Knowledge-graph-enhanced multi-scale modeling for drug-drug interaction prediction
Jing Chen, Qiang Deng, Peimeng Zhen, Jialu Hu, Yongtian Wang, Jiajie Peng, Zhuhong You, Xuequn Shang, Xu Zhang, Tao Wang

TL;DR
ALG-DDI is a new model that uses drug features and a knowledge graph to predict drug interactions more accurately than previous methods.
Contribution
ALG-DDI introduces a multi-scale modeling approach that integrates drug attributes, local correlations, and global knowledge graph semantics for DDI prediction.
Findings
ALG-DDI outperforms existing state-of-the-art methods in drug-drug interaction prediction.
The model integrates attribute, local, and global drug information using a transformer-based fusion mechanism.
Extensive evaluations on multiple datasets confirm the model's superior performance and generalization.
Abstract
Drug-drug interaction (DDI) prediction is crucial for understanding combined medication effects and preventing adverse reactions. Traditional machine learning methods rely on handcrafted features and lack generalization, while existing deep learning approaches often fail to capture global and multi-scale drug relationships. To overcome these limitations, we propose ALG-DDI, a multi-scale feature fusion model that integrates three types of drug information: attribute (intrinsic drug structure), local correlations (with proteins and diseases), and global semantic information from the medical knowledge graph PrimeKG. We encode these using attribute masking, the idea of RGCN and GraphSAGE, and ComplEx, respectively. A transformer encoder with attention mechanism then fuses these multi-scale representations. The resulting drug pair vector is fed into a fully connected network for DDI…
Genes, proteins, chemicals, diseases, species, mutations and cell lines named across the full text — each resolved to its canonical identifier and authoritative record.
Click any figure to enlarge with its caption.
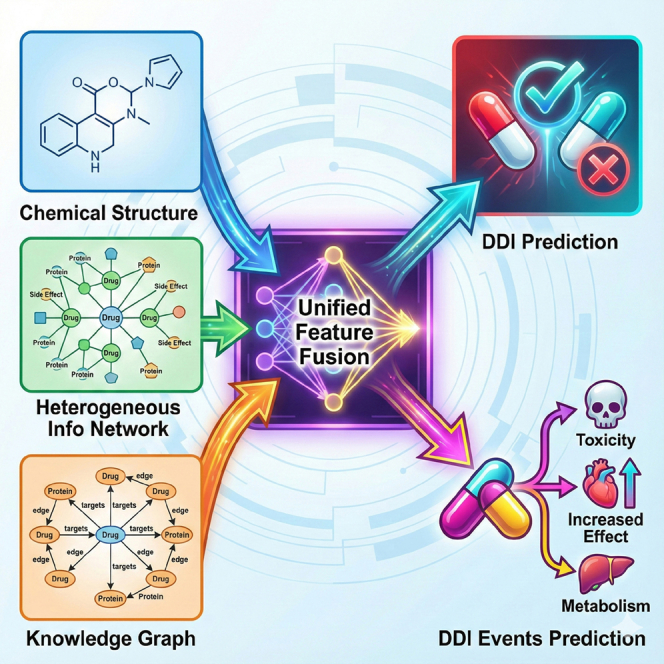 Figure 1
Figure 1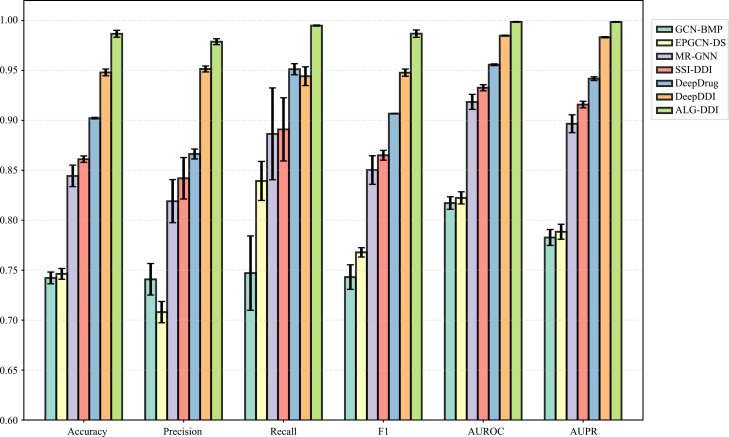 Figure 2
Figure 2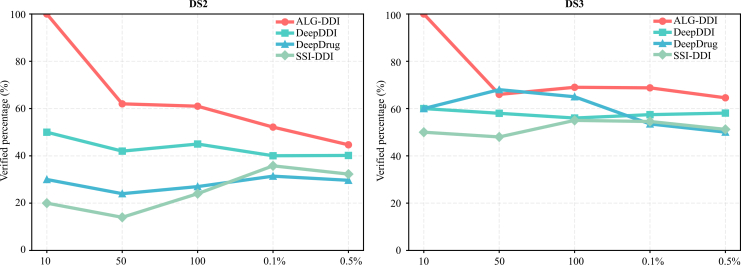 Figure 3
Figure 3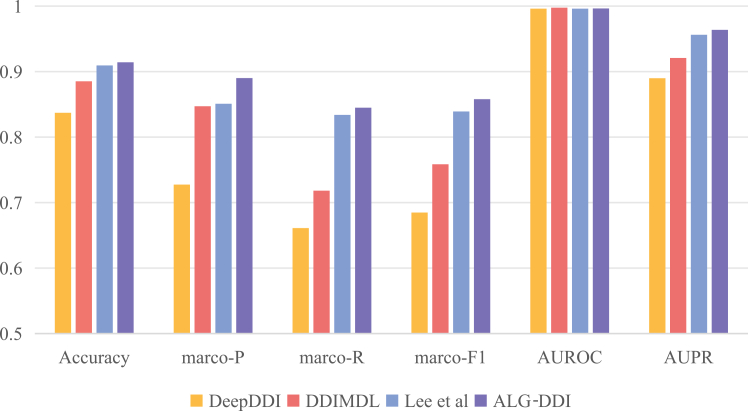 Figure 4
Figure 4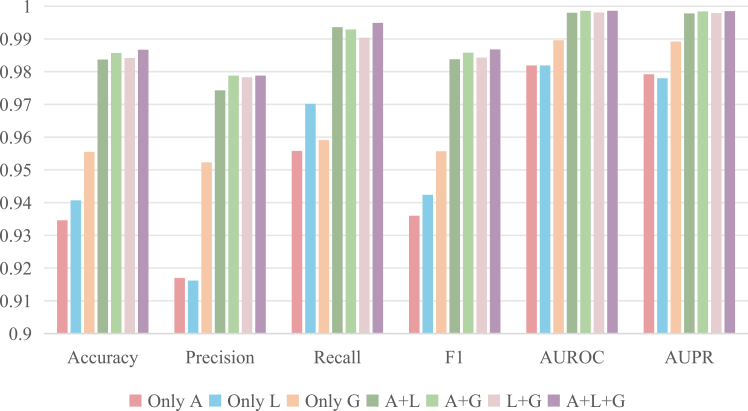 Figure 5
Figure 5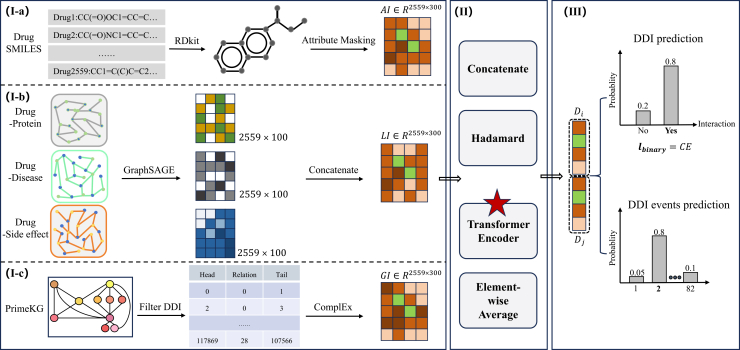 Figure 6
Figure 6Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsAdvanced Graph Neural Networks · Computational Drug Discovery Methods · Machine Learning in Healthcare
Introduction
Drug-drug interactions (DDIs) represent a critical challenge in pharmacotherapy, occurring when multiple medications interact to alter therapeutic effects or induce adverse reactions. ADRs caused by DDIs account for 3%–26% of drug-related hospitalizations,1 with recent studies showing 32% of these reactions are preventable.2 While traditional experimental methods for DDI detection remain costly and time-consuming, computational methods have emerged as efficient alternatives, evolving through several methodological paradigms.3^,^4
Early computational approaches to DDI prediction primarily relied on similarity-based methods, building on the fundamental assumption that structurally or functionally similar drugs exhibit analogous interaction patterns. Gottlieb et al. pioneered this approach by integrating multiple similarity measures to generate comprehensive drug features.5 Subsequent work by Zhang et al. expanded this paradigm by incorporating 14 distinct similarity measures derived from chemical, biological, phenotypic, and topological data.6 More recently, Ryu et al. advanced the field by developing structural similarity profiles processed through deep neural networks,7 while Qian et al. demonstrated the effectiveness of combining feature similarity with gradient boosting classifiers.8
Parallel developments in matrix factorization techniques have framed DDI prediction as a matrix completion problem. Yu et al. introduced DDINMF, employing semi-non-negative matrix factorization to analyze signed DDI networks.9 Zhang et al. further enhanced this approach through manifold regularized matrix factorization, incorporating drug-feature-based regularization.10 Zhu et al. devised a dependency network to simulate the relationships between drugs and introduced a probabilistic dependency matrix three-factorization method, known as property-supervised learning model probability dependency matrix three-factorization (PDMTF), for DDI prediction.11
The emergence of graph-based methods has represented a significant advancement in DDI prediction, enabling researchers to leverage topological information from various network representations. Initial work by Cami et al. demonstrated the value of network-derived covariates in predictive models.12 Subsequent breakthroughs came from Zitnik et al., who formulated DDI prediction as a multi-relational link prediction task using graph convolutional networks.13 Recent approaches by Karim et al. and Feng et al. have further refined these techniques through knowledge graph embeddings and specialized graph neural network architectures.14^,^15
While existing methods have advanced DDI prediction capabilities, they remain fundamentally constrained by their isolated consideration of either local structural features or global network patterns, neglecting the critical interplay between these complementary perspectives. To overcome these limitations, we introduce ALG-DDI, an innovative multi-scale fusion framework that systematically integrates (1) atomic-level molecular attributes extracted from molecular atomic structures, (2) local drug-entity correlations learned from heterogeneous drug association networks, and (3) global semantic patterns derived from biomedical knowledge graphs. The framework’s transformer-based fusion mechanism employs self-attention to dynamically weight and combine these multi-scale representations, enabling comprehensive modeling of drug interactions.
Comprehensive experimental evaluation demonstrates ALG-DDI’s superior predictive performance across multiple benchmark datasets, with rigorous ablation studies quantitatively validating the complementary contributions of each feature scale. Notably, the framework’s successful application to DDI event prediction—a more clinically challenging task—provides compelling evidence of its practical utility in real-world pharmacological scenarios. These results demonstrate the value of multi-scale feature integration for DDI prediction and provide a computational framework that combines molecular-level features with system-level pharmacological information.
Results
Comparison of other methods
To comprehensively evaluate the performance of ALG-DDI, we compared it with the baseline methods GCN-BMP,16 EPGCN-DS,17 MR-GNN,18 DeepDrug,19 SSI-DDI,20 DeepDDI,7 DDIMDL,21 and Lee et al.22 To ensure fairness, we uniformly used DS2 as the DDI dataset and reported mean values and standard deviation (sd) based on 5-fold cross-validation as experimental results, which are shown in Figure 1. The specific scores are shown in Table S1. The comparison results indicate that ALG-DDI performs best with outstanding improvements of 3.87%–24.45%, 2.74%–27.07%, 4.37%–24.78%, 3.90%–24.37%, 1.38%–18.14%, 1.53%–21.57%, 0.0107–0.2136, and 0.0123–0.1365 against others in terms of accuracy, precision, recall, F1, ROC-AUC, and PR-AUC, respectively.Figure 1. Comparison of DDI prediction performance on DS2We compared the prediction performance of ALG-DDI with several state-of-the-art methods across six key metrics: accuracy, precision, recall, F1-score, AUROC, and AUPR. Error bars represent the standard deviation of 5-fold cross-validation.
We attribute this superior performance to two factors. First, compared to baseline methods that only focus on a single scale, ALG-DDI has a more powerful capability to exploit multi-scale drug information, including the attribute information of drugs themselves, local information from the interactions with key medical entities, and global information from the large-scale knowledge graph. Second, the Transformer encoder based on the self-attention mechanism effectively integrates multi-scale information by assigning dynamic weights, which contributes to its performance.
Version validation experiment
To further test the efficacy of the model, we conducted a version validation experiment. We trained the model on a lower version of the dataset and made predictions for all other possible DDIs. We selected the top-N DDIs based on these scores and verified their existence in higher versions of the dataset. The results are shown in Figure 2. Specifically, we initially compile all possible drug pairs formed by Food Drug Administration (FDA)-approved drugs. The model was trained on DS1 (published in 2014) and used to predict all DDIs absent from DS1 (totaling 7,287,644 pairs). The predictions were then ranked by score, and the top-ranked DDIs were treated as candidates for validation. These candidates were subsequently verified against the newer datasets DS2 (published in 2017) and DS3 (published in 2022) to confirm their occurrence. In this experiment, the top 10, 50, 100, 0.1% (7,291), and 0.5% (36,452) predictions were selected as candidate sets for evaluation. Performance was compared against strong baseline methods, including DeepDDI, DeepDrug, and SSI-DDI.Figure 2. Result of version validation experimentThe line chart illustrates the proportion of predicted DDIs from DS1 that were validated in DS2 and DS3.
The results demonstrate that ALG-DDI consistently maintained leading predictive capability. Specifically, all top 10 DDIs predicted by ALG-DDI were subsequently validated in later datasets, whereas the best-performing baseline method validated at most six. Across other proportion thresholds, ALG-DDI achieved the highest validation count in nearly all settings, except for the top 50 predictions on DS3, where DeepDrug validated one more DDI than ALG-DDI. Detailed validation counts are provided in the Table S2.
Comparison of different fusion strategies
In the feature fusion module of ALG-DDI, we employ the Transformer encoder as a fusion strategy, achieving notable results. To highlight the effectiveness and superiority of the Transformer encoder in our work, we compared it with four common fusion strategies mentioned above. We conducted 5-fold cross-validation experiments on DS1, DS2, and DS3, and the average experimental results are presented in Table 1.Table 1. Performance comparison of four fusion strategiesDatasetStrategyPrecisionRecallF1AccuracyAUROCAUPRDS1Concat0.95210.96950.96060.96030.98910.9852Hadamard0.90340.93560.91910.91770.96700.9580Average0.93210.96510.94830.94740.98270.9766Transformer0.95210.98570.96860.96810.9899****0.9855DS2Concat0.97360.98940.98140.98130.99770.9974Hadamard0.91220.92890.92040.91970.97210.9694Average0.93830.97810.95780.95690.98980.9879Transformer0.97880.99490.98680.98670.9986****0.9985DS3Concat0.96890.98280.97580.97560.99750.9974Hadamard0.83280.84340.83800.83700.91940.9166Average0.89560.94650.92030.91810.97740.9762Transformer0.98000.99510.98750.98690.9991****0.9990This table presents the performance of four fusion strategies across three datasets (DS1, DS2, and DS3) based on six evaluation metrics: precision, recall, F1-score, accuracy, AUROC, and AUPR.
First, we can observe that ALG-DDI demonstrates good robustness, achieving excellent performance on datasets of various sizes. As the size of datasets increases, the results improve even further. Even in DS3, AUROC and AUPR reach the highest values of 0.9991 and 0.9990, respectively. This demonstrates that richer information and more training data enable ALG-DDI to learn more potential patterns, contributing to the improvement of its generalizability.
Additionally, we observed that as the dataset size increases, the advantage of the Transformer encoder becomes more pronounced. The lead in AUROC increases from 0.0008–0.0229 to 0.0016–0.0797. We attribute this to the self-attention mechanism’s ability to allocate weights to different scale features, enabling it to extract more crucial patterns for the task from large-scale data compared to other methods. Surprisingly, we found that the simplest concatenate operation also yields good results. We attribute this to the fact that drug embeddings have already integrated sufficient rich information through the feature extraction module, making straightforward fusion strategies effective as well.
Model performance on DDI events prediction task
To comprehensively assess the performance of ALG-DDI, we conducted a series of experiments focused on the DDI event prediction task. In this process, we employed multiple evaluating metrics, including macro-P, macro-R, macro-F1, Accuracy, AUROC, and AUPR. We compared ALG-DDI with other state-of-the-art models, including best-performing baseline DeepDDI in DDI prediction tasks, DDIMDL, and Lee et al., which are specifically designed for DDI event prediction. The average results of 5-fold cross-validation under the same experimental conditions are presented in Figure 3. The detailed scores are shown in Table S3. The confusion matrix, which provides an intuitive visualization of prediction accuracy for each class, is shown in Figure S1.Figure 3. Comparison of DDI events prediction performance on multi-DSWe compared the prediction performance of ALG-DDI with several state-of-the-art methods across six key metrics: accuracy, marco-P, marco-R, marco-F1, AUROC, and AUPR.
Ablation experiments
To validate the necessity and contribution degree of information on each scale, we designed six different variants for the ablation study, with three of them using single-scale drug information for experimentation and the other three using information from dual-scale. The results are presented in Figure 4, and the specific scores are shown in Table S4.Figure 4. Performance comparison of different feature scale selections on DS2We compared the performance across six evaluation metrics—accuracy, precision, recall, F1-score, AUROC, and AUPR—under three scenarios: using a single scale, any two scales, and all three scales.
First, when we use information from all scales, the model achieves the best performance. Reducing any of the scales results in a performance drop, and employing dual-scale information is more effective than using a single scale alone. These findings strongly demonstrate the necessity and effectiveness of multi-scale feature fusion, indicating that ALG-DDI can indeed enhance the performance through multiple information complementing.
Additionally, we observed that in single-scale experiments, using global information (G) yielded the best results, and in dual-scale experiments, the performance drop was most significant when not using only global information compared to using all scales (A + L + G). This implies that the impact of global information extracted from the knowledge graph is greater compared to other scales. It indicates the correctness of introducing the knowledge graph into the DDI prediction task.
Case study: Cannabidiol
To validate the excellent performance of ALG-DDI in practical prediction tasks, we conducted a case study using Cannabidiol (CBD). Specifically, we trained the model with the latest DS3 dataset and then scored all unknown drug pairs involving Cannabidiol that were not present in DS3. Higher scores indicate a greater likelihood of a relationship with Cannabidiol. The drugs with the top 15 predicted scores are shown in Table S5, where 14 of them have been further confirmed and included in the DrugBank database, along with detailed DDI descriptions.
To provide a biomedical speculation for the potential interaction between unconfirmed Cannabidiol-Goserelin, we consulted their pathophysiological knowledge. Cannabidiol has anti-tumor effects, which induce cell death pathways, cell growth arrest, and inhibition of tumor angiogenesis, invasion, and metastasis.23 Goserelin is a gonadotropin-releasing hormone (GnRH) analogue frequently utilized in the management of hormone-related tumors, including breast cancer and prostate cancer.24 Although their mechanisms of action differ, both can act on the relevant symptoms of breast cancer, and in certain situations, they may impact aspects like cancer cell growth, inflammatory responses, or cell apoptosis through different pathways. The relevant study by Alsherbiny et al. also suggests that the cytotoxic mechanisms of CBD are encouraging, providing an impetus for further research on the interaction between CBD and hormonal therapies, including aromatase inhibitors and new-generation drugs such as goserelin.25
Discussion
In this article, we introduced a model named ALG-DDI, which leverages a Transformer encoder to integrate multi-scale drug information for DDI prediction tasks, including attribute information from molecular graphs, local information from heterogeneous graphs, and global information from knowledge graphs. Experimental results have proved that our proposed model is better than state-of-the-art models. In addition, we demonstrated the effectiveness and robustness of our model by conducting experiments across various datasets and employing different fusion strategies. The ablation study also demonstrated the necessity of each scale in feature fusion. In summary, ALG-DDI is an effective model for discovering potential DDIs, which can be used for preliminary screening of potential DDIs before wet laboratory experiments. In the future work, we aim to further optimize the model and bring the idea of multi-scale drug information fusion to the DDI events prediction task, with the expectation of achieving good results.
Materials and methods
Datasets
We utilized three key data sources in our study: DrugBank for molecular attributes, PrimeKG for biomedical relationships, and three carefully curated DDI datasets for evaluation.
DrugBank provides comprehensive biochemical and pharmacological information, including drug mechanisms and targets.26 We extracted SMILES strings of FDA-approved drugs from the latest DrugBank release for molecular attribute extraction.
PrimeKG is a precision medicine knowledge graph integrating 20 high-quality biomedical resources, containing 129,375 entities and 8,100,498 relationships.27 From PrimeKG, we extracted drug-disease, drug-side effect, and drug-protein associations to construct bipartite graphs for local relationship modeling.
To evaluate model performance across different scales, we compiled three DDI datasets.
- •DS1: derived from DrugBank 4.0 (2014 release)26
- •DS2: extracted from DrugBank 5.0 (2018 release), containing ∼6× more interactions than DS128
- •DS3: consisting of DDI data from PrimeKG, with remaining PrimeKG data (KGD) reserved for global knowledge extraction
All datasets were rigorously filtered to include only FDA-approved drugs, preventing label leakage between training and knowledge graph sources. Complete dataset statistics are provided in Table 2.Table 2. Summary of dataset detailsDatasetSourceNodesEdgesDS1DrugBank 4.0129480,866DS2DrugBank 5.01637392,553DS3PrimeKG20951,202,514KGDPrimeKG127,9925,427,870
Model architecture
Figure 5 illustrates the overall architecture of ALG-DDI, which comprises three main components: (1) multi-scale drug feature extraction, (2) feature fusion, and (3) prediction modules.
- 1.Multi-scale feature extraction: the framework captures drug representations at three complementary scales:
- •Atomic-level attributes (AI): extracted from molecular graphs using attribute masking with graph neural network (GNN) followed by average pooling (Figure 5I-a)
- •Local interactions (LI): derived from heterogeneous graphs (drug-side effect, drug-disease, and drug-protein) through relational GraphSAGE (Figure 5I-b)
- •Global semantics (GI): obtained from PrimeKG using ComplEx knowledge graph embeddings (Figure 5I-c)
- 2.Feature fusion: a transformer encoder with self-attention mechanisms dynamically weights and combines the multi-scale representations (AI, LI, GI) to generate comprehensive drug embeddings. This fusion process enables the model to capture cross-scale interactions and learn context-aware representations.
- 3.Prediction module: for each drug pair, we concatenate their fused representations and process them through a three-layer fully connected neural network to predict interaction probabilities. The network architecture consists of an input layer (concatenated drug features), two hidden layers with ReLU activation, and output layer with sigmoid activation. Figure 5. The workflow of ALG-DDIMulti-scale drug feature extraction module (part I): this module extracts drug features at three distinct scales, including (I-a) drug attribute information, (I-b) drug local information, and (I-c) drug global information. Feature fusion module (part II): in this module, a Transformer encoder is employed to integrate features from the three scales to obtain a comprehensive and information-rich final representation. Prediction module (Part III): based on the fused representations of drug pairs, this module predicts both the regulatory relationships and the regulatory relationship categories using a neural network.
The following sections provide detailed descriptions of each component.
Multi-scale feature extraction
Atomic-level attribute representation
For each FDA-approved drug di∈D, we begin by converting its SMILES string to a molecular graph gi = (V,E) using RDKit,29 where V represents atoms (nodes) and E represents chemical bonds (edges). We employ an attribute masking approach to learn comprehensive molecular representations through a multi-stage process.30
First, we initialize node and edge features based on atomic properties and bond characteristics. The molecular graph then undergoes a feature masking procedure where 15% of node features are randomly replaced with special mask values. These masked features are reconstructed through an iterative graph neural network process. At each layer k, node embeddings are updated according to the following equations:
where N(v) denotes the set of neighboring nodes for atom v. To enhance the reconstruction of masked node features, we employ a linear prediction layer that learns to recover the original atomic attributes from the masked representations.31^,^32^,^33
Finally, we aggregate all atom-level representations through average pooling to obtain the graph-level embedding:
This pooled representation h_G∈R^d^ serves as the atomic-level attribute embedding ai_ for drug di, capturing its fundamental molecular characteristics while maintaining permutation invariance.
Local interaction representation
The local interaction patterns between drugs and related biomedical entities provide crucial information for DDI prediction. We model these relationships through a heterogeneous graph framework containing three key association types: drug-side effect, drug-protein, and drug-disease interactions, building upon GraphSAGE and RGCN architectures.34^,^35
For each relation type r∈R at layer k, our propagation mechanism first aggregates neighborhood information through mean pooling: , where Nr(v) denotes the set of neighbors connected to node v via relation r. The aggregated features are then combined with the node’s current representation and transformed through a relation-specific weight matrix W^k,r^∈R^d×2d^:
with σ representing the sigmoid activation function.
The model integrates information across all relation types through summation: . This architecture provides several advantages: relation-specific feature transformation through W^k,r^, gradual expansion of the receptive field with increasing k, efficient combination of multiple relation types via summation, and preservation of local topological information through neighborhood aggregation.
The final node embedding at layer K captures comprehensive local interaction patterns for drug di, forming its local representation li∈R^d^. This representation integrates multi-relational information while maintaining the distinct characteristics of each association type through the relation-specific transformations and aggregations.
Global semantic representation
The PrimeKG knowledge graph provides essential global semantic information for DDI prediction by capturing high-order relationships between drugs and various biological entities (e.g., pathways, molecular functions, and cellular components). These cross-domain associations help overcome limitations in local feature representations and reveal system-level interaction patterns.
We formalize the knowledge graph as GKG = {(h,r,t)|h,t∈E,r∈R}, where E denotes entities and R represents relationship types. Following recent advances in knowledge graph embedding,36 we employ the ComplEx model to learn distributed representations.37 ComplEx operates in complex vector space, enabling effective modeling of asymmetric relations through low-rank tensor factorization.
The scoring function evaluates triple plausibility by computing
where wr, eh and et∈C^K^ are complex embeddings, denotes the complex conjugate, and ⟨·⟩ represents the Hermitian product. The model parameters Θ = {wr,eh,et} are learned by minimizing the regularized logistic loss:
with indicating relation existence and λ controlling regularization strength. For each FDA-approved drug di, its global semantic representation gi∈R^d^ corresponds to the real component of the learned entity embedding . We compared the performance of ComplEx with several other knowledge graph embedding methods, including TransE_l_1_, TransE_l_2_, DisMult, RotatE, and SimplE. As shown in Table S6, the results demonstrate that ComplEx achieves the best overall performance and shows greater advantages on large-scale datasets.
Multi-scale feature fusion
To effectively combine information from different scales, we employ a transformer encoder architecture that dynamically weights and integrates atomic-level (ai), local interaction (li), and global semantic (gi) features. This approach enables the model to learn cross-scale relationships while preserving the unique contributions of each feature type.
Attention-based feature integration
The core of our fusion strategy is multi-head self-attention, which learns contextual relationships between different feature scales. Given the concatenated input X = Concat(ai,li,gi)∈R^3d^, we compute
where are learnable projection matrices for each attention head, and combines the heads’ outputs. The attention mechanism automatically learns to emphasize the most informative feature scales for each prediction task.
Network architecture components
The transformer encoder employs two key stabilization techniques:
- 1.Residual connections: we add skip connections that bypass each sub-layer (attention and feedforward),38 formulated as
- 2.Layer normalization: applied before each sub-layer, it normalizes activations across the feature dimension:
where μ and σ are the mean and standard deviation of activations, while γ and β are learnable parameters,39 and ϵ is a small constant to prevent division by zero.
Alternative fusion strategies
We compare our attention-based fusion against three baseline methods:
All fused representations are projected to dimension d through a linear layer for fair comparison. The attention mechanism’s advantage lies in its ability to learn context-dependent weightings of different feature scales, rather than using fixed combination rules.
DDI prediction
The prediction module processes learned drug representations to estimate interaction probabilities through a two-stage procedure. For each drug pair (di,dj), we first concatenate their final representations: Xpair = Concat(xi,xj), where are the fused feature vectors for each drug. This combined representation is then processed through a multilayer perceptron (MLP) with sigmoid activation: , producing an interaction probability .
The model parameters are optimized using binary cross-entropy loss:
The model parameter sensitivity analysis and computational cost analysis are presented in Figures S2 and S3, respectively.
DDI event prediction
We evaluate the model’s generalization capability by extending it to predict specific pharmacological interaction types (e.g., increased metabolism and reduced efficacy). The experimental setup begins with Ryu et al.'s dataset,7 from which we derive a DDI event dataset (named Multi-DS) through two preprocessing steps: first retaining only FDA-approved drugs, then removing rare interaction categories with fewer than 10 instances. The resulting Multi-DS contains 82 distinct event types across 172,323 DDIs.
To address the significant class imbalance in Multi-DS, we implement two complementary strategies. First, we employ a phased training approach that combines cross-entropy (CE) and focal loss (FL). During the first half of training (t<T/2), we use standard CE loss:
which provides stable initial learning, where N represents the number of DDI event types. For the second phase (t ≥ T/2), we switch to FL with γ = 2:
to focus learning on harder examples and rare classes.
Second, we employ stratified K-fold cross-validation to maintain proportional class representation across all folds. This approach prevents skewed evaluation metrics that could arise from random splitting, which is particularly important given the long-tailed distribution of interaction types in Multi-DS. The stratification ensures each fold contains representative samples from all 82 event categories, yielding more reliable performance estimates.
Benchmark
To evaluate the effectiveness of our model, we compared ALG-DDI with eight state-of-the-art methods, including GCN-BMP, EPGCN-DS, MR-GNN, DeepDrug, SSI-DDI, DeepDDI, DDIMDL, and Lee et al. In this work, we employed commonly used classification metrics to evaluate the performance of our framework from various angles, including five key metrics: accuracy, precision, recall, F1, ROC-AUC, and PR-AUC. In addition, we also evaluated the performance of ALG-DDI on the DDI events prediction task, so we introduced metrics suitable for multi-class tasks: macro-P (macro-precision), macro-R (macro-recall), and macro-F1 (macro-precision and recall). Please refer to supplemental information for the introduction of methods and metrics.
Data and code availability
The DrugBank 4.0 and 5.0 data used in this article are available at DrugBank: https://go.drugbank.com/. The PrimeKG data used can be obtained from Harvard Dataverse: https://doi.org/10.7910/DVN/IXA7BM. The source code of ALG-DDI is available at https://github.com/nwpudengqiang/ALG-DDI.
Acknowledgments
The authors thank the anonymous reviewers for their valuable suggestions. This work has been supported by Ningxia Central Government-guided Local Science and Technology Development Special Project (2024FRD05103), the 10.13039/501100001809National Natural Science Foundation of China (grant no. 62572391 and 62402382), and Special Talent Introduction Project of Ningxia Autonomous Region Key R&D Programs (2023BSB03053).
Author contributions
T.W. and X.Z. conceived the experiment(s); J.C, Q.D., and P.Z. conducted the experiment(s); J.H., Y.W., J.P., Z.Y., and X.S. analyzed the results. T.W., J.C, Q.D., and P.Z. wrote and reviewed the manuscript.
Declaration of interests
No competing interest is declared.
Declaration of generative AI and AI-assisted technologies in the writing process
During the preparation of this work, the authors used Deepseek in order to assist with language polishing and refinement. After using this tool, the authors reviewed and edited the content as needed and take full responsibility for the content of the published article.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1Dechanont S.Maphanta S.Butthum B.Kongkaew C.Hospital admissions/visits associated with drug–drug interactions: a systematic review and meta-analysis Pharmacoepidemiol. Drug Saf.2320144894972461617110.1002/pds.3592 · doi ↗ · pubmed ↗
- 2Laville S.M.Gras-Champel V.Moragny J.Metzger M.Jacquelinet C.Combe C.Fouque D.Laville M.Frimat L.Robinson B.M.Adverse drug reactions in patients with CKD Clin. J. Am. Soc. Nephrol.152020109011023261166210.2215/CJN.01030120 PMC 7409761 · doi ↗ · pubmed ↗
- 3Wang T.Yang J.Xiao Y.Wang J.Wang Y.Zeng X.Wang Y.Peng J.D Finder: a novel end-to-end graph embedding-based method to identify drug–food interactions Bioinformatics 392023 btac 83710.1093/bioinformatics/btac 837PMC 982814736579885 · doi ↗ · pubmed ↗
- 4Wang T.Luo Z.Large language models transform biological research: from architecture to utilization Sci. China Inf. Sci.682025170101
- 5Gottlieb A.Stein G.Y.Oron Y.Ruppin E.Sharan R.INDI: a computational framework for inferring drug interactions and their associated recommendations Mol. Syst. Biol.820125922280614010.1038/msb.2012.26PMC 3421442 · doi ↗ · pubmed ↗
- 6Zhang W.Chen Y.Liu F.Luo F.Tian G.Li X.Predicting potential drug-drug interactions by integrating chemical, biological, phenotypic and network data BMC Bioinf.1820171810.1186/s 12859-016-1415-9PMC 521734128056782 · doi ↗ · pubmed ↗
- 7Ryu J.Y.Kim H.U.Lee S.Y.Deep learning improves prediction of drug–drug and drug–food interactions Proc. Natl. Acad. Sci. USA 1152018 E 4304 E 43112966622810.1073/pnas.1803294115 PMC 5939113 · doi ↗ · pubmed ↗
- 8Qian S.Liang S.Yu H.Leveraging genetic interactions for adverse drug-drug interaction prediction P Lo S Comput. Biol.152019 e 100706810.1371/journal.pcbi.1007068 PMC 655379531125330 · doi ↗ · pubmed ↗