Agile human activity recognition for wearable devices based on online incremental learning
Lulu Fan, Hanyan Peng, Lei Xiao, Lang Shi, Siming Zhou, Yuyang Song, Huilong Fan

TL;DR
This paper introduces a framework for wearable devices that improves human activity recognition by balancing accuracy, speed, and power use in real-time.
Contribution
A closed-loop adaptive learning framework that synergistically optimizes feature extraction, model sparsity, and online learning for edge devices.
Findings
The framework achieves 85.6% to 97.4% accuracy across five datasets.
Inference latency is approximately 1.0 ms, meeting real-time requirements.
The system dynamically adapts to non-stationary sensor data streams.
Abstract
Achieving high-precision, low-latency, and continuously adaptive human activity recognition on resource-constrained edge devices represents a core challenge. Existing research primarily focuses on improvements in single directions, such as “online learning,” “model sparsification,” or “feature extraction,” lacking a framework that synergistically optimizes all three. This leads to difficulties in dynamically balancing accuracy, latency, and power consumption when processing non-stationary sensor data streams. To address this, this paper designs an end-to-end closed-loop adaptive learning framework. The core innovation of this framework lies in its system-level synergistic design: (1) Employing fast principal component analysis for adaptive feature dimensionality reduction; (2) Introducing an information theory-based dynamic sparse subnetwork activation mechanism to tackle the NP-hard…
Genes, proteins, chemicals, diseases, species, mutations and cell lines named across the full text — each resolved to its canonical identifier and authoritative record.
Click any figure to enlarge with its caption.
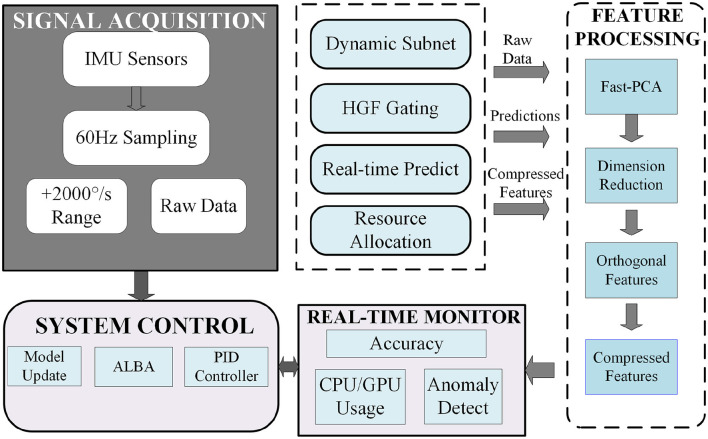 Figure 1
Figure 1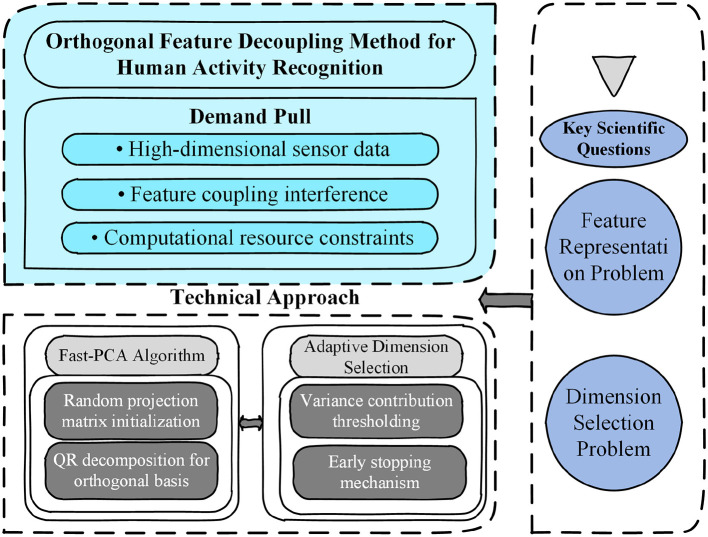 Figure 2
Figure 2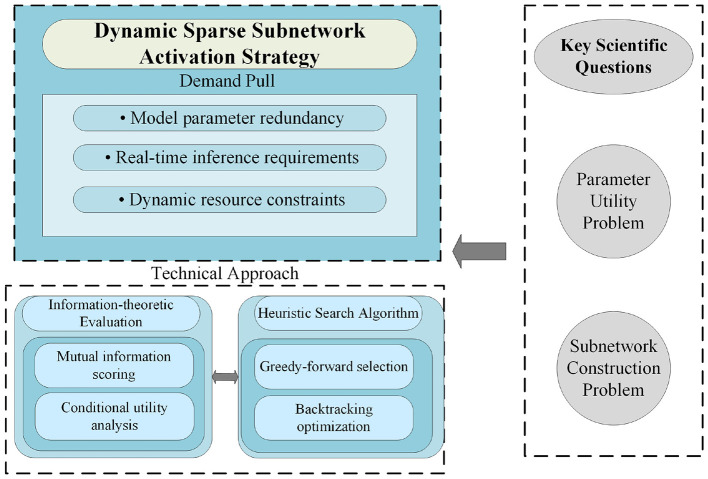 Figure 3
Figure 3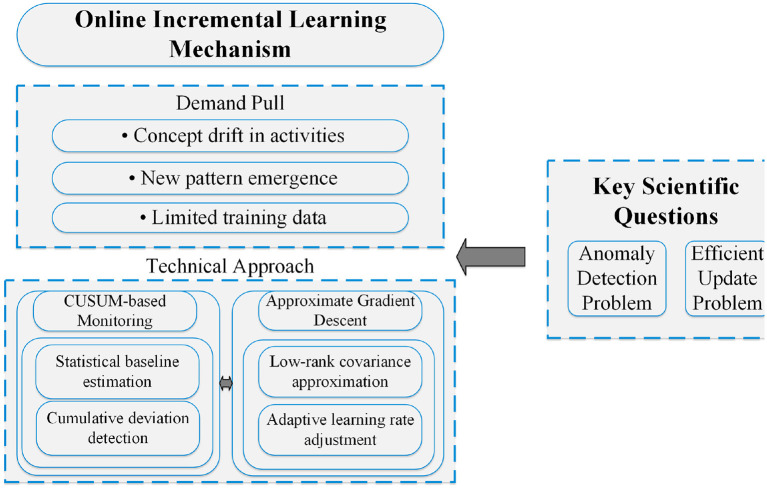 Figure 4
Figure 4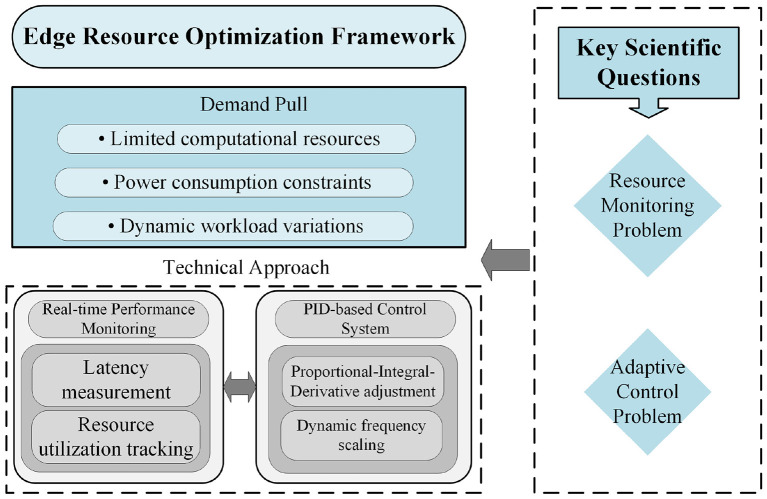 Figure 5
Figure 5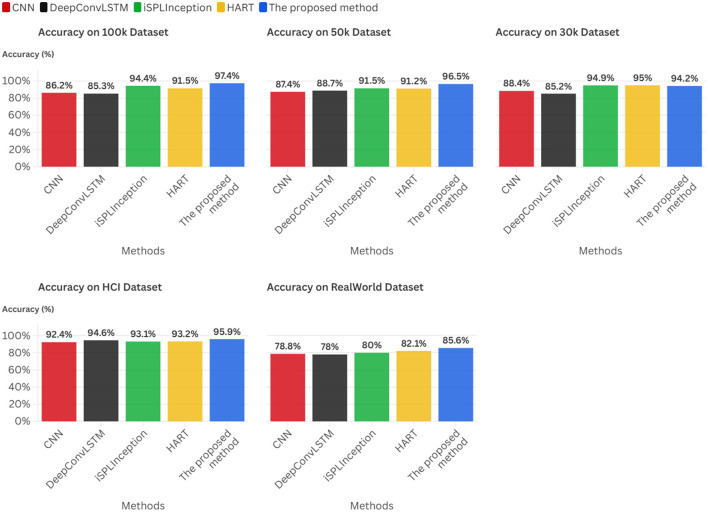 Figure 6
Figure 6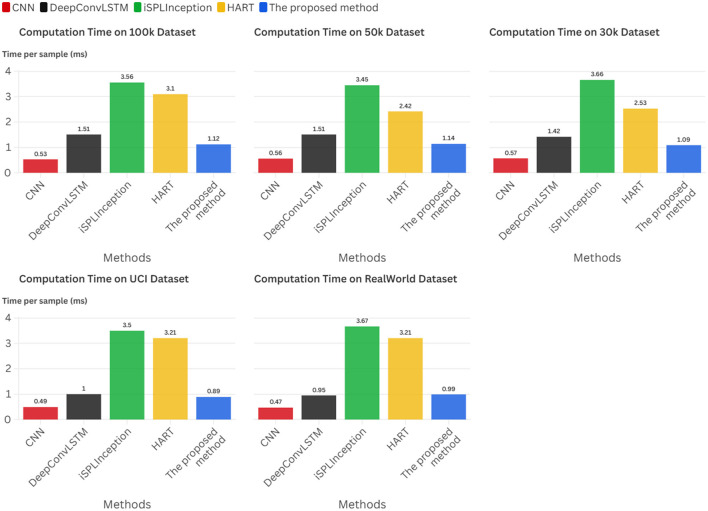 Figure 7
Figure 7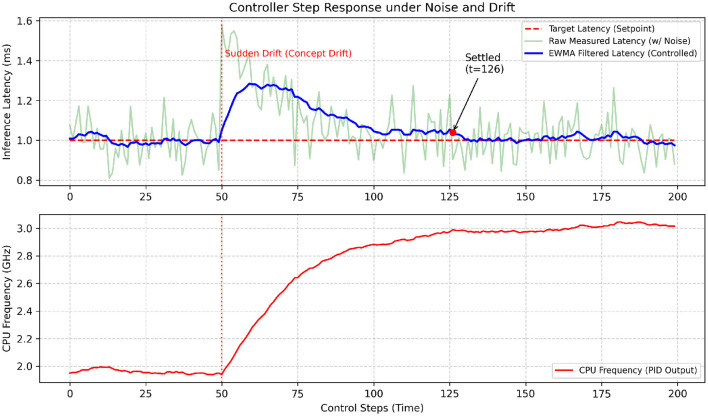 Figure 8
Figure 8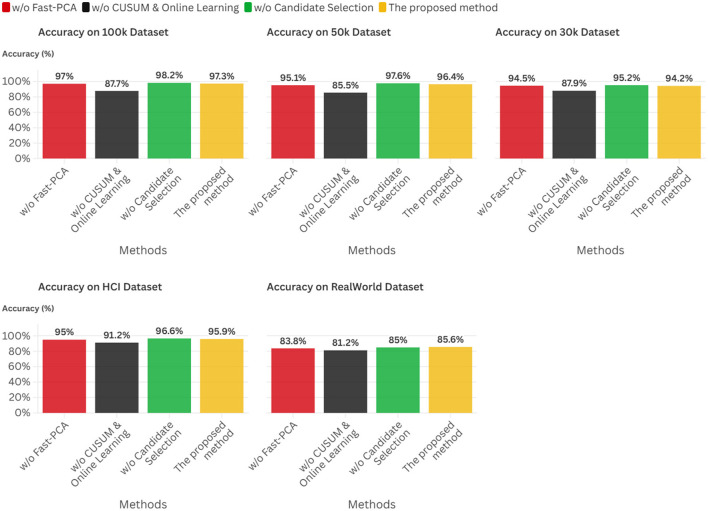 Figure 9
Figure 9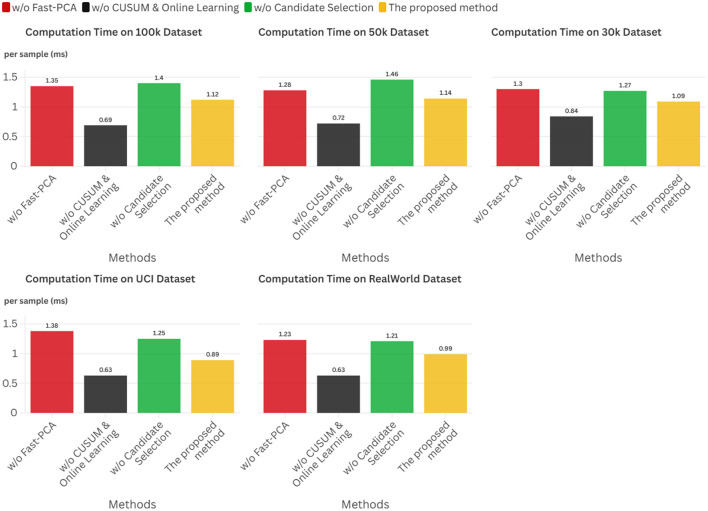 Figure 10
Figure 10|
|
|
|
|
|
|---|---|---|---|---|
| 100K Dataset | ||||
| 50K Dataset | 6 | 9 | Acc, Gyro, Mag | 60 Hz |
| 30K Dataset | ||||
| HCI_HAR Dataset | 6 | 6 | Acc, Gyro | 50 Hz |
| RealWorld Dataset | 8 | 9 | Acc, Gyro, Mag | 50 Hz |
|
|
|
|
|
|---|---|---|---|
| Input window | 9 | – | 9 × 128 |
| Conv1D+BN+ReLU+MaxPool | 64 | 5/1 + MaxPool( | 64 × 64 |
| Conv1D+BN+ReLU+MaxPool | 128 | 5/1 + MaxPool( | 128 × 32 |
| Conv1D+BN+ReLU | 256 | 5/1 | 256 × 32 |
| AdaptiveAvgPool1D + FC | 256 → | – | logits in ℝ |
|
|
|
|---|---|
| Windowing | window size 128, stride 64 (50% overlap) |
| Normalization | Z-score per channel |
| Train/val/test split | 70% / 20% / 10% |
| Optimizer | Adam |
| Learning rate | 0.001 |
| Batch size | 32 |
| Epochs | 100 |
| Fast-PCA oversampling | |
| Adaptive dimension selection | ηmin = 0.9, δ = 0.05 |
| Sparsity budget | |
| Online update step size | ηlearn = 0.001 |
| CUSUM parameters | αewma = 0.1, (δmin, αerr) = (2.0, 0.005) |
| PID gains | |
| Runtime measurement | per-sample time includes feature extraction + subnetwork activation + any online-learning trigger |
|
|
|
|
|
|
|
|---|---|---|---|---|---|
| CNN | 86.2 | 87.4 | 88.4 | 92.4 | 78.8 |
| DeepConvLSTM | 85.3 | 88.7 | 85.2 | 94.6 | 78.0 |
| iSPLInception | 94.4 | 91.5 | 94.9 | 93.1 | 80.0 |
| HART | 91.5 | 91.2 | 95.0 | 93.2 | 82.1 |
| Proposed method | 97.4 | 96.5 | 94.2 | 95.9 | 85.6 |
|
|
|
|
|
|
|
|---|---|---|---|---|---|
| CNN | 0.53 | 0.56 | 0.57 | 0.49 | 0.47 |
| DeepConvLSTM | 1.51 | 1.51 | 1.42 | 1.00 | 0.95 |
| iSPLInception | 3.56 | 3.45 | 3.66 | 3.50 | 3.67 |
| HART | 3.10 | 2.42 | 2.53 | 3.21 | 3.21 |
| Proposed method | 1.12 | 1.14 | 1.09 | 0.89 | 0.99 |
|
|
|
|
|
|
|
|---|---|---|---|---|---|
| w/o Fast PCA | 97.0 | 95.1 | 94.5 | 95.0 | 83.8 |
| w/o CUSUM & Online learning | 87.7 | 85.5 | 87.9 | 91.2 | 81.2 |
| w/o candidate selection | 98.2 | 97.6 | 95.2 | 96.6 | 85.0 |
| Proposed method | 97.3 | 96.4 | 94.2 | 95.9 | 85.6 |
|
|
|
|
|
|
|
|---|---|---|---|---|---|
| w/o Fast PCA | 1.35 | 1.28 | 1.30 | 1.38 | 1.23 |
| w/o CUSUM & Online learning | 0.69 | 0.72 | 0.84 | 0.63 | 0.63 |
| w/o candidate selection | 1.40 | 1.46 | 1.27 | 1.25 | 1.21 |
| Proposed method | 1.12 | 1.14 | 1.09 | 0.89 | 0.99 |
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsData Stream Mining Techniques · Context-Aware Activity Recognition Systems · Time Series Analysis and Forecasting
Introduction
1
Real-time monitoring of complex human activities (such as clinical venipuncture) through wearable sensors is essentially a dynamic optimization problem under strict resource constraints (1, 2). It not only requires algorithms to possess high classification accuracy and extremely low inference latency but also must adapt to the inherent high-dimensional and nonstationary characteristics of sensor data streams, i.e., effectively handling continuously occurring “concept drift” (3).
Currently, academia primarily pursues breakthroughs along three technical paths: designing lightweight static models (4, 5), utilizing network sparsification to compress models (6), and exploring online or continual learning algorithms (7, 8). However, these studies are largely isolated. Static models, once deployed, cannot adapt to changing conditions; sparsification techniques enhance efficiency but retain inherent static defects in models; online learning mechanisms often fail to meet millisecond-level latency requirements due to high computational overhead. A fundamental limitation is that existing methods fail to synergistically integrate the three key elements—“efficient feature extraction,” “dynamic model structure adjustment,” and “online parameter update”—into a unified, resource-aware closed-loop system. This “fragmented” research paradigm makes it difficult for systems to intelligently balance feature fidelity, computational sparsity, and learning stability in dynamic environments, thereby preventing the achievement of long-term, robust autonomous intelligence on edge devices.
This critical analysis unequivocally reveals a profound gap within the current body of research: the conspicuous absence of a unified mathematical framework capable of seamlessly integrating foundational principles derived from statistical signal processing, combinatorial optimization theory, and adaptive online learning into a cohesive, closed-loop system expressly engineered for the demanding constraints of edge computing platforms. Such an integrative framework is indispensable for intelligently navigating the intricate, often competing trade-offs inherent in real-time embedded intelligent systems, including the tension between preserving high-fidelity feature representations, enforcing extreme computational sparsity for efficiency, and ensuring provable stability in parameter convergence amid persistently dynamic operational landscapes.
To address this gap, we propose a novel framework that orchestrates three synergistic components. First, we employ a computationally efficient feature extraction module to create a robust data representation that is resilient to noise and input variations. Second, a dynamic subnetwork activation strategy adaptively allocates computational resources to dynamically balance inference accuracy against latency. Third, an online incremental learning mechanism ensures long-term model robustness by continuously adapting to the non-stationary data streams mentioned earlier. The entire system is stabilized and optimized by a closed-loop feedback controller that manages the interplay between these components.
In summary, this research establishes a pioneering cross-layer optimization paradigm for realizing adaptive intelligence on severely resource-constrained edge platforms. Its principal contributions are multifaceted: First, we establish a comprehensive methodological framework that unifies critical mathematical disciplines into a structured, theoretically grounded approach for developing edge-native adaptive systems. Second, we derive a suite of practical, low-complexity algorithms supported by strong theoretical guarantees encompassing approximation bounds and provable convergence properties, transforming the paradigm into implementable technology. Finally, we deliver exhaustive empirical validation demonstrating that our approach achieves accuracies ranging from 85.6% to 97.4% across five datasets, with inference latency of approximately 1.0 ms.
Related work
2
Our work is positioned at the intersection of three key research areas in edge computing: the design of efficient static models, the theory and application of network sparsity, and the challenge of adaptive online learning. This section reviews the state of the art in these domains to precisely situate our contribution.
Efficient static models for edge inference
2.1
The core idea of efficient static model methods is to develop computationally efficient models under the assumption of stationary data distributions, thereby enabling low-cost edge inference. Representative approaches include CNN (9) as the foundational framework for temporal processing, whose fixed structure precludes dynamic adjustment of computational load; DeepConvLSTM (10), which integrates CNN and LSTM to capture temporal dependencies, yet its recurrent architecture is computationally intensive and struggles to satisfy stringent latency constraints; iSPLInception (11), which employs multi-branch convolutions to extract multi-scale features, but exhibits high model complexity and substantial overhead for edge deployment; and HART (12), based on self-attention mechanisms, which can model long-range dependencies, although its Transformer architecture's quadratic complexity is challenging to sustain in real-time edge scenarios.
These models are all grounded in empirical risk minimization, and their static nature renders them incapable of adapting to variations in the data generation process, thereby constituting a primary limitation for deployment in dynamic edge environments.
Sparsity and model compression
2.2
The primary idea of sparsity and model compression methods is to reduce the number of parameters and operations in deep neural networks through network sparsification and model compression, thereby lowering inference computational costs and enhancing the efficiency of edge devices. Typical methods are based on the lottery hypothesis, which posits that densely randomly initialized networks contain sparse subnetworks that can be trained independently to high accuracy (6), thereby inspiring a series of pruning and sparsification techniques, such as static sparse subnetworks, used for offline identification of efficient substructures. Although these methods successfully reduce inference overhead, the generated models remain static and cannot handle non-stationary data, which has prompted the field to evolve toward dynamic sparse methods (13, 33, 34).
The challenge of adaptivity: online and continual learning
2.3
The core idea of adaptive online learning methods is to develop models capable of incrementally learning new data while retaining old knowledge, to address the challenges of concept drift in data streams, thereby achieving long-term robust deployment of machine learning systems in the real world. Typical methods include the use of experience replay and parameter regularization to avoid catastrophic forgetting (7), exploring various continual learning strategies in human activity recognition, but often facing a trade-off between plasticity and stability (8, 35, 36). Existing online learning mechanisms typically focus on weight updates, requiring substantial computational resources for retraining or backpropagation, rendering them unable to meet the demands of applications with millisecond-level latency constraints.
This reveals the critical research gap that our work aims to fill. There is a lack of a unified, mathematically-grounded framework that co-optimizes the entire adaptive pipeline on an edge device in a closed-loop fashion. Specifically, few studies have integrated adaptive feature extraction, dynamic model structure selection, and low-complexity online parameter updates into a single, cohesive system orchestrated by a formal resource-aware control mechanism. Our paper proposes such a framework, providing a principled approach to building truly adaptive and efficient edge intelligence systems.
Problem model
3
System model
3.1
To enable real-time and precise monitoring of venipuncture procedures, the study designs a lightweight edge intelligence system. The system architecture comprises two primary components: a smart wearable device and an edge computing node. The wearable device, equipped with gyroscope sensors, captures real-time data (X(t)) that reflects the practitioner's hand stability during the puncture process. This data is transmitted to the edge computing node for analysis.
The edge node hosts the core intelligence of the system, which consists of three synergistic software modules. The data processing pipeline commences with a Feature Extraction module that generates a low-dimensional feature vector, f∈ℝ^d^. This vector is fed into a Dynamic Sparse Subnetwork Activation module, which employs a lightweight convolutional neural network for classification. The module dynamically selects a weight matrix Wc based on the features f to produce the classification output, y. Finally, an Incremental Learning module continuously monitors anomalous behaviors, enabling rapid online model updates. This framework establishes a complete end-to-end data flow:
Among these, LCNN denotes Lightweight Convolutional Neural Network.
Problem definition
3.2
Given the raw sensor data stream X(t) from a practitioner's operation and the complete set of network parameters W, the primary objective of this study is to develop an optimal strategy for dynamic sparse subnetwork activation. This strategy requires real-time selection of an ideal weight subset to maximize monitoring accuracy while minimizing inference latency. Formally, this task constitutes a combinatorial optimization problem. The discrete nature of parameter selection renders it NP-hard, akin to the classic 0–1 knapsack problem, thereby posing a substantial theoretical challenge.
Operating constraints
3.2.1
The search for the optimal subnetwork is subject to practical constraints. Any viable solution must adhere to the stringent requirements of clinical monitoring on resource-constrained edge devices.
The solution must meet rigorous constraints on performance and resources: the inference latency of any subnetwork, Tinfer(Wc), does not exceed the maximum threshold Tmax to ensure real-time responsiveness; its power consumption, P(Wc), remains within the device's budget Pmax; and the classification accuracy on the current data window, Acc(Wc, X(t)), is maintained above the clinically acceptable minimum Acc_min_. To ensure computational efficiency, the model is subject to two sparsity constraints: the number of activated parameters (denoted by binary variables ai) does not exceed the total budget K, where K is significantly smaller than the total number of parameters in the full model; and the dimension of the input feature vector, dim(f), is limited to a maximum of dmax.
Finally, the system's adaptability is time-constrained, requiring that the time for any online model update, Tupdate, be completed within the maximum duration Tu, max.
Objective function
3.2.2
The objective function is a multi-objective optimization function combining accuracy and inference latency, defined using the weighted sum method:
where α, β are weighting coefficients satisfying α+β = 1. We formulate the optimization objective as:
The practical significance is to achieve the optimal trade-off between nursing monitoring accuracy and inference latency under the constraints of edge computing resources.
Computational complexity analysis
3.3
The problem of selecting an optimal sparse subnetwork, as described in the previous section, belongs to the class of combinatorial optimization problems. In particular, the task of selecting a subset of parameters to maximize accuracy under a sparsity constraint directly parallels the classical 0–1 Knapsack Problem.
A fundamental result in computational complexity theory establishes that the 0-1 Knapsack Problem is NP-hard (14). This implies that, unless P = NP, no polynomial-time algorithm exists to compute the exact optimal solution relative to the number of parameters. Proofs typically involve reductions from other known NP-complete problems, such as the Partition Problem (15). Consequently, by reduction, the dynamic subnetwork activation problem defined in this paper is also NP-hard. This classification emphasizes the necessity of the efficient heuristic and approximation algorithms presented in Section 4, as exact solutions prove computationally infeasible for networks of practical scale.
Methods
4
This section details our proposed adaptive edge computing framework. This framework addresses the core challenge of real-time monitoring of procedures such as venipuncture on resource-constrained devices.
To address the real-time demands of resource-constrained devices and the challenges of processing high-dimensional noisy signals, we propose a four-layer collaborative architecture guided by information-theoretic optimality and closed-loop feedback control principles. First, an orthogonal feature-extraction module is designed to address the inefficient representation of noisy raw signals (Section 4.1). Subsequently, to tackle the NP-hard problem of model selection, a dynamic subnetwork is developed that adaptively matches each input sample with a sparse model, achieving an optimal trade-off between computational efficiency and classification performance (Section 4.2). Next, an online adaptive learning module is introduced to handle concept drift in dynamic environments (Section 4.3). Finally, the framework integrates all functional components into a unified end-to-end architecture. Through a closed-loop feedback control system, it dynamically adjusts computational resources in real time to sustain high performance under stringent latency constraints (Section 4.4).
To elucidate the implementation details of this framework, Figure 1 illustrates its overall architecture. This highly integrated closed-loop system consists of five core modules that collaborate to form a complete processing pipeline: (1) the Signal Acquisition module for raw data collection, (2) the Feature Processing pipeline for efficient representation learning, (3) the Core Inference Engine for dynamic subnetwork activation, (4) the Real-time Monitor for performance evaluation and anomaly detection, and (5) the System Control module for feedback regulation and adaptation. The subsequent subsections provide a detailed exposition of the design of each core component, in accordance with the presented logical architecture.
System architecture of the proposed closed-loop adaptive framework for real-time edge intelligence.
Orthogonal feature extraction module
4.1
Building accurate and efficient data representations is fundamental. However, raw multimodal sensor data from gyroscopes, accelerometers, and magnetometers inherently exhibit high dimensionality, complex noise, and strong feature coupling. In particular, cross-channel correlations arising from the nonlinear dynamics of human motion make this data difficult to use directly for real-time analysis. Inputting such high-dimensional, highly correlated data without preprocessing results in an exponential increase in computational load, making real-time inference challenging to meet the latency constraints of edge devices.
To address this challenge, this section proposes a feature representation method based on an improved form of principal component analysis, termed Fast-PCA. This approach substantially reduces computational complexity while retaining the essential property of conventional PCA—namely, its capability to decorrelate feature dimensions. The overall conceptual framework, illustrated in Figure 2, consists of two main components: the feature projection mechanism (Section 4.1.1) and the adaptive criterion for determining the optimal number of retained features (Section 4.1.2).
Conceptual framework for the orthogonal feature decoupling method, outlining the demand pull, key scientific questions, and the proposed technical approach.
Feature projection via fast-PCA
4.1.1
Although traditional PCA effectively extracts principal components, its reliance on the full covariance matrix's singular value decomposition results in an O(n^3^) computational complexity, making it difficult to deploy in resource-constrained environments. Therefore, this section proposes a Fast-PCA projection method based on stochastic numerical linear algebra. By integrating statistical feature decoupling and adaptive dimension selection, this approach reduces computational complexity to O(n^2^d) while supporting dynamic optimization of the feature space and preserving feature orthogonality.
To accommodate real-time monitoring scenarios, this method applies short-time sliding window processing to sensor streams. The framework relies on the assumption that within sufficiently short time windows, the second-order statistical properties of the signal remain approximately stable. Consequently, each window can be treated as an independently modelable data block. Let the sliding window length be T. The n-dimensional raw signal output from the sensor forms a matrix within the window:
where is the raw gyroscope signal vector at time i.
Furthermore, we assume that sensor data possesses an implicit low-dimensional structure. Despite the high original dimension n, the most useful discriminative information is concentrated in a small number of principal directions. Therefore, our goal is to find an orthogonal projection that maps the data to a much smaller dimension, d≪n, while ensuring the cumulative variance explained by these components meets a minimum threshold, η_min_.
Fast covariance estimation and eigen-decomposition
4.1.1.1
The computational bottleneck of traditional PCA lies in the need to construct and decompose an n × n covariance matrix. To address this challenge, we adopt the “sketch-and-solve” approach from randomized linear algebra. By constructing low-dimensional random sketches to approximate the covariance structure of the original space, we reduce the overall complexity to O(n^2^d). This process involves two key steps:
Step 1: Randomized sketching First, instead of directly analyzing X, we follow the principles of random projection theory (16) to compress it into a smaller subspace using a random Gaussian matrix. From this, we generate an orthogonal basis that preserves the primary variance information. This step avoids recalculating the original high-dimensional matrix and serves as the primary acceleration source for the entire method.
Step 2: Decomposition on the sketch With this compact basis Q in hand, we project the original data onto it to form a much smaller matrix, B = Q^T^X. This k×n matrix contains a compressed representation of the original data's covariance structure. We then apply an efficient iterative method, such as the Lanczos bidiagonalization algorithm (17), to compute the Singular Value Decomposition (SVD) of B. The principal components and corresponding eigenvalues of the original data X can be accurately recovered from this decomposition. The final projection matrix P is constructed from the resulting right singular vectors V:
where V contains the right singular vectors derived from the SVD of B.
This process ensures that all computations are performed in a randomly projected subspace of significantly lower dimension than the original, thereby avoiding direct processing of the covariance matrix.
Specifically, our Fast-PCA improvements include two key innovations: (1) Adaptive sketch dimension tuning. Replacing traditional Fast-PCA's fixed sketch size, we dynamically adjust it based on the cumulative variance threshold to avoid redundant computation or information loss; (2) Decoupling-reorthogonalization integration. Optimizing Fast-PCA's core process by combining statistical feature decoupling with Lanczos bidiagonalization, using partial instead of full reorthogonalization to reduce SVD iteration costs while preserving feature orthogonality.
This approach significantly reduces computational complexity. The total complexity of Fast-PCA can be expressed as the sum of two terms:
where k is the sketched dimension and m is the number of Lanczos iterations. When k = O(d) and m = O(d), the total complexity effectively reduces to O(n^2^d), achieving an order-of-magnitude optimization compared to the O(n^3^) complexity of traditional PCA.
Adaptive feature selection criterion
4.1.1.2
The efficiency of the Fast-PCA algorithm requires integration with an intelligent selection of the feature dimension d^*^ to perform effectively in resource-constrained environments. This section thus introduces an adaptive mechanism: a criterion that adjusts the target dimensionality according to real-time computational load, thereby facilitating a dynamic and principled trade-off between the richness of the feature representation and processing latency.
The dynamic variance contribution ratio threshold η(t) is defined to determine the minimal effective dimension d^*^ through the optimization problem:
This constraint ensures the cumulative variance contribution of selected features meets the current threshold. The threshold η(t) adapts in real-time based on computational resources:
where α is a decay coefficient, and Tused is the computation time consumed within the current processing window.
This randomized approach is theoretically well-founded. Established results in randomized numerical linear algebra (16) demonstrate that the approximation error of the randomized SVD, which underlies our Fast-PCA method, possesses a rigorous theoretical bound. Specifically, the expected projection error is dominated by the magnitude of the largest discarded singular value, σ_r+1_(X). This guarantee ensures that the energy or information corresponding to the lost features during projection is negligible, thereby validating that the resulting low-dimensional feature space achieves a high-fidelity representation of the original signal.
Algorithm implementation
4.1.1.3
The pseudocode implementation for our Fast-PCA with the adaptive selection mechanism is presented in Algorithm 1.
Algorithm 1Fast-PCA with adaptive dimension selection.
Dynamic adaptive feature selection
4.1.2
Although the Fast-PCA mechanism in Section 4.1.1 effectively achieves dimensionality reduction, determining the optimal target dimension d^*^ remains challenging. Fixed dimensionality schemes prove inadequate due to complexity variations across venipuncture phases, while simultaneous constraints of real-time processing (Tmax ≤ 5 ms) and edge device capacity (dmax ≤ 6) necessitate dynamic dimensionality adaptation. However, recomputing the full eigenspectrum for variance contribution analysis at each iteration imposes prohibitive computational overhead, fundamentally compromising Fast-PCA's efficiency advantages.
To address this issue, this section proposes an adaptive selection criterion based on the variance contribution rate. By integrating variance energy distribution, real-time resource awareness thresholds, and rapid update strategies, it achieves dynamic dimension determination with minimal computational overhead. Its core principle is to leverage the energy concentration of PCA by monitoring the cumulative variance contribution rate of the preceding principal components to determine the required feature dimensions for the current window. For principal components sorted by eigenvalue in descending order, the cumulative variance contribution rate is defined as:
where λ_i_ denotes the i eigenvalue and Γ_j_ measures the coverage of the first j principal components over the total variance. Multiple physiological signals exhibit a structure of rapidly declining eigenvalues, typically showing a distinct inflection point after the first few principal components, causing subsequent components to contribute minimally to the overall variance. Therefore, the smallest j satisfying the cumulative variance contribution reaching a specified threshold can be regarded as the effective dimension for the current window.
However, in practical systems, maintaining a fixed threshold can create performance bottlenecks when signal complexity or computational resources change: during resource constraints, high thresholds lead to excessive dimensionality, causing delay overruns, while low thresholds under ample resources prematurely discard potentially valuable information. To address this, a dynamically varying threshold function η(t) is introduced. This function aims to reflect the system's remaining time and resource utilization in real time, enabling the dimension reduction process to automatically contract or expand the representation space based on the current environment. This threshold is defined as:
Here, Tused(t) denotes the computational time already consumed by the current window, where Tmax represents the maximum allowable time limit for the entire processing workflow. When sufficient time remains, the function output increases, favoring the retention of more principal components to enhance feature expression capabilities. As time progressively depletes, the function value gradually decreases, making the dimensionality reduction process more conservative to ensure the system completes computations before the deadline.
Fast iterative covariance update strategy
4.1.2.1
The dimensionality selection process achieves real-time performance largely due to the efficient update mechanism of PCA spectral information. In sliding window mode, each window shift only introduces a low-rank perturbation to the covariance matrix—specifically, adding one new sample and removing one old sample. This property enables rapid updates to eigenvalue changes using linear approximation methods, eliminating the need for repeated complex matrix decomposition operations. The computation required for such linear updates relies solely on vector-level operations, with an overall complexity of O(d), enabling millisecond-level real-time processing. The updated sequence of eigenvalues continues to reflect the energy ranking structure of principal components, ensuring stable and reliable calculation of cumulative variance contribution.
Dual-threshold triggering mechanism
4.1.2.2
To balance computational efficiency with decision stability, we propose a dimension adjustment strategy based on a dual-threshold mechanism. This approach combines a fixed, conservative baseline with a dynamic, adaptive criterion. The foundation of this mechanism is a hard threshold, η_min_, which ensures that the cumulative variance contribution rate never falls below a clinically acceptable lower limit (e.g., η_min_ = 0.95), thereby guaranteeing a minimum level of feature quality. To introduce adaptability, we augment this with a soft threshold, η_soft_(t), which is dynamically adjusted based on the real-time resource load. It is defined as:
This soft threshold allows the system to be more demanding on feature quality (higher η) when computational time is abundant and more lenient (lower η) when the system is under temporal pressure.
The final dimension decision rule is:
This rule employs a conservative dimensionality strategy to improve accuracy under sufficient resource conditions and an aggressive dimensionality reduction strategy to guarantee real-time performance under constrained resources. The effect of this decision rule on classification performance is grounded in established statistical learning theory (18), which delineates a direct relationship between the retained variance of features and the classification error rate. Specifically, it ensures that if the proportion of variance preserved by the selected features is adequate, the classification error resulting from dimensionality reduction possesses a well-defined and controllable theoretical upper bound. This principled framework guides the setting of a minimum threshold η_min_, thereby maintaining system performance at an acceptable level even in the most stringent resource-constrained scenarios.
Fast sorting and early stopping algorithm
4.1.2.3
To avoid the (O(dlogd)) cost of fully sorting all eigenvalues, we exploit their monotonic decay to design a linear-time early-stopping rule. The key idea is that once the cumulative variance at index j reaches the target level Γ_j≥η_min, and the remaining eigenvalues are sufficiently small, the cumulative variance will remain above the threshold for all subsequent indices.
This condition provides a computationally efficient check, as stated in the following theorem:
Theorem 1. If the (j+1)-th eigenvalue satisfies
then the cumulative variance contribution satisfies Γ_j≥η_min.
This result follows from the monotonicity of eigenvalues, which ensures that the tail sum is bounded by (d−j)λ_j+1_.
Thus, meeting these two conditions at the index j guarantees that the threshold is safely satisfied, allowing the search to terminate without examining the remaining components. This yields an O(d) early-stopping algorithm that preserves the correctness of the full sorting approach while significantly reducing computational cost.
Algorithm implementation
4.1.2.4
This entire adaptive process, achieving feature selection in O(d) complexity, is implemented in Algorithm 2.
Algorithm 2Adaptive dimension selection with early stopping.
The design of Algorithm 2 focuses on maximizing computational efficiency while maintaining robust and adaptive decision-making. Key design strategies are employed: first, the pre-sorted eigenvalues λ from the PCA process are leveraged to eliminate the costly O(dlogd) sorting step, thereby enhancing efficiency; second, a dynamic soft threshold (Line 4) is introduced, computed once per invocation, to adaptively adjust feature quality requirements based on real-time computational resource availability, improving adaptability.
The core of the algorithm lies in the main loop (Lines 8–18), which is optimized via a dual early stopping mechanism. This mechanism integrates a hard threshold and the condition from Theorem 1, enabling loop termination as soon as a suitable dimension is identified to prevent unnecessary iterations. Finally, the decision rule (Line 21) takes the maximum of the dimensions determined by the two thresholds, ensuring a minimum quality level ( ) while striving for higher fidelity ( ) when resources permit, thus achieving a robust balance between feature fidelity and real-time performance.
Dynamic sparse subnetwork activation strategy
4.2
Building upon the low-dimensional yet informative feature representations developed in Section 4.1, this paper addresses the critical challenge of real-time classification under stringent resource constraints by proposing a dynamic sparse subnetwork activation strategy. This approach intelligently tailors computational pathways to achieve an optimal balance between efficiency and accuracy.
Conventional static models employ fixed computational architectures that cannot adapt processing load according to input complexity, leading to suboptimal resource utilization. To overcome this, we formulate the optimal subnetwork selection as a combinatorial optimization problem in parameter space, which exhibits NP-hard complexity analogous to the 0–1 knapsack problem. This manifests in two key aspects: (1) the computational intractability of exhaustive search methods and (2) the inadequacy of simple greedy approaches to deliver satisfactory suboptimal solutions within millisecond-level latency constraints.
Our innovative solution transforms this intractable optimal subnetwork search into a computationally feasible heuristic optimization for maximum information gain. Grounded in information-theoretic principles, the strategy selectively activates the most discriminative network parameters for each input sample. As illustrated in Figure 3, our technical framework comprises three key components:
Conceptual framework for the dynamic sparse subnetwork activation strategy, outlining the demand pull, key scientific questions, and the proposed technical approach.
First, we establish theoretical foundations through information-gain-based parameter selection criteria, providing rigorous justification for dynamic subnetwork activation (Section 4.2.1).
Second, we develop dual implementation mechanisms: (1) a rapid gradient-aware gating function for real-time activation (Section 4.2.2) and (2) a dynamic weight adjustment method based on competitive neural networks (Section 4.2.3) (19).
Dynamic parameter selection mechanism based on heuristic information gain
4.2.1
The activation of a dynamic sparse subnetwork is formalized as the identification of an optimal parameter subset within a vast combinatorial space . The search space size, of order C(|W|, K), can exceed 10^6^, posing a significant challenge. Conventional greedy algorithms exhibit O(K|W|) complexity, which is infeasible under strict real-time constraints and fails to account for coupled information effects among features.
To address this, we propose a heuristic search strategy grounded in information theory, transforming parameter selection into a tractable problem of information gain maximization. Specifically, the utility of activating a parameter wj is quantified by its conditional mutual information I(fj; y∣fS), measuring the novel information about the label y contributed by feature fj given the selected feature set fS. This approach yields a near-optimal solution with substantially reduced complexity, approximately O(Klog|W|).
The viability of this strategy hinges on two key properties: computational feasibility and theoretical soundness.
Computational feasibility: Real-time mutual information computation is enabled by assuming local conditional independence among features, allowing efficient information gain estimation without succumbing to the “curse of dimensionality.”
Theoretical soundness: We assume the utility function exhibits sub-modularity (20), which formalizes the “diminishing returns” property: the marginal information gain from adding a parameter to a smaller set is no less than that from adding it to a larger set. This ensures that a simple greedy algorithm achieves a solution with a provable guarantee—no worse than (1 − 1/e) of the true optimum.
Fast conditional mutual information estimation
4.2.1.1
Direct mutual information computation requires joint probability distribution estimation with O(Cd^2^) complexity. For real-time feasibility, we introduce an incremental estimation method based on Kernel Density Estimation (KDE).
The reliability of this approach is ensured by the strong convergence properties of KDEs. As the sample size N increases and the kernel bandwidth h is reduced within an appropriate range, the density estimate provided by the KDE will converge to the true distribution p(fj, y) almost everywhere (21). It follows that entropy-related measures based on this density—including mutual information—will also approximate their true values in a probabilistic sense.
Under the aforementioned convergence conditions, the upper bound on the estimation error of mutual information can be described as:
The kernel bandwidth h can be selected using Silverman's empirical rule. The two error components in the above equation correspond to the variance term arising from finite sample size and the bias term introduced by kernel smoothing. When Nh → ∞ is satisfied, both gradually diminish, thereby ensuring the stability and accuracy of the estimation.
Overall, by leveraging the statistical convergence properties of KDE and its entropy estimation, this method achieves computationally efficient and theoretically grounded rapid estimation of conditional mutual information without requiring high-dimensional density modeling.
Hierarchical pruning heuristic search
4.2.1.2
We model the parameter selection as a constrained sub-modular function maximization problem:
Where U(S) denotes the information-based utility of a parameter set. Solving this problem exactly is computationally intractable due to its combinatorial nature. Therefore, we develop a hierarchical three-stage heuristic search strategy that exploits sub-modularity to improve efficiency.
In stage one, each parameter group undergoes independent utility evaluation, retaining the top 2K candidates with the highest utility. This step significantly reduces the search space while preserving most potentially valuable parameters. In stage two, perform a greedy search on the filtered parameter set, selecting the parameter group that yields the maximum conditional gain at each step—that is, the group with the highest marginal utility within the currently selected set. This phase features low computational complexity and stable performance, providing a robust initial solution. In stage three, to further enhance result quality, we introduce an improved lazy greedy backtracking method. This approach leverages the marginal diminishing properties of sub-modular functions to skip unpromising candidates during local search, thereby optimizing greedy solutions at minimal computational cost.
Due to the sub-modular property of the utility function, this method provides provable approximation quality. The utility of the resulting parameter subset s approximates that of the optimal set S^*^:
where ϵ denotes the truncation error introduced by the coarse-grained screening step. This bound demonstrates that the algorithm maintains a robust performance lower bound even under strong pruning conditions.
Algorithm implementation
4.2.1.3
The complete process is formally outlined in Algorithm 3, which details the synergistic interaction of its core components.
Algorithm 3Hierarchical pruning for dynamic activation.
The design of Algorithm 3 aims to balance solution quality with strict real-time constraints. The algorithm is structured into three synergistic stages: coarse screening, refinement, and backtracking. The coarse screening stage (Lines 2–3) employs a computationally efficient metric (independent mutual information) to rapidly prune irrelevant parameters, reducing the search space to meet latency requirements. The refinement stage (Lines 6–12) utilizes a lazy greedy approach with a priority queue, which avoids redundant evaluations of marginal gains by leveraging sub-modularity, thereby reducing the complexity from O(K|W′|) to O(Klog|W′|) for the selection phase. The backtracking stage (Lines 15–22) is an optional fine-tuning mechanism that executes only if residual time is available within the processing budget, enabling a dynamic trade-off between further improvement of solution quality and timely completion.
Dynamic sub-network activation mechanism design
4.2.2
Section 4.2.1 establishes the theoretical foundation for parameter selection based on information gain; however, a practical and computationally efficient mechanism is imperative for real-time implementation. The essence of dynamic subnetwork activation resides in the design of such a mechanism. Conventional gating techniques, including soft masks, typically necessitate gradient retention for all parameters, thereby infringing the strict sparsity constraint ∑ai ≤ K and compromising optimality guarantees.
To address these shortcomings, this section proposes a heuristic gating function (HGF). We model the activation decision as a constrained information gain maximization problem and prove that HGF furnishes a locally optimal solution. This method enables real-time activation decisions with O(1) complexity per parameter.
The proposed HGF determines the binary activation state aj∈{0, 1} for each parameter wj by thresholding its importance score sj:
where τ is the global baseline threshold, provides gradient-based modulation, and 𝕀[·] denotes the indicator function.
This dynamic thresholding mechanism adapts to sample difficulty: via the gradient term, the gate imposes less stringent constraints on high-loss samples.
The theoretical validity of this HGF design relies on two key assumptions:
First, parameter importance scores must remain stable to weight changes, meaning scores should not undergo abrupt shifts when weights experience minor perturbations. This smoothness ensures the gradient modulation process remains stable and avoids fluctuations during iterations.
Second, the overall information gain can be approximated as the sum of independent contributions from each parameter. This allows the original global selection problem to be decomposed into a series of parameter-level decisions, enabling the model to operate efficiently even in high dimensions.
Optimization modeling of heuristic gating
4.2.2.1
Building on the decomposability assumption of information gain, we formulate the dynamic activation problem as the following constrained binary optimization:
where Ij = I(f; y∣wj) denotes the conditional mutual information between feature f and class y given parameter wj. By introducing a Lagrange multiplier λ≥0, we derive the relaxed objective:
Maximizing the objective function after relaxation directly yields a concise activation criterion: a parameter is activated if and only if its information gain exceeds the threshold λ.
This unified threshold rule constitutes the core mechanism of HGF. Its theoretical validity stems from two key points. First, information gain exhibits a monotonic relationship with classification loss, enabling it to reliably reflect parameter importance and serve as a substitute for gradients in decision-making. Second, within the relaxed optimization framework, the threshold λ functions as a Lagrange multiplier to balance parameter importance against activation budget constraints, ensuring each local decision satisfies fundamental optimality conditions.
Dynamic threshold adjustment mechanism
4.2.2.2
To ensure the system adapts to real-time resource availability and satisfies the sparsity constraint |S| ≤ K, the global threshold τ is dynamically adjusted based on the elapsed processing time. We implement this with an exponential decay strategy:
This approach embodies an intuitive trade-off: the system exhibits higher selectivity (with an elevated τ) when computational time is ample and transitions progressively toward inclusiveness (with a reduced τ) as the processing deadline approaches.
A pivotal attribute of this mechanism is its integrated safety net, which prevents excessive sparsity in the subnetwork. In scenarios abundant with low-importance parameters, the threshold τ(t) might persist at undesirably high levels, leading to insufficient activations. Our design mitigates this issue through a formal convergence guarantee: by selecting a sufficiently large decay factor β (specifically, β≥ln(τ_0_/τ_min_)), the threshold is assured to decay to a predefined minimum value τ_min_ prior to the deadline Tmax. This ensures a baseline number of parameters are perpetually activated, upholding a minimal level of model performance even under adverse conditions.
Algorithm implementation
4.2.2.3
The Heuristic Gating Function (HGF) is elaborated in Algorithm 4. The HGF is engineered to be computationally efficient, intelligent, and resource-aware. Its efficiency predominantly stems from the parallelized importance scoring step (Line 2): leveraging rapid mutual information estimation, scores for all parameters are computed concurrently, achieving O(1) complexity in a parallel computing model. To imbue the gating mechanism with resource awareness, we introduce a dynamic threshold (Line 5) that enables real-time adjustment of activation criteria based on the processing deadline.
Algorithm 4Heuristic gating function (HGF) for dynamic activation.
The core intelligence of the HGF resides in its gating decision process (Lines 8–12). Herein, we incorporate a gradient modulation term ( ) to bolster robustness. This design guarantees that if a parameter, despite possessing a high intrinsic score sj, contributes to elevated classification loss, its activation threshold λ_j_ is effectively heightened, thereby diminishing its activation likelihood. This furnishes a defense against noisy or deceptive features. Ultimately, to rigorously adhere to the computational budget, we implement a sparsity enforcement step (Lines 15–19): by sorting parameters according to their marginal activation gain (sj−λ_j), this step deterministically executes the most confident activations or deactivations to precisely satisfy the sparsity constraint ∑ai_ ≤ K.
Dynamic weight adjustment method based on LCNN
4.2.3
The heuristic gating function (Section 4.2.2) enables rapid, feed-forward parameter activation; however, it primarily processes each parameter's activation decision in isolation. To more effectively address the complex, high-dimensional couplings within the feature space, this section introduces a dynamics-based alternative: the Dynamic Weight Adjustment via Local Competitive Neural Network (DWALCNN). The core concept shifts from an independent decision-making framework to a collective one, where parameters in a local neighborhood compete for activation. This competition-collaboration mechanism allows for a more refined parameter selection process, achieving dynamic optimization of weight states with O(K) complexity.
To formalize this mechanism, the following definitions and assumptions are introduced.
The operational procedure is as follows: For each parameter wj, its local competition domain is defined as the neighborhood within a radius r in the parameter space. Within this domain, the activation state aj is regulated by a competitive activation function. Specifically, a parameter is activated only if its intrinsic importance score sj is sufficiently large to overcome the collective inhibitory effect from its already-activated neighbors.
To ensure the stability and analyzability of the dynamic system, two fundamental conditions must be satisfied. First, the importance score must smoothly vary with the weight to ensure continuous activation dynamics and convergence. Second, competition must be symmetric and non-self-inhibiting, meaning interactions between parameters should be mutually consistent, and parameters must not inhibit themselves, thereby ensuring a balanced and stable competitive process.
LCNN dynamics modeling
4.2.3.1
We model the evolution of the parameter activation states as a dynamical system. The continuous-time differential equation describing this system is:
where σ(·) denotes a sigmoidal activation function and λ represents a decay coefficient. This system models the evolution of the activation state for each parameter, driven by its self-importance, inhibition from active neighbors, and natural decay. In practice, the discretized version is utilized.
Before applying LCNN, it is necessary to verify the stability of its dynamical system. Under the previously assumed conditions (smooth importance landscape and symmetric equilibrium of competition coefficients), the update process of LCNN guarantees convergence to a stable equilibrium point.
The core basis for stability stems from constructing a Lyapunov energy function:
Along the system's trajectory, the time derivative of this function is always non-positive, indicating that the system's energy is continuously decreasing. According to LaSalle's invariance principle (22), the system will ultimately converge to an invariant set satisfying , which corresponds precisely to the equilibrium points of the dynamic equations. Therefore, the activation state of LCNNs must converge stably.
In summary, LCNN maintains a structured activation mechanism while offering a rigorous guarantee of dynamical stability.
Competition coefficient learning mechanism
4.2.3.2
To allow the network to learn which parameters should compete, we design an update rule for the competition coefficients μ_jk_ based on Hebbian learning principles (“neurons that fire together, wire together”):
where η_learn_ denotes the learning rate, differing from η which denotes the threshold. This rule enhances competition among frequently co-activated parameters (i.e., increasing μ_jk_), thereby promoting the formation of specialized and non-overlapping functional modules.
The Hebbian-based update rule we design (see Equation 17) possesses a crucial intrinsic property—boundedness of coefficients—which is essential for system stability. Since the update rule is essentially a convex combination of values within the interval [0, 1] (i.e., a weighted average of the old coefficient and a new observation), it can be proven by simple induction that if the initial coefficients and the learning rate η_learn_ lie within [0, 1], all subsequent coefficients remain bounded. This property is fundamental to ensure that the learning dynamics of the LCNN do not diverge and remain stable.
Algorithm implementation
4.2.3.3
The complete workflow of the DWALCNN method is presented in Algorithm 5. In the design of DWALCNN (Algorithm 5), we develop a refined dynamics-based activation mechanism as an alternative to the single-shot HGF approach. The core of the algorithm involves simulating the dynamics of LCNN (Lines 9–15) to model competitive interactions among parameters. This competitive process is designed such that a parameter with a high intrinsic score sj may have its activation suppressed if its active neighbors exert strong inhibition (represented by μ_jk_). This enables the network to make more nuanced context-dependent activation decisions by incorporating feature couplings.
Algorithm 5Dynamic weight adjustment via LCNN (DWALCNN).
Furthermore, by incorporating a Hebbian learning step (Lines 18–20), we endow the competitive structure with meta-plasticity, allowing it to evolve autonomously. This mechanism enables the competition coefficients to adapt over long timescales, ultimately leading to the emergence of specialized and non-interfering functional modules within the network. The entire process is iterative: the system evolves over multiple steps (Tmax_iter) to converge to a steady state, and this hyperparameter allows a trade-off between solution quality and computational latency. Finally, after the dynamical system reaches equilibrium, a sparsity enforcement step is applied (Line 24). This final thresholding converts the continuous activation values into a binary vector, strictly adhering to the sparsity budget K, thereby producing an efficient and effective subnetwork for inference.
Online low-complexity incremental learning mechanism
4.3
The dynamic subnetwork activation strategies proposed in Section 4.2 enable a degree of adaptability at the sample level. However, real-world data streams often exhibit significant nonstationarity, and relying solely on such local adaptation is insufficient to guarantee long-term stable performance. Over time, data distributions may drift due to factors such as gradual sensor aging, physiological tremor variations (e.g., user fatigue), or slow shifts in individual behavioral patterns—a phenomenon known as “concept drift.” Even with dynamic architectures, models with static parameters will gradually become mismatched and degrade in performance.
To this end, this section introduces an online, low-complexity incremental learning framework tailored for resource-constrained edge devices to address the challenge of persistent distributed changes. Crucially, this framework is designed to bridge the gap between short-term anomaly detection and long-term model adaptation. Its core concept involves establishing a rigorous “detect-update” paradigm that supports continuous model evolution while maintaining minimal computational overhead.
The framework operates through two synergistic steps. First, it deploys an efficient recursive CUSUM-based algorithm to precisely identify concept drift occurrences (Section 4.3.1). It is worth noting that while this detection module focuses on identifying deviations from short-term stationarity (acting as a trigger), the continuous application of the subsequent updates enables the model to effectively track long-term, structural concept drift. Upon detection, the framework employs a rapid online learning algorithm, Adaptive Covariance Gradient Descent (ACGD), to facilitate swift model parameter updates (Section 4.3.2). By treating gradual drift as a sequence of incremental statistical shifts, this mechanism allows the decision boundary to continuously evolve. To theoretically ensure long-term reliability, a convergence analysis demonstrates that the combined “CUSUM-ACGD” process is stable and converges almost surely to the optimal parameters for the evolving distribution (Section 4.3.3).
The overall framework is conceptualized in Figure 4, highlighting key challenges in nonstationary data environments and decomposing the problem into two core tasks: precise drift detection and efficient online updating. Subsequent sections will detail the design and theoretical foundations of each component.
Conceptual framework for the online incremental learning mechanism, outlining the demand pull, key scientific questions, and the proposed technical approach.
Short-term stationarity detection method for abnormal behavior features
4.3.1
The core challenge in online learning lies in determining when model updates are truly necessary. Updates should only be triggered when statistically significant changes occur in the data distribution (concept drift). Since abnormalities in venous puncture actions typically occur within < 200 ms, and edge devices require millisecond-level responsiveness, drift detection must be exceptionally efficient. Traditional statistical methods (such as sliding t-tests) are unsuitable for this task due to their need for historical data storage (with O(Td) space complexity) and high computational cost O(dT^2^) complexity, making them infeasible for real-time applications. This section employs an enhanced CUSUM detection mechanism to perform drift detection with constant-time and constant-space complexity.
The method is based on the assumption that within a short time window, the sequence of features characterizing normal behavior can be regarded as locally stationary, with its mean and covariance remaining approximately constant. When new data deviates from this steady state, an anomaly may occur.
For each feature dimension, we maintain a recursively updated CUSUM statistic:
It accumulates standardized deviations and suppresses minor fluctuations through the parameter κ. When exceeds a preset threshold, drift is detected, thereby ensuring a controlled false alarm rate.
This detection method relies on two key assumptions:
Locally stable increment properties
4.3.1.1
Under normal conditions, the standardized feature increments can be approximated as a martingale sequence, meaning that given all historical information, the expectation of the next increment is zero. This property ensures that the false alarm probability of CUSUM can be rigorously analyzed.
Minimum detectable change
4.3.1.2
When concept drift occurs, the feature mean undergoes at least one quantifiable minimum change (a proportion of the relative standard deviation), defining the smallest drift magnitude detectable by the detector.
Based on this theoretical foundation, the enhanced CUSUM method enables efficient, reliable drift detection suitable for real-time edge devices.
Recursive CUSUM detection
4.3.1.3
To accommodate the strict memory constraints of edge devices, we implement the CUSUM test using recurrence relations. The statistic is updated at each time step, and the baseline parameters and are estimated online using an Exponentially Weighted Moving Average (EWMA):
where α_ewma_ is the EWMA smoothing factor. This avoids storing a window of historical data.
Although the recursive implementation achieves exceptional efficiency, its reliability requires theoretical justification. Under two fundamental assumptions: (i) feature increments can be regarded as a martingale sequence during the stable phase; (ii) the magnitude of distribution drift exceeds the detectable threshold, the CUSUM detector guarantees the capture of any significant changes.
When the relaxation parameter is set to κ = δ_min_/2, the CUSUM statistic will cross any finite threshold h>0 within a finite time after drift occurs:
Proof based on the Gamma theory (3): Before drift, the expected increment of the statistic is negative, thus keeping it close to zero; after drift, the expected increment becomes positive, causing the statistic to grow at a linear rate until it crosses the threshold. This guarantees a finite expected detection delay and nearly certain detection completion.
Adaptive threshold design
4.3.1.4
To maintain a constant false alarm rate while being sensitive to true changes, the detection threshold h must adapt to the estimated variance of the process. We design the threshold as:
where Φ^−1^ is the inverse of the standard normal CDF, α_err_ is the desired overall false alarm rate, and d is the number of features [a Bonferroni correction is applied (23)]. The fundamental principle of the Bonferroni correction method is to distribute the overall significance level α_err_ evenly across each feature dimension, thereby reducing the significance level for each individual dimension to α_err_/2d. This ensures that the overall false alarm rate remains controllable in high-dimensional monitoring scenarios.
Vt is the estimated variance of the CUSUM statistic, which for an EWMA process can be approximated as:
The stability of the adaptive threshold, ht (see Equation 20), is contingent upon the stability of the process variance estimate. The Exponentially Weighted Moving Average (EWMA) estimator used in this work provides the necessary theoretical guarantees for this condition. A well-established result in statistical process control (24) states that for any smoothing factor α_ewma_∈(0, 1), the variance of an EWMA estimator is bounded. This inherent boundedness ensures that the adaptive threshold ht is itself stable and bounded, thereby preventing runaway behavior caused by noise or data fluctuations and guaranteeing the long-term reliability of the CUSUM detection mechanism.
Algorithm implementation
4.3.1.5
The complete real-time CUSUM detection process is detailed in Algorithm 6. The algorithm's design was driven by the dual requirements of computational efficiency and statistical robustness for edge deployment. Its efficiency stems from a recursive and memoryless structure. Unlike sliding window approaches, this algorithm stores only the current estimates of the mean, variance, and CUSUM statistic (Line 1), resulting in a minimal space complexity of O(d). The EWMA (Lines 4–5) and CUSUM statistic updates (Lines 8–9) are performed recursively using computationally inexpensive, element-wise vector operations per time step. This design is critical for real-time processing on resource-constrained devices.
Algorithm 6Recursive CUSUM detection.
To ensure statistical robustness, the algorithm incorporates an adaptive thresholding and alarm mechanism (Lines 12–18). Rather than using a fixed threshold, which is sensitive to changes in data volatility, the threshold ht is dynamically recalculated at each step based on the current process variance. This design confers robustness against heteroscedasticity. A Bonferroni correction is applied to the threshold calculation to control the family-wise error rate when monitoring multiple feature dimensions. Upon triggering an alarm, the CUSUM statistic is reset immediately, preparing the system to detect subsequent concept drifts without delay and completing the real-time detection loop.
Fast online model parameter update mechanism construction
4.3.2
Upon receiving an alarm from the CUSUM detector (Section 4.3.1), the system must rapidly update its model parameters to adapt to the detected concept drift. This update process is constrained by two critical requirements: it must be completed within a strict time budget (Tupdate ≤ 2 ms) and executed on a resource-limited edge device (typically ≤ 100 MFLOPS). Conventional online learning algorithms are often unsuitable under these constraints; second-order methods, such as Newton's method, which involve computing and inverting the Hessian matrix—an O(d^3^) operation—are computationally infeasible. Even standard first-order gradient descent can exhibit slow convergence if the loss landscape is ill-conditioned.
To overcome these limitations, this section introduces a novel Adaptive Covariance Gradient Descent (ACGD) algorithm. The foundational concept is to substantially reduce the dimensionality of gradient computations by employing random projection techniques, supported by the Johnson-Lindenstrauss lemma. This methodology constructs a low-rank approximation of the gradient, thereby lowering the computational complexity to O(dlogd) while maintaining established theoretical convergence guarantees.
The development and theoretical analysis of the ACGD algorithm rely on a set of formal definitions and assumptions. We begin by formulating the local optimization problem through definitions of the loss function and the dimensionality reduction mechanism. Subsequently, we introduce necessary assumptions regarding the geometric properties of the loss landscape—specifically, strong convexity and smoothness—which form the basis for our convergence analysis.
To formalize the update procedure, we define the local loss function , which constitutes the objective for incremental learning. This function is formulated as the mean squared error over a recent window of anomalous data, augmented with a Tikhonov regularization term to mitigate overfitting. To optimize this loss efficiently, ACGD utilizes a random projection matrix P∈ℝ^r×d^ (where r≪d), with elements sampled from a standard normal distribution. This matrix enables the projection of the high-dimensional gradient into a lower-dimensional subspace, thus facilitating computationally tractable updates.
The convergence of ACGD depends on two geometric properties of the loss function:
Local strong convexity
4.3.2.1
Within the short adaptation window, the loss function exhibits sufficient curvature in parameter space to ensure the Hessian is bounded near zero, thereby guaranteeing linear convergence.
Gradient smoothness
4.3.2.2
When model parameters change, the gradient variation maintains a smoothness property proportional to the parameter change, enabling a stable and controllable optimization process.
Adaptive gradient approximation
4.3.2.3
To enable fast online updates on resource-constrained edge devices, ACGD avoids computing the full high-dimensional gradient . Instead, it constructs a low-dimensional approximation using a random projection matrix P:
This procedure compresses the gradient into an r-dimensional subspace, significantly reducing computational cost while retaining essential geometric information.
The accuracy of this approximation follows from the Johnson–Lindenstrauss (JL) lemma (25), which guarantees that random projection approximately preserves vector norms and inner products. Consequently, the sketched gradient remains close to the true gradient in both magnitude and direction.
Prior theoretical results (26) ensure that when the projection dimension r is chosen proportional to ln(d), the approximation error remains uniformly bounded with high probability. In particular, the vectorized sketched gradient satisfies:
This implies that the low-dimensional gradient can serve as a reliable substitute for the true gradient, thereby enabling ACGD to maintain stable convergence behavior even under low-complexity conditions.
ACGD algorithm convergence analysis
4.3.2.4
The parameter update rule for ACGD is a standard gradient descent step, but using the approximated gradient:
where η_learn_ is the learning rate.
Having established the update rule, the central question is whether this iterative process converges to the optimum, especially given the use of an approximated gradient. Under the aforementioned assumptions (including the local strong convexity of the loss function, the Lipschitz continuity of the gradient, and the gradient approximation guarantees based on JL projections), the ACGD iteration process can be proven to converge linearly. Strong convexity ensures that iterations consistently contract toward the optimal point, while smoothness controls perturbations introduced by the approximated gradient.
When the learning rate is set within a conventional range (e.g., η_learn_≈1/L), the distance between the current parameters and the optimal solution decreases with each iteration, satisfying the following.
This indicates that the error decays exponentially, with its contraction rate being only slightly affected by the approximate error (ϵ).
Overall, despite using “projected gradients” rather than true gradients, ACGD iterations maintain stability and linear convergence rates consistent with classical gradient descent, reliably converging toward the optimal solution.
Algorithm implementation
4.3.2.5
The implementation of the ACGD algorithm is detailed in Algorithm 7. The design of ACGD is singularly focused on achieving rapid convergence under a minimal computational budget, a critical requirement for online updates at the edge. The cornerstone of its efficiency is the gradient approximation step (Line 7). Unlike traditional second-order methods that require the costly full d×d Hessian matrix, ACGD performs all essential matrix multiplications within a compressed r-dimensional subspace, where r≪d. This compression is enabled by a one-time random projection (Line 2), which generates a projection matrix P that is reused throughout all iterations.
Algorithm 7Adaptive covariance gradient descent (ACGD).
Consequently, the update step (Line 8) remains a simple and computationally inexpensive first-order operation. The key innovation, therefore, lies not in altering the update rule itself, but in drastically reducing the cost of computing a more effective descent direction . By combining these design choices, ACGD captures essential second-order information—specifically, approximating the action of the Hessian-vector product—without explicitly constructing the Hessian matrix. This approach results in an overall computational complexity of O(dlogd), making the algorithm particularly suitable for real-time model updates in resource-constrained edge environments.
Convergence analysis of the online incremental learning mechanism
4.3.3
Having designed the individual mechanisms for drift detection (CUSUM) and rapid parameter adaptation (ACGD), a crucial question remains regarding their integrated behavior: does the combined “detect-then-update” system maintain stability and converge to a meaningful solution over time? This section addresses this question by presenting a convergence analysis for the unified CUSUM-ACGD framework, thereby establishing its long-term reliability.
Joint process modeling
4.3.3.1
The system's evolution is modeled as a stochastic process. The state at time t is defined by the tuple Zt = (St, Wt), where St is the CUSUM statistic and Wt is the current weight matrix. This process evolves as a Markov chain, with the transition probability ℙ(Zt+1|Zt) governed by two distinct operational modes. In the default Monitoring Mode, activated when the CUSUM statistic is below its threshold (St<ht), the model weights remain fixed (Wt+1 = Wt) while only the statistic St is updated. Upon detecting a drift (St≥ht), the system switches to an update mode. In this mode, the weights are updated via the ACGD algorithm (i.e., Wt+1 becomes the output of Algorithm 7), and the CUSUM statistic is reset to zero. The stability of this joint process hinges on demonstrating that updates are triggered sufficiently often and that each update progresses toward the optimal parameter set.
Under drift detection and parameter update conditions, the combined CUSUM–ACGD process guarantees convergence. Specifically, the sequence of parameter estimates {Wt} converges almost surely to the optimal parameter matrix W^*^ that tracks the evolving data distribution:
where represents the slowly varying optimal parameters for the current concept.
The proof is structured as a three-part argument that synthesizes the results established in the preceding sections.
First, the stability of CUSUM detection has been demonstrated in the preceding text; sustained drift will trigger an alarm within a finite time frame, thereby ensuring timely activation of updates.
Second, the update rules of ACGD ensure that parameter errors contract at a linear rate toward the new local optimum during each update phase.
Finally, by constructing the overall error process as super-martingale and utilizing the Robbins–Siegmund theorem from stochastic approximation theory (27), it can be demonstrated that the overall parametric error converges almost surely to zero.
Collectively, this three-step argument confirms that the CUSUM-ACGD framework constitutes a principled and provably convergent online learning system, aligning with recent theoretical advances in non-stationary online learning (28).
Algorithm implementation
4.3.3.2
The complete, integrated online learning mechanism is summarized in Algorithm 8, which encapsulates the “detect-then-update” loop forming the adaptive core of our method. This algorithm provides a unified framework that integrates the detection and update modules into a single, cohesive process. Central to our design is an event-triggered philosophy, which is essential for ensuring overall system efficiency. At each time step, the system operates primarily in a low-power monitoring state, performing an inexpensive O(d) detection check for concept drift (Line 7). The computationally intensive ACGD update procedure (Lines 10–13) does not execute on a fixed schedule; rather, it is triggered only when a statistically significant change is detected by the CUSUM module.
Algorithm 8CUSUM-ACGD online learning framework.
This event-triggered architecture is fundamental for enabling real-time operation on resource-constrained devices. By combining lightweight continuous monitoring with a sporadic yet rapid update mechanism, our framework addresses a core challenge in edge AI: it satisfies strict per-sample latency requirements for real-time inference while maintaining the long-term model adaptation necessary for robust performance in non-stationary environments.
Algorithm implementation
4.3.3.3
Algorithm 8 summarizes the complete, integrated online learning mechanism, encapsulating the “detect-then-update” loop that constitutes the adaptive core of our method. This algorithm provides a unified framework that seamlessly integrates the detection and update modules. The design is founded on an event-triggered philosophy, which is pivotal for achieving overall system efficiency. At each time step, the system primarily remains in a low-power monitoring state, performing an inexpensive O(d) detection check for concept drift (Line 7). The computationally intensive ACGD update process (Lines 10–13) is not executed periodically but is conditionally triggered only when a statistically significant change is detected by the CUSUM module.
Overall algorithm implementation and optimization strategy at the edge
4.4
The preceding sections have introduced the three core computational pillars of our framework: robust feature extraction (Section 4.1), dynamic subnetwork activation (Section 4.2), and online incremental learning (Section 4.3). While each module has been individually optimized, the final system performance depends crucially on their seamless integration into a unified pipeline that can operate reliably on resource-constrained edge devices.
This section addresses this system-level integration challenge. Our goal is to bridge algorithmic design and practical deployment by establishing a coherent execution workflow and a resource-aware control mechanism. To achieve this, we cast the computational load regulation problem as a feedback control problem, enabling the system to maintain stability and responsiveness under dynamic workloads.
The section is structured as follows: first, we outline the overall data and control flow of the integrated method (Section 4.4.1); second, we present the key pseudocode for the main control loop (Section 4.4.2); and third, we detail the design of an adaptive load balancing strategy for dynamically managing computational resources (Section 4.4.3).
Overall flow design of the dynamic subnetwork edge computing method
4.4.1
The real-time resource optimization problem at the edge constitutes a multi-objective dynamic decision problem within a high-dimensional constrained space. The primary challenges are threefold: the dynamic coupling between computational load and task features, the non-linear trade-offs between accuracy and latency/power consumption, and the system uncertainty introduced by incremental learning. Static scheduling or open-loop control strategies are inadequate for addressing these coupled challenges.
Our approach involves constructing a closed-loop coordination mechanism for the dynamic sparse subnetwork, drawing inspiration from state-space modeling in control theory. In this model, the feature vector f is treated as the system's state variable, the computational resource configuration parameters (e.g., CPU frequency) serve as the control input, and the classification accuracy and inference latency are the observed outputs. This transformation of the edge computing optimization task into a control system stability and regulation problem represents a key innovation of our design, enabling rigorous analysis and a principled implementation. The overall data and control flow operate as a continuous loop, described in the following paragraphs.
Data flow and module interconnection
4.4.1.1
The process initiates with the raw sensor data stream X(t), which is first input into the Feature Extraction Module. Operating under the short-term stationarity assumption, this module employs the Fast-PCA algorithm (Algorithm 1) to project the high-dimensional data into a low-dimensional, orthogonal feature vector f. The dimensionality d^*^ is adaptively selected by Algorithm 2 to balance information fidelity against computational cost.
Subsequently, this feature vector f is passed to the Dynamic Subnetwork Activation Module. This module addresses the NP-hard combinatorial optimization problem using one of the proposed heuristic strategies, selecting an optimal sparse subnetwork defined by weights and performing the classification to produce an output label yt.
Concurrently, the feature stream {ft} is monitored by the Online Incremental Learning Module. The CUSUM detector (Algorithm 6) tests for concept drifts; upon detection, it triggers the ACGD update mechanism (Algorithm 7), which refines the model parameters W using recent data. The updated parameters are then propagated to the activation module for subsequent classifications.
Closed-loop control flow
4.4.1.2
The entire process is governed by a resource control loop. Following each inference step, the measured inference time is compared against the target latency Tmax. The resulting error signal is processed by a PID (Proportional-Integral-Derivative) controller, whose output adjusts the system's computational resources (e.g., by modulating the CPU/GPU clock frequency) to influence the processing time of the subsequent cycle. This feedback mechanism ensures the system dynamically adapts its resource consumption to remain within the predefined latency budget, thereby constituting a complete, closed-loop adaptive system. This stands in contrast to open-loop systems, which lack the capability to react to unforeseen variations in workload or processing time.
Key algorithm pseudocode design and implementation details
4.4.2
To translate the overall flow design from Section 4.4.1 into a concrete implementation, this section presents the pseudocode for the main control loop of our edge computing framework. Algorithm 9 serves as the master algorithm, orchestrating the interplay between feature extraction, dynamic decision-making, online adaptation, and resource control in each processing cycle.
Algorithm 9Overall edge framework control loop.
The successful implementation of our master algorithm (Algorithm 9) relies on several key technical choices for its core functions. For the critical task of candidate subnetwork generation (Line 16), we employ a Monte Carlo Tree Search (MCTS) strategy to navigate the vast combinatorial space. This method was selected because it offers a principled approach to balancing exploration—searching for novel and effective structures—and exploitation—leveraging known high-performing structures. The search process is guided by an information gain metric, enabling the “ActivateSubnetwork” function to efficiently identify promising candidate architectures within a constrained time budget.
For CUSUM-based anomaly detection (Line 19), our implementation builds upon the Sequential Probability Ratio Test (SPRT) (3). The update procedure involves computing the log-likelihood ratio:
where p1 and p0 denote the probability density functions under the drift and null hypotheses, respectively. An alarm is raised when the cumulative sum St surpasses a predefined threshold h, which is carefully calibrated to balance the trade-off between false alarms and missed detections.
The PID control law (Line 27) is implemented in discrete-time form to compute the required resource adjustment uk. The update rule is given by:
where ek represents the latency error at cycle k. To ensure numerical stability, this formulation is derived from its continuous-time counterpart via the Tustin transformation. The controller gains (Kp, Ki, Kd) are subsequently tuned according to the system's dynamic response characteristics, guided by the stability conditions that will be formally established in the subsequent section.
These implementation decisions are firmly grounded in the theoretical foundations presented earlier. The Fast-PCA projection (Line 13) complies with the optimality conditions set forth. The subnetwork selection process (Line 16) utilizes heuristic methods to approximate solutions to the NP-hard problem, supported by theoretical guarantees on the approximation ratio. Furthermore, the tuning of PID parameters is informed by the stability analysis that will be detailed in Section 4.4.3.
Design of an adaptive load balancing strategy for edge computing
4.4.3
The final component of our framework is a system-level control mechanism designed to dynamically manage computational resources and maintain stable real-time performance. The objective is to continuously adjust resources—such as CPU frequency—to keep the inference latency Tinfer close to a target value Tmax, even under fluctuating workloads. This problem can be naturally formulated as a feedback control task.
Although advanced optimal control methods such as Model Predictive Control (MPC) (29) are applicable, their computational demands often render them impractical for real-time deployment on edge devices. To address this, we propose a pragmatic and effective alternative: modeling the system's latency dynamics using an approximate second-order linear model. This simplification allows the use of a classical Proportional-Integral-Derivative (PID) controller, thereby converting the challenging online optimization problem into a more tractable system stabilization task, for which PID control is a well-established and robust solution.
The resulting control-theoretic framework is illustrated conceptually in Figure 5. Our solution is structured as a closed-loop system comprising a real-time performance monitoring module, which supplies the feedback signal, and a PID-based control system, which computes the necessary resource adjustments. The following sections elaborate on this model and present a formal stability analysis of the proposed controller.
Conceptual framework for the edge resource optimization strategy, outlining the demand pull, key scientific questions, and the proposed technical approach.
System modeling
4.4.3.1
We model the dynamics of the inference latency Tinfer as a function of the control input uk = ΔfCPU, the change in CPU frequency. The latency at cycle k+1 can be approximated by a first-order Taylor expansion around the latency at cycle k, plus some process noise wk:
Assuming that latency is inversely proportional to frequency (Tinfer≈C/fCPU), the partial derivative is . By defining the state vector as the latency error and its derivative, , we can derive the discrete-time state-space representation of the system:
where δt is the control period. This state-space model provides the basis for our stability analysis.
With the system formally modeled, the crucial next step is to determine the conditions under which the PID controller can guarantee stability. To this end, we substitute the PID control law into the system model to obtain the corresponding closed-loop characteristic polynomial.
In the continuous-time s-domain, for simplicity of analysis, this equation takes the form:
where A is a positive constant related to the system parameters, and , , and denote the normalized proportional, integral, and derivative gains, respectively.
To determine whether the system is stable, we construct the Routh array for this third-order polynomial based on the Routh–Hurwitz criterion (30). According to the construction results, the four entries in the first column of the Routh array are:
According to the Routh–Hurwitz criterion, the system is stable if and only if all the above terms are positive. This yields the necessary and sufficient condition for the stability of a PID controller:
The third inequality defines the feasible range for the integral gain :
Provided that the PID gain satisfies the aforementioned three conditions, the closed-loop system can avoid oscillations and maintain stable dynamic response.
PID controller design for robustness
4.4.3.2
Although DVFS-based latency regulation forms a hybrid, mildly nonlinear feedback loop due to discrete frequency levels, actuator bounds, and workload/measurement disturbances. In our framework, the PID controller is not used to control the nonlinear learning dynamics; it regulates only the scalar inference latency.
The PID is implemented in discrete time using the incremental form in Equation 25, consistent with DVFS updates executed once per control period Δt (i.e., the sampling interval of the resource control loop). For analysis, we consider an operating region where the latency–frequency relation is monotonic and can be approximated by a locally linearizable form (e.g., Tinfer≈T0+C/fCPU). Under this local approximation, the closed-loop characteristic equation admits sufficient stability conditions via the Routh–Hurwitz criterion, which guides gain selection away from oscillatory regimes.
To improve robustness under noise and to prevent frequent switching among discrete DVFS levels, we employ (i) bounded control action enforced by the DVFS range and (ii) EWMA low-pass filtering of the measured latency before forming the error signal. In addition, common implementation refinements such as deadband/hysteresis, rate limiting, and integrator anti-windup can be enabled to further suppress chattering under high-frequency measurement noise.
Auxiliary optimization strategies
4.4.3.3
In addition to the core PID control, we employ two auxiliary strategies to further enhance the robustness and efficiency of the resource management.
Dynamic priority scheduling: In scenarios with multiple concurrent tasks, not all tasks are equally important. We introduce a dynamic priority weight ω_i_ for each task i, which could be based on its deadline or importance: ω_i_ = exp(−μ·delay_i_). The total available resource ftotal is then allocated proportionally:
This ensures that more critical tasks receive a larger share of the computational resources.
Resource reservation: To handle sudden bursts in workload or unexpected processing demands, a portion of the total resources is always kept in reserve. We set a hard threshold freserve = ρftotal, where the reservation factor ρ can be dynamically adjusted based on historical load statistics. This reserved capacity acts as a buffer, improving the system's resilience to transient spikes in demand.
Experiments
5
This section presents a systematic evaluation of the proposed framework across multiple datasets. The study methodically examines its effectiveness, computational efficiency, and robustness. The evaluation includes comparisons with four representative human activity recognition baselines (CNN, DeepConvLSTM, iSPLInception, and HART), ablation studies, and multi-dimensional performance analyses. The results demonstrate a superior trade-off between accuracy and efficiency and stable adaptation under non-stationary conditions.
Experimental design and setup
5.1
This subsection describes the experimental configuration, the construction of five heterogeneous datasets, the choice of four representative HAR baselines, a unified set of evaluation metrics, and a standardized runtime environment. The complete setup ensures fair comparison and reproducibility.
Datasets
5.1.1
To assess generalization and practical value, evaluation is performed on multiple sources and scales, including three simulated datasets (30K/50K/100K) and two real-world benchmarks (UCI, MotionSense, HHAR, and Real World), as detailed in Table 1.
Venipuncture simulation dataset
5.1.1.1
Three venipuncture datasets are constructed at different scales, including 100K, 50K, and 30K. The base streams are generated with high-fidelity physical modeling. Each sample contains nine-axis inertial measurement unit (IMU) sensor data, including three-axis accelerometer, three-axis gyroscope, and three-axis magnetometer, sampled at 60 Hz. Six operation classes are included: approaching, aiming, searching, stabilizing, puncture, tremor.
The simulation uses multi-layer physical models designed to introduce specific types of concept drift. Physiological tremor is modeled by a combination of harmonic and modulation components, simulating variations in user fatigue over time. Mechanical response is modeled with a bimodal exponential function. Sensor noise includes gradual sensor drift (modeled as random walk), cross-axis interference, and environmental noise. Parameters are randomized within ranges to mimic operator and environment variability.
HCI dataset
5.1.1.2
HCI is a standard benchmark for HAR (31). It contains daily activities from 30 subjects. The dataset uses a six axis sensor configuration with a three axis accelerometer and a three axis gyroscope. Six activities are included, namely walking, stair up, stair down, sitting, standing, and lying. This dataset supports comparison with prior work on a common task.
RealWorld dataset
5.1.1.3
RealWorld HAR is a large dataset collected in natural environments (32). It contains eight activities from 15 subjects. In this study, only the nine axis IMU channels are used, including gyroscope, accelerometer, and magnetometer. Only the sensor worn at the abdomen is selected for analysis. This setting targets lightweight deployment on edge devices and matches the constraint of a single sensor in resource limited scenarios. Multi sensor fusion increases communication and compute cost, which is beyond the scope here. Crucially, the data exhibit significant long-term drift, which primarily stems from changes in sensor placement (displacement during activity), individual behavioral variability (inter-subject and intra-subject variability), and environmental noise fluctuations. This dataset is used to assess robustness and generalization under real deployment conditions.
Data preprocessing
5.1.1.4
All datasets use Z score normalization and sliding windows for sample segmentation. The window size is 128 samples, the stride is 64 samples, and the overlap is 50%. For datasets with fewer channels, zero padding or feature selection is applied to match a nine dimensional input.
Baselines and time complexity analysis
5.1.2
Four representative HAR deep learning models are selected as baselines. The models cover different architectural families and support a clear comparison. Training and testing use a unified hardware environment and consistent settings.
CNN is a classic convolutional neural network for HAR (9). It uses two one-dimensional convolution layers for feature extraction. Each layer is followed by batch normalization and ReLU. Global average pooling reduces dimensionality, and a fully connected layer performs classification. The inference time complexity is approximately .
DeepConvLSTM combines convolutional layers with long short-term memory (LSTM) layers (10). Four one-dimensional convolution layers extract hierarchical features. The features are then processed by two LSTM layers for temporal modeling. The inference complexity is approximately , where H is the LSTM hidden size.
iSPLInception builds on an Inception ResNet style architecture for sensor-based HAR (11). It uses multi scale convolution kernels to capture features at different time scales. Residual connections ease training. Depthwise separable convolutions reduce compute. The inference complexity is approximately .
HART is a transformer-based model for HAR (12). It uses six Transformer encoder layers with self-attention to capture long-range temporal dependencies. Position encoding and sensor embeddings are combined. The main complexity comes from attention with O(T^2^·d).
The proposed adaptive edge inference framework integrates several components. The total complexity reflects combined costs. Fast PCA has complexity O(d^2^). Dynamic sparse subnetwork selection has complexity O(K·C·d·T). CUSUM detection has O(d). The PID controller has O(1). In total, the time complexity is approximately O(K·C·d·T+d^2^). Sparse activation and incremental updates keep practical runtime within acceptable limits.
Evaluation metrics
5.1.3
A unified set of evaluation metrics is used for fair comparison across all methods.
Accuracy. The ratio of correct predictions to all samples.Per sample time (ms). The average time to process a single sample in milliseconds. For the adaptive method this includes feature extraction, subnetwork activation, and any online learning trigger.
Experimental environment
5.1.4
Experiments were conducted on an 11th Gen Intel Core i7-11370H CPU at 3.30 GHz with 16 GB RAM. The software environment utilizes Windows 11 and Python 3.8.
Regarding the baseline methods, all models are trained using the Adam optimizer with an initial learning rate of 0.001, a batch size of 32, and for 100 epochs. The dataset split is 70% training, 20% validation, and 10% testing. We primarily adopted the default parameter settings as recommended in their respective original literature. However, to ensure a fair comparison, we also performed a limited grid search for key hyperparameters on the validation set to guarantee optimal convergence on our specific datasets.
Model architecture and hyperparameters
5.1.4.1
Key hyperparameters for the proposed method were determined through empirical validation using a grid search strategy on a separate validation set. Specifically, the selection criterion prioritized configurations that offer an optimal trade-off between recognition accuracy and computational efficiency, strictly adhering to the latency constraints of edge devices.
To improve reproducibility, the proposed model architecture (backbone used by the dynamic sparse activation module) and the key hyperparameters used in the experiments are summarized in Tables 2, 3. All hyperparameters in Table 3 are fixed across all reported experiments unless stated otherwise.
Main results and analysis
5.2
This subsection presents a comprehensive comparison across five datasets and four baseline models. The results verify strong performance and generalization under different data sources and scales.
Performance comparison across datasets
5.2.1
As reported in Table 4 and Figure 6, the proposed method's accuracy was evaluated across five datasets. The proposed method achieves the highest accuracy on four datasets, including 100K, 50K, HCI, and RealWorld. On the 30K dataset, its accuracy of 94.2% is marginally below that of HART (95.0%), marking a minor gap of 0.8 percentage points. Relative to the best baseline, gains on 100K and 50K are 3.0 and 7.8 percentage points. Gains on HCI and RealWorld are 1.3 and 3.5 percentage points. Inference latency remains between 0.89 and 1.14 ms across all datasets, and is lower than complex deep models such as iSPLInception at 3.45 to 3.67 ms and HART at 2.42 to 3.21 ms.
Accuracy comparison across five datasets.
On the venipuncture simulation datasets, the method shows clear advantages on 100K and 50K. As dataset size grows from 30K to 100K the advantage over iSPLInception increases from negative 0.7 to positive 3.0 percentage points. This pattern suggests that the incremental learning mechanism benefits from richer data and matches the convergence analysis in Section 4.3. The relative weakness on 30K may come from limited samples for robust mutual information estimation within the subnetwork selection.
On the HCI benchmark the accuracy reaches 95.9%, surpassing DeepConvLSTM at 94.6% and HART at 93.2%. On the RealWorld dataset the accuracy is 85.6%, an improvement of 3.5 percentage points over HART. RealWorld includes environmental noise, sensor drift, and subject variability. These results underscore the model's robustness under nonstationary conditions.
From an efficiency perspective, latency remains between 0.89 and 1.14 ms on all datasets, well below the 16.7 ms bound for 60 Hz processing. Relative to iSPLInception at 3.56 ms the reduction is about 69%. Relative to DeepConvLSTM at 1.51 ms the reduction is about 26%. Although CNN reaches 0.53 ms, the accuracy is 11.2 percentage points lower.
Sources of performance advantages
5.2.1.1
The gains arise from three components working together. Fast PCA adjusts the feature dimension according to the data, reducing noise while preserving key information. Orthogonal feature decoupling reduces the dimension from nine to about three to five while maintaining about 95% of total variance. Dynamic sparse subnetwork selection activates parameters according to input complexity. The average activation rate is about 35% of all parameters. The online incremental learning mechanism with CUSUM detection and ACGD updates adapts to distribution changes and maintains high accuracy. These effects are consistent with the theory in Sections 4.1, 4.2.
Efficiency analysis
5.2.2
Efficiency is a key factor for real time edge deployment. The method achieves a balanced point between accuracy and latency and meets the timing requirement.
Latency comparison
5.2.2.1
Patterns are clear across model families, as shown in Table 5 and Figure 7. Lightweight CNN models are fastest with 0.47 to 0.57 ms, due to a simple two layer design with complexity O(K·C·d). This speed comes with a notable accuracy drop. iSPLInception has higher cost from multi scale parallel convolutions with 3.45 to 3.67 ms and complexity . HART uses attention with complexity O(T^2^·d) and time of 2.42 to 3.21 ms. DeepConvLSTM reaches 0.95 to 1.51 ms, reflecting a balance between local feature extraction and temporal modeling but with O(T·H^2^) cost.
Per sample inference time comparison across five datasets.
The proposed method keeps latency between 0.89 and 1.14 ms. First, the values meet the 60 Hz timing bound, leaving headroom for system scheduling. Second, latency is stable across datasets with a standard deviation of 0.09 ms, showing robustness to changes in data characteristics. Third, relative to complex models the reduction is large. The main source is sparse activation that avoids redundant full network compute.
Accuracy and efficiency trade off analysis
5.2.3
Pareto optimality provides a clear view of the position on the accuracy and latency plane. On the 100K dataset the proposed method reaches 97.4% accuracy and 1.12 ms latency. Relative to iSPLInception at 94.4% and 3.56 ms, accuracy improves by 3.0 percentage points and latency reduces by about 69%. Relative to CNN at 86.2% and 0.53 ms, the additional 0.59 ms increases latency by about 111% but gains 11.2 percentage points in accuracy. A simple utility function U = α·Acc−(1−α)·T shows that for α>0.05 the proposed method is strictly better than CNN. Relative to DeepConvLSTM at 85.3% and 1.51 ms, accuracy improves by 12.1 percentage points while latency drops by about 26%.
Gains come from three coordinated mechanisms. Fast PCA lowers the feature complexity from O(n·d) to O(n·d^^) with d^^≈0.4d. Dynamic sparse selection activates only part of the parameters with constraint ∑ai ≤ K. Online learning maintains high accuracy under concept drift and avoids performance decay present in static models. The approximation ratio in Section 4.2 is not below 1 − 1/e, which supports near optimal performance.
System stability and disturbance rejection analysis
5.2.4
To rigorously validate the safety of the resource control mechanism in clinical settings, we conducted a numerical stress test based on the closed-loop dynamics modeled in Equation 26. The simulation utilized the exact PID gains (Kp = 0.5, Ki = 0.1, Kd = 0.05) and the EWMA filtering parameter (α = 0.1) defined in our experimental setup. Figure 8 illustrates the system's step response under two concurrent stress conditions: high-frequency sensor noise (σ = 0.1) and a sudden +50% workload surge simulating abrupt concept drift.
Numerical stress test validating closed-loop control stability under extreme edge cases.
Quantitative analysis yields the following performance metrics:
Settling time: Adopting the standard 5% criterion, the system restabilizes within 76 control cycles (approx. 1.2s) following the massive workload drift.Overshoot: The maximum overshoot is contained at 28.38%. The EWMA filter effectively dampens the initial physical impact, preventing secondary oscillatory overshoot.Steady-state error: The integral action eliminates residual error, maintaining a steady-state precision of 0.01680 ms (< 2% deviation), ensuring strict adherence to the real-time deadline.
These results confirm that the proposed control strategy maintains robust stability without oscillation, even under extreme edge cases.
Ablation study
5.3
This subsection is dedicated to quantifying the contribution of each module (summary results are provided in Table 6). Fast PCA, dynamic sparse subnetwork selection, and online learning are removed in turn. Changes in accuracy and latency are analyzed and the combined effect is reported.
Contribution of fast PCA
5.3.1
The removal of Fast PCA changes accuracy differently across datasets, as visualized in Figure 9. On 100K accuracy drops from 97.3% to 97.0%. On RealWorld it drops from 85.6% to 83.8%. On 30K it slightly increases from 94.2% to 94.5%. Two factors explain the overall pattern. First, raw nine dimensional sensor data have redundancy and noise, and feeding them directly can reduce discriminative power. Second, the random projection theory in Section 4.1 shows that Fast PCA preserves about 95% of variance and filters secondary noise components, improving the signal to noise ratio of features.
Accuracy comparison in ablation experiments across five datasets.
Removing Fast PCA increases computation time by about 21%, as illustrated in Figure 10. On 100K latency rises from 1.12 ms to 1.35 ms. Three effects explain this pattern. Although Fast PCA adds front end compute, it reduces the feature dimension from nine to about three to five. This lowers the complexity of subnetwork selection and classification from O(|W|·d) to O(|W|·d^^) with d^^≈4. Orthogonal decoupling reduces redundancy and lowers the condition number of the covariance matrix. Higher quality features improve mutual information estimates in the gating function, which reduces invalid parameter activation and avoids redundant compute paths. Together these effects reduce overall cost.
Per sample inference time in ablation experiments across five datasets.
Dynamic sparse subnetwork selection
5.3.2
Removing dynamic selection and using the full network gives a small accuracy increase on some datasets with gains up to about 1.2 percentage points. This shows that the full network can capture more features under some distributions. The increase comes with a notable latency cost of about 25%.
The trade off is asymmetric. Relative to dynamic selection, accuracy increases by about 1.0 percentage points while latency increases by about 0.28 ms. In cost and benefit terms, each 1% accuracy gain costs about 0.28 ms latency. The rise from 1.12 ms to 1.40 ms approaches real time limits. In the resource management framework in Section 4.4, under 60 Hz processing a 0.28 ms increase does not break the bound but reduces headroom and limits concurrency. More importantly, dynamic selection adjusts compute according to input complexity and provides flexibility under uncertain workloads on edge devices.
Efficiency gains come from two sources. Parameter level sparsity activates only part of the network according to the constraint ∑ai ≤ K. Sample adaptive control adjusts activation rate according to input complexity. According to Section 4.2, this strategy provides a locally optimal solution to the constrained problem in Equation 12.
Note that our “per-sample time” metric is end-to-end; for the proposed method it includes feature extraction, candidate selection, and any triggered online-learning update. Therefore, the reported latency already accounts for the selection overhead. As shown in Table 7, disabling candidate selection increases latency from 1.12 ms to 1.40 ms on the 100K dataset, and similarly degrades latency on other datasets. This indicates that the selection overhead is more than offset by the computation saved through sparse activation, yielding a net runtime benefit.
Online learning mechanism
5.3.3
Removing CUSUM detection and ACGD updates gives the largest accuracy drop, with an average reduction of 7.2 percentage points across datasets. This confirms the key role of online learning for long term robustness. Two factors explain the need. Both simulation and real datasets include concept drift, where statistics change across operation stages. Static models cannot adapt. According to Section 4.3, the CUSUM and ACGD combination converges to parameters that track the evolving distribution, which supports long term performance.
Removing online learning lowers latency by about 38% because detection and updates are no longer computed. The efficiency gain comes with a strong accuracy cost. On 100K accuracy drops by 9.6 percentage points from 97.3% to 87.7%, which is 6.7 percentage points below iSPLInception at 94.4%. This shows the value of online adaptation under nonstationary data. Static models run faster but their accuracy decays over time. From a deployment view the additional 0.43 ms remains within the real time bound of 16.7 ms and yields a 9.6 percentage point accuracy gain. Under nonstationary streams, the benefit from adaptation is larger than the cost.
Discussion
5.4
Results support generalization on three dimensions. Across data sources the method maintains advantage on both simulation and real sensor data, which suggests that adaptation does not depend on one generator. Across data scales performance improves steadily from 30K to 100K samples, which suggests robustness to training size. Across application scenarios differences between nursing operations and daily activities do not change relative performance, which suggests that the framework is domain independent.
On RealWorld the performance is notable. The dataset includes nonstationarity from sensor drift, intra class variability from subjects, and noise from environment. Under these strict conditions the method still outperforms HART, a Transformer based baseline. This shows that a lightweight architecture with adaptive mechanisms is effective under both resource limits and nonstationary data.
Limitations and future work
5.5
Several limitations remain. The CUSUM-based change detection is reactive and needs enough observations before triggering updates. Sudden distribution changes may cause a delay. System performance depends on hyperparameters including PID gains, CUSUM parameters, and projection dimension. Values are set by validation in this study, but may need adjustment in other scenarios. Behavior on larger datasets and longer time spans is not yet validated. The cumulative effect of online learning and long-term stability of CUSUM statistics need further study.
Future directions include predictive drift detection to trigger pre-adjustment, automatic online hyperparameter tuning, and support for multimodal sensor fusion. Extending the framework to edge and cloud collaboration can balance latency and compute by splitting tasks between real-time inference on the edge and periodic refinement in the cloud. Hardware-specific acceleration that uses random projection and sparse compute can further lower latency for stricter real-time conditions.
Conclusion
6
This paper addresses a problem at the intersection of applied mathematics and edge computing: the real-time classification of high-dimensional, non-stationary stochastic processes under stringent computational constraints. We establish that traditional methods, which rely on empirical risk minimization over static datasets, are theoretically ill-suited for such dynamic tasks due to their inherent violation of the stationarity assumption. To overcome this limitation, we propose a novel framework that integrates principles from stochastic signal processing, combinatorial optimization, and online learning theory. This framework synergistically combines a Fast-PCA variant for dimensionality reduction, a heuristic-based strategy to address the NP-hard problem of dynamic subnetwork activation, and a CUSUM mechanism for low-complexity, convergent parameter updates.
Experimental results corroborate the theoretical advantages of the framework. Across five datasets exhibiting significant concept drift, the proposed method achieves accuracies ranging from 85.6% to 97.4%. On the RealWorld dataset, which represents a real-world application scenario, the method attains an accuracy of 85.6%, outperforming the Transformer-based HART (82.1%) by 3.5 percentage points. This is achieved while maintaining an inference latency of approximately 1.0 ms, comfortably meeting the real-time requirement (16.7 ms threshold). These findings demonstrate that the method surpasses existing baselines in both accuracy and computational efficiency, striking an effective trade-off between adaptability and performance. This validates that the synergistic design of a lightweight architecture and an adaptive mechanism can overcome the limitations of traditional static models in nonstationary environments.
In conclusion, this work contributes a new methodological framework for designing adaptive intelligent systems in resource-constrained settings. Its primary contribution lies in the establishment of a unified, closed-loop system that provides a rigorous theoretical foundation for each core component, from feature extraction to model adaptation. The resulting solution is both robust and scalable, with significant potential for application in other domains challenged by dynamic data streams, such as financial time-series analysis or the Industrial Internet of Things. Future research will focus on the theoretical analysis of more sophisticated, predictive drift detection mechanisms to further advance the state-of-the-art in online adaptive learning.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1Lane ND Georgiev P Qendro L. Tiny ML: a new lens on the future of on-device AI. Commun ACM. (2021) 64:30–2. doi: 10.1145/3481581 · doi ↗
- 2Lin J Chen WM Lin Y Cohn J Han S Kung C. Mcunet: tiny deep learning on Io T devices. In: Advances in Neural Information Processing Systems (2020). p. 11711–11722.
- 3Gama J ŽliobaitẽI Bifet A Pechenizkiy M Bouchachia A. A survey on concept drift adaptation. ACM Comput Surv. (2014) 46:1–37. doi: 10.1145/2523813 · doi ↗
- 4Howard A Sandler M Chu G Chen LC Chen B Tan M . Searching for mobilenetv 3. In: Proceedings of the IEEE/CVF International Conference on Computer Vision (2019). p. 1314–1324. doi: 10.1109/ICCV.2019.00140 · doi ↗
- 5Khan A Sohail A Zahoora U Qureshi AS. A survey of the recent architectures of deep convolutional neural networks. Artif Intel Rev. (2020) 53:5455–516. doi: 10.1007/s 10462-020-09825-6 · doi ↗
- 6Frankle J Carbin M. The lottery ticket hypothesis: finding sparse, trainable neural networks. In: International Conference on Learning Representations (ICLR) (2019).
- 7Wang L Wang XY Zhang K Liu HS Liao JH Lin CS . A comprehensive survey on continual learning: From a unified framework to applications. ar Xiv preprint ar Xiv:230208138. (2023).
- 8Maschi Q Taillandier P Coulognge A. Continual learning for human activity recognition on embedded systems. In: IEEE International Conference on Systems, Man, and Cybernetics (SMC). IEEE (2022). p. 1116–1123.