Anomaly Detection for Automated Data Quality Monitoring in the CMS Detector
Andrew Brinkerhoff, Chosila Sutantawibul, Indara Suarez, Robert White, Caio Daumann, Jonathan Guiang, Chad Freer, Samuel May, Bennett Marsh, Darin Acosta, Alex Aubuchon, Emanuela Barberis, Aaron Bundock, Claudio Campagnari, Evan Collins, Preston Epps, Johannes Erdmann

TL;DR
This paper introduces AutoDQM, a system that uses machine learning to detect anomalies in data from the CMS particle detector at CERN.
Contribution
The novelty lies in applying beta-binomial and PCA-based anomaly detection for automated data quality monitoring in particle physics.
Findings
AutoDQM identifies bad data at 4–6 times the rate of good data.
The system is effective for general data quality monitoring in CMS.
Algorithms were tested on all 2022 proton-proton collision data.
Abstract
Successful operation of large particle detectors like the Compact Muon Solenoid (CMS) at the CERN Large Hadron Collider requires rapid, in-depth assessment of data quality. We introduce the “AutoDQM” system for Automated Data Quality Monitoring using advanced statistical techniques and unsupervised machine learning. Anomaly detection algorithms based on the beta-binomial probability function and principal component analysis are tested on the full set of proton-proton collision data collected by CMS in 2022. AutoDQM identifies anomalous “bad” data affected by significant detector malfunction at a rate 4 – 6 times higher than “good” data, demonstrating its effectiveness as a general data quality monitoring tool. The online version contains supplementary material available at 10.1007/s41781-025-00147-2.
Genes, proteins, chemicals, diseases, species, mutations and cell lines named across the full text — each resolved to its canonical identifier and authoritative record.
Click any figure to enlarge with its caption.
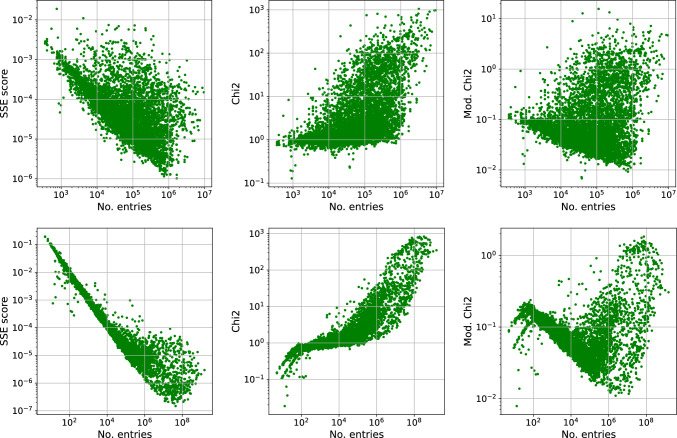 Figure 10
Figure 10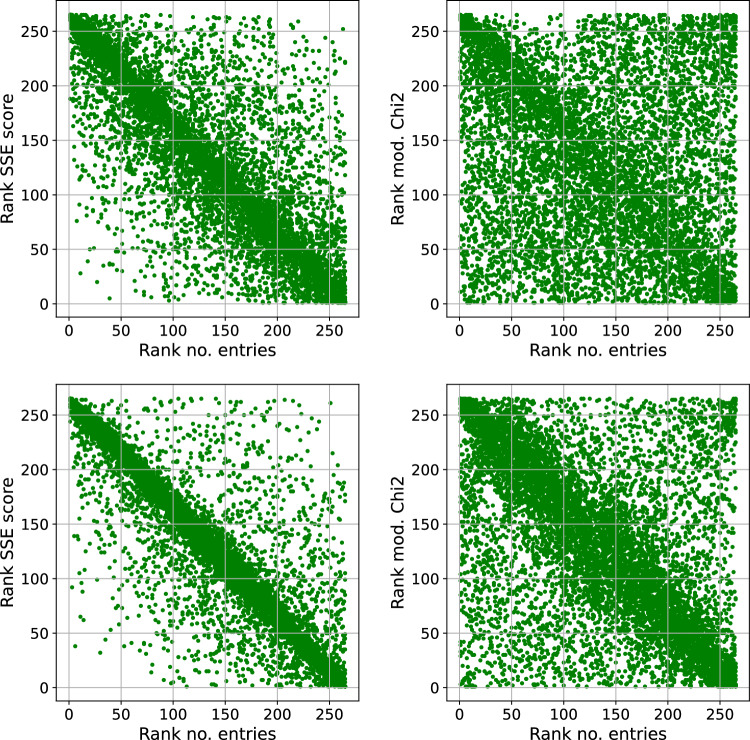 Figure 11
Figure 11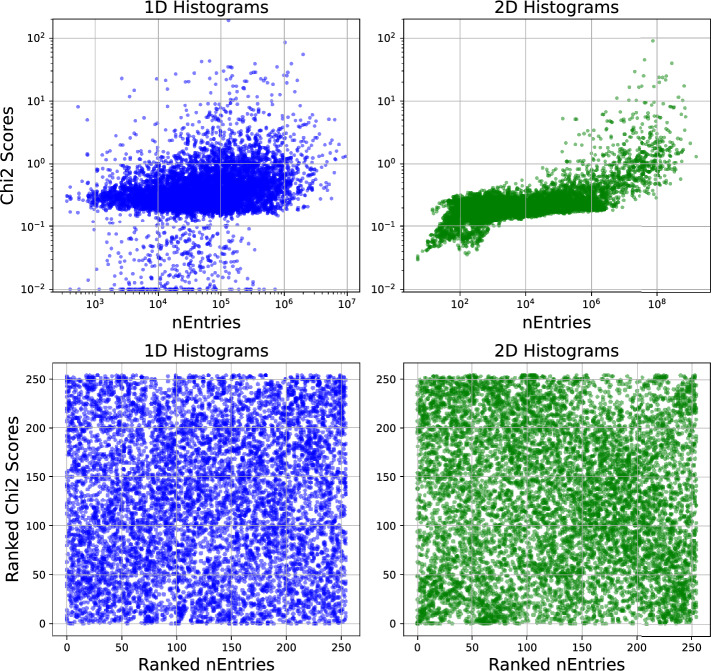 Figure 12
Figure 12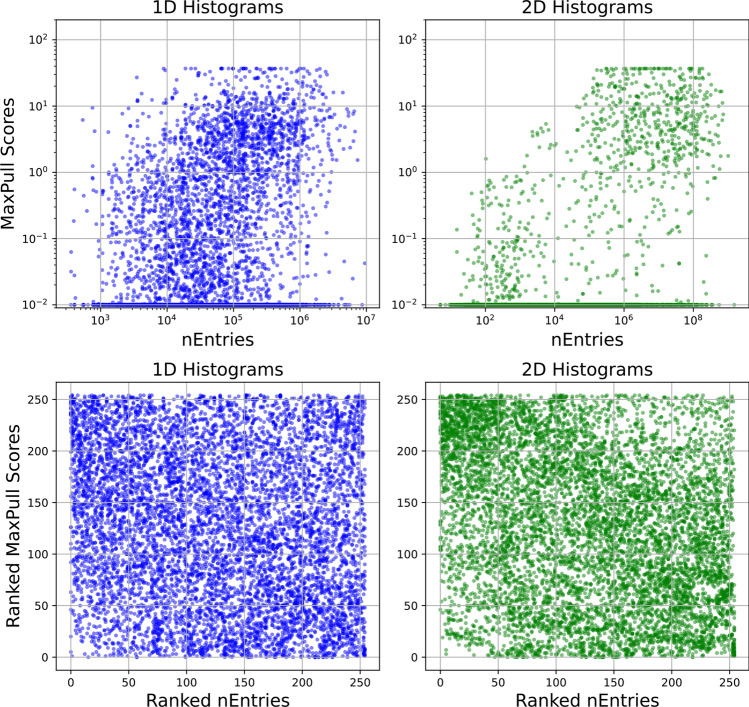 Figure 13
Figure 13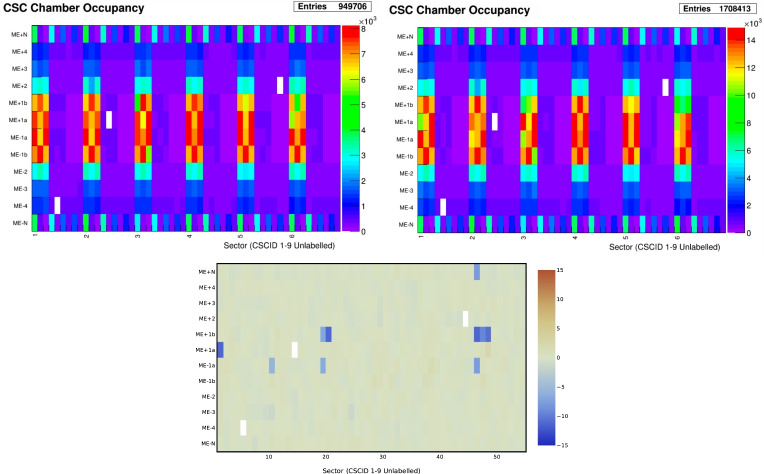 Figure 1
Figure 1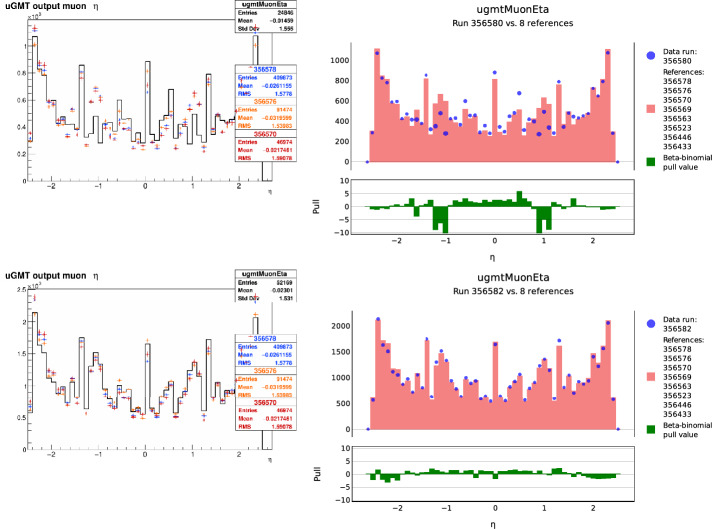 Figure 2
Figure 2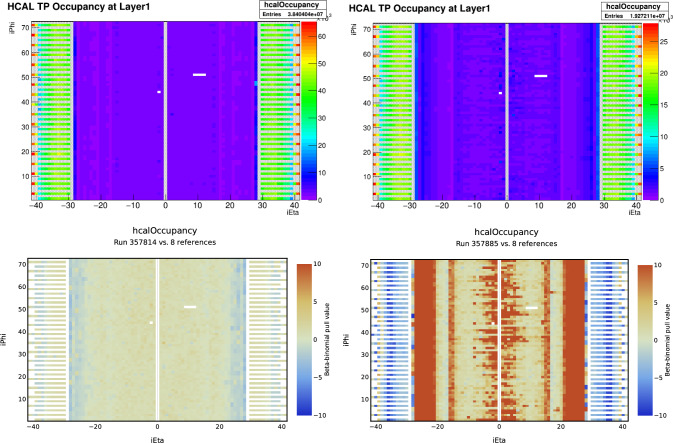 Figure 3
Figure 3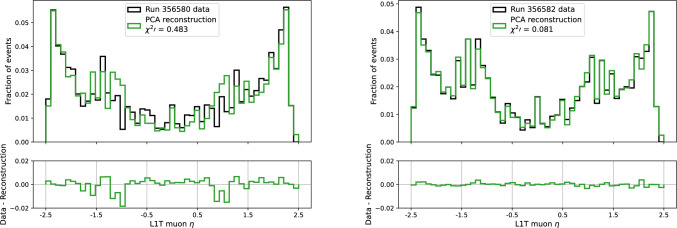 Figure 4
Figure 4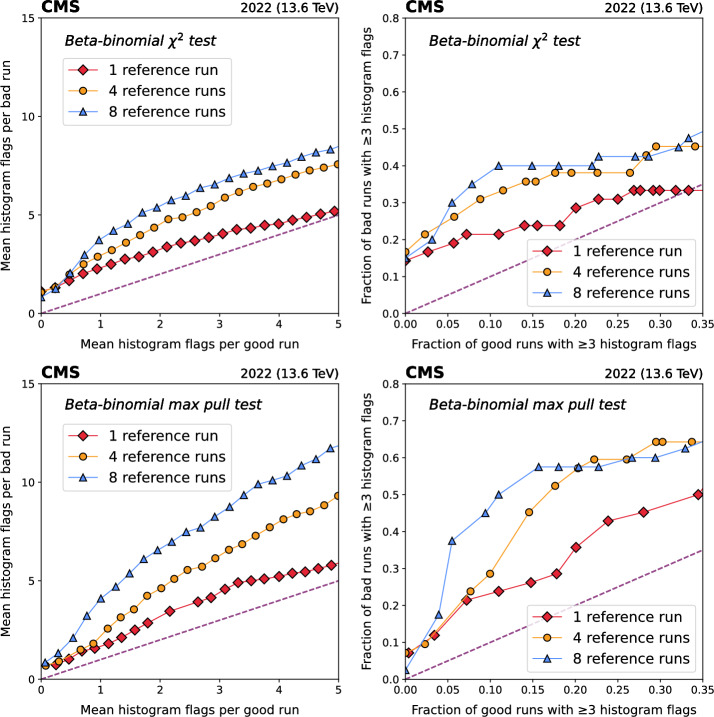 Figure 5
Figure 5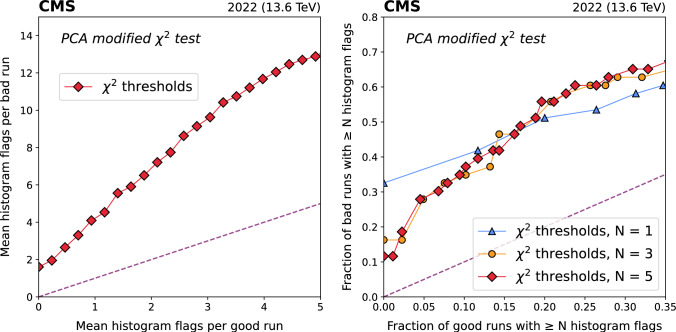 Figure 6
Figure 6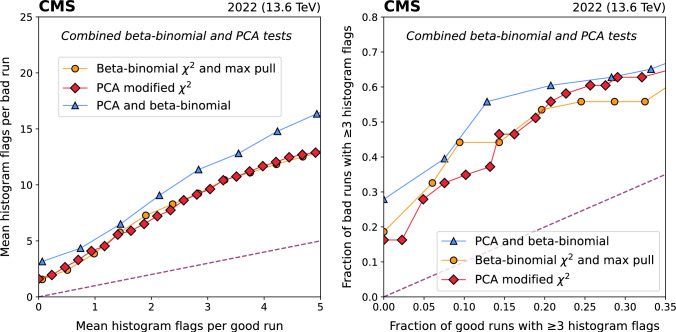 Figure 7
Figure 7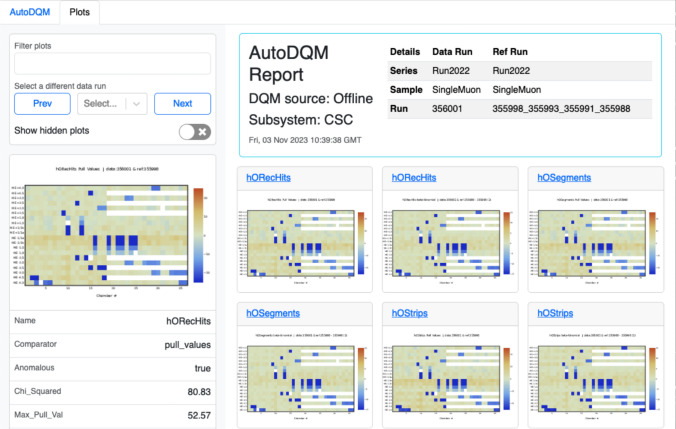 Figure 8
Figure 8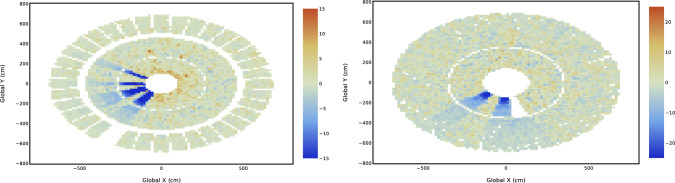 Figure 9
Figure 9- —https://doi.org/10.13039/100000015U.S. Department of Energy
- —https://doi.org/10.13039/501100000271Science and Technology Facilities Council
- —https://doi.org/10.13039/501100002347Bundesministerium für Bildung und Forschung
- —https://doi.org/10.13039/100000001National Science Foundation
- —https://doi.org/10.13039/501100001659Deutsche Forschungsgemeinschaft
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsParticle Detector Development and Performance · Big Data and Digital Economy
Introduction
The Compact Muon Solenoid (CMS) experiment is a multipurpose particle detector designed to collect large amounts of data from high-energy proton-proton (pp) collisions at the CERN Large Hadron Collider (LHC) [1, 2]. The ATLAS and CMS experiments jointly discovered the Higgs boson using LHC collision data collected between 2010 and 2012, and are currently seeking evidence for new physics which could explain dark matter, dark energy, or the matter–antimatter asymmetry of the universe [3–5].
CMS identifies and measures electrons, muons, \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\tau $$\end{document} leptons, photons, and hadrons using a global “particle-flow” (PF) algorithm, which combines information from various subdetectors situated concentrically around the proton beam [6]. A multi-layer silicon tracker traces the helical path of charged particles emerging from the collision point as they are deflected by the CMS solenoid’s 3.8 T magnetic field [7]. Both charged and neutral particles then deposit energy into the electromagnetic calorimeter (ECAL), made from lead tungstate crystals, and the hadron calorimeter (HCAL), made from interleaved brass absorbers and plastic scintillators [8–10]. Beyond the calorimeters, layers of muon tracking detectors, including drift tubes, cathode strip chambers, resistive plate chambers, and gas electron multipliers are embedded in the CMS magnet’s flux-return yoke [11]. While the LHC collision rate can exceed 30 MHz, at most around 100 kHz of events pass the initial selection by the CMS Level-1 Trigger (L1T), which uses calorimeter and muon detector inputs to perform preliminary event reconstruction on custom hardware boards in less than \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$4 \mu $$\end{document} s [12]. The High-Level Trigger (HLT) then reconstructs events in more detail using CPUs and GPUs, and sends around 1 kHz of collision data to storage on hard disks [13].
One of the main challenges in operating CMS is to monitor the detector, trigger, and particle reconstruction continuously to ensure that the collected data satisfy the stringent criteria necessary for precise measurements and sensitive searches for new physics phenomena. Data-taking “runs” comprising a few minutes to several hours of collision data are processed in real time to create thousands of histograms which measure various aspects of detector performance. Trained “shifters” monitor these histograms and may intervene if the plots indicate anomalous behavior compared to previous runs. This data quality monitoring (DQM) is performed for each subdetector system to immediately identify issues “online” based on raw data, and also “offline” after a few days when full-detector PF reconstruction is available. Each year a few percent of the total data collected by CMS, corresponding to a dozen or more hours of beamtime, are designated as “bad” due to detector or reconstruction issues during data taking. Without DQM, this fraction would be considerably higher, as problems would go unnoticed for a longer period of time. Data quality monitoring is thus a time-consuming and labor-intensive but important task, so it is critical to develop robust tools that can help shifters quickly and reliably identify problems in any part of the highly complex CMS detector.
In this paper, we introduce the AutoDQM tool ,1 a web-based service that employs a generalized approach to automated DQM using statistical techniques and unsupervised machine learning (Sect. 2). Anomaly detection algorithms based on the beta-binomial probability function and principal component analysis (PCA) are discussed in Sects. 2.1 and 2.2. AutoDQM performance studies using L1T monitoring plots from the entire 2022 data set are presented in Sect. 3, along with examples of muon detector monitoring using AutoDQM. These results and plans for future developments are summarized in Sect. 4.
The AutoDQM tool
Traditional DQM in CMS is performed using the online and offline DQM web-based GUIs, which contain hundreds of histograms for each CMS subdetector system [14]. DQM shifters for each subsystem examine selected histograms in a particular run and look for differences compared to histograms from previous reference runs. Such anomalies could indicate degraded detector, trigger, or reconstruction performance which would compromise the final physics analysis of the collected data. Of course, visual comparison of dozens or hundreds of histograms is fatiguing and error-prone. Basic Kolmogorov-Smirnov tests and approximate \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\chi ^2$$\end{document} comparisons between two histograms are available in the DQM GUIs, but are extremely unreliable at detecting true anomalies. More advanced DQM techniques have long been considered [15, 16], and in two recent cases were deployed by CMS [17, 18], but for a very limited selection of plots. The AutoDQM anomaly detection tool is a web-based service which evaluates all forms of online and offline DQM histograms and assists shifters in rapid and effective data monitoring. AutoDQM uses \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\chi ^2$$\end{document} and single-bin pull value tests based on the beta-binomial probability function to look for anomalies in a given set of histograms compared to data from multiple previous “reference” runs. PCAs are also trained on larger sets of reference histograms to generate complex models of good data, which are then used to identify histograms which deviate from the expectation. AutoDQM graphically represents these statistical and machine learning (ML) tests to highlight anomalous regions within the histograms, allowing shifters and detector experts to quickly identify and locate issues as they arise.
Statistical tests
Most one-dimensional (1D) and two-dimensional (2D) histograms in the CMS DQM GUI have an integer number of entries in each bin. Depending on the type of histogram and the duration of the data-taking run, a specific histogram may contain millions of entries, or just a few; and these entries may be distributed evenly, or concentrated in a small number of bins. For a given data histogram, the number of entries \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$d_i$$\end{document} in each bin i may be treated as the frequency of a distinct outcome out of D trials, where D is the integral of the histogram. A reference histogram from a prior run with integral R and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$r_i$$\end{document} entries in each bin can be used to compute the likelihood \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\mathcal {L}_i$$\end{document} to observe \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$d_i$$\end{document} in each corresponding bin from the later data run, using the beta-binomial function:
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\begin{aligned} \mathcal {L}_i = f(d_i|D,\alpha ,\beta ) = {\left( {\begin{array}{c}D\\ d_i\end{array}}\right) } \frac{B(d_i+\alpha ,D-d_i+\beta )}{B(\alpha ,\beta )} \end{aligned}$$\end{document}where B is the beta function, \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\alpha = \alpha _0 + r_i$$\end{document} , and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\beta = \beta _0 + R - r_i$$\end{document} . We set \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\alpha _0 = \beta _0 = 1$$\end{document} , consistent with uniform priors, and use the betabinom probability mass function (pmf) implementation in SciPy to compute \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\mathcal {L}_i$$\end{document} for all bins simultaneously using a numpy array representation of the histogram [19]. These \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\mathcal {L}_i$$\end{document} values can be compared to the maximum likelihood \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\mathcal {L}_i^{max}$$\end{document} for each bin, corresponding to \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$d_i^{max} = D \times r_i / R$$\end{document} (rounded up or down). The ratio \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\mathcal {L}_i / \mathcal {L}_i^{max}$$\end{document} gives a relative likelihood \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\mathcal {L}_i^{rel}$$\end{document} , which is converted to a pull value \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$Z_i$$\end{document} in units of standard deviations using the relation \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$Z_i^2 = -2~\textrm{ln}~\mathcal {L}_i^{rel}$$\end{document} . In order to ensure a minimum “tolerance” of \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\approx $$\end{document} 1% in the prediction, we scale both R and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$r_i$$\end{document} by a factor of \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\tau = 1/\sqrt{1 + (10^{-4}~r_i)^2}$$\end{document} when computing \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\mathcal {L}_i^{rel}$$\end{document} for each bin, such that \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\tau \times r_i \rightarrow 10^4$$\end{document} as \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$r_i \rightarrow \infty $$\end{document} , yielding a minimum uncertainty of about \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$1 / \sqrt{10^4} = 1\%$$\end{document} . When comparing a data run to multiple reference runs, \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$Z_i$$\end{document} is derived using the average of the \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\mathcal {L}_i^{rel}$$\end{document} values, which are computed separately with respect to each reference run. With this approach, if the observed data matches the expectation from at least one of the reference histograms well, the pull values will not be very large. For example, if seven reference runs each give \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\mathcal {L}_i^{rel} \approx 0$$\end{document} ( \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$Z_i \approx \infty $$\end{document} ) for a given bin, but one reference run gives \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\mathcal {L}_i^{rel} = 0.33$$\end{document} ( \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$Z_i \approx 1.5$$\end{document} ), the final \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$Z_i = \sqrt{-2~\textrm{ln}~(0.33 / 8)} \approx 2.5$$\end{document} , which is larger than 1.5 but much smaller than \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\infty $$\end{document} . This allows the statistical test to account for systematic variations in histogram shapes due to changing collision conditions between runs.
In the AutoDQM GUI, the pull values for each bin in a 2D histogram are displayed as a heat map, allowing shifters to quickly identify the location of any significant excess (red) or deficit (blue), as shown in Figs. 1 and 3. For 1D histograms, the data distribution in blue overlays a per-bin probability-weighted average of the reference distributions in red, with the pull values in a separate panel in green (Fig. 2). Only histograms identified as anomalous are displayed immediately to shifters, focusing their attention on confirmed discrepancies. Shifters can view the full set of histograms by clicking a button in the GUI (Fig. 8).Fig. 1A 2D muon track “stub” occupancy histogram for cathode strip chambers (CSCs) in reference run 356,937 (left), data run 357,001 (right), and the AutoDQM heat map showing regions of statistically significant deficits in blue when comparing the data run to 8 prior “good” reference runs (bottom). These deficits in run 357,001 are almost invisible in the original DQM GUI histogramFig. 2The standard DQM histogram for the pseudorapidity distribution \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\eta $$\end{document} of reconstructed muon tracks in the L1T from data run 356,580 in black, overlaid with normalized distributions from 3 previous reference runs (upper left). AutoDQM flags the data as anomalous compared to 8 previous reference runs, and makes the local deficit more visible with the beta-binomial pull value histogram in green (upper right). The corresponding plots for run 356,582, where the muon detector issue was resolved, are shown belowFig. 3The 2D \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\phi $$\end{document} vs. \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\eta $$\end{document} geometrical distributions of energy deposits in the HCAL detector transmitted to the L1T, from data runs 357,814 (upper left) and 357,885 (upper right). There is very little visible difference between these DQM histograms, which are monitored daily by L1T experts. The AutoDQM beta-binomial pull value “heat map” indicates no anomalous behavior for run 357,814 when comparing to 8 previous reference runs (lower left), but correctly flags run 357,885, which had an issue with HCAL timing (lower right)
The first statistical anomaly metric used by AutoDQM is \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\chi ^2 = \sum Z_i^2 / n$$\end{document} , where n is the number of bins. The second anomaly metric is the modified maximum pull magnitude \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$Z'_{max}$$\end{document} out of all the bins, where the smallest single-bin relative likelihood \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\mathcal {L}_{i~min}^{rel}$$\end{document} is first adjusted for the look-elsewhere effect: \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\mathcal {L}_{i~min}^{rel~\prime } = 1 - (1 - \mathcal {L}_{i~min}^{rel})^{n}$$\end{document} . The \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\chi ^2$$\end{document} and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$Z'_{max}$$\end{document} thresholds to flag histograms as anomalous can be configured independently for each type of histogram.
Machine learning for DQM anomaly detection
Machine learning algorithms can detect anomalies without the need for specific reference data, while also accounting for expected systematic variations in the histogram shapes. AutoDQM currently uses unsupervised ML algorithms based on Principal Component Analysis (PCAs), and we are developing algorithms based on normalized autoencoders and normalizing flows. This is preferred over the supervised approach, in which algorithms are trained with explicitly labeled “good” and “bad” data, for two reasons. First, bad data are rare – many detector subsystems do not have enough bad data to effectively frame this as a supervised problem. Second, past problems resulting in bad data may not be representative of future issues. The unsupervised approach only requires a sufficient quantity of good data to train the algorithm, and is agnostic to the particular type of anomaly which could indicate bad data.
More formally, our unsupervised approach to DQM anomaly detection can be framed as follows: given a collection of histograms from good runs, we seek to learn a transformation \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\mathcal T$$\end{document} from the input space (i.e. the entries in each bin) into a lower-dimensional “latent space”, such that the latent space can be used to approximately reconstruct the original histogram. The form of the transformation \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\mathcal T$$\end{document} and the cost function used to optimize its parameters is described for PCAs in section 2.2.1.
Once a transformation \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\mathcal T$$\end{document} has been learned, the anomaly score for data histogram d (normalized to area 1) can be calculated as the sum of the squares of the errors (SSE) between the original and reconstructed histograms:
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\begin{aligned} \textrm{SSE} = \sum _{i=1}^{n} (d'_i - d_i)^2, \end{aligned}$$\end{document}where \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$d_i$$\end{document} are the contents of bin i of the normalized data histogram, and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$d'_i$$\end{document} are the bin contents obtained after applying the transformation \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\mathcal T$$\end{document} and subsequently its inverse: \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$d' = \mathcal T^{-1} (\mathcal T d)$$\end{document} . Histograms that match the training data have a self-similar reconstruction under transformation \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\mathcal T^{-1} \mathcal T$$\end{document} , leading to low SSE scores, while those with significant deviations compared to the training set do not. In this way, bad runs which behave differently than the good runs used in training can be identified by DQM histograms with high SSE scores, regardless of the nature of the anomaly.
One shortcoming of the normalized SSE metric is its anti-correlation to the number of entries in a histogram, such that histograms in shorter runs consistently get higher anomaly scores (see Appendix Appendix A). To address this, we instead use a \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\chi ^2$$\end{document} metric, which is intrinsically less sensitive to statistical fluctuations than the SSE. We use the beta-binomial probability function (Eq. 1) with the original data histogram d (integral D, not normalized to 1), and take \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$d'$$\end{document} (integral \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$D'$$\end{document} , again not normalized) scaled by 100 as the “reference” histogram; so mathematically:
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\begin{aligned} \alpha = \alpha _0 + d'_i \times 100~\textrm{and}~\beta = \beta _0 + D' \times 100,~\textrm{with}~\alpha _0 = \beta _0 = 1 \end{aligned}$$\end{document}The factor of 100 suppresses any statistical uncertainty in the transformed bin contents \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$d'_i$$\end{document} , leaving only the uncertainty in the original \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$d_i$$\end{document} . However, this \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\chi ^2$$\end{document} score is consistently low for histograms with fewer entries, so a modified version is used, scaling by the number of entries D:
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\begin{aligned} \chi ^{2~\prime } = \chi ^{2}~/~D^{1/3}. \end{aligned}$$\end{document}This scaling mitigates the \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\chi ^2$$\end{document} score dependence on D, as shown in Appendix Appendix A.
Principal component analysis
Principal component analysis is an unsupervised ML approach frequently used in the context of dimensionality reduction [20]. AutoDQM uses the PCA implementation from scikit-learn [21]. The PCA takes a 1D or 2D histogram from a given run as input, and transforms it into 2 key components extracted from the training set of 216 good runs. 2D histograms are first flattened into 1D for both training and evaluation. We found that merging low-occupancy bins improves the PCA reconstruction by reducing the impact of statistical fluctuations. Merging proceeds iteratively until each bin contains at least 0.33% of the histogram entries, averaging the bin occupancy over the full training dataset. The reconstruction is produced from the latent space via re-transformation, with negative bins set to zero using a rectifier function as introduced in Ref. [22]. This avoids non-physical reconstructed histograms, and is applied in the last stage to avoid biasing the weights in the PCA re-transformation workflow.
The PCA reconstruction ought to closely agree with the input histogram for good histograms, but anomalous features will not be identified as principal components in the initial transformation, and thus will not appear in the same way in the reconstruction. By comparing the input and reconstructed histograms, the PCA can flag anomalous histograms based on high \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\chi ^{2~\prime }$$\end{document} scores (Eq. 4), typically \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$> 0.4$$\end{document} , as shown in Fig. 4.Fig. 4. Normalized reconstructions of the \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\eta $$\end{document} distribution of muon tracks from runs 356,580 (left) and 356,582 (right), using the PCA reconstruction. A deficit of tracks in \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$0.9< |\eta | < 1.2$$\end{document} in run 356,580 is indicated by the PCA \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\chi ^{2~\prime }$$\end{document} score over 0.4, and the data-reconstruction difference in the lower panel
Performance evaluation
Assessment strategy
When developing anomaly detection tools, it is often difficult to rigorously measure their performance identifying true anomalies in data. An unbiased assessment using real anomalies in real data requires an independent measure of “anomalousness” on the same set of data. Ideally, this independent measure would also focus on important anomalies, as many types of data variation have no bearing on whether the data is “good” – in the case of CMS, usable for later physics analysis. Previous anomaly detection studies for CMS DQM have either used histograms which were individually labeled as bad by visual inspection, or have generated artificial anomalies to mimic problematic detector behavior [15–18].
To measure the AutoDQM performance, we use a full year’s worth of data collection runs which were labeled as good or bad by the CMS Physics Performance and Datasets (PPD) group. The PPD team synthesizes information about each run from detector subsystem experts and analyzers who study reconstructed hadron jets, \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\tau $$\end{document} leptons, photons, electrons, and muons. PPD then decides whether any detector or reconstruction issues observed are serious enough to exclude all or part of the data in a run from CMS physics analyses. The final determination is made without reference to the AutoDQM tool, and frequently uses information which is not available in the DQM GUI at all. Thus the PPD evaluation is both independent of AutoDQM, and reflects the seriousness of anomalous behavior in the CMS detector.
Our assessment data set includes 265 good and 43 bad runs collected in 2022, representing an integrated luminosity of 36 fb \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$^{-1}$$\end{document} . Selected runs are required to have lasted at least 5 min and contain at least 3 pb \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$^{-1}$$\end{document} of collision data, to ensure a sufficient number of entries in the DQM histograms. Good runs must have at least 90% of their data labeled good by PPD; bad runs must be over 50% bad, or contain over 40 pb \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$^{-1}$$\end{document} of bad data. For each run, we examine 62 histograms from the L1T online DQM, covering inputs from the ECAL, HCAL, and muon chambers. Typical histograms produced for L1T reconstructed hadron jets, electrons and photons, \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\tau $$\end{document} leptons, and muons include 1D and 2D distributions of their \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\eta $$\end{document} and/or \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\phi $$\end{document} location, transverse momentum ( \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$p_{T}$$\end{document} ), and isolation- and identification-related quantities. Because the L1T does not receive any information from the silicon tracker, we exclude runs that PPD labeled bad due to tracker issues.
Assessment Metrics
For each histogram in each run, we compute the \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\chi ^2$$\end{document} and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$Z'_{max}$$\end{document} anomaly score values from the beta-binomial statistical test (Eq. 1), comparing to 1, 4, or 8 prior reference runs. Reference runs must be labeled as good by PPD, and must have lasted at least 30 min. This matches typical shifter procedures, where longer reference runs with no known issues are compared to the most recent data run. The PCA algorithms were trained on all 216 good runs from 2022 lasting at least 30 min, and the \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\chi ^{2~\prime }$$\end{document} from Eq. 4 is used as the anomaly score. The anomaly scores s for each histogram from the 265 good runs (including those lasting less than 30 min) are ranked, allowing us to set variable anomaly thresholds \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$t_i = (s_i + s_{i+1})/2$$\end{document} for each histogram type, based on the ranked values. At the lowest threshold for a given histogram type, \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$t_0 = (s_0 + s_1)/2$$\end{document} , that histogram will be flagged as anomalous in all but one good run. At \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$t_1 = (s_1 + s_2)/2$$\end{document} , this histogram will be flagged in all but two good runs, with the pattern continuing to higher thresholds. The maximum threshold for a given histogram type is set above the highest value seen in any good run: \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$t_{max} = s_{max} + (s_{max} - s_{max-1}) / 2$$\end{document} . For each good and bad run, at each threshold index, we count how many of the 62 different histograms are flagged as anomalous, i.e. for which \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$s \ge t_i$$\end{document} .
Ideally AutoDQM would flag a large number of histograms from bad runs, and only a few from good runs. It is also important to check what fraction of good and bad runs have a significant number of anomaly flags. If good runs consistently have many histograms flagged as anomalous, “alert fatigue” will set in, and shifters will start to ignore the AutoDQM output. Having a low number of flagged histograms is also important to allow shifters and experts to follow up on notable anomalies even in good runs, in case some intervention is needed.
We thus construct two types of receiver operating characteristic (ROC) curves based on the number of flagged histograms in each run. The histogram flags (HF) ROC shows the average number of histograms flagged as anomalous by a given test for a variety of thresholds in good and bad runs, as shown on the left-hand side of Figs. 5 – 6. The run flags (RF) ROC is based on the fraction of runs with at least N histograms (out of the 62) flagged as anomalous, and can be seen on the right-hand side of Figs. 5 – 6. We evaluate the RF ROC for \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$N =$$\end{document} 1, 3, and 5, to test both “tight” and “loose” anomaly thresholds.Fig. 5. Performance of the beta-binomial \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\chi ^2$$\end{document} and maximum single-bin pull ( \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$Z'_{max}$$\end{document} ) statistical tests (Sec. 2.1) on L1T DQM histograms from 308 runs containing 2022 data. ROC curves are constructed based on the mean number of histograms flagged per run (left), and the fraction of runs with at least 3 histograms flagged (right), comparing the data to 1, 4, or 8 prior reference runsFig. 6Performance of the PCA modified \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\chi ^2$$\end{document} test (Sec. 2.2) on L1T DQM histograms from 308 runs containing 2022 data. ROC curves are constructed based on the mean number of histograms flagged per run (left), and the fraction of runs with at least 1, 3, or 5 histograms flagged (right)
Assessment results
The beta-binomial and PCA algorithms both show strong discrimination between good and bad runs. When the mean number of histogram flags is low ( \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$< 3$$\end{document} ) for good runs, the HF ROC plots show 3 – 4 times more flags in bad runs. The RF ROC plots show similar behavior for the fraction of good and bad runs with \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$N \ge $$\end{document} 1, 3, and 5 histogram flags: with less than 12% of good runs flagged, 35 – 50% of bad runs exceed the threshold. It is worth noting that we do not expect AutoDQM (or any anomaly detection approach) to identify 100% of bad runs in this data set. In many cases, the relevant issue had no impact on the L1T, or was simply not visible in the online DQM histograms. We also do not expect to achieve a 0% flagging rate for good runs. In fact, many good runs have true anomalies which should be flagged. Nevertheless, AutoDQM applied to L1T monitoring alone was able to detect half of the serious issues affecting CMS data quality in 2022, with less than 12% of good runs flagged as anomalous.
The beta-binomial \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\chi ^2$$\end{document} and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$Z'_{max}$$\end{document} tests perform significantly better when using a larger number of reference runs for the comparison (Fig. 5). This is expected, as reconstructed particle occupancy distributions in the detector are sensitive to the number of simultaneous collisions (“pileup”), so runs taken with different amounts of pileup yield DQM histograms with different shapes. When using multiple reference runs, at least one of them is likely to have similar pileup conditions to the data run being tested. The pileup dependence is taken into account naturally in the PCA algorithms (Fig. 6), which are trained on a large number of runs spanning the full range of pileup conditions.
While there is some variation among the algorithms, none appears to be decisively superior to the others. The best performance is achieved by applying all three quality tests simultaneously (Fig. 7). In this case, the HF ROC plot shows 4 – 6 times more flags in bad runs than in good runs, and over 55% of bad runs have at least 3 flags for a threshold where only 13% of good runs have 3 flags. For the combined tests, the number of distinct flags is counted, i.e. if the same histogram is flagged by 2 tests, that counts as 2 anomaly flags.Fig. 7. Performance of the combined beta-binomial and PCA algorithms on L1T DQM histograms from 308 runs containing 2022 data. ROC curves are constructed based on the mean number of histograms flagged per run (left), and the fraction of runs with at least 3 histograms flagged (right)
Application to Muon Detector Monitoring
While the L1T online DQM histograms provide a good test case for global AutoDQM performance with inputs from multiple subdetectors, the AutoDQM tool has also been applied successfully in muon detector monitoring. Of the 43 bad runs used in the studies above, only 1 was flagged as bad by PPD due to issues in the muon detectors. Nevertheless, it is important to closely monitor and identify any significant changes in the muon detector performance, e.g. chambers which occasionally malfunction, requiring expert intervention. The CSCs in the CMS endcaps contain a total of 540 chambers, of which a handful may be disabled at any given time. Very rarely, a dozen or more chambers temporarily malfunction simultaneously. In this case, the AutoDQM webpage flags numerous CSC DQM histograms as anomalous (Fig. 8). Furthermore, the individual AutoDQM plots clearly show the geometrical regions with new deficits of muon tracks in blue (Fig. 9). This allows CSC experts to quickly assess the scope and identify the source of new detector issues, enabling prompt intervention.Fig. 8. AutoDQM GUI webpage for the cathode strip chambers (CSCs) in run 356,001 in 2022, showing numerous chambers with anomalously low occupancy of reconstructed muon “hits” in blue. Each plot can be expanded by clicking, and histograms not flagged as anomalous can be viewed using the “Show hidden plots” toggle. The precise anomaly scores for each histogram are displayed in a panel on the leftFig. 9AutoDQM GUI plots of the geometrical reconstructed muon “hit” distribution in the CSC detectors for run 356,001 in 2022, showing regions with anomalously low occupancy in blue. Regions which are consistently empty across multiple runs appear in white, allowing the shifter to distinguish between new and long-running issues
Summary and Outlook
Data quality monitoring (DQM) presents an immense challenge to particle physics experiments, which will only grow as the data collected increases in volume and complexity. The AutoDQM system for generalized, automated DQM dramatically augments the ability of physicists to quickly identify and localize anomalous behavior in the CMS detector. Using a set of monitoring histograms from the CMS Level-1 Trigger system covering the entire CMS proton-proton collision data set from 2022, AutoDQM’s combined statistical and machine learning tests successfully identified over 50% of all “bad” data with significant detector malfunction, while flagging less than 15% of “good” data as anomalous. AutoDQM also demonstrates its effectiveness in visually highlighting changes in CMS muon detector performance. Application to additional CMS subdetector systems will allow for more rapid, accurate identification of important issues affecting collision data in the future.
Supplementary Information
Supplementary file 1.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1Borisyak M, Ratnikov F, Derkach D, Ustyuzhanin A (2017) Towards automation of data quality system for CERN CMS experiment. J. Phys. Conf. Ser. 898(9) 10.1088/1742-6596/898/9/092041 ar Xiv:1709.08607
- 2CMS ECAL Collaboration (2024) Autoencoder-based Anomaly Detection System for Online Data Quality Monitoring of the CMS Electromagnetic Calorimeter. Comput. Softw. Big Sci. 8(11) 10.1007/s 41781-024-00118-zar Xiv:2309.10157
- 3Sci Py-Contributors: Sci Py beta-binomial implementation, accessed 2025-01-23:. Accessed: 2025-01-23. https://docs.scipy.org/doc/scipy/reference/generated/scipy.stats.betabinom.html
- 4Glorot X, Bordes A, Bengio Y (2011) Deep sparse rectifier neural networks. In: Proceedings of the Fourteenth International Conference on Artificial Intelligence and Statistics, 15, 315–323. PMLR, ???. https://proceedings.mlr.press/v 15/glorot 11a.html