Machine learning application in colon cancer treatment outcome prediction
Hadi Ghasemi, Seyed Vahid Hosseini, Abbas Rezaianzadeh, Ali Reza Safarpour, Hajar Khazraei, Pooneh Mokarram, Mozhdeh Zamani, Seyed Ali Nabavizadeh, Alimohammad Bananzadeh

TL;DR
This study uses machine learning to predict colon cancer patient survival outcomes, showing promising results for improving personalized care.
Contribution
The novel contribution is applying various machine learning models to colon cancer survival prediction and comparing their performance.
Findings
CatBoost achieved the highest accuracy of 0.813 for predicting survival outcomes.
Random forest demonstrated the best AUC of 0.83, balancing sensitivity and specificity effectively.
Machine learning models showed potential for personalized and timely interventions in colon cancer treatment.
Abstract
Colon cancer represents a significant global health burden, accounting for a substantial portion of cancer-related morbidity and mortality worldwide. Many studies have been conducted to predict survival outcomes; however, most of these analyses have been performed predominantly via basic statistical methods. The aim of this study was to perform machine learning techniques to build models for survival prediction in patients with colon cancer. A retrospective review of 764 colon cancer patients treated over a 10-year period facilitated the construction of a detailed dataset containing 44 predictor variables and one dependent variable, the survival status of the patients (alive or dead). The data were randomly split into 80% training and 20% testing sets. Prognostic features from the database were used to build machine learning algorithms, including random forest, logistic regression,…
Genes, proteins, chemicals, diseases, species, mutations and cell lines named across the full text — each resolved to its canonical identifier and authoritative record.
Click any figure to enlarge with its caption.
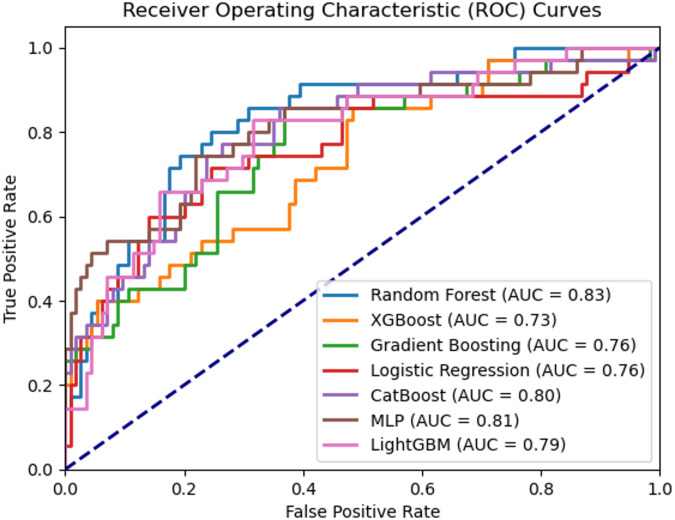 Figure 1
Figure 1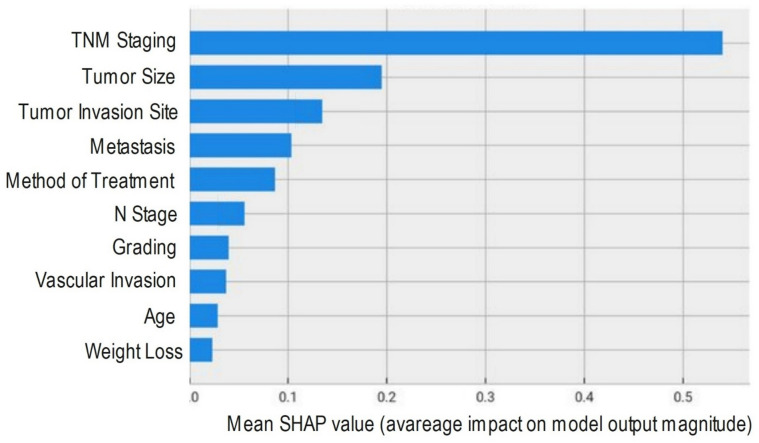 Figure 2
Figure 2- —http://dx.doi.org/10.13039/501100004320Shiraz University of Medical Sciences
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsColorectal Cancer Screening and Detection · Colorectal Cancer Surgical Treatments · AI in cancer detection
Introduction
Colon cancer represents a significant global health burden, accounting for a substantial portion of cancer-related morbidity and mortality worldwide^1–3^. Despite advancements in diagnosis and treatment, accurately predicting survival outcomes for patients with colon cancer remains a complex and challenging endeavor. Moreover, the identification and validation of prognostic factors are crucial to improve treatment strategies. In recent years, the advent of Machine Learning (ML) techniques has revolutionized the field of oncology by offering sophisticated tools for prognostic modeling and risk stratification^4,5^. Traditionally, clinicians have used basic statistical analyses, such as descriptive statistics, chi-square tests, t tests, and regression models, which are often implemented through software programs such as SPSS, Microsoft Excel, and STATA, to analyze factors influencing colon cancer survival rates^6,7^. However, these conventional statistical methods are limited in their ability to develop predictive models and generate complex, integrative visualizations^8^. This limitation has led to the widespread adoption of various machine learning approaches, such as random forests, XGBoost, logistic regression, gradient boosting, CatBoost, LightGBM, MLP, and 1D-CNN in this field^9–13^. ML algorithms offer unique capabilities in capturing complex relationships within the data, thereby providing a more comprehensive perspective on survival prediction in patients with colon cancer. In this context, recent reports have demonstrated that integrating gene expression data with clinical parameters can significantly improve prediction accuracy^14^. Notably, the effectiveness of ensemble methods such as random forest, XGBoost, and CatBoost, which achieve accuracies between 80% and 93%, has been shown in various types of cancer survival^15,16^.
Despite these advancements, few studies have focused on localized datasets that reflect country-specific clinical practices and patient characteristics. This study addresses this gap by developing and comparing multiple machine learning and deep learning models using a real dataset, aiming to provide more relevant insights for improving colon cancer outcome prediction in this context. Additionally, studies applying a comprehensive comparison of multiple advanced ML algorithms to Iranian patient data to identify key prognostic factors are lacking. Previous survival prediction studies in colon cancer patients have relied primarily on traditional statistical analyses, which often fail to capture complex nonlinear relationships among multiple variables. This study aims to fill these gaps by implementing and comparing various ML models, including deep learning approaches, to increase prediction accuracy and support personalized treatment strategies. Although machine learning models for colon cancer have been previously developed and analyzed, the influencing factors may vary on the basis of location, lifestyle, and available data. Therefore, it is necessary to build models specific to the Iranian context to determine the factors influencing the outcomes of colon cancer treatment in patients. Additionally, performing variable selection via machine learning methods in the medical domain is beneficial, especially when traditional statistical methods are preferred by clinicians^17,18^. Therefore, the primary objective of this study was to develop, compare, and evaluate the performance of multiple machine learning and deep learning models for predicting survival outcomes in colon cancer patients via retrospective clinical data. Specifically, this research (i) identifies the most influential prognostic factors, (ii) ranks and visualizes feature importance, (iii) compares the predictive performance of traditional ML algorithms and neural networks such as the MLP, and (iv) provides insights to support more personalized and timely interventions. This comprehensive approach contributes to the growing body of literature by addressing the need for localized, explainable, and clinically useful predictive models for colon cancer outcomes in Iran, addressing the limitations of traditional statistical approaches and contributing to more precise, data-driven clinical decision-making.
Materials and methods
In this study, we implemented a range of machine learning algorithms, including random forest, XGBoost, logistic regression, gradient boosting, CatBoost, LightGBM, MLP, and 1D-CNN. The RF algorithm, for example, operates as an ensemble of decision trees suitable for both supervised and unsupervised tasks. XGBoost, an ensemble of classification and regression trees, is well known for its parallel processing capabilities and high predictive performance. Logistic regression handles various variable types and is widely used for binary classification tasks. Gradient boosting combines multiple weak learners to increase the overall prediction accuracy. CatBoost efficiently handles categorical features and incorporates ordered boosting techniques. The LightGBM uses techniques such as gradient-based one-sided sampling (GOSS) and exclusive feature bundling (EFB) for improved speed and accuracy. The MLP, a type of ANN, is designed to address nonlinear problems via a feed-forward backpropagation structure.
Study design and data sources
We conducted a retrospective analysis using data from patients diagnosed with colon cancer who underwent surgery at the Colorectal Cancer Research Center at Shiraz University of Medical Sciences. The study protocol was evaluated and approved by the Ethics Committee of Shiraz University of Medical Sciences (IR.SUMS.REC.1402.355), and all methods were carried out in accordance with the guidelines provided by this Ethics Committee. The data were gathered from the Shiraz Colorectal Cancer Surgery registry, a sophisticated electronic database managed by Shahid Faghihi Hospital, which is affiliated with Shiraz University of Medical Sciences in Shiraz, Iran. This registry has meticulously documented patients who have undergone colorectal surgery at this tertiary care center since 2007. The study exclusively included patients with a confirmed diagnosis of colon cancer, as verified by pathological reports from intestinal tissue samples obtained prior to surgery. Following tumor resection, an expert pathologist conducted a thorough examination of each tumor, with the final diagnosis and report being meticulously recorded in the database. Upon admission, patients provided informed consent and their contact information to facilitate comprehensive database entry. The registry team encouraged patients to adhere to regular follow-up visits, thereby ensuring the accuracy and completeness of the database. All the methods were performed and visualized via Python (version 3.11.1) with default parameters.
Data preprocessing and feature selection
Initially, the dataset contained 83 unorganized variables. After several clinicians at the colorectal cancer research center at Shiraz University of Medical Sciences were consulted, 39 variables deemed less significant for predicting colon cancer survival were removed. The data preprocessing involved importing the remaining 44 variables in a comma-separated format and using the na.omit function to remove rows with substantial missing values. The data preprocessing involved importing the remaining 44 variables in a comma-separated format and using the na.omit function to remove rows with substantial missing values. The resulting clean dataset included 764 patient records, with 43 independent (predictor) variables and 1 dependent (categorical) variable indicating patient survival status (alive/dead). The dataset was carefully cleaned and plausibility checked. Implausible zero entries for numeric laboratory and clinical variables were corrected on the basis of the original medical records. The final minimum values for features such as age, BMI, RBC, hemoglobin (HB), hematocrit (Hct), white blood cell count (WBC), platelet count, tumor size, and involved lymph nodes now accurately reflect the lowest biologically plausible values in the patient cohort. Patients who were lost to follow-up were excluded to ensure accurate survival labeling. Tables 1 and 2 provide detailed summaries of all the variables, including descriptions, value ranges, and proportions for the nominal and numerical features. Therefore, the final dataset was slightly imbalanced, and to mitigate the effects of this imbalance, we applied stratified training/test splitting to preserve class distributions during training and testing, and the class weights were adjusted to compensate for the imbalance and reduce bias toward the majority class.
Table 1. Numerical feature characteristics.Variable NameDescriptionMinimumMeanMaximumAgeAge of the patients when they are diagnosed with colon cancer195797BMIBody mass indexes op patients13.122.751RBCThe count of red blood cells of patients’ blood2.713.777.78HBConcentration of hemoglobin in patients’ blood4.89.8541.4HctThe hematocrit of patient’s blood4.135.7960.5WBCThe count of white blood cells of patients’ blood2.458.4938.8PlateletThe platelet counts in patients’ blood30307.3979Size of tumor (cm)The size of tumor (cm)0.15.15224527Involved Lymph nodesThe number of lymph nodes identifiedas cancerous14.4833
Table 2. Categorical feature characteristics.Variable nameDescriptionValueProportion (%) Gender The gender status of the patientsMale53.8Female46.1 Familial marriage Being child of familial marriageYes25.2No74.7 Family history of colon cancer Presence of colon cancer in family historyYes19.3No80.6 Family history of rectal cancer Presence of rectal cancer in family historyYes2.1No97.8 Family history of other cancers Presence of other cancers in family historyYes32.7No67.2 Addiction CigaretteCigarette smoking by patientsYes47.5No52.4OpiumUsing opium by patientsYes26.2No73.7WaterpipeUsing waterpipe by patientsYes35.9No64AlcoholAlcohol consumption by patientsYes4No95.9 Clinical symptoms Abdominal painThe status of the patients weathers they have Abdominal pain symptom or not.Yes58.6No41.3CrampThe status of the patients weathers they have cramp symptom or not.Yes15.3No84.6ConstipationThe status of the patients weathers they have constipation or not.Yes41.2No58.7Weight lossThe status of the patients weathers they have lost their weight or not.Yes40.9No59Rectal bleedingThe status of the patients weathers they have constipation or not.Yes40.6No59.3ObstructionThe status of the patients weathers they have bowel obstructions or not.Yes15.9No84 Radiotherapy The status of the patients weathers they have been treated with radiotherapy or not.Yes5.5No94.4 Chemotherapy The status of the patients weathers they have been treated with chemotherapy or not.Yes7.6No92.3 Differentiation (grading) Description of a tumor based on how abnormal the tumor cells and the tumor tissue look under a microscope. It is an indicator of how quickly a tumor is likely to grow and spread.Well differentiation62.1Poorly differentiation6.3Mucinous type4.9Moderately differentiation26.5 Depth of invasion Depth of invasion of tumor into the colon tissue layersBehind Serosa9.5Muscularis20.2Omentum1.4Serosal65.6Sub mucosal3 Vascular invasion Description of a situation which tumor have a tendency to go into the vascular systemYes23.8No76.1 Neural invasion Description of a situation which tumor have a tendency to go into the neural systemYes14.6No85.3 Lymphatic invasion Description of a situation which tumor have invasion to the lymphatic systemYes26.4No73.5 Tumor deposit Description of the patients with clusters of cancer cells in the soft tissue that are discontinuous from the primary tumorFree16.1Involved83.8 T stage Description of the patient’s tumor size and extent of the main tumor; Cancer stage classificationT00.6T12.8T219.2T364.6T4a10.5T4b2 N stage Refers to the number of nearby lymph nodes that have cancer;N057.7N1a15.2N1b6.3N1c7.2N2a7.1N2b6.3 M stage Description of the patient’s tumor whether has been metastasizedM1a8.4M1b0.1MX91.4 Staging Description of the patient’s tumor size and how far it has grown00.8I17.2IIA32.7IIB2.6II C1III A3.4III B25.4III C7.6IV A9.2 Wall thickening of colon Description of the patients with thickened colon wallYes79.3No20.6 Liver metastasis Description of the patients with metastasis to the liverYes17.4No82.5 Para-aortic lymphadenopathy Description of the patients with Para-aortic lymphadenopathyYes10.1No89.8 Pelvic lymphadenopathy Description of the patients with pelvic lymphadenopathyYes32.5No67.4 Kind of surgery The kind of surgery done to the cancerpatients.Conversion6.8Laparoscopy66.5Laparotomy26.6 Type of surgery The type of surgery done to the cancerpatients. The type of surgery depends on the cancer stage and tumor size.Anterior resection18.6Extended left hemicolectomy5.9High anterior resection0.7Lt. Hemicolectomy19.6Rt. Hemicolectomy41.7Total colectomy10.6Total proctocolectomy2.8Ultra low anterior resection0.1
Preprocessing
Prior to model development, a series of preprocessing steps were undertaken to optimize the dataset for analysis. Responses indicating refusal or lack of knowledge were considered missing values. A threshold was established to filter out variables, and participants with substantial missing information variables lacking more than 20% of their data and participants missing crucial data points were removed from the study. Outlier detection was performed via the DBSCAN (density-based spatial clustering of applications with noise) algorithm, a robust technique that identifies and isolates outlier instances on the basis of density estimations without making assumptions about the underlying data distribution. Categorical and ordinal features were one-hot encoded and transformed into a machine-readable numerical format, whereas scalar normalization techniques were applied to numerical variables to mitigate the influence of outliers and ensure equitable feature contributions. Missing data were imputed using the mode for categorical variables and the mean for numerical variables, preserving the integrity of the dataset while enabling the inclusion of all relevant cases. Relevant features were selected on the basis of their potential association with postoperative outcomes in patients with colon cancer, as identified through a comprehensive literature review and consultation with clinical experts. To identify and interpret the most influential features for survival prediction, we applied multiple feature importance techniques. Recursive feature elimination (RFE) was utilized in conjunction with a random forest estimator to eliminate the least important features iteratively and retain the most relevant predictors. Additionally, we extracted built-in feature importance scores from the final trained tree-based models (Random Forest, XGBoost, and CatBoost) on the basis of their split and gain criteria. To further enhance interpretability at the individual prediction level, we computed SHAP (SHapley Additive exPlanations) values for the CatBoost model. SHAP values provide a unified measure of how each feature contributes to increasing or decreasing the model output for each patient. The resulting SHAP summary plot highlights the top predictors and their direction of impact on survival classification.
Our dataset, comprising 764 patient records, presented a significant class imbalance, with 173 patients (22.6%) in the ‘dead’ category and 591 patients (77.4%) in the ‘alive’ category. To prevent our machine learning models from being biased toward the majority class and to improve their ability to accurately predict the less frequent ‘dead’ outcome, we applied the synthetic minority oversampling technique (SMOTE) to the training dataset. This process involves generating synthetic samples for the minority class, ensuring a more balanced representation during model training while rigorously avoiding data leakage by applying SMOTE solely to the training set. To ensure the quality and suitability of our dataset for machine learning, rigorous preprocessing was conducted. Following the removal of variables with more than 20% missing values and rows with substantial missing data, the remaining missing entries were imputed: numerical features utilized mean imputation, whereas categorical features were imputed with their respective modes. Outlier detection was systematically performed via the DBSCAN algorithm, which effectively identified and isolated anomalous data points on the basis of density. Finally, to standardize feature scales and ensure equitable contributions during model training, numerical variables underwent scalar normalization, whereas categorical features were transformed via one-hot encoding.
Machine learning model development
The selected features were formatted appropriately for machine learning analysis. The following machine learning algorithms were explored for developing predictive models: random forest, XGBoost, gradient boosting, logistic regression, CatBoost, MLP, and LightGBM. The dataset was typically split into training/testing (80/20%) subsets, with the training data used to build the predictive models and the testing data used for model evaluation and performance assessment. To ensure robust model training, minimize bias, and select optimal hyperparameters, 5-fold cross-validation was consistently applied to the training dataset. Appropriate hyperparameter tuning was performed for each algorithm to optimize its performance on the given task. To identify and interpret the most influential features for survival prediction, we applied multiple feature importance techniques. First, we used recursive feature elimination (RFE) with a random forest estimator to rank all the input variables according to their contribution to model performance. Additionally, we extracted built-in feature importance scores from the final trained tree-based models (Random Forest, XGBoost, and CatBoost) on the basis of their split and gain criteria. To further enhance interpretability at the individual prediction level, we computed SHAP (SHapley Additive exPlanations) values for the CatBoost model. SHAP values provide a unified measure of how each feature contributes to increasing or decreasing the model output for each patient. The resulting SHAP summary plot highlights the top predictors and their direction of impact on survival classification.
Machine learning framework
In this study, we employed several machine learning algorithms to ensure robust comparisons and to identify the most effective predictive models for colon cancer treatment outcomes. Specifically, random forest, XGBoost, gradient boosting, CatBoost, and LightGBM were chosen for their strong performance with structured tabular data and their ability to handle nonlinear relationships and feature interactions. Moreover, logistic regression was selected as a classical baseline because of its interpretability and established use in clinical outcome prediction. We also included an MLP to represent standard artificial neural network architectures for learning complex, nonlinear feature representations. By including several types of algorithms, ranging from interpretable linear models to sophisticated tree ensembles and deep learning architectures, we aimed to comprehensively examine which methodological paradigm offers the best balance of performance and clinical interpretability. All the selected machine learning models were tuned to optimize performance and prevent overfitting. To optimize the performance of each machine learning model, we conducted systematic hyperparameter tuning via a combination of grid search and randomized search, depending on the model. For each algorithm, a range of key hyperparameters was defined on the basis of established guidelines and preliminary tests. Tuning was performed via 5-fold cross-validation, and the combination of hyperparameters yielding the highest average Area under the receiver operating characteristic curve (AUROC) on the training folds was selected as optimal. The final hyperparameter settings for each model are summarized in Supplementary Table 1.We also implemented a baseline lightweight 1D-CNN model. The architecture consisted of two convolutional layers (32 and 64 filters, kernel size = 3), each followed by batch normalization and ReLU activation, and a max-pooling layer. A global average pooling layer was used before a fully connected dense layer (128 neurons, ReLU activation) and a final output layer with sigmoid activation. To mitigate overfitting, dropout (rate = 0.4) was applied, and early stopping was used with a patience of 10 epochs based on validation loss. The model was trained with the Adam optimizer (learning rate = 0.001), batch size = 32, and a maximum of 100 epochs.
To ensure the robustness and generalizability of our machine learning models, we implemented several strategies to mitigate overfitting, a common challenge, especially with complex algorithms such as ensemble methods. Our primary defense involved a strict 80/20 training/testing split of the dataset, ensuring model evaluation on entirely unseen data. Furthermore, hyperparameter tuning for each algorithm incorporates regularization techniques inherent to their design and is often utilized early, stopping with a validation set for gradient-based models. The intrinsic properties of ensemble methods, such as random subsampling in random forest and ordered boosting in CatBoost, also inherently contribute to reduced variance and enhanced generalization capabilities.
Evaluation metrics
The performance of all the developed machine learning models was rigorously evaluated via a comprehensive suite of metrics derived from the confusion matrix. For a binary classification task (predicting ‘alive’ or ‘dead’), the confusion matrix components are defined as follows:
- True positives (TPs): the number of ‘dead’ patients correctly predicted as ‘dead’.
- True negatives (TN): Number of ‘alive’ patients correctly predicted as ‘alive’.
- False positive (FP): the number of ‘alive’ patients incorrectly predicted as ‘dead’. (Type I error)
- False negatives (FNs): the number of ‘dead’ patients incorrectly predicted as ‘alive’. (Type II error)
The following metrics were calculated to compare the performed ML models:
- Accuracy: The proportion of total correct predictions (both positive and negative).
Accuracy = (TP + TN)/(FP + FN + TP + TN).
- 2.Precision (positive predictive value): The proportion of correctly predicted ‘dead’ instances out of all instances predicted as ‘dead’. It measures the exactness of the model.
Precision = TP/(FP + TP).
- 3.Recall (sensitivity or true positive rate): The proportion of correctly predicted ‘dead’ instances out of all actual ‘dead’ instances. It measures the model’s ability to find all positive samples.
Recall = TP/(FN + TP).
- 4.Specificity (true negative rate): The proportion of correctly predicted ‘alive’ instances out of all actual ‘alive’ instances. It measures the model’s ability to correctly identify negative samples.
Specificity = TN/(FP + TN).
- 5.F1 score: the harmonic mean of precision and recall, providing a single metric that balances both. It is particularly useful when dealing with imbalanced datasets.
F1 score = (2 × Precision × Recall)/(Precision × Recall).
- 6.AUROC or AUC: A comprehensive metric that evaluates the classifier’s performance across all possible classification thresholds. It represents the probability that the model ranks a randomly chosen positive instance higher than a randomly chosen negative instance. A higher AUC value indicates better overall discriminative power.
Results
Machine learning model performance
The RFE was employed to select the optimal set of features for model development. Table 3 presents the performance metrics of the trained machine learning models, including accuracy, precision, recall, specificity, and F1 score. The results are reported as the mean values with standard deviations obtained through 5-fold cross-validation. Among the evaluated models, CatBoost achieved the highest accuracy of 0.813 (± 0.01) and an F1 score of 0.533 (± 0.05) on the test set. The random forest model demonstrated the best precision of 0.727 (± 0.08), whereas the logistic regression model exhibited the highest recall of 0.658 (± 0.12) on the test set.
Table 3. Performance metrics of machine learning models.ModelAccuracyPrecisionRecallspecificityF1ScoreRandom forest0.800 (± 0.01)0.727 (± 0.08)0.233 (± 0.07)0.972 (± 0.01)0.344 (± 0.07)XGBoost0.798 (± 0.02)0.577 (± 0.06)0.456 (± 0.10)0.901 (± 0.02)0.506 (± 0.08)Gradient boosting0.798 (± 0.01)0.630 (± 0.06)0.333 (± 0.04)0.939 (± 0.02)0.432 (± 0.04)Logistic regression0.731 (± 0.03)0.443 (± 0.04)0.658 (± 0.12)0.753 (± 0.03)0.527 (± 0.07)CatBoost0.813 (± 0.01)0.643 (± 0.06)0.520 (± 0.09)0.917 (± 0.03)0.533 (± 0.05)MLP0.775 (± 0.01)0.413 (± 0.34)0.058 (± 0.05)0.991 (± 0.01)0.102 (± 0.08)LightGBM0.771 (± 0.01)0.508 (± 0.02)0.442 (± 0.04)0.871 (± 0.01)0.472 (± 0.03)1D-CNN0.742 (± 0.02)0.487 (± 0.05)0.421 (± 0.07)0.832 (± 0.03)0.452 (± 0.06)
As shown in Table 3, certain models, such as random forest and MLP, exhibit relatively high precision but lower recall. This imbalance highlights the models’ tendency to favor correct predictions of the majority (alive) class while underdetecting true positive cases of the minority (dead) class.
Receiver operating characteristic analysis and model performance
The predictive performance of the machine learning models was comprehensively evaluated through ROC curve analysis. The AUC serves as a robust metric to assess the models’ ability to discriminate between classes, with higher values indicating superior classification performance. As illustrated in Fig. 1, the random forest algorithm exhibited the highest AUC of 0.83, demonstrating remarkable efficacy in achieving an optimal balance between sensitivity and specificity for the classification task. Closely following were the MLP and CatBoost models, with AUC values of 0.81 and 0.80, respectively. These models exhibited strong generalization capabilities across a wide range of threshold settings, indicating their robustness and potential for practical applications. While the XGBoost and gradient boosting algorithms presented relatively lower AUC values of 0.73 and 0.76, respectively, potentially attributable to overfitting or suboptimal parameter tuning, their performance was still respectable. The logistic regression model, with an AUC of 0.76, provided a reasonable baseline for the classification task, albeit it was outperformed by the ensemble methods.
Overall, the ensemble learning techniques, particularly random forest, demonstrated superior predictive performance in this scenario. This can be attributed to their ability to leverage multiple base learners, effectively mitigating individual model biases and enhancing overall accuracy and generalization capabilities. The CatBoost model demonstrated the overall best performance in predicting postoperative outcomes in colon cancer patients, achieving the highest accuracy and AUROC among the evaluated models. To offer more granular insight into classifier performance, particularly for the most effective model identified in our study, the confusion matrix for the CatBoost algorithm is presented in Table 4. Moreover, The CNN achieved the lowest performance with an AUC of 0.70, indicating that convolutional models are less suitable for small, structured clinical datasets compared to ensemble methods.
Fig. 1. Comparison of model performance, displaying the AUROC curves across the full range of specificity and sensitivity thresholds.
Table 4. Confusion matrix for the catboost model.Predicted\actualDead (positive)Alive (negative)Dead9049Alive83542
Feature importance analysis using SHAP values
To provide comprehensive insight into the factors driving our predictive models and to enhance clinical interpretability, we performed Shapley Additive exPlanations (SHAP) value analysis on the top-performing CatBoost model. SHAP values offer a unified and consistent measure of feature importance by calculating the contribution of each feature to the prediction for every instance on the basis of principles from cooperative game theory. On the basis of this analysis, the top ten most influential features for predicting colon cancer treatment outcome were identified and ranked (Fig. 2).
Fig. 2. Top ten most influential features for predicting colon cancer.
Discussion
In this study, machine learning models were developed using colon cancer data from the Colorectal Cancer Research Center at Shiraz University of Medical Sciences to identify important prognostic factors for postoperative outcomes. The analysis focused on multiple algorithms, including random forest, XGBoost, gradient boosting, logistic regression, CatBoost, MLP, 1D-CNN, and LightGBM. Among these, CatBoost demonstrated the highest overall accuracy and AUROC, indicating its strong potential for clinical application in predicting patient outcomes. The findings of this study offer valuable insights into the application of machine learning algorithms for predicting survival outcomes in colon cancer patients. The varying performance of the ML models underscores the importance of selecting appropriate modeling techniques and features to optimize predictive accuracy and clinical utility.
CatBoost achieved the highest accuracy and AUROC, highlighting its efficacy in handling complex datasets with mixed data types. This model’s superior performance can be attributed to its ability to effectively process categorical features and mitigate overfitting through robust parameter tuning. The random forest, with the highest AUROC, also proved to be a reliable model, demonstrating a balanced sensitivity and specificity, which is crucial for medical decision-making. The predictive power of logistic regression, particularly in terms of recall, underscores its ability to identify true positive cases effectively. This is essential in clinical scenarios where the cost of missing a positive case can be high. XGBoost and gradient boosting, although slightly less effective, still presented respectable AUROC values, suggesting their potential utility with further optimization. However, the imbalance between precision and recall observed in some classifiers is largely attributable to the skewed distribution of alive versus dead outcomes in our dataset. Despite hyperparameter tuning and balancing measures, traditional models such as random forest and MLP still achieve relatively low recall. This emphasizes the challenge of minority class detection in survival prediction tasks.
Recently, reported evidence has revealed that the increased survival rates among colon cancer patients are due primarily to advancements in treatment^19,20^. This highlights that effective treatment plays a vital role in determining the survival chances of individuals diagnosed with colon cancer. The location, distance and number of metastasis sites are also independent prognostic factors for colon cancer patient survival^21^. Therefore, diverse treatment strategies for patients with different metastatic patterns are needed. Consistent with prior studies, features such as tumor TNM stage, grade, tumor size, method of diagnosis, and surgical approach were shown to be crucial predictors that influence survival and the performance of ML algorithms^22^. In this context, surgery, as a treatment option, has become a significant factor, potentially indicating smaller, operable tumors. In contrast, primary chemotherapy is primarily used for locally advanced colon cancer patients. The method of diagnosis and type of surgery are crucial prognostic factors for colon cancer treatment outcomes. According to Grass et al.^23^, early and accurate surgery of tumors was positively associated with a higher survival rate in nonmetastatic colon cancer patients. Therefore, the diagnostic method plays a vital role in estimating the survival rate of breast cancer patients. The total lymph node (TLN) count also appeared to be an important prognostic factor, which is consistent with other studies that identified the TLN as a significant indicator of colon cancer prognosis^24–26^. Other variables, including tumor TNM stage, grade and tumor size, are crucial predictors of colorectal cancer survival and mortality rates and have potential effects on the performance of ML algorithms, such as accuracy and precision parameters^27^. A previous study used TNM staging (tumor, node, and metastasis) to investigate the prediction of tumor stage in colon cancer patients and reported that the tumor size variable might be a potential prognostic factor, and the random forest model outperformed all other algorithms, with an accuracy of 84% and an AUC of 82% for predicting five-year disease-free survival^11^.
Our results also revealed that performing the ML algorithm, CatBoost, on tumor-related variables alongside patient-related variables had the highest overall accuracy and AUROC, which indicates its potential for clinical application in predicting patient outcomes. The evaluation of model performance through multiple metrics, accuracy, precision, recall, specificity, F1 score, and AUROC, provided a robust framework for assessing the strengths and weaknesses of each algorithm. This multidimensional evaluation is crucial in medical research, where the implications of predictions extend beyond mere statistical accuracy. This multidimensional evaluation of algorithms revealed that the random forest algorithm and XGBoost might be potential algorithms for predicting colon cancer patient outcomes. The inclusion of features such as cancer stage, tumor size, tumor invasion site, treatment type, and clinical symptoms aligns with previous research findings^28–30^. In this context, SHAP value analysis of the top-performing CatBoost model revealed that TNM stage was the feature with the greatest impact on the output performance of the ML model. However, the combination of cancer-related variables with patient demographic variables is pivotal for enhancing the prediction performance of the ML model. Our results revealed that the next most influential variables, in descending order of importance, were tumor size, tumor invasion site, presence of metastasis, method of treatment, N stage, tumor grade, vascular invasion, patient age, and weight loss. This ranking demonstrates that combining tumor-specific characteristics with key demographic and clinical factors substantially enhances the predictive power of machine learning models for survival outcomes in patients with colon cancer.
In line with our findings, several recent studies have suggested that combining diverse data types can significantly improve the prediction accuracy for colorectal cancer outcomes. In this context, combining clinical parameters with gene expression data can increase the accuracy of the ML model^14,15^. Furthermore, a variety of machine learning classifiers, including random forest, XGBoost, and CatBoost, have achieved accuracies between 80% and 93% in similar contexts^15,16^. The use of comprehensive datasets, including data from the Cancer Genome Atlas or other large public cohorts, has been shown to support more robust training and validation of ML-based models to increase model performance in predicting cancer patient outcomes^31^. These findings have meaningful implications for medical practice. By confirming that models such as CatBoost and random forest can reliably identify high-risk patients via accessible clinical data, this study supports the use of ML-based decision-support systems in routine oncology workflows. In practice, these models could assist clinicians in stratifying patients by risk, planning closer monitoring for high-risk patients, and personalizing treatment plans on the basis of predicted survival outcomes. Additionally, the identified key prognostic factors align with clinical guidelines, making the model outputs interpretable and trustworthy for practitioners. Therefore, integrating these models with electronic health record systems could enable real-time risk prediction and continuous refinement as more data become available, ultimately helping to deliver more personalized, timely, and effective care for colon cancer patients.
Conclusion
In this study, we developed and compared seven machine learning algorithms using postoperative colon cancer data to identify key prognostic factors and predict survival outcomes. CatBoost and random forest achieved the highest accuracy and AUROC, demonstrating robustness in handling categorical variables and mitigating overfitting. Evaluating models across multiple metrics ensured balanced performance assessment, whereas SHAP-based feature importance highlighted clinically meaningful predictors such as TNM staging, tumor size, invasion site, and metastasis. However, the reliance on a single-center retrospective dataset and residual class imbalance may limit generalizability, and the exclusion of genomic or imaging data constrains predictive power. Future work should validate these models in multicenter settings, expand feature sets, and integrate cost-sensitive learning and advanced interpretability methods to increase their clinical impact.
Limitations
Despite its strengths, this study has several limitations. First, the retrospective design may introduce biases inherent to historical data collection practices, such as selection and information bias, which could affect the reliability of the input data and model outputs. Second, the dataset was sourced from a single research center, potentially limiting the generalizability of the findings to broader or more diverse patient populations. Third, while class imbalance was addressed via techniques such as stratified sampling and SMOTE, some models still exhibited low recall for the minority class, indicating the need for further improvements in sensitivity for rare outcomes. Fourth, although feature importance was analyzed and visualized, the lack of advanced interpretability tools such as SHAP explanations for individual predictions could limit immediate clinical adoption. Finally, the study did not integrate additional data types, such as genomic, imaging, or multiomics information, which could further increase the prediction accuracy and provide deeper insights into patient outcomes. Future research should aim to validate these models in larger, multicenter datasets, incorporate richer data sources, and adopt more advanced model interpretation methods to make AI-driven predictions more transparent and clinically actionable.
Supplementary Information
Below is the link to the electronic supplementary material.
Supplementary Material 1
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1Petrus, A. An Application of Survival Analysis on the Prevalence and Risk Factors of Breast Cancer in Namibia (University of Namibia, 2019).
- 2Das, S., Nayak, S. P., Sahoo, B. & Nayak, S. C. Machine learning in healthcare analytics: A state-of-the-art review. Arch. Comput. Methods Eng. 1–40 (2024).
- 3Britto, C. F. (Ed) Prediction of colon cancer disease with the handling of outliers and overfitting through neural network clustering and optimal tuning. In 2023 International Conference on Advances in Computation, Communication and Information Technology (ICAICCIT). 23–24 Nov 2023 (2023).