Bridging binarization: causal inference with dichotomized continuous exposures
Kaitlyn Lee, Alan Hubbard, Alejandro Schuler

TL;DR
This paper shows that dichotomizing continuous exposures can be a valid method for causal inference, under certain assumptions, and introduces a new parameter for better interpretation.
Contribution
The paper introduces a new target parameter for causal inference with dichotomized exposures and clarifies the assumptions of binarization.
Findings
Binarization is statistically valid under the assumption of preserved relative self-selection.
A new target parameter is introduced that considers the observed world as a benchmark.
Simulation and real-world applications demonstrate the method's implications and assumptions.
Abstract
The average treatment effect (ATE) is a common parameter estimated in causal inference literature, but it is only defined for binary exposures. Thus, despite concerns raised by some researchers, many studies seeking to estimate the causal effect of a continuous exposure create a new binary exposure variable by dichotomizing the continuous values into two categories. In this paper, we affirm binarization as a statistically valid method for answering causal questions about continuous exposures by showing the equivalence between the binarized ATE and the difference in the average outcomes of two specific modified treatment policies. These policies impose cut-offs corresponding to the binarized exposure variable and assume preservation of relative self-selection. Relative self-selection is the ratio of the probability density of an individual having an exposure equal to one value of the…
Genes, proteins, chemicals, diseases, species, mutations and cell lines named across the full text — each resolved to its canonical identifier and authoritative record.
Click any figure to enlarge with its caption.
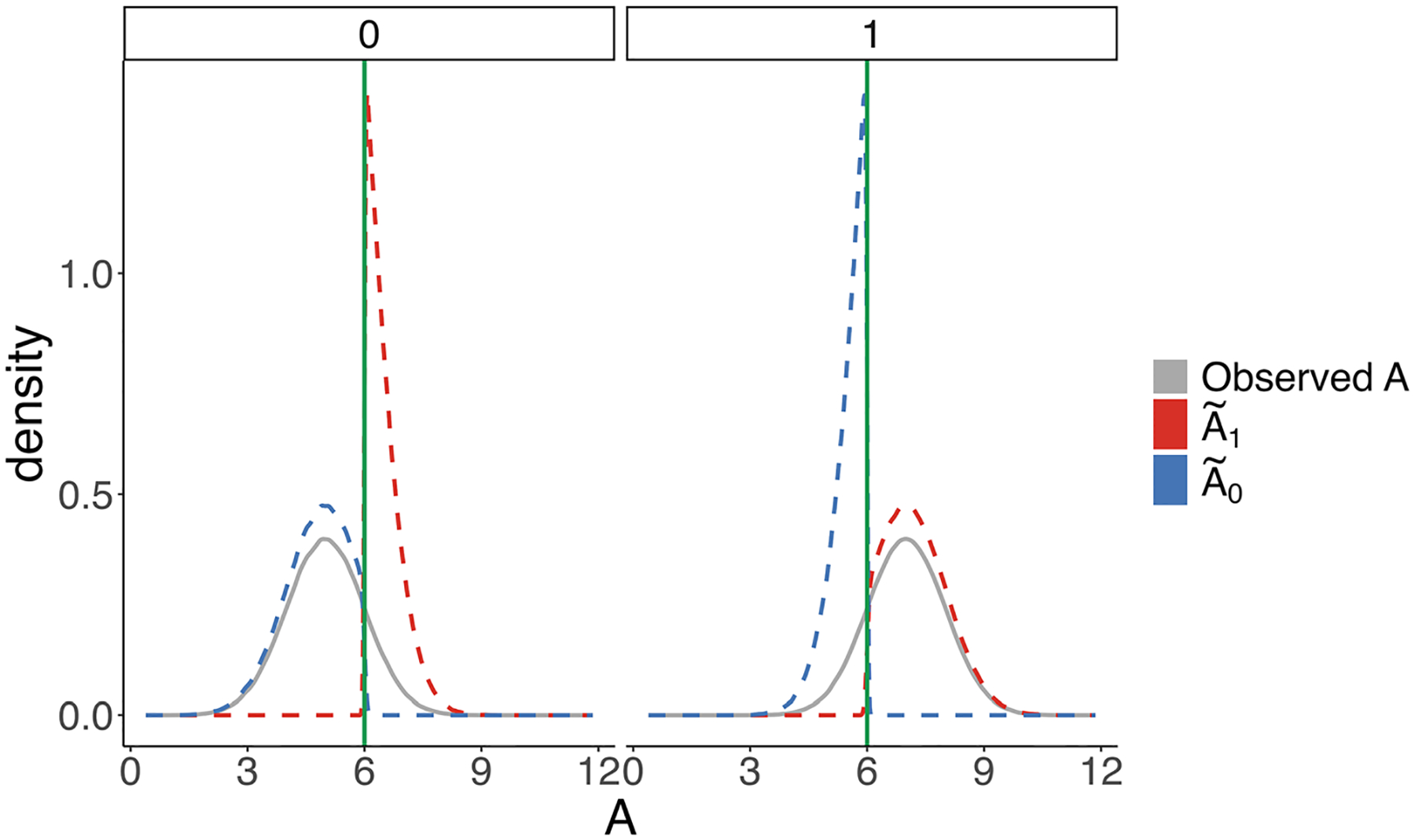 Figure 1
Figure 1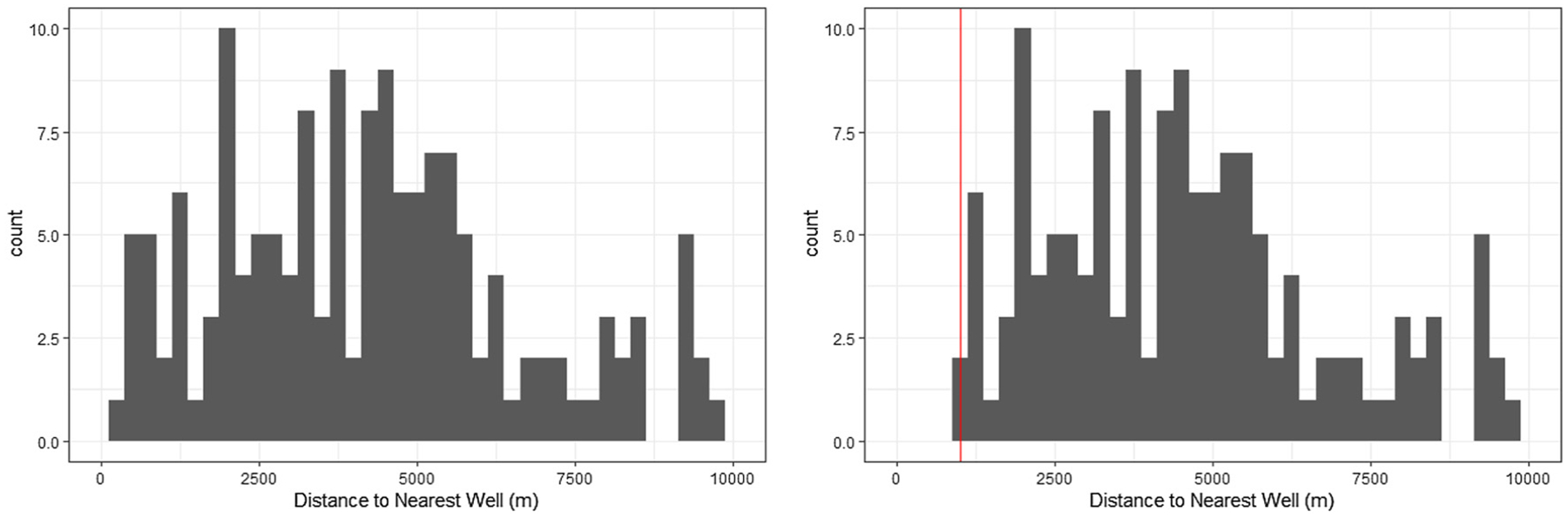 Figure 2
Figure 2Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsAdvanced Causal Inference Techniques
Introduction
1
Causal inference methodology historically has considered settings with binary exposure variables. For example, Neyman focused on estimating the average treatment effect (ATE), which compares the average outcome under treatment to the average outcome under no treatment [1]. The ATE continues to be a popular target parameter in causal literature focused on binary exposures. However, across a variety of disciplines, there is growing interest in quantifying the effects of continuous exposures. For example, recent research has explored the causal effects of income inequality [2], alcohol consumption [3], and pesticide use [4].
The ATE is not defined for continuous exposures; however, one popular method of quantifying the causal effect of a continuous exposure is to binarize or dichotomize the exposure variable, which enables researchers to target a parameter somewhat akin to the ATE. This method involves creating a new dummy variable that equals 1 when the exposure of interest is within some range of values and 0 otherwise. Then, researchers calculate the ATE using this new dummy variable as the exposure. We term this estimand the “binarized ATE” (BATE).
An example of this practice can be found in a 2015 paper by Hu et al., where the authors investigated the relationship between pesticide exposure and health effects in Chinese farmers [4]. Individuals were divided into two groups: those with relatively high pesticide exposure levels (more than 50 pesticide applications in 2009–2011) and those with relatively low pesticide exposure levels (less than 50 pesticide applications in the same three year period). The researchers implemented a regression estimator including baseline covariates. They found evidence suggestive of some causal relationship between “high” versus “low” levels of pesticide use and abnormal health test results (including blood tests, nerve conduction studies, and neurological exams).
There are numerous other examples of researchers binarizing continuous exposures in public health contexts. For example, Hu et al. investigated the relationship between being in a “low-risk” group versus a “high-risk” group and risk of type 2 diabetes in women [5]. Wu et al. calculated the effect of air pollution and mortality [6]. In addition, researchers employ the binarized ATE across the social sciences, like in political science and economics. Kurtz and Lauretig investigated the effect of economic liberalization on political protest activity [7]. Carneiro, Lokshin, and Umapathi looked at the effect of increased schooling on income in Indonesia [8].
In this paper, we show that the BATE is the same as the difference in average outcomes under two related modified treatment policies (MTPs). MTPs are an example of a population-level intervention in which one considers a counterfactual world in which changes to underlying distributions of the exposure of interest are considered [9]. In particular, MTPs are policies that change the underlying distribution of the exposure variable in a population such that the new distribution depends on covariates as well as an individual’s natural value of exposure, as defined by Haneuse and Rotnitzky [10].
Utilizing this framework, we show that the binarized ATE is equivalent to the difference in expected outcome under two policies that impose cut-offs corresponding to the cut-offs used to generate the binarized exposure variable and assume preservation of relative self-selection. Relative self-selection is the ratio of the probability density of an individual having an exposure equal to one value of the continuous exposure variable versus another. The policies assume that, for any two values of the exposure variable with non-zero probability density after the cut-off, this ratio will remain unchanged. Equivalently, we can also think of the resulting distribution of exposure as having the distribution of conditional on truncating the exposure to respect the imposed cut-off.
This equivalence addresses many of the common critiques put forward by methods researchers regarding binarization in causal inference. There have been textbook chapters written on epidemiological methods heavily dissuading researchers from categorizing/binarizing exposure variables [11]. Some researchers contend that binarization violates the Stable Unit Treatment Values Assumption (SUTVA), an assumption that some researchers make when prescribing a causal meaning to their statistical estimate of the ATE. In particular, one component of SUTVA is that there are no multiple versions of treatment [12]. VanderWeele et al. argue that binarization violates this assumption as encoding a continuous exposure into a binary one implies that there are several values of exposure embedded in one value of the binary exposure variable [13, 14]. Rothman et al. make a similar argument, stating that such “open-ended categories,” like cut-offs, are harmful because one category can contain many different exposure values or confounder effects [11]. However, the proposed MTPs circumvent these issues by defining the precise mechanism by which the distribution of the exposure changes. Specifically, one can re-write the average outcome under two seemingly deterministic binarized exposure levels in terms of the average outcomes under two policies that change the underlying distribution of exposure in a fully specified way. In addition to this critique, Bennette and Vickers contend that binarization assumes “homogeneity of risk within categories” [15]. However, the application of MTPs in this paper does not imply that the effect is the same for everyone; rather, in thinking about the effect of a modified treatment policy at a population level, we are considering a causal estimand that is an average of the exposure effect across the distribution of the exposure of interest in the target population.
This type of dichotomization was discussed by Stitelman et al. [16]. These interventions were also considered by Díaz and van der Laan as one example of an intervention which imposes some type of cut-off on the distribution of exposure [17]. McCoy et al. introduced the “average regional effect,” which considers how the average outcome changes under modified treatment policies which preserve relative self-selection [18]. Rose and Shem-Tov consider binarization in the context of noncompliance [19]. Additionally, the binarized ATE was considered in the context of non-random missingness by van der Laan et al. [20]. The estimand in ref. [20] reduces to the estimand we present when assuming missingness at random. In this paper, we aim to provide a thorough and detailed treatment of the assumptions underlying the BATE, as well as examples of when the assumptions may be more or less plausible, to provide practitioners with more clarity regarding whether the BATE is the answer to their particular research question. We also present a novel estimand, the causal attributable effect of binarization (CAB), which extends the additive risk estimand considered in ref. [16]. We argue that this estimand answers a more relevant causal question than the BATE as it compares the average outcome under one MTP to that in the observed world. In addition, we provide details for regression, inverse probability weighted, and augmented inverse probability weighted estimators that, under certain conditions outlined, will consistently estimate the BATE and the CAB. To our knowledge, these estimators and their underlying assumptions have not been discussed in the context of binarization.
The rest of the paper will proceed as follows. In Section 2, we present the proof of equivalence between the BATE and the difference in average outcome of modified treatment polices that restrict the value of the exposure variable while preserving relative self-selection. We also introduce the CAB and discuss its relevance. Finally, we introduce regression adjustment-based, inverse probability weighting, and augmented inverse probability weighting estimators for the two estimands. Section 3 follows with a simulation study in which we implement the regression, inverse probability weighting, and augmented inverse probability weighting estimators for the BATE and CAB. In Section 4, we apply the method of binarization to evaluate the effect of proximity to oil and gas wells during gestation on the probability of giving birth to an underweight newborn in the state of California. Lastly, in Section 5, we provide a discussion of the results.
Methods
2
Setup and notation
2.1
Consider an observational study with baseline confounders with , a single exposure (possibly continuous) , and a single outcome . Let the observed data be . Let and denote the support of the exposure and confounders, respectively.
We denote the data generating distribution as for the observed data . Assume that are i.i.d. draws of . Let our statistical target parameter be a mapping from our statistical model to the parameter space (in this case, real line). Then, the estimand can be thought of as a function of different distributions where gives us our true estimand of interest.
Each set of observed values can be fully described using an empirical probability distribution that puts point mass at each observation . Each draw from generates a new ; therefore, is also a random distribution. We can now define our statistical estimator as a function of our observed data that maps to the parameter space . Since is random, is also random, meaning that each set of observed data can correspond to a different value of the estimator.
Let be a subset of and be the complement of . Consider a binary exposure variable . An individual with a natural value of exposure is assigned a value of when and assigned when . In the traditional binarization setting, is some interval on (for example, when , and when , for some ).
As is standard practice in causal inference literature, we will adopt the potential outcome framework [21]. The framework assumes that, for each individual and each permissible value of exposure , there exists a counterfactual outcome corresponding to the value that the outcome would have taken in a world in which the exposure were deterministically set to . The observed outcome is .
Modified treatment policies
2.2
In causal inference, modified treatment policies (MTPs) are used to consider counterfactual worlds in which the distribution of the exposure conditional on confounders is changed in some way [10, 17]. The original measured exposure is called the “observed” or “status-quo” exposure, as it corresponds to the value of exposure an individual received in the observed world, prior to any intervention. We use to denote the post-intervention exposure, which can depend on and . By considering changes in the underlying population distribution of the exposure, MTPs allow for stochastic interventions in addition to more traditional deterministic interventions. These types of interventions can therefore represent counterfactual worlds that are more realistic in modeling the type of behaviors that researchers may expect in a given population given a particular policy. One example of a MTP is a shift intervention, where researchers consider a policy where individuals with an observed exposure value would instead have a shifted exposure value for some [17]. Estimation strategies have been studied extensively for MTPs. For a comprehensive overview of modified treatment policies and nonparametric estimation strategies of causal effects, we refer the reader to Díaz et al. [22].
Equivalence of binarized average treatment effect and average treatment effect under preservation of relative self-selection
2.3
Presume that we are analyzing the binarized data . A common practice is to regress onto and to obtain an estimate of the regression function and then report the coefficient on . This is a specific case of a more general plug-in estimation strategy where the estimand (binarized ATE; BATE) is given by
In other words, we use the regression model to impute or predict both “potential outcomes” for all subjects, then average across them all and take the difference.
This estimand is represented in terms of the binarized exposure . Our question is: what causal contrast (if any) does this estimand represent in terms of the original exposure ?
Consider the estimand . Using total expectation,
where we have defined and a variable such that for every . The density of follows directly from the conditioning: for , we have where we have defined . Thus, extending to the support of , the variable has density
The distribution of preserves what we term relative self-selection of exposure values within strata of the population (conditional on the exposures being within the desired region). Specifically, for any two exposure values . We can therefore think of as the unique exposure assignment mechanism for which that also preserves the relative self-selection preferences expressed by .
To further illustrate the concept of relative self-selection, consider a simple case with three exposure {1, 2, 3} and a population where the probabilities of receiving each exposure are , respectively. If we “outlaw” exposure 1 (i.e., threshold exposure so ), then under treatment policy , we would now have probability of of receiving exposure and probability of of receiving exposure (preserving the relative probabilities between the “allowed” exposures within strata of the population).
Preservation of relative self-selection is akin to Luce’s definition of independence of irrelevant alternatives (IIA) [23]. In the definition of IIA, actors are typically considering choosing between only two options before the introduction of irrelevant alternatives. However, in the BATE case, we can compare the ratio of probability density of selecting one value of exposure relative to another conditional on confounders given the choices present in the smaller set or the choices present in the full support . Under IIA, adding additional choices for exposure should not change the relative self-selection ratio. Therefore, interventions which act on individuals who follow IIA can be modeled by this MTP.
Given this exposition, we now define such that . By identical arguments as above, . Therefore,
Identification and causal assumptions
2.4
The reason we have cast the binarized ATE in the form given above is because it has a very natural causal interpretation under standard causal assumptions. Specifically, assume:
Positivity: for all .Conditional independence: for all .
Consider an arbitrary modified exposure or . Under these assumptions, we can write:
Note that the positivity assumption allows us to say that the expectations and will be welldefined. Moreover, the conditional independence between and implies the same for and .
Therefore, finally:
Under these assumptions, is equivalent to the difference in expected outcome under two modified treatment policies that affect the underlying distribution of exposure in the population. Specifically, we can consider setting equivalent to enacting a policy that restricts while preserving relative self-selection, and setting equivalent to enacting a policy that restricts while preserving relative self-selection. This interpretation is completely transparent and explicitly defines an intervention, negating concerns about “different versions of treatment.” Given the (standard) causal identification assumptions, this parameter is a perfectly reasonable causal contrast to use when estimating the effects of policies under which persons would have exposure probabilities in the thresholded region proportional to what they would have been without the thresholding. In Section 4, we give examples of policies where this assumption is sensible and when it is not.
New parameter
2.5
In the previous section, we showed that the BATE is equivalent to the difference between two average counterfactual outcomes under two different modified treatment policies, under causal assumptions. However, when considering the impact of a policy, it seems most natural to consider the difference between a counterfactual outcome under one MTP and the outcome under the status quo with no policy, as suggested by Hubbard and van der Laan [9]. For example, the estimand proposed by Haneuse and Rotnitzky is a difference that “quantifies the average effect in the studied population of a policy that switches each received dose…to the modified dose” [10]. As another example, when studying the effect of shift interventions, researchers often estimate the difference between the average outcome under the proposed shift intervention and the observed average outcome [17, 24].
To this end, we propose a new estimand of interest, the causal attributable effect of binarizing (CAB). The CAB is akin to the causal attributable risk (CAR) of the MTPs described, generalized to non-binary outcomes. The CAR is a common estimand in public health used to examine the excess risk that results from a particular exposure [25]. It requires no data beyond what is used to calculate the BATE. The CAB is defined as the difference between the expected outcome under one of the two policies and the expected outcome under the observed world:
Estimands of interest should correspond with the question researchers are interested in exploring. Researchers are usually interested in asking causal questions to help guide decisions when faced with a choice. For example, often in medicine, researchers are interested in knowing whether a particular treatment is effective in decreasing the probability of a bad outcome relative to no treatment. Therefore, the ATE is an appropriate choice, as it compares a counterfactual world where everyone in the target population receives the treatment versus a counterfactual world in which no one in the target population receives the treatment. In the case of testing a brand-new treatment, the second counterfactual world essentially represents the observed, status-quo world, which currently exists without the treatment. In the case of considering a binarized exposure variable, we argue that the relevant choices are not between the two counterfactual worlds under two MTPs, but rather between one counterfactual world and the status-quo world. Put in other words, the relevant question is, “On average, how would the outcome change from the status-quo if we were to restrict the exposure values into a particular interval of allowable values?” is the answer to this question.
In addition, if considering implementing a particular threshold, estimating the BATE rather than the CAB could result in researchers overstating the effect of such a policy. For example, suppose a hospital is considering implementing a policy in which patients with a systolic blood pressure greater than or equal to 140 mmHg are put on a medication to reduce the blood pressure to under 140 mmHg, and doctors want to know how this would affect the overall risk of patients at the hospital experiencing cardiac arrest. Here, if researchers were to estimate and report the BATE of implementing such a threshold on blood pressure, researchers would be comparing average risk of cardiac arrests in a world where all patients have a systolic blood pressure greater than or equal to 140 mmHg to that in a world where everyone has a systolic blood pressure under 140 mmHg. It is easy to see how such an estimate could overstate the effect of implementing such a policy because the counterfactual comparison world in which everyone has blood pressure greater than or equal to 140 mmHg overstates the current disease burden. Researchers could instead calculate the CAB to compare the risk of cardiac arrest in a counterfactual world in which all patients have systolic blood pressure under 140 mmHg to that in the current world, which would more accurately reflect the reduction doctors could reasonably expect.
In addition to answering a more relevant research question, should be convenient for researchers to consider in scenarios where they might consider . The identification assumptions are slightly weaker for the CAB than the BATE. Specifically, the positivity assumption becomes a one-way positivity assumption, which will depend on the particular causal contrast of interest. However, the two-way positivity assumption implies the one-way; therefore, any data generating process that allows for the identification of the BATE also allows for identification of the CAB. Thus, data generated by processes that satisfied conditions allowing for to be estimated are also data in which may be estimated. In the following section, we describe four methods by which researchers may implement estimators for , including details for calculating standard errors in Appendix A.
Estimators
2.6
Researchers can estimate the BATE using standard estimation techniques for the ATE by using the indicator as the binary treatment indicator. In Appendix A, we provide details for a regression-based adjustment estimator [26] and an inverse probability weighting (IPW) estimator [27]. The regression estimator results from modeling the outcome regression using a linear model and then plugging this estimate into the estimand of interest. The IPW estimator weights observations based on estimates of the propensity score, . We also provide details for two doubly-robust estimators: the augmented inverse probability weighted (AIPW) estimator [27] and the targeted maximum likelihood estimator (TMLE) [20]. We additionally provide details for how to use these estimation techniques to estimate the CAB. Though very similar, the estimators for the parameter and the variance differ slightly.
Under certain conditions, the proposed estimators are consistent for the true estimands, meaning that as the sample grows to infinity, the estimators will converge on the correct population level values of the estimands. Specifically, the regression estimator will be consistent if the outcome regression for , is correctly specified; for the model described in Appendix A.1, we describe in more detail when this will be true in Appendix B. The IPW estimator will be consistent if researchers have a correctly specified model for the propensity score for . As previously mentioned, the AIPW and TMLE estimators are doubly-robust. This means that the estimators will be consistent estimators if researchers are able to either consistently estimate the outcome regression or the propensity score for , .
The regression [28], IPW [29], AIPW [27], and TMLE [20] estimators are all asymptotically normal under certain conditions, allowing researchers the ability to construct valid confidence intervals based on the estimated standard errors. In Appendix A, we provide variance estimators for the proposed methods. It is important to note that, while the AIPW and TMLE estimators are doubly-robust, the influence curve based estimators presented in the Appendix for the variance presented are not doubly-robust – they are only consistent when both the outcome regression and the propensity score estimators are consistent [30]. In addition, if both the outcome regression and the propensity score are consistently estimated for , , then the AIPW and TMLE estimators are semi-parametrically efficient, meaning that they have the smallest variance as the sample size grows to infinity in settings where we assume no knowledge on the distributions of the observed variables.
As noted above, the four estimators rely upon estimators of conditional expectations or conditional probabilities. Given that the MTPs defined above result in exposure distributions that depend on the distribution of the observed , one may assume that one must first estimate the density of . However, the equivalence result shows that the only relevant piece of the distribution of that researchers need to estimate and is the distribution of , the binarized exposure. More concretely, if researchers only had access to the data for individuals and no other information about the actual value of exposure , they would still be able to consistently estimate and . Our result also shows that, to estimate , one can use any standard ATE estimation technique plugging in as the binary exposure variable. However, the estimators for take a different form, which can be found in Appendix A.
Simulation study
3
Data generating processes
3.1
To illustrate the equivalence between the binarized ATE and difference in expected outcomes under the proposed MTPs, we performed a simulation study. The data generating process (DGP) is as follows:
The estimands of interest are the binarized ATE and the causal attributable effect of binarization when implementing a cut-off at an exposure value of . Here, we define the CAB as , which contrasts the average outcome under the MTP which restricts values and preserves relative self-selection with the average outcome in the observed world. Under the data generating process, the true parameter values are and .
Over 5,000 simulations, we drew samples of size from the data generating process and calculated the estimates and using the regression, IPW, and AIPW estimators discussed detailed in Appendix A. The regression estimator is consistent for this DGP because is linear in and , as is binary. For a more general discussion of when the regression estimator will be consistent, see Appendix A.1. The estimate necessary for implementing the IPW estimator was calculated using logistic regression with as the predictor and as the binary outcome, which is consistent for the propensity score for this DGP. Finally, the AIPW estimator is doubly robust. Therefore, all three estimators are consistent. We also estimated the standard errors of the estimates using the methods described in Section 2.6. Finally, we present the bias of the estimates as well as the standard error of the estimators over the simulations to evaluate the performance of the estimators.
Visualizing the MTPs
3.2
Figure 1 illustrates the resulting densities after implementing the cut-off for the two values of the confounder . The green line represents the cut-off value of 6. The gray line is the density of in the observed world, the red dotted line is the density of , and the blue dotted line is the density of . As illustrated by this figure, the densities and differ depending on the value of the confounder . This is generally true of our result; the resulting distributions of exposure after binarizing can depend both on the distribution of the observed exposure as well as the pre-exposure confounders.
Both and have density equal to 0 for values of exposure that are not within the allowed range ( for and for ). It is also evident that both preserve relative self-selection for the values of exposure within the allowed range. The non-zero portions of the MTP distributions of exposure are simply scaled versions of the density of the observed .
Simulation results
3.3
Using the methods described in Appendix A, we calculated estimates for the target parameters and the standard errors of the estimates. What bears repeating is that *the only information the estimators require about the exposure is the value of the binarized exposure *. One may assume that, in order to estimate the expected outcomes under the MTPs, one must first estimate the full densities of and . However, through the equivalence with the binarized ATE, the relevant quantity one must estimate is instead the conditional probability for , which is easier to estimate.
As the results in Tables 1 and 2 show, the regression, IPW, and AIPW estimators for and have almost negligible bias, even for the smaller sample size of . When estimating both and , the regression, IPW, and AIPW estimators have relatively similar standard errors, and thus would result in relatively similar normal-based confidence intervals.
Application: oil/gas well exposure and birth outcomes in California, 2007–2015
4
To demonstrate how to think about binarization in an applied setting, we revisit the questions analyzed by Tran et al. investigating the effect of residential proximity of oil/gas wells during pregnancy on birth outcomes in the state of California from 2006 to 2015 [31]. The authors found a significant association between high production volume from oil and gas wells and small gestational age (SGA) in rural and urban areas. In response to “a growing body of research shows direct health impacts from proximity to oil extraction,” California Senate passed a law creating Health Protection Zones from oil and gas wells starting January 1, 2023 [32]. Health Protection Zones are 3,200 feet (≈1 km) buffers surrounding homes, schools, hospitals, and other sensitive locations. To evaluate the effect of such a law on the probability of SGA in newborns in California based on the 2007–2015 data, we considered a binarized exposure, where infants born to households within 1 km of oil and gas wells are considered “untreated,” and infants born to households outside of 1 km of an active oil/gas well are considered “treated.”
Our population of interest is infants born in California between 2007 and 2015 where the residential address of the pregnant parent was within 10 km of an active oil/gas well during the period of gestation, as in Tran et al. – we followed the same exclusion criteria as in Figure 1. We consider the same infant and maternal confounding factors as in Tran et al.; specifically, we adjust for infant sex, month (categorical) of birth, year of birth, maternal age in years, maternal race/ethnicity, maternal educational attainment, Kotelchuk index of prenatal care, and parity. All study protocols were approved by the Institutional Review Board of the CA Department of Public Health (#13-05-z).
Let be the vector of covariates, be the distance in meters to the closest well, and be the indicator of low birth weight (defined as a birthweight of <2, 500 g [31]). Some parents may live within 10 km of multiple wells – for the purposes of this analysis, we chose the distance to the closest well as our exposure of interest. We then binarize this exposure at 1 km (assigning individuals with a distance to and a distance . Our estimands of interest are and .
To estimate these quantities, we use the AIPW estimator presented in Appendix A.2. We estimate the outcome regression using a logistic regression estimator: . To estimate the propensity score , we use a logistic regression estimator: . If either of these estimators are consistent for the true function, then the estimates will be consistent. To estimate the standard deviation, we implement the nonparametric bootstrap. The results are presented in Table 3.
The key identifying assumption underlying our analysis is that, conditional on observed covariates, the distribution of distances to the nearest well among those who would be “treated” under the law (i.e., living more than 1 km from an active well) is proportional to the distribution observed in the current world. In our notation,
Intuitively, this means that within any stratum of pregnant people with the same observed covariates (e.g., Hispanic, aged 25–29, less than high school educated with a Kotelchuk index of adequate and nulliparous, giving birth in September 2010 to male babies), the histogram of distances to the nearest well in the post-law world should look like the observed histogram, but truncated at 1 km. A concrete way to visualize this is to imagine taking the empirical distribution of distances for a covariate subgroup and slicing it at the 1 km threshold, as in Figure 2. The remaining portion approximates what we expect under the intervention. While we only observe finite samples, the assumption is about the population distribution and must hold for all covariate strata. If this were not the case, the effect we estimate via a binarized analysis would not correspond to the real-world effect of closing or relocating wells within a 1 km radius of populated areas.
It may help to consider what this means in terms of the California law. When the law is enacted, households do not relocate – instead, the wells themselves are removed (or relocated beyond the buffer). Thus, the intervention acts by eliminating wells within 1 km of residences and perhaps relocating them outside of 1 km. Under the binarization assumption, the distances to the nearest well beyond 1 km remain unchanged. In reality, however, removing wells near households will often increase the distances to the nearest active well for other households, since the nearest active well may now be farther away. Therefore, the assumption is not literally true, though the degree of violation depends on the density and spatial configuration of wells. When wells are sparse, the shift could be substantial; when wells are dense, the effect may be negligible.
Finally, it is important to emphasize that the binarization assumption is not the only requirement for causal validity. A causal interpretation of this analysis still depends on the assumptions in Section 2.4 holding for our analysis. For example, we must have no unmeasured confounding. Despite controlling for maternal demographics, education, prenatal care, and birth timing, unmeasured socioeconomic or environmental factors (some of which were included in Tran et al.) could bias results. In addition, our parametric modeling choices introduce assumptions. Logistic regressions for outcome regressions and propensity scores are unlikely to be correctly specified in this context, which can induce bias. More flexible machine learning methods with cross-validation could mitigate these concerns, but pursuing that is beyond the scope of this paper. We therefore interpret our results as illustrative of how binarization can be applied, rather than definitive evidence of health effects.
Assuming the assumptions outlined above hold, is equivalent to the difference in probability of low birth weight under the intervention that restricts active oil/gas wells to outside of 1 km of homes and the intervention that restricts active oil/gas wells to within 1 km of homes. Under the same assumptions, is equivalent to the difference in probability of low birth weight under the intervention that restricts active oil/gas wells to outside of 1 km of homes and the observed world. The two estimates are around 0.205 % and 0.0080 %, respectively.
The results underscore the important distinction between the BATE and CAB, as the BATE can overestimate the effect of an intervention. If researchers had only considered the BATE, the estimate would suggest a 0.205 % increase in the probability of a baby being born with a low birthweight. However, considering the CAB, which compares the post-intervention world with the status quo world, we find only a 0.0080 % increase in the probability.
It may seem surprising that the BATE estimate here is positive, implying that a policy moving all wells outside of 1 km of households would increase the probability of low birth weight compared to a policy moving all wells within 1 km of households. There are two reasons our binarized estimand may be understating the protective effect of the policy. The first is that, as explained above, if the health harms of proximity decay smoothly with distance, then removing nearby wells should reduce exposure more than what is captured by a strict 1 km cut-off. Put differently, the real law is expected to do at least as well as, and likely better than, the scenario we analyze. On the other hand, if effects beyond 1 km are truly negligible, then the difference is immaterial, and the binarization assumption becomes a reasonable approximation for causal inference. The second is the exposure we consider, distance to closest well, may not fully capture the health harms of allowing active wells to be built within 1 km of households. For example, some individuals may live within 1 km of several wells, and some active wells may have higher levels of production than others. For example, the authors of the Tran et al. paper found that households exposed to high production volume had an average of 32 active wells within 1 km of the household. Thus, considering only the closest well may not capture the full health harms pregnant people are exposed to prior to the buffer zone being implemented. The fact that the estimates are very close to 0 lends further credence to this idea, suggesting that the distance to closest well may not be a good proxy for the amount of harm an individual may experience living within 1 km of active wells.
Discussion
5
In this paper, we show the equivalence between the binarized ATE and the difference between the average counterfactual outcomes under two MTPs that impose the relevant cut-off defined by the binarization and preserve relative self-selection. Relative self-selection is the ratio of the probability density of one value of exposure to another. Through this equivalence, we affirm that the binarized ATE is a valid causal estimand and is identified under standard causal identification assumptions, addressing many of the common concerns methods researchers have posited about such coarsening of a continuous exposure variable.
We also introduce a new estimand, the causal attributable effect of binarization (CAB), which contrasts the expected outcome under one of the MTPs associated with binarization with the expected outcome in the observed world. Identification of this estimand requires weaker assumptions, and these assumptions are implied by the assumptions required to identify the BATE – thus, a scenario in which researchers could estimate the BATE is also a scenario in which they could estimate the CAB. We argue that this estimand answers a more relevant causal question as it compares the counterfactual world under one MTP (the “treated” counterfactual) to the observed world (which is akin to a “control” counterfactual). As this estimand cannot be calculated using standard methods developed for the ATE, we also provide details for how to implement four different estimators of the causal attributable effect of binarization as well as how to estimate their standard errors.
We also conducted a simulation study to show analytically that the results hold using the estimators that we proposed. Specifically, using only the binarized variable based on the cut-off and no other information about the observed exposure distribution of , we were able to provide consistent estimates for both the BATE and the CAB. This result may be surprising, as typically estimating the effects of MTPs requires estimating the density of . For example, this is the case in the shift intervention considered by Díaz and van der Laan [17]. Therefore, the two MTPs discussed which impose a cut-off and preserve relative self-selection lend themselves to much easier estimation from a practioner’s point of view, which perhaps explains part of the reason why the method is so prevalent in the literature across disciplines. In fact, it has been shown that for all MTPs which impose a cut-off and restrict exposures to a certain region of the support, the causal effects for the unique MTP which preserves relative self-selection are indeed the easiest to estimate from a theoretical view point [20]. Finally, we consider an applied example, applying binarization to births in California to evaluate a 1 km buffer zones between active oil/gas wells and homes.
Although the BATE and CAB may be easier to estimate, they may not be relevant causal quantities depending on the specific research context. Ultimately, whether binarization should be employed as detailed in this paper depends on the expected behavior of individuals after implementing the intervention of interest. For example, suppose researchers were interested in estimating the effect of a policy that limits the amount of energy households use by fining households that consume more energy than a certain threshold. In this case, the assumption of preservation of relative self-selection is not very plausible, as one could reason that households above the threshold would change their energy usage to just barely meet the new limits, as there is no incentive to reduce energy consumption any further. Conversely, households that already use less energy than the threshold will likely make no change to their energy use. Therefore, the resulting distribution of household energy usage would have a “piling up” of households at the imposed threshold with the distribution below the threshold looking the same as that in the observed world. Therefore, in this case, it would likely not make sense to binarize household energy usage based on the proposed cut-off.
On the other hand, suppose researchers were interested in estimating the effect of the distance an individual lives from a manufacturing plant. Specifically, the researchers are interested in estimating the effect of a proposed policy which would give individuals who currently live within a specified cut-off distance of the plant a housing voucher which they can use to relocate throughout the city. In this case, it might be more reasonable that preservation of relative self-selection would hold after implementing the policy. Deciding where to live is a multifaceted decision based on individual needs that may depend on different factors such as access to public transportation, quality of local schools, and proximity to grocery stores, among other factors. The individuals who chose to live close to the factory may have done so based on different needs; therefore, it seems plausible that these individuals would relocate evenly across the other populated areas of the city if given the economic assistance to do so.
These are simply two examples of policies researchers may be interested in. Ultimately, the decision to binarize should depend on domain-specific knowledge and predictions regarding the effect of the relevant policy on the distribution of the exposure variable in the population. Unfortunately, before the policy is implemented, this is a completely untestable assumption. However, researchers can still make plausible educated guesses and choose a causal estimand of interest accordingly.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1Imbens GW, Rubin DB. Neyman’s repeated sampling approach to completely randomized experiments. In: Rubin DB, Imbens GW, editors. Causal inference for statistics, social, and biomedical sciences: an introduction. Cambridge: Cambridge University Press; 2015: 83–112 pp. Available from: https://www.cambridge.org/core/books/causal-inference-for-statistics-social-and-biomedical-sciences/neymans-repeated-sampling-approach-to-completely-randomized-experiments/55448 ADDB 6E 99F 33966 FA 4D 26F 34A 79D.
- 2Shimonovich M, Pearce A, Thomson H, Mc Cartney G, Katikireddi SV. Assessing the causal relationship between income inequality and mortality and self-rated health: protocol for systematic review and meta-analysis. Syst Rev 2022;11:20.35115055 10.1186/s 13643-022-01892-w PMC 8815171 · doi ↗ · pubmed ↗
- 3Zhou H, Vasiliou V. Alcohol use and use disorder and cancer risk: perspective on causal inference. Complex Psychiatry 2022;8:9–12.36601413 10.1159/000526407 PMC 9669948 · doi ↗ · pubmed ↗
- 4Hu R, Huang X, Huang J, Li Y, Zhang C, Yin Y, Long- and short-term health effects of pesticide exposure: a cohort study from China. P Lo S One 2015;10:e 0128766.26042669 10.1371/journal.pone.0128766 PMC 4456378 · doi ↗ · pubmed ↗
- 5Hu FB, Manson JE, Stampfer MJ, Colditz G, Liu S, Solomon CG, Diet, lifestyle, and the risk of type 2 diabetes mellitus in women. N Engl J Med 2001;345:790–7.11556298 10.1056/NEJ Moa 010492 · doi ↗ · pubmed ↗
- 6Wu X, Braun D, Kioumourtzoglou MA, Choirat C, Di Q, Dominici F. Causal inference in the context of an error prone exposure: air pollution and mortality. Ann Appl Stat 2019;13:520–47.31649797 10.1214/18-AOAS 1206 PMC 6812524 · doi ↗ · pubmed ↗
- 7Kurtz MJ, Lauretig A. Does free-market reform induce protest? Selection, post-treatment bias, and depoliticization. Br J Polit Sci 2022;52: 968–76.
- 8Carneiro P, Lokshin M, Umapathi N. Average and marginal returns to upper secondary schooling in Indonesia. J Appl Econom 2017;32: 16–36.