A Benchmark Dataset for Satellite-Based Estimation and Detection of Rain
Simon Pfreundschuh, Malarvizhi Arulraj, Ali Behrangi, Linda Bogerd, Alan James Peixoto Calheiros, Daniele Casella, Neda Dolatabadi, Clement Guilloteau, Jie Gong, Christian D. Kummerow, Pierre Kirstetter, Gyuwon Lee, Maximilian Maahn, Lisa Milani, Giulia Panegrossi

TL;DR
This paper introduces SatRain, a new benchmark dataset for improving satellite-based rain detection and estimation using machine learning.
Contribution
The novel contribution is the creation of SatRain, the first standardized AI benchmark dataset for satellite-based precipitation retrieval.
Findings
SatRain integrates multi-sensor satellite data with high-quality ground-based radar precipitation estimates.
The dataset includes out-of-distribution testing data from Asia and Europe for robust comparisons.
SatRain supports the development of next-generation AI models for global precipitation monitoring.
Abstract
Accurately tracking the global distribution of precipitation is essential for both research and operational meteorology. Satellite observations remain the only means of achieving consistent, global precipitation monitoring. While machine learning has long been applied to satellite-based precipitation retrieval, the absence of a standardized benchmark dataset has hindered fair comparisons between methods. To address this, the International Precipitation Working Group has developed SatRain, the first AI benchmark dataset for satellite-based detection and estimation of rain. SatRain integrates multi-sensor satellite observations from the primary platforms used in precipitation remote sensing with high-quality reference precipitation estimates derived from gauge-corrected ground-based radar composites over the conterminous United States. It offers a standardized evaluation protocol and…
Genes, proteins, chemicals, diseases, species, mutations and cell lines named across the full text — each resolved to its canonical identifier and authoritative record.
Click any figure to enlarge with its caption.
 Figure 10
Figure 10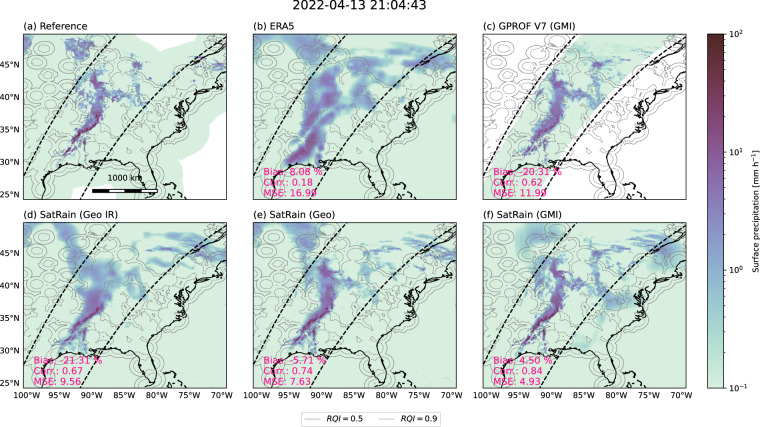 Figure 11
Figure 11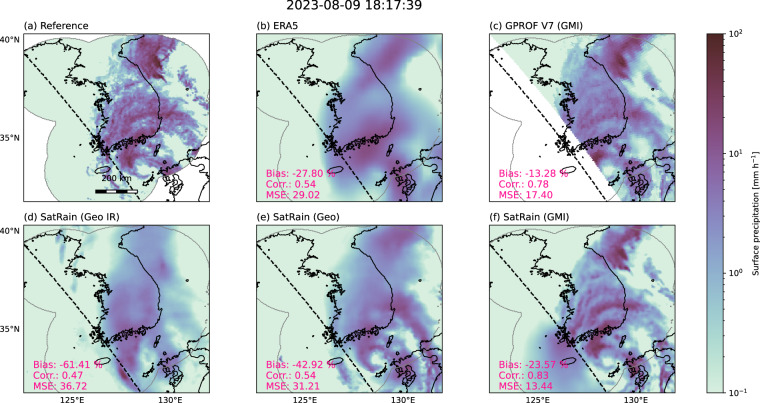 Figure 12
Figure 12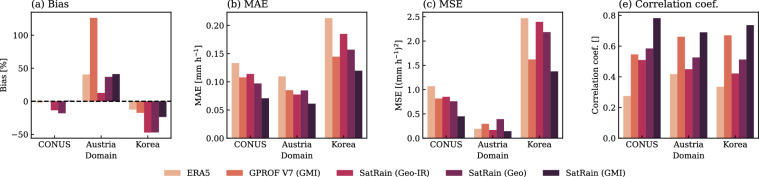 Figure 13
Figure 13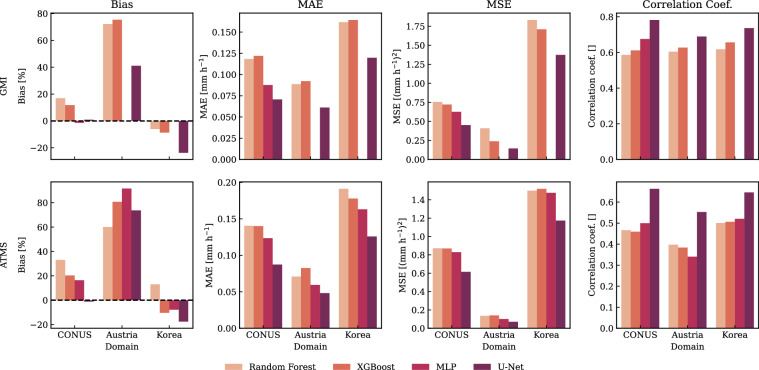 Figure 14
Figure 14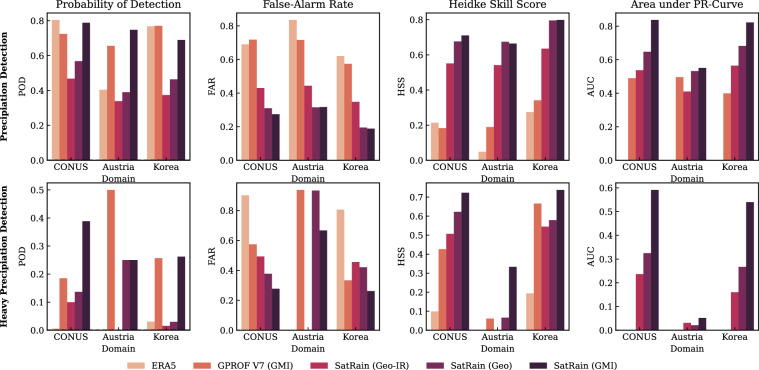 Figure 15
Figure 15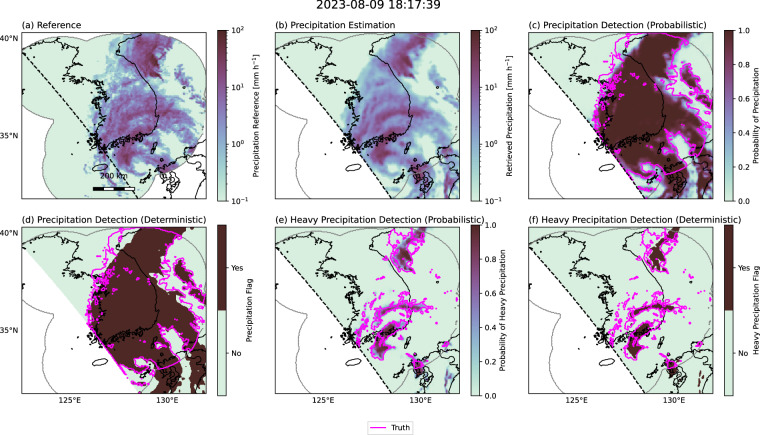 Figure 16
Figure 16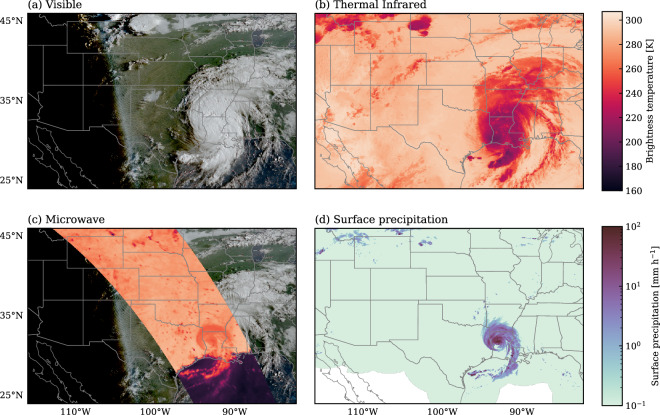 Figure 1
Figure 1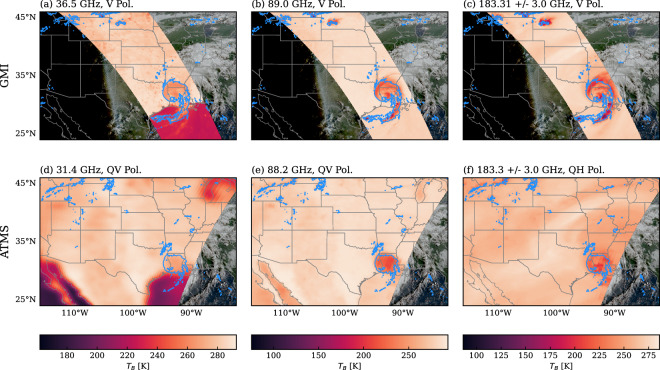 Figure 2
Figure 2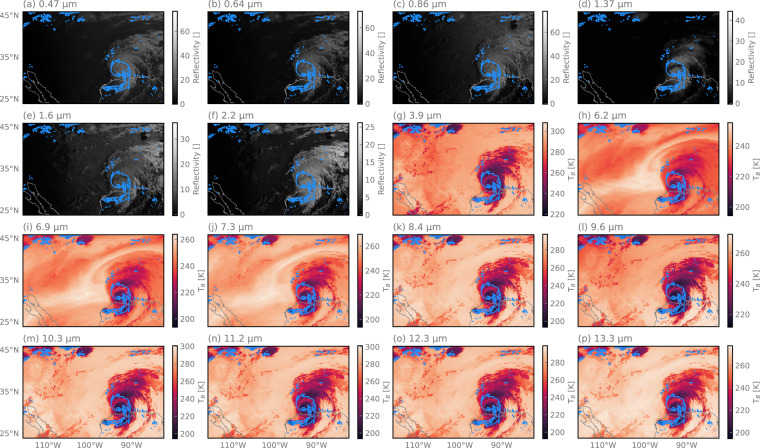 Figure 3
Figure 3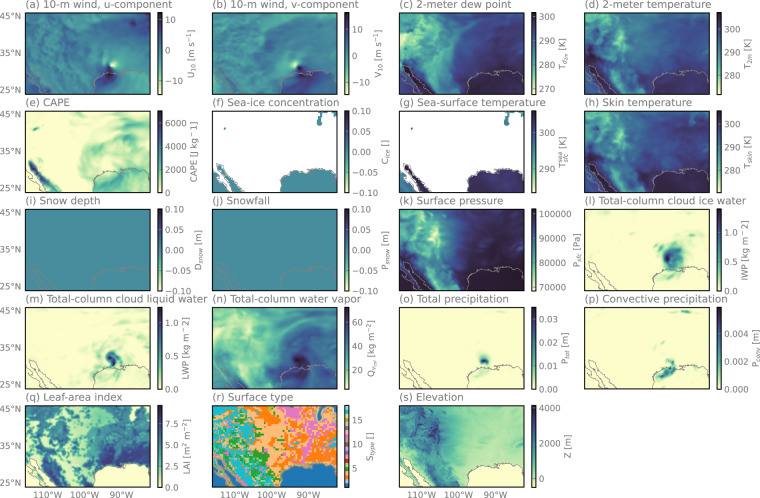 Figure 4
Figure 4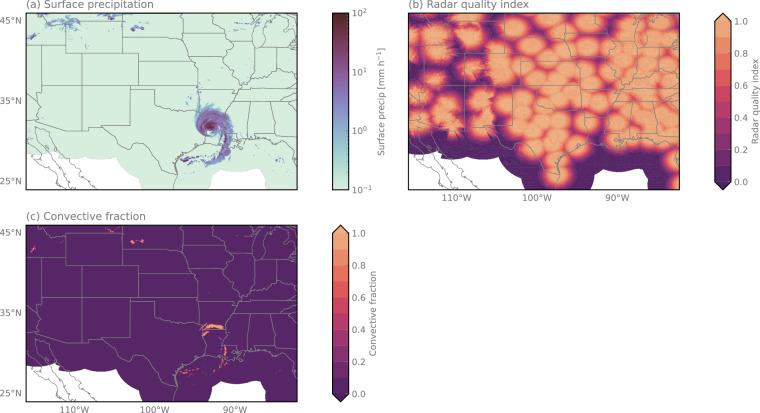 Figure 5
Figure 5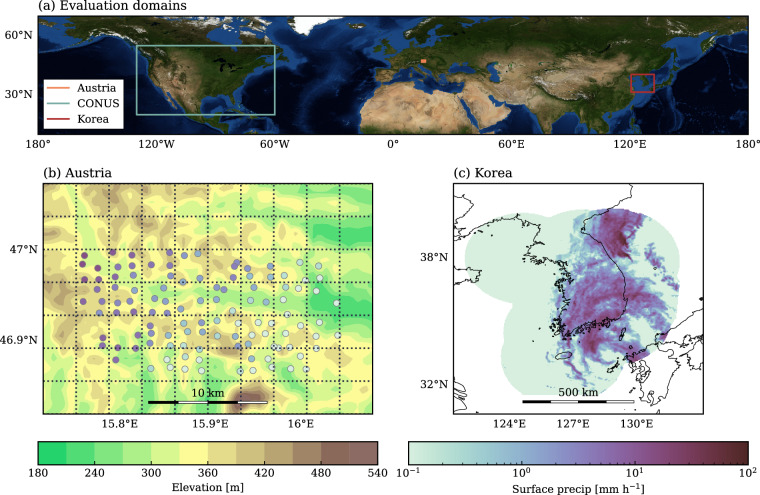 Figure 6
Figure 6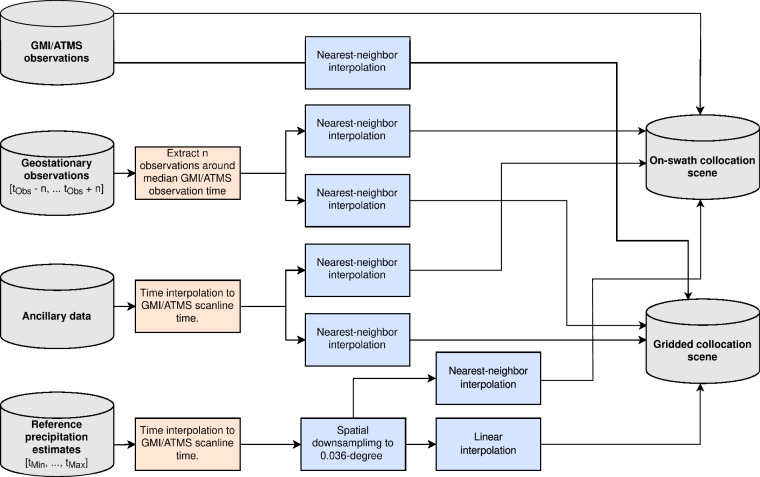 Figure 7
Figure 7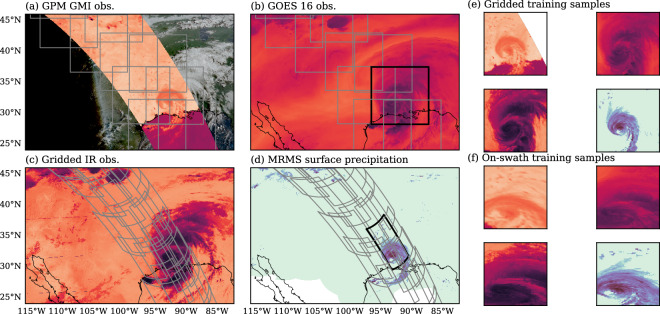 Figure 8
Figure 8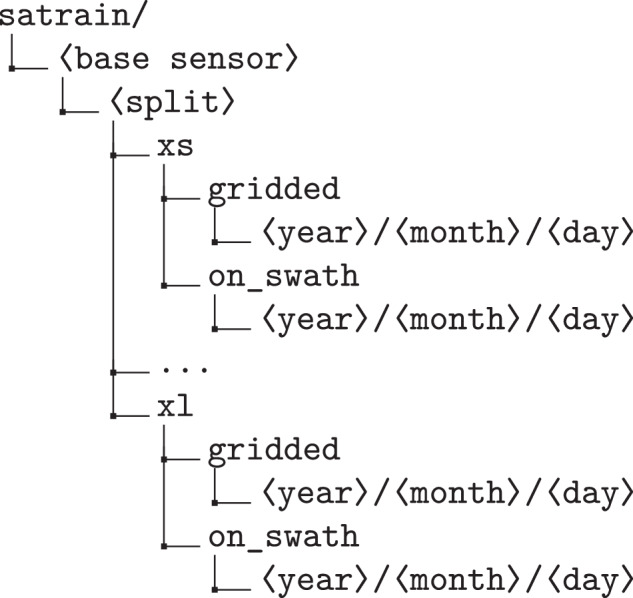 Figure 9
Figure 9- —100000104National Aeronautics and Space Administration (NASA)
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsPrecipitation Measurement and Analysis · Meteorological Phenomena and Simulations · Soil Moisture and Remote Sensing
Background & Summary
Precipitation, the deposition of water in liquid or frozen form from the atmosphere onto the Earth’s surface, is essential for sustaining ecosystems and a wide range of human activity. However, extreme events at both ends of the climatological distribution of precipitation, such as droughts or heavy precipitation, can cause substantial damage to societies and human livelihoods. Monitoring the global distribution of precipitation is therefore critical not only for advancing scientific understanding of the processes that shape precipitation patterns and drive extreme events but also economic planning and civil security. Despite its crucial role in many aspects of economic and social life on Earth, precipitation estimation still faces significant challenges in meeting the needs of hydrological and climate research, as well as operational applications. Precipitation is one of the most difficult atmospheric parameters to measure accurately because its estimation from both satellite and ground-based observations is complicated by several factors: its high spatial and temporal variability; its phase (liquid, solid, or mixed); its microphysical compositions (including particle shape, densities, and sizes); and the difficulties involved in converting radiometric measurements into quantitative precipitation estimates^1^.
Owing to its significance for socio-economic activities and its fundamental role within the climate system, numerous techniques have been developed to monitor and quantify it. The three principal approaches are rain gauges, ground-based radar, and satellite observations. Rain gauges yield direct and highly accurate measurements but are largely confined to continental regions and are often irregularly distributed^2^. In addition, because gauges measure precipitation only at a single point, they cannot adequately represent the spatial structure of rainfall systems. Ground-based weather radars yield spatially-continuous estimates at high spatial resolution but their coverage remains geographically limited. In contrast, satellites offer consistent, near-global observations, making them the only means of obtaining continuous and spatially comprehensive estimates of precipitation.
However, the accuracy with which precipitation can be estimated or detected from satellite observations varies significantly with sensor type and observing conditions^3^. Although a small number of precipitation radars have been deployed to measure precipitation from space, their spatial and temporal coverages are severly limited. Therefore, global precipitation monitoring has to rely mostly on passive sensors. Passive microwave (PMW) sensors operating in the 10-89 GHz range can detect emission signals associated with precipitation particles over the ocean. However, over land the emission signal from precipitation is hardly distinguishable from the high and variable emission signal from the surface. While higher microwave frequencies ( >80 GHz) are less sensitive to surface properties, their information content primarily derives from scattering by large rain drops and ice particles^4^, providing a weaker link to the precipitation at the surface. Furthermore, the spatial resolution achievable with PMW sensors is limited, requiring deployment in low-Earth orbits. As a result, even for satellite missions comprising constellations of multiple sensors, such as the Global Precipitation Measurement (GPM) mission^5^, the revisit times can exceed three hours in the tropics.
By contrast, geostationary satellites offer near-continuous temporal coverage over much of the globe, with spatial resolutions on the order of a few kilometers. Their main limitation is that they operate only in the visible (Vis) and infrared (IR) bands, which are primarily sensitive to the cloud tops and therefore provide a less direct link to surface precipitation than passive microwave observations.
Figure 1 illustrates the key characteristics of the various types of satellite observations used for the remote sensing of precipitation. Panel (a) presents a true-color composite from the Advanced Baseline Imager (ABI^6^) aboard GOES-16, showing Hurricane Laura as an expansive cloud system in the southeastern portion of the domain. Visible imagery such as this true-color composite can reveal detailed cloud structures but is limited to daylight hours due to its reliance on reflected sunlight. Panel (b) displays thermal IR imagery with a wavelength of 11 μm observed from a geostationary platform. At this wavelength, the clear-sky atmosphere exhibits high transmittance, while clouds are opaque. Consequently, the measured radiances primarily originate from the Earth’s surface in cloud-free regions and from cloud tops in cloudy regions. Due to the vertical thermal structure of the atmosphere, the cloud tops appear as areas of cold brightness temperatures against a relatively warmer background. Panel (c) shows horizontally-polarized passive microwave observations at a frequency of 36.5 GHz, corresponding to a wavelength of around 8 mm. Surface-sensitive passive microwave observations are characterized by a strong contrast between ocean and land surfaces. Over the radiatively cold ocean background, Hurricane Laura’s rainband appears as a region of enhanced brightness temperature due to emission from liquid hydrometeors. Over land, the surface itself emits strongly at microwave frequencies, making it difficult to isolate the emission signal from raindrops. Instead, precipitation is primarily detected through the scattering signature of large raindrops and ice particles, which reduce the observed brightness temperatures by attenuating surface emission.Fig. 1. Satellite observations and surface precipitation estimates from the landfall of Hurricane Laura on August 27, 2020, at 12:41 UTC. Panel (a) shows a true-color composite from the Advanced Baseline Imager (ABI) aboard the GOES-16 geostationary satellite. Panel (b) displays geostationary thermal infrared imagery at 11 μm. Panel (c) presents passive microwave observations from the GPM Microwave Imager (GMI) 36.5-GHz, horizontally-polarized channel, overlaid on the GOES true-color RGB. Panel (d) depicts surface precipitation rate estimates from NOAA’s Multi-Radar Multi-Sensor product.
Comparing the three panels to the corresponding radar-based surface precipitation estimates underscores the strength of PMW observations: while Vis and IR imagery primarily depict cloud-top features that may not correlate with surface rainfall, PMW observations exhibit higher spatial coherence with surface precipitation. The principal limitation of PMW imagery, however, is its limited spatiotemporal coverage due to narrower swath widths, longer revisit times, and lower spatial resolution.
From Satellite Observations to Precipitation Estimates
Satellite observations only contain an indirect signal from the near-surface precipitation and thus require careful processing to produce reliable surface precipitation estimates. This conversion of satellite measurements into precipitation estimates is commonly referred to as retrieval.
While a physics-based formulation of precipitation retrieval algorithms is possible, practical implementations typically require a range of simplifications and ad-hoc assumptions, such as normally distributed retrieval targets and measurement errors or close-to linear relationships between atmospheric variables and satellite observations^7–9^. Because of these difficulties, purely empirical approaches have long been used to directly relate satellite observations to precipitation estimates obtained from other measurement techniques^10–12^. The rise of machine learning (ML) and more recent AI techniques have led to the development of a range of new ML-based algorithms that yield promising results^13–16^.
Satellite-based precipitation retrievals form a core component of widely used merged precipitation products such as the Integrated Multi-satellite Retrievals for GPM (IMERG^17^) and the Global Satellite Mapping of Precipitation (GSMaP^18^). IMERG, for instance, relies on the Goddard Profiling Algorithm (GPROF^8^) to derive precipitation estimates from PMW observations and on the PERSIANN Dynamic Infrared-Rain Rate product^19^ to infer precipitation from geostationary 11 μm IR imagery, merging these inputs into global half-hourly precipitation fields.
The Need for a Unified Benchmark Dataset
The number of ML-based satellite precipitation retrievals is growing^20,21^, however the algorithms described in the literature are difficult to compare. This is largely because they are typically developed for specific sensors, regions, time periods, and even resolutions. Given the high spatiotemporal variability of precipitation, such differences in sampling and geographic focus significantly influence accuracy metrics, rendering published results incomparable. Moreover, the performance of empirical retrieval algorithms is influenced by the volume, quality, and spatiotemporal sampling of the training and evaluation data, and thus does not solely reflect the intrinsic qualities of a specific algorithm or model.
This lack of comparability makes it difficult to isolate algorithmic improvements driven by advancements in ML from differences introduced by the choice of training and evaluation data. To address this challenge, the International Precipitation Working Group (IPWG), a permanent Working Group of the Coordination Group for Meteorological Satellites (CGMS), has established a ML working group tasked with developing a standardized benchmarking dataset for empirical and ML-based precipitation retrievals^22^. The result of this effort is the Satellite-Based Estimation and Detection of Rain (SatRain) dataset, an AI-ready, large-scale benchmark dataset for the development and evaluation of precipitation retrieval algorithms covering a wide range of observations modalities and multiple climate zones. Despite its name, the dataset is not limited to rain but includes all types of precipitation encountered during the training and testing periods thus providing a comprehensive resource for developing and testing precipitation retrieval algorithms.
The SatRain Dataset
The SatRain dataset integrates multi-sensor satellite observations with gauge-corrected, ground-based radar precipitation estimates. It provides a large, curated training set over the conterminous United States (CONUS), encompassing diverse climate regimes ranging from subtropical humid regions to arid deserts, mountainous terrain, and temperate to cold continental zones. Data are available both on a 0.036° regular latitude-longitude grid and the native sampling of the passive microwave sensors. All input and reference fields are consistently mapped to these two spatial representations, enabling direct use for both pixel-based and image-based AI algorithms and ensuring the dataset’s AI-readiness. The satellite observations span a wide range of sensing modalities relevant to precipitation remote sensing, including temporally resolved imagery from geostationary platforms. To support model generalization studies, SatRain also includes independent test sets from Korea and Austria, covering distinct climate regimes and incorporating alternative reference measurement techniques.
The SatRain dataset is constructed using the same satellite observations that underpin major global merged precipitation products such as IMERG and GSMaP. Consequently, machine-learning models trained on SatRain can be directly benchmarked against the retrieval algorithms used to generate these products. This alignment creates a clear pathway for transferring methodological advances developed with SatRain into next-generation global precipitation datasets, thereby supporting progress in meteorological research and applications.
Methods
Data Sources
The SatRain dataset integrates the following data sources:
- PMW observations,
- Vis and IR observations from geostationary platforms,
- ancillary environmental data,
- reference precipitation estimates from ground-based weather radars over CONUS,
- independent precipitation estimates from ground-based radars over Korea and gauge measurements in Austria.
A key challenge in creating the SatRain dataset was reconciling differences in spatial resolution and sampling across sensors and datasets. To balance flexibility with manageable dataset size, SatRain data is provided in two spatial sampling geometries. The first geometry is a regular latitude-longitude grid at 0.036° resolution. This resolution matches the native grid of a major global geostationary IR dataset^23^ and remains finer than the effective resolution of current satellite precipitation products. The second is the on-swath geometry, which retains the native spatial sampling of the PMW base sensor. Because many precipitation retrieval algorithms were originally designed to operate on the native sensor sampling, SatRain retains this format to support these retrieval designs and cross-comparison against existing operational retrievals such as GPROF.
Since PMW observations are only available at discrete overpass times for a given location, SatRain is organized around these overpasses, with coincident data from other sources collocated accordingly. As a result, the available training and testing samples are limited to the overpass times of the underlying PMW sensors.
Passive Microwave Observations
The PMW observations used to build the SatRain dataset are sourced from two different sensors: the GPM Microwave Imager (GMI^24^) aboard the GPM Core Observatory, and a selection of channels of the Advanced Technology Microwave Sounder (ATMS^25^) aboard the NOAA-20 satellite^26^. The GMI and ATMS sensors were chosen to represent two ends of the spectrum of PMW instrumentation used for measuring precipitation. GMI, the flagship PMW sensor of the GPM constellation, has been designed for precipitation remote sensing and features optimized spectral coverage and comparably high spatial resolution. In contrast, ATMS was developed primarily for operational weather forecasting and, compared to GMI, offers fewer precipitation-sensitive channels and significantly coarser spatial resolution.
Figure 2 compares GMI and ATMS observations of Hurricane Laura, collected at 12:41 UTC and 08:41 UTC, respectively, on August 27, 2020. GMI offers higher spatial resolution than ATMS, allowing finer cloud and precipitation structures to be resolved, but this advantage comes at the cost of a narrower swath and thus reduced spatial coverage. The instruments also differ in their scanning strategies. GMI operates as a conical scanner, with its antenna beam sweeping out a cone relative to the spacecraft, producing near-circular scans on the surface at a nearly constant Earth-incidence angle. This geometry ensures uniform polarization and viewing characteristics across the swath. ATMS, by contrast, employs a cross-track scanning approach, in which the antenna beam sweeps perpendicular to the spacecraft track. For cross-track sensors, footprint size increases with scan angle, resulting in coarser resolution toward the swath edges, while variations in path length and polarization angle introduce additional systematic differences across the scan.Fig. 2. Passive microwave observations from the GMI (a–c) and ATMS (d–f) sensors from the landfall of Hurricane Laura on August 27, 2020. The top row displays three selected channels from the GMI sensor, highlighting its high-resolution but limited swath. The bottom row presents corresponding channels from the ATMS sensor for comparison. The blue contour line encloses regions with surface precipitation rates exceeding 1 mm h^−1^.
The PMW observations in SatRain are taken from the calibrated brightness temperature products of the GPM mission for GMI^27^ and from ATMS aboard the NOAA-20 satellite^28^. The channels used in the dataset are summarized in Table 1, along with their polarizations and approximate footprint sizes. Because the GPM data product does not include the ATMS temperature-sounding channels near 50 GHz, these channels are excluded from the SatRain ATMS subset.Table 1. Frequencies (Freq.), polarizations (Pol.), and footprint (FP) sizes of the PMW observations included in the SatRain dataset.GMIFreq. [GHz]Pol.FP [km × km]10.65V32 × 1910.65H32 × 1918.7V18 × 1118.7H18 × 1123.8V15 × 9.236.5V14 × 8.636.5H14 × 8.689.0V7.2 × 4.489.0H7.2 × 4.4166.5V7.2 × 4.4166.5H7.2 × 4.4ATMSFreq. [GHz]Pol.FP [km]23.800QV7531.400QV7588.2QV32165.5QH16183.31 ± 7.0QH16183.31 ± 4.5QH16183.31 ± 3.0QH16183.31 ± 1.8QH16183.31 ± 1.0QH16For GMI, footprint sizes are reported as the full width at half maximum (FWHM) along and across the boresight direction. For ATMS, only the nadir FWHM is given; at nadir the footprint is approximately circular and therefore represented by a single value. The polarization of ATMS are denoted quasi-horizontal (QH) and quasi-vertical (QV) as the polarization mixture changes with the sensor viewing angle.
Geostationary Visible and Infrared Observations
Vis and IR sensors benefit from the shorter wavelengths of the radiation they measure, enabling much higher spatial resolution and deployment on geostationary platforms. From this vantage point, they provide near-continuous coverage of the underlying hemisphere. Consequently, geostationary observations serve as a critical complement to PMW observations for real-time and continuous precipitation monitoring.
Figure 3 shows observations from the 16 spectral channels of the ABI sensor aboard GOES-16 during the landfall of Hurricane Laura. The native spatial resolution of ABI channels ranges from 500 meters to 2 kilometers at the sub-satellite point on the equator. Although this resolution degrades over CONUS due to increasing viewing angles, it remains higher than that of PMW sensors. The first six channels are Vis and near-IR bands that measure reflected solar radiation and are only available during daylight hours. The remaining ten channels operate in the thermal IR and provide data continuously, both day and night. Among the thermal IR bands, the main distinguishing feature is their sensitivity to atmospheric water vapor. For instance, channels centered at 6.2, 6.9, and 7.3 μm are more sensitive to upper-tropospheric moisture. This sensitivity to water vapor provides contextual information on the moisture content of the air but reduces the penetration depth of the observations.Fig. 3. The 16 channels of the GOES Advanced Baseline Imager (ABI) observing Hurricane Laura during landfall on August 27, 2020, at 08:41 UTC. The first six channels primarily measure reflected solar radiation. The remaining channels measure infrared radiation emitted from the atmosphere. Observations from geostationary sensors have the advantage of providing close-to continuous coverage but are sensitive primarily to cloud-top properties and thus only provide limited information on precipitation close to the surface. The blue contour encloses areas where surface precipitation exceeds 1 mm h^−1^.
A particular challenge related to incorporating geostationary observations into global precipitation retrievals is that the channel availability changes between sensors and thus the geographical coverage regions. SatRain integrates data from CONUS, the Korean peninsula, and Austria, which are covered by different geostationary platforms. While observations over CONUS are derived from the GOES-16^29^ platform, observations over Korea are derived from the Himawari-8 and -9 platforms^30^, and observations over Austria from the Meteosat-10 platform^31^. Table 2 lists the central wavelengths for the channels included from the ABI sensor on GOES-16, the Advanced Himaware Imager (AHI^32^), and the SEVIRI^33^ sensor on Meteosat-10. The observations from the ABI, AHI, and SEVIRI sensors were downloaded from^34–36^, respectively.Table 2. Channel central wavelengths ABI sensor on GOES-16, the AHI sensor on Himawari-8/9, and the SEVIRI sensor on Meteosat-10.ChannelABIAHISEVIRI10.470.4550.7520.640.510.63530.860.6450.8141.380.861.6451.611.613.9262.262.266.2573.93.857.3586.156.258.797.06.959.66107.47.3510.8118.58.612.0129.79.6313.41310.310.451411.211.201512.312.351613.313.3
Latest-generation geostationary platforms provide observations at temporal resolution of at least 10 minutes allowing them to closely track the evolution of precipitation systems. In order to allow users to explore the temporal information content in time-resolved geostationary observations, the SatRain dataset includes observations from multiple time steps around the overpass of the PMW sensor.
In addition to the multi-channel Vis and IR observations from the latest generation of geostationary sensors, the SatRain dataset also integrates 0.036° gridded thermal IR observations from the 11 μm infrared window sourced from the Climate Prediction Center (CPC) global gridded geostationary IR dataset^23^. Since these observations are available almost continuously from 1998, they play an important role for generating long-term precipitation records and are included as an independent input data source in the SatRain dataset.
Ancillary Data
Because the relationship between satellite observations and surface precipitation is often under-constrained, it is common to augment satellite observations with complementary environmental information, so-called ancillary data, to improve the accuracy of the precipitation estimates. Typical examples include the surface type, atmospheric and surface temperatures, humidity, and elevation. The SatRain dataset includes several static and dynamic ancillary variables. Dynamic ancillary data describing the state of the atmosphere and the surface are derived from the ERA5^37^ dataset. In addition to that, the ancillary data also contains an 18-class surface classification that has been developed for the GPROF precipitation retrieval^38^ combing microwave-based surface-type information with snow- and sea-ice coverage data from the Autosnow product^39^. In terms of static variables, SatRain provides the surface elevation sourced from the NOAA Global Land One-kilometer Base Elevation (GLOBE) digital elevation model^40^. Figure 4 showcases the ancillary variables included in the SatRain dataset for the landfall of Hurricane Laura.Fig. 4. Ancillary variables provided by the SatRain dataset for the scene depicted in Fig. 1. Panels (a) to (q) show the dynamic ERA5 fields included in the ancillary data. Panel (r) shows the 18-class surface classification from the GPROF algorithm and panel (s) the surface elevation from the NOAA Globe dataset.
Precipitation Reference
The precipitation reference used in the SatRain dataset is derived from gauge-corrected ground-based precipitation radar measurements from NOAAs Multi-Radar Multi-Sensor (MRMS^41^) product. MRMS is based on radar observations from NEXRAD, the most extensive network of precipitation radars in the world comprising around 160 polarimetric S-band radars. The radar-derived estimates of liquid precipitation are corrected using hourly gauge-correction factors thus enforcing consistency between instantaneous estimates and direct measurements of hourly accumulations from gauge stations. While a certain level of residual uncertainty in these estimates cannot be eliminated, they are generally considered to be the best currently available estimates of surface precipitation with near-complete coverage over CONUS. In addition to reference surface precipitation rates, the SatRain dataset contains a radar quality index and the gauge correction factor, allowing the user to customize the quality requirements for the radar estimates used during both training and evaluation. Furthermore, the dataset contains precipitation-type masks identifying convective and stratiform rain, snow, and hail as provided by the MRMS data. Examples of these fields are shown in Fig. 5.Fig. 5. Reference precipitation estimates and auxiliary fields during the landfall of Hurricane Laura. Panel (a) shows surface precipitation estimates from NOAA’s gauge-corrected Multi-Radar Multi-Sensor product. Panel (b) displays the radar quality index quantifying the reliability of the precipitation estimates. Panel (c) presents the convective fraction field, illustrating the hydrometeor classification data included in the SatRain dataset.
Independent Precipitation Reference
The SatRain training data is derived from four years (2018-2021) of ground-based radar measurements over CONUS. While this region encompasses a wide range of climate zones, it does not fully capture the diversity of precipitation systems observed globally. To mitigate this limitation, the testing data includes a full year withheld from the training period, as well as two additional test sets derived from distinct geographical regions and independent measurement systems. These complementary datasets help reduce the risk of overfitting to the weather patterns characteristic of the training domain.
The first geographically independent test dataset consists of gauge-corrected, ground-based radar rainfall estimates over South Korea, generated using radar compositing methods optimized for the Korean domain^42^. The Korea-specific merging technique uses radial basis function interpolation to combine radar and rain gauge observations resulting in a high-resolution rainfall product in both space and time^43^. Although the measurement approach is similar to that used in the MRMS reference data over CONUS, the processing of raw data into precipitation estimates differs. The dataset also represents a distinct climate regime from the training data, offering a valuable test of the precipitation retrieval model’s ability to generalize beyond the conditions typically encountered over CONUS. Studies such as^44^ showed that cloud characteristics affecting both PMW radiometers and IR observations differ substantially between Korea and CONUS and can cause significant biases in algorithms applied to these two regions. The independent testing data from Korea thus provides an opportunity to assess whether retrieval improvements are achieved at the cost of global generalizability.
The second independent evaluation dataset is derived from gauge measurements from the WegenerNet^45^ gauge network around the Feldbach region in Austria. While IPWG focuses primarily on gauge-corrected radar data for validation, WegenerNet is unique in that its gauge density is sufficiently high that the addition of radar data would not modify any of the gauge accumulations. In addition, it offers validation over a mountainous regime that radar and gauge networks still struggle with. For the comparison against satellite-based precipitation estimates, the half-hourly accumulations from the ground stations were converted to precipitation rates and aggregated to the 0.036° grid using binning. As can be seen in Panel (b) of Fig. 6, the gauge density is sufficient to cover 24 grid cells with at least two gauges per cell.Fig. 6. Independent test data included in the SatRain dataset. Panel (a) shows the spatial coverage of the three temporally or spatially independent test datasets. Panel (b) shows the location of the WegenerNet gauge stations used as reference measurements in the Austria domain and the grid they are aggregated to. Panel (c) shows an example in the Korea domain, with radar and rain-gauge data obtained from the Korea Meteorological Administration.
Dataset Generation
The SatRain dataset is generated by extracting observations from all available overpasses of the GMI and ATMS sensors over the target domain and adding the corresponding geostationary observations, ancillary data, and ground-based reference precipitation estimates. The resulting collocation scenes are then used to extract fixed-size training scenes to produce AI-ready training and validation sets suitable for training ML precipitation retrievals.
The SatRain dataset is partitioned into training, validation, and testing subsets that are designed to always be either temporally or spatially independent. Training and validation data are extracted from the years 2018 through 2021, with the first five days of each month allocated to the validation set and the remaining days to the training set. For testing, the CONUS subset uses data from 2022. The independent test set over Austria is based on observations from 2021 and 2022, while the Korea test set covers the period from October 2022 through October 2023.
Generation of Collocation Scenes
The first step of the creation of the SatRain dataset consists of the extraction of collocation scenes for every overpass of the PMW base sensor, i.e., GMI or ATMS, over the targeted domain (CONUS, Austria, or Korea). The resulting collocation scene contains all retrieval input data, i.e. satellite observations and ancillary data, combined with the coincident reference precipitation on a shared spatial grid. Two type of collocation scenes are extracted for every overpass of the base sensors: An on-swath scene, which uses the native sampling of the PMW observations, and a gridded scene, which contains all data regridded to a regular latitude-longitude grid with a resolution of 0.036°.
The collocation process, as illustrated in Fig. 7, starts out with the PMW observation from an overpass of GMI or ATMS over the domain containing the reference data. Corresponding ground-based reference data and ancillary data are extracted to cover the time range of the overpass and interpolated to the observation time of each scan-line of the PMW observations. The MRMS data, which have a native resolution of 0.01°, are reduced in resolution to match the 0.036° grid by smoothing using a Gaussian filter with a full width at half maximum of 0.036° and interpolated linearly to the target grid. The mapping of the reference precipitation estimates to the on-swath geometry is performed by nearest-neighbor interpolation. Similarly, the PMW observations are mapped to the regular latitude-longitude grid by nearest neighbor interpolation.Fig. 7. Flow diagram illustrating the data flow for collocating the satellite observations and ground-based reference precipitation estimates for the SatRain dataset.
The global gridded IR geostationary observations are extracted at a temporal resolution of 30 min over a time range of 8 h centered on the median overpass time. Multi-channel Vis and IR observations from the ABI, AHI, and SEVIRI sensors are extracted over a time window of 1 hour and a temporal resolution of 10 minutes. The geostationary observations are mapped to the gridded and on-swath geometries using nearest-neighbor interpolation.
Training Scene Extraction
To generate AI-ready training and validation data from the collocation dataset, fixed-size training scenes are extracted from the previously created collocation dataset, separately for the gridded and on-swath subsets. The scenes are extracted randomly, allowing an overlap of up to 50% between neighboring scenes, requiring 75% of the pixels to contain valid observations and reference data. The scene size for the gridded data is 256 pixel × 256 pixel and 64 pixel × 64 pixel for the on-swath data. The smaller size of 64 × 64 used for the on-swath data is to accomodate both the GMI sensor, which has 221 pixels per scan, and the ATMS sensor which records only 96 pixel per scan.
Figure 8 shows an example collocation scene from a GMI overpass of Hurricane Laura at 12:41 UTC on August 28, 2020. The grey boxes mark the randomly extracted fixed-size training scenes in both the gridded and on-swath geometries. Due to the irregular sampling pattern of PMW sensors, the on-swath scenes appear distorted when displayed in the equirectangular projection used for the figures. Training patches are restricted to the PMW swath to ensure that each sample includes valid PMW observations. Although this particular example covers only a small portion of the CONUS, the PMW swath shifts with each orbit, and the resulting training, validation, and testing datasets collectively span the full CONUS domain.Fig. 8. Fixed-size training scenes extracted from the SatRain collocation scenes. Panels (a), (b), and (c) show selected channels from the passive microwave (PMW), visible, and infrared observations that make up the input data of the SatRain dataset. Panel (d) shows the ground-radar-based precipitation reference used as training targets. Grey lines mark the outlines of the training samples extracted from this collocation scene for the gridded and on-swath observations. Black lines mark the sample training scenes displayed in Panel (e) and (f).
Data Records
Dataset Organization
The SatRain dataset is organized in a hierarchical folder structure that mirrors its conceptual structure. At the top level, it is divided into two independent subsets corresponding to collocation scenes from GMI overpasses and ATMS observations, with the underlying PMW instrument referred to as the base sensor. For each base sensor, the data are partitioned into training, validation, and testing splits in line with machine learning best practices.
To accommodate different computational and storage constraints, the training and validation data are further subdivided into size-based subsets (‘xs’, ‘s’, ‘m’, ‘l’, and ‘xl’). This design supports lightweight experimentation on smaller systems as well as large-scale training on modern deep learning architectures. Files are not repeated across the size-based subsets, instead each of the subsets is meant to include the files in the preceeding, smaller subsets. Users aiming to use the xl subset should thus combine files from all subsets.
Since all data is available in both gridded and on-swath geometries, the directory is split once more into the data represented using the on-swath and gridded spatial sampling. Finally, files are organized temporally into folders by year, month, and day of the month. The resulting folder hierarchy for the training and validation data is shown in Fig. 9.Fig. 9. Directory structure of the training and validation splits.
The testing data are organized slightly differently from the training and validation splits. The testing set is not subdivided into size-based subsets, since all evaluations must be performed on the same data to ensure comparability. Instead, the testing data are grouped by the underlying spatial domain: CONUS, Korea, and Austria, which correspond to the available reference data sources: MRMS over CONUS, ground-based radar data over Korea, and in-situ measurements from the WegenerNet stations in Austria. The resulting folder hierarchy is illustrated in Fig. 10.Fig. 10. Directory structure of the testing split.
A further distinction between the training and validation data and the testing data is that the collocation scenes in the testing set are not divided into fixed-size patches. The testing data preserves the original observation structure to avoid sampling distortions, simplify comparisons between gridded and on-swath retrievals, and enable direct evaluation of existing precipitation products on the test data.
Data Files
The various input and target data for each training scene are stored in separate NetCDF4 files. This modular organization allows users to download just the data they intend to use, for example, only the small (‘s’) subset of the GMI and target data to train and evaluate a retrieval using only PMW observations. Each file is identified using an individual prefix (‘gmi_’, ‘atms_’, ‘geo_’, ‘geo_ir_’, ‘ancillary_’,‘target_’) following a time stamp in the format YYYYMMDDHHMMSS containing the median observation time. Input and target files corresponding to a specific training, validation, or testing sample can thus be identified using this timestamp.
Due to the large size of the time-resolved geostationary observations, the geostationary observations are split into files containing only the observations closest to the reference precipitation estimates and files containing observations from multiple observations times. The multi-timestep observations are stored in separate files with the suffix ‘t’, i.e., ‘geo_t< timestamp>.nc’ and ‘geo_ir_t_< timestamp>.nc’.
PMW Observations
The PMW observations in the SatRain dataset consist of observations from the GMI sensor and the ATMS sensor on the NOAA-20 satellite. They are stored in files labeled ‘gmi_< timestamp>.nc’ for the subset using GMI as base sensor and, correspondingly, ‘atms_<timestamp>.nc’ for the subset using ATMS as base sensor. Each file contains the brightness temperatures in Kelvin for each channel (observations), the corresponding earth-incidence angles in degree (earth_incidence_angle), and the observation time (scan_time) corresponding to each scan line. The channels included for the GMI and ATMS sensors are listed in Table 1.
Geostationary Vis and IR Observations
The multi-channel, geostationary Vis and IR observations from the GOES, Himawari, and Meteosat platforms are stored in files named ‘geo_< timestamp>.nc’. These files contain the observations closest in time to the measurement time of the reference precipitation estimates in the variable observations. The visible channels are stored as reflectances while thermal IR channels are stored using brightness temperatures. The geostationary data currently do not include viewing angles so the user will have to add them manually. The multi-timestep files (geo_t_< timestamp >.nc’) contain observations from four 10-minute time steps prior to the collocation median time and three 10-minute time steps after the collocation median time.
Since GOES observations are only available over CONUS, the geostationary observations for the test data from the Korea and Austria domains are derived from the AHI sensor onboard Himawari-8 and -9 and the SEVIRI sensor onboard Meteosat-10. Table 2 lists the central wavelengths of the channels of each of the included sensors. Since the sensors have different channels, the observations differ in their spectral coverage and users will need to account for that in their algorithm design.
Geostationary IR Observations
The single-channel gridded IR observations from the global, merged CPC dataset^23^ are stored in files named ‘geo_ir_< timestamp>.nc’ and contain IR window-channel observations from wavelengths around 11 μm. The observed brightness temperatures in K are stored in the variable observations. The single-timestep files contain the Geo IR observations closest to the measurement time of the reference precipitation estimates. The temporally-resolved Geo IR observations contain 16 half-hourly observations centered on the median observation time and are stored in files named ‘geo_ir_t_< timestamp>.nc’.
Ancillary Data
The ancillary data is stored in separate files named ‘ancillary_< timestamp >.nc’. Each file contains the ancillary variables listed in Table 3.Table 3. List of the variables, their explanations, units, and data sources included in the ancillary data.Variable nameExplanationUnitSourceten_meter_wind_uZonal wind at 10 m altitudem s^−1^ERA5ten_meter_wind_vMeridional wind at 10 m altitudem s^−1^ERA5two_meter_dew_pointDew-point temperature at 2 m altitudeKERA5two_meter_temperatureNear-surface temperatureKERA5capeConvective available potential energyJ kg^−1^ERA5sea_ice_concentrationFractional sea-ice coverage—ERA5sea_surface_temperatureSea surface temperatureKERA5skin_temperatureSurface skin temperatureKERA5snow_depthSnow depthkg m^−2^ERA5snow_fallSnowfall ratem h^−1^ERA5surface_pressureSurface pressurehPaERA5total_column_cloud_ice_waterVertically integrated mass of cloud icekg m^−1^ERA5total_column_cloud_liquid_waterVertically integrated mass of liquid cloud dropletskg m^−2^ERA5total_column_water_vaporVertically integrated mass of water vaporkg m^−2^ERA5total_precipitationTotal precipitationm h^−1^ERA5convective_precipitationConvective precipitationm h^−1^ERA5leaf_area_indexHalf of the total green leaf area per unit ground aream^2^ m^−2^ERA5surface_typeGPROF 18-class dynamic surface classification—GPROF V7elevationSurface elevationmNOAA GLOBE
Reference Data
The reference data for every scene are stored in a file ‘target_< timestamp>.nc’, where the timestamp matches that of the input data. The reference data files contain the surface precipitation in a variable called ‘surface_precip’. Additionally, the reference data files derived over CONUS contain several quality indicator variables that can be used to filter the reference data samples used for training and validation. The primary quality indicator is the radar quality index (radar_quality_index), which provides an estimate of the quality of the surface precipitation estimates based on the radar beam height, beam blockage, and the height of the freezing level. Moreover, the files contain the gauge correction factor (gauge_correction_factor) that was applied to correct the radar-only precipitation estimates. Finally, the files also contain the fraction of valid (valid_fraction), snowing (snow_fraction), and hailing (hail_fraction) 0.01°-resolution pixels within the downsampled 0.036° grid box of the SatRain dataset. Since the radar data over Korea and the station data over Austria do not provide this additional information, these auxiliary fields are not provided by the target data files from the Korea and Austria domains.
Technical Validation
To assess the technical consistency of the dataset, we trained three precipitation retrieval models on the CONUS-based training data, each relying on one of the primary input observation types: single-channel IR data from the CPCIR dataset (Geo-IR), multi-channel Vis and IR geostationary observations from the GOES ABI (Geo), and PMW observations from GMI (GMI). All retrievals rely solely on satellite observations and exclude the ancillary data included in SatRain. Each retrieval is implemented U-Net-type encoder-decoder based on the EfficientNet-V2 architecture^46^ with 14 million parameters.
The SatRain-based ML retrievals are evaluated against two baseline precipitation datasets. The first is the version 7 of the GPROF retrieval (GPROF V7), the current operational PMW algorithm for the GPM constellation that underpins the precipitation estimates used in the IMERG gridded product. The second baseline is the ERA5 reanalysis, which offers continuous global precipitation fields and therefore serves as a natural reference for assessing satellite-based precipitation algorithms.
Case Studies
We first demonstrate retrieval results for two case studies from the test data of the SatRain dataset: A convective squall line over western CONUS and the landfall of Typhoon Khanun over Korea.
Figure 11 presents the reference and retrieved surface precipitation fields for a quasi-linear convective system that developed on the afternoon of April 13, 2022 over the Southern and Midwestern United States. The reference field shows scattered pockets of intense convection in the southern portion of the domain, which merge into a quasi-linear system farther north. In contrast, weaker, scattered patches of stratiform precipitation occur in the northernmost part of the scene.Fig. 11. Precipitation retrievals for a quasi-linear convective system, comparing models trained on the SatRain dataset with ground-based precipitation estimates and two baseline products. Panel (a) shows the ground-based reference precipitation, panel (b) the ERA5 reanalysis, and panel (c) the GPROF V7 retrieval applied to GMI observations. Panels (d), (e), and (f) present SatRain-trained retrievals using single-channel IR observations (Geo-IR), multi-channel Vis and IR observations (Geo), and GMI PMW observations, respectively.
Both the GPROF V7 baseline estimates and the SatRain-based retrievals capture the intense convective precipitation with high fidelity. Larger differences appear in the stratiform region to the north, particularly for the SatRain retrievals relying exclusively on visible and infrared observations. Despite this, all SatRain-based retrievals achieve strong accuracy metrics, with even the single-channel IR model surpassing the GPROF V7 baseline. ERA5 performs least well in representing the convective event: although it produces comparatively high rain rates in the south, these features are displaced relative to the reference, resulting in an elevated mean-squared error and a low linear correlation coefficient.
Figure 12 compares the same retrievals on a test scene from the Korea domain depicting the landfall of Typhoon Khanun on August 9, 2023. All estimates capture the large-scale precipitation features of the Typhoon but with clear differences in accuracy reflecting the information content of their input observations^47^. The PMW-based retrieval performs best, reproducing much of the fine-scale structure evident in the reference estimates. The multi-channel geostationary retrieval captures the primary precipitation bands but misses finer details resolved by the PMW retrieval. In contrast, the single-channel IR retrieval shows the weakest performance, with limited structural detail and correspondingly lower linear correlation and higher mean-squared error.Fig. 12. Same layout as Figure 11, but for a case depicting the landfall of Typhoon Khanun over the Korean Peninsula on August 9, 2023, taken from the Korea test-domain dataset.
Compared to the conventional baselines, the SatRain GMI retrieval shows visibly better agreement with the reference precipitation fields than GPROF V7, a result that is supported by scene-based accuracy metrics. The SatRain Vis and IR retrieval achieves accuracy comparable to ERA5 but worse than GPROF V7, which is expected since GPROF V7 leverages passive microwave observations that provide a more direct link to precipitation. The SatRain Geo-IR retrieval performs worse than both baseline methods for this specific case. However, this is consistent with the very limited information content available from its input observations.
Test-Set Accuracy
The ML models trained on the CONUS dataset were further evaluated using all test scenes from the three test regions (CONUS, Austria, and Korea). The test set includes 619 overpasses over the Austria domain, 600 over the Korea domain, and 2912 over the CONUS domain, covering one year for CONUS and Korea and two years for Austria. As shown in Fig. 13, the results align with the case studies discussed above. The SatRain-based GMI retrieval consistently outperforms the GPROF V7 baseline, even though both rely on the same input observations. Retrievals using geostationary measurements (Geo and Geo-IR) exhibit lower overall accuracy but still perform better than the ERA5 baseline.Fig. 13. Evaluation of quantitative precipitation estimates from two state-of-the-art precipitation datasets (ERA5 and GPROF) and a U-Net retrieval trained using the different satellite observations of the SatRain dataset. Each retrieval is evaluated for each of the three testing domains of the SatRain dataset. Panels (a) to (d) show the Bias, mean-absolute error (MAE), mean-squared error (MSE), and linear correlation coefficient, respectively.
While the SatRain retrievals demonstrate notable biases over Austria and Korea, these are likely attributable to the exclusive use of CONUS data for training. Such systematic errors align with previous studies documenting the sensitivity of precipitation retrievals to regional precipitation characteristics^44^. Importantly, these biases are not unique to SatRain but also affect operational algorithms such as GPROF V7. Beyond these biases, the relative performance of SatRain versus the baseline retrievals mirrors the results obtained over CONUS. Despite differences in absolute error magnitudes across domains, the ranking of retrieval methods remains largely consistent, suggesting that SatRain-based evaluations generalize well across independent regions, sensors, and time periods.
One exception occurs for the Geo retrieval over Austria, where MSE and MAE values increase relative to other domains. This degradation likely reflects differences between the SEVIRI channels available over Austria and the ABI channels on which the model was trained. Although training was limited to channels with the closest overlap and quantile remapping was applied to harmonize the distributions, discrepancies in channel characteristics and calibration still reduced performance. Accommodating such inter-sensor differences remains an open challenge for machine learning-based precipitation retrievals, and the SatRain dataset offers a platform to investigate these issues further.
In addition to cross-sensor comparisons, we also used SatRain to evaluate the performance of different machine learning approaches. Using GMI and ATMS observations, we trained four retrieval models based on Random Forests, XGBoost, a multi-layer perceptron (MLP), and the U-Net architecture assessed above. Their performance, shown in Fig. 14, reveals a consistent ranking across both sensors and all three domains with the U-Net-based models clearly outperforming the other techniques. Although the relative ordering of Random Forests, XGBoost, and MLP varies by region, their performance differences remain modest. These findings underscore SatRain’s utility as a robust and reliable benchmark for assessing the skill of machine learning-based precipitation retrievals.Fig. 14. Like Fig. 13 but for four different machine-learning techniques trained on GMI (first row) and ATMS (second row) observations.
We also evaluated the ability of the SatRain-based U-Net retrievals to detect precipitation and heavy precipitation using thresholds of 0.1 mm h^−1^ and 10 mm h^−1^, respectively. For the assessment, we distinguish between probabilistic detection (predicted using probabilities) and deterministic detection (predicted using binary classifications). To enable the SatRain U-Net models to produce probabilistic detection outputs, they were trained with a quantile loss^48^. The predicted quantiles were then used to compute exceedance probabilities for the precipitation and heavy precipitation thresholds. Deterministic classifications were obtained by applying a 50% probability threshold.
Figure 15 summarizes the detection performance of the various retrievals. ERA5 total precipitation was converted into binary detection masks by marking areas exceeding the respective threshold as positive. Because ERA5 does not provide probabilistic precipitation information, its probabilistic detection skill cannot be evaluated. GPROF V7, in contrast, provides both precipitation probabilities and a binary precipitation flag, which we use to assess its deterministic and probabilistic detection skill for precipitation detection. Since GPROF V7 does not include a dedicated output for heavy-precipitation detection, heavy-precipitation detections were inferred from regions where the estimated surface precipitation exceeds 10 mm h^−1^.Fig. 15. Detection skill for precipitation (first row) and heavy precipitation (second row) for the ERA5 and GPROF V7 baselines and a GMI-based U-Net retrieval trained on the SatRain data. Columns 1 to 3 show the probability of detection (POD), false-alarm rate (FAR), and Heidke Skill Score (HSS) for the deterministic detection. Column 4 shows the area under the precision-recall curve used to assess the probabilistic detection skill.
The resulting detection scores generally mirror the ranking observed for precipitation estimation: SatRain-based models outperform the baselines across most metrics and domains. An exception is the probability of detection (POD), for which ERA5 and GPROF V7 achieve higher values over the CONUS and Korea domains. However, POD is inherently biased because it ignores false alarms. The Heidke Skill Score, which accounts for both false positives and false negatives, provides a more balanced measure of detection performance and confirms the advantage of the SatRain models. Similar patterns are observed for heavy-precipitation detection. All models exhibit low skill over the Austria domain due to the rarity of heavy-precipitation events there. The 619 test scenes contain only four such cases across the two-year testing period. This underscores the challenge of detecting heavy precipitation across climatologically diverse regions.
These results show that the SatRain dataset can be used to train precipitation retrievals that outperform conventional baselines across target domains and tasks and thus demsonstrates the technical consistency of the dataset. The SatRain dataset offers a well-defined framework for training and evaluation thus enabling direct comparison of different ML techniques. The independent test data provide a crucial check, ensuring that performance gains generalize beyond the training domain rather than reflecting overfitting to regional measurement errors or precipitation characteristics. In addition, the ability to evaluate models across sensor types and to combine observations from multiple sensors and time periods makes SatRain a flexible foundation for developing advanced ML-based retrieval methods.
Usage Notes
Different scientific and societal applications may require precipitation retrievals to emphasize specific characteristics, such as retrievals targeting extreme precipitation or specific precipitation types such as snow or hail. While no single benchmark can serve every possible use case, the SatRain dataset defines five distinct evaluation tasks designed to test the ability of ML algorithms to reproduce key aspects of precipitation events. These tasks include: (1) precipitation rate estimation, (2) probabilistic detection of precipitation, (3) deterministic detection of precipitation, (4) probabilistic detection of heavy precipitation, and (5) deterministic detection of heavy precipitation. We adopt thresholds of 0.1 mm h^−1^ and 10 mm h^−1^ to define precipitation and heavy precipitation, respectively. Figure 16 illustrates example results for each of these tasks using the GMI retrieval presented in the previous section.Fig. 16. Example retrieval results for the five suggested precipitation estimation and detection tasks during landfall of Typhoon Khanun on August 9, 2023. Panel (b) shows quantitative precipitation estimates retrieved from GMI observations. Panel (c) shows the probability of precipitation for the probabilistic precipitation detection task. Panel (d) shows the precipitation flag for the deterministic precipitation detection task. Panel (e) and (f) show the corresponding probabilistic and deterministic results for the detection of heavy precipitation, defined as precipitation exceeding 10 mm h^−1^.
Evaluation Protocol
To ensure fair comparison of precipitation retrievals trained on the SatRain dataset, it is essential that models are evaluated using a consistent set of criteria. We therefore propose a standardized evaluation protocol for benchmarking ML retrievals on the SatRain dataset. Users may choose to evaluate their models on all or a subset of the defined tasks. The recommended accuracy metrics for each task are listed in Table 4.Table 4. Precipitation estimation and detection tasks and metrics for evaluating precipitation retrieval methods on the SatRain dataset.TaskMetricsPrecipitation quantificationRelative bias, mean absolute error, mean squared error, symmetric mean absolute percentage error, linear correlation coefficient, effective resolutionPrecipitation detectionProbability of detection, false alarm rate, Heidke Skill ScoreProbabilistic precipitation detectionPrecision–recall curveHeavy precipitation detectionProbability of detection, false alarm rate, Heidke Skill ScoreProbabilistic heavy precipitation detectionPrecision–recall curve
To ensure comparability of benchmark results across algorithms, evaluations should be performed against the gridded reference data. This approach avoids distortions in the evaluation statistics caused by the irregular spatial sampling of on-swath observations. For cross-track scanners, for example, both sampling density and spatial resolution decrease toward the swath edges. The reduced sampling at the swath edges would thus underestimate the effect of the reduced resolution compared to evaluation against the gridded data. To facilitate reproducible comparisons, the gridded reference data files include the scan and pixel coordinates of the nearest swath pixel of the corresponding on-swath file. Using this information, the on-swath retrieval results can be mapped to the gridded reference data easily and consistently.
A reference implementation of the proposed protocol is available through the satrain package. By default, the evaluation compares all retrieval outputs against the reference precipitation estimates on the 0.036° regular latitude-longitude grid, ensuring results are independent of the retrieval’s native coordinate system. For the CONUS domain, evaluations should be restricted to regions with a radar-quality index of at least 0.5 and should include all precipitation types. For the other two domains all reference estimates should be used for the evaluation.
The satrain package
To facilitate community access and encourage widespread adoption, we developed the satrain Python package. This package streamlines dataset download and management, allowing users to begin working with SatRain without the burden of manual data handling. Comprehensive documentation, including installation instructions, usage examples, and tutorials, is available at satrain.readthedocs.org.
In addition to data access, the package implements SatRain’s standardized evaluation protocol. This enables users to benchmark models trained directly on SatRain and to evaluate independently developed retrievals using the same criteria. A well-defined interface allows all users to leverage the package to automatically conduct evaluations across all testing domains, tasks, and metrics. The satrain package also provides automated tiling functionality to ease the transition from the fixed-size scenes of the training and validation data to the variable-size overpasses used for the testing data.
Limitations
The SatRain dataset is constructed from high-quality input datasets using state-of-the-art techniques designed to reduce uncertainties in both the satellite observations and the precipitation reference. Despite these efforts, residual uncertainties and measurement errors remain in both components.
On the input side, clearly corrupted satellite imagery is flagged and removed from the satellite-observation data used to construct the SatRain dataset. However, more subtle issues such as undetected artifacts or gradual changes in sensor characteristics may persist and affect the data. These represent practical challenges that any precipitation retrieval must contend with warranting their inclusion in the SatRain dataset.
The precipitation reference data are also subject to non-negligible uncertainties. Although gauge-corrected, ground-based radar composites are widely considered the most reliable spatially continuous precipitation estimates currently available, they are not without error. Beam overshooting, uncertainties in microphysical assumptions, and the inherent difficulty of quantifying snowfall all introduce systematic biases. Snowfall is particularly problematic: most gauges measure it poorly, and MRMS does not apply gauge corrections to snowfall estimates. As a result, snowfall present in the SatRain training and test data should be treated as highly uncertain. For the testing data from the Austria domain, which is derived from the WegenerNet gauge network, only data from heated gauges are used during snowfall, but this reduces gauge density, limits statistical robustness, and does not fully resolve the underlying uncertainties in gauge measurements.
Over ocean, the radar-based reference data are not gauge-corrected, further increasing their uncertainty. In addition, radar beam height increases with distance offshore, making beam overshooting more likely and reducing the reliability of the estimates the farther they are from the coastline.
Further limitations apply to mountain regions. While the SatRain training data covers all of CONUS, including the western mountains, the availability and quality of reference data in these areas are generally lower than in the more densely populated eastern United States. Reduced radar coverage, orographic enhancement, and the occurrence of mixed-phase precipitation processes all contribute additional uncertainty to the reference fields. These limitations inevitably propagate into any machine-learning retrievals developed using the SatRain dataset.
To reduce the impact of these uncertainties on retrieval evaluation, SatRain includes independent test datasets from geographically distinct domains that rely on entirely independent measurement systems. Performance gains that transfer to these independent datasets are more likely to reflect genuine improvements in retrieval capability, rather than overfitting to the same reference data used in training.
It is also important to note that the primary purpose of SatRain is to serve as a benchmark for evaluating and comparing retrieval algorithms, rather than as a basis for developing globally accurate precipitation retrievals. The SatRain dataset is limited to training data over the CONUS and is therefore not designed for the development of global precipitation retrievals. Algorithms trained on SatRain will learn to capture regional precipitation characteristics specific to North America, which may result in substantial biases or retrieval errors when applied to other parts of the world.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1Levizzani, V. et al. Satellite precipitation measurement (Springer, 2020).
- 2Huffman, G. J. et al. Integrated multi-satellite retrievals for the global precipitation measurement (gpm) mission (imerg). In Satellite precipitation measurement: Volume 1, 343–353 (Springer, 2020).
- 3Kubota, T. et al. Global satellite mapping of precipitation (gsmap) products in the gpm era. In Satellite precipitation measurement: Volume 1, 355–373 (Springer, 2020).
- 4Amell, A., Hee, L., Pfreundschuh, S., & Eriksson, P. Probabilistic near-real-time retrievals of Rain over Africa using deep learning. Journal of Geophysical Research: Atmospheres 130, e 2025 JD 044595, 10.1029/2025 JD 044595 (2025).
- 5NOAA Climate Prediction Center. Ncep/cpc level-3 merged infrared brightness temperatures (global, 4 km, half-hourly). https://gpm.nasa.gov/data/directory/ncepcpc-level-3-merged-infrared-brightness-temperatures-0 (2025).
- 6Goldberg, M. D. & Weng, F. Advanced technology microwave sounder. In Qu, J. J., Gao, W., Kafatos, M., Murphy, R. E. & Salomonson, V. V. (eds.) Earth Science Satellite Remote Sensing: Vol. 1: Science and Instruments, 243–253 (Springer, Berlin, Heidelberg, 2006).
- 7Berg, W. GPM GMI_R Common Calibrated Brightness Temperatures (Collocated, L 1C, 1.5-hour, 13 km, Version 07). https://data.nasa.gov/dataset/gpm-gmi-r-common-calibrated-brightness-temperatures-collocated-l 1c-1-5-hours-13-km-v 07-gpm-0e 459 (2022).
- 8Aminou, D. M. A. Msg’s seviri instrument. ESA Bulletin(0376-4265) 15–17 (2002).