Wavelet Transform and Hierarchical Hybrid Matching for Enhancing End-to-End Pediatric Wrist Fracture Detection
Bin Yan, Yuliang Zhang, Qiuming He

TL;DR
This paper introduces a new AI model for detecting wrist fractures in children using advanced image processing techniques.
Contribution
The novel WH-DETR model combines wavelet transforms and hierarchical hybrid matching for improved pediatric wrist fracture detection.
Findings
The WH-DETR model achieves state-of-the-art performance with 68.8% mAP50 score.
The model improves mAP50 by 1.78%, mAP50-90 by 1.69%, and F1 score by 1.75% over the next best model.
The model maintains high inference efficiency with only 43 million parameters.
Abstract
With the increasing frequency of daily physical activities among children and adolescents, the incidence of wrist fractures has been rising annually. Without precise and prompt diagnosis, these fractures may remain undetected, potentially leading to complications. Recent advancements in computer-aided diagnosis (CAD) technologies have facilitated the development of sophisticated diagnostic tools, which significantly improve the accuracy of fracture detection. To enhance the capability of detecting pediatric wrist fractures, this study presents the WH-DETR model, specifically designed for pediatric wrist fracture detection. WH-DETR is configured as a DEtection TRansformer framework, an end-to-end object detection algorithm that obviates the need for non-maximum suppression post-processing. To further enhance its performance, this study first introduces a wavelet transform projection…
Genes, proteins, chemicals, diseases, species, mutations and cell lines named across the full text — each resolved to its canonical identifier and authoritative record.
Click any figure to enlarge with its caption.
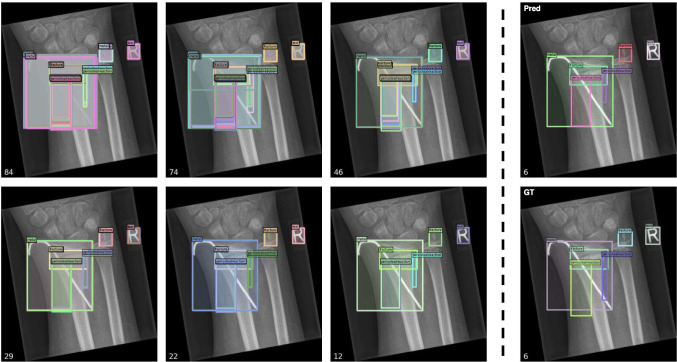 Figure 10
Figure 10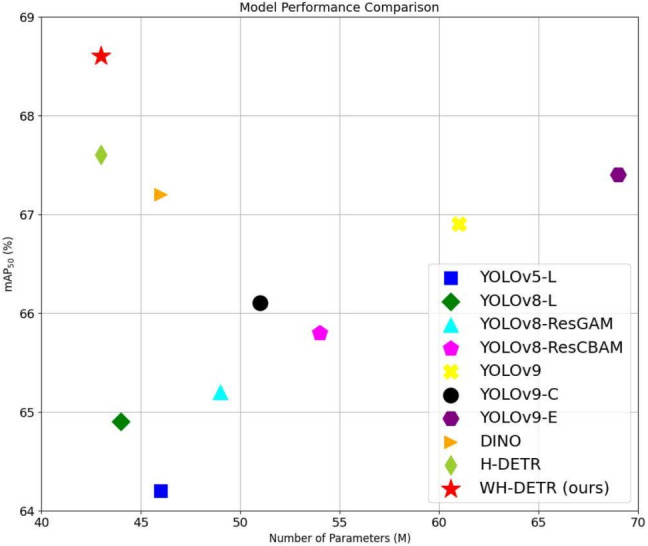 Figure 1
Figure 1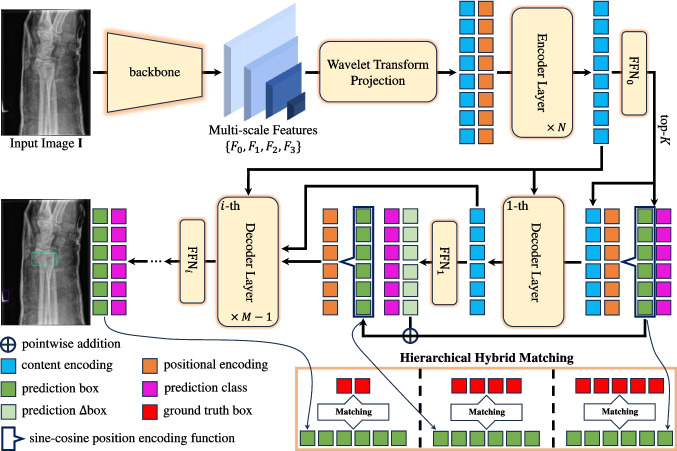 Figure 2
Figure 2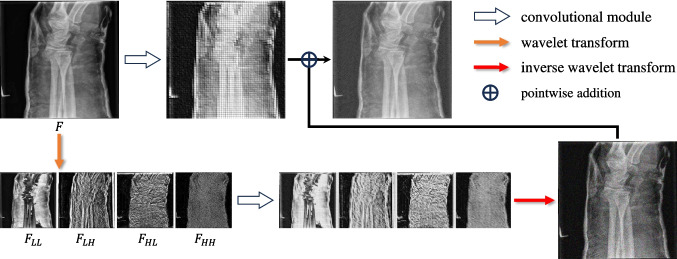 Figure 3
Figure 3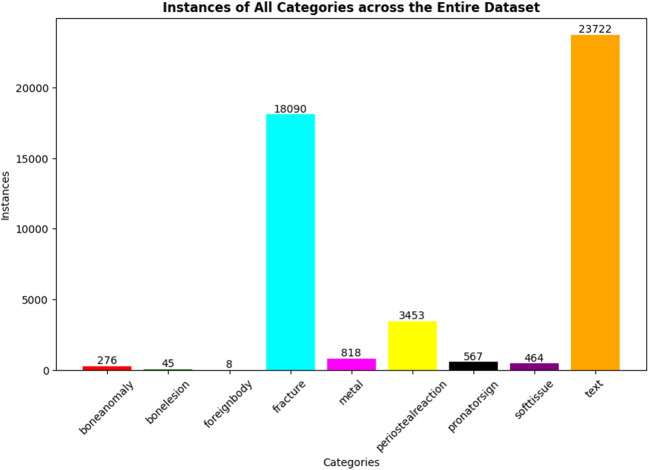 Figure 4
Figure 4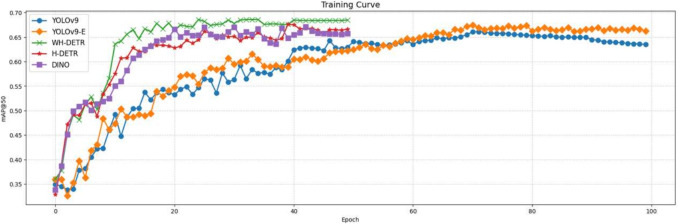 Figure 5
Figure 5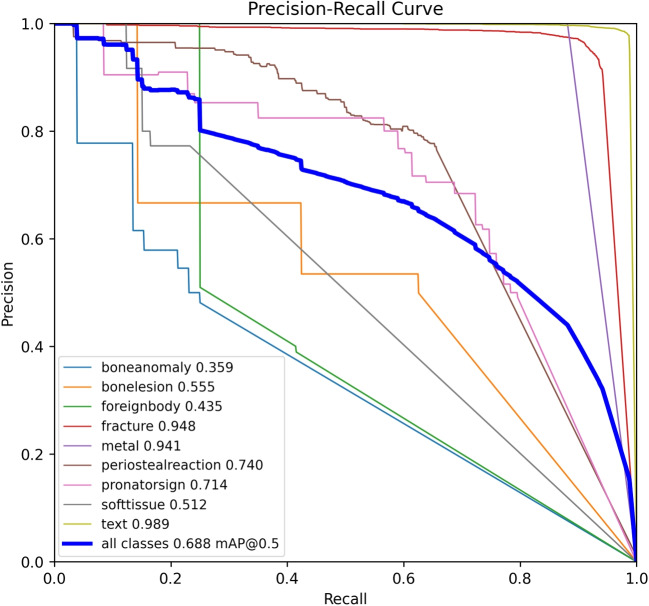 Figure 6
Figure 6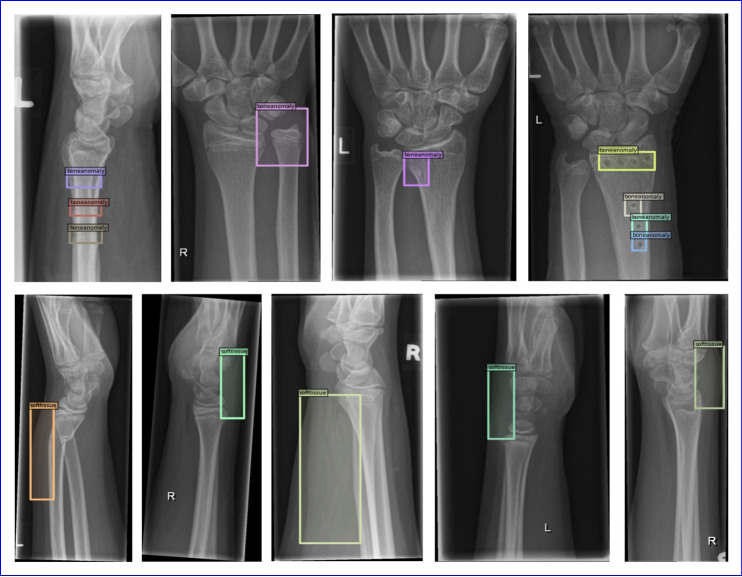 Figure 7
Figure 7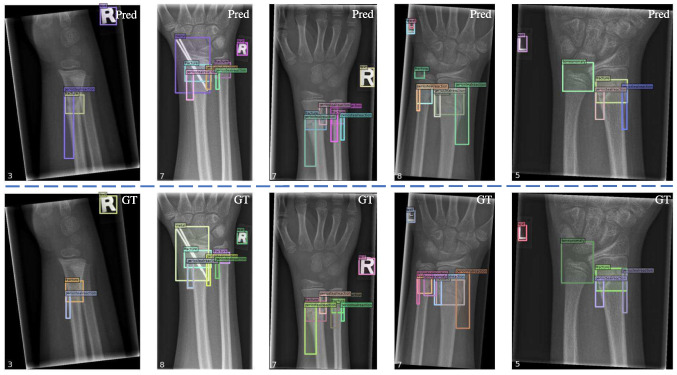 Figure 8
Figure 8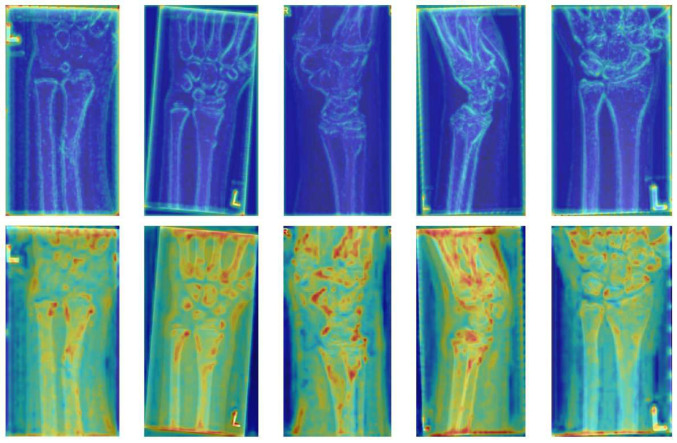 Figure 9
Figure 9- —http://dx.doi.org/10.13039/501100004000Guangzhou Municipal Science and Technology Program key projects
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsArtificial Intelligence in Healthcare and Education · Orthopedic Surgery and Rehabilitation · Bone fractures and treatments
Introduction
Pediatric wrist fractures pose a considerable concern due to their frequency and significance in pediatric injuries. These injuries commonly involve fractures of the radius and ulna, especially during children’s active growth stages. Such fractures can impact their long-term development and functionality [1–3]. In recent years, the incidence of distal forearm fractures in children has been increasing due to the rising frequency of physical activities among children and adolescents. Studies indicate that distal forearm fractures account for 24% of fractures requiring hospitalization [6]. Given the close anatomical proximity and shared biomechanical stress between the distal forearm and the wrist, wrist fractures often co-occur with distal forearm fractures. As a result, precise and prompt diagnosis is vital to prevent long-term repercussions. However, this process is frequently fraught with challenges stemming from various factors, including a lack of medical professionals and limitations in technology and expertise [4, 5]. These difficulties are particularly acute in underdeveloped regions, where a paucity of radiologists exacerbates the challenges of timely diagnosis and medical care [4, 7].
In the realm of medical imaging, three primary modalities—X-ray, MRI, and CT scans—are employed for fracture diagnosis. Among these, X-ray is the most extensively utilized due to its cost-effectiveness [9], but its precision heavily relies on the radiologist’s proficiency. Research indicates that in pediatric X-ray fracture diagnosis, the most commonly overlooked fractures occur in the hand phalanges, with a miss rate reaching up to 26% [8]. Consequently, enhancing diagnostic accuracy and diminishing reliance on radiological expertise present significant challenges.
In recent years, the relentless advancement of deep learning technologies has led to significant progress in medical image processing applications [10–13], and computer-aided diagnosis (CAD) systems have made notable strides. An increasing number of researchers within the computer vision community are applying object detection algorithms to the task of identifying wrist fractures in children. These algorithms boost diagnostic accuracy and reduce labor costs by automating the analysis of medical images [14–19].
Nevertheless, these algorithms predominantly depend on models from the You Only Look Once (YOLO) series [20, 22–25], which incorporate numerous manually designed components, such as anchor generation, rule-based training target assignment, and non-maximum suppression (NMS) post-processing. These methods are not entirely end-to-end, and there is a significant risk of misdetection and missed detection due to inaccurate bounding box selection.
In contrast, models from the detection transformer (DETR) series [27, 28] eliminate the need for these manually designed components and have developed the first fully end-to-end object detector, achieving highly competitive performance. DETR models utilize a straightforward architecture that integrates convolutional neural networks (CNNs) with transformer [26] encoder-decoder networks. These models leverage the versatile and robust relational modeling capabilities of transformers without necessitating manual rule design.Fig. 1. Comparison of various models. Each model is marked with a distinct marker. The red pentagram represents our proposed WH-DETR, which achieves the highest \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$ \text {mAP}_{50} $$\end{document} while maintaining the lowest parameter count
To capitalize on the advantages of DETR models and investigate their potential in other tasks, we adapt DETR models for the task of pediatric wrist fracture detection. Furthermore, we discovered that directly employing DETR models results in relatively inadequate performance. To rectify this, we propose two enhancements:
1) We incorporate a wavelet transform projection (WTP) module to capture varying frequency features from the feature maps extracted by the backbone. This assists the network in better capturing multi-scale and multi-frequency information from the images.
2) We devise a hierarchical hybrid matching (HHM) framework, which separates the prediction tasks of different decoder layers during training. This strategy enhances the model’s ultimate prediction capability without incurring any computational overhead during inference.
Building on these enhancements, we denominate the resulting model WH-DETR. As shown in Fig. 1, to substantiate the efficacy of our proposed model, we conducted comprehensive experiments on the GRAZPEDWRI-DX [32] dataset and compared our model with other sophisticated models, demonstrating the effectiveness of our proposed model. Additionally, we also present an in-depth discussion of the introduced WTP and HHM components through ablation experiments.Table 1. Summary of literaturesCategoryMethod/modelMain contributionFracture detectionDCFPN [33]mAP 82.1% for thigh fractures using dilated convolutionsParallelNet [34]Two-stage R-CNN for thigh fracturesFAMO [38]Mitigated feature ambiguity for bone fracture detectionDeepLoc [16]Combined YOLOv7 with Swin Transformer for pediatric fracturesYOLO Series [15]Advanced YOLO models for pediatric wrist fracture detectionTransformer modelsDETR [27]End-to-end object detection with Transformer backboneDNDetr [47]Improved training stability with denoisingDINO [29]Enhanced training efficacy with contrastive denoisingWavelet transformWT in DL [51]Combined WT with DL for richer feature mapsMatching trainingH-DETR [58]Hybrid matching strategy for better positive samples
Related Work
Fracture Detection
The significance of fracture detection, combined with the evolution of deep learning (DL) technologies, has sparked a surge of interest among researchers in applying DL to this domain. Guan et al. [33] developed a DL model named the dilated convolutional feature pyramid network (DCFPN), which attained a mean average precision (mAP) of 82.1% in detecting thigh fractures from X-ray images. Wang et al. [34] introduced ParallelNet, a two-stage R-CNN [35] network, and compared its performance against other state-of-the-art DL models, such as Faster R-CNN [36] and Cascade R-CNN [37], on a dataset comprising 3842 thigh fracture X-ray images, showcasing its superiority. Wu et al. [38] proposed the Feature Ambiguity Mitigate Operator (FAMO) model, leveraging ResNeXt101 [39] and Feature Pyramid Network (FPN) [40], for bone fracture detection across 9040 radiographs of various body parts. Dibo et al. integrated YOLOv7 [23] with the Shifted Window Transformer (Swin) [41] to create DeepLoc, which achieved enhanced performance in pediatric wrist fracture detection. Additional studies [14, 15, 18, 42, 43] have also employed state-of-the-art YOLO series models to improve the accuracy of pediatric wrist fracture detection.
Detection Transformer Models
In contrast to traditional object detection models, the detection transformer (DETR) [27] represents a novel transformer-based object detection model that minimizes dependence on manually designed components, thereby achieving true end-to-end detection. Many researchers have since proposed enhancements to DETR-like models [29–31, 44–49]. These improvements target various aspects such as the encoder, decoder, and training methodology, resulting in enhanced training efficiency, prediction accuracy, and inference speed.
Wavelet Transform Algorithms
Wavelet transform (WT) [50], a signal processing technique widely utilized for time-frequency analysis, has recently been integrated with DL architectures across various tasks to bolster the performance of the underlying structures [51–55]. These studies emphasize the advantages of disentangling low-frequency and high-frequency components of the input for separate convolution operations, resulting in richer feature maps. Consequently, we incorporate WT into our DETR model to harness the rich information present in the frequency domain, thereby elevating the performance of our model.
Hybrid Matching Training
The original DETR model utilizes a one-to-one matching strategy, pivotal for enabling end-to-end training. However, this approach results in only a minute fraction of the vast number of queries being matched and contributing to loss calculation, significantly hindering the model’s capacity to effectively train on positive samples. To mitigate this issue, DN-DETR [47] introduces noise into the ground truth bounding boxes, training the decoder to eliminate these disturbances. This denoising process aids network training and accelerates convergence. Similarly, DINO [29] improves network training by adopting a denoising mechanism akin to DN-DETR, employing contrastive denoising to enhance training efficacy. Although these methods still adhere to the one-to-one matching principle, they integrate denoising with standard training, thereby improving training stability. H-DETR [58] addresses the challenge of inadequate positive sample training by combining the original one-to-one matching branch with an auxiliary one-to-many matching branch during training. This hybrid training strategy enhances model performance by ensuring more effective utilization of positive samples.
To better present these literatures, we summarize them in Table 1, where the main contributions of each literature are concisely listed.Fig. 2. The framework of WH-DETR. Drawing inspiration from Deformable DETR [28], our approach utilizes a backbone to extract multi-scale features from the input image. Additionally, we apply the wavelet transform projection (WTP) to all scale features to encapsulate multi-frequency information. Throughout the model training phase, our hierarchical hybrid matching (HHM) framework facilitates matching between prediction anchors from different decoder layers and a varying number of ground truth anchors for loss computation. It is important to note that this diagram serves as a conceptual illustration; in practice, both prediction boxes and prediction classes are involved in the matching process
Methodology
Model Framework
DETR-like models typically comprise four essential components: a backbone, a multi-layer transformer [26] encoder, a multi-layer transformer decoder, and a feed-forward network (FFN). As illustrated in Fig. 2, our model architecture incorporates an additional projection component, corresponding to our proposed wavelet transform projection (WTP) module. The following sections offer detailed explanations of each component.
Backbone: The backbone of DETR, denoted as \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$ \mathcal {F}_b $$\end{document} , extracts preliminary features from the input image. In this study, we employ ResNet50 [56] as the backbone, which has proven to be an effective feature extractor in numerous studies. For an input image \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$ \textbf{I} \in \mathbb {R}^{3 \times \textsf{H} \times \textsf{W}} $$\end{document} , the backbone outputs four lower-resolution feature maps \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$ \{F_0, F_1, F_2, F_3\} $$\end{document} , with spatial dimensions \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$ H_i $$\end{document} and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$ W_i $$\end{document} scaled down by factors of \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$ \frac{1}{4^2} $$\end{document} , \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$ \frac{1}{8^2} $$\end{document} , \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$ \frac{1}{16^2} $$\end{document} , and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$ \frac{1}{32^2} $$\end{document} relative to the original image, respectively, and channel dimensions \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$ C_i $$\end{document} of 256, 512, 1024, and 2048, respectively. This can be concisely expressed as follows:
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\begin{aligned} \{F_0, F_1, F_2, F_3\} = \mathcal {F}_b(\textbf{I}) \end{aligned}$$\end{document}Fig. 3. Details of a single-level WTP module. The input feature and subband features are depicted as examples, not reflecting the actual features within the model
Projection Layer: The projection layer, denoted as \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$ \mathcal {F}_p $$\end{document} , transforms the feature maps from the backbone into the input format required by the transformer encoder. As shown in Eq. 2, this layer first processes the multi-scale feature maps to unify their channel dimensions, set to 256 in our experiments. These processed feature maps are then concatenated along the channel dimension to form the content encoding \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$ \textbf{C}_e \in \mathbb {R}^{256 \times \sum H_i W_i} $$\end{document} .
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\begin{aligned} \textbf{C}_e = \mathcal {F}_p(\{F_0, F_1, F_2, F_3\}) \end{aligned}$$\end{document}Feed-Forward Network: For clarity, we introduce the concept of a feed-forward network before discussing the transformer encoder and decoder in detail. Our model comprises a total of \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$ M+1 $$\end{document} FFN layers: \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$ \text {FFN}_e $$\end{document} corresponds to the final layer of the encoder, while \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$ \text {FFN}_1 $$\end{document} to \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$ \text {FFN}_M $$\end{document} correspond to the M decoder layers. Each FFN layer consists of a three-layer MLP network with ReLU activation, followed by an additional linear layer. The MLP network predicts bounding box offsets, while the linear layer predicts the corresponding class labels.
Transformer Encoder: The transformer encoder, denoted as \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$ \mathcal {F}_e $$\end{document} , consists of a stack of N transformer blocks, with \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$ N=6 $$\end{document} in this study. Its role is to enhance the understanding of the content encoding. For the input \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$ \textbf{C}_e $$\end{document} , positional encoding \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$ P_e $$\end{document} [27] is generated and added, which is then fed into the transformer encoder to produce the enhanced content encoding \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$ \dot{\textbf{C}_e} $$\end{document} . The output \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$ \dot{\textbf{C}_e} $$\end{document} is subsequently passed to a \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$ \text {FFN}_0 $$\end{document} , which predicts the offsets of bounding boxes \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$ {\delta b}_e $$\end{document} and their corresponding classes \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$ c_e $$\end{document} . In this study, we adopt the method from DINO [29] to generate the initial decoder bounding boxes: \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$ b_e = b'_e + {\delta b}_e $$\end{document} , where \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$ b'_e $$\end{document} are initialized with a uniform distribution over the input image. Given that the token count of \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$ \dot{\textbf{C}_e} $$\end{document} is \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$ \sum H_i W_i $$\end{document} , we select the top-K predictions based on confidence scores from \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$ c_e $$\end{document} :
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\begin{aligned} \textbf{C}_d^0, b_d^0, c_d^0= & \text {top-}K(\dot{\textbf{C}_e}, b_e, c_e)\end{aligned}$$\end{document} \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\begin{aligned} \dot{\textbf{C}_e}= & \text {FFN}_0(\textbf{C}_e) \end{aligned}$$\end{document}where \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$ K=300 $$\end{document} and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$ \textbf{C}_d^0, \textbf{b}_d^0, \textbf{c}_d^0 $$\end{document} are the selected results, which serve as the input to the transformer decoder.
Transformer Decoder: The transformer decoder, denoted as \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$ \mathcal {F}_d $$\end{document} , comprises M transformer blocks, with \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$ M=6 $$\end{document} in this study. Following standard transformer input protocols, we use a sine-cosine position encoding function [26] to generate positional encodings for each block input:
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\begin{aligned} \textbf{P}_d^i= & \text {sinusoidal}(\text {sigmoid}(b_d^i)), \; i \in \{0, 1, 2, \ldots , M -1\}\nonumber \\ \end{aligned}$$\end{document} \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\begin{aligned} b_d^i= & b_d^{i-1} + {\delta b}_d^i, \; i \in \{1, 2, \ldots , M\}\end{aligned}$$\end{document} \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\begin{aligned} {\delta b}_d^i, c_d^i= & \text {FFN}_i(\textbf{C}_d^{i}), \; i \in \{1, 2, \ldots , M\}\end{aligned}$$\end{document} \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\begin{aligned} \textbf{C}_d^{i}= & \mathcal {F}_d^i(\textbf{C}_d^{i-1}, \textbf{P}_d^{i-1}, \dot{\textbf{C}_e}), \; i \in \{1, 2, \ldots , M\} \end{aligned}$$\end{document}where \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$ \mathcal {F}_d^i $$\end{document} denotes the i-th decoder block (for \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$ i > 0 $$\end{document} ) and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$ \text {FFN}_i $$\end{document} represents the corresponding feed-forward network. To optimize the parameters of adjacent transformer decoder layers more effectively, we also incorporate the look forward twice scheme [29].
To expedite our model, we employ the deformable attention mechanism proposed in Deformable DETR [28]. This mechanism concentrates attention on a small set of critical sampling points around a reference, rather than computing attention over all inputs, significantly reducing the overall computational cost of the model.
Wavelet Transform Projection
The single-level WTP module’s details are illustrated in Fig. 3. Given an input feature F, we adopt the methodology outlined in [55, 57], applying a 2D Haar Wavelet Transform (WT). Specifically, four filters are employed:
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\begin{aligned} \begin{aligned} f_{LL}&= \frac{1}{2} \begin{bmatrix} \quad 1 & \quad 1 \\ \quad 1 & \quad 1 \end{bmatrix},&f_{LH}&= \frac{1}{2} \begin{bmatrix} \quad 1 & -1 \\ \quad 1 & -1 \end{bmatrix} \\ f_{HL}&= \frac{1}{2} \begin{bmatrix} \quad 1 & \quad 1 \\ -1 & -1 \end{bmatrix},&f_{HH}&= \frac{1}{2} \begin{bmatrix} \quad 1 & -1 \\ -1 & \quad 1 \end{bmatrix} \end{aligned} \end{aligned}$$\end{document}Here, \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$ f_{LL} $$\end{document} is a low-pass filter for extracting low-frequency features. \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$ f_{LH} $$\end{document} functions as a low-pass filter horizontally and a high-pass filter vertically. Similarly, \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$ f_{HL} $$\end{document} operates as a low-pass filter vertically and a high-pass filter horizontally, while \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$ f_{HH} $$\end{document} acts as a high-pass filter in both directions. Convoluting these filters with F across channels yields four corresponding subband features. Due to the stride of 2 in convolution, the spatial resolution of the resulting feature maps is halved. To revert the decomposed features to their original resolution, an inverse wavelet transform can be employed, implemented via transposed convolution. Thus, the two processes can be represented as follows:
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\begin{aligned} [F_{LL}, F_{LH}, F_{HL}, F_{HH}] = g([f_{LL}, f_{LH}, f_{HL}, f_{HH}], F) \end{aligned}$$\end{document} \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\begin{aligned} \begin{aligned} F = g_t(&[f_{LL}, f_{LH}, f_{HL}, f_{HH}],\\&[F_{LL}, F_{LH}, F_{HL}, F_{HH}]) \end{aligned} \end{aligned}$$\end{document}where \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$ g(\cdot ) $$\end{document} and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$ g_t(\cdot ) $$\end{document} denote convolution and transposed convolution operators, respectively.
To bolster feature representation, the original feature map F and the subband features \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$ F_{LL} $$\end{document} , \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$ F_{LH} $$\end{document} , \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$ F_{HL} $$\end{document} , and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$ F_{HH} $$\end{document} derived from the wavelet transform are each fed into a corresponding learnable convolution module. These modules further extract and integrate new feature information. The final feature map \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$ F' $$\end{document} is obtained via the following formula:
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\begin{aligned} F' = \mathcal {F}_{\text {conv}}(F) + \text {IWT}(\mathcal {F}_{\text {conv}}'(\text {WT}(F))) \end{aligned}$$\end{document}Here, \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$ \text {WT}(\cdot ) $$\end{document} and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$ \text {IWT}(\cdot ) $$\end{document} correspond to Eqs. 10 and 11, respectively, while \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$ \mathcal {F}_{\text {conv}} $$\end{document} and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$ \mathcal {F}_{\text {conv}}' $$\end{document} represent two learnable convolution modules with a kernel size of 5.
For multi-level WTP, the process involves sequentially applying WT and IWT to the low-frequency subband feature \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$ F_{\text {LL}} $$\end{document} produced by the WT decomposition of the previous level. After these transformations, the updated \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$ F_{\text {LL}}' $$\end{document} replaces the original \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$ F_{\text {LL}} $$\end{document} for subsequent operations.
It is crucial to note that the filter parameters used in WT and IWT are independent. Although both sets of parameters are initialized using Eq. 9, the WT parameters remain fixed, whereas the IWT parameters are adjusted by the model during training. This distinction is necessary because the features undergo non-linear transformation through \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$ \mathcal {F}'_{\text {conv}} $$\end{document} after WT. Therefore, it is imperative for the model to adjust the IWT parameters to prevent feature loss after applying IWT.
Hierarchical Hybrid Matching
Similar to [58], we incorporate one-to-many matching to enhance the model’s effective training on positive samples. Specifically, we compute auxiliary losses for the outputs of the final encoder layer and the M decoder layers. However, for each layer, we employ a varying number of one-to-many matches when calculating these auxiliary losses. This variation is due to the fact that shallower Transformer decoder layers may not fully capture cross-correlations between output elements, leading to multiple predictions for the same object. As the layers deepen, the self-attention mechanism increasingly aids the model in suppressing duplicate predictions [27]. Consequently, using too few matches in the first layer might cause the model to misinterpret many nearly correct predictions. Conversely, employing a large number of one-to-many matches in deeper decoder layers could impede the model’s ability to learn to suppress duplicates, thereby affecting overall training performance.
Based on this analysis, our proposed HHM is designed to gradually decrease the number of one-to-many matches as the decoder layers deepen. Specifically, we define \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$ \textbf{p}_i = \{b^i_d, c^i_d\} $$\end{document} as the prediction results of the i-th decoder layer (with \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$ i=0 $$\end{document} denoting the encoder’s predictions), and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$ \textbf{g} $$\end{document} as the ground truth annotations. Our loss function can thus be expressed as follows:
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\begin{aligned} \mathcal {L}= & \sum _{i=0}^{M-1} \frac{1}{w_i} \mathcal {L}_\text {Hungarian}(\textbf{p}_i, copy(\textbf{g}, w_i)) \nonumber \\ & + \mathcal {L}_\text {Hungarian}(\textbf{p}_M, \textbf{g})) \end{aligned}$$\end{document}Here, \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$ \mathcal {L}_\text {Hungarian} $$\end{document} represents the Hungarian loss [27], comprising a classification loss, an \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$ L_1 $$\end{document} regression loss, and a GIoU loss. Additionally, \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$ copy(\textbf{g}, w_i) $$\end{document} indicates duplicating the ground truth \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$ \textbf{g} $$\end{document} \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$ w_i $$\end{document} times. In our experiments, with \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$ M=6 $$\end{document} , the values of \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$ w_0 $$\end{document} to \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$ w_5 $$\end{document} are set to [12, 10, 8, 6, 4, 2].
This straightforward design allows us to decouple the prediction tasks across different decoder layers. Shallower decoders are tasked with locating approximate object positions, resulting in a larger number of candidate bounding boxes. In contrast, deeper decoders refine these positions more accurately by suppressing duplicate predictions, thus providing more precise predictions from a broader set of candidates.Fig. 4A bar chart illustrating the statistical count of instances across all categories within the entire dataset
Experiment
Dataset
For this study, we utilized the publicly accessible GRAZPEDWRI-DX dataset [32], kindly provided by the Medical University of Graz. This dataset comprises 20,327 X-ray images of pediatric wrist trauma. Figure 4 displays the distribution of instances among all categories, revealing a notable class imbalance. Specifically, the text and fracture categories account for 50.00% and 38.13% of the total instances, respectively, while the remaining seven categories collectively constitute only 11.73%.
It is important to note that all images are sourced from 6091 unique pediatric patients. During model training, we assume that the similarity between multiple images from the same patient can be neglected. To verify this assumption, we utilize the backbone of the trained model to generate feature maps for each image and subsequently pass them through a max-pooling layer to obtain features, which are generally considered to capture the most salient features of the model. For these features, we compute the cosine similarity matrix and then count how many features have their most similar counterpart belonging to the same patient. The results indicate that only 1.87% of the total features (323/17,278, using only the training set) have their most similar counterpart belonging to the same patient. In fact, since the subsequent model employs these features, we can consider the image correlation in this dataset to be negligible in our work.
Experimental Setup
In our experimental setup, we randomly divided the entire dataset into 85% for training (17,278 images) and 15% for testing (3047 images). During the training phase, we employed basic data augmentation techniques such as random horizontal flipping, random resizing, and random cropping. No data augmentation was applied during testing. Given that the X-ray images in the GRAZPEDWRI-DX dataset are single-channel with pixel values ranging from 0 to 65,535, we normalized these pixel values and replicated the channel three times to create RGB format inputs.
All experiments were carried out using two NVIDIA GeForce RTX 4090 GPUs. Due to resource constraints, the batch size utilized during training was set to 2. We employed the AdamW [59] optimizer, initializing the learning rate at \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$ 10^{-5} $$\end{document} for the backbone and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$ 10^{-4} $$\end{document} for other parameters. These learning rates were subsequently reduced to one-tenth of their initial values at the 10th and 30th epochs. The weight decay was set to \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$ 10^{-4} $$\end{document} , and the dropout rate was maintained at 0. The number of attention heads in the transformer was configured to 8, with an attention feature dimension of 256. The loss function weights used in our experiments were consistent with those in [27]. Our experimental procedure encompassed a total of 50 training epochs, which were completed in approximately 20 h.
Due to the DETR class model’s direct output of a number of boxes equal to the number of queries, our experimental setup specifies that the model will produce 300 candidate boxes, each accompanied by a probability for the predicted category. We retain only those results with a probability greater than 0.3, since the probability associated with predicted categories corresponding to unmatched queries is generally low.Fig. 5. Comparison of training curves between YOLO series and DETR series
Evaluation Metrics
The main evaluation metrics utilized in this study are outlined below:
- Number of parameters (Params): The number of parameters within a model reflects its architectural complexity, influenced by the quantity of layers and neurons per layer. A larger number of parameters typically signify a more extensive model, which may yield better performance but also necessitates more data and computational resources. Consequently, achieving a balance between model complexity and computational cost is crucial in practical applications.
- Floating point operations (FLOPs): FLOPs serve as a measure of the computational complexity of neural network models and are a standard metric for assessing computer or computing system performance. FLOPs denote the number of floating-point operations executed per second, acting as a key indicator of a model’s computational efficiency and speed. In resource-limited settings, models with lower FLOPs may be preferable, whereas those with higher FLOPs might require more robust hardware support.
- Mean average precision at 50% IOU ( \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$ {\textbf {mAP}}_{{\textbf {50}}} $$\end{document} ): mAP is a widely adopted metric for evaluating object detection model performance. In object detection tasks, models must identify objects within images and ascertain their locations. mAP integrates precision (the proportion of detected objects that are genuine) and recall (the proportion of actual objects detected). Specifically, mAP50 refers to the mean average precision calculated at a 50% Intersection over Union (IoU) threshold across all categories. IoU gauges the overlap between predicted and ground truth bounding boxes.
- \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$ {\textbf {mAP}}_{{\textbf {50-90}}} $$\end{document} : This metric offers a more comprehensive assessment by considering the mean average precision across IoU thresholds ranging from 50 to 95%. mAP \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$ _{50-90} $$\end{document} is computed by determining the average precision at ten distinct IoU thresholds, incrementing from 0.50 to 0.95 in steps of 0.05, and subsequently averaging these AP values. This metric provides a stricter and more meaningful evaluation of model performance.
- Additional classification metrics: To facilitate a more robust and interpretable analysis of the experimental results, we employed the F1 score and AUC as supplementary evaluation metrics. The F1 score, which harmonizes precision and recall, provides a balanced assessment of a model’s classification efficacy, particularly in scenarios involving class imbalance. This metric mitigates the potential bias associated with an exclusive focus on either precision or recall. The area under the curve (AUC) quantifies the area under the receiver operating characteristic (ROC) curve, which delineates the trade-off between the true positive rate and the false positive rate across varying classification thresholds. An AUC value approaching 1 signifies superior classification performance. Since our task contains multiple categories, we first calculate the metrics for each category and then take the average of these metrics as the final result. Table 2. Comparison results between WH-DETR and other advanced object detectorModelParams (M)FLOPs (G) \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$ \text {mAP}_{50} $$\end{document} (%) \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$ \text {mAP}_{50-90} $$\end{document} (%)F1 (%)AUC (%)YOLOv5-L46109.164.243.558.870.4YOLOv8-L44164.964.943.959.272.0YOLOv8-ResGAM49183.565.243.860.974.8YOLOv8-ResCBAM54164.965.845.661.676.2YOLOv9-C51239.066.145.961.878.3YOLOv961266.266.8±1.246.6±0.661.2±2.478.3±3.1YOLOv9-E69244.967.5±1.347.1±0.863.0±3.079.2±3.1DINO46238.167.1±1.347.3±0.662.5±2.681.8±2.4H-DETR43223.567.6±1.447.5±0.761.0±3.081.3±2.5WH-DETR (ours)43223.568.8±1.248.3±0.764.1±2.881.6±3.0
Comparative Experiments
Our primary focus was on comparing models from the YOLO series and the DETR series. Numerous models in the YOLO series are regarded as state of the art (SOTA), and the DETR series we examined are also at the cutting edge of technology. In our experiments, the YOLO series models were used with their default settings, including pre-trained weights, specific data processing techniques, and parameter configurations. To ensure a fair comparison, all DETR-like models used ResNet50 as their backbone and pre-trained weights from the MS COCO (Microsoft Common Objects in Context) 2017 Detection task [21]. Given that the pre-trained categories differed from those in our task, we randomly initialized layers with mismatched parameter dimensions. Notably, H-DETR builds on our base model by integrating the one-to-many matching branch they introduced.
Figure 5 shows the training curves of several YOLO models and DETR models. Given the differences in their loss functions, we select \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$ \text {mAP}_{{\textbf {50}}} $$\end{document} as the y-axis for display. From the results of this display, we can see that DETR models can usually converge within 50 training epochs. Therefore, in the entire experiment, YOLO series models are trained for 100 epochs , while DETR models are trained for 50 epochs.
To reduce experimental costs, we selected only the four most comparable models for statistical analysis. Specifically, to ensure the statistical significance of the results, each model was trained 5 times. The first training session was conducted fully, while the subsequent sessions were initialized using the parameters from the first training, with the addition of Gaussian noise with zero mean and a standard deviation of 5% of the parameter values. This approach significantly reduced training time, as models typically converged within 15 epochs, while maintaining the validity of the experiments through the introduced randomness.Table 3. Results of the one-way ANOVA test \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$ \text {mAP}_{50} $$\end{document} \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$ \text {mAP}_{50-90} $$\end{document} F1AUC0.0006<0.00010.01010.0027
The comparison results between our proposed WH-DETR and other advanced object detection methods are presented in Table 2. The best results are highlighted in bold, and the “±” values indicate the standard deviation.
To statistically examine the significant differences in these results, we first conducted a one-way ANOVA test. As shown in Table 3, each cell in the table presents the p-value obtained from the ANOVA test for the corresponding metric. For each metric with a p-value threshold of 0.05, we observed significant differences among the models.Table 4. Post hoc Tukey HSD test resultsWH-DETR vs. models \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$ \text {mAP}_{{50}} $$\end{document} \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$ \text {mAP}_{{50-90}} $$\end{document} F1AUCYOLOv9 \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$ \boldsymbol{<0.001} $$\end{document} \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$ \boldsymbol{<0.001} $$\end{document} 0.02930.1914YOLOv9-E0.0705 \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$ \boldsymbol{<0.001} $$\end{document} 0.78990.1578DINO0.0044 \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$ \boldsymbol{<0.001} $$\end{document} 0.47310.9997H-DETR0.12320.0045****0.01630.9985Table 5Effect size analysis using Cohen’s dWH-DETR vs. Models \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$ \text {mAP}_{{50}} $$\end{document} \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$ \text {mAP}_{{50-90}} $$\end{document} F1AUCYOLOv91.46 \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$^{\S }$$\end{document} 2.54 \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$^{\S }$$\end{document} 0.89 \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$^{\S }$$\end{document} 0.90 \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$^{\S }$$\end{document} YOLOv9-E0.86 \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$^{\S }$$\end{document} 1.56 \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$^{\S }$$\end{document} 0.31 \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$^{\dagger }$$\end{document} 0.65 \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$^{\ddagger }$$\end{document} DINO1.17 \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$^{\S }$$\end{document} 1.50 \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$^{\S }$$\end{document} 0.48 \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$^{\dagger }$$\end{document} 0.07 \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$^{\dagger }$$\end{document} H-DETR0.75 \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$^{\ddagger }$$\end{document} 1.11 \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$^{\S }$$\end{document} 0.88 \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$^{\S }$$\end{document} 0.11 \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$^{\dagger }$$\end{document} The symbols \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$^{\dagger }$$\end{document} , \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$^{\ddagger }$$\end{document} , and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$^{\S }$$\end{document} denote small, medium, and large effects, respectivelyTable 6Detection results for each categoryCategoryInstancesPrecision (%)Recall (%) \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$ \text {mAP}_{{50}} $$\end{document} (%) \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$ \text {mAP}_{{50-90}} $$\end{document} (%)F1 (%)AUC (%)All718771.061.868.848.364.181.6Boneanomaly5247.828.835.923.035.965.9Bonelession757.147.855.533.752.080.3Foreignbody450.037.543.535.842.981.4Fracture274491.094.194.864.292.591.4Metal11899.181.594.185.989.496.6Periostealreaction53076.565.074.042.170.375.5Pronatorsign8349.779.271.441.461.181.5Softtissue7370.423.451.233.635.170.9Text357697.298.898.975.398.096.0
We further performed the Tukey HSD analysis. The adjusted p-values (p-adj) between WH-DETR and the other four models are listed in Table 4. Each cell represents the p-adj for the corresponding model and metric. With a p-adj threshold of 0.05, which is a more common threshold in statistical analysis, values in bold indicate significant differences between the models. The results show that WH-DETR exhibits significant differences from the other models across all metrics except AUC.
Finally, we conducted an effect size analysis using Cohen’s d, calculated as follows:
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\begin{aligned} {d = \frac{\bar{X}_1 - \bar{X}_2}{s_p}} \end{aligned}$$\end{document}where the pooled standard deviation \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$ s_p $$\end{document} is given by:
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\begin{aligned} s_p = \sqrt{\frac{(n_1 - 1)s_1^2 + (n_2 - 1)s_2^2}{n_1 + n_2 - 2}} \end{aligned}$$\end{document}The sample variance was computed using an unbiased estimator (denominator \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$ n-1 $$\end{document} ). The results, presented in Table 5, were evaluated against thresholds of 0.3, 0.5, and 0.8, corresponding to small, medium, and large effects, respectively. The analysis indicates that most comparative experiments exhibit large effects.
The experiments reveal that WH-DETR achieves the best performance in terms of Params, mAP \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$ _{{\textbf {50}}} $$\end{document} , mAP \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$ _{\boldsymbol{50-90}} $$\end{document} and F1. Although WH-DETR does not achieve the best performance in AUC, statistical analysis indicates that there is no significant difference between WH-DETR and the other compared models in terms of AUC. For the comparison of FLOPs, we resized the inputs of all models to \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$ 640 \times 640 $$\end{document} . The findings indicate that our model has higher FLOPs, which can be attributed to the computationally demanding self-attention mechanism in transformers [26].
We discovered that DETR-based models surpass YOLO-based models in terms of mAP \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$ _{{\textbf {50-90}}} $$\end{document} . This is due to the YOLO series modifying the boundaries of predicted boxes during post-processing based on manually set rules. If these rules are not accurate, it may result in offsets in the bounding boxes, whereas DETR-like methods directly predict object bounding boxes, thereby avoiding this issue.
Detailed Experimental Results
Quantitative Experimental Results
To provide a more comprehensive understanding of the model’s performance, we present our quantitative experimental results. Table 6 displays the detection results for each category by WH-DETR, and Fig. 6 illustrates the precision-recall curves. Both precision and recall measurements employ an IOU threshold of 0.5. Our experimental results reveal that our model demonstrates superior performance in the text, fracture, and metal categories. This can be attributed to the larger number of instances in the first two categories, as well as the distinctive characteristics inherent in the third category. This observation implies that increasing the dataset size for the remaining categories may further enhance our model’s overall performance.
Concurrently, our model performs worst in the boneanomaly and softtissue categories. To elucidate this phenomenon, we provide the annotated examples for these two disease categories in Fig. 7. The category of bone anomaly represents a heterogeneous disease group, characterized by a diverse range of specific disease types and etiological factors. The complexity of this disease category means that its features are multifaceted. As a result, accurate identification solely through X-ray imaging is challenging. Therefore, increasing the accuracy of diagnosis can be achieved through methods such as oral inquiries. Similarly, the characteristic of soft tissue, being less dense than bone, leads to stronger X-ray penetrability and insufficient contrast. The feature of soft tissue in X-ray images is often less distinct compared to that of bone. This requires the integration of other imaging modalities, such as ultrasound and magnetic resonance imaging (MRI), for a more accurate and definitive diagnosis.Fig. 6. Precision-recall curves of each class using the WH-DETR modelFig. 7Examples of annotation for boneanomaly and softtissue
Qualitative Experimental Results
In order to more intuitively represent the outcomes of our model, we showcase our quantitative experimental results in Fig. 8. All presented results were obtained from the test set. In the illustrated examples, the predicted category and predicted candidate box for each instance are very close to the ground truth (GT). Moreover, in the second prediction, there are two overlapping periostealreaction in GT (gray and light blue), which our model predicts as a single entity, resulting in one fewer prediction than GT. In the fourth prediction result, we correctly predicted two texts, but one annotation was missing from the data. These examples illustrate that our model can predict more accurately than manually annotated results in certain cases, highlighting its strong generalization capability.
Fig. 8. Qualitative experimental results. The top row displays the predictions made by our model, while the bottom row represents the ground truth. The number of bounding boxes is indicated in the bottom-left corner of each image Table 7. Ablation results for each componentWTPHHMParams (M)FLOPs (G) \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$ \text {mAP}_{{50}} $$\end{document} (%) \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$ \text {mAP}_{{50-90}} $$\end{document} (%)F1 (%)AUC (%)✗✗46232.366.7±1.047.2±0.761.2±1.677.6±3.1✓✗43223.567.4±1.447.6±0.662.5±2.779.2±2.8✗✓46232.368.1±0.947.8±0.562.9±3.079.7±2.4✓✓43223.5 68.8±1.2
48.2±0.7
64.1±2.8
81.6±3.0 Bold entries highlight the best-performing metrics
Ablation Experiments
To reduce the cost associated with ablation experiments, we employ an approach analogous to that used in the comparative experiments. Specifically, during the initial run, the model undergoes full training. In subsequent runs, the model parameters are initialized by leveraging the weights obtained from the first training, with added noise. For the modules slated for removal, we bypass their parameter copying procedure entirely. Regarding the additional modules, we utilize the default initialization weights. All ablation experiments are repeated 5 times, and the model is evaluated based on the mean and standard deviation of the experimental results.
Impact of Each Component
To assess the contribution of each component to our model, we conducted ablation experiments for each component. Table 7 displays the effectiveness of the components we incorporated. When WTP is not utilized, we replace it with a convolution block with a kernel size of 3 to maintain comparable Params and FLOPs. The results indicate that incorporating WTP enhances the \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$ {\textbf {mAP}}_{\boldsymbol{50}} $$\end{document} , \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$ {\textbf {mAP}}_{\boldsymbol{50-90}} $$\end{document} , F1, and AUC by 0.7%, 0.4%, 1.3%, and 1.6%, respectively. This demonstrates that WTP effectively captures multi-frequency features of the input, thereby improving model performance. Furthermore, although HHM does not affect Params and FLOPs, it significantly benefits the model’s training process, leading to a 1.4%, 0.6%, 1.7%, and 2.1% in \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$ {\textbf {mAP}}_{\boldsymbol{50}} $$\end{document} , \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$ {\textbf {mAP}}_{\boldsymbol{50-90}} $$\end{document} , F1, and AUC, respectively.
Table 8. Performance of WTP under different experimental settingsWTP settings \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$ \text {mAP}_{{50}} $$\end{document} (%) \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$ \text {mAP}_{{50-90}} $$\end{document} (%)F1 (%)AUC (%)Levels168.2±1.248.0±0.963.7±2.581.3±3.0 2
68.8±1.2 48.2±0.7 64.1±2.8 81.6±3.03 68.8±1.1
48.3±0.8 64.0±2.9 81.7±2.9 LearnableNO68.4±1.147.9±0.863.8±3.081.2±2.9WT68.1±1.047.5±0.463.5±2.580.8±2.1 IWT
68.8±1.2
48.2±0.7
64.1±2.8
81.6±3.0 ALL68.5±1.148.0±0.764.0±3.2 81.6±3.0 Bold entries highlight the best-performing metrics
Fig. 9. The heatmap visualizations of feature maps before and after WTP. The upper row shows the feature maps prior to WTP, while the lower row exhibits those after WTP. For each sample, we perform a summation operation on all the channels of the feature maps, followed by normalization of the summed results, and then convert them into heatmaps. In these heatmaps, the regions of interest are highlighted in warm colors, while the background is shown in cold colors
WTP Under Different Settings
Table 8 illustrates the performance of WTP across various settings. Levels: The first three rows demonstrate the performance at different levels. As the level increases, the model performance improves. However, this is accompanied by a corresponding increase in computational complexity. Notably, the performance difference between levels 3 and 2 is marginal. This is because X-ray images are single-channel, which limits the available feature information. Additionally, when low-frequency components undergo successive wavelet transformations, the number of high-frequency components that can be extracted decreases. Consequently, there is no further performance enhancement. Learnable: The last four rows present the outcomes when different parameters are learnable, denoted as “NO,” “WT,” “IWT,” and “ALL,” indicating no parameters, only WT parameters, only IWT parameters, and all parameters being learnable, respectively. Our findings indicate that the model performs worst with only WT parameters learnable and best with only IWT parameters learnable. This is attributed to WT involving a downsampling process, while IWT involves upsampling, which is inherently more complex. Furthermore, fixing WT parameters allows the model to effectively learn multi-frequency features.
Table 9. Performance of HHM with different duplication timesDuplication times \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$ \text {mAP}_{{50}} $$\end{document} (%) \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$ \text {mAP}_{{50-90}} $$\end{document} (%)F1 (%)AUC (%)Match time (ms)[6, 6, 6, 2, 2, 2]67.9±1.448.0±0.763.1±2.580.6±3.05.827±0.108[7, 6, 5, 4, 3, 2]68.1±1.248.0±0.963.2±2.781.1±2.75.968±0.133[10, 8, 6, 4, 2, 1]68.5±1.348.3±0.563.8±2.980.9±3.16.042±0.190[20, 10, 8, 6, 4, 2]67.9±1.147.8±0.963.9±2.681.0±2.06.303±0.295[15, 12, 10, 8, 6, 3]67.6±1.247.6±0.6 64.1±2.7 81.3±2.86.301±0.272[12, 10, 8, 6, 4, 2] 68.8±1.2
48.2±0.7
64.1±2.8
81.6±3.0 6.133±0.218Bold entries highlight the best-performing metrics
To demonstrate the feature extraction ability of WTP, we systematically selected five representative examples. As shown in Fig. 9, we visualized the feature maps as heatmaps. We normalized the heatmap values using the maximum-minimum normalization method, enabling the visualization to reveal the relative intensity of the model’s attention to different features. Our analysis indicates that before WTP implementation, the features predominantly focus on bone edge information, while the bone interior features show significantly lower activation levels. After WTP processing, both the bone interior features and the inter-bone gaps exhibit substantial enhancement. This evidence demonstrates WTP’s effectiveness in filtering out secondary information while amplifying features of primary interest. Notably, the feature map’s upper and lower edge regions exhibit enhanced activation. This phenomenon arises due to the fact that the backbone architecture and WTP module focus on extracting preliminary feature representations, which are subsequently processed by the transformer architecture. By incorporating position encoding, the model adaptively modulates its attention mechanism, effectively reducing focus on edge regions.
HHM with Different Duplication Times
In Eq. 13, \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$ w_i $$\end{document} represents the duplication times for the target at the \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$ i $$\end{document} -th decoder layer, a crucial hyperparameter in HHM. Table 9 displays the results for various duplication times. We primarily tested six configurations, focusing on the differences in duplication times between layers and allocating more or fewer duplications to the shallower layers. Our findings suggest that the model performs optimally with duplication times set to [12, 10, 8, 6, 4, 2]. We hypothesize that this gradual reduction aids the model in progressively eliminating duplicate bounding boxes, leading to a more precise understanding of features and tasks across different layers. We also recommend adjusting duplication times based on the specific object detection task, as the number of bounding boxes varies. Excessive duplications can overwhelm certain layers, while insufficient duplications may result in overfitting.
Since hierarchical matching introduces additional matching costs, to analyze its impact on training time, the last column of Table 9 shows the matching time for a single match under different replication times. The matching time mainly depends on the size of the cost matrix. Given that the number of predicted queries is fixed at 300, the matching time approximately increases linearly with the number of targets. In our task, the number of targets in each image is small (less than 10). Consequently, hierarchical matching does not significantly increase the matching time. Experiments show that when hierarchical matching is not used, the matching time is approximately 5.719 ms. The matching time corresponding to the selected duplication times [12, 10, 8, 6, 4, 2] increases by an average of 0.4 ms. Therefore, the total training time increases by \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$ \frac{0.4\times 17278\times 50\times 0.001}{60}=5.76 $$\end{document} min. This increase is negligible and is acceptable.
To further scrutinize the role of HHM, we visualized the predictions of each layer in Fig. 10. The diminishing number of predicted bounding boxes illustrates that HHM functions as expected. The shallower decoder layers produce a greater number of candidate boxes, many of which are duplicates. Subsequent layers systematically eliminate these duplicates and refine the remaining boxes, culminating in the finest candidate boxes. Upon comparison, we observe only slight discrepancies between our predictions and the ground truth. Importantly, our predicted text boxes exhibit more precise boundaries, signifying the effectiveness of our model.Fig. 10. Prediction results from different decoder layers after applying HHM. The left side of the dashed line presents two rows, each containing three predictions. The first row corresponds to the outputs of decoder layers 0 to 2 (with layer 0 being the output of the last encoder layer), and the second row displays the outputs of layers 3 to 5. On the right side of the dashed line, the first row showcases the final predictions, and the second row reveals the ground truth. The bottom-left corner of each image indicates the number of bounding boxes
Discussion
Compared with previous YOLO-based object detection algorithms, this study introduces the DETR model for pediatric fracture detection for the first time. This model eliminates the need for post-processing, enabling accurate predictions without the post-processing required by previous YOLO models. This approach has been experimentally proven to be more effective in predicting bounding boxes of various sizes, which is critical for fracture detection. Additionally, this study introduces the WTP module, which better handles high- and low-frequency information in X-ray images compared to CNN modules, thereby preserving the most critical information when mapping the initial features extracted by CNN models to the input of the transformer model. Furthermore, this study proposes the HMM framework, which decouples the prediction targets of different decoder layers during training, resulting in more accurate final predictions. Experiments demonstrate that these improvements are well-suited for pediatric fracture detection tasks. Moreover, we believe that the WH-DETR model is also applicable to similar data, such as X-ray, MRI, and CT scan images, by appropriately adjusting the number of WTP layers and the replication count in HMM, and the proposed model can be adapted to other similar tasks.
Although this study achieves promising results, there are still limitations that can be improved. First, the WTP module tends to identify edge information as important features due to the prominence of edges after image rotation. Although subsequent positional encoding can mitigate this issue, an ideal module should directly ignore such irrelevant information. Second, determining the number of bounding box replications required for each decoder layer in the HMM framework for different tasks requires extensive experimentation, which can be time-consuming. Moreover, the proposed method performs poorly for certain detection categories, such as boneanomaly and softtissue. These categories feature more complex characteristics, and we believe that incorporating multimodal information, such as patient self-reports, MRI, or CT scans, can further improve detection results for these challenging categories.
Conclusion
In this study, we presented WH-DETR, a novel end-to-end model designed for detecting pediatric wrist fractures, and introduced two innovative components, WTP and HHM, to bolster its performance. The WTP module enhances detail detection by capturing multi-scale and multi-frequency features, while the HHM framework improves prediction accuracy by disentangling tasks across decoder layers. Experimental results on the GRAZPEDWRI-DX dataset reveal that WH-DETR surpasses existing models in critical metrics. Ablation studies validate the substantial contributions of WTP and HHM to model performance and offervaluable insights into parameter settings for each module. Future endeavors will investigate the applicability of WTP in other medical imaging tasks and refine the HHM framework to accommodate diverse data distributions and detection requirements.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1Randsborg PH, Gulbrandsen P, Šaltytė Benth J, Sivertsen EA, Hammer OL, Fuglesang HF, Årøen A: Fractures in Children: Epidemiology and Activity-Specific Fracture Rates. Journal of Bone and Joint Surgery, 95:e 42, 10.2106/jbjs.l.00369, 201310.2106/JBJS.L.0036923553305 · doi ↗ · pubmed ↗
- 2Kraus R, Wessel L: The Treatment of Upper Limb Fractures in Children and Adolescents. Deutsches Ärzteblatt international, 107:903-910, 10.3238/arztebl.2010.0903, 201010.3238/arztebl.2010.0903 PMC 302315421249137 · doi ↗ · pubmed ↗
- 3Rimmer A: Radiologist shortage leaves patient care at risk, warns royal college. BMJ, 359, https://www.bmj.com/content/359/bmj.j 4683, 201710.1136/bmj.j 468329021184 · doi ↗ · pubmed ↗
- 4Freed HA, Shields NN: Most frequently overlooked radiographically apparent fractures in a teaching hospital emergency department. Annals of Emergency Medicine, 13:900-904, 10.1016/s 0196-0644(84)80666-6, 198410.1016/s 0196-0644(84)80666-66476514 · doi ↗ · pubmed ↗
- 5Hedström EM, Svensson O, Bergström U, Michno P: Epidemiology of fractures in children and adolescents: Increased incidence over the past decade: a population-based study from northern Sweden. Acta Orthopaedica, 81:148-153, 10.3109/17453671003628780, 201010.3109/17453671003628780 PMC 285622020175744 · doi ↗ · pubmed ↗
- 6Burki TK: Shortfall of consultant clinical radiologists in the UK. The Lancet Oncology, 19:e 518, 10.1016/s 1470-2045(18)30689-2, 201810.1016/S 1470-2045(18)30689-230220623 · doi ↗ · pubmed ↗
- 7Choi JW, Cho YJ, Lee S, Lee J, Lee S, Choi YH, Cheon JE, Ha JY: Using a Dual-Input Convolutional Neural Network for Automated Detection of Pediatric Supracondylar Fracture on Conventional Radiography. Investigative Radiology, 55:101-110, 10.1097/rli.0000000000000615, 201910.1097/RLI.000000000000061531725064 · doi ↗ · pubmed ↗
- 8Tanzi L, Vezzetti E, Moreno R, Aprato A, Audisio A, Massè A: Hierarchical fracture classification of proximal femur X-Ray images using a multistage Deep Learning approach. European Journal of Radiology, 133:109373, 10.1016/j.ejrad.2020.109373, 202010.1016/j.ejrad.2020.10937333126175 · doi ↗ · pubmed ↗