Genetic Determinants of Coronary Artery Disease in Type 2 Diabetes Mellitus Among Asian Populations: A Meta-Analysis
Aida Kabibulatova, Kamilla Mussina, Joseph Almazan, Antonio Sarria-Santamera, Alessandro Salustri, Kuralay Atageldiyeva

TL;DR
This study identifies specific genes linked to heart disease risk in Asian patients with type 2 diabetes, highlighting the need for population-specific genetic research.
Contribution
The first meta-analysis focusing on genetic variants associated with coronary artery disease in Asian populations with type 2 diabetes.
Findings
The PCSK1, GLP1R, and ADIPOQ genes were associated with increased coronary artery disease risk in Asian T2DM patients.
The ACE and Q192R genes showed possible protective effects against coronary artery disease.
High heterogeneity suggests complex and population-specific genetic factors influencing CAD risk in this group.
Abstract
Background/Objectives: Type 2 diabetes mellitus (T2DM) significantly elevates the risk of coronary artery disease (CAD), particularly in Asian populations where both conditions are epidemic. While shared genetic factors contribute to this comorbidity, evidence from Asian cohorts remains fragmented, with limited focus on population-specific variants. This meta-analysis synthesizes evidence on genetic variants associated with CAD risk in Asian patients with T2DM. Methods: We systematically searched several databases according to the PRISMA statement and checklist. Pooled odds ratios (ORs) with corresponding 95% confidence intervals (CIs) were calculated using random-effects models, with heterogeneity assessed via I2 and Cochran’s Q, and publication bias via funnel plots and Egger’s test. Results: In total, data on 11,268 subjects were reviewed, including 4668 cases and 6600 controls.…
Genes, proteins, chemicals, diseases, species, mutations and cell lines named across the full text — each resolved to its canonical identifier and authoritative record.
Click any figure to enlarge with its caption.
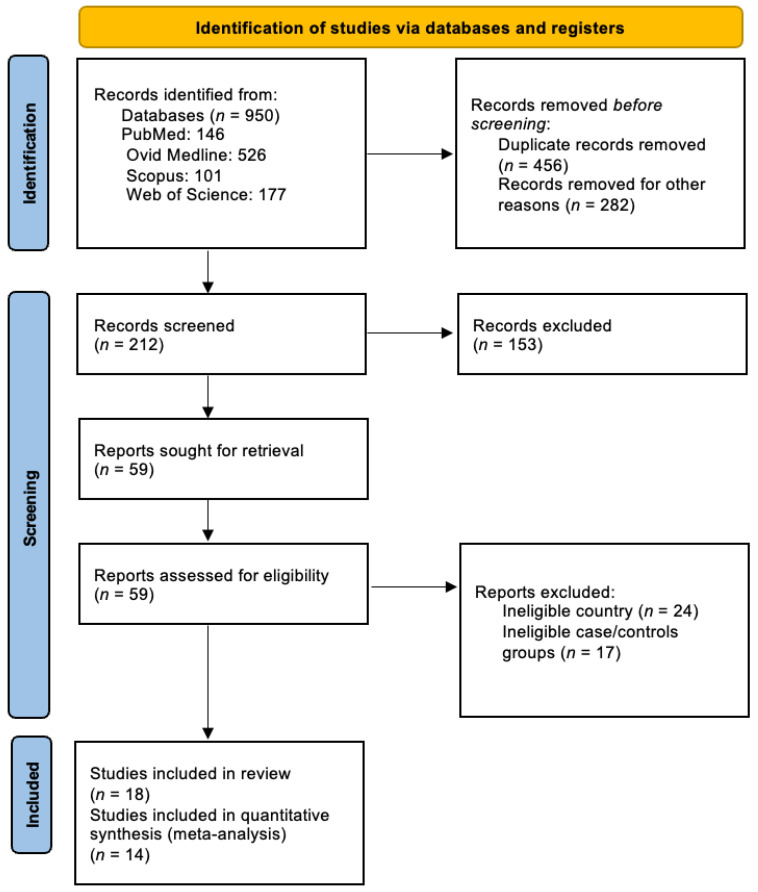 Figure 1
Figure 1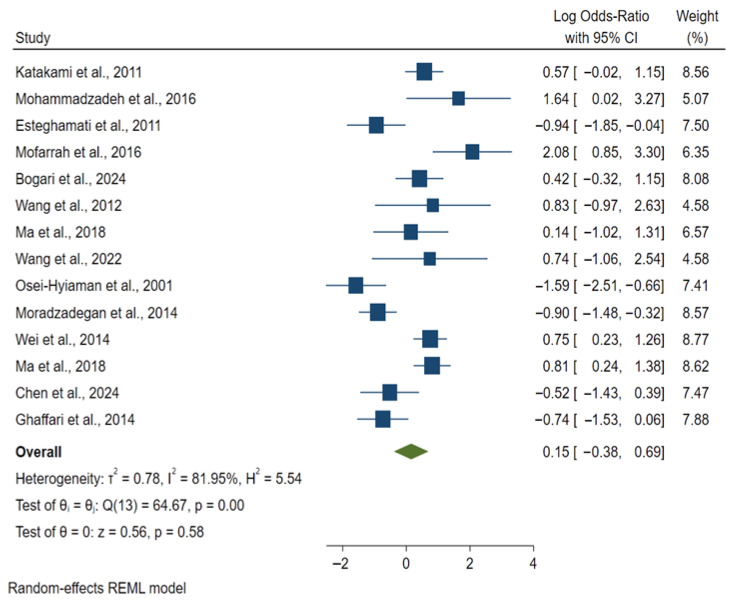 Figure 2
Figure 2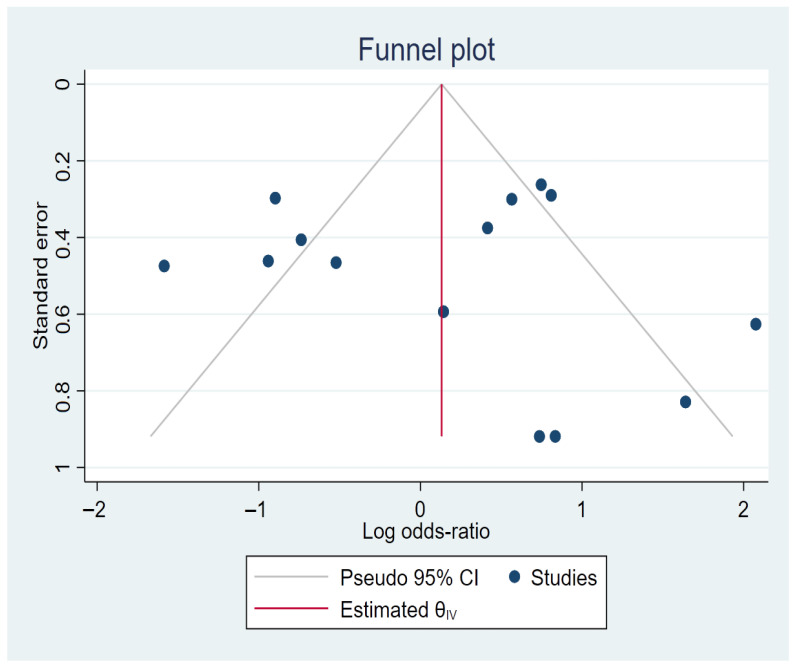 Figure 3
Figure 3- —Ministry of Science and Higher Education of the Republic of Kazakhstan
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsGenetic Associations and Epidemiology · Diabetes, Cardiovascular Risks, and Lipoproteins · Renin-Angiotensin System Studies
1. Introduction
Diabetes mellitus has emerged as one of the most pressing non-communicable diseases of the 21st century, contributing substantially to global morbidity and mortality. Diabetes has reached global epidemic proportions, according to the International Diabetes Federation (IDF) evaluations. To date, 589 million adults are living with it, and the number is projected to reach 853 million people by 2050 [1]. Asian regions, like East and Southeast Asia, are among the largest contributors in these proportions, accounting for 247.6 million diabetic patients [1,2,3]. Type 2 diabetes mellitus (T2DM) is the most prevalent type, according to the Global Burden of Disease (GBD) study, representing 96.0% of all cases worldwide in 2021 [4]. The burden of T2DM is rising and is projected to grow, with the steepest increases observed in the Asian region [5,6,7,8].
T2DM is a well-known independent risk factor for atherosclerosis and is currently considered a cardiovascular disease itself [9]. Comprehensive epidemiological data indicates that individuals with T2DM are most likely to die from coronary artery disease (CAD) with cardiovascular disease accounting for about 75–80% of all fatalities in the diabetic population [10,11]. Moreover, patients with T2DM have a higher prevalence of CAD compared to those without this condition [12,13,14], and cardiovascular diseases remain the main leading causes of death among all diabetes-related complications. This startling mortality rate emphasizes how vital it is to comprehend the complex relationship between both diseases and indicates the need for early diagnosis and accurate prognosis as well as efficient preventive strategies.
There are several pathogenetic pathways that converge to accelerate atherosclerosis in T2DM patients. Chronic hyperglycemia drives the non-enzymatic attachment of sugars to circulating and tissue-resident proteins, lipids, and nucleic acids, forming a diverse array of advanced glycation end products (AGEs) [15,16,17]. AGEs stiffen the vessel wall and trap low-density lipoprotein (LDL), making it more susceptible to oxidation and activating pro-atherogenic signaling cascades [18,19,20]. Simultaneously, hyperglycemia and insulin resistance increase oxygen form production, depleting nitric oxide availability and triggering oxidative stress [21,22,23]. The dysfunctional endothelium becomes pro-thrombotic, expressed through elevated fibrinogen, von Willebrand factor, and plasminogen activator inhibitor-1, leading to resistant fibrin clots [24,25,26,27,28,29,30]. An atherogenic lipid profile, characterized by elevated triglycerides, reduced high-density lipoprotein cholesterol, and abundant small, dense LDL particles, further accelerates atherogenesis [31,32,33,34].
However, classical risk factors and established pathophysiologic mechanisms do not fully account for the heightened CAD burden in T2DM. A substantial genetic component contributes significantly, as both diseases demonstrate high heritability, approximately 58% for CAD and 72% for T2DM, and genome-wide association studies (GWAS) have identified hundreds of susceptibility loci, with evidence of pleiotropic genes affecting both conditions [35,36,37,38,39,40,41,42]. Despite these advances, most genetic research focuses on European populations, severely limiting applicability to Asian cohorts [43,44,45]. CAD-specific genetic variants in T2DM patients remain understudied, particularly in Asian populations.
This meta-analysis synthesizes evidence on genetic determinants of CAD in T2DM across Asian cohorts.
2. Materials and Methods
2.1. Protocol and Registration
This meta-analysis followed the Preferred Reporting Items for Systematic Reviews and Meta-Analyses (PRISMA) 2020 guidelines [46]. The study protocol was registered in the International Prospective Register of Systematic Reviews (PROSPERO) under the registration number CRD420252163559.
2.2. Eligibility Criteria
Studies were selected according to the Population, Intervention/Exposure, Comparison, Outcome, and Study design framework (PICOS). The inclusion criteria were as follows: individuals older than 18 years, of Asian population with a confirmed diagnosis of T2DM based on a fasting blood glucose level of over 126 mg/dL (7 mmol/L); oral glucose tolerance test level higher than 200 mg/dL (11.1 mmol/L) after 2 h; level of glycated hemoglobin over 6.5%. Studies were included if they used a case–control or cross-sectional design that allowed comparison between T2DM patients with confirmed CAD (cases) and T2DM patients without CAD (controls).
The CAD in case group was defined using established clinical and diagnostic criteria aligned with American Heart Association (AHA) and European Society of Cardiology (ESC), including angiographically confirmed coronary stenosis of 50% or greater in major vessels, documented myocardial infarction according to standardized definitions, coronary revascularization procedures such as percutaneous coronary intervention or coronary artery bypass grafting, and acute coronary syndromes [47,48,49,50]. Secondary outcomes were defined to assess the phenotypic severity and premature CAD. CAD severity was assessed using standardized angiographic classification systems where data were available: for studies reporting detailed angiographic data, the SYNTAX score was applied [51]; if the study included categorization by the vessels’ obstruction, Coronary Artery Disease Reporting Data System (CAD-RADS) and risk stratification were used [52,53]. Premature CAD was defined as an atherosclerotic disease occurring at the at ≤55 years of age in men and ≤65 years of age in women, consistent with major clinical guidelines [54].
The genetic exposures of interest include various types of genetic variants; specifically single nucleotide polymorphisms (SNP) identified via GWAS arrays or sequencing.
Studies were excluded if they met any of the following conditions: did not present the summary statistics or effect estimate and its precision in terms of an odds ratio (OR) with the corresponding 95% confidence interval; non-original research formats, such as editorials, reviews, case reports, and conference abstract.
2.3. Search Strategy and Study Selection
A literature search was conducted using the Scopus, Web of Science, PubMed and Ovid MEDLINE databases. The search strategies applied various combinations of medical subject heading terms and keywords. Queries for searches were customized for each database according to its distinct characteristics. The search technique encompassed collecting English-language research published from 1 January 2001 to October 2025. The collected publications were organized and managed utilizing Zotero, version 7.0.30 (Corporation for Digital Scholarship, Vienna, VA, USA) reference management software.
2.4. Data Extraction and Quality Assessment
Data were extracted by two researchers independently (A.K. and K.M.). All disagreements were resolved by discussion to reach a final consensus. Discrepancies that could not be resolved by discussion were adjudicated by a third reviewer (K.A.). The information extracted from each eligible study was as follows: first author’s name, year of publication, ethnicity/geographic region of the study population, participants with and without CAD and T2DM, the number of participants, mean age and gender distribution of cases and controls, number of SNPs (rsID), OR (95% CI), and evidence of Hardy–Weinberg equilibrium (HWE). The OR was interpreted as a prevalence OR for cross-sectional studies and a disease OR for case–control studies. These measures were pooled under the standard genetic meta-analysis assumption that CAD is a stable outcome, allowing the prevalence OR to approximate the risk OR.
The quality of the study was evaluated using the Joanna Briggs Institute (JBI) critical appraisal tools specific to the study design. The JBI tool was chosen for its suitability to assess observational genetic association studies. For case–control studies, quality appraisal focused on clarity of inclusion criteria, appropriateness of control selection, assessment of confounding, and validity of statistical analysis [55]. Two reviewers (A.K. and K.M.) conducted an independent quality appraisal, with discrepancies resolved by consensus or consultation with a third reviewer (K.A.).
2.5. Statistical Analysis
The association of genetic variants with CAD among T2DM patients was calculated by pooled odds ratios (ORs) with corresponding 95% confidence intervals (CIs). Odds ratios from both case–control and cross-sectional study designs were synthesized together, a standard meta-analytic approach for genetic association studies, under the assumption that the CAD phenotype was consistently defined. In this meta-analysis, the natural logarithm of the odds ratio (log OR) was employed as the primary effect size metric for pooling genetic associations under the model reported as the primary analysis in each study (e.g., co-dominant, dominant, recessive, and multiplicative models). This approach was chosen to minimize post hoc data transformation and respect the original authors’ analytical design. For studies reporting multiple models, the most common model across the literature was identified from a pre-screening of published reports and selected to ensure consistency. The Z test was used to determine the significance of the pooled OR (p < 0.05) was considered statistically significant. A random-effects model with restricted maximum likelihood (REML) estimation was applied to account for potential heterogeneity among studies. Heterogeneity was also evaluated using the Cochran’s Q statistic (p ≤ 0.10 considered significant) and quantified with the I^2^ statistic with thresholds of 25%, 50%, and 75% representing low, moderate, and high heterogeneity, respectively. To assess data quality, genotype data from control groups were evaluated for deviations from Hardy–Weinberg equilibrium (HWE) using a Chi-square test (p < 0.05 considered a significant deviation). The potential influence of any study with significant HWE deviation was examined in a sensitivity analysis. For genes with multiple reported polymorphisms (e.g., ADIPOQ), each variant was assessed individually to account for potential differences in function and linkage disequilibrium, thereby avoiding conflation of distinct genetic effects. These variants were treated as independent genetic markers and analyzed separately; they were not pooled into a composite gene-level estimate.
Publication bias was evaluated through funnel plots and statistically using Egger’s regression test and Begg’s test. Funnel plot asymmetry was examined visually. Sensitivity analyses were performed by sequentially omitting individual studies to assess the stability of the results. All statistical analyses were conducted using STATA 16.1 version (STATA Corporation, College Station, TX, USA).
Superficial text editing (grammar, spelling, and punctuation) was performed using Grammarly (Grammarly Inc., San-Francisco, CA, USA).
3. Results
A total of 950 records were identified through database searches (PubMed = 146; Ovid Medline = 526; Scopus = 101; Web of Science = 177). After removing duplicates and a thorough full-text screening, 18 eligible studies were included. The detailed study selection process is illustrated in Figure 1.
In total, data on 11,268 subjects were reviewed, including 4668 cases and 6600 controls. Among 18 eligible studies [56,57,58,59,60,61,62,63,64,65,66,67,68,69,70,71,72,73] 14 studies were included for the meta-analysis, as they had sufficient quantitative data (Table 1). Most studies were case–control in design, with two cross-sectional studies. The majority originated from East Asia (China and Japan), while several were carried out in Middle Eastern populations (Iran, Saudi Arabia, and the United Arab Emirates). Patients with familial hypercholesterolemia, an inherited autosomal dominant disorder caused by mutations in genes like LDLR, APOB, or PCSK9, were not included in any of the studies selected for the metanalysis. The average age of participants ranged between 52 and 63 years, and women accounted for 35% to 57% of the study samples. The studies varied considerably in size, with cases ranging from 100 to 560 and controls from 72 to 2424 participants. The included studies evaluated a broad range of genetic polymorphisms. Variants within the ADIPOQ gene (3q27–28) were the most frequently examined, including rs266729, G276T, 276G/T and rs2241766. Other loci of interest comprised ACE (rs4646994, 17q23.3–4), APOE (rs429358, 19q13.2), CNR1 (G1359A, chr 6), PON1 (Q192R), GLP-1R (rs4714210, 6p21.2), SIRT1 (rs16924934, 10q21.3), STK11 (rs12977689, 19p13.3), PCSK1 (rs3811951, 5q15–q21), PLXDC2 (rs12219125), and PSRC1–CELSR2 (rs599839). Polymorphisms within ADIPOQ, ACE, APOE and PON1 were most consistently associated with elevated risk of CAD, while GIP, PCSK1 and PSRC1–CELSR2 variants were more frequent among T2DM patients without CAD.
Individual study estimates displayed considerable variability, with several indicating a potential significant association with the disease (log OR < 0) alongside others suggesting null or adverse associations; notably, the CIs for most studies overlapped the null value (log OR = 0), precluding statistical significance at the study level. The random-effects model yielded a pooled OR of 0.15 (95% CI: −0.38–0.69), suggesting a trend toward a protective effect. However, this was not statistically significant (z = 0.56, p = 0.58). Heterogeneity across studies was substantial (τ^2^ = 0.78; I^2^ = 81.95%; H^2^ = 5.54), Cochran’s Q test indicated significance (Q (13) = 64.67, p < 0.001). Individual study contributions in the forest plot (Figure 2) varied by direction and precision, with high-weight studies (8–9%) including Wei et al., 2014 [60]; PCSK1 gene; log OR = 0.75 [95% CI: 0.23, 1.26]; OR = 2.12 [95% CI: 1.26, 3.52]; p < 0.05; weight = 8.77%) and Ma et al., 2018 [57] GLP1R; log OR = 0.81 [95% CI: 0.24, 1.38]; OR = 2.25 [95% CI: 1.27, 3.97]; p < 0.01; weight = 8.62%), both indicating significant associations with increased risk, offset by protective effects in Moradzadegan et al., 2014 [62] ACE; log OR = −0.90 [95% CI: −1.48, −0.32]; OR = 0.41 [95% CI: 0.23, 0.73]; p < 0.01; weight = 8.57%). Outlying low-weight studies with wide CIs included Mofarrah et al., 2016 [69] ADIPOQ; log OR = 2.08 [95% CI: 0.85, 3.30]; OR = 8.00 [95% CI: 2.34, 27.14]; p < 0.01; weight = 6.35%; strong risk) and Mohammadzadeh et al., 2016 [65] ADIPOQ; log OR = 1.64 [95% CI: 0.02, 3.27]; OR = 5.15 [95% CI: 1.02, 26.32]; p = 0.05; borderline risk; weight = 5.07%; limited by small sample size), alongside significant protection in Osei-Hyiaman et al., 2001 [72] PON1 (Q192R); log OR = −1.59 [95% CI: −2.51, −0.66]; OR = 0.20 [95% CI: 0.08, 0.52]; p < 0.001; weight = 7.41%). These opposing signals contributed to the non-significant pooled estimate.
Potential publication bias was explored using a funnel plot Figure 3. The funnel plot analysis revealed a generally symmetrical distribution of studies around the pooled effect, with only a limited number of points slightly beyond confidence intervals. Studies located outside the funnel boundaries are more likely attributable to heterogeneity of studies. This analysis revealed no evident pattern of absent studies or distortion in the funnel plot, indicating a lack of significant publication bias and reinforcing the validity of the meta-analytic estimate; however, the influence of small-study effects cannot be entirely ruled out.
4. Discussion
This meta-analysis provides a comprehensive synthesis of genetic variants linked to the development of CAD in T2DM patients within Asian populations. Our findings illustrate the complex variations of genetic susceptibility and the diverse characteristics of coronary risk among diabetic patients in various Asian subgroups. Across the chosen 14 studies, examining different genetic polymorphisms provided substantial insight into the genetic component of CAD susceptibility among Asian T2DM patients. Variants of the ADIPOQ gene have been identified as the most investigated and consistently linked to the increased risk of CAD [74,75]. The established roles of the adiponectin pathway in insulin sensitization, anti-inflammatory processes, and cardiovascular protection support the biological plausibility of these associations. The mechanisms underlying risk signals in ADIPOQ variants align with reduced adiponectin levels, which contribute to pro-inflammatory and insulin-resistant conditions that enhance atherogenesis [76]. ACE rs4646994 presumably enhances vascular remodeling and thrombosis through elevated angiotensin II levels. APOE rs429358 is associated with elevated risk of coronary complications and adverse lipid profiles PON1 Q192R may affect the oxidative modification of lipoproteins [77,78]. In contrast, the protective associations for PCSK1 and PSRC1–CELSR2 align with improved prohormone processing and lipid regulation, respectively, whereas GIP-linked loci correspond with enhanced incretin action.
During the analysis, several polymorphisms showed higher frequency in TD2M without CAD, suggesting potential protective properties towards CAD. In some studies, the GLP-1R rs4714210 variant demonstrates protective effects, with GG genotype displaying a markedly decreased risk of CAD, even after optimizing for conventional risk variables [79]. This protection likely indicates enhanced GLP-1 receptor activation, which confers coronary protection via various mechanisms, including improved endothelial function, decreased inflammation, and increased insulin sensitivity. Enhanced GLP-1R activation may improve coronary outcomes by restoring endothelial homeostasis through cyclic adenosine monophosphate/protein kinase A—dependent endothelial nitric oxide synthase phosphorylation, increased nitric oxide bioavailability, and reduced oxidative stress. This results in improved flow-mediated dilation, coronary flow reserve, and myocardial perfusion [80]. Concurrently, GLP-1R agonism reduces vascular inflammation by decreasing macrophage infiltration and pro-inflammatory cytokines and reinstates endothelial redox signaling, thereby collectively decreasing atherosclerotic plaque progression and instability. The biological outcomes correspond with cardiovascular outcome trials indicating a reduction in major adverse cardiovascular events associated with GLP-1 receptor agonists, thereby supporting a translational connection between endothelial and anti-inflammatory advantages and event reduction. Recent meta-analyses provide evidence of significant reductions in major adverse cardiovascular events, stroke, and cardiovascular mortality at the class level, highlighting the cardioprotective effects of GLP-1 receptor agonists that extend beyond mere glycemic control [81]. This protection may arise because PCSK1 encodes prohormone convertase 1/3, which activates hormones by processing proinsulin to insulin and proglucagon to GLP-1. Therefore, any protective effect from rs3811951 is likely associated with altered prohormone processing, islet biology, and metabolic phenotypes [82]. This may also be attributed to findings from genome-wide meta-analysis indicating that rs599839 at chromosome 1p13.3 is significantly associated with LDL-cholesterol, suggesting the involvement of this locus in lipid regulation, which aligns with cardio protection through enhanced lipoprotein profiles [83]. The cardioprotective mechanism of rs599839(G) is closely associated with its effect on lipid homeostasis, a crucial pathway that is dysregulated in T2DM, leading to foam cell formation and plaque instability [84].
The minimal variability highlights how consistent these signals are across different studies, which may be due to common environmental modifiers in Asian cohorts, like high-carbohydrate diets and insulin resistance brought on by urbanization, which enhance genetic resilience without superseding it [85,86,87,88,89,90]. However, given that recent analyses show that shared genetic architectures between T2DM and CAD are still underpowered in smaller regional studies, the non-significant pooled OR emphasizes the need for larger, multi-ancestry GWAS to detect subtle polygenic effects.
Limitations of this analysis must be considered. A primary limitation is a non-significant pooled estimate. The lack of an overall significant association represents a serious constraint, indicating that the results do not support a unified genetic model. Consequently, the nominally significant subgroup findings should not be generalized; they require rigorous independent confirmation in larger, well-defined groups.
A substantial heterogeneity observed in our meta-analysis (I^2^ = 81.95%), is a probable cause of the non-significant pooled estimate. The observed inconsistency is likely attributable to divergent CAD diagnostic criteria, the substantial genetic and environmental diversity within the broadly defined Asian study populations, and technical discrepancies in sample sizes and genotyping protocols across the included studies.
Visual inspection of the funnel suggested approximate symmetry, and formal tests did not indicate significant publication bias. However, the small number of studies limits the power of these assessments. Phenotypic heterogeneity in CAD definitions across studies, ranging from angiographically confirmed stenosis (≥50%) to clinical diagnoses and revascularization procedures, may have contributed to inconsistent associations.
The studies included in the metanalysis did not provide systematic data on the glycemic control, presence of hypercholesterolemia, and smoking habits, which are well known risk factors for CAD. Although lifestyle can increase the risk for cardiovascular disease, the aim of this study was to look specifically into the genetic variants associated with CAD in T2DM among Asian population.
5. Conclusions
This first meta-analysis investigating genetic underpinnings of CAD in Asian individuals with T2DM identified specific locus-level associations but found no significant aggregate genetic effect across variants. The substantial heterogeneity and non-significant pooled estimate underscore the complexity and likely population-specific nature of this genetic risk. Consequently, these findings suggest that precision medicine approaches may need to target specific population-relevant variants rather than relying on a broad polygenic signal from these loci. Future research must prioritize larger, genetically homogeneous cohorts to validate these candidate gene associations and elucidate their interaction with environmental factors.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1International Diabetes Federation IDF Diabetes Atlas 2025: Global Diabetes Data & Insights International Diabetes Federation Brussels, Belgium 2025 Available online: https://diabetesatlas.org/resources/idf-diabetes-atlas-2025/(accessed on 11 November 2025)
- 2Bae J.H. Han K. Ko S. Yang Y.S. Choi J.H. Choi K.M. Kwon H. Won K.C. Diabetes fact sheet in Korea 2021 Diabetes Metab. J.20224641742610.4093/dmj.2022.010635656565 PMC 9171160 · doi ↗ · pubmed ↗
- 3Kohsaka S. Morita N. Okami S. Kidani Y. Yajima T. Current trends in diabetes mellitus database research in Japan Diabetes Obes. Metab.20212331810.1111/dom.1432533835639 · doi ↗ · pubmed ↗
- 4Ong K.L. Stafford L.K. Mc Laughlin S.A. Boyko E.J. Vollset S.E. Smith A.E. Dalton B.E. Duprey J. Cruz J.A. Hagins H. Global, regional, and national burden of diabetes from 1990 to 2021, with projections of prevalence to 2050: A systematic analysis for the Global Burden of Disease Study 2021 Lancet 202340220323410.1016/S 0140-6736(23)01301-637356446 PMC 10364581 · doi ↗ · pubmed ↗
- 5Huang Q. Li Y. Yu M. Lv Z. Lu F. Xu N. Zhang Q. Shen J. Zhu J. Jiang H. Global burden and risk factors of type 2 diabetes mellitus from 1990 to 2021, with forecasts to 2050 Front. Endocrinol.202516153814310.3389/fendo.2025.1538143 PMC 1239081440895618 · doi ↗ · pubmed ↗
- 6Yuan H. Li X. Wan G. Sun L. Zhu X. Che F. Yang Z. Type 2 diabetes epidemic in East Asia: A 35-year systematic trend analysis Oncotarget 201796718672710.18632/oncotarget.2296129467922 PMC 5805508 · doi ↗ · pubmed ↗
- 7Ramachandran A. Trends in prevalence of diabetes in Asian countries World J. Diabetes 2012311011710.4239/wjd.v 3.i 6.11022737281 PMC 3382707 · doi ↗ · pubmed ↗
- 8Ranasinghe P. Rathnayake N. Wijayawardhana S. Jeyapragasam H. Meegoda V.J. Jayawardena R. Misra A. Rising trends of diabetes in South Asia: A systematic review and meta-analysis Diabetes Metab. Syndr.20241810316010.1016/j.dsx.2024.10316039591894 · doi ↗ · pubmed ↗