Discovery of critical thresholds in mixed exposures and estimation of policy intervention effects
David B. McCoy, Alan Hubbard, Mark van der Laan, Alejandro Schuler

TL;DR
This paper introduces a new method to identify critical exposure thresholds and estimate policy effects for multiple chemical exposures, using advanced statistical techniques and real-world data.
Contribution
A novel methodology combining recursive partitioning and cross-validated targeted maximum likelihood estimation for multivariate exposure analysis.
Findings
Simulation studies confirm convergence to optimal exposure regions and accurate intervention effect estimation.
The method successfully identifies true interactions in synthetic mixture data.
Harmful metal exposures affecting telomere length are discovered in NHANES data.
Abstract
Regulations of chemical exposures often focus on individual substances, neglecting the amplified toxicity that can arise from multiple concurrent exposures. We propose a novel methodology to identify critical thresholds in multivariate exposure spaces and estimate the effects of policy interventions that limit exposures within these thresholds. Our approach employs a recursive partitioning algorithm integrated with targeted maximum likelihood estimation (TMLE) to discover regions in the exposure space where the expected outcome is minimized or maximized. To address potential overfitting bias from using the same data for threshold discovery and effect estimation, we utilize cross-validated TMLE (CV-TMLE), which ensures asymptotic unbiasedness and efficiency. Simulation studies demonstrate convergence to the optimal exposure region and accurate estimation of intervention effects. We apply…
Genes, proteins, chemicals, diseases, species, mutations and cell lines named across the full text — each resolved to its canonical identifier and authoritative record.
Click any figure to enlarge with its caption.
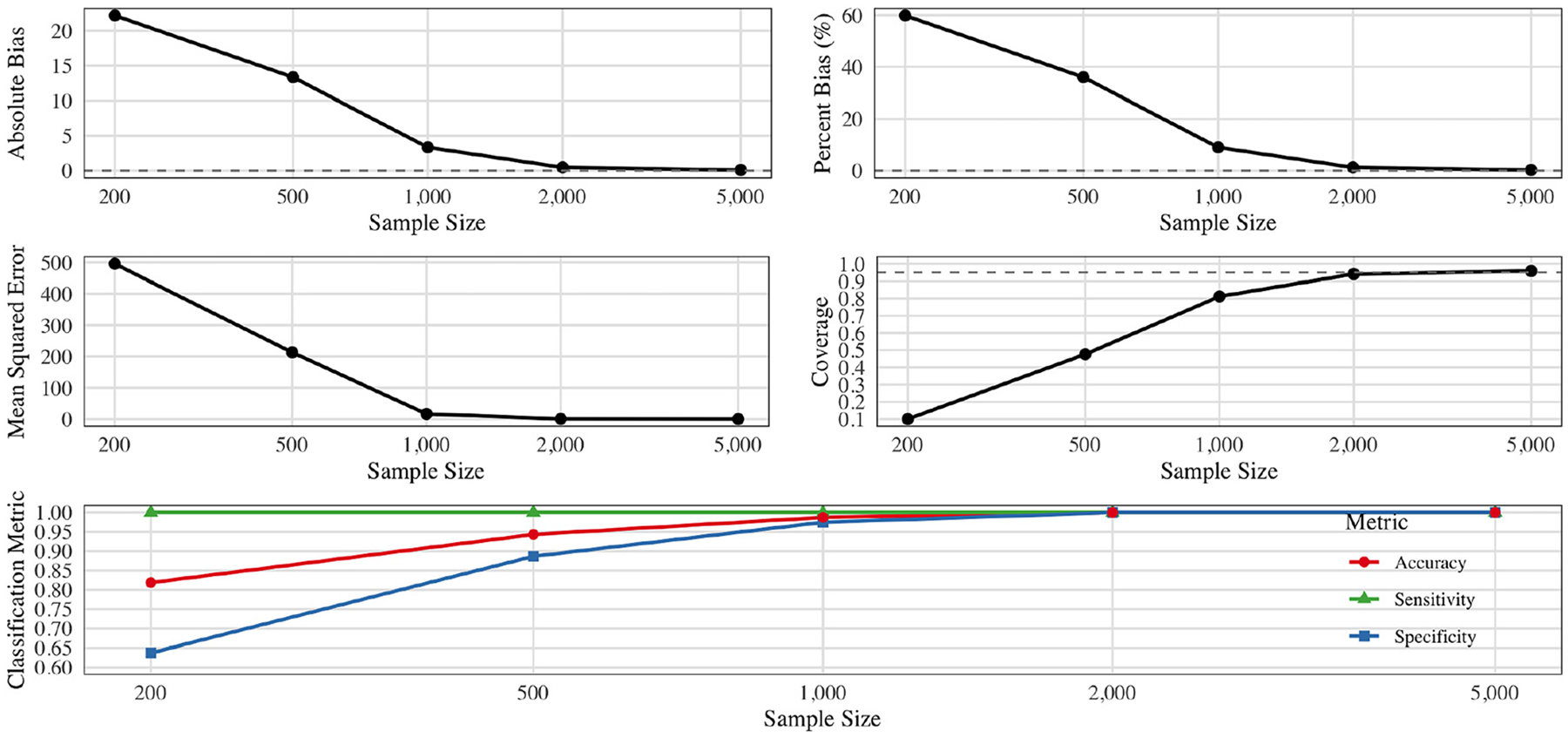 Figure 1
Figure 1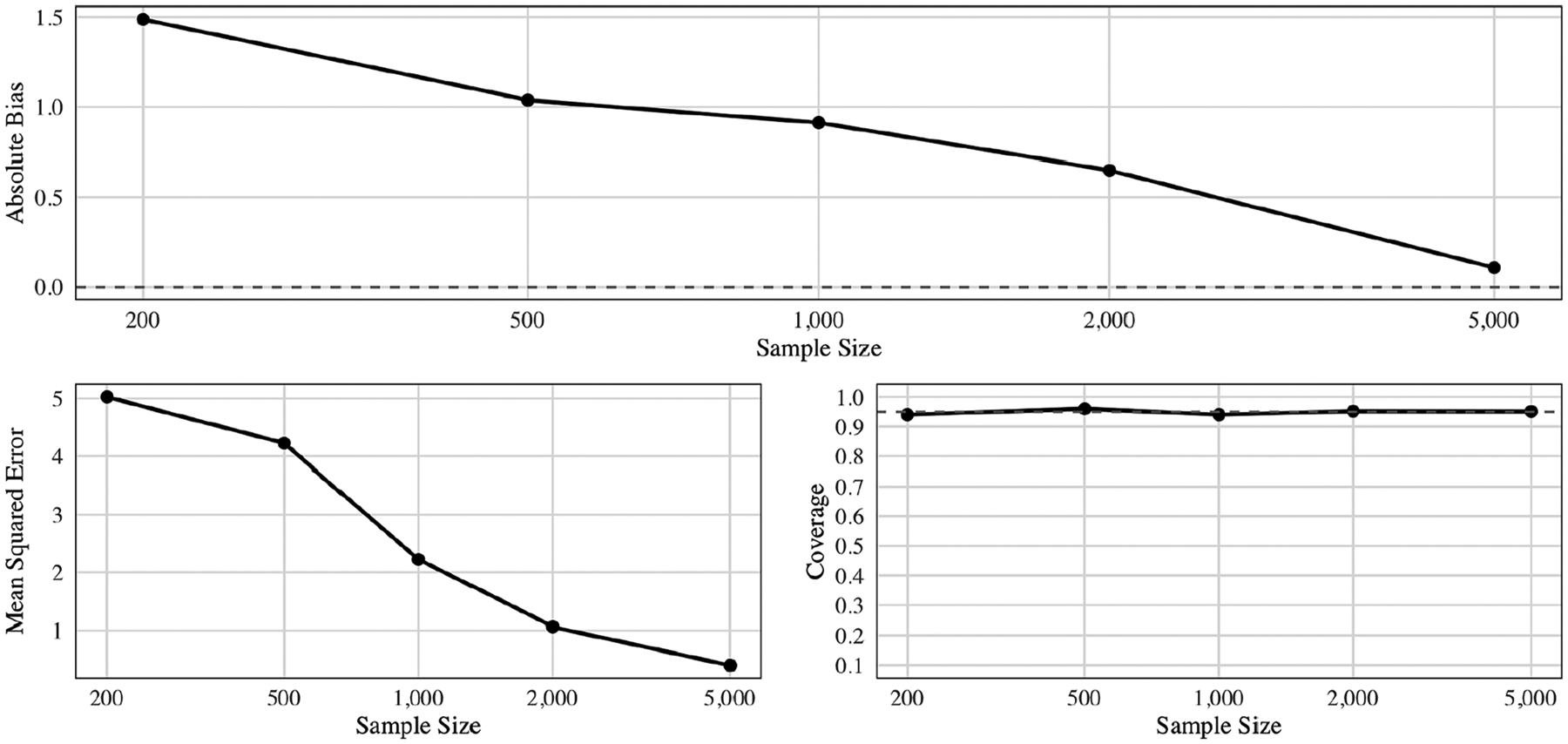 Figure 2
Figure 2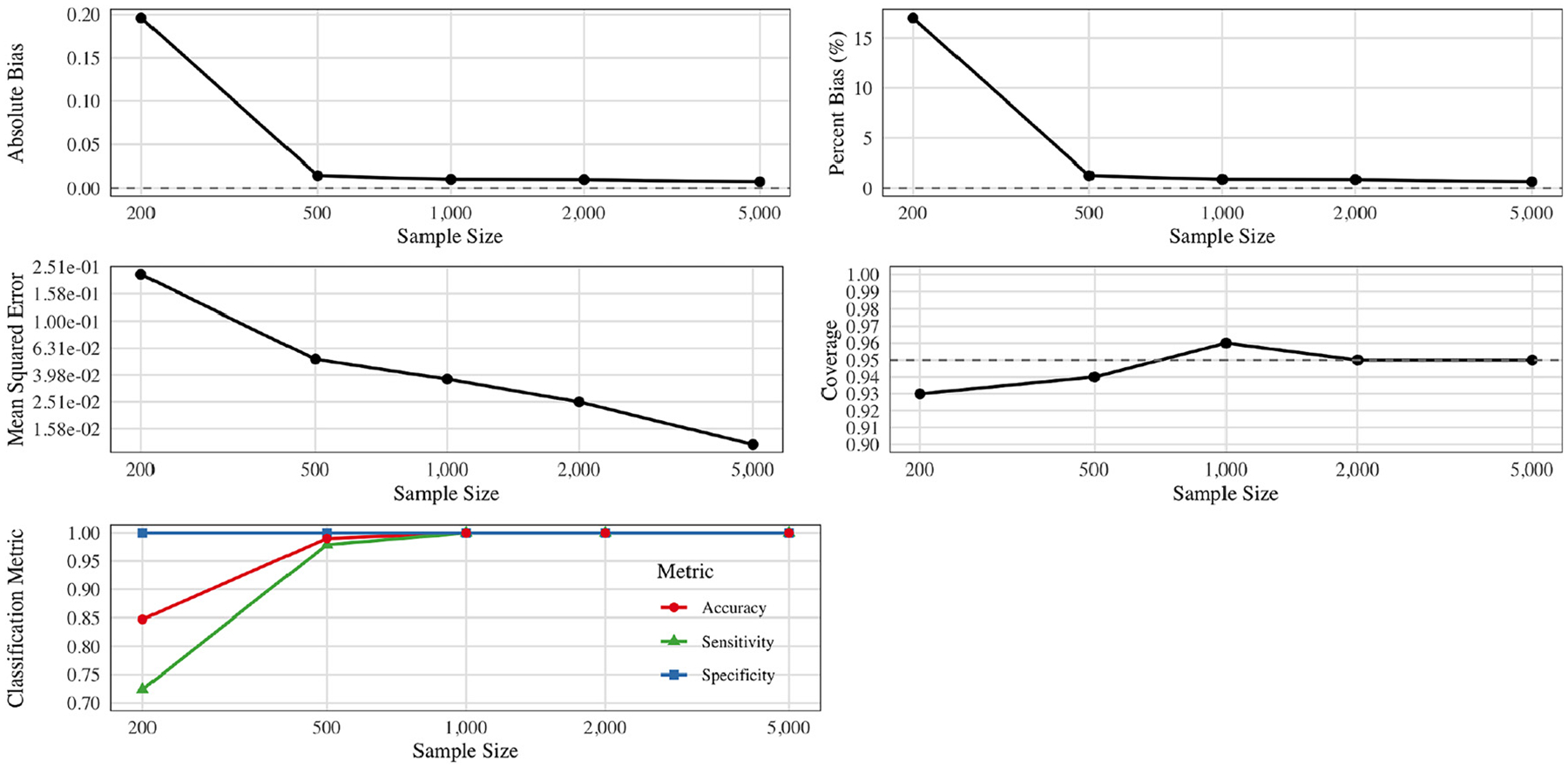 Figure 3
Figure 3| 1: |
| 2: |
| 1. If |
| 2. For each exposure |
| (a) Define |
| (b) If any |
| (c) Fit TMLE for mean outcome in |
| (d) Compute |
| (e) If |
| 3. If no valid splits found, |
| 4. Choose the best valid split (lowest/highest mean). Recursively call B |
| 3. |
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsHealth, Environment, Cognitive Aging · Effects and risks of endocrine disrupting chemicals · Per- and polyfluoroalkyl substances research
Introduction
1
Assessing the health impacts of multiple, simultaneously occurring chemical exposures – commonly called mixed exposures – is a major challenge in environmental epidemiology and public health [1–5]. Existing regulatory frameworks often consider one chemical at a time, overlooking the complex ways that combined exposures can amplify or counteract toxicity [6, 7]. This motivates a search for threshold-based interventions that limit exposures collectively, rather than individually, to reduce adverse outcomes and provide interpretable safe limits for multiple exposures.
Numerous approaches seek to evaluate multivariate exposures, including weighted quantile sum (WQS) regression [8], Bayesian mixture modeling [9], and Bayesian kernel machine regression (BKMR) [10]. While each offers insight – for example, capturing nonlinearity or estimating kernel-based dose-response surfaces – they usually either rely on strong model assumptions (directional homogeneity, strict linearity, or specified priors) or do not target a clear policy-relevant parameter. In particular, most do not explicitly define or estimate the causal effect of restricting exposures to certain thresholds in a high-dimensional mixture space [11, 12].
We propose a novel data-adaptive framework for discovering critical threshold regions in mixed exposures, together with a policy-oriented parameter that quantifies how forcing all individuals into those thresholds would change the population-average outcome. We define the Attributable Regional Effect (ARE) as the difference between the observed outcome and the counterfactual outcome under a subregion in the exposure space. Our approach integrates:
- Recursive partitioning of the exposure space via a significance-filtered decision tree. Rather than splitting on predictive variance (as in CART), we split on potential causal effects, discarding nodes with sparse data to maintain positivity.
- Cross-validated targeted maximum likelihood estimation (CV-TMLE) [13, 14] to generate robust, unbiased estimates of the ARE and valid confidence intervals, even in complex or high-dimensional exposures.
- Interpretability for regulation, since the discovered subregion can be written as simple “cut points,” e.g. , which are tangible for policy makers.
We demonstrate in simulations that our data-adaptive procedure identifies true critical thresholds and yields accurate causal estimates of restricting exposures to those thresholds under realistic conditions. We further apply the method to two empirical examples: (i) synthetic mixture data from NIEHS, and (ii) NHANES data on metal exposures and telomere length, revealing interpretable subregions associated with lower or higher health risks. Our CVtreeMLE R package, which has undergone peer review at the Journal of Open Source Software [15], implements the methodology for broader use.
The rest of this manuscript proceeds as follows. In Section 2.2, we define the causal parameter (ARE), explain its identification assumptions, and briefly outline TMLE (Section 4). We then present our threshold-discovery algorithm (Section 4), along with theoretical properties in Section 7. Section 8 document simulation results, while Section 9 applies the method to real data. Finally, Section 10 concludes with a discussion of limitations, policy interpretation, and future directions.
The estimation problem
2
Setup and notation
2.1
We consider an observational study with baseline covariates , multiple exposures , and a single timepoint outcome . Let denote the observable data. We assume that there exists a potential outcome function (that is, is a random variable for each value of a) that generates the outcome that would have been obtained for each observation had exposure been set to . These potential outcomes are not observed, but the observed outcome corresponds to the potential outcome for the observed value of the exposure, that is, . We use to denote the true data-generating distribution. We assume that our are independent and identically distributed (i.i.d.) draws of . We decompose the joint density as and make no assumptions about the forms of these densities. Let represent the observable (stratum-specific) dose-response function that can actually be estimated from observable data.
Let map from the set of possible data-generating distributions to the real numbers. Let , the value of this map at the true, unknown distribution , denote a target parameter (estimand) of interest. We can view our observed data ( ) as a (random) probability distribution that assigns a probability mass to each observation . Let mapping from empirical distributions to numbers denote our estimator (algorithm) such that is our estimate from data.
Defining the attributable regional effect (ARE)
2.2
We are interested in estimating the effect of a policy intervention that limits exposures to a specific region of the exposure space. For example, could represent allowable exposure levels that are considered safe. We define a binary indicator variable , where if and 0 otherwise. Let be the probability that an observation with covariates naturally self-selects treatment in the region .
We define the modified treatment variable to represent the exposure distribution once all exposures are forced to self-select within the region . The modified treatment has the following density:
which preserves the relative self-selection preferences for each available exposure and sets the preferences for “outlawed” exposures to zero. More formally, relative self-selection means that within the allowed exposure region , individuals maintain their original exposure preferences relative to each other (conditional on covariates), and exposures outside are set to zero probability. Now we can define the expected population outcome if we were to impose this policy:
We have shown that this parameter is a population average of the function when is forced to 1. For any value of is a weighted average of the conditional mean outcome across the different exposure levels within , thus collapsing it to a single number for each . We define the attributable regional effect (ARE) as
representing the difference in the average outcomes if we forced exposure to self-selection within versus the observed average outcome.
Policy interventions and the assumption of relative self-selection
2.3
If we do not assume relative self-selection, we would need to account for how each individual’s exposure preferences might change under the policy restriction. For any regulation or restriction, we would need to model the conditional density of exposures in the region given covariates, , to estimate how the exposure density profile would change under the restriction.
Alternatively, we might need to make assumptions about what the distribution would look like under the restriction. For example, individuals might aggregate just below the threshold, leading to higher densities near the boundary and lower densities farther from the threshold. However, we do not know this information a priori. In practice, this approach would involve building a density estimator that accounts for the restricted set of options for all possible policies, which is computationally infeasible, especially in high-dimensional exposure spaces.
We would then use these individualized densities to calculate the new exposure levels for each person under the restriction, which would require additional data and assumptions about how preferences change. This complexity makes it challenging to model alternative policies without strong assumptions or additional information.
For reasons of interpretability, the frequency of binarizing exposures in the literature (with the aforementioned implicit assumptions), and the ease of using existing tools for estimation, we choose to estimate a policy under the assumption of relative self-selection.
In most applications, it is not known a priori which region should be set. For example, we may not know how various chemicals or drugs interact and how to set safe limits for all of them. Therefore, itself is, in practice, something that should be estimated to optimize some objective, such as minimizing the expected outcome. However, for the purposes of establishing our theory, we first consider as known and fixed. We then show how we can choose what policy to enact (i.e., choose ) while also unbiasedly estimating its effect.
We first discuss the assumptions necessary for the statistical quantity estimable from the sample data to have causal interpretations, then we move on to discuss how can be determined.
Identification and causal assumptions
2.4
Our target parameter is defined in terms of the observable distribution and does not represent a causal quantity without additional assumptions. To add a causal interpretation, we define the causal ARE as
where with as defined above denoting the counterfactual outcome if exposure were restricted to while preserving relative per-covariate-stratum preferences. Under the following assumptions, :
- Consistency: If , then .
- Conditional Exchangeability (No Unmeasured Confounding): .
- Positivity: For all in the support of .
Putting these together:
Hence,
Therefore, under these assumptions, the causal attributable regional effect is identified by the observable quantity . The remainder of this manuscript will focus on estimating from the observed data in a manner that is both efficient and robust to model misspecification.
The conditional exchangeability assumption asserts that, within levels of , the potential outcomes are independent of the exposure . This implies there are no unmeasured confounders. The positivity assumption ensures that all exposure levels and covariate strata are represented in the data, which is critical for accurate effect estimation.
By satisfying these conditions, we can identify the causal ARE from the observable data. Our focus is on obtaining the observable ARE efficiently without additional assumptions such as linearity. Although our identification assumptions may not always hold in all applications, we aim to eliminate model misspecification bias and minimize random variation.
Estimating ARE with TMLE
3
We provide below a high-level summary of the TMLE procedure. For full technical details of the fluctuation model, the offset, and derivation of the influence function-based standard errors, see [11, 12], as these are beyond the scope of the present work.
In the previous sections, we established that the causal ARE is equivalent to the observable ARE under standard identification assumptions. Therefore, to estimate it, we need to: (1) create a new binary random variable and (2) proceed as if we were estimating the average counterfactual effect from the observational data structure .
We can adapt techniques for estimating the ATE to construct ARE estimators that offer unbiasedness (assuming no bias from potential violations of identification assumptions) and efficiency. Both Augmented Inverse Probability Weighting (AIPW) and Targeted Maximum Likelihood Estimation (TMLE) are suitable methods when used with machine learning and cross-fitting. Although they often produce similar results, TMLE has been found to perform more efficiently with smaller samples [11, 12], making it a generally preferable approach.
A comprehensive analysis by Li et al. [16] using ten different nutrition intervention studies showed that TMLE, especially in its cross-validated form (CV-TMLE), consistently provided robust and efficient estimates across various realistic simulation scenarios. The study concluded that the additional layer of cross-validation helps avoid unintentional over-fitting of nuisance parameter functionals, leading to more reliable inferences compared to other estimators. This reinforces the advantage of TMLE in practical applications, emphasizing its superior performance in maintaining efficiency and robustness in finite samples. Therefore, for estimating our data-adaptively identified region, we use the CV-TMLE approach.
The TMLE estimator is inspired by the fact that if we knew the true conditional mean , we could estimate the ARE with the empirical average . Of course, we do not know , but we can estimate it by regressing the outcome on the exposure and the covariates . However, in high-dimensional or nonparametric settings, the raw plug-in estimator can exhibit persistent bias that does not vanish asymptotically without additional targeting steps. TMLE corrects this bias by updating the initial regression fits in a way that aligns estimates with the parameter of interest. While we focus on the targeted-learning (TMLE) update, it is worth noting that the one-step estimator – formed by adding the efficient influence function to an initial plug-in fit – offers the same first-order bias reduction; in small samples, however, TMLE’s fluctuation step often yields slightly lower variance [16].
The process is as follows:
- Use cross-validated ensembles of machine learning algorithms (a “super learner”) to generate estimates of the conditional mean of treatment: (i.e., propensity score) and outcome: .
- Perform a TMLE update to adjust using the estimated propensity score , resulting in a targeted estimate .
- Compute the plug-in estimate using the targeted model: .
An estimated standard error for is given by the empirical variance of the efficient influence function evaluated at the estimated nuisance parameters.
To obtain these estimates, we need only to specify the ensemble of machine learning algorithms used to estimate the propensity and initial outcome regressions and . Theoretical guarantees hold as long as a sufficiently rich library is chosen. To estimate the ARE, we must also specify the region so that we can compute our binary “exposure” variable . This is the focus of the next section.
Finding a good exposure region
4
Our target parameter depends on the region to which we restrict the exposures. When such a region is not already provided (e.g., there are no existing thresholds for a multivariate exposure), it is natural to use the data to discover a region that would optimize population outcomes. Formally, we seek
where denotes the set of all admissible regions under consideration. In principle, one might consider all measurable subsets of , but such a search is computationally infeasible. Instead, we typically restrict to a family of axis-aligned hyper-rectangles, ensuring that each can be expressed via thresholds on the exposure coordinates (e.g., for one or more variables). This restriction not only makes the search problem tractable but also improves interpretability of the resulting threshold-based policy.
When searching over these regions, we also want to maintain the positivity assumption, which requires that is bounded away from 0 and 1 for all covariate values in the support of . This helps avoid instability or infinite variance in the estimates.
Even with these axis-aligned constraints, estimating the “oracle” region efficiently is highly non-trivial. In principle, one would have to compute plug-in estimates for every , which quickly becomes infeasible in moderate to large dimensions. To strike a balance between flexibility and efficiency, we propose a greedy recursive partitioning algorithm that builds a piecewise-constant approximation of the optimal region. At each step, the algorithm only pursues new splits if the estimated conditional probability of being in the proposed subregion remains bounded above and below , thereby enforcing the positivity requirement.
Moreover, we note that additional constraints can be imposed to prevent degenerate cases (e.g., single-point solutions when has a unique minimum). In the univariate case, for example, attains a global minimum at , so is not amenable to standard causal inference due to zero support. Our positivity restrictions circumvent such extremes, effectively ruling out set(s) that occur with probability zero or nearly zero.
The next subsection details how we implement this recursive partitioning scheme to approximate from the observed data.
Targeted decision trees
4.1
We introduce a novel decision tree algorithm developed to approximate the oracle parameter. This parameter, denoted as
represents the region that minimizes the expected outcome for a given set of covariates . Our approach is tailored to meet several key criteria: computational efficiency, interpretability, and implicit regularization to avoid overly granular and statistically insignificant regions.
Implicit regularization via split criteria
4.1.1
In this context, “implicit regularization” refers to the fact that new splits in the decision tree are only made when certain criteria are met: (i) a minimum node size is enforced (so that each child node contains sufficient observations), (ii) positivity constraints discard potential splits with near-zero probability of receiving treatment ( ), and (iii) a -value threshold ensures that each proposed split must yield a statistically meaningful improvement in the targeted parameter of interest. Consequently, the algorithm cannot continue subdividing the data unless it finds evidence of a substantial change in estimated average outcome. Thus, without requiring additional pruning or penalization, the tree is prevented from growing excessively and carving out tiny regions that might overfit the data.
Partitioning procedure
4.1.2
The core of our method is a regression tree that optimizes a simple plug-in estimator for the policy effect of a given axis-aligned rectangular region. This is based on using Random Forest or a similar straightforward model for nuisance parameter estimation paired with targeted learning. Our decision tree is constructed to search for the minimum (or maximum) region using this plug-in estimator, greedily evaluating splits in the exposure variables and selecting the region that minimizes (or maximizes) the estimated average outcome in the newly formed regions. In Section 5.1, we detail how statistical tests on the estimated causal quantity filter each split, naturally inhibiting excessive branching of the tree and promoting transparent, interpretable thresholds in multivariate exposure spaces.
Positivity and practical diagnostics
4.2
Positivity is a fundamental requirement for identification of causal effects, ensuring that every relevant subregion occurs with nontrivial probability across the covariate support. In practice, certain subpopulations may rarely (or never) appear with , leading to sparse data and large variance if one attempts estimation there. Our algorithm guards against such issues by discarding (or merging) any partitions that yield near-zero probabilities for some stratum. Specifically, if the empirical probability dips below a user-specified in that sub-node, we refrain from splitting on that cutpoint.
To implement this positivity check, we monitor sample sizes and empirical probabilities in each node as the tree grows. If a node’s effective cell counts become very small in some covariate strata, we deem that region unfit for stable estimation. Although this may lead to a slightly less aggressive search for the “best” threshold, it ensures that the final subregion remains well-supported by the data. From a causal standpoint, if certain individuals in never fall into , no statistical procedure can reliably learn the counterfactual outcome there.
Empirically, we recommend choosing in the range [0.001, 0.05], depending on sample size and whether more permissive or more conservative splits are appropriate. If is too large, the tree may under-split; if is too small, it may keep pursuing splits in highly sparse regions, risking unstable or extrapolative estimates. We also encourage a minimum node-size restriction (e.g. 10, 20, or more) to reinforce these positivity checks. Together, these diagnostics help maintain robustness and interpretability in real data settings.
Algorithm overview
4.3
Algorithm 1 outlines our recursive partitioning procedure. Below, we summarize its five main phases:
Partitioning criterion phase
4.3.1
For each exposure variable , the algorithm considers a set of potential thresholds , taken either from unique observed values (possibly rounded or binned) or from predefined domain knowledge (e.g. official safety cut points). In other words, we enumerate all candidate splits for all .
Debiasing with TMLE
4.3.2
For each candidate split, we define and use machine learning to obtain initial estimates of and (i.e., the mean outcome for vs. ). We then apply Targeted Maximum Likelihood Estimation (TMLE) to update these fits, removing asymptotic bias in the conditional mean estimates.
Significance testing
4.3.3
Next, we compute the difference in mean outcome between each child node and the parent node, along with its -value (using the TMLE influence function). If the -value lies below a user-specified significance level , we consider that split valid. This step ensures that any further partitioning reflects a meaningful shift in the causal parameter of interest. This helps find meaningful regions in finite samples but becomes less stringent as sample size increases and significance is easier to attain.
Optimal split selection
4.3.4
Among all valid splits, we select the one yielding the largest improvement in outcome in the desired direction (minimizing or maximizing). If no valid splits pass the positivity check (i.e. outside ) or fail significance, the node becomes a leaf.
Recursive partitioning
4.3.5
We continue splitting each child node until reaching the maximum tree depth or until no further splits improve the outcome. Ultimately, each path from the root to a leaf defines a subregion in the exposure space whose average outcome is estimated under relative self-selection.
Algorithm 1:: Recursive Partitioning Decision Tree with TMLE.
Choosing the maximum tree depth dmax
4.4
Depth controls a three-way trade-off: (i) interpretability – every extra split adds another Boolean clause; (ii) sampling variability – smaller leaves inflate variance and bias; (iii) empirical positivity – deep trees more easily violate the lower-bound constraint.
Practical rule of thumb.
For mixtures with ≤10 exposures a depth of 2–3 almost always exhausts the signal while keeping rules readable. If , begin with and increase only when the cross-validated risk (Section 6) improves. Analysts needing additional assurance may grid-search in an outer CV loop; the computational cost is modest because trees remain shallow.
Consistency check.
Large fold-to-fold disagreement in the selected interaction pattern usually indicates the depth is too large (or too small) for the sample size; reducing by one typically restores stability.
Positioning our causal decision tree in the literature
5
Significance-filtering splitting criterion
5.1
In classical decision tree frameworks (e.g., CART; [17]), splits typically aim to optimize predictive performance – such as minimizing within-node variance – without explicit consideration of a causal parameter. By contrast, our approach centers on identifying threshold-based subregions that meaningfully shift the policy-relevant attributable regional effect (ARE). To accomplish this, we evaluate each proposed split in terms of the child node’s TMLE-based difference from the parent node, then apply a -value threshold to ensure the difference is statistically significant. This procedure is reminiscent of the test-based splitting used in “conditional inference trees” [18], though we combine it with a targeted learning framework tailored to causal parameters rather than predictive error. Because our test statistic compares directly against the parent node’s estimate of the same semiparametric quantity, it offers a principled basis for discarding weak or spurious splits, thus guiding the tree expansion toward subregions that truly deviate in the estimated intervention effect. In effect, we only partition further when robust evidence suggests a given subregion alters the average outcome in a manner consistent with our oracle parameter of interest. This safeguards against overfitting and preserves interpretability, as each split directly reflects a significant change in the policy-based target rather than mere noise in the predictive fit.
Relation to honest trees and causal forests
5.2
The “honest” tree framework of Athey and Imbens [19] and the causal forest approach of Wager and Athey [20] both rely on rigorous sample-splitting to mitigate bias when estimating heterogeneous treatment effects in -space. In particular, honest trees separate the data used to build (or select) partitions from the data used to estimate treatment effects in each leaf. Our cross-validated procedure likewise prevents reusing the same observations for both partition discovery and final effect estimation.
Despite these conceptual parallels, there are two key distinctions in our method:
- Focus on Exposure Thresholds. Rather than identifying subpopulations of that exhibit differential responses, we search for threshold-based constraints on that globally optimize a population-level objective. This shift reflects our policy-oriented parameter: we seek a single region that would hypothetically improve outcomes if everyone were forced to lie within it, subject to positivity. By contrast, honest trees and causal forests typically aim to find subgroups in that have distinct conditional average treatment effects for a binary exposure.
- TMLE-Driven Significance. We explicitly employ TMLE (and an associated significance filter) at each split to assess changes in our policy-based causal quantity. In causal forests, each leaf often provides a local average treatment effect, whereas our method seeks to discover a subregion for a single intervention that (globally) minimizes or maximizes the outcome. Although this divergence in target parameters alters the splitting logic, both approaches share the concept of honest partitioning: the data used to define the partition must be distinct from the data used to estimate the effect in that partition, mitigating overfitting bias.
K-fold cross-estimation
6
As discussed, the identification of interaction regions and the estimation of ARE requires a data partitioning strategy that mitigates bias. We employ a K-fold cross-estimation technique that ensures the asymptotic properties of our estimators without reliance on additional assumptions. This involves dividing the data set into complementary estimation ( ) and parameter-generating ( ) samples, the latter being utilized to derive exposure regions and train nuisance parameters essential for the TMLE update. For each fold, we determine the exposure thresholds using and, with the same sample, train our nuisance estimators and . Subsequently, these estimators are applied to to obtain unbiased ARE estimates within the fold.
Pooled TMLE
6.1
Upon completion of the cross-estimation procedure, a pooled TMLE update provides a summary measure of the oracle region target parameter across folds. Specifically, we stack the predictions for each nuisance parameter from the estimation samples and run a pooled TMLE update on the cumulative initial estimates. The resulting average is then used for parameter estimation.
Our substitution estimator, denoted by , approximates the true conditional mean by plugging in the empirical distribution for each observation. The estimator is operationalized via a Super Learner algorithm followed by TMLE, and its cross-validated variant is expressed as
where is the TMLE-updated expectation of the outcome if everyone were exposed to levels within the data-adaptively determined region. The cross-estimation approach not only utilizes the full dataset for variance estimation, resulting in tighter confidence intervals, but also enables the derivation of fold-specific and pooled estimates.
That is, this pooled parameter represents the ARE for the determined maximizing/minimizing region in the exposure space. Of course, the actual regions determined in folds can vary, and thus this acts as an omnibus test, which can be used to evaluate fold-specific results. A significant pooled TMLE ARE for the oracle region can be interpreted as “there is a region in the exposure space where the expected outcome is significantly different compared to the average outcome”. The analyst can then evaluate the fold-specific results to determine what regions make up this oracle estimate. Of course, interpretability of the pooled oracle estimate is reliant on regions in the same sets of exposures that are found across the folds. Otherwise, this pooled estimate allows the analyst to understand if there is generally “signal” in the data for a region or set of regions that collectively differ in expected outcomes compared to the average. This dual presentation allows for the evaluation of variability across folds, offering insight into the stability of the pooled ARE. In particular, when exposure regions exhibit high variability between folds, fold-specific results provide an essential interpretive counterbalance to the pooled estimates.
Theoretical properties of the estimator
7
Thus far, we have introduced the Attributable Regional Effect (ARE) for a subregion of the exposure space, emphasizing that is unknown a priori but can be discovered from the data by threshold-based partitioning (Algorithm 1). We then employ cross-validated TMLE to estimate and infer the causal impact of restricting exposures to that region. This section clarifies why such a data-adaptive procedure, which uses the same dataset to both find and evaluate a subregion, remains valid under mild assumptions. We also discuss the difference between a globally optimal partition search and a more scalable greedy recursive strategy.
Data-adaptive parameters and cross-validated TMLE
7.1
Classical semiparametric inference on treatment effects (e.g., the ATE) focuses on fixed target parameters. Here, by contrast, the parameter
depends on a region that is identified by the data for the purpose of minimizing (or maximizing) the population mean outcome. Specifically, we aim to approximate the “oracle” region
making a data-adaptive target parameter [14]. When is learned with the same sample used for inference, naive estimators can severely overfit, compromising validity.
To address this, we adopt a -fold cross-validation (CV) approach (Section 6), which splits the dataset into folds. For each fold , we use the training sample (everything except fold ) to (i) estimate the nuisance parameters , and (ii) discover a region . We then apply that region and those fits to the held-out data to get an unbiased estimate of . Averaging these fold-specific estimates yields the cross-validated TMLE, which is asymptotically unbiased for under conditions outlined below [11, 14, 21].
Global versus greedy partitioning
7.2
While cross-validation mitigates overfitting bias, the question remains how to search for the optimal region within the exposure space. In principle, one might consider every axis-aligned subregion of – an intractable set in most settings. We therefore highlight two main strategies:
Global search (shallow depth)
7.2.1
If the decision tree depth is small and the exposures are either low-dimensional, discretized, or binned based on some rounding, one can exhaustively enumerate potential splits. Concretely, each exposure coordinate is restricted to a set of candidate thresholds (e.g., unique observed values), and we systematically form all hyperrectangles in up to splits. Evaluating each candidate via a plug-in or TMLE estimate of yields an empirical minimizer, which converges to the true as under standard assumptions (positivity, consistent nuisance estimation, no unmeasured confounders). Recent results show that such “optimal tree” searches can be formulated as mixed-integer programs [22–24], guaranteeing a global solution for shallow depths. However, the complexity of enumerating subregions can grow exponentially in and , making a greedy approach more practical in higher dimensions.
Greedy recursive partitioning
7.2.2
Algorithm 1 instead takes a CART-like strategy [17]: at each node, it selects the split that yields the largest local improvement in outcome (e.g., lowers the conditional mean if minimizing), subject to positivity and statistical significance constraints. This strategy is computationally efficient but can find only a local optimum if there are multiple partitions with similar risk. In practice, when the threshold signal is sufficiently strong, greedy splitting (in small depths) often provides an effective approximation to the global minimizer, especially when combined with cross-fitting or “honest” sample splits [19]. Indeed, we observe empirically in Sections 8 and 9 that the greedy procedure typically recovers meaningful threshold structures.
Optional exhaustive search for the optimal region
7.3
While the aforementioned decision tree algorithm follows a greedy strategy to quickly locate a high-performing subregion, it may identify only a locally optimal path of splits at each node. In some settings, especially with few exposures or a moderate tree depth limit, a more global search may be computationally tractable. To this end, we include an exhaustive search option in CVtreeMLE, designed to guarantee finding the globally best terminal leaf (i.e., the lowest- or highest-mean leaf, depending on min_max) among all valid partitions up to a specified depth.
Algorithmic overview
7.3.1
When exhaustive = TRUE, each node considers every candidate exposure threshold meeting the positivity and -value criteria described earlier (Sections 4–5.1). Rather than picking just the single top-scoring split (as in the greedy approach), the exhaustive mode:
- Branches on all thresholds that both pass the significance test and improve the parent node’s mean outcome in the desired direction (minimum or maximum).
- Recursively applies this branching procedure to each child node, up to the user-specified max_depth.
- Collects all resulting terminal leaves from every branch once no further valid splits can be made.
- Selects the single best leaf among these, measured by the smallest or largest estimated mean outcome (depending on min_max).
Hence, the algorithm produces a globally optimal subregion in the sense that no other leaf in the entire search space (up to max_depth) has a more extreme mean.
Computational considerations
7.3.2
Exhaustively branching on every valid threshold can expand the search tree exponentially, causing runtime to increase rapidly with the number of exposure variables, candidate split points, or allowed tree depth. In practice, exhaustive mode is most appropriate when:
- The dimensionality of the exposure space is relatively small, or the exposures are binned/coarsened sufficiently.
- The desired depth (i.e., the number of sequential splits) is modest, such that the total number of candidate subregions remains manageable.
- The analyst wishes to ensure no globally better region is overlooked by a purely local (greedy) strategy.
Practical implications
7.3.3
In higher-dimensional contexts or when each exposure has many finely spaced potential cutpoints, the branching factor becomes large. Consequently, the greedy search described in Section 4 typically remains far more computationally efficient and, under mild assumptions, converges to an equivalent solution in large samples (cf. Section 7.2). By contrast, the exhaustive procedure can locate the global optimum whenever computational resources permit a full enumeration of possible splits and sub-splits. This dual approach – greedy versus exhaustive – thus offers users the flexibility to balance interpretability, guaranteed optimality, and runtime constraints, depending on the structure and scale of their mixtures data.
Consistency and convergence
7.4
Having defined our data-adaptive procedure for discovering a subregion , we now present theoretical conditions ensuring that it converges to the “oracle” region that optimizes (minimizes or maximizes) the target parameter . Specifically, suppose there exists a true region
and we estimate it via and evaluate . Below, we outline high-level assumptions ensuring in probability.
Theorem 1: (Consistency and Convergence of Data-Adaptive Regions). Let be a family of pathwisedifferentiable target parameters mapping to real values, each with canonical gradient . Assume ( ) is a metric space, and for each we write . Let be estimators of , where is the empirical distribution of an i.i.d. sample from . Suppose:
- Separated Maximum: There is a unique such that
- Glivenko-Cantelli Class of Gradients: is Glivenko-Cantelli so that .
- Uniformly Vanishing Remainders: The estimators are asymptotically linear with influence functions , satisfying
Let be the data-adaptive maximizer of . Then .
Proof Sketch. Because is a strict arg max, it suffices (by van der Vaart’s Argmax Theorem [25, Theorem 5.7]) to show that . We decompose
Label the curly-bracketed difference as . Then
By assumption (ii), . By assumption (iii), . Hence the entire supremum vanishes in probability, ensuring arg . □ □
This argument is theoretical and does not directly apply to our procedure but it sets up some intuition that motivates our choices in finding a target parameter using recursive partitioning. For one, it shows that when a region gives the empirical maximum estimate among all considered regions (and other regularity conditions hold) then selecting it eventually leads to convergence to the appropriate region. This requires us to take the global empirical maximum over regions, which we approximate with a greedy algorithm: this is a trade-off with computational speed.
In terms of regularity conditions, the proof first requires a separated maximum. This condition is more likely to attain when we consider a class of regions that are constrained-this is one reason that we use shallow trees. Another reason is that the Glivenko-Cantelli condition is more easily satisfied when the index set of regions is small. Lastly, the proof requires uniformly vanishing remainders. It is difficult to verify this condition but again keeping the index set small helps us accomplish this.
As our simulations (Section 8) show, even a greedy strategy converges well when signal strength is moderate or strong and sample sizes are reasonably large. The real-data applications (Section 9) illustrate that CVtreeMLE can uncover meaningful threshold structures in more complex settings. Thus, both the theoretical guarantees and empirical results affirm the feasibility and reliability of our data-adaptive approach.
Simulations
8
In this section, we demonstrate using simulations that our approach identifies the correct exposure region that maximizes/minimizes the conditional mean and estimates the correct ARE target parameter built into a data-generating process (DGP) for this region. Henceforth we refer to our method as CVtreeMLE.
Two-dimensional exposure simulations
8.1
We created a squared dose-response relationship between two exposure variables where an interaction occurs between the exposures when each meets a particular threshold value. Specific outcome values were generated for each subspace of the mixture based on split points , but there exists a region with the maximum outcome (the truth that we want). The goal is to determine whether our adaptive target parameter is targeting the region that maximizes/minimizes the conditional mean outcome for the given sample and to evaluate how CVtreeMLE approaches this desired oracle parameter (the true ARE for this region) as the sample size increases.
This DGP has the following characteristics: . are three baseline covariates, . These distributions and values were chosen to represent a study with covariates for age, BMI, and sex.
Our generated exposures were created to represent two chemical exposures quantized into five discrete levels. We sample observations into a 5 × 5 grid based on combinations of two discrete exposure levels with values 1–5. We define a conditional categorical distribution and sample from it. The probabilities are defined using a multinomial logistic model with coefficients drawn from normal distributions.
We assign an outcome to each of these regions based on the main effects and interactions between exposures:
where . This indicates that there is a slightly weaker squared effect for relative to and a strong interaction between the exposures and confounding due to and .
Computing ground truth
8.1.1
In our discrete-exposure simulation, each exposure takes values in a finite set (e.g., {1, 2, 3, 4, 5}). This allows us to enumerate every possible subregion by selecting subsets of these discrete levels for each exposure coordinate. For each candidate subregion , we can compute the adjusted (or counterfactual) expected outcome conditioned on as
where is the true (known) conditional mean in our simulation. By integrating out under the true data-generating distribution , we obtain the population-level outcome under an intervention forcing :
We define the attributable regional effect (ARE) of as
Because the exposure space here is discrete and low-dimensional, we can compute for all candidate and select the *oracle region * that maximizes the adjusted outcome, in this case, the maximizing region was found to be when both exposures are equal to 5. The true ARE for this region was found to be 37.1.
Importantly, in the full population distribution , positivity is well satisfied for every and each candidate . In a finite sample of size , however, some subregions may become sparse (i.e., nearly zero observations for certain -strata), violating empirical positivity. Our tree-based algorithm thus may discard those subregions (or shrink them toward larger sets) to maintain stable estimation. Consequently, the discovered subregion in a small sample might differ slightly from the true , but as increases, the empirical distribution converges to and our data-adaptive procedure recovers the oracle region under standard conditions (see Section 7.2). Thus, we expect to see higher bias and lower coverage when comparing our estimates to ground truth for lower sample sizes which converge to the truth when is large. We also expect to see that the data-adaptive parameter (comparing our estimate to the true estimand when the discovered rule is applied to ), should have good coverage across all sample sizes.
Simulation study with continuous exposures
8.2
In this simulation, we generate a large dataset ( ) in order to (i) create realistic continuous, correlated exposures that driven by baseline covariates and (ii) enforce a known threshold-based effect on the outcome. Specifically:
- Baseline Covariates. We first sample three baseline covariates for each individual:
These represent possible confounding variables typically seen in biomedical contexts. 2. Exposure Generation. We next create two correlated continuous exposures and , each dependent on the covariates ( ). Formally, we specify
and we add a correlation structure via a covariance matrix , set to have correlation 0.5 between and . Concretely, we draw each ( ) using
with . This enforces that and are continuous, correlated random variables, and confounded by the baseline covariates. 3. Rounding. To avoid an explosively large number of unique split points in the decision tree, we round and to one decimal place. This minor binning maintains primarily continuous behavior while still keeping the candidate threshold space tractable for the partitioning algorithm. 4. Outcome Model with Threshold Effects. Finally, we define the outcome such that there is a known threshold-based signal in and , together with direct confounding effects from and . Specifically,
where is small Gaussian noise. In this way, and define the true region of interest for which the outcome is maximized. Moreover, and jointly confound the exposures and outcome because they appear both in the exposures’ linear predictors and directly in . Although only and enter the outcome model, still predicts the exposures. Including a non-confounding covariate lets us verify that CV-TMLE remains unbiased even when irrelevant variables are supplied; omitting would give identical large-sample results.
This data-generating process thus yields a continuous exposure scenario, with built-in correlation and confounding, and a latent threshold-based “oracle” region ( ). In the subsequent analyses, we repeatedly sample smaller -sized subsets (200, 500, 1,000, 2,000) from this large dataset, apply our recursive decision tree and targeted estimation procedures, and evaluate how effectively our method identifies the correct threshold-based region in a realistic continuous-exposure setting.
Null simulation: outcome independent of exposures
8.3
To assess how our proposed method behaves in the absence of any exposure effect, we conducted a simulation where the outcome is strictly independent of the exposures. Specifically, we generated of size from the following data-generating process (DGP):
- Covariates. For each individual , we sample baseline covariates, ( ) where , , and .
- Exposures. We then generate continuous, correlated exposures ( ) that may depend on the covariates , using a linear mean function plus a correlation structure. Concretely, we let
and draw ( ) from a bivariate normal with mean ( , ) and covariance
This ensures some correlation between and , as well as confounding structure whereby influences and . We round each exposure to one decimal place to keep the number of potential split points finite. 3. Outcome (Null). Crucially, the outcome does not depend on . Instead, we define
so that has a mild effect on but there is no direct or indirect relationship between and ( ). Thus, any attempt to discover an “optimal” exposure region should fail except by chance.
Because is generated independently of , the covariates and are not confounders in this design; the estimator would remain consistent were they omitted. We retain them to mimic a realistic analyst who is uncertain which baseline factors are relevant. Once the population is generated, we repeatedly draw smaller samples of size to simulate different data set sizes and run our CVtreeMLE procedure on each subsample. We set a nominal -value threshold (e.g., ) as part of the splitting rule: splits are only retained if they yield a statistically significant improvement in the estimated attributable regional effect (ARE). Under this null DGP, any apparent “benefit” from partitioning the exposure space should be purely due to random noise; hence, we expect most partitions to fail the significance test. Of note, if any one fold returns no region detected the CVtreeMLE algorithm returns “no consistent region found”, this is because if a fold has no region detected then no pooling effects can be estimated. We run this simulation with 2 fold CV and therefore expect a spurious region found in all folds 0.025 % of the time, or basically 0.
Metrics
8.3.1
For each simulated data set, we record:
- Whether the algorithm selects a non-empty region (despite the true effect being zero).
- The fraction of times the CVtreeMLE procedure reports a statistically significant region across all simulation replicates (Type I error rate).
- The average estimated ARE, , for any discovered region, which should be close to zero if the method is well-calibrated.
- Coverage of the 95 % confidence interval around zero, if a region is discovered.
Interpretation
8.3.2
Because our algorithm only deems a region “found” if every cross-validation fold discovers and confirms a significant split, the overall chance of detecting a spurious region in a strict null scenario is approximately , rather than . For example, with ten folds ( ) and , that rate would be , which is far below 5 %. Consequently, when there is truly no exposure effect, we should see much fewer than 5 % of runs returning a discovery. If the observed frequency of “found” regions is notably above , that suggests some residual correlation across folds or potential mis-specification of the selection logic. In any case, large deviations from this (very small) nominal rate would indicate that the split criterion or subsequent inference may be more permissive than intended under strictly null conditions.
Evaluating performance
8.4
To assess the ability of CVtreeMLE to recover an oracle region and accurately estimate the corresponding ARE, we conducted the simulation experiments explained in the previous section. Below, we describe our study design and the metrics used to quantify performance. Additionally, for the discrete case, we also evaluate the performance of CVtreeMLE to estimate the data-adaptive ARE, that is, when the discovered threshold is applied to how much our estimated ARE in that region deviates from the true ARE when the threshold is applied to .
Simulation design
8.4.1
For each sample size (e.g., 200, 500, 1,000, 2,000, 5,000), we replicated the fitting procedure 300 times to get estimates for independent datasets. Each simulation replicate proceeds as follows:
- Generate a Dataset: Sample i.i.d. observations from the DGP.
- Cross-Fitting: Perform -fold cross-validation. In each fold, a training partition estimates the threshold-based region (via our decision tree procedure) and nuisance functions ( ), which are then applied to the validation partition for TMLE.
- Pooled TMLE Estimate: Combine all fold-specific estimates into a pooled TMLE estimator for the ARE, restricted to (the final, combined region).
- Evaluation Against Oracle: Compare to the oracle pair , where denotes the true ARE.
Metrics
8.4.2
Region Identification: We treat and as subsets of the exposure space and compute:
Here, “true positives” means observations correctly classified inside , etc.Absolute Bias and Percent Bias (ARE): For each replicate, let be the estimated ARE and the true ARE. Then:
MSE and Coverage: We let
and compute the empirical 95 % coverage by checking the proportion of confidence intervals that contain .
In the following section, we present the simulation results, illustrating how CVtreeMLE performs under a variety of sample sizes and data-generating scenarios.
Default estimators
8.5
As discussed, CVtreeMLE needs estimators for and . CVtreeMLE has built in default algorithms to be used in a Super Learner [26] that are fast and flexible. These include random forest, general linear models, elastic net, and xgboost. These are used to create Super Learners for and . Users can pass in their own libraries for these nuisance and data-adaptive parameters. For these simulations, we use these default estimators in each Super Learner. Our partitioning algorithm to discover the region was set to have a maximum depth of 3 and a minimum number of observations per leaf to 10. In this simulation we are interested in finding the region with maximum outcome. The package has a “min_max” parameter which we set to “max” to find the region with maximum expected mean outcome. We used the greedy causal tree search algorithm to test if the greedy approach successfully identifies the oracle region in various data generating systems.
Results
8.6
Discrete exposure simulation: CVtreeMLE recovers the oracle region and estimates its effect
8.6.1
Figure 1 presents findings for a discrete-exposure scenario in which there is a true “oracle” subregion (involving an interaction of two exposure variables) that maximizes the outcome under positivity constraints. At lower sample sizes (e.g. ), the algorithm cannot always select the exact oracle region because it must maintain enough positivity for valid inference. In particular, the tree often identifies a nearby, slightly less extreme region with sufficient probability mass. This manifests as higher bias and reduced coverage for both the region classification (higher false-positives/negatives) and the corresponding attributable regional effect (ARE) estimate.
As increases, however, the method converges to the ground-truth subregion, as more samples satisfy the positivity requirement while still capturing the true threshold boundary. In turn, both absolute and percent bias for the estimated ARE diminish to near zero, and coverage rises to 95 %. The classification metrics (accuracy, sensitivity, specificity) likewise demonstrate improvement from moderate levels at to virtually perfect classification by . Put differently, once the tree can pinpoint the oracle threshold within a well-supported subregion, the effect estimates become nearly unbiased, achieving nominal coverage and very small mean-squared error. These results highlight how CVtreeMLE, even with simple greedy splits, recovers the true thresholding regime under realistic positivity constraints, provided the sample size is sufficient to ensure all relevant exposures and interactions appear with nontrivial frequency.
Performance for the data-adaptive rule applied to the true population
8.6.2
Figure 2 illustrates the absolute bias, mean squared error (MSE), and coverage for the ARE under a data-adaptive rule – that is, the region discovered by CVtreeMLE in each sample – applied to the true population . Unlike the “oracle-based” analysis (Section 8.6.1), where we evaluated the effect of a known, exact threshold rule, here we assess how accurately our estimated rule represents the best practical intervention in the limit as grows.
When is small (e.g., ), the estimated ARE for the selected rule deviates more from the true ARE when the threshold boundary is applied to the population, this is due to finite-sample constraints and random sampling variation, leading to higher bias ( ) and an MSE ( ). As increases, however, the discovered data-adaptive region converges to the same policy one would choose with full knowledge of , thereby aligning the estimated ARE with the true population-level counterfactual effect. Accordingly, bias declines by more than an order of magnitude from to , and the MSE drops from 5.03 to 0.4. Coverage is consistently at or close to 95 %. In short, these results confirm that CVtreeMLE not only estimates the correct oracle rule with increasing accuracy, but also yields valid inferences for the target parameter “ARE of the discovered rule” under the true population distribution.
Results for the continuous exposure simulation
8.7
Figure 3 shows the estimation performance for the simulation with two correlated, rounded continuous exposures . We considered sample sizes , each replicated 300 times. When is small (e.g., ), the procedure does not always discover the true threshold region ( ), leading to higher bias and slightly lower coverage. As grows, however, the estimated region converges to the oracle region, dramatically reducing both the absolute and percent bias.
In particular, absolute bias falls from roughly 0.20 at to near zero by . The mean squared error (MSE) decreases quickly (from about 0.219 at to 0.01 at ), reflecting both variance reduction and bias elimination. Coverage begins just under the nominal 95 % at and stabilizes close to or just above 95 % for .
Finally, the classification metrics illustrate how effectively the algorithm identifies whether each observation’s exposures lie inside or outside the true region. Specificity is nearly 100 % at all sample sizes, while sensitivity and overall accuracy rise from about 70–85 % at to nearly 100 % by . Taken together, these findings demonstrate that once the threshold region is accurately recovered, the corresponding effect estimates achieve negligible bias, small MSE, and nominal coverage, underscoring the reliable performance of our data-adaptive approach in continuous-exposure settings.
Null simulation results
8.7.1
At sample sizes through , the algorithm reported no discovered region in all (100 %) simulation runs. This reflects the conservativeness of our procedure under the strict null, as the cross-validation criterion requires each fold to find a significant subregion for a global region to be declared. At , about 96 % of runs did not discover a region, of the 4 % that did none excluded zero in the confidence interval. The mean estimated effect in these instances was roughly −0.644, with zero consistently included in all CIs. At a region passed the initial split test in 95 % of replications, yet none of the pooled TMLE estimates were significant (mean ARE = 0.001, 95 % CI [−0.012, 0.014] across 300 runs). Thus all confidence intervals still covered the null, confirming strict control of Type I error.
Interpretation.
These findings confirm that CVtreeMLE remains highly conservative when there is genuinely no relationship between the exposures and the outcome. Even for moderate sample sizes, it typically finds no region or, if a subregion is discovered, its estimated effect is not significantly different from zero. This conservatism is largely a consequence of our cross-validation rule, which declares a region only if every fold independently flags a significant improvement. Hence, under the null, the global false-positive rate is effectively reduced to the order of , making spurious discoveries extremely unlikely.
Applications
9
NIEHS synthetic mixtures
9.1
The NIEHS synthetic mixture dataset (found here on github) is a widely used benchmark for evaluating statistical methods that analyze chemical mixtures. These data can be viewed as originating from a prospective cohort study, where the outcome cannot affect the exposures (as might happen in a cross-sectional design). Correlations between exposures arise from shared sources or modes of exposure. The covariate (a binary variable here) is intended to act as a potential confounder rather than a collider.
Data structure
9.1.1
There are seven continuous exposures, denoted , each of which can influence an endocrine-disruption outcome through either synergistic or antagonistic pathways. Specifically:
- increase (positive coefficients).
- decrease (negative coefficients).
- have no net effect on , but remain correlated with other exposures, making them challenging to discard in a purely statistical screen.
In this synthetic setup, the seven exposures are further grouped by chemical or functional similarities. For instance, ( ) form a cluster, while ( ) form another. Each cluster shows high internal correlation, reflecting plausible biological scenarios (e.g., multiple polychlorinated biphenyl congeners that are chemically related yet differ in toxicity).
Toxicological background
9.1.2
These data exhibit a variety of dose-response patterns and interactions:
- and combine additively to raise .
- competes with or (“competitive antagonism”), partially offsetting their positive effect.
- and can be synergistic (supra-additive), intensifying the increase in .
- and each lower in an additive fashion, while can exhibit “unusual antagonism.”
Such structural assumptions echo real-world toxicology, where chemically related exposures may be correlated and yield complex interactions.
Analysis goal
9.1.3
We consider 500 observations and nine variables (the seven exposures plus and ). Our aim is to apply CVtreeMLE to identify threshold-based subregions of that minimize the outcome . Constraining exposures to these thresholds should, in principle, yield the largest reduction in . We used 10-fold cross-validation and default Super Learner libraries for the nuisance parameters, running the algorithm in parallel to assess computational feasibility.
Fold-specific results
9.1.4
Table 1 shows, for each fold, the discovered subregion associated with the strongest negative attributable regional effect (ARE) on . Most folds (70 %) favored a policy that forces above approximately 1.9–2.0, reflecting ’s substantial negative influence on . In contrast, two folds (20 %) constrained below a threshold (0.3–0.4), consistent with being a driver of higher . Finally, one fold indicated a joint rule and , suggesting an antagonistic interplay among and .
Pooled TMLE results
9.1.5
We then aggregated these fold-specific findings into a pooled TMLE analysis, shown in Table 2. Three subregions consistently emerged:
- (or 2.0), with an average effect of about −4.6;
- , around −4.5;
- A joint rule and , yielding about −4.1.
All are statistically significant, and the slight numerical differences suggest these thresholds have near-equivalent potential for reducing .
Interpretation
9.1.6
Overall, the data-adaptive procedure uncovered multiple threshold policies that each lowers by roughly 4–5 units. Restricting to low levels is intuitive since has a positive effect on . Conversely, requiring to be sufficiently high exploits ’s negative relationship with . The joint rule involving and aligns with their established synergistic relationship built into the data. In practice, regulators or policy analysts might choose among these subregions based on additional criteria – such as feasibility, cost, or tolerable exposure levels – given that all produce similar reductions in the outcome.
Thus, the NIEHS data example illustrates how CVtreeMLE can detect multiple plausible subregions in a complex mixture setting and highlights the interpretability of threshold-based results when exposures interact in realistic ways.
Comparison to existing methods
9.1.7
Quantile g-computation [8], prevalent in environmental epidemiology for mixture analysis, estimates the effects of uniformly increasing exposures by one quantile, based on linear model assumptions. This method quantizes mixture components, summing the linear model’s coefficients to form a summary measure ( ) for joint impact assessment. However, it inherently assumes additive, monotonic exposure-response relationships, overlooking complex, potentially nonlinear interactions typical in mixtures, like in endocrine disrupting compounds. Consequently, this method might not accurately capture the nuanced dynamics of mixed exposures, especially when interactions vary with other variable levels.
We run quantile g-computation on the NIEHS data using 4 quantiles with no interactions to investigate results using this model. The size of the scaled effect (positive direction, sum of positive coefficients) was 6.28 and included and the scaled effect size (negative direction, sum of negative coefficients) was −3.68 and included . Compared to NIEHS ground truth, are incorrectly included in these estimates. However, the positive and negative associations for the other variables are correct. Next, because we expect interactions to exist in the mixture data, we would like to assess for them but the question is which interaction terms to include? Our best guess is to include interaction terms for all exposures. We do this and show results in Table 3.
In Table 3 is the summary measure for the main effects and for interactions. As can be seen, when including all interactions, neither of the estimates are significant. Of course, this is to be expected given the number of parameters in the model and the sample size . However, moving forward with interaction assessment is difficult; if we were to assess for all 2-way interaction of 7 exposures, the number of sets is 21 and with 3-way interactions is 35. We would have to run these many models and then correct for multiple testing. Hopefully, this example shows why mixtures are inherently a data-adaptive problem and why popular methods such as this, although succinct and interpretable, fall short even in a simple synthetic data set.
NHANES data
9.2
We illustrate our method on a publicly available subset of the National Health and Nutrition Examination Survey (NHANES) from 1999 to 2002, focusing on urinary metal exposures and leukocyte telomere length (LTL). Telomere length is often investigated as a biomarker of cellular aging, and there is scientific interest in how various toxic metal exposures may shorten or lengthen telomeres. For concreteness, we include this data in CVtreeMLE’s open-source repository, which comprises 2,510 participants with measured LTL, demographic variables, and nine urinary metals: barium, cadmium, cobalt, cesium, molybdenum, lead, antimony, thallium, and tungsten.
We adjust for potential confounders, including age, gender, race, and select lifestyle variables. Our primary goal is to discover a region that minimizes LTL (i.e., identifies the “worst” combination of exposures).
Fitting strategy
9.2.1
We applied CVtreeMLE with 10-fold cross-validation. In each fold, the algorithm searched the 9-dimensional exposure space for a subregion that yielded the lowest counterfactual LTL when forcing all individuals into that region, subject to positivity constraints, an significance level of 0.05 and minimum node size of 25. A Super Learner ensemble (including GLMs and random forests) was used to estimate the nuisance functions and . Afterward, we pooled the fold-specific targeted estimates to obtain an overall Attributable Regional Effect (ARE).
Fold-specific results
9.2.2
Table 4 shows the estimates of the ARE and the discovered region in each fold. Notably, CVtreeMLE consistently selected a threshold on molybdenum (ranging between roughly 96.7 and 112.4) as the region that minimizes LTL. No fold identified a meaningful threshold interaction involving other metals. Each fold-specific point estimate was near zero, with confidence intervals consistently covering zero, implying no significant effect, although the fact molybdenum being selected as the minimizer for all folds suggest there is some positive association signal for this exposure.
Pooled ARE estimate
9.2.3
We then pooled all fold-specific estimates via cross-validated TMLE. As summarized in Table 5, restricting molybdenum to a threshold near 103.8 (the average discovered cut point) yields a pooled ARE estimate of −0.002, suggesting a minimal decrease in average LTL. The 95 % confidence interval (−0.006, 0.003) covers zero, indicating no statistically significant difference from the observed mean telomere length.
Interpretation
9.2.4
Our analysis did not reveal any strong evidence that restricting multiple metal exposures simultaneously would meaningfully decrease LTL. Instead, across folds, a single threshold on molybdenum emerged as the candidate “lowest LTL” region. However, the effect size is small, and the confidence intervals comfortably include zero.
These findings may diverge from some prior studies suggesting that molybdenum could affect telomere attrition. Differences might arise from population characteristics, the cross-sectional nature of this study, sample sizes, or unmeasured confounding. From a mixtures perspective, it is noteworthy that no other metal (e.g., cadmium, lead, barium) had a consistently discovered threshold, indicating that in this data set, limiting molybdenum alone provided the best – though statistically insignificant – candidate for reducing telomere length.
Overall, CVtreeMLE systematically searched a 9-dimensional exposure space using data-adaptive thresholds, returning an easily interpretable subregion and valid inference. Despite the absence of a strong signal here, this example highlights how the procedure can rigorously explore potential mixture effects in real-world environmental data.
Discussion
10
This paper introduces a data-adaptive procedure for identifying threshold-based subregions in high-dimensional exposure spaces and estimating the effects of hypothetical policies that restrict populations to those subregions. By defining the attributable regional effect (ARE) as a policy-oriented causal parameter and combining recursive partitioning with cross-validated targeted maximum likelihood estimation (CV-TMLE), we can discover interpretable “cut points” in multivariate exposures while maintaining statistical rigor.
Key contributions
10.1
Our method relaxes many of the strong assumptions commonly employed in mixture analysis. Unlike regression-based approaches such as weighted quantile sum (WQS) regression [8] or Bayesian kernel machine regression (BKMR) [10], our approach directly targets the effect of restricting exposures to data-determined subregions. In doing so, we leverage data-adaptive threshold discovery – ensuring that critical exposure boundaries reflect observed empirical patterns rather than a priori specifications. Moreover, our significance filtering at each split (Section 5.1) naturally guards against overfitting, while cross-validation (Section 6) yields valid inference despite reusing data for threshold selection and effect estimation.
Practical relevance for policy
10.2
From a policy standpoint, the discovered region can be interpreted as a candidate set of allowable exposures (or a “safety threshold”) that the population could be forced or encouraged to adhere to. By preserving relative selection densities within that region, we minimize modeling assumptions about how individuals might shift their exposure choices. Although such self-selection may not fully mirror how real regulations operate (e.g., individuals clustering below a boundary), it offers a transparent starting point for quantifying public-health gains. As our simulations and examples demonstrate, even simple bounding thresholds in multiple exposures can uncover meaningful interactions (e.g., synergy between and in the NIEHS data) or harmful univariate thresholds (molybdenum in the NHANES data).
Limitations and future directions
10.3
While our approach shows promise, several challenges remain:
- Fold-to-Fold Variability in Thresholds: If different cross-validation folds discover substantially different partitions, this suggests weaker underlying signals or high sensitivity to sampling variation. The responsibility lies with the practitioner to report all fold findings, thereby being transparent with consistency rather than picking folds to report that match preconceived notions.
- Positivity Constraints: By design, we discard splits that lead to near-zero probability for certain covariate strata. While this mitigates overfitting, it also excludes extremely sparse exposures that might be biologically relevant. More adaptive positivity thresholds (varying by sample size or exposure dimension) and advanced smoothing strategies may offer improvements.
- High-Dimensional Scaling: In settings with tens or hundreds of exposures, enumerating all candidate cut points is computationally onerous. Potential solutions include domain-based grouping (binning or combining chemically similar exposures), dimension reduction, or hierarchical Bayesian priors tailored to known toxicologic relationships. Future work may explore using more advanced search algorithm like neural network guided monte-carlo tree search algorithms [27–29].
- Alternative Policy Interpretations: We rely on the assumption of relative self-selection to define post-intervention exposures, yet real-world policies might concentrate populations near a boundary or reconfigure entire distributions. Incorporating domain knowledge of how exposures shift (e.g., partial or gradient-based compliance) stands as an important frontier for more realistic policy modeling.
Conclusions
10.4
Overall, this work adds to a growing literature on data-adaptive causal inference in environmental epidemiology. Our CVtreeMLE framework blends flexible machine learning and valid semiparametric inference with an explicitly policy-focused parameter: the attributable regional effect. Through theoretical analysis, simulations, and applications to NIEHS synthetic mixtures and NHANES metal data, we demonstrate that our method can discover threshold-based multi-exposure subsets that meaningfully alter population-level outcomes. Methodological enhancements, including stability diagnostics and algorithms that handle extremely high-dimensional exposures, promise to further strengthen the real-world applicability of threshold-based exposure interventions. We anticipate that such developments, combined with domain-specific insights, will make data-adaptive threshold inference ever more useful for guiding public health and regulatory decisions.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1Landrigan PJ, Goldman LR. Children’s health and the environment: public health implications of exposures to neurotoxic chemicals in early childhood. Pediatrics 2006;118:259–67.
- 2Vrijheid M, Slama R, van den Brandt PA. Mixtures of environmental exposures and health: challenges and opportunities for environmental epidemiology. Int J Environ Res Publ Health 2009;6:205–23.
- 3Kortenkamp A Low-dose mixture effects of endocrine disrupters: implications for risk assessment and human health. Environ Health Perspect 2014;122:A 10–15.24380927 10.1289/ehp.1307701 PMC 3888580 · doi ↗ · pubmed ↗
- 4Braun JM, Gennings C. The emerging science of environmental mixtures and the future of risk assessment. Environ Health Perspect 2018; 126:128–34.
- 5National Research Council. Cumulative environmental risks: building an integrated framework to better inform decision-making. Washington, DC: National Academies Press; 2018.
- 6NRC. Phthalates and cumulative risk assessment: the tasks ahead. Washington, DC: National Academies Press; 2008.
- 7Carlin DJ, Rider CV, Woychik R, Birnbaum LS. Unraveling the health effects of environmental mixtures: an niehs priority. Environ Health Perspect 2013;121:A 6–8.23409283 10.1289/ehp.1206182 PMC 3553446 · doi ↗ · pubmed ↗
- 8Keil AP, Buckley JP, O’Brien KM, Ferguson KK, Zhao S, White AJ. A quantile-based g-computation approach to addressing the effects of exposure mixtures. ar Xiv 2019;128:1–10.