Integrating optimization and machine learning for estimating water resistivity and saturation in shaley sand reservoirs
Muhammad A. El Hameedy, Walid M. Mabrouk, Ahmed M. Metwally

TL;DR
This paper presents a new method combining optimization and machine learning to improve water resistivity and saturation estimates in complex oil reservoirs.
Contribution
A novel framework integrating numerical optimization and ML for reliable petrophysical evaluation in shaley sand reservoirs.
Findings
Powell and Nelder-Mead optimization algorithms accurately estimated water resistivity with low error.
LSTM, CatBoost, and XGBoost ML models achieved high accuracy (R2 up to 0.944) in predicting water saturation.
The integrated framework reduces reliance on core analyses and improves hydrocarbon estimation accuracy.
Abstract
Accurate characterization of shaley-sand reservoirs remains a significant challenge in petroleum geophysics, where complex clay mineralogy often renders traditional evaluation methods unreliable. This study introduces an integrated, data-driven framework that synergizes numerical optimization and machine learning (ML) to accurately estimate formation water resistivity (Rw) and predict water saturation (Sw), overcoming the limitations of data scarcity. The workflow begins with rigorous preprocessing of well log data from 11 wells across the Norwegian North Sea and Egyptian Western Desert. First, we establish a robust, physically-constrained Rw by evaluating four optimization algorithms. The Powell and Nelder-Mead algorithms emerged as superior, demonstrating the ability to recover the true Rw from log data with low error (1×10-4 RMSE) against measured samples rapidly. This optimized Rw…
Genes, proteins, chemicals, diseases, species, mutations and cell lines named across the full text — each resolved to its canonical identifier and authoritative record.
Click any figure to enlarge with its caption.
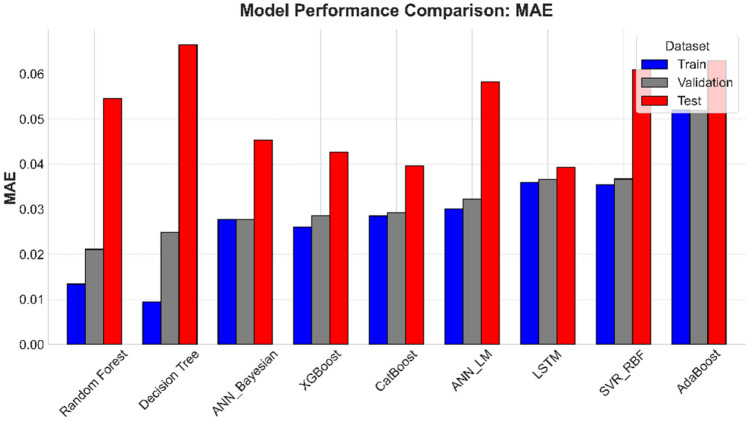 Fig. 16
Fig. 16- —Cairo University
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsHydrocarbon exploration and reservoir analysis · Geophysical and Geoelectrical Methods · NMR spectroscopy and applications
Introduction
Shaley sandstone reservoirs constitute a critical component of global hydrocarbon resources, contributing substantially to the world’s energy supply due to their substantial hydrocarbon-bearing potential^1,2^.However, their exploitation is complicated by inherent heterogeneity, complex pore geometries, and variable clay mineralogy, which collectively impedes accurate petrophysical evaluation. Effective reservoir characterization in such formations hinges on the accurate quantification of two key parameters: water saturation (Sw) and formation water resistivity (Rw). Sw - defined as the proportion of pore volume occupied by aqueous phases - serves as a critical petrophysical parameter for hydrocarbon volume estimation, reservoir performance forecasting, and economic feasibility assessments^3^. A persistent challenge arises from the conductive behavior of electrochemically active clay minerals (e.g., smectite, illite), whose cation exchange capacity (CEC) induces excess electrical conductivity in the pore network. This phenomenon deviates sharply from the assumptions of conventional clean-sand models such as Archie’s equation^4^, which neglects clay-related conductivity effects. Consequently, reliance on unmodified Archie-type models in shaley sandstone reservoirs often results in systematic overestimation of Sw, leading to undervalued hydrocarbon reserves and suboptimal field development strategies^5^.
The influence of shale on Sw demands specialized petrophysical interpretation methodologies. Although laboratory-based direct measurements of Sw (core analysis) offer high precision, they are prohibitively expensive, time-intensive, and restricted to discrete depth intervals, limiting their utility for continuous reservoir evaluation^6^. Consequently, well-log-derived petrophysical analysis has emerged as a practical alternative, enabling continuous in-situ quantification of reservoir properties - including porosity, permeability, and hydrocarbon saturation - along the borehole column^7–11^. However, the accuracy of log-based Sw models is inherently contingent on precise determination of Rw, as uncertainties in Rw propagate into Sw estimations, compromising reservoir assessments.
Multiple empirical models have been proposed over the past few decades, to account for clay-induced conductivity effects in Sw calculations for shaley reservoirs. Seminal methodologies include the DeWitte model^12^, Simandoux equation^13^, Waxman-Smits model^5^, and Indonesia model^14^, each designed to address distinct shale distribution patterns (e.g., dispersed, laminated, or structural clays). While these models improve Sw estimation accuracy in clay-rich formations compared to conventional clean-sand approaches, their applicability remains limited by lithological dependencies. Critically, they exhibit high sensitivity to input parameters such as Rw and shale volume (Vsh), which are often subject to measurement inaccuracies. Furthermore, their reliance on idealized assumptions about clay geometry and mineralogy restricts their utility to specific reservoir types, rendering them ineffective in highly heterogeneous or mixed lithologies. These limitations, compounded by inherent uncertainties in model-specific parameters (e.g., cation exchange capacity, and clay conductivity), frequently lead to misinterpretations of Sw, as underscored in critical reviews of their practical applicability^15^.
On the other hand, graphical methods for Rw determination, such as Hingle and Pickett plots^16,17^, similarly suffer from oversimplified petrophysical assumptions. The Hingle plot, for instance, presupposes shale-free lithologies and linear resistivity-porosity relationships, rendering it unreliable in complex formations such as shaly sands or carbonates. Its subjective graphical interpretation introduces additional variability in heterogeneous reservoirs, while errors in porosity or resistivity measurements propagate nonlinearly into erroneous Rw estimates. The Pickett plot, rooted in Archie’s equation^4^, requires calibration using water-bearing zones - a process prone to misidentification in multiphase or unconventional reservoirs^18^. Both methods fail to account for conductive minerals, organic matter, or data noise, significantly limiting their robustness in modern reservoirs with intricate mineralogy. Such shortcomings highlight the inadequacy of traditional graphical techniques in contemporary, data-driven petrophysical workflows.
Existing numerical methods for Rw estimation exhibit critical limitations in applicability and accuracy. For instance, Authors^19^ developed a deterministic approach for Rw and water saturation (Sw) determination, achieving high precision in clean reservoirs; however, their methodology fails to account for shale effects, rendering it unsuitable for clay-rich formations. Authors^20^ extended this work to shaley reservoirs, reporting a root mean square error (RMSE) of >10 % and < 2.1% for Rw and Sw predictions, respectively. Yet, their validation relied on sparse data from the Surma Basin (Bengal), without generalizability across diverse lithologies/basins and fluid types. To overcome these constraints, this study proposes a novel framework leveraging numerical optimization techniques to calculate Rw solely from three well-log inputs: neutron porosity (ϕ_N), gamma ray-derived shale volume (Vsh), and deep resistivity (Rt). The methodology optimizes Rw_ by minimizing the difference between measured Rt-meas and calculated Rt-calc via the Schlumberger shaley-sand Sw equation^21^, explicitly incorporating variable fluid saturations (water, oil, condensate, gas) across heterogeneous formations. This approach eliminates the dependency on core-calibrated parameters or idealized lithological assumptions, offering a robust and generalized, data-driven alternative to conventional methods especially when integrated with Machine learning (ML) workflows.
Regarding this manner, Emergence of ML as a transformative approach for water saturation (Sw) prediction, overcoming the limitations of traditional empirical models, which are often constrained by region-specific assumptions, parameter uncertainties, and poor generalizability. Among ML techniques, Artificial Neural Networks (ANN) and Fuzzy Logic (FL) have gained prominence, with ANN demonstrating exceptional versatility across diverse lithologies and fluid systems. Early innovations by^22^ leveraged committee neural networks to integrate sonic, density, neutron porosity, and resistivity logs to predict Sw, demonstrating superior accuracy compared to conventional petrophysical models. However, their methodology had a critical oversight: the exclusion of shale effects, which are essential for accurate Sw estimation in clastic reservoirs. This omission limits the framework applicability to heterogeneous shale-bearing formations, Authors^23^further improved predictive accuracy by incorporating self-potential (SP) logs alongside gamma ray, deep resistivity, neutron, and density measurements. Subsequent advancements focused on optimizing input selection and model architecture^24^:employed resilient backpropagation ANNs with feature ranking to prioritize critical log inputs (density, neutron, resistivity, and photoelectric factor), while^25^ utilized hybrid core-log datasets to calibrate saturation exponents (n) and cementation factors (m), demonstrating ANN superiority over conventional dual-water models.
Authors^26^ applied Levenberg-Marquardt-trained ANNs to quantify the sensitivity of log variables (e.g., GR, R_t_, ϕ_N_) to reservoir parameters, validating ANN capability to predict not only Sw and porosity (ϕ) but also composite petrophysical indices. Region-specific applications, such as^27^ feed-forward backpropagation ANN for Sw, ϕ, and permeability (k) prediction in the Niger Delta, achieved high accuracy using minimal inputs (GR, density, and R_t_). Most recently, Authors^28^ derived an empirical Sw correlation directly from ANN weight matrices, optimizing predictions in shale-rich formations using Vsh, Rt, ϕ, and k logs. Collectively, these studies underscore ANN adaptability, accuracy, and capacity to bypass restrictive assumptions inherent to conventional models.
In Middle Eastern carbonate reservoirs, hybrid machine learning (ML) frameworks integrating ANN with FL have demonstrated significant advantages over standalone empirical and ANN models. For instance^29^, reported that the Adaptive Neuro-Fuzzy Inference System (ANFIS) achieved marginally higher accuracy than ANN in Sw prediction tasks, while^30^ observed FL’s superior performance over ANN in similar lithologies. Further innovations in ANN optimization have enhanced computational efficiency and robustness: Authors^31^ integrated ANN with an Imperialist Competitive Algorithm (ICA) for unconventional reservoirs, emphasizing that outlier detection and noise reduction improved prediction reliability. Similarly, study^32^ utilized radial basis function (RBF) neural networks in Iran’s Sarvak Formation, noting RBF’s rapid convergence and structural simplicity as key advantages over traditional ANN architectures. Collectively, hybrid systems such as ANFIS, ICA-ANN, and RBF-ANN have advanced reservoir modeling by balancing generalization capacity with computational efficiency.
In parallel, FL networks have emerged as competitive tools for petrophysical prediction. Authors^6^ demonstrated FL computational efficiency and deterministic solutions for Sw and ϕ estimation, contrasting with ANN stochastic training processes. Authors^33^ refined FL accuracy by testing metaheuristic optimizers - including Differential Evolution, Particle Swarm Optimization (PSO), and Covariance Matrix Adaptation Evolution Strategy (CMAES) - with PSO achieving the highest predictive stability. These advancements underscore FL adaptability to complex reservoir systems, particularly where interpretability and computational speed are balanced.
Support Vector Machines (SVM) have also gained traction as robust ML tools for Sw prediction. Authors^34^ demonstrated SVM superior accuracy over ANN while developed a least-squares SVM (LS-SVM) variant that leveraged feature ranking to reduce input dimensionality without sacrificing performance. Comparative studies further validate SVM efficacy^35^ found SVM outperformed ANN, Random Forest (RF), and gradient boosting in limited-data sandstone reservoirs. Meanwhile, Authors^36^ evaluated ensemble methods (XGBoost, LightGBM, Adaboost, Catboost, Random Forest, and Super learner) in Russian sandstone reservoirs, with XGBoost marginally surpassing Super Learner models.
A notable contribution by authors^37^ optimized LS-SVM models for ϕ and Sw prediction in Norway’s Varg Field, identifying a minimal log suite - medium resistivity (Rm), gamma ray (GR), caliper (CALI), and self-potential (SP) - as sufficient for maximal accuracy. Counterintuitively, expanding input variables degraded performance, suggesting parsimonious log selections may mitigate overfitting in data-constrained environments. A comprehensive literature survey about the applicability of machine learning in oil and gas exploration with emphasis on reservoir properties prediction discussed included in^37,38^
The reviewed literature highlights that most ML approaches for Sw prediction either rely on conventional, and often inaccurate, log-derived Sw for training, or depend on sparse and prohibitively expensive core data. This dependency represents a fundamental bottleneck in developing robust, field-scale ML models.
This research addresses this gap by proposing a novel, integrated two-stage framework. Our primary contribution is not simply the application of ML, but the 'optimization-first’ methodology that creates a high-fidelity, physics-informed training dataset from log data alone. First, the framework employs numerical optimization (e.g., Powell, Differential Evolution) to accurately determine a single, globally optimized Rw from a minimal log suite. Second, this robust Rw is used to generate a continuous, high-quality Sw log. This 'optimized-Sw’ log then serves as a 'pseudo-core’ target variable to train and rigorously evaluate a comprehensive suite of ML models, including advanced ensembles (XGBoost, CatBoost) and neural networks (ANNs, LSTM). This approach effectively bypasses the traditional reliance on sparse core analyses, representing the first systematic investigation to couple Rw optimization with advanced ML prediction for this purpose in shaley-sand formations. Furthermore, we rigorously validate the robustness and generalizability of this framework on two distinct datasets: a primary dataset from the Norwegian North Sea and a blind-test dataset from the Egyptian Western Desert. By demonstrating consistent accuracy across different basins, this study advances a universally adaptable and cost-effective solution for Sw estimation, bridging the gap between ML innovation and operational petrophysical workflows.
Material and methodology
Dataset description
This study utilizes a total of 11 well logs (Table 1), comprising nine wells from the Norwegian North Sea offshore region, and two additional wells from the Egyptian Western Desert, situated in the Abu El-Gharadig and Matruh - Shushan basins. The Norwegian dataset is sourced from the publicly available Geolink Dataset^39^, licensed under NOLD 2.0, and provided by Geolink AS company*.* Complementary sample and cores analyses for the Norwegian wells were derived from the Norwegian Petroleum Directorate (NPD) fact pages^40^.Table 1. Geographic distribution, basin affiliation, and key parameters of the wells included in this study.Well No.Location/BasinBasin/Sub-basinFormation (Age)Depth interval (m)Rw^^ (Ω·m)Data sourceNS-01Norwegian North SeaSouthern Viking GrabenSleipner andHugin(M. Jurassic)2985 - 30450.047Geolink and factpagesNS-02Norwegian North SeaSouthern Viking GrabenSleipner andHugin(M. Jurassic)2895 - 29360.045Geolink and factpagesNS-03Norwegian North SeaSouthern Viking GrabenHugin(M. Jurassic)2384 - 24300.05Geolink and factpagesNS-04Norwegian North SeaSouthern Viking GrabenSleipner andHugin(M. Jurassic)3342 - 34900.051Geolink and factpagesNS-06Norwegian North SeaSouthern Viking GrabenHugin(M. Jurassic)2278 - 25050.015Geolink and factpagesNS-07Norwegian North SeaSouthern Viking GrabenHeimdal (Paleocene)2216 - 21600.05Geolink and factpagesNS-08Norwegian North SeaSouthern Viking GrabenHeimdal (Paleocene)2068 - 22200.030Geolink and factpagesNS-09Norwegian North SeaSouthern Viking GrabenSleipner(M. Jurassic)Statfjord (E. Jurassic)3180 - 33100.045Geolink and factpagesNST-05Norwegian North SeaSouthern Viking GrabenStatfjord (E. Jurassic)3695 - 38850.043Geolink and factpagesEGT-01AEgyptian Western DesertMatruh - Shushan BasinUpper and Lower Safa(Jurassic)1519 - 15700.027Proprietary DatasetEGT-02BEgyptian Western DesertAbu El-GharadigBahariya(upper cretaceous)2913 - 29530.038Proprietary Dataset** Rw Listed in the table along with lithology factors (a, m and n) are measured from samples and cores and utilized primarily for comparison with results obtained from current research.
Rw estimation via optimization
This section details the systematic methodology developed to estimate Rw through optimization techniques. The framework integrates global and local optimization algorithms to minimize discrepancies between measured resistivity (Rt) and Resistivity values derived from physics-based shaley-sand model^21^. The workflow is structured into three phases:
- Data preparation.
- Optimization framework.
- Validation against conventional petrophysical models.
The methodology begins with log anomalies removal (De-spiking) and quality control to ensure robust input for optimization. Gamma-ray (GR) logs are utilized to calculate shale volume (Vsh) using the following mathematical representation:
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$V_{sh} = \frac{{GR_{{{\mathrm{reading}}}} - GR_{{{\mathrm{clean}}}} }}{{GR_{{{\mathrm{shale}}}} - GR_{{{\mathrm{clean}}}} }}$$\end{document}Where \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$G{R}_{\mathrm{shale}} and G{R}_{\mathrm{clean}}$$\end{document} , obtained from log measurements from a thick unit of shale in the well of study calibrated to data from the Norwegian North Sea. Invalid entries are removed to exclude non-physical values. Neutron porosity and deep resistivity logs are retained as primary inputs.
The inverse problem is formulated to estimate global Rw and corresponding Sw that minimizes the difference between modeled and measured Rt. The physics-based resistivity model integrates shale conductivity effects through a derivation from Schlumberger equation^21^:
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${R}_{t}=\frac{{\phi }^{2}}{0.2\cdot {R}_{w}\cdot \left(1-{V}_{sh}\right)\cdot \left({\left({S}_{w}\cdot \frac{{\phi }^{2}}{0.4\cdot {R}_{w}\cdot \left(1-{V}_{sh}\right)}\right)}^{2}+2\cdot {S}_{w}\cdot \frac{{\phi }^{2}}{0.4\cdot {R}_{w}\cdot \left(1-{V}_{sh}\right)}\cdot \frac{{V}_{sh}}{{R}_{sh}}\right)}$$\end{document}where Rsh denotes shale resistivity.
The objective function incorporates regularization to stabilize solutions:
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$Minimize f\left({s}_{w}^{ }, {R}_{w}^{ }\right)=\sqrt{\frac{1}{N}{\sum }_{i=1}^{N}{\left(R{t}_{\mathrm{meas}}^{\left(i\right)}-R{t}_{\mathrm{model}}^{\left(i\right)}\left({s}_{w}^{ }, {R}_{w}^{ }\right)\right)}^{2}} + \lambda \left({s}_{w}^{ 2}+{R}_{w}^{ 2}\right)$$\end{document}subject to physical constraints (based on regional analysis of Rw measurements from any nearby wells):
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$0 \le Sw \le 1, \hspace{1em}0.01 \le Rw \le 0.1 \hspace{0.17em}\Omega \cdot m$$\end{document}Where:
- f(Sw,Rw): The objective function to be minimized.
- Rtmeas^(i)^: Measured deep resistivity at depth interval i (Ω⋅m).
- Rtmodel^(i)^ (Sw,Rw): Modeled resistivity at depth interval i, calculated using the Schlumberger shaley-sand equation (Equation 2).
- N: Total number of depth intervals (data points) in the log.
- λ: L2 regularization coefficient.
Four optimization algorithms were rigorously evaluated. They were selected for their complementary strengths to systematically compare the performance of different optimization philosophies:
- Powell and Nelder-Mead: These are high-efficiency, gradient-free local search (direct search) methods. They are well-suited for rapidly refining solutions in smooth, uni-modal problems and do not require derivatives.
- Differential Evolution (DE): This is a powerful, stochastic global optimization algorithm. It was chosen to robustly explore the entire search space and mitigate the risk of being trapped in a local minimum, which is common in complex geophysical inverse problems.
- COBYLA (Constrained Optimization BY Linear Approximation): This algorithm was specifically included for its ability to handle non-linear optimization problems with inequality constraints, which directly aligns with our problem’s need to bound Rw within physically realistic limits.
A concise summary of each method mathematical foundation is provided in Table 2, omitting detailed theoretical derivations to maintain focus on the applied framework. While acknowledging the mathematical complexity inherent to optimization techniques, this study prioritizes their practical implementation and comparative performance, as exhaustive algorithmic expansions fall beyond the scope of this reservoir characterization-focused investigation.Table 2. Summary of optimization techniques employed in this study.MethodMathematical formulationReferencePowellIteratively minimizes along conjugate directions without derivatives: \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$x_{k + 1} = x_{k} + {\upalpha }_{k} d_{k}$$\end{document} ^41^Nelder-MeadSimplex-based direct search adjusting vertices via reflection (ρ), expansion (χ), contraction (γ), and shrinkage (σ): \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${x}_{c}=\frac{1}{n}{\sum }_{i\ne h}{x}_{i}$$\end{document} ^42^Differential evolution (DE)Population-based global optimization with mutation, crossover, and selection: \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${v}_{i}={x}_{r1}+F\left({x}_{r2}-{x}_{r3}\right)$$\end{document} \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${u}_{ij}=\left\{\begin{array}{c}{v}_{ij},\hspace{1em}{\mathrm{i}}{\mathrm{f}} \, {\mathrm{r}}{\mathrm{a}}{\mathrm{n}}{\mathrm{d}}\le CR\\ {\mathrm{x}}_{\mathrm{ij}},\hspace{1em}{\mathrm{o}}{\mathrm{t}}{\mathrm{h}}{\mathrm{e}}{\mathrm{r}}{\mathrm{w}}{\mathrm{i}}{\mathrm{s}}{\mathrm{e}}\end{array}\right.$$\end{document} ^43^COBYLALinear approximation of constraints: \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\mathrm{min}f\left(x\right)\text{ s.t. }{c}_{i}\left(x\right)\le 0$$\end{document} ^44^
Validation against conventional models
Results are benchmarked against Three industry-standard shaley-sand models:
- Simandoux^13^:
- Schlumberger^21^:
- Poupon and Leveaux (Indonesia)^14^:
Discrepancies between optimized and conventional Sw-Rw pairs are quantified using root mean square error (RMSE) with the following equation:
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${\mathrm{RMSE}}=\sqrt{\frac{1}{N}{\sum }_{i=1}^{N}{\left({R}_{{t}_{\mathrm{meas}}}^{\left(i\right)}-{R}_{{t}_{\mathrm{model}}}^{\left(i\right)}\right)}^{2}}$$\end{document}Where:
- N: Total number of depth intervals or data points.
- Rtmeas ^(i)^: Measured resistivity at depth interval i.
- Rtmodel ^(i)^: Modeled resistivity at depth interval ii, calculated using the Schlumberger shaley-sand equation.
Dataset preparation
The integrity of petrophysical data forms the cornerstone of robust machine learning applications in reservoir characterization. This study adopts a systematic, multi-stage preprocessing pipeline to address inherent challenges in shaley sand formations, including data heterogeneity, measurement noise, and depth-dependent variability. The methodology encompasses five principal phases, each designed to enhance data quality while preserving geological realism.
Log quality control and initial processing
The wireline dataset from twelve wells underwent rigorous quality assurance protocols. Initial processing included alignment of depth indices to a consistent sampling interval (0.1 m) to resolve discrepancies arising from tool stick-slip or borehole rugosity. Range validation excluded nonphysical values. Composite log displays were generated to visualize parameter distributions and detect Zones of interest, such as neutron-density crossover indicating porous reservoir formations (Fig. 1).Fig. 1. Log Display of well NS-08 showing Zone of interest (Top Paleocene Heimdal reservoir) fluid contacts. Gas-Oil-Contact (GOC) in Black dashed line, and Oil-Water-Contact (OWC) in blue dashed line.
Handling missing data
Approximately 0.0012 % of the dataset exhibited missing values. Depths with any missing features were discarded to prevent any biased imputation.
Feature normalization
To minimize the impact of data fluctuations during the modeling process, and to avoid overfitting both input and output variables are normalized by the following equation:
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${n}{\prime}=\frac{n-{n}_{\mathrm{min}}}{{n}_{\mathrm{max}}-{n}_{\mathrm{min}}}$$\end{document}Where:
- \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$n$$\end{document} : the original value,
- \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${n}_{\mathrm{min}}$$\end{document} : the minimum value in the dataset,
- \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${n}_{\mathrm{max}}$$\end{document} : the maximum value in the dataset,
- \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${n}{\prime}$$\end{document} : the normalized value scaled between 0 and 1.
Figure 2 represents well NS-03 offering a dual perspective on petrophysical data: the raw data plot reveals distinct scaling differences among Sw__optimized, RHOB, NPHI, and Vsh_ across depth, highlighting inherent measurement variability and reservoir heterogeneity, while the normalized plot - achieved via scaling - facilitates a direct visual comparison by aligning the disparate logs onto a uniform [0,1] scale. This juxtaposition not only underscores the critical need for normalization in multi-variable reservoir analyses but also enhances interpretability by revealing subtle trends and correlations that are otherwise masked by scale differences, thereby supporting more informed reservoir characterization and integrated data interpretation.Fig. 2. Raw and Normalized Petrophysical Logs vs. Depth for well NS-03. (a) Raw plots of versus depth (b) After applying normalization.
Hybrid outlier detection framework
Outlier removal combined statistical leverage analysis with domain-specific constraints. The Williams plot methodology identified high-leverage points through hat matrix decomposition:
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$H=X{\left({X}^{T}X\right)}^{-1}{X}^{T}$$\end{document}where X represents the normalized feature matrix. Observations exceeding a 3(p/n) leverage threshold (p=features, n=samples) were flagged. This threshold was not chosen randomly; it was determined after empirical testing of standard cutoffs (e.g., 2p/n, 4p/n, 5p/n) and was found to provide the optimal balance between high-leverage outlier removal and data preservation for our subsequent ML models. These statistical outliers were further filtered through petrophysical bounds GR (10–180 API), NPHI (0.05–0.50.05.50), Rt (0.2–1000.2 \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\Omega \cdot m$$\end{document} ), and RHOB (1.9 to 2.96 gm/cc). This dual approach removed 3.2% of data, balancing noise reduction with sample retention (Fig.3).Fig. 3. Delineation of potential outliers (Points within red zones) before further preprocessing the data for ML phase.
Sensitivity analysis using relevancy factor and SHAP
To quantitatively assess the relative influence of petrophysical variables on the water saturation, a critical parameter in shaley-sand resistivity models, a sensitivity analysis was conducted using the relevancy factor (r). This statistical metric evaluates the linear correlation between input variables and the output (n), providing insight into parameter interdependencies that govern reservoir behavior.
The relevancy factor for each input variable x_j_ is computed as:
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${r}_{j}=\frac{{\sum }_{i=1}^{N}\left({x}_{j,i}-\overline{{x }_{j}}\right)\left({y}_{i}-\overline{y }\right)}{\sqrt{{\sum }_{i=1}^{N}{\left({x}_{j,i}-\overline{{x }_{j}}\right)}^{2}}\cdot \sqrt{{\sum }_{i=1}^{N}{\left({y}_{i}-\overline{y }\right)}^{2}}}$$\end{document}where:
- xj,i: Value of the j-th input variable at depth i.
- yi: Corresponding water saturation derived from optimization phase.
- \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\overline{{x }_{j}}$$\end{document} , \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\overline{y }$$\end{document} : Mean values of the j-th input and output, respectively.
- N: Total number of data points.
The relevancy factor ranges from −1 (perfect inverse correlation) to +1 (perfect direct correlation), with magnitudes > 0.3 indicating significant relationships (Fig.4)Fig. 4. Relative impact of the well logs on Sw using relevancy factor (r) for adopted Machine learning algorithms.
To move beyond simple linear correlations and gain a deeper, model-agnostic understanding of our trained models, we employed SHAP (SHapley Additive exPlanations). SHAP is a state-of-the-art method from cooperative game theory that provides robust, locally accurate, and consistent feature attributions. The core of SHAP is the Shapley value, which quantifies the contribution of each feature to a specific prediction by averaging its marginal contribution across all possible feature coalitions.
The Shapley value \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${\upphi }_{i}$$\end{document} for feature \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$i$$\end{document} is formally defined as:
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${\upphi }_{i}\left(f,x\right)={\sum }_{S\subseteq F\setminus \{i\}}\frac{\left|S\right|!\left(\left|F\right|-\left|S\right|-1\right)!}{\left|F\right|!}\left[{f}_{x}\left(S\cup \{i\}\right)-{f}_{x}\left(S\right)\right]$$\end{document}where \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$F$$\end{document} is the set of all features, \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$S$$\end{document} is a subset of features, \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${f}_{x}\left(S\right)$$\end{document} is the model prediction using the feature values in \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$S$$\end{document} .
SHAP unites this concept with an additive feature attribution model, which explains a prediction \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${f}_{x}$$\end{document} as the sum of the base value ( \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$E[f(z)]$$\end{document} ) plus the SHAP values for each of the \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$M$$\end{document} features:
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$f\left(x\right)=E\left[f\left(z\right)\right]+{\sum }_{i=1}^{M}{\upphi }_{i}\left(f,x\right)={\upphi }_{0}+{\sum }_{i=1}^{M}{\upphi }_{i}$$\end{document}The resulting SHAP summary plots (Fig. 5) providing two critical insights:
- Global Feature Importance: Features ranked by their mean absolute SHAP value.
- Local Feature Impact: A distribution visualizing the magnitude and direction (positive or negative) of each feature contribution to predicting water saturation. Fig. 5SHAP summary plots for the top-performing models. Features are ranked by global importance. The horizontal axis is the SHAP value (impact on output), and the color indicates the original feature value (red=high, blue=low), revealing the direction and magnitude of each feature influence.
ML model training, refinement, and validation
The principal objective of this section is to delineate a systematic, data-driven framework for the development, validation, and refinement of ML models designed to predict Sw with high fidelity from well-derived datasets. This framework integrates critical phases of data preprocessing, algorithmic selection, performance benchmarking, and hyperparameter optimization - each structured to ensure the derivation of models that are both statistically robust and operationally generalizable for subsurface reservoir assessment.
Summarized ML algorithms in Table 3 when appropriately selected and rigorously optimized, exhibit the capacity to discern intricate, non-linear relationships within high-dimensional and noise-contaminated datasets, thereby offering transformative potential for reservoir characterization. The efficacy of such models, however, is contingent upon a methodologically sound modeling pipeline. This necessitates judicious algorithm selection aligned with data characteristics, the application of stringent validation protocols, and systematic hyperparameter optimization to maximize predictive performance while mitigating overfitting. The entire framework for Rw estimation alongside Sw prediction integrates advanced machine learning with rigorous validation protocols, as outlined in Figure 6.Table 3. Comparative summary for ML algorithms implemented in the current study.**ModelDescriptionMathematical principleMathematical formulation & key conceptsDecision Tree (DT)**Hierarchical, rule-based model splitting features at optimal thresholds^60^Recursive binary splitting to minimize MSEby choosing the best split that reduces variancein target values.Splits features to minimize impurity: \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${\mathrm{MSE}}=\frac{1}{n}{\sum }_{i=1}^{n}{\left({y}_{i}-\widehat{{y}_{i}}\right)}^{2}$$\end{document} **Random Forest (RF)**An ensemble of decision trees using bagging and feature randomness^48^Reduces overfitting by averaging predictions from many uncorrelated trees trained on bootstrapped samples.Averaging predictions: \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\widehat{{f}_{RF}}\left(x\right)=\frac{1}{T}{\sum }_{t=1}^{T}\widehat{{f}^{\left(t\right)}}\left(x\right)$$\end{document} **AdaBoost (AB)**Sequential ensemble where each model corrects predecessor’s errors^49^Emphasize difficult samples by assigningthem higher weights, improving weak learners.Weighted voting: \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\widehat{y}={\sum }_{m=1}^{M}{\alpha }_{m}{h}_{m}\left(x\right)$$\end{document} \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${\alpha }_{m}=\frac{1}{2}\mathrm{ln}\left(\frac{1-{\epsilon }_{m}}{{\epsilon }_{m}}\right)$$\end{document} **XGBoost (XGB)**Gradient boosting with regularization and shrinkage^46^Optimizes a regularized loss function,improving generalization.Additive model: \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\widehat{{y}_{i}}={\sum }_{k=1}^{K}{f}_{k}\left({x}_{i}\right),\hspace{1em}{f}_{k}\in \mathcal{F}$$\end{document} Objective: \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${\mathrm{Obj}}=\sum l\left({y}_{i},\widehat{{y}_{i}}\right)+\sum\Omega \left({f}_{k}\right)$$\end{document} \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\Omega \left(f\right)=\gamma T+\frac{1}{2}\lambda |w{|}^{2}$$\end{document} **CatBoost (CB)**Categorical boosting with ordered boosting to avoid overfitting^47^Handles categorical variables usingpermutations and target statistics.Uses ordered statistics to prevent target leakage; minimizes: \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$L=\sum {\left({y}_{i}-\widehat{{y}_{i}}\right)}^{2}+{\mathrm{Reg}}$$\end{document} **SVR (RBF Kernel)**Regression model that minimizes error within an epsilon-insensitive tube^51^Uses kernel trick to fit nonlinear functions inhigh-dimensional space.Optimization objective: \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$min\frac{1}{2}{w}^{T}w+C{\sum }_{i}\left[\mathrm{max}\left(0,\left|{y}_{i}-f\left({x}_{i}\right)\right|-\varepsilon \right)\right]$$\end{document} \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$K\left(x,{x}{\prime}\right)=\mathrm{exp}\left(-\gamma |x-{x}{\prime}{|}^{2}\right)$$\end{document} **Feedforward ANN (Bayesian Regularization)**Fully connected layers for regression tasks^54^Learns weights to minimize error and avoidoverfitting using Bayesian probabilityPosterior over weights: \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$P\left( {w\left| D \right.} \right) \propto \exp \left( { - \frac{1}{{2\sigma^{2} }}\sum \left( {y_{i} - \widehat{{y_{i} }}} \right)^{2} - \frac{\lambda }{2}\sum w_{j}^{2} } \right)$$\end{document} **ANN (Levenberg-Marquardt)**Fully connected layers for regression tasks^55^Learn weights to minimize error and avoidoverfitting using Levenberg-Marquardt optimization.Optimization via second-order update: \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${w}_{\mathrm{new}}=w-{\left({J}^{T}J+\mu I\right)}^{-1}{J}^{T}e$$\end{document} LSTMRecurrent neural network with memory gates for sequential data^57^Maintains long-term memory via gatedcell structures (forget, input, output gates).Memory cell and gates:Forget gate: \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${f}_{t}=\sigma \left({W}_{f}\left[{h}_{t-1},{x}_{t}\right]+{b}_{f}\right)$$\end{document} Input gate: \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${i}_{t}=\sigma \left({W}_{i}\left[{h}_{t-1},{x}_{t}\right]+{b}_{i}\right)$$\end{document} State: \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${C}_{t}={f}_{t}*{C}_{t-1}+{i}_{t}*\widetilde{{C}_{t}}$$\end{document} Fig. 6. Workflow schematic for the automated estimation of Rw and Sw prediction.
The preprocessed dataset, comprising data from eight distinct wells in the North Sea (NS-01 through NS-09), was designated solely for the training and cross-validation phase. A comprehensive 5-fold cross-validation protocol was implemented on this entire pooled training set to rigorously assess model performance and generalizability. The three remaining wells (NST-05 from Norway, EGT-01A and EGT-02B from Egypt) were held out as a completely separate blind test dataset. These wells were not used in any aspect of training, validation, or hyperparameter tuning, and were used only once to evaluate the final, ability of the trained models to generalize to unseen data and geologically distinct basins.
This section methodically articulates the architecture of the proposed pipeline, structured as follows:
- Evaluates a suite of supervised learning algorithms, encompassing Tree-based ensemble methods (e.g., XGBoost, AdaBoost, CatBoost, Decision Tree, and Random Forest) alongside regularized regression techniques, to benchmark predictive accuracy and performance efficiency (Figures. 7, 8 and 9).
- Employs multi-metric evaluation - including root mean square error (RMSE), mean absolute error (MAE), and coefficient of determination (R^2^) - to quantify model fidelity and guide algorithm selection.
- Implements combinatorial search strategies, such as grid search and randomized cross-validation, to identify model configurations that optimally balance bias-variance trade-offs. Fig. 7. Actual versus predicted Sw from All ML Models - Training Phase.Fig. 8. Actual versus predicted S_w_ from All ML Models - Validation Phase.Fig. 9. Actual versus predicted S_w_ from All ML Models - Testing Phase.
The algorithmic selection for this investigation was guided by rigorous evaluation of machine learning techniques with demonstrated efficacy in addressing the characteristic challenges of geophysical datasets - including non-linear parameter interactions, high-dimensional feature spaces, and heteroscedastic data structures. The following methodologies were prioritized based on their theoretical compatibility with petrophysical prediction tasks and empirical performance in analogous regression applications:
- Tree-Based Ensemble Methods (Random Forest, Decision Trees, XGBoost, CatBoost, AdaBoost):
Exhibit inherent noise tolerance through bootstrap aggregation and stochastic subspace sampling, coupled with interpretability via feature significance metrics. Their hierarchical decision boundaries enable robust modeling of non-linear relationships in tabular petrophysical data while mitigating overfitting through ensemble variance reduction.
- 2.Support Vector Regression (SVR):
Kernel-based transformations (e.g., radial basis functions) facilitate high-dimensional hyperplane construction for continuous Sw prediction, particularly effective in complex, non-convex solution spaces where linear separability is absent. Theoretical guarantees on generalization error bounds enhance reliability in sparse-data regimes.
- 3.Artificial Neural Networks (ANNs):
Feedforward Architectures: Leverage multi-layer perceptron (MLP) to model hierarchical feature representations, excelling in capturing deep non-linearities between static well log variables and Sw.
Long Short-Term Memory (LSTM) Networks: Specialized for sequential data analysis, these architectures were included to decode spatial dependencies in the depth-indexed logging measurements. Our rationale is that geological properties are not independent point-to-point but follow vertical depositional sequences (e.g., fining-upward or coarsening-upward cycles). We hypothesized an LSTM may capture these spatiotemporal patterns, which a standard feedforward ANN would miss. This approach is supported by a growing body of literature where LSTMs have been successfully applied to decode sequential dependencies in well-log data for tasks such as synthetic log generation, lithology identification, and missing log prediction In the development of machine learning models for predicting Sw from well log data, a suite of optimization methodologies was rigorously implemented, each tailored to the architectural and functional characteristics of the respective algorithms.
For gradient-boosted ensemble architectures (XGBoost, CatBoost), sequential additive learning frameworks were employed, wherein successive decision trees were iteratively constructed to minimize residual errors from prior ensemble iterations^45^. To regulate model complexity and counteract overfitting, these algorithms incorporated shrinkage mechanisms (i.e., learning rate attenuation), which attenuate the contribution of individual trees during gradient updates^46^. Both models further integrated early stopping protocols, whereby training was halted upon stagnation of validation loss improvement over predefined epochs, thereby enhancing computational efficiency while preserving generalization capacity^47^. For Random Forest and AdaBoost, bootstrap aggregation (bagging) and adaptive reweighting of misclassified samples were implemented to reduce variance and bias, respectively^48,49^^.^
The SVR framework adopted an ε-insensitive loss function, which tolerates residual errors within a margin of ε, thereby prioritizing corrections for deviations exceeding this threshold^50^. Optimization entailed solving a convex quadratic programming problem to minimize a regularized objective function, balancing a penalty term (governed by hyperparameter C) against the ε-insensitive loss^51^. This formulation ensures a principled trade-off between model complexity and error tolerance, rendering SVR particularly adept at capturing nonlinear relationships in high-dimensional feature spaces^52^.
For neural network-based models - specifically the Long Short-Term Memory (LSTM) network and two variants of feedforward Artificial Neural Networks (ANNs) optimized using Bayesian Regularization (BR) and the Levenberg-Marquardt (LM) algorithm - gradient-based optimization formed the backbone of the training process. Central to this was the backpropagation algorithm^53^, which computed the gradients of the loss function with respect to the network weights, thereby enabling iterative parameter updates through variants of gradient descent to minimize the overall prediction error.
In the Bayesian Regularization (BR) framework, the standard error-based loss function was augmented with a Tikhonov regularization term that penalized large weight magnitudes. This not only mitigated overfitting but also provided a probabilistic interpretation of model complexity, promoting smoother and more generalizable solutions by effectively balancing data fidelity and model simplicity^54^. In the ANN-LM architecture, the Levenberg-Marquardt (LM) optimization algorithm was employed as a robust second-order method that combined the curvature-sensitive Gauss-Newton approximation with the stability of gradient descent. This hybrid strategy was particularly advantageous for small-to-medium sized nonlinear regression problems, offering faster convergence and superior stability compared to traditional first-order methods^55^.
The LSTM network incorporated stochastic dropout regularization with a dropout rate during training, randomly deactivating a subset of neurons in each iteration. This method effectively reduced the risk of co-adaptation among neurons, thereby enhancing the model’s ability to generalize to unseen data^56^. Additionally, activation functions were carefully selected based on empirical performance and architectural demands: the hyperbolic tangent (tanh) activation function was employed in the recurrent layers to support stable gradient flow over long temporal sequences, which is critical for capturing sequential dependencies^57^; conversely, Rectified Linear Units (ReLU) were used in the feedforward layers due to their non-saturating nature, which promotes efficient training and alleviates vanishing gradient problems^58^.
The preprocessed dataset, comprising data from eight distinct wells in the North Sea, was designated solely for the training phase of the modeling process. During this phase, a comprehensive 5-fold cross-validation protocol was implemented to rigorously assess and improve model performance, ensuring the generalizability and robustness of the learned relationships. Within each fold, a further internal partitioning of 20% of the training data was utilized during hyperparameter tuning of deep learning architectures - such as LSTM and ANN models - to fine-tune model parameters and mitigate overfitting. This division and validation strategy provided iterative feedback on model accuracy across diverse subsets of the training set.
Hyperparameter optimization is a critical component of the proposed framework, directly influencing the predictive accuracy and generalizability of the machine learning models. In our study, a systematic and rigorous hyperparameter tuning strategy was implemented using both grid search and randomized cross-validation approaches (Table 4). This strategy enabled a comprehensive exploration of the hyperparameter space encompassing parameters such as the number of estimators, maximum tree depth, learning rate, regularization coefficients, and dropout rates to achieve an optimal balance between model complexity and generalization performance. For neural network architecture, advanced techniques including Bayesian Regularization and the Levenberg-Marquardt algorithm were leveraged alongside stochastic dropout and early stopping criteria based on validation loss. These measures not only mitigated the risk of overfitting but also enhanced the stability and convergence speed during training. Collectively, the fine-tuned hyperparameters, as delineated in Table 5, underpin the robust performance observed across the training, validation, and test phases, cementing the framework efficacy in predicting water saturation in shaley-sand reservoirs with high precision^59^Table 4. Hyperparameter search space for machine learning models.HyperparameterXGBoostRandom ForestSVR (RBF)CatBoostAdaBoostDecision TreeTuning MethodGrid SearchRandomized Search (20 iter)Grid SearchGrid SearchGrid SearchGrid Searchn_estimators[50, 100, 150][50, 100, 150, 200][50, 100, 150]iterations[50, 100, 150]max_depth[3, 5, 7][None, 5, 10, 15]Fixed at 4*[None, 3, 5, 7]depth[3, 4, 5]learning_rate[0.01, 0.1, 0.3][0.05, 0.1, 0.15]min_samples_split[2, 4, 6][2, 4, 6]min_samples_leaf[1, 2, 3][1, 2, 3]C[0.1, 1, 10, 100]epsilon[0.01, 0.1, 0.5]gamma[‘scale’, ‘auto’]HyperparameterLSTMANN_LM****ANN_BayesianTuning MethodKeras Tuner (Random Search)Keras Tuner (Random Search)Keras Tuner (Random Search)unitsInteger: 20 to 60dropoutFloat: 0.1 to 0.5units1Integer: 32 to 128Integer: 16 to 48units2Integer: 16 to 64Integer: 8 to 32dropoutFloat: 0.1 to 0.5LSTM_LRLog-uniform: 1×10^−4^ to ×10^−2^ANN_LRLog-uniform: 1×10^−4^ to ×10^−2^Log-uniform: 1×10^−4^ to ×10^−2^Table 5. Hyperparameters settings for each ML Algorithm.ModelNumber of EstimatorsMaximum DepthLearningrateKernelCepsilongammaHidden LayersNeurons per LayerActivationEpochsXGBoost200100.05Random Forest15015CatBoost100100.1AdaBoost1000.05SVR (RBF)RBF1000.10.01LSTM1 LSTM + Dense50Tanh + Linear100ANN (BR)220, 10ReLU200ANN (LM)330, 15, 10Tanh150
To ensure optimal performance and mitigate overfitting, the hyperparameters for each machine learning model were systematically optimized using a 5-fold cross-validation (CV) strategy. The search was guided by maximizing the R^2^ score. We employed GridSearchCV for models with smaller search spaces and RandomizedSearchCV (Keras Tuner) for larger spaces to balance computational cost and search breadth and presented.
A 5-fold cross-validation protocol was implemented. In our current study, we used a single fixed random_state=42 for our 5-fold cross-validation strikes an optimal balance between computational efficiency and bias-variance trade-offs, reducing dependence on a single train-test partition^61^. This was an intentional choice to ensure that all models were trained and validated on the exact same 5 folds, allowing for a fair and reproducible comparison. This approach, coupled with early stopping and hyperparameter tuning, ensures that model performance reflects true generalizability rather than overfitting idiosyncratic data configurations^62^.
Evaluation metrics
To evaluate the predictive performance of the regression models, three established metrics were employed: Mean Absolute Error (MAE), Root Mean Squared Error (RMSE), and the Coefficient of Determination (R^2^). These metrics collectively assess accuracy, error sensitivity, and explanatory power, addressing distinct facets of model performance.
Mean Absolute Error (MAE)
The MAE quantifies the average magnitude of absolute deviations between predicted ( \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\widehat{{y}_{i}}$$\end{document} ) and observed ( \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${y}_{i}$$\end{document} ) values, computed as:
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${\mathrm{MAE}}=\frac{1}{n}{\sum }_{i=1}^{n}\left|{y}_{i}-\widehat{{y}_{i}}\right|$$\end{document}where n denotes the total number of observations. MAE is inherently interpretable and robust to scale, though it imparts equal weight to all residuals, potentially underemphasizing the influence of extreme outliers^63^.
Root Mean Squared Error (RMSE)
RMSE penalizes larger errors quadratically, offering sensitivity to outliers, and is defined as:
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${\mathrm{RMSE}}=\sqrt{\frac{1}{n}{\sum }_{i=1}^{n}{\left({y}_{i}-\widehat{{y}_{i}}\right)}^{2}}$$\end{document}This metric is particularly advantageous in contexts where substantial prediction errors carry disproportionately higher operational or financial risks^64^.
Coefficient of determination (\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${R}^{2}$$\end{document})
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${R}^{2}$$\end{document} evaluates the proportion of variance in the dependent variable explained by the model, expressed as:
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${R}^{2}=1-\frac{{\sum }_{i=1}^{n}{\left({y}_{i}-\widehat{{y}_{i}}\right)}^{2}}{{\sum }_{i=1}^{n}{\left({y}_{i}-\overline{y }\right)}^{2}}$$\end{document}where \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\overline{y }$$\end{document} represents the mean of observed values. Values approaching 1 indicate near-complete explanatory capability, while values near 0 suggest the model performs comparably to a naïve mean predictor^65^.
Statistical significance via paired T-Test
To rigorously validate whether the observed differences in performance between our top-performing machine learning models were statistically significant or merely the result of random chance, we employed a paired-sample t-test. This statistical test is specifically suited for comparing two models because their performance metrics (RMSE) were derived from the same 5-fold cross-validation dataset. The “paired” nature of the test arises from the fact that both models were trained and validated on the exact same five data splits (folds), allowing for a direct, fold-by-fold comparison of their errors.
The test is centered on analyzing the differences in the performance scores (in our case, the RMSE) for each fold. Let \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${D}_{i}$$\end{document} be the difference in RMSE between Model 1 and Model 2 on the \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$i$$\end{document} -th fold:
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${D}_{i}={\mathrm{RMSE}}_{\text{Model 1, fold }i}-{\mathrm{RMSE}}_{\text{Model 2, fold }i}$$\end{document}Our primary goal was to test the null hypothesis (H_0_), which states that there is no mean difference in performance between the two models. The alternative hypothesis ( \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${H}_{a}$$\end{document} ) states that a significant difference exists.
- Null Hypothesis ( \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${H}_{0}$$\end{document} ): \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${\upmu }_{D}=0$$\end{document} (The mean of the differences is zero).
- Alternative Hypothesis ( \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${H}_{a}$$\end{document} ): \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${\upmu }_{D}\ne 0$$\end{document} (The mean of the differences is not zero).
The t-statistic is calculated as the mean of the differences ( \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\overline{D })$$\end{document} divided by its standard error ( \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$S{E}_{D}$$\end{document} ):
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$t=\frac{\overline{D }-{\upmu }_{0}}{S{E}_{D}}=\frac{\overline{D}}{{s }_{D}/\sqrt{n}}$$\end{document}where:
- \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\overline{D }$$\end{document} is the sample mean of the differences \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${D}_{i}$$\end{document} across the \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$n$$\end{document} folds.
- \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$n$$\end{document} is the number of folds (in our case, \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$n$$\end{document} =5).
- \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${s}_{D}$$\end{document} is the sample standard deviation of the differences.
- \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${\upmu }_{0}$$\end{document} is the hypothesized population mean difference (0 under the null hypothesis).
From this t-statistic, a p-value is computed. This p-value represents the probability of observing our results (or more extreme) if the null hypothesis were true. In line with conventional scientific practice, we used a significance level \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${(}\alpha {)}$$\end{document} of 0.05. A p-value less than 0.05 indicates that the observed difference in model performance is statistically significant, allowing us to reject the null hypothesis and conclude that the models’ performances are genuinely different.
Computational methods and software
The entire data processing, petrophysical optimization, and machine learning workflow was conducted using the Python 3.11.9 programming language and its scientific computing ecosystem. Numerical computation and data structuring were performed using NumPy and Pandas, respectively. The primary machine learning framework was Scikit-learn, which was utilized for data preprocessing (e.g., MinMaxScaler), model cross-validation (KFold, GridSearchCV, RandomizedSearchCV), and evaluation (r2_score, mean_absolute_error). We implemented classical models including RandomForestRegressor, AdaBoostRegressor, DecisionTreeRegressor, and SVR from Scikit-learn, supplemented by specialized gradient boosting libraries XGBoost and CatBoost. Deep learning models (ANN and LSTM) were constructed using the TensorFlow framework with its high-level Keras API. The Scikeras library was employed as a wrapper to ensure Scikit-learn compatibility for the Keras models, and Keras Tuner was used for neural network hyperparameter optimization. Model interpretability was assessed using SHAP. Statistical significance was tested using the paired t-test function (ttest_rel) from SciPy. All visualizations were generated using Matplotlib and Seaborn.
Results and discussion
Optimization results
The results of Rw estimation via our advanced optimization framework demonstrate the efficacy of the proposed methodology in reconciling the inherent complexities of shaley-sand reservoirs. Four optimization algorithms - Powell, Nelder-Mead, Differential Evolution, and COBYLA - were evaluated based on their root mean squared error (RMSE) performance in estimating Rw.
integrating water saturation profiles derived from multiple physics-based saturation models (based on water sample and core analyses) and an optimization-derived saturation curve obtained from equation 3 (second track from the right), as well as a differential curve comparing calculated versus measured deep resistivity (first track from the right).
Results comparison (Fig. 10) revealed that algorithms such as Powell and, in certain cases, Nelder-Mead consistently produced the lowest RMSE values. For instance, in well NS-01, Powell’s algorithm achieved an optimized Rw value of 0.04704, which is virtually indistinguishable from the true measured value of 0.047, as evidenced by an RMSE close to zero. By contrast, Differential Evolution, while robust in exploring the global search space and handling constraints respectively, exhibited slightly higher RMSE values in several wells. These trends underscore the importance of algorithm selection in balancing local refinement and global exploration are critical aspects in capturing complex reservoir heterogeneities and mitigating the influence of measurement noise.Fig. 10. Composite Log Display for Well NS-02 Illustrating the Middle Jurassic Hugin and Sleipner Reservoirs.
Table. 6 and 7 provide a detailed comparison that reinforces these observations. The numerical data reveal that the discrepancies between the optimized and true Rw values are minimized across most cases, with the Powell and Nelder-Mead algorithms frequently emerging as the most accurate estimator and recommended for such workflow based on both computation time and performance as highlighted in Figure. 11. Furthermore, Figure 12 graphically illustrates this trend by depicting error margins that are tightly clustered around low values, thereby visually confirming the efficacy of our optimization approach. These consistent results, achieved across diverse well conditions, suggest that our methodology is robust, effectively accommodating variations in local lithology and measurement inconsistencies. Minor deviations observed in well NS-02 are likely attributable to residual noise within the well-log measurements, phenomena that our regularization and constraint-based framework is designed to mitigate but not entirely eliminate.Table 6. Optimized formation water resistivity (Rw) and associated RMSE for each well.Well No.True* RwOptimized Rw (Ω·m)RMSE(Optimized Rw vs True Rw)PowellNelder-MeadDifferentialEvolutionCOBYLAPowellNelder-MeadDifferentialEvolutionCOBYLANS-010.0470.047040.051330.058700.061820.000010.00430.01170.0148NS-020.0450.032480.053910.069640.069640.01250.00890.02460.0246NS-030.050.047080.04000.053150.039900.00290.01000.00320.0101NS-040.0510.055750.051600.069920.069800.00470.00060.01890.0188NS-060.0150.017170.016500.019190.017670.00220.00150.00420.0027NS-070.050.047120.038940.066100.069900.00290.01110.01610.0199NS-080.0300.035000.035000.035010.350000.00500.00500.00500.0050NS-090.0450.028000.028000.028000.028000.00800.00800.00800.0080NST-050.0430.040000.040000.040000.040000.00300.00300.00300.0030EGT-01A0.0270.024360.024750.024360.021620.00260.00230.00260.0054EGT-02B0.0380.031000.031000.031000.031000.00600.00600.00600.0060Table 7RMSE between Optimized S_w_ and true S_w_.Well No.RMSE(Optimized Sw vs Core based Sw^^)PowellNelder-MeadDifferentialEvolutionCOBYLANS-010.04010.03460.02620.0231NS-020.06690.04420.04780.0478NS-030.04320.06680.02510.0671NS-040.03680.04360.03340.0332NS-060.05150.05660.04070.0482NS-070.11100.13120.07320.0672NS-080.14540.14540.14540.1454NS-090.16930.16930.16930.1693NST-050.16840.16840.16840.1684EGT-01A0.12870.12470.12870.1584EGT-02B0.17230.17230.17230.1723^**^ S_w_ discussed in the table is the average S_w_ obtained from averaging S_w_ from three saturation models based on water samples and special core analysis to obtain (R_w,_ R_sh,_ m, n, a*).Fig. 11. Computation time for each algorithm against all wells in the current study. Nelder-Mead with the lowest computational time algorithm and DE as the highest.Fig. 12. Root Mean Square Error (RMSE) of R_w_ for each well and algorithm quantifing the discrepancies between optimized Rw values and the true (measured) Rw.
It is important to note that the near-zero RMSE values observed for the Powell algorithm (for NS-01 well) represents a powerful validation of the methodology. This specific RMSE (Table 6) represents the absolute difference between the algorithm-derived Rw and the ground-truth Rw from core samples. This result demonstrates that the optimization framework is capable of accurately recovering the true formation water resistivity from the log data alone, serving as a robust physics-based anchor for the subsequent ML models.
The validation of our optimized Sw values against conventional petrophysical models (Fig. 13) - obtained from core parameters - further substantiates the rigor of the optimization approach. When comparing our Sw estimates with those derived from established models such as Simandoux, Schlumberger, and Poupon-Leveaux, our results consistently exhibited low RMSE values (as detailed in Table 7). These results in error signifies not only a methodological improvement but also accurately capturing the underlying geophysical processes, particularly in accounting for shale-induced conductivity effects. These findings carry important geophysical implications, as even minor improvements in Sw estimation can substantially alter the interpretation of reservoir quality and hydrocarbon reserve calculations. The enhanced predictive accuracy afforded by our approach points to a significant advancement over conventional methods that require expensive and time-consuming coring and water samples.Fig. 13. Root Mean Square Error (RMSE) of optimized Sw for each well and algorithm, quantifying the discrepancies between Sw derived from each optimization method and the Sw calculated from core-based parameters.
Machine learning results
In parallel to the optimization framework, ML models developed for predicting Sw showcased robust performance across training, validation, and testing phases. A multi-metric evaluation (Figs. 14 - 16) and numerically summarized in Table 8 was undertaken using MAE, RMSE, and R^2^ to assess model fidelity. Tree-based ensemble methods - specifically Random Forest and XGBoost - demonstrated exceptional predictive accuracy, achieving CV-R^2^ values in the range of 0.967 and 0.9483 respectively, with low MAE and RMSE values. These results indicate that ensemble methods, benefiting from techniques such as bagging and subspace sampling, are particularly effective in reducing overfitting and capturing non-linear interdependencies within the data. Neural network approaches, including both feedforward architectures optimized via Bayesian as well as Levenberg-Marquardt designed for sequential data analysis, also exhibited strong performance with R^2^ scores consistently in range of 0.9481 to 0.9331. The slight differences in performance between ensemble methods and neural network models are reflective of inherent methodological strengths; whereas ensemble models benefit from reduced variance via aggregation, the neural networks are adept at modeling complex, depth-dependent patterns in the logs.Fig. 14. Comparison of the coefficient of determination across training, validation, and test Sets.Fig. 15. Comparison of root mean squared error across training, validation, and test sets.Table 8. Performance metrics of ML Models across training, validation, and test Sets.Green filled cells represent best two candidates best on performance metrics. While red cells representing lowest two models in performance. Fig. 16.Comparison of Mean Absolute Error across training, validation, and test sets.Fig. 16.Comparison of Mean Absolute Error across training, validation, and test sets.Fig. 16.Comparison of Mean Absolute Error across training, validation, and test sets.
Comparison of Mean Absolute Error across training, validation, and test sets.
The stability and generalizability of these ML models were further investigated by a rigorous 5-fold cross-validation protocol, and its results are visualized in Figure 17. This methodological rigor ensured that performance metrics obtained on the training data closely mirrored those seen in the validation sets, thereby providing confidence that the models are well-calibrated for unseen data. When subjected to independent test sets - comprising wells from both the Norwegian North Sea and the Egyptian Western Desert - the models retained high predictive power, confirming that the integration of robust cross-validation techniques and stringent hyperparameter tuning (as detailed in Table 4) has resulted in models with reliable generalizability across varied geological contexts. Graphical illustrations spanning Figures 7 through 9 vividly capture these trends by juxtaposing actual versus predicted Sw values, with error analyses revealing minimal deviations even in instances where complex lithological transitions may challenge predictive accuracy.Fig. 17. Boxplot comparison of 5-fold cross-validation RMSE for all ML models. The box shows the interquartile range (IQR), the line indicates the median, and the whiskers represent the full range of the 5-fold scores, providing a clear view of model performance and stability.
Comprehensive statistical validation of the nine developed models was conducted using a 5-fold cross-validation framework, with model performance differentials assessed via paired t-tests (at \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\alpha =0.05$$\end{document} ) (Fig. 18). This rigorous analysis, based on the mean Root Mean Squared Error (RMSE) of water saturation, established a definitive performance hierarchy. The Random Forest (RF) model (RMSE = 0.0337) emerged as the statistically dominant architecture, demonstrating a significantly lower prediction error than all other evaluated algorithms ( \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$p \le 0.0017$$\end{document} in all comparisons). A distinct, high-performance cluster was also identified, comprising XGBoost (RMSE = 0.0423), CatBoost (RMSE = 0.0427), ANN_Bayesian (RMSE = 0.0424), and Decision Tree (RMSE = 0.044). These models, while statistically outperformed by RF, exhibited no significant performance difference relative to one another (e.g., CatBoost vs. XGBoost, p = 0.540; XGBoost vs. Decision Tree, p = 0.073), confirming their equivalent and robust predictive capabilities for this application.Fig. 18. Boxplot comparison of 5-fold cross-validation RMSE for all ML models. The box shows the interquartile range (IQR), the line indicates the median, and the whiskers represent the full range of the 5-fold scores, providing a clear view of model performance and stability.
Conversely, the analysis statistically segregated the remaining models into lower-performance tiers. The ANN_LM (RMSE = 0.0477) and LSTM (RMSE = 0.0528) models formed an intermediate group, performing statistically similarly to each other (p = 0.243) but proving significantly less accurate than the top-tier ensemble and Bayesian architectures. At the lowest performance bound, the AdaBoost (RMSE = 0.0607) and SVR_RBF (RMSE = 0.0608) models were found to be statistically indistinguishable (p = 0.904). These two models, however, demonstrated a significantly inferior predictive accuracy compared to all seven other models in the study, confirming their in-suitability for this specific subsurface characterization problem. This statistical validation provides a clear mandate for the selection of Random Forest, or models from the equivalent XGBoost/CatBoost cluster, for deployment.
This statistical analysis creates a clear narrative when compared with the final blind test set performance (Table 8). The Random Forest model, which was the statistically undisputed winner of the cross-validation, showed a significant drop in performance on the unseen test data (Test R^2^: 0.880). This indicates that it overfit to the Norwegian dataset. Conversely, the models in the "second-tier" of CV performance - LSTM (Test R^2^: 0.9448), CatBoost (Test R^2^: 0.9417), ANN_Bayesian (Test R^2^: 0.9307), and XGBoost (Test R^2^: 0.9308) - all demonstrated good and stable generalization, outperforming the overfit Random Forest model significantly. This result is crucial, as it confirms that the gradient-boosted ensemble methods and well-tuned neural networks are the most robust and reliable for this framework, while the standard Random Forest, despite its high CV score, is less generalizable.
A salient aspect of our integrated methodology is the model interpretability analysis, for which we employed SHAP (SHapley Additive exPlanations). This advanced technique provides a robust, model-specific measure of feature importance, superseding the simple linear correlation of a relevancy factor. These SHAP summary plots (Fig. 5) confirm that RDEP,NPHI,and V_sh__GR are consistently the most impactful features, as expected from petrophysical principles. However, SHAP also reveals complex non-linear interactions. For example, high NPHI (high porosity) and low RHOB (low density) both correctly contribute positively to higher predicted Sw (as they indicate water-filled pore space), but their relative importance varies between different model architectures. This analysis confirms that all four input features are critical and that the models successfully learned the underlying, non-linear petrophysical relationships.
The results from the three independent test wells (Fig. 19) conclusively validate the generalizability and robustness of the proposed integrated framework, demonstrating its capacity to resolve spatial heterogeneity in Sw across distinct geological provinces. For well NST-05 (Norwegian North Sea), the ML models achieved exceptional predictive accuracy (RMSE = 0.04, MAE = 0.030, and R^2^ = 0.97) for LSTM algorithm, attributable to the synergistic alignment between the training dataset lithostratigraphic features (E. Jurassic Statfjord Formation) and the test well depositional environment. This consistency in geological setting enabled the algorithms to effectively map the nonlinear relationships between input petrophysical variables and optimization-derived Sw, leveraging learned patterns from analogous facies architectures.Fig. 19. Testing results comparing optimization-derived versus Machine Learning-predicted Sw. (a) well NST-05 from Norway north sea (b) well EGT-01A (Egypt) Matruh - Shushan Basin (c) well EGT-02B (Egypt) Abu El-Gharadig basin.
In contrast, Wells EGT-01A (Egyptian Matruh-Shushan Basin) and EGT-02B (Abu El-Gharadig Basin) presented a more rigorous validation scenario, as these reservoirs - characterized by upper cretaceous Bahariya and Jurassic Safa formations - were entirely excluded from the training corpus. Despite this deliberate exclusion, the models exhibited commendable generalizability. The marginal reduction in accuracy relative to Well NST-05 reflects inherent domain adaptation challenges, including covariate possible shifts in shale mineralogy and disparities in diagenetic overprints. Crucially, this performance was achieved without reliance on core-calibrated parameters or formation water samples, underscoring the ability of our framework to decode latent petrophysical interactions solely from conventional log suites.
The differential in predictive fidelity across basins highlights a critical trade-off: while training data homogeneity enhances model precision, the proposed methodology retains sufficient flexibility to extrapolate beyond its immediate experiential domain. This balance positions the framework as a pragmatic tool for frontier exploration, where core data scarcity and lithological novelty often constrain conventional interpretation workflows. The results collectively affirm that the integration of optimization-derived Sw targets with ensemble ML architectures mitigates overfitting risks while preserving sensitivity to subtle, depth-dependent reservoir signatures a paradigm shift toward scalable, data-driven petrophysics.
The broader implications of integrating optimization and machine learning frameworks are profound. By delivering more reliable water saturation estimates, our approach provides reservoir engineers with a powerful tool for accurate hydrocarbon reserve evaluation and reservoir performance forecasting. The operational advantages are clear: reduced dependency on extensive core analyses, enhanced cost-effectiveness, and a marked improvement in the generalizability of petrophysical evaluations across diverse formations. In direct comparison with conventional empirical and graphical methods - such as Archie-based interpretations - the proposed framework overcomes intrinsic limitations by offering a dynamic, data-centric approach that captures the inherent complexities of heterogeneous reservoirs.
Strengths of the integrated framework
A primary strength of this framework is its integrated, data-driven, two-stage "optimization-first" approach. By first optimizing for a single, global Rw, we anchor the subsequent Sw prediction in a physically constrained parameter. This optimized Sw serves as a high-quality, continuous "pseudo-core" label for the ML models, removing the reliance on sparse and expensive core data. A second strength is the rigorous validation across geologically distinct basins (Norwegian North Sea and Egyptian Western Desert), which intentionally mimics a realistic “scarce data” scenario and demonstrates the framework ability to generalize beyond its training domain.
Limitations and future work
Nevertheless, despite the notable successes, several limitations warrant acknowledgement and provide direction for future research.
- Dataset Size and Generalizability: The training dataset, while representative, is limited to 8 wells from one basin. Despite successfully mimics a scarce-data exploration scenario. However, scaling this framework for other, more complex geological settings (e.g., carbonates, volcaniclastics) would require further testing. A promising avenue for future work is the application of transfer learning, where a model could be pre-trained on a large public dataset and then fine-tuned using only one or two wells from a new frontier basin.
- Optimization Sensitivity: The optimization results (Very low RMSE) is a key strength, but it may also be sensitive to poor data quality. Future work should include a sensitivity analysis to test the optimization robustness to varying levels of data noise, which could cause convergence to a non-representative local minimum.
- CV Reproducibility: As discussed our 5-fold cross-validation protocol used a single fixed random seed for reproducibility. Future work could involve running the CV multiple times with different random seeds to provide a statistical distribution of model performance and a more robust measure of variance.
- Overfitting: Minor instances of overfitting, particularly the significant case of the Random Forest model, suggest that continued refinement in hyperparameter tuning and model architecture is necessary.
Conclusion
This study successfully developed and validated an innovative, two-stage integrated framework that couples numerical optimization with machine learning to accurately characterize shaley-sand reservoirs. Our primary contribution is the 'optimization-first’ workflow: by first optimizing for a single, physically-constrained global Rw, we generate a continuous, high-fidelity 'pseudo-core’ Sw log. This approach was validated by the Powell algorithm, which consistently recovered the true Rw from log data with near-zero error (e.g., 1×10^−4^ RMSE) against measured samples, confirming its robustness.
This high-quality optimized Sw log served as the training target for a comprehensive suite of ML models. The results revealed a critical insight into model selection, validated by statistical (paired t-test) and blind-well analyses. While Random Forest model was the statistically significant winner during cross-validation (CV R^2^: 0.967), it failed to generalize to the blind test data (Test R^2^: 0.88), indicating it had overfit to the training dataset. Conversely, the gradient-boosting ensembles, specifically CatBoost (Test R^2^: 0.942), XGBoost (Test R^2^: 0.9308) and well-tuned neural networks like LSTM (Test R^2^: 0.945), and ANN_ Bayesian (Test R^2^: 0.9307) demonstrated superior and more stable generalization. This finding underscores that "Optimization + LSTM/ANN_Bayesian " and "Optimization + CatBoost/XGBoost" hybrid as the most reliable and recommended workflow.
Our interpretability analysis using SHAP confirmed that all models successfully learned the complex, non-linear petrophysical relationships, identifying and RDEP, NPHI, and V_sh__GR as the most impactful features, as expected. Beyond technical accomplishments, this framework offers tangible operational advantages. By demonstrating that a robust model can be trained in a “scarce data” scenario and successfully deployed in a completely different geological basin, it provides a cost-effective and scalable alternative to traditional workflows. This methodology significantly reduces reliance on expensive core analyses, fostering improved accuracy in hydrocarbon reserve evaluations.
While this research marks a significant step toward more data-centric petrophysics, we acknowledge the path for future work. This includes exploring transfer learning to fine-tune models for new basins and conducting further sensitivity analysis on the optimization performance in noisy log environments with utilization of metaheuristics optimization algorithms paving the way for wider adoption of robust, data-driven workflows in reservoir characterization.
Supplementary Information
Supplementary Information.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1Worthington, P. F. The evolution of shaly-sand concepts in reservoir evaluation. The Log Analyst 26, (1985).
- 2Adeniran, A., Elshafei, M. & Hamada, G. Functional network softsensor for formation porosity and water saturation in oil wells. In 2009 IEEE Instrumentation and Measurement Technology Conference 1138-1143 (IEEE, 2009).
- 3Poupon, A. & Leveaux, J. Evaluation of water saturation in shaly formations. In SPWLA Annual Logging Symposium SPWLA-1971 (SPWLA, 1971).
- 4Hingle, A. T. The use of logs in exploration problems. In Society of Exploration Geophysicists, 29th Meeting (sn, 1959).
- 5Aguilera, R. Extensions of Pickett plots for the analysis of shaly formations by well logs. The Log Analyst 31, (1990).
- 6Schlumberger, A. A guide to well site interpretation of the gulf coast. Schlumberger Well Services, Houston (1975).
- 7Shokir, E. M. E.-M. Prediction of the hydrocarbon saturation in low resistivity formation via artificial neural network. In SPE Asia Pacific Conference on Integrated Modelling for Asset Management SPE-87001 (spe, 2004).
- 8Gad, M. et al. Predicting water saturation in a greek oilfield with the power of artificial neural networks. ACS Omega (2025).10.1021/acsomega.4c 07175 PMC 1173994339829518 · doi ↗ · pubmed ↗