Accounting for the Influence of Community Turnover Along Environmental Gradients on Compositional Uniqueness
Daniel Hernández‐Carrasco, Anthony J. Gillis, Hao Ran Lai, Tadeu Siqueira, Jonathan D. Tonkin

TL;DR
This paper introduces a new method to better understand how environmental factors influence biodiversity by distinguishing between different types of community changes.
Contribution
The paper introduces Generalised Dissimilarity Uniqueness Models (GDUM) to disentangle directional and non-directional drivers of beta diversity.
Findings
GDUM improves the interpretability of LCBD–environment relationships by accounting for directional turnover.
The framework distinguishes between environmental filtering and stochastic processes affecting biodiversity.
GDUM is consistent with conventional models but offers better generalisability for biodiversity projections.
Abstract
Compositional uniqueness has become increasingly relevant for understanding how local communities contribute to regional biodiversity. The most widely used metric is the Local Contribution to Beta Diversity (LCBD), which is typically regressed against environmental predictors. However, LCBD can vary either because of environmental processes that affect the overall variance in community composition, or because communities change directionally along environmental gradients. The latter implies that LCBD–environment relationships can strongly depend on how the environment is sampled. To address this issue, we introduce Generalised Dissimilarity Uniqueness Models (GDUM), a framework that embeds effects on community uniqueness within pairwise dissimilarity modelling. GDUMs are consistent with conventional uniqueness models, while explicitly accounting for directional changes in composition.…
Genes, proteins, chemicals, diseases, species, mutations and cell lines named across the full text — each resolved to its canonical identifier and authoritative record.
Click any figure to enlarge with its caption.
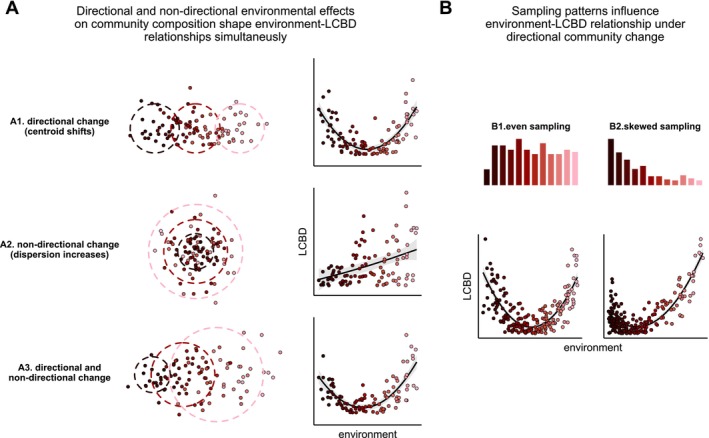 FIGURE 1
FIGURE 1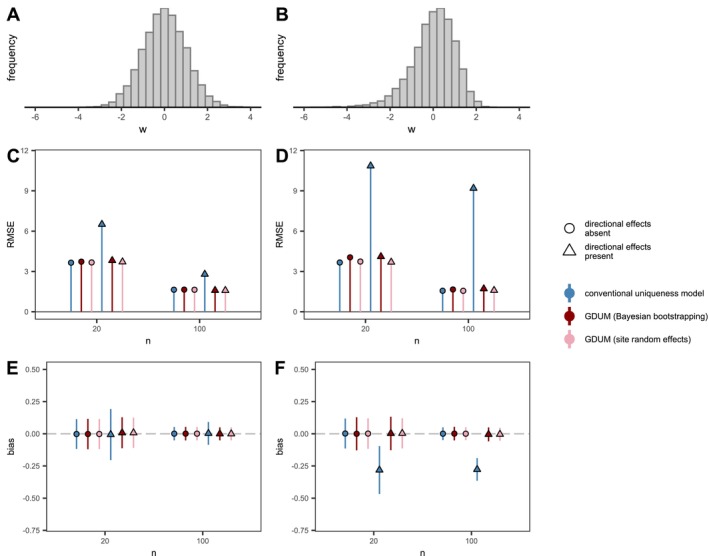 FIGURE 2
FIGURE 2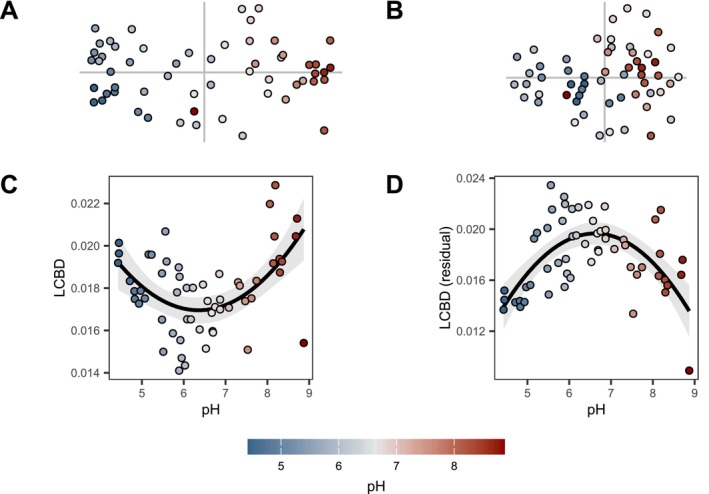 FIGURE 3
FIGURE 3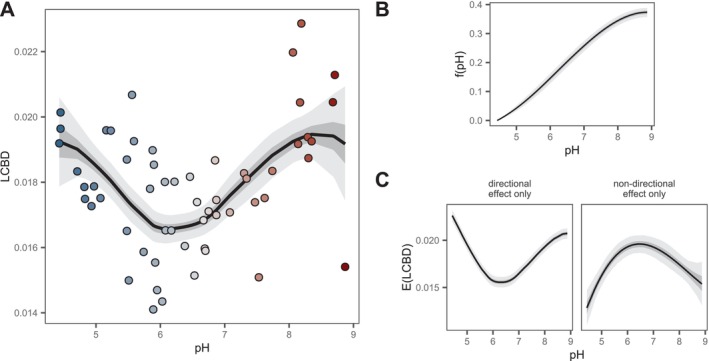 FIGURE 4
FIGURE 4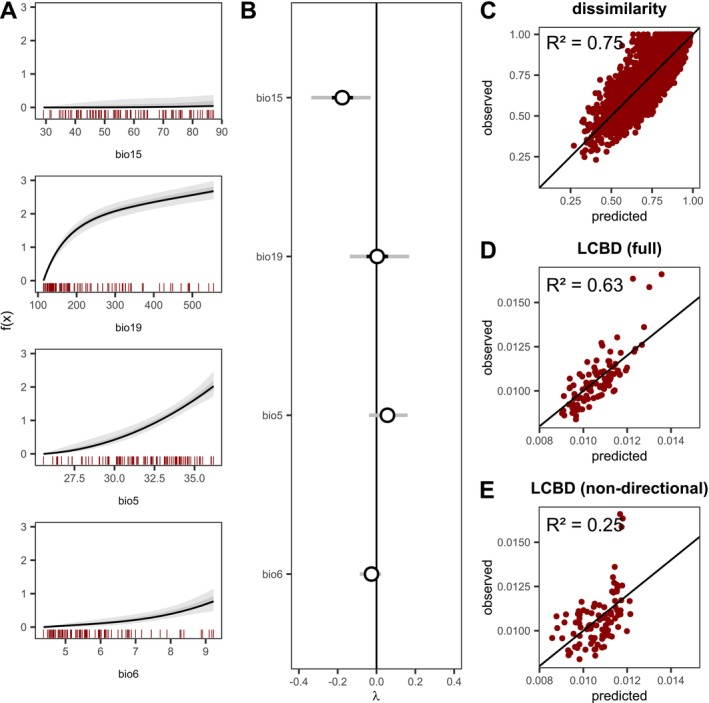 FIGURE 5
FIGURE 5- —Royal Society Te Apārangi10.13039/501100001509
- —Conselho Nacional de Desenvolvimento Científico e Tecnológico10.13039/501100003593
- —Bio‐Protection Research Centre10.13039/100014111
- —Te Pūnaha Matatini10.13039/501100019680
- —Tertiary Education Commission10.13039/100007879
- —University of Canterbury10.13039/100008414
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsIsotope Analysis in Ecology · Ecology and Vegetation Dynamics Studies · Insect and Arachnid Ecology and Behavior
Introduction
1
Beta diversity, the variation in community composition across space and time, has become a cornerstone of community ecology. It has helped uncover patterns in community structure (Anderson et al. 2011; Villarino et al. 2022; Zellweger et al. 2017), disentangle mechanisms driving community assembly (Chase 2010; Dobrovolski et al. 2012; Jacobi and Siqueira 2023; Soininen et al. 2018), and detect the footprint of human impact on biodiversity (Gutiérrez‐Cánovas et al. 2013; Socolar et al. 2016; Su et al. 2021). These broad applications have sparked increasing interest in improving statistical tools (Mokany et al. 2022). Conceptually, beta diversity encompasses two complementary interpretations (Anderson et al. 2011): directional community change, where communities change predictably along environmental or spatial gradients, and non‐directional variation, where the focus is on the overall dispersion of community composition (Figure 1A). While recent methodological advances have focused on capturing directional changes (Dias et al. 2022; Mokany et al. 2022; White et al. 2024), metrics related to overall community variance and the contribution of individual sites have been analysed separately (Anderson et al. 2006; Legendre and De Cáceres 2013). This separation hinders both inference and prediction about biodiversity change.
LCBD‐environment relationships depend on directional and non‐directional environmental effects on community composition, and how environmental gradients have been sampled. Colour gradient represents a hypothetical environmental variable. (A) Example of three patterns of variation in community composition driven by directional and/or non‐directional environmental effects (left), and resulting environment‐LCBD relationships (right). (B) Effect of sampling patterns (top) on environment‐LCBD relationship (bottom) under directional community change.
Understanding how individual sites contribute to spatial biodiversity patterns and overall beta diversity can provide insight into local processes that shape the site's relative uniqueness. The uniqueness of a community within a region can be quantified as its average dissimilarity to other communities, its distance to the centroid in an ordination space, or more commonly, as the community's Local Contribution to Beta Diversity (LCBD) (Anderson et al. 2006; Legendre and De Cáceres 2013). LCBD indices have been used as a tool for identifying high priority conservation sites across biomes, habitats, and taxa (Dubois et al. 2020; Fernández‐Calero et al. 2024; Heino and Grönroos 2017; Hill et al. 2021; Liu et al. 2024; Rodríguez‐Lozano et al. 2023; Yan et al. 2021), and for detecting the impact of localised stressors (Landeiro et al. 2018; Schneck et al. 2022; Shi et al. 2024). Unravelling the causes of compositional uniqueness can therefore aid conservation planning and shed light on mechanisms governing biodiversity change. For instance, high LCBD values have been linked to ecological drift, as well as spatial processes including habitat isolation and dispersal limitation (Fernández‐Calero et al. 2024; Li et al. 2020; Lozada et al. 2023). Similarly, the degree of invasion by non‐native species can be an important driver of variability in compositional uniqueness (Bando et al. 2023). These effects on uniqueness are typically interpreted as effects on non‐directional variability in community composition, but current approaches do not explicitly account for processes that generate directional community change (Figure 1).
While LCBD may appear as an individual site‐level metric, it is based on pairwise dissimilarities between the focal and other sites. Consequently, environmental gradients such as elevation, latitude, or nutrient concentration (Qian and Ricklefs 2012; Wang et al. 2012) that produce directional changes in community composition (i.e., turnover sensu Anderson et al. (2011)), can influence LCBD by shaping the underlying dissimilarity matrix. Environmental effects on LCBD may therefore reflect the availability of those environmental conditions in the landscape or their sampling frequency, resulting in arbitrarily complex LCBD–environment relationships (Figure 1B) (Tsang et al. 2023). For instance, continuous community change across an evenly sampled environmental gradient can produce a U‐shaped LCBD–environment relationship because communities at the extremes of the gradient would be relatively rare, such as at either end of an elevational gradient (Wang et al. 2020; Yang et al. 2022). However, if more samples are taken at the ends of the gradient, the observed pattern could be reversed. Environmental variables can therefore influence LCBD through two non‐exclusive pathways: First, they can act non‐directionally by changing overall community variability (dispersion) across sites; for example, spatial isolation is expected to increase LCBD via non‐directional effects because isolated communities are generally more dissimilar to all other communities—even those in equally isolated sites (Fernández‐Calero et al. 2024; Lozada et al. 2023). Second, environmental drivers can generate directional compositional change (turnover), which makes LCBD dependent on the availability and sampling frequency of environmental conditions: rare environments tend to host communities that are, on average, more dissimilar to those from more common or more heavily sampled environments. These two mechanisms simultaneously shape LCBD–environment relationships (Figure 1).
Here, we present Generalised Dissimilarity Uniqueness Models (GDUM), a multi‐level regression framework that extends previous community dissimilarity models by enabling estimation of non‐directional environmental effects on beta diversity. We prove that, under the assumption of null directional turnover, non‐directional effects are mathematically equivalent to those obtained using conventional LCBD approaches. Because GDUM is a type of dissimilarity model, it can also account for community turnover along environmental gradients (Mokany et al. 2022), allowing the joint modelling of directional and non‐directional community change and improving the estimation and ecological interpretation of both. We use simulated data to test the ability of the proposed model to disentangle directional and non‐directional environmental effects, and then demonstrate the applicability of our approach with two empirical case studies.
Generalised Dissimilarity Uniqueness Models
2
Model Overview
2.1
We define a model for the element yij of a square matrix Y, representing the dissimilarity between site i and j (with i,j∈1,2,⋯,n and i>j) as follows:
where g· denotes a link function mapping the mean of an assumed distribution (often a binomial or beta distribution for dissimilarity matrices bounded between 0 and 1) to a linear predictor. In Equation (1), β0 is a global intercept. When predictors are standardised, β0 represents the expected dissimilarity between two sites with identical average environmental conditions. It therefore captures the baseline level of compositional dissimilarity in the system, arising from stochastic ecological processes, imperfect sampling procedures, and unexplained sources of community variation. As indicated by their indices, hij is a pairwise sub‐model, whereas vi and vj are site‐level components as row and column sub‐models.
For the pairwise sub‐model, let xik be the value of the k‐th environmental predictor of site i from a matrix of predictors X. Following Ferrier et al. (2007), we define hij as a function of the distance between predictors after applying a non‐linear transformation
where f· are usually defined as monotonic splines to capture non‐linear community change (Appendix S1; see Mokany et al. (2022) for a detailed discussion of the approach). For the case where f· is assumed to be a linear function, hij can be simply written as hij=∣xi−xj∣β, where β is a column vector of coefficients. The pairwise sub‐model therefore determines the dissimilarity of samples i and j as a function of their environmental distance, reflecting directional community turnover along environmental gradients.
For the row and column sub‐models (site component), let wi be the i‐th row of a second matrix of environmental predictors W, λ be a column vector of coefficients, and zi, zj represent site‐level random effects:
We note that λ appears in both Equations 3 and 4, representing the same effect of the same environmental predictor on both sites of the pair. Likewise, zi and zj represent two elements from the same vector of random effects z. While the pairwise term (hij) reflects directional community changes, the symmetric row and column sub‐models (vi, vj) capture non‐directional effects on beta diversity by shifting the expected dissimilarity of each site to all other sites. The site component therefore intuitively relates to the expected site's uniqueness—a formal interpretation is provided in the following subsection.
Link to a Conventional Site Uniqueness Model
2.2
The Local Contribution to Beta Diversity (LCBD) is computed by double‐centring the pairwise dissimilarity matrix Y. This yields a matrix G whose diagonal entries gii are site‐specific sums of squares (SSi) interpreted as uniqueness scores (Legendre and De Cáceres 2013). The double‐centring procedure corresponds to the first step in a Principal Coordinates Analysis (PCoA) (Gower 1966), where SSi=gii represents the multivariate distance of each site to the centroid. LCBD scores are obtained after scaling SSi:
but we consider unscaled SSi values in the following for simplicity. Site uniqueness is commonly modelled as a function of site‐level covariates (Hill et al. 2021; Montràs‐Janer et al. 2024; Ochieng et al. 2024) with the linear predictor
where wi is the vector of environmental predictors at site i, λ* are their associated model coefficients (slopes) and β0* is the intercept. We show that a simple mathematical relationship exists between the coefficients in the site uniqueness model (Equation 5) and those in the site‐level component of GDUMs when the pairwise component (hij) is omitted (see full proof in Appendix S2):
which implies that environmental effects in the vi and vj sub‐models are equivalent to those in a conventional site uniqueness model. This mathematical relationship provides a clear interpretation of coefficients in the site‐level model component of GDUMs, linking them directly to environmental effects on community uniqueness. Moreover, site‐level random effects (zi,zj) can be related to the error term in the conventional site uniqueness model (Appendix S2).
Estimation
2.3
In the accompanying R package ** gdmmTMB **, all model parameters are estimated jointly using maximum likelihood. We implement the model in ** C++ ** using the ** Template Model Builder ** (TMB) framework, which provides efficient marginal likelihood evaluation (Kristensen et al. 2016). Optimisation is carried out in R using the ** nlminb ** algorithm from the ** stats ** package. We consider two alternative strategies for parameter estimation, both used in previous versions of dissimilarity models to account for non‐independencies in dyadic (pairwise) data (Dias et al. 2022; Woolley et al. 2017):
- Full Hierarchical Model: Site‐Level Random Effects Are Included Explicitly, Capturing Site‐To‐Site Heterogeneity. We Specify the Joint Log‐Likelihood of All Parameters θ and Random Effects z as
Parameters for different sub‐models are therefore estimated simultaneously. Classic gradient‐based standard errors for model parameters are computed via ** sdreport ** in TMB. For derived quantities such as dissimilarity and uniqueness, we implement parametric bootstrapping to obtain robust credible intervals. In brief, parametric bootstrapping consists in drawing S samples from the multivariate normal distribution defined by the estimated parameters (θ^) and their covariance matrix θs∼MVNθ^Σ^,s∈1…S. Expected dissimilarity and uniqueness are then recomputed for each draw, and the resulting distribution is used to construct credible intervals.
The full hierarchical model definition is the default strategy used in ** gdmmTMB ** to estimate model parameters. However, constraints in model coefficients—such as those required to fit monotonic splines—can complicate the calculation of standard errors from the Hessian, in which case we recommend the Bayesian bootstrapping approach (see below).
- 2 Bayesian bootstrapping: Instead of site‐level random effects, random weights (wi) drawn from a Dirichlet distribution are assigned to each observation (site) i and used in the computation of the (weighted) log‐likelihood:
We repeat this process by fitting the model with different weight combinations and analyse the empirical distribution of parameters to quantify uncertainty in both model parameters and derived quantities. This procedure is analogous to common bootstrapping with replacement, where the model is fitted with different permutations of the original data. We note that, while Bayesian bootstrapping avoids the need to estimate the variance–covariance matrix, it requires refitting the model multiple times, which can be computationally intensive (Figure S2). To reduce computation time, ** gdmmTMB ** provides options for parallel computation.
Dissimilarity Metrics
2.4
Because the response variable in GDUM is a dissimilarity index, special attention must be paid to the link function and error distribution to ensure that the mathematical properties of the selected index are appropriately accounted for. For instance, many dissimilarity indices commonly used in community ecology represent proportions of shared species or individuals. In those cases, a beta distribution is a natural choice (Dias et al. 2021), although an appropriate transformation of the dissimilarity data is required to handle zeros and ones. An alternative approach is to recognise that some dissimilarity indices can be expressed as ratios of counts, which makes them compatible with a binomial likelihood (Woolley et al. 2017). For example, the Sørensen–Dice dissimilarity represents the proportion of unshared species relative to the total number of species across a pair of sites:
where aij is the number of shared species between sites i and j, and bi and bj are the numbers of species unique to each site. The expected Sørensen–Dice dissimilarity can therefore be modelled as the probability π=Eyij that a randomly chosen species from the combined pool is not shared between the two sites:
For the purposes of the case studies presented here, we use the Sørensen–Dice dissimilarity index and model it using a binomial distribution and the canonical logit link function. However, different options for dissimilarity indices, error distributions, and link functions can be accommodated within the GDUM framework—many of them supported in ** gdmmTMB **.
Simulation Study
3
We compared the ability of GDUM to recover non‐directional effects on beta diversity to that of conventional uniqueness models with a simulation study. Data were generated from a “true” model (Equation 1) with known parameter values for λ and β, and a range of realistic sample sizes. For each combination of parameter values and sample sizes, we generated 1000 replicate datasets. We considered two field‐sampling scenarios regarding the sampled distribution of the environmental predictor x: (1) normally distributed values or (2) slightly skewed distribution, where small values were less frequently sampled (Figure 2A,B). To further test the robustness of our approach, we performed an additional set of simulations with two environmental effects and varying degrees of correlation between them. Each simulated dataset was analysed using three competing models: a GDUM with site‐level random effects (Equation 1), a GDUM estimated with Bayesian bootstrapping, and a conventional model of SSi (Equation 5). We scaled the true parameters from the latter using Equation (6) to enable the comparison between different models. For each fitted model, we quantified bias (mean difference between estimated and true values), root mean square error (RMSE), and evaluated inferential performance by estimating coverage probabilities of 95% confidence or credible intervals. Site‐level and pairwise‐level error terms were drawn from Gaussian distributions with standard deviation σ=0.5. The site‐level error represents heterogeneity among sites implemented in the model as a site‐specific random effect (zi, zj). In contrast, the pairwise‐level error corresponds to the observation‐level (residual) variation associated with the assumed sampling distribution (e.g., Binomial), which we defined as Gaussian noise for the purpose of this simulation study.
Comparison of model performance in our simulation study. Each model contained n values of a predictor w sampled from a symmetric, Gaussian distribution (A, C, D) or a slightly skewed distribution (B, D, F). We considered cases where (1) w only had a direct effect on uniqueness (directional effects absent; β=0) and (2) w was also associated with a dissimilarity gradient (directional effects present β=1). Panels (C) and (D) show model error as the Root Mean Square Error (RMSE) between the recovered regression parameter λ and the true simulated parameter, for models fitted with the symmetric and skewed predictor, respectively. Panels (E) and (F) show the bias of recovered λ coefficients as the average deviation from the true parameter. Error bars indicate one standard deviation from the average.
The error associated with the estimated non‐directional effect (λ) was similar for all three models in scenarios where directional effects were not included (β=0). However, RMSE was almost doubled for the conventional site uniqueness model when present (Figure 2), and more than tripled when the predictor had a skewed distribution. Moreover, the slight skewness in the predictor variable introduced a systematic underestimation of λ values in the conventional site uniqueness model (average bias: −0.160), while estimates from GDUMs were largely unaffected (average bias: <0.001). Confidence intervals aligned with the expected 95% true parameter coverage (α = 0.05) for GDUMs with site‐random effects (Figures S3 and S4). GDUMs fitted with Bayesian bootstrapping also showed a true parameter coverage close to 95% except for small sample sizes (n=20) which showed slightly lower coverage rates (86%). True parameter coverage of conventional uniqueness models was consistently lower than 90% when the predictor was normally distributed, and lower than 50% when the predictor was skewed. When multiple predictors were included, moderate (0.5) and strong (0.8) correlation between them increased RMSE in all models, but bias and parameter coverage were generally unaffected (Figure S5). Overall, the full hierarchical implementation of GDUM showed the best performance in terms of bias, RMSE, and parameter coverage across all scenarios.
Case Studies
4
We demonstrate the applicability of GDUM with two case studies. First, we show how strong directional patterns of community change along an environmental gradient can drive the observed patterns of community uniqueness, and how GDUMs can account for such effects. Second, we showcase the use of our approach for studies with multiple predictors.
A Cautionary Tale: Microbial Communities Along a pH Gradient
4.1
To demonstrate the potential influence of directional community change on environment–LCBD relationships, our first example centres on community composition along a relatively steep environmental gradient. We used a dataset of microbial communities available as part of the ** gllvm ** R package (Niku et al. 2025), which contains a known pattern of change in species composition from low to high pH levels (Niku et al. 2017). The dataset was originally published in Nissinen et al. (2012), and contains presence–absence information for 985 species across 56 sites. Although the dataset contains multiple environmental variables, we focused on pH as the main driver of community change.
As is standard in the literature (Da Silva et al. 2018; García‐Navas et al. 2022; Valente‐Neto et al. 2020), we first computed LCBD scores from the dissimilarity matrix and regressed them against pH and the quadratic pH term. To represent how compositional changes along the pH gradient influence the pH–LCBD relationship, we repeated the process using the residual dissimilarity after accounting for directional community change within the hij component of a dissimilarity model. We performed a Non‐Metric Multidimensional Scaling (NMDS) with two dimensions on (1) the raw dissimilarity matrix and (2) the residual dissimilarity to visualise this effect. For comparison, we also fitted a full GDUM with both directional and non‐directional effects on beta diversity. Potential non‐linear effects of pH in the site‐level component were accounted for with 3 I‐spline basis functions of degree 2.
The conventional uniqueness model (Figure 3C) showed a U‐shaped relationship between LCBD and pH, driven by the strong, directional change in community composition along the pH gradient (Figure 3A). By contrast, accounting for such directional change revealed that the non‐directional effect of pH had the opposite shape, with intermediate pH being associated with higher community uniqueness (Figure 3D). This pattern was also reflected in the ordination of residual dissimilarities (Figure 3B), where samples at both ends of the pH gradient appeared closer to the centroid. The full GDUM approach successfully captured both the expected U‐shaped relationship driven by directional community change, and the hump‐shaped relationship driven by the increased variability in community composition at intermediate pH levels (Figure 4C). Combined, both components provided an expected pH‐LCBD relationship that adjusted remarkably well to the observed pattern (Figure 4A). Our approach therefore overcomes a crucial limitation of uniqueness models (Tsang et al. 2023), namely, distinguishing true environmental effects on uniqueness (non‐directional effects) from patterns caused by a combination of directional community change and arbitrary sampling schemes.
Empirical pattern of compositional uniqueness along a steep environmental gradient (pH; colour gradient) is driven by directional community change. (A) Variability in microbial community composition represented by a Non‐Metric Multidimensional Scaling (NMDS). (B) Variability in community composition after accounting for directional community change along the pH gradient. Residual dissimilarities were obtained after fitting a dissimilarity model with directional community change driven by pH. (C) Empirical LCBD‐pH relationship. The shape of a quadratic regression is displayed with associated standard error. (D) LCBD‐pH relationship after accounting for directional change in community composition.
Contribution of pairwise and site‐level environmental effects to the expected LCBD. (A) Relationship between LCBD and pH obtained from a GDUM with both directional and non‐directional effects on beta diversity. Circles represent empirical values computed using the LCBD.comp function in the adespatial R package (Dray et al. 2025). Expected LCBD values from GDUM were derived from the expected dissimilarity matrix. (B) Fitted dissimilarity gradient showing the directional community change with pH. (C) Contribution of directional and non‐directional effects of pH on LCBD.
The contribution of the fitted dissimilarity gradient (Figure 4B) to the observed uniqueness pattern depends not only on the estimated coefficients in hij, but also on the distribution of the environmental variable (Figure S6). This property of the GDUM framework provides the necessary flexibility to project community uniqueness under counterfactual sampling schemes. For instance, projections given new environmental data can represent the availability of different environmental conditions across the whole landscape (rather than the sampled locations only), alternative management scenarios, or potential environmental changes, representing combinations of environmental variables different from those used to fit the model. We further tested GDUM's ability to generate estimates of uniqueness that are robust to the distribution of predictors by refitting models using a subset of the microbial communities. We conducted 1000 resampling iterations in which 10 samples were removed either (1) randomly from across the whole pH gradient, (2) the lower half (lower pH values), or (3) the upper half (higher pH values). As expected, the conventional uniqueness model produced inconsistent results across the three scenarios, inflating uniqueness projections where samples had been removed (Figure S7). In contrast, GDUM‐based projections were largely unchanged, indicating greater robustness to shifts in predictor coverage and distribution.
Usage Example: Plant Community Change Along Environmental Gradients
4.2
Our second example demonstrates the applicability of the GDUM approach to broader studies. We used a dataset comprising plant community composition from South‐West Australia available as part of the ** gdm ** R package (Fitzpatrick et al. 2025). The dataset contains information on species presence‐absence, as well as local and bioclimatic environmental predictors compiled from multiple sources. We limited the scope of the case study to four bioclimatic predictors: BIO5 (maximum temperature of warmest month), BIO6 (minimum temperature of the coldest month), BIO15 (precipitation seasonality) and BIO19 (precipitation of the coldest quarter).
We included the four predictors in both the pairwise (as X in hij) and site‐level components (as W in vi,vj), and estimated their effects using Bayesian bootstrapping. We decomposed variables in the pairwise component into 3 I‐spline basis of degree 2 (fk·) to account for non‐linear, directional community change (Ferrier et al. 2007) except for spatial distance (dij), which we included directly as a pairwise variable:
As is common in dissimilarity models (Ferrier et al. 2007; White et al. 2024), we defined fk· as monotonic I‐splines by constraining associated coefficients to the positive domain. This constraint ensures parameter identifiability and improves the interpretation of the pairwise component. We assumed linear site‐level effects in the row and column sub‐models (i.e., linear, non‐directional effects on beta diversity):
Model results showed strong directional community change along variables BIO19 and BIO5 (Figure 5A). Specifically, the representation of the dissimilarity gradients revealed higher rates of community change at low BIO19 values, whereas community change along BIO5 was relatively linear. Although directional community change along BIO15 was relatively small, it had a significant non‐directional effect on beta diversity, implying higher expected compositional uniqueness in sites with higher precipitation seasonality (Figure 5B). Using a hierarchical partitioning of the explained variance (Lai et al. 2022), we found that the relative importance of these components differed substantially between the two facets of beta diversity. Directional effects on beta diversity (the pairwise sub‐model) accounted for 29.5% of the explained variance in site uniqueness (LCBD), and 89.3% of the variance in pairwise dissimilarities. In contrast, non‐directional effects (the site‐level sub‐model) explained the majority of the variance in uniqueness (70.5%) but played a much smaller role in pairwise dissimilarities (10.7%). Overall, the inclusion of directional effects on beta diversity via the pairwise sub‐model (hij) provided a better fit for both pairwise dissimilarities and site uniqueness (Figure 5C–E, Figure S8C–F), and had a strong influence on recovered environmental effects (Figure S8A,B).
Directional and non‐directional effects of bioclimatic variables on beta diversity. (A) Dissimilarity gradients representing directional community change. fx represents the value of environmental predictors after applying the fitted non‐linear transformation with monotonic I‐splines. Red vertical lines indicate the empirical distribution of each variable in the data. (B) Estimated non‐directional effects of bioclimatic variables on beta diversity. Error bars indicate 95% and 50% credible intervals. Panels (C) and (D) show the relationship between predicted and observed dissimilarities and LCBD values, respectively. Observed LCBD values represent empirical scores computed with the LCBD.comp function in the adespatial R package (Dray et al. 2025). (E) Relationship between predicted and observed LCBD values when dissimilarity gradients are excluded from the model.
Discussion
5
Developing robust frameworks for modelling beta diversity is crucial for understanding and predicting biodiversity change. Here, we introduce Generalised Dissimilarity Uniqueness Models (GDUM), an extension of previous dissimilarity models that enables the inclusion of non‐directional environmental effects on beta diversity. In doing so, GDUMs address severe limitations of current approaches to modelling community uniqueness and unify two facets of beta diversity: compositional turnover along gradients and non‐directional change (Anderson et al. 2011).
If not accounted for, turnover along environmental gradients (directional effects) can lead to biassed estimates of non‐directional community change. This was reflected in our simulations, where even mildly skewed environmental predictors led to systematic bias in parameter estimation. We note that non‐linear community changes would lead to qualitatively similar results even if predictors were not skewed. Transforming the variables prior to model fitting would therefore not solve this issue in realistic scenarios (D'Amario et al. 2019; Xiong et al. 2020). Thus, variables associated with directional changes in community composition can lead to spurious uniqueness–environment relationships in conventional uniqueness models that depend on their sampled distribution (Tsang et al. 2023). For instance, U‐shaped relationships between LCBD and environmental variables associated with strong species turnover, such as elevation, have been repeatedly reported (Ochieng et al. 2024; Ren et al. 2024; Vad et al. 2017). Similarly, linear relationships are often found when the distribution of the variable of interest is strongly skewed (García‐Navas et al. 2022; Valente‐Neto et al. 2020). These relationships represent the real correlations in the data, but unless the role of directional community change is explicitly accounted for, it remains unclear whether they reflect true ecological processes or stem from arbitrary sampling schemes.
Moreover, because environment‐uniqueness relationships are contingent on the sampled distribution of environmental predictors, they may shift under novel conditions, as environments that were relatively rare can become more common and vice‐versa (Vasconcelos et al. 2018; Williams and Jackson 2007). Our approach offers a solution to this widespread issue by explicitly incorporating gradients of directional community change—which allows recalibrating expected uniqueness as new environmental data arrives. As a result, GDUM provides a more robust framework for projecting shifts in community composition and future uniqueness patterns under environmental changes (such as climate change and localised anthropogenic impacts), and is better suited for scenario testing of management and conservation interventions.
Alternative methods have been proposed to address the influence of directional community change on recovered environment‐uniqueness effects, most notably: (1) incorporating ‘environmental uniqueness’ as a measure of environmental rarity (Snåre et al. 2024) and (2) simulating homogeneous sampling scenarios after fitting dissimilarity models for each site separately (Tsang et al. 2023). However, both strategies pose important limitations. Environmental uniqueness can be informative, but it is typically calculated across all predictors simultaneously, which may obscure the role of individual environmental drivers. This approach also requires the assumption of linear community change and can lead to multicollinearity when both the raw predictors and their rarity are included as they would be strongly correlated under many sampling scenarios. Correcting uniqueness estimates for uneven distributions of predictors by simulating homogeneous sampling offers a potential improvement. However, (simulated) sites at the extremes of environmental gradients would still appear to host more unique communities under directional community change.
Unlike conventional approaches, the response variable in GDUM is a pairwise dissimilarity, so accounting for directional community change is straightforward. In our case studies, we included environmental gradients as absolute differences after a monotonic, non‐linear transformation (Ferrier et al. 2007; Mokany et al. 2022), implying increasing dissimilarities with increasing environmental distance. Such non‐linear transformations of pairwise predictors can capture differences in the rate of community change along environmental gradients, offering great flexibility. Empirical studies have occasionally reported negative relationships between environmental distances and compositional dissimilarity (Graco‐Roza et al. 2022; Zhang et al. 2022); where such patterns are plausible, GDUMs can be specified without monotonic or non‐negative constraints. In addition to environmental variables, the pairwise component of GDUMs can capture spatio‐temporal dependencies in community composition. For instance, incorporating a distance decay of similarity can capture unexplained spatial autocorrelation (Dias et al. 2021; Soininen et al. 2007) as shown in our second case study.
In addition to accounting for gradients of community turnover, GDUMs incorporate direct influence of local processes on compositional uniqueness with site‐level predictors that capture non‐directional effects on beta diversity. We have shown that these effects are mathematically equivalent to those of predictors in conventional uniqueness models. Good candidates for site‐level predictors are variables that could affect community uniqueness through processes beyond directional changes, by increasing or decreasing the average dissimilarity between a given site and all other sites. That is, by increasing community variance (beta diversity) in a non‐directional manner (sensu Anderson et al. (2011)) (Figure 1A). For instance, spatial isolation can lead to more unique assemblages due to the small influence of surrounding communities compared to more connected sites. Highly isolated communities are not necessarily more similar to other isolated communities, but rather present distinct assemblages compared to all other habitats (higher variance), ultimately leading to higher uniqueness (Fernández‐Calero et al. 2024; Lozada et al. 2023). Other examples of variables with potential non‐directional effects on beta diversity include habitat size, which can modulate the effect of ecological drift (Green et al. 2022; Lozada et al. 2023); herbivory, through the lower occurrence rate of rare taxa (Villar et al. 2020); and productivity, through an increased variability in community composition (Chase 2010). For predictive purposes, standard model‐selection procedures (e.g., AIC or BIC) can be used to select site‐level predictors, particularly when many candidate variables are available. For inference of ecological processes, however, we encourage the use of prior ecological knowledge and explicit hypotheses to guide model specification (Shmueli 2010).
The GDUM framework can be extended to account for heterogeneity in these effects across grouping variables such as geographic regions or habitat types. This can be achieved by including interactions with site‐level predictors or by specifying group‐specific random slopes, allowing the influence of local processes on compositional uniqueness to vary across ecological contexts. This flexibility of GDUMs enables the testing of a wide range of hypotheses in community ecology and allows the framework to be adapted to different research questions and ecological settings.
Conclusions
6
Quantifying the uniqueness of ecological communities–a key facet of beta diversity–and correctly inferring the role of environmental drivers is central to both basic and applied ecology, particularly for conservation planning. However, conventional modelling approaches can obscure the underlying causes of uniqueness by inflating, downplaying, or confounding relationships with environmental predictors. By disentangling directional from non‐directional effects, GDUMs overcome this limitation and unlock new opportunities to investigate how specific drivers shape beta diversity patterns. Moreover, GDUMs offer the necessary flexibility to project uniqueness to non‐sampled locations, future environments and different management strategies, making them a powerful tool for applied studies.
Author Contributions
D.H.‐C., H.R.L. and A.J.G. conceived the ideas and designed methodology. D.H.‐C. led the data analysis and the writing of the manuscript. J.D.T. obtained funding. All authors contributed critically to the drafts and gave final approval for publication.
Funding
This work was supported by Royal Society Te Apārangi (MFP‐UOC2102, RDF‐18‐UOC‐007), Conselho Nacional de Desenvolvimento Científico e Tecnológico, Productivity Grant (309496/2021‐7), Bio‐Protection Research Centre.
Supporting information
Data S1: ele70338‐sup‐0001‐supinfo.pdf.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1Anderson, M. J. , T. O. Crist , J. M. Chase , et al. 2011. “Navigating the Multiple Meanings of Diversity: A Roadmap for the Practicing Ecologist.” Ecology Letters 14, no. 1: 19–28. 10.1111/j.1461-0248.2010.01552.x.21070562 · doi ↗ · pubmed ↗
- 2Anderson, M. J. , K. E. Ellingsen , and B. H. Mc Ardle . 2006. “Multivariate Dispersion as a Measure of Beta Diversity.” Ecology Letters 9, no. 6: 683–693. 10.1111/j.1461-0248.2006.00926.x.16706913 · doi ↗ · pubmed ↗
- 3Bando, F. M. , B. R. S. Figueiredo , D. A. Moi , et al. 2023. “Invasion by an Exotic Grass Species Homogenizes Native Freshwater Plant Communities.” Journal of Ecology 111, no. 4: 799–813. 10.1111/1365-2745.14061. · doi ↗
- 4Chase, J. M. 2010. “Stochastic Community Assembly Causes Higher Biodiversity in More Productive Environments.” Science 328, no. 5984: 1388–1391. 10.1126/science.1187820.20508088 · doi ↗ · pubmed ↗
- 5Da Silva, P. G. , M. I. M. Hernández , and J. Heino . 2018. “Disentangling the Correlates of Species and Site Contributions to Beta Diversity in Dung Beetle Assemblages.” Diversity and Distributions 24, no. 11: 1674–1686. 10.1111/ddi.12785. · doi ↗
- 6D'Amario, S. C. , D. C. Rearick , C. Fasching , et al. 2019. “The Prevalence of Nonlinearity and Detection of Ecological Breakpoints Across a Land Use Gradient in Streams.” Scientific Reports 9, no. 1: 3878. 10.1038/s 41598-019-40349-4.30846827 PMC 6406005 · doi ↗ · pubmed ↗
- 7Dias, F. S. , M. Betancourt , P. M. Rodríguez‐González , and L. Borda‐de‐Água . 2021. “Analysing the Distance Decay of Community Similarity in River Networks Using Bayesian Methods.” Scientific Reports 11, no. 1: 21660. 10.1038/s 41598-021-01149-x.34737354 PMC 8569194 · doi ↗ · pubmed ↗
- 8Dias, F. S. , M. Betancourt , P. M. Rodríguez‐González , and L. Borda‐de‐Água . 2022. “Beta Bayes—A Bayesian Approach for Comparing Ecological Communities.” Diversity 14, no. 10: 858. 10.3390/d 14100858. · doi ↗