Confidence-weighted integration of human and machine judgments for superior decision-making
Felipe Yáñez, Xiaoliang Luo, Omar Valerio Minero, Bradley C. Love

TL;DR
This paper shows that combining human and AI judgments using confidence weights improves decision-making, even when AI outperforms humans.
Contribution
A scalable, confidence-weighted method for integrating human and machine judgments in decision-making.
Findings
Human-AI teams outperformed individual AI systems in forecasting tasks.
Adding a human to a team of AI systems consistently improved performance.
Confidence-weighted integration is effective across different domains like image classification and neuroscience.
Abstract
Large language models (LLMs) can surpass humans in certain forecasting tasks. What role does this leave for humans in the overall decision process? One possibility is that humans, despite performing worse than LLMs, can still add value when teamed with them. A human and machine team can surpass each individual teammate when team members’ confidence is well calibrated and team members diverge in which tasks they find difficult (i.e., calibration and diversity are needed). We simplified and extended a Bayesian approach to combining judgments using a logistic regression framework that integrates confidence-weighted judgments for any number of team members. Using this straightforward method, we demonstrated its effectiveness in both image classification and neuroscience forecasting tasks. Combining human judgments with one or more machines consistently improved overall team performance. Our…
Genes, proteins, chemicals, diseases, species, mutations and cell lines named across the full text — each resolved to its canonical identifier and authoritative record.
Click any figure to enlarge with its caption.
 Figure 1
Figure 1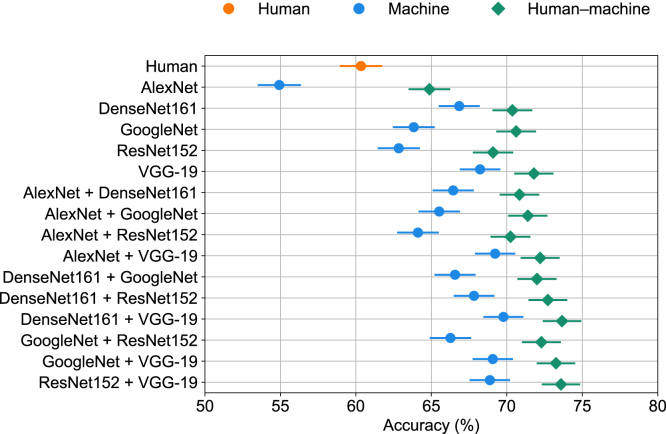 Figure 2
Figure 2 Figure 3
Figure 3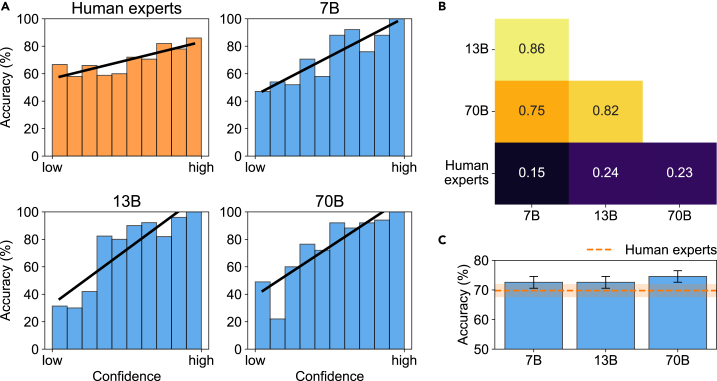 Figure 4
Figure 4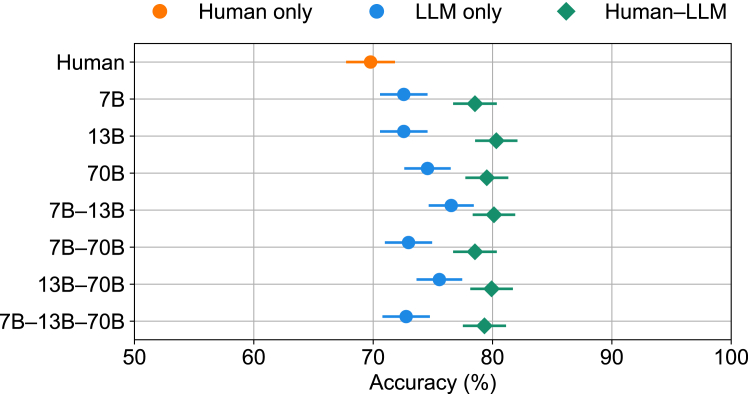 Figure 5
Figure 5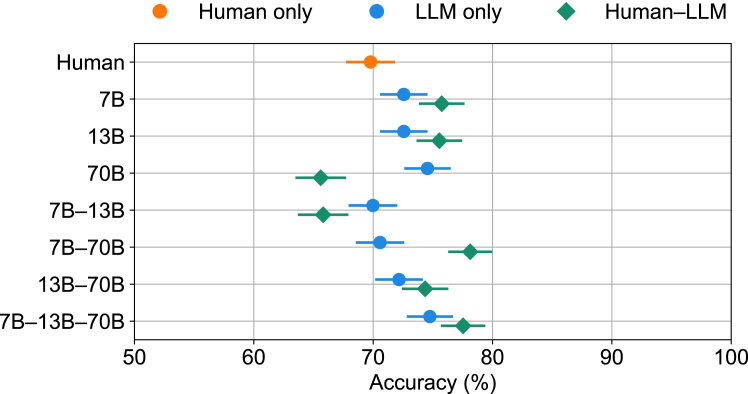 Figure 6
Figure 6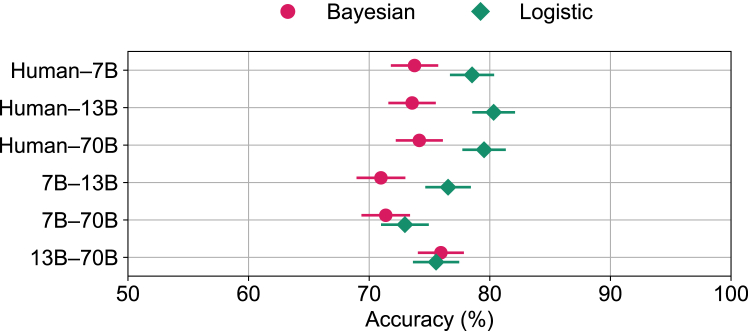 Figure 7
Figure 7Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsArtificial Intelligence in Healthcare and Education · Explainable Artificial Intelligence (XAI) · Ethics and Social Impacts of AI
Introduction
Modern environments increasingly stretch our ability to process the vast amounts of information available to us.1^,^2 In contrast, machine systems can often take advantage of vast information resources.3^,^4^,^5^,^6 As machines reach superhuman performance levels,5^,^7^,^8 one concern is whether machines will supplant human judgment in critical areas.9^,^10
One potential solution is forming human-machine teams in which judgments from humans and machines are integrated.11^,^12^,^13 It might be possible that humans can contribute to and make the overall team better even when their performance is worse on average than their machine teammates.
We will begin evaluating this possibility in an object recognition task where human and machine performance overlap according to experimental conditions.13 Human-machine teaming combines the individual judgments of humans and machines. We will then evaluate a knowledge-intensive task in which large language models (LLMs) surpass humans in predicting the outcomes of neuroscience studies,14 posing a real challenge for effective team collaboration. Complementarity is realized when a team’s performance improves beyond that of either teammate alone.12^,^13 We investigate whether human-LLM teams outperform LLMs even when humans have inferior performance compared to LLMs. There are two key conditions for team complementarity to be fulfilled.13^,^14^,^15 The first requirement is calibration of confidence. This implies that when humans and LLMs have a higher degree of confidence in their judgments, the accuracy of those judgments tends to be greater.14 The second requirement is classification diversity among team members. Diversity holds when the errors in classification made by humans and LLMs are not the same.14
Previous work13 has explored the conditions for complementarity in the context of object recognition. Humans outperformed machines in the classification of natural images with low levels of noise, raising the question of whether a combined approach could achieve superhuman performance. They developed a Bayesian model that integrates the judgments of humans and machines. With this approach, human-machine complementarity was observed. However, the combination model is computationally expensive and challenging to extend to additional teammates. Ideally, a model that combines the judgments of humans and machines should be adaptable and scalable, easily interpretable, and allow for any number of teammates.
Here, we aim to offer this ideal solution to human-machine teaming while evaluating complementarity in an object recognition task and a knowledge-intensive task that is not based on perceptual judgment. Critically, in both scenarios, humans were surpassed by machine systems. Foreshadowing our results, we find support for effective human-machine teaming through our resource-efficient procedure. Our procedure comprises a logistic-regression-based strategy that provides confidence-weighted integration of teammates’ predictions for any number of team members. Our approach is particularly well suited for combining human and machine judgments and assessing their contribution in predictive tasks.
Results
In this study, we explore whether humans can contribute to decisions when machine models, such as LLMs, are superior to them. We developed a logistic-regression-based method that integrates a weighted average of judgments from teammates, whether humans or machines. The proposed approach adheres to similar previously reported principles,13 offering a number of advantages: it is easy to use, flexible, and resource efficient (details can be found in the methods). We evaluate our method in an object recognition task where effective human-machine collaboration has been demonstrated.13 We then shift our focus to BrainBench14 because LLMs significantly outperform human experts, posing a real challenge for team collaboration.
Performance is improved when a human collaborates in a machine-only team
We first assessed the performance of human-machine teams in the classification of noisy natural images.13 The images were distorted by phase noise at each spatial frequency, where the phase noise was uniformly distributed in the interval [−Ω,Ω].16 We considered two noise levels: images distorted by low (Ω = 80) and high (Ω = 125) noise. In the case of low noise, machines are surpassed by humans (t(4) = −4.77, p < 0.01). The Bayesian combination model13 demonstrated human-machine complementarity (Figure S1). Despite its simpler setup, our confidence-weighted logistic combination model was able to provide team complementarity not only for human-machine teams but also for machine-machine teams (Figure S2). Furthermore, our approach outperformed the Bayesian combination model (Welch’s t(20.87) = 2.91, p < 0.01). Figure 1 shows the performance of our confidence-weighted logistic combination model in the case of high noise, where most machines outperform humans (Figure S3). Of primary interest was whether teams including humans performed better than machine-only teams. We assessed machine-only teams comprising either one or two machines. Adding a human teammate to machine-only teams always improved the team’s performance (Welch’s t(22.78) = 4.70, p < 0.0001). Bayesian integration is marked by combining judgments based on confidence ratings from team members, whether human or machine. Our confidence model can use this information as well. However, it remains unclear whether confidence weighting is crucial or if improved team performance simply reflects an averaging or wisdom-of-the-crowd effect. This question has not been asked with this dataset but is straightforward to evaluate using variations of our regression approach. We found that removing confidence in our approach did not negatively impact team performance in this noisy object recognition task (Figure S4). For human-machine teams, there is no difference between our standard model and the variant that does not weight by confidence (Welch’s t(26.71) = 0.29, p = 0.77). Surprisingly, for machine-machine teams, the no-confidence model outperformed the standard (Welch’s t(17.47) = 2.58, p < 0.01). A similar performance between signed confidence and sign-only features indicates that confidence does not contribute to improved predictions. This is a consequence of machine classifiers being skewed toward high probability scores (Figure S5). On the one hand, these results demonstrate the versatility of our approach in that different variations of our model can assess the basis for the success of human-machine teams. On the other hand, the fact that the object recognition dataset did not require confidence-weighted integration motivates considering another dataset for which we know that the confidence of humans and machines is calibrated such that higher confidence is associated with higher accuracy. The next dataset considered provides a valuable test of our standard confidence-weighted model.Figure 1. Performance of the confidence-weighted logistic combination model in the noisy object recognition taskAccuracy results on high levels of image noise (Ω = 125) with the logistic combination model. Human-machine teams (green points) consistently outperform teams without humans (blue points). Each data point corresponds to the average across 7,239 image evaluations. Error bars represent the standard error of the mean using a binomial model.
Calibration of confidence and classification diversity affords reliable human-LLM teaming
Our contribution also relies on previous efforts that developed BrainBench14 to assess the capacity of humans and LLMs to predict the outcomes of neuroscience studies. The benchmark includes test cases based on abstracts from the Journal of Neuroscience. Each test case contains an original abstract and an altered version (Figure 2). The BrainBench task is to identify the correct study outcome by choosing between the original abstract and its altered counterpart. We evaluated the conditions for effective collaboration (i.e., complementarity), namely, calibration of confidence and classification diversity among team members. Both humans and LLMs were calibrated in that accuracy was positively correlated with confidence (Figure 3A). Diversity held in that LLMs and humans differed on which test items led to errors (Figure 3B). In terms of accuracy (Figure 3C), LLMs numerically surpassed humans by a small margin (t(2) = 5.20, p < 0.05). Thus, we can consider whether humans can benefit teams consisting of machines that perform comparably or better. Similar to the image classification task, we investigated whether teams including humans performed better than LLM-only teams in the prediction of neuroscience results. All 15 possible team combinations, ranging from individual teammates to a 4-way human-LLM team, were considered (Figure 4). Adding a human teammate to LLM-only teams always improved the team’s performance (Welch’s t(8.29) = 8.24, p < 0.0001). Pairing a human with an LLM led to a more effective (i.e., accurate) team than pairing the LLM with a different LLM (t(2) = 10.39, p < 0.01). In the object recognition task, team performance was not affected by teammates’ confidence. Does the fluctuating confidence on a trial-by-trial basis matter for LLMs? Or could complementarity be achieved by just forming a weighted average of responses, as is done in the object recognition task? We evaluated the impact of confidence by setting the magnitude of the confidence scores to 1. This setting mimics the concept of the wisdom of the crowds, where responses are considered without factoring in confidence levels. We find that confidence is particularly important in this knowledge-intensive task, as the overall performance diminishes when confidence scores are neglected (Figure 5). With this variant, human-LLM teams do not always surpass LLM-only teams (Welch’s t(7.36) = 0.38, p = 0.36). The model including confidence (Figure 4) outperforms the variant without confidence (Figure 5) by a significant margin (Welch’s t(17.08) = 3.16, p < 0.01). We then assessed whether our regression approach would benefit from a more elaborate formulation. Equation 4 presents a function that modulates the magnitude of a team member’s confidence rating to adjust their calibration. In an optimal setting (Figure S6), the resulting model was indistinguishable from the standard regression model (Welch’s t(19.32) = 0.05, p = 0.96). Adding interaction terms to the confidence-weighted features does not improve the performance of either human-LLM or LLM-only teams (Figure S7). More complex model variants may perform better in other tasks, especially when there are more and less noisy data. Simpler model variants seem to be more robust to noise in our cross-validated experiments. Thus, the simplicity of our approach provides effective team collaboration. Our confidence-weighted logistic regression approach follows from the principles of a Bayesian combination model that fosters human-machine complementarity13 (Figure S1). One question is how well our logistic regression approach compares to the Bayesian approach beyond image classification. Our confidence-weighted regression model outperformed (Figure 6) the Bayesian model when evaluated on the three human-LLM and three LLM-LLM teams for which the Bayesian model is intended to apply (Welch’s t(8.75) = 2.91, p < 0.01). This success is impressive given that the regression approach takes seconds to compute on a current desktop, whereas the Bayesian approach is orders of magnitude slower.Figure 2. Assessing humans and LLMs using BrainBench(A) The benchmark comprises test cases constructed from the Journal of Neuroscience abstracts. Abstracts consist of background, methods, and results. The test taker chose which of the two versions of the abstract was the original version. The altered version maintained coherence while significantly altering the results. The 100 test cases considered here were constructed by GPT-4 with human oversight and quality control.(B) An example test case. Humans were instructed to select which version of the abstract was the original by clicking on either the blue or the green text to select that set of options. Test cases varied in the number of alternatives, but a single click chose all options of the same color. After their choice, humans indicated their confidence. LLMs chose the version of the abstract that had the lower perplexity score, and their confidence was assessed by the absolute difference in perplexity of the two options.Figure 3. Conditions for effective collaboration between human experts and LLMs are satisfied(A) When human experts and LLMs were confident in their BrainBench judgments, they were more likely to be correct. Confidence ratings were sorted into equal bins, and the mean accuracy for each bin was plotted. The positive slope of the black regression lines for humans and Llama 2 chat models (7 billion (7B), 13 billion (13B), and 70 billion (70B) parameters) indicates well-calibrated confidence,14^,^17^,^18^,^19 meaning higher confidence correlates with higher accuracy.(B) Item difficulty Spearman correlations among LLMs and human experts. For LLMs, the difference in perplexity between incorrect and correct abstracts was used to determine the relative difficulty of test cases. Mean accuracy was used for human experts. LLMs align more with each other than with humans, which implies human-machine teams will be diverse. The heatmap color scale ranges from 0.1 to 0.9.(C) LLMs surpass human experts on BrainBench overall. Error bars represent the standard error of the mean using a binomial model.Figure 4. Performance of all possible teams using the confidence-weighted logistic combination modelAdding a human to a team with one or more machines (blue points) always has a benefit (green points). Llama 2 chat models with 7 billion (7B), 13 billion (13B), and 70 billion (70B) parameters are considered. Each data point corresponds to the average across 503 test-case evaluations. Error bars represent the standard error of the mean using a binomial model.Figure 5. Removing confidence from the logistic combination model diminishes team performanceAccuracy results on the neuroscience forecasting task with the confidence-weighted logistic combination model, where the magnitude of the confidence scores was set to 1, i.e., f(x) = 1 in Equation 4. Adding a human to a team with one or more machines (blue points) does not necessarily improve performance (green points). Llama 2 chat models with 7 billion (7B), 13 billion (13B), and 70 billion (70B) parameters are considered. Each data point corresponds to the average across 503 test-case evaluations. Error bars represent the standard error of the mean using a binomial model.Figure 6. Comparison between Bayesian and confidence-weighted logistic combination models for human-LLM and LLM-LLM teamsThe confidence-weighted logistic combination model more effectively integrates human and machine judgments. Llama 2 chat models with 7 billion (7B), 13 billion (13B), and 70 billion (70B) parameters are considered. Each data point corresponds to the average across 503 test-case evaluations. Error bars represent the standard error of the mean using a binomial model.
Discussion
Can humans team effectively with machines such as LLMs when the humans perform worse? We developed a confidence-weighted regression approach that can integrate judgments from any number of teammates. Using this method and testing on two forecasting benchmarks,13^,^14 we found that human-machine teams achieve complementarity; that is, their combined performance bests that of either teammate alone (Figures 1 and 4). Complementarity was achieved because two critical conditions were satisfied, namely, confidence was well calibrated and classification diversity held among teammates (Figure 3). Strikingly, every combination of machines benefited from adding a human to the team (Figures 1 and 4). Confidence in individual responses significantly impacted team performance in the knowledge-intensive task. The overall performance diminished when confidence scores were neglected (Figure 5). However, in the noisy object recognition task, this effect was not present (Figure S4). In both scenarios, the performance of the confidence-weighted integration of judgments from teammates was equal to or better than the weighted average of responses, i.e., the wisdom of the crowds. For the confidence-weighted model variants to thrive, confidence judgments need to be calibrated such that higher confidence is associated with higher accuracy. Our approach was informed by a Bayesian method for combining judgments of humans and machines.13 Our approach has a number of advantages, including ease of implementation, very fast runtime, an interpretable solution, and being readily extendable to any number of teammates. Surprisingly, our confidence-weighted regression approach performed better than the Bayesian approach (Figure 6). One possibility is that the discretization of continuous confidence measures, which the Bayesian model requires, limited its performance. Perhaps an alternative formulation would perform better. Unfortunately, reformulating the Bayesian model and properly implementing it requires substantial effort and expertise. In contrast, because our confidence-weighted integration model is formulated within a regression framework, it is straightforward to extend the formulation, for example, by including a function that modulates the calibration of a teammate (Figure S6) or nonlinear relationships (e.g., polynomial terms) between confidence-weighted predictions and outcomes (Figure S7). While we selected three LLMs with superhuman performance on BrainBench, these LLMs are not the highest-performing models on this benchmark.14 Our choice was deliberate because a vastly superior teammate may hinder complementarity. In the limit, a teammate who is never wrong does not need to be part of a team. This limiting condition may become more prevalent should LLMs continue to improve and, therefore, diminish the benefits of human-LLM teaming. For the foreseeable future, we suspect there will be tasks for which humans and LLMs can effectively team. Moreover, our method for integrating the judgments of teammates is not limited to human-LLM teams. Instead, the method is general and applies to any set of agents (natural or artificial) that can report how confident they are in their decisions. This study explored the possibility of a collaborative approach between humans and machines for superior decision-making in classifying noisy natural images and forecasting neuroscience outcomes. Our confidence-weighted regression method effectively combined human and machine judgments because teammates fulfilled the conditions of well-calibrated confidence and classification diversity. Our results suggest that there is a place for humans in teams with machines, even when the machines perform better. We hope our work facilitates successful collaborations between humans and machines in addressing important challenges.
Methods
Datasets
ImageNet 16H
A subset of the 2012 large-scale visual recognition challenge (LSVRC) ImageNet training set20 was utilized. Namely, the dataset comprised 1,200 test cases (i.e., images) divided equally into 16 classes (chair, oven, knife, bottle, keyboard, clock, boat, bicycle, airplane, truck, car, elephant, bear, dog, cat, and bird). Four levels of phase noise were independently applied to distort the image dataset (Ω = {80,95,110,125}). We considered two noise levels: low (Ω = 80), where humans outperform machines (Figure S2), and high (Ω = 125), where most machines outperform humans (Figure 1). 145 participants classified between 34 and 74 noisy images (i.e., test cases) into the 16 aforementioned categories. For each evaluation, participants also provided a discrete confidence level (low, medium, or high). The total number of human classifications corresponded to 7,247 for low-noise images and 7,239 for high-noise images. Five different machine classifiers pretrained for ImageNet 16H were utilized: AlexNet,21 DenseNet161,22 GoogleNet,23 ResNet152,24 and VGG-19.25 One pass through the noisy image data (epoch) was performed during stochastic gradient training. For a given image, the classifiers produced probability scores for each of the 16 classes. The class label was assigned to the class with the highest probability.
BrainBench
The benchmark includes test cases created either by expert neuroscientists or by prompting GPT-4 (Azure OpenAI API; v.2023-05-15) to create test cases. Since LLMs outperform humans by a large margin in both scenarios14 and substantial differences in performance may preclude complementarity,13 we used the GPT-4-generated test cases because the performance difference between humans and LLMs was smaller for these test cases, though LLMs were still clearly superior. We considered a dataset comprising 100 machine-generated test cases. These test cases were created from abstracts in the Journal of Neuroscience published in 2023. These abstracts are categorized into five sections: behavioral/cognitive, systems/circuits, development/plasticity/repair, neurobiology of disease, and cellular/molecular. Each test case contains a published abstract and an altered version produced by GPT-4. These modifications, though minimal, significantly change the results—for instance, by changing the roles of brain regions or reversing a result’s direction (e.g., from “decreases” to “increases”). The altered abstracts remain logically coherent despite the changes. The BrainBench task is to identify the correct study outcome by choosing between the original abstract and its altered counterpart. 171 neuroscience experts were recruited to complete an online study.14 Each participant evaluated three out of the 100 test cases. Two versions of an abstract were presented: one with the actual results and one that was altered (Figure 2). Participants chose the version they believed to be the original and rated their confidence using a slider bar. After applying several exclusion criteria, the 171 participants yielded 503 observations (2–9 instances per test case). We considered LLMs from the Llama 2 chat family with 7 billion (7B), 13 billion (13B), and 70 billion (70B) parameters.26 LLMs chose the version of the abstract with the lower perplexity (PPL). Confidence was calculated as the absolute difference in PPL between the original and altered versions of the abstract (Figure 2).
Bayesian combination model
Human and machine judgments were combined by adapting a Bayesian framework for human-machine complementarity.13 The problem setting for combining two team members, human and machine, is as follows: let N denote the number of test cases to be analyzed with L possible choices. The ground-truth labels of the original test cases are z∈{0, …,L − 1}^N^. For the human classifier, the predicted labels y∈{0, …,L − 1}^N^ and their corresponding confidence ratings r∈{0, …,R − 1}^N^, with “0: lowest possible confidence” and “R − 1: highest possible confidence,” are given. For the machine classifier, we used the probability scores . In the case of LLMs, π = Softmax(−q), where q is the PPL score, reflecting a measure of uncertainty.14 The first step of this model is to generate correlated probability scores for human and machine classifiers using a bivariate normal distribution:
The means of the underlying distribution, μH and μM, depend whether the label of test case i, zi, is correct or not, i.e.,
with . Note that the scalar parameters aH, aM, bH, bM, σH, σM, and ρHM in Equation 1 are learned from data. The parameter ρHM from the covariance matrix learns the correlation between the human and machine classifiers. In the case of the machine classifier, πM is compared to the empirical probability scores, π. Then, for the human classifier, πH is a latent variable that is used to calculate classifications,
where τ denotes a temperature parameter, usually small, that helps convergence.13 The predicted classifications, yH, are compared to actual human predictions, y. Ordered logit and probit models27 yield practically indistinguishable results.28 Departing from Steyver et al.,13 we used ordered logit because of software availability. We successfully reproduced their prior results with probit using ordered logit (see Figure S1). Ordered logit maps the continuous probability scores, πH, to an ordinal confidence rating, rH. This means that
where the parameters are the breakpoints of the intervals that map πH into rH and δ is a scalar that controls the sharpness of the rating probability curves. Finally, rH is compared to the empirical human confidence ratings, r. See the supplemental information for implementation details.
Confidence-weighted logistic combination model
We introduce a logistic regression approach that combines the judgments of any number of teammates. The logistic combination model follows the principles of the Bayesian combination model but is formulated within an easier-to-implement-and-extend regression framework. In its most basic form, which we consider here, each teammate is captured by a single predictor in the regression model. The value of the predictor on a trial depends on the teammate’s choice and their confidence. In particular, the magnitude of the predictor is the teammate’s confidence on that trial (i.e., confidence-weighted integration), and the sign is determined by the teammate’s choice. In general, the fitted β weight for a teammate will reflect their accuracy and calibration. As in the Bayesian combination model, y, r, and π are given. The logistic function is of the form
where px is the predicted probability of the arbitrarily assigned first option, and the evidence is
The fitted weights βI, βH, and βM correspond to the intercept and human and machine teammates, respectively. The term xi,j,k is the signed confidence of the i-th test case for the class label j selected by team member k. For human participants, xi,j,H is ri if yi = j is the selected class label and −ri otherwise. Similarly, for machine team members, xi,j,M = πi,j if yi = j is the selected class label and xi,j,M = −πi,j otherwise. In the binary case of LLMs, we consider the absolute PPL difference as a measure of confidence. This means that xi,0,M is |Δqi| if yi = 0 is the selected class label and −|Δqi| otherwise. Consider the case where an agent is accurate but its confidence is not calibrated. Then, a slightly more complex version of this logistic regression can be formulated by introducing a single-parameter function for each team member. This function can either pass through the magnitude of a team member’s confidence rating or squash its magnitude toward 1 for every confidence rating, e.g.,
That more complex model should work better if an agent is a good predictor of outcomes but its confidence is random. In that case, α will be high, and the magnitude of the confidence weighting will always be f(x) = 1 in Equation 4. Thus, the fitted weights for logistic regression would not penalize the agent as much in the combination. For a really well-calibrated agent, α should be close to 0. Thus, Equation 4 becomes the identity function, f(x) = x. It turns out that for the two tasks, there was no significant difference when including a more complex model optimizing α. However, the no-confidence variant (Figure 5) was considered as a foil to our approach, which values confidence. Additionally, this model can be easily expanded by including additional terms to Equation 3. For example, a third fitted weight could be included for an interaction term xHxM. Likewise, polynomial regression could be used to include and and corresponding fitted weights.
Cross-validation procedure
Given a total of M observations across N different test cases (with M > N), we performed a leave-one-out cross-validation (LOOCV) that provides the best bias-variance trade-off for small datasets. We evaluated the consistency of performance estimates across different cross-validation procedures, demonstrating that our results reflect true model generalization rather than artifacts of a particular validation strategy (Figure S8). Consider the evaluation of the i-th test case. With this procedure, we removed all instances of test case i, leaving the remaining N − 1 test cases with all their instances to train the classifier teams. For testing, we utilized all the instances of test case i. This was repeated for all N test cases, yielding M predictions. Note that for individual teammates, the evaluation comprised only the testing phase. When the predicted labels of any team or individual teammate in this study were randomly shuffled, the LOOCV accuracy dropped to approximately chance level (i.e., 1/L).
Resource availability
Lead contact
Requests for further information and resources should be directed to and will be fulfilled by the lead contact, Felipe Yáñez ([email protected]).
Materials availability
This study did not generate new unique reagents.
Data and code availability
For ImageNet 16H13 and BrainBench,14 the previously reported human participant data and machine confidence scores utilized in each study are available at https://osf.io/2ntrf and https://github.com/braingpt-lovelab/BrainBench, respectively. All computer code associated with this work, including combination model implementations, team evaluations, and analyses, is publicly available at https://github.com/braingpt-lovelab/haico and has been archived in Edmond.29
Acknowledgments
This work was supported by a NeuroData Discovery Award from the 10.13039/100001201Kavli Foundation to F.Y., the 10.13039/501100000269ESRC (ES/W007347/1), Microsoft (Accelerate Foundation Models Research Program), a Royal Society Wolfson Fellowship (18302), an AI safety grant from the Foresight Institute, and the Laboratory Directed Research and Development program of Los Alamos National Laboratory under project number 20250637DI to B.C.L.
Author contributions
Conceptualization, F.Y. and B.C.L.; methodology, F.Y., X.L., and B.C.L.; investigation, F.Y. and X.L.; writing – original draft, F.Y.; writing – review & editing, F.Y., X.L., and B.C.L.; funding acquisition, F.Y. and B.C.L.; resources, F.Y. and O.V.M.; supervision, B.C.L.
Declaration of interests
The authors declare no competing interests.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1Eppler M.J.Mengis J.The Concept of Information Overload: A Review of Literature from Organization Science, Accounting, Marketing, MIS, and Related Disciplines Inf. Soc.20200432534410.1080/01972240490507974 · doi ↗
- 2Bawden D.Robinson L.The dark side of information: overload, anxiety and other paradoxes and pathologies J. Inf. Sci.35200918019110.1177/0165551508095781 · doi ↗
- 3Le Cun Y.Bengio Y.Hinton G.Deep learning Nature 521201543644410.1038/nature 1453926017442 · doi ↗ · pubmed ↗
- 4Silver D.Huang A.Maddison C.J.Guez A.Sifre L.van den Driessche G.Schrittwieser J.Antonoglou I.Panneershelvam V.Lanctot M.Mastering the game of Go with deep neural networks and tree search Nature 529201648448910.1038/nature 1696126819042 · doi ↗ · pubmed ↗
- 5Jumper J.Evans R.Pritzel A.Green T.Figurnov M.Ronneberger O.Tunyasuvunakool K.Bates R.Žídek A.Potapenko A.Highly accurate protein structure prediction with Alpha Fold Nature 596202158358910.1038/s 41586-021-03819-234265844 PMC 8371605 · doi ↗ · pubmed ↗
- 6Zhang T.Ladhak F.Durmus E.Liang P.Mc Keown K.Hashimoto T.B.Benchmarking Large Language Models for News Summarization Trans. Assoc. Comput. Linguist.122024395710.1162/tacl_a_00632 · doi ↗
- 7Radford A., Wu J., Child R., Luan D., Amodei D., Sutskever I. (2019). Language Models are Unsupervised Multitask Learners. Open AI blog. https://openai.com/index/better-language-models/.
- 8Brown T.Mann B.Ryder N.Subbiah M.Kaplan J.D.Dhariwal P.Neelakantan A.Shyam P.Sastry G.Askell A.Language Models are Few-Shot Learners Larochelle H.Ranzato M.Hadsell R.Balcan M.Lin H.Advances in Neural Information Processing Systems 33202018771901