MAGNET: Counterfactual samples synthesizing for mitigating hallucination in large language models
Byeong Su Kim, Beomsoo Kim, Beakcheol Jang, Sonia Vasconcelos, Sonia Vasconcelos, Sonia Vasconcelos, Sonia Vasconcelos

TL;DR
This paper introduces MAGNET, a method to reduce hallucinations in large language models by using counterfactual samples during fine-tuning.
Contribution
The novelty lies in using counterfactual samples to mitigate biases from pre-training data co-occurrence statistics.
Findings
MAGNET improved factual knowledge probing by 12% on the GPT-Neo 2.7B model.
It showed a 2.27% performance improvement in the TruthfulQA experiment on the GPT-Neo 125M model.
Abstract
Hallucinations are widely recognized as a significant drawback of large language models. Several attempts have been made to reduce the intensity of hallucinations. Among the various attempts, our research has been directed towards mitigating hallucinations caused by the co-occurrence statistics of pre-training corpora. We introduce Model-AGNostic countErfacTual synthesis and adaptive fine-tuning framework (MAGNET), a fine-tuning method that can mitigate the bias of co-occurrence statistics on large language models pre-training data when generating sentences. Our pipeline generates the counterfactual sample sentences and subject and object information for the counterfactual sample from the language model, and filters them to make sure they contain these three pieces of information before using them as fine-tuning data. Next, it utilizes both the generated counterfactual sample and the…
Genes, proteins, chemicals, diseases, species, mutations and cell lines named across the full text — each resolved to its canonical identifier and authoritative record.
Click any figure to enlarge with its caption.
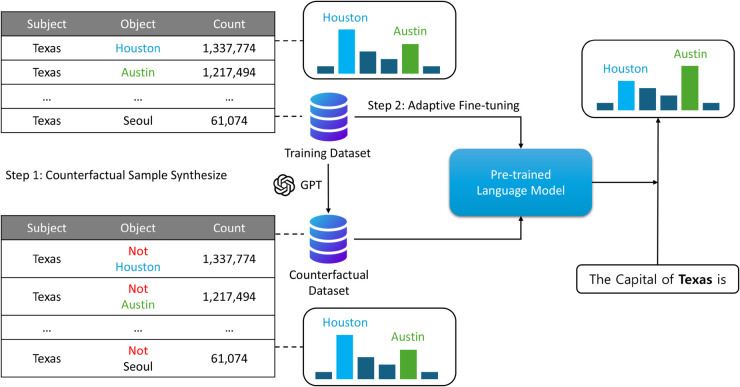 Fig 1
Fig 1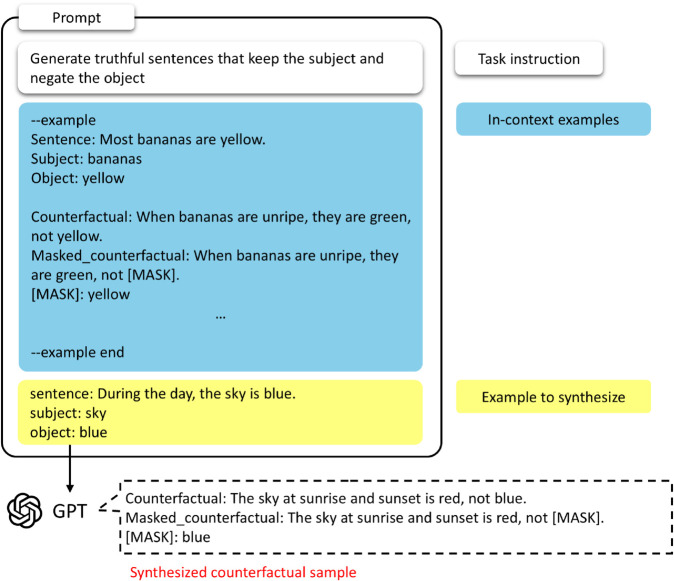 Fig 2
Fig 2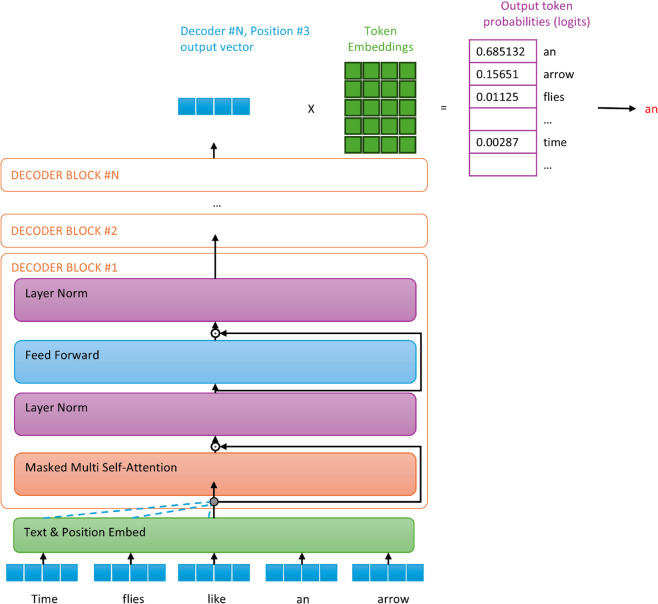 Fig 3
Fig 3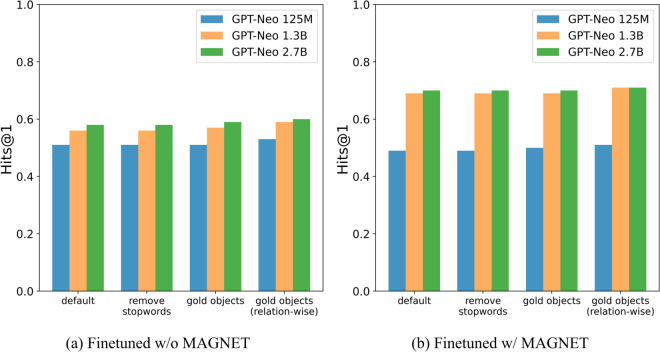 Fig 4
Fig 4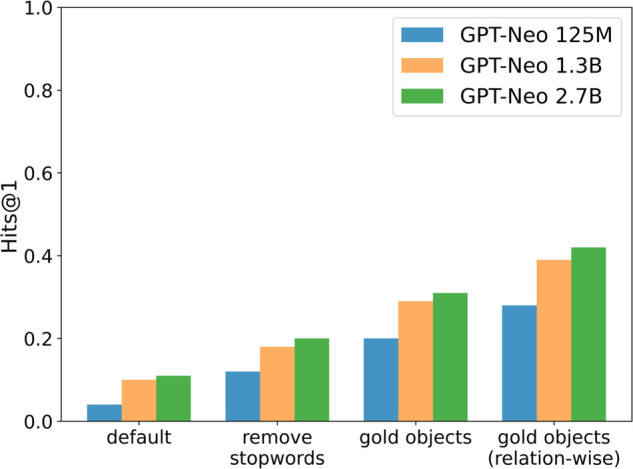 Fig 5
Fig 5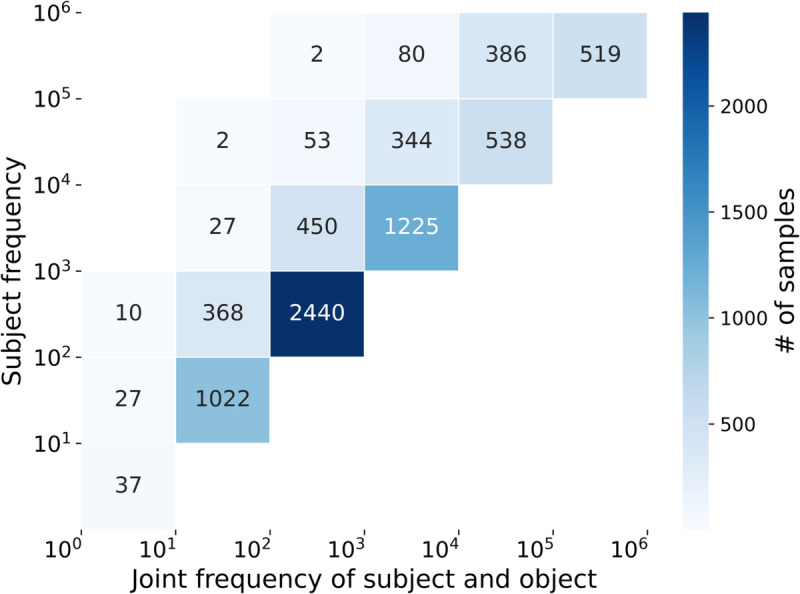 Fig 6
Fig 6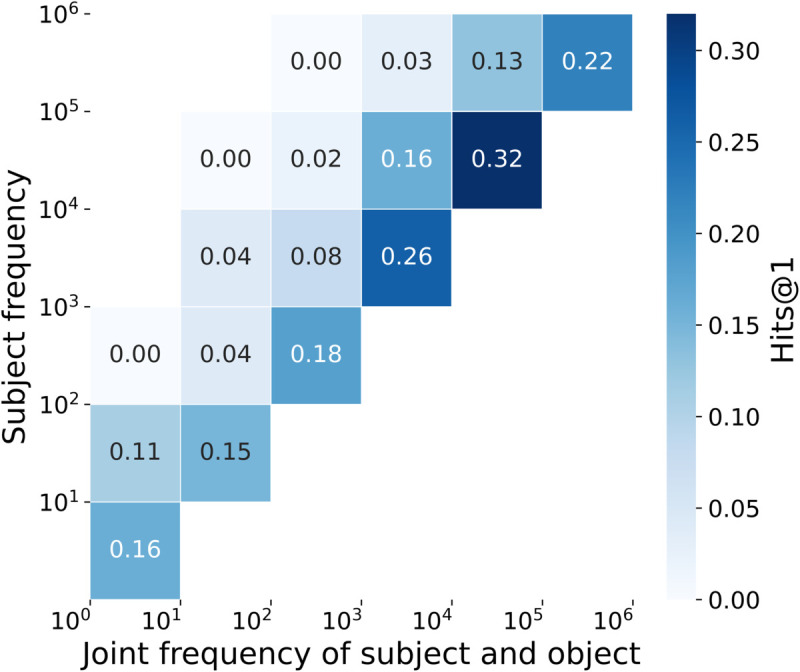 Fig 7
Fig 7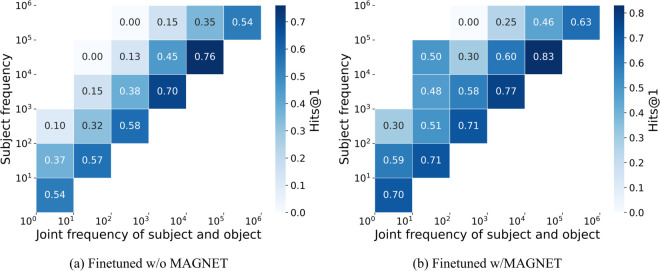 Fig 8
Fig 8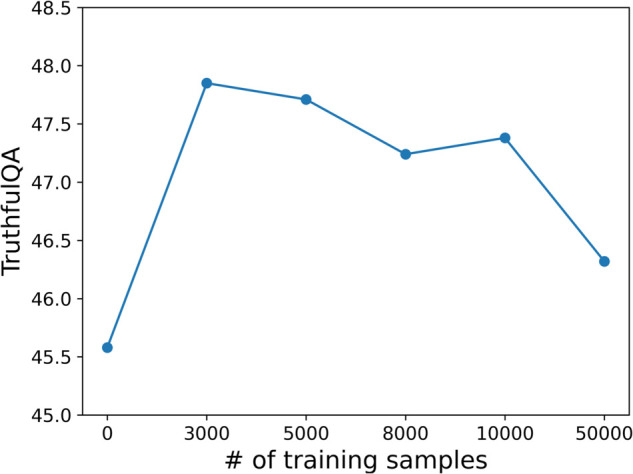 Fig 9
Fig 9- —Ministry of Education of the Republic of Korea and the National Research Foundation of Korea
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsTopic Modeling · Mental Health via Writing · Misinformation and Its Impacts
Introduction
Natural language processing (NLP) research has recently experienced rapid growth with the emergence of large language models (LLMs) [1,2]. LLMs have demonstrated strong performance across a wide range of NLP tasks, including natural language inference [3], question answering [4], common-sense reasoning [5], and translation [6]. They have also achieved significant gains in natural language generation tasks. However, the problem of hallucination—the generation of plausible but untruthful sentences—has attracted considerable attention. Early work focused on the likelihood-maximizing objective function used during training and decoding, showing that natural language generation models can produce sentences that are plausible yet nonsensical or untruthful [7,8].
Recent studies suggest that LLMs often learn spurious features, which can lead to untruthful sentences [9]. Inspired by [10], we identify co-occurrence statistics in pre-trained sentences as a major contributor to these spurious features. Kang et al. proposed a fine-tuning method that removes biased samples from the dataset. While this approach mitigates hallucination caused by high co-occurrence statistics, it can hurt generalization due to the reduced data size.
In this paper, we propose MAGNET (Model-AGNostic coutErfacTual synthesis and adaptive fine-tuning), a framework designed to address bias in fine-tuning datasets by generating counterfactual samples for all instances, rather than removing biased samples. Counterfactual samples have been widely used in NLP to mitigate spurious features such as co-occurrence bias [11], and several studies have leveraged them for data augmentation [12–15]. Most methods generate counterfactuals by identifying and replacing terms that play a crucial role in a sentence’s causality.
Using MAGNET presents two main challenges. First, generating counterfactuals to address subject-object co-occurrence bias requires extracting the subject and object, typically using part-of-speech (POS) tagging. In our approach, we directly utilize the subject and object information provided by LAMA-TREx. Second, counterfactual sentences should retain the subject while negating the object. This task requires broad knowledge and common-sense reasoning. To address this, we leverage GPT-3’s powerful few-shot learning ability to generate counterfactual sentences effectively.
Related works
Spurious features in language models
LLM often produces plausible sentences that have no basis in truth [8,16]; this is because LLM learns shortcuts by relying on spurious features when learning, and spurious features include word-overlap, priming, surface form, and co-occurrence [10,17–19].
Word-overlap is one of the shortcuts that predicts the answer to entailment, contradiction, or neutrality from the perspective of natural language inference by learning the frequency of words commonly used between premise and hypothesis. For example, “The doctors visited the lawyer” as a premise and “The lawyer visited the doctors” as a hypothesis is a non-entailment sentence. However, LLM, which has learned the word-overlap bias, judges it as an entailment sentence.
Priming is an unconscious form of human memory that involves the perceptual identification of words and objects [20]. It refers to the pre-contextual effect that influences the interpretation of new or unfamiliar information. For example, if you are asked to fill in the blank in ‘SO_P’ and you have recently heard the word ‘eat,’ you are more likely to complete the word with ‘SOUP,’ whereas if you have just come out of the bath, you are more likely to complete the word with ‘SOAP.’
Surface form refers to relying too heavily on the surface form of an entity name, such as predicting that a person with an Italian-pronounced name will speak Italian, regardless of the facts.
Co-occurrence implies that the subject and object occur simultaneously in the pre-training data. For example, if the pre-training data contains a total of 1,337,774 sentences with the subject ‘Texas’ and the object ‘Houston’ and 1,217,494 sentences with the subject ‘Texas’ and the object ‘Austin’, a model pre-trained on this data might output the word Houston when the sentence ‘The capital of Texas is’ is input, even though Austin is the correct answer.
These spurious features can help generate plausible sentences but are not suitable for generating factual sentences. In addition, existing evaluations have not been able to control these spurious features; therefore, new evaluation methods have been proposed [21]. The study [22] also found that removing spurious features reduced the accuracy of the model. In our study, we created a counterfactual sample to avoid overparameterization owing to spurious feature removal.
Counterfactual data augmentation
Recently, augmenting counterfactual data has emerged as a way to mitigate spurious correlations and increase model robustness [23]. [24] employed humans to augment counterfactual examples. They found that counterfactually generated data mitigated spurious patterns in the training data. However, these methods are expensive, time-consuming, and prone to human error. In contrast, there are two main methods for automatic generation: 1) rule-based methods using certain templates or patterns and 2) deep learning-based language models.
Rule-based methods include [25], which uses templates, and [26], which uses decision trees. Owing to the well-defined rules, this method produces well-balanced sentences as intended by the authors. However, owing to the complexity of the rules, the sentences generated are uncreative and too monotonous. In addition, rules may be followed too frequently, resulting in nonsensical sentences that are not applicable to the task. A recent study [27] proposed two ways to adjust the perturbation: adjusting the size of the word replacement in the sentence and adjusting the offset of the sentence matrix representation, to generate richer sentences.
There have also been attempts to use deep learning-based language models to generate counterfactual samples. One such example is Polyjuice [28]. Polyjuice combines a finetuned GPT-2 [29] model with control codes to generate a variety of sentences that match the control codes. [30] used LaMDA [31] to generate counterfactual samples; these are then subjected to human ratings to get a high-quality, diverse, and complex sample.
To generate counterfactual samples for common sense, we adopt the method of using deep learning-based language models to fully utilize the knowledge retrieval and reasoning capabilities of LLMs. Prompting is scalable because it allows pre-trained models to adapt well to various tasks and domains without parameter modification. LLMs such as GPT-3 [32] have shown strong zero-shot and few-shot performance with prompting.
Prompt tuning and fine-tuning
To improve the performance of LLMs, there have been two main methods, prompt tuning [33–38] and fine tuning, and GPT-3, in particular, has shown the possibility of solving various tasks with zero or few shot methods. However, manually writing prompts is not a simple task, and the proposed Mining-based Prompt tuning [39,40] and Learning-based Prompt Tuning [41,42] methods require prompt data that can be extracted and ranked, or learning additional models to rewrite prompts. [43] explains that finetuned LMs perform better at factual knowledge probing than prompt-tuned LMs, and while GPT-3 and T0 were designed to perform well on a variety of tasks without fine-tuning [32,44], recent research has shown that fine-tuning LLMs improves performance on reasoning [45], report generation [46], and more.
Materials and methods
Experimental setup
Target model.
We used GPT-Neo 125M, GPT-Neo 1.3B, and GPT-Neo 2.7B, which are open-source versions of GPT-3. The model is publicly available at Huggingface’s transformers [47]. The model is pre-trained on The Pile dataset. The Pile [48] is an open-source language modelling dataset that combines 22 small and high-quality datasets.
Training data synthesis details.
To generate the counterfactual sentences, we used GPT-3.5 Turbo and 10 in-context examples of common common sense. The samples were human-written and followed the rules of retaining the subject but negated the object. We mainly sample counterfactual sentences for biased examples, such as grass and green, animal and dog, which tend to co-occur in general.
From this generated sample, we formally checked that Counterfactual, masked counterfactual, and [MASK] generated the three items well.
Methods
In this section, we introduce MAGNET, a Model-AGNostic countErfacTual synthesis and adaptive fine-tuning framework. Fig 1 is an overview of MAGNET.
Proposed framework: Counterfactual generation and bias reduction.
MAGNET comprises two main steps:
Synthesize a counterfactual sample for the training dataset.Adaptive fine-tuning was performed on the data in the counterfactual sample and the corresponding existing training dataset.
In the following sections, we introduce how to synthesize counterfactuals of training data using GPT and adaptively fine-tune the language model between the generated data and the original data.
Training data synthesis.
The rule that the counterfactual sample in this study must follow is to negate the object while maintaining the subject.
We chose LAMA-TREx because it contains the subject and object information needed to comply with this rule and can provide the appropriate information for the prompts needed to synthesize the sample.
In addition, we used GPT-3 to generate counterfactual samples. Existing methods for performing knowledge-based related tasks retrieved external knowledge from various sources of knowledge graphs [49–51], Wikipedia [52,53] and web search [54,55]
However, a recent study [56] shows that LLMs such as GPT-3 are particularly efficient in text-generation tasks; this is due to the LLM’s superior knowledge retrieval and reasoning capabilities.
We go through the same process as in Fig 2 to synthesize fine-tuning data for the language model to mitigate bias in the co-occurrence statistics. The prompt P provided to the GPT (the full content of which is provided in S1 File) consists of a Task instruction T, In-context Examples I, and Example to synthesize E:
where T describes the rules that the counterfactual sample should obey and , which contains examples that generate counterfactuals for human-constructed commonsense.
GPT in-context learning for counterfactual sample generation.
Finally, the E consists of a sentence S to generate a counterfactual, a subject Sub for the sentence, and an object Obj for the sentence:
In the LAMA-TREx dataset, there are sentences for each fact, and these sentences are composed of masked_sentence with the object processed as [MASK], sub_surface, the subject information for the masked_sentence, and obj_surface, the object information.
Language model adaptive fine-tuning.
In our study, we performed adaptive fine-tuning to adjust the model for sentences based on triple-data to remove the bias for co-occurrence.
Instead of commonly used fine-tuning, for example, supervised fine-tuning for natural language inference and classification tasks, we reuse the next word prediction, which is an unsupervised pre-training already used for learning GPT.
Given a corpus of tokens K = , we use a standard language modeling objective to maximize the following likelihood:
where w is the context window size, i.e., the number of previous tokens that can be seen. And the conditional probability P is modeled by a neural network with parameters Θ. These parameters were learned using stochastic gradient descent [57].
GPT-Neo, which was used in our experiments, has the structure of a multi-layer transformer decoder because it is a large language model trained by exploiting the structure of the GPT. The model performs multi-head self-attention operations on input context tokens and applies a position-wise feedforward layer to generate output distributions over the target tokens:
where is the context vector for the tokens, n is the number of decoder layers, We is the token embedding matrix, and Wp is the position embedding matrix. The architecture of GPT-Neo is shown in Fig 3.
GPT-Neo architecture for next-word prediction, similar to GPT-3.
Results
Table 1 provides a concise overview of the datasets, benchmarks, and evaluation metrics used in our experiments. Each experiment category—Factual Knowledge Probing, Counterfactual Training (MAGNET), Bias Analysis, and General Evaluation—is associated with its respective dataset and metrics, offering a clear summary of the experimental configuration prior to discussing detailed results.
Table 1: Overview of datasets, benchmarks, and corresponding evaluation metrics for each experiment category.
Factual knowledge probing
Fig 4 shows the results of the Factual Knowledge Probing experiment in the study by [10], which investigates the factual knowledge of LLMs using the LAMA-TREx dataset. The sentences used for validation are represented as subject-relation-object triples and converted into natural language using a predefined template. For example, the triple ‘Texas’-‘capital’-‘Austin’ is converted to “The capital of Texas is Austin.” Each fact masks the object and is converted into a Cloze statement (e.g., “The capital of Texas is [MASK]”).
MAGNET effect on Hits@1: improves GPT-Neo 2.7B by 0.12 and 1.3B by 0.13; fine-tuning alone has minimal impact.
We trained the model for 3 epochs on 4 RTX 3090 GPUs. The batch size per device was 32, giving a total batch size of 128. The learning rate was 2e-5, and the Adam optimizer was used with and .
For fine-tuning, the input prompt follows the format “### Input:\n {X} \n\n### Response:”, where X is a masked sentence. For instance, “Hydatius has the position of [MASK].” The model is supervised to predict “bishop,” which is the expected answer. Details are provided in S2 File.
The factual knowledge dataset contains 20,587 samples. We used 10,294 original sentences and 10,294 counterfactual samples as random samples to train MAGNET. To evaluate the quality of counterfactuals, we computed Self-BLEU, which measures sentence similarity. The score of 0.4668 indicates moderate diversity, showing that the generated sentences are sufficiently varied while remaining natural and coherent. This balance is important for effective fine-tuning.
For evaluation, we used Hits@1. It is 1 if the correct answer is ranked first among predicted candidates, and 0 otherwise. Because LLMs are not specifically trained for factual knowledge probing, we tested three restricted output vocabularies: (1) remove stopwords, (2) gold objects, and (3) gold objects (relation-wise). The first excludes NLTK 3.8.1 stopwords. The second restricts candidates to gold objects in the entire dataset, while the third restricts them per relation.
Fig 5 shows Hits@1 under a zero-shot setting with limited candidate sets. MAGNET improves the score by 0.12 for the largest model and by 0.13 for the 1.3B model.
Zero-shot Hits@1: larger models and more restricted candidates yield higher scores.
Table 2 compares GPT-Neo 2.7B performance under different training strategies. The Baseline model does not address subject-object co-occurrence biases, resulting in moderate Hits@1 scores. Undersampling removes biased samples, reducing training data and diversity. This increases overfitting risk and lowers generalization, especially in Gold Objects and Relation-wise evaluations. In contrast, MAGNET generates counterfactual samples that negate frequent object associations while preserving subjects. Learning from both original and counterfactual data maintains diversity and improves generalization, yielding substantially higher Hits@1 scores across all evaluation scenarios.
Table 2: Comparison of Hits@1 performance on Factual Knowledge Probing across different training methods.
Correlation analysis
We analyzed co-occurrence statistics in the Pile dataset [48], a pre-training dataset for GPT-Neo, and correlated them with LLMs’ ability to probe factual knowledge. Entities with uncountable co-occurrence counts or consisting of more than three tokens (less than 6% of all entities) were excluded. We then computed correlations for (1) zero-shot, (2) fine-tuning alone, and (3) fine-tuning using MAGNET.
Fig 6 illustrates the number of samples in each joint subject-object frequency bin, organized according to the subject frequency bin.
Subject and joint frequency analysis in pre-training data for factual knowledge probing outputs.
Fig 7 shows co-occurrence correlations in the zero-shot setting. Hits@1 scores increase linearly with subject frequency up to approximately 10^4^-10^5^ for the joint subject-object frequency. However, for high-frequency subjects with relatively rare object occurrences, Hits@1 drops sharply. This indicates that LLMs struggle to predict rare facts due to co-occurrence bias.
Correlation between the conditional probability of subject-object pairs and Hits@1 in GPT-Neo 2.7B pre-training under the remove stopwords setting.
Fig 8 presents co-occurrence correlations for fine-tuning and MAGNET. Fine-tuning roughly doubles Hits@1 compared to zero-shot but still shows sharp drops for rare facts. MAGNET, in contrast, improves overall performance by approximately three times over zero-shot and shows a slower performance decline, even for rare subject-object pairs. For bins with subject frequency 10^3^-10^4^ and joint frequency 10^1^-10^2^, MAGNET demonstrates about threefold robustness to co-occurrence bias compared to zero-shot and slower decline than standard fine-tuning.
MAGNET’s impact on Hits@1: improves performance over fine-tuning, especially for rare subject-object pairs, with GPT-Neo 2.7B pre-trained under the remove stopwords setting.
Without MAGNET, GPT-Neo 2.7B produced 5,154 correct and 3,670 incorrect answers out of 8,824. With MAGNET, the model achieved 6,177 correct and 2,647 incorrect answers. This means 1,521 predictions changed from incorrect to correct, while 498 changed from correct to incorrect.
Among the 3,670 errors without MAGNET, 989 cases involved predictions of words with higher co-occurrence counts than the ground truth. MAGNET corrected 311 of these bias-induced errors (examples in Table 3). Conversely, of the 498 predictions that changed from correct to incorrect, 382 had higher conditional probabilities under the base model, indicating that MAGNET occasionally flipped answers despite the model’s original preference for the correct option (examples in Table 4).
Table 3: Examples where MAGNET corrected originally incorrect predictions.
Table 4: Examples where MAGNET flipped originally correct answers into incorrect ones (predictions with similar co-occurrence likelihoods).
Overall, MAGNET effectively corrects bias-induced errors, though it occasionally flips correct answers to incorrect ones. These cases typically occur when the object distribution for a subject is relatively uniform, meaning no single object dominates co-occurrence statistics. As a future direction, constraining counterfactual generation to subjects with strongly skewed object distributions could reduce unnecessary flips and further improve model performance.
Results for open LLM
We evaluated the impact of MAGNET on the target models across multiple benchmarks. In addition to TruthfulQA, we included HellaSwag and Winogrande, with results summarized in Table 5. For TruthfulQA, we used MC2 (Multi-true), which computes the normalized probability assigned to the correct answer set given multiple true/false options. HellaSwag and Winogrande were evaluated using multiple-choice accuracy, representing the proportion of correct selections among four candidate continuations and pronoun disambiguation questions, respectively.
Table 5: Evaluation of MAGNET’s generation performance compared to others.
Models were trained on 4 RTX 3090 GPUs for 3 epochs, using a batch size of 256 and a learning rate of 2e-5. The Adam optimizer was employed with and . All other procedures follow HuggingFace’s causal language modeling scripts [58]. Details of fine-tuning and evaluation are provided in S3 File.
We further investigated the effect of training data size on GPT-Neo 125M using MAGNET, as shown in Fig 9. These experiments were single runs.
Relationship between the number of GPT-Neo 125M fine-tuning samples and TruthfulQA scores, using MAGNET.
Overall, MAGNET effectively mitigates co-occurrence bias, reducing the likelihood of generating incorrect words with high co-occurrence probability. This improves the factual accuracy and truthfulness of model outputs.
Ablation study
To evaluate the quality of counterfactual sentences, we conducted generation experiments using 1-shot, 5-shot, and 10-shot prompt settings. Results are summarized in Table 6.
Table 6: Evaluation of counterfactual sentence generation performance across different n-shot prompts.
As Table 6 shows, increasing the number of shots improves the model’s ability to follow the prompt and produce correctly formatted outputs, enabling more effective data collection. The 10-shot setting consistently yielded the highest performance across benchmarks.
To ensure the factual accuracy of generated sentences, we performed human filtering to verify that the subject and object were preserved. Table 7 compares performance with and without this filtering.
Table 7: Evaluation of counterfactual sentence generation performance across different n-shot prompts, with and without human filtering.
Human filtering consistently improved performance, confirming that maintaining subject-object fidelity and factual consistency enhances model outputs.
We also compared counterfactual generation using GPT-3.5 Turbo and GPT-4 Turbo. Table 8 summarizes the results.
Table 8: Comparison of counterfactual sentence generation performance using GPT-3.5 Turbo and GPT-4 Turbo across benchmarks.
As shown, GPT-4 Turbo consistently outperformed GPT-3.5 Turbo across all benchmarks. These results emphasize the importance of generating high-quality, factually grounded counterfactual sentences while preserving the subject-object structure. They also indicate that using a sufficient number of in-context shots and leveraging more advanced LLMs can further enhance MAGNET’s effectiveness, improving both the factual robustness and truthfulness of the target models.
Discussion
The experimental findings indicate that MAGNET substantially improves the factual robustness and truthfulness of LLMs by addressing biases introduced by co-occurrence patterns in the pre-training data. In the Factual Knowledge Probing task, MAGNET fine-tuning resulted in a notable increase in Hits@1 accuracy across model sizes, particularly showing a 12% improvement in the GPT-Neo 2.7B model. In the TruthfulQA benchmark, which evaluates the truthfulness of generative responses, MAGNET consistently outperformed baseline models, with a maximum improvement of 2.27% in the GPT-Neo 125M setting.
These results validate our hypothesis that hallucinations in LLMs often stem from spurious correlations, particularly co-occurrence biases between subjects and objects in pre-training corpora. Traditional mitigation strategies—such as filtering out biased samples—tend to reduce data volume and hurt generalization performance. In contrast, MAGNET synthesizes counterfactual samples that negate the object while preserving the subject, offering a more data-efficient and scalable approach. This allows models to encounter alternative semantic structures during training without sacrificing data diversity.
Importantly, our analysis of the co-occurrence frequency in the Pile dataset revealed that LLMs tend to over-predict high-frequency object associations, even when they are incorrect. By introducing counterfactual samples that deliberately break these associations, MAGNET enables the model to better distinguish between frequency-based and fact-based predictions. This effect was most pronounced in low-frequency subject-object pairs, where traditional models performed poorly. With MAGNET, these rare factual associations were retained more accurately, suggesting enhanced model generalization and resistance to spurious correlations.
Nonetheless, the approach introduces certain trade-offs. A small portion of correctly predicted samples without MAGNET became incorrect after applying it. Our analysis indicates that this mainly occurred when the distribution of possible objects for a given subject was relatively uniform, i.e., no single object strongly dominated. In such cases, MAGNET sometimes flipped the prediction despite the ground truth having a higher conditional probability. Therefore, future improvements may benefit from mechanisms to dynamically weight or filter counterfactuals, especially in high-confidence cases.
In a broader context, MAGNET has implications for improving factual alignment in LLMs across tasks such as open-domain question answering, commonsense reasoning, and factual sentence generation. As the complexity and deployment scale of LLMs continue to grow, mitigating training-set-driven biases will become increasingly critical. MAGNET demonstrates a promising direction toward achieving this goal without compromising the scalability and efficiency of fine-tuning workflows.
Furthermore, extending MAGNET to more complex reasoning settings remains an important avenue for future work. For instance, multi-hop reasoning often requires chaining intermediate facts, where co-occurrence biases can propagate across steps. Integrating MAGNET with chain-of-thought prompting may help stabilize such reasoning by reducing spurious associations at each step. Similarly, in temporally sensitive tasks where factual correctness depends on evolving knowledge, combining MAGNET with retrieval-augmented generation (RAG) could ensure that counterfactual training remains aligned with up-to-date evidence. Together, these directions highlight the broader applicability of MAGNET beyond single-hop factual recall.
Conclusion
In this study, we introduced MAGNET, a model-agnostic counterfactual data synthesis and fine-tuning framework designed to mitigate hallucination in LLMs by addressing co-occurrence bias in pre-training corpora. Unlike prior approaches that remove biased samples at the cost of data volume and generalization, MAGNET augments training data with synthetically generated counterfactual sentences that retain the subject but negate the object. This enables models to learn more robust, factually grounded representations.
Our experiments demonstrate that MAGNET significantly improves performance across two key benchmarks. On the Factual Knowledge Probing task, we observed up to a 12% increase in Hits@1 accuracy, while in the TruthfulQA benchmark, MAGNET led to a 2.27% improvement in truthfulness for the GPT-Neo 125M model. Furthermore, correlation analysis confirmed that MAGNET reduces the model’s over-reliance on spurious co-occurrence patterns, particularly in low-frequency scenarios.
These results highlight MAGNET’s potential as a general-purpose bias mitigation technique for enhancing the factual reliability of LLMs. Its compatibility with various model sizes and architectures, along with its minimal reliance on manual annotation, makes it a scalable and practical solution. Future work may explore extending this framework to other forms of bias and broader NLP tasks.
Supporting information
S1 FilePrompts used to generate counterfactual samples.(PDF)
S2 FileData description of factual knowledge probing experiments.(XLSX)
S3 FileDescription of datasets used with MAGNET for the target model.(XLSX)
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1Touvron H, Martin L, Stone K, Albert P, Almahairi A, Babaei Y, et al. Llama 2: open foundation and fine-tuned chat models. ar Xiv preprint 2023. doi: ar Xiv:230709288
- 2Zhao WX, Zhou K, Li J, Tang T, Wang X, Hou Y, et al. A survey of large language models. ar Xiv preprint 2023. https://arxiv.org/abs/2303.18223
- 3Wang S, Fang H, Khabsa M, Mao H, Ma H. Entailment as few-shot learner. ar Xiv preprint 2021. https://arxiv.org/abs/2104.14690
- 4Chu Z, Chen J, Chen Q, Yu W, He T, Wang H, et al. A survey of chain of thought reasoning: advances, frontiers and future. ar Xiv preprint 2023. https://arxiv.org/abs/230915402
- 5Ji Z, Lee N, Frieske R, Yu T, Su D, Xu Y, et al. Survey of hallucination in natural language generation. ACM Computing Surveys. 2023;55(12):1–38.
- 6Tulving E, Schacter DL. Priming and human memory systems. Science. 1990;247(4940):301–6. doi: 10.1126/science.2296719 2296719 · doi ↗ · pubmed ↗
- 7Potamianos G, Jelinek F. A study of n-gram and decision tree letter language modeling methods. Speech Communication. 1998;24(3):171–92.
- 8Zhou N, Yao N, Zhao J, Zhang Y. Rule-based adversarial sample generation for text classification. Neural Computing and Applications. 2022;34(13):10575–86.