Different BI-RADS breast cancer diagnosis using MobileNetV1 and vision transformer based on explainable artificial intelligence (XAI)
Israa Abdelsabour, Ahmed Elgarayhi, Mohammed Sallah, Mohammed Elmogy

TL;DR
This paper proposes a new AI system combining MobileNetV1 and Vision Transformer for accurate and interpretable breast cancer diagnosis using mammograms.
Contribution
A novel dual-stream framework using MobileNetV1 and ViT with XAI for multi-class BI-RADS classification of breast cancer.
Findings
The proposed framework achieved over 99% accuracy, sensitivity, and specificity across all BI-RADS categories.
XAI techniques like Grad-CAM provided interpretable visual explanations for AI-based diagnoses.
The model outperformed existing CNN and transformer models in multi-class BC classification.
Abstract
Breast cancer (BC) remains one of the leading causes of death among women in the world, depending on the requirement for precise, effective, and interpretable computer-aided diagnosis systems (CADs). In this work, a hybrid deep learning (DL) framework is presented for multi-class BI-RADS BC classification using mammographic images. This framework fuses MobileNetV1, a lightweight convolutional neural network (CNN), to capture fine-grained local features and combines it with a Vision Transformer (ViT) to model global contextual connections, thereby enabling corresponding representation learning through a dual-stream structure. The evaluation was performed on the publicly available King Abdulaziz University BC Mammogram Dataset (KAUBC), which includes multi-view mammograms (craniocaudal (CC) and mediolateral oblique (MLO)) arranged according to the BI-RADS classification scheme and…
Genes, proteins, chemicals, diseases, species, mutations and cell lines named across the full text — each resolved to its canonical identifier and authoritative record.
Click any figure to enlarge with its caption.
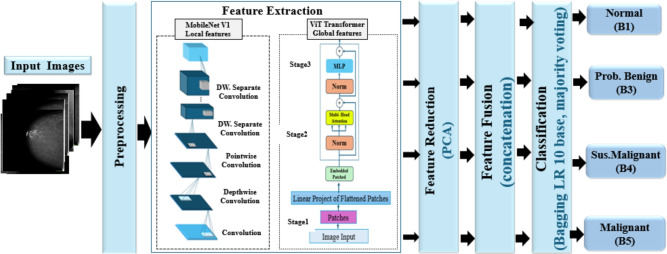 Figure 1
Figure 1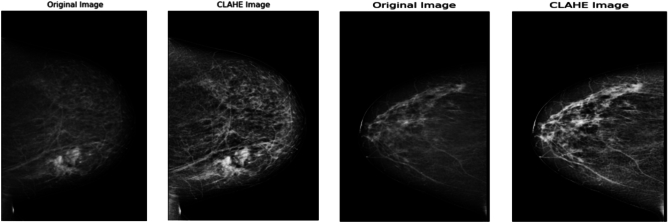 Figure 2
Figure 2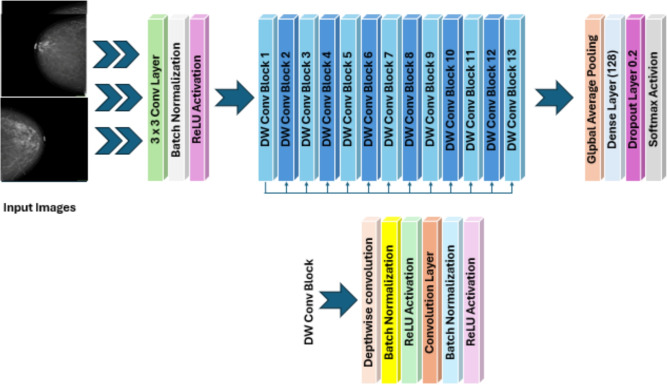 Figure 3
Figure 3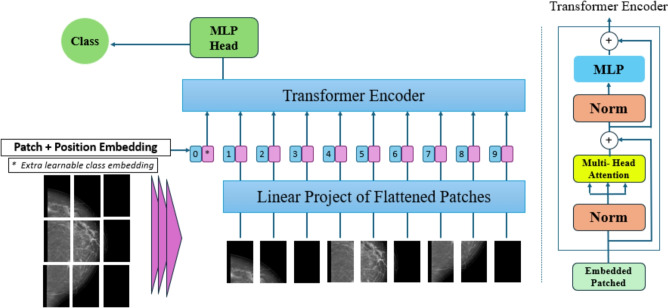 Figure 4
Figure 4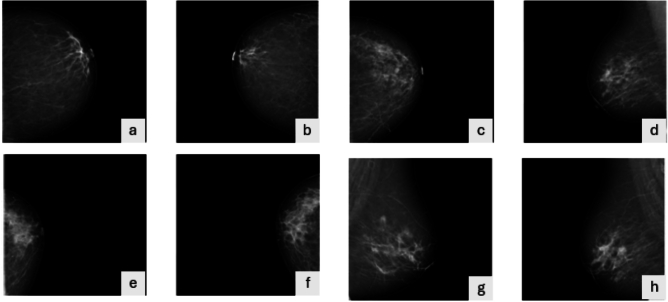 Figure 5
Figure 5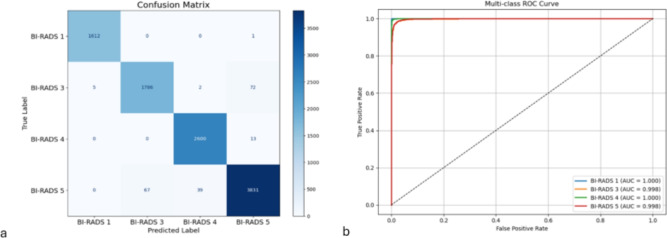 Figure 6
Figure 6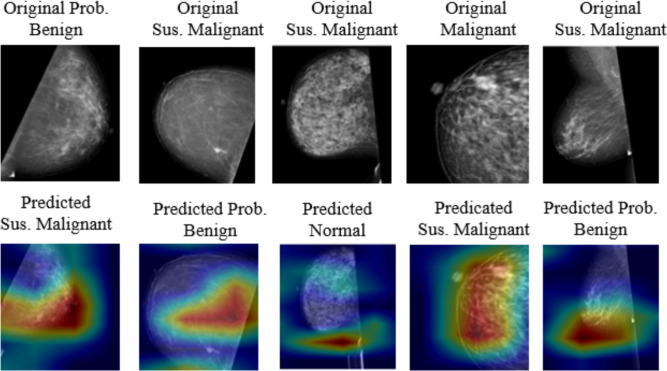 Figure 7
Figure 7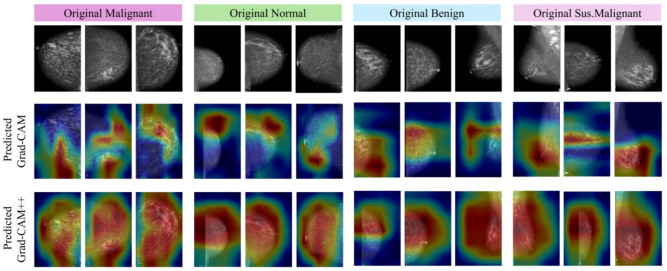 Figure 8
Figure 8- —Mansoura University
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsAI in cancer detection · Infrared Thermography in Medicine · COVID-19 diagnosis using AI
Introduction
Breast cancer (BC) is the most common cancer among women worldwide, with approximately 2.3 million new cases per year^1^. Despite advances in imaging and pathology, early detection remains challenging due to variations in mammograms, ultrasound (US), and histological (HI) slides, leading to inaccurate classification and delayed diagnosis^2^. A mammogram is a key tool for early detection, as it evaluates tissue density, microcalcifications, and masses to assess cancer risk.
The Breast Imaging Reporting and Data System (BI-RADS) categorizes mammogram findings into seven groups (0–6) and classifies breast density from ACR-A (fatty) to ACR-D (highly dense)^3^. Dense tissue obscures lesions, complicating BI-RADS assignment and increasing prediction errors, particularly under time constraints or limited radiologist experience^4–6^.
Artificial intelligence (AI) refers to computational methods that allow machines to achieve tasks traditionally requiring human intelligence, such as pattern recognition, learning from data, decision-making, and prediction. In healthcare, AI, primarily through machine learning (ML) and deep learning (DL), has emerged as an essential tool for analyzing complex, high-dimensional medical data and supporting clinical decisions. AI has shown considerable commitment in medical imaging, particularly in BC diagnosis. DL models, including convolutional neural networks (CNNs), have become effective at detecting and classifying tumors in mammogram images, enhancing early diagnosis and treatment planning^7^. Moreover, explainable AI (XAI) techniques have improved the interpretability of these models, enabling doctors to understand model decisions and build trust in automated systems^8^. Despite this progress, challenges remain in achieving high ACC across all BI-RADS categories while maintaining computational efficiency and clinical interpretability, prompting the development of hybrid and explainable models for BC classification^9^.
AI, DL, and ML enhance imaging explanation, improving BC classification, ACC, and reproducibility^10,11^. Computer-aided diagnosis (CAD) systems, particularly those using CNNs, automate abnormality detection, segmentation, and classification, achieving performance comparable to that of expert radiologists^12,13^. XAI further increases interpretability and trust^14^. CAD systems can also identify high-risk cases, increase delay times, and improve clinical outcomes; however, challenges remain due to the complexity of mammography and limitations of existing feature-extraction and classification techniques^15^. DL architectures such as AlexNet, GoogleNet, ResNet, MobileNet, and EfficientNet have been employed to enhance BC classification^16^. Ensemble learning, fused multimodal data, imaging, clinical, and molecular biomarkers further enhance predictive ACC. Nevertheless, current CNN–CNN-Transformer fusion frameworks often require end-to-end training of large models, incurring substantial computational cost and limiting interpretability, which contradicts clinical assumptions^17^.
Despite the progress of CNNs and transformer-based models in BC classification, present approaches face several limitations: CNNs efficiently catch local patterns, but miss encode global contextual connections; transformers apply global feature modeling but are computationally large and require huge datasets; and many fusion techniques lack interpretability, limiting clinical acquisition^14^. Unlike existing end-to-end CNN-Transformer hybrid architectures, this study introduces a lightweight, interpretable feature-level fusion framework that combines MobileNetV1 for fine-grained local feature extraction with a Vision Transformer (ViT) for global contextual modeling. The fused features are further reduced using PCA and classified by a bagging logistic regression (LR) classifier to improve robustness, computational efficiency, and clinical interpretability^18^.
Unlike pure benchmarking works, this work focuses on the delineation and validation of the lightweight and interpretable MobileNetV1–ViT framework. The evaluation of multiple CNN and transformer-based fusion is included entirely as a supporting investigation to explain architectural options and classifier selection, rather than as the main contribution of the study. A bagging classifier with LR is applied for classification due to its simplicity, interpretability, and resistance to overfitting. The main contributions of this study are summarized as follows:
- Enhanced Image Quality: Adaptive preprocessing with contrast improvement and noise normalization enhances feature visibility for superior lesion characterization.
- Holistic Feature Representation: Local features extracted by MobileNetV1 are integrated with global features from ViT, allowing effective multi-scale lesion analysis.
- Improved Prediction Performance: The fusion of features and ensemble classification enhances superior ACC, SEP, SEN, precision, and F1-score compared to individual DL models and traditional CAD approaches.
- Computational Efficiency: MobileNetV1 gives lightweight feature extraction, while ViT captures long-range dependencies efficiently, supporting practical computational overhead.
- Robust and Interpretable Classification: Bagging with LR increases variance, stabilizes decision borders, and enhances robustness on the KAUBC dataset.
- XAI: Grad-CAM and Grad-CAM++ highlight clinically relevant regions, improving model transparency and consistency for medical applications. The paper is structured as follows: Section 1 reviews mammographic image analysis. Section 2 presents the methodology, including preprocessing, feature extraction, fusion, and LR classification. Section 3 details the experimental setup, dataset, metrics, and comparisons with existing CAD systems, including XAI visualization. Section 4 concludes and discusses future research directions.
Related work
BC image analysis has made significant progress in recent years, with techniques commonly divided into conventional feature-based techniques and DL approaches. Although traditional methods hang on hand-crafted descriptors, DL models automatically learn characteristic features, enhancing detection and classification ACC.
Transformer-based DL approaches
Ahmed et al.^19^ proposed a MAX-ViT-based DL system with multi-scale feature extraction, a Gated Attention Fusion (GAF) module, and Harris Hawks Optimization (HHO) for feature selection, achieving high performance on the King Abdulaziz University Breast Cancer (KAUBC) dataset (ACC 98.2%). Granted that, effectively, the dependence on complex optimization and an XGBoost classifier increases computational cost and may limit clinical deployment. Abimouloud et al.^20^ compared transformer-based architectures (ViT, CCT, TViT) for binary BC classification, achieving remarkable ACCs (>99%). However, recent studies have further investigated transformer-based and hybrid DL frameworks, demonstrating enhanced global and multi-scale feature representation in medical image analysis^21^. Transformer-based architectures have also shown favorable performance across various medical imaging tasks, prompting their adoption for mammography-based BC diagnosis^22^.
CNN-based multi-view and ensemble approaches
Nguyen et al.^23^ introduced a multi-view Deep Convolutional Neural Network (DCNN) framework integrated with Light Gradient Boosting Machine (LightGBM) for simultaneous BI-RADS and density evaluation, enhancing F1 scores by 5–10% over single-view approaches. This highlights the importance of multi-view fusion, yet interpretability and generalization to other datasets remain unaddressed. Diwakaran et al.^24^ and Qasrawi et al.^25^ leveraged CNN ensembles and hybrid models with multimodal data, achieving high ACC (up to 98.9%) and fast assumptions. However, these frameworks often lack XAI (XAI) components, decreasing clinical transparency. Hybrid CNN models and multi-view ensembles continue to exhibit robust classification on mammography datasets^26,27^.
Traditional ML approaches
Lee et al.^28^ applied ML classifiers, decision tree (DT), Support Vector Machine (SVM), k-Nearest Neighbor (kNN) for mammographic breast density classification, illustrating moderate Area Under the Curve (AUC) values (80–81%). While this work asserts the utility of ML in BC evaluation, it is limited to breast density assessment and lacks multi-class BI-RADS classification.
Hamyoon et al.^29^ developed an SVM-based framework for US images that merges five morphometric properties with BI-RADS descriptors. The model achieved an AUC of 88.5%, surpassing experienced radiologists, and highlighted the benefits of fusing morphometric features with BI-RADS descriptors to enhance US-based BC classification reliability.
XAI and interpretability
Tsai et al.^30^ proposed a fully automated BI-RADS classification into eight classes using a block-based Deep Neural Network. Despite high ACC (94.2%) and AUC (97.2%), model complication and block-based input restrictions may decrease adaptability to various mammogram datasets. Mardones et al.^31^ proposed a DNN for US image analysis, employing You Only Look Once (YOLO) for exact Region Of Interest(ROI) detection and multi-class BI-RADS prediction, attaining Cohen’s kappa scores of 0.58–0.64. This study demonstrated that integrating BI-RADS descriptors improves interpretability, offering a clinically transparent US-based BC classification system.
Shi et al.^32^ proposed QGANet for HI image classification, improving noise robustness via quaternion algebra. While effective, these models were primarily evaluated on HI datasets, and their performance on mammogram images still needs to be investigated. Wani et al.^33^ Integrating AI for BC Classification with Explainable Predictions proposed a hybrid CNN + LightGBM framework that achieved high performance (ACC 98.3%, PRE 98.7%, SEN 98.7%, F1 98.7%) and provided explanations using SHAP at local and global levels. While effective in binary BC classification and enhancing interpretability, the approach does not combine multi-scale feature representations, lacks multi-class BI-RADS assist, and may not generalize to various mammogram datasets. This prompts our MobileNetV1 + ViT hybrid framework, which addresses these gaps by combining local and global features, supporting multi-class classification, and incorporating XAI for robust clinical interpretability.
Saharan et al.^34^ proposed a Hybrid CNN + Random Forest (RF) Scheme for BC Detection with XAI Predictions, a CNN + RF hybrid framework that reaches high predictive performance and provides explanations using SHAP at both local and global levels. While DXAIB improves interpretability and transparency, it primarily addresses binary BC classification, lacks multi-scale feature integration, and does not utilize ensemble strategies, limiting generalization to multi-class BI-RADS scenarios. These gaps motivate our MobileNetV1 + ViT framework, which supports multi-class classification, integrates local and global features, and employs bagging for robust and interpretable BC diagnosis.
The importance of XAI for clinical trust has been progressively highlighted in recent medical imaging studies using Grad-CAM, SHAP, and multimodal explanations^35,36^.
Summary and gap analysis
In summary, prior works achieve high ACC but have common limitations: many need large annotated datasets, the absence of multi-class BI-RADS classification, produce limited interpretability, or are computationally intensive. These gaps motivate the development of our hybrid MobileNetV1 + ViT framework, which efficiently integrates local and global features, supports multi-class BI-RADS classification, and incorporates XAI for transparent, clinically trustworthy diagnosis. Table 1 summarizes the previous studies of BC diagnosis and classification.
Despite significant advances in mammograms for BC diagnosis, assorted challenges remain. First, many studies rely on private or public datasets that lack diversity or external validation, which limits the generalizability of the models advanced to real-world clinical settings^30,31^. Second, class imbalance and insufficient representation of intermediate BI-RADS categories remain significant limitations, as most studies focus on binary or simple classification tasks, thereby reducing ACC^28^.
Third, the lack of XAI techniques, such as Grad-CAM or SHAP, obstructs interpretability and reduces clinicians’ trust in automated predictions. Fourth, most approaches do not utilize multimodal or multi-view information, rely primarily on single-view mammograms, and ignore other relevant medical data that could improve performance^33^.
Fifth, although CNN-Transformer fusion models show promising results in BC diagnosis, they often depend on end-to-end training of large, complex architectures, increasing computational cost and restricting deployment in resource-constrained environments. Furthermore, these models often produce hard-to-interpret outputs and typically require large datasets, which are difficult to obtain in medical imaging^23,24^.
Recent studies in ensemble and hybrid learning provide methodological innovation for our framework. Bagging and meta-learner ensembles have been shown to reduce variance and improve classification robustness on complex datasets^37,38^. At the same time, dimensionality-depleting techniques such as PCA can enhance classifier efficiency by focusing on relevant features^35,39^. Hybrid CNN-based models with advanced embeddings have demonstrated superior feature representation and ACC^40^, and review studies confirm the overall effectiveness of ensemble techniques for robust prediction^40^. These findings collectively justify integrating MobileNetV1 for feature extraction, ViT embeddings for global context, PCA for dimensionality reduction, and Bagging for final classification in our proposed BC diagnosis framework.
The primary research problem identified in this study is the lack of a cohesive BC diagnosis framework that effectively addresses class imbalance, provides interpretable explanations, and ensures computational efficiency for the KAUBC dataset. The identified limitations necessitate a hybrid approach that optimizes computational efficiency, interpretability, and robust multi-class classification performance within the assessed experimental conditions, as proposed in this study with MobileNetV1 + ViT^41^.
To address this research problem, we sought to improve the model’s performance and reduce dataset-specific bias in the KAUBC dataset for BC diagnosis. The KAUBC dataset comprises a diverse set of mammographic images spanning various BI-RADS categories. To mitigate class imbalance and enhance representation of intermediate classes, extensive data augmentation and class-weighted learning were used to ensure balanced model training and improve recognition of minority classes. Unlike previous studies that focused solely on binary classification tasks, our framework accommodates multi-class BI-RADS classification, providing interpretable insights for the assessed dataset.
Additionally, XAI techniques such as Grad-CAM and Grad-CAM++ were employed to visualize and interpret the proposed model’s decision-making processes, thereby improving transparency and fostering clinical trust. The model integrates complementary feature representations to enhance robustness across all BI-RADS categories, with specific architectures detailed in the Methods section. Recent studies underscore prevailing trends in transformer-, CNN-, and XAI-based BC diagnosis systems, thereby reinforcing the justification for our MobileNetV1 + ViT hybrid framework^42^. Table 1 provides a summary of prior research on the diagnosis and classification of BC.
Materials and methods
This section describes the proposed DL framework for classifying BC using mammographic images. The proposed framework integrates multiple complementary techniques to address key limitations identified in previous BC diagnostic studies, including class imbalance, limited interpretability, and computational inefficiency. The framework consists of four main steps. Image preprocessing was applied to enhance image quality by adjusting contrast, applying data augmentation, resizing, and normalization. The feature extraction method used MobileNetV1 and the ViT Transformer. MobileNetV1 effectively captures small local features, while ViT models excel in understanding global contextual relationships.
Feature fusion subsequently integrates the extracted representations into a unified descriptor that encompasses both local and global information. Feature reduction and classification involved applying PCA to eliminate duplicate features, while a bagging ensemble classifier improved ACC and contributed to more stable predictions in the KAUBC dataset. To improve model interpretability, XAI techniques, such as Grad-CAM and Grad-CAM++, were used to identify regions the model focused on in the evaluated dataset, highlighting the regions that influenced its decisions.
This can raise radiologists’ trust and improve diagnostic understanding. Figure 1 illustrates the comprehensive structure of the proposed DL framework for BC categorization. This figure illustrates the dual-stream architecture, combining MobileNetV1 for local feature extraction and ViT for capturing global contextual relationships, thereby enhancing feature richness and supporting accurate multi-class BI-RADS classification.Table 1. The comparison of some recent studies.StudyDatasetProposed methodResultsAhmed et al. (2025)^19^KAUBCMHybrid DL combining MAX-ViT with attention-based fusion (GAFM), HHO feature selection, and XGBoost classifierACC: 98.2%, Precision: 98.0%, Recall: 98.1%, F1-score: 98.0%, AUC: 98.9%, MCC: 95.0%Nguyen et al. (2022)^23^Internal + DDSMMulti-view DCNN feature extraction fused with LightGBM classifierF1-score gains of 5–10% over single-view methods on malignant casesLee et al. (2022)^28^DDSMML-based BI-RADS density classification using DT, SVM, and kNNAUC: 80.1% (DT), 80.5% (SVM), 81.0% (kNN)Abimouloud et al. (2024)^20^DDSMTransformer-based models (ViT, CCT, TViT) integrating convolution and attentionACC: 99.81% (ViT), 99.92% (CCT), 99.05% (TViT)Tsai et al. (2022)^30^Taiwanese MammogramsDNN with block-based inputs for 8-class BI-RADS classificationACC: 94.22%, SEN: 95.31%, SPE: 99.15%, AUC: 97.23%Diwakaran et al. (2023)^24^MIASTransfer learning using Xception and Channel-Boosted CNN (BCP-TL)ACC: 98.96%Qasrawi et al. (2024)^25^20,000 Mammo + 800 clinicalEnsemble model with image enhancement, YOLOv5, and multi-DL classifiersACC: 99.7%, Malignant: 98.6%, Benign: 97.2%Sabani et al. (2022)^43^7242 Patches / 1744 MammoDCNN for soft-tissue BI-RADS classification (opacities only)ACC: 73.8–89.8%, SEN: 84.0%, SPE: 100.0%Hamyoon et al. (2023)^29^1288 US lesions (Malaysia, Iran, Turkey)SVM with five morphometric features + BI-RADS descriptorsAUC: 88.5%, Radiologist: 81.4%, Resident: 63.2%Mardones et al. (2022)^31^749 US nodulesYOLO for ROI detection + DNN for multi-class BI-RADS and malignancy classificationCohen’s Kappa: 0.58–0.64, high concordance with expertsWani et al. (2024)^33^Real-world BC datasetHybrid CNN + LightGBM with SHAP explanations at local and global levelsACC: 98.3%, Precision: 98.7%, SEN: 98.7%, F1: 0.987; Binary classification with improved interpretability
Fig. 1. The breast cancer classification framework based on the MobileNetV1 and ViT transformer models.
Image preprocessing
Image preprocessing is a computer-assisted process that modifies digital images to enhance their quality, making them more suitable for subsequent feature extraction stages^44,45^. Mammograms often exhibit noise, low contrast, and class imbalance, which can make feature extraction and classification more challenging^46^. We employ several preprocessing methods to mitigate these problems, including image enhancement, normalization, data augmentation, and resizing, as described in the following paragraphs.
The first preprocessing step is contrast-limited adaptive histogram equalization (CLAHE). It is an advanced preprocessing method that improves local contrast in medical images while reducing the likelihood of noise overamplification^44,45^. CLAHE is notably effective in mammographic imaging for highlighting subtle tissue abnormalities, particularly in areas where traditional global contrast enhancement may be inadequate^47,48^. In contrast to conventional histogram equalization, which modifies pixel intensities across the entire image, CLAHE operates on localized regions, called tiles or windows.
Histogram equalization is applied independently to each tile, and the resulting regions are integrated via bilinear interpolation to produce a seamless final image. CLAHE reduces the excessive amplification of high-frequency noise while preserving local contrast. For mathematical specifics about global histogram equalization, histogram clipping, and mapping functions, refer to Supplementary Material S1. Figure 2 illustrates the impact of CLAHE on mammograms. The graphic illustrates how CLAHE improves local contrast and accentuates tiny features like microcalcifications and lesion borders, which are essential for enhancing the ACC of downstream feature extraction and BC classification.
Using raw mammographic images in a DL model can increase computational complexity and reduce learning efficiency. Image normalization involves adjusting pixel intensities based on statistical metrics. Each pixel value is normalized by subtracting the mean and dividing by the standard deviation (see Supplementary Material S2 for full equation details). This preprocessing method diminishes inter-image variability and accelerates the convergence of DL models, particularly when utilizing transfer learning from pre-trained architectures. By reducing the impact of extraneous brightness and contrast fluctuations, it preserves a uniform distribution of data across the dataset. This stage is crucial for improving the model’s generalization performance in BC classification.
Third, class-wise image data augmentation is an essential method in medical image analysis, particularly when annotated datasets are scarce, as observed in BC classification^18,49^. This study applied geometric transformations to simulate realistic variations in mammogram acquisition and patient positioning. Rotation ( \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\pm 15^\circ$$\end{document} ) simulates minor patient misalignment, horizontal flipping addresses variations in breast orientations, shifting and shearing ( \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$10\%$$\end{document} ) replicate small positional discrepancies, and zooming ( \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$10\%$$\end{document} ) represents differences in breast size or image scaling. These augmentations enhance dataset diversity while maintaining diagnostically relevant features, thereby improving model generalization and robustness.
All mammogram images were standardized and resized during preprocessing. Subsequently, images were resized to the input dimensions required by the pre-trained MobileNetV1 and ViT models ( \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$224 \times 224$$\end{document} pixels), in compliance with established pretreatment standards in radiological imaging. Augmentation is performed using TensorFlow’s ImageDataGenerator, recognized for its effectiveness and reproducibility in medical imaging research.Fig. 2. Some sample images from the breast cancer mammogram dataset after applying CLAHE enhancement.
This augmentation method effectively addresses class imbalance, a prevalent issue in medical datasets. It corresponds with scientifically substantiated data-level methodologies to mitigate overfitting and improve model generalization in unbalanced classification issues.
To statistically examine class imbalance, Table 2 presents the count of images and patients per BI-RADS category, indicating that the suspicious and malignant classes are underrepresented. A stratified five-fold cross-validation was employed to maintain class balance across folds. Furthermore, data augmentation was implemented more comprehensively for the minority classes, guaranteeing a more equitable representation during training and improving model generalization across all BI-RADS categories.
A limitation of the preprocessing steps is that the resizing and grayscale conversion of mammographic images may lead to a loss of dynamic range and subtle diagnostic features. Implementing these steps is essential for standardizing input to neural network models; however, they may diminish visibility of fine structures, including microcalcifications and small masses. Future research may investigate adaptive resizing, multi-resolution inputs, or the preservation of original image channels to address these issues.
The preprocessing pipeline includes the application of Contrast Limited Adaptive Histogram Equalization (CLAHE) to enhance local contrast and improve the visibility of subtle mammographic structures, in addition to image resizing to ensure consistent input dimensions for the DL models. While these preprocessing steps improve model convergence and reduce overfitting, it is acknowledged that image resizing may result in a partial loss of dynamic range and attenuation of very fine diagnostic details. However, this effect is mitigated by using contrast enhancement techniques and moderate resizing factors. Future work may explore advanced data augmentation strategies, multi-scale learning approaches, or GAN-based synthetic image generation to further preserve subtle diagnostic cues and enhance model robustness.
Resizing input images to appropriate dimensions is a crucial preprocessing step to ensure compatibility with the input requirements of selected pre-trained models. In this study, MobileNetV1 and the Vision Transformer (ViT) require fixed-size inputs; therefore, mammographic images were resized to 224 \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\times$$\end{document} 224 pixels. Ensuring uniform image dimensions facilitates batch processing and reduces input shape inconsistencies during both training and inference.
Bilinear interpolation was employed during the resizing process to preserve spatial coherence and minimize geometric distortion while maintaining essential structural information. Nevertheless, it is recognized that interpolation-based resizing may slightly affect intensity distribution and very subtle textural patterns in mammograms. Despite this limitation, the adopted resizing strategy provides a practical balance between computational efficiency and preservation of diagnostic information, enabling effective feature extraction and robust learning within the proposed hybrid DL framework for BC diagnosis.
Feature extraction
Feature extraction is an essential process for detecting distinguishing patterns that enable discerning between diverse stages and types of BC in mammographic images^50^. The quality of extracted features significantly influences the precision and effectiveness of the classification process. This section outlines the feature-extraction methodology used in the proposed DL system. The proposed method uses MobileNetV1, a lightweight CNN pre-trained on ImageNet, to extract key local features from mammographic images^26^. As illustrated in Fig. 3, MobileNetV1 functions as the main feature extractor, pointing up how its depthwise separable convolutions efficiently capture local texture patterns and fine-grained details such as calcifications and lesion boundaries, making it well-suited for resource-constrained clinical environments^51^.
MobileNetV1 offers several advantages in BC imaging, including computational efficiency, local feature SEN, and suitability for low-resource environments. For detailed mathematical formulations of depthwise convolution, pointwise convolution, and residual connections, see Supplementary Material S3.Fig. 3. The structure of the MobileNetV1 architecture.
These characteristics make MobileNetV1 particularly appropriate as a backbone for mammographic BC analysis, as it combines computational efficiency with valuable extraction of local spatial features crucial for detecting fine-grained patterns like microcalcifications, and lesion contours. The proposed study also appoints a ViT architecture to extract global contextual relationships and high-level semantic features from mammographic images. Unlike CNNs, which operate within limited receptive fields, ViT treats the entire image as a sequence of patches and processes them with a transformer encoder^52^.
This mechanism enables ViT to capture long-range dependencies, crucial for recognizing fine diagnostic patterns in mammographic scans. Figure 4 illustrates that the input image is initially segmented into fixed-size, non-overlapping patches. This figure illustrates how the ViT architecture treats each patch as a distinct token, enabling the model to capture long-range dependencies and global contextual information across the entire mammogram, which is critical for recognizing fine diagnostic patterns such as architectural distortions and dispersed microcalcifications. Each patch is flattened and planed into a latent vector space via a linear embedding layer, with positional encoding and a learnable classification token attached. For full mathematical details of patch embedding, positional encoding, and the self-attention system, see Supplementary Material S4. ViT was selected as a complementary backbone because it captures long-range dependencies and global contextual relationships in mammograms, effectively complementing the local feature extraction of MobileNetV1 and improving overall model performance in multi-class BC classification.
Fine-tuning
Pre-trained ViT and MobileNetV1 were used as the foundational architectures for feature extraction in the proposed DL framework for BC classification. Using pre-trained models with small, domain-specific datasets, such as mammograms, is beneficial because it allows networks to be initialized with weights from large datasets like ImageNet. This improves generalization^10,18^. A fine-tuning strategy was implemented utilizing various essential techniques to tailor these pre-trained models to the specific attributes of our mammogram dataset.
- Freezing of initial layers The early layers of both MobileNetV1 and ViT were kept frozen, as they capture fundamental, domain-independent visual features such as edges and textures. Preserving these pre-trained weights helps retain useful feature representations learned from ImageNet, thereby reducing overfitting on the KAUBC mammographic dataset.
- Progressive unfreezing for domain adaptation After training the top classification layers, selective lower layers were gradually unfrozen. This progressive unfreezing strategy enables the models to fine-tune incrementally, starting with layers closest to the output and gradually extending deeper into the network. Such a controlled adaptation promotes smoother convergence and enhances the network’s ability to capture domain-specific BC characteristics.
- Regularization via Dropout Dropout layers were incorporated within the final dense layers to help reduce overfitting on the KAUBC dataset. By randomly deactivating a subset of neurons during training, the model is encouraged to learn more diverse feature representations within the dataset under evaluation.
- Lower learning rate for controlled adjustment A smaller learning rate was adopted during the fine-tuning phase to ensure subtle and stable updates to model parameters, preserving valuable pre-trained features while refining them for BC image classification. This fine-tuning strategy enables MobileNetV1 and ViT to transfer knowledge from large-scale natural image datasets and adapt it to mammographic data, thereby improving classification accuracy and contributing to more stable predictions on the KAUBC dataset.Fig. 4. The structure of the ViT transformer used for breast cancer classification. The model processes mammogram images as sequences of patches, each linearly embedded and fed into a transformer encoder to capture long-range dependencies.
Feature reduction with PCA
After feature extraction, PCA is applied to improve generalization and reduce feature dimensionality. PCA projects the high-dimensional feature spaces of ViT and MobileNetV1 onto a lower-dimensional subspace while preserving the maximum variance. To select the number of primary elements, 95% of the growing variance was maintained, ensuring minimal information loss while notably reducing dimensionality and computational cost^35^.
This procedure separates redundant or less instructive assignments, enhancing the signal-to-noise ratio, mitigating overfitting, improving model training efficiency, and decreasing memory running, a crucial factor for clinical implementation. Consequently, PCA yields more compressed and interpretable feature sets by concentrating variance in a smaller number of principal components, thereby improving the effectiveness of the subsequent classifier^39^.
From a clinical perspective, combining ViT and MobileNetV1 yields a powerful, complementary feature-extraction system. MobileNetV1 efficiently extracts local, texture-based patterns using its lightweight depthwise convolutions, making it highly effective at capturing fine-grained details, such as microcalcifications and lesion margins. In parallel, ViT excels at modeling long-range, global dependencies through its self-attention mechanism, thereby integrating contextual information across the entire image, including structural asymmetries and tissue distribution patterns.
Within the proposed hybrid DL framework, this dual approach ensures a comprehensive analysis by capturing both localized details and global context. This synergy contributes significantly to a more accurate, robust, and explainable BC diagnosis, providing a solid foundation for scalable, real-time clinical systems.
Feature fusion
Feature-level fusion functions are employed at a higher abstraction level than pixel-based techniques, combining extensive semantic information from multiple sources^53^. Our proposed DL framework for multiclass classification employs feature-level fusion to integrate the advantages of MobileNetV1 and the ViT Transformer. After feature extraction, the feature vectors from each model are aggregated to obtain a cohesive representation. The mathematical formulation for the fused feature vector is provided in Supplementary Material S2. The resulting unified feature vector integrates both granular and contextual cues, enhancing multi-class BC classification.
The proposed hybrid framework fuses MobileNetV1 and ViT to support their complementary strengths. MobileNetV1, a lightweight CNN, is productive in capturing fine-grained local features relevant to mammographic analysis. In contrast, ViT employs a self-attention mechanism to capture long-range domination and contextual connections across the entire image. The integration of these two architectures enables the framework to benefit from both precise local feature extraction and global contextual understanding.
While other hybrid models, such as ViT combined with EfficientNet or ResNet, could attain similar performance, MobileNetV1 was selected due to its computational efficiency and suitability for deployment in resource-constrained clinical environments. Previous studies have similarly highlighted the advantage of combining multiple feature extraction techniques and fusion strategies in medical image classification^54^, demonstrating enhanced performance and robustness.
Detecting subtle mammographic features, such as microcalcifications and architectural distortions, is extremely challenging in dense breast tissue or early-stage lesions. The proposed hybrid framework addresses these challenges by combining MobileNetV1, which captures fine-grained local features, with a ViT that models global context and long-range dependencies. Image preprocessing techniques, such as CLAHE, enhance local contrast and improve the visibility of subtle features. Additionally, data augmentation increases model robustness to variations in tissue density and imaging conditions. XAI methods, including Grad-CAM and Grad-CAM++, enable the visualization of regions that influence model predictions, ensuring that clinically relevant, subtle features are effectively considered.
Once the fused features are obtained, they are given into a robust classification stage designed to efficiently handle high-dimensional, multi-class data. The combination of MobileNetV1, ViT, and Bagging LR forms a complementary and synergistic pipeline: MobileNetV1 captures fine-grained local features, ViT models global contextual relationships, and bagging LR combines these features into robust, stable, and interpretable predictions. Together, these components ensure comprehensive feature representation, accurate multi-class BI-RADS classification, and improve model generalization, addressing challenges such as class imbalance and intra-class variability.
Classification
After integrating feature representations from MobileNetV1 and the ViT Transformer to create a full feature set, the proposed framework proceeds to the classification step using a Bagging ensemble^37^. This design was selected for multiple reasons: the extracted deep features exhibit high discriminative power, enabling a straightforward linear model such as logistic regression to effectively learn class boundaries without increasing network complexity, thereby minimizing the risk of overfitting on moderately sized datasets while delivering well-calibrated probability outputs for ensemble aggregation. Bagging (Bootstrap Aggregating) trains several LR models on distinct bootstrap samples, thereby reducing variance and enhancing stability, which is especially crucial for high-dimensional fused features, where individual logistic regression models may be susceptible to data volatility^38^.
While LR may theoretically manage high-dimensional data, training directly on unprocessed fused features may be computationally demanding; employing PCA for dimensionality reduction allows LR to function effectively by retaining the most useful elements, so improving both performance and efficiency. LR maintains interpretability owing to its linear characteristics, and although bagging marginally diminishes the interpretability of individual models, it greatly enhances resilience and generalization^40^.
Despite LR being linear, the integration of MobileNetV1 and ViT features encapsulates nonlinear interactions, rendering LR appropriate for classifying these deep characteristics. Multiple traditional classifiers, such as SVM and RF, were assessed within the identical fused feature space. LR has consistently demonstrated competitive performance while offering enhanced stability and reduced model complexity, which justifies its inclusion in the proposed framework. Our investigations have shown that Bagging LR achieves performance equivalent to, or superior to, that of softmax or CNN classifiers trained on identical features, underscoring its suitability for medical imaging tasks.
Each base learner predicts class probabilities, and the final decision is determined via majority voting across all LR classifiers. The mathematical formulation for this ensemble method is provided in Supplementary Material S3. The integration of LR with bagging efficiently mitigates intra-class variability, class imbalance, and diverse feature distributions in the KAUBC dataset, yielding a robust and generalizable classifier for BC diagnosis.
Experimental results
Dataset description
This research used the KAUBC dataset^41^, a publicly available, real-world clinical dataset designed to enhance BC detection and classification research. The dataset was collected from the Sheikh Mohammed Hussein Al-Amoudi Center of Excellence in BC, affiliated with King Abdulaziz University in Jeddah, Saudi Arabia, and spans the period from April 2019 to March 2020. The KAUBC dataset contains more than 6,000 digital mammograms from 1,416 patients, spanning various breast conditions and BI-RADS assessment categories.
The images were labeled and verified by experienced radiologists according to clinical reports and the standardized BI-RADS lexicon, ensuring reliable ground truth annotations and facilitating the development and evaluation of CAD systems with high ACC. Each patient’s record contains bilateral 2D mammograms captured in two standard views: CC and MLO for each breast. The images are provided in DICOM format, preserving high spatial resolution and diagnostic detail for comprehensive analysis using DL techniques.
The KAUBC dataset comprises authentic clinical screening data, as opposed to synthetic or simulated images. All mammograms underwent anonymization before release, with no personally identifiable information included, thereby ensuring adherence to ethical standards and patient privacy regulations. Ethical approval was secured from the originating institution during data collection, and the dataset is provided exclusively for research purposes. The KAUBC dataset comprises 1,416 female patients aged 25-75 years, with a mean age of 48.3 years. The distribution of patients by age group is as follows: 212 patients (15%) are under 40 years of age, 906 patients (64%) are between 40 and 60 years of age, and 298 patients (21%) are over 60 years of age. All patients originate from the Jeddah region of Saudi Arabia, potentially introducing geographic and demographic bias in the dataset.Table 2. The description of the KAUBC dataset.BI-RADS categoryNumber of imagesNumber of casesAge range (mean)Breast density distribution (%)0 (Incomplete)44011030–80 (55)10% Low, 30% Mild, 40% Moderate, 20% High1 (Normal)188447130–79 (52)5% Low, 25% Mild, 50% Moderate, 20% High2 (Benign)325081232–77 (50)4% Low, 28% Mild, 47% Moderate, 21% High3 (Probably Benign)3879034–78 (53)6% Low, 24% Mild, 46% Moderate, 24% High4 (Suspicious)1022635–76 (56)2% Low, 15% Mild, 50% Moderate, 33% High5 (Malignant)24638–72 (58)0% Low, 10% Mild, 40% Moderate, 50% High
To mitigate information leakage and guarantee an unbiased evaluation, the KAUBC dataset was divided at the patient level into training and test sets, adhering to an 80–20 ratio. All mammograms from an individual patient were assigned to a single subset, ensuring that images from the same patient were not present in both the training and test sets. This patient-level splitting mitigates the risk of overoptimistic performance estimates that may occur if the model encounters similar patterns from the same patient during training.
Compliance with this procedure was verified through programming, confirming that patient identifiers in the training and test sets are disjoint, thereby ensuring a clinically meaningful assessment of the proposed MobileNetV1–ViT framework. KAUBC, like many real-world medical imaging datasets, exhibits class imbalance across BI-RADS categories, especially for suspicious and malignant cases. A stratified five-fold cross-validation strategy was utilized to ensure reliable evaluation by preserving representative class distributions across all folds. Table 2 presents the dataset characteristics. Our study focused on images categorized as BI-RADS 1, 3, 4, and 5, which denote normal, probably benign, suspicious for malignancy, and malignant findings, respectively.
Figure 5 illustrates representative sample images from the KAUBC dataset. This figure highlights the diversity of mammographic appearances across BI-RADS categories, demonstrating variations in tissue density, lesion size, contrast, and morphology. These variations underscore the challenges inherent in multi-class BC classification and underscore the need for robust, discriminative feature extraction strategies.Fig. 5. Examples representing the four BI-RADS categories included in the KAUBC dataset: (a,b) Normal, (c,d) Malignant, (e,f) Probably Benign, and (g,h) Suspicious Malignant in both CC&MLO image views.
Performance evaluation
To thoroughly assess the performance of the proposed DL model for multi-class BC classification, a set of evaluation metrics was employed, presented in Eqs. (1)–(8). These metrics provide a comprehensive view of the model’s effectiveness, capturing overall ACC, the ability to correctly identify positive and negative cases, and consistency across classes. The key metrics include:
- ACC The ratio of correctly classified cases to the total number of cases^55^.
where TP (True Positives) and TN (True Negatives) denote accurately classified cases, whereas FP (False Positives) and FN signify misclassified examples.
- SEN / Recall The proportion of TP cases correctly identified^55^.
- SPE The proportion of TN cases correctly identified^55^:
- Precision The fraction of predicted positive cases that are actually positive^55^:
- F1-Score The harmonic mean of precision and SEN^55^:
- Receiver Operating Characteristic (ROC) Curve Plots the true positive rate (TPR) against the false positive rate (FPR), which is \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$1 - \text {TNR}$$\end{document} . It is widely used in radiology to evaluate diagnostic performance^56^:
- Area Under the ROC Curve (AUC) Quantifies the classifier’s ability to distinguish between classes. Higher AUC indicates better discrimination^57^:
- Balanced Accuracy (BACC) Addresses class imbalance by averaging SEN and SPE across all classes^55^:
The use of these metrics ensures a holistic evaluation of the proposed DL model. This multi-metric assessment provides critical insights into the model’s strengths and limitations, particularly in BC classification, where high SEN and SPE are essential for reliable diagnosis and treatment planning.
Results
In this section, we present the experimental results of the proposed framework and compare its performance with that of a range of DL architectures, hybrid CNN+ViT models, and traditional classifiers. Furthermore, we analyze the impact of the proposed framework’s components by evaluating the standalone performance of MobileNetV1, its performance with feature reduction and ensemble classifiers, and the effects of various optimization strategies on overall ACC and computational efficiency.
The computational complexity of the proposed framework was assessed on a personal workstation utilizing Anaconda Python 3.1, equipped with an Intel Core i5 CPU (4–6 cores, 2.4–3 GHz) and 16 GB of RAM. MobileNetV1 is a lightweight convolutional neural network (CNN) comprising approximately 3.2 million parameters and 0.57 GFLOPs, facilitating efficient local feature extraction in resource-constrained clinical settings. ViT-B/16, with over 86 million parameters and 17.6 GFLOPs, effectively captures global contextual information in mammographic images. The Swin Transformer (Swin-Tiny), comprising 28 million parameters and 4.5 GFLOPs, employs hierarchical attention to balance local and global feature modeling while maintaining a moderate computational cost.
Feature extraction is conducted independently utilizing pre-trained MobileNetV1, ViT, and Swin models, followed by feature-level fusion and bagging ensemble classification. This method circumvents end-to-end joint training, thereby decreasing computational demands while utilizing complementary local, global, and hierarchical representations.
Average inference latency was assessed on the test set at full image resolution, and memory usage was tracked, validating the framework’s appropriateness for practical clinical applications. Table 3 summarizes the computational analysis, detailing parameters, FLOPs, model size, inference time, and memory usage for each component, thereby demonstrating the framework’s efficiency and usability in practical applications. The proposed hybrid framework exhibits moderate computational complexity, leveraging ViT’s representational capabilities while avoiding end-to-end joint training. Feature-level fusion and Bagging ensemble classification incur negligible additional computational overhead relative to fully integrated deep architectures.Table 3. The estimated computational efficiency of the proposed hybrid framework components, including MobileNetV1, ViT-B/16, Swin Transformer Tiny, and the proposed hybrid model. Metrics include number of parameters, floating point operations (FLOPs), model size, inference time, and memory footprint based on experiments on a personal workstation with Intel Core i5 CPU and 16 GB RAM.ModelParams (M)FLOPs (G)Size (MB)Inference (ms/img)Remarks / Memory (MB)MobileNetV13.20.5712 50–70Lightweight CNN; approximate memory: 50–60 MBViT-B/168617.6330 400–500Global feature modeling; approximate memory: 1200–1300 MBSwin-T (Tiny)284.590 150–200Hierarchical local-global attention; approximate memory: 400–450 MBProposed Hybrid8918.2342 450–550Feature-level fusion; no end-to-end training; approximate memory: 1250–1350 MB
We performed an extensive evaluation process to determine the most effective DL methodology for BC diagnosis. Several pre-trained CNN architectures, including EfficientNetB0, DenseNet121, InceptionV3, MobileNetV1/V2, InceptionResNetV2, and VGG16/VGG19, were systematically compared using the KAUBC dataset to identify the optimal feature extractor for accurate BC classification. To mitigate overfitting and guarantee reliable performance assessment, a 5-fold cross-validation strategy was utilized during the experimental procedure. The objective was to assess the proposed framework against selected existing methods and to evaluate its diagnostic performance using the KAUBC dataset. Various regularization techniques, including dropout and early stopping, were used during model training. Dropout was applied at multiple network layers to mitigate overfitting associated with specific neuron activations.
Simultaneously, early stopping was implemented to terminate training when validation performance ceased to improve, thus enhancing generalization to unseen data. The 5-fold cross-validation implementation reinforced this objective by minimizing variance and improving model generalization. Among the pre-trained models, MobileNetV1 achieved the highest independent ACC (97%), followed by VGG16 (96.9%) and MobileNetV2 (96.4%), indicating that lightweight architectures enhance BC detection. Table 4 provides an evaluation of pretrained models, outlining their effectiveness in BC classification.
After identifying the most optimistic pre-trained models, we conducted a systematic investigation to examine how different classifiers affected overall diagnostic performance for BC detection. Different ML classifiers were applied, like DT, RF, KNN, Gradient Boosting (GB), LR, and SVMs with various kernels (linear, radial basis function (RBF), and polynomial). Each classifier was paired with the extracted features from the pretrained models to evaluate their combined performance and determine whether any classifier could further enhance the models’ discriminative capability. The SVM achieved the highest classification accuracy with the RBF kernel (94.7%), MobileNetV1 (93.1%), and DenseNet121 (93.1%).Table 4. The performance comparison of various pre-trained models for breast cancer classification.ModelPRE (%)SEN (%)SPE (%)F1-Score (%)ACC (%)BACC (%)EfficientNetB090.591.095.291.090.893.1DenseNet12195.594.798.296.094.796.5InceptionV394.594.098.095.093.996.0MobileNetV197.797.199.097.297.098.1MobileNetV297.094.498.897.096.496.6InceptionResNetV295.094.598.195.094.496.3VGG1697.296.998.997.296.997.9VGG1995.294.698.295.594.696.4
The detailed results of all pre-trained models integrated with different classifiers are presented in Table 5, which indicates that the selection of the classifier significantly influenced the overall classification ACC. Some models, such as MobileNet, exhibit improved performance when combined with specific classifiers, such as SVMs, highlighting the synergistic interaction between feature extractors and classifiers. These findings highlight the importance of investigating the interaction between pre-trained models and classifier selection to achieve the maximum diagnostic ACC in BC diagnosis.
In the next phase, we examined the chance of merging Swin transformers with the most effective pre-trained CNN models identified in the earlier experiments. We hypothesized that the Swin Transformer’s ability to capture long-range dependencies in mammographic images could further enhance BC detection ACC. All ensemble models were evaluated under the same 5-fold cross-validation protocol to ensure consistent and unbiased performance comparison. Each ensemble model, formed by combining a pretrained CNN with Swin, was evaluated using the same set of classifiers applied previously to determine which classifier best leveraged the complementary strengths of both architectures.Table 5. The performance comparison of various pre-trained models with different classifiers for breast cancer classification.ModelClassifierPRE (%)SEN (%)SPE (%)F1-Score (%)ACC (%)BACC (%)EfficientNetB0SVM (Linear)90.390.296.390.290.293.3SVM (Poly)89.388.795.788.888.792.2SVM (RBF)90.289.896.189.889.392.9DT73.173.090.273.073.081.6RF86.586.194.886.286.190.5MLP88.381.295.380.280.288.3KNN83.782.893.883.082.888.3GB85.585.194.485.285.189.8LR86.986.695.086.686.690.8DenseNet121SVM (Linear)91.591.496.891.491.494.1SVM (Poly)93.192.897.292.892.895.0SVM (RBF)93.393.197.393.093.195.2DT75.975.991.375.975.983.6RF90.090.096.290.090.093.1MLP93.093.097.493.093.095.2KNN93.093.097.093.093.095.0GB89.389.195.989.189.192.5LR90.890.796.590.790.793.6InceptionV3SVM (Linear)89.489.396.089.289.392.7SVM (Poly)91.090.596.390.590.593.4SVM (RBF)91.891.596.791.591.594.1DT74.674.590.974.674.582.7RF88.888.395.588.388.391.9MLP90.690.696.690.690.693.6KNN86.385.394.885.385.390.0GB88.087.795.387.787.791.5LR88.888.695.788.688.692.2MobileNetV1SVM (Linear)93.793.697.693.693.695.6SVM (Poly)94.894.697.894.594.696.2SVM (RBF)94.094.797.994.694.796.3DT80.380.292.880.280.286.5RF92.392.096.992.092.094.5MLP93.993.997.893.993.995.9KNN88.087.295.487.287.291.3GB91.791.596.791.591.594.1LR92.992.797.292.792.795.0ModelClassifierPRE (%)SEN (%)SPE (%)F1-Score (%)ACC (%)BACC (%)MobileNetV2SVM (Linear)94.294.297.894.194.296.0SVM (Poly)95.094.898.094.894.896.4SVM (RBF)95.195.098.094.995.096.5DT76.676.692.676.679.684.6RF92.492.196.992.192.194.5MLP93.893.897.793.793.895.8KNN90.189.696.389.689.693.0GB91.591.396.791.391.394.0LR93.393.297.493.293.295.3InceptionResNetV2SVM (Linear)88.187.995.587.987.991.7SVM (Poly)89.989.996.089.989.593.0SVM (RBF)90.990.596.490.590.593.45DT70.870.889.570.870.880.15RF87.486.995.086.986.990.95MLP89.989.996.389.989.993.1KNN84.082.593.882.682.588.15GB85.985.594.585.585.590.0LR87.086.795.086.886.790.85VGG16SVM (Linear)87.687.495.387.587.491.35SVM (Poly)88.888.095.388.188.091.65SVM (RBF)91.090.796.590.790.793.6DT74.874.790.974.774.782.8RF87.587.095.187.187.091.05MLP88.588.595.888.588.592.15KNN84.282.993.983.082.988.4GB85.985.594.585.685.590.0LR86.886.594.986.586.590.7VGG19SVM (Linear)87.487.295.287.287.291.2SVM (Poly)88.787.995.388.087.991.6SVM (RBF)90.990.596.490.690.593.45DT76.576.491.576.476.483.95RF87.086.594.986.686.590.7MLP89.189.196.089.189.192.55KNN84.783.594.183.683.588.8GB85.685.394.485.385.389.85LR86.586.294.886.386.290.5
Remarkable results were achieved by integrating different pre-trained models with Swin Transformers. The combination of MobileNetV2 with Swin and LR classifier achieved an impressive 98.5% ACC, while MobileNetV1 with Swin and LR achieved 98.4%. The performance of all CNN–ViT hybrid configurations across various classifiers is presented in Table 6, demonstrating the strong potential of these hybrid architectures for precise BC diagnosis. The proposed hybrid model significantly improved the accuracy and reliability of BC diagnosis from mammographic images by leveraging the strengths of each component.
Table 7 shows that highly approving outcomes were established. The integration of MobileNetV1, ViT, and a bagging LR classifier achieves a prominent overall ACC of 99%, surpassing all other tested architectures. This superior performance demonstrates the advantages of combining the local feature-extraction efficiency of MobileNetV1 with the global contextual representation learning of ViT, and the strong generalization capacity of bagging LR. This presentation balances precision and generalization by enabling the model to distinguish both fine structural features, such as variations in tissue texture and microcalcifications, and long-range relationships associated with the organization of breast tissue and lesion positioning.
The bagging ensemble further improves performance by averaging the predictions of many LR base methods. This reduces variation and enhances the model’s stability across folds. This ensemble technique is particularly effective for the imbalanced BI-RADS categories, as it reduces the probability of alignment toward more common classes while preserving SEN for high-risk, less normal classes. This study meticulously evaluated several combinations of pre-trained models, transformers, and ensemble classifiers, ultimately pinpointing a clear leader for clinical use. The MobileNetV1–ViT–Bagging LR configuration consistently outperformed the alternatives, indicating its potential as an effective and interpretable AI framework to assist radiologists in making early and precise BC diagnoses.
Table 8 summarizes the performance of the Bagging + LR model compared to SVM Linear for BI-RADS classification using deep features. The metrics are reported as the mean ± standard deviation across 5-fold cross-validation, with small standard deviations indicating stable, consistent performance. Bootstrap 95% confidence intervals were also computed, and the narrow intervals confirm the reliability and robustness of the model.Table 6. The performance comparison of different pre-trained CNN models combined with the SWIN Transformer using various classifiers for BC classification.ModelClassifierPRE (%)SEN (%)SPE (%)F1 (%)ACC (%)BACC (%)EfficientNetB0+SWINSVM (Linear)97.097.098.697.097.097.8SVM (Poly)89.688.995.889.088.992.4SVM (RBF)90.590.096.290.090.093.1DT79.379.192.379.279.185.7RF92.692.397.092.392.394.7MLP96.996.998.896.996.997.9KNN83.182.293.582.482.287.9GB95.094.998.094.994.996.5LR98.098.099.298.098.098.6DenseNet121+SWINSVM (Linear)97.297.298.897.297.298.0SVM (Poly)92.792.497.192.492.494.8SVM (RBF)93.192.997.392.892.995.1DT78.678.392.078.378.385.2RF92.392.096.992.092.094.5MLP97.497.499.097.497.498.2KNN86.985.895.085.885.890.4GB94.794.798.094.794.796.4LR98.398.399.398.398.398.8InceptionV3+SWINSVM (Linear)97.097.098.797.097.097.9SVM (Poly)91.791.296.691.291.293.9SVM (RBF)92.291.996.991.991.994.4DT81.081.093.081.081.087.0RF93.092.797.292.792.795.0MLP97.197.198.997.197.198.0KNN87.086.095.086.086.090.5GB95.295.198.195.195.196.6LR98.098.099.298.098.098.6MobileNetV1+SWINSVM (Linear)97.497.498.897.497.498.1SVM (Poly)94.894.597.894.594.596.2SVM (RBF)95.094.797.994.794.796.3DT79.679.492.579.479.486.0RF92.892.597.192.592.594.8MLP97.597.599.197.597.598.3KNN88.086.895.386.986.891.1GB95.395.298.195.295.296.7LR98.498.499.498.498.498.9ModelClassifierPRE (%)SEN (%)SPE (%)F1 (%)ACC (%)BACC (%)MobileNetV2+SWINSVM (Linear)97.597.598.897.597.598.2SVM (Poly)95.094.897.994.794.896.4SVM (RBF)95.094.998.094.894.996.5DT79.679.692.679.679.686.1RF92.692.397.092.392.394.7MLP97.097.098.997.097.098.0KNN90.089.796.389.789.793.0GB95.795.698.395.695.697.0LR98.598.599.498.598.599.0InceptionResNetV2+SWINSVM (Linear)96.696.698.596.696.697.55SVM (Poly)90.790.296.390.290.293.25SVM (RBF)91.991.596.891.491.594.15DT79.579.392.479.479.385.85RF92.692.397.092.392.394.65MLP96.296.298.696.296.297.40KNN84.082.693.982.682.688.25GB94.994.998.094.994.996.45LR97.997.999.297.997.998.55VGG16+SWINSVM (Linear)97.397.398.997.397.398.10SVM (Poly)88.387.695.287.787.691.40SVM (RBF)90.990.696.590.690.693.55DT79.579.592.679.579.586.05RF92.392.096.992.092.094.45MLP94.594.597.994.594.596.20KNN83.982.493.782.582.488.05GB95.295.198.195.195.196.60LR98.198.199.298.198.198.65VGG19+SWINSVM (Linear)96.896.898.796.896.897.75SVM (Poly)89.388.495.588.588.491.95SVM (RBF)91.290.996.690.990.993.75DT80.580.392.880.380.386.55RF92.792.397.092.392.394.65MLP94.594.598.094.594.596.25KNN83.782.693.882.782.688.20GB95.094.998.094.994.996.45LR98.098.099.298.098.098.60
Paired t-tests comparing Bagging LR with SVM Linear produced p-values exceeding 0.05 for all metrics, suggesting no statistically significant differences and underscoring the superior stability of Bagging LR. Furthermore, class-level AUC values are notably high (BI-RADS 1: 1.000, 3: 0.998, 4: 1.000, 5: 0.998), indicating exceptional discrimination across all categories, including rare and critical classes. The results indicate that the proposed model is robust, reproducible, and highly effective for multi-class BI-RADS classification. The proposed framework exhibits consistent performance across all BI-RADS classes, as summarized in Table 11 and illustrated in the confusion matrix (Fig. 6). This figure demonstrates the model’s ability to effectively differentiate among categories, with minimal misclassifications. This underscores the efficacy of the proposed feature fusion strategy and the Bagging LR classifier in addressing intra-class variability and alleviating class imbalance.
The results in Table 9 confirm the effectiveness of the hybrid framework within the KAUBC dataset, which combines Bagging with transformer-based models. The proposed structure effectively mitigates overfitting and addresses class imbalance. The configuration of MobileNetV1 with ViT and Bagging of LR yielded the highest ACC of 98.9% on this dataset among all tested integrations. The findings from the 5-fold cross-validation and the confusion matrix analysis validated the model’s stability under the assessed experimental conditions.
Table 10 presents the results of the ablation study assessing the role of each component in the proposed MobileNetV1–ViT framework. The results of single-backbone models demonstrate that ViT-only outperforms MobileNetV1-only across all evaluation metrics, highlighting the enhanced global representation ability of transformer-based features. Both individual models exhibit lower performance compared to the hybrid setups. The LR classifier implementation exhibits a notable performance drop, particularly with the MobileNetV1 backbone, underscoring the limited discriminative capacity of linear decision boundaries for complex mammographic features. The integration of PCA consistently enhances performance by reducing feature redundancy and improving generalization.
Each class achieved high values of ACC, SEN, SPE, and F1-score, confirming the model’s ability to differentiate between different BC risk levels. Notably, BI-RADS 4 (Suspicious Malignant) attained a recall of 98%, effectively reducing FNs in clinically high-risk cases. Furthermore, the Malignant and Likely Benign categories demonstrated near-optimal performance across the assessed metrics. Minor misclassifications predominantly occurred between clinically adjacent classes (e.g., Normal and Probably Benign), which exhibit overlapping imaging characteristics due to subtle visual differences, variations in tissue density, or borderline lesion appearance; nonetheless, no systematic or biased error patterns were detected.
The MobileNetV1 + ViT + PCA + Bagging framework was assessed through 5-fold cross-validation with various random seeds. Table 12 presents the performance metrics for each fold, encompassing ACCC, Precision, Recall, F1-Score, BACC, and the average SEN and SPE across all BI-RADS classes. The model demonstrates consistently high performance across all folds, with fold-wise accuracy ranging from 97.9% to 98.1% and an F1-Score of approximately 97.9%. The slight variations observed across folds reflect inherent differences in the training and test splits, suggesting that the model’s performance is stable and not dependent on any particular split.
The average ACC across folds is 98%, with a peak overall performance of 99% achieved through the optimal combination of random seed and fold. This indicates that the model achieves high accuracy in multi-class classification, while the marginally lower fold-wise averages provide a realistic evaluation of stability and generalization. The results demonstrate that the proposed framework achieves reliable, reproducible classification performance, with no evidence of overfitting or data leakage.
Table 13 compares the proposed hybrid approach with selected state-of-the-art models on the KAUBC dataset. The results demonstrate that our method achieves superior performance across multiple metrics, including accuracy, sensitivity, specificity, and XAI-enabled multi-class BI-RADS support.Table 7. The comparison of performance metrics for various pre-trained CNN models combined with the ViT Transformer using different classifiers for breast cancer classification.ModelClassifierPRE (%)SEN (%)SPE (%)F1 (%)ACC (%)BACC (%)EfficientNetB0+ViTSVM (Linear)98.498.499.398.498.498.9SVM (Poly)91.190.596.390.690.593.4SVM (RBF)93.192.897.292.792.895.0DT88.988.996.088.988.992.5RF96.396.298.596.196.297.4MLP98.198.199.398.198.198.7KNN83.982.993.883.082.988.4GB97.897.899.197.897.898.5LR98.498.499.498.498.498.9Bagging98.498.499.398.498.498.9DenseNet121+ViTSVM (Linear)98.098.099.198.098.098.6SVM (Poly)93.593.297.493.293.295.3SVM (RBF)93.893.697.593.593.695.6DT88.688.595.888.588.592.2RF96.696.498.696.496.497.5MLP98.198.199.398.198.198.7KNN87.386.195.186.286.190.6GB97.497.499.097.497.498.2LR98.298.299.398.298.298.8Bagging97.997.999.197.997.998.5InceptionV3+ViTSVM (Linear)97.897.899.297.897.898.5SVM (Poly)93.493.097.393.093.095.2SVM (RBF)94.794.597.994.494.596.2DT88.588.495.888.488.492.1RF96.496.298.596.196.297.4MLP98.198.199.398.198.198.7KNN87.686.595.286.586.590.9GB97.497.499.097.497.498.2LR98.198.199.398.198.198.7Bagging98.298.299.398.298.298.8MobileNetV1+ViTSVM (Linear)98.498.499.398.498.498.9SVM (Poly)95.194.897.994.794.896.4SVM (RBF)95.495.198.095.095.196.6DT89.088.996.088.988.992.5RF96.696.498.696.496.497.5MLP98.398.399.398.398.398.8KNN88.287.095.487.187.091.2GB97.597.599.097.597.598.3LR98.998.999.698.998.999.3Bagging99.099.099.599.099.099.3ModelClassifierPRE (%)SEN (%)SPE (%)F1 (%)ACC (%)BACC (%)MobileNetV2+ViTSVM (Linear)98.298.299.398.298.298.8SVM (Poly)95.395.198.195.195.196.6SVM (RBF)95.595.498.295.495.496.8DT89.789.696.289.689.692.9RF96.496.298.596.296.297.4MLP98.198.199.398.198.198.7KNN90.690.096.490.090.093.2GB97.697.699.097.697.698.3LR98.398.399.498.398.398.9Bagging98.398.399.398.398.398.8InceptionResNetV2+ViTSVM (Linear)98.198.199.298.198.198.7SVM (Poly)92.892.497.092.392.494.7SVM (RBF)93.593.297.493.293.295.3DT89.389.296.189.389.392.7RF96.496.298.596.296.297.4MLP97.997.999.297.997.998.6KNN85.183.594.283.583.588.9GB97.597.599.097.597.598.3LR98.498.499.498.498.498.9Bagging98.298.299.298.298.298.7VGG16+ViTSVM (Linear)98.498.499.398.498.498.9SVM (Poly)88.487.795.387.787.791.5SVM (RBF)91.491.196.691.191.193.9DT90.290.296.490.290.293.3RF96.396.198.496.096.197.3MLP96.496.498.796.496.497.6KNN83.982.493.782.582.488.1GB97.497.499.097.497.498.2LR98.798.799.598.798.799.1Bagging98.798.799.398.798.799.0VGG19+ViTSVM (Linear)98.498.499.498.498.498.9SVM (Poly)89.488.695.688.788.692.1SVM (RBF)91.991.596.891.591.594.2DT90.190.096.490.090.093.2RF96.796.598.696.596.597.6MLP95.795.798.495.795.797.1KNN83.882.693.882.782.688.2GB97.397.399.097.397.398.2LR98.198.199.398.198.198.7Bagging98.498.499.398.498.498.9Table 8The comprehensive evaluation of the proposed Bagging + LR model for BI-RADS classification using deep features. Performance metrics are reported as mean ± standard deviation across 5-fold cross-validation, along with 95% bootstrap confidence intervals. Paired t-tests were conducted against the baseline SVM (Linear), and class-level AUC values are also reported.MetricBagging + LRBootstrap 95% CISVM Baselinep-valueAUC per classACC0.9802 ± 0.00180.9782 – 0.98370.9808 ± 0.00370.6805–Precision0.9801 ± 0.00180.9784 – 0.98360.9808 ± 0.00370.6495–Recall0.9802 ± 0.00180.9781 – 0.98360.9808 ± 0.00370.6805–F1-score0.9801 ± 0.00180.9783 – 0.98360.9807 ± 0.00370.6666–SPE0.9914 ± 0.00090.9904 – 0.99300.9917 ± 0.00190.6749–AUC (per class)––––BI-RADS 1: 1.000, 3: 0.998, 4: 1.000, 5: 0.998Table 9The hyperparameter settings for the ViT Transformer and MobileNetV1 models used in the breast cancer classification experiments. Data augmentation included rescaling, rotation, flipping, and intensity adjustments. Early stopping was applied with a patience of 5 based on the validation loss.HyperparameterViT TransformerMobileNetV1Learning Rate0.000010.001OptimizerAdamWSGDWeight Decay0.010.001Dropout Rate0.10.5Batch Size3232Epochs50 (with early stopping)50 (with early stopping)Loss FunctionCategorical Cross-EntropyCategorical Cross-EntropyPatch Size4 \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\times$$\end{document} 4—Window Size7 \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\times$$\end{document} 7—Table 10. The ablation study evaluating the contribution of different components in the proposed MobileNetV1–ViT framework. Results are reported as mean ± standard deviation across five-fold cross-validation.Model VariantACC (%)SEN (%)SPE (%)PrecisionF1-scoreBACC (%)MobileNetV1 only9797.199989898.5ViT only98.598.899.2999999MobileNetV1 + LR92.792.797.292.992.795ViT + LR98.7989998.898.998.5MobileNetV1 + PCA + LR9493.998949494MobileNetV1 + ViT + PCA + LR98.398.399.498.398.398.8MobileNetV1 + ViT + PCA + SVM98.198.199.398.298.298.6MobileNetV1 + ViT + PCA + Bagging (Ours)999999.5999999.3Table 11. The per-class performance metrics for the classification model.ClassPRE (%)SEN (%)SPE (%)F1-Score (%)ACC (%)BACC (%)Malignant100100100100100100Normal9898100989899Probably Benign99100100100100100Suspicious Malignant999899989898.5
Fig. 6(a) The confusion matrix illustrating the multi-class BI-RADS classification performance of the proposed framework on the KAUBC dataset, highlighting correct predictions and limited misclassifications between clinically adjacent categories. (b) The class-wise ROC curves demonstrating the diagnostic discrimination capability of the proposed model across different BI-RADS categories. Table 12. The evaluation metrics of the proposed model across 5-fold cross-validation. Average SEN and SPE are calculated across all BI-RADS classes.FoldACC (%)Precision (%)Recall (%)F1-Score (%)Balanced Acc (%)SEN (%)Avg SPE (%)Fold-197.9197.9197.9197.9098.6998.3599.05Fold-297.8697.8597.8697.8598.5798.2098.95Fold-398.3598.3698.3598.3598.9898.5099.10Fold-498.0097.9998.0098.0098.6698.3599.07Fold-597.9697.9597.9697.9598.6398.4099.00 Average 98.0298.0398.0298.0398.7198.3699.03 Table 13. The comparative evaluation of the proposed hybrid approach against selected state-of-the-art models on the KAUBC dataset.StudyModel/architectureDataset usedKey performance metricsEskandari et al. ^58^MobileNetV1 + ViT TransformerIDC histopathological imagesValidation ACC: 93%.Alotaibi et al. ^22^ViT + DeiT (Ensemble by Averaging)BreakHis datasetACC: 98.17%; F1-score: 98.12%.Ahmed et al. ^19^MAX-ViT + GAFM + HHO + XGBoostKAUBC mammogramsACC: 98.2%; Precision: 98.0%; Recall: 98.1%; F1-score: 98.0%; AUC: 98.9%; MCC: 95%.Wani et al. (2024)^33^Hybrid CNN + LightGBM with SHAP explanationsReal-world BC datasetACC: 98.3%; Precision: 98.7%; SEN: 98.7%; F1: 0.987; Binary BC classification, XAI-enabled. Proposed Method
MobileNetV1 + ViT Transformer + Bagging (LR)
KAUBC mammograms
ACC: 99.0%; SEN: 99.0%; SPE: 99.5%; Multi-class BI-RADS support; XAI-enabled.
Analysis of misclassified cases
We conducted an analysis of representative misclassified samples generated by the Bagging + LR classifier to gain a deeper understanding of the proposed framework’s behavior. Table 14 and Fig. 7 demonstrate that the majority of misclassifications arise in visually ambiguous scenarios, characterized by dense tissue or low-contrast lesions, which result in partial activation discrepancies in the Grad-CAM maps. Misclassifications predominantly occurred between adjacent BI-RADS categories, particularly between Normal, Probably Benign, and Suspicious Malignant, highlighting the challenges of differentiating subtle or borderline mammographic findings. These errors are frequently linked to dense breast tissue, low-contrast or small lesions, and subtle calcifications, which pose detection challenges even in clinical practice.
This error analysis demonstrates that the identified misclassifications are clinically plausible and align with established diagnostic challenges in mammography interpretation. Borderline cases underscore situations in which additional clinical context or expert evaluation may be necessary, underscoring the need for careful interpretation in automated BC diagnosis systems.Table 14. The misclassified mammogram cases corresponding to the Grad-CAM visualizations shown in Fig. 7.IndexTrue labelPredicted labelObservation777Probably BenignSuspicious MalignantDense fibroglandular tissue mimicking suspicious patterns133Suspicious MalignantProbably BenignLesion boundary partially obscured by surrounding tissue161Suspicious MalignantNormalLow-contrast lesion with weak visual saliency806MalignantSuspicious MalignantDiffuse mass appearance causing uncertainty in risk level43Suspicious MalignantProbably BenignAttention spread over dense tissue rather than lesion core
Fig. 7. The representative XAI visualizations for misclassified mammogram cases.
Explainability and ethical considerations using Grad-CAM and Grad-CAM++
Grad-CAM and Grad-CAM++ visualization tools were utilized to demonstrate the application of the proposed hybrid DL model and to elucidate its decision-making process. The techniques generate class-discriminative heatmaps that highlight regions in mammography images that significantly influence the model’s classification results^27^. Visual explanations enable radiologists to correlate the model’s focus areas with their clinical knowledge, thereby improving trust and interpretability in AI-assisted diagnosis.
The examination of Grad-CAM and Grad-CAM++ heatmaps across different BI-RADS categories demonstrated the model’s ability to highlight clinically relevant features. In patients with malignant conditions, both methods reveal significant activation in areas with rare masses and clustered calcifications, aligning with radiological annotations of malignancy. This alignment demonstrates that the model’s predictions are based on medically relevant patterns rather than extraneous visual artifacts. In contrast, the benign class heatmaps demonstrated significant activation in dense parenchymal areas, without focusing on isolated mass-like features. This is consistent with radiologists’ views on benign conditions.
Grad-CAM and Grad-CAM++ showed low activation across the entire breast region in normal images, which was appropriate given the lack of abnormal tissue patterns. In the comparison of the two methods, Grad-CAM demonstrated enhanced localization of suspicious areas, effectively balancing computational efficiency and diagnostic relevance. Grad-CAM++ enhanced localization and increased SEN at subtle lesion boundaries, effectively demonstrating that the proposed model focuses on clinically significant areas, such as masses, calcifications, and tissue asymmetries, thereby offering visual interpretability and improving relevant indicators.
The model’s visual interpretability increases confidence in its predictions and supports its incorporation into clinical workflows, where explainable artificial intelligence is crucial for diagnostic validation. Figure 8 illustrates the Grad-CAM and Grad-CAM++ heatmaps corresponding to the four BI-RADS classes. This figure illustrates the proposed model’s emphasis on clinically significant areas, including masses, calcifications, and tissue asymmetries, thereby enhancing visual interpretability and reinforcing the reliability of model predictions within a diagnostic framework.
Ethical considerations are essential in the application of medical AI. The incorporation of XAI techniques, including Grad-CAM and Grad-CAM++, enhances trust by visually highlighting the regions that affect model predictions, enabling clinicians to confirm that the model targets pertinent mammographic features. In this study, a seasoned radiologist evaluated the model outputs to validate the clinical significance of the highlighted regions. Ethical concerns, including data privacy, annotation transparency, and the responsible use of AI in clinical decision-making, are examined. The KAUBC dataset has been fully anonymized, and all experiments adhere to institutional ethical standards. XAI plays a crucial role in enhancing interpretability, accountability, and the safe deployment of AI-based BC screening tools.Fig. 8. The representative Grad-CAM and Grad-CAM++ heatmaps for malignant, suspicious malignant, benign, and normal mammogram images. Warmer colors (red, orange, and yellow) indicate stronger model attention and higher diagnostic relevance, while cooler colors (green and blue) indicate lower activation.
Discussion
This section evaluates the performance of several pre-trained DL models, classifiers, and their fusion for BC classification on mammographic images within the proposed DL framework. A series of assessments was conducted to compare various feature-extraction architectures, including Inception, MobileNet, VGG, InceptionResNetV2, DenseNet, EfficientNet, ViT Transformers, and Swin Transformers.
We employed various ML classifiers on these models to evaluate their effectiveness in distinguishing among distinct BI-RADS categories in mammography scans. The results presented in Table 4 provide valuable insights into each model’s effectiveness at identifying discriminative features. The subsequent transformer-augmented configurations represent the most dependable diagnostic setups. All pre-trained CNNs exhibited a trade-off between computational efficiency and diagnostic ACC. Deep architectures, such as VGG, effectively capture complicated texture patterns; however, they require substantial computational resources. Lightweight variants, such as MobileNet, achieve an optimal balance between precision and efficiency, making them suitable for real-time clinical applications. The proposed system selected MobileNet as the primary feature extractor due to its favorable trade-off between high diagnostic accuracy and low computational cost. While it may not identify as many subtle patterns as more complex networks, its speed and ACC render it a suitable option for practical medical imaging applications.
The connection between classifiers and the features extracted influenced the overall validation of the diagnosis. Table 5 illustrates that specific fusion, especially MobileNetV1 with SVM, gave strong results on the KAUBC dataset, highlighting the relevance of carefully selecting classifier–model connections. In our experiments, SVMs outperformed alternative classifiers when integrated with transformer-enhanced features, likely due to their ability to handle high-dimensional feature spaces and to generate effective decision boundaries within the evaluated dataset.
The incorporation of Vision and Swin Transformers significantly improved categorization ACC by leveraging their ability to capture long-range dependencies and global contextual information, complementing the strengths of CNNs in obtaining localized spatial details. Tables 6 and 7 indicate that Swin Transformers outperformed traditional ViT Transformers. The sequence design likely enables the learning of features at varying scales, thereby facilitating more accurate spatial performance. The proposed dual-stream architecture, combining MobileNetV1 with ViT, leverages the strengths of both CNNs and transformers to enhance mammogram interpretation.
In this configuration, MobileNetV1 effectively identified small local features critical for detecting microcalcifications and focal abnormalities. ViT effectively captured a broader global context, enhancing our understanding of tissue structures. This hybrid integration enabled the precise identification of both minor lesions and significant issues, thereby enhancing overall diagnostic ACC. ViT Transformers typically require large datasets to generalize effectively because they lack categorical alignment. However, integrating structural priors from CNNs reduces this issue. The MobileNetV1–ViT hybrid achieved superior efficiency in distinguishing benign from malignant instances, thereby enhancing both diagnostic interpretation and ACC. The hybrid MobileNetV1–ViT architecture achieved significant performance gains when combined with a bagging classifier.
Bagging improved model performance by aggregating predictions from multiple base learners, reducing overfitting, and yielding more stable results on the KAUBC dataset. This ensemble technique enhanced feature diversity and increased model robustness, achieving high ACC across malignant, normal, probably benign, and suspicious malignant categories in the evaluated dataset, as shown in Table 5.
The proposed framework focuses on image-level BI-RADS classification rather than explicit lesion detection; however, the hybrid CNN–Transformer architecture enables the model to attend to multiple spatially distinct regions within a single mammogram. Grad-CAM and Grad-CAM++ visualizations demonstrate that, in cases of heterogeneous or multifocal abnormalities, the model can simultaneously focus on multiple suspicious regions. This indicates a strong capability in managing mammograms that may include multiple small tumors, although the current study does not address lesion-level localization and enumeration.
This study emphasized the significance of explainability. We employed Grad-CAM and Grad-CAM++ visualizations to elucidate the model’s decision-making process on the KAUBC dataset. The heatmaps generated by this methodology indicate that the model primarily focuses on regions corresponding to irregular masses and clustered calcifications within this dataset. Grad-CAM offered a broad yet characteristic set of features, whereas Grad-CAM++ produced more detailed and precise attention maps, facilitating the identification of lesion boundaries and subtle changes in the evaluated cases. The results suggest that the proposed approach demonstrates interpretability aligned with the diagnostic patterns observed by experienced radiologists in this dataset.
The KAUBC dataset offers annotations solely in BI-RADS categories, lacking histopathological or molecular BC subtype labels such as Luminal A/B, HER2-positive, or triple-negative. Thus, the performance evaluation in this study focuses on radiological risk assessment rather than subtype-specific diagnosis, an area of significant future research that could leverage datasets with more comprehensive clinical annotations.
Although we report ACC, SEN, SPE, and F1-score to evaluate model performance, we acknowledge that additional metrics, such as Matthews correlation coefficient (MCC) and AUC, could offer further insights, particularly in the context of imbalanced datasets. These metrics can complement traditional measures and provide a more comprehensive assessment of model effectiveness; their inclusion is therefore suggested for future studies.
The lightweight design of MobileNetV1, in conjunction with transformer-based feature fusion, facilitates efficient inference from a clinical deployment perspective. The proposed framework enables rapid image processing, facilitating the analysis of a complete four-view mammographic examination (CC and MLO for both breasts) in less than 1 second on standard GPU hardware. This throughput level facilitates the potential incorporation of the system into standard clinical decision-support workflows.
The reported performance is based on cross-validation results from a clinically curated BI-RADS dataset and does not necessarily generalize to all real-world screening populations without additional external validation. Although the results are promising, implementing the MobileNetV1–ViT–Bagging system in medical contexts poses numerous challenges. Ensuring ethical and safe outcomes requires protecting data privacy and complying with healthcare regulations, including HIPAA, as well as applicable local governance frameworks.
Differences in mammography equipment, imaging protocols, and patient demographics across medical facilities can affect image quality and the model’s effectiveness. To maintain flexibility and generalization across diverse contexts, continuous retraining and scaling on diverse datasets, including KAUBC, are essential. Trust and acceptance from physicians are essential components for successful therapeutic integration. Radiologists will have access to feature contributions and attention maps via XAI to obtain transparent, comprehensible model results. This will enhance their confidence and facilitate collaboration with patients in decision-making. Ethical and operational factors must also inform the incorporation of AI-driven solutions in healthcare. The model should enhance, rather than supplant, radiologists’ skills, ensuring human oversight and accountability in clinical decision-making. Mitigating algorithmic bias is crucial to ensuring equitable diagnostic performance across diverse populations and imaging scenarios, thereby reducing inequities in clinical outcomes.
The suggested MobileNetV1 + ViT + PCA + Bagging framework exhibits strong and superior performance in multi-class BI-RADS classification. In 5-fold cross-validation, the fold-wise accuracy ranged from 97.9% to 98.1%, while the F1-Scores remained consistently around 97.9%. The small discrepancies among folds indicate inherent variability in the data partitions, affirming the model’s robustness. The fold-average ACC is 98%, although the model achieved a maximum of 99% for certain seeds and folds, underscoring its ability to achieve precise classification. These results demonstrate consistent, replicable performance, with no indications of overfitting or data leakage.
Conclusion
This study presents an efficient hybrid DL framework for BC diagnosis using mammographic images. The proposed architecture integrates MobileNetV1 for efficient local feature extraction with a ViT to capture global contextual representations, while a bagging ensemble classifier further enhances classification reliability. Experimental evaluation on the KAUBC dataset demonstrates strong diagnostic performance, with ACC, SEN, and SPE of 99%, 99%, and 99.5%, respectively. These results highlight the effectiveness of combining convolutional and transformer-based models for robust BI-RADS classification. The dual-stream design leverages complementary feature representations, reducing FB and improving robustness in challenging scenarios such as dense breast tissue and early-stage abnormalities. Despite promising performance, several limitations should be acknowledged. First, the lack of external clinical validation is a key constraint, as all experiments were conducted solely on the KAUBC dataset. Although this dataset is clinically annotated using BI-RADS categories, it primarily comprises patients from the Jeddah region of Saudi Arabia, limiting geographic and racial diversity and potentially affecting the generalizability of the proposed framework. In addition, class imbalance across BI-RADS categories, particularly the underrepresentation of BI-RADS 4 and 5 cases, may compromise classification robustness for minority high-risk classes, despite the use of data augmentation, class weighting, cross-validation, and early stopping. Furthermore, the proposed framework is designed for image-level BI-RADS classification and does not perform explicit lesion-level detection or localization. Consequently, precise localization or enumeration of multifocal abnormalities within a single mammogram remains beyond the scope of the current study. Although Grad-CAM and Grad-CAM++ visualizations indicate that the model attends to diagnostically relevant regions, explicit lesion-level supervision constitutes an important direction for future investigation. Moreover, the KAUBC dataset lacks histopathological or molecular annotations of BC subtypes (e.g., Luminal A/B, HER2-positive, or triple-negative), limiting evaluation to radiological measures and preventing subtype-specific diagnostic analysis. In addition, the adopted preprocessing steps, including image resizing and grayscale conversion, may introduce a partial loss of dynamic range and attenuate very subtle diagnostic features in mammographic images. Although mammograms are inherently acquired in grayscale, and contrast enhancement techniques were applied to mitigate these effects, slight degradation of fine textural details cannot be entirely excluded. This represents a recognized limitation of the current preprocessing pipeline. The current study is confined to mammography images and does not incorporate complementary imaging modalities such as US, MRI, or DBT, which could provide additional diagnostic insights in clinical practice. From a computational perspective, certain components of the hybrid architecture, particularly the Vision Transformer, increase computational complexity and may pose deployment challenges in resource-limited clinical environments. Additionally, the framework assumes the presence of high-quality DICOM images; degraded or noisy acquisitions may adversely affect classification performance. Although multiple evaluation metrics were reported, incorporating supplementary measures, such as MCC and class-wise AUC, could further refine the interpretation of performance on highly imbalanced datasets. Future research will focus on validating the proposed framework using independent, multi-center datasets and conducting prospective clinical studies in collaboration with radiologists to assess real-world applicability. Additional directions include lesion-level detection and localization, subtype-aware learning using datasets with pathological annotations, multi-modal fusion of mammography with ultrasound or MRI, and systematic robustness evaluation under variations in image contrast, brightness, and resolution. Ultimately, efforts will focus on optimizing model complexity to enhance computational efficiency, scalability, and clinical throughput, thereby facilitating the integration of reliable, high-performance hybrid DL models into routine BC screening workflows.
Supplementary Information
Supplementary Information.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1D’Orsi, C. J., Bassett, L. & Feig, S. A. ACR BI-RADS Atlas: Breast Imaging Reporting and Data System; Mammography, Ultrasound, Magnetic Resonance Imaging, Follow-up and Outcome Monitoring, Data Dictionary (American College of Radiology, 2013).
- 2Alotaibi, A. et al. Vit-deit: An ensemble model for breast cancer histopathological images classification. In 2023 1st International Conference on Advanced Innovations in Smart Cities (ICAISC) 1–6 (IEEE, 2023).
- 3Nguyen, H. T., Tran, S. B., Nguyen, D. B., Pham, H. H. & Nguyen, H. Q. A novel multi-view deep learning approach for bi-rads and density assessment of mammograms. In 2022 44th Annual International Conference of the IEEE Engineering in Medicine & Biology Society (EMBC) 2144–2148 (IEEE, 2022).10.1109/EMBC 48229.2022.987156436085843 · doi ↗ · pubmed ↗
- 4Wu, P., Ma, R. & Toe, T. T. Stacking-enhanced bagging ensemble learning for breast cancer classification with cnn. In 2023 3rd International Conference on Electronic Engineering (ICEEM) 1–6 (IEEE, 2023).
- 5Qi, Y. et al. A comprehensive overview of image enhancement techniques. Arch. Comput. Methods Eng. 1–25 (2021).
- 6Ferris, M. H. et al. Using roc curves and auc to evaluate performance of no-reference image fusion metrics. In 2015 National Aerospace and Electronics Conference (NAECON) 27–34 (IEEE, 2015).
- 7Eskandari, S., Eslamian, A. & Cheng, Q. Comparative analysis of transfer learning models for breast cancer classification. ar Xiv preprintar Xiv:2408.16859 (2024).