Unveiling key descriptors via machine learning: toward rational molecular design of chromophores with excited-state intramolecular proton transfer
Shengsheng Wei, Zipeng Yang, Chao Yang, Hongmei Zhao, Yang Li, Yuanyuan Guo, Andong Xia, Zhuoran Kuang

TL;DR
This paper presents a machine learning approach to design molecules with specific light-emitting properties, validated by creating and testing two new compounds.
Contribution
A data-driven framework for predicting and designing ESIPT molecules with accurate ΔE* prediction and experimental validation.
Findings
An interpretable ML model identified key H-bond descriptors influencing ΔE*.
Two AI-designed ESIPT molecules with distinct dual emission were successfully synthesized.
The framework accelerates high-throughput screening and molecular design of ESIPT compounds.
Abstract
Precise design of excited-state intramolecular proton transfer (ESIPT) molecules targeting advanced optoelectronic or biological sensing applications presents a fundamental challenge. Controlling the energy difference (ΔE*) between normal (N*) and tautomeric (T*) excited-state forms is crucial, yet the complex interplay of hydrogen bond (H-bond) strength, proton donor acidity, and proton acceptor basicity with ΔE* remains insufficiently explored. Conventional trial-and-error approaches for designing tailored ESIPT compounds suffer from inefficient synthesis. To address this, we constructed a high-quality ESIPT dataset by introducing ten substituents with progressively increasing electron-donating capacity into six representative ESIPT parent scaffolds. Integrating qualitative descriptors with data-driven machine learning (ML) enabled precise ΔE* prediction, significantly accelerating…
Genes, proteins, chemicals, diseases, species, mutations and cell lines named across the full text — each resolved to its canonical identifier and authoritative record.
Click any figure to enlarge with its caption.
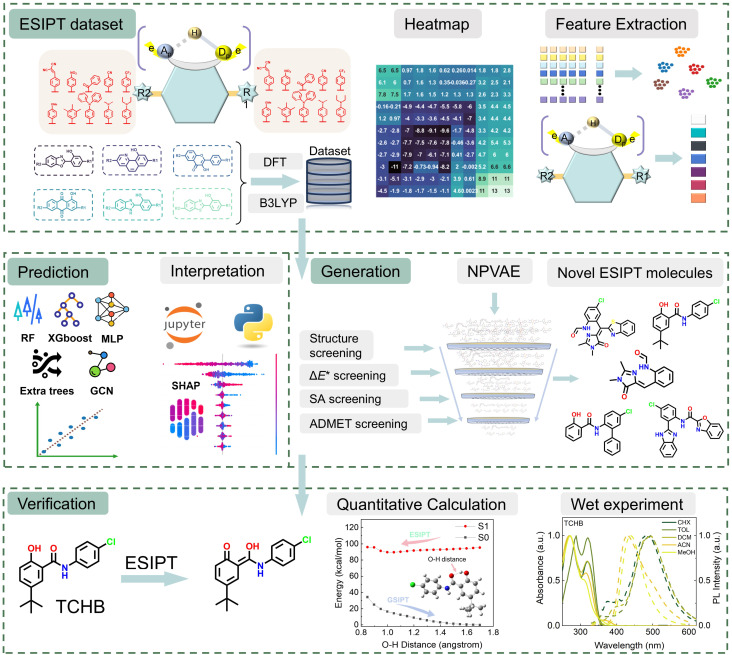 Fig. 1
Fig. 1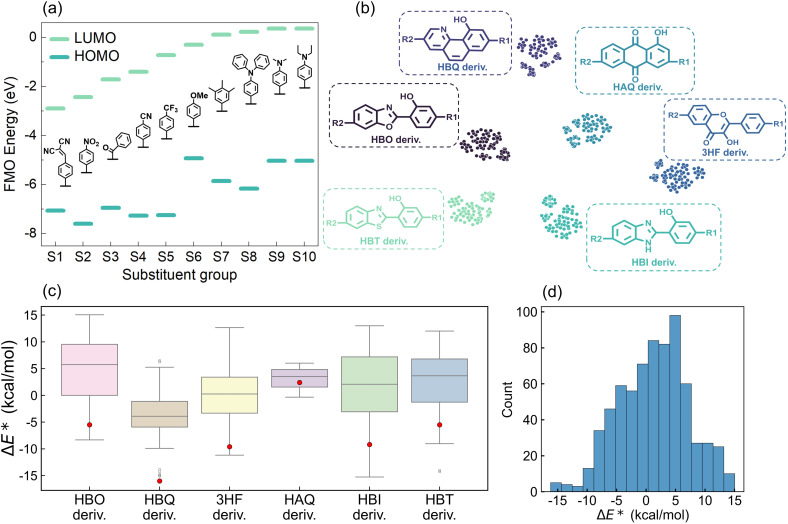 Fig. 2
Fig. 2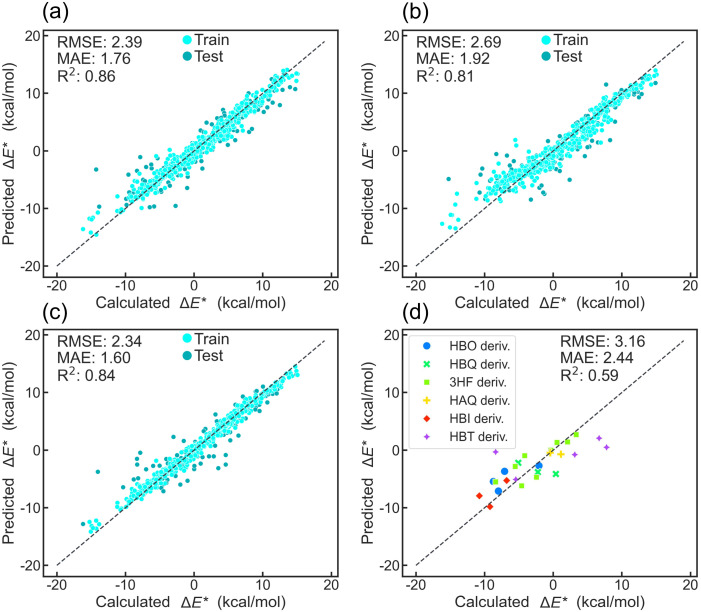 Fig. 3
Fig. 3 Fig. 4
Fig. 4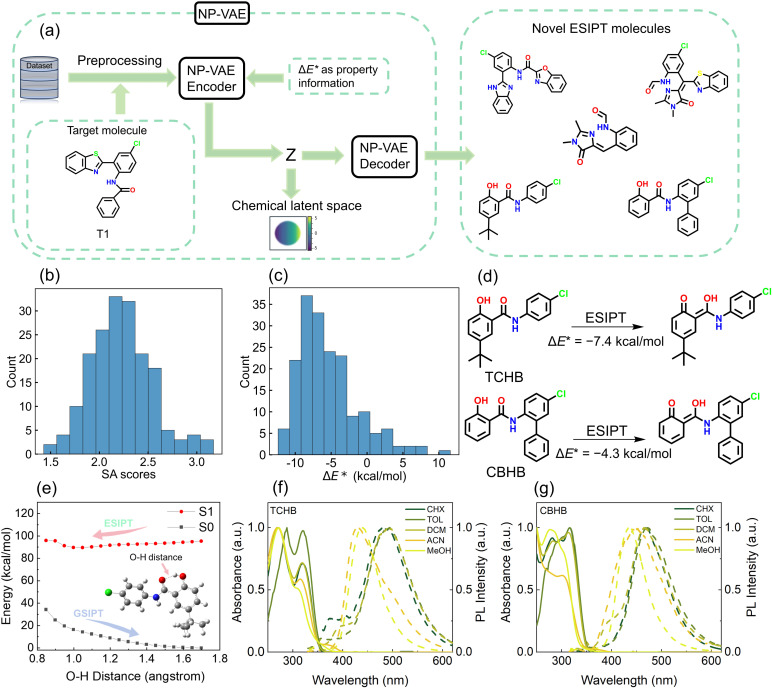 Fig. 5
Fig. 5- —Natural Science Foundation of Beijing Municipality10.13039/501100005089
- —National Natural Science Foundation of China10.13039/501100001809
- —State Key Laboratory of Information Photonics and Optical Communications10.13039/501100011351
- —Beijing University of Posts and Telecommunications10.13039/501100002766
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsPhotochemistry and Electron Transfer Studies · Molecular Sensors and Ion Detection · Photochromic and Fluorescence Chemistry
Introduction
Excited-state intramolecular proton transfer (ESIPT) is a photophysical process wherein a photoexcited molecule undergoes proton-transfer isomerization from its excited normal (N*) to tautomeric (T*) configurations. ESIPT emitters have garnered substantial research interest owing to their exceptionally large Stokes-shifted emission, arising from the energy difference between N* and T* state (ΔE**), and pronounced microenvironment sensitivity to pH, solvent polarity, and viscosity. These properties render ESIPT-based materials highly promising for bioimaging probes with ratiometric detection capability,^1–5^ spectrum-tunable organic light-emitting diodes (OLEDs), and single-molecule white-light emitters.^6–13^ Numerous studies have focused on modulating ΔE** to control the ESIPT kinetics reaction. Molecular engineering with strategic modification of electron-donating groups (EDGs) or electron-withdrawing groups (EWGs) and microenvironment tuning of media polarization or viscosity modulate ΔE** in experiments.^14–16^ Computational methods, such as time-dependent density functional theory (TD-DFT) or complete active space self-consistent field (CASSCF), enable ΔE** determination via N* and T* energy calculations, thereby circumventing the high experimental costs.^15,17^ However, the computational burden escalates with molecular size and dataset scale, limiting its applicability in high-throughput screening.
Artificial intelligence (AI) has revolutionized high-throughput molecular screening by significantly accelerating the discovery of promising candidates. Central to this advancement are interpretable property prediction models, AI systems that predict molecular properties while decoding structural–activity relationship. The integration of interpretable machine learning (ML) methods has shifted the paradigm from empirical optimization or purely data-driven approaches to mechanism-oriented discovery frameworks, quantitatively resolving feature importance to extract chemical design principles. ML-based property-prediction models have enabled high-throughput screening across diverse functional materials, including thermally activated delayed fluorescence (TADF) emitters,^18,19^ lithium battery electrolytes,^20,21^ solid-state optical materials,^22^ organic photovoltaics,^23,24^ nonlinear optical crystals,^25,26^etc. However, despite these successes, the reliance of property-prediction models on pre-enumerated molecular libraries can become a bottleneck when aiming to explore ultra-large or uncharted regions of chemical space within a practical timeframe.^27–29^
In contrast to the property-prediction model, generative AI enables de novo design of molecular structures with target properties while bypassing costly enumeration-evaluation cycles. These models explore expansive chemical spaces beyond predefined in silico libraries, facilitating the discovery of structurally innovative motifs critical for breakthrough applications.^30–36^ However, a fundamental limitation persists in that a large proportion of AI-generated compounds exhibit synthetic inaccessibility due to unrealistic ring strain, forbidden bond angles, or lack of retrosynthetic pathways, rendering experimental validation unfeasible. Consequently, there has been growing interest in developing generative AI models that can design synthesizable molecules. Although several methods have shown promising in silico results, very few studies undergo experimental synthesis validation.^18,20,36–39^ Moreover, only a few studies have attempted ΔE** prediction and ESIPT molecular design using AI methods, such as the work by Zeng et al.^27^ and Raucci.^40^ Nevertheless, the extensive literature on ΔE** modulation provides valuable insights, inspiring our investigation into the key descriptors governing ESIPT behaviour.^14–17,41–46^ In this study, we presented an integrated framework combining quantum-chemical calculations, ML, and experimental validation to discover novel ESIPT molecules (Fig. 1). A high-quality ESIPT dataset was constructed through theoretical calculations and analyzed via statistical methods and substituent-ΔE** heatmaps. Molecular descriptors generated using RDKit and DeepChem^47,48^ were visualized by t-distributed stochastic neighbor embedding (t-SNE)^49^ and principal component analysis (PCA). Subsequent ML model training enabled accurate prediction of ΔE**. Employing an interpretable algorithm, Shapley additive explanations (SHAP),^50^ we identified and rationalized key descriptors influencing ΔE** (e.g., hydrogen-bond length difference between N and N) and evaluated their relative importance. To explore novel chemical space, we utilized a variational autoencoder (NPVAE)^36,51,52^ to generate promising ESIPT candidates. These candidates were rigorously filtered based on predicted ΔE**, ADMET (absorption, distribution, metabolism, excretion, and toxicity) properties, and synthetic accessibility (SA) scores. Notably, two prioritized candidates synthesized for experimental validation exhibited distinct N and T* emissions, validating our data-driven molecular design strategy. This work demonstrates the power of integrating ML, TD-DFT calculations, and experiments for the efficient design of functional ESIPT systems.
Schematic representation of identifying promising ESIPT molecules utilizing AI, quantitative computational analysis, and experimental verification.
Results and discussion
Construction of the ESIPT dataset
A high-quality ESIPT dataset containing ΔE** was systematically constructed to enable accurate ΔE** prediction and AI-based molecular design. Initial ESIPT-active molecules were collected through comprehensive literature screening. From this collection, eighteen parent ESIPT molecular scaffolds were extracted, where Δ*E** was calculated from eleven of them (Table S1). These scaffolds were classified into five categories based on proton donor-proton acceptor interactions: OH⋯O, OH⋯N, NH⋯N, N(R)H⋯N, and NH⋯O (Fig. S1). Six representative scaffolds were selected for dataset construction: 2-(2′-hydroxyphenyl)benzoxazole (HBO), 10-hydroxybenzo[h]quinoline (HBQ), 3-hydroxyflavone (3HF), 1-hydroxyanthraquinones (HAQ), 2-(2′-hydroxyphenyl)benzimidazole (HBI), and 2-(2′-hydroxyphenyl)benzothiazole (HBT). Selection criteria included: (1) intrinsic ultrafast ESIPT kinetics and (2) extensive literature validation of their stability as ESIPT-active compounds. All six scaffolds feature proton donor/acceptor moieties integrated within five- or six-membered ring systems.
To maximize chemical diversity, ten substituents, ranked by electron-withdrawing strength (from strongest to weakest) based on LUMO energies (Fig. 2a), were systematically introduced at R1 and R2 positions along the long molecular axis of each scaffold. Ground-state (N) and excited-state (N*, T*) geometries of all 704 derivatives underwent full geometric optimization using density functional theory (DFT) and time-dependent DFT (TD-DFT) with the B3LYP functional, ensuring convergence to energy minima. This yielded the final ΔE** dataset for quantitative analysis (see SI Files, XLSX file 1 for the ESIPT dataset). Data visualization provides critical insights for intuitive dataset interpretation. To map chemical space, molecules were clustered using ECFP^53^ and visualized via t-SNE. The t-SNE algorithm projects structural similarities into 2D space with proximate points indicating molecular resemblance. The ESIPT derivatives classified as HBO, HBQ, 3HF, HAQ, HBI, and HBT types exhibit distinct clustering in the t-SNE plot (Fig. 2b), validating the classification approach. The clear classification of the six groups not only demonstrates the effectiveness of the clustering method and the fingerprint, but also indirectly confirms the capability of the subsequent AI algorithm to recognize molecular structures based on fingerprints. Systematic derivatization significantly modulates the ΔE** relative to parent molecules (Fig. 2c). For instance, HBI parent exhibits ΔE** = −9.2 kcal mol^−1^, while derivatization extends this range to approximately −15 to 13 kcal mol^−1^, indicating effective ESIPT thermodynamic tuning via excited-state intramolecular charge transfer (ESICT). Similar ΔE** modulation breadth was observed for five other derivative classes. Notably, HAQ derivatives show a narrow ΔE** distribution, suggesting skeletal vibration-dominated ESIPT rather than ESICT mediated processes.^54–56^ The calculated ΔE** of all compounds spans between −16 and 15 kcal mol^−1^ with an average of 1.32 kcal mol^−1^ (Fig. 2d).
(a) Frontier molecular orbital (FMO) energy level alignment of substituent groups. (b) Chemical space visualization of the ESIPT dataset based on the t-SNE clustering method. Points represent individual molecules color-coded by derivative (deriv.) class: HBO, HBQ, HAQ, 3HF, HBI, and HBT. (c) Distributions of ΔE for the six types of derivatives, respectively. The red dots represent the ΔE* values of the parent ESIPT molecules. (d) Distribution of ΔE* for the ESIPT molecular dataset.*
To elucidate substituent effects on ESIPT energetics, ΔE** regulation heatmaps were generated for all six derivative classes (Fig. S2). Crucially, ΔE** variations exhibited no monotonic correlation with substituent electron-withdrawing strength (as ranked by LUMO energies), demonstrating that ESICT serves as merely one contributing factor in dictating ESIPT thermodynamics. The substituent-ΔE** heatmaps indicate that ΔE** values of modified derivatives are almost higher than those of their corresponding parent molecules. Using 3HF derivatives as an example, compared to the ΔE** of 3HF which is −9.6 kcal mol^−1^, most of the 3HF derivatives show a higher value, except when the R1 site is connected to the S3 substituent and the R2 site is attached to the S2 substituent, in which case the value is −11 kcal mol^−1^ (Fig. S2c). For other types of derivatives, the cases in which ΔE** is lower than that of the corresponding parent molecules are rarely observed. Additionally, substitution of EDGs (S8, S9, and S10) at R1 and R2 positions consistently resulted in higher ΔE** values, systematically exceeding those observed for EWG substitutions. Though ΔE** trends deviate from simple substituent FMO's energetic ordering, substituents regulate ESIPT through synergistic electronic and steric effects, necessitating multidimensional descriptors for predictive modeling and laying the groundwork for machine learning applications.
ΔE* prediction using ML with multidimensional descriptors
To predict ΔE** using ML, molecules were characterized using three complementary descriptor categories: quantitative descriptors (209-dimensional features), qualitative descriptors (encode 2048-bit in length), and molecular graphs (represented by DMPNN feature^28^), which were computed by RDkit and DeepChem.^47,48^ This multifaceted approach effectively captures quantitative, qualitative, and structural properties of the ESIPT dataset. Ten popular ML algorithms were then employed for ΔE** prediction. Algorithm performance was comprehensively evaluated using the mean absolute error (MAE), root-mean-square error (RMSE), and the squared Pearson correlation coefficient (R^2^). In addition to ML algorithms, five graph convolution models, such as Attentive FP Model, GAT Model, etc., were also applied to predict Δ*E** with MAE reaching 2.91 kcal mol^−1^. In our experiment, 5-fold cross-validation (CV) was used to evaluate different algorithms in combination with various molecular descriptors and select hyperparameters (see SI Files, XLSX file 2 for the full list of 5-fold CV results and model configurations for ML algorithms and graph convolution models).
The atom-pair fingerprint^57^ consistently outperforms all fingerprints across all evaluated metrics (Fig. S3–S12). This superiority was further elucidated by t-SNE visualization, which reveals a distinct clustering pattern between atom-pair and other fingerprints (RDKit, ECFP, and topological torsion). While other fingerprints form six well-separated clusters based on parent molecule types, the atom-pair fingerprint exhibits a more complex and less clustered distribution (Fig. S14). Notably, HBO, HBI, and HBT derivatives appear as paired clusters, reflecting their shared structural features: an NX2-(5)-OX1 atom pair (Fig. S14e). The distinct distribution pattern of atom-pair fingerprints is also observed in the PCA visualization (Fig. S15). Among all ML algorithms, XGBoost, Random Forest (RF), and Gradient Boosting (GB) rank highest in predictive performance. The combination of the XGBoost model and atom-pair descriptors delivers the best results, achieving an average MAE of 1.55 kcal mol^−1^ through 5-fold CV. It outperforms RF and GB in terms of MAE at one of the folds, reaching 1.60 kcal mol^−1^ (Fig. 3a–c). Test data points closely align with the ideal prediction line, mirroring the training set distribution, indicating the robust ability of XGBoost to capture the atom-pair descriptors and ΔE** relationship. To assess the generalization capability of the model, the XGBoost–atom-pair combination was applied to predict ΔE** for documented ESIPT molecules (see SI Files, XLSX file 3). The model demonstrated reliable accuracy for molecules that share parent scaffolds with those in the training set, achieving an MAE of 2.44 kcal mol^−1^. For molecules whose scaffolds differ from those represented in the dataset, predictive performance exhibited reduced accuracy (Fig. 3d and S17). These results indicate that the model performs robustly within its training scaffold domain, while its applicability to structurally distinct scaffolds remains more limited. A web-based platform has been established to enable users to predict Δ*E** values of their ESIPT molecules using our optimized ML model (see SI, Section S2).
The plot of predicted versus calculated ΔE of (a) GB, (b) RF, and (c) XGBoost models used atom-pair fingerprints as input at one of the folds in the ESIPT dataset. (d) The plot of predicted versus calculated values of the XGBoost model, which used atom-pair fingerprints as input for documented ESIPT molecules.*
Feature engineering revealing ESIPT key descriptors
Intramolecular hydrogen bond (H-bond) parameters, including bond lengths, angles, and energies, critically govern ESIPT reactivity. While empirical correlations between H-bond strengthening and ESIPT thermodynamics have been reported,^15,41,42,58–61^ the relative importance of individual or complex H-bond parameters contributing to these correlations remains unquantified. To address these gaps, we systematically evaluated the impact of H-bond parameters on Δ*E** through data-driven interpretable ML across ∼700 O–H⋯O and O–H⋯N-type ESIPT systems.
Previous studies have established that H-bond strength and the variation in electron populations on the proton donor and acceptor play pivotal roles in governing ESIPT behavior.^15,41^ Accordingly, feature engineering was used to extract key parameters for N and N* states: H-bond length (lenHB), proton donor-proton distance (lenDpH), and atomic dipole moment corrected Hirshfeld electron population^62^ for the proton donor (eDp) and acceptor (eAp) (Fig. 4a). For T* states, identical features except for lenDpH were obtained. To enhance the model's applicability to different H-bond types, preprocessing then generates three geometric differential descriptors: lenHB (N*–N), lenDpH (N*–N), and lenHB (T*–N*) and four electronic differential descriptors: eDp (N*–N), eAp (N*–N), eDp (T*–N*), and eAp (T*–N*), where “N*–N” or “T*–N*” denotes inter-state differential values. These key descriptors enable Δ*E** prediction via the ML model. The extra trees (ET) model achieved optimal performance (5-fold CV MAE = 1.26 kcal mol^−1^) with one-fold MAE reaching 1.25 kcal mol^−1^. Test data points show tight alignment with the ideal prediction and exhibit a distribution similar to that of the training set (Fig. 4b). External validation on documented ESIPT molecules confirms the generalizability of above key descriptors (MAE = 1.82 kcal mol^−1^) (Fig. 4c).
(a) Schematic representation of key parameters. (b) Predicted versus calculated ΔE for the ET regressor model on the ESIPT dataset at one of the folds, and (c) validation on documented ESIPT molecules. (d) Pearson's correlation matrix among ΔE* and key descriptors. (e) SHAP summary plot of the ET regressor model, which visualizes the contribution of each descriptor to ΔE*. Each dot represents the SHAP value for a descriptor across the dataset, with the color indicating the actual value of the descriptors. Descriptors are ranked by the impact on ΔE*, with positive SHAP values driving higher ΔE* predictions and negative values indicating a reduction in ΔE*.*
Pearson correlation coefficient (r) analysis identified descriptors strongly correlated with ΔE** (Fig. 4d). Three geometric H-bond descriptors exhibited |r| > 0.5, indicating that H-bond geometric parameters play a primary role in determining ΔE** in ESIPT systems. Significantly, lenHB (N*–N) and lenDpH (N*–N) exhibit strong mutual anticorrelation (r = −0.85), while lenHB (T*–N*) shows minimal correlation with either descriptor, indicating its independence in predicting ΔE**. The four H-bond electronic descriptors exhibit weaker ΔE** correlation than geometric descriptors, indicating that ESICT plays a secondary role in modulating ΔE**. Notably, eAp (N–N) shows the strongest correlation with Δ*E** among electronic descriptors.
SHAP analysis was employed to interpret descriptor impacts on ΔE** (Fig. 4e). For individual descriptors, vertical point distribution manifests molecular count, while horizontal direction reflects the contribution of the descriptor value to the prediction result. Within the ESIPT dataset, lenHB (T–N*) exhibits the strongest negative correlation with ΔE**, confirming that reduced H-bond energy leads to lower ΔE** and facilitates ESIPT. Furthermore, lenDpH (N*–N) and lenHB (N*–N) also significantly influence ΔE** with covalent bond length (lenDpH (N–N)), demonstrating greater impact than H-bond length (lenHB (N*–N)). This suggests that covalent Dp–H bond modulation (e.g., altering R groups from the EWG (e.g. tosyl group) to the EDG in N(R) H⋯N ESIPT systems)^15^ more effectively tunes ΔE** than H-bond adjustments. SHAP analysis further reveals opposing correlations: lenHB (N–N) exhibits positive correlation with ΔE**, while lenDpH (N–N) shows negative correlation. This indicates that excited-state H-bond strengthening favors exergonic ESIPT thermodynamics.^15^
In SHAP analysis, electronic descriptors exhibit narrower value distributions than H-bond descriptors, demonstrating that charge redistribution (ESICT) exerts less influence on ΔE** than H-bond parameters during ESIPT. We further observe a negative correlation between eAp (N–N) and ΔE**, contrasting with the positive correlation for eDp (N–N). This is consistent with our earlier findings,^41,58^ though initially validated in limited systems. Crucially, SHAP ranks eDp above eAp in descriptor importance, demonstrating that changes in proton donor charge dominate ΔE** determination. This proton donor-centric mechanism aligns with the greater influence of covalent Dp–H bond variations versus H-bond modifications during ESIPT. This may provide an explanation why S–H⋯O ESIPT systems^59,61^ sharing the 3HF derivative scaffold but differing in the proton donor exhibit fundamentally distinct ESIPT behavior from OH⋯O systems. Overall, the application of interpretable ML in the ESIPT dataset holds great significance for understanding the factors that influence ΔE**.
Molecular generation
To explore novel ESIPT structures in an expanded chemical latent space, we implemented the NPVAE framework, a VAE developed by Ochiai et al. for molecular generation with an optimal combination of stability, reconstruction accuracy, and latent space organization. NPVAE's functional group-level preprocessing enables it to model large, structurally complex ESIPT molecules more accurately than atomic-level models, because it preserves essential structural motifs, including proton donor and acceptor groups. By retaining these functional groups during both training and generation, NPVAE exhibits a substantially higher probability of producing molecules with the characteristic features required for ESIPT, whereas atomic-level generative models often fail to capture or reproduce these critical functionalities.^36,51,52^ Trained on our constructed ESIPT dataset and documented ESIPT molecules, this framework was leveraged to design fluorescent probes targeting cell imaging applications. We selected a reported structurally minimal ESIPT probe^63^ (T1, Fig. 5a and S16) as our latent space navigation anchor, generating 182 novel analogs from its vicinity that potentially preserve T1-like properties (see SI Files, XLSX file 4 for generated ESIPT molecules). We also employed multiple anchor molecules to generate new structures, thereby demonstrating the model's capability to produce diverse molecular scaffolds (see SI, Section S3 and SI Files, XLSX file 5). The molecular generation workflow is depicted in Fig. 5a.
(a) The workflow of NPVAE for ESIPT molecule generation. Distribution of the (b) SA scores and (c) ΔE for generated ESIPT molecules. (d) Schematic representation of the ESIPT process for TCHB and CBHB, where the prediction of ΔE* is marked. (e) Potential energy curves of the S0 and S1 states of TCHB along with the H-bond distance in a vacuum. The inset shows the stepwise scanned H-bond distance. Normalized steady-state absorption (solid line) and emission spectra (dash line) upon excitation at 310 nm of (f) TCHB and (g) CBHB in cyclohexane (CHX), toluene (TOL), dichloromethane (DCM), acetonitrile (ACN) and methanol (MeOH) at 298 K.*
The SA scores and ADMET properties of the generated ESIPT molecules were predicted using ADMETlab 3.0.^64^ SA scores ranged from 1.5 to 3.5 (scale: 1 = easiest; scale 10 = hardest), indicating favorable synthetic feasibility through simple structural motifs and accessible routes (Fig. 5b). Subsequently, Δ*E** values of generated ESIPT molecules were predicted using our XGBoost model combined with atom-pair descriptors (Fig. 5c). Given the increasing use of ESIPT fluorophores in bioimaging, intracellular sensing, and live-cell fluorescence studies,^1–5^ we further evaluated the generated ESIPT molecules using ADMET, log S, and log D to assess their potential suitability as fluorescent probes. (see SI Files, XLSX file 4).
Following multi-parametric evaluation (ΔE**, SA scores, ADMET, etc.), candidate ESIPT molecules were prioritized for experimental validation. Selection criteria emphasized: (i) thermodynamic favorability (ΔE** < 0), (ii) optimal safety/pharmacokinetic profiles, and (iii) high synthetic accessibility (SA) to ensure experimental feasibility. Balancing these factors, we identified two novel candidates: 5-(tert-butyl)-N-(4-chlorophenyl)-2-hydroxybenzamide (TCHB, SA = 1.67, ΔE** = −7.4 kcal mol^−1^) and N-(5-chloro-[1,1′-biphenyl]-2-yl)-2-hydroxybenzamide (CBHB, SA = 1.75, ΔE** = −4.3 kcal mol^−1^).
Their exergonic Δ*E** values indicate ESIPT capability (Fig. 5d), and low SA scores suggest excellent synthetic accessibility. Both compounds are unreported in previous literature, confirming their novelty and potential for further exploration. Both compounds were synthesized for experimental validation (see SI, Section S4).
TD-DFT calculations performed at the theoretical level used to construct the ESIPT dataset yielded ΔE** values of −11.6 kcal mol^−1^ for TCHB and −10.4 kcal mol^−1^ for CBHB. Moreover, calculations using the M06-2X functional, which is known to better describe H-bond interactions, gave values of −12.9 kcal mol^−1^ and −12.3 kcal mol^−1^, respectively. These results also suggest that both molecules are capable of undergoing ESIPT. However, the predicted and calculated ΔE** values for TCHB and CBHB show a notable discrepancy, likely because their molecular scaffolds are not represented among the six types in the ESIPT dataset. The potential curves of TCHB and CBHB in S_0_ and S_1_ states were scanned based on constrained optimizations with varying O–H distances (Fig. 5e and S17). The results suggested a feature barrierless ESIPT (N* → T* isomerization) reactions. Steady-state spectroscopy (Table S2) in varied solvents showed N*/T* dual emission upon 310 nm excitation (Fig. 5f and g), directly evidencing photoinduced ESIPT. Crucially, the solvent-dependent N*/T* dual-emission ratio highlights the role of solvation in modulating ESIPT dynamics. These integrated theoretical and experimental results fully validate the AI-designed ESIPT molecules. Additionally, to validate the synthetic accessibility of other ESIPT candidates, concise synthetic routes with minimal steps were designed for several representative compounds (Schemes S1 and S2). Collectively, our models demonstrate high proficiency in identifying promising candidates in expansive chemical spaces, substantially outperforming traditional trial-and-error approaches in material development.
Conclusions
In summary, we systematically constructed a high-quality ESIPT dataset by introducing ten substituents with progressively enhanced electron-donating abilities. Through a combination of qualitative descriptors and data-driven machine learning models, we achieved efficient and accurate prediction of ΔE**, significantly improving the throughput of high-efficiency ESIPT material screening. To enhance model interpretability, SHAP analysis was employed to quantify the contributions of key H-bond descriptors to ΔE** prediction. Furthermore, a variational autoencoder (VAE) was used to generate novel ESIPT molecules, which were subsequently filtered based on synthetic accessibility (SA) scores, predicted ΔE**, and ADMET properties. Notably, two AI-designed ESIPT molecules were successfully synthesized and experimentally validated, confirming the effectiveness of our data-driven molecular design strategy. Collectively, this work presents a robust and interpretable framework for ΔE** prediction and accelerates the discovery of novel, functional ESIPT materials.
Author contributions
S. W., A. X., and Z. K. conceived the concepts. S. W., Z. K., and Z. Y. constructed the dataset, carried out the training and prediction of machine learning and machine learning models, and performed the interpretability analysis. C. Y., Y. L., and Y. G. designed and synthesized the TCHB and CBHB molecules, as well as the synthetic routes of other molecules. S. W. and H. Z. performed the quantum chemical calculations. Z. K. and A. X. polished the language and supervised this project. S. W. and Z. K. wrote this paper. All authors discussed the results and commented on the manuscript at all stages.
Conflicts of interest
There are no conflicts to declare.
Supplementary Material
SC-OLF-D5SC07051A-s001
SC-OLF-D5SC07051A-s002
SC-OLF-D5SC07051A-s003
SC-OLF-D5SC07051A-s004
SC-OLF-D5SC07051A-s005
SC-OLF-D5SC07051A-s006
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1Demchenko A. P. Tang K.-C. Chou P.-T. Excited-state proton coupled charge transfer modulated by molecular structure and media polarization Chem. Soc. Rev.201342137914082316938710.1039/c 2cs 35195 a · doi ↗ · pubmed ↗
- 2Tang L. Shi J. Huang Z. Yan X. Zhang Q. Zhong K. Hou S. Bian Y. An ESIPT-based fluorescent probe for selective detection of homocysteine and its application in live-cell imaging Tetrahedron Lett.20165752275231
- 3He L. Dong B. Liu Y. Lin W. Fluorescent chemosensors manipulated by dual/triple interplaying sensing mechanisms Chem. Soc. Rev.201645644964612771165110.1039/c 6cs 00413 j · doi ↗ · pubmed ↗
- 4Shynkar V. V. Klymchenko A. S. Kunzelmann C. Duportail G. Muller C. D. Demchenko A. P. Freyssinet J.-M. Mely Y. Fluorescent Biomembrane Probe for Ratiometric Detection of Apoptosis J. Am. Chem. Soc.2007129218721931725694010.1021/ja 068008 h · doi ↗ · pubmed ↗
- 5Oncul S. Klymchenko A. S. Kucherak O. A. Demchenko A. P. Martin S. Dontenwill M. Arntz Y. Didier P. Duportail G. Mély Y. Liquid ordered phase in cell membranes evidenced by a hydration-sensitive probe: Effects of cholesterol depletion and apoptosis Biochim. Biophys. Acta 20101798143614432010045810.1016/j.bbamem.2010.01.013 · doi ↗ · pubmed ↗
- 6Tang K.-C. Chang M.-J. Lin T.-Y. Pan H.-A. Fang T.-C. Chen K.-Y. Hung W.-Y. Hsu Y.-H. Chou P.-T. Fine Tuning the Energetics of Excited-State Intramolecular Proton Transfer (ESIPT): White Light Generation in A Single ESIPT System J. Am. Chem. Soc.201113317738177452195792910.1021/ja 2062693 · doi ↗ · pubmed ↗
- 7Azarias C. BudzákŠ. Laurent A. D. Ulrich G. Jacquemin D. Tuning ESIPT fluorophores into dual emitters Chem. Sci.20167376337742999786410.1039/c 5sc 04826 e PMC 6008603 · doi ↗ · pubmed ↗
- 8Padalkar V. S. Seki S. Excited-state intramolecular proton-transfer (ESIPT)-inspired solid state emitters Chem. Soc. Rev.2016451692022650646510.1039/c 5cs 00543 d · doi ↗ · pubmed ↗