Accurate and interpretable prediction of chemical oxygen demand using explainable boosting algorithms with SHAP analysis
Khaled Merabet, Sungwon Kim, Salim Heddam, Fabio Di Nunno, Francesco Granata, Ozgur Kisi, Rana Muhammad Adnan, Mohammad Zounemat-Kermani, Christoph Külls

TL;DR
This study compares machine learning models to predict chemical oxygen demand in water, finding that NGBoost provides the most accurate and interpretable results.
Contribution
The novel contribution is the use of NGBoost for COD prediction, which provides probabilistic outputs and uncertainty quantification.
Findings
NGBoost achieved the highest predictive accuracy at Toilchun with R = 0.979 and NSE = 0.958.
SHAP analysis identified TOC, BOD₅, and SS as the most influential variables for COD prediction.
NGBoost's probabilistic outputs allow for better quantification of COD variability and model uncertainty.
Abstract
Accurate prediction of Chemical Oxygen Demand (COD) is vital for effective water quality management and pollution control. This study compares six ensemble boosting models, AdaBoost, CatBoost, XGBoost, LightGBM, HistGBRT, and NGBoost, for estimating COD from multiple water quality parameters, including pH, dissolved oxygen, suspended solids, and specific conductance. Data from two monitoring stations in South Korea (Toilchun and Hwangji) were used to train and validate the models. Model performance was evaluated using RMSE, MAE, R, NSE, and PBIAS, while interpretability was assessed through SHapley Additive exPlanations (SHAP). Results showed that NGBoost achieved the highest predictive accuracy at Toilchun (R = 0.979, NSE = 0.958, RMSE = 0.397 mg/L), while CatBoost performed best at Hwangji (R = 0.861, NSE = 0.733, RMSE = 0.477 mg/L). As NGBoost provides predictive probability…
Genes, proteins, chemicals, diseases, species, mutations and cell lines named across the full text — each resolved to its canonical identifier and authoritative record.
Click any figure to enlarge with its caption.
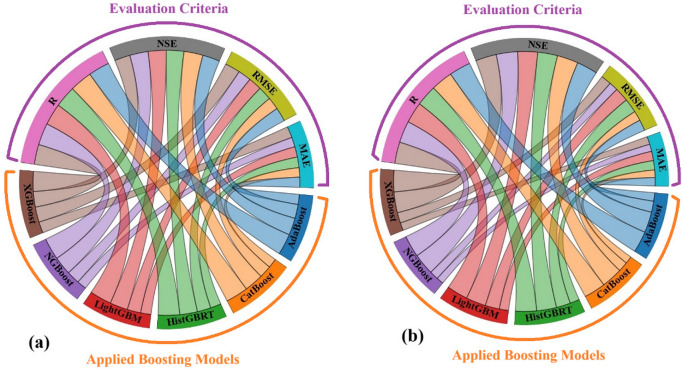 Figure 10
Figure 10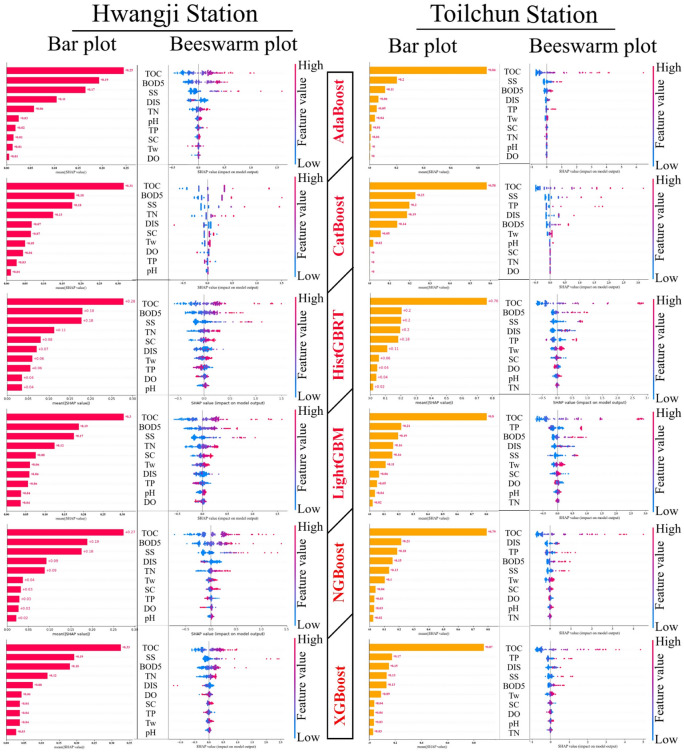 Figure 11
Figure 11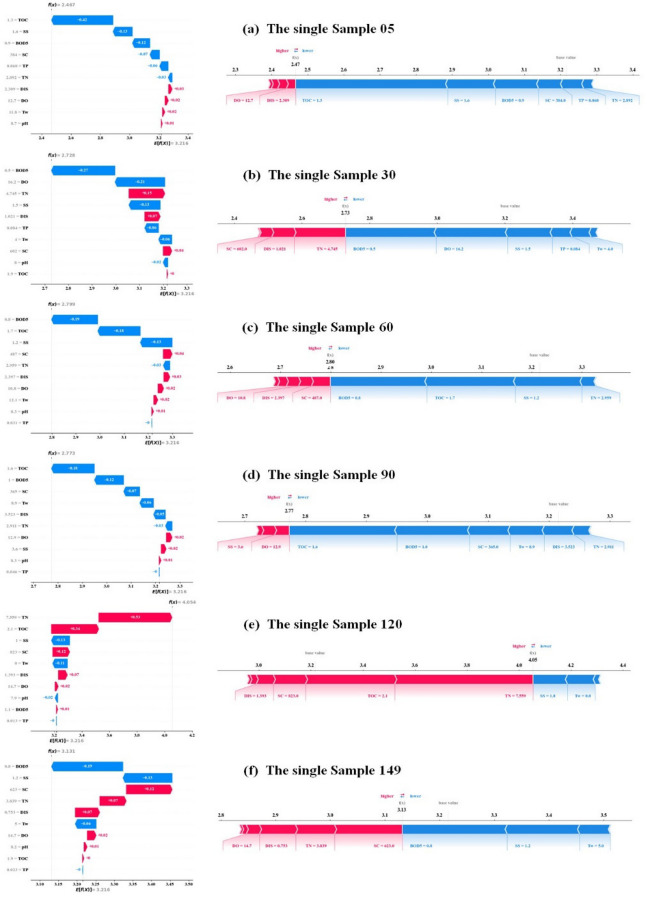 Figure 12
Figure 12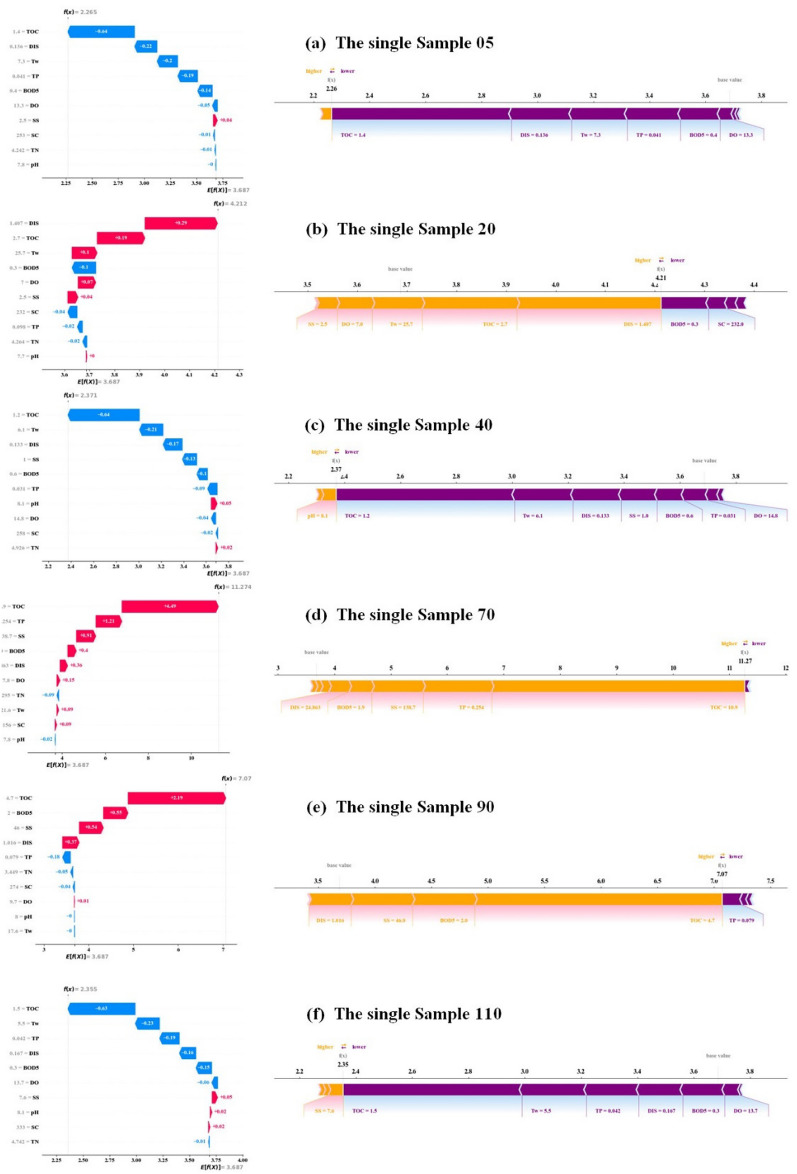 Figure 13
Figure 13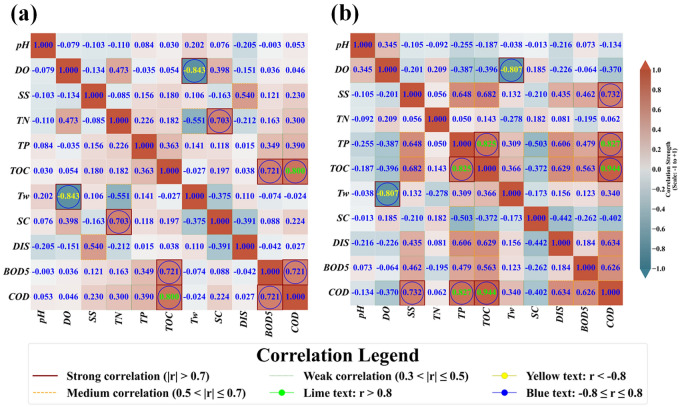 Figure 1
Figure 1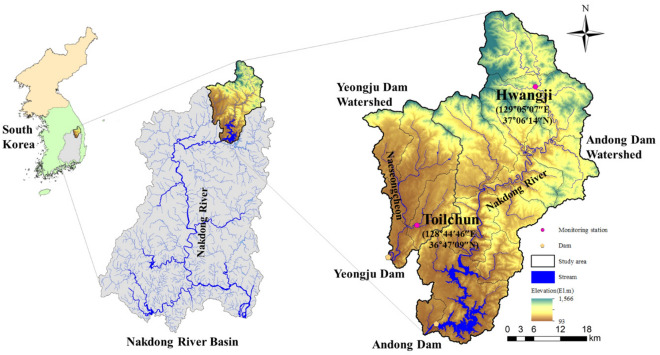 Figure 2
Figure 2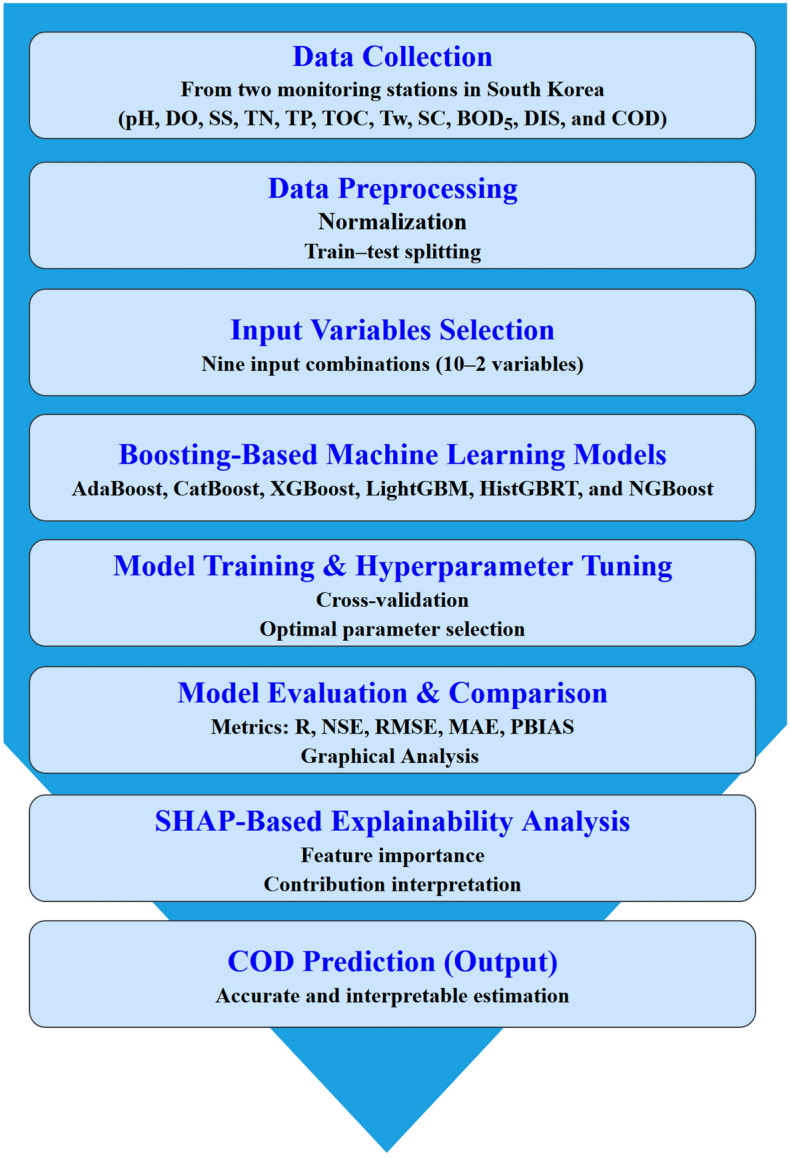 Figure 3
Figure 3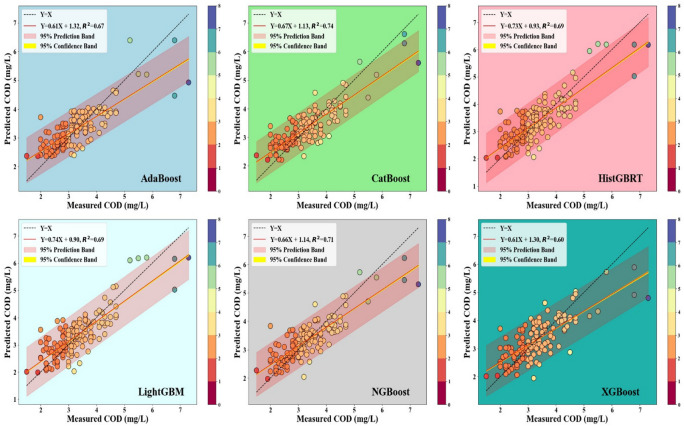 Figure 4
Figure 4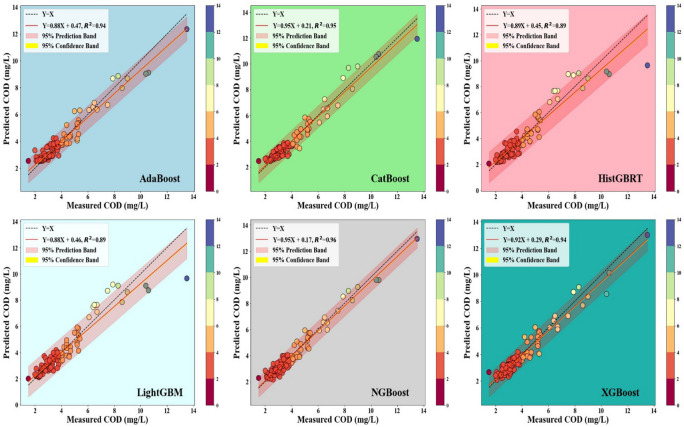 Figure 5
Figure 5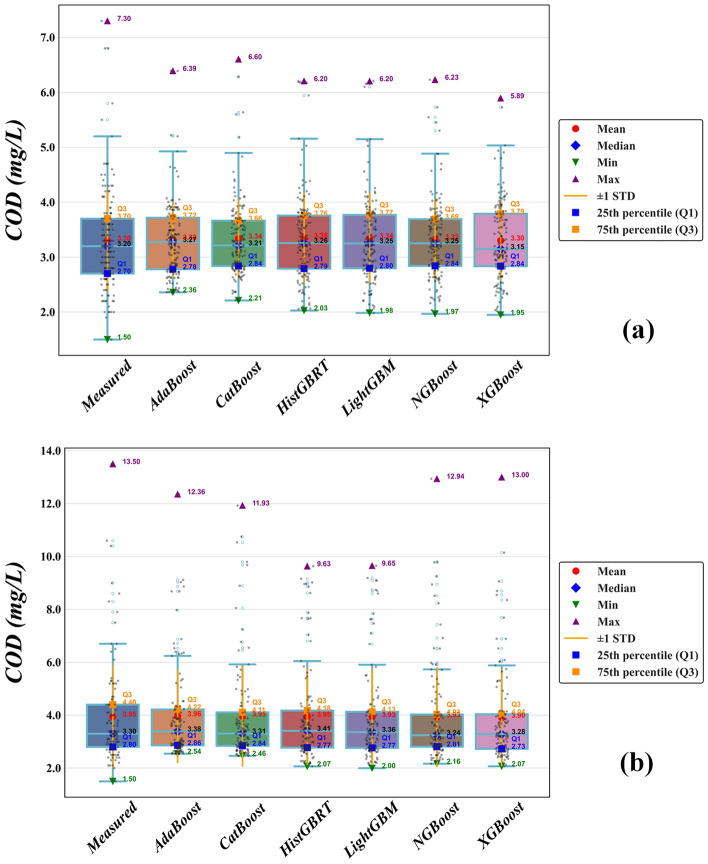 Figure 6
Figure 6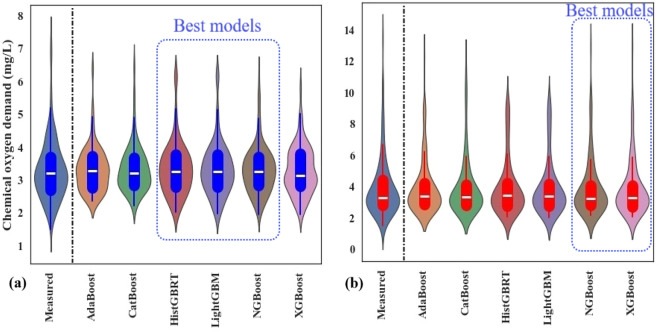 Figure 7
Figure 7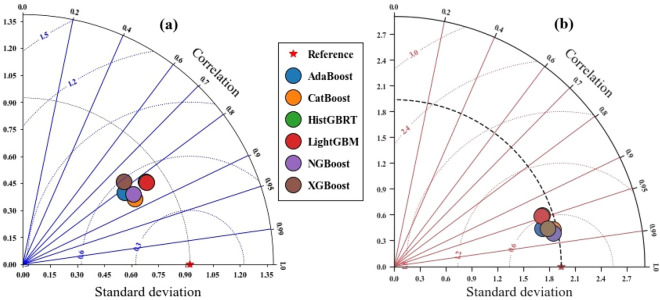 Figure 8
Figure 8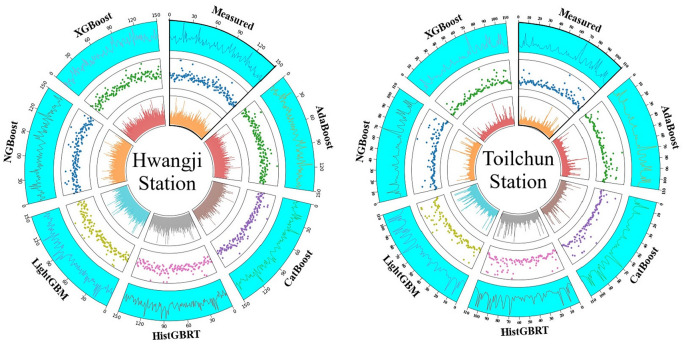 Figure 9
Figure 9- —Technische Hochschule Lübeck (3333)
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsWater Quality Monitoring and Analysis · Hydrological Forecasting Using AI · Water Quality Monitoring Technologies
Introduction
The degradation of water quality is an increasingly urgent issue globally, affecting ecosystems, public health, and economic stability. COD, a key indicator of water pollution, measures the oxygen amount needed for chemically oxidizing organic and inorganic matter in water. COD is commonly used to assess the health of aquatic systems and to evaluate the effects of anthropogenic pressures, since elevated values often indicate industrial discharges, agricultural runoff, or urban effluents.
COD levels accurately forecasting is necessary for sustainable management of water quality and early mitigation of pollution events. However, COD cannot be regarded as a purely standalone response variable; its behavior is strongly influenced by hydrological processes such as flow regime, dilution effects, and seasonal variability, which alter concentration patterns and the underlying pollutant transport mechanisms. Neglecting these hydrological controls may oversimplify COD dynamics by assuming that they are driven solely by physicochemical variables, whereas in reality, COD variability emerges from the combined interaction of chemical, physical, and flow-related processes. This interdependence introduces additional nonlinearity and non-stationarity, posing a further modeling challenge for accurate COD prediction.
Traditional physically based models, though valuable for understanding processes, rely heavily on empirical equations and long-term datasets for calibration, which limits their transferability^1^. Statistical approaches, while faster and more economical, often assume linearity and normality, limiting their ability to capture the nonlinear relationships often found in hydrological systems^2^.
Recently, data-driven models have emerged as effective alternatives to statistical and physical approaches. Machine learning (ML) and deep learning (DL) models can learn complex nonlinear relationships directly from data without requiring explicit physical formulations^3^. These models offer adaptability and high predictive accuracy, making them suitable for dynamic environments where variable data quality and spatial heterogeneity are common^4–6^.
However, the performance of ML frameworks depends strongly on data scale, temporal resolution, and system characteristics, which often limit the direct comparability of published studies. For instance^7^, applied a multilayer perceptron (MLP) to predict COD in urban rivers of Wuxi, China, where nutrient loads were dominant, while^8^ used a Long Short-Term Memory–Recurrent Neural Network (LSTM-RNN) in a highly dynamic urban river network in Shanghai, emphasizing temporal continuity in COD variation^9^ demonstrated an edge artificial intelligence (edge-AI) approach for real-time, low-cost monitoring with a minimal sensor suite, including potential of hydrogen (pH), dissolved oxygen (DO), and BOD, whereas^10^ employed a Bidirectional Long Short-Term Memory (Bi-LSTM) model to address data gaps and irregular sampling in the Yamuna River. More recently^11^, combined neuro-fuzzy algorithms with metaheuristics to estimate COD in the same river, demonstrating the value of hybrid AI frameworks for complex water quality prediction. These applications differ not only in data availability but also in hydrological regimes, pollutant sources, and model objectives, highlighting that predictive strength alone does not ensure methodological transferability.
A rigorous conceptualization of ML frameworks has recently emerged in studies on horizontal flow constructed wetlands (HFCWs), where learning algorithms are explicitly linked to system design and process understanding^12^ used Support Vector Regression (SVR) and Multiple Linear Regression (MLR) to predict effluent BOD, COD, and nutrient levels from secondary datasets, showing that classifying data by organic loading rate improved interpretability and reduced error by 68%. Extending this approach^13^, combined ML with grey wolf optimization to identify optimal media depth for pollutant removal, integrating data-driven and mechanistic design principles^14^ further refined the first-order P–k–C* model by predicting realistic nutrient removal rate coefficients (k-values) through Artificial Neural Network (ANN), Random Forest (RF), and SVR models, while^15^ applied ML regionally to optimize wetland area requirements without compromising removal efficiency. Collectively, these studies show that ML can move beyond black-box prediction toward process-based understanding and design optimization, serving as a scientifically grounded complement to conventional physical models.
Building upon these advances, the present study investigates six boosting-based ensemble models—Adaptive Boosting (AdaBoost), Categorical Boosting (CatBoost), Extreme Gradient Boosting (XGBoost), Histogram Gradient Boosting (HistGBRT), Light Gradient Boosting (LightGBM), and Natural Gradient Boosting (NGBoost)—for COD prediction at two monitoring stations in South Korea. To enhance interpretability, the SHapley Additive exPlanations (SHAP) approach was employed to identify the contribution and influence of each input parameter on model outcomes^16^.
While previous research has examined COD or general water quality prediction using ML in Korea^17,18^, these studies have largely emphasized single-model prediction accuracy without addressing model interpretability or uncertainty. The novelty of this study lies in:
- (i)the integration of multiple boosting-based ensemble models into a unified, explainable framework;
- (ii)the comparative assessment of probabilistic (NGBoost) and deterministic boosting algorithms under identical hydro-environmental conditions, and
- (iii)the use of SHAP-based global and local explanations to uncover the physical and chemical drivers of COD dynamics.
This hybrid evaluation–interpretation framework moves beyond conventional model benchmarking by linking predictive accuracy with process understanding and uncertainty quantification. Therefore, the study not only identifies the most reliable algorithm for COD forecasting in complex river systems but also provides an interpretable and transferable modeling strategy to support transparent, data-informed water quality management.
Materials and methods
Study area and available data
This study utilized various water quality and discharge parameters to predict COD concentrations at the Toilchun and Hwangji stations in South Korea. Since these two stations are located upstream of and close to the Yeongju Dam, a multipurpose dam in the region, their water quality and discharge characteristics can significantly influence eutrophication processes within the dam reservoir. Therefore, accurate prediction of COD at both stations can provide reliable data for assessing water quality within the reservoir boundary.
For both stations, long-term water quality datasets were available. As described earlier, evaluating different boosting-based ensemble models (i.e., AdaBoost, CatBoost, HistGBRT, LightGBM, NGBoost, and XGBoost) for COD prediction constitutes a central objective of this study. Another key aim is to extract information on how different models utilize the input parameters to make predictions.
Table 1 provides summary statistics of water quality and discharge indicators (i.e., pH, DO, BOD_5_, suspended solids (SS), total phosphorus (TP), total nitrogen (TN), total organic carbon (TOC), electrical conductivity (SC), water temperature (Tw), and station discharge (DIS)) at Toilchun Station. In the table, X_mean_ = average value; X_max_ = maximum value; X_min_ = minimum value; SD = the value of standard deviation; Cv = the value of variation coefficient; and R = the correlation coefficient between each input indicator and COD concentration. Table 1 shows that the standard deviation of the indicator SC is higher than that of the other indicators. Also, the indicators of SS and DIS exhibit higher Cv values than those of other indicators. The value of the R between each indicator and COD is also provided in Table 1 at Toilchun Station. The SS, TN, TP, TOC, Tw, DIS, and BOD_5_ exhibit positive R for corresponding COD concentrations, while the pH, DO, SC showed negative R for the corresponding COD concentration at Toilchun Station.Table 1. Brief statistics for water quality variables at Toilchun station.VariablesSubsetUnitXmeanXmaxXminSD**CvR**pHTraining*/7.8228.9007.0000.3720.048 − 0.155Validation/7.8179.0007.1000.3230.041 − 0.092All data/7.8209.0007.0000.3580.046 − 0.134DOTrainingmg/L10.84216.1006.0002.0650.191 − 0.370Validationmg/L10.68314.8006.9002.1600.202 − 0.370All datamg/L10.79416.1006.0002.0930.194 − 0.370SSTrainingmg/L7.004225.3000.20019.0342.7180.646Validationmg/L11.279152.0000.20026.6792.3650.855All datamg/L8.282225.3000.20021.6552.6150.732TNTrainingmg/L4.3387.5660.8791.3910.3210.094Validationmg/L4.2149.3420.7581.4940.3540.011All datamg/L4.3019.3420.7581.4220.3310.062TPTrainingmg/L0.0520.3020.0080.0480.9160.829Validationmg/L0.0560.2680.0110.0520.9290.825All datamg/L0.0540.3020.0080.0490.9200.827TOCTrainingmg/L2.48310.3000.5001.2900.5200.930Validationmg/L2.69710.9000.6001.5890.5890.966All datamg/L2.54710.9000.5001.3870.5450.944TwTraining°C15.54329.9002.6007.0950.4560.357Validation°C15.65629.6002.1007.4480.4760.310All data°C15.57729.9002.1007.1920.4620.340SCTrainingµ.s/cm272.535355.000129.00042.8930.157 − 0.413Validationµ.s/cm270.764370.000133.00040.7640.151 − 0.386All dataµ.s/cm272.005370.000129.00042.2200.155 − 0.402DISTrainingm*^3/^s1.17458.5970.0194.5843.9050.657Validationm^3/^s1.05024.8630.0383.1022.9540.656All datam^3/^s1.13758.5970.0194.1923.6880.634BOD_5_Trainingmg/L0.7583.9000.3000.4870.6420.566Validationmg/L0.8433.0000.3000.6030.7160.717All datamg/L0.7833.9000.3000.5250.6700.626CODTrainingmg/L3.68713.0001.6001.6250.4411.000Validationmg/L3.94613.5001.5001.9470.4931.000All datamg/L3.76413.5001.5001.7290.4591.000
Table 2 supplies the summary statistics of water quality and discharge indicators including pH, DO, SS, TN, TP, TOC, Tw, SC, DIS, and BOD_5_ at Hwangji station. As shown in Table 2, the SD for the SC indicator was higher than that of the other indicators. Also, the indicators of SS and DIS provided higher variation coefficients than those of other indicators. The value of the R between each indicator and COD was also given in Table 2 at Hwangji station. The indicators of pH, DO, SS, TN, TP, TOC, SC, DIS, and BOD_5_ produced a positive R for the corresponding COD, whereas the Tw indicator gave a negative R for the corresponding COD at Toilchun Station. Figure 1 illustrates the heatmap correlation between the water quality variables at the two monitoring stations.Table 2. Summary statistics of water quality variables at Hwangji station.VariablesSubsetUnitXmeanXmaxXminSD**CvR**pHTraining*/8.2169.1007.0000.3550.0430.041Validation/8.2499.0007.0000.3480.0420.077All data/8.2269.1007.0000.3530.0430.053DOTrainingmg/L11.37617.2007.8002.0550.1810.042Validationmg/L11.83917.5007.3002.2240.1880.044All datamg/L11.51517.5007.3002.1160.1840.046SSTrainingmg/L3.65948.0000.2005.8411.5970.532Validationmg/L7.285266.0000.30026.9683.7020.168All datamg/L4.746266.0000.20015.6093.2890.230TNTrainingmg/L3.3637.2151.8240.8410.2500.277Validationmg/L3.4877.5591.7261.0250.2940.348All datamg/L3.4007.5591.7260.9010.2650.300TPTrainingmg/L0.0420.1510.0050.0290.6850.347Validationmg/L0.0510.2180.0040.0340.6770.476All datamg/L0.0450.2180.0040.0310.6890.390TOCTrainingmg/L1.9379.4000.8000.7880.4070.793Validationmg/L2.0225.6001.0000.6680.3300.823All datamg/L1.9639.4000.8000.7540.3840.800TwTraining°C12.91426.3000.0006.8900.534 − 0.017Validation°C12.14525.000 − 1.0006.9420.572 − 0.033All data°C12.68326.300 − 1.0006.9070.545 − 0.024SCTrainingµ.s/cm456.948794.000201.000120.5820.2640.210Validationµ.s/cm461.362823.000191.000130.0890.2820.256All dataµ.s/cm458.272823.000191.000123.3930.2690.224DISTrainingm*^3/^s5.09474.9030.4889.6301.8910.044Validationm^3/^s7.282330.6500.63028.7503.9480.015All datam^3/^s5.750330.6500.48817.6783.0750.027BOD_5_Trainingmg/L1.1579.0000.3000.8520.7370.736Validationmg/L1.2466.5000.3000.7390.5930.680All datamg/L1.1849.0000.3000.8200.6930.721CODTrainingmg/L3.21610.0001.6000.9600.2981.000Validationmg/L3.3017.3001.5000.9270.2811.000All datamg/L3.24110.0001.5000.9500.2931.000Fig. 1Heatmap correlation plot between water quality variables: (a) Hwangji station and (b) Toilchun station.
It is noted that some correlation coefficients are similar between both stations (e.g. the negative correlation between Tw and DO), while other correlation coefficients differ between stations (e.g. SC versus COD). There are common model characteristics, representing underlying general correlations, and regional or specific characteristics, pertaining to the different basins.
Also, various arrangements of water quality and discharge indicators were chosen to build different input combinations. Therefore, six boosting ensemble models were made for predicting COD concentration depending on nine input combinations of different complexity (Table 3). Since the indicators of TOC and SC were selected as the basic unit for building input combinations, this research used the indicators of TOC and SC as the 9th input combination to predict COD concentration. In addition, the first input combination consists of all ten available indicators including pH, DO, SS, TN, TP, TOC, Tw, SC, DIS, and BOD_5_. The seven intermediate input combinations were obtained by gradually reducing the number of parameters and model complexity, omitting pH, DO, Tw, Dis, Tp, BOD, SS and TN.Table 3. The input combinations of the Boosting models.ModelsInputsOutputAdaBoost1CatBoost1HistGBRT1LightGBM1NGBoost1XGBoost1pH, DO, SS, TN, TP, TOC, Tw, SC, DIS, BOD_5_CODAdaBoost2CatBoost2HistGBRT2LightGBM2NGBoost2XGBoost2DO, SS, TN, TP, TOC, Tw, SC, DIS, BOD_5_CODAdaBoost3CatBoost3HistGBRT3LightGBM3NGBoost3XGBoost3SS, TN, TP, TOC, Tw, SC, DIS, BOD_5_CODAdaBoost4CatBoost4HistGBRT4LightGBM4NGBoost4XGBoost4SS, TN, TP, TOC, SC, DIS, BOD_5_CODAdaBoost5CatBoost5HistGBRT5LightGBM5NGBoost5XGBoost5SS, TN, TP, TOC, SC, BOD_5_CODAdaBoost6CatBoost6HistGBRT6LightGBM6NGBoost6XGBoost6SS, TN, TOC, SC, BOD_5_CODAdaBoost7CatBoost7HistGBRT7LightGBM7NGBoost7XGBoost7SS, TN, TOC, SCCODAdaBoost8CatBoost8HistGBRT8LightGBM8NGBoost8XGBoost8TN, TOC, SCCODAdaBoost9CatBoost9HistGBRT9LightGBM9NGBoost9XGBoost9TOC, SCCOD
Figure 2 presents the schematic map of water quality and discharge stations, South Korea. The dataset available for water quality and discharge can be directly accessed and downloaded from the website (http://water.nier.go.kr). The period of the collected dataset corresponds to the period from 2011/07–2020/12 for Toilchun (longitude 128°44′46″E; latitude 36°47′09″N) and 2008/02–2020/12 for Hwangji (longitude 129°05′07″E; latitude 37°06′74″N) stations, respectively. In addition, the training length of the collected dataset involved the first 70% (i.e., n = 258 for Toilchun and n = 348 for Hwangji stations), and the validation length involved the remaining 30% (i.e., n = 110 for Toilchun and n = 149 for Hwangji stations) of the collected dataset. The respective statistics of the training, validation, and entire datasets were calculated and provided in Tables 1 and 2 for both stations as underlying information regarding the similarity of training and validation records.Fig. 2. Schematic map of water quality and discharge stations, South Korea.
Accuracy evaluation criteria
Root-mean-square error (RMSE), mean absolute error (MAE), Nash–Sutcliffe efficiency (NSE), correlation coefficient (R), and Percent Bias (PBIAS) were used for assessing models’ accuracy.
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$MAE=\frac{\sum_{i=1}^{N}|{COD}_{pre,i}-{COD}_{obs,i}|}{N}$$\end{document} \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$RMSE=\sqrt{\frac{\sum_{i=1}^{N}({COD}_{obs,i}- {COD}_{pre,i}{)}^{2}}{N}}$$\end{document} \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$NSE=1-\left[\frac{\sum_{i=1}^{N}({COD}_{obs,i}- {COD}_{pre,i}{)}^{2}}{\sum_{i=1}^{N}({{COD}_{obs,i}- \overline{{COD }_{obs}})}^{2}}\right]$$\end{document} \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$R=\left(\frac{\sum_{i=1}^{N}\left({COD}_{obs,i}- \overline{{COD }_{obs}}\right) \left({COD}_{pre,i}- \overline{{COD }_{pre}}\right) }{\sqrt{\sum_{i=1}^{N}({{COD}_{obs,i}- \overline{{COD }_{obs}})}^{2} \sum_{i=1}^{N}({{COD}_{pre,i}- \overline{{COD }_{pre}})}^{2} }}\right)$$\end{document} \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$PBIAS=\frac{{\sum }_{i}^{N}\left({COD}_{pre,i}-{COD}_{obs,i}\right)}{{\sum }_{i}^{N}{COD}_{obs,i}}\times 100$$\end{document}Here \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${COD}_{pre,i}$$\end{document} and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${COD}_{obs,i}$$\end{document} represent calculated and measured daily COD at an ith time step, N is the observation quantity, \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\overline{{COD }_{pre}}$$\end{document} and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\overline{{COD }_{obs}}$$\end{document} are the means of calculated and measured daily COD.
Machine learning models
AdaBoost (Adaptive boosting)
The AdaBoost algorithm, developed by^19^, is an ensemble learning method that combines multiple weak classifiers to form a strong predictive model. In AdaBoost, bias control is achieved by integrating several boosting iterations into a consolidated prediction framework. During training, data samples misclassified by previous classifiers are assigned higher weights and reused to train subsequent classifiers^20^. Compared with other boosting-based ensemble methods, AdaBoost is generally less prone to overfitting or underfitting in specific classification problems. The base classifier used in AdaBoost may be weak; that is, it initially exhibits relatively high classification error but performs better than random guessing. The overall predictive performance of AdaBoost improves through a weighted voting process, where the final decision depends on the combined output of all weak classifiers^21,22^. AdaBoost operates iteratively, updating the weak classifier at each step until the overall classification error converges to a minimum. The weight assigned to each sample is adjusted based on its classification accuracy: correctly classified samples receive lower weights, while misclassified samples receive higher weights, thereby increasing their influence in the next iteration^19,23^. Through this adaptive weighting mechanism, AdaBoost enhances the precision of weak learners by focusing on more challenging samples. Ultimately, the collection of weak classifiers is integrated to construct a robust composite model^19,24^. The algorithm thus improves predictive accuracy by emphasizing samples with higher training errors and iteratively refining the ensemble with stronger classifiers^22,23^. Detailed formulations and applications of the AdaBoost algorithm can be found in^19,22,23^.
CatBoost (Categorical boosting)
The CatBoost algorithm, developed by^25^, provides a practical and precise approach for handling categorical features during model training. It enhances generalization performance by addressing issues related to bias and variance, thereby improving prediction accuracy and model stability. To reduce the risk of overfitting or underfitting, CatBoost employs an advanced technique known as ordered boosting, a refined version of traditional gradient boosting that enhances learning efficiency and model generalization^26–28^. In the CatBoost framework, training samples are arranged according to a predefined order to construct multiple models based on sequential training subsets^29^. This ordered sampling strategy prevents target leakage by ensuring that each model is trained only on data available before the prediction target, thus maintaining unbiased learning. CatBoost also employs target-based encoding to convert categorical variables into numerical representations. For each observation, numerical transformations are computed using target statistics derived from prior training data, allowing the model to assign appropriate weights and priorities to categorical features^25,30^. Furthermore, CatBoost adopts a greedy, iterative optimization process to minimize a specified loss function efficiently^25,31^. This combination of ordered boosting, target encoding, and iterative optimization enables CatBoost to achieve superior predictive performance while maintaining robustness against overfitting. Detailed explanations and applications of the CatBoost algorithm for various predictive modeling tasks can be found in^25,27^.
HistGBRT (Histogram gradient boosting)
The HistGBRT model is a modified version of the well-known gradient boosting, which is commonly used for solving various gradient boosting problems in classification and regression issues^32^. The primary objective of HistGBRT is to transform weak learners into a strong predictive model by sequentially adding new weak classifiers that correct the residual errors of previously fitted ones. In other words, each weak learner is trained to reduce the mistakes made by the preceding classifiers^33–35^. HistGBRT was developed to overcome one of the main drawbacks of traditional gradient boosting, its long training time when applied to large datasets. This limitation is addressed by discretizing continuous input features into a fixed number of discrete bins, thereby constructing histograms that approximate the feature distributions. This process substantially reduces computational complexity and accelerates training. Among the hyperparameters of the HistGBRT model, the learning rate plays a particularly important role in balancing model accuracy and overfitting^36^. Unlike standard gradient boosting approaches, HistGBRT stores continuous feature values in separate containers (bins) and utilizes these binned values to build histograms during model training. This histogram-based approach not only accelerates computation but also significantly reduces memory usage, making HistGBRT well-suited for large-scale data analysis^32,37^. Comprehensive discussions and applications demonstrating the performance of the HistGBRT model can be found in^32,36,37^.
LightGBM (Light gradient boosting machine)
The LightGBM algorithm is an advanced form of gradient boosting, developed to address computational challenges associated with earlier boosting techniques, such as long training times, high complexity, and memory inefficiency. It uses decision trees as base learners within a gradient boosting framework, enabling the model to handle both regression and classification problems effectively^38,39^. To improve computational efficiency and model performance, LightGBM introduces two key innovations: Gradient-based One-Side Sampling (GOSS) and Exclusive Feature Bundling (EFB). These techniques significantly reduce computational cost while maintaining high prediction accuracy^40,41^. The LightGBM model employs the histogram algorithm combined with a depth-limiting strategy for leaf-wise growth to reduce memory loss. It also achieves higher accuracy with lower computational overhead while mitigating the risks associated with the gradient boosting decision tree (GBDT) model^42,43^. Furthermore, LightGBM incorporates a maximum depth constraint and other structural design features to further enhance efficiency and model stability during training^40,41^. Another advantage of LightGBM is its ability to handle categorical variables directly. Unlike many machine learning algorithms that require one-hot encoding for categorical inputs, a process that often increases dimensionality and reduces efficiency, LightGBM processes categorical features natively, thereby improving both computational speed and predictive accuracy^43,44^. Comprehensive discussions and applications of the LightGBM algorithm for various predictive modeling tasks can be found in^40,41,43,44^.
NGBoost (Natural gradient boosting)
NGBoost model, which employs natural gradient boosting, combines scoring rules, types of probability distribution, and base learners^45–47^. Conventional gradient boosting models build predictive systems by modeling correlations between inputs and outputs^47^. This method creates a comprehensive, probabilistic model for input and output parameters, enabling the calculation of predictive uncertainty via probabilistic prediction^38,48^. In addition, the NGBoost model incorporates natural gradients with ensemble methods. By organizing individual models that adjust to natural gradients, it builds a compound predictor within the gradient boosting scheme. It allows the system to calculate the distribution parameters, eventually assisting probability prediction^47–49^. The NGBoost model can enhance the original one. For estimating multiple parameters, the original model, based on gradient boosting and employing a single parameter, may be suboptimal with respect to the gradients of other parameters^48^. The natural gradient can be increased by the inverse method of the Riemann metric to adjust multiple parameters against conventional gradient, also admitting it to carry out boosting of multiple parameters^38,48^. Unlike the other gradient boosting variants used in this study which provide deterministic point estimates, NGBoost’s probabilistic framework allows it to model the entire conditional distribution of the target variable. This special feature of the NGBoost technique is critical because it enables the model to account for predictive uncertainty. Also, this characteristic can significantly enhance generalization on unseen validation data. The featured instruction for the development and investigation of the NGBoost model to address predictive issues can be expressed from various documents, including^45–48^.
XGBoost (Extreme gradient boosting)
XGBoost, an outstanding model employed for supervised training, was introduced by^50^. It is an approach that assumes a gradient boosting classifier and has a significant impact on gradient enhancement^51,52^. It serves as a powerful solution for regression and classification problems by applying the classifier theorem to them^53^. The XGBoost model is built on the concept of boosting^54^. In practice, boosting combines several simple models, and each of them makes predictions only slightly better than a random selection model. By combining these models into an ensemble that performs slightly better than a random model via boosting, developers and modelers can create a single powerful model that makes highly accurate predictions^55^. In predictive modeling, ensemble learning combines multiple weak learners to produce a stronger and more accurate predictive system. Each base learner contributes a partial estimation of the target variable, and their aggregated results help minimize bias and variance^50,56^. XGBoost applies this principle by constructing an ensemble of Classification and Regression Trees (CARTs), where each successive tree focuses on correcting the residuals of the previous ones. Through iterative boosting and aggregation, XGBoost achieves high flexibility and robustness, making it suitable for a wide range of classification and regression tasks^50^. Comprehensive explanations and applications of the XGBoost algorithm can be found in^50,52,53^.
Results and discussion
This section presents the representation and analysis of predicted COD values using six boosting models: AdaBoost, CatBoost, XGBoost, HistGBRT, LightGBM, and NGBoost. The results are discussed in three distinct parts: (i) mathematical analysis based on evaluation criteria, (ii) diagrammatic analysis through visualization, and (iii) interpretation using SHAP via bar plots, beeswarm plots, force plots, and waterfall plots. Finally, a general discussion of the study findings is provided. Figure 3 illustrates the overall study flowchart.Fig. 3. Flowchart summarizing the overall study steps.
Mathematical analysis based on the evaluation criteria
The analysis of the results for predicting COD using six ML models at the two stations is presented in Tables 4 and 5 for the Hwangji and Toilchun Stations, respectively. In these tables, the best model for each boosting category is highlighted. As can be concluded from the statistical measures for the training and validation sets across both stations, model accuracy generally decreases (lower values for the R and NSE and higher values for the RMSE and MAE) when moving from the training set (70% of the total data) to the validation set (30% of the total data). This trend is typical, as models tend to fit the training data better than unseen validation data. For the Hwangji Station (Table 4), NGBoost and CatBoost show more stable results on the validation set than the other boosting methods (with NGBoost5 achieving an R value of about 0.842 and CatBoost1 around 0.861). While XGBoost5 performs well on the training set, it shows higher RMSE (= 0.588 mg/L) and MAE (= 0.435 mg/L) on the validation set. This matter might indicate potential overfitting at this station. From a scientific perspective, the overfitting observed in models like XGBoost, characterized by near-perfect training metrics but a significant performance drop in validation, has critical implications for environmental inference. Overfitting suggests that the model is learning specific noise or transient anomalies in the water quality data rather than the robust biochemical relationships governing COD. Consequently, such models may provide misleading results when used for real-time monitoring or policy-making. This highlights the necessity of using more stable ensemble methods, such as NGBoost and CatBoost, which demonstrate better generalization and thus offer more reliable scientific insights into pollution dynamics. This systematic performance gap confirms the inherent risks of over-parameterization in environmental datasets. When models overfit, the resulting feature importance rankings (e.g., via SHAP) may be biased toward variables that explain local variance in the training set rather than the actual drivers of organic pollution. On the other hand, the CatBoost1 model provides more consistent prediction errors in comparison to the other applied models and can be introduced as the most accurate model.Table 4. Performances of different boosting models for COD prediction at Hwangji station.ModelTrainingValidationRNSERMSEMAEPBIASRNSERMSEMAEPBIAS(mg/L)(mg/L)(%)(mg/L)(mg/L)(%)AdaBoost10.9070.8190.4080.337 − 0.3680.8070.6420.5530.401 − 0.171AdaBoost20.9070.8190.4080.3370.4080.8110.6490.5470.3940.385AdaBoost30.9060.8180.4090.3400.3290.8030.6410.5540.3990.375AdaBoost40.9030.8140.4130.3430.4690.8160.6600.5390.3920.518AdaBoost50.9000.8070.4200.3510.8380.8050.6430.5520.3950.521AdaBoost60.8960.8000.4290.3610.9050.8040.6410.5540.3990.397AdaBoost70.8730.7600.4700.3880.6610.7430.5470.6220.4781.353AdaBoost80.8350.6950.5300.4401.2660.7650.5750.6030.4791.237AdaBoost90.8190.6700.5510.4410.2330.7720.5580.6150.474 − 1.029CatBoost10.8840.7730.4560.355 − 0.3680.8610.7330.4770.364 − 0.171CatBoost20.8880.7770.4520.3500.4080.8530.7090.4980.3760.385CatBoost30.8840.7750.4550.3510.3290.8490.7090.4990.3770.375CatBoost40.8880.7790.4510.3530.4690.8380.6910.5140.3850.518CatBoost50.8850.7740.4550.3490.8380.8570.7210.4880.3620.521CatBoost60.8790.7670.4630.3600.9050.8540.7200.4890.3850.397CatBoost70.8550.7240.5040.3940.6610.8130.6560.5420.4281.353CatBoost80.8290.6830.5400.4251.2660.8150.6590.5390.4351.237CatBoost90.8180.6660.5540.4270.2330.8180.6590.5400.438 − 1.029HistGBRT10.9510.8980.3070.163 − 0.3680.8190.6670.5330.400 − 0.171HistGBRT20.9490.8950.3100.1680.4080.8130.6580.5400.4100.385HistGBRT30.9490.8940.3110.1750.3290.8090.6520.5450.4190.375HistGBRT40.9440.8850.3250.1880.4690.8070.6460.5500.4240.518HistGBRT50.9320.8630.3540.2040.8380.8280.6790.5230.4080.521HistGBRT60.9150.8330.3910.2320.9050.8290.6780.5250.4120.397HistGBRT70.9100.8210.4050.2520.6610.7590.5570.6150.4931.353HistGBRT80.8750.7580.4720.3071.2660.7510.5640.6100.4761.237HistGBRT90.8080.6480.5690.3780.2330.7430.5500.6200.473 − 1.029LightGBM10.9490.8940.3110.169 − 0.3680.8190.6680.5320.401 − 0.171LightGBM20.9500.8950.3110.1730.4080.8140.6610.5380.4140.385LightGBM30.9470.8900.3170.1790.3290.8180.6650.5340.4050.375LightGBM40.9430.8820.3300.1950.4690.8100.6520.5450.4150.518LightGBM50.9270.8540.3660.2120.8380.8330.6880.5160.4030.521LightGBM60.9150.8320.3930.2370.9050.8310.6810.5220.4080.397LightGBM70.9070.8160.4110.2600.6610.7670.5690.6060.4901.353LightGBM80.8700.7480.4810.3161.2660.7500.5620.6120.4751.237LightGBM90.8000.6360.5780.3830.2330.7380.5430.6240.474 − 1.029NGBoost10.9630.9220.2670.213 − 0.3680.8370.6980.5080.375 − 0.171NGBoost20.9610.9200.2710.2160.4080.8350.6940.5110.3800.385NGBoost30.9610.9200.2720.2160.3290.8390.7010.5050.3750.375NGBoost40.9580.9140.2810.2240.4690.8310.6890.5160.3850.518NGBoost50.9550.9080.2910.2310.8380.8420.7050.5020.3720.521NGBoost60.9490.8970.3070.2460.9050.8320.6890.5150.3860.397NGBoost70.9270.8550.3650.2900.6610.7870.6060.5800.4391.353NGBoost80.9080.8190.4080.3211.2660.8150.6600.5390.4311.237NGBoost90.8980.8040.4250.3320.2330.8180.6660.5340.430 − 1.029XGBoost10.9990.9990.0010.001 − 0.3680.7730.5950.5880.437 − 0.171XGBoost20.9990.9990.0010.0010.4080.7670.5870.5940.4400.385XGBoost30.9990.9990.0030.0020.3290.7480.5590.6140.4440.375XGBoost40.9990.9990.0030.0020.4690.7580.5750.6020.4390.518XGBoost50.9990.9990.0060.0040.8380.7740.5990.5850.4350.521XGBoost60.9990.9990.0060.0040.9050.7620.5710.6050.4520.397XGBoost70.9990.9990.0110.0070.6610.7390.5260.6360.5061.353XGBoost80.9990.9990.0320.0231.2660.7320.5300.6330.5231.237XGBoost90.9920.9840.1220.0700.2330.7490.5600.6130.500 − 1.029The best model for each category is highlighted by an asterisk ().Table 5. Performances of different models for COD prediction at Toilchun station.ModelTrainingValidationRNSERMSEMAEPBIASRNSERMSEMAEPBIAS(mg/L)(mg/L)(%)(mg/L)(mg/L)(%)AdaBoost10.9710.9400.3970.333 − 0.3680.9660.9280.5210.387 − 0.171AdaBoost20.9720.9410.3950.3290.4080.9650.9260.5270.3960.385AdaBoost30.9720.9410.3930.3270.3290.9660.9290.5170.3950.375AdaBoost40.9720.9410.3920.3240.4690.9670.9310.5100.3780.518AdaBoost50.9690.9350.4130.3450.8380.9650.9270.5240.3960.521AdaBoost60.9680.9340.4170.3470.9050.9660.9310.5100.3990.397AdaBoost70.9640.9280.4360.3600.6610.9680.9340.4990.3801.353AdaBoost80.9580.9170.4680.3721.2660.9650.9260.5270.3941.237AdaBoost90.9550.9100.4850.3870.2330.9630.9250.5310.414 − 1.029CatBoost10.9700.9400.3970.317 − 0.3680.9740.9480.4420.336 − 0.171CatBoost20.9680.9360.4090.3220.4080.9720.9450.4560.3410.385CatBoost30.9680.9370.4080.3180.3290.9700.9400.4750.3520.375CatBoost40.9660.9310.4250.3330.4690.9690.9400.4760.3650.518CatBoost50.9610.9220.4530.3500.8380.9710.9430.4640.3580.521CatBoost60.9610.9230.4500.3580.9050.9740.9480.4420.3560.397CatBoost70.9560.9130.4780.3700.6610.9720.9450.4560.3551.353CatBoost80.9500.9020.5090.3721.2660.9590.9090.5840.4081.237CatBoost90.9480.8990.5150.3850.2330.9700.9340.4970.365 − 1.029HistGBRT10.9730.9450.3800.193 − 0.3680.9420.8870.6530.441 − 0.171HistGBRT20.9710.9410.3940.2020.4080.9440.8900.6420.4250.385HistGBRT30.9710.9400.3960.2080.3290.9440.8920.6380.4240.375HistGBRT40.9700.9380.4030.2170.4690.9440.8910.6380.4310.518HistGBRT50.9680.9360.4120.2360.8380.9420.8880.6490.4280.521HistGBRT60.9640.9280.4340.2540.9050.9440.8900.6410.4260.397HistGBRT70.9500.9010.5090.2830.6610.9350.8710.6960.4171.353HistGBRT80.9340.8710.5820.3231.2660.9320.8620.7200.4221.237HistGBRT90.9210.8480.6330.3810.2330.9220.8440.7660.466 − 1.029LightGBM10.9710.9410.3930.204 − 0.3680.9400.8830.6620.436 − 0.171LightGBM20.9700.9390.4010.2120.4080.9400.8840.6610.4380.385LightGBM30.9700.9390.4010.2170.3290.9450.8930.6340.4200.375LightGBM40.9670.9340.4160.2270.4690.9450.8920.6370.4280.518LightGBM50.9660.9320.4220.2430.8380.9420.8860.6530.4350.521LightGBM60.9630.9260.4410.2600.9050.9440.8920.6380.4270.397LightGBM70.9490.8990.5150.2890.6610.9390.8770.6790.4151.353LightGBM80.9340.8720.5800.3251.2660.9340.8640.7140.4261.237LightGBM90.9190.8450.6390.3870.2330.9220.8430.7680.462 − 1.029NGBoost10.9940.9870.1830.147 − 0.3680.9730.9460.4500.329 − 0.171NGBoost20.9940.9870.1830.1490.4080.9720.9440.4570.3320.385NGBoost30.9940.9870.1840.1500.3290.9730.9460.4490.3250.375NGBoost40.9920.9840.2030.1630.4690.9730.9460.4510.3320.518NGBoost50.9910.9810.2250.1770.8380.9730.9470.4480.3330.521NGBoost60.9890.9780.2410.1920.9050.9770.9550.4120.3350.397NGBoost70.9870.9730.2660.2040.6610.9790.9580.3970.3231.353NGBoost80.9850.9700.2820.2201.2660.9750.9480.4410.3491.237NGBoost90.9780.9560.3390.2580.2330.9680.9360.4890.373 − 1.029XGBoost10.9990.9990.0010.001 − 0.3680.9640.9280.5210.371 − 0.171XGBoost20.9990.9990.0010.0010.4080.9680.9350.4950.3620.385XGBoost30.9990.9990.0010.0010.3290.9640.9260.5290.3800.375XGBoost40.9990.9990.0010.0010.4690.9640.9280.5220.3870.518XGBoost50.9990.9990.0010.0010.8380.9660.9320.5060.3880.521XGBoost60.9990.9990.0020.0010.9050.9650.9310.5080.3950.397XGBoost70.9990.9990.0030.0020.6610.9710.9410.4700.3571.353XGBoost80.9990.9990.0120.0071.2660.9560.9130.5710.4351.237XGBoost90.9990.9980.0780.0360.2330.9500.9020.6070.450 − 1.029The best model for each category is highlighted by an asterisk ().
At the Toilchun station (Table 5), the NGBoost and XGBoost models achieve the highest R values during training (NGBoosts 1, 2, 3 = 0.994, XGBoosts 1, 2, 7 = 1.000), but in total, the NGBoost maintains a more stable validation (R > 0.972 and NSE > 0.936) compared to XGBoost. This means that the NGBoost is more reliable for this specific application. The superior performance and stability of NGBoost can be scientifically attributed to its probabilistic prediction capability. While models like XGBoost and HistGBRT focus on minimizing a loss function based on deterministic residuals, NGBoost estimates the parameters of a probability distribution. This feature allows the model to better navigate the stochastic nature of water quality data. The statistic measures, including RMSE and MAE, also highlight NGBoosts lower RMSE values during validation (NGBoost7, RMSE = 0.470 mg/L and MAE = 0.357 mg/L), indicating more accurate predictions. In contrast, HistGBRT and LightGBM provide higher RMSE values, which indicate they are not as accurate as the other boosting models for the prediction of COD at this station. An interesting point is the different behavior of the applied models using various input parameters, as given in Table 3. For both stations, the Catboost1 model acts the best when it uses all of the 10 independent variables (pH, DO, SS, TN, TP, TOC, Tw, SC, DIS, BOD_5_), however, other models such as NGBoost7 and XGBoost7 act better in prediction using the seventh combination as inputs (SS, TN, TOC, SC). Comparing the provided results of the two stations, the overall performance of the models for the Hwangji Station is slightly lower compared to Toilchun Station, which may be due to differences in data characteristics, as seen in the summary statistics (Tables 2, 3). Although the NGBoost model does not provide the best error metrics in the training set, it was the most accurate model in predicting the COD values based on the error metrics in the validation set.
The systematic drop in validation performance across both stations confirms the generalization limits inherent in high-variance models like gradient boosting machines. While these models capture complex patterns in training data, their sensitivity to local noise restricts their predictive reliability when applied to unseen data. Furthermore, the clear difference in accuracy between the two stations, with Toilchun consistently yielding higher R and NSE values than Hwangji, suggests a lack of model transferability.
Diagrammatic analysis based on visualization of the results
To gain a clearer insight into model performance, several visualization techniques were applied to complement the statistical evaluation. Scatter, violin, and box plots were first used to examine the distribution and agreement between measured and predicted COD values. These visual tools supported the quantitative results presented in Tables 4 and 5. Furthermore, Taylor diagrams were employed to summarize the correlation and standard deviation of each model relative to the observed data. In contrast, Circos and Chord diagrams helped illustrate the complex interrelationships among variables. All visual analyses correspond to the validation datasets to ensure consistent comparison.
Figures 4 and 5 display the scatter plots for the Hwangji and Toilchun stations, showing that CatBoost achieved the strongest agreement with the observed COD values, yielding the highest coefficients of determination (R^2^ ≈ 0.71 for Hwangji and ≈ 0.95 for Toilchun). CatBoost and XGBoost models also demonstrate higher accuracy in Toilchun (R^2^ ≈ 0.948 and ≈0.942, respectively) compared to the Hwangji Station (R^2^ ≈ 0.742 and ≈0.599, respectively). However, LightGBM, AdaBoost, and HistGBRT show moderate accuracy, with lower R^2^ values than NGBoost and CatBoost, especially at Hwangji Station. As for the Toilchun Station, the dispersion of the predicted values (dots in the scatter plots) aligns closely with the 1:1 line, indicating more accurate modeling. Also, comparing the slope values of the trendlines for the Hwangji (0.605 < m < 740) and Toilchun (0.891 < m < 0.951) stations shows that the predicted COD values are closer to the measured values. Consequently, it can be clearly concluded that the predictions are more accurate for Toilchun Station, potentially due to lower correlations among the independent variables and COD at Hwangji Station (refer to the correlation values provided in Tables 1 and 2).Fig. 4. Scatterplots of the six applied boosting models for the Hwangji station.Fig. 5. Scatterplots of the six applied boosting models for the Toilchun station.
In the next step, the accuracy of the six applied boosting methods in predicting COD was analyzed using boxplots for the two stations. As indicated by the lower whiskers of the boxes, none of the models captured the minimum COD values. It can be observed that the XGBoost model performed slightly better than the others in this regard. The systematic underprediction of minimum COD values for all boosting algorithms suggests an intrinsic model bias toward central tendency conditions (see the PBIAS results contained in Tables 4 and 5). This limitation, clearly visible in the lower whiskers of the boxplots and the lower tails of the violin plots, indicates that the models are more effective at capturing average pollution levels than predicting very low COD concentrations. Specifically, the positive PBIAS values observed for several models, such as NGBoost5 (PBIAS = 0.521%) at Hwangji and XGBoost7 (PBIAS = 1.353%) at Toilchun, further quantify this tendency to deviate from the observed extremes. This matter confirms that while the models are globally accurate, they maintain a slight systematic offset when dealing with the full range of hydrological variability.
For Hwangji Station (Fig. 6a), which has a lower COD range (approximately 2–6 mg/L), CatBoost and LightGBM align well with the median (the middle line of each box) and exhibit fewer outliers. At Toilchun station (Fig. 6b), the models closely match the median COD value, but the body of the boxes shows varying spreads. Overall, CatBoost and NGBoost provided a smaller body box in comparison to the measured values; however, they acted fairly in predicting extreme values.Fig. 6. Boxplots of the measured and predicted COD values from different boosting models in the validation set, (a) Hwangji station; (b) Toilchun station.
Figure 7 illustrates the violin plots for COD predictions at the Hwangji and Toilchun stations. These plots depict the distribution of COD data using density curves. As in the boxplots (Fig. 6), each density curve has a small box plot at its center showing the ends of the 1st and 3rd quartiles and the median. However, unlike boxplots, violin plots do not distinguish between outliers and extreme values. Considering the median lines of the applied models at both stations, the predicted data aligned well with the measured COD data. At Hwangji Station (Fig. 7a), where COD levels range from 1 to 8 mg/L, AdaBoost and CatBoost struggled to predict the lower COD values (COD < 2 mg/L). In general, HistGBRT, NGBoost, and LightGBM models show more similar density curves to the measured values. At the Toilchun Station (Fig. 7b), COD concentrations reached up to 14 mg/L. NGBoost and XGBoost models exhibited broader distributions, indicating a stronger ability to represent high-end or extreme COD values. This trend was further supported by the presence of additional outliers in the corresponding boxplots (Fig. 6b).Fig. 7. Depicted violin graphs of the measured and predicted COD values from different boosting models in the validation set, (a) Hwangji station; (b) Toilchun station.
Figure 8 presents Taylor diagrams summarizing the accuracy of the machine learning models for COD prediction at both stations. At Hwangji (Fig. 8a), most models achieved strong correlations with observed values (R > 0.75). Among them, CatBoost and LightGBM were positioned closest to the reference point, indicating superior predictive accuracy and stability. AdaBoost, on the other hand, displayed a lower standard deviation, reflecting a narrower prediction range. For Toilchun Station, the models formed a tighter cluster, indicating consistent behavior across algorithms. Nevertheless, NGBoost stood out as the best-performing model, with predicted values aligning more closely with the measured COD than at Hwangji Station.Fig. 8. Taylor diagrams showing the performance of the boosting models: (a) Hwangji station; (b) Toilchun station.
Figure 9 shows the Circos plots, which provide an overall visualization of the boosting models’ performance at the Hwangji and Toilchun stations. The radial layout of these plots allows a direct comparison between observed and predicted COD values, illustrating each model’s accuracy and variability across the validation data. Each diagram consists of three concentric rings representing the density distribution, the spread of individual predictions, and the temporal pattern of the COD series. Among the tested models, XGBoost and CatBoost displayed the closest agreement with the observed data, indicating their strong ability to reproduce COD dynamics. Differences in the density and spread of points within the inner rings further reflect how sensitively each model responds to variations in COD levels. For example, in both stations, HistGBRT and LightGBM display more noticeable deviations compared to models like AdaBoost and CatBoost models.Fig. 9. Circos Plot for circular visualization of the models’ performances.
The chord diagrams, presented in Fig. 10, illustrate the relationships between the applied boosting models, and statistical measures including R, NSE, RMSE, and MAE, for the predicted COD values at both the Hwangji and Toilchun stations. In these diagrams, each chord band represents a contribution of a specific model to a performance metric, assisting with a visual judgment of the effectiveness and accuracy of each model. In the chord diagram for Hwangji Station (Fig. 10a), the NGBoost model shows a strong association with NSE. CatBoost is also well-represented by high NSE and R values, indicating good generalization to the validation data. XGBoost shows a clear relationship with the correlation coefficient but also exhibits a drawback: a tendency to produce higher RMSE values, which can be a sign of overfitting. AdaBoost model displays a balanced relationship between NSE and RMSE. This matter suggests a steady prediction, but less optimal performance compared to NGBoost and CatBoost models. For the Toilchun Station (Fig. 10b), compared to the other models, XGBoost and CatBoost demonstrate slightly stronger ties to high R and NSE values, indicating its ability to achieve a high degree of correlation and similarity between the predicted and observed COD values. Based on the narrower chords of NGBoost to the RMSE and MAE values, it can be concluded that this model outperformed the other applied models, highlighting its consistency across performance metrics. CatBoost and LightGBM show moderate associations with NSE. Overall, the chord diagrams in Fig. 10 emphasize that NGBoost and CatBoost offer a good balance between predictive accuracy and similarity.Fig. 10. Interrelationships for models’ comparison using Chord Diagram, (a) Hwangji station; (b) Toilchun station.
Results analysis using Shapley additive explanations (SHAP)
The ability to understand an ML model is crucial, as it allows users to interpret its processes and make informed decisions^57^ introduced SHAP, an interpretability framework grounded in Shapley’s cooperative game theory. In this study, SHAP was applied to interpret the most accurate predictive model and to better understand the contribution of each input variable to the model output. The SHAP method provides a transparent way to explain model decisions without compromising predictive accuracy. As noted by^58^, SHAP uniquely satisfies three desirable properties for interpretability—consistency, missingness, and local accuracy. It calculates Shapley values as indicators of feature importance, quantifying how each input influences an individual prediction. In essence, the method compares the model output when a feature is included versus when it takes a baseline (mean) value, thereby estimating the marginal contribution of that feature to the overall prediction^59^. Each input feature’s contribution to the model output is assessed by SHAP, which also determines whether the contribution is positive or negative. In the meantime, SHAP can determine each feature’s contribution to each anticipated output^60^. Figure 11 provides a comprehensive view of the feature importance for COD prediction at two stations using SHAP-based feature ranking.Fig. 11. Features ranking and Global models explainability using SHAP for the Hwangji and Toilchun stations in terms of Bar plots (Mean SHAP value of features) and Beeswarm plots (SHAP global explanation), The input variables (i.e., features) were ranked according to their mean absolute SHAP values, as shown on the x-axis.
The mean absolute SHAP value for each variable is shown in the bar plot in Fig. 11. The importance of each feature is determined by the mean of its absolute Shapley values, with features listed along the y-axis. The distribution of SHAP values for the dataset is presented in Fig. 11 as a beeswarm plot, where each point represents a predicted outcome. SHAP values are displayed on the x-axis, and color coding represents feature values, with red indicating higher values and blue indicating lower values. Plot colors reflect changing values, as indicated by the color scale bars on the right side of the figures. In the SHAP plots, positive values indicate that a feature increases the model’s predicted COD, while negative values represent a decreasing effect. Among all input variables, TOC, BOD₅, and SS consistently show positive SHAP contributions, demonstrating their strong influence on the model output. Across all models, TOC is the most influential predictor, indicating that higher organic carbon concentrations are strongly associated with higher COD levels. This consistent relationship underscores the critical role of TOC in driving COD variability within the studied river systems.
From a physico-chemical perspective, the dominance of TOC, BOD_5_, and SS is highly significant. The measures of TOC and BOD_5_ both represent organic carbon content and its various states. In addition to this relationship, both TOC and BOD_5_ are critical elements of each component of COD’s total oxygen demand. SS, the most significant volume of COD, represents the sediment and debris brought into a river system as a result of extreme surface runoff created by high flows. Despite architectural differences, several boosting algorithms returned the same three variables (TOC, BOD5, and SS) as top predictors, indicating that the underlying process captured by these algorithms is consistent across a variety of boosting algorithms and does not simply reflect statistical correlations.
At the Hwangji Station, followed by TOC, BOD_5_, and SS had the most influence on the prediction of COD values. Therefore, BOD_5_ and SS are also among the high-ranking features that substantially influence COD levels in this area. At the Toilchun Station, in addition to TOC, other independent parameters, such as SS, BOD5, TP, and DIS, emerged as the most effective variables for predicting COD. Among the applied boosting models, the AdaBoost and CatBoost models show a similar ranking pattern at both stations, with TOC, BOD_5_, and SS standing out at Hwangji, while TOC, TP, and BOD_5_ are more critical for Toilchun. While TOC and BOD_5_ reflect the organic load of the water and its impact on COD, SS is an indicator for a COD contribution from suspended sediments and organics attached to it, that originate from surface flow and erosion. The parameter TP (total phosphorus) represents the contribution of surface erosion or treated wastewater without sufficient phosphorus removal. On the other hand, HistGBRT, LightGBM, NGBoost, and XGBoost highlight TOC as the primary independent variable but show slight variations in the importance of other input parameters. In general, in the presence of variables such as TOC, BOD5, SS, and TN, other input variables, such as pH, TP, SC, Tw, and DO, do not directly impact the prediction of COD. This claim can also be supported by the fact that input parameters like pH, DO, TO, Tw, and DIS were neglected in HistGBRT5, LightGBM5, XGBoost, and NGBoost5 were chosen as the optimal boosting models for the Hwangji Station (see Tables 3 and 4). In addition, at the Toilchun Station, some best predicted boosting models were constructed based on the 7th input vectors (see Table 3) such as AdaBoost7, NGBoost7, and XGBoost7 (see Table 4), which indicates that only SS, TN, TOC, and SC were the effective independent parameters.
The findings of SHAP show that there are large differences between the two locations regarding the relative importance of features within the model. Organic indicators are still the main drivers of both sites, but the relative importance of discharge and total phosphorus is higher at Toilchun than at Hwangji. This difference indicates that the Toilchun station may be more affected by non-point source pollution, such as agricultural runoff, and that discharge acts as a means of transporting nutrients and organic-rich sediments. In contrast, the more localized influence of SC and SS at the Hwangji site indicates that the pollution source may be more related to industrial or other stable point-source waste. The differences in importance between features at the two sites also highlight the necessity for localized interpretation in developing appropriate water quality management strategies.
Alongside the bar plot in Fig. 11, the beeswarm plots provide a detailed summary of how the top features in the dataset influence the model’s output. In these plots, each dot represents a sample and is colored by feature value (red for higher values, blue for lower values), allowing the relationship between feature values and their impact on COD predictions to be observed. As expected, the beeswarm plots for TOC show that higher values consistently lead to greater SHAP impacts across both stations, indicating a positive correlation between TOC and COD. This is further confirmed by the correlation values in Table 1, where TOC exhibits the highest correlation with COD (R = 0.944).
Figures 12 and 13 illustrate the local interpretability of COD predictions for the two stations (Hwangji and Toilchun) using SHAP. Each Figure includes waterfall plots (left panels) and force plots (right panels) for individual samples, depicting the contributions of different parameters to the model output. All samples’ SHAP waterfall plots are displayed in Fig. 12 for the Hwangji Station, which interprets each variable’s distinct contribution to the outcome at any given point. In this figure, the baseline, or average expected value, is E[f(x)], while the final prediction is f(x). Each row’s SHAP values indicate how individual features interact and contribute to the final predicted value. Positive feature contributions are shown in red, while negative contributions are indicated in blue. While features with a negative influence helped reduce the output, features with a positive impact helped provide strong predictive results. Overall, the two factors that most significantly affect prediction outcomes are TOC and DIS. However, this order of significance varies for various samples: (a) TOC has gr negative impact, (b) DIS has the highest positive impact, (c) TOC has the highest negative impact, (d) TOC has the most significant positive influence, (e) TOC shows a positive impact, (f) TOC has the most significant negative influence. Figure 12 presents the SHAP force plot, which can be interpreted as a horizontal projection of the waterfall plot, highlighting features that drive predictions higher (orange) or lower (purple).Fig. 12SHAP local explanation for the Hwangji station, Left panel: SHAP waterfall plot on selected, Right panel: SHAP force plot on selected samples.Fig. 13SHAP local explanation for the Toilchun station, Left panel: SHAP waterfall plot on selected, Right panel: SHAP force plot on selected samples.
Figure 13 presents the SHAP waterfall plot for Toilchun Station, which illustrates each variable’s distinct contribution to the predicted outcome. The baseline, or average expected value, is \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$E[f(x)]$$\end{document} , while the final prediction is \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$f(x)$$\end{document} . Each row’s SHAP values show how individual features interact and contribute to the final predicted value. Positive contributions are shown in red, and negative contributions are shown in blue. Features with negative influences reduce the output, whereas features with positive influences enhance prediction. Overall, TOC, BOD5, and TN exerted the most significant influence on prediction outcomes, though the order of importance varies across samples: (a) TOC has the highest negative impact, (b) BOD_5_ has the highest negative influence, (c) BOD_5_ has the highest negative impact, (d) TOC has the highest negative impact, (e) TN has the highest positive impact, (f) BOD_5_ has the highest negative impact. The SHAP force plot in Fig. 13 serves as a horizontal projection of the waterfall plot, highlighting features that increase the prediction (red) or decrease it (blue).
The application of ensemble learning methods demonstrates high potential in modeling complicated hydro-environmental parameters such as COD. Since ensemble models integrate the predictions of multiple weak learners, they tend to achieve better accuracy and robustness than single-model approaches. According to the obtained results, it can be reported that the gradient boosting models (e.g., XGBoost, LightGBM, HistGBRT) achieved higher similarity measures (i.e., R and NSE) values and lower deviance error metrics (i.e., RMSE and MAE) in training, but adaptive models like NGBoost and CatBoost offered better stability in the validation set (see Tables 4 and 5). This outcome suggests that, while gradient boosting models may fit the training data closely, adaptive methods performed better in handling variability within the dataset. Additionally, models using more comprehensive qualitative input variables such as SS, TN, TOC, SC, and BOD_5_ (Table 3) tend to perform better, with lower RMSE and higher R values compared to those using fewer variables. This indicates that the diversity of inputs plays a crucial role in capturing the complex relationships necessary for accurate COD prediction. However, it should be noted that including all available input variables (as shown in the 8th and 9th model configurations in Table 3, e.g., AdaBoost8 and AdaBoost9) did not yield the most accurate COD predictions.
Overall, the outcomes of this research demonstrated the high ability of boosting ML models for predicting water quality parameters such as COD. However, there are some limitations in this study worth mentioning. Firstly, the dataset employed in this study may not fully capture the seasonal or long-term variations in water quality parameters. This limitation may have influenced the model’s capability to generalize across different temporal conditions. Future research could enhance model robustness by incorporating longer and seasonally diverse datasets that capture the temporal variability of COD dynamics. Another constraint arises from the limited range of water quality parameters available for analysis. Although this was determined by the existing monitoring program, it remains an important consideration. While TOC, BOD_5_, and SS were identified as the most influential predictors, incorporating additional parameters such as other nitrogen and phosphorus species or microbial indicators could further enhance model accuracy and provide a more comprehensive understanding of COD dynamics. Moreover, future studies might explore alternative ensemble strategies, including bagging^61^, Dagging^62^, and stacking^63^, to potentially enhance predictive performance beyond that achieved with boosting algorithms.
In terms of practicality, the confirmation that TOC is the most important predictor of COD suggests that water quality degradation in South Korean rivers is largely caused by organic loading. Therefore, using TOC as a means of monitoring COD may provide valuable information regarding water quality changes over time. Overall, Recent developments in the field of water quality modeling indicate that the current popularity of ensemble boosting appears to give better predictive accuracy than traditional methods, including neural networks, when dealing with the tabular format of data that water quality models typically require.
Conclusion and future research
This study evaluated the performance of six boosting-based ensemble machine learning models: AdaBoost, CatBoost, XGBoost, HistGBRT, LightGBM, and NGBoost. These models were used to predict COD at two long-term monitoring stations in South Korea. Based on various statistical performance measures, including R, NSE, RMSE, MAE, and PBIAS, NGBoost and CatBoost showed better predictive ability than the other models, especially in validation datasets. Although XGBoost performed almost perfectly during training, its lower validation accuracy raised concerns about overfitting. This highlights the need for thorough model evaluation that goes beyond training accuracy.
In addition to predictive accuracy, this study focused on model interpretability using SHapley Additive exPlanations. The SHAP analysis consistently identified TOC as the main factor influencing COD variability, followed by BOD_5_, SS, and DIS. These findings are meaningful and align well with established biochemical and hydrological processes that control organic pollution in rivers. The consistency between SHAP insights and known water quality processes boosts confidence in the explanatory reliability of the proposed models.
However, there are some limitations to consider. First, while NGBoost provides probabilistic predictions, it assessed uncertainty implicitly through predictive distributions. This approach did not include explicit uncertainty propagation or confidence interval validation against independent observations. Although NGBoost’s framework is useful for risk-informed decision-making, future studies should explicitly evaluate prediction intervals, coverage probability, and uncertainty calibration to better support water management decisions.
Second, the models developed are specific to particular stations and were trained and validated using historical data from two monitoring sites. This means we cannot directly transfer them to other basins or climatic regions without recalibration or external validation. The strong performance observed at Toilchun and Hwangji stations reflects local hydro-environmental features, making spatial generalization a challenge for future research. Incorporating multi-site or cross-basin validation strategies would be essential to assess model reliability on a larger scale.
Third, although the proposed framework shows promise for operational use, this study did not explicitly test real-time applicability. Practical use would require continuous access to key predictors like TOC and BOD_5_, which might need high-frequency sensors or reliable surrogate measurements. Sensor noise, missing data, and latency issues could also impact real-time performance. Thus, while the results suggest potential for monitoring and early warning systems, future work should examine model performance under real-time data limitations and streaming conditions.
In summary, NGBoost and CatBoost strike a good balance between predictive accuracy, robustness, and interpretability for estimating COD. By combining explainable boosting models with SHAP, the study offers accurate predictions and clear insights into the main drivers of water quality changes. Future research should focus on uncertainty quantification, cross-site generalization, and real-time application to enhance the practical value of explainable machine learning frameworks for water quality monitoring and environmental decision support.
Supplementary Information
Supplementary Information.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1Ye, Q., Yang, X., Chen, C. & Wang, J. River water quality parameters prediction method based on LSTM-RNN model. In 2019 Chinese Control and Decision Conference (CCDC) 3024–3028. 10.1109/CCDC.2019.8832885. (IEEE, 2019).
- 2Bhutada, H., Khurshid, A., Yadav, M., Yadav, N. & Baheti, P. COD prediction in water using Edge Artificial Intelligence. In 2022 10th International Conference on Emerging Trends in Engineering and Technology - Signal and Information Processing (ICETET-SIP-22) 01–05. 10.1109/ICETET-SIP-2254415.2022.9791550. (IEEE, 2022).
- 3Chen, T. & Guestrin, C. XG Boost: A Scalable tree boosting system. In Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining. 785–794. 10.1145/2939672.2939785. (ACM, San Francisco California USA, 2016).