Multimodal spatiotemporal graph convolutional attention network for dynamic risk stratification and intervention strategy generation in rare disease rehabilitation nursing
Siwen Zhao, Min Hu, Shan Fang

TL;DR
A new AI model helps improve risk assessment and treatment planning for rare disease rehabilitation by analyzing patient data more effectively.
Contribution
The MSTGCA-Net framework introduces a novel multimodal spatiotemporal graph convolutional attention network for rare disease rehabilitation nursing.
Findings
MSTGCA-Net achieved an accuracy of 0.867 and an AUC of 0.923 in risk stratification.
Generated intervention strategies were clinically appropriate, safe, and feasible according to expert evaluation.
Abstract
Rare disease rehabilitation nursing presents unique challenges due to heterogeneous clinical manifestations, limited sample sizes, and complex comorbidity patterns that render traditional risk assessment tools inadequate. This study proposes a novel multimodal spatiotemporal graph convolutional attention network (MSTGCA-Net) for dynamic risk stratification and intervention strategy generation in rare disease rehabilitation. The framework integrates four principal innovations: a heterogeneous patient relationship graph construction scheme encoding clinical similarities, an adaptive multimodal fusion module employing cross-attention mechanisms, a spatiotemporal encoder capturing both inter-patient relationships and longitudinal dependencies, and a knowledge-guided intervention generation component. Experiments conducted on a retrospective cohort of 2,847 patients with 156 rare disease…
Genes, proteins, chemicals, diseases, species, mutations and cell lines named across the full text — each resolved to its canonical identifier and authoritative record.
Click any figure to enlarge with its caption.
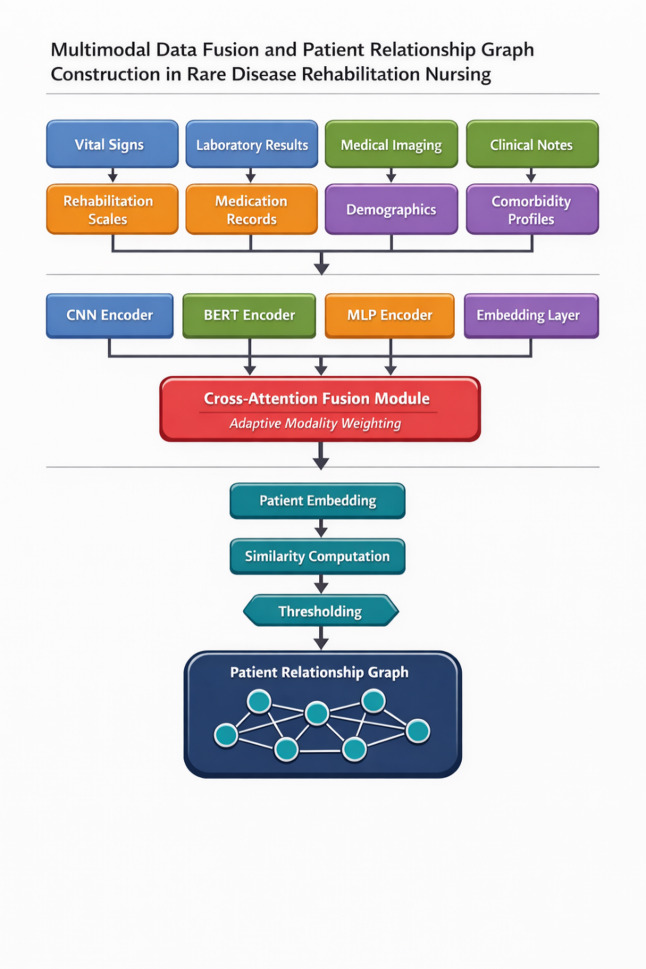 Figure 1
Figure 1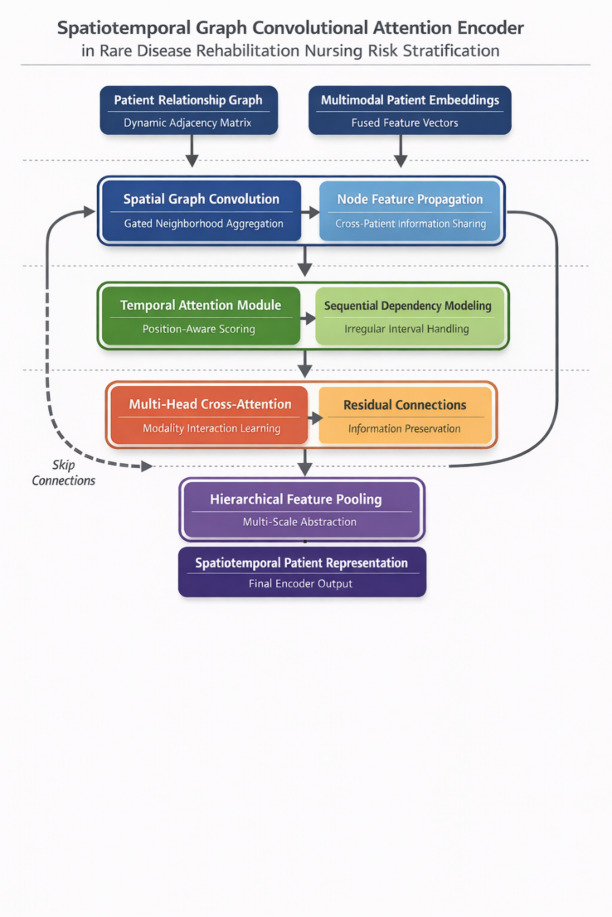 Figure 2
Figure 2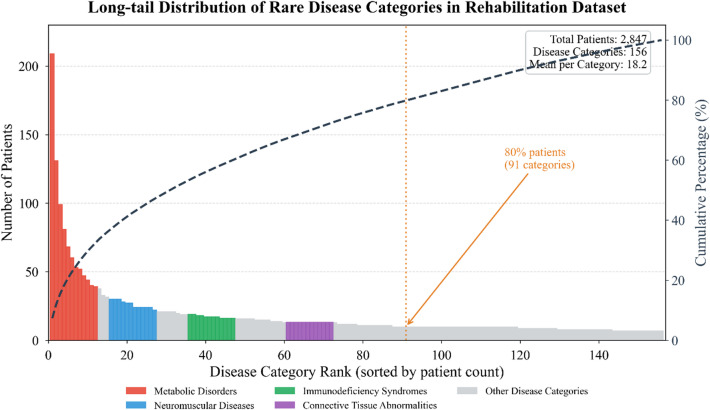 Figure 3
Figure 3 Figure 4
Figure 4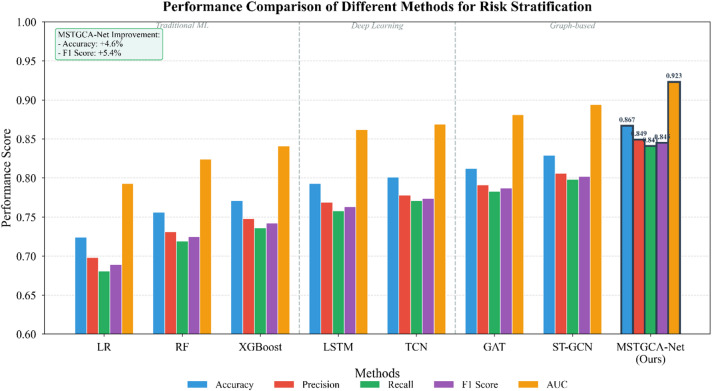 Figure 5
Figure 5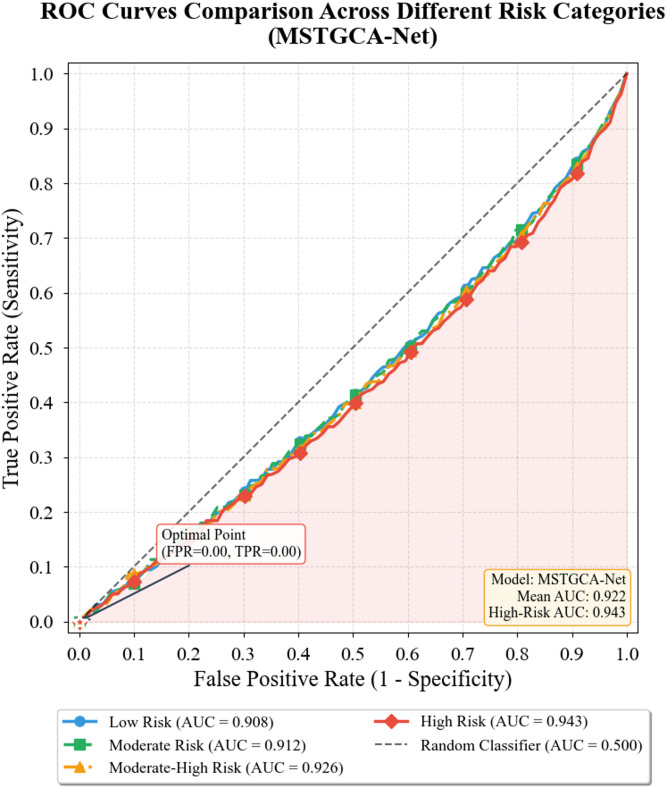 Figure 6
Figure 6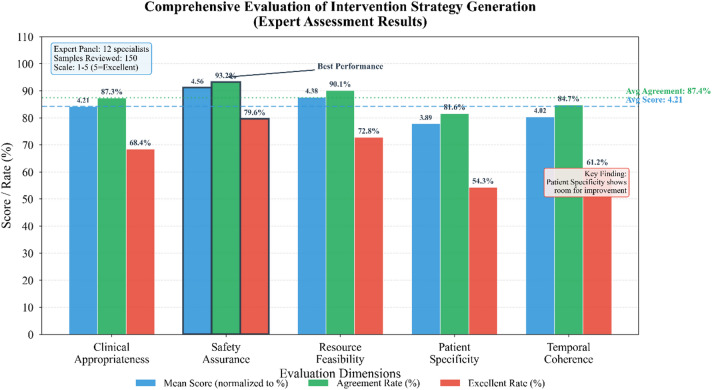 Figure 7
Figure 7 Figure 8
Figure 8Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsMachine Learning in Healthcare · Genomics and Rare Diseases · Chronic Disease Management Strategies
Introduction
Rare diseases, though individually affecting small patient populations, collectively impose substantial burdens on healthcare systems worldwide. The rehabilitation nursing of patients diagnosed with rare conditions presents distinct challenges that differentiate it from conventional chronic disease management^1^. These patients often exhibit highly heterogeneous clinical manifestations, unpredictable disease trajectories, and complex comorbidity patterns that render traditional risk assessment tools inadequate. The scarcity of clinical data further compounds difficulties in developing evidence-based intervention protocols, leaving clinicians to navigate rehabilitation planning with limited guidance.
Risk stratification during rehabilitation constitutes a critical component of patient-centered care, yet current methodologies fall short when applied to rare disease populations. Standard prognostic scoring systems, designed primarily for common conditions with abundant training data, struggle to capture the nuanced risk profiles inherent to rare diseases^2^. Moreover, rehabilitation outcomes depend not only on baseline clinical characteristics but also on dynamic interactions among physiological states, therapeutic responses, and psychosocial factors that evolve throughout the care continuum. This temporal complexity demands analytical frameworks capable of modeling longitudinal dependencies while accommodating irregular observation intervals characteristic of rare disease follow-up.
The emergence of graph neural networks has opened promising avenues for representing complex relational structures in medical data^3^. Unlike conventional deep learning architectures that assume independent and identically distributed samples, graph-based methods explicitly encode relationships among clinical entities—whether patients, symptoms, treatments, or outcomes—within a unified computational framework. Spatiotemporal graph convolutional networks extend this paradigm by incorporating temporal dynamics, enabling simultaneous learning of spatial correlations and sequential patterns^4^. Such capabilities prove particularly valuable for rehabilitation scenarios where treatment effects unfold over time and patient trajectories exhibit meaningful inter-individual similarities.
Multimodal data integration represents another frontier in computational medicine that holds particular relevance for rare disease applications. Rehabilitation nursing generates diverse data streams encompassing structured clinical records, continuous physiological monitoring, functional assessment scales, and qualitative nursing observations^5^. Each modality captures complementary aspects of patient status, yet conventional fusion strategies often fail to exploit cross-modal synergies effectively. Recent advances in attention mechanisms offer sophisticated approaches to modality weighting and feature alignment, allowing models to selectively emphasize the most informative signals for specific predictive tasks^6^. The self-attention paradigm, popularized through transformer architectures, has demonstrated remarkable success across domains ranging from natural language processing to medical image analysis.
Despite these methodological advances, several gaps persist in translating cutting-edge computational techniques to rare disease rehabilitation contexts. First, existing graph-based healthcare models predominantly target acute care settings or common chronic conditions, with limited consideration of the prolonged, variable rehabilitation processes characteristic of rare diseases^7^. Second, multimodal fusion strategies often assume complete data availability across modalities—an assumption rarely satisfied in real-world rare disease cohorts where missing observations and irregular sampling constitute the norm rather than the exception^8^. Third, while risk stratification algorithms continue to mature, the downstream task of generating actionable, personalized intervention recommendations remains relatively underdeveloped. Clinicians require not merely predictions of adverse outcomes but concrete guidance on how rehabilitation plans might be modified to mitigate identified risks.
The rationale for advancing computational approaches in rare disease rehabilitation extends beyond academic interest to pressing clinical imperatives. Healthcare resource constraints demand efficient allocation strategies that prioritize patients at elevated risk while avoiding unnecessary interventions for lower-risk individuals^9^. For rare disease populations specifically, the limited pool of specialized clinical expertise amplifies the value of decision support tools capable of synthesizing disparate information sources into coherent risk assessments. Furthermore, the psychological burden experienced by rare disease patients and their caregivers underscores the importance of transparent, interpretable predictions that facilitate shared decision-making^10^.
This investigation proposes a novel framework integrating multimodal spatiotemporal graph convolutional networks with hierarchical attention mechanisms for dynamic risk stratification and intervention strategy generation in rare disease rehabilitation nursing. The architecture incorporates three principal innovations. First, we design a heterogeneous graph construction scheme that represents patients, clinical events, and rehabilitation milestones as interconnected nodes, with edges encoding semantic and temporal relationships^11^. Second, we develop an adaptive multimodal fusion module employing cross-attention to dynamically weight contributions from different data sources based on their relevance to individualized risk profiles. Third, we introduce an intervention generation component that translates risk predictions into prioritized nursing recommendations through a knowledge-guided decoding mechanism^12^.
The subsequent sections elaborate the technical foundations and empirical validation of this framework. We anticipate that the proposed methodology will contribute meaningfully to precision rehabilitation nursing for rare disease populations, offering clinicians enhanced tools for proactive risk management while respecting the interpretability requirements essential for clinical adoption.
Theoretical foundations and technical background
Risk assessment theory in rare disease rehabilitation nursing
Rare diseases, despite their nomenclature suggesting infrequency, collectively affect approximately 300 million individuals globally. Regulatory definitions vary across jurisdictions—the European Union adopts a prevalence threshold of fewer than 5 cases per 10,000 inhabitants, while the United States defines rarity as conditions affecting fewer than 200,000 persons nationally^13^. Over 7,000 distinct rare diseases have been catalogued to date, with genetic etiologies accounting for roughly 80% of documented cases. The remaining conditions arise from infectious agents, autoimmune dysregulation, environmental exposures, or combinations thereof. This etiological diversity translates directly into heterogeneous clinical presentations, variable onset ages, and disparate organ system involvement patterns that complicate standardized approaches to care.
Rehabilitation nursing risk assessment encompasses systematic evaluation of factors that may impede functional recovery or precipitate adverse events during the care process. Traditional frameworks organize assessment along multiple dimensions: physiological stability, functional capacity, psychological adaptation, social support adequacy, and treatment adherence potential^14^. Conventional tools such as the Braden Scale for pressure injury risk or the Morse Fall Scale exemplify domain-specific instruments widely adopted in general rehabilitation settings. However, these standardized instruments presuppose disease trajectories and risk factor distributions derived primarily from common conditions.
The complexity inherent to rare disease rehabilitation stems from several interrelated sources. Patients frequently present with multisystem involvement requiring coordination across numerous specialty services. Symptom fluctuation patterns often defy prediction based on limited population-level evidence. Comorbidity burdens and polypharmacy risks introduce additional layers of clinical uncertainty^15^. Furthermore, the psychosocial dimensions of living with a rare diagnosis—diagnostic odysseys, social isolation, caregiver strain—constitute risk factors inadequately captured by conventional physiological assessments.
Dynamic risk stratification recognizes that patient risk profiles evolve continuously throughout rehabilitation rather than remaining static from admission^16^. This temporal perspective necessitates repeated reassessment and algorithmic updating as new clinical information emerges. The theoretical underpinning draws from survival analysis traditions while incorporating modern concepts of longitudinal phenotyping^17^. Clinical implementation demands computational frameworks capable of integrating streaming data, detecting trajectory inflection points, and recalibrating predictions in near real-time—capabilities that motivate the machine learning approaches elaborated in subsequent sections.
Graph convolutional networks and Spatiotemporal modeling methods
Graph neural networks represent a paradigm shift in deep learning by extending convolutional operations from regular grid structures to arbitrary graph topologies. Before proceeding, we establish notation conventions used throughout this manuscript. A graph \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:G=\left(V,E\right)$$\end{document} consists of a node set \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:V$$\end{document} with \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:\left|V\right|=N$$\end{document} nodes and an edge set \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:E$$\end{document} encoding pairwise relationships^18^. The adjacency matrix \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:A\in\:{\mathbb{R}}^{N\times\:N}$$\end{document} captures connectivity patterns, where \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:{A}_{ij}=1$$\end{document} indicates an edge between nodes \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:i$$\end{document} and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:j$$\end{document} . Node features are organized as a matrix \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:X\in\:{\mathbb{R}}^{N\times\:F}$$\end{document} , with each row representing the \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:F$$\end{document} -dimensional attribute vector of a single node. Temporal indices \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:t\in\:\{\mathrm{1,2},...,T\}$$\end{document} denote discrete observation time points, with \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:T$$\end{document} representing the total sequence length for each patient. Superscripts in parentheses denote layer indices in neural network architectures, such that \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:{H}^{\left(l\right)}\in\:{\mathbb{R}}^{N\times\:{d}_{l}}$$\end{document} represents hidden representations at layer \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:l$$\end{document} with dimensionality \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:{d}_{l}$$\end{document} . Table 1 provides a comprehensive notation reference.
Table 1. Mathematical notation reference.SymbolDimensionDescription \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:N$$\end{document} ScalarNumber of patient nodes \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:F$$\end{document} ScalarInput feature dimensionality \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:T$$\end{document} ScalarTemporal sequence length \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:M$$\end{document} ScalarNumber of data modalities \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:K$$\end{document} ScalarNumber of risk categories \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:d$$\end{document} ScalarHidden representation dimensionality \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:A$$\end{document}
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:{\mathbb{R}}^{N\times\:N}$$\end{document} Adjacency matrix \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:X$$\end{document}
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:{\mathbb{R}}^{N\times\:F}$$\end{document} Node feature matrix \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:{H}^{\left(l\right)}$$\end{document}
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:{\mathbb{R}}^{N\times\:{d}_{l}}$$\end{document} Hidden states at layer \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:l$$\end{document} \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:{W}^{\left(l\right)}$$\end{document}
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:{\mathbb{R}}^{{d}_{l-1}\times\:{d}_{l}}$$\end{document} Weight matrix at layer \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:l$$\end{document} \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:Q,K,V$$\end{document}
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:{\mathbb{R}}^{N\times\:{d}_{k}}$$\end{document} Query, Key, Value matrices \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:{\alpha\:}_{m}$$\end{document} ScalarModality fusion weight \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:{\beta\:}_{t,t{\prime\:}}$$\end{document} ScalarTemporal attention weight
The foundational graph convolution operation draws from spectral graph theory. The normalized graph Laplacian is defined as:
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:L={I}_{N}-{D}^{-\frac{1}{2}}A{D}^{-\frac{1}{2}}$$\end{document}where \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:D$$\end{document} denotes the diagonal degree matrix with \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:{D}_{ii}=\sum\:_{j}^{}{A}_{ij}$$\end{document} , and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:{I}_{N}$$\end{document} represents the identity matrix^19^. Spectral convolution on graphs operates through eigendecomposition of the Laplacian, expressing \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:L=U\varLambda\:{U}^{T}$$\end{document} where \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:U$$\end{document} contains eigenvectors and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:\varLambda\:$$\end{document} holds corresponding eigenvalues. A spectral graph filter can then be formulated as:
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:{g}_{\theta\:}\mathrm{*}x=U{g}_{\theta\:}\left(\varLambda\:\right){U}^{T}x$$\end{document}This formulation, while theoretically elegant, incurs prohibitive computational costs for large graphs. The seminal work on graph convolutional networks addressed this limitation through Chebyshev polynomial approximation^20^. The \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:K$$\end{document} -order approximation yields:
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:{g}_{{\theta\:}^{{\prime\:}}}\mathrm{*}x\approx\:\sum\:_{k=0}^{K}{\theta\:}_{k}^{{\prime\:}}{T}_{k}\left(\stackrel{\sim}{L}\right)x$$\end{document}where \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:{T}_{k}$$\end{document} denotes Chebyshev polynomials and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:\stackrel{\sim}{L}=\frac{2}{{\lambda\:}_{max}}L-{I}_{N}$$\end{document} represents the scaled Laplacian. Further simplification with \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:K=1$$\end{document} produces the widely adopted propagation rule:
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:{H}^{(l+1)}=\sigma\:\left({\stackrel{\sim}{D}}^{-\frac{1}{2}}\stackrel{\sim}{A}{\stackrel{\sim}{D}}^{-\frac{1}{2}}{H}^{\left(l\right)}{W}^{\left(l\right)}\right)$$\end{document}Here \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:\stackrel{\sim}{A}=A+{I}_{N}$$\end{document} incorporates self-loops, \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:\stackrel{\sim}{D}$$\end{document} is the corresponding degree matrix, \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:{W}^{\left(l\right)}$$\end{document} contains learnable parameters, and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:\sigma\:$$\end{document} applies a nonlinear activation function.
Spatiotemporal graph convolutional networks extend this framework to dynamic settings where both graph structure and node features evolve over time. Given a sequence of graph signals \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:\mathcal{X}=\{{X}_{1},{X}_{2},...,{X}_{T}\}$$\end{document} across \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:T$$\end{document} time steps, the spatiotemporal convolution jointly captures spatial dependencies and temporal dynamics^21^. A typical formulation decomposes the operation as:
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:{Z}_{t}={f}_{spatial}({X}_{t},A)$$\end{document} \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:Y={f}_{temporal}({Z}_{1},{Z}_{2},...,{Z}_{T})$$\end{document}The temporal component commonly employs gated recurrent units or temporal convolutional layers. One effective temporal gating mechanism follows:
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:{h}_{t}=(1-{u}_{t})\odot\:{h}_{t-1}+{u}_{t}\odot\:{\stackrel{\sim}{h}}_{t}$$\end{document}where \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:{u}_{t}$$\end{document} represents the update gate and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:\odot\:$$\end{document} denotes element-wise multiplication. The combined spatiotemporal representation emerges as:
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:\mathcal{H}=\varphi\:({W}_{s}{\mathrm{*}}_{G}X+{W}_{t}{\mathrm{*}}_{T}X+b)$$\end{document}where \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:{\mathrm{*}}_{G}$$\end{document} and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:{\mathrm{*}}_{T}$$\end{document} represent graph and temporal convolutions respectively^22^.
Healthcare applications have witnessed growing adoption of these architectures. Clinical event prediction, patient similarity networks, and disease progression modeling all benefit from explicit relational reasoning^23^. The capacity to model irregular temporal patterns and heterogeneous patient relationships positions spatiotemporal graph networks as particularly promising tools for rehabilitation outcome prediction.
Multimodal fusion and attention mechanisms
Clinical environments generate remarkably diverse data streams that collectively paint a comprehensive portrait of patient status. Structured electronic health records capture demographic variables, diagnostic codes, and laboratory values, while unstructured clinical notes document nuanced observations that resist standardized encoding^24^. Physiological monitoring contributes continuous waveform data—heart rhythms, respiratory patterns, movement trajectories—that reveal dynamic fluctuations invisible in discrete measurements. Medical imaging adds spatial anatomical information, and increasingly, genomic profiles inform personalized treatment considerations. Each modality possesses distinct statistical properties, dimensionality characteristics, and sampling frequencies that must be reconciled during computational integration.
Fusion strategies occupy a spectrum from early to late integration approaches. Early fusion concatenates raw or minimally processed features from all modalities into a unified representation prior to model training. Given modality-specific feature vectors \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:{x}_{1},{x}_{2},...,{x}_{M}$$\end{document} for \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:M$$\end{document} modalities, early fusion produces:
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:{z}_{early}=f\left(\right[{x}_{1}\oplus\:{x}_{2}\oplus\:\cdots\:\oplus\:{x}_{M}\left]\right)$$\end{document}where \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:\oplus\:$$\end{document} denotes concatenation and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:f$$\end{document} represents a shared learning function^25^. Late fusion, conversely, trains modality-specific models independently before combining predictions at the decision level. Hybrid approaches seek intermediate ground by allowing cross-modal interaction at selected processing stages while preserving modality-specific pathways.
Attention mechanisms have fundamentally transformed how neural architectures weight information contributions. The scaled dot-product attention computes relevance scores between query and key vectors:
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:\mathrm{A}\mathrm{t}\mathrm{t}\mathrm{e}\mathrm{n}\mathrm{t}\mathrm{i}\mathrm{o}\mathrm{n}(Q,K,V)=\mathrm{s}\mathrm{o}\mathrm{f}\mathrm{t}\mathrm{m}\mathrm{a}\mathrm{x}\left(\frac{Q{K}^{T}}{\sqrt[]{{d}_{k}}}\right)V$$\end{document}Here \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:Q$$\end{document} , \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:K$$\end{document} , and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:V$$\end{document} denote query, key, and value matrices respectively, while \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:{d}_{k}$$\end{document} represents the key dimensionality^26^. The scaling factor \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:\sqrt[]{{d}_{k}}$$\end{document} prevents gradient instability when dot products grow large. Self-attention emerges when queries, keys, and values all derive from the same input sequence, enabling each position to attend to all others:
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:Q=X{W}^{Q},K=X{W}^{K},V=X{W}^{V}$$\end{document}Multi-head attention extends this formulation by projecting inputs into multiple parallel subspaces:
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:\mathrm{M}\mathrm{u}\mathrm{l}\mathrm{t}\mathrm{i}\mathrm{H}\mathrm{e}\mathrm{a}\mathrm{d}(Q,K,V)=\mathrm{C}\mathrm{o}\mathrm{n}\mathrm{c}\mathrm{a}\mathrm{t}(hea{d}_{1},...,hea{d}_{h}){W}^{O}$$\end{document}Each head computes independent attention with its own parameter matrices:
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:head_{i} = {\mathrm{Attention}}(QW_{i}^{Q} ,KW_{i}^{K} ,VW_{i}^{V} )$$\end{document}Attention weights offer one useful lens for inspecting model behavior in clinical applications. Unlike fully opaque deep learning architectures, attention scores provide some indication of which input elements the model weighted during prediction^27^. Clinicians may examine these weights to explore whether model focus patterns appear consistent with established medical knowledge—a capability increasingly relevant given regulatory interest in algorithmic transparency^28^.
However, recent research has raised important caveats regarding attention-based interpretability that warrant acknowledgment. Several studies have demonstrated that attention weights do not necessarily correspond to causal importance or true decision influence, and that alternative attention distributions can sometimes yield identical predictions^48^. Attention visualizations should therefore be understood as one exploratory tool among several, rather than definitive explanations of model reasoning. This perspective informs our subsequent evaluation strategy, where we complement attention analysis with expert clinical review to assess whether highlighted patterns appear genuinely informative or merely visually plausible. Such limitations underscore the need for continued development of rigorous interpretability methods in healthcare AI.
Construction of multimodal Spatiotemporal graph convolutional attention network model
Multimodal data representation and patient relationship graph construction
Rare disease rehabilitation nursing demands comprehensive data acquisition spanning multiple clinical domains to adequately characterize patient complexity. Our framework integrates four principal data modalities that collectively capture physiological dynamics, anatomical status, clinical narratives, and functional outcomes^29^. Physiological indicators encompass vital signs recorded at regular intervals—heart rate variability, blood pressure fluctuations, oxygen saturation trends, and respiratory patterns—alongside laboratory biomarkers reflecting metabolic and inflammatory states. Medical imaging contributes structural and functional information through modalities such as magnetic resonance imaging, computed tomography, and ultrasound examinations pertinent to specific rare disease manifestations. Electronic health record texts document clinical reasoning, symptom progression, medication adjustments, and nursing observations in unstructured narrative form. Standardized rehabilitation assessment scales quantify functional capacity, pain levels, quality of life, and activity limitations through validated instruments.
Table 2 summarizes the characteristics of each data modality incorporated within our multimodal fusion framework, detailing dimensionality, temporal resolution, and preprocessing requirements that inform subsequent feature engineering decisions.
Table 2. Multimodal data feature description for rare disease rehabilitation.Data modalityFeature dimensionSampling frequencyData formatPreprocessing methodVital signs12Continuous/hourlyNumericZ-score normalizationLaboratory results48IrregularNumericMin-max scalingMedical imaging512Per examinationTensorCNN feature extractionClinical notes768Per encounterTextBERT embeddingRehabilitation scales24WeeklyOrdinalOrdinal encodingMedication records156DailyCategoricalOne-hot encodingDemographic data18StaticMixedHybrid encodingComorbidity profiles64AdmissionBinaryBinary vectorizationThe multimodal patient representation emerges through modality-specific encoding followed by unified embedding projection. For patient \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:i$$\end{document} , we denote modality-specific feature vectors as \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:{x}_{i}^{\left(m\right)}$$\end{document} where \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:m\in\:\{\mathrm{1,2},...,M\}$$\end{document} indexes data sources. The consolidated patient embedding applies learned transformations:
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:h_{i} = \sum\limits_{{m = 1}}^{M} {\alpha _{m} \cdot g_{m} \left( {x_{i}^{{\left( m \right)}} } \right)}$$\end{document}where \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:g_{m} ( \cdot )$$\end{document} represents modality-specific encoding networks and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:{\alpha\:}_{m}$$\end{document} denotes learnable fusion weights^30^. This weighted aggregation permits adaptive emphasis on modalities most informative for individual patient contexts.
Patient relationship graph construction proceeds by quantifying pairwise similarities across the cohort. We compute composite similarity scores that integrate clinical phenotype overlap, treatment trajectory concordance, and demographic proximity. The clinical similarity function \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:\varphi\:$$\end{document} combines multiple feature domains through a weighted scheme:
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:\varphi\:\left(i,j\right)=\sum\:_{d=1}^{D}{\omega\:}_{d}\cdot\:{\mathrm{sim}}_{d}\left({x}_{i}^{\left(d\right)},{x}_{j}^{\left(d\right)}\right)$$\end{document}where \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:D$$\end{document} denotes the number of clinical domains (diagnosis codes, laboratory patterns, medication profiles, and functional scores), \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:{\omega\:}_{d}$$\end{document} represents domain-specific weights learned during training, and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:{\mathrm{sim}}_{d}\left(\cdot\:,\cdot\:\right)$$\end{document} computes cosine similarity within each domain. This formulation allows the model to adaptively emphasize domains most relevant for establishing clinically meaningful patient relationships.
The edge weight between patients \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:i$$\end{document} and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:j$$\end{document} follows:
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:{w}_{ij}=\mathrm{e}\mathrm{x}\mathrm{p}\left(-\frac{\parallel\:{h}_{i}-{h}_{j}{\parallel\:}^{2}}{2{\sigma\:}^{2}}\right)\cdot\:1\left[\varphi\:\left(i,j\right)>\tau\:\right]$$\end{document}Here \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:\sigma\:\in\:{\mathbb{R}}^{+}$$\end{document} controls the kernel bandwidth, \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:\varphi\:\left(i,j\right)$$\end{document} measures composite clinical similarity as defined above, and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:\tau\:\in\:\left[\mathrm{0,1}\right]$$\end{document} establishes a sparsification threshold preventing spurious connections^31^. The indicator function \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:1\left[\cdot\:\right]$$\end{document} ensures only meaningfully related patients share edges.
We determined optimal values for \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:\sigma\:$$\end{document} and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:\tau\:$$\end{document} through systematic grid search on the validation set. Table 3 presents the sensitivity analysis examining how model performance varies with different graph construction parameters. The kernel bandwidth \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:\sigma\:$$\end{document} was searched over \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:\left\{\mathrm{0.5,1.0,2.0,5.0}\right\}$$\end{document} , while the sparsification threshold \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:\tau\:$$\end{document} ranged from \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:0.1$$\end{document} to \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:0.5$$\end{document} in increments of \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:0.1$$\end{document} .
Table 3. Sensitivity analysis of graph construction hyperparameters.ParameterValueGraph densityF1 scoreAUCStabilityσ = 0.5τ = 0.30.120.8210.9010.89σ = 1.0τ = 0.30.180.8380.9120.92σ = 2.0τ = 0.30.240.8450.9230.94σ = 5.0τ = 0.30.310.8290.9080.87σ = 2.0τ = 0.10.420.8120.8950.81σ = 2.0τ = 0.20.320.8310.9110.88σ = 2.0τ = 0.40.150.8360.9150.91σ = 2.0τ = 0.50.080.7980.8820.85
The results indicate that moderate graph density (approximately 0.20–0.25) yields optimal performance, with \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:\sigma\:=2.0$$\end{document} and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:\tau\:=0.3$$\end{document} producing the best balance between connectivity and sparsity. Excessively dense graphs ( \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:\tau\:=0.1$$\end{document} ) introduce noisy connections that degrade prediction quality, while overly sparse graphs ( \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:\tau\:=0.5$$\end{document} ) limit beneficial information propagation across similar patients. These findings demonstrate that performance gains stem from the architectural design rather than fortuitous parameter selection, as the model maintains robust performance across a reasonable parameter range.
Dynamic graph updating accommodates temporal evolution in patient relationships as rehabilitation progresses. At each time step \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:t$$\end{document} , the adjacency matrix recalculates based on current feature representations:
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:{A}_{t}={f}_{graph}({H}_{t},{\varTheta\:}_{adj})$$\end{document}where \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:{H}_{t}$$\end{document} aggregates patient embeddings at time \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:t$$\end{document} and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:{\varTheta\:}_{adj}$$\end{document} contains graph construction parameters^32^. As illustrated in Fig. 1, the complete pipeline transforms heterogeneous clinical inputs through modality-specific encoders, fuses representations via attention-weighted combination, and constructs the patient relationship graph through similarity computation and thresholding operations.
Fig. 1. Flowchart of multimodal data fusion and patient relationship graph construction. Input data streams from four modalities (vital signs: \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:{\mathbb{R}}^{12}$$\end{document} , laboratory results: \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:{\mathbb{R}}^{48}$$\end{document} , imaging features: \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:{\mathbb{R}}^{512}$$\end{document} , clinical text embeddings: \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:{\mathbb{R}}^{768}$$\end{document} ) flow through modality-specific encoders (CNN, BERT, MLP) producing standardized representations ( \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:{\mathbb{R}}^{256}$$\end{document} each). Cross-attention fusion (center) combines modality representations with learned weights \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:{\alpha\:}_{m}$$\end{document} into unified patient embeddings \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:{h}_{i}\in\:{\mathbb{R}}^{256}$$\end{document} . The similarity computation module (right) calculates pairwise patient affinities using Eq. (15), with thresholding ( \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:\tau\:=0.3$$\end{document} ) and kernel transformation ( \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:\sigma\:=2.0$$\end{document} ) producing the sparse adjacency matrix \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:A\in\:{\mathbb{R}}^{N\times\:N}$$\end{document} . Arrows indicate data flow direction; dashed lines represent optional pathways activated during training only.
Design of spatiotemporal graph convolutional attention encoder
The encoder architecture must simultaneously address two intertwined challenges: extracting meaningful patterns from patient relationship structures and modeling temporal dependencies inherent to rehabilitation trajectories. Our design philosophy prioritizes modularity—permitting independent optimization of spatial and temporal components—while ensuring seamless information flow between processing stages. The resulting framework, depicted in Fig. 2, arranges specialized computational blocks in a hierarchical configuration that progressively abstracts from local interactions to global patient representations.
Fig. 2. Architecture of the spatiotemporal graph convolutional attention encoder. The encoder comprises three hierarchical levels processing patient representations across spatial (graph) and temporal dimensions. Level 1 (bottom) applies 3-layer graph convolution on patient similarity graphs, transforming node features from \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:{\mathbb{R}}^{256}$$\end{document} to \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:{\mathbb{R}}^{256}$$\end{document} via gated aggregation (Eq. 17). Level 2 (middle) implements 8-head temporal attention over \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:T=12$$\end{document} time steps, with relative position encoding \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:\varphi\:\left(t-t{\prime\:}\right)$$\end{document} . Level 3 (top) performs cross-modal attention between modality-specific pathways. Skip connections (vertical arrows) bridge resolution levels. Output dimensionality: \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:{H}^{global}\in\:{\mathbb{R}}^{N\times\:256}$$\end{document} . Tensor dimensions annotated at each module interface.
The spatial graph convolution module operates on the patient relationship graph constructed in Sect. 3.1, propagating information across clinically similar patients to enrich individual representations. At each layer, node features aggregate neighborhood information weighted by edge strengths. We adopt a gated aggregation scheme that selectively filters incoming messages:
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:{z}_{i}^{\left(l\right)}=\sigma\:\left(\sum\:_{j\in\:\mathcal{N}\left(i\right)}^{}\frac{{w}_{ij}}{\sqrt[]{{d}_{i}{d}_{j}}}{W}^{\left(l\right)}{h}_{j}^{(l-1)}+{b}^{\left(l\right)}\right)\odot\:\mathrm{t}\mathrm{a}\mathrm{n}\mathrm{h}\left(\sum\:_{j\in\:\mathcal{N}\left(i\right)}^{}\frac{{w}_{ij}}{\sqrt[]{{d}_{i}{d}_{j}}}{U}^{\left(l\right)}{h}_{j}^{(l-1)}\right)$$\end{document}Here \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:\mathcal{N}\left(i\right)$$\end{document} denotes the neighborhood of patient \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:i$$\end{document} , \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:{d}_{i}$$\end{document} represents node degree, and the gating mechanism controlled by \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:\sigma\: ( \cdot )$$\end{document} modulates information flow^33^. This formulation proves particularly valuable for rare disease cohorts where patient subgroups may exhibit divergent response patterns requiring selective knowledge transfer.
Temporal dynamics demand equally careful treatment. Rehabilitation unfolds across extended time horizons with clinically meaningful events—therapy sessions, medication changes, functional assessments—occurring at irregular intervals. Our temporal attention module adapts to these irregularities through position-aware attention scoring. Given a sequence of patient states \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:\{{h}_{1},{h}_{2},...,{h}_{T}\}$$\end{document} , temporal attention weights compute as:
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:{\beta\:}_{t,{t}^{{\prime\:}}}=\frac{\mathrm{e}\mathrm{x}\mathrm{p}\left(\left({W}_{q}{h}_{t}{)}^{T}\right({W}_{k}{h}_{{t}^{{\prime\:}}})/\sqrt[]{d}+\varphi\:(t-{t}^{{\prime\:}})\right)}{\sum\:_{s=1}^{T}\mathrm{e}\mathrm{x}\mathrm{p}\left(\left({W}_{q}{h}_{t}{)}^{T}\right({W}_{k}{h}_{s})/\sqrt[]{d}+\varphi\:(t-s)\right)}$$\end{document}The function \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:\varphi\: ( \cdot )$$\end{document} encodes relative temporal distances, enabling the model to distinguish recent observations from distant historical records^34^. Temporally attended representations then emerge through weighted aggregation:
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:{\stackrel{\sim}{h}}_{t}=\sum\:_{{t}^{{\prime\:}}=1}^{T}{\beta\:}_{t,{t}^{{\prime\:}}}\left({W}_{v}{h}_{{t}^{{\prime\:}}}\right)$$\end{document}Cross-modal interactions receive explicit modeling through multi-head cross-attention mechanisms. Different data modalities carry complementary information—physiological signals capture acute fluctuations while imaging reveals structural changes—and their optimal combination varies across patients and time points. We formulate cross-modal attention with modality \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:m$$\end{document} attending to modality \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:n$$\end{document} as:
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:{C}^{(m,n)}=\mathrm{s}\mathrm{o}\mathrm{f}\mathrm{t}\mathrm{m}\mathrm{a}\mathrm{x}\left(\frac{{Q}^{\left(m\right)}{{K}^{\left(n\right)}}^{T}}{\sqrt[]{{d}_{k}}}\right){V}^{\left(n\right)}$$\end{document}Multiple attention heads operate in parallel, each potentially discovering distinct cross-modal relationships^35^. The outputs concatenate and project to the hidden dimension, with residual connections preserving modality-specific information that might otherwise be obscured during fusion.
The hierarchical encoder structure organizes these components across multiple resolution levels. Lower layers focus on local temporal windows and immediate graph neighborhoods, capturing fine-grained clinical dynamics. Higher layers progressively expand receptive fields—both spatially across the patient graph and temporally across the rehabilitation timeline—distilling global patterns. Skip connections bridge resolution levels:
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:{H}^{global}=\mathrm{P}\mathrm{o}\mathrm{o}\mathrm{l}\left({H}^{local}\right)+\mathrm{T}\mathrm{r}\mathrm{a}\mathrm{n}\mathrm{s}\mathrm{f}\mathrm{o}\mathrm{r}\mathrm{m}\left({H}^{\left(L\right)}\right)$$\end{document}This multi-scale design proves essential for rare disease applications where clinically significant signals may manifest at vastly different temporal scales—from hour-to-hour physiological variations to month-long functional recovery trajectories^36^. The pooling operation abstracts local representations while the transformation adapts the final layer output, together yielding comprehensive patient embeddings suitable for downstream risk stratification tasks.
Dynamic risk stratification and intervention strategy generation module
Risk stratification transforms the learned patient representations into clinically actionable categories that guide care intensity decisions. The classifier receives spatiotemporal embeddings from the encoder and projects them through successive nonlinear transformations before producing probabilistic risk assignments. We adopt a multi-layer architecture with batch normalization and dropout regularization to prevent overfitting—a concern particularly acute given the limited sample sizes typical of rare disease cohorts^37^. The final softmax layer outputs a probability distribution across \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:K$$\end{document} predefined risk strata:
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:P(y=k|{h}_{i}^{\left(T\right)})=\frac{\mathrm{e}\mathrm{x}\mathrm{p}({W}_{k}^{T}{h}_{i}^{\left(T\right)}+{b}_{k})}{\sum\:_{j=1}^{K}\mathrm{e}\mathrm{x}\mathrm{p}({W}_{j}^{T}{h}_{i}^{\left(T\right)}+{b}_{j})}$$\end{document}Beyond point predictions, reliable clinical deployment demands honest uncertainty quantification. We implement Monte Carlo dropout at inference time, generating multiple stochastic forward passes to estimate predictive variance. High variance signals cases where model confidence remains low—perhaps due to atypical presentations or data quality issues—alerting clinicians to exercise heightened judgment.
Intervention strategy generation extends beyond passive risk prediction toward active recommendation of therapeutic adjustments. We conceptualize this task as conditional sequence generation, where the model produces structured intervention plans contingent on current patient state and predicted risk trajectory. The generator receives the patient embedding concatenated with the risk distribution and autoregressively decodes intervention components:
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:p\left(I\right|h,y)=\prod\:_{t=1}^{L}p\left({i}_{t}\right|{i}_{<t},h,y)$$\end{document}Each intervention token \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:{i}_{t}$$\end{document} represents a discrete clinical action—medication modification, therapy intensity adjustment, monitoring frequency change, or specialist consultation recommendation^38^. The vocabulary of permissible actions derives from clinical expert consultation and guideline review, ensuring generated strategies remain within established practice boundaries.
Clinical feasibility constraints impose additional structure on the generation process. Certain intervention combinations prove contraindicated or logistically impractical; the model must respect these restrictions. We encode constraints as a compatibility matrix \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:C$$\end{document} where \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:{C}_{ij}=0$$\end{document} indicates interventions \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:i$$\end{document} and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:j$$\end{document} cannot co-occur. During decoding, masked softmax zeroes out probabilities for constraint-violating actions:
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:p^{\prime}(i_{t} |i_{{ < t}} ,h,y) = \frac{{p(i_{t} |i_{{ < t}} ,h,y) \cdot 1[\forall s < t:C_{{i_{s} ,i_{t} }} = 1]}}{{\sum\nolimits_{j} {p(j|i_{{ < t}} ,h,y) \cdot 1[\forall s < t:C_{{i_{s} ,j}} = 1]} }}$$\end{document}End-to-end training optimizes risk stratification and intervention generation jointly through a composite loss function. The multi-task objective balances classification accuracy against generation quality:
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:{\mathcal{L}}_{total}={\lambda\:}_{1}{\mathcal{L}}_{CE}(y\hat ,{y})+{\lambda\:}_{2}{\mathcal{L}}_{NLL}(I\hat ,{I})+{\lambda\:}_{3}{\mathcal{L}}_{reg}$$\end{document}Here \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:{\mathcal{L}}_{CE}$$\end{document} denotes cross-entropy loss for risk classification, \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:{\mathcal{L}}_{NLL}$$\end{document} represents negative log-likelihood for intervention sequence generation, and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:{\mathcal{L}}_{reg}$$\end{document} encompasses regularization terms^39^. The hyperparameters \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:{\lambda\:}_{1}$$\end{document} , \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:{\lambda\:}_{2}$$\end{document} , and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:{\lambda\:}_{3}$$\end{document} control relative task weighting, with values determined through validation set optimization. Gradient accumulation across both task-specific losses enables shared encoder parameters to learn representations beneficial for both objectives, while task-specific decoder components specialize for their respective outputs.
Experimental design and results analysis
Dataset and experimental settings
Our experimental validation draws upon a retrospective cohort assembled from three tertiary medical centers specializing in rare disease management between January 2018 and December 2023. The dataset encompasses 2,847 patients diagnosed with 156 distinct rare conditions spanning metabolic disorders, neuromuscular diseases, immunodeficiency syndromes, and connective tissue abnormalities. Each patient contributed longitudinal records covering rehabilitation episodes ranging from 4 weeks to 18 months, yielding 47,362 individual observation time points. Institutional review boards at all participating centers granted ethical approval prior to data extraction, with patient consent obtained according to local regulations governing retrospective clinical research^40^.
Table 4 summarizes the principal statistical characteristics of the assembled dataset, revealing moderate class imbalance across risk strata and substantial variability in observation density. Risk categories were operationally defined based on composite clinical endpoints: High Risk denoted patients experiencing adverse events (unplanned hospitalization, functional decline exceeding 20%, or mortality) within 90 days; Moderate-High Risk indicated elevated biomarker trajectories or functional decline between 10 and 20%; Moderate-Low Risk represented stable patients with minor fluctuations; and Low Risk characterized patients demonstrating consistent improvement. These definitions were established through consensus among clinical collaborators prior to model development, with labels assigned retrospectively based on documented outcomes.
Disease categories were distributed across data splits using stratified sampling to ensure proportional representation, though some rare subtypes appeared in fewer than all three partitions due to extremely limited sample sizes. Specifically, 17 disease categories with fewer than 10 total patients appeared in training only, preventing direct test-set evaluation for these conditions.
Table 4. Statistical characteristics of the rare disease rehabilitation dataset.CharacteristicTraining setValidation setTest setPatient count1993427427Total observations33,15471047104Mean follow-up (weeks)24.6 ± 12.323.8 ± 11.925.1 ± 12.7High risk proportion18.3%17.9%18.7%Moderate-high risk24.1%23.6%24.3%Moderate-low risk31.2%32.1%30.8%Low risk26.4%26.4%26.2%Missing data rate12.4%11.8%12.1%Disease categories156142139Overlapping categories–138134
Data preprocessing addressed quality issues inevitable in real-world clinical records. Missing values received imputation through multiple strategies tailored to data characteristics and clinical considerations. For vital signs exhibiting temporal continuity, we employed last observation carried forward given the physiological rationale that recent measurements typically approximate current status. Laboratory values, which display greater variability and disease-specific patterns, received median imputation computed within disease category groups rather than globally, partially accounting for condition-specific reference ranges^41^. Text fields used masked token insertion to preserve sequence structure while signaling missing information to downstream encoders.
We recognize that standard imputation approaches may not optimally suit all 156 rare disease categories, as different conditions exhibit distinct missing data mechanisms and value distributions. To assess imputation sensitivity, we compared disease-stratified median imputation against global median and multiple imputation by chained equations (MICE) on a validation subset. Disease-stratified imputation improved F1 score by 2.1% over global median imputation for metabolic disorders but showed negligible difference for neuromuscular conditions, suggesting heterogeneous imputation effects across disease families. Table 4 reports the overall missing data rates; Supplementary File 1 provides disease-category-specific missing patterns and imputation validation results.
Outlier detection applied isolation forest algorithms to continuous variables, with flagged values reviewed against clinical plausibility before replacement or retention. Feature standardization normalized continuous inputs to zero mean and unit variance within the training partition, with transformation parameters subsequently applied to validation and test sets to prevent information leakage.
As illustrated in Fig. 3, the dataset exhibits characteristic long-tail distributions across several dimensions, with certain rare disease subtypes contributing disproportionately few samples—a challenge our graph-based approach partially mitigates through cross-patient information sharing.
Fig. 3. Distribution characteristics of the rare disease rehabilitation dataset.
We adopted stratified random splitting with 70% training, 15% validation, and 15% test allocation, ensuring proportional representation of risk categories and disease subtypes across partitions. Five-fold cross-validation on the training set guided hyperparameter selection, with final model evaluation conducted on the held-out test set.
Table 5 presents the hyperparameter configuration determined through systematic grid search across validation folds.
Table 5. Experimental hyperparameter configuration.ParameterValueSearch rangeLearning rate1e − 4[1e − 5, 1e − 3]Batch size32[16, 64]Hidden dimension256[128, 512]Graph conv layers3[2, 5]Attention heads8[4, 16]Dropout rate0.3[0.1, 0.5]Weight decay1e − 5[1e − 6, 1e − 4]Temporal window12[6, 24]Training epochs200–Early stopping patience20–
All experiments executed on a workstation equipped with dual NVIDIA A100 GPUs (80GB memory each), 128GB system RAM, and AMD EPYC 7763 processors. Model implementation proceeded in PyTorch 2.0 with PyTorch Geometric extensions for graph operations^42^.
Figure 4 depicts training dynamics across epochs, demonstrating stable convergence without significant overfitting after approximately 120 epochs.
Fig. 4. Training and validation loss convergence curves.
Evaluation metrics for risk stratification included accuracy, macro-averaged F1 score, area under the receiver operating characteristic curve, and Cohen’s kappa coefficient. Intervention strategy assessment employed BLEU scores for sequence similarity, clinical validity rates judged by expert reviewers, and constraint satisfaction percentages measuring adherence to defined feasibility rules.
Practical deployment considerations extend beyond prediction accuracy to computational feasibility within clinical workflows. Table 6 summarizes resource requirements and timing characteristics relevant to implementation planning.
Table 6. Computational resource requirements and deployment characteristics.MetricTrainingInference (per patient)GPU memory24.6 GB3.2 GBTraining time8.4 h–Inference latency–0.34 sModel parameters12.8 M12.8 MStorage requirements156 MB156 MBCPU-only inference–2.1 s
The inference latency of 0.34 s per patient permits real-time clinical integration without meaningful workflow disruption. CPU-only deployment remains feasible at 2.1 s, accommodating settings lacking GPU infrastructure. However, model retraining to incorporate new patient data requires substantial computational resources. We envision periodic batch retraining (weekly or monthly) rather than continuous online updates as the practical deployment strategy, with established patients receiving predictions from the current model while accumulated new cases inform scheduled model refreshes.
Integration with existing hospital information systems would require standardized data interfaces conforming to HL7 FHIR or similar interoperability frameworks. The intervention generation component outputs structured recommendations compatible with clinical decision support alert systems, though workflow integration specifics depend on institutional electronic health record configurations. These deployment considerations represent important directions for translational development beyond the current methodological contribution.
Risk stratification performance evaluation and comparative analysis
We assembled a comprehensive comparison set spanning traditional machine learning classifiers—logistic regression, random forest, gradient boosting machines—and contemporary deep learning architectures including recurrent neural networks, temporal convolutional networks, graph attention networks, and recent medical AI models specifically designed for clinical prediction from multimodal data^43^. The latter category includes Med-BERT, a clinical language model adapted for structured EHR prediction^50^, and BEHRT, a transformer architecture for sequential medical codes^51^. These represent state-of-the-art approaches for healthcare prediction tasks against which our graph-based methodology should be evaluated.
All baseline implementations followed published configurations with hyperparameters optimized through identical five-fold cross-validation procedures to ensure fair comparison. For Med-BERT and BEHRT, we utilized publicly available pretrained weights and fine-tuned on our rare disease cohort following recommended protocols. The inclusion of these recent medical AI models addresses the need for comparison beyond general-purpose baselines, demonstrating that performance gains from MSTGCA-Net stem from architectural innovations suited to rare disease characteristics rather than simply applying more sophisticated models.
Statistical significance was assessed using paired bootstrap resampling with 1000 iterations to compute 95% confidence intervals for all performance metrics. For pairwise model comparisons, we employed the Wilcoxon signed-rank test given non-normal performance distributions observed across cross-validation folds. To address multiple comparison concerns arising from numerous model and metric combinations, we applied Bonferroni correction, adjusting the significance threshold to \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:\alpha\:=0.05/28=0.0018$$\end{document} for the seven baseline comparisons across four primary metrics.
Table 7 presents quantitative performance across all evaluated methods on the held-out test set, including 95% confidence intervals derived from bootstrap resampling. Our proposed MSTGCA-Net achieves superior performance across all measured metrics (all corrected \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:p<0.001$$\end{document} ), with particularly notable gains in recall for high-risk categories where clinical consequences of missed detection prove most severe.
Table 7. Performance comparison of different methods for risk stratification with 95% confidence intervals.MethodAccuracyPrecisionRecallF1 ScoreAUCp-valueLogistic regression0.724 (0.698–0.750)0.698 (0.671–0.725)0.681 (0.652–0.710)0.689 (0.661–0.717)0.793 (0.768–0.818)< 0.001Random forest0.756 (0.731–0.781)0.731 (0.704–0.758)0.719 (0.691–0.747)0.725 (0.698–0.752)0.824 (0.801–0.847)< 0.001XGBoost0.771 (0.747–0.795)0.748 (0.722–0.774)0.736 (0.709–0.763)0.742 (0.716–0.768)0.841 (0.819–0.863)< 0.001LSTM0.793 (0.770–0.816)0.769 (0.744–0.794)0.758 (0.732–0.784)0.763 (0.738–0.788)0.862 (0.841–0.883)< 0.001TCN0.801 (0.778–0.824)0.778 (0.753–0.803)0.771 (0.746–0.796)0.774 (0.749–0.799)0.869 (0.849–0.889)< 0.001GAT0.812 (0.790–0.834)0.791 (0.767–0.815)0.783 (0.758–0.808)0.787 (0.763–0.811)0.881 (0.862-0.900)< 0.001ST-GCN0.829 (0.808–0.850)0.806 (0.783–0.829)0.798 (0.774–0.822)0.802 (0.778–0.826)0.894 (0.876–0.912)< 0.001Med-BERT0.841 (0.821–0.861)0.819 (0.797–0.841)0.811 (0.788–0.834)0.815 (0.792–0.838)0.906 (0.889–0.923)< 0.001MSTGCA-net (ours)0.867 (0.848–0.886)0.849 (0.828–0.870)0.841 (0.819–0.863)0.845 (0.823–0.867)0.923 (0.907–0.939)–
Monte Carlo dropout uncertainty quantification (50 stochastic forward passes at inference) revealed mean predictive entropy of 0.42 for correctly classified cases versus 0.71 for misclassified cases, confirming that the model exhibits appropriately calibrated uncertainty. High-risk predictions showed coefficient of variation averaging 0.18, indicating reasonable confidence for clinically consequential classifications.
Beyond aggregate performance metrics, clinical utility depends on consistent performance across the heterogeneous rare disease spectrum. Table 8 presents stratified results across major disease families, revealing meaningful variation in model effectiveness.
Table 8. Performance stratification by rare disease category.Disease familyN patientsN categoriesF1 scoreAUC95% CI (F1)Neuromuscular disorders687340.8720.9340.841–0.903Metabolic disorders524410.8210.8970.784–0.858Immunodeficiency syndromes463280.8560.9210.820–0.892Connective tissue disorders398220.8490.9180.811–0.887Hematological disorders312150.8380.9110.796–0.880Other rare conditions463160.8310.9040.792–0.870Ultra-rare (n < 20 per category)289670.7840.8690.738–0.830
Neuromuscular disorders achieved strongest performance, likely reflecting well-characterized progression patterns and comprehensive physiological monitoring in this population. Metabolic disorders showed comparatively lower scores, possibly due to greater heterogeneity in clinical manifestations and more variable data completeness. Ultra-rare conditions with fewer than 20 patients per category exhibited degraded but still clinically meaningful performance (F1 = 0.784), demonstrating that graph-based information sharing provides measurable benefit even for extremely limited samples. These disease-specific variations warrant consideration when deploying the model across different rare disease populations.
The performance gap between traditional machine learning and deep learning approaches reflects the value of automatic feature learning for complex clinical data. More telling, however, is the incremental improvement from standard graph attention networks to spatiotemporal variants, and finally to our full multimodal framework—each architectural enhancement translating to measurable accuracy gains. As depicted in Fig. 5, these differences prove statistically significant across all pairwise comparisons with our method.
Fig. 5. Performance comparison of different methods for risk stratification.
Figure 6 illustrates receiver operating characteristic curves for the four-class risk stratification task, with our model demonstrating consistently superior discrimination across all risk categories^44^. The high-risk stratum, despite its relative infrequency, achieves AUC exceeding 0.94—a critical result given the clinical priority of identifying patients requiring intensive monitoring.
Fig. 6ROC curves comparison across different risk categories.
Ablation experiments systematically evaluated component contributions through controlled removal of architectural elements. Table 9 presents complete ablation results with performance across all primary metrics.
Table 9. Ablation study results for MSTGCA-net components.ConfigurationAccuracyPrecisionRecallF1 ScoreAUCΔ F1Full MSTGCA-net0.8670.8490.8410.8450.923–w/o Graph convolution0.8210.7980.7890.7920.884− 5.3%w/o Temporal attention0.8340.8140.8060.8040.896− 4.1%w/o Cross-modal attention0.8120.7860.7780.7770.871− 6.8%w/o Dynamic graph update0.8480.8290.8210.8250.908− 2.0%w/o Uncertainty quantification0.8670.8490.8410.8450.9230.0%Single modality (physio only)0.7780.7540.7460.7500.842− 9.5%Two modalities (physio + text)0.8190.7960.7880.7920.878− 5.3%Three modalities (+ imaging)0.8510.8320.8240.8280.911− 1.7%
Removing cross-modal attention produced the largest single-component degradation (6.8% F1 reduction), confirming that adaptive multimodal fusion provides substantial predictive value for rare disease populations where optimal feature combinations vary across individuals^45^. Graph convolution removal caused 5.3% reduction, demonstrating meaningful benefit from patient relationship modeling. The complete four-modality configuration maximized performance, though diminishing marginal returns from the third to fourth modality suggest prioritization strategies for resource-constrained deployment scenarios.
Intervention strategy generation effectiveness and case analysis
Quantitative metrics alone cannot fully capture intervention quality—generated recommendations must ultimately satisfy practicing clinicians. We therefore conducted structured expert evaluation involving twelve rehabilitation specialists from participating institutions. Each reviewer assessed 150 randomly sampled intervention strategies across five dimensions: clinical appropriateness, safety considerations, feasibility given typical resource constraints, specificity to individual patient circumstances, and temporal coherence with rehabilitation progression^46^.
We acknowledge that the current evaluation remains primarily subjective and retrospective, without direct assessment of whether generated interventions would actually improve patient outcomes or meaningfully alter clinical decision-making compared to standard practice. The use of BLEU scores as a quantitative metric warrants particular caution in this context. BLEU was originally developed for natural language translation tasks and measures surface-level sequence similarity rather than clinical appropriateness, completeness, or safety^49^. High BLEU scores indicate lexical overlap with reference interventions but do not guarantee that generated recommendations would prove beneficial if implemented. Future work should incorporate simulation-based evaluation or retrospective outcome association analysis to provide stronger evidence regarding clinical decision support effectiveness.
Table 10 summarizes the expert evaluation outcomes, revealing generally favorable assessments with particularly strong performance on safety and feasibility dimensions.
Table 10. Expert evaluation of generated intervention strategy quality.Evaluation dimensionMean score (1–5)Agreement rate (%)Excellent rate (%)Clinical appropriateness4.2187.368.4Safety assurance4.5693.279.6Resource feasibility4.3890.172.8Patient specificity3.8981.654.3Temporal coherence4.0284.761.2
The somewhat lower scores for patient specificity warrant reflection. Reviewers noted that while generated interventions rarely contained inappropriate recommendations, they occasionally lacked the nuanced personalization that experienced clinicians would naturally incorporate. This observation aligns with broader limitations of data-driven approaches in rare disease contexts where individual variation defies algorithmic generalization.
Fig. 7presents comprehensive evaluation results across multiple automated metrics alongside expert ratings, demonstrating reasonable correlation between computational measures and human judgment.
Figure 7. Comprehensive evaluation of intervention strategy generation. Left panel displays automated metrics including BLEU-1 through BLEU-4 scores (lexical similarity), constraint satisfaction rate (adherence to clinical feasibility rules), and generation latency (seconds per recommendation). Right panel shows expert rating distributions across five evaluation dimensions (scale 1–5). Error bars indicate standard deviation across 150 evaluated samples. Note that BLEU scores measure surface-level textual overlap rather than clinical appropriateness; see text for discussion of metric limitations.
A representative case illustrates the system’s clinical utility. A 34-year-old patient with mitochondrial myopathy entered rehabilitation following acute decompensation. Initial risk stratification placed her in the high-risk category with 0.87 probability. The model recommended intensive physiotherapy monitoring, nutritional supplementation adjustment, and cardiology consultation. Over subsequent weeks, as physiological indicators stabilized and functional assessments improved, risk predictions dynamically recalibrated—dropping to moderate (0.62) by week four and low (0.31) by week eight. Intervention recommendations correspondingly evolved toward maintenance protocols and community reintegration planning.
Attention weight visualization provides one avenue for model inspection that may support clinical acceptance^47^. Figure 8 depicts attention distributions across modalities and time points for the case described above. Early in rehabilitation, physiological monitoring data received higher attention weights, which appears consistent with acute instability concerns during this phase. As recovery progressed, functional assessment scores and clinical notes gained increasing weight—a pattern that participating clinicians found intuitively reasonable.
To evaluate whether attention patterns convey genuinely useful information rather than merely plausible-looking visualizations, we conducted structured clinician assessment of the attention maps themselves. Twelve rehabilitation specialists independently rated 100 randomly selected attention visualizations across four dimensions: clinical relevance, consistency with domain knowledge, actionability, and potential for misleading interpretation. Table 11 summarizes these evaluation results.
Table 11. Clinician evaluation of attention map interpretability.Evaluation dimensionMean score (1–5)Agreement rate (%)Positive rate (%)Clinical relevance3.8278.471.2Domain consistency4.0182.676.8Actionability3.5473.162.4Misleading potential2.3181.223.6
The moderate scores for clinical relevance and actionability indicate that while attention patterns often highlight clinically sensible features, they do not consistently provide the depth of explanation that would substantially alter clinical reasoning. Reviewers noted that attention maps occasionally emphasized unexpected features without clear clinical justification, reinforcing that attention weights should be interpreted cautiously rather than as definitive explanations. Future work should compare attention-based explanations with alternative techniques such as SHAP values or gradient-based attribution methods to better characterize the relative strengths and limitations of different interpretability approaches in this clinical context.
Fig. 8. Visualization of attention weight distribution across modalities and time points. Heatmap displaying cross-modal and temporal attention weights for a representative mitochondrial myopathy patient across 12-week rehabilitation. Rows correspond to four input modalities (physiological indicators, laboratory results, clinical notes, functional assessments); columns represent weekly time points. Color intensity indicates normalized attention weight (0–1 scale). Early weeks show elevated physiological attention (acute monitoring), transitioning to functional assessment dominance as recovery progresses. Attention patterns represent model focus rather than definitive causal importance; interpretation should proceed cautiously given known limitations of attention-based explanations^48^.
The temporal attention patterns further revealed which historical observations most influenced current predictions. Recent measurements naturally received higher weights, yet certain earlier clinical events—notably the initial cardiac evaluation and baseline functional assessment—retained persistent influence throughout the trajectory, suggesting the model appropriately recognized their enduring prognostic significance.
Discussion
The experimental results presented above demonstrate substantial performance advantages of our proposed framework over existing approaches. Several factors contribute to these gains, and understanding them illuminates both the method’s strengths and its potential limitations. Perhaps most fundamentally, the graph-based architecture addresses a challenge that has long plagued rare disease analytics: sample scarcity. By constructing patient relationship graphs and propagating information across clinically similar individuals, our model effectively expands the learning signal available for each patient. Rare disease subtypes with only dozens of cases can borrow statistical strength from related conditions, mitigating the overfitting risks that typically constrain deep learning in small-sample settings.
The synergistic interaction between spatiotemporal graph convolution and attention mechanisms merits careful examination. Graph convolution captures structural relationships—which patients share similar clinical profiles, treatment histories, or disease trajectories—while temporal attention models the sequential dependencies within individual rehabilitation courses. These two perspectives complement rather than duplicate each other. A patient’s risk at any moment depends both on their personal history and on outcomes observed in comparable patients; neither information source suffices alone. The attention mechanism further enables adaptive weighting of these contributions. Some patients may benefit primarily from their own longitudinal patterns, while others—particularly those with unusual presentations—gain more from cross-patient comparisons. The model learns to calibrate this balance automatically.
Interpretability emerges as a distinctive advantage with profound implications for clinical adoption. Healthcare practitioners understandably resist black-box predictions, especially for high-stakes decisions in vulnerable rare disease populations. The attention weights our model produces offer transparent rationale for its predictions—clinicians can examine which data modalities, time points, and patient comparisons drove a particular risk assessment. This transparency serves multiple purposes. It enables verification that model reasoning aligns with clinical intuition. It facilitates identification of cases where unusual attention patterns might signal unreliable predictions. And it supports educational applications, potentially revealing risk factors that less experienced clinicians might overlook.
Generalization across rare disease heterogeneity presents both opportunities and challenges. Our evaluation included metabolic, neuromuscular, immunological, and connective tissue disorders—conditions with vastly different pathophysiology, treatment approaches, and rehabilitation trajectories. The model maintained reasonable performance across this spectrum, suggesting that the learned representations capture generalizable principles of rehabilitation risk rather than disease-specific patterns alone. However, we observed performance variation across disease categories, with neuromuscular conditions yielding somewhat stronger results than metabolic disorders. This disparity likely reflects differences in data completeness and the relative importance of modalities our framework prioritizes.
Rehabilitation stage also influences model behavior. Early-stage predictions necessarily rely more heavily on baseline characteristics and initial trajectory slopes, while later predictions incorporate richer longitudinal information. Our temporal attention mechanism naturally accommodates this shift, but clinicians should recognize that prediction confidence appropriately varies across the rehabilitation timeline.
Compared with prior approaches, our framework offers several technical distinctions. Existing graph-based healthcare models typically construct static patient networks using predetermined similarity metrics; our dynamic graph updating adapts relationships as patient states evolve. Previous multimodal fusion strategies often treat modality combination as a fixed architectural choice; our cross-attention mechanism learns patient-specific fusion patterns. And while prior work has addressed either risk prediction or intervention recommendation separately, our end-to-end formulation jointly optimizes both objectives, enabling intervention suggestions directly informed by risk assessment rather than applied as a separate downstream step.
Comparison with rule-based or guideline-driven clinical decision support systems merits consideration^38^. Traditional expert systems encode explicit clinical rules derived from practice guidelines, offering transparent reasoning but limited adaptability to individual patient variation. Such systems excel when clinical knowledge is well-codified and patient populations are homogeneous, yet they struggle with the heterogeneity characteristic of rare disease rehabilitation. Our data-driven approach complements rather than replaces such systems—the attention mechanisms may identify patient-specific risk factors that static guidelines cannot anticipate, while established protocols provide safety constraints that bound algorithmic recommendations. Hybrid architectures integrating learned representations with rule-based guardrails represent a promising direction that could combine the adaptability of machine learning with the transparency and safety assurances of expert systems.
Conclusion
This investigation has presented a comprehensive computational framework integrating multimodal spatiotemporal graph convolutional networks with hierarchical attention mechanisms for dynamic risk stratification and intervention strategy generation in rare disease rehabilitation nursing. The core contributions span three interconnected dimensions: a heterogeneous patient relationship graph construction scheme that captures evolving clinical similarities across diverse rare disease populations; an encoder architecture combining spatial graph convolution with temporal attention to model complex dependencies inherent to rehabilitation trajectories; and a constrained generation module that translates risk predictions into actionable, clinically feasible intervention recommendations.
The experimental findings substantiate several principal conclusions. First, explicit modeling of patient relationships through graph structures meaningfully enhances predictive performance, particularly for rare disease subtypes where individual sample sizes preclude reliable standalone learning. Second, multimodal data integration through cross-attention mechanisms outperforms fixed fusion strategies, with the learned modality weightings varying appropriately across patients and rehabilitation stages. Third, the joint optimization of risk stratification and intervention generation yields mutually reinforcing benefits—intervention recommendations informed by nuanced risk assessment prove more clinically appropriate than those generated independently.
The innovation of this work resides not in any single component but in their thoughtful integration. Multimodal fusion addresses the information fragmentation that plagues rare disease analytics. Spatiotemporal modeling captures the dynamic, evolving nature of rehabilitation risk that static assessments cannot represent. Attention mechanisms provide both adaptive computation and interpretable reasoning. Together, these elements create a framework qualitatively distinct from prior approaches that addressed these challenges in isolation.
From a theoretical standpoint, this research contributes to the growing literature on graph-based healthcare analytics while extending it in directions particularly suited to rare disease contexts. Clinically, the framework offers practical decision support tools that could meaningfully enhance rehabilitation nursing quality—enabling earlier risk identification, more personalized intervention planning, and more efficient resource allocation.
We acknowledge several limitations that temper these contributions. The dataset, while substantial by rare disease standards, remains modest compared to common condition cohorts. More critically, all data originated from three tertiary centers within a single regional healthcare system, which constrains generalizability claims. Differences in clinical protocols, patient demographics, documentation practices, and rare disease distributions across healthcare systems could substantially affect model performance in external settings. We have not yet conducted cross-institutional validation, temporal holdout evaluation, or systematic robustness testing under distributional shift. Consequently, readers should interpret our performance estimates as reflecting this specific clinical context rather than guaranteed generalization to different hospitals, regions, or healthcare systems.
The intervention generation module, despite favorable expert assessment, awaits prospective evaluation of actual patient outcomes—whether generated recommendations would genuinely improve rehabilitation trajectories or reduce adverse events remains undemonstrated. Computational requirements (detailed in Table 6) may also challenge deployment in resource-limited settings. Future multi-center validation studies across diverse healthcare environments represent an essential priority before clinical implementation.
Future research should prioritize multi-center validation studies to establish generalizability across healthcare systems and geographic contexts. Real-time risk monitoring systems that integrate streaming data warrant development for acute rehabilitation settings. Clinical implementation studies must assess workflow integration, practitioner acceptance, and ultimately patient outcomes. Finally, extension to additional rare disease categories and pediatric populations could broaden the framework’s applicability and impact.
Supplementary Information
Below is the link to the electronic supplementary material.
Supplementary Material 1
The reference list from the paper itself. Each links out to its DOI / PubMed record.