A two-stage GAN-based instrumental variable method for causal analysis of omics data
Yuan Zhou, Pei Geng, Shan Zhang, Weijia Jin, Li Chen, Feifei Xiao, Zhigang Li, Qing Lu

TL;DR
This paper introduces a new deep learning method using GANs to better understand the causal relationships between gene expression and disease outcomes in complex omics data.
Contribution
A novel two-stage GAN-based instrumental variable framework that handles nonlinearities and unobserved pleiotropy in causal analysis of omics data.
Findings
The GAN-IV method outperforms traditional and deep learning-based MR methods in simulations.
GAN-IV effectively captures complex exposure distributions and nonlinear causal effects in real omics data.
The framework is robust to unobserved pleiotropy and linkage disequilibrium in genetic studies.
Abstract
While considerable progress has been made in identifying candidate genes associated with complex diseases, their potential causal roles in disease etiology remain unknown. Mendelian randomization (MR) utilizes genetic variants as instrumental variables (IVs) to estimate the causal effects of disease-associated genes, thereby establishing putative causal associations and reducing spurious association findings due to confounding. To mitigate the potential bias due to the violation of IV conditions and nonlinear exposure–outcome relations in MR studies, we propose a two-stage deep learning framework, which is free from distribution assumptions of exposure given IVs and flexible to capture complex exposure–outcome relations. Specifically, we adapt the generative adversarial networks (GAN) to estimate the conditional distribution of gene expression given IVs in the first stage and apply deep…
Genes, proteins, chemicals, diseases, species, mutations and cell lines named across the full text — each resolved to its canonical identifier and authoritative record.
Click any figure to enlarge with its caption.
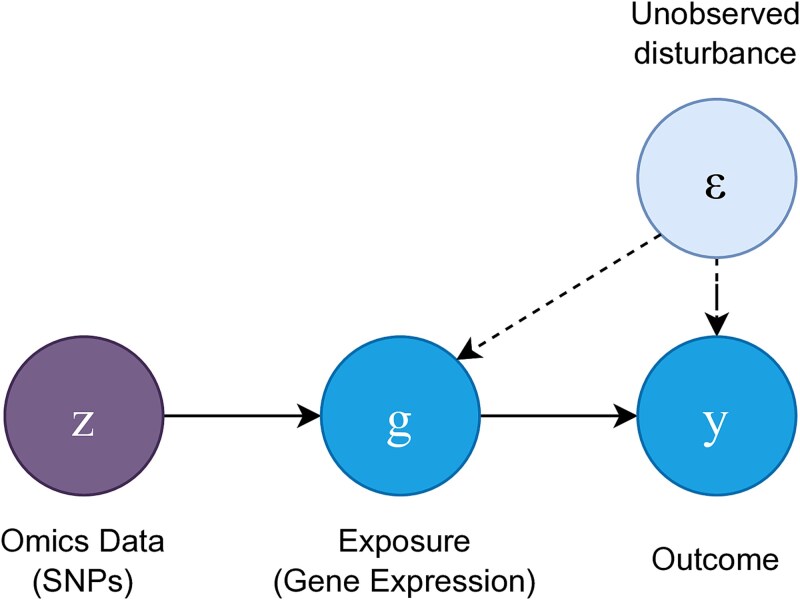 Figure 1
Figure 1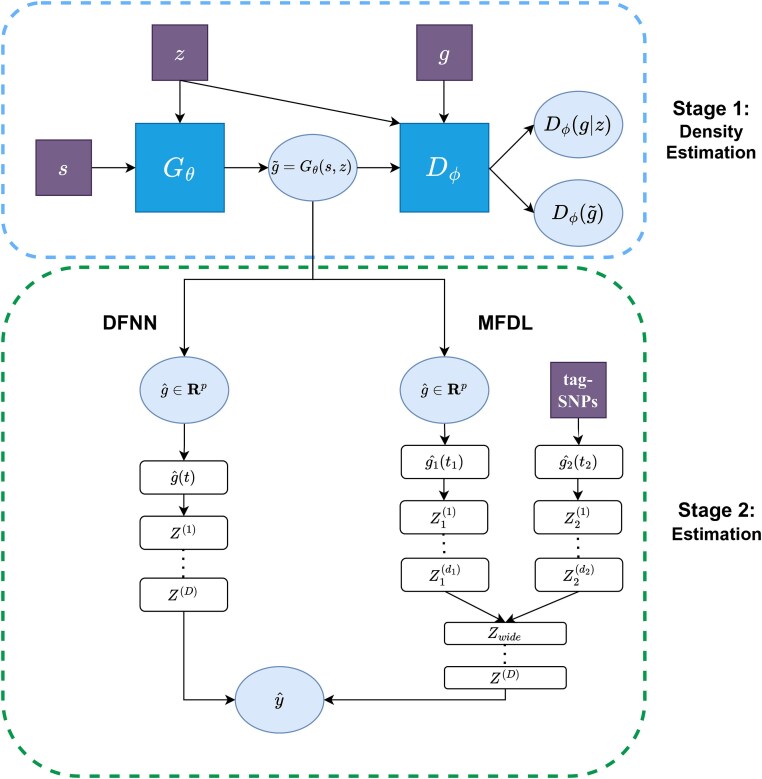 Figure 2
Figure 2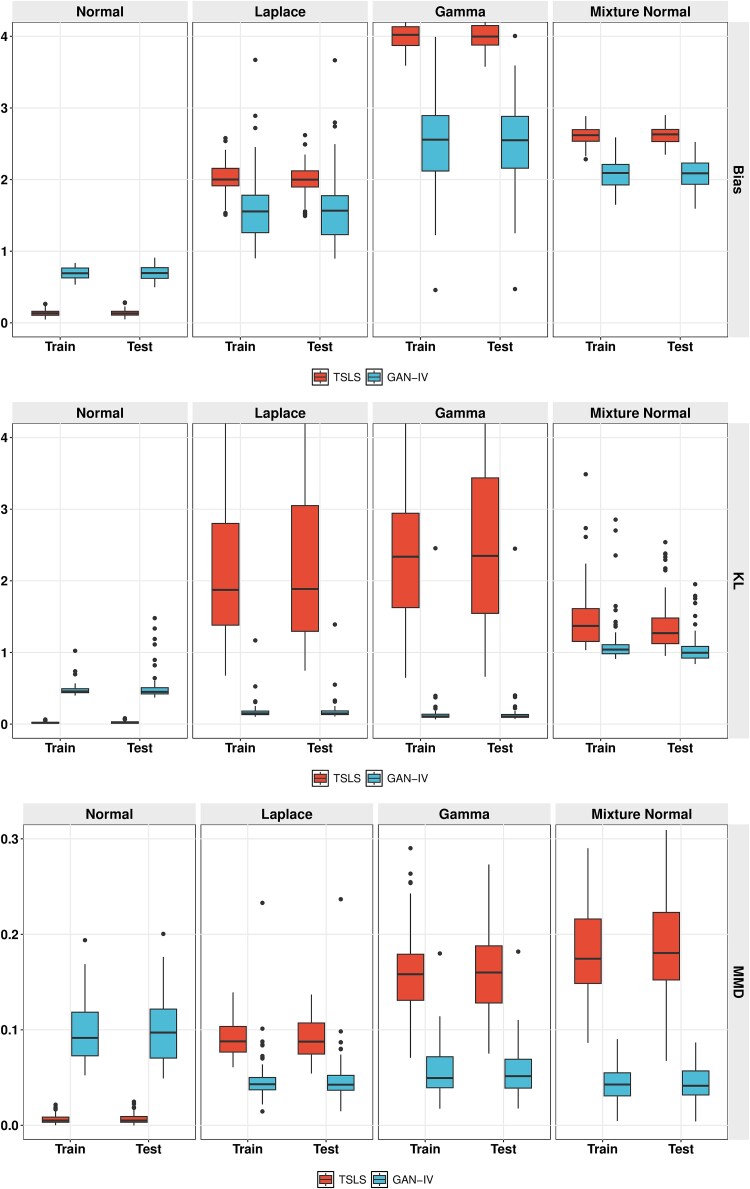 Figure 3
Figure 3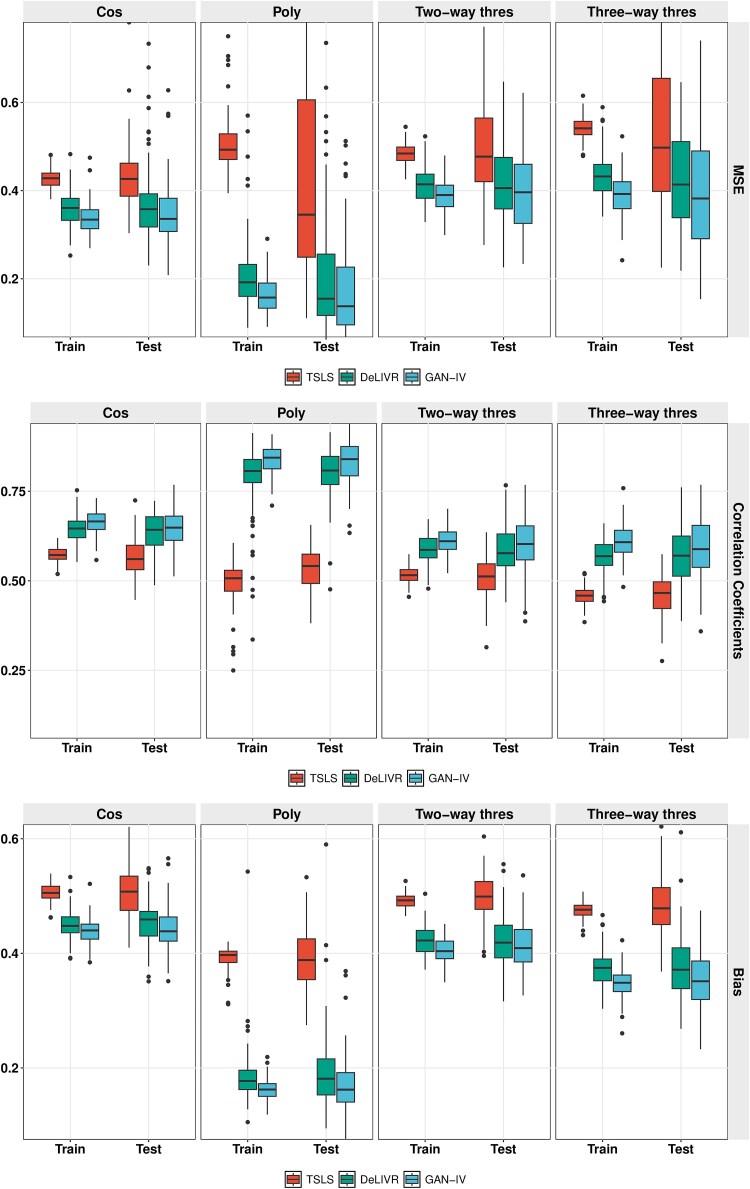 Figure 4
Figure 4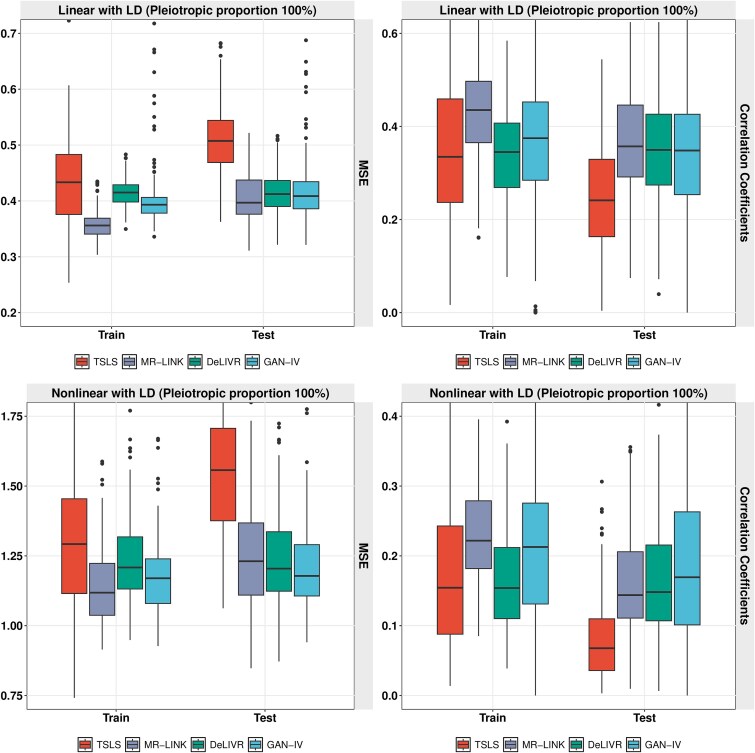 Figure 5
Figure 5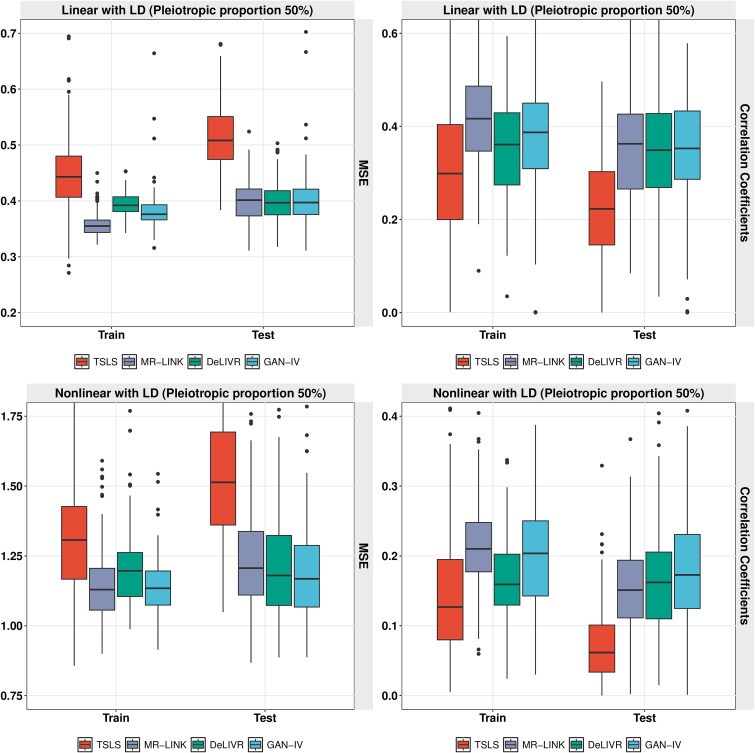 Figure 6
Figure 6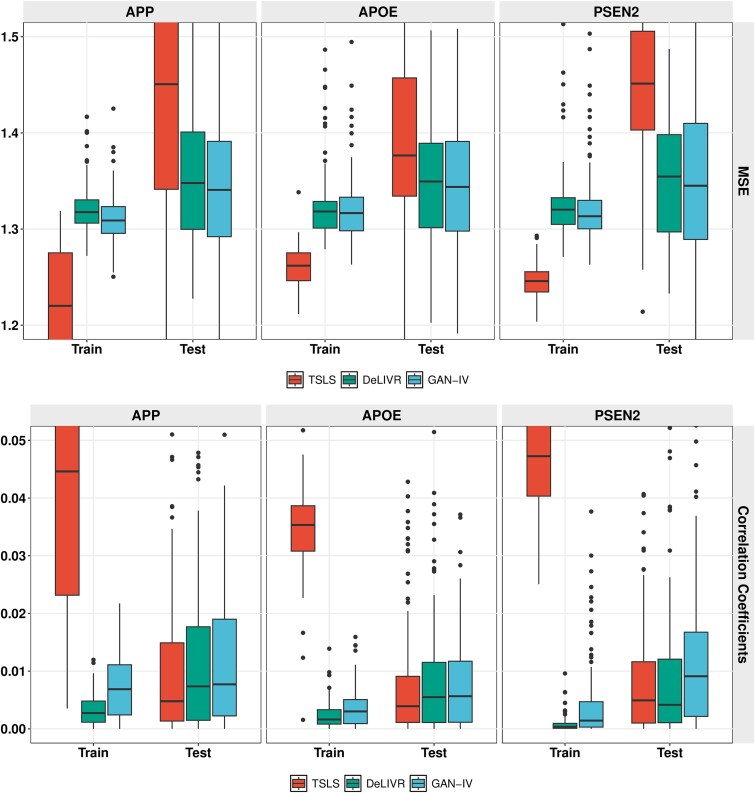 Figure 7
Figure 7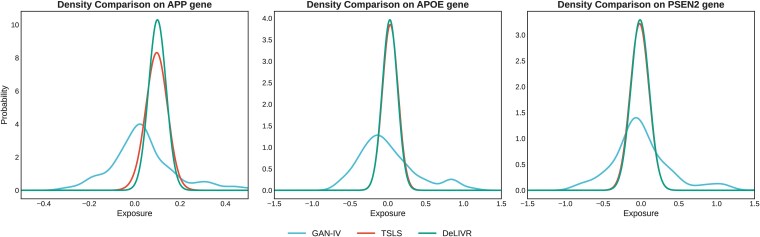 Figure 8
Figure 8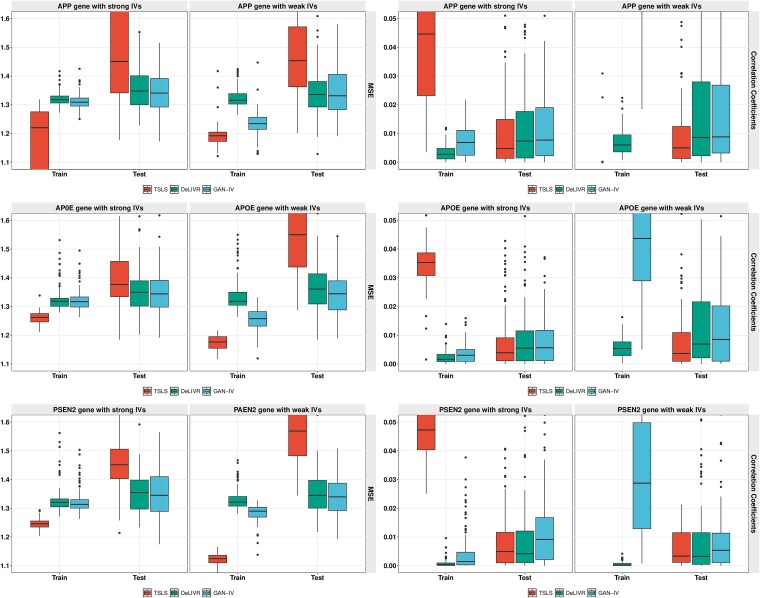 Figure 9
Figure 9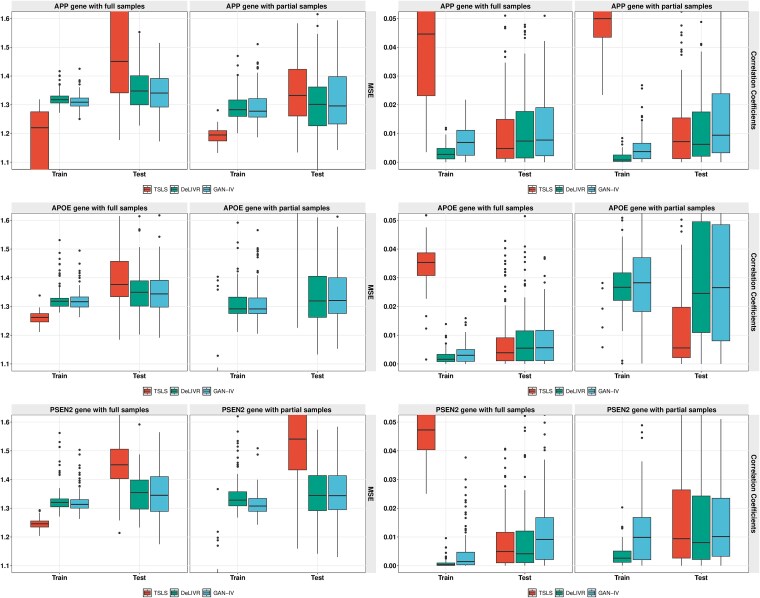 Figure 10
Figure 10- —National Institute on Drug Abuse10.13039/100000026
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsGenetic Associations and Epidemiology · Advanced Causal Inference Techniques · Bioinformatics and Genomic Networks
Introduction
Mendelian randomization (MR) studies provide important insights into the causal relationship between genes and the disease phenotype of interest, using genetic variants as instrumental variables (IVs). The IV analysis is a classic method to estimate and test the causal effect in the presence of an unobserved confounder. To ensure an unbiased estimation, the variable that is used as IV needs to satisfy at least three conditions, referred to as IV conditions [1]. If all IV conditions are satisfied, the two-stage least squares (TSLS) estimation using individual-level data or summary data is a commonly adopted MR framework. Specifically, in the first stage, the gene expression exposure is regressed on the IV to obtain the predicted gene expression, which is uncorrelated with the unobserved confounders. Then, the outcome is regressed on the predicted exposure in the second stage. When using single-nucleotide polymorphisms (SNPs) as genetic IVs, the IV conditions are often violated due to pleiotropy and linkage disequilibrium, causing bias in parameter estimation. Extensions of the TSLS framework that are pleiotropy-robust include MR-Egger [2], MR-PRESSO [3], LDA-MR-Egger [4], and MR-LINK [5]. However, all of those methods require linearity assumptions in both the IV-exposure relations and exposure–outcome relations across different levels of exposure. In practice, it is often not the case for complex diseases, where genes are linked to disease in a complicated manner (e.g. interactions). In this paper, we propose a deep learning approach to handle the pleiotropy and nonlinear exposure–outcome relationships simultaneously.
Recently, nonlinear MR estimations have been proposed to capture the complex exposure–outcome relationship including the nonparametric IV method [6], the kernel methods and orthogonal series [7], and a semi-parametric method using fractional polynomial functions and piecewise linear functions [8]. Moreover, the state-of-the-art deep learning models, as a type of nonparametric models with powerful representative ability, are applied to the estimation of nonlinear causal effects, such as DeepIV [9] and DeLIVR [10]. DeepIV [9] is a two-stage method that applies deep neural network (DNN) in both stages. In the first stage, to estimate the conditional expectation of exposure given IV using DNN, Monte Carlo simulation is applied on the DNN estimator of the conditional distribution of exposure given IV. This could lead to unstable estimation and high computational burden. In the second stage, another DNN is trained with the estimated conditional expectation and the outcome. As pointed out in He et al. [10], all nonparametric models, including DeepIV, will suffer from the ill-posed inverse problem. DeLIVR, on the other hand, circumvents this issue by combining parametric estimation of the conditional expectation of exposure on IV with the nonparametric estimation of the nonlinear exposure effect. This hybrid framework not only improves the estimation accuracy and computational performance at the same time, but also provides a valid statistical inference procedure. However, with the parametric distribution assumptions, the nonlinear effect estimator is only unbiased and consistent, provided the true density distribution is from the exponential family. Hence, it is desirable to develop methods that are robust in distribution assumptions and effective in capturing complex exposure–outcome relationships.
Despite the development of TSLS MR methods in extending nonlinear causal effects, little attention has been drawn to the impact of exposure distribution assumptions given IV. Unlike the linear causal effects, where the exogeneity moment condition breaks down to the conditional mean of exposure given IV regardless exposure distribution, the nonlinear causal effect models require careful study of the conditional distribution of exposure given IV. In this paper, we propose a two-stage generative adversarial network (GAN) based IV method that is free of distribution assumptions, robust to pleiotropy, and effective in capturing exposure–outcome relationships. In the first stage, we adopt the conditional GAN, a type of generative model, to fit the conditional distribution of exposures given IV and further obtain the fitted conditional mean exposures. GAN-based models have been proven to be a likelihood-free tool to model complex underlying data distributions that outperform other deep-generative models, especially in high-dimensional datasets [11]. Although GAN models do not provide an explicit density function estimator, a well-trained GAN model produces high-quality samples that follow the desired distribution, considering the underlying complexity. In MR studies that adopt a two-stage estimation strategy, samples from the underlying distribution are sufficient for the second stage estimation. In the second stage, with the fitted conditional mean exposure values from the first stage, we adopt the deep learning frameworks to provide nonparametric estimation of the nonlinear causal effects. These deep learning frameworks are versatile to accommodate both scalar and multiple gene expression data. Furthermore, to utilize tag-SNP data in handling pleiotropy, we adopt a multimodal functional deep learning (MFDL) model [12] in the second stage. As discussed in simulation studies in Section 3, when accounting for the pleiotropy introduced by multiple pathways, the flexible multimodal structure of MFDL can incorporate tag-SNPs, providing robust estimators that outperform competing methods.
This paper is organized as follows: in Section 2, we first introduce notations and the classic TSLS, then describe our GAN-IV framework; in Section 3, we design three simulation studies including non-Gaussian underlying exposure density, nonlinear causal effect of exposure, and confounding caused by LD effect. We compare our proposed model with other competing methods under different evaluation criteria. In Section 4, we further evaluate our models and competing methods in a real data analysis. Finally, in Section 5, we summarize our findings and discuss potential limitations of our proposed framework.
Methods
In this section, we first present the causal inference model setting and the classic TSLS in Section 2.1 and then introduce the foundational GAN model in Section 2.2. In Section 2.3, we present our proposed two-stage GAN-based IV method for causal analysis using omics data.
Model setting and TSLS
In the causal inference framework, we are interested in the causal effect of the exposure \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} G\end{document} (e.g. gene expression) on the outcome \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} Y\end{document} , in the presence of an unobserved disturbance \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} \varepsilon \end{document} , as shown in Fig. 1. Let
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} \begin{align*}& Y = f(G)+\varepsilon , \,\,E(\varepsilon)=0,\,\, E(\varepsilon|G)\neq 0,\end{align*}\end{document}Causal diagram of an MR problem using genetic IVs.
allowing \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} \varepsilon \end{document} to be correlated with exposure \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} G\end{document} .
Let \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} Z\end{document} be the IV for exposure \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} G\end{document} . The exogeneity condition \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} E(\varepsilon |Z=z)=0\end{document} yields
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} \begin{align*}& E(Y|Z=z) = E[f(G)|Z=z] +E(\varepsilon|Z=z) = \int f(g)dF(g|z),\end{align*}\end{document}where \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} F(g|z)\end{document} is the conditional distribution function of G given \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} Z=z\end{document} . We see that the conditional distribution \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} F(G|Z)\end{document} plays a critical role when linking the outcome to the IV, especially when the causal effect \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} f\end{document} is nonlinear. \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} E(Y|Z)\end{document} and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} F(G|Z)\end{document} are two directly estimable functions from the data, and the estimation of \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} f(g)\end{document} can be achieved. In practice, estimation with the directed acyclic graph in Fig. 1 is implemented in two stages: first estimating \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} F(G|Z)\end{document} , and then estimating \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} {f}(g)\end{document} after replacing \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} F\end{document} with the estimator \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} \hat{F}\end{document} . In the special cases of linear effects between both \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} (Z, G)\end{document} and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} (G, Y)\end{document} , i.e.
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} \begin{align*}& G = \alpha_{0}+\alpha_{1} Z+\varepsilon_{G},\space\space Y = \beta_{0} +\beta_{1} G+\varepsilon_{Y},\end{align*}\end{document}(2) is simplified as \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} E(Y|Z=z) = \beta _{0} + \beta _{1}E(G|Z=z)\end{document} and the estimation process can be described using a TSLS model. The TSLS model solves two linear regressions below to obtain an unbiased and consistent estimator \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} \hat{\beta _{1}}\end{document} . With the linearity and homogeneity assumptions, TSLS first obtained \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} \hat{G} = \hat E(G|Z=z)\end{document} from the first-stage linear regression, then plugged in \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} \hat{G}\end{document} into the second-stage linear regression and solved for \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} \hat{\beta {1}}\end{document} . The closed form of the TSLS estimator is \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} \hat{\beta }{1, TSLS} = \frac{{Cov}(Z,Y)}{{Cov}(Z,G)}\end{document} .
Generative adversarial network and the conditional extension
For the two-stage methods using (2), a key component is the estimation of the conditional distribution of \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} F(g|z)\end{document} , which represents the exposure distribution given the IV. To accurately estimate \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} F(G|Z)\end{document} in the first stage, we apply a conditional GAN model to estimate the conditional distribution. The conditional GAN consists of two models that compete with each other: a generative model denoted as \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} G_{\theta }\end{document} with parameters \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} \theta \end{document} that map from a noise distribution \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} s \thicksim p_{s}\end{document} to a generator distribution denoted as \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} p_{NetG}\end{document} ; a discriminative model denoted as \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} D_\phi \end{document} with parameters \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} \phi \end{document} that determine the inputs as real versus “fake” (i.e. generated from \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} p_{NetG}\end{document} ). Both models are nonlinear mapping functions. In our case, we construct them using two DNN models with different model structures. The generator and discriminator are trained iteratively as follows: 1) sampling noise \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} s\end{document} and feeding both the generated data \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} G_\theta (s)\end{document} and observed data \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} g\end{document} to the discriminator \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} D_\phi \end{document} ; 2) calculating \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} D_\phi (G_\theta(s))\end{document} and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} D_\phi (g|z)\end{document} , respectively, producing a probability ranging from \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} [0,1]\end{document} ; 3) calculating an objective function and updating parameters \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} \theta ,\phi \end{document} alternately until the objective function converges. With IV information, we propose the conditional GAN by modifying the classic minimax objective function of GAN as
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} \begin{align*} & \min_\theta \max_\phi V(G_\theta,D_\phi)=\min_\theta \max_\phi E_{g\thicksim p_{data}} [\log D_\phi(g|z)] \nonumber\\ &\quad + E_{s \thicksim p_{s} (s)}[log(1-D_\phi(G_\theta (s|z)))] ,\end{align*}\end{document}which attains the global optimum at \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} p_{NetG}=p_{data}\end{document} [13]. When this global optimum is reached, data points generated from \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} \hat{G}\theta (g|z)\end{document} is considered to have the same distribution as the observed data. Here, \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} Z\end{document} can be any auxiliary information, as shown in Mirza et al [14]. The estimator \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} \hat{G}\theta (g|z)\end{document} serves as a generating distribution for samples needed in the second stage.
In this paper, the generator \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} G_\theta \end{document} of GAN is implemented as a DNN with three hidden layers, using the tanh activation function in all layers except for the output layer. The discriminator \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} D_\phi \end{document} is implemented as a DNN with three hidden layers, using ELU activation function in hidden layers and sigmoid activation function in the output layer. We train the model with non-saturating generator loss \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} L_{G}\end{document} and BCE discriminator loss \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} L_{D}\end{document} with \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} R_{1}\end{document} gradient penalty in discriminator nets [15] defined as
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} \begin{align*} L_{G} &=-E_{z\thicksim p_{z}, s\thicksim p_{s}}[-logD_\phi(G_\theta(s|z), z)],\quad L_{D} =1/2(L_{D}^{real}+L_{D}^{fake})+L_{D}^{R_{1}}, \\ L_{D}^{real} & = E_{(g|z)\thicksim p_{data}}[-logD_\phi (g|z)],\\ L_{D}^{fake}& = E_{z\thicksim p_{z}, s\thicksim p_{s}}[-log(1-D_\phi (G_\theta(s|z), z))],\\ L_{D}^{R_{1}} & = \frac{\lambda}{2} E_{(g|z)\thicksim p_{data}}[\Vert \triangledown_{g} D_\phi (g,z)\Vert_{2}^{2}]. \end{align*}\end{document}It can be shown that, for any fixed generator that induces \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} p_{G}(g|z)\end{document} , the discriminator that optimizes the loss function of (4) is
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} \begin{align*}& D^\star_{G} (g,z) = \frac{p_{data}(g|z)}{p_{data}(g|z)+p_{G}(g|z)} \end{align*}\end{document}The proof is similar to the proof of Proposition 1 in Goodfellow et al.. If plugging \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} D^\star \end{document} into (4), the minimax game can be reformulated as
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} \begin{align*} \max_\phi V(G_\theta,D_\phi) &= E_{z\thicksim p_{z}}[E_{g\thicksim p_{data}(\cdot|z)} [\log D^\star_{G} (g|z)]\\&\quad + E_{g \thicksim p_{G} (\cdot|z)}[log(1-D^\star_{G} (g|z))]]\\ &=E_{z\thicksim p_{z}}[-log4+2\space JSD(p_{data}(\cdot|z) \Vert p_{G}(\cdot|z))]. \end{align*}\end{document}Here \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} JSD(p_{data}(\cdot |z) \Vert p_{G}(\cdot |z))\end{document} is the Jensen–Shannon divergence between the true conditional distribution and the generated conditional distribution. Since \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} JSD(p_{data}(\cdot |z) \Vert p_{G}(\cdot |z)) \geq 0\end{document} , the optimality of the loss function is equivalent to \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} p_{G}(\cdot |z) = p_{data}(\cdot |z)\end{document} . In practice, to check for optimality, we look for whether the discriminator accuracy equals 0.5 and the discriminator loss is almost the same as the generator loss when convergence. When achieving optimality, we obtain a sampler \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} \hat G_\theta (s|z)\end{document} for the conditional distribution \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} p(g|z)\end{document} . For a fixed \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} Z=z\end{document} and independent noises \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} s_{1},..., s_{M}\end{document} , let \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} \tilde{g}{m} = \hat G\theta (z, s_{m}), m = 1,...,M\end{document} be samples generated from the sampler \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} \hat G_\theta (s|z)\end{document} . Summarizing the \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} M\end{document} data points, we can obtain the Monte Carlo estimator of the conditional mean for \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} Z=z\end{document} :
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} \begin{align*}& \hat{E}(G|Z=z) = \frac{1}{M}\sum_{m}^{M} \hat G_\theta(s_{m}|z) \end{align*}\end{document}In our implementation, both DNNs are optimized with the Adam optimizer [16] and trained for a fixed epochs of 50 000. The training process is described in Algorithm 1.
To evaluate the estimation performance of the exposure distribution given IV in the first stage, we introduce the following three criteria that will be used in the simulation study. Denote the underlying relation between exposure and IV as \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} h(z)\end{document} , i.e. \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} G = h(Z) + \varepsilon _{G}\end{document} .
(1) Bias between the estimated exposure \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} \hat g\end{document} and the true mean exposure given IV \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} E(g|z)\end{document}
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} \begin{align*}& Bias(\hat{G},h(Z)) = \frac{1}{n} \sum_{i=1}^{n}|\hat{g_{i}}-h(z_{i})| \end{align*}\end{document}For instance, \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} h(z) = \beta _{0} + \beta {1} z\end{document} in the classic setting of (3) and the estimated exposure using TSLS is computed as \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} \hat g{TSLS} = \hat \beta _{0} + \hat \beta _{1} z\end{document} , where \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} \hat \beta _{0}\end{document} and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} \hat \beta {1}\end{document} are the TSLS estimators. The estimated exposure using GAN \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} \hat g{GAN}\end{document} is calculated as
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} \begin{align*}& \hat g_{i,GAN} = \frac{1}{M}\sum_{m=1}^{M} \hat G_\theta(s_{i,m}|z_{i}),\,\, i = 1,...n \end{align*}\end{document}(2) KL divergence approximation between generated data points and data points from the true underlying distribution [17]. For the \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} i\end{document} th sample, let \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} p_{i}(\cdot )=p(g\mid z_{i})\end{document} and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} \widehat p_{i}(\cdot )\end{document} be the true and estimated conditional density, respectively. For TSLS, \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} \widehat p_{i,TSLS} = \mathcal N(\hat \alpha {0}+\hat \alpha {1} z{i},\hat \sigma {G}^{2})\end{document} . For GAN, there is no explicit form of the estimated density. Instead, we draw \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} M\end{document} samples from the trained generator \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} \hat G\theta \end{document} , denoted as \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} {\tilde g^{(m)}{i}}{m=1}^{M}\end{document} , and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} \widehat p{i,GAN}\end{document} is obtained as a Gaussian kernel density estimator (KDE) using \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} {\tilde g^{(m)}{i}}{m=1}^{M}\end{document} . To calculate the KL divergence, we draw \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} {x^{(m)}{i}}{m=1}^{M} \sim p_{i}\end{document} , and calculate
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} \begin{align*}& \widehat D_{\mathrm{KL}} = \frac{1}{n}\sum_{i=1}^{n} \widehat D_{\mathrm{KL}}\big(p_{i} \,\Vert\, \widehat p_{i}\big) \\& =\; \frac{1}{n}\sum_{i=1}^{n}\frac{1}{M}\sum_{m=1}^{M} \Big\{\exp\!\big[\log{\widehat p}(x^{(m)}_{i})-\log{p}(x^{(m)}_{i})\big] \;-\; 1 \\& \quad -\; \big[\log{\widehat p}(x^{(m)}_{i})-\log{p}(x^{(m)}_{i})\big]\Big\}. \end{align*}\end{document}(3) Maximum mean discrepancy (MMD) [18] between the estimated exposure distribution and true exposure distribution. For the \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} i\end{document} th sample with instrument \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} z_{i}\end{document} , we draw \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} M\end{document} samples \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} {\tilde g^{(m)}{i}}{m=1}^{M} \sim \widehat p(g\mid z_{i})\end{document} from the first–stage model (GAN and TSLS), and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} M\end{document} samples \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} {g^{(m)}{i}}{m=1}^{M} \sim p(g\mid z_{i})\end{document} from the ground-truth density. Let \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} k(\cdot ,\cdot )\end{document} be a Gaussian RBF kernel and form a Gram matrix \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} K\end{document} over stacked data set \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} {\tilde g^{(m)}{i}}{m=1}^{M} \cup {g^{(m)}{i}}{m=1}^{M}\end{document} . Then partition \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} K\end{document} into three blocks \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} K_{\tilde{g}\tilde{g}}\end{document} , \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} K_{\tilde{g}g}\end{document} , and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} K_{gg}\end{document} , each of size \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} M\times M\end{document} . Denote the min-max scaler transformer as \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} \phi (x) = (x-\min _{x})/(\max _{x}-\min _{x})\end{document} , and the estimator of squared MMD is defined as
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} \begin{align*} \widehat{\mathrm{MMD}}^{\,2} &= \frac{1}{n}\sum_{i=1}^{n}\widehat{\mathrm{MMD}}^{\,2}_{i} \\& =\frac{1}{n}\sum_{i=1}^{n} \Big\{\overline{\phi(K_{\tilde g_{i}\tilde g_{i}})} \;-\; 2\,\overline{\phi(K_{\tilde g_{i} g_{i}})} \;+\; \overline{\phi(K_{g_{i}g_{i}})}\Big\}, \end{align*}\end{document}where \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} \overline{A}\end{document} is the mean of all entries of \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} A\end{document} . It has been proven that squared MMD is equivalent to complete agreement between two distributions [18]. The model estimator is closer to the true data-generating mechanism with lower values of \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} \widehat{\mathrm{MMD}}^{2}\end{document} .
The proposed two-stage framework: GAN-IV method
After obtaining the trained sampler \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} \hat G_\theta (s|z)\end{document} and the estimated conditional mean exposure from the first stage, in the second stage of causal effect estimation, we propose to use deep learning models to capture the nonlinear exposure–outcome relationship. Particularly, we consider two scenarios: multiple gene expressions over time and gene expression with tag-SNP data. To handle multiple gene expression data, we denote \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} g=(g_{1}, g_{2},...,g_{p})\end{document} as the exposure data collected at different time points that can be considered as functionals. We apply the deep functional neural network (DFNN) [19] to efficiently utilize the nearby locations of genetic data, yielding robust estimation of the nonlinear causal effects \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} f(g)\end{document} . DFNN treats \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} g\end{document} as an ordered sequence and applies basis expansion and functional linear models in functional data analysis to obtain smoothed functional curves as the input and hidden layers. The case of gene expression with tag-SNP data available is particularly useful in the presence of pleiotropy, where the bias introduced by the LD effect in eQTLs can be corrected using individual-level tag-SNP information [5]. In this case, the multimodal extension of the DFNN with the application to multi-omics data [12] is well suited to integrate both gene expression and tag-SNP data, which introduces separate basis functions built on each omics modality. Compared with concatenating all inputs into a column into a single vector, the multimodal structure achieves better latent representation and captures correlations between different data sources.
In practice, we construct a DFNN model with two hidden layers and apply the basis expansion with B-Spline functions of \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} n_{basis}=10\end{document} and order \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} 3\end{document} . The activation function of DFNN is the ReLU function except for the output layer. The mean squared error (MSE) is used as loss function. The model is optimized using the Adam optimizer with \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} L_{2}\end{document} regularization and early stopping. The learning rate and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} L_{2}\end{document} regularization parameter are determined via grid search using a three-fold cross validation. The detailed implementation settings are described in the appendix. In summary, the two-stage GAN-IV method uses the GAN model to estimate the conditional density in the first stage and the deep learning models to estimate causal effects using omics data in the second stage. The workflow and the architecture of the whole framework are shown in Fig. 2.
Hierarchical structure of the proposed GAN-IV framework.
To comprehensively evaluate the causal effect modeling performance in the second stage, we introduce the following criteria: bias, MSE, and RV correlation coefficient. Let \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} \mathbf{Y}\end{document} and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} \hat{\mathbf{Y}}\end{document} be the vectors of all observations and predicted values of \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} Y\end{document} , respectively.
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} \begin{align*}& \begin{aligned} Bias(\hat{\mathbf{Y}},\mathbf{Y}_{0}) &= 1/n \sum_{i=1}^{n}|\hat y_{i}-y_{0}|, \\ MSE(\hat{\mathbf{Y}},\mathbf{Y}) &= 1/n \sum_{i=1}^{n}(\hat{y_{i}}-y_{i})^{2},\quad RV(\hat{\mathbf{Y}},\mathbf{Y}) = \frac{tr(\mathbf{Y}\mathbf{Y}^{T} \hat{\mathbf{Y}}\hat{\mathbf{Y}}^{T})}{\sqrt{tr(\mathbf{Y}\mathbf{Y}^{T})^{2}tr(\hat{\mathbf{Y}}\hat{\mathbf{Y}}^{T})^{2}}}. \end{aligned} \end{align*}\end{document}The bias criterion refers to the absolute difference between \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} \hat{Y}\end{document} and the true unobserved \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} Y_{0}\end{document} , while MSE evaluates the modeling accuracy between \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} \hat Y\end{document} and the observed \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} Y\end{document} . The RV correlation coefficient is a multivariate extension of the squared Pearson’s correlation.
Simulations
In this section, we designed three simulation studies to evaluate the performance of our proposed model compared with the TSLS model, MR-LINK, and DeLIVR. Simulation 1 shows the model performance of the conditional density estimation in stage 1 under various distribution choices, and Simulation 2 presents the estimation performance in stage 2 under different nonlinear causal effects. Simulation 3 focuses on the model performance when there is pleiotropy through LD effect in the IV.
Simulation 1: exposure distributions
This simulation evaluates the exposure distribution estimation in the first stage of the proposed GAN-IV method. To mimic real-world genetic architecture, we generated IV SNPs for 1000 samples assuming a minor allele frequency (MAF) of 0.2 under Hardy–Weinberg Equilibrium. To evaluate the robustness of our model against density assumption violations, the error terms of the exposure variable \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} \varepsilon _{G}\end{document} were generated from four distributions: Normal, Laplace, Gamma, and a Mixture of Normals. Furthermore, we assume that \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} Y\end{document} is a scalar, following a linear relationship with exposure \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} G\end{document} , an unobserved confounder term correlated with first stage noise term, and generate \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} Y\end{document} as a scalar. Detailed data generation mechanisms and mathematical formulations are provided in the appendix.
In this simulation setting with linear causal effects and exposure–IV relations, DeLIVR and TSLS share the same modeling results, while MR-LINK is not applicable with no pleiotropy. Hence, only the performance of TSLS and GAN-IV is evaluated separately at the first and second stages. Since TSLS assumes normality of the exposure distribution, the TSLS distribution estimator is a normal distribution \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} \mathcal N(\hat \alpha _{0}+\hat \alpha {1} z{i},\hat \sigma _{G}^{2})\end{document} , where \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} \hat \alpha _{0}\end{document} , \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} \hat \alpha _{1}\end{document} , and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} \hat \sigma _{G}^{2}\end{document} are the linear regression estimators in the first stage as described in (3); our proposed GAN-IV method learns the exposure distribution through GAN. The three criteria defined in Section 2.2, bias, KL divergence and MMD, are used to evaluate the estimation effectiveness.
Similar to most two-sample estimation procedures, in stage 1, we use 20% of samples to train a density estimator, then apply the estimated transformations on the rest 80% of Z dataset to prepare the estimated exposure \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} \hat{G}\end{document} for the second stage model fitting. For the model fitting on the rest 80% of the dataset \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} G, \hat{G},Y\end{document} , we further split it into a training set and a testing set using a ratio of 4:1. For both models compared in this simulation, the stage 2 estimators are trained using training data and evaluated on testing data. The results of 100 replicates are summarized and presented in Fig. 3.
Distribution estimation performance in stage 1 regarding bias, KD divergence, and MMD for four choices of distributions.
As we can see in Fig. 3, all three figure panels show that under all non-normal underlying distributions (Laplace, Gamma, and Mixture Normal), GAN-IV outperforms TSLS. Meanwhile, unsurprisingly, TSLS achieves lower but comparable performance with GAN-IV under the normal distribution. Moreover, GAN-IV attains robust performance for all four distributions and the three criteria, while TSLS shows inconsistent performance in several cases, such as high bias in Gamma and unstable KL in Laplace and Gamma.
Simulation 2: nonlinear causal effects
In this simulation, we focus on the estimation of the nonlinear causal effect under different chosen nonlinear exposure–outcome relationships. Similar to Simulation 1, \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} Z\end{document} and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} G\end{document} are generated following the same procedure with the exposure \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} G\end{document} following a normal distribution. To construct the outcome variable, the phenotype \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} Y\end{document} is generated by a latent function of the exposure, \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} f(G)\end{document} , with an unobserved confounder U and an additive noise term \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} \varepsilon _{Y}\end{document} . Four different nonlinear forms are chosen as the causal relation \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} f(g)\end{document} , including the cosine function (Cos), the polynomial function (Poly), the linear function with a two-way interaction term truncated with a threshold (rwo-way thres), and the linear function with a three-way interaction term truncated with a threshold (three-way thres). The detailed simulation settings are described in the appendix.
We compare our proposed GAN-IV model with TSLS and DeLIVR [10]. Note that MR-LINK is not applicable in this setting without pleiotropy. The data splitting procedure is the same across all three methods as in simulation 1. In this simulation, when applying DeLIVR, as the first step, a linear regression is fitted using 20% of instrument-exposure data \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} (Z,G)\end{document} . This linear model is then applied on the rest 80% to obtain \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} \hat{G}\end{document} . In the second step, a shallow neural network with one hidden layer using the early-stopping technique is trained in the subtrain-valid dataset, and finally evaluated separately on the whole training dataset and testing dataset. The hidden nodes, learning rate, and patience in early-stopping are fixed as recommended values in He et al. [10].
As shown in Fig. 4, GAN-IV achieves the best performance for all four nonlinear relationships and the three criteria, followed by DeLIVR and TSLS. The performance of TSLS gets worse when the causal relations deviate further from linearity. For instance, the MSE of TSLS is comparable with GAN-IV and DeLIVR in the two interaction models, while the MSE disparity becomes more evident in the Poly and Cos cases. On the other hand, the performance of GAN-IV and DeLIVR is robust across all four nonlinear causal choices, while GAN-IV consistently outperforms DeLIVR. The finding that GAN-IV and DeLIVR produce similar estimation performance in the second stage could be resulted from the similar deep learning architecture in the second stage.
Causal effect estimation performance in stage 2 regarding MSE, RV correlation, and bias for four choices of nonlinear causal effects.
Simulation 3: causal effects with pleiotropy and LD
In genetic data analysis, the IV assumptions in causal inference can be violated in the presence of linkage disequilibrium (LD) between the eQTL variants used as IVs, or in the presence of pleiotropy. In those cases, the presence of LD brings overfitting in MR, hence extended MR methods, such as MR-LINK, are developed to correct for LD and pleiotropy. MR-LINK uses summary statistics of an exposure combined with individual-level data on the outcome to estimate the causal effect of an exposure from IVs, and to correct for pleiotropic effects using genetic variants that are in LD with these IVs.
In this simulation, we simulate a causal scenario with pleiotropy through LD where the outcome is affected through two pathways from correlated SNPs. To mimic the real data scenarios with LD effects in SNPs and fairly compare with MR-LINK, we use the same data generating procedure as in van Der Graaf et al. [5]. For the genotype simulation, we downloaded Chromosome 2 genotypes from the 1000 Genomes Project [20] Phase 2 and extracted the interval chr2:100 000 000–105 000 000 on GRCh37. We downloaded the HapMap genetic map for chromosome 2 and computed each variant’s genetic position by linear interpolation between two flanking map markers, where local recombination rate is the segment slope. No extrapolation was performed beyond the map range. We then simulated \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} 1500\end{document} samples using HAPGEN2 [21]. The full cohort was further split into three cohorts: exposure (500), reference (500), and outcome (500). This step yielded 3101 variants in the region. For the exposures, we generated two sets: the observed exposure \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} g_{E}\end{document} and the unobserved exposure \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} g_{U}\end{document} . We first randomly selected 10 causal SNPs \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} Z_{E}\end{document} from the entire genetic region for the observed exposure, then for each causal IV in set \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} Z_{E}\end{document} , we identified an SNP in LD and included it in set \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} Z_{U}\end{document} for the unobserved exposure, making the pleiotropic proportion 100%. We simulated two exposure sets: the observed exposure \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} G_{E}\end{document} and the unobserved exposure \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} G_{U}\end{document} . To represent the genetic architecture under LD effect, both \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} G_{E}\end{document} and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} G_{U}\end{document} are generated as a linear combination of their corresponding causal SNPs \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} Z_{E}\end{document} and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} Z_{U}\end{document} with an independent confounding term. Finally, the phenotype \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} Y\end{document} is generated from both linear and nonlinear causal effect models. For the linear scenario, \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} Y\end{document} is constructed as a linear function of \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} G_{E}\end{document} and the confounder \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} G_{U}\end{document} ; for the nonlinear scenario, the construction of \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} Y\end{document} incorporates quadratic and trigonometric transformations of \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} G_{E}\end{document} besides the linear term of \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} G_{E}\end{document} and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} G_{U}\end{document} . The specific implementation is provided in the appendix.
The methods compared in this simulation include TSLS, MR-LINK, DeLIVR, and our proposed model, GAN-IV. For each simulated dataset, we first applied MR-LINK to obtain qualified IV SNPs and further identified a set of tag-SNPs that are correlated with the IVs. For TSLS and GAN-IV, tag-SNPs are included in the second stage. For the proposed GAN-IV method, we apply the MFDL model in the second stage to accommodate the tag-SNPs. The results of the MSE and RV correlation for the chosen linear and nonlinear causal relations are summarized in Fig. 5. For the linear causal relation with LD effects, MR-LINK, GAN-IV, and DeLIVR share similar performance. They all outperform TSLS, although MR-LINK shows slight overfitting. For nonlinear causal relation with LD, our proposed GAN-IV achieves the best performance in the test set in terms of both MSE and RV correlation among the four methods, followed by DeLIVR and MR-LINK. Overfitting remains an issue in TSLS in the nonlinear case.
Causal effect estimation performance for linear (upper panel) and nonlinear (lower panel) causal relationships with pleiotropy proportion of 100%.
We further evaluated the effect of pleiotropic proportion by conducting an additional simulation. We consider a pleiotropic proportion of 50%, i.e. for 10 causal IVs in set \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} Z_{E}\end{document} , we randomly selected five of these IVs and included their corresponding in-LD SNPs in the set \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} Z_{U}\end{document} . The data generating process was the same as described above. Figure 6 shows results summarizing MSE and RV correlation for linear and nonlinear causal effects when pleiotropic proportion equals 50%. Overall, all four methods show improved MSE and RV accuracy in comparison with the results in Fig. 5. The comparison among the four methods shows a similar pattern to the scenario with a pleiotropic proportion of 100%. In the linear scenario, GAN-IV shows comparable performance to MR-LINK and DeLIVR, but all three methods outperform TSLS. In the nonlinear scenario, our proposed method presents more evident superiority among all the methods in both MSE and RV correlation, which validates the robustness of GAN-IV across different levels of pleiotropic proportions.
Causal effect estimation performance for linear (upper panel) and nonlinear (lower panel) causal relationships with pleiotropic proportion of 50%.
Real data application
We apply the proposed framework to the ROSMAP dataset, which involves two prospective aging studies, the Religious Order Study (ROS) and the Memory and Aging Project (MAP) [22], to study the causal effect of genes on the development of Alzheimer’s disease (AD). We obtained matched genotype and gene expression data in the ROSMAP cohort. Specifically, the genotype data were obtained using whole-genome sequencing technology, and the gene expression profiles were obtained using microarray technology. Both are available via Synapse [23]. In this analysis, we focus on four key AD causal genes, which include early-onset AD causal genes (i.e. PSEN1, PSEN2, and APP) and late-onset AD (i.e. APOE). For each gene, variants within \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} \pm \end{document} 500 kb of the gene coding region were extracted using bcftools v1.13 [24]. Genotypes were converted to a dosage format (0 = homozygous reference, 1 = heterozygous, 2 = homozygous alternate). Quality control was applied to retain only biallelic SNPs and to remove indels or sites with missing alternate alleles. Gene-level expression values were averaged across probes when multiple probes were mapped to the same gene and were normalized.
The phenotype of interest is the CERAD score, which originally was an ordinal variable summarized using the cognition test score. We transformed this score into a binary outcome using the recommended table provided by the institution [25]. The candidate genes and the number of variants in each gene are as follows: APOE ( \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} 14,682\end{document} ), APP ( \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} 13,364\end{document} ), PSEN1 ( \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} 13,489\end{document} ), PSEN2 ( \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} 12,641\end{document} ), with a sample size of 415 after data matching. The data preprocessing steps included removing SNPs with MAF <0.05 for all three genes, adjusting for covariates including sex, education level, race, and age. To amplify the genetic association, we regressed the transformed CERAD binary variable on covariates, then used the standardized residuals as the adjusted CERAD scores for model fitting. LD pruning was applied to all genes to remove SNPs with LD above 0.9 and leave one SNP to represent the information of window size 50.
For the IV selection, we adapted the procedure in He et al. [10]. Specifically, we fitted a linear regression of gene expression on the available SNPs and applied the backward selection with AIC to choose an optimal model and select the significant predictive SNPs. We also calculated the F statistics of the final model. Among all three genes, we identified PSEN2 with three IVs, APOE with three IVs, and APP with one IV, all with F statistics larger than 10. There were no significant SNPs selected by the procedure for PSEN1, hence no further results were reported for PSEN1. We applied TSLS, DeLIVR, and GAN-IV to the three genes with the selected IVs, normalized gene expression, and phenotypes. Note that MR-LINK is not applicable in this application as it requires additional summary statistics. To address the potential pleiotropic confounding, we identified an additional tag-SNP set and added them to the second stage estimation in the three methods. The number of variants in the tag-SNP set of three genes vary based on the LD range used to select tag-SNPs. The details of tag-SNP set are described in the appendix.
To avoid chance findings caused by data splitting, we randomly split the dataset and repeated the experiments 100 times. For each run, the dataset was randomly divided into a training set and a testing set in a ratio of 4:1. MSE and RV correlation for the three methods are summarized in Fig. 7. GAN-IV achieves the highest estimation accuracy in both MSE and RV correlation among the three methods for all three genes. Despite similar deep learning structures in both GAN-IV and DeLIVR in the second stage, the superior performance of GAN-IV over DeLIVR may indicate that the GAN efficiently captured the exposure distribution in the first stage and hence improved the overall model accuracy. The computational cost of the three methods applied to each gene is included in the appendix.
Causal effect estimation performance of the PSEN2, APOE, APP genes in the CERAD score.
We also conducted the exposure density estimation comparison estimated by GAN, TSLS, and DeLIVR, conditioning on the sample median of the selected IVs. We averaged the first stage exposure outputs \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} \hat g\end{document} from 100 experiments of TSLS, DeLIVR and our proposed GAN-IV. For a fair comparison and informative illustration, we computed the KDEs for all three methods with a Gaussian kernel and a bandwidth selected by Scott’s rule of thumb. We evaluated the density estimators for all three methods at 1000 equally spaced points spanning the observed range of the true gene expression using densities estimated via KDE shown as in Fig. 8 showing the gene expression density of PSEN1, APOE, and APP. From the figure, we observed that both TSLS and DeLIVR reflect the normality assumption in their density estimates, whereas our GAN-based method learns the distribution directly from the data and captures the heavier tails of the exposure distribution across all three gene applications.
Exposure density estimation for the three genes conditioned on the sample median of IVs using GAN, TSLS, and DeLIVR.
To further assess the robustness of both stages of the proposed GAN-IV, we conducted two sensitivity analyses using the ROSMAP dataset: a weak IV scenario and a partial sample scenario. The weak IV scenario refers to IVs with moderate F-statistics ranging from 8 to 10, other data generating functions remain the same as in the previous analysis. The number of selected IVs is described in detail in the appendix. The comparison in terms of MSE and RV correlation between the strong IV scenario and the weak IV scenario across three genes is summarized in Fig. 9. By comparing two subpanels across three genes, it is observed that with weaker IVs, TSLS is prone to a higher level of overfitting. Although GAN-IV and DeLIVR also suffer from overfitting due to the violation of the strong IV assumption, GAN-IV outperforms TSLS and DeLIVR in all three genes. This is likely attributed to the ability of the conditional GAN model used in the first stage to capture signal from noise.
Causal effect estimation performance comparison of the PSEN2, APOE, APP genes in the CERAD score with strong and weak IVs.
Another scenario we considered as part of the sensitivity analysis is the evaluation of all three methods using a smaller sample size. We randomly selected 300 samples out of the ROSMAP data for each gene; MSE and RV correlation of all three methods are shown in Fig. 10. For GAN-IV and DeLIVR, which use DNN-based models, fewer samples usually lead to worse model fitting. This phenomenon is evidenced by the larger variance observed in the partial sample subpanels across all genes. In some cases, the MSE and RV correlation distributions also become skewed, where the median remains lower despite the higher placement of the box. While GAN-IV is more sensitive to sample size due to the usage of deep learning models in both stages, it still achieves comparable or better performance across all three genes.
Causal effect estimation performance comparison of the PSEN2, APOE, APP genes in the CERAD score with full and partial samples.
Overall, in the sensitivity analysis, we validate the robustness of our model against the violation of an important assumption in causal inference and the limitation of sample size. It should be pointed out that in both scenarios, the tuning process for hyper-parameters will require more computational resources and iterations.
Discussion
To summarize, we develop a two-stage nonparametric estimation for the causal effect in omics data, which uses SNPs as genetic IVs and gene expression as the exposure. In this research, we focus on several common problems faced by the causal analysis of omics data, the unknown distributions of omics data, LD and pleiotropic effects, and nonlinear exposure effects. To address these problems, we propose a nonparametric framework, GAN-IV, that provides robustness against omics data distribution assumptions, the ability to capture nonlinear causal effects, and consistency even in the presence of the IV condition violation (e.g. in the presence of pleiotropy). We extensively investigated both the exposure distribution estimation in the first stage and the modeling performance in the second stage. Compared with DeepIV, our approach avoids the inner-loop Monte Carlo step and ill-posed inversion of a conditional density. Compared with DeLIVR, we do not require an exponential-family or completeness condition on the exposure distribution. In terms of MR-LINK, which corrects for both LD effect and pleiotropy, our proposed method relieves the linear structure of the first-stage estimator and provides a more powerful model by accommodating extra tag-SNP information. Throughout the simulation studies and real data analysis, we elaborate on the above advantages by comparing the proposed framework with existing methods under different conditional densities, different exposure–outcome relationships, the presence of the LD effect and pleiotropy, and under different evaluation criteria. As demonstrated by both simulations and real data analysis, the proposed GAN-IV method achieves superior or comparable performance compared with the competing methods.
One possible limitation of the proposed approach lies in a failure mode of GAN called mode collapse. It refers to the situation in which a trained generator only outputs several fixed values regardless of the input. Although we do not observe this phenomenon in our model, for future applications, we can further improve the performance of GANs. Plenty of research has been conducted to improve the stability of the discriminator on the GAN-based models. Kurach et al. [26] conducted an analysis of several competing regularization and normalization methods on the GAN model. In our case, two possible extensions can be considered based on the conclusion in Kurach et al. [26]. When the computation resources are limited, we can add non-saturating GAN loss as proposed in Goodfellow et al. [13] and spectral normalization to the loss function. With enough resources, we can further add gradient penalty regularization or even switch the vanilla conditional GAN to a conditional version of Wasserstein GAN with gradient penalty, which is shown to provide better density estimation [27].
Another limitation of the proposed GAN-IV relates to the hyperparameter selection and the sample size requirement. Like most deep learning approaches, both the GAN in the first stage and the DFNN in the second stage of the proposed GAN-IV involve the choice of network architectures, the tuning of learning rates and regularization parameters, which typically require large sample sizes. Moreover, the complex modeling often requires a high computational cost. To mitigate these limitations, implementation details of the GAN-IV network structure and hyperparameter selection are provided in the appendix for practical guidance. Our experience in simulation and real data analysis shows that the cross-validation process is an effective tool for hyperparameter selection. The sensitivity analysis in the real data analysis indicates our proposed method achieves higher accuracy even with a limited sample size of 300. The computational costs provided in the appendix show relatively affordable computational time of GAN-IV compared with existing methods, given its improved performance.
Key Points
- The two-stage GAN-based instrument variable method (GAN-IV) utilizes conditional generative adversarial networks to estimate the conditional distribution of gene expression given IVs in the first stage and the functional neural networks to model the causal effects between gene expression and the phenotype.
- The GAN-IV method is free of distribution assumptions of the exposure variables and is powerful to capture nonlinear causal effects compared with other two-stage methods such as the two-stage least squares method and MR-LINK.
- In the second stage of GAN-IV, the functional neural network structure is flexible to handle complex omics data (e.g. tag-SNPs) in the presence of pleiotropy and linkage disequilibrium.
Supplementary Material
supplement_bbag071
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1Sanderson E, Glymour MM, Holmes MV et al. Mendelian randomization. Nat Rev Methods Primers 2022;2:6. 10.1038/s 43586-021-00092-537325194 PMC 7614635 · doi ↗ · pubmed ↗
- 2Bowden J, Davey Smith G, Burgess S. Mendelian randomization with invalid instruments: effect estimation and bias detection through Egger regression. Int J Epidemiol 2015;44:512–25. 10.1093/ije/dyv 08026050253 PMC 4469799 · doi ↗ · pubmed ↗
- 3Verbanck M, Chen C-Y, Neale B et al. Detection of widespread horizontal pleiotropy in causal relationships inferred from Mendelian randomization between complex traits and diseases. Nat Genet 2018;50:693–8. 10.1038/s 41588-018-0099-729686387 PMC 6083837 · doi ↗ · pubmed ↗
- 4Barfield R, Feng H, Gusev A et al. Transcriptome-wide association studies accounting for colocalization using Egger regression. Genet Epidemiol 2018;42:418–33. 10.1002/gepi.2213129808603 PMC 6342197 · doi ↗ · pubmed ↗
- 5van Der Graaf A et al. Mendelian randomization while jointly modeling cis genetics identifies causal relationships between gene expression and lipids. Nat Commun 2020;11:4930. 10.1038/s 41467-020-18716-x 33004804 PMC 7530717 · doi ↗ · pubmed ↗
- 6Newey WK . Nonparametric instrumental variables estimation. Am Econ Rev 2013;103:550–6. 10.1257/aer.103.3.550 · doi ↗
- 7Hall P, Horowitz JL. Nonparametric methods for inference in the presence of instrumental variables. Ann Stat 2005;33:2904–29. 10.1214/009053605000000714 · doi ↗
- 8Staley JR, Burgess S. Semiparametric methods for estimation of a nonlinear exposure-outcome relationship using instrumental variables with application to Mendelian randomization. Genet Epidemiol 2017;41:341–52. 10.1002/gepi.2204128317167 PMC 5400068 · doi ↗ · pubmed ↗