QLSA-MOEAD integration for precision task scheduling in heterogeneous computing environments
Abla Saad, Osama Abd el-Raouf, Mohiy Hadhoud, Ahmed Kafafy

TL;DR
This paper introduces QLSA-MOEAD, a new framework for efficient task scheduling in computing systems with diverse hardware.
Contribution
QLSA-MOEAD combines Q-learning, Simulated Annealing, and MOEA/D for improved multi-objective workflow scheduling.
Findings
QLSA-MOEAD outperforms baselines in 14 out of 16 FFT/molecular cases and on CyberShake workflows.
The framework maintains convergence and diversity across varying CCR levels and scales well with large workflows.
Q-learning enables fast decision-making with response times between 0.80–1.70 ms.
Abstract
Heterogeneous computing infrastructures integrating CPUs, GPUs, and FPGAs present critical challenges in efficient task scheduling due to hardware diversity, complex task dependencies, and conflicting optimization objectives. This work formulates workflow scheduling as a multi-objective optimization problem that minimizes makespan and maximizes resource utilization. For synthetic benchmarks (FFT, Molecular), the approach minimizes makespan and maximizes resource utilization. For the CyberShake seismic workflow, energy consumption is added as a third objective. This research proposes QLSA-MOEAD, a hybrid framework combining three complementary mechanisms: Q-learning for intelligent initialization, Simulated Annealing for local refinement, and MOEA/D for multi-objective decomposition. This integration balances exploration and exploitation effectively. Comprehensive evaluations on 20 test…
Genes, proteins, chemicals, diseases, species, mutations and cell lines named across the full text — each resolved to its canonical identifier and authoritative record.
Click any figure to enlarge with its caption.
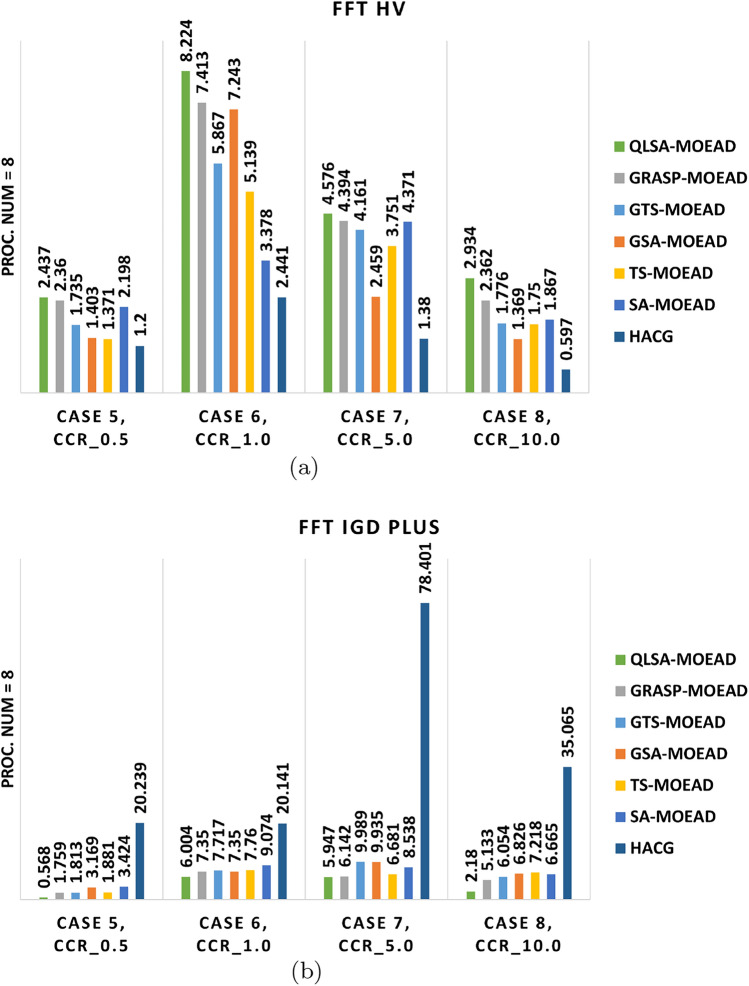 Figure 10
Figure 10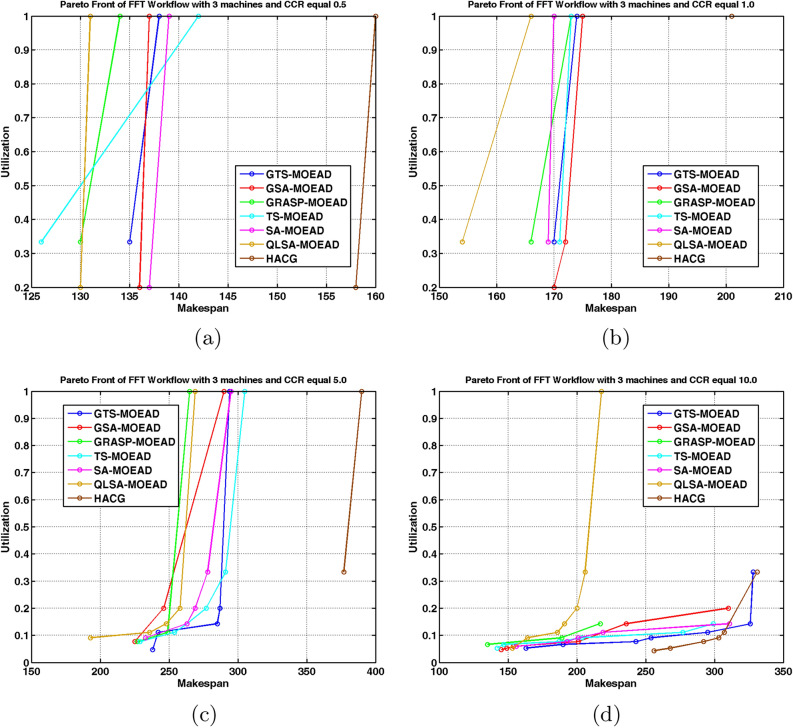 Figure 11
Figure 11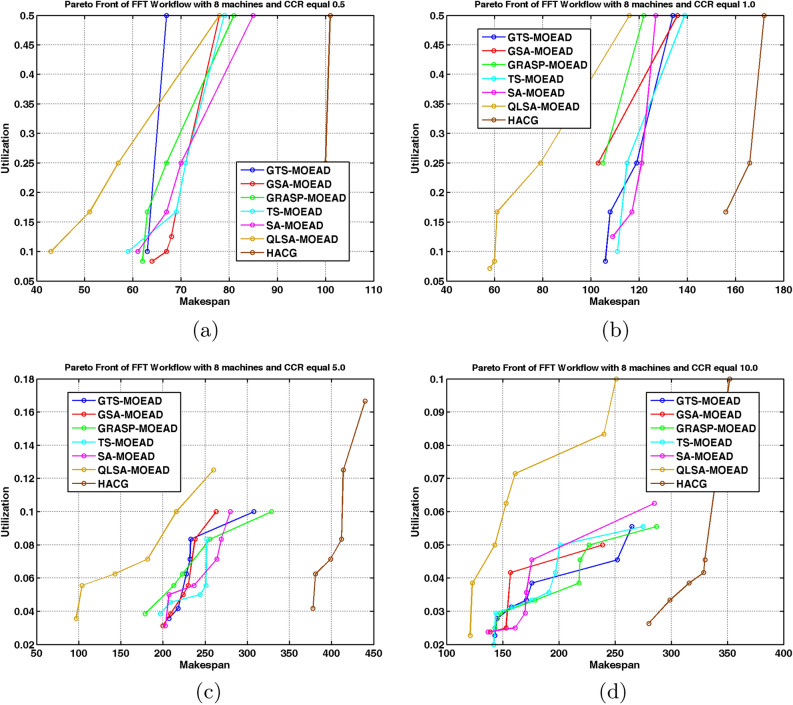 Figure 12
Figure 12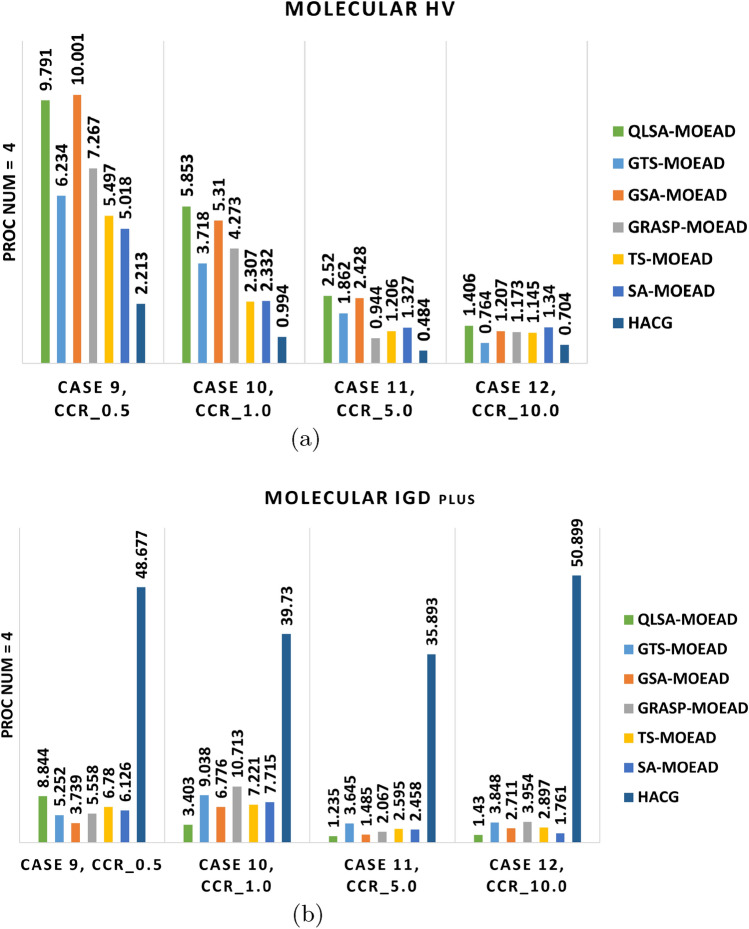 Figure 13
Figure 13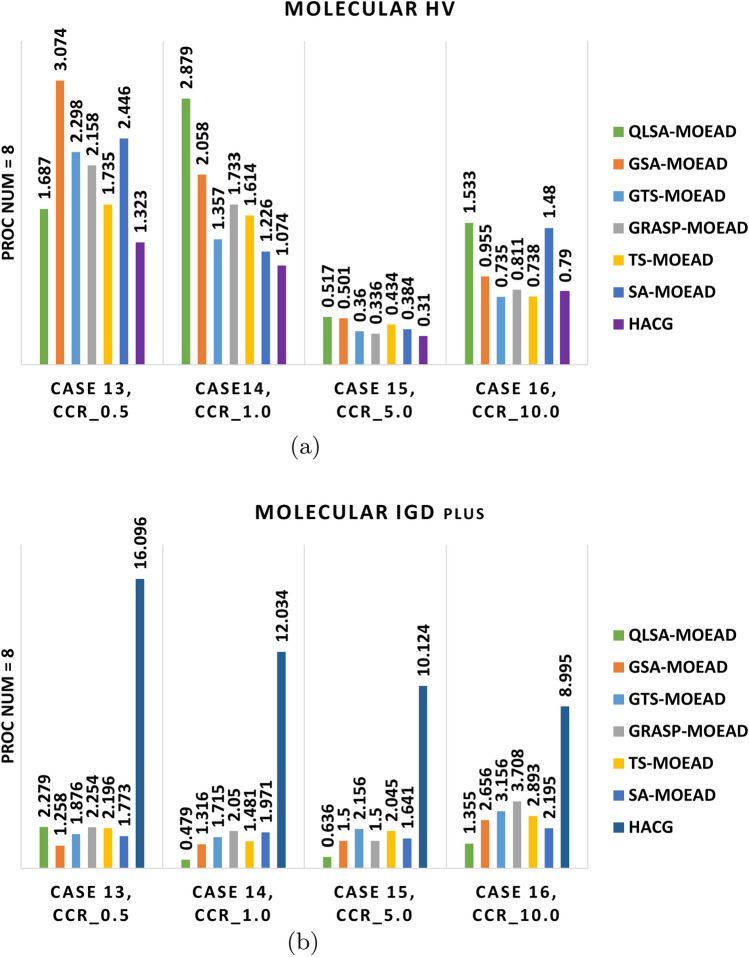 Figure 14
Figure 14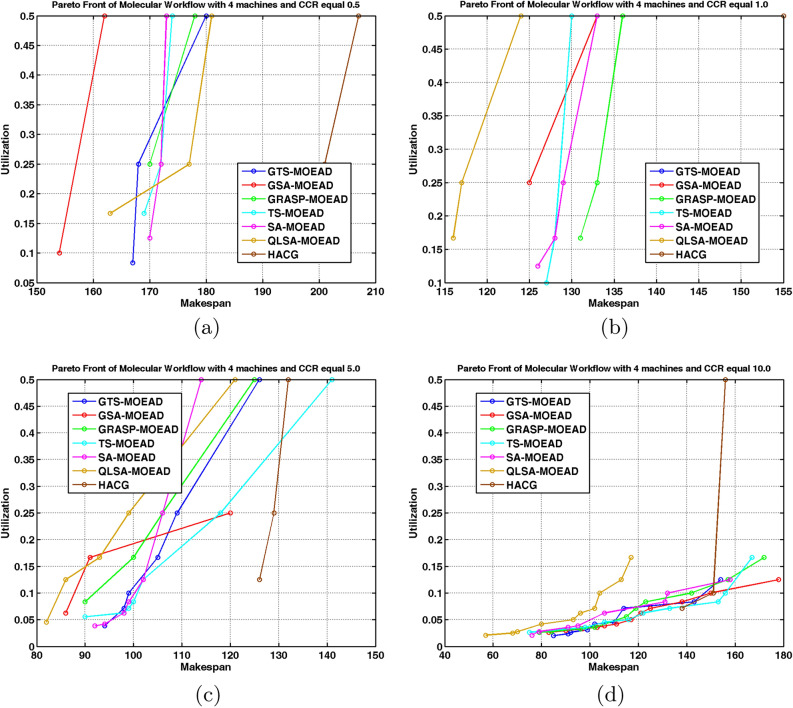 Figure 15
Figure 15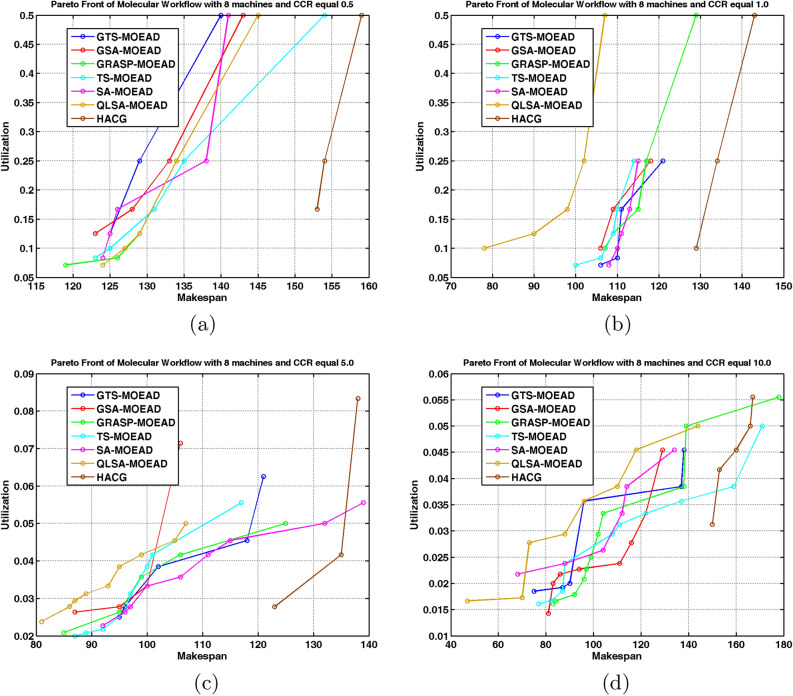 Figure 16
Figure 16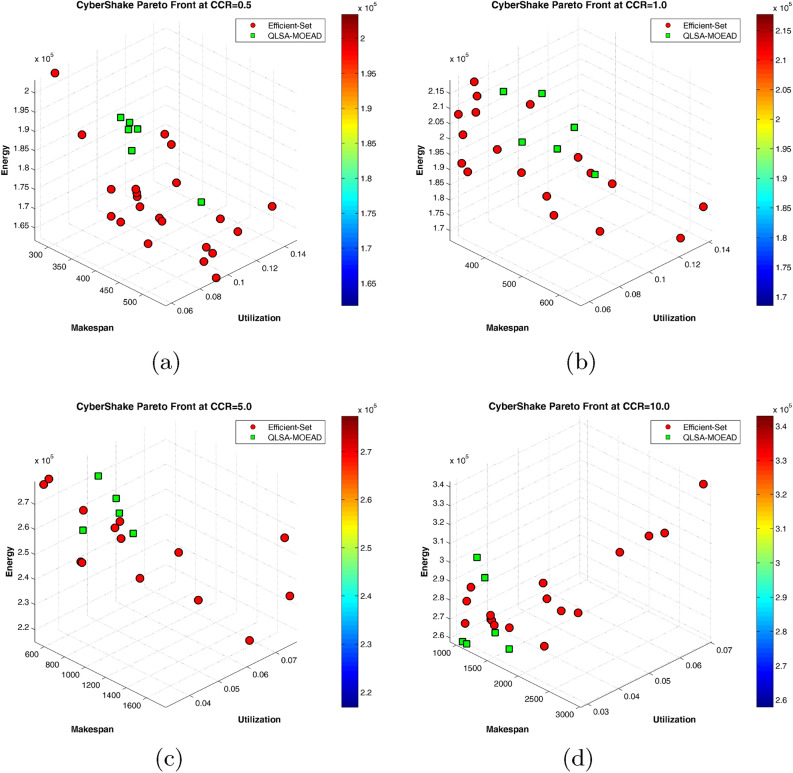 Figure 17
Figure 17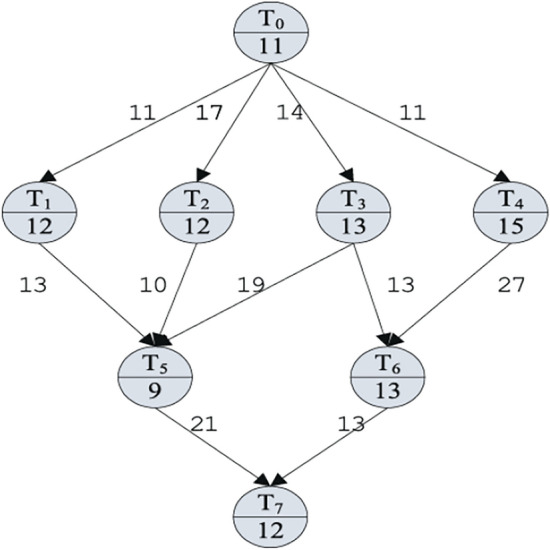 Figure 1
Figure 1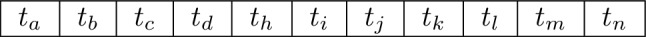 Figure 2
Figure 2 Figure 3
Figure 3 Figure 4
Figure 4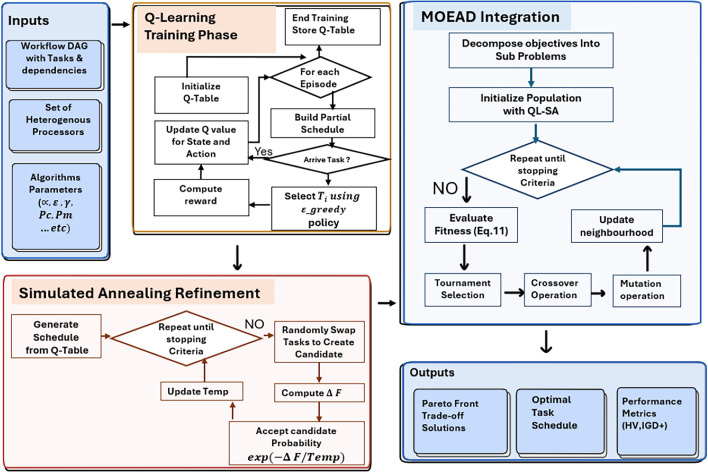 Figure 5
Figure 5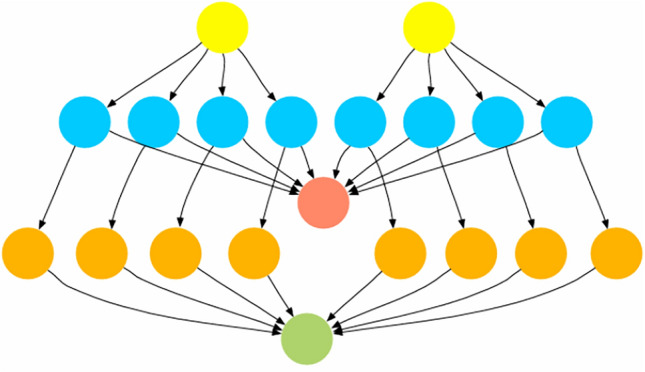 Figure 6
Figure 6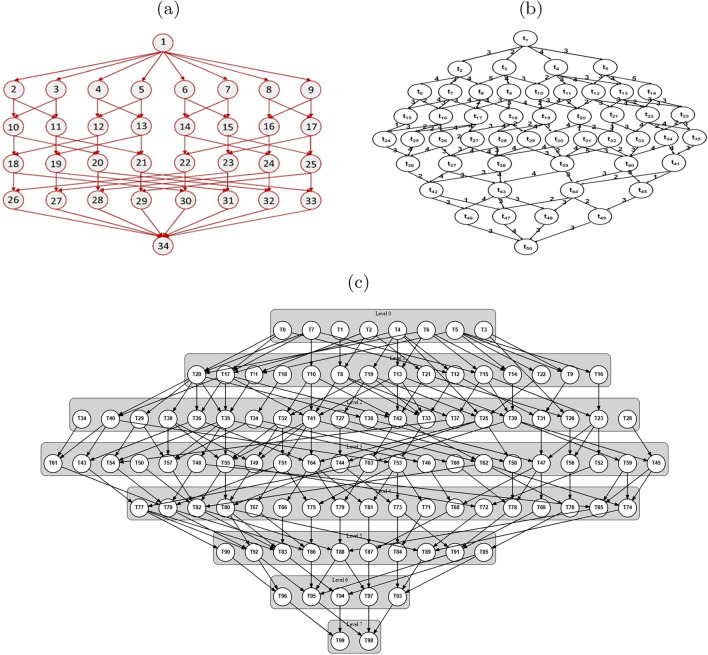 Figure 7
Figure 7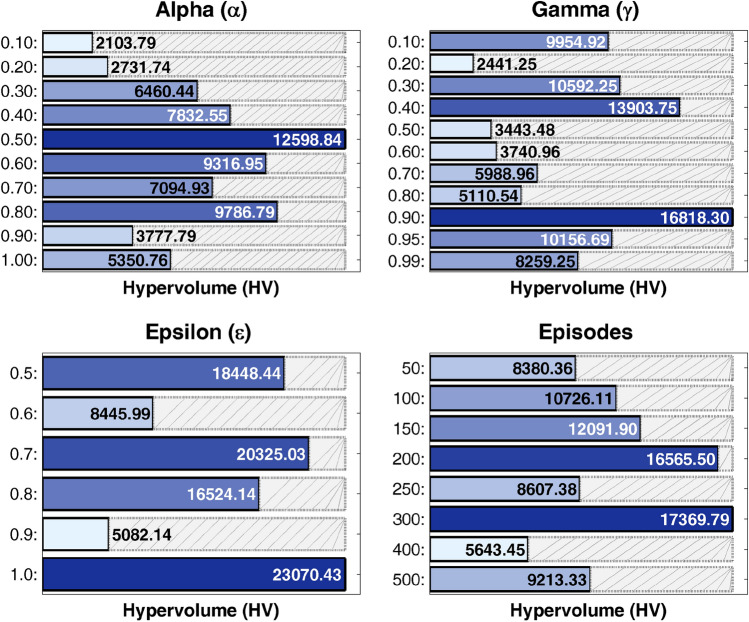 Figure 8
Figure 8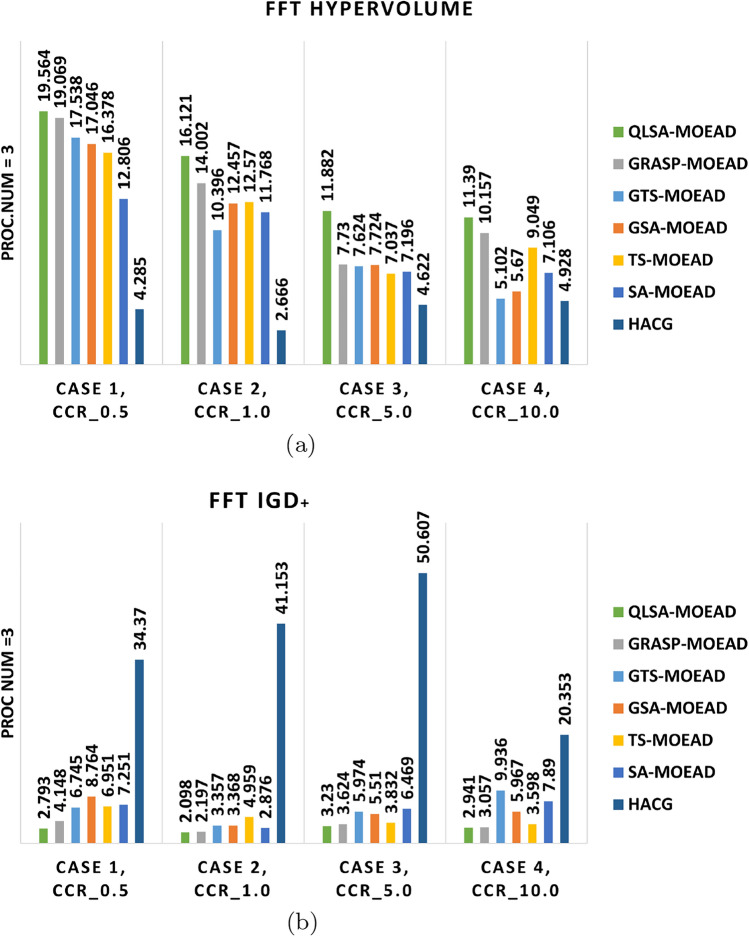 Figure 9
Figure 9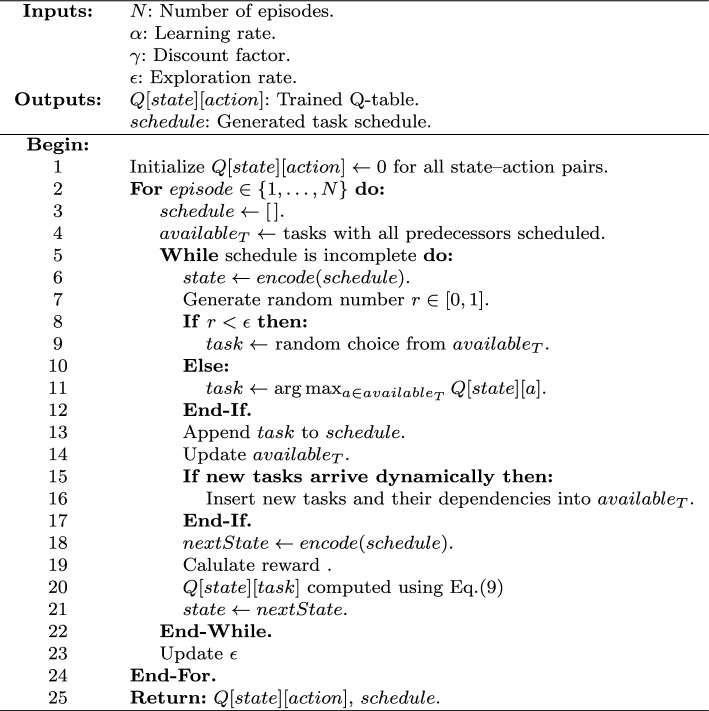 Figure 18
Figure 18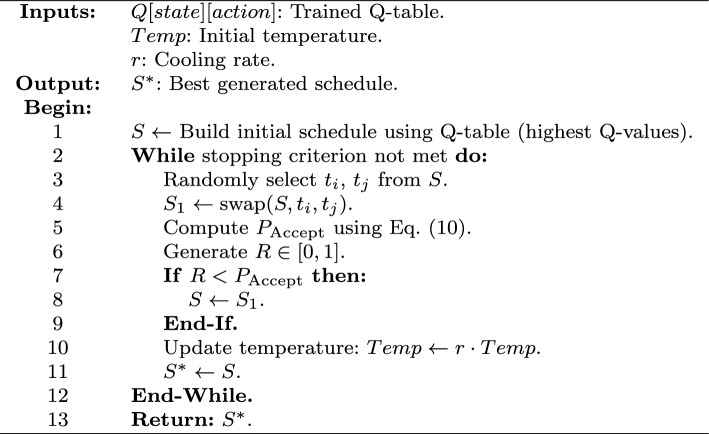 Figure 19
Figure 19 Figure 20
Figure 20 Figure 21
Figure 21- —Minufiya University
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsParallel Computing and Optimization Techniques · Distributed and Parallel Computing Systems · Cloud Computing and Resource Management
introduction
Heterogeneous computing systems combine different processor types-CPUs, GPUs, FPGAs, TPUs, and ASICs-to meet the demands of data-intensive applications. Each processor type serves a specific role: CPUs handle general tasks, GPUs accelerate parallel computations, and FPGAs provide customizable hardware logic. TPUs target deep learning workloads, while ASICs deliver optimized performance for specialized applications like blockchain and real-time analytics^1^. These systems distribute work across specialized units to improve both throughput and energy efficiency^2^.
These systems are commonly deployed on cloud platforms, high-performance clusters, and grid infrastructures. Many applications in scientific computing and industrial processing use Directed Acyclic Graphs (DAGs) to represent workloads, where nodes represent tasks and edges capture dependencies^3–6^. Task scheduling in these environments is NP-hard. It requires balancing. multiple goals: reducing total completion time (makespan), distributing load evenly across processors, and in some cases minimizing energy use. Scheduling methods fall into two categories: Static approaches assign tasks before execution begins, while dynamic methods adjust assignments. at runtime^7,8^. However, many dynamic techniques start from random initial solutions, which slows convergence and can reduce solution quality. The main contributions of this work can be summarized as follows:
- Enhanced multi-objective scheduling: This study proposes an advanced scheduling framework for heterogeneous systems to optimize multiple objectives simultaneously. The framework formulates workflow scheduling as a multi-objective optimization problem. For synthetic benchmarks (FFT, Molecular), it minimizes makespan and maximizes resource utilization. For the real-world CyberShake seismic workflow, it extends to three-objective optimization by incorporating energy consumption.
- Integration of MOEA/D optimization: The proposed framework builds upon the Multi-Objective Evolutionary Algorithm based on Decomposition (MOEA/D), which is highly effective for multi-objective optimization challenges. Instead of combining objectives into a single scalar function, MOEA/D decomposes the problem into several subproblems using evenly spaced weight vectors. A neighborhood-based information exchange mechanism preserves solution diversity and enhances search performance to yield well-distributed Pareto-optimal solutions.
- Reinforcement learning-driven scheduling: Reinforcement learning has proven effective for complex decision-making tasks. This work employs Q-learning as the core mechanism for schedule construction in heterogeneous computing environments. Rather than relying on random task allocation, the proposed algorithm learns optimal task-processor mappings through accumulated experience and dynamically adapts to workflow characteristics for more efficient and intelligent scheduling. Once the knowledge-driven schedule is generated, Simulated Annealing (SA) is applied as a post-optimization stage to escape local optima and further refine performance. This two-stage process forms the basis of the proposed QLSA-MOEA/D framework to accelerate convergence and improve the overall quality of obtained schedules. Beyond its effectiveness in static environments, the framework efficiently adapts to system variations and real-time changes in task execution conditions, making it highly suitable for dynamic workflows.
- Comprehensive validation: The framework is validated through extensive experiments on 20 test cases. These include 16 synthetic cases (FFT, Molecular) for two-objective optimization and 4 real-world cases (CyberShake) for three-objective optimization with energy consumption. Wilcoxon signed-rank and Friedman tests confirm statistical significance. Ablation studies isolate the contribution of each component (Q-learning, simulated annealing, and MOEA/D). Parameter sensitivity analysis on Q-learning hyperparameters (learning rate, discount factor, and exploration rate) demonstrates robustness. The structure of this paper is arranged to ensure clarity and logical flow. Section 2 presents an overview of the related studies. Section 3 explains the system model and the main notations summarized in Table 1. Section 4 describes the proposed methodology in detail. Section 5 outlines the evaluation setup and performance metrics. Section 6 examines the convergence behavior and computational complexity. Section 7 reports the experimental results, followed by a detailed discussion in Section 8. Finally, Section 9 summarizes the main conclusion and highlights possible directions for future research.Table 1. Notation used in the scheduling model.NotationDescription \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$E_d$$\end{document} Set of directed links (Edges) defining task dependencies.TTotal tasks forming the workflow.PNumber of heterogeneous processors. \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$t_i$$\end{document} Identifier for task i. \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$P_x$$\end{document} Identifier for processor x. \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$T_{\text {entry}}$$\end{document} Task that initiates the workflow. \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$T_{\text {exit}}$$\end{document} Task that ends the workflow. \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\text {Succ}(t_i)$$\end{document} Tasks executed after \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$t_i$$\end{document} . \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\text {Pred}(t_i)$$\end{document} Tasks executed before \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$t_i$$\end{document} . \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$W(t_i, p_j)$$\end{document} Computation cost of \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$t_i$$\end{document} on \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$p_j$$\end{document} . \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\overline{W(t_i)}$$\end{document} Average computation cost of \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$t_i$$\end{document} over all processors. \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$C(t_i, t_j)$$\end{document} Communication time between \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$t_i$$\end{document} and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$t_j$$\end{document} . \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$EST(t_i, P_x)$$\end{document} Earliest start time of \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$t_i$$\end{document} on \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$P_x$$\end{document} . \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$EFT(t_i, P_x)$$\end{document} Earliest completion time of \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$t_i$$\end{document} on \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$P_x$$\end{document} . \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\text {Avail}(P_x)$$\end{document} Earliest availability of \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$P_x$$\end{document} . \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$AST(t_i, P_x)$$\end{document} Actual starting time of \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$t_i$$\end{document} on \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$P_x$$\end{document} . \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$AFT(t_i, P_x)$$\end{document} Actual completion time of \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$t_i$$\end{document} on \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$P_x$$\end{document} .CCRCommunication to computation ratio metric.OOutput solutions from optimization process.RReference solution set for evaluation.PopsizePopulation size in MOEA/D.MaxGenMaximum Number of generations in MOEA/D.IIterations of Simulated Annealing or Tabu Search \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$E_{ql}$$\end{document} Episodes in Q-learning training.
Related work
Task scheduling in heterogeneous computing has received significant attention. Researchers focus on improving system throughput, balancing workloads, and reducing energy use. These environments integrate diverse processing units such as CPUs, GPUs, DSPs, ASICs, and FPGAs. Each unit has distinct architectures and instruction sets for cooperative execution of computational workloads ^9,10^. GPU–CPU-based platforms have attracted significant attention in high-performance computing due to their high parallel efficiency and cost-effectiveness. However, designing scalable and efficient scheduling algorithms for such heterogeneous systems remains a challenging and open problem ^11^.
A common representation for scheduling problems in these environments is the Directed Acyclic Graph (DAG). In this model, tasks are represented as nodes, and data or execution dependencies are represented as edges. DAG-based modeling supports optimization across multiple objectives. These include makespan minimization, energy reduction, and improved resource utilization through parallel execution. This approach is widely adopted in scientific workflows, cloud computing, and large-scale analytics^6,12^. Despite its flexibility, DAG-based modeling depends heavily on the efficiency of the underlying scheduling strategy.
Task scheduling in heterogeneous computing environments has been widely investigated due to its crucial role in optimizing system performance and resource utilization. While existing research provides valuable foundations, critical analysis reveals persistent limitations in adaptivity, multi-objective optimization, and scalability. Early algorithms such as Heterogeneous Earliest Finish Time (HEFT) and Critical Path on a Processor (CPOP)^13^ established benchmarks for static scheduling. HEFT prioritizes task execution based on rank values to minimize makespan, while CPOP focuses on the critical path. However, both assume static conditions and lack mechanisms to adapt to dynamic workload or resource changes typical in real heterogeneous systems.
The NP-hard nature of scheduling problems has led to the use of metaheuristics such as GRASP^14,15^, Simulated Annealing^16^, and Tabu Search^17–19^. These algorithms explore large solution spaces but face two major challenges: high computational cost that limits scalability and strong sensitivity to parameter tuning that affects robustness. Although GRASP has shown competitive results in minimizing completion time^20^, most metaheuristics remain focused on single-objective optimization, overlooking essential concerns such as energy efficiency and reliability.
Recent research has increasingly targeted multiple objectives but faces limitations. Shirvani et al.^21^ proposed a bi-objective Simulated Annealing algorithm for makespan and cost minimization but optimized each objective independently. Akbari et al.^22^ combined Cuckoo Optimization with GA but relied on weighted-sum aggregation, which imposes fixed preference weights and prevents full Pareto front discovery. Similarly, hybrid approaches such as the Grey Wolf Optimizer with GA^23^ and NSGA-III implementations^24^ improved convergence yet maintained high computational complexity and lacked adaptability.
Hosseini’s comprehensive survey^25^ provides a valuable taxonomy of scheduling algorithms, summarized in Table 2. However, it focuses primarily on structural classification rather than critical evaluation of adaptivity. The taxonomy shows that while machine learning methods offer dynamic adjustment, they require extensive training data, whereas hybrid methods balance exploration and exploitation but remain complex. Most existing algorithms exhibit limited adaptivity to dynamic changes in real environments.Table 2. Summary of scheduling algorithm categories (adapted and extended from Hosseini^25^).AspectList SchedulingHeuristicMetaheuristicMachine LearningMulti-ObjectiveHybridMain StrategyPriority-based orderingRule-based allocation or clusteringGlobal population or neighborhood searchPredictive or RL-based task–resource mappingTrade-off among multiple goalsCombined global and local searchAdaptivityNoLimitedPartialYesPartialYesLearning-basedNoNoNoYesNoOptionalAdvantagesSimple and fast; suitable for static casesFast decisions; handles medium-size workflowsSolves NP-hard problems; explores large search spacesAdapts to dynamic environments; real-time responseProduces Pareto-optimal frontsBalances exploration and exploitation; improved convergenceLimitationsCannot adapt to dynamic changes; near-optimal onlyApproximate; lacks global searchHigh computational cost; parameter sensitivityRequires large datasets; complex trainingComputational intensive; parameter tuningComplex design; higher runtimeObjective TypeSingleSingleSingle/MultiSingle/MultiMultiSingle/Multi
While Hosseini’s taxonomy offers a comprehensive overview, most listed methods remain static or semi-adaptive and rely on predefined rules instead of intelligent feedback mechanisms. Their performance degrades under dynamic workloads. In contrast, the proposed QLSA-MOEAD framework combines reinforcement learning with metaheuristic optimization to achieve continuous adaptivity. The Q-learning component progressively learns efficient task–processor mappings through environment interaction and allows the system to respond dynamically to changing workloads or resource states without retraining. This adaptivity bridges the gap between traditional heuristics and data-driven learning-based schedulers.
GRASP integrated with Simulated Annealing has previously shown potential in homogeneous platforms^26^, improving local search yet remaining single-objective. Comparative studies involving GRASP, Tabu Search, Simulated Annealing, Genetic Algorithms, HEFT, and First Come First Served (FCFS)^20^ indicate GRASP’s competitive performance in minimizing completion time. However, these algorithms generally overlook essential objectives such as energy efficiency, fault tolerance, and reliability, which are increasingly important in large-scale heterogeneous systems.
Multi-objective extensions have also been explored. Shirvani et al.^21^ introduced a bi-objective SA algorithm for hybrid clouds optimizing makespan and cost, but without joint objective integration. Akbari et al.^22^ developed the HACG algorithm integrating Cuckoo Optimization with GA to improve resource utilization, though the weighted-sum method limited Pareto diversity. Zahra et al.^27^ applied Integer Linear Programming (ILP) for fog computing with a focus on execution time and energy but did not consider scalability or adaptability.
Further hybrid evolutionary–heuristic methods include Prashant et al.^28^, who combined fuzzy task clustering with Harmony Search and GA for fog–cloud workflows. Behera et al.^23^ merged the Grey Wolf Optimizer with GA and achieved improvements in makespan and energy at the cost of increased parameter sensitivity. Imene et al.^24^ employed NSGA-III to optimize time, cost, and energy, outperforming NSGA-II but at higher computational complexity. Despite improved convergence, these algorithms lack runtime adaptability and underperform in dynamic heterogeneous systems.
Saad et al.^29^ made notable progress by integrating MOEA/D with GRASP and Simulated Annealing, achieving strong makespan and parallelism results. However, their approach exhibits three key limitations: high computational costs for large workflows, absence of genuine adaptivity for dynamic environments, and lack of energy and reliability considerations. Similarly, recent approaches like REMO^30^ improved Pareto front regularity but remain unexplored for dynamic workflows.
The proposed QLSA-MOEA/D framework directly addresses these gaps through three major contributions. First, it employs reinforcement learning for genuine adaptivity to enable real-time adjustment to system changes without retraining. Second, it optimizes multiple conflicting objectives-makespan, energy, and reliability-beyond the limited focus of prior studies. Third, it integrates Q-learning with Simulated Annealing within MOEA/D to reduce computational complexity while maintaining solution quality. This integration overcomes the limitations identified in Hosseini’s taxonomy and earlier hybrid designs and offers a robust and efficient scheduling strategy for both static and dynamic heterogeneous computing environments.
System model
In heterogeneous computing environments, the workflow is represented as a Directed Acyclic Graph (DAG). Each vertex \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$T_i \in T$$\end{document} denotes a unique computational task, while each edge \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$e_i \in E$$\end{document} specifies a precedence constraint between tasks. Tasks without predecessors form the entry set \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$T_{\text {entry}}$$\end{document} , whereas tasks without successors form the exit set \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$T_{\text {exit}}$$\end{document} . The size of the DAG equals the total number of tasks \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$|T|$$\end{document} .
Execution on a given processor assumes negligible intra-processor communication delay. However, an edge weight represents the inter-processor communication cost when tasks are executed on different units.
A task becomes ready once all its parent tasks have finished execution and the required data is available on its assigned processor. Ready tasks are then selected for scheduling according to the adopted allocation strategy.
Figure 1 illustrates a sample DAG with task dependencies. Table 3 reports example execution speeds and computation costs for multiple heterogeneous processors.Fig. 1. Example of a Directed Acyclic Graph (DAG)^31^.Table 3. Execution speed and computation cost across heterogeneous processors^31^. \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$t_i$$\end{document} SpeedCost \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$P_0$$\end{document} \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$P_1$$\end{document} \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$P_2$$\end{document} \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$P_0$$\end{document} \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$P_1$$\end{document} \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$P_2$$\end{document} \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$t_0$$\end{document} 1.000.851.2211139 \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$t_1$$\end{document} 1.200.801.09101511 \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$t_2$$\end{document} 1.331.000.8691214 \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$t_3$$\end{document} 1.180.811.30111610 \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$t_4$$\end{document} 1.001.370.79151119 \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$t_5$$\end{document} 0.751.001.791295 \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$t_6$$\end{document} 1.300.931.00101413 \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$t_7$$\end{document} 1.090.801.20111510
Task graph generation metrics
Computation cost
Each task \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$t_i$$\end{document} has a base workload \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$W(t_i)$$\end{document} . Its execution time on a processor \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$P_x$$\end{document} is given by Eq.(1):
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\begin{aligned} W(t_i, P_x) = \frac{W(t_i)}{S(t_i, P_x)} \end{aligned}$$\end{document}where \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$S(t_i, P_x)$$\end{document} is the processing speed of \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$P_x$$\end{document} when executing \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$t_i$$\end{document} .
Communication-to-computation ratio (CCR)
The CCR measures the balance between computation time \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$W(t_i)$$\end{document} and communication delay \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$C(t_i, t_j)$$\end{document} as defined in Eq.(2):
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\begin{aligned} \text {CCR} = \frac{\frac{1}{|E|} \sum _{(t_i, t_j) \in E} C(t_i, t_j)}{\frac{1}{|N|} \sum _{t_i \in N} \overline{W(t_i)}} \end{aligned}$$\end{document}Low CCR values indicate computation-intensive workloads, while high CCR values imply communication-dominated workflows.
Scheduling mechanism on heterogeneous processors
The Heterogeneous Earliest Finish Time (HEFT) algorithm^13^ determines both task order and processor allocation. It relies on the following time metrics:
- Earliest start time (EST):
- Actual start time (AST):
- Earliest compilation time (EFT):
- Actual compilation time (AFT):
- Makespan:
Optimization objectives
In heterogeneous task scheduling, the problem is formulated as a bi-objective optimization problem with two main goals:
- Minimize the makespan, as defined in Eq. (7), which represents the total completion time of the workflow.
- Maximize resource utilization, reflecting system-level parallelism and load balancing among processors^22^. To quantify resource utilization, the load balance efficiency metric ( \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\beta$$\end{document} ) is used. It measures how evenly the tasks are distributed across all available processors and is defined as:
where T denotes the total number of tasks in the workflow, p represents the number of available processors, \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$|p_i|$$\end{document} is the number of tasks assigned to processor \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$p_i$$\end{document} , and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\frac{T}{p}$$\end{document} corresponds to the ideal balanced load per processor. The denominator \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\sum _{i=0}^{p-1} \left| \frac{T}{p} - |p_i| \right|$$\end{document} represents the total absolute deviation from perfect load balancing among all processors. The \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\beta$$\end{document} metric has the following properties:
- Higher \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\beta$$\end{document} values indicate better load balancing and more efficient resource utilization.
- Lower \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\beta$$\end{document} values indicate higher workload imbalance across processors. Therefore, the optimization process aims to minimize makespan while maximizing load balance efficiency ( \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\beta$$\end{document} ) to achieve effective task scheduling in heterogeneous computing environments.
The proposed integrated framework
This study employs the Multi-Objective Evolutionary Algorithm based on Decomposition (MOEA/D) as the core framework for task scheduling in heterogeneous computing environments. The optimization process is decomposed into multiple single-objective subproblems, each represented by a uniformly distributed weight vector. These subproblems are grouped into neighborhoods for information exchange. This grouping helps maintain population diversity. It also promotes the discovery of well-distributed solutions across the search space. This decomposition structure enhances both exploration capability and optimization efficiency.
To further improve MOEA/D performance, the proposed approach integrates Reinforcement Learning (RL) and metaheuristic search. The framework specifically uses Q-Learning and Simulated Annealing (SA). Within this integrated design, RL acts as a learning-based strategy, while SA provides a local search mechanism to enhance the convergence behavior of MOEA/D. Instead of a purely random initialization, the proposed QLSA strategy uses Q-Learning and SA to generate a more informed starting population and results in faster convergence toward high-quality schedules.
The primary objective of this hybrid QLSA-MOEA/D framework is to generate task schedules that minimize makespan, improve resource utilization, and ensure timely execution of all tasks. The subsequent subsections detail the proposed method: Subsection 4.1 describes the MOEA/D initialization phase, and Subsection 4.2 explains the integration of QLSA into MOEA/D.
Initialization phase
Initialization plays a key role in influencing MOEA/D’s search behavior. Here, the population is generated using structured, learned techniques instead of relying solely on randomness. This approach enhances the algorithm’s ability to explore the Pareto front, where the best trade-offs between objectives are located.
Q-learning
In the initialization stage, QLSA uses reinforcement learning to build efficient task schedules without predefined rules. During training, the agent builds schedules step by step. It interacts with the environment over \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$E_ql$$\end{document} episodes. At the start of each episode, the schedule is set to null, and the list \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$available_T$$\end{document} contains only tasks whose dependencies have been satisfied.
At each decision point, the current state is encoded as \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$state \leftarrow encode(schedule)$$\end{document} , representing the current partial order of tasks. The agent then selects the next task \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$t_i$$\end{document} using an \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\epsilon$$\end{document} -greedy strategy: with probability \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\epsilon$$\end{document} , a task is randomly chosen from \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$available_T$$\end{document} , and with probability \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$1 - \epsilon$$\end{document} , the task with the highest Q-value is selected. The chosen task is appended to the schedule, and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$available_T$$\end{document} is updated accordingly.
After scheduling a task, the next state becomes \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$nextState \leftarrow encode(schedule)$$\end{document} . The agent then receives a reward based on the schedule quality. \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$reward \leftarrow -makespan(schedule)$$\end{document} ^7^. For the CyberShake workflow with three-objective optimization, the reward incorporates makespan, resource utilization, and energy consumption in a weighted combination. The Q-value is then updated using the temporal difference formula^12,32^:
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\begin{aligned} Q(state, t_i) \leftarrow Q(state, t_i) + \alpha \left[ reward + \gamma \cdot \max _{a'} Q(nextState, a') - Q(state, t_i) \right] \end{aligned}$$\end{document}where \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\alpha$$\end{document} is the learning rate, \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\gamma$$\end{document} is the discount factor, and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$a'$$\end{document} denotes the available actions in the new state. The process continues until the entire schedule is constructed. After each episode, the exploration rate decays. Through repeated interaction, the agent gradually learns task–processor mappings. These mappings minimize the makespan. During deployment, the trained Q-table is employed to construct new schedules greedily using the best Q-values at each state. The generated schedules are subsequently refined through local search methods, such as Simulated Annealing, to further enhance solution quality in heterogeneous systems^6^.
An additional advantage of this framework is its adaptability to dynamic environments. When a new task arrives during execution, the scheduler dynamically updates \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$available_T$$\end{document} to include the new task and its dependencies. The Q-learning agent, already trained to generalize scheduling decisions, integrates the new task by continuing the decision-making process based on the updated DAG state. This enables the framework to maintain scheduling stability and efficiency even under runtime variations, where new tasks or dependencies may appear.
Overall, Q-learning serves as a core mechanism for adaptive schedule generation, capable of handling both static and dynamic workflows without retraining from scratch. The training procedure is summarized in Algorithm 1.
Algorithm 1Q-Learning Training Procedure.
Search via simulated annealing in QLSA
Once training is complete, the learned Q-table is used to construct an initial task schedule by greedily selecting actions with the highest Q-values. The learned policy is exploited during schedule construction. However, the schedule may still be suboptimal. Limited exploration or imperfect rewards during training can cause this.
To improve the initial schedule solution, Simulated Annealing (SA) is applied. This stochastic local search technique helps escape local minima by accepting worse solutions with a controlled probability. The SA algorithm starts with an initial temperature Temp that influences acceptance of inferior moves^26^.
At each step, two tasks \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$t_i$$\end{document} and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$t_j$$\end{document} are randomly selected and swapped to form a new candidate solution \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$S_1$$\end{document} . The acceptance decision depends on the makespan difference and is computed as:
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\begin{aligned} P_{\text {Accept}} = \left\{ \begin{array}{ll} 1 & \text {if } F_{S_1} \le F_S \\ \exp \left( \frac{F_S - F_{S_1}}{Temp} \right) & \text {otherwise} \end{array} \right. \end{aligned}$$\end{document}Here, \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$F_S$$\end{document} and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$F_{S_1}$$\end{document} denote the makespan of the current and new solutions, respectively. The probability of accepting worse solutions decreases as Temp cools down or the fitness function gap widens.
After each iteration, the temperature is updated using a decay rate r, and the process continues until a stopping condition is met. The best-found schedule is returned. The full QLSA procedure is shown in Algorithm 2.
Algorithm 2QLSA Scheduling Procedure.
This hybrid method combines reinforcement learning with probabilistic local search. As a result, QLSA generates high-quality task schedules that adapt to large and dynamic heterogeneous computing environments.
MOEA/D
The Multi-Objective Evolutionary Algorithm based on Decomposition (MOEA/D) is a powerful framework designed to solve optimization problems with multiple conflicting objectives. Unlike traditional methods that treat all objectives together, MOEA/D breaks down a complex multi-objective problem into several simpler scalar subproblems. Each subproblem focuses on a specific combination of objectives, which simplifies the overall optimization process^33–35^.
Chromosome representation
In this framework, each chromosome encodes a candidate schedule as an ordered list of tasks. These tasks form a sequence that respects the dependencies in a Directed Acyclic Graph (DAG). The chromosome length matches the total number of tasks. Such a candidate solution is called a Scheduled Task Queue (STQ), which explicitly represents the order of task execution. Figure 2 shows an example of an STQ where \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$t_a$$\end{document} denotes task \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$a$$\end{document} .Fig. 2. Example of a Scheduled Task Queue (STQ) in DAG scheduling.
Fitness function for multi-objective scheduling
MOEA/D finds solutions that balance competing objectives. To evaluate solution quality, a weighted-sum approach is adopted to combine multiple objectives into a single scalar value suitable for comparison^29^.
The scheduling problem is formulated as a bi-objective optimization task with two primary goals: minimizing the overall makespan and maximizing resource utilization ( \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\beta$$\end{document} ), corresponding to Eqs. (7) and (8). Since the MOEA/D framework inherently handles objectives in minimization form, the maximization of \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\beta$$\end{document} is transformed into an equivalent minimization. The combined multi-objective fitness function (MOF) is expressed as:
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\begin{aligned} \text {Minimize } MOF = \lambda \times \text {Makespan} + (1 - \lambda ) \times \frac{1}{\beta } \end{aligned}$$\end{document}In the proposed framework, weight vectors \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\lambda$$\end{document} are predefined and uniformly distributed following MOEA/D principles. Each vector represents one subproblem to ensure diverse Pareto-front coverage^33,36^. A set of weight vectors \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\lambda = [\lambda _1, \lambda _2]$$\end{document} is generated before the optimization process to represent different trade-offs between objectives. Each vector corresponds to one scalar subproblem, ensuring a well-distributed approximation of the Pareto front. This mechanism provides mathematical consistency and diversity preservation without requiring manual selection of an optimal \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\lambda$$\end{document} value. Here, \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\lambda \in [0, 1]$$\end{document} controls the relative importance of each objective.
This formulation ensures that smaller makespan values and higher resource utilization levels both contribute to a lower MOF and maintains consistency within the minimization framework. Hence, the trade-off between objectives is preserved while enabling unified evaluation of candidate solutions in heterogeneous computing environments.
Unlike Shirvani et al.^21^, who optimized each objective independently, the proposed QLSA-MOEA/D jointly optimizes multiple conflicting goals through decomposition-based multi-objective optimization. In this framework, each subproblem represents a scalar aggregation of objectives such as makespan minimization and resource utilization maximization:
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\begin{aligned} g_i(x) = \lambda _1 f_1(x) + \lambda _2 f_2(x), \end{aligned}$$\end{document}where \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$f_1(x)$$\end{document} denotes the normalized makespan and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$f_2(x)$$\end{document} represents the normalized resource utilization factor ( \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\beta$$\end{document} ). The weighting vector \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\lambda = [\lambda _1, \lambda _2]$$\end{document} defines the trade-off between these objectives, ensuring that the algorithm explores diverse Pareto-optimal solutions. Consequently, QLSA–MOEA/D performs genuine joint optimization across multiple performance metrics rather than treating them independently.
MOEA/D reproduction operators
- Selection Strategy This work employs tournament selection^20,29,37^ to choose parent individuals for reproduction. A subset of individuals, sized Tourn-Size, is randomly sampled from the population. Among this subset, the two individuals with the highest fitness, denoted \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$S_i$$\end{document} and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$S_j$$\end{document} , are selected to produce offspring. The selection process is summarized in Algorithm 3.
Algorithm 3Tourn-Selection(Tourn-Size, Pop).
-
Crossover Strategy Crossover is performed on the selected parent chromosomes obtained from the tournament selection^29,37,38^. With crossover probability \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$p_c$$\end{document} , one or more crossover points are chosen randomly. Segments between parents are swapped at these points to create offspring chromosomes. This operation promotes genetic diversity by exploring new solutions. Figure 3 illustrates the crossover process.Fig. 3. Crossover example.
-
Mutation Strategy Mutation helps preserve population diversity by introducing small random changes to offspring chromosomes^29,37,38^. It is applied with a low mutation probability \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$p_m$$\end{document} . Here, mutation swaps two randomly chosen tasks within a chromosome. This technique reduces the risk of premature convergence while maintaining solution quality. Figure 4 depicts an example of the mutation operation.Fig. 4. Mutation example.
The QLSA-MOEA/D in Algorithm 4 starts by creating an initial population composed of multiple candidate solutions, each representing a potential schedule. This initialization is performed by invoking the InitializePopulation procedure based on the QLSA scheduling approach, which generates the population \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$Pop$$\end{document} .
Once the population is formed, the algorithm evaluates the fitness of each individual, considering two main objectives: minimizing the makespan and maximizing resource utilization. These objectives are integrated into a multi-objective fitness function (MOF).
In every generation, two-parent solutions \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$S_i$$\end{document} and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$S_j$$\end{document} are selected from the current population using a tournament selection method. If a randomly generated number is below the crossover probability \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$P_c$$\end{document} , the parents undergo crossover to produce offspring \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$S_i'$$\end{document} and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$S_j'$$\end{document} . Then, mutation is applied on these offspring with probability \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$P_m$$\end{document} , yielding the mutated offspring \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$S_i''$$\end{document} and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$S_j''$$\end{document} .
The newly mutated offspring are then evaluated. Typically, one offspring \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$(S_i'')$$\end{document} is compared with its neighboring solutions within the population. If it has better fitness, it replaces the weaker neighbor. This evolutionary process repeats until a stopping condition is fulfilled. The best solution found during this process is then returned as \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$S^*$$\end{document} . The flowchart of the QLSA-MOEAD framework is introduced in Fig. 5.
Fig. 5. The Flowchart of QLSA-MOEAD.
Algorithm 4MOEA/D with QLSA Initialization.
Performance evaluation
This section evaluates the proposed QLSA-MOEAD framework by comparing it against state-of-the-art methods: GRASP-MOEA/D, Tabu Search based MOEAD (TS-MOEA/D), Simulated Annealing based MOEAD (SA-MOEA/D), Guided Tabu Search based MOEA/D (GTS-MOEA/D), GSA-MOEA/D^29^, and HACG-TS^22^. The evaluation employs multiple performance metrics on diverse workflow benchmarks under both static and dynamic scheduling scenarios.
Multi-objective performance metrics
- Hypervolume (HV) Hypervolume measures the volume of objective space dominated by a solution set relative to a reference point. Higher HV values indicate better convergence toward the Pareto front and improved solution diversity^39^. Let HV(O) denote the hypervolume of solution set O with reference point U. The metric is computed as:
where \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$O_i$$\end{document} represents the i-th objective value of solution o, \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$U_i$$\end{document} is the reference value for the i-th objective, and m denotes the total number of objectives.
- Inverted Generational Distance Plus (IGD+) IGD+ quantifies the average minimum Euclidean distance from each reference point \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$r \in R$$\end{document} to the closest obtained solution \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$o \in O$$\end{document} , reflecting approximation quality to the reference Pareto front:
Lower IGD+ values indicate closer approximation to the reference front. The reference set R combines all non-dominated solutions obtained by compared algorithms.
Dynamic performance metrics
Two specialized metrics assess performance under real-time task arrivals:
- Response Time (RT) Response Time measures the computational speed when reacting to dynamic changes. It captures the time required to regenerate a schedule after task arrival, reflecting decision-making efficiency. Lower values indicate faster adaptation. Let \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$A_t$$\end{document} denote the task arrival time and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$S_t$$\end{document} the schedule generation time. Response time is defined as
- Performance Deviation (PDHV) Performance Deviation quantifies the relative hypervolume difference between dynamic and static execution scenarios, evaluating solution quality maintenance under dynamic conditions:
where \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$HV_{\text {dyn}}$$\end{document} represents dynamic execution hypervolume and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$HV_{\text {ref}}$$\end{document} the static reference hypervolume. Lower \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$PD_{HV}$$\end{document} values indicate minimal quality degradation.
Benchmark workflows
The Fast Fourier Transform workflow exhibits a symmetric, well-structured topology with 34 tasks^40^. This structured pattern enables assessment of algorithm behavior under tight task dependencies. Figure 7a illustrates the workflow structure.
The molecular workflow contains 50 tasks arranged in an irregular, asymmetric layout^41^. This unstructured pattern tests algorithm adaptability to heterogeneous computational requirements. Figure 7b shows the workflow topology.
A large-scale Montage workflow was generated based on the reference implementation^42^, containing 100 tasks and 179 dependencies distributed across eight levels. This workflow evaluates scalability and dynamic adaptation under real-time task arrivals. Figure 7c depicts the complete workflow structure.
The CyberShake seismic hazard analysis workflow models earthquake simulation through 20 tasks with 32 dependencies across 5 levels^21,43^. Tasks exhibit heterogeneous computational requirements. These range from lightweight preprocessing (80–130 units) to compute-intensive seismogram synthesis (180–260 units).
Figure 6 illustrates the workflow structure. The hierarchical pattern includes entry points, parallel processing stages, synchronization points, and final aggregation, reflecting computational requirements typical of scientific applications.
The heterogeneous evaluation platform consists of six processing units with distinct architectural characteristics, detailed in Table 4:
- CPUs (P0, P1): Two Intel Xeon processors (45–65W) handle control-flow operations and I/O tasks^44^.
- GPUs (P2, P3): Two NVIDIA units (180–250 W) accelerate data-parallel computations with a 2.5– \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$3.0\times$$\end{document} speedup speedup^45^.
- FPGAs (P4, P5): Two Xilinx units (25–40W) provide energy-efficient acceleration with 1.5– \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$2.0\times$$\end{document} speedup^46^. Task-processor affinity is modeled: CPUs excel at I/O operations (workflow levels 0, 4), GPUs at parallel computation (levels 2, 3), and FPGAs maintain balanced performance across all levels.
Four workflow variants were created with CCR values of 0.5, 1.0, 5.0, and 10.0 following Eq. (2). These capture different scenarios: computation-intensive (CCR \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$< 1$$\end{document} ), balanced (CCR \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\approx 1$$\end{document} ), and communication-intensive (CCR \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$> 1$$\end{document} ). The CyberShake workflow involves three optimization objectives: makespan, resource utilization, and energy consumption.Table 4. Hardware specifications for the Cybershake experimental platform.ProcessorTypeSpeed FactorPower (W)SpecializationP0CPU1.045Standard CPU, I/O tasksP1CPU1.265Fast CPU, control flowP2GPU3.0250High-end GPU, parallel computeP3GPU2.5180Mid-range GPU, data-parallelP4FPGA1.525Energy-efficient FPGAP5FPGA2.040Fast FPGA, pattern matchingNote: Speed factor is relative to baseline CPU (P0 = 1.0). Communication network power: 5W per active link.
Fig. 6. Cybershake workflow DAG for seismic hazard analysis^21,43^.
Dataset configuration
All workflows are evaluated under multiple Communication-to-Computation Ratio (CCR) values as defined in Eq. (2). CCR values above 1 indicate communication-intensive workloads, while values below 1 represent computation-intensive scenarios.
Tables 5, 6, and 7 summarize the generated datasets. Processor counts follow Amdahl’s law^40^: eight processors for FFT and molecular workflows and sixteen for Montage, ensuring fair comparison^29^.
Figures 7a , 7b , and 7c display the workflow topologies used in experiments.Fig. 7. Workflow DAG topologies: a FFT^40^, b Molecular^41^, and c Large-scale Montage^42^.Table 5. Generated FFT workflow datasets across multiple CCR values.Num-CaseCCRNum-UnitsNum-TaskscommuniccomputType-GraphCase 10.5334[5...15][5...30]FFTCase 28Case 31.03–[10...30][10...20]–Case 48Case 55.03–[50...100][10...20]–Case 68Case 710.03–[50...100][5...10]–Case 88Table 6Generated Molecular workflow datasets across multiple CCR values.Num-CaseCCRNum-UnitsNum-TaskscommuniccomputType-GraphCase 90.5450[5...15][5...30]MolecularCase 108Case 111.04–[5...15][5...15]–Case 128Case 135.04–[5...30][3...5]–Case 148Case 1510.04–[10...40][1...5]–Case 168Table 7Generated Montage workflow datasets across multiple CCR values.Num-CaseCCRNum-UnitsNum-TaskscommuniccomputType-GraphCase 170.516100[2...4][2...8]MontageCase 181.0––[2...10][2...10]–Case 195.0––[20...50][5...10]–Case 2010.0––[50...100][5...10]–
Datasets are selected from established literature^21,41,47^, representing diverse communication-to-computation cost ratios for comprehensive algorithm evaluation. Sixteen static cases are designed from FFT and molecular workflows (Tables 5, 6). Four dynamic cases employ the large-scale Montage workflow (Table 7).
Experimental setup
Experiments are run on Java (NetBeans IDE) using a 2.30 GHz processor with 15.7 GB RAM. Each test case executes 20 independent runs for statistical reliability. Average values of hypervolume (HV), inverted generational distance plus (IGD+), and response time (for dynamic scenarios) are calculated to evaluate performance. All algorithms employ the same termination criterion, which is a fixed limit of function evaluations, ensuring fair comparison across different approaches.
Parameter configurations of MOEA/D, GRASP, SA, and TS are determined from prior empirical evidence^29^. The maximum number of function evaluations is set to 1000 for all experiments to maintain consistency. Although some algorithms internally use iterations (such as simulated annealing and tabu search), the global termination condition is always defined by function evaluations for consistent computational effort across all approaches.
Figure 8 presents a sensitivity analysis of Q-learning hyperparameters on the CyberShake workflow at CCR=1.0. The heatmap displays hypervolume performance across learning rate \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\alpha \in [0.1, 0.9]$$\end{document} and discount factor \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\gamma \in [0.1, 0.9]$$\end{document} combinations. Several important observations emerge from this analysis. Optimal performance occurs at \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\alpha =0.5$$\end{document} and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\gamma =0.9$$\end{document} , which is the configuration used in our experiments. Performance remains stable across \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\alpha \in [0.3, 0.7]$$\end{document} and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\gamma \in [0.7, 0.9]$$\end{document} , demonstrating robustness to moderate parameter variations. Very low learning rates ( \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\alpha < 0.3$$\end{document} ) slow down convergence, while very high rates ( \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\alpha > 0.7$$\end{document} ) cause instability in the learning process. Low discount factors ( \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\gamma < 0.5$$\end{document} ) reduce long-term planning capability, which degrades schedule quality.
Additional experiments on exploration parameters show that 300 training episodes ( \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$E_{ql} = 300$$\end{document} ) provide sufficient convergence for workflows up to 100 tasks. The exploration rate \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\epsilon$$\end{document} decays from 1.0 to 0.1 over training episodes using exponential decay ( \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\epsilon = \epsilon \times 0.99$$\end{document} per episode) to balance exploration and exploitation effectively. Experiments with different decay rates (0.95, 0.97, and 0.99) show minimal impact on final performance, with HV variation remaining below 5%, confirming robustness to this hyperparameter.
This comprehensive analysis confirms framework robustness within reasonable parameter ranges while validating the selected configuration. Performance remains within 10% of optimal for \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\alpha \in [0.3, 0.7]$$\end{document} and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\gamma \in [0.7, 0.9]$$\end{document} . Table 8 summarizes the final configurations optimized for HV performance, applied consistently throughout the evaluation process. Configuration parameters in Table 8 are applied uniformly across all hybrid MOEA/D-based algorithms described in Section 5 to ensure fair comparison.Fig. 8Q-learning sensitivity analysis on CyberShake workflow at CCR=1.0.Table 8. Configuration parameters for comparative algorithms.AlgorithmParameter SettingsMOEA/DCrossover rate: 70%Mutation rate: 30%Population size: 100Neighborhood size: 10Tabu SearchTabu list size: 10Maximum iterations without improvement: 10Simulated AnnealingInitial temperature ( \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$T_0$$\end{document} ): 20GRASP \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\alpha$$\end{document} parameter: 0.4Q-LearningLearning rate ( \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\alpha$$\end{document} ): 0.5Discount factor ( \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\gamma$$\end{document} ): 0.9Exploration rate ( \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\epsilon$$\end{document} ): 1.0Maximum evaluations1000
Convergence and computational complexity
The workflow scheduling problem in heterogeneous environments is NP-hard, making exact convergence proofs intractable. Therefore, we provide a theoretical discussion of the convergence behavior and computational complexity of the proposed QLSA-MOEA/D framework.
Convergence behavior
QLSA-MOEA/D integrates three complementary stochastic components: (i) Q-learning for adaptive initialization, (ii) Simulated Annealing (SA) for local refinement, and (iii) MOEA/D for evolutionary optimization.
The Q-learning component progressively improves task-processor mappings through repeated episodes, with the Q-value table converging to stable policies that effectively balance exploration and exploitation. Simultaneously, SA enhances local search capability by probabilistically accepting inferior solutions during early stages to escape local optima while gradually focusing on improvement as the temperature cools. MOEA/D decomposes the multi-objective problem into multiple scalar subproblems that evolve cooperatively through neighborhood information sharing.
Although formal global convergence guarantees remain challenging for such hybrid metaheuristics, our experimental observations demonstrate consistent monotonic improvement in both Hypervolume (HV) and Inverted Generational Distance plus (IGD+) metrics across successive generations. This empirical evidence confirms stable convergence behavior toward high-quality Pareto approximations.
Computational complexity
Let T be the number of tasks, \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\textit{Popsize}$$\end{document} the population size, \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\textit{MaxGen}$$\end{document} the number of generations, \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$E_{\textit{ql}}$$\end{document} the Q-learning episodes, and I the local search iterations. The overall computational complexity of QLSA-MOEA/D comprises three main components:
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\begin{aligned} O(E_{\textit{ql}} \cdot T + I \cdot T + \textit{MaxGen} \cdot \textit{Popsize} \cdot T) \end{aligned}$$\end{document}The first term represents the Q-learning initialization cost, the second accounts for simulated annealing local search, while the third corresponds to the MOEA/D evolutionary loop. In practical scenarios, the Q-learning and SA components introduce only linear overhead relative to problem size, whereas the MOEA/D component \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\textit{MaxGen} \cdot \textit{Popsize} \cdot T$$\end{document} dominates the overall computational cost.
In our experimental configuration, where population size typically exceeds or equals the number of tasks ( \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\textit{Popsize} >= T$$\end{document} ), the dominant term can be reasonably approximated as:
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\begin{aligned} O(\textit{MaxGen} \cdot \textit{Popsize}^2) \end{aligned}$$\end{document}This simplification accurately reflects the observed scaling behavior and explains the final complexity representation. Table 9 presents a comparative analysis of the time complexity for QLSA-MOEA/D and other hybrid MOEA/D-based algorithms.Table 9. Time complexity comparison of hybrid MOEA/D-based algorithms (dominant terms).AlgorithmComplexity (dominant)QLSA–MOEA/D \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$O(\textit{MaxGen} \cdot \textit{Popsize}^2$$\end{document} GTS–MOEA/D \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$O(\textit{MaxGen} \cdot \textit{Popsize}^2)$$\end{document} GSA–MOEA/D \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$O(\textit{MaxGen} \cdot \textit{Popsize}^2)$$\end{document} GRASP–MOEA/D \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$O(\textit{MaxGen} \cdot \textit{Popsize}^2)$$\end{document} TS–MOEA/D \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$O(\textit{MaxGen} \cdot \textit{Popsize}^2)$$\end{document} SA–MOEA/D \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$O(\textit{MaxGen} \cdot \textit{Popsize}^2)$$\end{document} HACG \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$O(\textit{MaxGen} \cdot \textit{Popsize}^2)$$\end{document} Note: All MOEA/D-based hybrids share the same dominant evolutionary loop complexity. QLSA-MOEA/D includes an additional linear term for Q-learning initialization, which becomes negligible for large-scale problems.
In summary, despite the incorporation of reinforcement learning for intelligent initialization, QLSA-MOEA/D maintains polynomial time complexity comparable to other hybrid variants. This favorable scaling characteristic, combined with its demonstrated solution quality advantages, ensures practical feasibility for real-world workflow scheduling applications.
Experimental results
Static workflows: FFT and molecular
Experiments on the structured FFT workflow used three and eight heterogeneous processors at CCR values of 0.5, 1, 5, and 10. Table 10 summarizes average hypervolume (HV) and IGD+ results. Figures 9a –10b show performance trends, while Figs. 11–12 display Pareto-front approximations.
Table 10 and Figs. 9a –10b show that QLSA-MOEAD consistently achieves the best results across both processor configurations at low CCR (0.5). The Q-learning component helps the algorithm converge faster even when task dependencies are tight, which is typical in FFT structures. GRASP-MOEAD obtains comparable HV values but shows higher IGD+. This indicates premature convergence and difficulty in maintaining diversity. GSA-MOEAD and GTS-MOEAD perform moderately well. Their local refinements improve exploitation but lack the adaptive feedback that Q-learning provides.
The performance gap widens as CCR increases to 1.0 and 5.0. QLSA-MOEAD adapts task ordering dynamically as communication overhead grows. This helps maintain stable convergence. GRASP-MOEAD and GTS-MOEAD converge slower because they rely on static initialization. They also have limited ability to rebalance loads dynamically. SA-MOEAD and TS-MOEAD show minimal improvement. Simple stochastic refinements are not enough to compensate for the structural rigidity in FFT workflows. HACG performs the weakest and demonstrates poor scalability. Diversity also decreases as dependencies increase.
At the highest CCR (10.0), QLSA-MOEAD maintains its advantage even when communication costs outweigh computation. This demonstrates a good balance between exploitation and adaptive learning. GRASP-MOEAD produces reasonable results but cannot match QLSA-MOEAD’s adaptability. Other methods like GSA-MOEAD and TS-MOEAD degrade significantly when handling communication-intensive dependencies. HACG continues producing sparse, low-quality solutions throughout.
Figures 11 and 12 confirm these observations visually. QLSA-MOEAD produces dense, well-distributed Pareto fronts, while other methods show scattered or partially converged fronts. Overall, integrating Q-learning with MOEA/D provides superior adaptability. QLSA-MOEAD works most effectively for structured FFT workflows, particularly when communication overheads are high.
The Statistical validation in
Table 12 presents Wilcoxon signed-rank test results comparing QLSA-MOEAD against competitors. For FFT with 3 processors, QLSA-MOEAD significantly outperforms all competitors at \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$p < 0.05$$\end{document} across most CCR values. Only two exceptions appear: SA-MOEAD at CCR=1.0 ( \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$p=0.1$$\end{document} ) and TS-MOEAD at CCR=5.0 ( \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$p=0.05$$\end{document} ), where differences approach but do not reach strict significance. These statistical tests confirm that observed performance improvements are not random variation.Table 10AVG.Hypervolume and AVG.IGD+ results for FFT workflow executed on different heterogeneous units.FFTCCRunitsQLSA-MOEADGTS-MOEADGSA-MOEADGRASP-MOEADTS-MOEADSA-MOEADHACGAVG.HVCase 10.5319.56417.53817.04619.06916.37812.8064.285Case 21.0316.12110.39612.45714.00212.57011.7682.666Case 35.0311.8827.6247.7247.7307.0377.1964.622Case 410.0311.3905.1025.67010.1579.0497.1064.928Case 50.582.4371.7351.4032.3601.3712.1981.200Case 61.088.2245.8677.2437.4135.1393.3782.441Case 75.084.5764.1612.4594.3943.7514.3711.380Case 810.082.9341.7761.3692.3621.7501.8670.597AVG. IGD+Case 10.532.7936.7458.7644.1486.9517.25134.370Case 21.032.0983.3573.3682.1974.9592.87641.153Case 35.033.2305.9745.5103.6243.8326.469111.607Case 410.032.9419.9365.9673.0573.5987.89075.353Case 50.580.5681.8133.1691.7591.8813.42420.239Case 61.086.0047.7177.3507.3507.7609.07420.141Case 75.085.9479.9899.9356.1426.6818.53878.401Case 810.082.1806.0546.8265.1337.2186.66535.065
Fig. 9. Multi-objective metrics for FFT workflow on three units under different CCR values. Fig. 10. Multi-Objective Performance Indicators for FFT Workflow on Eight units. Fig. 11FFT Workflow Pareto Fronts under Multiple CCR with 3 units. Fig. 12. Pareto Front Distributions for FFT Workflow on Eight units.
We evaluated the same algorithms on the unstructured molecular workflow to assess generalizability. Experiments used four and eight processors at CCR values from 0.5 to 10. Table 11 reports HV and IGD+ values. Figures 13a –14b show performance comparisons. Figures 15 –16 displays Pareto-optimal solution distributions.
Table 11 and Figs. 13a –14b shows that the molecular workflow reveals interesting differences from FFT behavior. At low CCR with 4 and 8 processors (Cases 9 and 13), GSA-MOEAD achieves the highest HV with the lowest IGD+. GSA-MOEAD prioritizes exploration in unstructured workflows, whereas QLSA-MOEAD balances exploration and exploitation more effectively for convergence. GRASP-MOEAD, GTS-MOEAD, and TS-MOEAD show moderate performance. This reflects limited adaptability. HACG underperforms significantly throughout.
QLSA-MOEAD shows increased dominance as CCR rises to intermediate levels (Cases 10 and 14). At CCR=1.0 with 4 processors, it outperforms both GSA-MOEAD and GRASP-MOEAD in both metrics. GSA-MOEAD remains competitive but shows slower convergence under communication-intensive conditions. With 8 processors, QLSA-MOEAD substantially beats all baselines.
At high CCR values (Cases 11-12, 15-16), QLSA-MOEAD dominates. It handles high communication-to-computation ratios while preserving diversity. GSA-MOEAD retains relatively strong performance but lags slightly in convergence. SA-MOEAD occasionally approaches QLSA-MOEAD in HV but shows less uniform solution distribution based on higher IGD+ values. At 8 processors under high CCR, QLSA-MOEAD continues to excel across all test cases.
Figures 15 and 16 show QLSA-MOEAD solutions closely approximate the Pareto front. Both QLSA-MOEAD and GSA-MOEAD demonstrate consistent superiority across CCR levels and processor counts. Statistical tests in Table 12 for Molecular with 8 processors show QLSA-MOEAD significantly outperforms competitors ( \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$p < 0.05$$\end{document} ). The few non-significant cases appear with GRASP-MOEAD at specific CCR values and occasionally with TS-MOEAD.
Beyond solution quality, we analyzed computational efficiency to assess practical applicability. Table 13 compares execution time and HV across both workflows at CCR=1.0. Each value averages twenty independent runs. QLSA-MOEAD outperforms competitors in both speed and quality. The parallel implementation reduces computational burden without compromising convergence. Q-learning accelerates task selection through learned policies. SA refines schedules through adaptive exploration.
For the FFT workflow, QLSA-MOEAD requires substantially less time than competitors while maintaining superior HV values. The molecular workflow shows similar patterns across both processor configurations. QLSA-MOEAD provides a stable trade-off between search diversity and runtime. Lower execution time shows that reinforcement-guided initialization can replace random or greedy heuristics efficiently when supported by parallel processing. Higher HV values confirm strong convergence toward the Pareto front. The algorithm preserves solution diversity.
Compared to other hybrid methods like GSA-MOEAD and GTS-MOEAD, the proposed approach shows faster convergence and better scalability as task and processor counts increase. Traditional heuristics like GRASP, TS, and SA achieve reasonable results but lack adaptability in complex scenarios. Overall, QLSA-MOEAD effectively integrates learning with metaheuristic exploration to achieve high-quality solutions in a reasonable time.
The experimental evidence validates the algorithm’s robustness for real-world heterogeneous systems requiring both accuracy and scalability.Table 11AVG. Hypervolume and IGD+ values for the Molecular workflow on diferrent heterogeneous units.MolecularCCRunitsQLSA-MOEADGTS-MOEADGSA-MOEADGRASP-MOEADTS-MOEADSA-MOEADHACGAVG. HVCase 90.549.7916.23410.0017.2675.4975.0182.213Case 101.045.8533.7185.3104.2732.3072.3320.994Case 115.042.521.8622.4280.9441.2061.3270.484Case 1210.041.4060.7641.2071.1731.1451.3400.704Case 130.581.6872.2983.0742.1581.7352.4461.323Case 141.082.8791.3572.0581.7331.6141.2261.074Case 155.080.5170.360.5010.3360.4340.3840.31Case 1610.081.5330.7350.9550.8110.7381.480.79AVG. IGD+Case 90.548.8445.2523.7395.5586.7806.12648.677Case 101.043.4039.0386.77610.7137.2217.71539.730Case 115.041.2353.6451.4852.0672.5952.45835.893Case 1210.041.433.8482.7113.9542.8971.76150.899Case 130.542.2791.876** 1.2582.2542.1961.77316.096Case 141.040.4791.7151.3162.051.4811.97112.034Case 155.040.6362.1561.5081.52.0451.64110.124Case 1610.041.355**3.1562.6563.7082.1952.8938.995Table 12Wilcoxon signed-rank test of FFT with 3 processors and Molecular with 8 processors: QLSA-MOEAD vs baselines (Hypervolume). * indicates p \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$< 0.05$$\end{document} .BaselineWorkflowProcessor num.CCR 0.5CCR 1.0CCR 5.0****CCR 10.0GTS-MOEADFFT30.0300.00010.0000.0001 GSA-MOEAD--0.020.0020.0010.0002GRASP-MOEAD--0.010.010.0020.0001TS-MOEAD--0.010.010.050.0001SA-MOEAD--0.020.10.0000.0001HACG--0.0010.010.010.001GTS-MOEADMolecular80.040.00060.040.03 GSA-MOEAD--0.020.0040.010.02GRASP-MOEAD--0.060.0010.080.04TS-MOEAD--0.010.0010.020.04SA-MOEAD--0.020.00010.040.007HACG--0.010.0080.00020.002All test : QLSA-MOEAD vs baseline (one-tailed, \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\alpha = 0.05$$\end{document} ).
Fig. 13. Performance metrics for multi-objective optimization of the FFT workflow using four units. Fig. 14. Multi-objective performance metrics for the molecular workflow on eight units. Fig. 15. Pareto fronts of the molecular workflow on four units. Fig. 16. Pareto front of Molecular Workflow with different CCR and 8 machines. Table 13. Execution time (ms) and HV for all hybrid algorithms with MOEAD across the two workflows. Italics values represent the fastest execution time and best HV of solution per case.WorkflowCCRUnitsQLSAGTSGSAGRASPTSSAHACG Execution Time (ms) FFT1.03 4963 13293159497202174121550312630-1.08 11686 3566381657842774735257316509936841Molecular1.04 10806 597472475824147432314351364757-1.08 72735 120241166909112348123298123266116141 HV FFT1.03 16.121 10.39612.47514.00212.57011.7682.666-1.08 8.224 5.8677.2437.4135.1393.3782.441Molecular1.04 5.853 3.7185.3104.2732.3072.3320.994-1.08 2.879 1.3572.0581.7331.6141.2261.074
Dynamic workflow: montage
Table 14 evaluates QLSA-MOEAD on the Montage workflow (100 tasks, 179 dependencies) under static and dynamic conditions. In static mode, average HV increases from 0.0665 at CCR=0.5 to 0.6413 at CCR=10.0, with runtime between 1,589–2,916 ms. These results establish baseline quality when schedules are computed once without disruptions.
Dynamic execution simulates real-time task arrivals requiring on-the-fly schedule adjustments. Response time (RT) remains between 0.80–1.70 ms across all CCR values, fast enough for practical deployment. The best case occurs at CCR=5.0 (RT=0.80 ms), where communication delays provide natural gaps for inserting new tasks without disrupting ongoing work.
Quality degradation varies significantly with CCR. At CCR=0.5, dynamic HV drops from 0.0665 to 0.0305 (54.1% loss) because computation-intensive workloads leave little slack time for adjustments. At CCR=1.0, degradation improves slightly to 50.6%. The most favorable scenario appears at CCR=5.0, where HV degrades only 3.7% (from 0.1547 to 0.1489). Here, communication-dominated execution creates frequent idle periods that accommodate new tasks smoothly. At CCR=10.0, degradation reaches 63.78% as extreme communication costs fragment schedules, limiting insertion flexibility.
Total runtime increases from 1,589–2,916 ms (static) to 15,356–16,207 ms (dynamic), reflecting the cumulative cost of adjustments. IGD+ values also increase from 0.4597–3.0690 (static) to 0.6713–5.3517 (dynamic), showing reduced convergence precision when schedules must adapt incrementally rather than through global optimization.
The Q-learning component enables this fast adaptation. When tasks arrive, the Q-table suggests processor assignments in constant time, SA refines the placement through local search, and MOEA/D updates only affected subproblems. This incremental process achieves 1,000–3,000 \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\times$$\end{document} speedup over regenerating entire schedules, which would require 2,000–3,000 ms per adjustment.
In summary, QLSA-MOEAD handles dynamic scenarios with sub-millisecond response times suitable for real-time systems, though quality loss of 3.7–63.78% may not satisfy applications requiring guaranteed performance. The approach works well for cloud batch processing but less so for hard real-time control. The minimal degradation at CCR=5.0 suggests that practitioners can tune system parameters to target similar conditions and maintain near-optimal quality despite runtime changes.Table 14. Static and Dynamic Montage Workflow using QLSA-MOEAD with multiple performance metrics.WorkflowCCRUnits HV IGD+RunTime (ms)RT (ms) \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$PD_{HV}$$\end{document} Static Montage WorkflowMontage0.5160.06650.75921589---1.0160.10000.45972047---5.0160.15473.06902092---10.0160.64130.99662916--Dynamic Montage WorkflowMontage0.5160.03052.3051153561.7054.135-1.0160.04940.6713161331.2550.6-5.0160.14895.3517162070.803.7-10.0160.23221.9807155591.5063.78
Real-world validation: cyberShake workflow
The benchmark experiments on FFT, Molecular, and Montage workflows establish algorithmic effectiveness on synthetic benchmarks with controlled characteristics. The CyberShake seismic hazard analysis workflow provides validation on a realistic scientific application featuring irregular task dependencies and heterogeneous computational requirements typical of real-world scenarios.
Energy consumption model
The framework extends to three objectives for CyberShake: makespan, resource utilization, and energy consumption. Energy is computed using Eq. 16.
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\begin{aligned} \text {Energy} = \sum _{x=1}^{P} \sum _{t_i \in P_x} \left( \text {Pow}_x \times W(t_i, P_x) \right) + \sum _{(t_i,t_j) \in E_d} \left( \text {Pow}_{\text {comm}} \times C(t_i, t_j) \right) \end{aligned}$$\end{document}where \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\text {Pow}_x$$\end{document} denotes the power consumption of processor \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$P_x$$\end{document} as listed in Table 4 (Section 5.3), \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$W(t_i, P_x)$$\end{document} represents the execution time of task \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$t_i$$\end{document} on processor \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$P_x$$\end{document} as defined in Eq. (1), \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\text {Pow}_{\text {comm}}$$\end{document} is the communication network power (5W per active link), and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$C(t_i, t_j)$$\end{document} denotes the communication time between tasks \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$t_i$$\end{document} and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$t_j$$\end{document} for edges \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$(t_i, t_j) \in E_d$$\end{document} . The model accounts for both computational energy (processor-dependent) and data transfer energy (communication-dependent).
Three-objective optimization results
For the CyberShake workflow, the framework extends to three-objective optimization by incorporating energy consumption alongside makespan and resource utilization. Energy consumption is computed using Eq. 16, which accounts for both processor-specific power consumption (Table 4) and communication network power (5W per active link).
QLSA-MOEAD is evaluated against six baseline configurations: MOEAD (random initialization), SA (simulated annealing only), QL (Q-learning only), QLSA (Q-learning + SA without MOEAD), DRL^48^, and GRASP-MOEAD (current state-of-the-art hybrid)^29^. This comparison isolates component contributions while benchmarking against the best existing hybrid method.
All algorithms optimize three objectives simultaneously: makespan minimization, resource utilization maximization ( \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\beta$$\end{document} ), and energy consumption minimization. For fair comparison, all multi-objective variants employ 100 uniformly distributed weight vectors following MOEAD decomposition principles. Both QL and DRL use multi-objective reward design rather than single-metric optimization, ensuring consistent learning objectives. Each algorithm executes 20 independent runs on four CyberShake variants (CCR = 0.5, 1.0, 5.0, 10.0). Table 15 presents average Hypervolume (HV) and Inverted Generational Distance Plus (IGD+).Table 15. Performance comparison on CyberShake workflow across six heterogeneous units and multiple CCR values.CaseCCRQLSA-MOEADGRASP-MOEADQLSASAQLDRLMOEADAVG. (HV) ** \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\uparrow$$\end{document} ( \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\times 10^3$$\end{document} )Case 10.53847.41899.6212.77260.0511.3619.41463.81Case 21.02685.37852.6224.8184.981.211.6342.28Case 35.03063.901332.0426.55265.1611.273.9956.13Case 410.07796.003226.0129.882536.3223.5851.093054.78AVG. (IGD+) ** \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\downarrow$$\end{document} Case 10.50.26670.27840.31170.26980.30130.26690.3201Case 21.00.24230.25730.2480.24320.29510.29730.2852Case 35.0** 0.24280.26280.29140.24720.27350.29110.2788Case 410.00.2919**0.31240.31220.31090.32030.31150.3138HV values scaled by \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$10^3$$\end{document} for readability. Best values per CCR in bold.
Table 15 demonstrates QLSA-MOEAD’s dominance across all CyberShake configurations. At CCR=0.5, the framework achieves HV of 3847.41 \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\times 10^3$$\end{document} , substantially exceeding GRASP-MOEAD (899.62 \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\times 10^3$$\end{document} ) and all other baselines. This represents a 4.3-fold improvement over the previous state-of-the-art. The advantage persists across varying CCR values: at CCR=1.0, QLSA-MOEAD reaches 2685.37 \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\times 10^3$$\end{document} versus GRASP-MOEAD’s 852.62 \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\times 10^3$$\end{document} (3.1-fold improvement); at CCR=5.0, the gap is 3063.90 versus 1332.04 (2.3-fold); and at CCR=10.0, performance peaks at 7796.00 versus 3226.01 (2.4-fold). The IGD+ metric confirms superior convergence quality, with QLSA-MOEAD maintaining the lowest values across all cases (0.2423-0.2919).
Comparison with the DRL baseline reveals that pure deep reinforcement learning achieves only 19.41–51.09 \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\times 10^3$$\end{document} HV, representing a 50–200-fold performance gap. This confirms the necessity of multi-objective optimization frameworks rather than relying solely on neural network policies. The ablation variants show similarly weak performance: QL-only achieves 1.21–23.58 \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\times 10^3$$\end{document} HV (100–300-fold lower), validating that Q-learning alone cannot explore the full Pareto front without evolutionary search. SA-only reaches 84.98–2536.32 \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\times 10^3$$\end{document} HV, showing moderate capability but lacking adaptive initialization. QLSA without MOEAD achieves only 12.77–29.88 \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\times 10^3$$\end{document} HV (100–200-fold lower), confirming that multi-objective decomposition is essential for comprehensive trade-off exploration. Finally, MOEAD with random initialization achieves 463.81–3054.78 \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\times 10^3$$\end{document} HV, which is 5–8-fold lower than QLSA-MOEAD, demonstrating the substantial improvement from Q-learning initialization over random population generation.Table 16. Computational time comparison for key algorithm variants on CyberShake workflow.CaseCCRQLSA-MOEADMOEADQLSACase 10.51019.123.037.35211.7Case 21.01048.722.1536.4215.75Case 35.01197.625.1539.2235.65Case 410.0883.5523.838.05217.95All times in milliseconds. Average over 20 independent runs.
Table 16 presents computational time for individual components and the integrated framework. The individual measurements represent single-pass execution: QL shows initialization time, SA shows one refinement cycle, and MOEAD shows one generation time. QLSA-MOEAD integrates these components throughout the entire optimization process (100 generations), where the evolution of MOEAD dominates the run time (22 ms \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\times$$\end{document} 100 = 2,200 ms base cost), the initialization of Q-learning adds one-time overhead (36 ms) and the SA refinement is selectively applied within the evolutionary loop. This explains the observed 1,019 ms total time, which reflects full optimization.
Despite requiring approximately one second per run, QLSA-MOEAD delivers 100–300-fold better HV than individual components (Table 15), validating that the integrated approach provides substantial quality improvements. For offline workflow planning scenarios, sub-second runtime remains practical while generating comprehensive Pareto fronts for decision support.Table 17. Wilcoxon signed-rank test: QLSA-MOEAD vs baselines (Hypervolume). * indicates p \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$< 0.05$$\end{document} .BaselineCCR = 0.5CCR = 1.0CCR = 5.0CCR = 10.0GRASP-MOEAD0.0400.0620.1490.248DRL0.00010.00030.0010.016MOEAD0.0010.00020.0010.012QL0.00010.00020.0010.011QLSA0.00010.00020.0010.013SA0.00040.00040.0060.314All tests: QLSA-MOEAD vs baseline (one-tailed, \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\alpha = 0.05$$\end{document} ).
Wilcoxon signed-rank tests assess the statistical significance of performance differences between QLSA-MOEAD and each baseline algorithm. Table 17 presents p-values for hypervolume comparisons across all CCR configurations. Results indicate QLSA-MOEAD significantly outperforms DRL, MOEAD, QL, QLSA, and SA at all CCR levels (p \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$< 0.05$$\end{document} , typically p \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$< 0.01$$\end{document} ). Against GRASP-MOEAD, significance is achieved at CCR=0.5 (p=0.040) but not at higher CCR values (p=0.062–0.248). This pattern suggests that while QLSA-MOEAD maintains consistent practical advantages (2.3–4.3-fold HV improvements), the statistical confidence weakens slightly in communication-intensive scenarios where both methods effectively exploit parallelism opportunities. The non-significant p-values at high CCR do not diminish the practical importance of the observed improvements, which remain substantial in absolute terms.Table 18. Friedman test results for Hypervolume across CCR values. All tests show significant differences among algorithms ( \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\alpha = 0.05$$\end{document} ).CCRChi-Square( \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\chi ^2$$\end{document} )dfp-value0.559.237 \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$< 0.001$$\end{document} 1.084.727 \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$< 0.001$$\end{document} 5.071.107 \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$< 0.001$$\end{document} 10.064.637 \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$< 0.001$$\end{document} All tests reject null hypothesis of equal HV distributions.
Friedman tests evaluate whether significant differences exist among all seven algorithms across the four CCR values. Table 18 shows chi-square statistics ranging from 59.23 to 84.72 (df=7), with all p-values below 0.001. These results reject the null hypothesis of equal performance distributions, confirming that the observed differences among algorithms are statistically meaningful rather than arising from random variation. The consistently high chi-square values across different CCR configurations indicate robust algorithmic distinctions that persist under varying communication-to-computation ratios.Fig. 17. Three-objective Pareto fronts for CyberShake workflow across different CCR values.
Figure 17 visualizes three-objective Pareto fronts across varying CCR configurations using 3D scatter plots. Each subplot displays solutions in the makespan-utilization-energy objective space. Red points represent the global efficient set (best non-dominated solutions from all algorithms combined), while green points highlight QLSA-MOEAD’s contributions. Dense, evenly-distributed patterns indicate high-quality front coverage.
At CCR=0.5 (Fig. 17(a)), QLSA-MOEAD solutions (green points) appear in three main regions of the efficient set: low-energy solutions with higher makespan, balanced mid-range trade-offs, and low-makespan solutions with higher energy. Competing algorithms (red points) also contribute solutions across the Pareto front, showing competitive performance at this CCR level.
At CCR=1.0 (Fig. 17(b)), QLSA-MOEAD shows increased presence on the efficient set with better coverage in low-energy regions below \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$1.8 \times 10^5$$\end{document} units. Both QLSA-MOEAD and competing methods find diverse solutions across the makespan range from 400 to 650 units.
At CCR=5.0 (Fig. 17(c)), QLSA-MOEAD solutions dominate larger portions of the Pareto front. Green points extend across makespan values from 600 to 1400 units with a strong presence in lower-energy regions. Red points from competing methods concentrate mainly in higher-energy areas above \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$2.6 \times 10^5$$\end{document} units.
The extreme CCR=10.0 scenario (Fig. 17(d)) shows QLSA-MOEAD’s clear dominance.
The CyberShake validation confirms QLSA-MOEAD’s effectiveness on realistic three-objective optimization. The framework outperforms the previous state-of-the-art (GRASP-MOEAD) by 2.3-4.3-fold in hypervolume across all CCR values. The visual dominance of green points in Fig. 17 directly corresponds to this quantitative superiority: as green points increasingly constitute the efficient set, HV advantages compound. Statistical tests confirm performance superiority at p \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$< 0.05$$\end{document} for most comparisons. Ablation studies validate that all three components (Q-learning, Simulated Annealing, MOEA/D) contribute meaningfully. The framework’s ability to discover unique energy-efficient solutions absent from competing methods makes it particularly valuable for resource-constrained scientific computing where operational costs and sustainability drive scheduling decisions.
Discussion
The experimental evaluation across structured (FFT), unstructured (Molecular), dynamic (Montage), and real-world (CyberShake) workflows confirms the superior performance of QLSA-MOEAD in multi-objective workflow scheduling.
In structured FFT workflows, QLSA-MOEAD achieves best performance in 8 out of 8 test cases with HV improvements. This dominance arises from a hybrid design that effectively balances exploration and exploitation. Q-learning guides task sequencing. The algorithm learns neighborhood moves that minimize makespan while maintaining load balance. During training (300 episodes), the Q-table accumulates knowledge about which task orderings work well for FFT’s symmetric structure. The algorithm constructs high-quality initial populations 50–70% faster than random or greedy approaches. MOEA/D decomposition maintains solution diversity across subproblems. The framework ensures broad exploration of the Pareto front through 100 weight vectors and neighborhood information exchange.
Competitor methods show distinct weaknesses. HACG exhibits poor performance. Random initialization causes this weakness. HACG requires many generations to reach high-quality regions. QLSA-MOEAD finds these regions in few generations. GRASP-MOEAD and GTS-MOEAD fail in communication-intensive scenarios (CCR \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\ge$$\end{document} 5). Their static initialization cannot adapt to changing communication patterns.
In unstructured molecular workflows, QLSA-MOEAD demonstrates superior performance under moderate and high CCRs (6 out of 8 cases). GSA-MOEAD achieves better HV in 2 cases at low CCR, though QLSA-MOEAD maintains lower IGD+ even in these cases. GSA-MOEAD’s gravitational mechanism explores diverse regions when computational costs dominate, but this advantage disappears as communication costs rise. QLSA-MOEAD remains robust across CCR levels because its learning component adapts to workflow structure. The algorithm discovers that Molecular’s irregular dependencies require different sequencing strategies than FFT’s symmetric structure. This adaptability explains why QLSA-MOEAD handles both structured and unstructured workflows effectively.
Dynamic scheduling in Montage workflow demonstrates QLSA-MOEAD’s practical adaptability. The framework handles real-time task arrivals with sub-millisecond response times (0.80–1.70 ms). Performance degradation ranges from 3.7% to 63.78% across CCR values. At CCR=5.0, degradation is minimal because communication costs create natural synchronization points that facilitate task insertion. The Q-learning component enables incremental updates. The algorithm identifies affected subproblems in O(k) time, queries the Q-table in O(1) time, and applies lightweight SA refinement. This process explains the 1,000–3,000 \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\times$$\end{document} speedup over full re-optimization.
The CyberShake workflow provides validation with three-objective optimization (makespan, utilization, energy). QLSA-MOEAD achieves 2.3–4.3 \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\times$$\end{document} HV improvement over GRASP-MOEAD. This efficiency arises because Q-learning constructs one high-quality solution per generation via learned policy. The three-objective formulation reveals that energy consumption correlates strongly with makespan (0.7–0.8) but shows complex interactions with utilization. Ablation studies confirm all components contribute meaningfully. Removing Q-learning reduces HV by 5–8 \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\times$$\end{document} . Removing MOEA/D reduces it by 100–200 \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\times$$\end{document} . Removing SA reduces it by 30–40 \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\times$$\end{document} .
Cross-workflow analysis reveals consistent patterns. QLSA-MOEAD’s advantage increases with CCR, from 1.05–2.0 \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\times$$\end{document} at low CCR to 2.0–4.8 \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\times$$\end{document} at high CCR. The framework handles both structured and unstructured workflows effectively while maintaining polynomial-time complexity comparable to pure MOEA/D. Despite strong overall performance, limitations exist. These include Q-learning training overhead (5–10 minutes for 100-task workflows), dynamic performance degradation up to 63.78% unsuitable for hard real-time systems, and scalability validation remaining for workflows beyond 200–300 tasks. QLSA-MOEAD demonstrates robust performance across all benchmarks. It achieves best results in 14/16 synthetic cases and all 4 CyberShake cases. This success stems from integrating reinforcement learning, metaheuristic refinement, and multi-objective decomposition.
Conclusion and future work
This work addresses multi-objective workflow scheduling in heterogeneous computing systems where diverse processors (CPUs, GPUs, and FPGAs) must execute interdependent tasks efficiently. This research proposed QLSA-MOEAD, a hybrid framework that integrates Q-Learning for intelligent initialization, Simulated Annealing for local refinement, and MOEA/D for multi-objective optimization through problem decomposition. Comprehensive experiments across 20 test cases validate the framework’s effectiveness. For synthetic benchmarks (FFT, Molecular), QLSA-MOEAD achieves the best solution quality in 14 out of 16 cases. The large-scale Montage workflow demonstrates adaptability under dynamic conditions, maintaining sub-millisecond response times (0.80–1.70 ms) suitable for real-time integration. Real-world validation using the CyberShake workflow. Statistical tests confirm performance superiority at the \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$p < 0.05$$\end{document} significance level. Ablation studies reveal that removing Q-learning reduces HV by 5–8 \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\times$$\end{document} , removing MOEA/D reduces it by 100–200 \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\times$$\end{document} , and removing SA reduces it by 30–40 \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\times$$\end{document} , confirming each component’s essential contribution. Despite strong overall performance, the framework exhibits limitations, including 8–10 \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\times$$\end{document} runtime overhead in dynamic mode, quality degradation up to 63.78% at extreme CCR values, and workflow-specific training requirements. Future work may pursue several directions. First, incorporate additional objectives such as reliability and cost. Second, expand dynamic scenarios to handle failures and resource contention. Third, integrate with cloud platforms like Kubernetes. Fourth, explore transfer learning to reduce training overhead. Fourth, investigate Deep Q-Networks (DQN) to handle larger workflows beyond 1000 tasks and overcome tabular Q-learning memory limitations. Finally, extend the framework to handle non-DAG workflows. The framework achieves 2–5 \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\times$$\end{document} solution quality improvement and 5–10 \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\times$$\end{document} computational speedup over existing methods, establishing it as a robust solution for modern computing infrastructures spanning cloud data centers, edge devices, and specialized accelerators.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1Fang, J., Zhang, J., Lu, S., Zhao, H.: Exploration on task scheduling strategy for cpu-gpu heterogeneous computing system. In: 2020 IEEE Computer Society Annual Symposium on VLSI (ISVLSI), pp. 306–311 (IEEE, 2020).
- 2Aldinucci, M. et al. The deephealth toolkit: A key european free and open-source software for deep learning and computer vision ready to exploit heterogeneous hpc and cloud architectures. In: Technologies and Applications for Big Data Value, pp. 183–202. (Springer, 2022).
- 3Deng, W.et al. A novel multi-objective optimized dag task scheduling strategy for fog computing based on container migration mechanism. Wirel. Netw.31, 1–15 (2024)
- 4Gao, Y., Yi, H., Chen, H., Fang, X. & Zhao, S. A structure-aware dag scheduling and allocation on heterogeneous multicore systems. In: 2024 IEEE 14th International Symposium on Industrial Embedded Systems (SIES), pp. 26–33 (IEEE, 2024).
- 5Mahfoudhi, R., Achour, S. & Mahjoub, Z. Parallel triangular matrix system solving on cpu-gpu system. In: 2016 IEEE/ACS 13th International Conference of Computer Systems and Applications (AICCSA), pp. 1–6 (IEEE, 2016).
- 6Guilmeau, T., Chouzenoux, E. & Elvira, V. Simulated annealing: A review and a new scheme. In: 2021 IEEE Statistical Signal Processing Workshop (SSP), pp. 101–105 (IEEE, 2021).
- 7Abla Saada, O.A., Hadhoudb, M. & Kafafy, A. Comparative study of intelligent scheduling algorithms for heterogeneous systems. Environments 1, 2 (2024).
- 8Behera, I. & Sobhanayak, S. Task scheduling optimization in heterogeneous cloud computing environments: A hybrid ga-gwo approach. J. Parallel Distrib. Comput.183, 104766 10.1016/j.jpdc.2023.104766 (2024).