ChatGPT Relies More Heavily on Consonants Than on Vowels to Recognize Words
Juan Manuel Toro

TL;DR
This paper shows that ChatGPT, like humans, relies more on consonants than vowels when judging word similarity.
Contribution
The study demonstrates that ChatGPT exhibits a consonant bias in word similarity judgments, similar to human language processing.
Findings
ChatGPT uses consonants more than vowels to judge similarity between words.
This consonant bias was observed in both English and Spanish.
The model's behavior suggests it learns and mimics human language patterns.
Abstract
Humans develop biases during language learning. For example, we rely more heavily on consonants than on vowels to identify words. Advances on artificial intelligence have allowed the development of proficient large language models that sometimes mimic humans’ language use. They do so by tracking regularities in natural language datasets that are used to train them. Here we test the hypothesis that tracking such regularities is enough for the emergence of responses that resemble the consonant bias. We asked ChatGPT which of two nonsense words (one with a vowel and one with a consonant change) was more similar to a target word. We observed that the model uses more the consonants than the vowels to perform similarity judgments across words in the two languages that we tested (English and Spanish).
Genes, proteins, chemicals, diseases, species, mutations and cell lines named across the full text — each resolved to its canonical identifier and authoritative record.
Click any figure to enlarge with its caption.
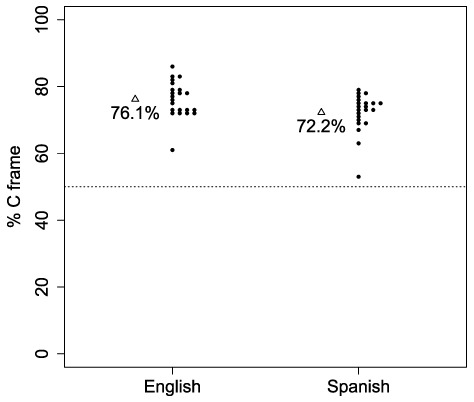 Figure 1
Figure 1Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsNeurobiology of Language and Bilingualism · Language Development and Disorders · Phonetics and Phonology Research