Correction for Participation Bias in Nonprobability Samples Using Multiple Reference Surveys
Victoria Landsman, Lingxiao Wang, Ivan Carrillo‐Garcia, Aya A. Mitani, Peter M. Smith, Barry I. Graubard, Trang Bui, Nancy Carnide

TL;DR
This paper introduces a new method to correct for participation bias in nonprobability samples by using multiple reference surveys, improving accuracy in health research.
Contribution
A general framework for addressing participation bias using multiple reference surveys, including calibration estimators and variance estimation methods.
Findings
The raking ratio calibration estimator performs well with highly dispersed participation probabilities.
Calibration estimators offer practical advantages when survey microdata is limited.
The proposed methods were successfully applied to a real-world study of working adults in Canada.
Abstract
Health researchers are increasingly adopting nonprobability sampling strategies in survey studies. However, the participation mechanism in such samples is unknown and estimated target parameters and exposure‐outcome associations obtained from nonprobability samples can be biased. Current approaches developed to support statistical inference from nonprobability samples are unable to accommodate more than one reference sample. In this paper, we propose a general framework to address participation bias in nonprobability samples using multiple reference surveys. Previously published methods that use one reference survey are special cases within this framework. We focus primarily on the calibration estimators, another important special case in the proposed framework. These estimators have greater flexibility in situations with limited access to survey microdata and are straightforward for…
Genes, proteins, chemicals, diseases, species, mutations and cell lines named across the full text — each resolved to its canonical identifier and authoritative record.
Click any figure to enlarge with its caption.
 Figure 1
Figure 1 Figure 2
Figure 2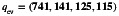 Figure 3
Figure 3 Figure 4
Figure 4 Figure 5
Figure 5 Figure 6
Figure 6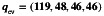 Figure 7
Figure 7 Figure 8
Figure 8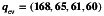 Figure 9
Figure 9 Figure 10
Figure 10 Figure 11
Figure 11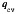 Figure 12
Figure 12| Estimator | Continuous outcome | |||||||
|---|---|---|---|---|---|---|---|---|
| Unweighted | −42.78 | 0.22 | 0.22 | 1.02 | 1.02 | 289.36 | 0.00 | 0.00 |
| TW | −0.19 | 4.43 | 4.85 | 0.78 | 0.79 | 4.83 | 90.30 | 90.40 |
| ALP | −0.12 | 3.91 | 4.62 | 0.74 | 0.76 | 4.34 | 89.00 | 89.20 |
| CLW | 0.00 | 4.02 | 4.76 | 0.73 | 0.75 | 4.47 | 89.47 | 89.60 |
| Calibration | 0.01 | 0.15 | 0.16 | 1.00 | 1.02 | 0.15 | 95.10 | 95.40 |
| Calibration | 0.00 | 0.14 | 0.15 | 0.97 | 0.99 | 0.15 | 94.07 | 94.03 |
| Calibration | 0.00 | 0.14 | 0.15 | 0.96 | 0.99 | 0.15 | 93.87 | 94.03 |
| Calibration‐PC | 0.00 | 0.14 | 0.15 | 0.96 | 0.99 | 0.15 | 93.87 | 94.03 |
| Estimator | Continuous outcome | |||||||
|---|---|---|---|---|---|---|---|---|
| ALP | −41.52 | 0.21 | 0.21 | 1.00 | 0.99 | 272.65 | 0.00 | 0.00 |
| CLW | −41.52 | 0.21 | 0.21 | 1.00 | 0.99 | 272.65 | 0.00 | 0.00 |
| Calibration | −41.53 | 0.21 | 0.21 | 1.00 | 0.99 | 272.68 | 0.00 | 0.00 |
| Calibration | −3.32 | 0.19 | 0.20 | 0.97 | 0.99 | 1.94 | 15.17 | 16.07 |
| Calibration | 0.02 | 0.17 | 0.19 | 0.97 | 1.02 | 0.18 | 94.53 | 95.53 |
| Calibration‐PC | 0.02 | 0.17 | 0.15 | 1.07 | 1.01 | 0.15 | 96.67 | 95.23 |
| Estimator | Continuous outcome | |||||||
|---|---|---|---|---|---|---|---|---|
| ALP | −35.26 | 0.24 | 0.25 | 1.00 | 1.00 | 196.72 | 0.00 | 0.00 |
| CLW | −35.26 | 0.24 | 0.25 | 1.00 | 1.00 | 196.67 | 0.00 | 0.00 |
| Calibration | −35.25 | 0.20 | 0.20 | 1.01 | 1.01 | 196.57 | 0.00 | 0.00 |
| Calibration | −1.06 | 0.16 | 0.16 | 1.00 | 1.01 | 0.33 | 80.00 | 81.00 |
| Calibration | −0.02 | 0.15 | 0.15 | 1.00 | 1.02 | 0.15 | 95.53 | 95.90 |
| Calibration‐PC | −0.02 | 0.15 | 0.15 | 1.01 | 1.02 | 0.14 | 95.77 | 95.63 |
| Estimator | Continuous outcome | |||||||
|---|---|---|---|---|---|---|---|---|
| ALP | −1.48 | 3.25 | 3.56 | 0.81 | 0.82 | 3.77 | 80.53 | 80.60 |
| CLW | −1.37 | 3.33 | 3.66 | 0.80 | 0.82 | 3.82 | 81.47 | 81.23 |
| Calibration | −1.07 | 0.17 | 0.18 | 0.96 | 0.98 | 0.36 | 80.43 | 81.20 |
| Calibration | −35.22 | 0.20 | 0.21 | 1.01 | 1.01 | 196.24 | 0.00 | 0.00 |
| Calibration | 0.01 | 0.33 | 0.41 | 0.98 | 1.10 | 0.34 | 94.67 | 96.60 |
| Calibration‐PC | −0.01 | 0.33 | 0.16 | 1.42 | 0.99 | 0.16 | 99.53 | 94.60 |
| Outcome: Work‐related injury | ||||||
|---|---|---|---|---|---|---|
| Estimator | Overall | Safety‐sensitive work | Non‐safety‐sensitive work | |||
| mean | SE | mean | SE | mean | SE | |
| Unweighted | 7.78 | 0.06 | 13.93 | 0.08 | 1.70 | 0.03 |
| ALP | 7.96 | 0.08 | 14.45 | 0.15 | 1.38 | 0.04 |
| CLW | 7.96 | 0.08 | 14.45 | 0.15 | 1.38 | 0.04 |
| Calibration | 7.77 | 0.08 | 14.15 | 0.15 | 1.38 | 0.04 |
| ALP | 8.69 | 0.09 | 14.98 | 0.15 | 1.73 | 0.05 |
| CLW | 8.69 | 0.09 | 14.98 | 0.15 | 1.73 | 0.05 |
| Calibration | 8.61 | 0.08 | 14.84 | 0.14 | 1.71 | 0.04 |
| Calibration | 7.76 | 0.08 | 14.09 | 0.16 | 1.36 | 0.04 |
| Calibration‐PC | 7.85 | 0.08 | 14.01 | 0.15 | 1.47 | 0.04 |
- —Canadian Institutes of Health Research10.13039/501100000024
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsSurvey Methodology and Nonresponse · Statistical Methods and Bayesian Inference · Advanced Causal Inference Techniques
Introduction
1
Large‐scale probability surveys are considered the gold standard in applied health research. These surveys are characterized by a rigorous sampling design that controls the selection mechanism of survey participants. More specifically, each participant is assigned a survey sampling weight to reflect their probability of selection (and thus the number of people in the target population they represent), allowing findings from the sample to be generalized to the target population. However, assembling such survey samples can be challenging due to the high cost of data collection, declining response rates, and the time required to develop accurate sampling frames from which potential participants can be sampled and recruited [1, 2]. To overcome these barriers, health researchers are increasingly adopting nonprobability sampling strategies and recruiting participants via in‐person settings (e.g., clinics, community centers), smartphone apps, social media platforms, membership lists, or opt‐in panels composed of individuals who have agreed to participate in surveys periodically. In contrast to large‐scale probability surveys, the participation mechanism in nonprobability samples is unknown. As such, nonprobability samples can often over‐ or under‐represent certain demographic, lifestyle, occupational, and health‐related characteristics in the target population, which can, in turn, lead to biased estimates of the target parameters. In addition, when factors associated with the outcomes and exposures of interest are associated with the decision of individuals to participate in the nonprobability sample, exposure‐outcome regression analyses can produce biased estimates of association parameters.
Recently, methods have been developed to support statistical inference from nonprobability samples, including the adjusted logistic propensity method [3] and the method proposed by Chen, Li and Wu [4] (see Sections 3.1 and 3.2 in that paper); hereafter called the ALP and CLW methods, respectively. The main premise behind these methods is to estimate an individual's probability to participate in a nonprobability sample using information from an external probability reference survey. The inverse of this estimated probability is a so‐called pseudo‐weight, similar to the survey sampling weight assigned to each individual in a probability survey. Specifying the participation model is the key step in the implementation of the ALP and CLW methods. All auxiliary variables that are potentially related to an individual's decision to participate in the nonprobability sample and are available in both the nonprobability sample and the reference survey should be harmonized to be included in the participation model.
Both ALP and CLW methods have been developed for a single reference survey that is assumed to contain all the auxiliary variables associated with participation in the nonprobability sample. However, in many practical situations, a single reference sample will lack some potentially important auxiliary variables. This was the case with the cannabis study sample discussed in Section 7, in which working‐age adults were interviewed about their cannabis use and perceptions of cannabis use at work. It is plausible to assume that variables related to both occupational and health characteristics may have determined an individual's decision to participate in this type of survey. However, no single available reference survey contained the information about both work and health required for specification of the participation model. Omitting important auxiliary variables from the participation model will lead to bias in the subsequent pseudo‐weighted analyses using the data from the nonprobability sample. While additional reference sample(s) may contain the potentially important missing auxiliary variables, currently available approaches are unable to accommodate more than one reference sample in the generation of pseudo‐weights. In this paper, we address this gap by describing a general statistical framework that allows for the integration of multiple reference samples to generate pseudo‐weights for nonprobability samples. This framework also includes the ALP and CLW methods for one reference survey as special cases.
The remainder of the paper is organized as follows. In Section 2, we define the problem, introduce the notation, and state the assumptions. We describe the general framework for estimation of pseudo‐weights and, consequently, the population means using one reference survey in Section 3. We also show that the ALP and CLW methods are special cases within this framework and describe the calibration estimator. In Section 4, we propose to extend this general framework to include multiple reference surveys, focusing our attention on the calibration estimator. Section 5 addresses variance estimation. In particular, we use the Taylor linearization method to derive analytic formulae for variance estimators and describe a leave‐one‐out jackknife variance estimator. In Section 6, we design and implement a simulation study to evaluate the performance of the different pseudo‐weighted estimators discussed in Sections 3 and 4. We then illustrate the application of these estimators in a real‐world example in Section 7. We conclude with a brief discussion in Section 8.
Problem Statement
2
Let FP denote the finite target population of size N and {yi,xi} denote the values of the outcome variable y and a set of L auxiliary variables xi=(xi1,⋯,xiL) for each i∈FP (recorded without measurement errors). The finite population mean μ=∑i∈FPyi/N is the target parameter in this study.
Suppose a nonprobability sample sc of size nc is obtained from FP and define δic to be the indicator variable that takes the value of 1 if i∈FP is included in the nonprobability sample sc and the value of 0 otherwise. We start with the positivity assumption about πic:=ℙ(δic=1|i∈FP), which is referred to as a participation probability.
Assumption 1Each unit in FP has a nonzero probability of being included in the nonprobability sample: πic>0 for each i∈FP.
The two inverse probability weighted estimators commonly used to estimate μ are the Horvitz–Thompson [5] (H‐T) and Hajek [6] estimators:
where N^=∑i∈sc(1/πic). Both estimators are consistent for μ under Assumption 1 and standard regularity conditions if the true participation probabilities πic are known [7]. Here, we focus on the Hajek estimator (μ^Hajek), as it has been shown to have better efficiency and is recommended even when N is known [8]. For brevity, we omit the subscript ‘Hajek’ and define μ^:=μ^Hajek.
The participation probabilities πic are generally unknown in the nonprobability sample and need to be estimated. Utilizing additional information from an available probability (reference) survey has been proposed to estimate these probabilities. For generality, assume that we have access to K≥1 probability surveys {spk}k=1K of sizes np1,np2,…,npK, respectively. Each reference survey is selected from the same finite population FP with known probabilities πi(pk):=ℙ(δi(pk)=1|i∈FP), where δi(pk) is the indicator variable that takes the value of 1 if i∈FP is selected in spk and the value of 0 otherwise, for k=1,…,K. We adopt the following assumptions about the selection processes of sc and spk.
Assumption 2For each i∈FP, the indicator variable δic and the response variable yi are independent given the set of L auxiliary variables in xi; that is, πic=ℙ(δic=1|yi,xi)=ℙ(δic=1|xi) for i∈FP.
Assumption 3The K≥1 reference surveys randomly selected from the same finite population FP with probabilities πi(pk)>0 (k=1,…,K and i∈FP) collectively contain all L auxiliary variables in xi so that Assumption 2 holds.
Assumption 4For each i,i′∈FP, the indicator variables δic and δi′c are independent given xi and xi′ for i≠i′.
Assumption 5For each i∈FP and 1≤k≠l≤K, the indicator variables δic, δi(pk), and δi(pl) satisfy cov(δic,δi(pk))=0 and cov(δi(pk),δi(pl))=0.
Assumptions 2, 3 reflect the noninformative participation in sc given the auxiliary variables x. The K reference surveys {spk}k=1K collectively contain these variables, which are also observed in the nonprobability sample sc. Under Assumption 4, Poisson sampling is used to approximate the selection process of sc in all variance derivations in this paper. However, variance derivations can be written under other complex designs if this assumption is not feasible and needs to be relaxed. Assumption 5 allows for elegant variance decomposition between different sources of variation involved in estimating probabilities πic. Importantly, the methods discussed in this paper are designed for situations in which outcomes of interest are measured only in the nonprobability sample and are not available in any of the reference surveys.
Estimation Using One Reference Survey
3
In this section, we assume that a single reference survey sp contains all the auxiliary variables so that Assumption 2 holds. We also assume a parametric model πic:=πc(xi,β), where β=(β0,β1,…,βL) is a vector of nuisance parameters and x=(1,x1,…,xL) is a vector of size L+1. There can be multiple choices for the functional form of πc(xi,β) (see Section 3.1 for examples). When the parametric model of πc(xi,β) is correctly specified, β can be estimated approximately unbiasedly by solving a class of L+1 estimating equations
where h(xi,β) is a prespecified vector‐valued smooth function of the same dimension as β and di=1/πip are the (known) sampling weights for the reference survey sp. The sample versions of these equations can be solved using a Newton–Raphson iterative algorithm, leading to a solution denoted by β^. Then, the resulting pseudo‐weighted Hajek estimator of the FP mean can be obtained by
Notice that although h(xi,β) is arbitrary, the choice of h(xi,β), combined with the functional form of w(xi,β), can result in different values of β^ and μ^(β^) with different efficiencies (see Section 6 for details). In the following, we describe two previously published pseudo‐weighting approaches as special cases of the general estimating equations approach above.
To make inference about the estimator μ^(β^) defined in (3), define η=μ,β⊤⊤ to be the vector of parameters. The estimator η^=μ^(β^),β^⊤⊤ combines μ^(β^) and the estimator β^ for the pseudo‐weights w(xi,β), that can be obtained by solving the following system of the estimating equations:
Under Assumptions 1, 2, 3, the estimating equations in (4) are unbiased in the sense that 𝔼cp[Φ(η0)]=0, where η0 is the true value of η and the expectation 𝔼cp is taken with respect to the joint distribution of the indicator variables δic and δip. The unbiasedness of the system of the estimating equations implies, under standard regularity conditions, the consistency of the estimator η^ using the theory of general estimating functions similar to those presented in Section 3.2 in Tsiatis [9], as well as in Binder [10] and Schiopu‐Kratina [11] for complex survey designs. Additionally, this theory allows derivation of the design‐based finite population variance of the estimator η^ as
where ϕ(η)= ∂Φ(η)/∂η . See Appendix A for the derivation of the analytic expression for 𝕍cp{μ^(β^)}.
Important Special Cases
3.1
The ALP and CLW Estimators
3.1.1
The ALP [3] and CLW [4] methods proposed in the literature can be formulated as special cases of the general estimating equations approach described above. Specifically, using
in (2), implies the estimating equations presented in Section 2.3 of the ALP paper [3]; and using
in (2) implies the estimating equations presented in Section 3.1 of the CLW paper [4]. We denote the solutions of these estimating equations as β^ALP and β^CLW, respectively.
Note that the ALP and CLW approaches assume different parametric forms of πc(xi,β), which, therefore, can lead to different values of β^, and, consequently, to the final estimates of μ^(β^), especially when the sample fraction of the nonprobability sample (i.e., fc=nc/N) is large [3].
The Calibration Estimators
3.1.2
Setting h(xi,β)=xi in (2) implies the estimating equations
that resemble the calibration equations in Deville and Särndal [12]. In our setting, the pseudo‐weights w(xi,β) for i∈sc are obtained by minimizing the averaged distance between the pseudo‐weights and the “naive” weights of 1 for all i∈sc under the condition (8). This condition ensures that the pseudo‐weighted totals of x from sc are equal to the survey‐weighted totals of x from sp. The parametric form of the weight function w(xi;β) is determined by the distance measure [12]. For example, the linear distance function is defined by w(xi;β)=(1+β⊤xi) and the multiplicative (also called raking ratio) distance function is defined by w(xi;β)=exp(−β⊤xi). To avoid negative pseudo‐weights that can be produced by the linear distance, we choose the raking ratio distance function and denote the corresponding solution of (8) as β^cal and refer to the corresponding estimator of the mean as the raking ratio calibration estimator.
Notice that the raking ratio calibration and the ALP methods are defined by the same parametric form of the weight function w(xi;β)=exp(−β⊤xi). Therefore, β^cal and β^ALP converge to the same true β if the weight function is correctly specified. However, β^cal and β^ALP can have different variances because the raking ratio calibration method uses h(xi;β)=xi, whereas the ALP method uses h(xi,β)=[1+w(xi,β)]−1xi. As a result, μ^(β^cal) and μ^(β^ALP) can have different efficiencies (see Sections 5 and 6 for theoretical and empirical results, respectively).
Estimation Using Multiple Reference Surveys
4
The calibration estimating equations in (8) can be extended further to the case where a single reference survey does not contain all the auxiliary variables that determine the individual's decision to participate in sc. For that purpose, assume that we have access to K>1 probability reference surveys {spk}k=1K (np1<np2<…<npK) sampled from the same target population FP, which collectively contain all L auxiliary variables. Let x(pk) define a vector of unique auxiliary variables available in both sc and spk. If the surveys contain overlapping variables, these will be selected from the largest survey, without loss of generality, to ensure that each auxiliary variable appears in each vector x(pk) (k=1,…,K) only once. Following this rule, a constant term ‘1’ that corresponds to the intercept β0 in the participation model is included together with the auxiliary variables of the largest survey. For example, let K=2,L=3 and np2>np1. Assume that {x1,x2} are observed in sp2 and {x1,x3} are observed in sp1. Then, x(p2)=(1,x1,x2) and x(p1)=x3. In this example, the overlapping variable x1 was selected from the reference survey sp2 because it is the largest survey.
Using this notation, the calibration estimating equations in (8) for one reference survey can be extended as
where x=x(pK)⊤,⋯,x(p2)⊤,x(p1)⊤⊤ is a vector of size L+1 and di(pk)=1/πipk, i∈spk are the (known) sampling weights in the reference survey spk for k=1,…,K.
Let β^cal be the solution to (9). The theoretical properties of the resulting Hajek estimator μ^β^cal follow from the unbiasedness of the estimating equations in (9) combined with the first equation in (4), similar to the case with one reference survey in Section 3. Using similar derivations to the case with one reference survey (see Appendix A), the analytic expression for the finite population variance 𝕍cpKμ^β^cal can be obtained as
where b⊤=UβSβ−1 with Uβ=N−1∑i=1Nπc(xi,β)(yi−μ)∂w(xi,β)∂β⊤ and Sβ=N−1∑i=1Nπc(xi,β)xi∂w(xi,β)∂β⊤; and D is a block‐diagonal matrix with diagonal blocks defined by the matrices Dk=𝕍pk∑i=1Nδi(pk)di(pk)xi(pk). The variances 𝕍pk are determined according to the sampling design of the k‐th reference survey spk.
The estimating equations in (9) require the estimated population totals of the auxiliary variables and the analytic variance formula (10) requires the corresponding variance estimates of these totals. These estimates can be obtained from survey microdata or from published resources provided by government agencies. This flexibility might be helpful in practical situations with limited access to survey microdata. The resulting calibration estimators also have a number of attractive features described in Section 6.
The Precalibration Procedure
4.1
The raking ratio calibration method proposed in Section 4 assumes that only unique variables are included in (9). However, certain auxiliary variables, particularly sociodemographic variables (e.g., age, sex, education) are routinely measured in probability surveys. In these situations, reference surveys will contain overlapping variables. To preserve the information on the relationships between the overlapping and the unique auxiliary variables within each reference survey, survey weights can be precalibrated such that the estimated weighted totals of the overlapping auxiliary variables, as well as the sum of the weights, are equal across the surveys. To illustrate this idea, consider the example above, in which x1 is an overlapping variable in the two surveys. In this case, the overlapping variable x1 will be selected from the larger reference survey (sp2). However, the weights of the smaller survey, sp1, can be precalibrated to ensure that the total of x1 and the sum of the weights are equal to the corresponding totals in sp2. Since the variable x1 in sp1 will not be used in (9), such precalibration procedure will ensure that the information on the relationship between x1 and x3 in sp1 is preserved in the precalibrated survey weights. In the case of no overlapping variables, the precalibration is performed only on the sum of the survey weights to ensure the same estimated size of the finite population. The precalibrated weights are further used in estimating equations in (9). In Section 6 we study the effect of the precalibration procedure on the bias and variance of the mean estimator under various simulated scenarios. The precalibration procedure requires access to the survey microdata and can be implemented using the function survey::calibrate [13] in R [14].
Variance Estimation
5
In this section, we describe two approaches for variance estimation: (1) the Taylor linearization approach to obtain the analytic formula for the variance estimator (Section 5.1) and (2) the leave‐one‐out jackknife approach, which is a replication approach (Section 5.2).
Analytic Formula Using Taylor Linearization Method
5.1
In the following, we derive an analytic formula for the variance estimator of the domain mean, which is also used in the real data application in Section 7. For this purpose, the domain mean estimator can be written as μ^:=μ^(β^)=T1T2, where T1=∑i∈scw(xi,β^)yizi and T2=∑i∈scw(xi,β^)zi. Here, zi is an indicator variable that equals 1 for observations that are members of the domain (e.g., males) and zero, otherwise, and w(xi,β^) are the estimated pseudo‐weights. The overall mean estimator is a special case if zi=1 for every i∈sc.
By applying the Taylor deviates rules in Graubard and Fears [15] to any i∈sc∪k=1Kspk, the delta operator Δi(μ^) is computed as
where
and
and the expression for Δi(β^) is defined from the system of estimating equations depending on the method used to estimate β^ (see Appendix B for details in the case of the raking ratio calibration method).
The variance of the mean estimator 𝕍^(μ^(β^)) is then approximated by the variance of the sum of Δi(μ^), which, in turn, is determined by the sampling design of the corresponding surveys [15]. Each of the methods for estimating the pseudo‐weights mentioned above is characterized by different parametric forms for the functions w(·) and h(·). In Appendix B, we provide the derivation of Δi(μ^) for the raking ratio calibration estimator with one reference survey (i.e., w(xi,β)=exp(−β⊤xi) and h(xi,β)=xi) under the Assumptions 1, 2, 3, 4, 5. The extension to multiple reference surveys is straightforward and the derivations for other methods are very similar. Specifically, the estimated variance of the raking ratio calibration mean estimator with K reference surveys is given by
where b^⊤=U^βS^β−1=∑i∈scw(xi,β^)zi(yi−μ^)xi⊤∑i∈scw(xi,β^)xixi⊤−1 and D^ is a block‐diagonal matrix with diagonal blocks defined by the matrices D^k=𝕍^pk∑i∈spkdi(pk)xi(pk). The variances 𝕍^pk are estimated according to the sampling design of the k‐th reference survey spk. The component of the estimated variance that corresponds to the nonprobability sample sc is obtained under the assumption of Poisson sampling.
Leave‐One‐Out Jackknife Estimator
5.2
A leave‐one‐out jackknife variance estimator can be used to approximate the variance estimator of the mean estimated from a multi‐stage stratified sample in which kh primary sampling units (PSUs) are sampled from a stratum h, h=1,…,H. The implementation of the method requires construction of kh×L replicates of the estimated mean μ^(ht) for t=1,…,kh in the following three steps: (1) exclude the observations of the t‐th PSU in the stratum h; (2) increase the sample weights of the remaining observations in the h‐th stratum by kh(kh−1)−1 and do not change the weights in the other strata; (3) estimate the mean μ^(ht) from the resulting replicate dataset. Then, the jackknife variance estimator is given by
where μ^ is the mean estimator obtained from the entire data set. To implement the jackknife variance estimator in our setting, we view the combined sample sc∪k=1Kspk as a stratified sample with H=K+1 strata, since all the samples are independently selected. The sampled individuals for sc are their own sampled PSU's so they are treated as a one‐stage sample. To create replicates in the stratum that corresponds to the nonprobability sample, the method of random groups [16] can be used. By this method, each random group plays the role of a sampled PSU, which is more computationally efficient than treating each individual as a sampled PSU.
Simulation Study
6
The simulation study design in this paper was inspired by the design used in the previously published papers [3, 4]. First, we generated the finite population FP of size N=500 000 that contains:
- 1.The vector of four auxiliary variables x=(x1,x2,x3,x4)⊤ generated as
where ν1i∼Bernoulli(0.5),ν2i∼Unif(0,2),ν3i∼Exp(1),ν4i∼χ2(4) and
- 2.The outcome variables: a continuous outcome yi∼Norm(μi;1) and a binary outcome ybi∼Bernoulli(expit(μi)), where μi=−x1i−x2i+x3i+x4i. By this design, x4 has the strongest correlation and x1 has the weakest correlation with the outcome y (i.e., ρ(y,x4)≈0.87,ρ(y,x1)≈−0.14). Also, the correlation between yb and x4 is about three times smaller than the correlation between y and x4 (i.e., ρ(yb,x4)≈0.30). The two parameters of interest are: μ=∑i∈FPyi/N for the continuous outcome (population mean) and μ=∑i∈FPybi/N for the binary outcome (population prevalence). In this example, the true values of the target parameters in the finite population were μ=3.975 and μ=0.890 for the continuous and binary outcomes, respectively.
Next, the two probability reference surveys sp1 of size np1=12500 and sp2 of size np2=25000 were sampled independently from FP. The sample sp1 was selected using Poisson sampling with inclusion probabilities np1qi/∑i∈FPqi, where qi=const1+x3i+0.03yi for i∈FP. The sample sp2 was selected using the randomized systematic probability proportional to size (PPS) sampling method [17, 18] with inclusion probabilities proportional to zi=const2+x2i, i∈FP. We set const1=0.97 and const2=0.05 to ensure sufficient variation in the sampling weights.
Finally, the nonprobability sample sc of size nc was sampled from FP, independently of sp1 and sp2, using Poisson sampling with the participation probabilities defined by the model πc(xi,β)=exp(β⊤xi) with β=(β0,β˜⊤)⊤ and β˜=(0.18,0.18,−0.27,−0.27). The choice of β0 is determined by the desired sample size. For this study, we set β0=−4.33, which corresponds to the expected sample size nc=2500 that is similar to the size of the nonprobability sample in the real data application in Section 7. The choice of β coefficients ensures that 0<πc(xi,β)<1 for each i, and implies ρ(πc,x4)≈−0.81 and ρ(πc,x1)≈0.10.
By design, the outcome variable is available in the nonprobability sample sc but not in the reference surveys sp1 and sp2. The four auxiliary variables are available in the nonprobability sample sc. The availability of the auxiliary variables in each of the two reference surveys is defined by different scenarios as described in Section 6.1. The two reference surveys also contain the sampling weights equal to the inverse of their respective inclusion probabilities.
Simulation Scenarios
6.1
We focused our attention on the following four scenarios:
- 1.Case 0: sp1 and sp2 surveys contain {x1,x2,x3,x4}; that is, x(p2)=(1,x1,x2,x3,x4).
- 2.Case PC.1: sp2 survey contains {x3,x4} and sp1 survey contains {x1,x2}; that is, x(p2)=(1,x3,x4) and x(p1)=(x1,x2).
- 3.Case PC.2: sp2 survey contains {x2,x3,x4} and sp1 survey contains {x1,x2,x3}; that is, x(p2)=(1,x2,x3,x4) and x(p1)=x1.
- 4.Case PC.3: sp2 survey contains {x1,x2,x3} and sp1 survey contains {x2,x3,x4}; that is, x(p2)=(1,x1,x2,x3) and x(p1)=x4.
These scenarios were developed with a few goals in mind: (1) to evaluate and compare the performance of various methods using one and two reference surveys under correctly specified models (Case 0); (2) to study the effect of the precalibration procedure described in Section 4.1 on the performance of the raking ratio calibration estimator with two reference surveys; in particular, the performance of the jackknife variance estimator compared to the variance estimator obtained using the analytic formula (12) (Cases PC.1‐PC.3); (3) to study the effect of the omitted covariate in the participation model on the performance of the various estimators (Cases PC.1‐PC.3).
To achieve these goals, we considered the following 8 different estimators for the target parameter (μ):
E1 is the unweighted estimator that computes the sample mean using the nonprobability sample sc only; E2 is the true weights (TW) estimator that utilizes the true sampling weights used to generate the nonprobability sample sc; E3 is the ALP sp1 estimator that utilizes the pseudo‐weights estimated using the ALP approach with the reference survey sp1; E4 is the CLW sp1 estimator that utilizes the pseudo‐weights estimated using the CLW approach with the reference survey sp1; E5 is the calibration sp1 estimator that utilizes the pseudo‐weights estimated using the raking ratio calibration method (Section 3.1.2) with the reference survey sp1; E6 is the calibration sp2 estimator that utilizes the pseudo‐weights estimated using the raking ratio calibration method (Section 3.1.2) with the reference survey sp2; E7 is the calibration sp2,sp1 estimator that utilizes the pseudo‐weights estimated using the raking ratio calibration approach (Section 4) with two reference surveys sp1 and sp2; E8 is the calibration‐PC sp2,sp1 estimator that utilizes the pseudo‐weights estimated using the raking ratio calibration approach (Section 4) with two reference surveys sp1 and sp2 and the precalibration procedure applied to match the population totals (including the sum of the weights) of the overlapping auxiliary variables in sp1 to those of sp2.
Estimators E1 and E2 were computed only for Case 0 because they do not use data from the reference surveys. The remaining estimators E3‐E8 were computed for each scenario. In Case 0, estimators E7‐E8 are essentially the same estimators as E6 because all four auxiliary variables were observed in sp2, the largest of the two reference surveys. In Case PC.1, the two reference surveys do not contain overlapping covariates, in which case the precalibration procedure was used to ensure that the sum of the weights in sp1 is equal to the sum of the weights in sp2.
Evaluation Metrics
6.2
Each simulation experiment was repeated B=4000 times for each scenario to obtain the b‐th estimated value (b=1,…,B) of the population mean μ^(b), the variance estimator v^(b) using the analytic formula, and the delete‐a‐group jackknife variance estimator v^JK(b) for each estimation method. For the delete‐a‐group jackknife estimator, we used 50 random groups in each stratum to optimize the computational time.
To evaluate the performance of the point estimators, the relative bias (%RB) and the mean squared error (MSE) were computed as follows:
To evaluate the performance of the variance estimators that rely on the analytic formulae, we computed the standard error ratio SER and the coverage probability %CP as follows:
where V=1B−1∑b=1Bμ^(b)−1B∑b=1Bμ^(b)2 is the empirical (‘true’) variance of μ^ and CI(b)=(μ^(b)−z1−α/2v^(b),μ^(b)+z1−α/2v^(b)) for α=0.05. To evaluate the performance of the delete‐a‐group jackknife variance estimator and compare its performance with the variance estimator obtained using the analytic formulae, we computed SERJK and CPJK that rely on the variance estimator v^JK(b).
Simulation Results
6.3
The results for all four scenarios are presented in Tables 1, 2, 3, 4. Each table contains the results for the continuous outcome followed by the results for the binary outcome.
Case 0
6.3.1
In terms of bias, the results for Case 0 (Table 1) show that all the estimators, except the unweighted estimator, have satisfactory performance. The unweighted estimator has a large negative bias, as expected by design. In terms of variance estimation, the estimated standard errors of the raking ratio calibration estimators for the continuous outcome appeared very close to the simulated standard errors (SER and SERJK are both close to 1), leading to optimal coverage probabilities (95%). This was not the case for the estimator with true weights and the ALP and CLW estimators for the continuous outcome. For these three estimators, we observed underestimated standard errors and less than optimal coverage probabilities. Our investigation showed that these estimators do not perform well in situations where the true sampling weights associated with the nonprobability sample are very dispersed. For more details, see Appendix C. The values of SER and SERJK were very close to or equal to 1 for all the estimators for the binary outcome, indicating satisfactory performance in the case of very dispersed weights for this type of outcome.
The results in Table 1 indicate that compared to the ALP and CLW estimators, the calibration estimators have markedly smaller variances for the continuous outcome but larger variances for the binary outcome. The profound reduction in variance of the calibration estimators for the continuous outcome is likely explained by the linear relationship between the outcome and the auxiliary variables. Kim and Riddles [19] proved the optimality of the classic calibration estimator that relies on (known) population totals in the framework of the superpopulation linear regression model.
Cases PC.1–PC.3
6.3.2
The results for the cases PC.1–PC.3 (Tables 2, 3, 4) show that the precalibration procedure does not have an effect on the bias of the mean estimator for both continuous and binary outcomes. In terms of variance estimation, the jackknife variance estimator performs reasonably well in all three cases, demonstrating that it successfully accounts for the potential correlation between the reference surveys introduced by the precalibration procedure, which is not accounted for by the analytic formula (12). In addition, the precalibration procedure tends to somewhat improve the efficiency of the estimators without an increase in bias. Both observations are demonstrated in Case PC.3 (Table 4).
The simulation results in Tables 2, 3, 4 also provide insight into the effect of the omitted variable on the bias of various estimators. We observed satisfactory performance of the calibration estimator with two reference surveys in all scenarios (bias in the range of −0.02 to 0.12%), which was expected since the four auxiliary variables were always available from the two reference surveys combined. Estimators that utilize only one reference survey demonstrate a sizable bias which is significantly larger for scenarios in which the variable x4 is omitted as opposed to scenarios in which the variable x1 is omitted from the reference survey: for example, the bias is approximately −35% in PC.2 (Table 3) as opposed to up to −1.5% in PC.3 (Table 4) for the estimators that rely on sp1. Importantly, in the case of the calibration estimators, the size of the bias was not affected by the size of the reference survey: the bias for the calibration sp2 estimator in PC.2 (Table 3) is practically identical to the bias of the calibration sp1 estimator in PC.3 (Table 4) and vice versa, despite the fact that np2 is twice as large as np1 by design. The observed pattern is very similar for both continuous and binary outcomes.
One additional simulation scenario is presented in Appendix D. It corresponds to the Case PC.3 but with participation model defined by πc(xi,β)=exp(β⊤xi) with β=(β0,β˜⊤)⊤, β˜=(0.18,0.18,0,0) and β0=−5.61 (to obtain nc=2500). In this case, the participation probabilities are only weakly correlated with the outcome y, leading to a very small bias in the unweighted estimator. Nevertheless, the results demonstrate that the variances of the pseudo‐weighted mean estimates were smaller than the variance of the unweighted estimator for both continuous and binary outcome and for all the estimators (E3‐E8) discussed in this paper. These results confirm the importance of using the pseudo‐weighted estimators even in situations when the unweighted estimators are believed to be unbiased.
Real Data Example
7
In this section, we demonstrated the application of the methods described above to real‐world data collected via a national Canadian survey of approximately 2000 workers (hereafter, ‘cannabis sample’). The original purpose of this survey was to collect information on workers' cannabis use and perceptions of cannabis use at work before the legalization of non‐medical cannabis use in Canada in October 2018. A detailed description of the sample is available from Carnide et al. [20]. The target population of the study consisted of Canadians at least 18 years of age, currently employed, and working at least 15 or more hours per week in workplaces with at least 5 employees. Due to time and funding constraints, eligible volunteers were recruited in June 2018 from an existing household panel of over 100,000 Canadians maintained by a private research firm.
We performed preliminary descriptive analyses to compare (unweighted) prevalence estimates for selected auxiliary variables from the nonprobability cannabis sample and the corresponding survey‐weighted prevalence estimates from two large‐scale population‐based reference surveys: (1) the Canadian Tobacco, Alcohol and Drugs Survey (CTADS, n=7390) [21] and (2) the Labour Force Survey (LFS, n=50 294) [22], collected around the same time as the cannabis sample. The estimates presented in Appendix E demonstrate sizable discrepancies in the distributions of participants' age, cannabis use in the past 12 months, perceived health, education level, and workplace size. These findings suggest that the decision to participate in the cannabis sample can be influenced by various demographic, socioeconomic, health, and lifestyle characteristics, as well as characteristics related to work. These characteristics must be taken into account using the methods described in this paper to improve the generalizability of the inference from the cannabis sample to the target population. Methods that can accommodate multiple reference surveys are particularly appealing in this application, since none of the existing reference surveys contain all the important auxiliary variables that may influence the individual's decision to participate (e.g., no single available reference survey contains the information on both health/lifestyle and workplace characteristics).
To demonstrate the application of these methods, we aimed to estimate the prevalence of work‐related injury (self‐reported), overall and stratified by safety‐sensitive and non‐safety‐sensitive jobs, from the cannabis sample of individuals who provided complete data on all the variables used in this analysis (n=1993 participants in total, approximately half of whom reported working in safety‐sensitive jobs). Establishing this baseline (prelegalization) prevalence is vital for future studies of the policy effects on people's health and safety.
The application of the methods described in this paper starts from fitting a participation model to estimate the unknown participation probabilities and, subsequently, the pseudo‐weights. The auxiliary variables were included in the participation model if they (1) were plausible determinants of the individual's decision to participate in the cannabis survey; (2) were potentially associated with the outcome(s) of interest; and (3) were available in both the cannabis sample and at least one of the reference surveys. In our study, the variables age, sex, cannabis use in the past 12 months, perceived health, education, hours of work per week, job permanency, and establishment size met these requirements and were included in modeling and estimating the participation rates.
Next, we estimated the prevalence of work‐related injury (overall and stratified by safety‐sensitive jobs) and their corresponding standard error using the ALP, CLW and raking ratio calibration methods with one reference survey (3 estimates using the CTADS survey and 3 estimates using the LFS survey), as well as using the raking ratio calibration method with two reference surveys (2 estimates with and without the precalibration of the overlapping auxiliary variables). The sum of the weights in the CTADS survey was precalibrated to match the sum of the weights in the LFS survey for both estimates that use two reference surveys in agreement with our recommendations in Section 4.1. The overlapping auxiliary variables (sex, age, and education) were used from the LFS and their totals in the CTADS were precalibrated to match the estimated totals in the LFS. The standard errors estimates were obtained using the corresponding analytic formulae developed for each method. The 𝕍c component of the variance estimator was obtained under the Poisson sampling assumption for the cannabis sample. The 𝕍pk components of the variance estimator were obtained using bootstrap weights provided by Statistics Canada to reflect the information about multi‐stage complex sampling design used in the CTADS and LFS surveys (500 bootstrap weights for the CTADS survey and 1000 bootstrap weights for the LFS survey) [21, 22].
The results are summarized in Table 5. Overall, we did not observe significant discrepancies of practical importance between the point estimators using various pseudo‐weighted approaches and the unweighted point estimator for this specific outcome. The standard error estimates for the prevalence of work‐related injury in safety‐sensitive jobs were twice as high for all the pseudo‐weighted estimators compared to the unweighted estimator. The standard errors for other pseudo‐weighted prevalence estimates for work‐related injury (overall and non‐safety‐sensitive job) were only slightly larger than the standard errors of the corresponding unweighted estimators. Also, the standard errors of the pseudo‐weighted estimators in Table 5 are practically identical across various estimation methods.
Although the point estimates generated by the different methods are similar to one another and to the unweighted estimate for this particular outcome, estimates may look different for other outcomes. It may not be possible to determine a priori whether the discrepancies between the pseudo‐weighted and unweighted estimates will be practically important. In addition, underestimated standard errors will result in too narrow confidence intervals and inflated type I errors. As such, applying the methods proposed in this paper to account for participation bias is warranted when working with data from nonprobability samples.
Discussion
8
In this paper, we presented a general statistical framework for bias correction in estimating mean (prevalence) from nonprobability samples. This framework enables us to estimate the unknown participation probabilities in the nonprobability sample and construct pseudo‐weighted Hajek‐type estimators for mean (prevalence) in the finite population. To estimate the unknown participation probabilities, the system of estimating equations is assembled by equating the finite population totals estimated using data from the nonprobability sample and unknown participation weights, with their counterparts, estimated using data from the existing probability survey(s) and the provided sampling weights. The resulting estimating equations are solved with respect to the parameters in the assumed participation model, which are further used to estimate the so‐called pseudo‐weights. The previously published ALP and CLW methods that rely on one reference survey are special cases within this framework. We devoted special attention to the calibration estimation approach, another important special case within the proposed framework. This method can be viewed as a natural extension of the classic calibration method, popular in survey sampling, in which the pseudo‐weights play the role of the sampling weights to be calibrated and known population totals are replaced with the estimates from available probability survey(s). The described framework is flexible in the sense that it can integrate multiple reference surveys into the estimating equations. This flexibility is very important in real‐world applications where the variables that determine the individual participation in the nonprobability sample cannot be found in a single reference survey. This was our experience when analyzing the data from the cannabis sample that motivated this study.
The consistency and asymptotic properties of the resulting estimators follow from the unbiasedness of the estimating equations under the models that define the participation in the nonprobability sample and in the reference survey(s). In addition, we used the method of Taylor deviates to derive the analytic formulae for the variance estimators of the pseudo‐weighted means and described a leave‐one‐out jackknife estimator, a replication method. Both methods properly account for all sources of variability in the derivation of pseudo‐weights. The jackknife estimator also accounts for potential correlation between the reference surveys introduced by the precalibration procedure aimed at addressing the overlapping auxiliary variables in multiple reference surveys.
We evaluated the performance of various estimators in the simulation study. Our simulation results demonstrated that, in contrast to the ALP and CLW estimators, a calibration estimator is very efficient for continuous outcomes and has very good performance for both continuous and binary outcomes in situations with highly dispersed pseudo‐weights in the nonprobability sample. Additionally, assembling the estimating equations for the calibration estimator does not require access to the reference survey microdata for auxiliary variables, for which the estimated totals and their standard errors are disseminated to the general public (e.g., on a government agency website). This flexibility can be helpful in expanding the set of auxiliary variables to be included in the participation model.
We demonstrated the application of the methods in a real‐world context to establish a baseline prevalence of work‐related injury in the Canadian workforce before cannabis legalization. It appears that for this outcome variable, the pseudo‐weighted point estimates obtained by various methods did not reveal any discrepancies of practical importance in comparison with the unweighted estimate. Although reassuring for this particular outcome, this finding does not diminish the importance of applying the proposed methods to nonprobability samples. In a multi‐outcome study, like the Cannabis study, it is not unlikely to discover larger discrepancies between the estimates when applying the same set of the estimated pseudo‐weights to estimating mean (prevalence) of other outcomes of interest. On the other hand, one cannot exclude the possibility of omitting an important variable that is strongly associated with both survey participation and outcomes of interest. If this is the case, the resulting point estimates using pseudo‐weights might not fully correct for participation bias. For example, in previously published analyses, we found that workers in safety‐sensitive jobs were more likely to report workplace cannabis use [20] and that workplace cannabis use (but not non‐workplace‐use) was associated with workplace injury risk [23]. Although we accounted for cannabis use overall, we could not account for cannabis use at work or safety‐sensitive work in modeling the participation probabilities because they were not measured in any of the available reference surveys. In addition, the standard errors of the pseudo‐weighted estimates for the prevalence of work‐related injury in safety‐sensitive jobs were twice as high for all the pseudo‐weighted estimators compared to the unweighted estimator. The standard errors of the estimates for other categories (overall and non‐safety‐sensitive jobs) were only slightly larger for the pseudo‐weighted estimates compared to the standard errors of the corresponding unweighted estimators. These findings demonstrate the importance of applying the proposed methods for point and variance estimation not only to minimize participation bias but also to properly account for all sources of variability in the point estimates.
Funding
This work was supported by the Canadian Institutes of Health Research (Grant No. PJT‐186242).
Conflicts of Interest
The authors declare no conflicts of interest.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1J. S. Mindell , S. Giampaoli , A. Goesswald , et al., “Sample Selection, Recruitment and Participation Rates in Health Examination Surveys in Europe–Experience From Seven National Surveys,” BMC Medical Research Methodology 15, no. 1 (2015): 1–19.26438235 10.1186/s 12874-015-0072-4PMC 4595185 · doi ↗ · pubmed ↗
- 2F. J. Mölenberg , d C. Vries , A. Burdorf , and v F J. Lenthe , “A Framework for Exploring Non‐Response Patterns Over Time in Health Surveys,” BMC Medical Research Methodology 21, no. 1 (2021): 1–9.33602123 10.1186/s 12874-021-01221-0PMC 7890886 · doi ↗ · pubmed ↗
- 3L. Wang , R. Valliant , and Y. Li , “Adjusted Logistic Propensity Weighting Methods for Population Inference Using Nonprobability Volunteer‐Based Epidemiologic Cohorts,” Statistics in Medicine 40, no. 24 (2021): 5237–5250.34219260 10.1002/sim.9122 PMC 8526388 · doi ↗ · pubmed ↗
- 4Y. Chen , P. Li , and C. Wu , “Doubly Robust Inference With Nonprobability Survey Samples,” Journal of the American Statistical Association 115, no. 532 (2020): 2011–2021.
- 5D. G. Horvitz and D. J. Thompson , “A Generalization of Sampling Without Replacement From a Finite Universe,” Journal of the American Statistical Association 47, no. 260 (1952): 663–685.
- 6J. Hájek , “Comment on an Essay on the Logical Foundations of Survey Sampling, Part One,” in The Foundations of Survey Sampling, ed. V. P. Godambe and D. A. Sprott (Holt, Rinehart and Winston, 1971), 236.
- 7A. Delevoye and F. Sävje , “Consistency of the Horvitz–Thompson Estimator Under General Sampling and Experimental Designs,” Journal of Statistical Planning and Inference 207 (2020): 190–197.
- 8C. E. Särndal , B. Swensson , and J. Wretman , Model Assisted Survey Sampling (Springer Science & Business Media, 2003).