Identifying and avoiding design related biases in observational studies using the target trial framework
Harrison J Hansford, Nazrul Islam, Hopin Lee, Barbra A Dickerman, Aidan G Cashin

TL;DR
This paper explains how to reduce design-related biases in observational studies by using a target trial framework to better emulate randomized trials.
Contribution
It introduces the target trial framework as a novel method to identify and avoid design-related biases in observational study design.
Findings
Design-related biases are common in observational studies and often overlooked.
Using the target trial framework can help align study design with a hypothetical randomized trial.
This approach helps shift focus to addressing data-related biases like confounding.
Abstract
Observational studies are necessary to provide evidence to inform decision making in the absence of a relevant randomised trial. Although commonly criticised for potential problems due to confounding bias, design related biases in observational studies are often overlooked yet highly prevalent. Design related biases occur because of decisions made by researchers during analyses of observational data. Common design related biases include bias related to selection and treatment misclassification, resulting from misalignment of eligibility ascertainment, treatment strategy assignment, and start of follow-up. Conceptualising the analysis of observational data to estimate the causal effects of interventions as an attempt to explicitly emulate a target trial can help avoid design related biases, so that investigators can instead focus on data related biases (eg, confounding, measurement…
Genes, proteins, chemicals, diseases, species, mutations and cell lines named across the full text — each resolved to its canonical identifier and authoritative record.
Click any figure to enlarge with its caption.
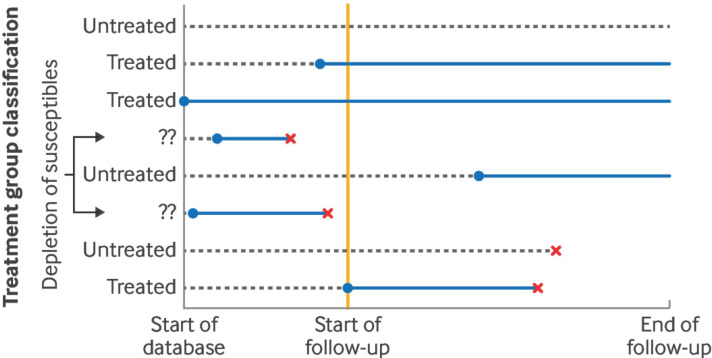 Figure 1
Figure 1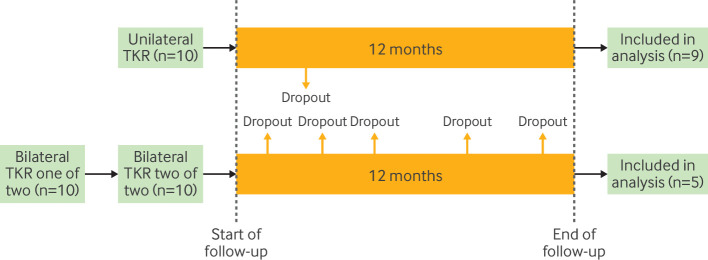 Figure 2
Figure 2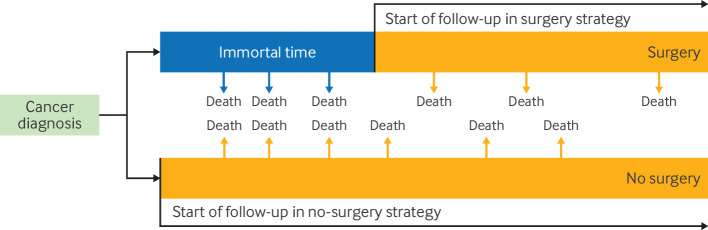 Figure 3
Figure 3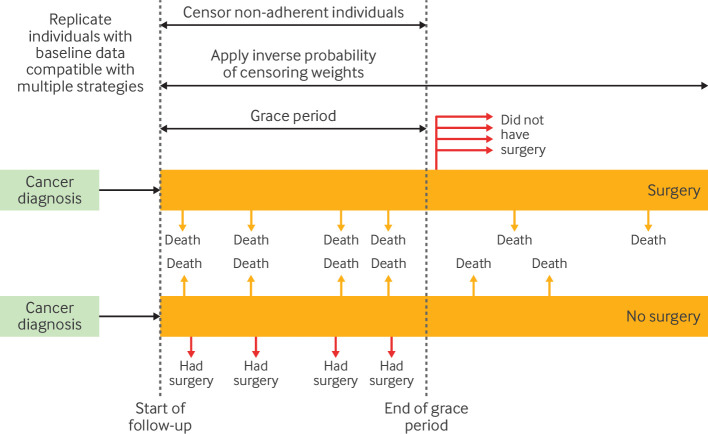 Figure 4
Figure 4 Figure 5
Figure 5| Term | Definition |
|---|---|
| Target trial | Hypothetical randomised trial that would be conducted to answer the question of interest, with respect to the variables available in the observational data. |
| Target trial emulation | Process of mapping the analysis of observational data to the components of the target trial (eligibility criteria, treatment strategies, assignment procedures, follow-up, outcomes, causal contrast, data analysis plan) with specification of the assumptions necessary for causal inference. |
| Time zero | Time at which follow-up begins, which should align with the time of eligibility ascertainment and treatment strategy assignment. |
| Design related bias | Biases introduced by investigator decisions about the design of an observational study, often occurring when investigators deviate from the design principles of a randomised trial. |
| Selection bias | Systematic inclusion or exclusion of individuals into an analysis resulting in a biased treatment effect estimate. |
| Misclassification of treatment assignment | Errors when classifying individuals into a treatment strategy caused by the use of information that emerges after the beginning of follow-up to assign individuals to a treatment strategy. This scenario often occurs when baseline information alone is insufficient to classify individuals into a treatment strategy. |
| Clone-censor-weight method | Analytical approach where the study dataset is replicated (cloned), and replicates (clones) are assigned to each treatment strategy with compatible data at baseline and are censored when they deviate from their assigned strategy; inverse probability weights are then applied to overcome biases introduced by the censoring. This approach is used to handle scenarios in which baseline information alone is insufficient to classify individuals into a treatment strategy. |
| Sequential trial emulation | Analytical approach where a series of hypothetical target trials are conceptualised and emulated where individuals who are eligible at multiple times are included at each time of eligibility. This approach is used to handle scenarios where individuals may meet the eligibility criteria at multiple times over follow-up and is more statistically efficient than selecting only one of those times as time zero. |
- —http://dx.doi.org/10.13039/100000002National Institutes of Health
- —http://dx.doi.org/10.13039/501100000925National Health and Medical Research Council
- —http://dx.doi.org/10.13039/100012769Neuroscience Research Australia
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsAdvanced Causal Inference Techniques · Meta-analysis and systematic reviews · Statistical Methods in Clinical Trials
Introduction
Randomised trials are the preferred approach to estimate the causal effects of medical interventions.1 2 However, it is often not feasible to conduct randomised trials to investigate the long term safety and effectiveness of interventions,3 identify specific groups who benefit (or are harmed) most from interventions,4 or to provide evidence when timely information is needed for decision making.5 Routinely collected, observational data (eg, in the form of electronic health records and claims data) have become increasingly available for research6 and are frequently used to inform decision making where randomised trials are not available.7 8 Because of the ability to complement evidence from randomised trials, regulators such as the European Medicines Agency are reviewing the use of observational data to inform regulatory decision making around the safety and effectiveness of medicines.9 Despite the necessity of using observational data to inform health decision making in the absence of a relevant randomised trial, clear challenges exist in drawing valid causal inferences from observational data.10
Clinicians and policymakers are often hesitant to rely on evidence from observational studies, because of concerns of confounding bias due to the lack of randomisation.10 11 However, design related biases12 can explain discrepancies between findings in observational data and randomised trials, sometimes even more so than confounding.1317 These biases are introduced when observational studies are designed in a manner that deviates from the design principles of a randomised trial.18 For example, well designed randomised trials will follow participants from the time of randomisation (treatment strategy assignment) immediately after meeting eligibility criteria, such that there is a clear “time zero.” In observational studies of longitudinal data, the timing of eligibility, treatment strategy assignment, and start of follow-up are not naturally aligned, and analysts must therefore define these timepoints retrospectively.19 The choice of these timepoints is where errors commonly occur.13 20 In a cross sectional study of 200 observational studies of drug interventions,21 Yaacoub et al highlighted that over 75% of studies were subject to at least one avoidable design related bias caused by the misalignment of time zero.
All investigators and readers—including clinicians, peer reviewers, and other health and policy decision makers—must be able to identify and avoid these often-overlooked biases related to design, to maximise the usefulness of observational data for decision making.22 23 This article aims to provide a detailed outline of how design related biases may occur and how target trial emulation can help avoid these biases, with reference to the growing literature on this topic in health and medical research.1213 17 19 2429 29 Although target trial emulation can help to avoid design related biases, it does not eliminate the potential for biases inherent to the observational data, such as confounding.25 While not the focus of this article, we briefly discuss approaches to handle confounding.36 We also highlight the importance of transparent reporting for observational studies of interventions to be appraised and used in practice.37 Key terms used in this article are defined in table 1, with references to articles with more detail.
Identifying common design related biases in observational studies
The design related biases described in this section all stem from deviation from the design principles of a randomised trial. These biases include selection bias due to the inclusion of prevalent users, and immortal time generated when information after the start of follow-up is used to ascertain eligibility or classify individuals into treatment strategies (discussed further below). While desirable, predicting the magnitude and direction of these design related biases is challenging.38 We hope that by providing the structure of how these biases occur in this article, readers may be better placed to assess the potential direction of bias in the context of their own research questions or studies they may appraise.
Prevalent user bias
Studies that include prevalent users of treatment are prone to selection bias (sometimes referred to as prevalent user bias, or depletion of susceptibles).39 40 This bias arises when the treated group includes individuals who had been taking treatment for some time before the start of follow-up and who remained alive and event-free until the start of follow-up (figure 1).
Graphical depiction of prevalent user bias. Blue lines=treatment; dashed lines=no treatment; red crosses=people who died, experienced the outcome of interest, or were lost to follow-up; yellow line=start of follow-up (ie, time zero). Depletion of susceptibles occurs when individuals who experience outcomes during treatment before the start of follow-up are systematically excluded. Figure adapted from Fu et al24
Immortal time
Immortal time refers to a period of time included in the analysis where individuals cannot experience the outcome of interest owing to choices about the study design.12 28 41 In a randomised trial, all outcomes that occur after eligibility ascertainment, treatment strategy assignment, and the start of follow-up are attributed to the appropriate treatment strategy. However, in observational analyses, when information that is ascertained after the start of follow-up is used to inform eligibility (or classification into treatment strategies), immortal time may be introduced. Below are examples of specific design decisions that can introduce immortal time.
Use of information emerging after treatment assignment to define eligibility (selection bias)
Using information that emerges after treatment assignment (eg, adherence to treatment strategy, duration of treatment use, providing follow-up data) to define the eligibility criteria induces selection bias when the analysis starts the follow-up at treatment assignment. In a study comparing the effect of unilateral total knee replacement with staged bilateral total knee replacement for the outcome of functional impairment, investigators included only participants who provided follow-up data at 12 months after surgery.29 This decision will result in a biased treatment effect estimate if response rates differ on the basis of the intervention, and if there are common causes of response and the outcome of interest (eg, persistent pain). In general, if information measured after treatment strategy assignment and the start of follow-up is used to determine eligibility, the treatment differentially influences those eligibility criteria, and there are common causes of the eligibility criteria and the outcome, then the treatment effect can be biased (figure 2).21 In a well designed and executed randomised trial, the time of eligibility ascertainment is anchored to the time of treatment strategy assignment (randomisation) and the start of follow-up, avoiding this issue.
Immortal time due to selection bias. Immortal time can arise when eligibility criteria (eg, 12 month follow-up response) are applied after treatment assignment (eg, unilateral v bilateral total knee replacement (TKR)) and the start of follow-up, thereby creating a period of immortal time between baseline and eligibility ascertainment where the outcome cannot occur for included individuals (ie, everyone who is included in the analysis must have survived and not dropped out of the study, and is therefore “immortal”). This example also includes bias due to misclassification of treatment assignment (see Errors in classifying individuals into treatment strategies, below)
Errors in classifying individuals into treatment strategies (misclassification bias)
Immortal time can also arise when individuals are classified into a treatment strategy that differs from the one they should have been assigned to. This misclassification often occurs when treatment strategies under comparison cannot be distinguished at time zero. In a study that compared surgery with no surgery for lung cancer in elderly people, a grace period of six months was necessary to allow individuals time from their diagnosis to receive surgery, because surgery often does not occur immediately after diagnosis.30 Using only information at cancer diagnosis, it is unclear which treatment strategy individuals should be classified to, because their data at baseline may be compatible with both strategies (ie, surgery within six months or no surgery). If investigators look forward and classify individuals who undergo surgery within six months to the surgery strategy, all individuals in that strategy would have survived until their surgery. Therefore, in this scenario, events (eg, death) that occur before surgery will be attributed to the strategy of no surgery. This scenario may result in up to six months of immortal time for participants classified to the surgery strategy (figure 3).30 In a randomised trial, participants would be allocated prospectively to either strategy and events attributed to the strategy assigned at baseline, avoiding this issue. To avoid introducing immortal time, analysts of observational data can use approaches that overcome the lack of knowledge on what treatment strategy individuals were intended to be allocated, without using information that is measured after baseline.
Immortal time created due to misclassification of treatment assignment. This scenario can arise when treatment strategies (eg, surgery within six months or no surgery) are assigned using information after the start of follow-up (eg, cancer diagnosis), which can result in events being misattributed to one of the treatment groups (eg, early deaths marked by blue arrows in the figure are misattributed to the strategy of no surgery)
Avoiding design related biases with target trial emulation
Carefully mapping the analysis of an observational study to the framework of a randomised trial that would answer the question of interest, known as target trial emulation, can help investigators avoid design related biases.25 38 42 The emulation of a target trial involves two steps. The first step is to design the hypothetical pragmatic trial—the target trial—that would answer the question of interest, and use only variables that are available in the observational data source (ie, the target trial is able to be emulated with the available data).25 The target trial can be considered a detailed description of the causal question (or estimand) that is being targeted.25 The critical components to be considered when specifying the target trial are: eligibility criteria, treatment strategies, treatment assignment, outcomes, follow-up, and causal contrasts of interest (eg, intention-to-treat effect), as well as any identifying assumptions and the data analysis plan.14 25 After the target trial is specified, the second step is to map the components of the target trial to the observational data (ie, emulate the target trial) and apply appropriate analytical techniques to adjust for confounding.27 43 44 There may be instances where data on all variables needed to emulate the target trial are not available; however, still specifying the target trial can help readers understand these limitations.45
Several approaches under the target trial framework can help investigators avoid inducing design biases common in observational studies, such as to avoid inclusion of individuals already taking treatment at baseline (avoiding prevalent user bias) and to avoid the use of information that is available after baseline to assign individuals to treatment strategies or to define eligibility (avoiding immortal time).
Avoiding prevalent user bias
Prevalent user bias can be avoided by applying eligibility criteria in the target trial that restrict entry into the hypothetical trial to individuals who have not used the treatment for a defined period. This same criterion must be applied in the analysis of the observational data (emulation) and is often implemented using a so-called look-back period where individuals cannot have used the treatment for some defined period before baseline (time zero). Including only individuals who are just starting treatment has also been termed a new user design or incident user design in pharmacoepidemiology.46 There are also occasions where prevalent users are of interest, and designs are emerging to handle the depletion of susceptibles appropriately47 48; however, such designs can be challenging to apply and interpret.49
An example of prevalent user bias occurred in observational studies investigating hormone replacement therapy for the prevention of coronary heart disease.50 51 Grodstein et al51 compared women using hormone therapy (prevalent users) to women who did not use hormone therapy. The observational study suggested a reduced risk of coronary heart disease among users of hormone therapy compared with non-users,51 a result that conflicted with a later randomised trial showing an increased risk of coronary heart disease for those assigned to initiate hormone therapy compared with placebo.52 The same data in Grodstein et al51 were used by Hernán et al,50 although these investigators adhered more closely to the principles of the randomised trial by comparing initiators to non-initiators and found a similarly increased risk of coronary heart disease to the trial.50 In the original observational study,51 the inclusion of prevalent users introduced bias as individuals who were susceptible to adverse events of hormone therapy or who had coronary heart disease were less likely to be included in the study (depletion of susceptibles), resulting in an underestimation of the true risk of hormone therapy. The comparison between initiators and non-initiators of treatment better aligns with common clinical decisions about whether to start a new treatment, and how a randomised trial would be conducted.50
Avoiding immortal time
Immortal time is introduced by the selection of individuals based on eligibility criteria defined after treatment strategy assignment, when the analysis starts the follow-up at assignment; or the misclassification of individuals into treatment strategies based on information available after eligibility ascertainment and the start of follow-up. These biases do not exist in well designed randomised trials, which have negligible gaps between eligibility ascertainment, treatment strategy assignment, and the start of follow-up. Specifying a target trial that similarly aligns these features will avoid the introduction of immortal time.12 53
Immortal time can have substantial impacts on study results. To illustrate this difference, Kuehne et al systematically applied different approaches to estimate the effect of LOT2 (a type of chemotherapy for ovarian cancer), including designs subject to immortal time, to highlight how the estimates change with design decisions.17 With the naive approach subject to immortal time, the researchers estimated a hazard ratio of 0.56 (95% confidence interval (CI) 0.49 to 0.64). By contrast, when they emulated the design of an index trial, they estimated a hazard ratio of 1.12 (0.96 to 1.28), which was compatible with the results of the trial.17
This alignment is straightforward when estimating the effect of receiving an intervention that occurs at a single timepoint such as a surgery or single dose vaccine. However, this alignment is more complex when estimating the effect of treatment strategies that are indistinguishable at baseline, such as when the effect of the timing of treatment is of interest (eg, start treatment within six months of diagnosis or after six months). Several strategies have been developed to handle these situations.32
Clone-censor-weight approach
An approach to handle questions where treatment strategies are indistinguishable at the start of follow-up, in conjunction with the target trial framework, is the clone-censor-weight approach.32 34 54 To implement this, investigators can clone participants—that is, replicate individuals, and assign replicates to as many treatment strategies as their data are compatible with at baseline. Because a person's observed treatment pattern becomes incompatible with their assigned strategy, their follow-up in that treatment strategy is artificially stopped or censored by the investigator at the time of deviation from their assigned strategy. This artificial censoring ensures that individuals classified into each strategy are only included in follow-up while they adhere to their assigned treatment strategy. However, if adherence is differential (non-random) between the treatment strategies, the artificial censoring may induce selection bias,55 requiring a third step: weighting. Inverse probability weights are estimated and applied to adjust for the selection bias induced by this censoring.32 34 For further discussion, Hernán and Gaber et al provide in-depth explanations of how to conduct a clone-censor-weight analysis.32 34
An example of where the clone-censor-weight approach may be helpful is when comparing treatment strategies that involve a grace period for initiating treatment (ie, a predefined period of time after baseline during which treatment can begin, reflecting delays common in clinical practice) (figure 4).34 Consider the example of comparing receipt of surgery within six months (the grace period) of baseline (lung cancer diagnosis) with no surgery over follow-up (figure 3). Since it is unclear which treatment strategy individuals should be assigned to at baseline, all individuals who have baseline data compatible with both treatment strategies (eg, have not had surgery immediately on cancer diagnosis) are replicated. Then, as replicates classified at baseline to no surgery then have surgery during follow-up, they are censored at that time because their data are no longer compatible with their strategy assigned at baseline. Similarly, for replicates classified to the surgery strategy who do not have surgery by the end of the grace period, they are censored at six months. Inverse probability weights are applied throughout the follow-up period to account for the censoring.
Illustration of clone-censor-weight approach. Red arrows=deviation from treatment strategies leading to censoring (eg, when individuals classified to receive no surgery, end up receiving surgery, or when individuals classified to surgery within a certain grace period strategy do not receive surgery by the end of the grace period)
Applying target trial emulation with cloning, censoring, and weighting prevented immortal time in a recent example by Boyne et al investigating survival after short or longer duration of adjuvant chemotherapy for colon cancer.56 Before this study, findings from a randomised trial (the IDEA trial)57 conflicted with those from observational studies. In these previous observational studies, information emerging after baseline (achieved duration of treatment) was used to classify individuals into treatment strategies, leading to immortal time.56 It demonstrated that with the naive approach taken in previous observational studies, estimates suggested that shorter durations of treatment substantially worsened survival (hazard ratio 3.33 (95% CI 1.04 to 10.65)).56 However, when information emerging after baseline was not used to classify individuals into treatment strategies, and cloning, censoring, and weighting was applied instead, the estimates were compatible with those from the IDEA trial (emulation hazard ratio 0.96 (95% CI 0.43 to 2.14); trial hazard ratio 0.96 (95% CI 0.85 to 1.08)).56 Aside from the clone-censor-weight approach, we note that the plug-in g formula is another approach available to analysts; however, it is not described in this article with further reading available elsewhere.58 59
Redefining the treatment strategies
Another approach to avoid immortal time where treatment strategies are not distinguishable at baseline is reformulating the causal question to make the strategies distinguishable at baseline.33 54 Consider the example outlined previously: comparing receipt of surgery within six months of baseline with no surgery over follow-up. Investigators could reformulate the first strategy as receipt of surgery at baseline—that is, without a grace period. Therefore, individuals who initiate surgery at baseline will be classified into the surgery strategy, and into the no-surgery strategy otherwise. This approach avoids the introduction of immortal time due to treatment strategy misclassification; however, whether the new causal question (eg, without grace periods, which may be realistic in many real world treatment strategies) is still of interest should be considered.
In principle, using only one eligible time (eg, the first, or a random eligible time) would be an unbiased approach, because it relies only on baseline information to classify individuals into a treatment strategy.12 19 However, a large amount of information could be lost, leading to less precise estimates.12 A more efficient approach could be to instead emulate a sequence of nested trials, each initiated at a certain calendar period (eg, each day, week, or month), which becomes time zero of a given nested trial.33 For example, eligible individuals who initiate surgery in the first week of each nested trial could be compared with eligible individuals who do not have surgery in that week (figure 5). Information across these trials can then be pooled to provide a single estimate of the treatment effect.
Emulation of sequential trials. Each target trial recruits each week (or other relevant time period, where follow-up begins (time zero)), where investigators classify individuals into the treatment strategy their data is compatible with during that week, and then follows individuals for 12 months
Applying target trial emulation with sequential trial emulation prevented design related biases in an evaluation of statins and risk of cancer.13 In earlier observational analyses, investigators reported a substantially lower risk of cancer among statin users than among non-users (odds ratio for lung cancer of 0.23 (95% CI 0.20 to 0.26), comparing long term (>4 years) statin users with non-users).60 These analyses had two flaws previously discussed31 50: post-baseline information on achieved duration of statin use was used to classify individuals into treatment strategies, generating immortal time, and prevalent users of treatment were included, leading to selection bias. Dickerman et al reframed this analysis as a target trial with sequential trial emulation and classified individuals into one of two strategies (statin initiators v non-initiators) based on information available at the baseline of each sequential target trial, finding a null effect (hazard ratio 1.02 (95% CI 0.99 to 1.05)), consistent with meta-analyses of randomised trials.61 62 Despite the potential benefits of sequential trial emulation, the approach may become computationally intensive in large datasets.63
Common approaches to handle confounding
Although target trial emulation can help to avoid the design related biases outlined above, it does not eliminate data related biases, such as confounding or measurement error.44 Such biases must be dealt with through careful measurement and adjustment for key variables via appropriate analytical techniques in combination with unverifiable assumptions.64 Analytical approaches to adjust for confounding may involve modelling the probability of treatment (eg, inverse probability of treatment weighting65), the probability of the outcome (eg, multivariable outcome regression,66 the g formula58 59), or both (eg, doubly robust approaches such as targeted maximum likelihood estimation67 and augmented inverse probability weighting68). Matching, often on the propensity score,69 70 71 may be used to adjust for time-fixed confounding for point interventions but not for time-varying confounding for sustained intervention strategies.72 73 Confounding by indication may be more of a concern when comparing an active intervention (eg, a drug) to no intervention; the use of an active comparator (eg, another drug) may reduce the magnitude of confounding by indication.74 Similarly, as with all analyses aiming to estimate causal effects of sustained intervention strategies, time-varying confounding should be managed by appropriate methods (such as inverse probability weighting73) when necessary.
Transparent reporting of observational studies of interventions
Observational studies of interventions should be considered as attempts to emulate a target trial,25 42 and the design related issues described in this article are easier to assess when authors explicitly report their analysis as a target trial emulation.21 The TARGET guideline37 75 76 aims to assist investigators to report relevant information and support readers to identify key aspects of the target trial emulation. TARGET was not designed to be, and should not be, used as a tool to assess risk of bias or quality of a study. However, although not the intention, the TARGET guideline may help improve study conduct by serving as an educational tool and clarifying key methodological issues to be resolved by investigators. Study design diagrams, such as those described by Schneeweiss et al,77 can also assist investigators to communicate the timing of different aspects of the study design.77
Conclusion
In settings where trials are unavailable or infeasible, observational studies may provide evidence to answer the relevant clinical question. Design related biases are common in observational studies on the comparative benefits and harms of interventions, but explicit emulation of a target trial can help investigators avoid these biases and enable readers to identify them when present. The use of the target trial framework and transparent reporting of these studies may support sound policy and clinical decisions from observational studies.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1Cochrane AL Effectiveness and efficiency: random reflections on health services 197210.1016/0197-2456(89)90008-12691208 · doi ↗ · pubmed ↗
- 2Concato J Shah N Horwitz RI Randomized, controlled trials, observational studies, and the hierarchy of research designs N Engl J Med 200034218879210.1056/NEJM 20000622342250710861325 PMC 1557642 · doi ↗ · pubmed ↗
- 3Matthews AA Dahabreh IJ Fröbert O et al Benchmarking Observational Analyses Before Using Them to Address Questions Trials Do Not Answer: An Application to Coronary Thrombus Aspiration Am J Epidemiol 202219116526510.1093/aje/kwac 09835641151 PMC 9437817 · doi ↗ · pubmed ↗
- 4Moler-Zapata S Hutchings A O’Neill S et al Emulating Target Trials With Real-World Data to Inform Health Technology Assessment: Findings and Lessons From an Application to Emergency Surgery Value Health 20232611647410.1016/j.jval.2023.04.01037164043 · doi ↗ · pubmed ↗
- 5Hulme WJ Williamson EJ Green ACA et al Comparative effectiveness of Ch Ad Ox 1 versus BNT 162b 2 covid-19 vaccines in health and social care workers in England: cohort study using Open SAFELYBMJ 2022378 e 06894610.1136/bmj-2021-06894635858680 PMC 9295078 · doi ↗ · pubmed ↗
- 6Burns L Roux NL Kalesnik-Orszulak R et al Real-World Evidence for Regulatory Decision-Making: Guidance From Around the World Clin Ther 2022444203710.1016/j.clinthera.2022.01.01235181179 · doi ↗ · pubmed ↗
- 7Hansford HJ Cashin AG Jones MD et al Reporting of Observational Studies Explicitly Aiming to Emulate Randomized Trials: A Systematic Review JAMA Netw Open 20236 e 233602310.1001/jamanetworkopen.2023.3602337755828 PMC 10534275 · doi ↗ · pubmed ↗
- 8Benchimol EI Smeeth L Guttmann A et al The R Eporting of studies Conducted using Observational Routinely-collected health Data (RECORD) statement P Lo S Med 201512 e 100188510.1371/journal.pmed.100188526440803 PMC 4595218 · doi ↗ · pubmed ↗