Global temperature anomaly prediction by using additive twin LSTM networks
Cemal Keles, Burhan Baran, Baris Baykant Alagoz

TL;DR
This paper introduces an improved LSTM model for predicting global temperature anomalies, showing better long-term forecasts compared to existing methods.
Contribution
The novel Additive Twin LSTM (AT-LSTM) model is proposed to enhance long-term temperature anomaly forecasting.
Findings
The AT-LSTM model outperforms conventional LSTM variants in long-term global temperature anomaly forecasts.
The model predicts a 2042 global temperature anomaly of 1.415 °C with ± 0.073 °C error, aligning with climate organization expectations.
Abstract
Due to the complexity of climate systems, data-driven modeling based on observed time series data is essential for predicting future climatic trends. This study aims to improve the long-term global temperature anomaly forecast performance of Long Short-Term Memory (LSTM) based neural network models. Although several LSTM variants and hybrid architectures have been suggested for time series data prediction problems, the long-term forecast performance of these models may not be satisfactory in practice. To address solution of these problems, firstly, authors focused on evaluating the forecast performance of models and suggested performance and test assessment procedures. Secondly, authors suggest an Additive Twin LSTM (AT-LSTM) model that can improve the forecast performance for the global temperature anomaly. Our test on the Berkeley Global Temperature Anomaly dataset demonstrates that…
Genes, proteins, chemicals, diseases, species, mutations and cell lines named across the full text — each resolved to its canonical identifier and authoritative record.
Click any figure to enlarge with its caption.
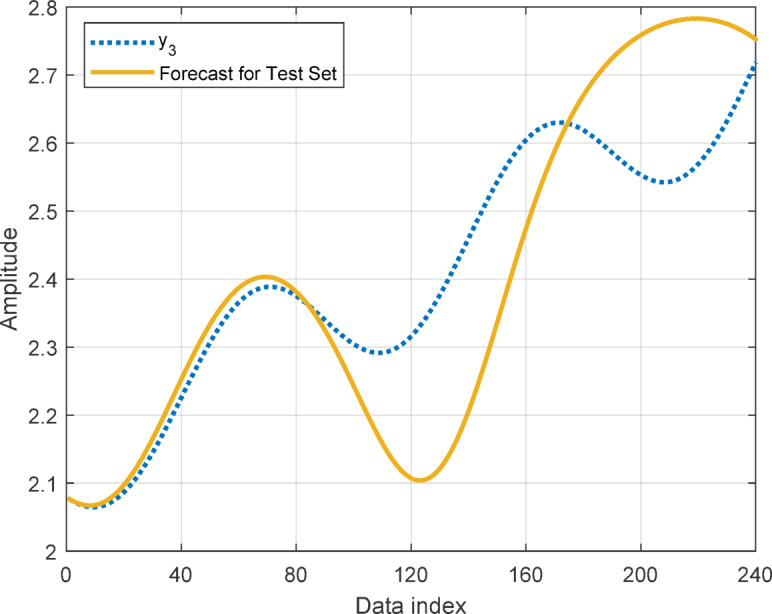 Figure 10
Figure 10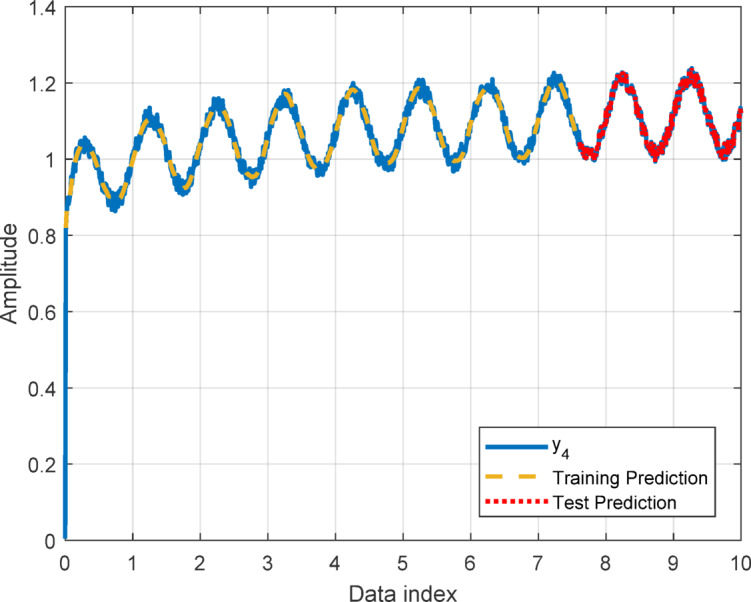 Figure 11
Figure 11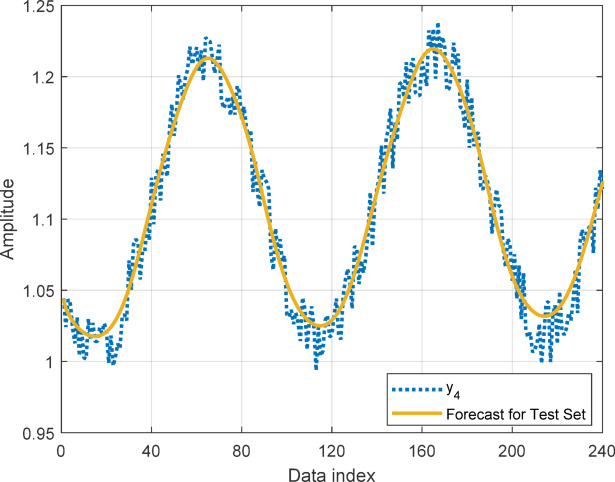 Figure 12
Figure 12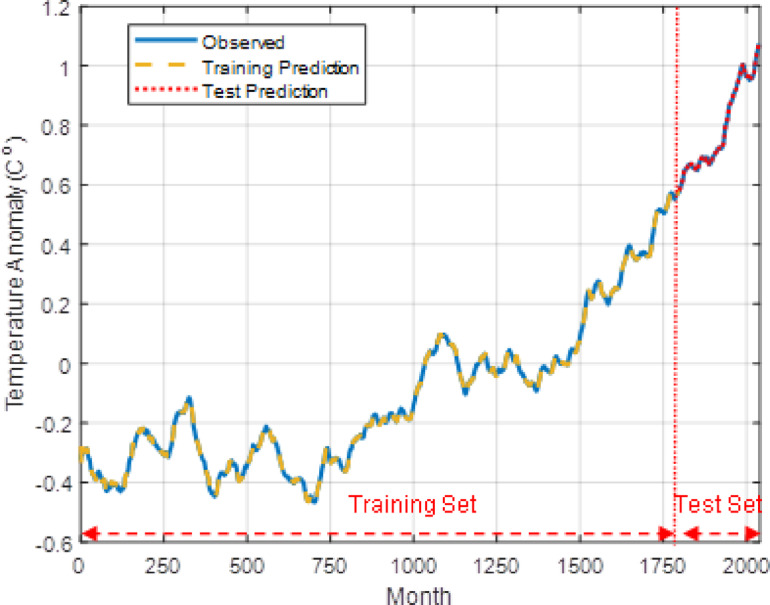 Figure 13
Figure 13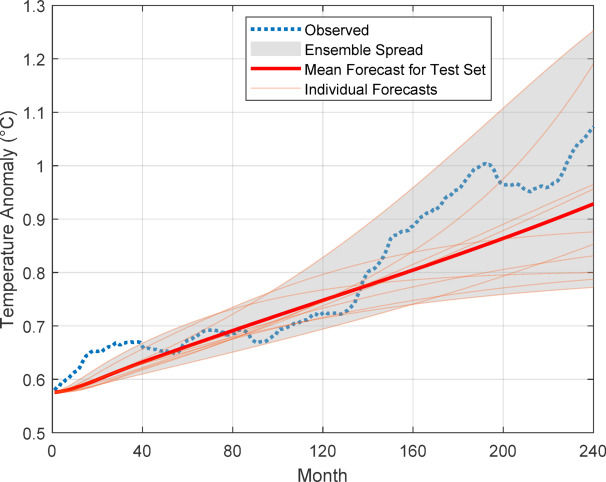 Figure 14
Figure 14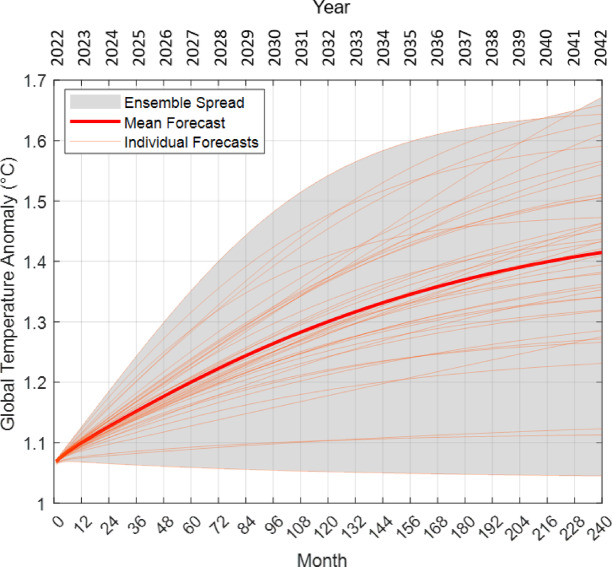 Figure 15
Figure 15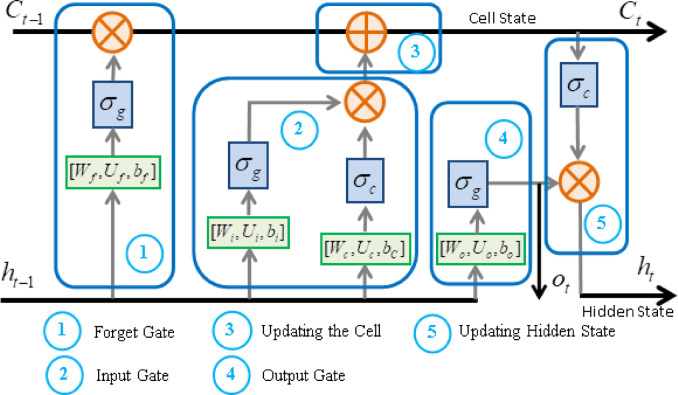 Figure 1
Figure 1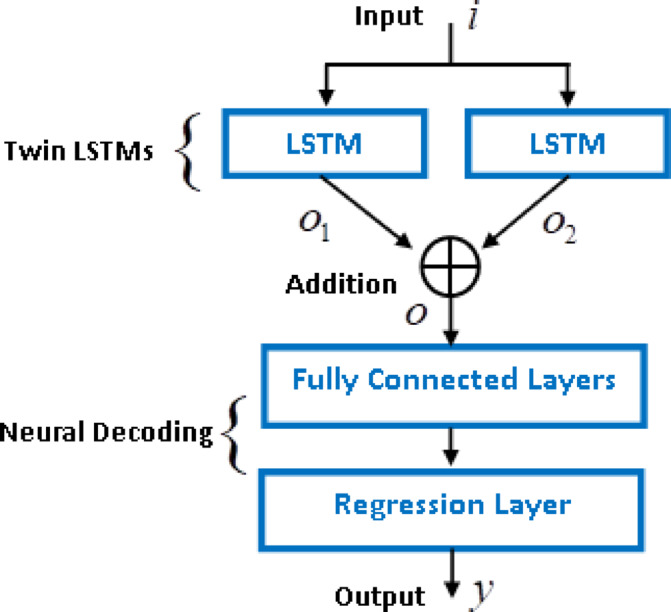 Figure 2
Figure 2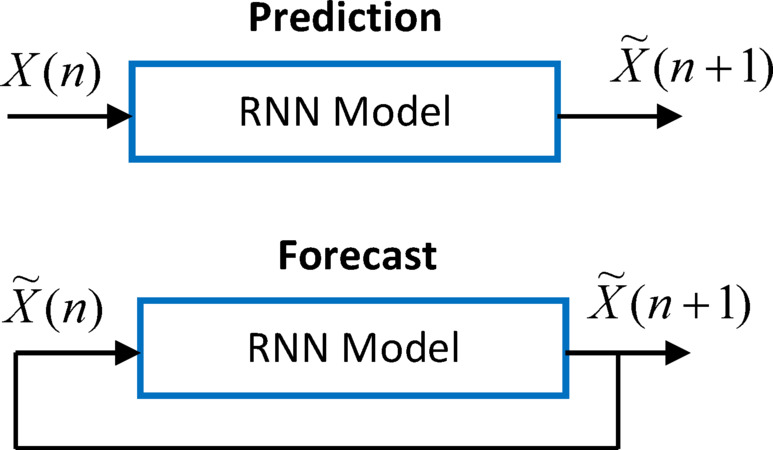 Figure 3
Figure 3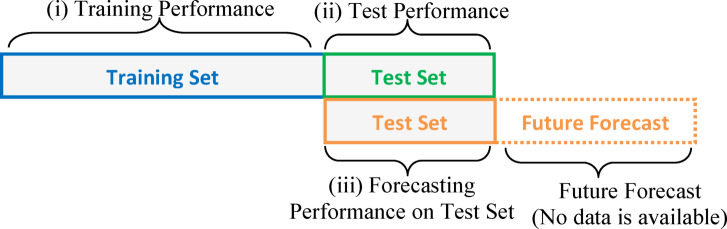 Figure 4
Figure 4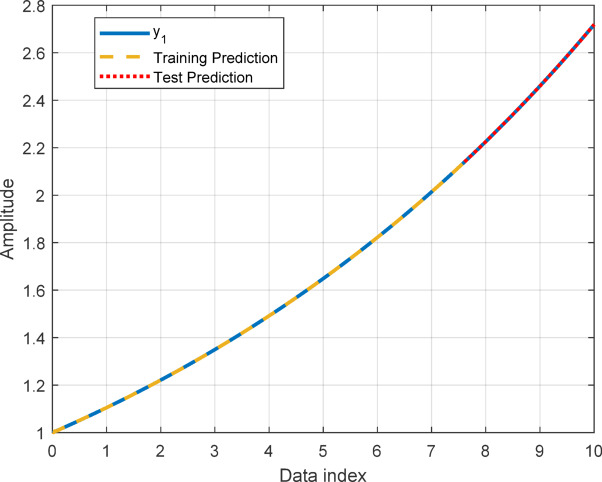 Figure 5
Figure 5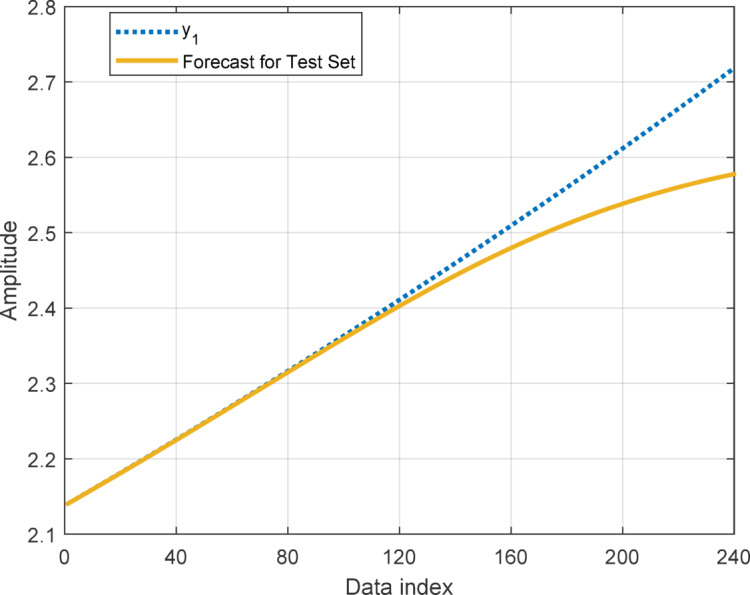 Figure 6
Figure 6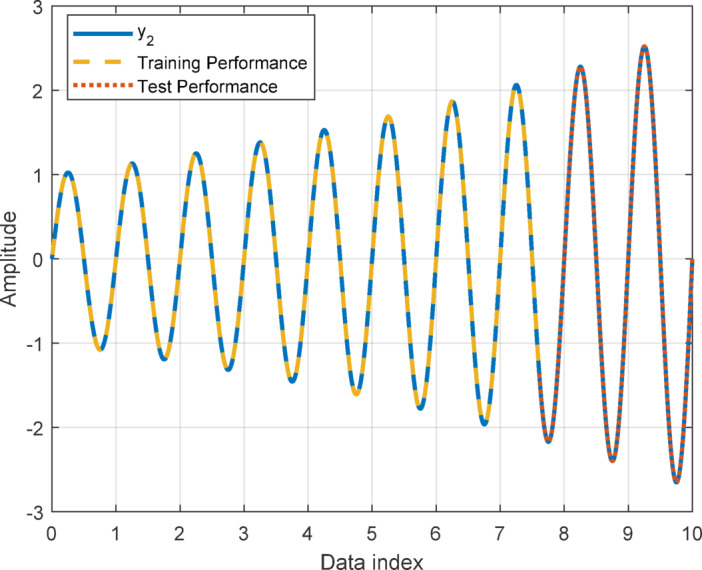 Figure 7
Figure 7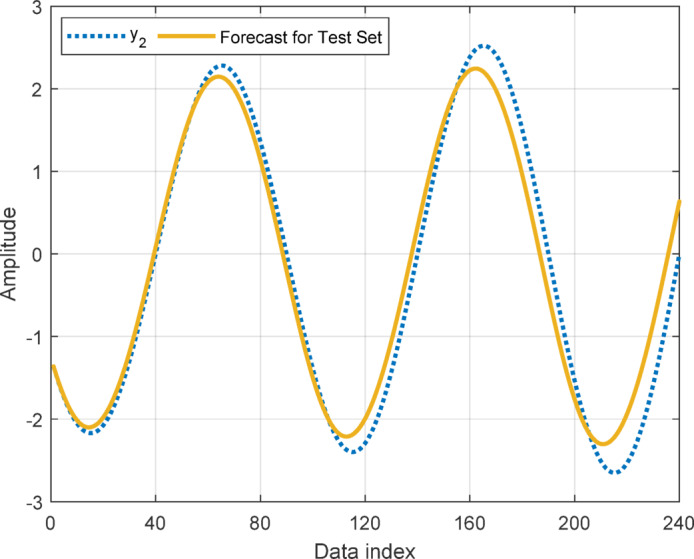 Figure 8
Figure 8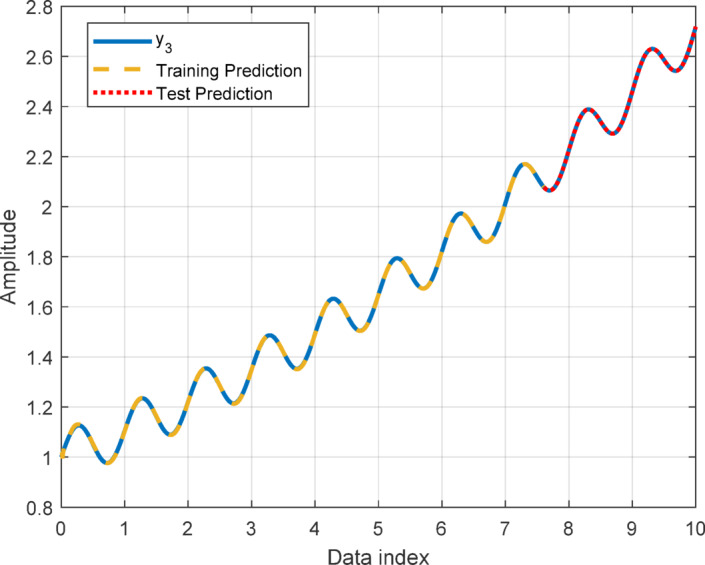 Figure 9
Figure 9- —Inonu University Scientific Research Projects Coordination Unit
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsClimate variability and models · Hydrological Forecasting Using AI · Meteorological Phenomena and Simulations
Introduction
Global warming is one of the global-scale climatic transition problems, leading to increases in global temperatures, glaciers melting, sea-level rise, expanding desert zones, and abnormal climatic changes such as intermittent hurricanes, floats and landslides^1^. Among these effects, the mean global temperature rises have a significant impact on daily-life activities from energy consumption, agricultural and livestock activities, as well as, its serious depression on social, economic and environmental systems^2^. Therefore, forecasting global temperature anomalies is crucial for improving resource management policies, understanding long-term climate change trends, and taking measures to prevent or mitigate associated problems^3,4^. To address this problem, time series prediction is one of the developing fields of big data analysis^5^. Traditional methods for time series data forecasting have not been successful in capturing complicated sequential relationships and long-term dependencies^6^.
Recurrent neural networks (RNN) can inherently learn sequential relations in time series data. Popularly, long short-term memory (LSTM) models have become widely used due to their ability to manage both short-term and long-term dependencies in time series data patterns compared to conventional RNNs^3^. In other words, the learning process of LSTM models is assumed to be relatively insensitive to the sequence length that is important in case of long-term dependencies in datasets^7^. This property of LSTM is very significant for the data-driven modeling practice because deciding the necessary sequence length of RNNs for a real-world data is not an easy problem. To possess this useful property, LSTMs involve specially designed building blocks: A classical LSTM unit is composed of a cell state and three gates, which are known as an input gate, an output gate^8^, and a forget gate^9^. Cell states mainly function as selective memories and gate performs for updating and forgetting information. Following the success of LSTMs in practice, a gated type of RNNs, known as the gated recurrent unit (GRU), was suggested to achieve similar capabilities with fewer parameters. The GRU has similar elements to those of LSTMs. Specifically, the GRU has a two-gate system (i.e., update and reset gates) to handle long-term temporal dependencies in time-series prediction^7^. Practically, GRUs are simpler and faster than LSTMs because they lack a separate cell state^10^. LSTMs are preferable for data sequences that have long-term dependencies, whereas GRU can be potentially effective in learning the relations that do not involve the long-term dependencies. Recent studies have also shown that hybrid architectures combining LSTM, CNN, and GRU models can enhance predictive performance depending on the characteristics of the dataset^11^. Table 1 briefly summarizes research works in the literature, which are related to temperature prediction. Changes in global temperature anomaly were analyzed by using the LSTM, and the NOAA and NASA datasets were used for training LSTM models^12^.
To improve consistency in the collected sequential temperature anomaly data, we used the Berkeley Global Temperature Anomaly monthly data averaged over five years. The five-year long averaging monthly data can significantly reduce uncertainty in global temperature anomaly observations. In our numerical experiments, we observed that the long-term global temperature forecasting performance of LSTM models and many hybrid forms may not be dependable. Even though they can be highly accurate in the short-term prediction (in the next temperature prediction), recursive prediction efforts for long-term temperature forecasting towards future in time, which is called future forecasting, cannot be consistent enough. To address this limitation, we propose two twin-branch architectures: the Additive Twin LSTM (AT-LSTM) and the Multiplicative Twin LSTM (MT-LSTM). The proposed AT-LSTM differs fundamentally from conventional LSTM and GRU architectures by employing a twin-branch recurrent design that allows the model to learn partially uncoupled dominant dynamics within the sequence. This structural distinction enhances long-horizon forecasting stability, as confirmed by benchmark and climate-data evaluations, where AT-LSTM can improve performance relative to representative recurrent models in RMSE, MAE, and R^2^ metrics. Our results indicate that the AT-LSTM model improves future forecasting performance for global temperature anomaly data compared to conventional LSTM and hybrid LSTM architectures. Main advantageous comes from the twin LSTM utilization with a common decoder network, where each LSTM can focus on learning behavior of an uncoupled dominating climate dynamic.
Table 1A brief survey for temperature prediction models.WorksMethodsPredicted dataPerformance/remarksDiffenbaugh et al. (2023)^13^ANN, XAIGlobal warming1.5 °C global warming threshold is expected to be reached in 2033–2035Guo et al. (2024)^14^ANN, RNN, LSTM, CNN, CNN-LSTMMonthly climate parameterCNN-LSTM model provides higher accuracy with MAE, RMSE, R²Uluocak et al. (2024)^15^LSTM-CNN, GRU-CNNDaily air temperatureLSTM-CNN and GRU-CNN models make higher accuracy predictions with MAE, RMSE, NSE, and R²Guo et al. (2023)^16^ANN, GRU, LSTM, CNN, CNN-GRU, CNN-LSTMAtmospheric temperatureThey use R², RMSE, MAE as success scales. The best R² value is 0.9952 with ANN. Average atmospheric temperature in 2030 is predicted to be 17.23 °CHamdan et al. (2023)^12^A mathematical model with RNN and LSTMGlobal temperature and greenhouse gas emission changingLSTM model obtains high accuracy results with RMSE: 2.018 (NOAA) and 0.814 (NASA)Li et al. (2023)^17^SARIMA-LSTMAir temperatureThe accuracy of the model increase from 10.0% to 27.7%Hou et al. (2022)^18^CNN-LSTMHourly air temperatureR²: CNN-LSTM is 0.7258, LSTM is 0.5949, CNN is 0.5291Haque et al. (2021)^19^SRN, GRU, LSTM, CNN, CNN-LSTM, GRU-LSTMHourly air temperatureThe lowest RMSE (1.691 °C) is obtained with GRU-LSTMZhao et al. (2021)^20^CNN-GRU-RPASMAir temperatureCNN-GRU-RPASM shows the best performance compared to traditional methodsZhang et al. (2020)^21^CRNN (model consisting of CNN and RNN components)Air temperatureFor the CRNN, MAE is calculated as 0.907 °C and RMSE is as 1.697 °C.Gong et al. (2024)^22^CNN-LSTMDaily average temperatureThe predicted curve shows strong agreement with the actual test dataLi et al. (2024)^1^CNN-LSTMTemperatureobtained MSE (3.26217) and RMSE (1.80615) values are higher than the traditional methodsKarabulut et al. (2022)^4^LSTMAir temperatureR^2^ value is 0.9937 for LSTM, 0.8869 for SVM
Additive twin LSTM (AT-LSTM) for time series data prediction
Basics of LSTM model
In principle, it employs information-flow controlling mechanisms (gates) in order to exhibit the long-term memory effect by using short-term memory elements. A basic LSTM unit consists of a cell and three gates that are known as an input gate, an output gate^8^, and a forget gate^9^. Cell states mainly function as selective memories that can convey useful (relevant) information over longer time intervals by means of updating and forgetting control of the gates. Here, the forget gate is designed to forget (suppress) irrelevant information, and the input gate is proposed to update the cell memory with relevant new information. Thus, the cell determines cell states ( \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:{C}_{t}$$\end{document} ) to maintain useful information over arbitrary time intervals, thereby leading to a long-term memory effect. The output gate determines how the memory is translated at the output at each step. It also contributes to determining the hidden state ( \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:{h}_{t}$$\end{document} ) by regulating the cell state. This selective memory property makes the LSTM more efficient and flexible in learning which parts of the sequence are important and should be preserved through the information-flow. Figure 1 shows the fundamental elements of a LSTM unit that describes mathematical relations between the basic elements in a LSTM unit. The information in the cell state flows throughout a sequence of subsequent LSTM units, and such unit array forms a long memory effect that is based on selective learned control of short-memory elements in each LSTM unit.
Fig. 1. Fundamental elements of a LSTM unit and their mathematical relations.
The mathematical foundation of each element can be summarized as:
- A forget gate determines the amount of information from the previous cell state should be discarded. It calculates the weighted sum of the previous hidden state ( \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:{h}_{t-1}$$\end{document} ) and the current input ( \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:{x}_{t}$$\end{document} ), then applies a sigmoid activation function ( \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:{\sigma\:}_{g}$$\end{document} ) to regulate the gate output between 0 and 1. A value of 0 means “completely forget”, and a value of 1 means “completely keep”.
where the weight coefficients in forget gate are denoted by the vectors \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:{W}_{f}$$\end{document} for the current input \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:{x}_{t}$$\end{document} and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:{U}_{f}$$\end{document} for the hidden state \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:{h}_{t-1}$$\end{document} . They are optimized during the training stage of LSTM via the backpropagation algorithm. This allows learning irrelevant information patterns that should be suppressed through cell states.
- 2)An input gate determines the amount of new information that will be added to the cell state. It uses two networks:
The first one is a layer neuron network with sigmoid activation that regulates the amount of new information ( \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:{\stackrel{\sim}{C}}_{t}$$\end{document} ).
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:{i}_{t}={\sigma\:}_{g}({W}_{i}{x}_{t}+{U}_{i}{h}_{t-1}+{b}_{i})$$\end{document}where vectors \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:{W}_{i}$$\end{document} and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:{U}_{i}$$\end{document} stand for weight coefficients for the current input \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:{x}_{t}$$\end{document} and previous hidden state \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:{h}_{t-1}$$\end{document} , respectively. The \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:{i}_{t}$$\end{document} takes a value between 0 and 1 and for regulating \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:{\stackrel{\sim}{C}}_{t}$$\end{document} .
The second one is a neuron network with a tanh activation ( \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:{\sigma\:}_{c}$$\end{document} ) that generates a vector of new candidate values ( \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:{\stackrel{\sim}{C}}_{t}$$\end{document} ) that is added to the cell state after regulating by the \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:{i}_{t}$$\end{document} .
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:{\stackrel{\sim}{C}}_{t}={\sigma\:}_{c}({W}_{c}{x}_{t}+{U}_{c}{h}_{t-1}+{b}_{C})$$\end{document}The input gate and the candidate cell state are then used to update the cell state. The vectors \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:{W}_{c}$$\end{document} and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:{U}_{c}$$\end{document} are weights for the current input and previous hidden states, respectively. Values of these vectors are optimized during the training stage.
- 3)A current cell state is updated by weighted sum of the previous cell state \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:{C}_{t-1}$$\end{document} and the new cell state \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:{\stackrel{\sim}{C}}_{t}$$\end{document} as follows
Here, \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:{f}_{t}\in\:\left[\mathrm{0,1}\right]$$\end{document} performs for suppression of the previous cell state \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:{C}_{t-1}$$\end{document} and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:{i}_{t}\in\:\left[\mathrm{0,1}\right]$$\end{document} performs for update with the new cell state \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:{\stackrel{\sim}{C}}_{t}$$\end{document} . The operator \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:\otimes\:$$\end{document} represents Hadamard product (element-wise product).
- 4)The output gate decides the next hidden state that is used in the next LSTM unit, and it is also used as the output of the LSTM at each time step. The output state is calculated as
where the \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:{W}_{o}$$\end{document} and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:{U}_{o}$$\end{document} denotes the weight coefficient vectors for optimizing during the training stage. The terms \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:{U}_{o}{h}_{t-1}$$\end{document} and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:{U}_{c}{h}_{t-1}$$\end{document} stand for the learned dynamics response from the data sequence and they are essential components in determination of the next hidden state in from of
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:{h}_{t}={O}_{t}\otimes\:{\sigma\:}_{c}\left({C}_{t}\right)$$\end{document}Additive twin LSTM
In nature, data sequences, which are collected from complex systems, can involve more than one uncoupled dominating dynamics, which can be almost independently acting^23–25^, and measured data involves components from these dynamics. Inherently, a composition of these dominating dynamic factors can establish the sequential relations in the collected data sequences. For the case of uncoupled two dominating dynamics, state transitions can be expressed \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:{d}_{t+\mathrm{1,1}}={F}_{1}\left({d}_{t,1},{x}_{t,1}\right)$$\end{document} and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:{d}_{t+\mathrm{1,2}}={F}_{2}\left({d}_{t,2},{x}_{t,2}\right)$$\end{document} , the measured data sequence can be expressed in the form of
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:{y}_{t}=G({d}_{t,1},{d}_{t,2})$$\end{document}where the function \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:G(.)$$\end{document} represents the measurement function, which can be referred to as the decoding function. In multi-component systems, the measurement function (decoding function) can be expressed as a weighted sum of each dynamic factors. (See the property of approximation to independent recurrent relations in Supplementary Material). For data-driven modelling of complex systems with uncoupled multi-dynamic factors, the multi-dynamics modeling approach based on consideration of uncoupled dominating dynamics can present potential of better expressing sequential relations in data sequences. To benefit from this asset, we considered a twin additive LSTM model, where each LSTM can focus on learning one of uncoupled dominating dynamics transition functions ( \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:{F}_{1}$$\end{document} , \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:\:{F}_{2}$$\end{document} ) and the neural decoding network learns the function of the measurement function ( \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:G)$$\end{document} .
In fact, the global temperature anomaly measurements involve impacts of more than one weakly-coupled or uncoupled dynamic factors, such as dynamics associated with global scale CO_2_ emission and Albedo perturbation etc. Energy budget models indicate that global temperature evolution is driven by multiple uncoupled components of the climate system (e.g., radiative forcing response, ocean–atmosphere adjustments, and slow–fast feedback mechanisms)^26–28^. These models suggest that climate dynamics naturally consist of distinct, partially independent temporal processes. This physical characteristic directly aligns with the structural design of the proposed AT-LSTM architecture, in which two parallel recurrent branches are intended to learn disentangled and uncoupled dynamic modes of the underlying system. For these reason, two LSTM approach well suits for the solution of the global temperature anomaly forecasting problem.
In this perspective, the proposed AT-LSTM implements the addition of two identical LSTMs. Figure 2 shows basic blocks of the AT-LSTM that combines two identical LSTM blocks by using an additional block and a neural decoder that yields the output of the model. This implementation provides behavioral and computational benefits: For behavioral benefits, two separate LSTMs can focus on learning two uncoupled dynamics, which are dominative in the composition of sequential relations in the data sequence. For computational benefit, the outputs of two LSTM are added and the sum of two sigmoid functions at the output gates forms a joint activation characteristic. In other words, sum of the two sigmoid functions ( \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:{\sigma\:}_{g}\left(v\right)=1/(1+{e}^{-v})$$\end{document} ) establishes a activation function that can be expressed in the form of a joint activation as
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:{\sigma\:}_{sg}({v}_{1},{v}_{2})={\sigma\:}_{g}\left({v}_{1}\right)+{\sigma\:}_{g}\left({v}_{2}\right)=\frac{2+{e}^{-\left({v}_{1}\right)}+{e}^{-\left({v}_{2}\right)}}{(1+{e}^{-\left({v}_{1}\right)})(1+{e}^{-\left({v}_{2}\right)})}$$\end{document}By considering the Eq. (8), the joint activation function \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:{\sigma\:}_{sg}({v}_{1},{v}_{2})$$\end{document} can map output of LSTM networks into the range of 0 to 2 in additive form, and it provides range expansion at input of the neural decoding part.
Fig. 2. Basic blocks of the AT-LSTM.
To form the AT-LSTM network, the outputs of two LSTM networks are summed:
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\begin{gathered} \:o_{t} = o_{{t,1}} + o_{{t,2}} = \sigma \:_{g} \left( {W_{{o,1}} x_{{t,1}} + U_{{o,1}} h_{{t - 1,1}} + b_{{o,1}} } \right) + \sigma \:_{g} \left( {W_{{o,2}} x_{{t,2}} + U_{{o,2}} h_{{t - 1,2}} + b_{{o,2}} } \right) \hfill \\ = \sigma \:_{{sg}} (W_{{o,1}} x_{{t,1}} + U_{{o,1}} h_{{t - 1,1}} + b_{{o,1}} ,\:W_{{o,2}} x_{{t,2}} + U_{{o,2}} h_{{t - 1,2}} + b_{{o,2}} ) \hfill \\ \end{gathered}$$\end{document}The output gates can be expressed in the form of additive sigmoid activation as follows
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:{o}_{t}={o}_{t,1}+{o}_{t,2}=\frac{2+{e}^{-({W}_{o,1}{x}_{t,1}+{U}_{o,1}{h}_{t-\mathrm{1,1}}+{b}_{o,1})}+{e}^{-({W}_{o,2}{x}_{t,2}+{U}_{o,2}{h}_{t-\mathrm{1,2}}+{b}_{o,2})}}{(1+{e}^{-({W}_{o,1}{x}_{t,1}+{U}_{o,1}{h}_{t-\mathrm{1,1}}+{b}_{o,1})})(1+{e}^{-({W}_{o,2}{x}_{t,2}+{U}_{o,2}{h}_{t-\mathrm{1,2}}+{b}_{o,2})})}$$\end{document}This section theoretically considers mechanisms that make the AT-LSTM more advantageous in learning sequential relations compared to the conventional LSTM.
A forecast performance evaluation procedure for time series data
RNNs can learn sequential relations through sequential data. To evaluate RNN model performance, it is useful to distinguish the prediction error, which refers to the error for predicting data instance in the dataset, and the forecast error, which refers to the error for a forecasted sequence that does not exist in the dataset. For prediction performance evaluation, one applies an element of the sequence ( \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:X\left(n\right)$$\end{document} ) from the dataset and predicts the next element ( \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:\stackrel{\sim}{X}(n+1)$$\end{document} ) in the dataset. For forecasting performance evaluation, one applies a predicted element ( \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:\stackrel{\sim}{X}\left(n\right)$$\end{document} ) and predicts the next elements ( \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:\stackrel{\sim}{X}(n+1)$$\end{document} ). Therefore, it forms feedback from the output of the RNN to the input of RNN and enables consequential future forecasting for a time horizon. However, in this case, this feedback loop causes accumulation of errors in long-term performance evaluation. Figure 3 depicts the prediction and forecast states of RNN models. Consequently, the prediction performance based on training and test data does not truly express the forecast performance of RNN for time series data. In fact, the prediction performance expresses the performance mainly for reproducing the dataset by using elements of the dataset. The forecast performance can express the performance of estimating future elements of a time series. For this reason, the future estimation performance of RNNs should be considered by using the forecast performance. However, assessment of future forecasting performance is a complicated problem because future data is not available, yet. For this case, the nearest forecast performance (the best forecast performance estimate) for the long-term future forecasting can be estimated by considering the forecast performance of the model at the latest part of the dataset. This part can be the last section of test datasets as illustrated in Fig. 4. The test dataset is commonly formed by using the last part (the most recent part) of the time series datasets. Due to being the closest to future prediction, the forecast performance on the test dataset can be used for the nearest forecast performance estimation of future prediction performance of RNNs. Figure 4 describes performance regions on the sequential dataset.
Fig. 3. Prediction state (upper figure) and forecasting state (bottom figure).
Fig. 4. Performance evaluation regions on time-series dataset.
In the long-term forecast process, the forecasted element is used as input in order to predict the next value of the model, and this feedback in the forecasting process causes the accumulation of model prediction errors in the long-term processing. This error accumulation can mislead the forecasting process. Consequently, the forecasting error of RNNs can grow as the forecasting horizon expands into the future, a limitation that has also been emphasized in recent studies on data-driven long-term prediction frameworks^29,30^.
Global temperature anomaly forecast
Berkeley’s global temperature anomaly dataset
The temperature anomaly indicates temperature differences in measured temperatures relative to the average reference temperatures of a reference period^31^. It is an important observational parameter for climate change studies. Berkeley Temperature Anomaly (Berkeley Earth Surface Temperature-BEST) data^32^ are generally utilized in global warming and climate change studies^22,33–37^. The BEST has been widely used for monitoring temperature changes on the Earth’s surface^38^. This dataset provides long-term (1850–2024) temperature anomaly from temperature measurements from hundreds of meteorological stations worldwide^32^. It includes temperature anomaly data for monthly, annual, five-year average, ten-year average, and twenty-year averages. Short-term (monthly and even annual) temperature data can usually contain noise and short-term fluctuations. The long-term temperature averages are useful to compensate the effects of measurement noises and short-term fluctuations in the temperature data, and they provide more reliable results that can reveal general climate trends. The analyses of global temperature anomalies should be independent of transient local impacts. Evidently, long-term temperature averages can be more expressive dominating trends in climatic changes, such as signs of the warming or cooling trends. For this reason, five-year average values were considered in this study, and temperature anomaly data between the 6th month of 1852 and the 3rd month of 2022 were used in our numerical study. This time interval excludes the earliest years due to sliding window average operation. This 5-years averaging improves the reliability of the input sequence used for neural network training. The resulting 170-year time series provides a sufficiently large dataset for training deep learning models and for analyzing long-term climate dynamics. The complete dataset is publicly accessible through the Berkeley Earth repository, allowing independent verification and replication of all preprocessing procedures.
Some benchmark functions for global warming trends
Benchmark functions are commonly preferred to evaluate performance of algorithms (e.g., optimization algorithm, machine learning algorithms) in a controlled test environment (without uncertainty, environmental disturbances, measurement noise etc.). These functions are used to produce synthetically generated data for specific test cases and allows comparison of algorithms for those specific cases. We suggested three different benchmark functions in Table 2. These functions can characteristically simulate extreme temperature anomaly trends and produce synthetic data to benchmark forecast models.
Table 2. The suggested benchmark functions and parameters.Benchmark functionsEquationsParametersExponential function \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:{y}_{1}={\mathrm{e}}^{a\mathrm{n}}$$\end{document}
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:a=0.1$$\end{document} Sinusoidal function with exponential amplitude \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:{y}_{2}={\mathrm{sin}\left(2\pi\:fn\right)\mathrm{e}}^{a\mathrm{n}}$$\end{document}
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:f=1$$\end{document}
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:a=0.1$$\end{document} Sinusoidal function with exponential offset \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:{y}_{3}={A\mathrm{sin}\left(2\pi\:fn\right)+\mathrm{e}}^{a\mathrm{n}}$$\end{document}
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:A=0.1$$\end{document}
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:f=1$$\end{document}
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:a=0.1$$\end{document} Nonstationary trend–sinusoidal function with additive noise \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:{y}_{4}={n}^{a}+A\mathrm{sin}\left(2\pi\:fn\right)+\epsilon\:$$\end{document} \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:a=0.05$$\end{document} ; \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:A=0.1$$\end{document} ; \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:{\upepsilon\:}=0.05\left(rand\right(1,length\left(n\right)-0.5)$$\end{document}
In this section, to assess the performance of the proposed AT-LSTM model, the prediction performances on both the training and test sets for the benchmark functions were analyzed. Figures 5, 7, 9, and 11 show predictions of AT-LSTM models for training and test datasets for benchmark functions in Table 2. One can observe that the AT-LSTM model can accurately predict training and test data and provides satisfactory training and test performances. However, complication related to the long-term forecasting process, consequences of the error accumulation effect, is apparent in Figs. 6, 8, 10, and 12. These figures show the forecasting performances over the test dataset for the benchmark functions, and as forecasting horizon expands, divergences from test data becomes more apparent. Those divergences clearly indicate decreases in consistency of long-term forecasting and it better reveals long-term forecast performance of models. Therefore, the forecasting performances over test dataset should be considered in order to estimate practical performance of the forecaster models. Major reason of these growing errors is the accumulation of each prediction error in the feedback loop as illustrated in Fig. 3. In these figures, one observes that the forecast performance is acceptable up to about the first 80 data in the 240 data forecast horizon. Although the AT-LSTM model exhibits notable training and test performances in predicting the training and test sets, the long-term forecasting effort can maintain consistency up to a window of 80 data in forecast horizon for these benchmark functions. It should be noted that consideration of only training and test performances cannot sufficient to evaluate forecaster model performance.
Fig. 5. Training and test performances for the benchmark function \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:{y}_{1}$$\end{document} .
Fig. 6. Forecast performance over test set for the benchmark function \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:{y}_{1}$$\end{document} .
Fig. 7. Training and test performances for the benchmark function \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:{y}_{2}$$\end{document} .
Fig. 8. Forecast performance over test set for the benchmark function \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:{y}_{2}$$\end{document} .
Fig. 9. Training and test performance for the benchmark function \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:{y}_{3}$$\end{document} .
Fig. 10. Forecast performance over test set for the benchmark function \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:{y}_{3}$$\end{document} .
Fig. 11. Training and test performance for the benchmark function \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:{y}_{4}$$\end{document} .
Fig. 12. Forecast performance over test set for the benchmark function \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:{y}_{4}$$\end{document} .
Comparison of the forecasting performance of several LSTM models
This section presents performance data for the AT-LSTM model and other LSTM networks from literature. The proposed AT-LSTM consists of two independently parameterized LSTM branches. Each branch contains an LSTM layer with 128 hidden units, and no weight sharing is employed. The outputs of the two branches are merged using an addition layer, after which the combined representation is passed to a two-stage fully connected decoder composed of a 10-unit fully connected layer followed by a 1-unit output layer. A standard regression layer is used for loss computation. No dropout layers or explicit L2 regularization are used; stabilization is primarily achieved through gradient thresholding and the learning-rate schedule (Detailed descriptions of the model architectures are provided in the Supplementary Material). The training, test, and forecast performance of these models allow us to discuss the suitability of this model for long-term forecasting of the global temperature anomaly. The parameters and their values used in training are given in Table 3.
Table 3. Parameters used in training processes.ParameterValue/methodEpochs500Initial learning rate0.005OptimizerAdaptive moment estimation (Adam)Gradient threshold1Learning rate schedulePiecewiseLearning rate drop period125Learning rate drop factor0.2
- Training performance evaluation Synthetic and real datasets were utilized for rigorous performance evaluation. For synthetic data generation, 1000 sequential sample of each benchmark function were used. For real data, the five-year average temperature anomaly data of the Berkeley Temperature Anomaly dataset, consisting of 2038 data, were implemented. For all datasets, the last 240 data sample are used for the test set. The remaining part is allocated for the training set, and they are used for training of models. The training process was repeated 10 times for each model architecture, and the average values of the training performance indices were calculated for both the benchmark functions ( \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:{\mathrm{y}}_{1}$$\end{document} , \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:{y}_{2}$$\end{document} , \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:{y}_{3}$$\end{document} ) and the temperature anomaly. Results are reported in Tables 4, 5 and 6. One observes that some models can provide better performances than the proposed AT-LSTM model. However, it should be noticed that the training performance does not truly express long-term forecasting performance of models. In fact, it can indicate the data reproduction performance of models over the training dataset.
Table 4. Average of root mean square error (RMSE) for training performance.Architecture \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:{\boldsymbol{y}}_{1}$$\end{document}
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:{\boldsymbol{y}}_{2}$$\end{document}
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:{\boldsymbol{y}}_{3}$$\end{document}
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:{\boldsymbol{y}}_{4}$$\end{document} Temp. AnomalyAT-LSTM0.0004070.0015350.0009820.0137990.004065Multiplication of Twin LSTM0.0077530.0047920.0082370.0138460.006370Single LSTM with 128 hidden layers0.0015130.0020580.0025130.0142940.005962Single LSTM with 256 hidden layers0.0020190.0012430.0028940.0141800.006430Single biLSTM with 128 hidden layers0.0016780.0060730.0018550.0004770.003867Single biLSTM with 256 hidden layers0.0019490.0066250.0020140.0003460.004030Two LSTM (stacked and DC LSTM)^39^0.0006030.0016660.0012400.0137230.006240LSTM with 2-layer CNN in series^14^0.0002580.0026150.0014820.0018080.002402CNN-LSTM connected in parallel^19^0.0012500.0045290.0019870.0096870.002835GRU-LSTM connected in parallel^19^0.0006170.0051420.0031980.0151000.003882Attention-LSTM^40^0.0047250.0057430.0058560.0150380.006966
Table 5. Average of mean absolute error (MAE) for training performance.Architecture \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:{\boldsymbol{y}}_{1}$$\end{document}
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:{\boldsymbol{y}}_{2}$$\end{document}
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:{\boldsymbol{y}}_{3}$$\end{document}
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:{\boldsymbol{y}}_{4}$$\end{document} Temp. AnomalyAT-LSTM0.0002060.0007640.0007010.0117600.003046Multiplication of Twin LSTM0.0006340.0014520.0010020.0118100.004227Single LSTM with 128 hidden layers0.0002180.0013160.0005140.0122540.004296Single LSTM with 256 hidden layers0.0002140.0008470.0005490.0121520.004548Single biLSTM with 128 hidden layers0.0004160.0014880.0005200.0001820.002569Single biLSTM with 256 hidden layers0.0004760.0014820.0005450.0002000.002544Two LSTM (stacked and DC LSTM)^39^0.0002520.0010990.0006160.0117180.004433LSTM with 2-layer CNN in series^14^0.0001790.0019810.0010750.0012520.001870CNN-LSTM connected in parallel^19^0.0002630.0018230.0011030.0078020.002122GRU-LSTM connected in parallel^19^0.0005100.0021970.0026730.0127710.002921Attention-LSTM^40^0.0012570.0038840.0026260.0128310.004969
Table 6. Average of R^2^-score for training performance.Architecture \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:{\boldsymbol{y}}_{1}$$\end{document}
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:{\boldsymbol{y}}_{2}$$\end{document}
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:{\boldsymbol{y}}_{3}$$\end{document}
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:{\boldsymbol{y}}_{4}$$\end{document} Temp. AnomalyAT-LSTM0.9999980.9999980.9999910.9728160.999750Multiplication of Twin LSTM0.9994070.9999780.9993660.9726080.999381Single LSTM with 128 hidden layers0.9999740.9999960.9999350.9708350.999461Single LSTM with 256 hidden layers0.9999500.9999990.9999170.9712960.999371Single biLSTM with 128 hidden layers0.9999730.9999670.9999690.9999650.999773Single biLSTM with 256 hidden layers0.9999640.9999600.9999620.9999820.999751Two LSTM (stacked and DC LSTM)^39^0.9999930.9999970.9999850.9731040.999404LSTM with 2-layer CNN in series^14^0.9999990.9999940.9999770.9994460.999912CNN-LSTM connected in parallel^19^0.9999800.9999820.9999640.9865900.999878GRU-LSTM connected in parallel^19^0.9999960.9999740.9999060.9673870.999771Attention-LSTM^40^0.9997860.9999700.9996870.9677090.999258
- b)Test performance evaluation
High prediction performance for the training dataset does not ensure high performance for test dataset because test data were not used in the training process of the models. If the prediction performance severely decreases for unseen data in the test set, it is an indication of the overfitting case. The overfitted models are useless in terms of prediction practice because these models cannot learn general relations from data and they can exhibit very poor prediction performances for unseen data. Generalization, which implies learning general relations from data, can provides satisfactory prediction performance for unseen data. To detect overfitting state or evaluate generalization case, test datasets was allocated only for testing of the trained model for unseen data. In this study, the last 240 values of the dataset were allocated for the test dataset. In our test, training of forecaster models was repeated 10 times and mean and standard deviation values of the test performance indices were reported for both the benchmark function and the temperature anomaly in Tables 7, 8 and 9. When both the training performance (Tables 4, 5 and 6) and the test performance (Tables 7, 8 and 9) are considered together, one observes that the performance of the proposed AT-LSTM model indicate improved generalization performance because it exhibits better performances for the majority of test datasets. Particularly, the AT-LSTM model exhibits the highest R^2^-score (0.999427 for temperature anomaly dataset), the lowest RMSE value (0.003335 for temperature anomaly dataset) and the lowest MAE value (0.002484 for temperature anomaly dataset) than those of other models. These findings reveal that the AT-LSTM model has improved generalization for real dataset. This improvement can be closely related with the property that the AT-LSTM is capable of learning uncoupled dynamics in the temperature anomaly dataset.
Table 7. Root mean square error (RMSE) for test performance (mean ± std).Architecture \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:{\boldsymbol{y}}_{1}$$\end{document}
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:{\boldsymbol{y}}_{2}$$\end{document}
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:{\boldsymbol{y}}_{3}$$\end{document}
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:{\boldsymbol{y}}_{4}$$\end{document} Temp. AnomalyAT-LSTM0.0054 ± 0.0040.1065 ± 0.0000.0050 ± 0.0010.0246 ± 0.0070.0033 ± 0.001Multiplication of Twin LSTM0.1426 ± 0.0710.1032 ± 0.0020.0727 ± 0.0990.0210 ± 0.0060.0212 ± 0.014Single LSTM with 128 hidden layers0.0108 ± 0.0050.1060 ± 0.0010.0069 ± 0.0010.0158 ± 0.0010.0086 ± 0.003Single LSTM with 256 hidden layers0.0089 ± 0.0070.1062 ± 0.0010.0049 ± 0.0000.0167 ± 0.0020.0148 ± 0.008Single biLSTM with 128 hidden layers0.0373 ± 0.0130.1041 ± 0.0010.0169 ± 0.0060.0211 ± 0.0000.0200 ± 0.008Single biLSTM with 256 hidden layers0.0338 ± 0.0100.1041 ± 0.0010.0115 ± 0.0030.0211 ± 0.0000.0151 ± 0.014Two LSTM (stacked and DC LSTM)^39^0.0343 ± 0.0180.1040 ± 0.0010.0288 ± 0.0150.0170 ± 0.0010.0199 ± 0.009LSTM with 2-layer CNN in series^14^0.1589 ± 0.0190.1251 ± 0.0180.1092 ± 0.0140.0243 ± 0.0020.1160 ± 0.016CNN-LSTM connected in parallel^19^0.0132 ± 0.0050.1060 ± 0.0030.0090 ± 0.0020.0197 ± 0.0030.0113 ± 0.008GRU-LSTM connected in parallel^19^0.0259 ± 0.0230.1040 ± 0.0040.0131 ± 0.0060.0151 ± 0.0010.0144 ± 0.011Attention-LSTM^40^1.8913 ± 0.3891.2599 ± 0.3882.0774 ± 0.6780.0707 ± 0.0231.4983 ± 0.252
Table 8. Mean absolute error (MAE) for test performance (mean ± std).Architecture \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:{\boldsymbol{y}}_{1}$$\end{document}
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:{\boldsymbol{y}}_{2}$$\end{document}
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:{\boldsymbol{y}}_{3}$$\end{document}
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:{\boldsymbol{y}}_{4}$$\end{document} Temp. AnomalyAT-LSTM0.0041 ± 0.0030.0942 ± 0.0010.0043 ± 0.0000.0199 ± 0.0050.0025 ± 0.000Multiplication of Twin LSTM0.1107 ± 0.0610.0898 ± 0.0020.0506 ± 0.0600.0173 ± 0.0050.0148 ± 0.010Single LSTM with 128 hidden layers0.0076 ± 0.0030.0933 ± 0.0010.0058 ± 0.0010.0133 ± 0.0010.0065 ± 0.002Single LSTM with 256 hidden layers0.0064 ± 0.0050.0938 ± 0.0010.0042 ± 0.0000.0140 ± 0.0020.0112 ± 0.006Single biLSTM with 128 hidden layers0.0276 ± 0.0100.0921 ± 0.0010.0105 ± 0.0040.0171 ± 0.0000.0164 ± 0.008Single biLSTM with 256 hidden layers0.0257 ± 0.0080.0923 ± 0.0010.0069 ± 0.0030.0171 ± 0.0000.0103 ± 0.015Two LSTM (stacked and DC LSTM)^39^0.0242 ± 0.0130.0921 ± 0.0010.0226 ± 0.0120.0144 ± 0.0010.0144 ± 0.006LSTM with 2-layer CNN in series^14^0.1215 ± 0.0170.1037 ± 0.0090.0691 ± 0.0100.0185 ± 0.0010.0753 ± 0.012CNN-LSTM connected in parallel^19^0.0058 ± 0.0030.0941 ± 0.0020.0053 ± 0.0010.0156 ± 0.0020.0043 ± 0.001GRU-LSTM connected in parallel^19^0.0196 ± 0.0180.1040 ± 0.0040.0107 ± 0.0050.0127 ± 0.0010.0105 ± 0.008Attention-LSTM^40^1.8837 ± 0.3911.1463 ± 0.3532.0692 ± 0.6800.0623 ± 0.0221.4915 ± 0.253
Table 9R^2^-score for test performance (mean ± std).Architecture \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:{\boldsymbol{y}}_{1}$$\end{document}
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:{\boldsymbol{y}}_{2}$$\end{document}
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:{\boldsymbol{y}}_{3}$$\end{document}
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:{\boldsymbol{y}}_{4}$$\end{document} Temp. AnomalyAT-LSTM0.9985 ± 0.0020.9961 ± 0.0000.9992 ± 0.0000.9577 ± 0.0650.9994 ± 0.000Multiplication of Twin LSTM0.1142 ± 0.8030.9963 ± 0.0000.5625 ± 1.1910.9088 ± 0.0620.9685 ± 0.050Single LSTM with 128 hidden layers0.9951 ± 0.0040.9961 ± 0.0000.9985 ± 0.0010.9521 ± 0.0050.9960 ± 0.002Single LSTM with 256 hidden layers0.9958 ± 0.0050.9961 ± 0.0000.9993 ± 0.0000.9461 ± 0.0150.9861 ± 0.017Single biLSTM with 128 hidden layers0.9453 ± 0.0320.9963 ± 0.0000.9902 ± 0.0060.9150 ± 0.0000.9774 ± 0.016Single biLSTM with 256 hidden layers0.9564 ± 0.0220.9963 ± 0.0000.9956 ± 0.0030.9150 ± 0.0000.9795 ± 0.046Two LSTM (stacked and DC LSTM)^39^0.9475 ± 0.0530.9963 ± 0.0000.9678 ± 0.0330.9445 ± 0.0080.9764 ± 0.025LSTM with 2-layer CNN in series^14^0.0880 ± 0.2100.9945 ± 0.0020.6251 ± 0.0920.8874 ± 0.0180.3141 ± 0.185CNN-LSTM connected in parallel^19^0.9930 ± 0.0050.9961 ± 0.0000.9973 ± 0.0010.9246 ± 0.0260.9908 ± 0.015GRU-LSTM connected in parallel^19^0.9590 ± 0.0830.9963 ± 0.0000.9938 ± 0.0050.9566 ± 0.0060.9840 ± 0.026Attention-LSTM^40^-131.45 ± 55.100.4094 ± 0.333-145.52 ± 97.6-0.045 ± 0.586-114.28 ± 36.77
- c)Evaluation of forecast performances on test dataset
For estimation of future forecast performance of models, forecasting tests were carried out in test dataset. Here, the first data of test dataset is applied to the models and predictions of models are used to feed inputs of models in order to forecast the next data. This feedback loop is performed 240 times to perform long-term forecasting trough test dataset. For 10 repeated modeling of each model architecture is carried out and the mean and standard deviation values of the forecast performances were calculated for both the benchmark functions and the temperature anomaly in Tables 10, 11 and 12. These performance data were considered, the AT-LSTM model mostly exhibited better forecasting performance on the test dataset. It provided the highest R^2^-score (0.521012 for temperature anomaly dataset), the lowest RMSE value (0.093977 for temperature anomaly dataset) and the lowest MAE value (0.072846 for temperature anomaly dataset). This performance improvement can indicate advantages of the AT-LSTM model, which is the learning uncoupled dynamics in the temperature anomaly dataset.
Table 10. Root mean square error (RMSE) for forecast performance (mean ± std).Architecture \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:{\boldsymbol{y}}_{1}$$\end{document}
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:{\boldsymbol{y}}_{2}$$\end{document}
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:{\boldsymbol{y}}_{3}$$\end{document}
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:{\boldsymbol{y}}_{4}$$\end{document} Temp. AnomalyAT-LSTM0.0714 ± 0.0150.4264 ± 0.0840.3838 ± 0.1020.0211 ± 0.0040.0940 ± 0.029Multiplication of Twin LSTM0.2514 ± 0.0340.2857 ± 0.0680.5425 ± 0.2280.0227 ± 0.0040.2313 ± 0.040Single LSTM with 128 hidden layers0.1994 ± 0.0260.3747 ± 0.1050.5340 ± 0.4720.0251 ± 0.0090.1946 ± 0.054Single LSTM with 256 hidden layers0.0893 ± 0.0540.3733 ± 0.0800.3771 ± 0.0940.0222 ± 0.0070.3004 ± 0.131Single biLSTM with 128 hidden layers0.5214 ± 0.0361.7388 ± 0.0150.5301 ± 0.0310.0824 ± 0.0010.7754 ± 0.031Single biLSTM with 256 hidden layers0.5227 ± 0.0601.7532 ± 0.0240.5344 ± 0.0560.0816 ± 0.0010.7909 ± 0.050Two LSTM (stacked and DC LSTM)^39^0.2003 ± 0.0300.3271 ± 0.0960.3348 ± 0.0260.0223 ± 0.0020.2372 ± 0.061LSTM with 2-layer CNN in series^14^0.9255 ± 0.0041.7259 ± 0.0170.9165 ± 0.0070.0866 ± 0.0020.9037 ± 0.022CNN-LSTM connected in parallel^19^1.2081 ± 0.9491.7178 ± 0.0581.5010 ± 1.2300.0912 ± 0.0021.4521 ± 1.031GRU-LSTM connected in parallel^19^0.1382 ± 0.0600.5442 ± 0.3120.4675 ± 0.1120.0678 ± 0.0340.2853 ± 0.140Attention-LSTM^40^0.1767 ± 0.0481.7541 ± 0.0130.9578 ± 0.1240.0895 ± 0.0070.9213 ± 0.059
Table 11. Mean absolute error (MAE) for forecast performance (mean ± std).Architecture \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:{\boldsymbol{y}}_{1}$$\end{document}
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:{\boldsymbol{y}}_{2}$$\end{document}
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:{\boldsymbol{y}}_{3}$$\end{document}
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:{\boldsymbol{y}}_{4}$$\end{document} Temp. AnomalyAT-LSTM0.0492 ± 0.0120.3295 ± 0.0640.3398 ± 0.0990.0172 ± 0.0030.0728 ± 0.019Multiplication of Twin LSTM0.2028 ± 0.0340.2278 ± 0.0570.4650 ± 0.1850.0184 ± 0.0030.1889 ± 0.041Single LSTM with 128 hidden layers0.1553 ± 0.0240.2970 ± 0.0810.4133 ± 0.3950.0202 ± 0.0070.1562 ± 0.051Single LSTM with 256 hidden layers0.0653 ± 0.0410.2936 ± 0.0630.3224 ± 0.0980.0180 ± 0.0050.2559 ± 0.121Single biLSTM with 128 hidden layers0.4772 ± 0.0351.4964 ± 0.0080.4967 ± 0.0320.0672 ± 0.0000.7567 ± 0.032Single biLSTM with 256 hidden layers0.4818 ± 0.0581.5064 ± 0.0040.5012 ± 0.0590.0668 ± 0.0000.7729 ± 0.051Two LSTM (stacked and DC LSTM)^39^0.1564 ± 0.0280.2593 ± 0.0780.2865 ± 0.0250.0185 ± 0.0020.1918 ± 0.064LSTM with 2-layer CNN in series^14^0.9075 ± 0.0041.5546 ± 0.0190.8958 ± 0.0080.0696 ± 0.0010.8911 ± 0.023CNN-LSTM connected in parallel^19^1.1787 ± 0.9421.5354 ± 0.0721.4530 ± 1.1870.0723 ± 0.0021.4284 ± 1.018GRU-LSTM connected in parallel^19^0.1116 ± 0.0500.4403 ± 0.2550.4285 ± 0.1160.0553 ± 0.0260.2391 ± 0.134Attention-LSTM^40^0.1358 ± 0.0411.5802 ± 0.0110.9393 ± 0.1280.0718 ± 0.0050.9093 ± 0.060
It is noteworthy to consider performance data in Table 11. The table reveals that future forecast error of the AT-LSTM model has an average 0.072846 °C for 10 repeated modelling. This forecast error level in test set implies that forecasting error for the following 240 months in future can be expected at the level of 0.072846 °C or slightly more. In other words, for the 240 months future temperature forecasts, the nearest error level expectation of AT-LSTM model can be estimated as 0.072846 °C. This error level for long-term global temperature anomaly forecasting is meaningful for climate studies. For instance, for the model CNN-LSTM connected in parallel, an average error of 1.428369 °C was observed and it expresses the nearest error level expectation for 240 months future forecasting of this model. When compared, 240 months forecast error expectation level of the AT-LSTM model is much less (about 5%) and therefore the temperature anomaly forecasting of AT-LSTM model can be more consistent in average.
Table 12R^2^-score for forecast performance (mean ± std).Architecture \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:{\boldsymbol{y}}_{1}$$\end{document}
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:{\boldsymbol{y}}_{2}$$\end{document}
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:{\boldsymbol{y}}_{3}$$\end{document}
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\:{\boldsymbol{y}}_{4}$$\end{document} Temp. AnomalyAT-LSTM0.8109 ± 0.0810.9355 ± 0.026-3.8574 ± 2.050.9129 ± 0.0300.5210 ± 0.259Multiplication of Twin LSTM-1.2909 ± 0.6870.9706 ± 0.014-9.567 ± 9.7160.8997 ± 0.033-1.7515 ± 0.965Single LSTM with 128 hidden layers-0.4394 ± 0.3590.9485 ± 0.033-14.04 ± 31.470.8666 ± 0.092-1.0294 ± 1.097Single LSTM with 256 hidden layers0.6218 ± 0.3310.9502 ± 0.021-3.651 ± 2.1650.8976 ± 0.079-4.2889 ± 4.255Single biLSTM with 128 hidden layers-8.7414 ± 1.339-0.0366 ± 0.02-7.734 ± 1.027-0.2937 ± 0.020-29.1605 ± 2.45Single biLSTM with 256 hidden layers-8.8616 ± 2.303-0.054 ± 0.029-7.938 ± 1.871-0.2681 ± 0.028-30.445 ± 4.04Two LSTM (stacked and DC LSTM)^39^-0.4604 ± 0.4460.9605 ± 0.025-2.493 ± 0.5570.9004 ± 0.019-1.9867 ± 1.546LSTM with 2-layer CNN in series^14^-29.553 ± 0.259-0.0214 ± 0.02-25.03 ± 0.391-0.4307 ± 0.074-39.9226 ± 1.95CNN-LSTM connected in parallel^19^-79.983 ± 153.5-0.0127 ± 0.06-111.0 ± 203.4-0.5854 ± 0.069-152.53 ± 224.1GRU-LSTM connected in parallel^19^0.2044 ± 0.5820.8685 ± 0.143-6.122 ± 3.334-0.0707 ± 1.085-3.9579 ± 4.72Attention-LSTM^40^-0.1866 ± 0.518-0.0549 ± 0.01-27.856 ± 6.18-0.5338 ± 0.24-41.6746 ± 5.11
Figure 13 shows the temperature prediction of 10th AT-LSTM model for the training set and test set allocations throughout the Berkeley temperature anomaly dataset. The prediction on training and test sets are very consistent with the observed data and indicates high prediction performances. However, the long-term forecast performance over test set should be considered to estimate the practical forecast performance. The temperature anomaly forecasting over the test set for 10 AT-LSTM models and their average forecasting is illustrated in Fig. 14. This figure reveals that forecasts of AT-LSTM models are consistent with the temperature anomaly trend of 240 months test data to some extent. The average forecasting of 10 AT-LSTM models is rather consistent with trend of the test data. However, the average forecasts are enough consistent with the first 140 months data and almost express the trend curve of the 5 year-averaged 140 months global temperature anomaly data. As expected, although next data prediction performances on training and test dataset are very accurate as illustrated in Fig. 13, the long-term forecasting on test dataset is not very accurate as illustrated in Fig. 14. The main reason for effect is the long-term forecast error accumulation in the long-term forecasting process as explained in A forecast performance evaluation procedure for time series data.
Fig. 13. The temperature predictions of 10th LSTM model for training and test set.
Fig. 14. Forecast performance over test set of temperature dataset.
- d)Future projection for global temperature anomaly trends based on forecasts of AT-LSTM models
This section discusses global temperature anomaly forecasts of AT-LSTM models for the next 20 years (240 months) from 2022 to 2042. Figure 15 shows the temperature anomaly forecasts of 40 AT-LSTM models for the next 20 years, and average forecasts of these models were indicated with red solid line in the figure. To increase consistency of average forecasts, we trained 40 AT-LSTM models and show their forecasts with yellow thin lines. Based on the forecasting performance on test set in Table 11, the average forecast error can be expected at a level of 0.072846 °C. This error level assumes an ± 0.073 °C uncertainty range in in average forecasting error and indicates reliability of the average model.
Figure 15 demonstrates that all models forecast an increasing trend in the global temperature anomaly in next 20 years. The temperature anomaly forecast for the year 2042 is varied between 1.05 °C and 1.67 °C. The average of temperature anomaly forecasts (red line) for the year 2042 forecasts 1.415 °C ± 0.073 °C global temperature anomaly. The average temperature anomaly forecast of 1.415 °C by the year 2042 aligns with global temperature projections in the literature, confirming that the model provides reasonable and consistent forecasts with other studies. For example, the Intergovernmental Panel on Climate Change (IPCC) Sixth Assessment Report (2021)^41^ highlights that global temperatures could rise by 1.5 °C above pre-industrial levels by 2030–2050 under high-emission scenarios. The 1.415 °C forecasting by the 2042 from the AT-LSTM model is consistent with outputs from traditional climate models (e.g., CMIP6 models^42^ and emphasizes the growing confidence in machine learning-based approaches for climate forecasting. If the global temperature anomaly reaches at a level of 1.40 °C by 2040, climatic analyses for such a high temperature anomaly suggests that there will be urgent need for applying required environmental policies (The Paris Agreement (2015) and others) and feasible technological solutions^43–45^ in order to mitigate the global warming. The Paris Agreement (2015) aims to limit global warming to well below 2 °C, with efforts to limit it to 1.5 °C. The AT-LSTM model’s forecast reveals potential of the current trend coming near or exceeding the 1.5 °C threshold by mid-century. This analysis highlights the urgency of implementing climate mitigation measures to reduce greenhouse gas emissions and prevent catastrophic climate impacts, as emphasized in reports by organizations like the IPCC and the World Meteorological Organization (WMO).
The forecasts for 2042, which ranges between 1.05 °C and 1.67 °C, reflect the training diversity of models, which can be clearly observed in the long-term climate forecasts. However, all trained models suggested the potential of increasing trend in the temperature anomaly. As noted in the literature, Tebaldi et al. (2021)^42^ emphasized that future temperature forecasts were subject to significant uncertainty due to numerous unpredictable factors such as future of greenhouse gas emissions, dynamics and chaotic response of climate systems, natural climate variabilities, world policy, and socio-economic developments, several other anthropogenic factors. The current forecasts are based on collected data in a period of (1850–2024) and the trained models assume that similar dynamics and factors continue in future. That is why, the model diversity and multi-model analyses is useful to consider possible scenarios in the forecasting and achieve the most probable estimates. Obviously, the diversity in model forecast and the uncertainty level should increase as the forecast horizon extends into the future.
Fig. 15. Future forecasts of global temperature anomaly by AT-LSTM models and the average forecast line (red line) for next 20 years.
Discussion and conclusions
Data-driven modeling of climate responses and time series forecasting are very important in these days because Earth climate is very near to or exceeding a critical point, where monitoring current trends and estimation of future trends in the global warming problem is highly vital to maintain Earth habitability and future of humankind. Unfortunately, observations and measured climate data is quite limited to accurately model highly complex earth climate system. In this case, data-driven modeling and machine learning techniques can helpful to improve forecast model.
Training and performance evaluation forecaster model, which learn the dominant dynamics of the climate responses from insufficient sequential data, is a particularly challenging problem. To improve time series forecasting performance, three stages gain more importance; the first one is suitably preprocessing of raw data sequences (selection of sampling period, reducing noise and uncertainty in raw data etc.), the second one is the design of suitable models (models should be capable of exploring and learning responses of dominating dynamics (factors) from sequential data) and the third one is the dependable performance evaluation strategies (considering prediction performance in training and test dataset cannot reveal long-term future forecast performance of these models.) Some remarks of this study are summarized:
- * An AT-LSTM model is proposed to learn two uncoupled dominating dynamic responses from the monthly temperature anomaly data. It involves two LSTMs (to learn response of two dominating dynamics from data sequence) and the neural decoder (to learn characteristics of measurement process).
- * Benchmark functions were designed to establish a sterile and controlled test environment (without noise, uncertainty and disturbances) that resembles specific global temperature anomaly trends. The benchmark function is useful to reveal expressive capability of models for specific characteristics in applications.
-
- In order to reduce negative impacts of noise on the modeling process, the five-years averaged monthly sampled temperature anomaly data were used. The averaged data better expresses consistent trends in temperature anomaly observation and facilitates learning these trends by the forecaster models.
-
- The forecast performance on the test set is used to estimate long-term future forecast performance of models. It was emphasized that data prediction in training and test sets does not express long-term future forecast performance of the forecaster models.
The average temperature anomaly forecast of the AT-LSTM models was 1.415 °C with ± 0.073 °C average error expectation for a projection to the year 2042. It is consistent with the global temperature anomaly projections in the literature. Potential of rising temperature anomaly up to 1.415 °C in 20 years is very important because it is alerting point for urgently activating reduction policies and necessary climate mitigation measures. We highlight the urgency of implementing climate mitigation measures for reducing greenhouse gas emissions and other feasible solution to prevent catastrophic climate changes, as emphasized in reports by other organizations.
Supplementary Information
Below is the link to the electronic supplementary material.
Supplementary Material 1
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1Hochreiter, S. & Schmidhuber, J. LSTM can solve hard long time lag problems. In Proceedings of the 9th International Conference on Neural Information Processing Systems, NIPS’96 473–479MIT Press, Cambridge, MA, USA, (1996).
- 2Azevedo, B. F., Rocha, A. M. A. C. & Pereira, A. I. Hybrid Approaches to Optimization and Machine Learning Methods: A Systematic Literature Review. Mach. Learn. vol. 113Springer US, (2024).
- 3Zhao, X., Huang, L. & Nie, Y. Temperature Prediction Based on Integrated Deep Learning and Attention Mechanism. in IEEE 6th International Conference on Computer and Communication Systems, ICCCS 2021 163–167 (IEEE, Chengdu, China, 2021). 163–167 (IEEE, Chengdu, China). 10.1109/ICCCS 52626.2021.9449176 (2021).
- 4Zhang, Z., Dong, Y. & Yuan, Y. Temperature Forecasting via Convolutional Recurrent Neural Networks Based on Time-Series Data. Complexity 1–8 (2020).
- 5Gong, Y., Zhang, Y., Wang, F. & Lee, C. Deep learning for weather forecasting: A CNN-LSTM hybrid model for predicting historical temperature data. 1-710.48550/ar Xiv.2410.14963 (2024).
- 6Jaggard, A. D., Lutz, N., Schapira, M. & Wright, R. N. Self-stabilizing uncoupled dynamics. In International Symposium on Algorithmic Game Theory vol. 8768 74–85, (2014).
- 7Berkeley Earth. https://berkeleyearth.org/data/
- 8Muller, R. A. et al. A new estimate of the average Earth surface land temperature spanning 1753 to 2011. Geoinformatics Geostatistics Overv 1, (2013).