Semiparametric discovery and estimation of interaction in mixed exposures using stochastic interventions
David B. McCoy, Alan Hubbard, Mark van der Laan, Alejandro Schuler

TL;DR
This paper introduces InterXshift, a new method for identifying and estimating interactions among multiple environmental exposures using machine learning and statistical techniques.
Contribution
The novel semiparametric method InterXshift enables model-independent discovery and estimation of mixed exposure interactions.
Findings
InterXshift accurately identifies true interaction directions in simulations and real-world data.
The method highlights significant impacts of exposure interactions in environmental health studies.
InterXshift is applied to NHANES data to assess furan exposure effects on telomere length.
Abstract
Understanding the complex interactions among multiple environmental exposures is critical for assessing their combined impact on health outcomes. This study introduces InterXshift, a novel semiparametric method that provides a nonparametric definition of interaction and facilitates both the discovery and efficient estimation of interaction effects in mixed exposures. Leveraging stochastic shift interventions and ensemble machine learning, InterXshift identifies and quantifies interactions through a model-independent target parameter, estimated using targeted maximum likelihood estimation (TMLE) and cross-validation. The approach contrasts expected outcomes from joint interventions against those from individual exposures, enabling the detection of synergistic and antagonistic interactions. Validation through simulations and application to the National Institute of Environmental Health…
Genes, proteins, chemicals, diseases, species, mutations and cell lines named across the full text — each resolved to its canonical identifier and authoritative record.
Click any figure to enlarge with its caption.
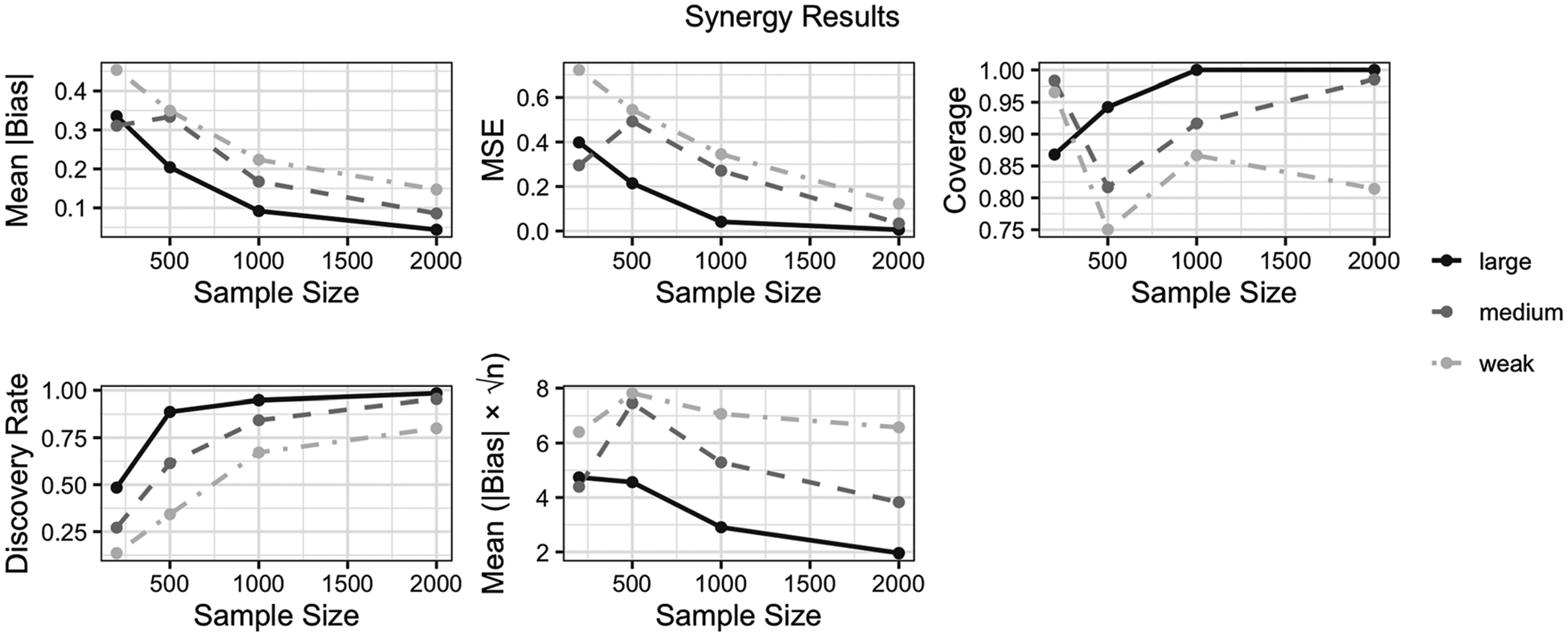 Figure 1
Figure 1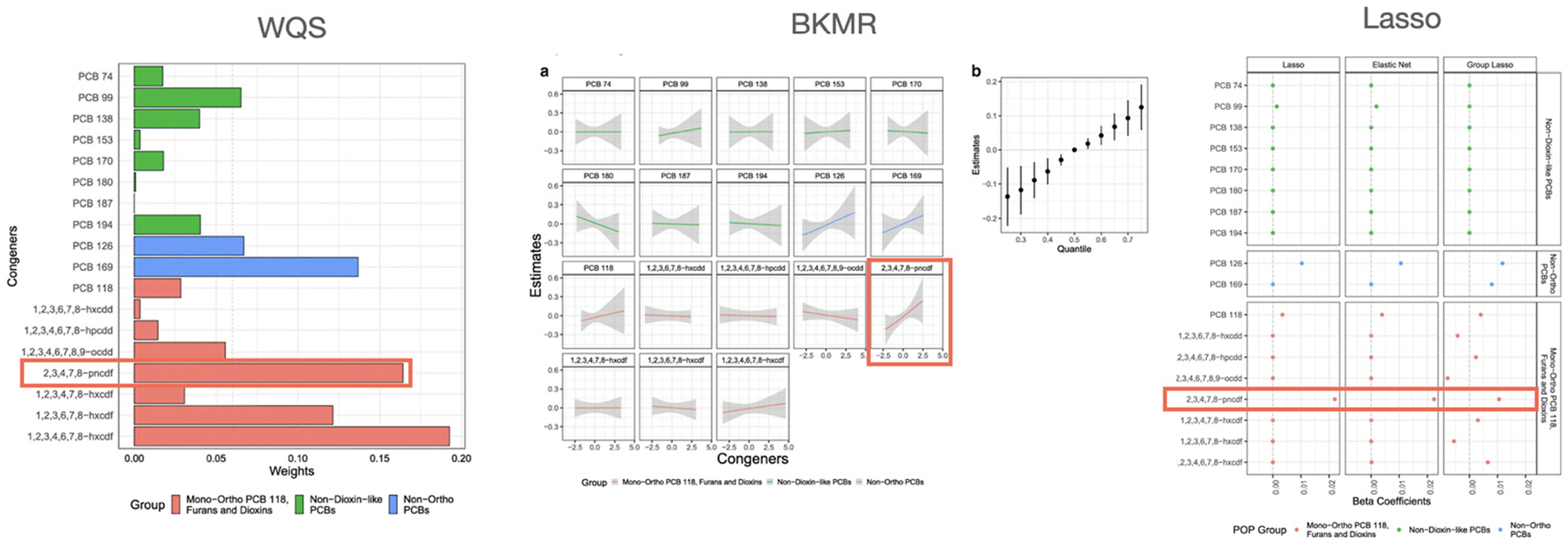 Figure 2
Figure 2Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsHealth, Environment, Cognitive Aging · Advanced Causal Inference Techniques · Effects and risks of endocrine disrupting chemicals
Introduction
1
Understanding the combined effects of multiple exposures on health outcomes remains a pivotal challenge in environmental epidemiology. Researchers frequently seek to determine whether such exposures act additively or if they exhibit synergistic or antagonistic interaction. Classical approaches to interaction often focus on two binary treatments [1, 2], employing metrics like the relative excess risk due to interaction (RERI) to measure deviations from additivity. However, extending these concepts to multiple, continuous exposures – such as environmental pollutants – introduces substantial complexity, particularly when exposures may be correlated, nonlinearly associated with outcomes, or confounded by additional covariates.
Connection to Prior Work on Additive Interaction.
While the concept of additive interaction has long been formalized in terms of risk difference and metrics such as the RERI [1, 2], these existing frameworks typically assume binary exposures and rely on parametric modeling. Our approach, in contrast, generalizes the RERI notion of “departure from additivity” to accommodate continuous exposures through shift interventions. This perspective preserves the fundamental interpretation of synergy or antagonism but embeds it in a semiparametric framework, allowing for partial or scaled exposure reductions. Further, whereas Vansteelandt et al. [1] introduced methods for multiply robust estimation of interaction parameters, we rely on nonparametric machine-learning algorithms for both outcome regression and exposure mechanisms to provide robustness and flexibility in high-dimensional settings. By recasting classical additive interaction ideas into a stochastic intervention framework, InterXshift unifies these influential concepts with modern data-adaptive causal inference techniques for continuous exposures.
Methods Used in Environmental Mixtures.
The growing literature on environmental mixtures has highlighted both the importance and the difficulty of detecting and quantifying interaction effects. Traditional regression-based strategies that include pairwise product terms in generalized linear models may suffer from exponential growth in model parameters and from interpretability issues when numerous interactions are present. Recently developed approaches address mixture effects more flexibly: Bayesian kernel machine regression [3] can model nonlinearities without explicitly enumerating interactions, weighted quantile sum regression [4, 5] and quantile-based g-computation [5] handle correlated exposures in a more aggregated manner, and factor or clustering methods group exposures [6, 7]. Although these techniques can reveal overarching mixture signals, they are less suited for systematically isolating which exposure pairs are synergistic or antagonistic.
Several recent methods have advanced the state of the art in interaction detection. Forward selection algorithms [8] and machine-learning-based approaches [9] attempt to identify important nonlinear interactions among exposures. Bayesian factor analysis and Gaussian processes [10, 11] have been adapted to infer high-dimensional interactions, while others use semiparametric priors for mixtures [12, 13]. Notably, Chattopadhyay et al. [14] recently proposed Bayesian procedures to characterize synergy and antagonism in mixtures from a toxicological perspective, echoing classical notions of super-additive and sub-additive joint effects [15, 16]. However, many of these approaches either rely on specific model formulations or focus on measures (like posterior inclusion probabilities) that are not grounded in a direct, nonparametric causal definition of interaction.
Limitations of Common Dimension-Reduction and Penalized Methods.
Other popular strategies reduce the dimensionality of an exposure set or impose sparsity in a regression framework but may overlook or conflate interactions on an additive outcome scale. For instance, principal component analysis (PCA) and related factor-based methods project exposures onto a small number of components, capturing broad variance structure but blending possible synergy signals into aggregate factors. Penalized regressions such as the LASSO can, in theory, detect pairwise interactions by including product terms, yet tuning choices and interpretability become challenging when many interaction terms are possible. Although such methods can aid in screening or dimension reduction, they do not yield a target parameter for synergy that directly represents additive departures from “no interaction.” Likewise, while Bayesian kernel machine regression (BKMR) flexibly models nonlinearities among multiple exposures, it does not inherently provide a causal, additive interaction parameter. In contrast, our proposed InterXshift approach defines and estimates a stochastic-intervention-based measure of synergy or antagonism, anchored in the potential outcome framework. This perspective facilitates clearer scientific interpretation – quantifying how a joint shift in two exposures modifies the outcome beyond their individual effects – and avoids the interpretability pitfalls or heavy modeling constraints often encountered in dimension-reduction or penalized regression approaches.
Beyond Binary Exposures.
Within causal inference, it is well understood that interactions can be defined as departures from additivity of causal effects [1, 2]. For binary treatments, one can interpret additive interaction in terms of potential outcomes. Yet, for observational data with multiple continuous exposures, key questions arise: (i) how to specify a realistic intervention, and (ii) how to define synergy or antagonism on the outcome scale. A promising route is to replace the notion of “set ” with a stochastic shift in the distribution of [17], enabling analyses of partial exposure reductions that resonate with practical regulatory or clinical scenarios.
InterXshift, the method we propose, leverages these ideas to deliver both a discovery and an estimation strategy for interaction among continuous exposures. We build upon the insight that if two exposures exceed their additive contribution, they demonstrate synergy (or antagonism, if the joint effect is less than the sum of individual effects). Concretely, we define an interaction effect as the difference between (i) the expected outcome under a joint stochastic shift of two exposures and (ii) the sum of the expected outcomes under separate shifts of each exposure – plus baseline. This echoes classical additive interaction concepts (e.g., RERI) but extends them to continuous multi-exposure contexts in a nonparametric, potential-outcomes framework [1, 2, 17].
Our Data-Adaptive Procedure to Interaction Discovery and Estimation.
To estimate this interaction parameter in high-dimensional observational data, InterXshift uses targeted maximum likelihood estimation (TMLE) [18], deploying flexible machine learning to capture confounding and nonlinearities in both the outcome regression and the exposure density. Because the potential number of pairwise interactions grows quadratically with the count of exposures, we incorporate a data-adaptive discovery stage. Specifically, we partition the data into training and validation sets (or folds), rank all pairwise synergies or antagonisms by their estimated departures from additivity in the training portion, and then formally estimate and infer those top interactions using the validation set. This cross-validated approach guards against overfitting, clarifies which pairs matter most, and preserves valid statistical inference even when the parameter being estimated is selected in a data-driven way [19].
Relative to existing mixture-interaction approaches, InterXshift introduces several unique features:
Causal, Model-Agnostic Interaction Definition. Our parameter is anchored in potential outcomes under stochastic shifts, requiring no specific functional-form assumptions and offering a clear definition of synergy/antagonism in terms of departures from additivity.Semiparametric Efficiency. By deriving the efficient influence function for continuous-exposure shifts, we harness TMLE’s strong theoretical guarantees and robust inference properties.Adaptive Discovery in High Dimensions. We systematically identify which exposure pairs exhibit the strongest synergy or antagonism, reducing the multiple-testing burden common in mixture analysis.Open-Source Implementation and Validation. We provide an R package, InterXshift, with comprehensive vignettes and apply it to both synthetic data from the National Institute of Environmental Health Sciences (NIEHS) and real data from the National Health and Nutrition Examination Survey (NHANES) on persistent organic pollutants (POPs) and leukocyte telomere length.
Together, these contributions unite recent advances in causal inference with the practical demands of environmental mixtures research. The remainder of the paper is organized as follows. In Section 2, we outline the stochastic intervention framework and introduce our interaction parameter. Section 3 details the TMLE-based estimation strategy. Section 4.1 explains how we discover key interactions in large exposure sets via cross-validation. In Section 5, we demonstrate performance through simulations, and in Section 6, we showcase real-data applications on synthetic NIEHS mixtures and NHANES POP data. We conclude in Section 8 with a discussion of limitations, possible extensions, and future directions.
Data and parameter of interest
2
Overview
2.1
At a high level, consider that an analyst has data on a mixture of 15 chemicals (e.g., 15 Persistent Organic Pollutants (POPs)). Our approach first splits the data into a discovery sample, used to identify interactions, and an estimation sample, used to formally estimate those discovered interactions via targeted maximum likelihood estimation (TMLE). For example, suppose we discover a strong signal of synergy between POP-1 and POP-6 through g-computation [20, 21] on the discovery sample. We then estimate the parameter for that pair in the estimation sample to avoid overfitting bias.
Because our estimand itself (the “top synergy or antagonism”) is data-adaptive, this splitting step is critical for preserving valid statistical inference. Specifically, if the same dataset were used to both discover and estimate interactions, the resulting confidence intervals would be anti-conservative. In practice, this discovery–estimation step can be performed within each fold of a cross-validation scheme, cycling multiple times (e.g., 10 times) to reduce variance. Subsequent sections detail how the parameter is defined and how these interaction-based shifts are constructed.
Notation and framework
2.2
We build on the notion of stochastic interventions introduced by Díaz and van der Laan [22]. In particular, let
be a single observation, where:
– is a vector of confounders, including both classical covariates (e.g. demographics) and, when relevant, other exposures not under direct investigation. For instance, in a multi-exposure setting where the primary focus is on the potential interaction between and , any remaining exposures that could confound this relationship should be included in . This practice ensures an appropriate adjustment for correlated influences of secondary exposures on the outcome , thereby preserving valid inference for the focal exposures.– is the set of main exposures of interest;– is a continuous or binary outcome.
Assume are i.i.d. from an unknown distribution . We can factorize
Let
denote the conditional density (or probability mass) of given , and let
A shifted version of is defined for a given shift vector via
leading to a “shifted” density over all variables:
In many practical scenarios, might be a scalar shift (e.g., subtract 1 unit from some pollutant), or a small function of that ensures positivity (i.e., no extreme density ratios). Although we initially treat as fixed, we later discuss how it can be scaled adaptively.
Remark (Generalized Shifts).
Although we focus primarily on additive shifts of the form , the same stochastic-intervention logic readily accommodates any bijective transformation . For example, one might apply a multiplicative shift to uniformly scale exposures by , or a logistic re-parameterization to ensure positivity when exposures must remain in a constrained range. In such cases, we replace
where denotes the Jacobian determinant of the inverse mapping . This recovers the shifted (or otherwise transformed) density under the new exposure law. Thus, one could define a proportionate reduction to reflect a 20% decrease for all individuals, or a more elaborate mapping that depends on individual covariates . We focus on additive shifts in the main text for conceptual clarity, but the broader framework – constructing via and its inverse – holds in general.
Causal vs. Statistical Parameters.
We can interpret
as the mean outcome if a population were subjected to a -shift in all components of . Specifically, we assume and admit a strictly positive joint density on the region of interest, so that shifting by remains within its support. Under certain assumptions – namely ignorability and positivity (i.e., over the support) – this parameter corresponds to a causal estimand:
When these assumptions may not hold, still measures a statistical association or partial “what-if” shift, sometimes called a variable-importance parameter [23]. Either way, the shift perspective is appealing in environmental health, where exposures are rarely set to zero but may be reduced or partially controlled.
Interaction target parameter
2.3
We now define our interaction parameter for two exposures, building on the single-exposure shift described above. Concretely, suppose , and we wish to see whether and exhibit synergy (super-additivity) or antagonism (sub-additivity). Let and be the shift amounts for each exposure individually; then denotes the joint shift of both and . We define:
Recall that is the mean outcome if we only shift by (keeping at its observed levels), and so forth. The expected outcome under a joint shift of and may be additive, supra-additive, or sub-additive. We capture this by the difference from additivity:
where is the baseline mean outcome without shifting.
A positive implies super-additivity, indicating synergy (the combined shift is larger than the sum of parts). A negative value implies sub-additivity or antagonism. This mirrors an interaction term in a linear model but is derived here via the stochastic shift framework, making no parametric assumption about the exposure–outcome relationship.
Practical Interpretation.
Because shifting continuous exposures requires careful consideration of data support (positivity), we typically use smaller shifts or data-adaptive that remain in the region where is non-negligible. Realistically, an environmental scientist might say “What if we reduce by 20% and by 10% across the population?” and interpret as how much extra (or reduced) benefit arises from reducing both together rather than separately.
Three-Way (and Higher-Order) Interactions
Although our primary focus is on two-way synergy or antagonism, one can in principle define a similar three-way interaction parameter using stochastic shifts. To motivate this generalization, let
be the expected outcomes under marginal shifts of exposures , and , respectively. Next, let
denote the means under pairwise shifts, and
be the mean under a three-way shift of . Finally, let
be the baseline mean outcome (i.e., no exposures are shifted).
A three-way interaction parameter can be formulated by comparing the observed triple-shifted mean to all the lower-order shifts and the baseline. Specifically, define:
This can be viewed as a natural extension of departure from additivity in the context of stochastic shifts. Concretely,
would imply that shifting all three exposures simultaneously equals exactly the sum of their single and pairwise contributions (i.e., no three-way interaction). When , it indicates super-additivity (synergy) among the three exposures; when , it reflects sub-additivity (antagonism).
Practical Caveats.
Extending from two-way to three-way (or higher-order) interactions quickly expands the number of shifted expectations that must be estimated. This is especially challenging in typical environmental-exposure settings with finite sample sizes and high-dimensional . Furthermore, the risk of positivity violations and complex correlation patterns grows with each additional exposure. For these reasons, we generally restrict our focus to pairwise interactions, which often hold the greatest practical relevance for regulatory or public-health contexts. However, if the data and sample size permit, one could apply the same semiparametric framework to estimate (and beyond) following the definitions above.
Summary.
This section describes the basic setting, from the representation of the data and the single-exposure stochastic shift, to the interaction target parameter that quantifies synergy versus antagonism on an additive outcome scale. In the following sections, we detail how to estimate this parameter using targeted maximum likelihood estimation (Section 3), how to discover which exposure pairs are most synergistic or antagonistic (Section 4.1), and finally present both simulations (Section 5) and real-world applications (Section 6).
Estimation and interpretation
3
In this section, we detail how to estimate the proposed interaction parameter
We first present the efficient influence function (EIF) for shift-based parameters, then describe two approaches for inferring this interaction: (i) a separate (“Delta Method”) strategy, and (ii) a direct-targeting (single-step) TMLE. We conclude by discussing practical considerations for implementing either approach and how each constructs confidence intervals.
Efficient influence function for shift interventions
3.1
Basic Idea.
In the targeted maximum likelihood estimation (TMLE) framework, one typically seeks the efficient influence function (EIF) of the parameter of interest in order to build an efficient and unbiased estimator. For a single-exposure shift , Muñoz and van der Laan [17] derived such an EIF. Here, we extend that result to the vector shift for two exposures .
Notational Setup.
Let and . Shifting by modifies the conditional density to
leading to
Similarly, define and for shifts of only or .
EIF for the Single-Shift Mean.
When shifting by , the EIF of is
where
One may think of as the clever covariate for the shift-based mean.
Derivation of the clever covariate
3.1.1
Equation (1) highlights that the ratio debiases the naive outcome regression . Conceptually, this ratio arises from the pathwise derivative of the shift-based parameter with respect to . Small perturbations in produce changes in that factor through this ratio, ensuring unbiasedness in the limit. Hence, multiplying by forces the resulting estimator’s score equation to have mean zero at the truth – a key property for TMLE’s asymptotic efficiency.
EIF for the two-exposure interaction parameter
3.1.2
By linearity, the EIF of
is simply
where , and follow the form in Equation (1) for each shift. Intuitively, the interaction’s EIF subtracts off the individual-shift contributions from the joint shift.
Interpretation.
The difference captures how shifting multiple exposures jointly affects , while
debiases the plug-in outcome regression. Summing this EIF over all observations yields a statistic that (under regularity conditions) has mean zero at the truth, enabling unbiased and efficient estimation of the additive-interaction effect.
Two approaches to estimating 𝚿Interaction
3.2
We now present two complementary TMLE-based strategies for estimating . The first estimates each component separately and combines them via the Delta Method; the second directly targets the entire interaction parameter in one step. While both yield valid estimates and asymptotic inference, they differ in complexity and finite-sample trade-offs.
Approach 1: separate estimation (“Delta Method”)
3.2.1
Overview.
The “Delta Method” approach calculates , and individually, each via a standard TMLE for shift parameters [22]. It then combines these four estimates by
For variance estimation, one applies the usual Delta Method, summing variances and covariances among the four estimated components.
Implementation Steps.
TMLE of Each Component: For each shift plus the baseline , run a separate shift-based TMLE using Equation (1).Combine Estimates and Variances: Form by linear combination. Approximate the covariance terms with sample covariances of each component’s EIF.Construct CIs: Use the estimated variance from the linear combination to get standard errors and confidence intervals.
Pros and Cons.
– Pros:
-
– Straightforward implementation if you already want each marginal shift ( , etc.) individually.
-
– Easy to “plug in” new shift magnitudes for any single exposure without redoing the entire interaction calculation. – Cons:
-
– May accumulate extra variance from combining multiple separate TMLE estimates, especially in smaller samples.
-
– Overlapping nuisance parameters can lead to correlated estimates of the single shifts, inflating covariance terms.
Overall, this method can be simpler to implement or interpret when the analyst wants to separately examine each marginal shift. In very large samples, it is often comparable to the direct-targeting approach.
Approach 2: direct targeting (single-step interaction TMLE)
3.2.2
Overview.
Rather than estimating each component separately, one can directly encode the interaction effect in a single TMLE update. This approach constructs a combined clever covariate representing and updates the outcome regression to make the EIF’s empirical mean zero in one pass.
Algorithm Steps.
Initial Fits: Obtain preliminary and from flexible machine learning.Construct Combined Clever Covariate:
Update the Outcome Regression: For a bounded outcome , insert into a logistic (or linear) fluctuation submodel and solve a score equation making the final EIF average zero.Compute Final Plug-In: Evaluate the updated regression at , and , then combine them to obtain .
Pros and Cons.
– Pros:
-
– Potentially smaller variance in moderate sample sizes, since you target the entire interaction parameter in one shot.
-
– Only one submodel fluctuation step is required, which may yield more stable finite-sample performance. – Cons:
-
– Implementation is slightly more involved: one must carefully build the “combined” clever covariate.
-
– If you later decide to study or alone, you must run a separate TMLE for those single shifts, as they were never individually targeted.
Conceptual Trade-Offs.
In smaller samples where synergy or antagonism can be quite strong, direct targeting may reduce finite-sample variance by leveraging a unified submodel. However, if the main interest is separately examining each single shift as well as the interaction, it might be more convenient to use the Delta Method approach. Indeed, many analysts may find it simpler to first estimate , and individually, and only afterward combine them to assess synergy or antagonism as this allows the analyst to interpret the marginal effects as well.
Additional details and practical considerations
3.3
Bounded vs. Unbounded Y.
If is naturally in [0,1] (e.g., a binary outcome), one typically uses a logistic fluctuation in the TMLE update. For continuous unbounded outcomes (e.g., biomarker levels), a linear fluctuation is often simpler:
Both approaches solve . Often, one can rescale to [0,1] to allow for a logistic fluctuation even when is originally unbounded.
Double Robustness and Local Efficiency.
In typical TMLE settings with a single binary treatment, double robustness arises if either the outcome regression or the propensity score is correct. Importantly, this double robustness property extends to our stochastic shift interaction parameter . As established in the original work on stochastic interventions by Muñoz and van der Laan [17], consistent estimation is possible if either the outcome regression or the conditional density is correctly specified, although estimating both components well improves efficiency. This double robustness provides an important safeguard against model misspecification in practice. Furthermore, when both components are correctly specified, TMLE remains locally efficient, yielding minimal asymptotic variance among all regular asymptotically linear estimators.
Variance and Confidence Intervals.
Regardless of which approach (Delta or Direct Targeting) is used, final inference leverages the empirical variance of the EIF:
where is the final influence function under the estimated nuisance parameters. Then, confidence intervals follow as
Exposure set identification
4
The estimation of marginal, joint, and interaction shift parameters assumes a priori knowledge of important mixture subsets and pairs with statistical interaction evidence. However, in finite samples with many mixture variables , including all components and possible interactions leads to unacceptable sample variability. We propose a data-adaptive target parameter approach [19] to discover exposure sets and their interaction values through g-computation, then estimate the resulting data-adaptively defined parameters in separate data using TMLE. We employ K-fold cross-validation, splitting the sample data into K approximately equal folds. Let denote the k-th training sample indices and the k-th validation sample indices for . We use to identify important set of variables based on the g-computation interaction values and to estimate our stochastic shift intervention parameters on these exposures.
Exposure set identification
4.1
In practice, when investigating multiple exposures , one may wish to identify which pairs exhibit the strongest synergy or antagonism under stochastic shifts. Naively enumerating all two-way interactions (there are such pairs) and testing them on the same dataset can result in substantial multiple-testing burdens and inflated type I error if not carefully corrected (e.g., via false-discovery rate (FDR) procedures). Conversely, applying a standard FDR approach might detect fewer signals (less power) if interactions are relatively weak. In this section, we describe a data-adaptive target-parameter strategy [19] that splits the data into discovery and estimation samples, thereby reducing the multiple-test burden by focusing subsequent estimation only on the top candidate interactions.
Cross-validation to discover and estimate interactions
4.2
Overview of the Two-Stage Procedure.
We propose splitting the full sample into folds, where is the -th training subset and is the -th validation subset (disjoint from ). In each fold:
Discovery (Training). Using only , we fit an algorithm for (via the discrete Super Learner or other flexible ML). We then compute a -computation estimate of our interaction parameter for each pair , thus obtaining a “rank” of synergy or antagonism.Estimation (Validation). The top synergy pairs and antagonism pairs (or some user-chosen criterion) form the discovered sets . We then re-estimate the stochastic shift parameter for these discovered interactions in the validation data using a formal TMLE (Sec. 3).
We repeat the above for , and combine the fold-specific estimates via cross-validation to get a final inference.
Discovering interactions using training data
4.3
G-Computation for Ranking.
To identify interactions, we adopt a quick approximate approach in the training fold. Let be the fitted regression for . For each pair , define a small shift (e.g., subtract 1 unit from each of ). We compute
where each component is evaluated via the same but with the relevant shifts. Comparing across all identifies which pairs appear strongly synergistic (large positive) or antagonistic (large negative).
Ranking
Following some rank ordering of (descending order for synergy, ascending for antagonism), we write
to indicate the top pairs. We now treat these as our data-adaptive target parameters to be estimated in the validation data.
Comparisons to a multiple-testing (FDR) approach
4.4
Full-Data Testing vs. Discovery-Estimation.
A natural alternative is to test every pair on the entire dataset, applying a multiple-comparisons correction to control the false discovery rate. While feasible, it can be conservative if many interactions are weak. In contrast:
– Discovery–Estimation uses a smaller estimation set (hence possibly lower nominal power) but avoids heavy multiple-testing penalties by formally testing only the top few discovered pairs.– FDR Approach keeps the full for each pair’s p-value (arguably more precise if a single pair is of main interest), but must apply e.g. Benjamini–Hochberg corrections across tests, which can reduce power and hamper detection of smaller signals.
In some simulations (not shown), if a large fraction of pairs truly have , an FDR approach can succeed. But if the number of active interactions is small or the signals are faint, the discovery–estimation approach can be more powerful.
Pooling Over Folds for Strength.
An additional advantage of cross-validated discovery is that if the same pair repeatedly ranks in the top synergy across folds, one effectively “votes” it in, producing an overall estimate that uses the entire . This can recover power lost from splitting. Nonetheless, if results differ drastically across folds (i.e. different top pairs each time), the method indicates that no single pair stands out robustly. Environmental epidemiologists may interpret that as either: (a) no strong, consistent interaction is present, or (b) multiple interactions of similar magnitude exist (leading to instability in ranks). Either way, the cross-validation approach provides a transparent measure of consistency.
Interpretation of Inconsistencies Across Folds.
A recurring practical question is how an analyst should interpret results if different folds yield different top-ranked pairs. In our experience, such discrepancies commonly signal at least one of the following scenarios:
No Dominant Interaction. If no single exposure pair consistently outranks all others in multiple folds, it may suggest there is no strong synergy or antagonism in the dataset; or that the effects are too small relative to sampling variation.Multiple Interactions of Comparable Magnitude. When two or more interactions have near-equal effect estimates, cross-validation splits can cause the top ranks to fluctuate.High Variability or Limited Sample Size. Environmental data often exhibit strong correlations or small sample sizes, making it difficult for any single pair to dominate consistently.
As a practical step, we advise researchers to track how frequently each pair appears in the top across folds. If a pair appears in, say, over half the folds, one may consider it a robust candidate for synergy (or antagonism). In contrast, if a pair appears only once or not at all, the signal is likely weak. One may also form the union of top interactions from each fold and re-estimate them on a different dataset, providing a final, consolidated inference that can further validate (or refute) whether an interaction is truly important. Another approach is, for a set of ranked synergistic effects, if the same variable pairs are included in the ranks across all the folds, the analyst could in principle report the average rank for the interaction pairs even if there is slight variability in the ranks across the folds.
Estimation of shift interventions for discovered pairs
4.5
CV-TMLE.
Having identified top synergy/antagonism sets in the training data, we estimate the final parameters in the validation data. Concretely, for each fold :
Train nuisance functions on .On , compute the TMLE for each discovered pair’s shift-based interaction parameter, controlling for overfitting via cross-validation [19, 24].
This yields a fold-specific interaction estimate and standard error for each pair in . We then combine across folds to form final estimates and confidence intervals.
Data-adaptive deltas and pooled estimates
4.6
Positivity Constraints and Adaptive Shifts.
Choosing a fixed shift magnitude can lead to extreme density ratios if the shifted values fall outside the natural support. In particular, if is too large, then for at least one observation , the ratio
could “blow up” beyond a practical threshold. To avoid this violation of positivity, one may adaptively shrink within each fold. Concretely, one can start with a candidate and evaluate for all observations in the training fold. If any ratio exceeds a user-defined ceiling (e.g. ), is reduced (e.g. by stepping down on a grid or via bisection) until . Because ratios less than 1 do not typically pose the same risk of positivity violations (they reflect moving an observation into a denser region), we do not impose a symmetric lower bound. In practice, our software automates this iterative procedure; users need only specify the initial and the threshold .
Averaging Shifts Across Folds.
In the case of adaptive shifts, because may differ across folds (depending on each fold’s empirical distribution), we then “average” the chosen shifts into a single . Specifically, if is the largest feasible shift in fold , we define . We pair this average shift with the previously estimated nuisance components to produce a single, final shift-based estimate. That is, we do a pooled TMLE update with the nuisance parameters (that may be based on different shifts) and pair this estiamte with the average shift across the folds. While is more complicated to interpret than a pre-fixed shift, it helps prevent positivity issues in at least some folds and thus provides an average feasible shift across the population. In many analyses, however, one might simply choose a modest fixed well within the data’s support and forego adaptivity entirely – especially if no substantial positivity concerns are apparent.
Exposure density estimation
4.7
Estimating the joint density of given covariates is central to our stochastic-shift parameter. In particular, we require – the conditional density (or probability mass) of the exposures – both to construct the clever covariates for TMLE and to implement the shifts . Although this step may appear straightforward, it can pose significant challenges in practice, especially in high-dimensional data or when includes heterogeneous continuous exposures. This section provides an overview of the two main strategies currently supported by our approach and software, while also highlighting alternative ratio-estimation methods from recent literature.
Direct Modeling of the Conditional Density.
A natural approach is to model directly using machine-learning regressors tailored to density estimation. For instance, one can employ parametric or semiparametric density estimators (e.g., mixture models) or nonparametric machine-learners (e.g., random forests or gradient boosting) that predict the density of given . We then form the ratio
as needed to define the clever covariate for the shift. While conceptually straightforward, direct density modeling can be difficult in high dimensions or with multi-modal, heavily skewed exposure distributions. It also demands careful hyperparameter tuning to avoid instability in ratio estimates. In our software, Super Learner [25] is used to select the best density estimator from a set of candidates based on cross-validated loss; however, machine learning density estimators are substantially lacking compared to classification counterparts.
Classification-Based Reparameterization.
An alternative, and often more robust, strategy recasts density-ratio estimation as a binary classification problem in an augmented dataset [26,27]. We duplicate each observation and label one copy as “shifted” , meaning its exposure vector is replaced by , and the other copy as “unshifted” . A flexible classifier (e.g., a Super Learner ensemble) then predicts . From Bayes’ rule, the probability ratio
directly encodes , yielding the necessary clever-covariate component. This classification-based approach often proves more numerically stable than direct density modeling, thanks to the maturity of binary classification algorithms and regularizers for high-dimensional data.
Implementation in InterXshift.
Our software package supports both direct density modeling and classification-based reparameterization. In either case, users can leverage the Super Learner [25] framework to combine multiple candidate learners (e.g., generalized linear models, random forests, gradient boosting) adaptively. We default to the classification-based approach in high-dimensional settings for its computational stability, but direct density modeling may be appropriate when prior knowledge suggests a particular parametric or semiparametric form for .
Advanced Ratio-Estimation Alternatives.
Recent methodological developments offer additional tools that could be readily integrated into our framework. For instance,
– Neural-network-based importance sampling methods [28] learn flexible parametric forms of the exposure distribution that can be advantageous for extremely high-dimensional , or for imposing specific structural assumptions (e.g., normalizing-flow models).– Energy balancing [29] is another emerging strategy for density-ratio estimation that aims to match the distributions of shifted and unshifted samples by minimizing an energy distance. This approach can help address positivity violations or regions of low overlap in the data, potentially improving finite-sample stability.
While we have not yet implemented these novel ratio-estimation strategies in InterXshift, their inclusion would be conceptually straightforward. We view such innovations as a promising direction for future research, particularly in scenarios where classical machine-learning or classification-based approaches struggle with very large or complex exposure spaces.
Overall, the density-estimation step must not be viewed as trivial. Choosing among direct modeling, classification-based reparameterization, or more recent specialized approaches can profoundly influence both the numerical stability of the algorithm and the accuracy of the final stochastic-shift estimates.
Simulations
5
We conducted a simulation study to assess the performance of InterXshift under a range of synergy and antagonism strengths, with particular focus on (i) identifying the correct interacting exposures and (ii) accurately estimating interaction parameters. The scenarios we consider approximate small, moderate, and large interaction magnitudes, reflecting effect sizes plausible in environmental exposure settings.
Data-generating mechanism (DGM)
5.1
We extend the basic framework described in Section 2 to include two explicit interaction terms among six exposures, and . Specifically, we generate confounders
where encodes moderate pairwise correlations (e.g., 0.2–0.4). Next, for each observation, we sample six continuous exposures via gamma, beta, or truncated-normal distributions. These distributions are chosen to mimic features commonly seen in environmental exposures, such as right-skew (lognormal-like) or bounded support (beta).
We then define the outcome as
with . Here, confounds and because simultaneously affects the exposures and has a direct effect on . By shifting A while adjusting for , we emulate realistic observational data and explore how well InterXshift uncovers synergy in this continuous exposure setting. Hence, while we included both synergy and antagonism terms in the data-generating mechanism, we focus primarily on detecting synergy in these simulations for clarity and succinctness; there is little reason to believe synergy is either more or less challenging to estimate than antagonism, and our aim here is to examine whether weak synergy signals remain detectable under realistic confounding and correlated exposures with additional interactions.
Simulation scenarios and sample sizes
5.2
To capture a spectrum of interaction intensities, we vary the terms:
– SynergyStrength ∈ {0.25, 0.40, 0.60} (small, moderate, large positive interaction between and );– AntagonismStrength ∈ {−0.20, −0.45, −0.70} (small, moderate, large negative interaction between and ).
These ranges were selected to reflect additive-scale interaction sizes typical of modest (0.20–0.40) or more pronounced (0.50–0.70) synergistic or antagonistic effects found in certain environmental exposures.
We consider sample sizes . Smaller settings allow us to assess performance when data are relatively limited, a common situation in environmental epidemiology. Larger illustrates whether -rate consistency emerges as theory predicts.
True values of synergy
5.3
To evaluate estimation accuracy, we compare each estimated interaction to its “true” value, computed via a large sample (e.g., ) from the same DGM. Concretely, for our interaction parameter, we define
where and shift and by 0.5 unit each, chosen to lie within the typical range of and . We approximate each expectation by sampling from the DGM at very large , thus obtaining stable reference values for comparison.
Implementation
5.4
Data Generation: Draw i.i.d. observations from the above DGM.Cross-Validation for Discovery–Estimation:
- – Discovery Stage: Fit flexible ML models for and on the training fold. For each exposure pair, compute a g-computation approximation of synergy. Rank pairs by positive (synergy) or negative (antagonism) values.
- – Estimation Stage: For the top-ranked synergy pair and the top-ranked antagonism pair, estimate the final interaction parameter via targeted maximum likelihood estimation (TMLE), using only the validation fold. Repetition and Summary: Repeat for replicates (e.g., 100) under each scenario and sample size. Pool the estimates across folds to obtain and its corresponding confidence interval in each replicate.Comparison to Truth: Compare to (Section 5.3) to quantify bias and coverage.
Performance metrics
5.5
We summarize each simulation’s output over replicates:
– Mean Squared Error (MSE):
– 95% Coverage: Fraction of replicates whose 95% CIs contain .– Scaled Bias: , to check near- consistency.
Synergy results and key findings
5.6
We evaluated the performance of InterXshift in detecting and estimating a positive interaction (synergy) between exposures across three effect magnitudes: weak (0.25), moderate (0.40), and large (0.60). Figure 1 displays the method’s behavior for a range of sample sizes in terms of mean absolute bias, mean squared error (MSE), coverage, discovery rate, and scaled bias . Below we highlight the principal findings:
Accurate Discovery of the Synergistic Pair.
(1)
Even with relatively small samples , InterXshift correctly ranked among the top synergy pairs in most replicates when the true synergy was moderate or large. Occasional misses arose under the weakest synergy (0.25) combined with small , illustrating that detecting subtle interactions can require additional data. Nonetheless, by and above, the discovery rate consistently exceeded 75% for weak synergy and approached or exceeded 90% for moderate and large synergy.
Reduced Bias and MSE With Increased Sample Size.
(2)
As shown in Figure 1, the mean absolute bias and MSE decreased markedly with . At , absolute bias ranged from roughly 0.2 to 0.35 across different synergy strengths, whereas at or , both bias and MSE became notably smaller (often under 0.10 bias for moderate/large synergy). These patterns reflect the benefits of having more observations for the targeted maximum likelihood estimation (TMLE) procedure to learn both outcome and exposure-density relationships.
Confidence Interval Coverage Approaching 95%.
(3)
Coverage for moderate and large synergy converged toward the nominal 95% level by , typically reaching or exceeding 90% at . Even for weak synergy, coverage climbed steadily from around 75–80% at to near 90% at . These findings support the theoretical robustness of TMLE in finite samples, provided that key positivity conditions are not seriously violated.
Stable or Decreasing Scaled Bias.
(4)
A key indicator of -rate convergence is whether remains roughly constant or declines with increasing . Consistent with TMLE theory, we observed that scaled bias either plateaued or decreased across larger sample sizes, suggesting that InterXshift can achieve efficient asymptotic performance under flexible machine-learning estimation of nuisance functions.
Overall Implications for Environmental Data.
These results underscore InterXshift’s practical feasibility in typical environmental-mixture studies. Even when exposures are moderately correlated and confounded by covariates, the method can reliably detect and quantify an additive-scale synergy – particularly as sample sizes surpass a few hundred observations. While very weak interactions and limited data may hamper detection, the consistent reduction in bias and growth in coverage at higher reflect the benefits of a data-adaptive discovery-and-estimation framework. Thus, InterXshift offers a robust solution for isolating key synergies in multi-exposure settings and guiding follow-up toxicological or epidemiologic investigations.
Applications
6
Analysis of NIEHS synthetic mixtures data
6.1
The NIEHS synthetic mixtures data is a commonly used data set to evaluate the performance of statistical methods for mixtures. These synthetic data can be considered the results of a prospective cohort study, where the outcome cannot cause exposures, and correlations between exposure variables can be thought of as caused by common sources or modes of exposure. The variable can be assumed to be a potential confounder and not a collider. The data set has 7 exposures with a complex dependency structure based on endocrine disruption. Two groups of exposure ( and ) lead to high correlations within each group. positively contribute to the outcome, have negative contributions, while and have no impact on the outcome. Rejecting and is difficult due to their correlations with the members of the cluster group. This correlation and effects structure is biologically plausible, as different congeners of a group of compounds may be highly correlated but have different biological effects. Exposures have various agonistic and antagonistic interactions, a breakdown of the variables sets and their relationships are: both increase Y by concetration addition, competetive antagonism, supra-additive or synergistic, both addivively decrease Y, unusual antagonism. Synthetic data and the key for dataset 1 are available on GitHub. This resource shows the interactions and marginal dose relationships built into the data. Given these toxicological interactions, we expect these sets of variables to be determined in InterXshift. For example, we might expect a positive counterfactual result for A1, A2, A7 and negative results for A4 and A5. Table 1 shows the interactions built into this data.
Likewise, in the case for antagonistic relationships such as A1–A5 (third row in 1), we would expect a joint shift to come closer to the null, since A5 antagonizes the positive effects of A1. For A1 and A2, we would expect the joint shift to be close to the sum of individual shifts (not much interaction), but for A1 and A7 we expect to estimate more than an additive effect (some interaction). The NIEHS data set has 500 observations and 9 variables. is a binary confounder. Based on this table, we can gauge InterXshift’s performance by determining if the correct synergistic and antagonistic relationship are found and if the correct variables are rejected.
We apply InterXshift to these NIEHS synthetic data using a three-fold CV (smaller CV to save space here in k-fold result tables). We use the default libraries of learners for the estimation of and . We parallelize over the cross-validation to test computational run-time on a newer personal machine an analyst might be using. We use a delta of 1 for all the exposures in the mixture. We present the pooled TMLE results and the k-fold specific results.
NIEHS synthetic data results
6.2
InterXshift accurately rejects exposures , finding the correct top positive marginal effects of in all the folds and the top inverse association in all the folds. Likewise, we found the correct synergistic results built into the DGP for and . In all the folds, was found to have the strongest antagonistic relationship, which is also true based on the DGP key provided from the NIEHS.
Table 2 presents the rank 1 positive marginal results for the NIEHS data. The first three rows display fold-specific results, with representing the expected change in the outcome under the exposure shift compared to the average observed outcome. Here, is identified as the top positively associated mixture variable across all folds. The pooled TMLE column provides the aggregate results, showing an average of 16.31 with a standard error of 0.37 and a 95% confidence interval of 15.59–17.04. These results underscore the consistent positive association of with the outcome across different data folds.
Table 3 presents the rank 1 inverse marginal results for the NIEHS data. The first three rows show fold-specific results, with indicating the expected change in the outcome under the exposure shift compared to the average observed outcome. Here, A5 is identified as the top negatively associated mixture variable across all folds. The pooled TMLE column provides the aggregate results, demonstrating that a 1-unit increase in A5 leads to an average decrease of −3.67 in endocrine disruption, with a standard error of 0.50 and a 95% confidence interval of −4.65 to −2.70. These results highlight the consistent negative association of A5 with the outcome across different data folds.
Table 4 presents the rank 1 synergistic interaction results for the NIEHS data. The table shows fold-specific results, with indicating the expected change in the outcome under a 1-unit shift in the specified exposure(s). Here, we observe that A1 and A7 are identified as the top synergistic relationship in two folds, while A2 and A7 are identified in the remaining fold. The joint shift for A1 and A7 and for A2 and A7 reveals significant synergistic interactions built into the data-generating process. The interaction effects reflect the combined effect of shifting both exposures compared to the sum of their individual shifts, indicating strong synergy where the Psi under interaction is positive.
Table 5 presents the pooled TMLE estimates for the rank 1 synergistic relationships in the NIEHS data. The first two rows show the average individual effects of the variables involved in the top synergistic relationships, identified as Var 1 and Var 2, here because Var 1 changed across the folds it is the average across A1 and A2 and Var 2 corresponds to A7. The third row represents the joint effect of shifting both exposures simultaneously, while the fourth row shows the average synergistic interaction effect, which is significantly greater than the sum of individual shifts. This pooled estimate reflects the average effect across the identified top synergistic relationships.
Table 6 presents the k-fold specific antagonistic rank 1 results for the NIEHS data. The column represents the expected change in the outcome under a 1-unit shift in the specified exposures. For the first fold, variable A5 shows a negative shift of −3.97, indicating a strong inverse association. Similarly, variable A7 shows a positive shift of 3.00. The combined shift of A5 and A7 results in an estimated change of −1.76, while the interaction term, which compares the joint shift to the two marginal shifts, shows a negative shift of −0.78. These patterns are consistent across all three folds, demonstrating significant evidence for antagonistic interactions between these variables.
Comparison to existing methods
6.2.1
Quantile g-computation [5], prevalent in environmental epidemiology for mixture analysis, estimates the effects of uniformly increasing exposures by one quantile, based on linear model assumptions. This method quantizes mixture components, summing the linear model’s coefficients to form a summary measure for joint impact assessment. However, it inherently assumes additive, monotonic exposure-response relationships, overlooking complex, potentially nonlinear interactions typical in mixtures, like in endocrine disrupting compounds. Consequently, this method might not accurately capture the nuanced dynamics of mixed exposures, especially when interactions vary with other variable levels.
We run quantile g-computation on the NIEHS data using 4 quantiles with no interactions to investigate results using this model. The size of the scaled effect (positive direction, sum of positive coefficients) was 6.28 and included and the scaled effect size (negative direction, sum of negative coefficients) was −3.68 and included . Compared to NIEHS ground truth, are incorrectly included in these estimates. However, the positive and negative associations for the other variables are correct. Next, because we expect interactions to exist in the mixture data, we would like to assess for them but the question is which interaction terms to include? Our best guess is to include interaction terms for all exposures. We do this and show results in Table 7.
In Table 7 is the summary measure for the main effects and for interactions. As can be seen, when including all interactions, neither of the estimates are significant. Of course, this is to be expected given the number of parameters in the model and the sample size . However, moving forward with interaction assessment is difficult; if we were to assess for all 2-way interaction of 7 exposures, the number of sets is 21 and with 3-way interactions is 35. We would have to run these many models and then correct for multiple testing. Hopefully, this example shows why mixtures are inherently a data-adaptive problem and why popular methods such as this, although succinct and interpretable, fall short even in a simple synthetic data set.
Comparison with a group lasso-based approach (glinternet)
6.3
Although quantile g-computation is a commonly used screening tool for mixtures, it was never designed to systematically isolate pairwise interactions. We therefore also compared InterXshift with a penalized-regression strategy that does attempt automatic interaction detection in high dimensions. Specifically, we employed the glinternet algorithm [30], which fits a generalized linear model with hierarchical pairwise interactions using an -type group-lasso penalty. By penalizing the inclusion of main and interaction terms together, glinternet can parsimoniously select or discard interaction effects without manual enumeration of all pairwise products – a feature appealing in high-dimensional mixture settings [7, 9].
Implementation on the NIEHS Synthetic Data.
We applied glinternet (with a Gaussian family) to the NIEHS synthetic dataset described in Section 6, using five-fold cross-validation to choose the optimal penalty level. Following standard practice, we adopted the “one-standard-error” rule, favoring a more parsimonious solution whenever multiple penalties produced near-equal cross-validation errors. Table 1 (Section 6) lists the ground-truth interactions built into the synthetic data – e.g., and exhibit supra-additive synergy, whereas and exhibit antagonism, and are null exposures.
Key Findings and Comparison to Ground Truth.
Table 8 shows the main and interaction terms selected by glinternet, along with their estimated coefficients under the cross-validated model. On the positive side, glinternet captured several true interactions, including , and – all of which appear in the synthetic data dictionary. However, several discrepancies arose:
Negative Coefficients for Pairs That Are Actually Synergistic.
(1)
For instance, glinternet discovered but assigned a negative interaction coefficient. Biologically, and are nearly toxic equivalents that increase in an additive or slightly super-additive way. In a linear model, if and are strongly correlated and both positively correlated with , this can paradoxically yield a negative interaction term, reflecting how the model partitions the linear predictor among correlated covariates. Thus, the sign of a glinternet interaction coefficient does not necessarily indicate super- or sub-additivity in the usual epidemiologic sense.
Spurious Interactions Involving Null Exposures.
(2)
glinternet also selected terms involving – exposures that the NIEHS synthetic key designates as inactive. This likely reflects the model’s attempt to fit residual correlation patterns in . Because glinternet estimates a linear projection of onto main and product terms, even exposures with zero true additive effect can appear if they help reduce squared error by capturing correlated structures. By contrast, InterXshift – which quantifies synergy via departures from additivity under hypothetical exposure shifts – did not single out or as having strong interactions.
Linear vs. Shift-Based Interpretations.
(3)
By design, glinternet fits a penalized linear model, so an “interaction” is merely a coefficient for on the linear predictor scale. InterXshift, on the other hand, defines synergy or antagonism via the difference
i.e., an explicit causal contrast comparing a joint shift to separate individual shifts. Consequently, a large positive coefficient in glinternet can correspond to sub-additive behavior for the actual outcome, or vice versa.
Implications for Environmental Mixtures.
Our findings underscore that glinternet can help screen for interaction candidates in large exposure sets. Its selection mechanism is relatively fast and requires minimal manual specification of product terms. However, the interpretability of glinternet’s interaction coefficients is limited when the scientific question centers on truly additive synergy (or antagonism). In particular:
– A negative penalized coefficient for may not mean that and are antagonistic in an epidemiologic sense, but rather that, given the partial correlations, the linear model “subtracts” from one slope when the other exposure is present.– Even null exposures can be selected if they slightly improve predictive fit – leading to additional product terms that do not align with the synthetic data’s known synergy/antagonism structure.
By contrast, InterXshift relies on a direct, causal definition of “departure from additivity” via population-wide shift interventions. This often yields more transparent estimates for public-health and policy discussions – e.g., “Would reducing chemical by 1 unit and by 1 unit together yield more or less benefit than reducing each alone?” Nonetheless, penalized methods like glinternet offer a pragmatic exploratory tool, and can complement our shift-based approach by quickly highlighting which pairs warrant deeper investigation.
Methods applied to NHANES dataset
6.4
The National Health and Nutrition Examination Survey (NHANES) 2001–2002 cycle serves as the foundation of our analysis. This data source, known for its credibility in the public health domain, boasts interviews with 11,039 individuals. Of this subset, 4,260 provided blood samples and willingly consented to DNA analysis. The data set used aligns with that of Mitro et al. [31] focusing on the correlation between persistent exposure to organic pollutants (POPs), specifically those binding to the aryl hydrocarbon receptor (AhR) and extended leukocyte telomere length (LTL). However, this subset was further refined to ensure complete exposure data, yielding 1,007 participants for our analysis, compared to 1,003 in the initial study by Mitro et al. In alignment with protocols detailed by Mitro et al. [31], exposure was quantified, focusing on 18 congeners. These include 8 non-dioxin-like PBCs, 2 non-ortho PCBs, 1 mono-ortho PCB, 4 Dioxins, and 4 Furans. All congeners underwent lipid serum adjustments using an enzymatic summation methodology. The telomere length, was analyzed using the quantitative polymerase chain reaction (qPCR) methodology [31]. This technique measures the T/S ratio by comparing the length of the telomere to a standardized reference DNA. To enhance accuracy, samples underwent triple assays in duplicate, generating an average from six data points. The CDC conducted a blinded quality control assessment. Our modeling accounted for several covariates, including demographic factors such as age, sex, race/ethnicity and level of education, as well as health indicators such as BMI, serum cotinine, and blood cell distribution and count. Categorizations for race/ethnicity, education, and BMI are consistent with previous studies. Furthermore, this comprehensive dataset is integrated into the InterXshift package for replicable analysis.
Gibson et al. [6] reanalyzed this same data using more contemporary statistical methods. They found that clustering methods identified high, medium, and low POP exposure groups with longer log-LTL observed in the high exposure group. Principal component analysis (PCA) and exploratory factor analysis (EFA) revealed positive associations between overall POP exposure and specific POPs with log-LTL. Penalized regression methods identified three congeners (PCB 126, PCB 118, and furan 2,3,4,7,8-pncdf) as potentially toxic agents. WQS identified six POPs (furans 1,2,3,4,6,7,8-hxcdf, 2,3,4,7,8-pncdf, and 1,2,3,6,7,8-hxcdf, and PCBs 99, 126, 169) as potentially toxic agents with a positive overall effect of the POP mixture. BKMR found a positive linear association with furan 2,3,4,7,8-pncdf, suggestive evidence of linear associations with PCBs 126 and 169, a positive overall effect of the mixture, but no interactions among congeners. These results (in the supervised methods) controlled for the same covariates. Figure 2 shows the results for WQS, BKMR and Lasso regression from their paper. We highlight furan 2,3,4,7,8-pncdf as the chemical which shows consistent positive association with LTL across the methods. As such, we might expect that this chemical would consistently be found as the top positive marginal impact based on our target parameter across all the folds.
We configured our methodology using default learners and employed a 5-fold CV. Given the data range, a value of half a standard deviation was used for all exposures, denoting a focus on counterfactual changes in telomere length for an increase in half a standard deviation across exposures that predict the telomere length depending on the scale of exposure.
NHANES furan results
6.5
Generally, when applying our InterXshift method to identify the top positive and negative marginal effects; and the top synergistic and antagonistic interactions, we do not find consistent estimates for these parameters. Table 9 shows the estimates of the top positive association between the folds. Although we see 2,3,4,7,8-pncdf is identified as the top positive effect in 3 of the folds, 2 of the folds estimate a different chemical as the top positive effect; therefore, the estimates are inconsistent. Likewise, the estimates for the top inverse association with LTL were also inconsistent across the folds. The top synergistic and antagonistic interactions were also inconsistent and, therefore, indicate no interaction in the mixed POP exposure.
Software
7
We have developed the InterXshift R package to implement the proposed methodology for the semiparametric discovery and estimation of interaction effects in mixed exposures using stochastic interventions. The package is accompanied by comprehensive documentation, which includes a detailed vignette elucidating the underlying semiparametric theory, practical application examples, and comparative analyses with existing methodologies. This ensures that researchers can accurately replicate and extend our analyses.
InterXshift is designed with computational efficiency in mind, optimized to operate effectively on standard personal computing environments while retaining scalability for high-performance computing platforms necessary for extensive simulations and large-scale data analyses. The package offers flexible functionalities for density estimation, interaction discovery, and TMLE, thereby allowing users to customize analyses to their specific research requirements.
Furthermore, InterXshift incorporates parallel processing capabilities to improve computational speed, which is particularly advantageous for performing simulations and cross-validation procedures inherent in our methodology. Rigorous testing has been conducted to ensure the robustness and reliability of the package, adhering to best practices in statistical software development [32].
Researchers can access the InterXshift package through our GitHub repository.^1^ The repository provides installation instructions, usage guidelines, example scripts demonstrating typical workflows, and a suite of unit tests to verify functionality and ensure reproducibility of results. By offering an accessible, well-documented, and robust statistical tool, InterXshift facilitates the application of advanced semiparametric methods in the analysis of complex exposure mixtures within the domain of causal inference and environmental health research.
Discussion and conclusion
8
InterXshift offers a new semiparametric perspective on detecting and estimating interactions among complex mixtures of environmental exposures. At its core is a model-agnostic causal interaction parameter that draws on stochastic shift interventions, extending earlier work on continuous treatments [17]. By defining interaction as the deviation from additivity in marginal and joint shifts, our framework resonates with traditional RERI-based approaches [1, 2] while providing greater flexibility for continuous exposures.
A central contribution of our work is the explicit derivation of the efficient influence function for interactions in vector-valued exposures. Building on this, we implement a cross-validated targeted maximum likelihood estimation (CV-TMLE) procedure that guards against overfitting and maintains asymptotic efficiency, even when numerous exposures are modeled. The CV-based discovery stage pinpoints which pairs (or subsets) of exposures exhibit synergy or antagonism, while the estimation stage then applies TMLE to quantify these interactions. Through this two-step process, InterXshift helps researchers focus on the most consequential pairwise interactions without incurring a large multiple-testing burden.
Empirically, our simulations underscore several appealing properties of InterXshift. First, we observe that the method consistently identifies true synergy or antagonism, often with high accuracy and convergence toward negligible bias under moderate sample sizes. Even in scenarios with correlated exposures and potentially limited sample size, the framework demonstrates encouraging robustness. The application to the NIEHS synthetic mixture data further illustrates how InterXshift can successfully uncover known additive and supra-additive effects, rejecting spurious signals introduced by correlated but causally inert exposures. Such strong performance suggests that this method may be applicable to a range of real-world mixture settings, where interactions are often poorly understood.
From a theoretical perspective, the shift-based definition of interaction offers a transparent causal interpretation. By conceptualizing an intervention that partially reduces or augments specific exposures, researchers can link findings to practical regulatory questions (e.g., “What if we reduced chemical A by 20% and chemical B by 10% across the population – would there be a super-additive health benefit relative to each reduction alone?”). In this way, InterXshift moves beyond merely detecting product terms in a regression and instead aligns with policy-relevant questions about actual exposure modifications.
Despite these strengths, certain limitations merit attention. The computational overhead of repeated density estimation – particularly in high-dimensional mixtures – can be substantial, and further methodological improvements are needed to ensure reliability when exposures are extremely numerous. Similarly, the method largely centers on pairwise interactions; although we show how it might extend to three- or higher-order interactions, such expansions require combinatorial increases in the number of stochastic shifts and more elaborate positivity diagnostics. Another challenge lies in mitigating positivity violations: if the shift pushes exposures outside their observed support, ratio-based estimators may exhibit inflated variance or bias. While we implement data-adaptive shrinking of the shift parameter and classification-based reparameterization to mitigate these issues, they remain points for careful monitoring in practice.
In ongoing work, we envision multiple avenues to refine and generalize the InterXshift framework. One priority is a thorough comparison of “direct targeting” and “separate estimation” approaches for the interaction parameter, including further simulations with varied density-estimation techniques. Another is to incorporate advanced neural-network or energy-balancing methods [28, 29] for ratio estimation, potentially enhancing performance under sparse or high-dimensional exposures. Additional efforts might target broader applications to longitudinal data, exploring how partial exposure shifts unfold over time, or to larger population-based datasets where interactions could be modest but still epidemiologically meaningful.
Conclusions
9
By merging a flexible additive-interaction definition with stochastic interventions and modern machine learning, InterXshift provides a principled way to investigate synergy and antagonism in multi-exposure data. Empirical findings in both simulations and synthetic mixtures illustrate its potential to uncover important joint effects that might otherwise remain hidden under traditional modeling. As environmental health increasingly confronts mixtures of correlated chemicals, precisely identifying synergistic hazards can guide policy to prioritize co-reductions in exposures with the greatest protective effect. We believe that, with continued methodological refinements and expanded computational strategies, InterXshift will help move the field of causal inference toward more nuanced, data-adaptive analyses of complex exposures and lead to more informed decision-making in both research and regulatory contexts.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1Vansteelandt S, Vander Weele TJ, Tchetgen EJ, Robins JM. Multiply robust inference for statistical interactions. J Am Stat Assoc 2008;103: 1693–704.21603124 10.1198/016214508000001084 PMC 3097121 · doi ↗ · pubmed ↗
- 2Vander Weele TJ, Richardson TS. General theory for interactions in sufficient-cause models with dichotomous exposures. Ann Stat 2012; 40:2128–61.25552780 10.1214/12-aos 1019 PMC 4278668 · doi ↗ · pubmed ↗
- 3Bobb JF, Valeri L, Henn BC, Christiani DC, Wright RO, Mazumdar M, Bayesian kernel machine regression for estimating the health effects of multi-pollutant mixtures. Biostatistics 2014;16:493–508.25532525 10.1093/biostatistics/kxu 058PMC 5963470 · doi ↗ · pubmed ↗
- 4Carrico C, Gennings C, Wheeler DC, Factor-Litvak P. Characterization of the impact of collinearity and variable selection on the estimations of the exposure–outcome associations in epidemiologic studies of exposure mixtures. Environ Health 2015;14:1–9.25564290 10.1186/1476-069X-14-1PMC 4417249 · doi ↗ · pubmed ↗
- 5Keil AP, Buckley JP, O’Brien KM, Ferguson KK, Zhao S, White AJ. A quantile-based g-computation approach to addressing the effects of exposure mixtures. Environ Health Perspect 2019;127:047004.30986088 10.1289/EHP 3711 PMC 6785227 · doi ↗ · pubmed ↗
- 6Gibson EA, Nunez Y, Styczynski A. An overview of methods to address distinct research questions on environmental mixtures: an application to persistent organic pollutants and leukocyte telomere length. Environ Health 2019;18:1–12.30606207 10.1186/s 12940-018-0440-8PMC 6318965 · doi ↗ · pubmed ↗
- 7Boss J, Roy J, Coull BA, Narisetty NN, Wu Z, Ferguson KK, A hierarchical integrative group least absolute shrinkage and selection operator for analyzing environmental mixtures. Environmetrics 2021;32:e 2698.34899005 10.1002/env.2698 PMC 8664243 · doi ↗ · pubmed ↗
- 8Narisetty NN, Zhang L, Furr J, Minnier J, Fang X, Omaye ST, Selection of nonlinear interactions by a forward stepwise algorithm: application to identifying environmental chemical mixtures affecting health outcomes. Stat Med 2019;38:1582–600.30586682 10.1002/sim.8059 PMC 7134269 · doi ↗ · pubmed ↗