On the degrees of freedom of gridded control points in learning‐based medical image registration
Wen Yan, Qianye Yang, Yipei Wang, Shonit Punwani, Mark Emberton, Vasilis Stavrinides, Yipeng Hu, Dean Barratt

TL;DR
This paper introduces GridReg, a new method for medical image registration that uses sparse control points to reduce computational cost while maintaining accuracy.
Contribution
The novel contribution is a registration framework that uses sparse gridded control points with cross-attention and grid-adaptive training for efficient and accurate registration.
Findings
GridReg achieves improved computational efficiency by predicting sparse-grid displacements.
The method outperforms existing algorithms in registration accuracy with similar or lower compute cost.
GridReg supports adaptive inference at multiple grid sizes without retraining.
Abstract
Many registration problems are ill‐posed in homogeneous/noisy regions, and dense voxel‐wise decoders can be unnecessarily high‐dimensional. A sparse control‐point parameterization provides a compact, smooth deformation representation while reducing memory and improving stability. This work investigates the required control points for learning‐based registration network development. In particular, as sparse as 5×5×5 control points are configured and compared with alternative approaches, including those using scattered control points and displacements sampled at every voxel, that is, dense displacement fields. We present GridReg, a learning‐based registration frametwork that replaces dense voxel‐wise decoding with displacement predictions at a sparse grid of control points. This design substantially cuts the parameter count and memory while retaining registration accuracy. Multiscale 3D…
Genes, proteins, chemicals, diseases, species, mutations and cell lines named across the full text — each resolved to its canonical identifier and authoritative record.
Click any figure to enlarge with its caption.
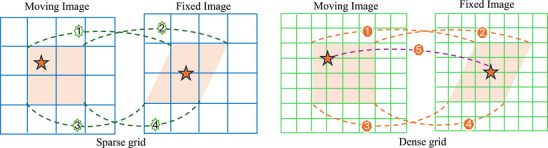 FIGURE 1
FIGURE 1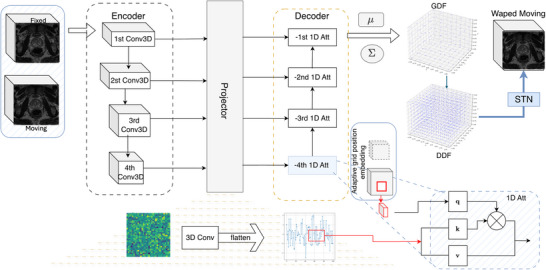 FIGURE 2
FIGURE 2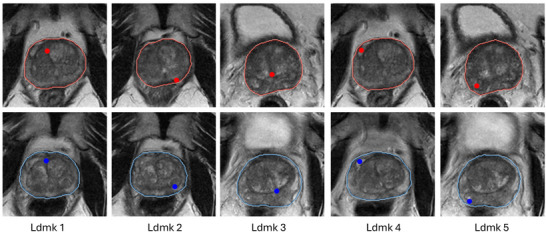 FIGURE 3
FIGURE 3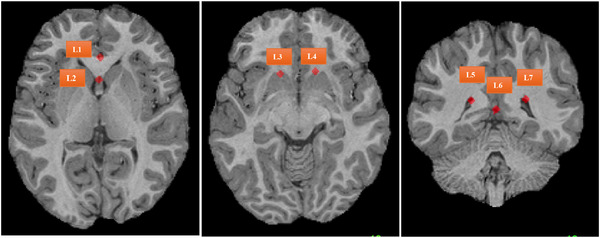 FIGURE 4
FIGURE 4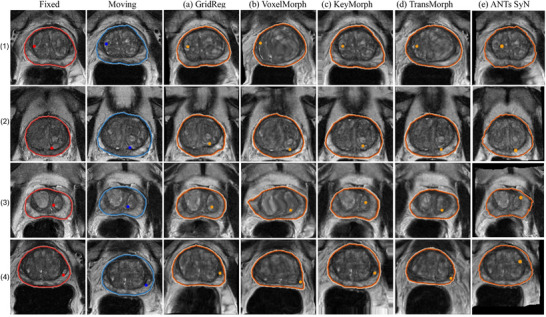 FIGURE 5
FIGURE 5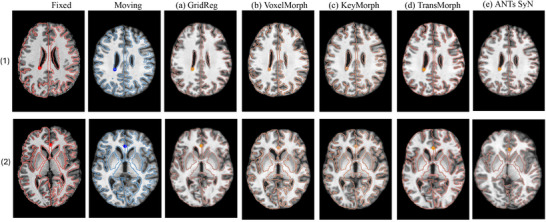 FIGURE 6
FIGURE 6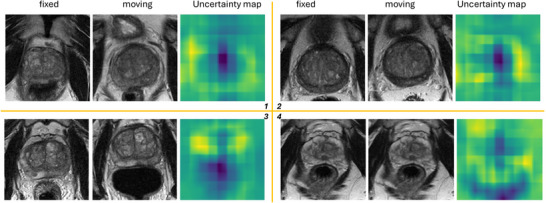 FIGURE 7
FIGURE 7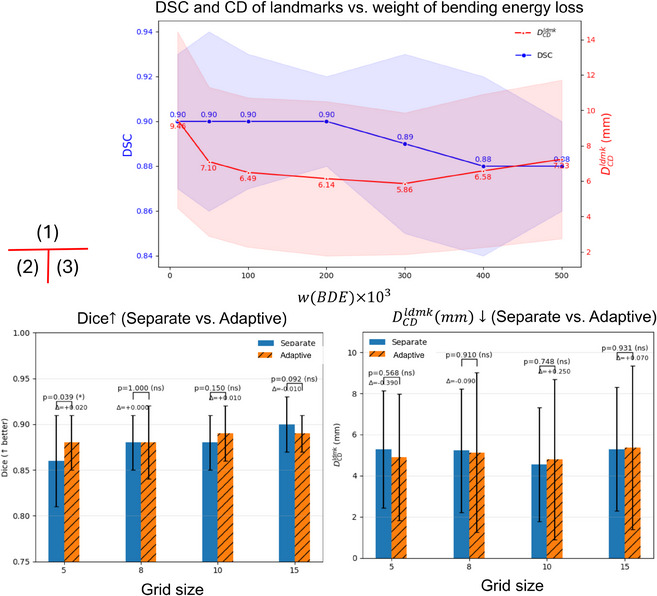 FIGURE 8
FIGURE 8| Dataset | Metric | Original | ANTs SyN | VoxelMorph | TransMorph | KeyMorph | GridReg(Ours) |
|---|---|---|---|---|---|---|---|
|
| 0.70 ± 0.10 | 0.86 ± 0.02 | 0.84 ± 0.03 | 0.86 ± 0.05 |
| ||
| (mm) | 9.60 ± 4.09 | 9.09 ± 8.09 | 8.76 ± 8.59 | 7.73 ± 6.98 |
| 4.54 ± 2.77 | |
| (mm) | 8.76 ± 4.04 | 3.38 ± 0.78 | 2.70 ± 0.54 | 3.05 ± 0.84 | 2.56 ± 0.66 |
| |
| GPU (Mb) | / | / | 208 | 377 | 274 |
| |
|
| 0.69 | 0.73 ± 0.16 | 0.73 ± 0.09 |
| 0.78 ± 0.09 | ||
| (mm) | 10.65 | 6.03 | 5.99 | 4.47 |
| 4.52 ± 2.88 | |
| GPU (Mb) | / | / | 168 | 333 | 225 |
| |
|
| Dice | 0.70 ± 0.05 | 0.69 |
| 0.77 ± 0.05 | 0.77 ± 0.06 |
|
| (mm) | 8.67 ± 6.58 | 8.45 ± 6.64 | 8.70 ± 6.64 | 8.35 ± 6.85 |
| ||
| (mm) | 4.16 ± 1.94 | 3.98 | 3.11 ± 1.73 | 3.80 |
| 3.05 ± 1.47 | |
| GPU (Mb) | / | / | 317 | 486 | 378 |
| |
| Trainable parameters (bytes) | / | / | 524 181 | 4 1476 659 | 1 410 329 | 252 960 | |
| Inference time (case/s) | / | 8.08 | 0.23 | 0.25 | 0.24 | 0.23 | |
| Layers | KeyMorph | GridReg | ||||
|---|---|---|---|---|---|---|
| Dice | (mm) | Cost (Mb) | Dice | (mm) | Cost (Mb) | |
| 4 layers | 0.54 ± 0.14 | 14.74 ± 9.46 | 169 | 0.88 ± 0.03 | 6.05 ± 3.43 | 145 |
| 5 layers | 0.56 ± 0.14 | 14.69 ± 12.40 | 171 | 0.88
| 4.54 ± 2.77 | 146 |
| 6 layers | 0.58 ± 0.19 | 10.97 ± 7.52 | 174 | 0.89 ± 0.03 | 3.97 ± 2.38 | 147 |
| 7 layers | 0.82 ± 0.18 | 4.42 ± 3.24 | 182 | 0.89 ± 0.02 | 4.59 ± 3.09 | 148 |
| 8 layers | 0.84 ± 0.07 | 4.33 ± 2.84 | 195 | 0.89 ± 0.04 | 4.25 ± 2.46 | 152 |
| 9 layers | 0.86 ± 0.05 | 3.98 ± 2.14 | 208 | 0.90 ± 0.03 | 4.64 ± 2.82 | 157 |
| Setting | Grid | Base‐NC | Upsample | Projector | Bayesian | Dice | (mm) | Cost (Mb) |
|---|---|---|---|---|---|---|---|---|
| Config 1 | 5 | 32 | Trilinear | 0.86 ± 0.05 | 5.29 ± 2.85 | 146 | ||
| Config 2 | 10 | 32 | Trilinear | 0.89 ± 0.03 | 4.89 ± 3.19 | 148 | ||
| Config 3 | 10 | 8 | Trilinear | 0.87 ± 0.04 | 5.88 ± 3.27 | 144 | ||
|
| 10 | 16 | Trilinear | 0.88 ± 0.02 | 4.54 ± 2.77 | 146 | ||
| Config 5 | 10 | 16 | Trilinear | 0.86 ± 0.03 | 6.06 ± 3.23 | 145 | ||
| Config 6 | 10 | 16 | deconv | 0.89 ± 0.04 | 4.18 ± 2.88 | 171 | ||
| Config 7 | 10 | 16 | bspl | 0.89 ± 0.03 | 4.45 ± 2.95 | 290 | ||
| Config 8 | 10 | 16 | Trilinear | 0.88 ± 0.03 | 4.90 ± 3.65 | 146 | ||
| Config 9 | 15 | 16 | Trilinear | 0.90 ± 0.03 | 5.29 ± 3.09 | 148 |
| Dataset | Metric | GridReg Bayesian | GridReg | KeyMorph | VoxelMorph | TransMorph |
|---|---|---|---|---|---|---|
| Prostate |
| |||||
| (%) | 0 | 0 | 3.8 | 0.4 | 0.03 | |
| Brain |
| |||||
| (%) | 0 | 0 | 11.0 | 0.2 | 4.5 |
- —Cancer Research UK10.13039/501100000289
- —NIHR University College London Hospitals, Biomedical Research Centre
- —Canary Center at Stanford University
- —OHSU Knight Cancer Institute
- —University of Cambridge10.13039/501100000735
- —University College London10.13039/501100000765
- —University Of Manchester10.13039/501100000770
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsMedical Image Segmentation Techniques · Medical Imaging and Analysis · AI in cancer detection
INTRODUCTION
1
Medical image registration aligns images from different modalities, patients, or time points to the same spatial coordinates, with many clinical utilities.1 Traditional pairwise image registration methods optimize parametric or nonparametric transformation models iteratively given a pair of images.2 Learning‐based image registration enables a data‐driven approach with fast inference to predict transformations that represent spatial correspondences.3, 4, 5, 6, 7 Examples are discussed in Section 2.
An interesting observation in the development of learning‐based image registration techniques is that early deep learning approaches largely bypassed the use of gridded control points for modeling deformation.3, 4, 5, 6, 8 Instead, these methods commonly predicted dense displacement fields (DDFs), in which a displacement vector is estimated at every voxel location. This architectural choice is likely influenced by the evolution of computing capabilities, particularly the advent of high‐performance GPUs and parallelized training frameworks, which have substantially reduced the computational burden associated with predicting and optimizing per‐voxel displacements. DDFs can be viewed as an extreme case of grid‐based models where the grid resolution equals the image resolution—effectively treating every voxel as a control point.
A higher‐resolution control grid, defined by a larger number of sampled control points, indeed allows the model to represent more localized, fine‐scale transformations. However, this increase in resolution does not necessarily improve registration performance.9, 10 When the transform has excessively high DoF in medical imaging and similar domains, many regions of interest—such as homogeneous tissue areas or regions with strong random noise—inherently lack well‐defined local correspondences. Allowing the network to resolve extremely localized deformations under dense transformation may be unnecessary or even detrimental. It can introduce noise, overfitting, or anatomically implausible correspondences, especially if the similarity metrics used during training fail to distinguish meaningful local variation from spurious noise. Moreover, increasing the grid density comes at a substantial computational cost. This burden is particularly observed in the decoder, which is responsible for reconstructing latent representations into high‐resolution structured deformation outputs. Such decoders typically rely on multiscale feature integration and upsampling mechanisms, which become progressively more complex and expensive as the output resolution increases.11 Coarser control grids reduce the degrees of freedom, acting as an implicit regularizer that limits high‐frequency, voxel‐level warps and can reduce sensitivity to unreliable local correspondences. As illustrated in Figure 1, the choice of grid resolution plays a crucial role in controlling the granularity of the estimated transformation field. A coarser grid may act as a form of implicit denoising or regularization, effectively filtering out high‐frequency similarity that is not consistently supported by the underlying anatomy or image evidence. This insight suggests that, depending on the application context and anatomical region, using a coarser control grid can lead to more anatomically meaningful and computationally efficient deformation estimates.
Demonstration of an illustrative example of false‐positive correspondence (orange stars), possibly caused by similar intensity patterns (e.g., unsupervised loss similarity) or label errors (e.g., segmentation noise). A sparse low‐resolution grid helps filter out such a noise, as stronger “true” correspondences (four corners of the shaded ROIs) dominate. In contrast, a finer high‐resolution grid may amplify the noise, distorting additional control points within the ROIs and leading to inaccurate registration.
Our approach differs from pyramidal registration, in which downsampled images still yield a high‐DoF dense field via a learned high‐resolution decoder.3, 12 Instead, we predict a sparse control‐point displacement field from flattened 1D feature tokens with positional encoding (PE), and then reconstruct a dense voxel‐wise displacement field via interpolation (e.g., trilinear or B‐spline13). Constraining DoF of the predicted transformation acts as built‐in spatial regularization, reducing overfitting in noisy or homogeneous regions. Crucially, low DoF is not low expressivity, where spline interpolation can produce smooth yet highly nonlinear, nonrigid deformations. We do not claim that high‐resolution displacement fields are never useful; rather, their necessity is often overestimated.
Our main contributions are as follows:
- We introduce a lightweight decoder that projects multiscale 3D features into control‐point embeddings and predicts sparse displacements via local cross‐attention.
- We propose a grid‐adaptive framework that trains across multiple control‐grid resolutions and selects an effective grid density for each dataset via validation‐driven model selection.
- We achieve comparable or improved registration accuracy relative to voxel‐wise DDF decoders, while substantially reducing memory and computation and improving deformation regularity, which is attractive for computation‐limited settings.
RELATED WORKS
2
The degree‐of‐freedom (DoF) of gridded control points reflects the resolution of correspondence in registration, discussed above. A higher DoF (dense) implies the ability to capture finer, local correspondence, while a lower DoF represents coarser correspondence. For scattered control points, correspondence resolution varies spatially, depending on its local sampling mechanisms for allowed DoF per unit space (volume in 3D). The spatial adaptability from scattered points allows versatility and, arguably, efficiency, but requires optimization or predefined with prior knowledge. In nonlearning‐based algorithms based on iterative optimization, these two categories of transformation representation are closely related to free‐form deformation14 and point‐feature‐based method.15 We discuss example studies in the context of learning‐based algorithms as follows.
Gridded control points
2.1
Spatial transformation network (STN)16 applies a predicted DDF through a differentiable sampling operator, enabling end‐to‐end optimization using image‐domain losses between the warped source and the target.17 Based on this, much work using encoder–decoder structured networks predicts the transformation. These works utilized unsupervised methods to predict the displacement field between two real‐world images by minimizing image similarity loss between the warped source image and the target image. In the case of complex tasks like multi‐modality registration, refining the dense deformation field (DDF) requires a more focused investigation into training strategies. Yang proposed a work8 that benefits from exploiting additional images during training for cross‐modalities registration. Zhou18 proposed a structured cross‐modality latent space to represent 2D‐pixel features and 3D features via a differentiable probabilistic Perspective‐n‐Points solver. Hussain19 proposes a hierarchical cross‐attention‐based transformer structure to extract features of fixed and moving images at multiple scales, enabling more precise alignment and improved registration accuracy. This structure strengthens the ability of decoder, enabling it to facilitate progressive deformation field refinement across multiple resolution levels.
Scattered control points
2.2
The scattered control points method can utilize manually selected anatomical landmarks, aiming to register specific regions of interest.20, 21 Otherwise, it can automatically detect key points using feature extraction methods. Keymorph5 utilized a center of mass layer to generate corresponding key points for source and target images, respectively, and produced a deformation field based on these paired key points. Wang22 extended KeyMorph as a tool that supports multimodal, pairwise, and scalable groupwise registration, solving 3D rigid, affine, and nonlinear registration in brain registration. Ekvall et al.23 presented an unsupervised spatial landmark detection and registration network to address the challenges in nonlinear deformations between histological tissue sections. Zachary et al.24 present a free point transformer (FPT) in which the scattered points are sampled to represent the surface of the organ via a separate segmentation process for nonrigid point‐set registration. Fu et al.25 generate volumetric prostate point clouds from segmented prostate masks using tetrahedron meshing and then use a point cloud matching network to obtain the deformation field for registration. SuperPoint26 operates on full‐size images and jointly computes pixel‐level interest point locations and associated descriptors in one forward pass using homographic adaptation. Zhang et al.27 proposed a two‐stage method for multimodel image registration. In the coarse stage, the method uses a key‐point based method inherited from DeTone et al.26 to generate a course deformation field from the segmentation map, and in the fine stage, the method uses a voxel‐based method to refine the deformation field.
METHODS
3
Predicting gridded displacement fields
3.1
Let I={(Fj,Mj)∣j=1,⋯,J} be a dataset of J source–target image pairs, where each image is a 3D tensor Fj,Mj∈RW×H×D. Define the voxel domain Ω={1,⋯,W}×{1,⋯,H}×{1,⋯,D} and N=|Ω|=WHD. We write the vectorized forms as fj∈RN,mj∈RN, so that fj=[fj(x1),⋯,fj(xN)]⊤ with voxel coordinates xn=(xn,yn,zn)∈Ω. A spatial transform is represented by a DDF Tj:Ω→R3 over the voxel domain Ω={1:W}×{1:H}×{1:D}. We denote warping by W(Mj,Tj)=Mj∘Tj, where ∘ denotes spatial transform operation.16 Learning‐based image registration optimizes the model weights to find transformations that align each pair of source and target images. This can be formulated as an optimization problem: argminTj∑n=0NL(Mj∘Tj,Fj), where L is a registration loss function of the transformed moving image and the fixed image. In this study, we propose a registration method based on a sparse gridded displacement field (GDF) with size G=gw×gh×gd. As illustrated in Figure 2, we describe a simple, easy‐to‐implement registration network, GridReg, denoted by gθ(·), with network parameter θ={θ0,θ1,θ2},
GridReg can be viewed as three submodules: (1) gencθ0(·) extract feature Ej(l)∈RCl×Dl×Hl×Wl; (2) multiple projection layers gprojθ1(l)(·), which project 3D features at lth layer of the encoder into compact 1D vectors; and gdecθ2(·) is used to aggregate features from encoder and projector and produce the gridded displacement μj∈R3×gw×gh×gd, as shown in Figure 2.
Illustration of GridReg. The encoder extracts multiscale 3D feature maps; at each scale, a skip‐projection flattens features into 1D tokens that are fused with grid‐cell queries via (local) attention. The resulting features are mapped to a sparse control‐point displacement field via Bayesian integration, and a dense displacement field (DDF) is obtained by interpolation (e.g., trilinear, B‐spline, or transposed convolution).
In detail, each layer in the encoder consists of a 3D convolutional layer with ReLU activation and downsampling by a stride of 2. We set a base C channels and doubled the number of channels for each subsequent layer in the encoder.
Then, the features at lth layer from the encoder are passed through a projection layer, which includes 3D convolutional layers with fixed output channels and flattening operation, resulting in a vector at lth layer: Pj(l)=gprojθ1(l)(Ej(l))∈RNp×Cp with a length of Np=pw·ph·pd and Cp is projection channels. Instead of using a symmetric decoder to reconstruct the output, as in previous work,3 we use a 1D cross‐attention predictor gdecθ2(·) to progressively refine the decoder features, from bottom to top in Figure 2. The decoder at (l‐1)th layer is expressed as follows: Yj−(l−1)=gdecθ2(l)(Y^j−(l)), where Y^j−(l)=[(Pj(l)),(Yj−(l))]∈RNp×(Cp+Cd−(l)), where Cd−(l) is decoder channel number at lth layer.
Let G=gwghgd be the number of control points (queries) and control points coordinates stacked as R∈RG×3 and position embedding ψ(·) produce ψ(R)∈RG×Cpe, where Cpe is the position embedding channels. Given a multi‐attention head and dimension in each head as H and d, define learned projections: WQ∈RCpe×Hd,WK,WV∈R(Cp+Cd−(l)))×Hd,WO∈RHd×Cout−(l). Queries, keys, and values are formed by matrix multiplication:
Reshape into H heads:
The product‐attention is computed as follows:
where softmax(·) is applied row‐wise over the N tokens. Concatenating heads and projecting gives the decoder output: Y=ConcatY(1),⋯,Y(H)WO∈RG×Cout−(l), which is reshaped to Cout−(l)×gw×gh×gd at last layer of decoder.
Registration models with adaptive grid sizes: To avoid training one network per control–point grid, we implement a single model that adapts to multiple grid sizes during training and selects an optimized grid size on the validation set. We modified how the query PEs are generated as described above to adapt the attention‐based decoder to dynamic grid sizes. In addition, the dynamic grid implementation calculates and caches the PEs for use at runtime, enabling flexibility in target grid size. In summary, the encoder is shared across all settings. The position embedding width Cpe sets the embedding feature length of each query. In decoder, the grid size (gw,gh,gd) changes only the number of queries G=gwghgd. According to Equation (3.1), the projection weights WQ,WK,WV,WO and head sizes (H,d) are independent of (gw,gh,gd). Thus, the model can adapt to different grid sizes without additional computational cost.
To support a dynamic grid, we treat the grid resolution as a discrete hyperparameter and, during training, sample (gw,gh,gd)∼U{(5,5,5),(8,8,8),(10,10,10),(15,15,15)},. The sampled grid is embedded by a position embedding ϕ(gw,gh,gd). The cross attention module takes a position embedding as the query and produces deformation parameters μ and σ on a flexible, dynamic grid. This approach offers computational efficiency comparable to fixed‐grid models while significantly reducing storage and deployment overhead. During inference, we select the optimal, fixed grid size based on validation metrics for each dataset.
Transformation sampling
3.2
Bayesian grid transformer: We adopted a previously proposed probabilistic registration algorithm12, 28 and learn a grid‐based posterior over deformations, to estimate uncertainty in medical image registration. This allows the method to assess uncertainty for deformation as well as improve the performance according to.12, 28 Thus, we add a Bayesian head after the decoder, which predicts a mean and variance per control point,
for each pair j. During training, we use the reparameterization trick to draw S Monte–Carlo samples at the grid,
We optimize the similarity objective with an uncertainty‐weighting:
σj2(x) is the spatially varying uncertainty, and λ0 controls the uncertainty penalty. Intuitively, σj grows in ambiguous (e.g., homogeneous or artifact‐corrupted) regions and reduces where correspondences are clear. This pathwise sampling provides an unbiased Monte Carlo estimate of the expectation, discouraging sharp, unstable deformations in homogeneous areas.
In inference, we use only the mean field to warp the moving image, Tμ,j≡(μj), while σj is used solely for uncertainty visualization.
Transformation interpolation: Given a predicted GDF T(x)∈R3×gw×gh×gd, three interpolation methods are investigated to upsample the sparse GDF to image size, obtaining T↑(x), where represents upsampling operation. To interpolate at each voxel xn=(xi,yν,zk), the locations of GDF are represented as xijk. We describe three upsampling strategies that can consistently be considered by using a basis function to convolve with the GDF, denoted as
where the terms Bx(xi), By(xi), and Bz(xi) represent the basis functions in three dimensions. These basis functions share the same functional form across all three dimensions (x, y, and z). For clarity, let us consider Bx(xi) as an example to illustrate the three interpolation methods:
- 1.Trilinear interpolation: The basis function in trilinear interpolation is defined as Bx(xi)=1−x−xi along 1st dimension (similarly for the other two dimensions).
- 2.Cubic B‐spline interpolation: The base function of cubic B‐spline interpolation is defined recursively from 0º to 3º, that is, the 1st dimension basis function at 0ºis defined as follows:
is a linearly sampled knots vector t=[0,0,0,t0,…,ti,…,tI,1,1,1]. Then, basis functions at p={1,2,3} degree are defined recursively by the following:
(similarly for the other two dimensions).
- 3.Transposed convolution upsampling: The 3D transposed convolutions were used to implement a Gaussian spline‐based transformation resampling. In this case, the basis function of 1st dimension is defined as follows:
where σ is the standard deviation controlling the width of the kernel, which can also be empirically configured to efficiently approximate the B‐spline interpolation, should it be beneficial. All implementations for the trilinear, B‐spline interpolation and its approximation are differentiable during backpropagation, which allows the network to learn the optimal interpolation method for the task at hand.29
Loss function
3.3
We define image‐ and grid‐level similarity as the displacement field sampled at full resolution and a sparse, lower resolution using mean squared error, denoted as Lsimimage, where
and denotes an upsampling operation (described in Section 3.2). Sim is a similarity function, such as mutual information, MSE and cross‐correlation functions. Here, we adopted MSE for faster training. Additionally, Lsimimg is adapted into an uncertainty‐weighted loss, enabling the model to identify and adjust for regions with unreliable registration in Equation (2).
We additionally calculated Dice loss function between fixed mask sfix and warped mask from moving mask smov:
to measure the overlap between the predicted segmentation mask and the ground truth segmentation mask. A bending energy loss is defined as follows:
where ∇2 is the Laplacian operator, and ti is the displacement field at voxel location i, ρ,ϱ∈{x,y,z} denote three spatial dimensions. The bending energy loss penalizes the second derivative of the displacement field, encouraging the network to generate smoother deformation fields.30
The final loss can be written as follows: L=λ1Luncertainty+λ2LDSC+λ3Lbend, where λ1,λ2, and λ3 are hyperparameters that control the relative importance of the different loss terms. Dice loss is only included when segmentation masks for training data are available, that is, Datasets 1 and 2.
EXPERIMENTS
4
Datasets
4.1
Dataset 1: Longitudinal prostate T2‐weighted MR images were acquired from 86 patients at University College London Hospitals NHS Foundation. All patients provided written consent. Among them, 60 patients had two visits, eight patients had three visits, and 18 patients had four visits, yielding a total of 216 T2‐weighted volumes. This dataset was used to perform intrapatient registration. All the image and mask volumes were resampled to 0.7×0.7×0.7 mm3 isotropic voxels. The intensity of all image volumes is normalized to a range of [0,1]. To facilitate computation, all images and masks were also cropped from the center of volume to 128×128×102 voxels with preserved prostate glands. The dataset was divided into 70, 6, and 10 patients for training, validation, and holdout test sets, composing 156, 32, and 38 intrapatient pairs, respectively. For images in the holdout test set, pairs of corresponding anatomical and pathological landmarks are manually identified on moving and fixed images by a radiologist with more than 5 years of experience in reading prostate cancer mpMR images. Examples are shown in Figure 3, including patient‐specific fluid‐filled cysts, calcification, and centroids of zonal boundaries. The landmarks differ from patient to patient because of the complex anatomical structure of the prostate.
Examples of anatomical landmarks annotated for the same patient at two different time points. The first and second rows show five landmarks at the first and second time points, respectively.
Dataset 2: We used pelvis data from 850 prostate cancer patients at University College London Hospital for interpatient registration. Details of the data can be found in Refs. 31, 32, 33, 34, 35. All patients provided written consent, and ethics approval was granted as per trial protocols in Hamid et al.36 We use 313, 58, and 69 patients for training, validation, and holdout test sets, respectively. This dataset spans several clinical trials conducted at UCLH, with images acquired from various clinical scanners. The patient group includes both biopsy and therapy cases. Specifics on vendors and imaging protocols for each study can be found in Yan et al.37 All patients provided written consent, and ethics approval was granted as per trial protocols.36 We perform interpatient registration on Dataset 2. The 850 patients (30 patients have multiple T2 modalities) were randomly partitioned into train, validation, and holdout test sets, on patient‐level, resulting in 626, 116, and 118 patients, respectively. Within each set, image pairs are randomly formed and sampled without replacement, yielding 313, 58, and 59 pairs for train, validation, and holdout test sets, respectively. T2‐weighted images have in‐plane dimensions ranging from 180×180 to 640×640, with a resolution of 1.31×1.31 to 0.29 ×0.29 mm2, and slice thickness between 0.82 and 1 mm. All image modalities were resampled to isotropic voxels of 1 ×1×1 mm3 using linear interpolation, with intensity normalized between 0 and 1 per modality. Prostate masks are labeled by radiologists with more than 5 years of experience in interpreting prostate mpMR images. Intersubject corresponding landmarks are unavailable in this dataset.
Dataset 3: We use a public brain MR dataset LUMR from Learn2Reg38 to perform interpatient registration, which contains 3384 training and 40 validation sets, respectively. All image modalities were resampled to isotropic voxels of 1 ×1×1 mm3 using linear interpolation, with intensity normalized between 0 and 1 per modality. We split the dataset into 3000, 384, and 40 for training, validation, and holdout test, respectively. We used FreeSurfer39 to generate brain zonal segmentation, and seven landmarks were labeled by experienced experts for holdout test data as shown in Figure 4.
Examples of seven landmarks labeled by experts in brain dataset.
No segmentation label was provided for training; thus, the dice loss was not used during training for this dataset.
It is worth noting that only training and validation sets are used in updating weights and tuning hyperparameters. Holdout test sets are only used for model inference; all the results in this paper are based on the holdout test set.
Comparison and ablation studies
4.2
Comparison studies
4.2.1
To rigorously assess the performance of the proposed method, we conducted extensive experiments across three datasets, comparing against representative state‐of‐the‐art approaches: DDF estimation and keypoint‐based methods. For dense‐grid‐based approaches, we selected VoxelMorph,3 a CNN‐based method that predicts voxel‐wise displacement fields using U‐Net architectures, and TransMorph,4 a recent transformer‐based variant that leverages self‐attention mechanisms to model long‐range spatial dependencies. In the keypoint‐based category, we benchmarked against KeyMorph,5 which employs a sparse set of automatically detected anatomical keypoints to drive the registration. To further elucidate the efficiency advantages of our method, we performed a focused architectural comparison with KeyMorph, analyzing the relationship between model complexity (quantified by encoder depth) and registration accuracy. We included a strong iterative baseline: ANTs SyN(diffeomorphic)3 with matched preprocessing and masks, tuned on the validation set.
Ablation studies
4.2.2
We evaluated the significance of key components by isolating these elements. We identified their individual contributions to model performance and validated the effectiveness of our architectural decisions. Ablation studies involved the following experiments: (1) projected‐skip connection: We compared the performance of the proposed method with and without the skip‐projection connection, which is used to project 3D features into 1D vectors. (2) Grid size: We investigated the impact of varying grid sizes on registration performance, specifically using grid sizes of 5, 8, 10, and 15 in each dimension. (3) Encoder channel gencθ: We assessed the influence of different base channels (8, 16, and 32) in the encoder on registration performance. (4) Hyperparameters in loss function: We evaluated the effect of different hyperparameters in the loss function. (5) Bayesian head: We evaluate how the Bayesian head affects registration accuracy and deformation regularity.
Network and baseline implementations
4.3
We implemented all experiments with PyTorch 2.0 under CUDA 12.4 on NVIDIA‐SMI 550.107.02 with 32GB memory. The optimizer was Adam, with a learning rate of 10−4 and a batch size of 4. The network was trained for 300 epochs. All comparison methods were trained with their official implementation.
Evaluation metrics
4.4
Registration accuracy metrics:
The Dice similarity coefficient (DSC) was used to measure the overlap between the fixed and warped prostate masks. Centroid distance (CD) is adopted to evaluate the mean Euclidean distance between corresponding centroids: DCD=1K∑i=1Kcifix−ciwarp2, where ci(·) denotes the ith landmark center or region of interest mask center in the fixed/warped image, denoted as DCDldmk and DCDmsk, respectively. The centroids of the fixed and warped ROI masks, computed as c(·)=∑x∈Ωxs(·)(x)∑x∈Ωs(·)(x), with s(x)∈{0,1} the mask value at voxel x.
Jacobian‐based deformation regularity:
Let ϕ:Ω⊂R3→R3 denote the estimated spatial transformation. The Jacobian matrix of ϕ at voxel x is Jϕ(x)=∇ϕ(x)∈R3×3. We quantify local volume change using the log‐Jacobian determinant logdet(Jϕ(x)), where values near 0 indicate near‐incompressible mappings, positive values indicate local expansion, and negative values indicate local contraction, denoted as logdetJ. We also reported the folding rate, defined as the percentage of voxels with a negative Jacobian determinant, det(Jϕ(x))<0, which corresponds to noninvertible (folded) transformations.
For the overall methods comparison, we compared GridReg to each baseline on the same cases using paired, one‐sided tests and controlled multiplicity within each dataset × metric family using Benjamini–Hochberg FDR correction40 at 5%; we report q‐values. For the ablation study, as they are independent one‐by‐one comparisons, we performed a paired t‐test with a significance level α=0.05.
RESULTS
5
Comparison results
5.1
In Table 1, ANTs SyN was 40× slower than learning‐based methods and yielded lower Dice/CD. VoxelMorph and Transmorph, which used DDF, emphasized global shape registration and achieved much larger landmark TRE (8.76 and 7.73 mm) in Table 1 with Dataset 1.
For Dataset 2, GridReg achieved a DSC of 0.78, slightly lower than KeyMorph's score of 0.79 but higher than TransMorph and VoxelMorph. Both GridReg and KeyMorph achieved comparable performance in mask‐based CD for the pelvis, with GridReg at 4.52 mm and KeyMorph at 4.14 mm, suggesting reliable mask alignment. For Dataset 3, GridReg maintained a DSC of 0.75, outperforming VoxelMorph and TransMorph. GridReg matched KeyMorph on mask‐based CD (2.97 vs. 3.05 mm, p=0.832) and trailed slightly on Dice (0.77 vs. 0.78, p=0.471) but using less computation cost. These results suggested that when data features were rich in correspondence, architectural or transformation constraints mattered less, and performance differences were narrow. Figure 5 showed prostate registration, where large homogeneous regions made dense DDF models (e.g., VoxelMorph, TransMorph) more prone to physically unlikely local distortions, despite comparable Dice scores. Despite fine‐tuning the hyperparameters for bending energy loss, the network struggled to preserve the prostate structure. This highlights the importance of method selection in registering various medical images. In contrast, Figure 6 shows two fixed–moving brain pairs (first two columns) and the corresponding results from four methods, that is, GridReg, VoxelMorph, KeyMorph, and TransMorph, respectively, without implausible deformation readily visible across all methods.
Visualization of prostate registration. The first column and the second column show four examples of the fixed and moving images, respectively. The next four columns show the registration results from (a) GridReg, (b) VoxelMorph, (c) KeyMorph, (d) TransMorph, and (e) ANTs SyN, respectively.
Visualization of brain registration. The first column and the second column show four examples of the fixed and moving images, respectively. The next four columns show the registration results from (a) GridReg, (b) VoxelMorph, (c) KeyMorph, (d) TransMorph, and (e) ANTs SyN, respectively.
As shown in the last two rows of Table 1, The inference time were GridReg 0.23, VoxelMorph 0.23, KeyMorph 0.24, and TransMorph 0.25 s, respectively. Although GridReg used 2×–163× fewer parameters than the baselines, single‐image inference time is similar because GPU execution is dominated by reading the input images and copying them from memory to the compute units. Our method substantially reduces the number of parameters, enabling deployment on smaller GPUs, but it does not noticeably reduce inference time due to the nature of GPU computing. Keymorph achieved slightly lower DSC than the proposed method. It achieved higher accuracy in terms of CDs of landmarks, but it required more computation cost, as shown in Table 2. We compared KeyMorph and GridReg with varying encoder layers. KeyMorph's DSC improved from 0.54 at four layers to 0.86 at nine layers, requiring deeper networks for improved performance. GridReg consistently outperforms KeyMorph across all configurations, with DSC from 0.88 to 0.90. This highlighted GridReg's ability to maintain high performance with fewer parameters. Though GridReg achieved slightly lower landmark distances compared to KeyMorph with more than seven layers, it achieved more stable CD across all layers, further demonstrating its efficiency and reduced computation cost. KeyMorph demonstrated good performance on Dataset 3 (brain imaging), where structural consistency supports its keypoint‐based design, but performed less effectively on prostate datasets, where such consistency is lacking, as shown in Table 1.
Ablation studies
5.2
We conducted ablation studies to assess the effectiveness of the proposed method on Dataset 1. (1) Removing the skip‐projection module resulted in a lower DSC of 0.86 compared to GridReg (p=2.02×10−234). The skip‐projection and decoder refine the deformation field, capturing both global and local information for better accuracy. (2) Varying the grid control points showed that (10,10,10) control points achieved the best accuracy (Table 3). (3) Increasing base channels improved accuracy, with 32 channels performing best Dice, though the difference from 16 channels was not significant (DSC p=0.053). (4) Cubic B‐spline (via transposed convolution) achieved higher CDs (p = 0.800) than trilinear interpolation, while trilinear was slightly faster. The transposed‐convolutional B‐spline is markedly more efficient than the zero‐insertion B‐spline, which inflates memory by expanding the grid with zero before filtering.
(5) The Bayesian head has been used as a regularizer in prior work.12, 28 In our experiments, adding this head did not significantly improve registration accuracy (p=0.815). Likewise, Jacobian‐based regularity metrics showed no significant differences, although we observed a near‐significant trend on brain (prostate: p=0.513; brain: p=0.063; Table 4). Figure 7 presents two representative cases from the holdout test set, showing the fixed image, moving image, and corresponding uncertainty maps (σ2), where homogeneous regions exhibit higher uncertainty than high‐contrast boundaries. (6) Figure 8(1) shows that balancing bending energy loss weight (2×105) optimally reduces distortion and aligns regions of interest, achieving DSC = 0.90 and DCDldmk=6.14 mm. Figure 8(2,3) compares the separately trained and the grid‐variable model across different grid sizes on Dataset 1. Using the same grid sizes, performances are similar: No significant differences were detected (p>0.205). The only visible gap is at grid = 5, where the grid‐adaptive model shows a 0.39 mm lower CD than that of the model with prefixed grid size (p=0.570) and 0.02 higher Dice than the prefixed grid size (p=0.043).
This figure shows four examples of uncertainty maps generated by the Bayesian Grid transformer. A lighter area in the uncertainty map represents lower uncertainty, while a darker area represents higher uncertainty.
(1) Effect of bending energy weight on segmentation accuracy (DSC) and contour distance (CD); (2), (3) comparisons on Dataset 1 showing Dice and centroid distance between separately trained and auto‐adapted models with the same grid size range from 5 to 15.
DISCUSSION
6
Learning‐based registration trades hand‐crafted objectives for data‐driven models that learn complex, nonlinear correspondences and provide single‐pass fast inference with sufficient data requirements. Besides, with the domain‐shift strategy, it could transfer across domains.41 In data‐scarce settings, classical methods with strong inductive priors may remain competitive. With moderately more data, as demonstrated in all our experiments, however, learning‐based registration attains state‐of‐the‐art accuracy with substantially lower runtime. Across three datasets, our results highlight complementary strengths and failure modes of current 3D registration strategies, and motivate design choices behind GridReg. Dense DDFs can overfit locally in homogeneous tissue. On Dataset 1 (prostate), VoxelMorph and TransMorph achieved reasonable Dice but large landmark TRE and visibly distorted gland interiors (Figure 5). Increasing the bending‐energy weight reduced local distortion but also impeded convergence (Figure 8(1)), reflecting a known smoothness–fidelity trade‐off: Excessive regularization suppresses deformations, whereas weak regularization permits implausible warps.9, 10 Dice alone did not fully expose these issues, underscoring the need to consider geometric plausibility alongside overlap.
Prostate MR images often exhibit relatively homogeneous intensity with the prostate gland and substantial anatomical variation across patients. These characteristics make it challenging for deep networks to reliably identify consistent keypoints or correspondences between different subjects. Constraining the DoFs at prediction time using a simple coarse grid reduces the hypothesis space of admissible flows (often unnecessary local deformation), limiting spurious local distortions without sacrificing mask overlap. In contrast, brain MR (Dataset 3) provides abundant, consistent edges; all methods produced visually plausible deformations with similar CDs.
In prostate registration, the best‐performing grids were over 20× coarser than voxel‐level DDFs, providing no evidence that a full‐resolution parameterization is necessary for these datasets. Instead, coarse grids benefit from inherent spatial regularization, and performance was relatively insensitive to the exact grid size within a reasonable (albeit potentially application‐dependent) range, from 5×5×5 to 15×15×15. We observed that using a grid size of approximately 10% of the image size, in each dimension, led to generally good registration performance, based on Dataset 1.
Although Bayesian head did not improve registration performance, we included this uncertainty estimation for reference purposes for those interested in Figure 7 and Table 3. These visualizations highlight two main observations: regions with weak local features (e.g., homogeneous areas such as prostate) are assigned high uncertainty due to the lack of distinctive gradients for unambiguous alignment, whereas contours and high‐contrast structures exhibit lower uncertainty.
Clinical relevance
Higher DSCs in the prostate and pelvis regions suggest that GridReg could support future clinical applications in organ tracking and atlas construction, pending prospective validation and task‐specific accuracy benchmarks. The low memory consumption of GridReg makes it suitable for use in resource‐constrained environments, such as mobile devices and edge computing systems.
CONCLUSION
7
This work provides a systematic comparison of learning‐based registration parameterizations that predict deformation from either (1) sparse, coarse regular grids of control points; (2) scattered nongridded control points; and (3) DDFs. We show that regular grids offer a practical advantage: They enable fast and stable reconstruction of DDFs via standard interpolation (e.g., trilinear) or transpose‐convolution‐based spline approximations, avoiding the additional complexity and overhead of resampling from irregular point sets. Importantly, a sparse deformation parameterization provides implicit capacity control: Fewer DoFs suppress high‐frequency voxel‐wise warps driven by noisy or ambiguous correspondences, while reducing memory and computational cost. GridReg further supports grid‐adaptive training, allowing a single model to operate across multiple grid resolutions and to select an effective grid density for each dataset through validation, rather than committing to a fixed resolution a priori. Finally, the approach is encoder‐agnostic: It can be attached to different backbone encoders from existing registration networks with minimal changes. Overall, GridReg provides a simple, general, and efficient path to sparse deformation modeling, improving the efficiency–accuracy trade‐off and broadening applicability across diverse medical image registration tasks.
CONFLICT OF INTEREST STATEMENT
Mark Emberton receives research support from the United Kingdom's National Institute of Health Research (NIHR) UCLH/UCL Biomedical Research Centre. He acts as consultant/lecturer/trainer to Sonacare Inc., Angiodynamics Inc., Early Health Ltd, and Albemarle Medical Ltd. The remaining authors declare no conflicts of interest.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1Hill DL , Batchelor PG , Holden M , Hawkes DJ . Medical image registration. Phys Med Biol. 2001;46(3):R 1.11277237 10.1088/0031-9155/46/3/201 · doi ↗ · pubmed ↗
- 2Fitzpatrick JM , Hill DL , Maurer CR , et al. Image registration. In: Handbook of Medical Imaging. SPIE Press, Vol 2. 2000:447‐513.
- 3Balakrishnan G , Zhao A , Sabuncu MR , Guttag J , Dalca AV . Voxel Morph: a learning framework for deformable medical image registration. IEEE Trans Med Imaging. 2019;38(8):1788‐1800.10.1109/TMI.2019.289753830716034 · doi ↗ · pubmed ↗
- 4Chen J , Frey EC , He Y , Segars WP , Li Y , Du Y . Trans Morph: transformer for unsupervised medical image registration. Med Image Anal. 2022;82:102615.36156420 10.1016/j.media.2022.102615 PMC 9999483 · doi ↗ · pubmed ↗
- 5Evan MY , Wang AQ , Dalca AV , Sabuncu MR . Key Morph: robust multi‐modal affine registration via unsupervised keypoint detection. In: Medical Imaging With Deep Learning. 2022.
- 6Hoffmann M , Billot B , Greve DN , Iglesias JE , Fischl B , Dalca AV . Synth Morph: learning contrast‐invariant registration without acquired images. IEEE Trans Med Imaging. 2021;41(3):543‐558.10.1109/TMI.2021.3116879 PMC 889104334587005 · doi ↗ · pubmed ↗
- 7Chen J , Liu Y , Wei S , et al. A survey on deep learning in medical image registration: new technologies, uncertainty, evaluation metrics, and beyond. Med Image Anal. 2024;100:103385.39612808 10.1016/j.media.2024.103385 PMC 11730935 · doi ↗ · pubmed ↗
- 8Yang Q , Atkinson D , Fu Y , et al. Cross‐modality image registration using a training‐time privileged third modality. IEEE Trans Med Imaging. 2022;41(11):3421‐3431. doi:10.1109/TMI.2022.3187873 35788452 · doi ↗ · pubmed ↗