Distinguishing between the exponential and Lindley distributions: An illustration from biological psychology
Shovan Chowdhury, Marco Marozzi, Freddy Hernández-Barajas, Fernando Marmolejo-Ramos

TL;DR
This paper compares the exponential and Lindley distributions for modeling skewed data in biological psychology and introduces a method to distinguish between them.
Contribution
A new method is introduced to differentiate between exponential and Lindley distributions using likelihood ratio analysis.
Findings
The Lindley distribution is a viable alternative to the exponential distribution for modeling skewed data.
The proposed method effectively distinguishes between the two distributions, even with small sample sizes.
The method works for type I censored data and is implemented as an R function.
Abstract
The exponential distribution has been used for modeling positively skewed data in biological psychology. However, the lesser-known Lindley distribution, although not typically used for this purpose, has a density and cumulative distribution that are very similar to those of the exponential distribution. This similarity suggests that the Lindley distribution could be a strong candidate for modeling such data types. While the probability density and cumulative distribution functions of these two one-parameter distributions can be quite similar, their hazard rate functions differ markedly. Therefore, selecting the most appropriate distribution significantly impacts the interpretation of the hazard rate function. To aid in this selection, we introduce a method that distinguishes between the exponential and Lindley distributions by examining the ratio of their maximized likelihood functions.…
Genes, proteins, chemicals, diseases, species, mutations and cell lines named across the full text — each resolved to its canonical identifier and authoritative record.
Click any figure to enlarge with its caption.
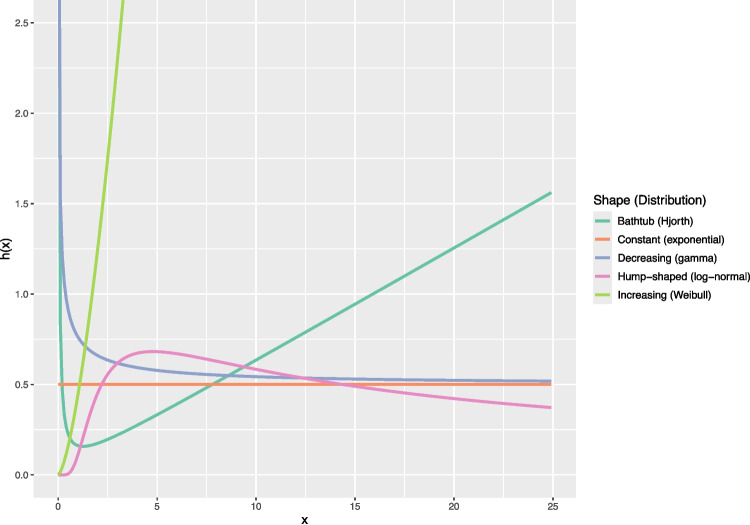 Figure 1
Figure 1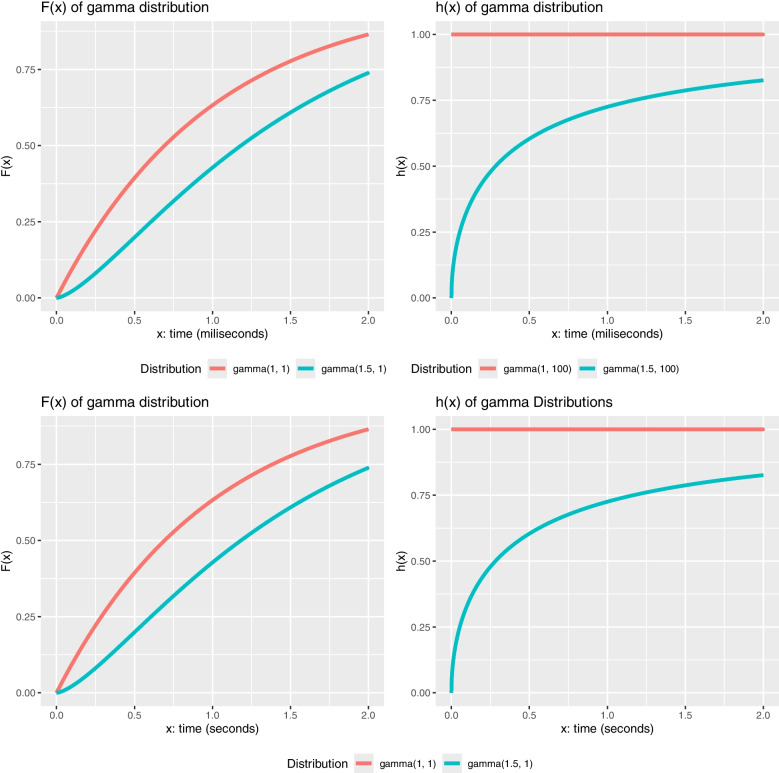 Figure 2
Figure 2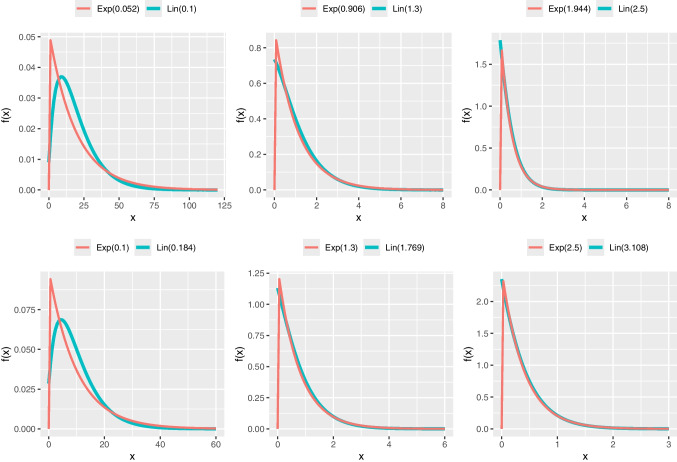 Figure 3
Figure 3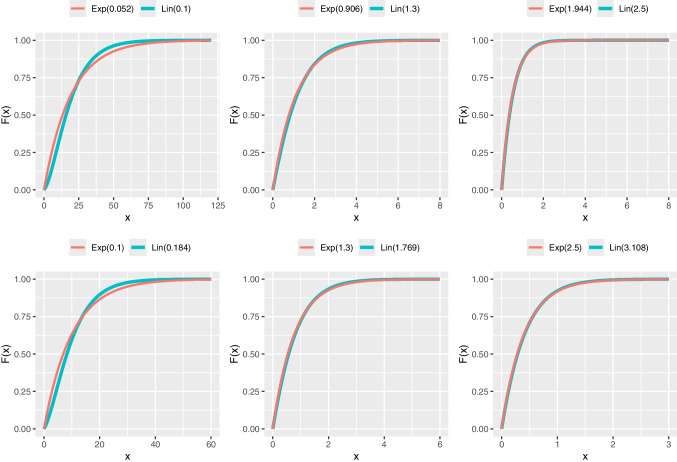 Figure 4
Figure 4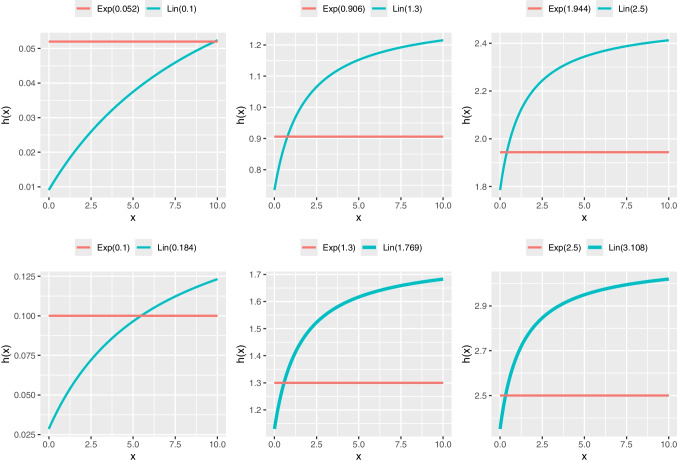 Figure 5
Figure 5- —Flinders University
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsStatistical Distribution Estimation and Applications · Statistical Methods and Bayesian Inference · Advanced Statistical Methods and Models
Introduction
Research in biological psychology frequently encounters data that are positively skewed, meaning the tail of the data distribution extends further to the right, with a concentration of data points at the lower end of the scale and fewer, more extreme values at the higher end. This characteristic is observed in various types of data, including reaction times, certain physiological measures, and scores on psychological scales assessing symptoms or distress. Several factors contribute to the prevalence of positive skew in biological psychology data. For instance, reaction times, a biomarker measure in biological psychology (Jiménez-Figueroa et al., 2017), are inherently bounded by zero (responses cannot be faster than instantaneous) and often exhibit a pattern where most responses are relatively quick, but a smaller number of trials elicit significantly slower responses due to various cognitive or motor factors. Similarly, physiological measures or symptom scores in clinical populations may show a floor effect, where many individuals have low or zero scores (indicating absence or low levels of a symptom/measure), while a smaller subset exhibits higher scores reflecting greater severity or activity (Tomitaka et al., 2017). Effectively modeling such non-normal and skewed data distributions is central for appropriate statistical analysis and interpretation.
To address the characteristics of such positively skewed data, probability distributions are employed. Evidence suggests that the exponential distribution, or models incorporating it, have been widely utilized in biological psychology and related neuroscience fields. A prominent example is the modeling of reaction time data using the ex-Gaussian distribution. The ex-Gaussian distribution is a convolution of a Gaussian (normal) distribution and an exponential distribution. This composite model effectively captures the typical shape of reaction time distributions, with the exponential component accounting for the positively skewed tail (Marmolejo-Ramos et al., 2023). Beyond reaction times, the exponential distribution has been considered in other biological and psychological contexts where the probability of an event occurring remains constant irrespective of elapsed time, thereby facilitating analyses of reaction time variability in cognitive tasks. Some research indicates that the distributions of psychological distress scores in large populations can exhibit an exponential pattern (Tomitaka et al., 2017). Furthermore, in neuroscience, the timing of neuronal firing intervals is sometimes analyzed using exponential distributions, reflecting the stochastic nature of these events (Roberts et al., 2016). Studies in computational neuroscience also note that brain activities can follow distributions belonging to the exponential family, highlighting the relevance of such distributions in understanding neural processes (Changbo et al., in press).
While the exponential distribution, as discussed, has proven a useful model for certain types of positively skewed data in biological psychology, the task of identifying the most appropriate distribution for a given dataset can be challenging when multiple models offer a seemingly good fit. This challenge is particularly relevant when considering distributions with the same number of parameters, such as different one-parameter distributions like the Lindley one that might both provide a good fit for the response variable in the context of distributional regression modeling (Klein, 2024) (e.g., Generalized Additive Models for Location, Scale, and Shape (GAMLSS) modeling). In such cases, standard model comparison criteria like the Akaike information criterion (AIC) or Bayesian information criterion (BIC) estimates may be too close, and the probability density functions (pdfs) and cumulative distribution functions (cdfs) may show significant overlap, making it problematic to definitively decide which distribution is best. While differences between distributions are usually examined via their pdfs or cdfs, it has recently been suggested that examining the hazard rate function (hrf) of the distributions may help to better discriminate between distributions and provide novel information (Kang, 2017; Loeys et al., 2014; Panis et al., 2020).
This study emphasizes the critical need to select the appropriate distribution for accurate interpretation of hrfs and introduces an innovative method based on the ratio of the likelihoods of different distributions. Our study tackles the central issue of distinguishing between the exponential distribution and the less commonly employed but potentially significant Lindley distribution. The proposed discrimination method demonstrates effective handling of type I censored data, making it very useful in practice, given its prevalence in this context.Fig. 1. Illustration of hazard rate function h(x) shapes corresponding to different probability distributions: Hjorth (Bathtub), exponential (Constant), gamma (Decreasing), log-normal (Hump-shaped), and Weibull (Increasing)
The paper is structured as follows. We begin by discussing the importance of selecting an appropriate probability distribution and its influence on interpreting hazard rate functions, followed by an exploration of the role of hazard rate functions in biological psychology data analysis. Next, we examine the statistical properties of the exponential and Lindley distributions. We then introduce our novel discriminating method based on the logarithm of the ratio of maximized likelihoods (RML). Subsequently, we detail the procedure for selecting between the exponential and Lindley distributions using this method, supported by a comprehensive simulation study. We consider the exponential distribution because it is one of the most used distributions in applied psychology. The Lindley distribution is considered because it can be particularly useful in scenarios where the hazard rate might be increasing, offering flexibility. A practical application of the proposed method is demonstrated using data from a biological psychology experiment. Note that scholars in biological psychology typically prefer using distributions like the exponential and Lindley to balance parsimony with empirical usefulness in their quantitative frameworks. Concluding remarks are provided in the final section. Supplementary material, including the Appendix with asymptotic analytical results, implementation of the proposed method in R (R Core Team, 2025) and additional examples and simulation results, is available online in a GitHub repository (see https://github.com/fhernanb/T_exp_lin).
The influence of probability distributions on hazard rate functions
In linear regression, the location parameter of the dependent variable is modeled by the conditional distribution’s mean, and the normal distribution is used by default. That is, in linear regression, it is assumed that the residuals are normally distributed. In practice, however, continuous dependent variables often deviate from normality, so linear regression may not guarantee normally distributed residuals. Generalized linear models (GLM) extend linear regression by accommodating response variables with various error distribution models from the exponential family, including normal, binomial, Poisson, gamma, and exponential distributions. GAMLSS enhance the capabilities of traditional regression models, such as linear regression and GLMs, by offering several advantages. These include the ability to utilize a broader range of distributions beyond those typically employed in GLMs, thereby providing increased flexibility for different types of data (Klein, 2024; Stasinopoulos et al., 2024). That is, GAMLSS allows the selection of an optimal distribution that best fits the response variable. Furthermore, GAMLSS modeling encourages researchers to explore beyond “mean differences" (Kneib, 2013; Kneib et al., 2023) and to examine all parameters of probability distributions in their statistical analyses (Trafimow et al., 2018).
GAMLSS modeling may reveal scenarios where different distributions with the same number of parameters fit a dataset equally well, as indicated by goodness-of-fit metrics like AIC or BIC. In such cases, the choice of distribution may have minimal practical impact on regression estimates, with the similarity visually confirmed by comparing their pdfs or cdfs (e.g., see Figs. 3 and 4). For example, the probability of a number being smaller than 1 in an exponential distribution with \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\lambda =1.944$$\end{document} and a Lindley distribution with \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\theta =2.5$$\end{document} are 0.8568 and 0.8592 respectively (i.e., \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\approx 86\%$$\end{document} ); these probabilities are very similar (see the plot in row 1, column 3 in Fig. 4). However, their hrfs convey quite different narratives (see the plot in row 1, column 3 in Fig. 5).
The hrf or failure rate quantifies the instantaneous risk or rate at which an event of interest (such as a response, failure, or occurrence) happens at a specific time t, given that the event has not occurred before time t. In other words, it represents the likelihood that an event will occur in the next instant, given that it has not occurred up to that point. The hazard rate function h(t) is defined as the ratio of the probability density function f(t) to the survival function S(t). The survival function S(t) gives the probability that the event has not occurred by time t, and it is defined as \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$S(t)=1-F(t)$$\end{document} , where F(t) is the cumulative distribution function (i.e., for any given value x, the cdf gives the probability that the random variable X will take on a value less than or equal to x; \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$F(x) = P(X \le x)$$\end{document} ). That is, \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$h(t)=\frac{f(t)}{S(t)}$$\end{document} . It is thus clear that while the pdf influences the hazard rate function by determining the instantaneous likelihood of the event at a given time (e.g., a higher pdf value at time t generally leads to a higher hazard rate function at that time, assuming the survival function does not change drastically), the cdf affects the hazard rate function through the survival function (e.g., as the cdf increases [meaning the probability of the event having occurred by time t increases], the survival function decreases. This, in turn, generally leads to an increase in the hazard rate function). All of this underscores that the choice of a probability distribution directly impacts the hazard rate function and its interpretation.
Hazard rate functions can display various shapes, as illustrated in Fig. 1 (also refer to Fig. 1A from Panis et al. (2020)), which consequently affects their interpretation. Some of these shapes include a constant hazard rate function, indicating that the risk of an event remains consistent over time, suggesting a random failure pattern (e.g., exponential and Poisson distributions); an increasing hazard rate function, implying that the risk of an event increases with time, as seen in wear-out processes (e.g., Weibull [with shape parameter > 1] and Lindley distributions); a decreasing hazard rate function, indicating that the risk of an event decreases over time, suggesting improvement (e.g., gamma [with shape parameter < 1] and Pareto distributions); a bathtub-shaped hazard rate function, which combines an initial decreasing hazard rate function, followed by a constant period, and then an increasing hazard rate function (e.g., Hjorth and Chen distributions); and a hump-shaped hazard rate function, characterized by an initial increasing hazard rate function that reaches a peak and then declines (e.g., Birnbaum-Saunders and log-normal distributions). Note also that certain probability distributions can display various hrfs shapes. For instance, when the shape parameters in the two-parameter Weibull and gamma distributions are greater than 1, equal to 1, or less than 1, they exhibit increasing, constant, and decreasing hrfs, respectively.
Examining hrfs offers valuable insights into the changing probability of an event (like a response or an error) over time within biological psychology experiments. Across different tasks that utilize temporal or performance measures, the resulting hazard rate functions can adopt distinct shapes, as the following scenarios illustrate. For instance, consider a task measuring the instantaneous probability of a basic sensory or motor response occurring immediately after a stimulus presentation, where the underlying process is simple and automatic. In such a scenario, involving pure detection or reflexive action without complex decision-making, a constant hazard rate function shape could result, indicating a consistent instantaneous likelihood of response over time once processing begins. A different hrf can occur in a working memory task where participants must retain information in memory, and the risk of error increases as cognitive load accumulates. Such tasks can lead to fatigue or resource depletion effects, and thus an increasing hazard rate function would be expected. A decreasing hazard rate function effectively models the learning curve for a new motor skill, where the high risk of initial errors drops with practice as performance demonstrates adaptation. For complex decision-making, the trajectory of performance–beginning with a high error rate during understanding, stabilizing optimally, and then rising again with fatigue–creates a profile best captured by a bathtub-shaped hazard rate function. Finally, the temporal dynamics of response activation in a priming task, marked by an increasing response probability that peaks and then declines, could be represented by a hazard rate function with a distinct hump shape.Fig. 2. Distributions modeled with gamma distributions. The distributions have positive skews (first column) but different hazard rate functions (second column). The same data are presented in two analogous metricsFig. 3Probability density function f(x) of Lindley (Lin) and exponential (Exp) distributions for different parametersFig. 4Cumulative density function F(x) of Lindley (Lin) and exponential (Exp) distributions for different parametersFig. 5Hazard rate function h(x) of Lindley (Lin) and exponential (Exp) distributions for different parameters
The units of the hazard rate function are typically expressed as events per unit of time. While the hazard rate function is always non-negative (i.e., there cannot be a negative risk), there is no upper limit on its potential value. To illustrate these concepts with a specific example from cognitive assessment, consider a scenario where participants undergo a digit recognition memory task. In this task, participants are shown a sequence of single digits (0–9) and must quickly identify if a digit has appeared previously in the sequence, under time constraints. One experimental condition, termed ‘immediate recognition’, requires participants to compare the current digit only with the immediately preceding trial. As the working memory load remains constant in this condition, a constant hazard rate function is expected, reflecting the relatively simple comparison process. In contrast, the ‘cumulative recognition’ condition demands that participants compare the current digit against all previously presented digits in the sequence. This leads to an increasing memory load as the sequence progresses. Consequently, an increasing hazard rate function is expected due to the growing demands of memory search. This phenomenon is illustrated in the first row of Fig. 2.
In terms of interpreting the hrf plots, it is evident that the instantaneous rate at which the event occurs differs between the ‘immediate recognition’ and ‘cumulative recognition’ tasks. For instance, at a given time point (e.g., 1000 time units), the hazard rate function is higher in the immediate recognition condition (represented by a gamma(1, 100) distribution with a rate of approximately 0.01 events per time unit) compared to the cumulative recognition condition (represented by a gamma(1.5, 100) distribution with a rate of approximately 0.0096 events per time unit). As illustrated in the plot in the first row, second column of Fig. 2, the probability of the event occurring in the immediate recognition task stays relatively constant over time, assuming the event has not yet occurred. Conversely, the cumulative recognition task shows an increasing probability of the event occurring over time, signaling a growing certainty of a correct identification as the memory search becomes more challenging. The second row in Fig. 2 illustrates this phenomenon using a different time scale (seconds) for the same mock task, further emphasizing the impact of memory load on the hazard rate function.
As the preceding examples illustrate, hrfs offer a powerful means of capturing the temporal dynamics inherent in psychophysiological processes. Because hrfs are fundamentally properties derived from the probability distribution fitted to event-based or time-to-event data, they serve as a versatile tool for investigating temporal structure across various phenomena in biological psychology. This analytical approach is not limited to the specific types of events previously discussed. Many other measures commonly encountered in biological psychology, such as various physiological indices and symptom severities tracked over time, also yield positively skewed data suitable for modeling with similar probability distributions. Consequently, the application and interpretation of hrfs can be broadly extrapolated to these diverse datasets. Analyzing hazard rate functions thus provides a unique, distribution-informed perspective on the temporal unfolding of biological and psychological events, offering insights that go beyond analyses focused merely on central tendency.
What hazard rate functions offer to data analysis
Panis et al. (2020) argue for using hrfs to model positively skewed data, based on the following points:
- The hrf of response occurrence is much more useful in describing the data than pdf or cdf, being able to emphasize important differences between two situations that are not clear when comparing the corresponding pdfs or cdfs. Two hrfs can be sharply different while the corresponding pdfs or cdfs look very alike (Holden et al., 2009) (see Figs. 3, 4, and 5).
- Townsend (1990) showed that the comparison of hrfs allows stronger conclusions than the comparison of distributions or means, because a complete ordering on the hazard functions implies a complete ordering on the cumulative distribution and survival functions that implies an ordering on the two distribution means, whereas the reverse is not always true. Therefore, an ordering on the two distribution means may happen in the presence of either a complete ordering on the hazard functions or crossing hazard functions. In other words, comparing the means may give a distorted picture of what is really going on.
- Right-censored observations are common when dealing with positively skewed data and can be incorporated into hrf analyses, giving important information often overlooked when using other standard methods (e.g., ANOVA).
- Time-varying explanatory covariates are commonly encountered in biological psychology (e.g., biomarkers related to the respondent autonomic nervous system) and they are easier to incorporate into hrf-based analyses than into standard methods (e.g., ANOVA).
- The hazard function is a critical measure in many biological psychology experiments. It quantifies the instantaneous rate at which an event of interest occurs (e.g., a response or task completion) at a given moment in time, provided the event has not occurred previously. Analyzing hrfs allows for a direct assessment of this instantaneous rate of occurrence over time, whereas standard statistical methods (such as ANOVA) are typically less suited to directly evaluate these specific temporal dynamics. We thus believe that hrfs are very suitable to examine positively skewed data and in general to compare distributions with different shapes. We thus echo Panis et al. (2020) in that this analytical approach needs to be incorporated into current data modeling practices, particularly in the framework of distributional regression modeling. Figure 5 shows the hazard for various Lindley distributions and shows that it is very different from the hazard for the exponential distribution, which is constant.
The Lindley and exponential distributions
The Lindley distribution with scale parameter \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\theta $$\end{document} , written as Lin \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$(\theta )$$\end{document} , having probability density function (pdf) and cumulative distribution function (cdf)
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\begin{aligned} f_{L}(x;\theta )=\frac{\theta ^2}{1+\theta }\left( 1+x\right) e^{-\theta x};~x,\theta >0, \end{aligned}$$\end{document}and
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\begin{aligned} F_{L}(x;\theta )=1-\frac{\theta +1+\theta x}{1+\theta } e^{-\theta x};~x,\theta >0, \end{aligned}$$\end{document}respectively, was introduced by Lindley (1958). The pdf is decreasing for \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\theta \ge 1$$\end{document} and is unimodal for \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\theta <1$$\end{document} . It is also known that the hazard function and the mean residual life (MRL) function of the distribution increase for all \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\theta $$\end{document} . Several aspects of this distribution are studied in detail by Ghitany et al. (2008). It has been found that many of the mathematical properties of the Lindley distribution are more flexible than those of the exponential distribution. As pointed out in Ghitany et al. (2008), due to the popularity of the exponential distribution in statistics and many applied areas, the Lindley distribution has not been very well explored in the literature. Still, the Lindley distribution has found its place in many applications where it is found to be preferable over other competitor distributions. For example, this distribution has been used to model lifetime data, especially in applications relating to stress-strength reliability (Lindley, 1958, 1965). Mazucheli and Achcar (2011) used the Lindley distribution to model lifetime data relating to competing risks and Ghitany et al. (2008) used it to model the waiting time of bank customers. That is, the Lindley distribution seems suitable for fitting data akin to lifetime data, i.e., survival times, failure times, or fatigue-life data.Table 1. Key properties of the exponential and Lindley distributionsDistributionf(x)F(x)S(x)H(x)MeanMedianVarianceexponential \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\lambda e^{-\lambda x}$$\end{document} \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$1-e^{-\lambda x}$$\end{document} \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$e^{-\lambda x}$$\end{document} \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\lambda $$\end{document} \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\frac{1}{\lambda }$$\end{document} \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\frac{\log 2}{\lambda }$$\end{document} \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\frac{1}{\lambda ^2}$$\end{document} Lindley \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\frac{\theta ^2}{1+\theta }\left( 1+x\right) e^{-\theta x}$$\end{document} \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$1-\frac{\theta +1+\theta x}{\theta +1} e^{-\theta x}$$\end{document} \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\frac{\theta +1+\theta x}{\theta +1} e^{-\theta x}$$\end{document} \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\frac{\theta ^2(1+x)}{\theta +1+\theta x}$$\end{document} \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\frac{\theta +2}{\theta (\theta +1)}$$\end{document} through iteration \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\frac{\theta ^2+4\theta +2}{\theta ^2(\theta +1)^2}$$\end{document} f(x), F(x), S(x) and H(x) represent the pdf, cdf, survival and hazard functions, respectively
The exponential distribution is among the most popular univariate continuous distributions with several significant statistical properties, most importantly, its characterization through lack of memory property. The exponential distribution with scale parameter \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\lambda $$\end{document} , written as blue Exp \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$(\lambda )$$\end{document} , has pdf and cdf given by
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\begin{aligned} f_{E}(x;\lambda )=\lambda e^{-\lambda x};~x,\lambda >0 \end{aligned}$$\end{document}and
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\begin{aligned} F_{E}(x;\lambda )=1-e^{-\lambda x};~x,\lambda >0. \end{aligned}$$\end{document}While the pdf of the exponential is decreasing for all \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\lambda $$\end{document} , the hazard and MRL functions are constant. This exhibits one of the distinguishable characteristics of exponential and Lindley distributions. However, both one-parameter distributions can be very similarly effective in analyzing positively skewed data. Moreover, the pdfs or cdfs of both distributions can be very close to each other for certain ranges of parameter values. Figures 3 and 4 illustrate the similarity between the distributions when their parameter takes different values. Such similarity translates in that while data could come from the exponential or Lindley distribution, the other distribution could provide a very good fit too.
In Table 1 we present a summary with key properties of the exponential and Lindley distributions. Although the two models may provide a similar fit for small or moderate sample sizes, it is still important to select the best fit for a given data set, and much more importantly to select the correct model in those cases where the difference between a constant and a monotonically increasing hazard function has practical consequences.
The problem of selecting the correct distribution is not new in the statistics literature. The problem of discriminating between two non-nested models for a complete data set was first considered by Cox (1961, 1962) and was later studied by other scholars, including Bain and Engelhardt (1980), and Fearn and Nebenzahl Fearn and Nebenzahl (1991). Due to the increasing applicability of distributions suitable to fit lifetime-like data, special attention has been paid to selecting between the Weibull and log-normal distributions (Kim & Yum, 2008; Kundu & Manglick, 2004), the gamma and log-normal distributions (Kundu & Manglick, 2005), the Lindley and xgamma (Sen et al., 2021), the Lindley, gamma, and Weibull (Raqab et al., 2017), and the exponential and Lindley distributions (Chowdhury, 2019; Vaidyanathan & Varghese, 2019). On the other hand, related literature in the censored data setup is limited and includes papers on selecting between Weibull, log-normal, and gamma distributions for type I censored samples (Quesenberry, 1982), and between Weibull and log-normal distributions for type II censored samples (Cain, 2002; Dey & Kundu, 2012; Kim et al., 2000).
Discrimination procedure
Data analyzed in biological psychology, as well as in many other fields such as biology and ecology, can be affected by censoring or truncation. While censoring can reduce information by not having access to some observations that are out of range or simply not known, truncation removes existing observations. Censoring can also lead to skewed distributions of the response variable, with an excess of either low (floor effect) or high (ceiling effect) values, and analysis of such data using traditional methods can lead to biased results (Ahmadi et al., 2021; Liu & Wang, 2021).
Two common types of censoring discussed in statistics are type I, where n participants are observed up to a fixed time t, resulting in a random number of observed events, and type II, where n participants are observed until a fixed number of events r ( \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$r \le n$$\end{document} ) occurs, resulting in a random study duration \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$t = X_{(r)}$$\end{document} (the time of the r-th event). While these specific censoring schemes are uncommon in typical cross-sectional biological psychology experiments, the underlying issue of incomplete observation can arise. For example, a scenario resembling type I censoring occurs when a researcher imposes a maximum allowable response value; any true response exceeding this limit is only recorded as the maximum, effectively censoring the actual value. An analogue to type II censoring might emerge if a researcher stopped a study once a specific count of participants yielded a response within a defined range, thereby censoring the potential responses of other participants who had not yet met that criterion.
To further clarify how censoring can occur in a biological psychology context, consider a hypothetical longitudinal cognitive neuroscience study. Suppose researchers are following ten patients recovering from traumatic brain injury undergoing a novel cognitive rehabilitation program, periodically assessing their cognitive function using standardized cognitive assessments. The event of interest for analysis could be achieving a specific milestone of cognitive recovery, defined by reaching a pre-defined performance criterion on these assessments. However, not all patients may reach this milestone during the study period, or some might drop out for unrelated reasons, leading to incomplete observation of their event time—a situation known as censoring. Two ways this censoring might be structured, following standard definitions, are:
- Type I censoring: The study has a fixed duration, for example, 12 months. For any patient who has not reached the cognitive recovery milestone by the end of 12 months, their event time is censored at 12 months. We know they remained in the ‘at-risk’ state for at least this period.
- Type II censoring: The study continues until a fixed number of patients achieve the milestone, for instance, the first seven patients. For the three patients who have not yet reached the milestone when the 7th patient does, their event time is censored. Data collection stops for everyone once the 7th event occurs. In this section, we describe the selection procedure for the most common right censoring scheme, known as type I censoring. The scheme is briefly described as follows. Let us consider n items being observed in a particular experiment. Also suppose that \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$x_{i:n}, i=1,2,...,n$$\end{document} be the ith ordered observation. In the conventional type I censoring scheme, the experiment is aborted at a pre-determined time \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$t_0$$\end{document} such that \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$x_{t_0}<x_{n:n}$$\end{document} .
Let us first discuss the case of the complete data setting. It is assumed that the data is generated from one of the Exp \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$(\lambda )$$\end{document} or Lin \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$(\theta )$$\end{document} distributions and the corresponding likelihood functions for the complete data set are respectively
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\begin{aligned} L_{E}\left( \lambda \right) =\prod _{i=1}^n f_{E}(x_i;\lambda ) \quad \text {and} \quad L_{L}\left( \theta \right) =\prod _{i=1}^n f_{L}(x_i;\theta ), \end{aligned}$$\end{document}where \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$x_i>0$$\end{document} . The ratio of RMLs is defined as \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$L=\frac{L_{E}\left( \hat{\lambda }\right) }{L_{L}\left( \hat{\theta }\right) };$$\end{document} when \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\hat{\lambda }$$\end{document} and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\hat{\theta }$$\end{document} are the maximum likelihood estimators (MLE) of \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\lambda $$\end{document} and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\theta $$\end{document} respectively. Hence the logarithm of the RML, written as, \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$T=\log L=l_{E}(\hat{\lambda })-l_{L}(\hat{\theta })$$\end{document} is obtained as
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\begin{aligned} T=n\log \left( \frac{\hat{\lambda }\left( \hat{\theta }+1\right) }{\hat{\theta }^2}\right) +(\hat{\theta }-\hat{\lambda })\sum _{i=1}^n x_i-\sum _{i=1}^n \log (1+x_i). \end{aligned}$$\end{document}This step is essential because the log-likelihood ratio statistic is mathematically simpler to compute and analyze compared to the plain likelihood ratio statistic. In the case of the exponential distribution, \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\hat{\lambda }$$\end{document} can be readily derived by differentiating \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$l_{E}(\lambda )$$\end{document} with respect to \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\lambda $$\end{document} , equating the derivative to zero, and solving for \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\lambda $$\end{document} .
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\begin{aligned} \hat{\lambda } = \frac{n}{\sum _{i=1}^n x_i}. \end{aligned}$$\end{document}Similarly, \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\hat{\theta }$$\end{document} , the MLE of the Lindley distribution can be obtained as
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\begin{aligned} \hat{\theta }=\frac{-(\bar{x}-1)+\sqrt{(\bar{x}-1)^2+8\bar{x}}}{2\bar{x}}. \end{aligned}$$\end{document}The natural model selection criterion will be to choose the exponential distribution, if \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$T > 0$$\end{document} ; otherwise, choose the Lindley distribution (Cox, 1961, 1962). Next, we discuss the selection procedure for the right-censored sample.Table 2. Values for n given \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\lambda $$\end{document} , p and K−S distance between Exp \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$(\lambda )$$\end{document} and Lin \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$(\widetilde{\theta })$$\end{document} distributions \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\lambda \rightarrow $$\end{document} 0.10.50.91.31.52.02.5 \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$n~(p=0.6)$$\end{document} 2820374988144 \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$n~(p=0.7)$$\end{document} 93684159208375617 \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$n~(p=0.8)$$\end{document} 23932164085369671590K-S0.1060.0540.0340.0270.0210.0180.012Table 3Values for n given \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\theta $$\end{document} , p and K−S distance between Lin \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$(\theta )$$\end{document} and Exp \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$(\widetilde{\lambda })$$\end{document} distributions \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\theta \rightarrow $$\end{document} 0.10.50.91.31.52.02.5 \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$n~(p=0.6)$$\end{document} 14918244578 \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$n~(p=0.7)$$\end{document} 5174077103194332 \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$n~(p=0.8)$$\end{document} 1345103199265499856K-S0.1200.0700.0490.0360.0310.0220.015
For type I censoring, the likelihood functions (Lawless, 2003) are given as
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\begin{aligned} L^*_{E}\left( \lambda \right)&\!=\! \prod _{i=1}^n \left\{ f_{E}(x_i;\lambda )\right\} ^{\delta _i}\left\{ 1 \!-\! F_{E}(t_0;\lambda )\right\} ^{1 \!-\!\delta _i}\quad \text {and}\quad L^*_{L}\left( \theta \right) \\&=\prod _{i=1}^n \left\{ f_{L}(x_i;\theta )\right\} ^{\delta _i}\left\{ 1-F_{L}(t_0; \theta )\right\} ^{1-\delta _i}. \end{aligned}$$\end{document}where
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\begin{aligned} \delta _i&= 1 \quad \text {if}\quad x_i\le t_0\nonumber \\ \delta _i&= 0 \quad \text {if}\quad x_i>t_0. \end{aligned}$$\end{document}The log-likelihood function of \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\lambda $$\end{document} (ignoring constants) is obtained as
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$ l^*_{E}(\lambda )=\log \lambda \sum _{i=1}^n \delta _i-\lambda \sum _{i=1}^n \delta _ix_i-\lambda t_0\sum _{i=1}^n (1-\delta _i). $$\end{document}Assuming d observations fall below the censoring time \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$t_0,$$\end{document} the MLE of \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\lambda $$\end{document} is obtained as
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\begin{aligned} \hat{\lambda ^*}= & \frac{\sum _{i=1}^n \delta _i}{\sum _{i=1}^n \delta _ix_i+ t_0\sum _{i=1}^n (1-\delta _i)}\\= & \frac{d}{\sum _{i=1}^d x_i+ (n-d)t_0}. \end{aligned}$$\end{document}Similarly, the log-likelihood function of \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\theta $$\end{document} is obtained as
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\begin{aligned} l^*_{L}(\theta )= & 2\log \theta \sum _{i=1}^n \delta _i-\theta \sum _{i=1}^n \delta _ix_i+\log (1+\theta +\theta t_0)\sum _{i=1}^n (1-\delta _i)\nonumber \\ & -n\log (1+\theta )-\theta t_0\sum _{i=1}^n (1-\delta _i)+\sum _{i=1}^n\delta _i \log (1+x_i) \end{aligned}$$\end{document}.
and the MLE of \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\theta $$\end{document} is obtained iteratively from the following equation
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\begin{aligned} \frac{2d}{\hat{\theta ^*}}+\frac{(n-d)(1+t_0)}{1+\hat{\theta ^*}+\hat{\theta ^*}t_0}-\frac{n}{1+\hat{\theta ^*}}=\sum _{i=1}^d x_i+(n-d)t_0. \end{aligned}$$\end{document}The logarithm of the RML for the right-censored sample in a similar line can be found as
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\begin{aligned} T^{*}= & \sum _{i=1}^n \left[ \delta _i\left\{ \log f_{E}(x_i,\hat{\lambda ^*})-\log f_{L}(x_i,\hat{\theta ^*})\right\} \right. \nonumber \\ & \left. + (1-\delta _i)\left\{ \log \bar{F}_{E}(t_0,\hat{\lambda ^*})-\log \bar{F}_{L}(t_0,\hat{\theta ^*})\right\} \right] . \end{aligned}$$\end{document}The results concerning the asymptotic distribution of T and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$T^*$$\end{document} , along with the asymptotic mean and variance, are detailed in the Appendix for two different cases, namely when the data come from Exp( \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\lambda $$\end{document} ) and when the data come from a Lin( \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\theta $$\end{document} ).
Selection procedure and simulation results
In this section, we present the selection procedure (Gupta & Kundu, 2003) for discriminating between the exponential and Lindley distributions. We determine the minimum sample size for a given probability of correct selection (PCS) and tolerance limits, which can be measured by the distance between two cdfs. Practically, the tolerance limit measures the closeness between two cdfs. It is obvious that if the distance between two cdfs is minimal, one needs a very large sample size to discriminate between them for a given PCS. On the other hand, if the cdfs are far apart, a moderate to small sample size may be sufficient to discriminate between the two for a given PCS. Here, we use Kolmogorov–Smirnov (K−S) distance to discriminate between the two cdfs with K−S distance being defined as \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\sup _{x} |F(x)-G(x)|$$\end{document} , where F and G are the cdf of exponential and Lindley distributions, respectively. One may use other distance measures with the same selection criterion. So, the minimum sample size can be determined based on the given PCS (p, say) and the tolerance limit (D, say) as described in the next subsection.
Determination of sample size
In view of Theorem 1 in the Appendix, T is asymptotically normally distributed with mean \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$E_E(T)$$\end{document} and variance \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$V_E(T)$$\end{document} . The PCS for selecting exponential distribution is given by
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$ PCS(\lambda )=P(T>0~|~\lambda )\approx \Phi \left( \frac{E_E(T)}{\sqrt{V_E(T)}}\right) =\Phi \left( \frac{\sqrt{n}AM_E(T)}{\sqrt{AV_E(T)}}\right) , $$\end{document}where \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\Phi $$\end{document} denotes the cdf of the standard normal random variable (AM and AV stand for asymptotic mean and asymptotic variance respectively). Sample size can be determined by equating the PCS( \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\lambda $$\end{document} ) to the given protection level \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$p \in [0,1]$$\end{document} as given by
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\begin{aligned} \Phi \left( \frac{\sqrt{n}AM_E(T)}{\sqrt{AV_E(T)}}\right) =p \end{aligned}$$\end{document}to get
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\begin{aligned} n=\frac{z^2_{p}AV_E(T)}{\left( AM_E(T)\right) ^2}. \end{aligned}$$\end{document}Here, \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$z_p$$\end{document} is the pth quantile of a standard normal distribution. For different values of \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\lambda $$\end{document} , \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$p=0.6,0.7,0.8$$\end{document} and K−S distance, sample sizes n are reported in Table 2. From this table, it is evident that as \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\lambda $$\end{document} increases, the K−S distance decreases, necessitating a larger sample size. Additionally, it is noticeable that as the probability of correct selection p increases, a larger sample size becomes necessary, as anticipated. Proceeding similarly and using Theorem 2 in Appendix A, sample sizes when the true distribution is Lindley, can be determined by the next expression:
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\begin{aligned} n=\frac{z^2_{p}AV_L(T)}{\left( AM_L(T)\right) ^2}. \end{aligned}$$\end{document}Table 3 presents results that exhibit a pattern similar to that observed in Table 2.
Using Theorem 3 in Appendix B, the values of n for censored data are obtained. Tables 4 and 5 report the required sample sizes for specified \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\lambda $$\end{document} (or \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\theta $$\end{document} ), p and K−S distance, with 10% censoring. As expected, a higher percentage of censored observations results in larger sample sizes.Table 4. Values for n given \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\lambda $$\end{document} , p and K−S distance between Exp \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$(\lambda )$$\end{document} and Lin \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$(\widetilde{\theta })$$\end{document} distributions with 10% of censored observations \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\lambda \rightarrow $$\end{document} 0.10.50.91.31.52.02.5 \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$n~(p=0.6)$$\end{document} 211275372137236 \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$n~(p=0.7)$$\end{document} 10461142293095881011 \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$n~(p=0.8)$$\end{document} 2611729459097515142603K-S0.1060.0540.0340.0270.0210.0180.012Table 5Values for n given \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\theta $$\end{document} , p and K−S distance between Lin \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$(\theta )$$\end{document} and Exp \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$(\widetilde{\lambda })$$\end{document} distribution with 10% of censored observations \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\theta \rightarrow $$\end{document} 0.10.50.91.31.52.02.5 \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$n~(p=0.6)$$\end{document} 2513263570126 \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$n~(p=0.7)$$\end{document} 62254111152301541 \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$n~(p=0.8)$$\end{document} 15571392853907761393K-S0.1200.0700.0490.0360.0310.0220.015Table 6PCS based on asymptotic and simulated (in parentheses) results when the data come from Exp \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$(\lambda )$$\end{document} distribution for different values of \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\lambda $$\end{document} and n \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\lambda \downarrow ~n\rightarrow $$\end{document} 204060801002000.10.7830.8640.9120.9410.9590.993(0.712)(0.840)(0.899)(0.936)(0.958)(0.995)0.50.6520.7090.7500.7820.8080.891(0.552)(0.646)(0.705)(0.749)(0.785)(0.884)0.90.6010.6410.6710.6960.7160.791(0.494)(0.566)(0.613)(0.646)(0.675)(0.770)1.30.5740.6040.6260.6450.6610.722(0.451)(0.517)(0.562)(0.589)(0.611)(0.692)1.50.5670.5900.6120.6340.6480.701(0.438)(0.502)(0.538)(0.573)(0.582)(0.667)2.00.5530.5750.5840.6080.6170.655(0.410)(0.469)(0.512)(0.529)(0.547)(0.607)2.50.5370.5530.5640.5750.5830.617(0.403)(0.454)(0.484)(0.500)(0.523)(0.584)Table 7PCS based on asymptotic and simulated (in parentheses) results when the data come from Lin \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$(\theta )$$\end{document} distribution for different values of \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\theta $$\end{document} and n \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\theta \downarrow ~n\rightarrow $$\end{document} 204060801002000.10.8500.9300.9660.9830.9880.990(0.884)(0.933)(0.963)(0.979)(0.988)(0.998)0.50.7140.7860.8320.8610.8910.965(0.780)(0.828)(0.861)(0.889)(0.908)(0.963)0.90.6440.7040.7480.7730.8090.882(0.733)(0.759)(0.780)(0.801)(0.819)(0.894)1.30.6010.6560.6830.7020.7270.804(0.706)(0.710)(0.723)(0.751)(0.763)(0.825)1.50.5980.6320.6550.6830.7020.776(0.698)(0.699)(0.707)(0.722)(0.731)(0.791)2.00.5770.5910.6130.6340.6570.708(0.684)(0.674)(0.674)(0.689)(0.692)(0.735)2.50.5550.5790.5940.6060.6150.669(0.670)(0.651)(0.660)(0.664)(0.667)(0.695)
We now discuss the use of PCS and the tolerance level to discriminate between the exponential and Lindley models. Suppose the data are generated from an exponential population, with the tolerance level based on the K−S distance fixed at \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$D = 0.054$$\end{document} , and the protection level set at \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$p=0.8$$\end{document} . It implies that discrimination between exponential and Lindley cdfs is desired only when their K−S distance exceeds 0.054. From Table 2, a sample size \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$n=93$$\end{document} is required to achieve \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$p=0.8$$\end{document} when the data follow an exponential model. Conversely, for data from a Lindley population, Table 3 indicates an approximate \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$n=103$$\end{document} for \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$D=0.054$$\end{document} and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$p=0.8$$\end{document} . Therefore, to meet the protection level \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$p = 0.8$$\end{document} at the specified tolerance level, a sample size of \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$max \{ 93, 103 \} = 103$$\end{document} is required to satisfy both cases. Although Table 3 does not directly list \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$D = 0.054$$\end{document} , the adjacent values \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$D = 0.070$$\end{document} and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$D = 0.049$$\end{document} suggest that n lies close to 103.
For the case of censored data, a similar interpretation follows from Tables 4 and 5. For instance, with \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$D = 0.054$$\end{document} , \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$p = 0.8$$\end{document} , and assuming up to 10% censored observations, a sample size of \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\max \{ 117, 139 \} = 139$$\end{document} is required to satisfy both cases simultaneously. The sample sizes in Tables 4 and 5 are slightly higher than those without censoring, as shown in Tables 2 and 3.Table 8PCS based on asymptotic and simulated (in parentheses) results when the data come from Exp \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$(\lambda )$$\end{document} distribution for different values of \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\lambda $$\end{document} , n, and 10% of censored observations \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\lambda \downarrow ~n\rightarrow $$\end{document} 204060801002000.10.7690.8500.8980.9290.9500.990(0.704)(0.817)(0.882)(0.921)(0.949)(0.989)0.50.6360.6890.7260.7570.7820.864(0.530)(0.629)(0.669)(0.715)(0.747)(0.844)0.90.5870.6220.6480.6700.6880.756(0.478)(0.538)(0.582)(0.62)(0.643)(0.724)1.30.5620.5870.6060.6220.6350.688(0.440)(0.506)(0.533)(0.568)(0.582)(0.640)1.50.5530.5750.5910.6050.6170.664(0.431)(0.491)(0.528)(0.544)(0.564)(0.623)2.00.5390.5540.5670.5770.5860.620(0.409)(0.47)(0.497)(0.512)(0.529)(0.578)2.50.5290.5420.5510.5590.5660.592(0.408)(0.448)(0.472)(0.496)(0.510)(0.552)Table 9PCS based on asymptotic and simulated (in parentheses) results when the data come from Exp \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$(\lambda )$$\end{document} distribution for different values of \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\lambda $$\end{document} , n, and 20% of censored observations \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\lambda \downarrow ~n\rightarrow $$\end{document} 204060801002000.10.7570.8380.8860.9180.9410.986(0.660)(0.791)(0.857)(0.900)(0.922)(0.984)0.50.6250.6740.7100.7390.7630.844(0.522)(0.604)(0.641)(0.679)(0.706)(0.802)0.90.5790.6100.6340.6540.6710.735(0.459)(0.532)(0.571)(0.587)(0.609)(0.684)1.30.5550.5780.5950.6090.6210.669(0.442)(0.483)(0.525)(0.541)(0.564)(0.622)1.50.5470.5670.5810.5940.6050.646(0.430)(0.473)(0.504)(0.524)(0.554)(0.596)2.00.5340.5480.5590.5680.5760.606(0.416)(0.463)(0.485)(0.509)(0.509)(0.552)2.50.5260.5370.5450.5520.5580.581(0.411)(0.453)(0.471)(0.488)(0.501)(0.531)
Computation of PCS for finite sample sizes
In this subsection, we demonstrate that the asymptotic results derived in the Appendix work well for finite sample sizes. The PCS is computed using both the asymptotic results and Monte Carlo simulations for sample sizes \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$n=20, 40, 60, 80, 100$$\end{document} , and 200. We first consider the case of a complete sample. Assuming the null distribution to be exponential and the alternative to be Lindley, the results obtained from the asymptotic theory are presented in Table 6 for various choices of the exponential scale parameter \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\lambda =0.1, 0.5, 0.9,1.3, 1.5, 2.0, 2.5$$\end{document} . Similarly, for the same sample sizes and corresponding scale parameter \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\theta $$\end{document} of the Lindley distribution, when the null distribution is Lindley and the alternative is exponential, the results are reported in Table 7.
From Tables 6 and 7, clear patterns emerge. As the sample size increases, the asymptotic PCS also increases, as expected. The PCS further increases as the values of \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\lambda $$\end{document} and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\theta $$\end{document} decrease. Notably, the asymptotic results perform well even for small sample size (e.g., \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$n=20$$\end{document} ) across all parameter ranges. The simulated PCS values, shown in parentheses, follow the same trend and closely agree with the asymptotic PCS.Table 10PCS based on asymptotic and simulated (in parentheses) results when the data come from Lin \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$(\theta )$$\end{document} distribution for different values of \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\theta $$\end{document} , n and 10% of censored observations \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\theta \downarrow ~n\rightarrow $$\end{document} 204060801002000.10.8330.9140.9530.9730.9850.999(0.869)(0.918)(0.951)(0.974)(0.983)(0.998)0.50.6910.760.8070.8410.8680.943(0.769)(0.807)(0.84)(0.862)(0.887)(0.945)0.90.6250.6740.7100.7380.7620.843(0.706)(0.739)(0.753)(0.78)(0.796)(0.858)1.30.5880.6240.6500.6720.6910.759(0.689)(0.689)(0.706)(0.714)(0.728)(0.779)1.50.5760.6060.6290.6480.6650.727(0.680)(0.676)(0.687)(0.687)(0.706)(0.757)2.00.5540.5760.5930.6060.6190.665(0.666)(0.650)(0.648)(0.666)(0.665)(0.685)2.50.5400.5570.5690.5800.5890.625(0.651)(0.638)(0.630)(0.639)(0.636)(0.653)Table 11PCS based on asymptotic and simulated (in parentheses) results when the data come from Lin \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$(\theta )$$\end{document} distribution for different values of \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\theta $$\end{document} , n and 20% of censored observations \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\theta \downarrow ~n\rightarrow $$\end{document} 204060801002000.10.8200.9020.9430.9660.9800.998(0.855)(0.913)(0.945)(0.965)(0.975)(0.997)0.50.6770.7420.7870.8210.8480.927(0.754)(0.784)(0.813)(0.839)(0.862)(0.92)0.90.6130.6580.6910.7180.7400.819(0.702)(0.709)(0.720)(0.748)(0.763)(0.832)1.30.5790.6110.6350.6550.6720.735(0.669)(0.664)(0.677)(0.688)(0.698)(0.749)1.50.5670.5950.6150.6320.6470.704(0.659)(0.65)(0.662)(0.668)(0.679)(0.725)2.00.5470.5670.5820.5940.6050.647(0.653)(0.642)(0.631)(0.639)(0.645)(0.662)2.50.5350.5500.5610.5700.5780.610(0.634)(0.613)(0.611)(0.630)(0.618)(0.638)
We also conducted a secondary analysis of the PCS using random samples with censored observations. Tables 8 and 9 present the PCS for 10% and 20% of censoring, respectively, when the random sample is drawn from an exponential distribution. Similarly, Tables 10 and 11 report the PCS for 10% and 20% censoring when the samples are drawn from a Lindley distribution.
To generate censored random samples, we employed a two-step procedure. First, we identified a threshold value \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$t_0$$\end{document} corresponding to a specified quantile such that a fixed proportion (10% or 20%) of the observations exceeded \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$t_0$$\end{document} . Second, observations greater than \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$t_0$$\end{document} were replaced by \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$t_0$$\end{document} and assigned the indicator \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\delta =0$$\end{document} , while those less than \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$t_0$$\end{document} were assigned \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\delta =1$$\end{document} .
When comparing Tables 6, 8, and 9 for the exponential case, it is evident that increasing the percentage of censored observations leads to a decrease in both asymptotic and simulated PCS, indicating a consistent downward. A similar pattern is observed in the Lindley case when comparing Tables 7, 10, and 11. In all cases, the simulated PCS values closely align with their asymptotic counterparts.
Moreover, when comparing the PCS for the exponential and Lindley distributions under the same level of censoring (complete, 10%, or 20%), the PCS tends to be higher when the samples are drawn from a Lindley population than from an exponential one.
Table 12. Goodness-of-fit metrics of the distributions fitted to two data setsData setDistributionMLEMax log-likelihoodAICBICKS (p value)TVSymp | BLExponential2.251-36.25774.51377.7720.0543 (0.622)Lindley2.837-36.64075.27978.5370.0500 (0.724)TVSymp | n-backExponential2.97917.560-33.120-29.8630.0449 (0.724)Lindley3.62317.648-33.296-30.0380.0433 (0.846) Table 13. Results from the data analysisData setDistribution Censoring Statistic (T) AM AV PCSTVSymp | BLexponentialNo0.382430.001200.002550.629LindleyNo0.38243-0.001140.002160.633exponentialCase 10.563030.003030.00439LindleyexponentialCase 20.520710.002800.00368LindleyTVSymp | n-backexponentialNo-0.08770.000620.001300.594LindleyNo-0.0877-0.000590.001130.596exponentialCase 10.043010.002730.00378LindleyexponentialCase 2-0.0472110.002160.00226Lindley
Application to biological psychology
Posada-Quintero et al. (2019) had 16 participants undergoing three cognitive tasks; a psychomotor vigilance task (PVT), an auditory working memory task (n-back), and a visual search task (SS). A condition that did not require any psychomotor activity was used as a baseline task (BL). The researchers measured several biomarkers related to the body’s autonomic nervous system (ANS). The participants’ electrodermal activity related to the ANS’ sympathetic component (EDASymp), time-varying index of sympathetic tone (TVSymp), and low- and high-frequency components of heart rate variability (HRVLF and HRVHF) were measured over 12 trials in each task. We have identified two conditional data sets from Posada-Quintero et al. (2019) suitable for Lindley and exponential fits; TVSymp|BL (i.e., time-varying index of sympathetic tone during the baseline task) and TVSymp|n-back (i.e., time-varying index of sympathetic tone during the auditory working memory task). See Supplementary material for details. Table 12 shows the results of the fits for the data sets. The p values of the Kolmogorov–Smirnov test indicate that there is not enough evidence that the distributions underlying the data differ from both the Lindley and exponential distributions. Now, we illustrate the application of our proposed statistical test using complete and censored data sets. Although the original data sets are complete, we intentionally censor them to measure the performance of the test. Each data set of size 16 is censored in two ways.
Case 1. The data is censored at the 15th observation so that the 15th and 16th data become identical.
Case 2. The data is censored at the 14th observation so that the 14th–16th data becomes identical.
It is also interesting to study the asymptotic results for such a small sample size of 16. The results for each data set are described below and are shown in Table 13.
TVSymp | BL data
When exponential and Lindley distributions are used to fit the complete data, maximized log-likelihood functions are given as \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$l_{E}(2.251)=-36.257$$\end{document} and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$l_{L}(2.837)=-36.640$$\end{document} respectively resulting in \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$T=l_{E}(2.251)-l_{L}(2.837)=0.382>0$$\end{document} which indicates to choose the exponential model. Let us compare this finding with the asymptotic results, as also shown in Table 13. Assuming the data come from exponential cdf, the asymptotic mean and variance are obtained as \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$AM_E(2.251)=0.00120$$\end{document} and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$AV_E(2.251)=0.0026$$\end{document} along with the \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$PCS=0.629$$\end{document} yielding an estimated risk around 37% to choose the wrong model. Similarly, assuming that the data are from Lindley cdf, we compute \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$AM_L(2.837)=-0.0011$$\end{document} and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$AV_L(2.837)= 0.0022,$$\end{document} with the \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$PCS=0.633$$\end{document} to yield an estimated risk nearly 27% to choose the wrong model. Therefore, the PCS is at least \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$min(0.629,0.633)=0.629$$\end{document} . The PCS attains the maximum when the data are coming from the Lindley distribution and hence we should choose the Lindley distribution to fit the data.
TVSymp | n-back data
The Lindley and exponential distributions also fit the data well (see Table 12). When exponential and Lindley distributions are used to fit the data, maximized log-likelihood functions are given as \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$l_{E}(2.979)=17.648$$\end{document} and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$l_{L}(3.623)=17.648$$\end{document} respectively, resulting in \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$T=l_{E}(2.979)-l_{L}(3.623)=-329+319=-0.088<0$$\end{document} , which indicates to choose the Lindley model. Now, we compute the PCS based on asymptotic results. Assuming that the data come from exponential cdf, the asymptotic mean and variance are obtained as \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$AM_E(2.979)=0.00062$$\end{document} and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$AV_E(2.979)=0.00129$$\end{document} along with the \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$PCS=0.594$$\end{document} yielding an estimated risk around 40% to choose the wrong model. Similarly, assuming that the data are from Lindley cdf, we compute \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$AM_L(3.623)=-0.00059$$\end{document} and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$AV_L(3.623)= 0.0011,$$\end{document} with the \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$PCS=0.596$$\end{document} to yield an estimated risk nearly similar to what was obtained using the exponential cdf. Therefore, in this case, the PCS is at least \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$min(0.594,0.596)=0.594$$\end{document} . The PCS attains the maximum when the data are coming from a Lindley distribution and hence we should choose Lindley distribution to fit the data.
It is noteworthy that, in both datasets, the Lindley distribution demonstrates the most favorable fit according to our methodology. However, based on the AIC, the exponential distribution emerges as the optimal fit in the first dataset, whereas the Lindley distribution exhibits the best fit in the second dataset. While it may be coincidental that the Lindley distribution provides the best fit for both datasets using our method, this consistency simplifies the interpretation and comparison between the two datasets. In the Posada–Quintero and Bolkhovsky study, Posada-Quintero et al. (2019) data were analyzed via ANOVA, task classification analysis (via k-nearest neighbor classifiers, support vector machines, decision trees, and discriminant analysis), and classifier performance (via leave-one-subject-out cross-validation). We believe that Lindley distributional regression modeling via GAMLSS (Klein, 2024) would have been helpful to investigate the potential effects of the explanatory variables on the rate scale parameter. In addition, Lindley time-dependent hrf plots would have been informative for estimating the likelihood of an event increasing over time. Specifically, only Lindley hrf plots could have estimated the likelihood of ANS sympathetic tone increasing over time given a cognitive task. If an exponential distribution were the best fit, there would instead be a constant hazard rate function, indicating that a cognitive task has a monotonic likelihood of affecting ANS sympathetic tone over time. Thus, the data example visited above signals that choosing the correct probability distribution has relevant applied consequences, that is, choosing the Lindley or exponential distributions would lead to radically opposite conclusions in an hrf analysis.
Conclusion
In this paper, we highlight the role of hazard rate functions in discriminating between distributions and show the practical significance of discriminating between two distributions with very similar shapes like the exponential and Lindley ones, suitable to model positively skewed data. We propose a method to address this problem based on the ratio of the likelihood functions. The method is flexible and can be applied to type I censored data, making it very useful in biological psychology as well as in other fields where censored data are common.
It was mentioned earlier that GAMLSS is a framework promoting careful consideration of probability distributions for data interpretation and prediction. As previously explained, hrfs are directly dependent on the pdf and the cdf through the survival function, and they represent an underutilized yet informative approach to analyzing data (see Panis et al. (2020)). We believe that while GAMLSS offers a powerful tool for selecting optimal distributions, our proposed method provides an additional layer of refinement, particularly when dealing with distributions that have an equal number of parameters and similar pdfs and cdfs. By carefully selecting the most suitable distribution, we can optimize the shape of the hrf and enhance the accuracy of our analysis.
Supplementary Information
Below is the link to the electronic supplementary material.Supplementary file 1 (pdf 444 KB)
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1Changbo, Z., Zhou, K., Tang, F., Tang, Y., & Si, B. (in press). A hierarchical Bayesian inference model for volatile multivariate exponentially distributed signals. Frontiers in Computational Neuroscience.
- 2Cox, D. R. (1961). Tests of separate families of hypotheses, Proceedings of the Fourth Berkeley Symposium in Mathematical Statistics and Probability. University of California Press, 105-123.
- 3Kim, D. H., Lee, W. D., & Kang, S. G. (2000). Bayesian model selection for life time data under type II censoring. Communications in Statistics-Theory and Methods,29(12), 2865–2878.
- 4Lindley, D. V. (1958). Fiducial distributions and Bayes’ theorem. Journal of the Royal Statistical Society. Series B (Methodological), 102-107.
- 5Panis, S., Schmidt, F., Wolkersdorfer, M. P., & Schmidt, T. (2020). Analyzing response times and other types of time-to-event data using event history analysis: a tool for mental chronometry and cognitive psychophysiology. I-Perception,11(6), 2041669520978673.
- 6Roberts, W. M., Augustine, S. B., Lawton, K. J., Lindsay, T. H., Thiele, T. R., Izquierdo, E. J., Faumont, S., Lindsay, R. A., Britton, M. C., Pokala, N., Bargmann, C. I., & Lockery, S. R. (2016). A stochastic neuronal model predicts random search behaviors at multiple spatial scales in C. elegans. e Life, 5, e 12572. 10.7554/e Life.12572.
- 7Tomitaka, S., Kawasaki, Y., Ide, K. et al. (2017). Exponential distribution of total depressive symptom scores in relation to exponential latent trait and item threshold distributions: a simulation study. BMC Reseach Notes, 10, 614. 10.1186/s 13104-017-2937-6. · doi ↗
- 8Vaidyanathan, V., & Varghese, A. (2019). Discriminating between exponential and Lindley Distributions. Journal of Statistical Theory and Applications,18(3), 295–302.