\alpha \kappa ^{(\tau )}_{t}+(1-\alpha )\bar{\kappa }^{(\tau -1)}_{t}$$\end{document} where \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\tau $$\end{document} is the training iteration number and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\alpha \in [0, 1]$$\end{document} is the discount factor. Larger values of \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\alpha $$\end{document} prioritize more recent examples.
Sample-Level Prioritization. For task \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$T_{t}$$\end{document} , we first define the task-specific loss (e.g., cross-entropy) denoted by \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$L_{t}(\cdot )$$\end{document} . Since some samples may not be available for specific tasks \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$T_{t}$$\end{document} at a particular training time, we use \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\delta _{t, i}\in {0, 1}$$\end{document} to denote the availability of ground-truth data for sample i, task \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$T_{t}$$\end{document} . Then we use \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\delta _{t, i}$$\end{document} to mask task loss \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\mathcal {L}_{t}(\cdot )$$\end{document} is defined in
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\begin{aligned} \mathcal {L}_{t}(\cdot )=\frac{1}{N}\sum _{i=1}^{N}\delta _{t, i}L_{t}(p_{t}^{i},y_{t}^{i}), \end{aligned}$$\end{document}where i is the index of the training sample, \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$p_{t}^{i}$$\end{document} is the model’s output for sample i for task \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$T_{t}$$\end{document} , and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$y_{t}^{i}$$\end{document} is the ground-truth for sample i for task \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$T_{t}$$\end{document} .
We now describe how difficult samples are identified. Consider pixel-wise binary classification with cross-entropy (CE):
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\begin{aligned} \textrm{CE}(j)=-\log \left( \texttt{softmax} \left( p^{(j)} \right) \right) , \end{aligned}$$\end{document}where \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$p^{(j)}$$\end{document} is the model segmentation logit result for the j-th pixel.
We down-weight easier samples and focus on harder samples during training based on sample performance metrics. Let i denote the current sample index being considered from the dataset. Samples are ordered according to their difficulty \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\mathcal {D}_{S}(i)$$\end{document} . We assign different priorities to samples by using sample-level weights. After that, we solved masked weight \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\delta _{t, i}$$\end{document} by performing a hard assignment of the sample-level weights which is determined by the sample difficulty \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\mathcal {D}_{S}(i)$$\end{document} with a threshold of \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\eta $$\end{document} . Unlike [29], our weight parameters are discrete \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\delta _{t, i}$$\end{document} and defined by the threshold after top-k filtering [34]. In summary, the \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\delta _{t, i}$$\end{document} for sample i, task t can be computed by:
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\begin{aligned} \delta _{t, i}=\left\{ \begin{array}{ll} 0,& \quad \text {if}\ i\notin \texttt{Top}^{K}(\mathcal {D}_{S}(i))\\ 1 , & \quad \text {otherwise} \end{array}\right. , \end{aligned}$$\end{document}where \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\texttt{Top}^{K}(\mathcal {D}_{S}(i))$$\end{document} denotes the set of indices that are top-k filtering in the dataset.
Task-Level Prioritization. Similar to sample-level prioritization, we use task-specific KPI to assign weight to tasks. If the KPI \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\ll $$\end{document} 0.5, we can assume that task \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$T_{t}$$\end{document} is difficult for the model and this should be assigned more resources for training. To balance easy and difficult tasks, we proposed to scale each task-specific loss \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\mathcal {L}_{t}$$\end{document} by computing the task difficulty \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\mathcal {D}_{T}(t)=1/\bar{\kappa }_{t}$$\end{document} . Our dynamic resource prioritization loss \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\mathcal {L}_\textrm{total}$$\end{document} is:
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\begin{aligned} \mathcal {L}_\textrm{total}=\frac{1}{\bar{\kappa }_{t}}\mathcal {L}_{t}(\cdot ), \end{aligned}$$\end{document}To summarize, our total loss \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\mathcal {L}_\textrm{total}$$\end{document} uses learning progress signals (i.e., \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\bar{\kappa }_{t}$$\end{document} ) to automatically compute a priority level at both a task-level and sample-level. These priority levels vary throughout the training procedure. On the other hand, the DTP [29] is a focal loss-based approach with focusing parameters to sort the tasks and is easily influenced by hyperparameters.
For catheter detection and segmentation task, we define \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\kappa _{t}$$\end{document} as follow:
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\begin{aligned} \kappa _{\texttt {d}}=\text {MAE}(\mathcal {S}_\texttt {d})^{-1}\ \ \kappa _{s}=\text {IoU}(\mathcal {S}_\texttt {s}), \end{aligned}$$\end{document}where \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\mathcal {S}_\texttt {d}$$\end{document} and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\mathcal {S}_\texttt {s}$$\end{document} are training samples for detection and segmentation tasks.
Loss Functions There were two loss functions for multi-task learning for the detection and segmentation of catheters in X-ray images. That is, the final loss is
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\begin{aligned} \mathcal {L}_{\text {total}}=\frac{1}{\bar{\kappa }_{\texttt {d}}}\mathcal {L}_{\texttt {d}}+\frac{1}{\bar{\kappa }_{\texttt {s}}}\mathcal {L}_{\texttt {s}} \end{aligned}$$\end{document}For the catheter detection task, following [35], the loss function for catheter heatmap regression training is focal loss, and we use an L1 loss at the box size,
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\begin{aligned} \mathcal {L}_{\texttt {d}}=\mathcal {L}_{focal}+\lambda \mathcal {L}_{size} \end{aligned}$$\end{document}where \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\lambda $$\end{document} is set to 1.
For the segmentation task, we adopt the same loss function with [36] to jointly measure the prediction at the pixel level by binary cross entropy (BCE) loss as well as in the region level by IoU loss:
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\begin{aligned} \mathcal {L}_{\texttt {s}}(\hat{M}, M)=\mathcal {L}_{bce}(\hat{M}, M)+\mathcal {L}_{iou}(\hat{M}, M), \end{aligned}$$\end{document}where \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\hat{M}$$\end{document} denotes the segmentation prediction and M refers to the binary ground-truth.
Experiments
Experimental setup
Datasets and evaluation metrics. To train and test our model, we use a public dataset (UCL catheter segmentation dataset [37], 3000 images) and a private dataset. The private dataset contains 2450 X-ray images, which were acquired in 62 different clinical cases using two mono-plane X-ray systems (both are Philips X-ray systems) at St. Thomas’ Hospital London and University Hospitals Coventry & Warwickshire. All clinical cases are standard atrial fibrillation ablation procedures. The manual labeling of catheters and wires in X-ray images is very time-consuming and tedious. To speed the process up, vessel enhancement filters [38] were used to extract catheters and wires. The resulting image was automatically binarized by an adaptive binarization method [6]. Not all wires were labeled in our training data. As we are only interested in surgical devices inside the heart, stationary wires such as ECG leads and sternal wires from open-heart surgeries are not labeled. Therefore, an experienced clinician manually removed the non-target objects.Table 1. Quantitative results on the UCL catheter segmentation dataset and our catheter detection and segmentation benchmarks are reported using Average Precision (AP) and region similarity ( \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\mathcal {J}$$\end{document} )Methdos#Param.UCLCatheter detection and segmentationRuntimevalvaltestMSegmentationDetectionSegmentationDetectionSegmentationFPS \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\uparrow $$\end{document} Mean \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\mathcal {J}\uparrow $$\end{document} AP \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\uparrow $$\end{document} Mean \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\mathcal {J}\uparrow $$\end{document} AP \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\uparrow $$\end{document} Mean \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\mathcal {J}\uparrow $$\end{document} U-Net [42]34.5276.4581.7762.9080.2760.3965Attention U-Net [43]34.8776.2183.0863.5282.5361.2859U-Net++ [44]26.9076.4881.5862.9780.0660.2457U-Net 3+ [45]26.9776.3381.6462.7180.7160.1520TransU-Net [46]105.3276.5682.8963.0281.4360.8726MedT [47]1.3775.1380.0761.8878.5658.7215UNeXt [48]1.4775.1980.3862.3679.9958.99143Y-Net [49]7.4676.4981.8363.1380.3960.4484SwinU-Net [50]27.1474.0576.1359.4575.8656.48265CMU-Net [51]49.9376.4681.0163.2180.1160.6941CMU-NeXt [52]3.1476.5380.6763.1979.4760.53174SANet [53]23.9077.1883.3564.7882.8763.0176TransFuse [54]26.3376.5482.9663.8882.6361.84101FCN \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$^{*}$$\end{document} [14]29.2076.2679.9362.6477.5559.1641DeepLabV3 \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$^{*}$$\end{document} [15]35.8877.0782.4764.5580.9762.3831Ours \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$^{*}$$\end{document} 32.3977.21****84.15****65.37****83.13****63.9737The best performance scores are highlighted in bold \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$*$$\end{document} is use ResNet34 as the backbone. The abbreviation ‘M’ in the ‘#Param.’ cell represents a million
To test the performance of our multi-task learning strategy, we carry out comprehensive experiments and evaluate the model performance by object detection precision and region similarity. For the segmentation evaluation, we adopt a standard metric suggested by [39], namely region similarity \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\mathcal {J}$$\end{document} , which is the IoU of the prediction and the ground-truth. In the detection task, we report the average precision over all IoU thresholds (AP).
Implementation details. The backbone of the model is ResNet34 [40], for each input image of size \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$256\times 256 \times 1$$\end{document} , the image is down-sampled to the size of \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\left\{ 128, 64, 32, 16\right\} $$\end{document} in the first four layers of ResNet34. The channel dimension of the attention module is set to 512. For the prediction, we add a separate head for each prediction including segmentation, center, and size prediction heads, respectively. We implement each prediction head by using two 3 \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\times $$\end{document} 3 convolutional layers with 64 channels and a final 1 \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\times $$\end{document} 1 convolution then produce the desired output.
The whole network is trained using the AdamW optimizer ( \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\beta _{1}=0.9$$\end{document} and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\beta _{2}=0.999$$\end{document} ) with a learning rate of \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$10^{-4}$$\end{document} . We first initialize our model by pre-training for 100 epochs each on the Duke OCT [41] and UCL catheter segmentation [37] datasets. Then, we train our network for 100 epochs on our private dataset in the multi-task object detection and segmentation training stage using our proposed multi-level dynamic resource prioritization strategy. Data augmentation (e.g., scaling, flipping, and rotation) is also adopted for both images and video data. Our model is implemented in PyTorch. All experiments and analyses are conducted on an NVIDIA RTX 6000 GPU, and the overall training time is about 5 h.Fig. 2. Qualitative results of the proposed method on challenging scenarios from the catheter detection and segmentation dataset. The green crosses are the positions of electrodes. The orange mask indicates the segmentation results of the catheter
Comparisons with SoTA
We compare our proposed multi-task learning model with SoTA methods. Experiments are conducted on the val set of the UCL catheter segmentation dataset, as well as on the val and test sets of our private dataset. The UCL dataset is primarily used to evaluate performance on the single-task segmentation, while the private dataset is used to assess the effectiveness of the proposed model in a multi-task learning setting. Detailed results are presented in Table 1, including comparisons with several biomedical image analysis methods, i.e., U-Net [42], Attention U-Net [43], U-Net++ [44], U-Net 3+ [45], TransU-Net [46], MedT [47], UNeXt [48], Y-Net [49], SwinU-Net [50], CMU-Net [51], CMU-NeXt [52], SANet [53], TransFuse [54], FCN [14], and DeepLabV3 [15], selected from the biomedical image analysis benchmark. Note that all methods are trained using the same dataset and the same training strategy, namely our proposed multi-task learning framework.
We observe that our proposed model delivers competitive performance on both the val and test datasets, compared to other existing methods. As shown in Table 1, our method achieves the results of 84.15% and 65.37% in terms of AP and mean \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\mathcal {J}$$\end{document} on the val set as well as 85.13% and 63.97% on the test set. Compared to Attention U-Net [43] and SANet [53], which are the best-performing methods in U-Net and ResNet-based architectures, our method based on a lighter weight architecture gives performance gains of 1.07%, 0.80% and 1.85%, 0.59% on AP and mean \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\mathcal {J}$$\end{document} on the val set, respectively. The same results can be observed on the test set. The results indicate that our proposed multi-task learning strategy can effectively improve the overall performance in object detection and segmentation. For the single segmentation task, our method achieves the best performance among all of the methods in terms of mean \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\mathcal {J}$$\end{document} . Compared to the second-best method SANet [53], our model achieves a gain of 0.03% in mean \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\mathcal {J}$$\end{document} .
The primary advantage of our architecture lies in its use of the first four layers of ResNet34, combined with an attention module implemented through the temporal and spatial fusion of the embedding feature map. This design enhances spatial stability, increases the attention receptive field, and helps recover important information lost in regions with attention values close to zero in the feature map. Additionally, the resolution of the X-ray images in both UCL dataset and catheter detection and segmentation dataset is 256 \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\times $$\end{document} 256. However, when images are downsampled across five layers of the encoder, the activated feature area for a slender foreground object, such as a catheter, is significantly reduced, making it challenging to maintain clear and consistent boundaries.
Figure 2 visualizes our multi-task model catheter detection and segmentation results with the last row being a low accuracy case (Sect. Conclusion and discussions). We choose some X-ray sequences from the catheter detection and segmentation dataset with the cases of collimation, 3D rotation, and low-dose fluoroscopy. It can be seen that our model can effectively detect and locate the position of the catheter, and our method is able to discriminate the target catheter from complex background distractors.
Ablation study
To demonstrate the influence of each component and hyper-parameters in our method, we perform an ablation study on the val set of our private catheter detection and segmentation dataset. The evaluation criterion is the object detection precision AP and the mean region similarity \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\mathcal {J}$$\end{document} .
Choice of Backbone. For the backbone selection, we have compared the performance of the proposed method with different backbones, including VGG16 [55], ResNet18 [40], ResNet34 [40], HRNet-W18 [56], and HRNet-W32 [56], as shown in Table 2. To verify of the overall performance of the multi-task learning strategy, we also define a new evaluation criterion, the mean KPI which denotes the average value of AP and mean \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\mathcal {J}$$\end{document} .Table 2. Comparison of the several different backbones, measured by the AP, mean \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\mathcal {J}$$\end{document} , Mean KPIs and FPSBackboneAP \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\uparrow $$\end{document} Mean \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\mathcal {J}\uparrow $$\end{document} Mean KPI \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\uparrow $$\end{document} FPS \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\uparrow $$\end{document} VGG16 [55]82.9762.7072.8457ResNet18 [40]83.7463.9273.8345ResNet34 [40]84.1565.3774.7637HRNet-W18 [56]83.2364.0873.6241HRNet-W32 [56]83.8765.5774.7229The best performance scores are highlighted in boldTable 3Single-task and state-off-the-art multi-task versus our proposed multi-task methodTaskAP \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\uparrow $$\end{document} Mean \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\mathcal {J}\uparrow $$\end{document} Runtime (s/frames) \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\downarrow $$\end{document} Single taskDetection84.96–0.021Segmentation–66.130.024 Multi-taskSelf-paced [57]83.24 ( \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$-$$\end{document} 1.72)63.94 ( \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$-$$\end{document} 2.19)0.031DTP [29]83.88 ( \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$-$$\end{document} 1.08)64.28 ( \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$-$$\end{document} 1.85)0.027Ours84.15 ( \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$-$$\end{document} 0.81)65.37 ( \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$-$$\end{document} 0.76)0.027The best performance scores are highlighted in bold
The results of the Table 2 show that the ResNet34 achieves the best performance in terms of AP and mean KPI. The HRNet-W32 backbone achieves the best performance in terms of mean \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\mathcal {J}$$\end{document} , and the VGG16 outperforms in the terms of FPS due to its light-weight architecture but not in terms of accuracy. In summary, the ResNet34 backbone achieves the best trade-off between performance and speed, with a frame rate of 37 FPS. Therefore, we choose ResNet34 as the backbone for the proposed method.
Effectiveness of learning strategies. We evaluate the effectiveness of our overall learning strategy as defined in Eq. (6). Specifically, we compare the performance of our model, trained simultaneously on both tasks using Eq. (6), against single-task specific models. These single-task models employ the same architecture outlined in Section “Network formulation” but are trained exclusively on a single task. Notably, the single-task models are optimized for detection and segmentation tasks separately, representing their respective optimal training targets. The results of this comparison are presented in Table 3.
As shown in Table 3, our proposed multi-level dynamic resource prioritization achieves an AP score of 84.15% and a mean \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\mathcal {J}$$\end{document} score of 65.37% in the multi-task learning setting. Compared to other multi-task learning strategies, such as Self-Paced [57] and DTP [29], the proposed method demonstrates precision scores for detection and segmentation that are closest to the optimal results achieved by the single-task models. Furthermore, our method achieves both detection and segmentation tasks with a runtime of 0.027 s per frame, significantly outperforming multiple single-task models, which require a combined runtime of 0.045 s (0.021 for detection and 0.024 for segmentation).
In addition, the proposed sample-level prioritization uses performance metrics to weight samples, and a threshold-based parameter \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\delta _{t, i}$$\end{document} is applied to filter out easy samples, thereby accelerating the training process. We have compared the speed of convergence with DTP and other examples of weighting/filtering methods used in our proposed method, as shown in Table 4.
The main reason for the rapid convergence of our method is that the easy samples are filtered out using a threshold, allowing the model to focus more effectively on the difficult samples.
Task weight. Table 5 reports the performance of the multi-task total loss function 6 with respect to the different weights \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\kappa _{\texttt {d}}$$\end{document} and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\kappa _{\texttt {s}}$$\end{document} . We compared the constant, variable weighting strategy with our proposed methods.Table 4. The speed of convergence comparison with DTP on the val set of the catheter detection and segmentation datasetMethodsConvergence speed (h)DTP [29]6.1 Oursw/. Soft assignment6.2w/. Hard Assignment5.3w/. \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\texttt{Top}^{K}$$\end{document} Soft assignment6.3w/. \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\texttt{Top}^{K}$$\end{document} Hard assignment5.5The best performance scores are highlighted in boldTable 5Ablation study of the task weightWeightsAP \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\uparrow $$\end{document} Mean \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\mathcal {J}\uparrow $$\end{document} Mean KPI \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\uparrow $$\end{document} \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\kappa _{\texttt {d}}\equiv 1$$\end{document} , \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\kappa _{\texttt {s}}\equiv 1$$\end{document} 82.8663.4573.16 \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\kappa _{\texttt {d}}\equiv 2$$\end{document} , \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\kappa _{\texttt {s}}\equiv 1$$\end{document} 82.9463.3973.17 \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\kappa _{\texttt {d}}\equiv 5$$\end{document} , \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\kappa _{\texttt {s}}\equiv 1$$\end{document} 83.5763.2273.40 \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\kappa _{\texttt {d}}\equiv 10$$\end{document} , \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\kappa _{\texttt {s}}\equiv 1$$\end{document} 83.7860.8772.33 \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\kappa _{\texttt {d}}\equiv 1$$\end{document} , \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\kappa _{\texttt {s}}\equiv 2$$\end{document} 82.7762.0672.42 \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\kappa _{\texttt {d}}\equiv 1$$\end{document} , \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\kappa _{\texttt {s}}\equiv 5$$\end{document} 82.7462.1172.43 \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\kappa _{\texttt {d}}\equiv 1$$\end{document} , \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\kappa _{\texttt {s}}\equiv 10$$\end{document} 82.4462.3972.42GradNorm [58]78.4656.2267.34Ours84.15****65.37****74.76The symbol ‘ \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\equiv $$\end{document} ’ indicates always equal to the constant valueThe best performance scores are highlighted in bold
For the constant weighting strategy, we directly set \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\kappa _{\texttt {d}}=\{$$\end{document} 1, 2, 5, 10, 1, 1, 1 \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\}$$\end{document} and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\kappa _{\texttt {d}}=\{$$\end{document} 1, 1, 1, 1, 2, 5, 10 \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\}$$\end{document} respectively. Adopting the constant weight loss function does not outperform our multi-level adaptive weighting strategy in terms of mean KPI. In multi-task learning with variable weighting schemes, GradNorm [58] which automatically adjusts weights for loss according to gradient achieves a 7.46% lower mean KPI compared to our method.
Resource prioritization metrics. We evaluate the different metrics for KPIs \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\kappa $$\end{document} to define sample and task difficulty \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\mathcal {D}$$\end{document} on the val set to get a better impression of the performance. Table 6 shows the results of the detection and segmentation metrics set by the MAE, RMSE, Focal Loss, and IoU, Dice, CE Loss.Table 6. Ablation study of the resource prioritization metricsMetricsAP \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\uparrow $$\end{document} Mean \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\mathcal {J}\uparrow $$\end{document} Mean KPI \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\uparrow $$\end{document} DetectionSegmentationMAEIoU84.15****65.37****74.76MAEDice84.0865.2274.65RMSEIoU83.9265.2674.59RMSEDice84.2864.8874.58Focal lossCE77.6559.7068.68The best performance scores are highlighted in bold
We notice that the detection and segmentation metrics defined by the Focal Loss and the CE Loss yield the worst performance compared to the definition by the precision metric. An improper metric is problematic, and the loss cannot reveal the difficulty of samples and tasks and guarantee that more learning resources are allocated to difficult tasks rather than easier ones. We also compare different precision metrics for the KPIs. We see that the KPIs based on the precision metrics outperform the loss-based KPIs, and the proposed method can achieve promising performance when we define the detection and segmentation KPIs by MAE and IoU respectively.
Sample prioritization strategies. Table 7 compares different sample prioritization strategies and shows the importance of sample-level resource prioritization for multi-task learning. We first sort all samples by the KPIs in the training procedure and apply 7 kinds of samples selected methods.Table 7. Ablation study of the sample selection strategySample sort and selected strategyAP \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\uparrow $$\end{document} Mean \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\mathcal {J}\uparrow $$\end{document} Mean KPI \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\uparrow $$\end{document} Soft assignment81.6861.2571.47Hard assignment ( \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\delta>$$\end{document} 0.5)83.4763.2273.80 \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\texttt{Top}^{30\%}$$\end{document} hard samples82.9261.0872.00 \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\texttt{Top}^{50\%}$$\end{document} hard samples83.1161.4672.29 \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\texttt{Top}^{70\%}$$\end{document} hard samples83.1962.8573.02Dynamic \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\texttt{Top}^{K}$$\end{document} soft assignment (70% \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\rightarrow $$\end{document} 30%)84.0364.2374.31Dynamic \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\texttt{Top}^{K}$$\end{document} hard assignment (70% \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\rightarrow $$\end{document} 30%)84.15****65.37****74.76The best performance scores are highlighted in bold
Fig. 3. Difficulty change curve of the selected samples during the training process. The x-axis represents the training iterations, and the y-axis represents the difficulty of the samples. The blue, orange, and green lines represent the easy, medium, and hard samples, respectively. The red mask represents the top-k filtering threshold, which retains 70% of the samples. a The difficulty curve of the samples without momentum update. b The difficulty curve of the samples with momentum update
If we select all of the samples for training and define the weights of each sample by their KPI metrics, such as soft and hard assignment methods, the mean KPI scores reach 71.47% and 73.80% respectively. And the training samples are selected with 30%, 50%, and 70% hard samples (defined by KPI) and the final KPI scores are 72.00%, 72.29%, and 73.02%. The optimal sample selection scheme is to dynamically select the number of samples (i.e., from 70% to 30% hard samples) during the training process based on the training iterations using the \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\texttt{Top}^{K}$$\end{document} algorithm to achieve the optical KPI scores of 74.31% and 74.76% respectively.
On the other hand, we randomly selected three samples (i.e., easy, medium, and hard samples) from the training set to visualize their difficulty change curve during training, as shown in the Fig. 3. We observe that the difficulty of the samples does not change significantly during the training process, especially when using the momentum update. More fluctuating and unstable samples are filtered out by the top-k algorithm, thus reducing disruptive signals.
Runtime comparison
To further investigate the computational efficiency of our proposed method, we report the inference time comparisons on the private datasets at 256 \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\times $$\end{document} 256 resolution. We compare our model with the SoTA biomedical image analysis methods that share their codes or include the corresponding experimental results. For the inference time comparison, we run the public code of other methods and our code under the same conditions on the NVIDIA RTX 6000 GPU. The analysis results are summarized in the last column of Table 1.
As shown in Table 1, our method achieves 37 FPS, surpassing that of DeepLabV3 [15], which has the same backbone architecture as our methods. Our model achieves a more favorable accuracy-efficiency trade-off than the existing best method SANet [53], while achieving higher accuracy. In practice, our model yields real-time speed.
Conclusion and discussions
In this paper, we present a novel convolutional neural network architecture capable of electrode localization using a center heatmap and catheter segmentation. We also propose a novel multi-level dynamic resource prioritization method for multi-task learning, designed to optimize performance across both tasks. Our method dynamically adjusts the weights of both samples and tasks based on their difficulty. Experimental results clearly demonstrates that our method outperforms existing state-of-the-art (SoTA) approaches in both electrode detection and catheter segmentation tasks, using our multi-task learning strategy. Furthermore, our method achieves real-time performance at 37 FPS, simultaneously detecting electrode positions and segmenting the catheter. On the other hand, using separate models for detecting electrode positions and segmenting the catheter may not achieve real-time performance due to the increased computational overhead and doubled inference time. Our framework’s output enables the recognition of electrode catheter types [6] based on electrode patterns. The computational cost of post-processing for this recognition is negligible, as it only involves a few dot-product and Euclidean distance calculations [6]. Finally, the computational cost of extracting the centerline from the catheter segmentation results is minimal, as it only involves removing neighbouring pixels and generating a one-pixel-wide skeleton [6].
By utilizing the outputs from our framework, we can develop numerous clinical applications for enhanced image guidance in cardiac interventional procedures. For example, it can be used for real-time motion compensation to improve the registration accuracy between the 3D roadmap and live X-ray fluoroscopic images. This can be achieved by computing a motion model using a stationary catheter, such as one positioned inside the coronary sinus [59]. It also can be used for enhancing the visualization of electrode catheters in 3D transesophageal echocardiography [60, 61] using both 3D echo image volume and live X-ray fluoroscopic images. Furthermore, our framework could pave the way for an advanced computer vision system in future surgical robots by providing real-time positions of each catheter.
The presence of similar objects or complex backgrounds can degrade the model’s performance, which explains why our method performs worse when multiple catheter-like object distractors are present. One such low accuracy case is shown on the last row of Fig. 2. This issue could be addressed by incorporating spatial constraints for each target object within the video sequence. In the future, we aim to extend our multi-task learning method to tackle more complex tasks and datasets, such as brain tumor classification, detection and segmentation, as well as melanoma segmentation and detection from skin images.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1Ren S, He K, Girshick R, Sun J (2015) Faster r-cnn: towards real-time object detection with region proposal networks. In: Advances in neural information processing systems (Neur IPS), vol 2810.1109/TPAMI.2016.257703127295650 · doi ↗ · pubmed ↗
- 2Long J, Shelhamer E, Darrell T (2015) Fully convolutional networks for semantic segmentation. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition (CVPR)10.1109/TPAMI.2016.257268327244717 · doi ↗ · pubmed ↗
- 3Chen L-C, Papandreou G, Schroff F, Adam H (2017) Rethinking atrous convolution for semantic image segmentation. ar Xiv preprint ar Xiv:1706.05587
- 4You C, Xiang J, Su K, Zhang X, Dong S, Onofrey J, Staib L, Duncan JS (2022) Incremental learning meets transfer learning: application to multi-site prostate mri segmentation. In: Distributed, collaborative, and federated learning, and affordable AI and healthcare for resource diverse global health. pp 3–1610.1007/978-3-031-18523-6_1PMC 1032396237415747 · doi ↗ · pubmed ↗
- 5Yang Y, Hospedales T (2016) Deep multi-task representation learning: a tensor factorisation approach. ar Xiv preprint ar Xiv:1605.06391
- 6Zhou X, Wang D, Krähenbühl P (2019) Objects as points. ar Xiv preprint ar Xiv:1904.07850
- 7Oktay O, Schlemper J, Folgoc LL, Lee M, Heinrich M, Misawa K, Mori K, Mc Donagh S, Hammerla NY, Kainz B, Glocker B, Rueckert D (2018) Attention u-net: learning where to look for the pancreas. ar Xiv preprint ar Xiv:1804.03999
- 8Zhou Z, Rahman Siddiquee MM, Tajbakhsh N, Liang J (2018) Unet++: a nested u-net architecture for medical image segmentation. In: Deep learning in medical image analysis and multimodal learning for clinical decision support. pp 3–1110.1007/978-3-030-00889-5_1PMC 732923932613207 · doi ↗ · pubmed ↗