Bloodwork-free Early Screening for Alzheimer’s Disease via Comorbid Pattern Recognition in Electronic Health Records
Dmytro Onishchenko, James A. Mastrianni, Ishanu Chattopadhyay

TL;DR
A new AI tool called ZeBRA can predict Alzheimer’s disease up to 10 years before diagnosis using only routine health records, without needing blood tests or imaging.
Contribution
ZeBRA introduces a scalable, bloodwork-free early screening method for Alzheimer’s using EHR data with high accuracy and interpretability.
Findings
ZeBRA achieved an AUC of 0.93 for 1-year and 0.83 for 10-year prediction of Alzheimer’s disease.
Higher ZeBRA scores correlated with lower MoCA scores, indicating greater cognitive impairment.
The model maintains consistent performance across diverse demographic subgroups and over time.
Abstract
Early identification of Alzheimer’s disease and related dementias (ADRD) remains limited by the need for specialized tests and late-stage diagnosis. The Zero-burden Risk Assessment (ZeBRA) is a AI-driven score that predicts incident ADRD up to a decade before diagnosis, using only routine electronic health record (EHR) data, without laboratory tests, imaging, or questionnaires. Trained on 487,989 cases and 12,483,718 controls from nationwide U.S. insurance claims and validated on held-back samples, and two independent cohorts, ZeBRA achieved AUC = 0.93 and 0.83 for predicting out to 1-year and 10-year horizons respectively, maintaining positive likelihood ratios (>10) at 95% specificity and stable discrimination over time (AUC drop ≈ 1 to 1.3% per year). Performance was consistent across age, sex, race, and ethnicity subgroups. In a limited prospective pilot, higher ZeBRA scores…
Genes, proteins, chemicals, diseases, species, mutations and cell lines named across the full text — each resolved to its canonical identifier and authoritative record.
Click any figure to enlarge with its caption.
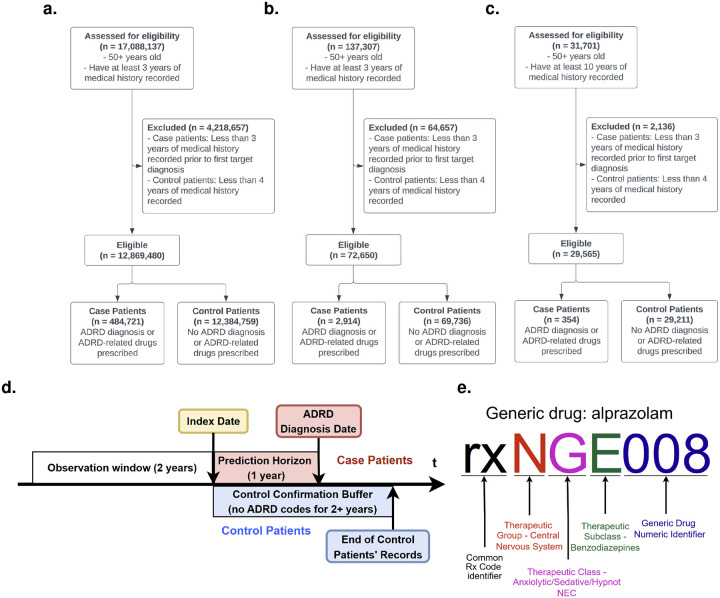 Figure 1
Figure 1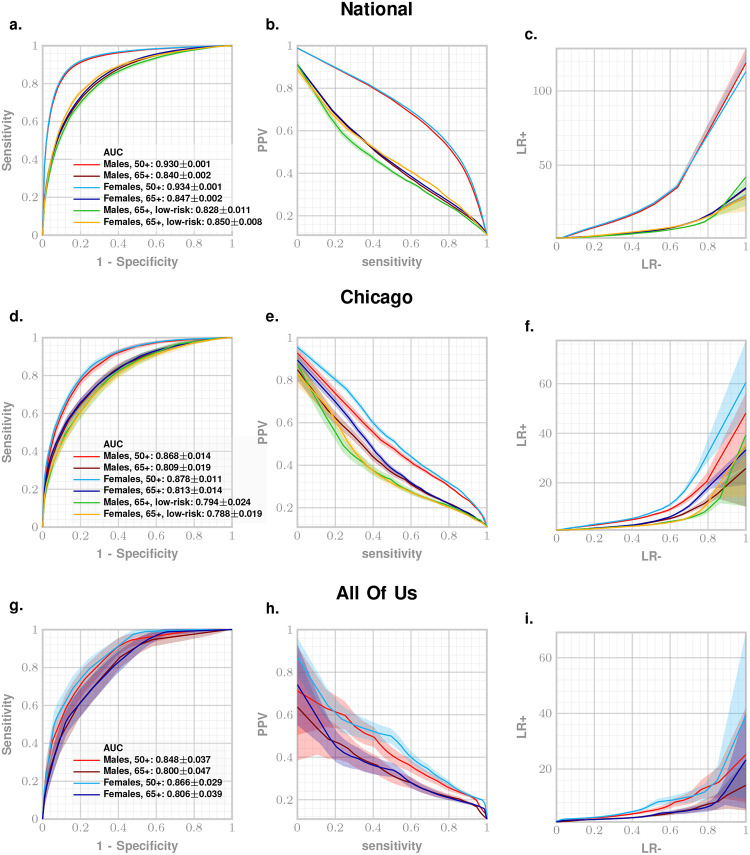 Figure 2
Figure 2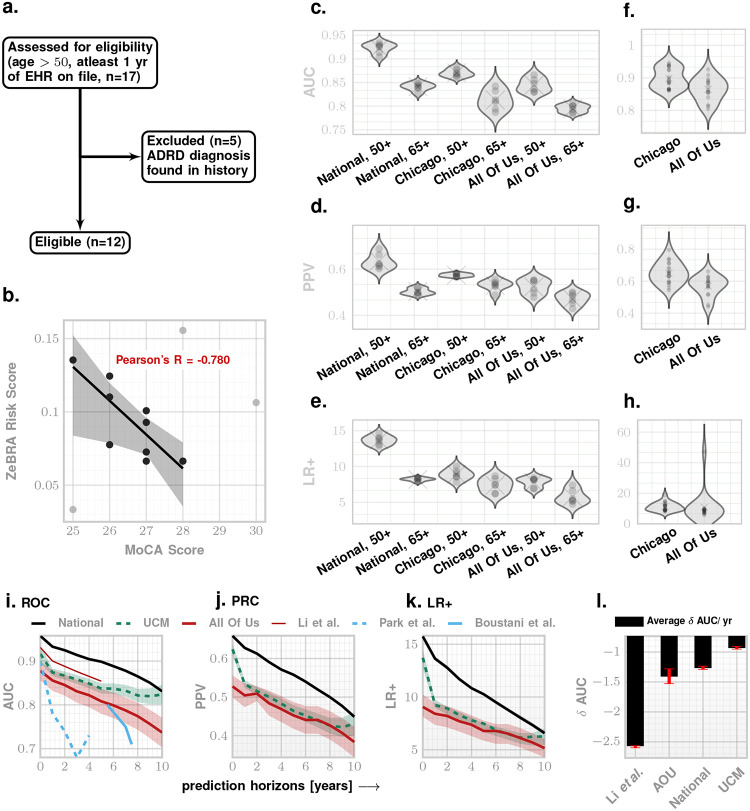 Figure 3
Figure 3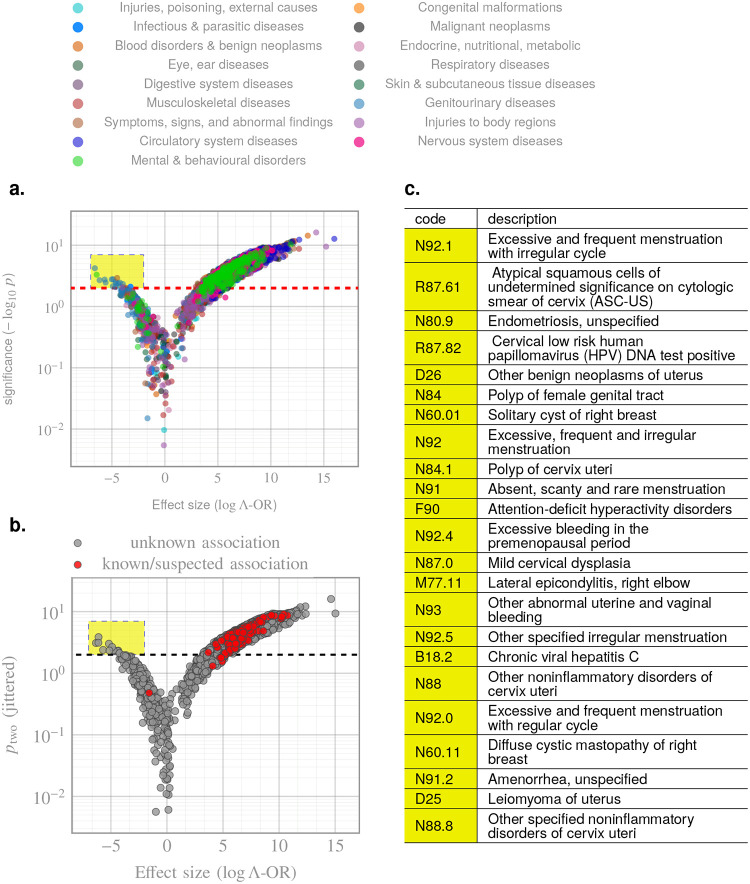 Figure 4
Figure 4Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsMachine Learning in Healthcare · Dementia and Cognitive Impairment Research · Health, Environment, Cognitive Aging
Introduction
Alzheimer’s disease (AD), the leading cause of dementia, accounts for 60–80% of cases worldwide^1,2^. The global burden of AD and related dementias (ADRD) has more than doubled since 1990, with prevalence projected to reach 13.8 million in the United States by 2050 and over 80 million worldwide by 2040^3–6^. In the U.S. alone, ADRD contributed to over 120,000 deaths in 2022 and more than $400 billion in annual unpaid caregiving costs^4^. Despite decades of research, therapeutic progress has been modest, with recent agents such as lecanemab and donanemab showing only limited benefits^4^.
AD is now suspected to have a prolonged presymptomatic phase during which molecular pathology accumulates in the absence of overt cognitive symptoms^7,8^. The 2024 NIA-AA framework redefined AD biologically, based on amyloid or tau positivity regardless of clinical presentation^9,10^. However, biomarker-based diagnostics are still expensive and/or invasive, and particularly impractical for population-wide screening, making direct adoption of this criteria difficult in practice. Blood-based assays show promise but remain unapproved for routine use^4^. These limitations underscore the need for passive, scalable, and cost-effective tools that can identify at-risk individuals before cognitive decline^11–14^.
Here we present the Zero-burden Risk Assessment (ZeBRA) algorithm, that analyzes routinely collected electronic health records (EHRs) to detect longitudinal comorbidity patterns predictive of a future ADRD diagnosis, realizing a reliable non-invasive point-of-care screening tool. Unlike existing approaches, ZeBRA requires no laboratory testing, imaging, or questionnaires, enabling low-cost, near-instantaneous risk assessment. Using multiple large, heterogeneous datasets, we demonstrate that ZeBRA predicts ADRD onset with clinically useful accuracy up to ten years in advance, and is robust across age, sex, race, and baseline risk. These findings support its potential as a presymptomatic screening tool for population health management and for enriching clinical trial cohorts with high-risk individuals.
ZeBRA models the joint comorbidity structure of diagnosis, prescription, and procedure codes in patient EHRs, achieving a 5–8 % absolute AUC gain over the nearest competitor^15^, sustained over a decade-long horizon across four independent data sources. The model remains stable across demographically disparate populations and provides robust, literature-consistent risk attribution through a noise-corrected odds-ratio metric (the Λ-OR) that enables an interpretable robust universal point-of-care screening tool for early diagnosis of ADRD.
Results
Datasets:
We evaluated ZeBRA on four cohorts: (1) the Merative MarketScan^®^, 2007–2024^36^) comprising over seven billion time-stamped diagnosis codes and tracking over 96 million patients for 1–16 years, referred to as the National dataset; (2) a de-identified patient cohort from the University of Chicago Medical Center, comprising patients treated between 2006 – 2021 (Chicago); (3) the NIH All of Us Research Program, comprising patient data collected between 2000 – 2023 (All Of Us), with > 80% participants historically underrepresented in biomedical research^37^; and (4) data from a limited prospective pilot at UChicago (UCM Pilot).
We formulated the prediction of a future diagnosis as a binary classification problem of patients’ time-stamped sequences of diagnostic codes into case and control subcohorts. We defined cases as individuals who met at least one of the following criteria: (1) a recorded diagnosis of Alzheimer’s disease and related dementias (ADRD), identified via corresponding International Classification of Diseases, Tenth Revision (ICD-10) diagnostic codes (see Supplementary Table SI-I, we focus on ADRD codes exclusively following literature^15^, and do not target mild cognitive impairment); or (2) a prescription record for an anti-dementia medication (see Supplementary Table SI-II). Control patients were defined as individuals with no diagnoses or prescriptions specified in the case definition, and with no recorded conditions known to be associated with or causally related to dementia (See Supplementary Table SI-III).
For National, Chicago, and All Of Us we included patients aged ≥ 50 years with ≥ 3 years of continuous history; we excluded cases with < 3 years before first ADRD code and controls with < 4 years of history. To address All Of Us heterogeneity, we required ≥ 10 years of records. CONSORT diagrams for National/Chicago/All Of Us and UCM Pilot appear in Figures 1 and 3a. In total, with . We used 66% of National for training and 34% for primary out-of-sample validation; Chicago, All Of Us, and UCM Pilot were reserved entirely for independent validation (Table I).
For case patients the index date was 1 year before the first ADRD code, yielding a 1-year Prediction Window. For controls, the index date was 2 years before end-of-record, yielding a 2-year control confirmation buffer to mitigate misclassification. For both, the model training period or the Observation Window was the 2 years preceding the index date (Fig. 1d).
Model and Evaluation:
We used three EHR modalities within each observation window: diagnoses (DX), generic prescriptions (RX), and procedures (PROC) without pre-selection, leveraging all available code sets and abbreviations. ZeBRA comprises six LightGBM base models^38,39^ (presence and odds-ratio embeddings for DX, RX, PROC) whose outputs, together with sex and age, feed a final classifier producing the ADRD risk score (training/validation workflows in Supplementary Figures SI-I, SI-II). Metrics include AUC, sensitivity, specificity, PPV, NPV, accuracy, and likelihood ratios (LR^+^, LR^–^); LR^+^ ≥ 10 indicates strong diagnostic utility^40–42^. High-risk and low-risk strata are defined by presence/absence of known ADRD comorbidities^16,18,21–25,28,29,32,34^ (Supplementary Table SI-IV). To harmonize prevalence across datasets, performance is reported assuming a 10.9% ADRD prevalence (1 in 9)^4^. While the true prevalence in the broader 50+ population is lower, positive and negative predictive values scale approximately linearly with prevalence, whereas discrimination metrics (AUC, sensitivity, specificity, likelihood ratios) are prevalence-invariant; we therefore adopt a fixed 10.9% prevalence for all datasets to enable direct performance comparison, consistent with prior EHR-based studies including Li etal.^15^, which report results under a similar prevalence assumption.
Predictive Performance:
We measure our performance using standard metrics including the Area Under the receiver-operating characteristic curve (AUC), sensitivity, specificity, Positive Predictive Value (PPV), Negative Predictive Value (NPV), and accuracy. We also report positive likelihood ratio (LR+) that indicates how much a positive screening result increases the odds of a patient to be diagnosed with ADRD in future, and negative likelihood ratio (LR-) that indicates how much a negative screening result decreases those odds. While lower limit of a clinically meaningful positive likelihood ratio is 2,^40^ positive likelihood ratios of 10 and higher are generally indicative of a screening tool with strong diagnostic utility and high clinical significance.^41,42^
To demonstrate performance stratified for different ADRD risk groups, we define the high-risk subcohort as patients having one or more conditions in the observation window that are known ADRD co-morbidities^16,18,21–25,28,29,32,34^ (See Supplementary Table SI-IV), and a low-risk subcohort as patients that have none of these conditions recorded in the observation window. Results in the low risk sub-cohort are of particular significance, because these patients lack common risk factors of ADRD and are at a higher risk of delayed or missed diagnosis.
Our main results are presented in Fig. 2 as ROC, precision-recall (PRC) and likelihood ratio (LR) curves for National, Chicago, and All Of Us datasets. Predictive performance for 50+ and 65+ age groups at 95% specificity setting is enumerated in Table II. We achieve out-of-sample AUC of 93% and 84% for both males and females on held-back samples from the National dataset for 50+ years and 65+ year sub-cohorts respectively (Figure 2).
Performance of ZeBRA stays robust across the other independent datasets reaching AUC of 87–88% for 50+ years old and 81% for 65+ years old subcohorts of Chicago dataset (Figure 2d), and AUC of 85–86% for 50+ years old and 80% AUC for 65+ years old cohorts for All Of Us dataset (Fig. 2g).
Translated into screening tool performance in primary care settings with a 95% specificity risk threshold, for every 100 patients to be diagnosed with ADRD in 1 year with no currently present risk factors of ADRD, ZeBRA raises flag on 104 patients, out of which 65 are true positives, 40 are false alarms, and 35 cases are missed.
Additionally, ZeBRA achieves AUC of 82–85% AUC for 65+ years old low risk subcohorts of National dataset and 79% AUC for 65+ years old low risk subcohorts of Chicago dataset. Translated into screening tool performance in primary care settings with a 95% specificity risk threshold, for every 100 patients to be diagnosed with ADRD in 1 year with no currently present risk factors of ADRD, ZeBRA raises flag on 72 patients, out of which 37 are true positives, 35 are false alarms, and 63 low-risk cases are missed.
Additionally, for the Chicago and All Of Us datasets (which include structured information on patients’ race, ethnicity, and sex) we report model performance across demographic subcohorts (Table III, Fig. 3c–h). Performance remains consistent across all reported demographic strata: sex (male, female), race (White, Black, Asian, Other), and ethnicity (Hispanic, non-Hispanic) groups (AUC 86% – 94% for the Chicago dataset, and 73% – 85% for the All Of Us dataset, Mean LR+ were 10.2 for Chicago and 8.9 for All Of Us). These findings are particularly relevant given persistent socioeconomic and demographic disparities in ADRD screening access and outcomes.
Our predictive performance expectedly degrades as we predict the onset of ADRD earlier. To assess this degradation of performance, we conducted a retrospective validation on National, Chicago, and All Of Us datasets with prediction horizon ranging from 0 to 10 years. For each horizon, we ensured that corresponding control cohort comprises patients who are not diagnosed with ADRD for a period that is at least one year longer than the prediction horizon (ranging from 1 years to 11 years respectively, Figure 3i–k). Our results show that ZeBRA AUC degrades approximately 1 – 1.3% per year. This degradation is slow enough to suggest that we can use ZeBRA with acceptable reliability to predict diagnoses up to 10 years into the future. Importantly, ZeBRA significantly outperforms reported ADRD studies that provide AUC for extended prediction horizons^15,43,44^ (Figure 3i–k and Table IV and Supplementary Table SI-V).
Prospective Pilot:
Having established performance in retrospective data, we next evaluated ZeBRA ‘s clinical relevance via prospective correlation with cognitive scores (Fig. 3a–b). For our limited prospective validation, we collected EHR data as part of a pilot study conducted at the University of Chicago Medical Center to assess the risk of ADRD onset using ZeBRA and assessed participants in person using Montreal Cognitive Assessment (MoCA) score^45^. In this validation, we included all patients with available MoCA scores and corresponding EHR data, and excluded individuals with ADRD recorded in medical history (Fig. 3a).
MoCA assessment results were available in two formats: the full-scale version with a maximum score of 30 (MoCA-30), and a subset version excluding visual tasks, with a maximum score of 22 (MoCA-22). For consistency, all MoCA-22 scores were converted to the standard 30-point scale using a validated conversion method^46^.
We computed ZeBRA risk scores for these patients using the date of MoCA assessment as the index date, and an observation window of 2 years leading to the index date, and evaluated the association between ZeBRA-predicted risk of future ADRD and cognitive performance as measured by MoCA (Figure 3b): lower MoCA scores, indicating greater cognitive impairment were strongly correlated with elevated ZeBRA risk scores (Pearson’s ).
ZeBRA Comorbidity Patterns:
Beyond predictive accuracy, we examined how individual ICD codes in patient histories modulate the risk of ADRD onset. To address potential label noise, arising from misdiagnosed cases and undiagnosed or late-diagnosed controls, we introduced a model-informed metric for effect-size estimation and feature attribution, termed the Λ-OR (see Online Methods). The resulting volcano plot (Fig. 4a) exhibited the expected pattern, with circulatory and nervous system diseases showing the most pronounced risk-increasing effects. We also identified a subset of codes with statistically significant protective associations (see Discussion). ZeBRA ‘s estimated impacts for known or suspected risk factors of ADRD are summarized in Table V, demonstrating strong alignment with previously reported comorbid associations. All codes whose prefixes match indications in Table V are highlighted in Fig. 4b, showing that such prior diagnoses are almost universally attributed as risk-increasing.
Performance Comparison against existing models:
We benchmarked ZeBRA against prior EHR-based ADRD prediction frameworks from Li et al.^15^ and Wang et al.^35^ using the National dataset for direct comparison (Tables VI – VII). Li et al. evaluated four progressively stringent case definitions: CP1 (one or more encounters with an ADRD diagnosis), CP2 (two or more encounters), CP3 (five or more encounters), and CP4 (at least one ADRD diagnosis and one anti-dementia prescription). Across all definitions, ZeBRA demonstrated consistently higher discrimination. At the 1-year horizon, ZeBRA improved mean AUC by 5–8% relative to Li et al. (e.g., 0.93 → 0.96 for CP1 and 0.90 → 0.95 for CP2), with performance advantages persisting through five years (AUC ≥ 0.91 for ZeBRA vs. 0.85 for Li). The difference widened further at longer horizons, where Li’s model degraded rapidly beyond three years ( AUC/year ≈ −2.6%), while ZeBRA exhibited only gradual decay ( AUC/year ≈ −1.0 to −1.3%), maintaining AUC ≥ 0.90 through five years and AUC ≥ 0.83 at ten years (Fig. 3l).
When compared with the large-language-model framework of Wang et al., which combined structured EHR input with in-context embedding refinement, ZeBRA achieved markedly higher precision and overall balance (Table VII). At the 1-year horizon, ZeBRA improved F1 scores from 0.31–0.34 to 0.56–0.60 on the same cohort, reflecting both superior discrimination and better calibration.
These comparisons, all performed on the National dataset, demonstrate that ZeBRA not only outperforms existing ADRD predictors in absolute accuracy and temporal stability but also retains calibrated, noise-corrected risk attributions via Λ-OR analysis, capabilities unavailable in conventional machine-learning or LLM-based approaches.
DISCUSSION
We developed and validated ZeBRA, an automated, zero-burden screening tool for ADRD that leverages longitudinal comorbidity patterns in routine EHR data. Across sex, age, race/ethnicity, and baseline risk strata, ZeBRA accurately preempts incident ADRD for up to ten years before the first recorded diagnosis.
Across four independent datasets, ZeBRA achieved consistently high discrimination, with AUCs of 0.93 ± 0.01 at 1 year and 0.83 ± 0.01 at 10 years, corresponding to LR^+^ > 10 at 95% specificity. Performance remained stable across sex, age, race, and ethnicity subgroups (Table III), indicating minimal demographic bias and strong generalizability. Notably, predictive strength persisted even within the low-risk subcohort lacking known ADRD comorbidities (AUC > 0.80), underscoring ZeBRA ‘s ability to detect latent preclinical signals invisible to conventional risk models. Importantly, temporal analysis revealed that ZeBRA ‘s discriminative power degrades only gradually over time, with a mean compared with ≈ 2.6% for Li et al., maintaining AUC ≥ 0.83 at ten years (Fig. 3l). This stability across horizons suggests that predictive signals encoded in comorbidity trajectories remain informative throughout the prolonged preclinical phase.
Using the lambda-Odds Ratio (Λ-OR) for noise-corrected attribution, we identified the comorbid indications with the strongest population-level associations (Fig. 4), including malignant neoplasms, congenital malformations, and diseases of the nervous, digestive, and integumentary systems. These signals align with previously reported ADRD risk factors and comorbidities^16–34^ (Table V), suggesting that ZeBRA offers dependable explainability: high-effect-size factors modulating ZeBRA risk align with established or suspected ADRD risk drivers in current clinical literature.
In addition, our Λ-OR analysis revealed several comorbidity codes with statistically significant “protective” associations (Fig. 4a). These predominantly comprise reproductive and gynecologic disorders including excessive or irregular menstruation, endometriosis, benign uterine and breast neoplasms, cervical polyps and dysplasia, and ovarian cysts. Although clinically heterogeneous, these conditions share a common endocrine substrate, namely prolonged or dysregulated exposure to endogenous estrogen. There is extensive epidemiologic and experimental evidence that cumulative lifetime estrogen signaling is neuroprotective^47^. Women with longer reproductive spans (later menopause, later age at last childbirth) exhibit reduced dementia risk, whereas abrupt loss of estrogen (e.g., surgical oophorectomy, premature menopause) is consistently associated with heightened risk^48–50^. Mechanistically, estrogen enhances synaptic plasticity, modulates hippocampal connectivity, reduces -amyloid aggregation, improves mitochondrial function, and buffers oxidative stress—all pathways implicated in Alzheimer’s disease pathogenesis^51,52^. Thus, the appearance of these gynecologic codes as protective within our framework is biologically consistent with established estrogen-mediated resilience against neurodegeneration.
We observed ADHD as a protective comorbidity, which requires a more nuanced interpretation. ADHD is characterized by lifelong executive and attentional dysfunction involving frontostriatal circuits, domains that overlap substantially with those affected in MCI and early dementia^53,54^. In older adults, this overlap complicates differential diagnosis and has been described as a phenotypic mimic of prodromal neurodegeneration, raising the possibility of diagnostic substitution or delayed dementia coding in real-world clinical data. Thus, the negative association is unlikely to reflect true neurobiological protection and may instead capture care-pathway and ascertainment effects, whereby individuals with longstanding ADHD engage earlier with psychiatric or neurologic care and follow distinct diagnostic trajectories. A secondary, speculative explanation is differential exposure to psychostimulants, which increase dopaminergic and noradrenergic signaling/neuromodulatory systems supporting attention and executive function in aging^55^, although evidence that stimulant use modifies ADRD risk remains limited.
Importantly, ZeBRA does not posit causality; instead, it identifies latent comorbidity signatures that shift the likelihood surface for ADRD onset. The emergence of reproductive codes in the protective direction highlights the interpretability of the framework: clinically meaningful and biologically plausible signals surface naturally when the model is trained on unconstrained diagnostic histories.
Positioning relative to prior EHR models:
The strongest previously reported EHR-based screeners include Li et al.^15^ (AUC = 90% at 1-year and 85% at 5-year windows) and Wang et al.^35^, who combined supervised learning with in-context LLM refinement (precision = .2442±.0247 at recall = .5560±.0524 at 1-year). Both represent important advances; however, neither reports performance across age bands, demographics, or high-/low-risk subcohorts, nor evaluation on datasets from independent health systems. These gaps are critical for clinical translation, given the known heterogeneity in EHR coding across sites. ZeBRA achieves the best overall performance among the three (Tables VI, VII), maintains robust accuracy up to ten years before diagnosis (versus five and three years, respectively), validates retrospectively on two independent datasets (Chicago, All Of Us) (Table II, Fig. 2), and demonstrates prospective concordance with cognitive screening (Fig. 3b). Notably, the average rate of AUC degradation with horizon ( ) was approximately 1.0% for ZeBRA compared with 2.6% for Li et al., confirming that predictive fidelity is preserved over longer time frames.
Methodological contributions:
Although all three approaches are data-driven, ZeBRA addresses EHR sparsity, skew, and heterogeneity via (i) multi-channel embeddings (presence and odds ratio) for diagnoses, prescriptions, and procedures; (ii) an ensemble of LightGBM classifiers^38,39^; and (iii) hierarchical code groupings that enrich rather than truncate comorbidity representation. This design reduces vulnerability to coding inconsistency and incompleteness common in practice^56,57^. The study’s scale ( ) exceeds that of Li ( ) and Wang ( ), representing, to our knowledge, the largest cohort used for EHR-based early screening of ADRD or any other condition. Finally, we introduce a model-informed, regularized effect-size estimator (Λ-OR) tailored to large observational datasets, complementing headline metrics with clinically interpretable signals.
Clinical integration and use cases:
Without the requirement for laboratory testing, imaging, or questionnaires, ZeBRA can operate as a low-cost, near-instantaneous screen in primary care or specialty settings (e.g., neurology, geriatrics), either alone or adjunctive to brief, validated neuropsychological instruments as recommended by the American Academy of Neurology^58^, including within the Medicare Annual Wellness Visit cognitive assessment^59^. Such integration could help address underuse of cognitive screening in primary care, where time, workflow, and follow-up uncertainty remain barriers^13,60,61^. ZeBRA could also be applied to individuals with subjective memory concerns or incipient mild cognitive impairment who have not undergone biomarker evaluation, and for presymptomatic trial enrichment, where scalable, passive, and equitable identification of high-risk participants is a critical unmet need.
Translational context:
Therapeutic progress in ADRD has been limited, and the amyloid cascade hypothesis remains debated^62–67^. With >130 disease-modifying trials active as of 2025 and modest effects from recent anti-amyloid agents^4,68^, shifting earlier—into the prolonged presymptomatic phase defined biologically by amyloid/tau positivity^7–10^—is a priority. Yet PET/CSF-based diagnostics are costly and operationally complex, and blood-based assays are not FDA-approved for routine use^4^. Passive, scalable screens are therefore essential^11–14,69–71^. By exploiting what already exists in the EHR, ZeBRA offers a pragmatic path to earlier identification, broader outreach, and more inclusive recruitment, potentially lowering costs and widening access to presymptomatic interventions.
Limitations and future work:
This study is retrospective for National, Chicago, and All Of Us, and includes a limited prospective pilot; larger, multi-site prospective trials are needed to quantify impact on clinical decision-making, downstream testing, and health outcomes. Although we harmonize evaluation at a fixed prevalence (10.9%), site-specific calibration will be important for deployment. While we report performance across demographics and risk strata, formal fairness assessments (e.g., subgroup calibration, error parity) and health-economic analyses were beyond scope. Finally, Λ-OR offers population-level interpretability, but patient-level explanations and workflow-aligned thresholds (e.g., referral vs. watchful waiting) merit further study.
In conclusion, ZeBRA delivers accurate, generalizable, and interpretable ADRD risk screening across heterogeneous datasets—including two external retrospective cohorts and a prospective pilot—without requiring new tests. Its scalability, long-horizon stability, and low operational burden position it as a practical tool for population health management and for enriching presymptomatic clinical trials, complementing (rather than replacing) biomarker-based diagnostics and neuropsychological assessment.
Online Methods
Feature Engineering
We denote the observation window of the patient records contain of each patient as:
where is a set of used EHR data channels, are codes recorded in each channel, are time points for the recorded codes measuring weeks since the time of the first recorded DX code , and is the set of valid codes for each EHR data channel. We map each patient’s observation window to representations, namely the binary presence feature vector and the odds-ratio embedding vector, with each EHR data channel mapped separately, totaling 6 feature vectors per patient.
Prescription Drug Coding
Prescription drug (RX) codes in our primary (National) dataset are provided in the National Drug Code (NDC) format^72^, which is designed to facilitate the identification and commercial distribution of pharmaceuticals. This coding system, as well as the widely adopted RxNorm^73^ emphasizes product-specific and manufacturer details of the generic drugs rather than their therapeutic classification and characteristics, thus hindering its use for EHR data analysis.
To facilitate the analysis of prescriptions according to their therapeutic effect, we developed a custom NDC-compatible coding scheme to convert all RX codes in the used datasets. This system, analogous to ICD-10 for diagnostic codes, progressively details therapeutic information of a generic drug with each successive character in the code. Each RX code begins with an “rx” prefix to enhance readability and facilitate parsing. This is followed by three alphanumeric characters encoding, respectively, the Therapeutic Group, Therapeutic Class, and Therapeutic Subclass, latter derived from the Therapeutic Class column in the RED BOOK. In cases where any of these attributes are missing or listed as NEC (i.e., not elsewhere classifiable), we use the placeholder character “X”. Finally, to identify a specific generic drug, we append a numeric identifier indicating its order within the set of drugs sharing the same initial five-letter therapeutic code (see Figure 1e for the example of generic drug coding).
Information on NDC codes and the corresponding therapeutic attributes of the generic drugs they represent is sourced from the Micromedex RED BOOK^©^ ^74^, which accompanies the Merative MarketScan dataset.
Code Presence Embedding Vectors
For each EHR data channel , we define a binary presence embedding based on the patient observation window . Let denote the set of all distinct codes observed across the embedding inference set, augmented with hierarchical code prefixes to enable generalization across varying code granularities.
Specifically, we include for each code its prefixes according to the following scheme:
- DX: prefixes of length 1, 2, 3, 5 and 6,
- RX: prefixes of length 3, 4, 5, and 8,
- PROC: prefixes of length 1, 2, 3, 4, and 5.
We define the augmented code set for channel as:
Let be the set of codes and code prefixes present in the observation window for patient . Then, the presence vector is defined elementwise as:
In total, the number of codes and code prefixes we track is 21,070 for DX channel, 2,156 for RX channel, and 17,261 for PROC channel. See Supplementary Table SI-VI for the total number of codes and prefix-based aggregations used in each presence model. The resulting binary vectors serve as input to the gradient boosting classifiers for each EHR channel.
Odds Ratio Embedding Vectors
For each code , in each data channel , we compute the dictionary of cubed odds ratios based on patients from the Code Inference Set:
Then we compute odds ratios for all codes in the patients’ observation windows:
and finally map the computed odds ratios of each patient to a 12-dimensional embedding via aggregation functions
See Supplementary Table SI-VII for the complete list of aggregation functions .
Posterior Odds Ratios
Large-scale observational datasets — spanning genomics biobanks, administrative claims, and electronic health records (EHR) — increasingly drive scientific discovery and risk modeling. Odds ratios (ORs) and related effect-size estimates remain the dominant tools for summarizing exposure-outcome associations. Yet as cohort sizes reach hundreds of thousands or millions, naive OR analysis breaks down: effect sizes inflate, -values vanish, and nearly all features appear statistically significant, even when no true association exists.
This pathology reflects two structural vulnerabilities of large observational studies:
- Label Noise: Case/control labels are often derived from imperfect sources such as diagnostic codes or weak classifiers, introducing systematic misclassification^75^.
- Large Sample Size Effects: As , variance estimates collapse, magnifying even trivial fluctuations or structural biases, yielding spurious discoveries^76,77^.
In randomized trials, ORs approximate causal contrasts under minimal assumptions. In contrast, observational settings lack experimental control; naive OR computations applied directly to raw exposure-outcome tables, without adjustment for label noise or structural confounding, produce exaggerated significance that worsens with scale.
Post-hoc attribution methods such as SHAP and LIME^78^ offer model-agnostic feature importance scores, but inherit related limitations: they remain artificially stable under weak, non-predictive models, overlook interaction-driven effects, and fail to correct for misclassification or instability^79^.
Existing corrections for OR bias primarily target small-sample misclassification adjustment^76^, or require external gold-standard validation cohorts, which are rarely available at scale.
We introduce the *lambda-Odds Ratio (*Λ-OR), a model-informed, asymptotically faithful method for effect-size estimation and feature attribution tailored to large, noisy observational datasets. Λ-OR differs from classical OR estimation:
- Individuals are stratified by calibrated model-predicted risk, forming empirical high- and low-risk cohorts.
- Exposure odds contrasts are computed across these strata, rather than from unstratified marginal tables.
- A ridge-regularized inversion corrects for outcome misclassification and ensures numerical stability, even under near-degenerate class distributions.
We consider retrospective observational studies where binary case/control labels are derived from imperfect classifiers or noisy diagnostic records (e.g., EHR-derived phenotypes), and exposure status is assumed to be known without error. Let the observed (noisy) 2-by-2 contingency table be
where denotes the count of individuals with and , and so on. These observed labels are subject to misclassification governed by sensitivity and specificity , where denotes the true latent label.
The misclassification process is represented by the stochastic matrix
so that the observed counts satisfy, in expectation,
where is the true (unknown) count matrix under perfect case/control assignment.
Ill-posed Inversion and the Need for Regularization:
Inversion of to estimate via can result in infeasible solutions where the recovered cell counts are negative or numerically unstable, particularly when is nearly singular or . To address this, we adopt a ridge-regularized inverse:
where is chosen to ensure all entries of remain nonnegative and greater than a small threshold , preserving interpretability as approximate counts. The minimal such , if it exists, defines our feasible correction. The regularized corrected contingency table is denoted
and the corrected log-odds ratio is
We estimate the standard error using the delta method, optionally incorporating the uncertainty in , (from validation data) via an analytic extra-variance term.
This framework generalizes classical odds ratio inference by explicitly modeling outcome misclassification and providing a consistent correction even when label quality varies or depends on classifier thresholds.
Interpretation:
This approach defines a class of corrected log-odds ratio estimators indexed by , each balancing fidelity to the noisy data against feasibility under misclassification uncertainty. In the limit , the estimator recovers the unregularized inverse, which may become undefined or yield negative entries. The practical estimator uses the smallest such that all recovered counts exceed a small threshold , typically .
This formulation enables consistent odds ratio estimation in large-scale electronic health record (EHR) studies, where label noise is prevalent and direct validation of every case/control label is infeasible.
Λ-OR Variance Estimation:
Under the assumption of independent cell counts, the classical variance of the log-odds ratio is
However, when the table is obtained via inversion from noisy labels, additional uncertainty arises from the estimation of the misclassification rates and . Let denote the size of the validation cohort used to estimate and , assumed independent of the main study population. Define the extra-variance component via the delta method as
where . The total variance is given by
The corrected Wald statistic is: ,, with a two-sided p-value obtained from the standard normal tail: , with the confidence interval:
using as the critical value from the standard normal distribution.
Supplementary Files
This is a list of supplementary files associated with this preprint. Click to download.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1Association, A. Alzheimer’s disease facts and figures. Alzheimer’s & dementia 13, 325–73 (2017).
- 2Scheltens P. Alzheimer’s disease. The Lancet 397, 1577–1590 (2021).
- 3Nichols E. Global, regional, and national burden of alzheimer’s disease and other dementias, 1990–2016: a systematic analysis for the global burden of disease study 2016. The Lancet Neurology 18, 88–106 (2019).30497964 10.1016/S 1474-4422(18)30403-4PMC 6291454 · doi ↗ · pubmed ↗
- 4Association, A. 2025 alzheimer’s disease facts and figures (2025). Special Report: American Perspectives on Early Detection of Alzheimer’s Disease in the Era of Treatment.
- 5Chu L. Alzheimer’s disease: early diagnosis and treatment. Hong Kong Med J 18, 228–237 (2012).22665688 · pubmed ↗
- 6Winblad B., Amouyel P., Andrieu S. Defeating alzheimer’s disease and other dementias: a priority for european science and society. The Lancet Neurology 15, 455–532 (2016).26987701 10.1016/S 1474-4422(16)00062-4 · doi ↗ · pubmed ↗
- 7Rafii M. S. & Aisen P. S. Detection and treatment of alzheimer’s disease in its preclinical stage. Nature aging 3, 520–531 (2023).37202518 10.1038/s 43587-023-00410-4PMC 11110912 · doi ↗ · pubmed ↗
- 8Jack C. R., Bennett D. A., Blennow K. Nia-aa research framework: Toward a biological definition of alzheimer’s disease. Alzheimer’s & Dementia 14, 535–562 (2018).