Performance of large language model in cross-specialty medical scenarios
Zhen Cui, Wuzheng Liu, Xuan Tian, Conglei You, Xiangyu Meng, Huijuan Zhang, Kangzi Gong, Xu Wang, Jun Wu

TL;DR
This study compares the diagnostic and therapeutic accuracy of three large language models across 12 medical specialties, finding that GPT-4o performs best for diagnosis but shows mixed results for treatment recommendations.
Contribution
The study provides a systematic evaluation of LLMs' cross-specialty diagnostic and therapeutic performance using standardized clinical cases and physician assessments.
Findings
GPT-4o showed superior diagnostic accuracy compared to GPT-3.5-Turbo and Claude-3-Sonnet across 12 medical specialties.
GPT-4o's therapeutic recommendations were highly variable, performing significantly better than GPT-3.5-Turbo but not Claude-3-Sonnet.
LLMs demonstrated high consistency in diagnostic outputs but inconsistent therapeutic performance, limiting clinical adoption.
Abstract
Large language models (LLMs) demonstrate transformative potential in healthcare, yet their diagnostic and therapeutic accuracy across medical specialties remains inadequately characterized. This study aimed to compare diagnostic and therapeutic capabilities of GPT-4o, GPT-3.5-Turbo, Claude-3-Sonnet across 12 medical specialties using standardized clinical vignettes. 50 PubMed-derived clinical cases between 2007 and 2024 were assessed. Two board-certified physicians independently evaluated LLMs outputs, with a senior clinician adjudicating discrepancies. All LLMs received identical text-based case descriptions with or without images, generating free-text diagnostic and therapeutic recommendations for blinded, randomized evaluation. Among the three evaluated LLMs, GPT-4o demonstrated superior diagnostic accuracy (median 10; IQR, 7.5–10), outperforming Claude-3-Sonnet (median 8; IQR,…
Genes, proteins, chemicals, diseases, species, mutations and cell lines named across the full text — each resolved to its canonical identifier and authoritative record.
Click any figure to enlarge with its caption.
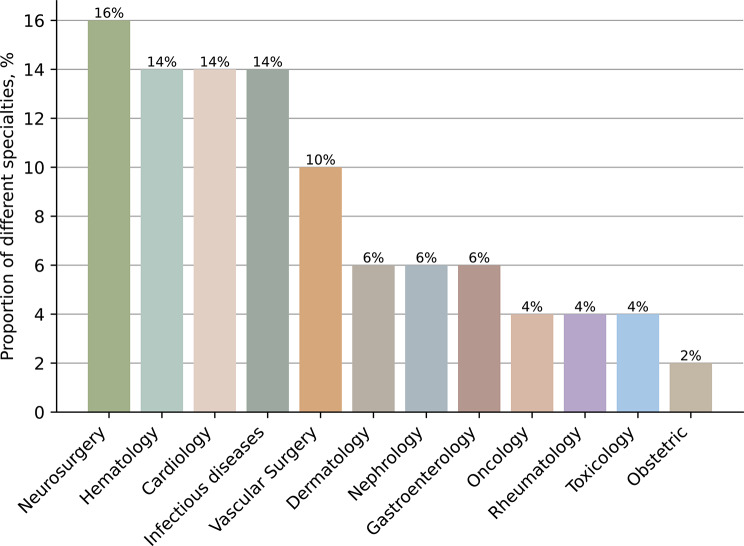 Figure 1
Figure 1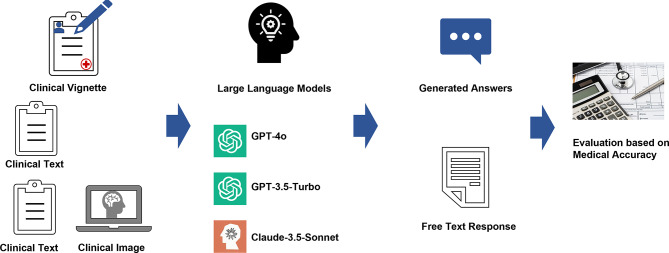 Figure 2
Figure 2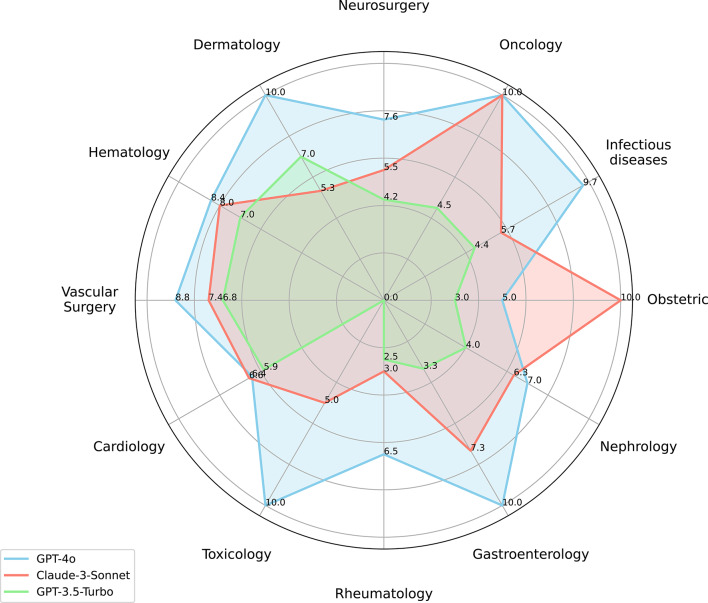 Figure 3
Figure 3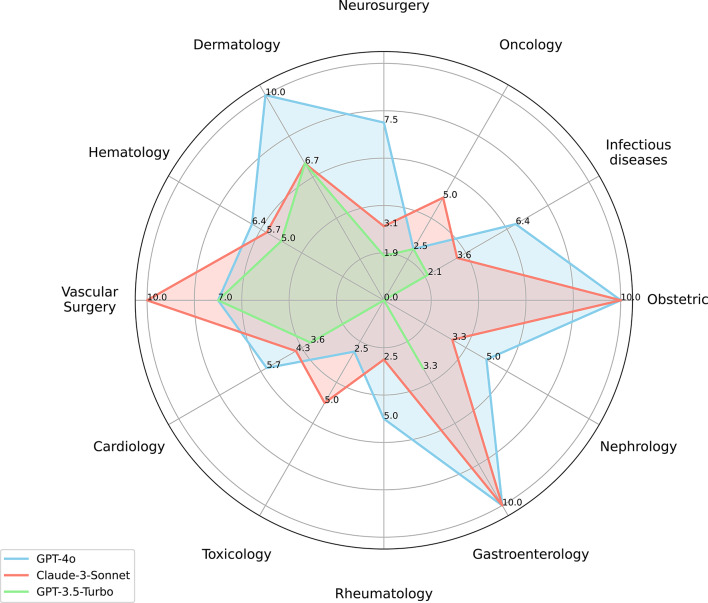 Figure 4
Figure 4Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsArtificial Intelligence in Healthcare and Education · Genomics and Rare Diseases · Machine Learning in Healthcare