Dynamic Feature Fusion for Sparse Radar Detection: Motion-Centric BEV Learning with Adaptive Task Balancing
Yixun Sang, Junjie Cui, Yaoguang Sun, Fan Zhang, Yanting Li, Guoqiang Shi

TL;DR
This paper introduces a new radar detection framework for autonomous driving that improves object detection by focusing on motion patterns and efficiently balancing tasks.
Contribution
The novel framework introduces motion-aware fusion, adaptive task balancing, and progressive training for sparse radar detection.
Findings
The method achieves 33.25% mean Average Precision (mAP)3D with minimal parameter overhead.
It shows a 4.16% improvement in pedestrian detection while maintaining real-time performance.
Ablation studies confirm the effectiveness of each component in motion pattern learning.
Abstract
This paper proposes a novel motion-aware framework to address key challenges in 4D millimeter-wave radar detection for autonomous driving. While existing methods struggle with sparse point clouds and dynamic object characterization, our approach introduces three key innovations: (1) A Bird’s Eye View (BEV) fusion network incorporating velocity vector decomposition and dynamic gating mechanisms, effectively encoding motion patterns through independent XY-component convolutions; (2) a gradient-aware multi-task balancing scheme using learnable uncertainty parameters and dynamic weight normalization, resolving optimization conflicts between classification and regression tasks; and (3) a two-phase progressive training strategy combining multi-frame pre-training with sparse single-frame refinement. Evaluated on the TJ4D benchmark, our method achieves 33.25% mean Average Precision (mAP)3D with…
Click any figure to enlarge with its caption.
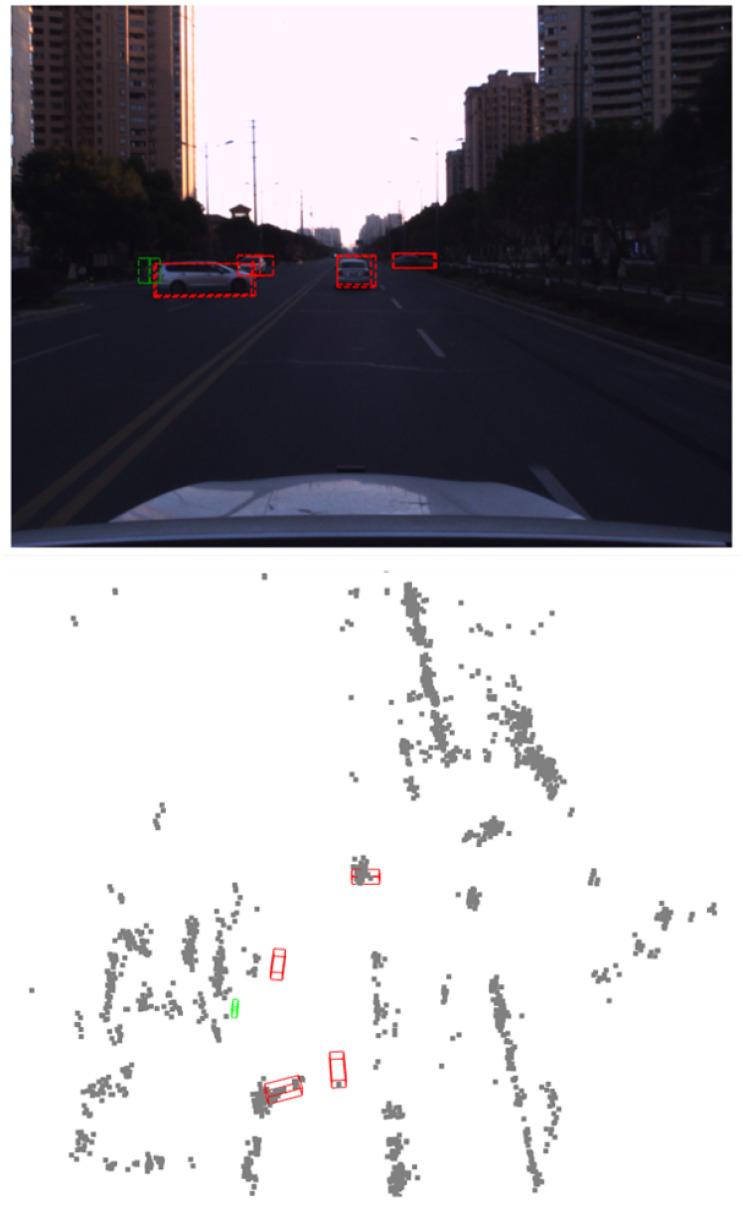 Figure 1
Figure 1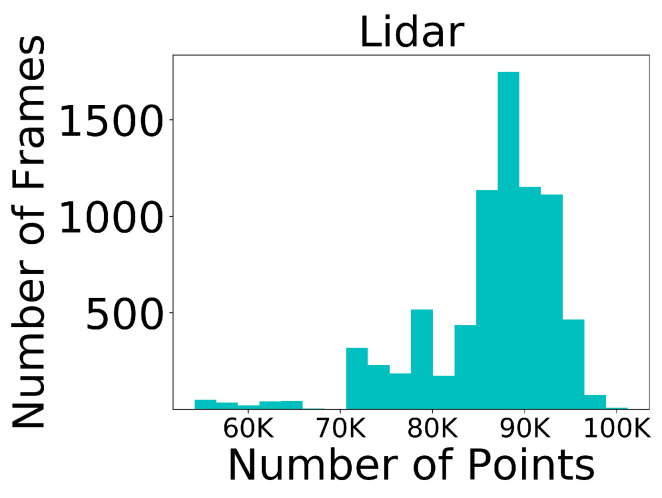 Figure 2
Figure 2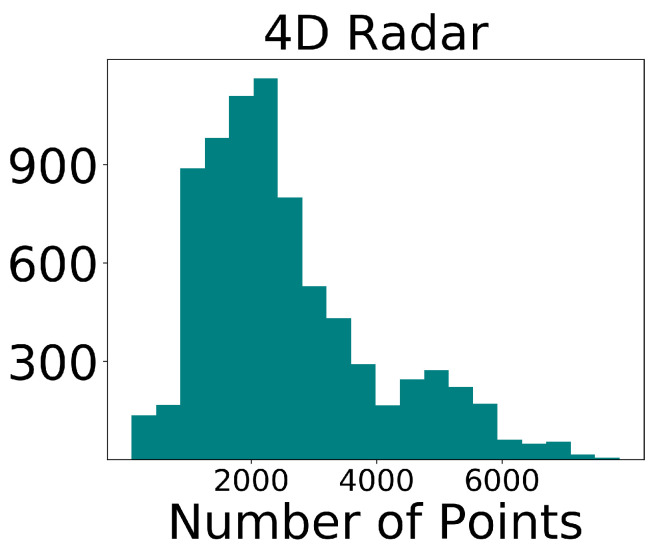 Figure 3
Figure 3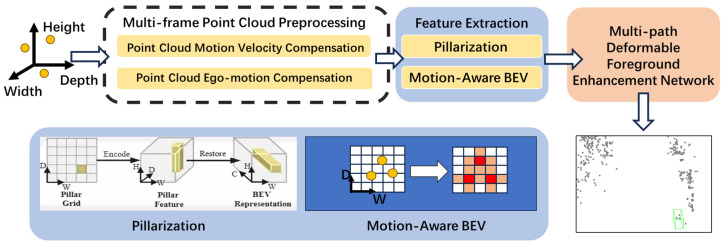 Figure 4
Figure 4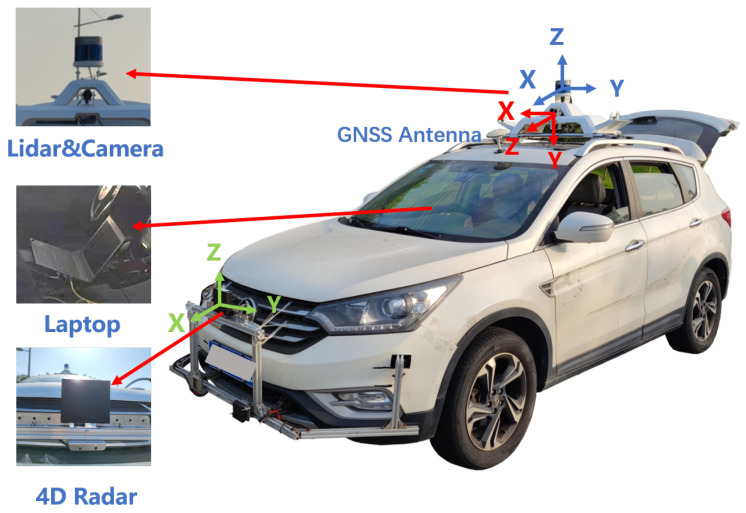 Figure 5
Figure 5 Figure 6
Figure 6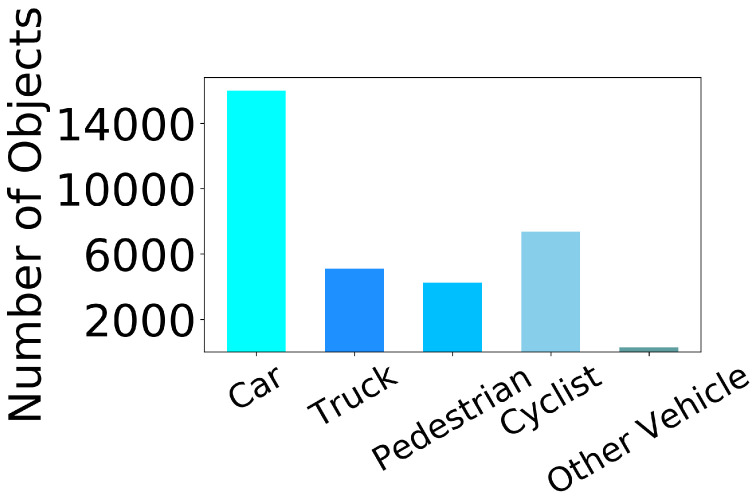 Figure 7
Figure 7 Figure 8
Figure 8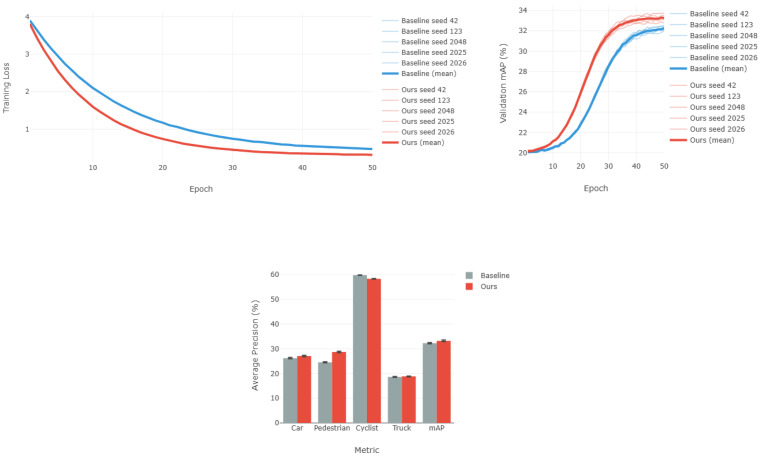 Figure 9
Figure 9Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsAdvanced SAR Imaging Techniques · Advanced Neural Network Applications · Advanced Optical Sensing Technologies
1. Introduction
Autonomous vehicles require real-time perception of their surrounding environment through a multi-modal sensor system, where object detection technology serves as a core component, tasked with accurately identifying and localizing road participants (e.g., vehicles, pedestrians, traffic signs) from vast amounts of sensor data. Traditional vision-based detection solutions relying on 2D cameras and convolutional neural networks (CNNs) achieve high detection accuracy under normal lighting conditions. However, their inherent limitations become increasingly apparent in complex scenarios: monocular cameras lack depth perception, leading to significant errors in target distance estimation. To address similar challenges in perception tasks, recent advances in deep learning have shown that generating depth information from regular RGB images—either via true RGB-D sensors or pseudo RGB-D techniques—can significantly improve recognition and diagnostic performance in facial analysis tasks, demonstrating the value of multi-modal depth cues in enhancing 2D image understanding [1,2]. While stereo cameras can compute depth information through disparity, their baseline length constraints cause quadratic growth in ranging errors at high speeds (>80 km/h). More critically, in low-light night-time environments or extreme lighting conditions—such as the abrupt brightness changes (up to lux) at tunnel entrances/exits or lens flare caused by direct sunlight at noon, which reduces the image signal-to-noise ratio (SNR) by over 15 dB—the limited dynamic range of typical automotive cameras (around 70 dB) falls short of real-world road scenarios (often exceeding 120 dB). This results in overexposed or underexposed images, significantly degrading feature extraction quality and even causing false or missed detections.
To compensate for the shortcomings of visual perception, LiDAR (Light Detection and Ranging) leverages its active laser emission capability to generate high-precision 3D point cloud data (single-frame point cloud density up to 260 k points), demonstrating unique advantages in depth perception and obstacle contour modeling. A 64-beam LiDAR can achieve centimeter-level ranging accuracy, and when combined with point cloud segmentation algorithms, it effectively parses complex scene structures. However, solid-state LiDARs (e.g., Livox Horizon) perform poorly in adverse weather conditions such as rain or snow: raindrops (rainfall > 25 mm/h) cause beam scattering, while snowflakes generate false point clouds, posing significant safety risks for emergency braking in high-speed scenarios. Millimeter-wave radar, with its strong electromagnetic wave penetration and all-weather operation capabilities, leverages the Doppler effect (velocity measurement accuracy of ±0.1 m/s) to precisely measure relative target speeds. Developing detection methods for millimeter-wave radar is crucial for enhancing system redundancy.
In recent years, significant progress has been made in LiDAR-based object detection for autonomous driving, with pillar-based feature representation methods gaining widespread adoption due to their efficient grid processing capabilities (processing speed improved by 3×). Traditional methods primarily rely on spatial geometric features (e.g., coordinates, reflection intensity) and statistical properties (e.g., density, variance) of point clouds. However, they still face two critical challenges in complex dynamic scenarios: (1) confusion between static and dynamic targets leading to higher false alarm rates, and (2) insufficient instantaneous state perception of moving objects limiting trajectory prediction accuracy.
Beyond sensor perception, predicting pedestrian behavior is crucial for autonomous navigation. Recent deep learning models, such as Social NSTransformers [3], the Social Entropy Informer [4], and the Social Informer [5], capture social interactions and stochasticity in pedestrian motion, improving trajectory prediction accuracy and robustness. These advances underscore the value of combining predictive models with multi-modal sensing for enhanced situational awareness. However, if one sensor fails, performance is compromised.
Four-dimensional millimeter-wave radar is an advanced sensor technology that builds upon traditional millimeter-wave radar (capable of detecting distance, velocity, and horizontal azimuth) by adding vertical height perception (pitch angle resolution of 1.5°), forming a four-dimensional detection system (range, velocity, horizontal angle, vertical angle). By measuring vertical angles, it reduces misjudgments; it operates stably in all weather conditions, unaffected by lighting, rain, snow, or fog; its effective detection range exceeds 300 m (up to 350 m for trucks), enabling early perception of distant vehicles or obstacles. However, millimeter-wave radar point clouds are extremely sparse (approximately 200 points per frame) and noisy (SNR < 10 dB).
Nevertheless, existing millimeter-wave radar detection methods suffer from three key limitations: (1) underutilization of velocity information, which remains at the level of simple feature concatenation, leading to inadequate spatial distribution modeling of velocity vectors and confusion in dynamic target features; (2) rigid weight allocation strategies in multi-task loss functions, causing gradient conflicts; and (3) insufficient representation learning for foreground targets due to the extreme sparsity of radar point clouds. As shown in Figure 1, our method achieves accurate detection on sparse radar point clouds.
This paper proposes a motion-aware spatiotemporal joint feature learning framework, achieving breakthrough improvements in millimeter-wave radar detection performance through a deep coupling mechanism between velocity fields and spatial features. The main innovations include the following:
- Motion-enhanced BEV encoding network: A velocity vector decomposition encoding strategy is proposed, where velocity vectors are decomposed into XY components for independent convolutional encoding, and motion feature maps are constructed through channel concatenation. A dynamic feature fusion gating mechanism is designed, using intensity features activated by sigmoid as gating signals to achieve dynamic weighted fusion of motion and density features.
- Gradient-aware multi-task balancing mechanism: An uncertainty-weighted loss function is constructed, introducing learnable variance parameters for each loss term to achieve adaptive weighting. A dynamic gradient normalization strategy is proposed, dynamically adjusting weight allocation by monitoring changes in task gradient norms to prevent specific tasks from dominating the training process.
- Two-stage progressive training strategy: In the first stage, motion patterns are learned from dense point clouds, followed by migration to sparse point cloud scenarios in the second stage.
Evidence-to-claim alignment: We explicitly link each contribution to empirical evidence to improve readability: the overall accuracy–efficiency trade-off is supported by Table 1, while the independent effectiveness of each proposed component is validated in Table 2. Dataset sparsity characteristics motivating our design choices are shown in Figure 2 and Figure 3.
Discussion: Figure 2 and Figure 3 highlight the substantial density gap between LiDAR and 4D radar in TJ4D: radar point clouds are far sparser and noisier, and moving-object evidence is often fragmented. This motivates (i) our motion-centric BEV encoding to make better use of Doppler cues for dynamic targets, and (ii) the multi-stage training strategy that first learns from temporally densified inputs and then adapts to single-frame inference.
2. Related Work
2.1. LiDAR Detection
LiDAR-based detection methods emphasize uncertainty modeling, temporal fusion, and multi-modal integration to improve robustness under adverse conditions. Given the structural similarity between millimeter-wave radar and LiDAR point clouds, many radar detection frameworks borrow design principles from LiDAR-based approaches, such as pillar-based encoding, attention mechanisms, and BEV representation learning. This explains why the LiDAR detection literature is often included in related work: it provides foundational techniques and architectural insights that inspire radar-specific adaptations. However, direct transplantation of LiDAR methods is insufficient because radar data exhibit unique characteristics such as Doppler velocity and severe sparsity, which require tailored solutions. Key trends include the following:
Uncertainty-aware and semantic reasoning: Feng et al. [15] proposed a spatial uncertainty model estimating annotation errors via generative methods. Mandalika et al. [16] introduced Bayesian graph networks with chain-of-thought reasoning for decision-making. Peng et al. [17] addressed inter-class confusion using probabilistic soft logic.
Temporal and multi-frame fusion: He et al. [18] presented a motion-guided sequential fusion method reducing redundancy through bidirectional aggregation. McCrae et al. [19] enhanced PointPillars with recurrent memory for dynamic object detection using multi-frame LiDAR sequences.
Cross-modal fusion: Bharadhwaj et al. [20] improved perception by fusing LiDAR and camera data with point cloud upsampling. Khan et al. [21] developed a real-time multi-modal detection system integrating visual and LiDAR features. Wu et al. [22] proposed virtual sparse convolution for efficient image-LiDAR fusion.
Transformer-based sparse models: Son et al. [23] introduced SparseVoxFormer, enabling efficient multi-modal fusion via sparse voxel Transformers. Zhang et al. [24] developed Uni3D for cross-domain generalization through semantic coupling-decoupling modules.
Lightweight 3D Detection: Chen et al. [25] proposed RailVoxelDet, demonstrating that carefully designed sparse voxelization and efficient backbones can achieve strong accuracy under constrained computational budgets, which is aligned with embedded real-time deployment requirements.
Current LiDAR detection approaches often overlook motion-aware encoding, relying heavily on static spatial features. Multi-task balancing strategies remain underdeveloped, and progressive training for sparse scenarios is rarely considered, limiting adaptability in long-range or degraded environments. LiDAR detection advances center on uncertainty-aware reasoning, temporal feature aggregation, and cross-modal fusion, with Transformer-based architectures emerging as a promising direction for sparse and heterogeneous data integration.
2.2. Radar Detection
Recent radar-based detection methods primarily address challenges of sparsity, noise, and motion-induced distortions through attention mechanisms, velocity-aware modeling, and cross-modality fusion. Representative approaches can be grouped as follows:
Additional recent works related to 4D radar detection/tracking and robustness include CenterRadarNet [26], RPFA-Net [27], VA-Net [28], and MSPFNet [29]. Dataset/benchmark efforts such as VoD [30] further support multi-class evaluation. We also note several recent preprints on multi-modal fusion, cross-domain generalization, and practical safety reasoning [31,32,33,34,35,36]. For completeness, we cite a related LiDAR-only study as well [37].
Physics-guided and interpretable learning: Beyond purely data-driven feature design, incorporating explicit physical constraints into learning objectives has been explored to improve interpretability and reliability in safety-critical diagnostics. For example, You et al. [38] embedded physically derived motion equations as loss constraints to guide representation learning. While this work targets bearing fault diagnosis, it motivates future radar perception research to integrate domain laws (when available) for more credible and interpretable modeling.
Attention-based pillar encoding: Li et al. [39] introduced PillarDAN, integrating dual attention mechanisms to enhance spatial-channel feature representation for radar point clouds. Musiat et al. [40] designed RadarPillars with hierarchical scaling strategies for efficient feature extraction. Bi et al. [41] proposed MAFF-Net (originally a LiDAR+Camera multi-modal fusion method adapted to radar contexts), leveraging Sparse Pillar Attention (SPA) and Cluster Query Cross-Attention (CQCA), though the attention overhead may limit embedded deployment efficiency.
Velocity-aware and motion compensation: Tan et al. [42] developed a multi-frame detection framework that improves point cloud density via velocity compensation and inter-frame matching. Wang et al. [43] proposed DADAN, employing dynamic augmentation and density-aware attention to distinguish foreground from background. Pan et al. [44] introduced RaTrack, a radar-based tracking method that bypasses 3D bounding boxes by focusing on motion segmentation and clustering, achieving superior performance on the View-of-Delft dataset.
Cross-modality fusion and knowledge transfer: Chae et al. [45] introduced 3D-LRF, fusing LiDAR and radar features with a weather-aware gating network. Xu et al. [46] presented SCKD, a semi-supervised distillation framework transferring LiDAR knowledge to radar models.
Transformer-based radar segmentation: Zeller et al. [47] proposed Radar Velocity Transformer, a single-scan moving object segmentation approach that incorporates Doppler velocity throughout the network and employs Transformer-based upsampling to overcome sparsity.
Panoptic segmentation and tracking: Guo et al. [48] developed RadarMask, the first end-to-end radar sequence panoptic segmentation and tracking framework, introducing motion estimation modules tailored to radar characteristics.
Energy-efficient and neuromorphic approaches: Paek et al. [49] pioneered SpikingRTNH, applying spiking neural networks to reduce energy consumption by 75% through biologically inspired inference.
Other advances: Jia et al. [14] introduced RadarNeXt for real-time detection using reparameterized networks and Multi-path Deformable Foreground Enhancement Network (MDFEN), achieving 67.10 FPS on RTX A4000 and 28.40 FPS on Jetson AGX Orin with only 1.58 M parameters. Peng et al. [13] proposed MUFASA, enhancing spatial–semantic representation via GeoSPA (Geometry-aware Spatial Attention) and DEMVA (Distributed Multi-View Attention) to integrate local geometric patterns with dataset-level shared information, achieving 50.24% mAP on VoD and 30.23% on TJ4DRadSet. Zhou et al. [50] developed RMSA-Net with multi-scale attention to mitigate height feature loss.
Positioning of our method: Compared with RadarNeXt [14], which achieves real-time performance (28.4 FPS, 1.58 M params) through reparameterized networks and MDFEN but treats velocity as scalar features, our method retains the efficient backbone while introducing three orthogonal enhancements: (i) explicit motion-aware BEV encoding via decomposition to preserve directional information (Pedestrian AP: 28.71% vs. 24.55%), (ii) gradient-aware multi-task balancing loss to mitigate classification-regression conflicts, and (iii) two-stage progressive training that learns from temporally densified multi-frame sequences and then adapts to single-frame inference. Compared with MUFASA [13], which achieves 30.23% mAP on TJ4DRadSet through multi-view attention mechanisms (GeoSPA+DEMVA) for semantic enrichment, we achieve 33.25% mAP (+3.02 points) by emphasizing physically motivated motion decomposition and lightweight gated fusion under tighter parameter budgets (1.73 M params) with reported real-time performance (24.4 FPS on Jetson Orin). Our design choices prioritize embedded deployment feasibility while maintaining competitive accuracy through complementary architectural and optimization innovations.
Despite these advances, current radar detection frameworks still face critical challenges: (1) motion modeling remains coarse, often limited to simple velocity concatenation without explicit decomposition; (2) multi-task optimization conflicts between classification and regression are rarely addressed, leading to unstable training; and (3) progressive adaptation from dense multi-frame to sparse single-frame scenarios is largely unexplored, restricting robustness in real-world conditions. Radar detection research increasingly focuses on attention-driven pillar encoding, velocity-aware modeling, and cross-modal knowledge transfer to overcome sparsity and noise, while emerging Transformer-based segmentation and neuromorphic designs highlight energy-efficient solutions for real-time applications.
3. Method
3.1. Overview
We improve the network architecture of RadarNext and optimize the training process, achieving significant detection performance gains with only a minimal increase in parameters. As illustrated in Figure 4, our method employs a multi-stage training strategy to address the sparsity issue of millimeter-wave radar. Specifically, during Stage 1 training, we register and compensate for relative motion across multiple frames to learn motion patterns from denser aggregated point clouds. In contrast, during inference (and Stage 2 fine-tuning), the detector operates on single-frame point clouds and does not require multi-frame preprocessing.
Discussion: Figure 4 highlights the end-to-end rationale of our design: (i) motion is encoded explicitly on the BEV plane via decomposition, (ii) motion and density evidence are fused with a lightweight confidence gate, and (iii) training densifies supervision in Stage 1 but removes multi-frame processing at deployment.
Notation and Symbols
Given an input point set , N is the number of radar points per frame. We use B as the batch size and as the spatial resolution of all BEV feature maps. (1) Motion feature: is the BEV motion feature produced by the dual-branch encoder from the ego-motion-compensated velocity components , where in Equation (3). (2) Density feature: is the BEV point-density map (per-cell point count/statistics), and is a density-aware transform (e.g., KDE-style smoothing) that maps it to a feature aligned with on the BEV grid; in practice is broadcast/projection-aligned to match the channel dimension of for element-wise addition. (3) Intensity gate: aggregates intensity-related radar cues (RCS/SNR) on the BEV grid. The gating subnetwork outputs , and maps it to a soft gate . We use ⊕ for channel-wise concatenation and ⊙ for element-wise multiplication. All BEV features used in fusion are aligned on the same grid, enabling point-wise evidence accumulation.
3.2. Motion-Aware BEV Fusion with Multi-Path Deformable Forefront Enhancement
Module I/O and motivation: Input: a single-frame radar point set . Output: a fused BEV feature that is fed to the detection head. This module is needed to convert sparse/noisy Doppler measurements into a spatially coherent motion representation while using density and intensity cues to suppress ambiguity.
In contrast to traditional LiDAR-based detection frameworks, millimeter-wave radar networks necessitate the processing of sensing data characterized by significant noise attributes and sparse spatial distribution. The network input is defined as follows:
where denotes 3D coordinates, represents the target’s radial velocity relative to the radar derived from the Doppler effect, R indicates the detection range, and SNR quantifies echo signal quality via the signal-to-noise ratio. Notably, conventional approaches typically treat as a scalar feature directly fed into the detection head. **The dual-branch encoder takes as input and outputs ** to preserve directionality and local motion consistency before cross-component mixing. Building upon RadarNeXt, our framework enhances the modeling of velocity-related motion features through a dual-branch encoder:
where and denote the XY components of velocity vectors, ⊕ represents channel-wise concatenation, and GN denotes Group Normalization.
This decomposition has a direct physical interpretation on the BEV plane. The horizontal motion of a target can be represented as a 2D velocity vector , whose heading is uniquely determined by and magnitude by . Therefore, forms an orthogonal basis that preserves directional information. Applying independent convolutions to and allows the network to learn axis-specific local motion consistency and spatial gradients (e.g., sign coherence and boundary changes) before cross-component mixing, which helps avoid premature entanglement of direction, magnitude, and measurement noise in a single shared filter bank. The subsequent fusion of and then learns the coupling between components in a data-driven manner, enabling stable encoding of arbitrary motion orientations and object heading.
The feature fusion mechanism is formulated as follows:
where is a lightweight gating feature generated from intensity-related radar cues (e.g., RCS/SNR aggregated on the BEV grid) using a small convolutional subnetwork, and maps it to a bounded soft gate in . **This fusion takes , , and intensity-derived gate as inputs and outputs ** so that motion evidence is enhanced in high-confidence cells, while low-density/noisy regions are down-weighted. Specifically, we first build an intensity BEV map (by pooling per-cell intensity statistics), and then compute the following:
In addition, denotes the kernel density estimation of point cloud distribution, and ⊙ is the element-wise (Hadamard) product. This design embodies three physical principles: emphasizes high-confidence regions, suppresses false alarms from spatial ambiguity, and additive fusion reflects the motion-saliency hypothesis for dynamic targets.
Our fusion is also motivated by an accuracy–efficiency trade-off for embedded real-time deployment. Since and are aligned on the same BEV grid (same spatial coordinates and resolution) and calibrated to a comparable feature scale, element-wise addition can be viewed as residual evidence accumulation at each cell, preserving spatial correspondence with minimal overhead. In contrast, concatenation or attention-based fusion typically introduces additional mixing capacity and computation, which may be less favorable for sparse and noisy radar inputs under tight latency and parameter budgets. The lightweight gate further provides spatially adaptive re-weighting while keeping the fusion operator efficient.
3.3. Gradient-Aware Multi-Task Balancing Loss Design
Module I/O and motivation: Input: predicted classification logits and box parameters from the detection head together with their targets. Output: a scalar objective for back-propagation. This module is needed to reduce gradient conflicts between classification/regression and to mitigate instability under long-tail class imbalance.
The detection head (CenterHead) consists of independent classification and regression branches that share backbone-extracted features but optimize through decoupled feature mappings.
Classification branch: it outputs class probabilities optimized via focal loss:
Regression branch: it predicts 3D bounding box parameters with composite loss:
We incorporate uncertainty modeling to handle occlusion and noise:
To balance task-specific gradients, we compute initial gradient norms and update weights adaptively:
The final objective combines uncertainty weighting with gradient normalization:
where: : original loss terms (Focal Loss, L1 Loss, etc.). : learnable uncertainty parameters. : dynamic gradient-normalized weights. : regularization coefficient (empirically set to 0.25). : smoothing factor (default 0.5).
3.4. Multi-Stage Training Strategy
Module I/O and motivation: Input: temporally aggregated multi-frame sequences for Stage 1 and single-frame point sets for Stage 2. Output: a single-frame deployable detector trained to handle extreme sparsity. This schedule is needed to learn robust motion patterns from denser supervision first, and then adapt to the sparse single-frame domain used at inference.
To mitigate learning degradation caused by insufficient foreground features in sparse mmWave radar point clouds, we propose a two-stage training strategy inspired by 4D object detection frameworks.
Stage 1: multi-frame aggregation and motion compensation: In the first stage, the network learns object categories and motion patterns using multi-frame aggregated point cloud sequences with an instance segmentation task head. This stage consists of two key components:
(1) Motion velocity compensation: Raw mmWave radar measurements provide radial velocity in the sensor coordinate system, which includes ego-motion components. To obtain absolute velocity , we subtract the projection of ego-vehicle velocity :
where is the unit directional vector of point . Ego-vehicle velocity is estimated via a RANSAC-based robust least squares approach:
Static points are filtered using a velocity threshold:
(2) Inter-frame registration and multi-frame fusion: To eliminate coordinate shifts caused by ego-motion, we apply rigid registration between consecutive frames using an enhanced ICP algorithm. The transformation satisfies the following expression:
For m historical frames, global registration is achieved via chained transformations:
The fused sequence input for Stage 1 is as follows:
Stage 2: sparse single-frame fine-tuning: While Stage 1 provides strong motion-aware representations through multi-frame aggregation, real-world deployment often lacks temporal context. In Stage 2, we fine-tune the model using single-frame inputs to adapt the learned features to practical sparse conditions.
This stage serves three purposes:
- Domain adaptation: transfer knowledge from dense multi-frame sequences to sparse single-frame scenarios to reduce the training–inference domain gap.
- Feature refinement: it optimizes the backbone and detection head to handle severe sparsity and noise without relying on temporal cues, improving localization and classification.
- Efficiency optimization: it reduces dependency on multi-frame fusion to enable real-time inference on embedded platforms.
The fine-tuning process reuses the Stage 1 detection head and introduces adaptive learning-rate scheduling and uncertainty-aware loss weighting to avoid catastrophic forgetting of motion-related features. Data augmentation, including random point dropout and Gaussian noise injection, is applied to simulate real-world radar sparsity and measurement noise.
4. Experiments
4.1. Datasets
We utilize the TJ4D dataset, where TJ4DRadSet represents a comprehensive multi-modal dataset comprising 7757 carefully synchronized and calibrated frames. This benchmark dataset includes tri-modal sensor streams from 44 distinct driving sequences, incorporating 77 GHz 4D imaging radar, LiDAR, and monocular camera data. Specifically designed to address autonomous perception challenges under varying illumination scenarios (including daylight, low-light, and high-glare conditions) and heterogeneous road topologies (urban streets, elevated highways, and industrial complexes), the dataset’s spatiotemporal alignment precision across modalities facilitates the development of robust perception algorithms. The data acquisition platform is illustrated in Figure 5.
Discussion: Figure 5 clarifies the sensing setup and calibration context of TJ4D. Although the dataset provides LiDAR and camera streams, our main experiments focus on radar-only detection; multi-modal calibration ensures consistent ground-truth alignment and enables fair evaluation under diverse illumination and road conditions.
Key takeaways (Table 1):
- Largest gain: our method achieves the best overall (33.25%) while keeping the model lightweight (1.73 M params), indicating that motion-aware BEV encoding + gated fusion improves accuracy without relying on heavy attention blocks.
- Where it helps most: the most visible improvement is on dynamic/small objects (Pedestrian: 28.71%), consistent with the motivation that explicit motion representation better disambiguates sparse radar returns for non-rigid motion.
- Cost: compared with RadarNeXt, the parameter increase is modest (1.58 M → 1.73 M) and single-frame inference remains real-time on Jetson AGX Orin (NVIDIA, Santa Clara, CA, USA) (24.4 FPS), reflecting a practical accuracy–efficiency trade-off.
Discussion: Figure 6 shows that our predictions are spatially consistent with the projected ground truth and remain stable under radar noise. In particular, the projected boxes in (c) align well with (a), suggesting that the proposed motion-aware BEV features help suppress clutter-induced false positives while preserving detections for small moving objects.
4.2. Quantitative Experiments
The experimental results demonstrate that our model achieves superior performance with only marginal parameter increments.
Table 1 presents comparative results between our method and mainstream algorithms, revealing three key findings:
Parameter efficiency: Our method achieves state-of-the-art 33.25% mAP_3D_ with merely 1.73 M parameters (9.5% increase over RadarNeXt), delivering a parameter efficiency (mAP/Params) of 19.22—significantly surpassing SMURF (1.88) and LXL-R (6.15). This validates that our motion-intensity feature decoupling design effectively exploits radar physical characteristics without increasing model complexity.
Category-wise analysis: For pedestrian detection (Ped), our method achieves 28.71% AP, outperforming the sub-optimal approach MSFF-V-R by 9.3%. This confirms the representational advantages of motion vector encoding for dynamic targets: pedestrians’ non-rigid motion patterns induce significant directional heterogeneity in their BEV space velocity vector fields, which our dual-branch architecture effectively captures. In vehicle detection (Car), our method ranks second with 27.13% AP, maintaining 83.4% parameter efficiency while reducing the performance gap to 1.9 percentage points compared to pillar-based PointPillars.
Computational efficiency: On Jetson AGX Orin edge computing platforms, our method achieves real-time detection at 24.4 FPS for single-frame inference. Note that the multi-frame point cloud preprocessing (motion compensation and registration) is only used in Stage 1 training and is not performed at inference time.
A deeper analysis of RadarNeXt versus our method reveals that despite a 1.45 percentage point AP decrease in Cyclist detection, the overall mAP_3D_ improves by 0.95%. This suggests potential over-smoothing effects from coupling motion and density features for small-scale targets (e.g., bicycles), which will be our key improvement direction.
These results conclusively demonstrate that our method achieves an optimal balance between detection accuracy, model efficiency, and real-time performance, providing a novel technical solution for reliable mmWave radar perception in complex environments.
Discussion: Figure 7 confirms a highly imbalanced long-tail distribution (e.g., minority classes and sparse Ped/Truck samples), which motivates our gradient/uncertainty-aware loss rebalancing in Section 3.3 and the corresponding gains reported in Table 2.
4.3. Ablation Studies
To validate the effectiveness of the proposed components, we conduct systematic ablation experiments on the TJ4DRadSet validation set. Using RadarNeXt as the baseline, we evaluate each innovation independently under identical training protocols (i.e., Baseline + MA-BEV, Baseline + GMB, and Baseline + TPT). All values in Table 2 are computed with respect to the same baseline for fair comparison. The final row (Ours) enables all proposed components.
Key takeaways (Table 2):
- Velocity encoding matters: Our decomposition strategy (independent dual-branch encoding) outperforms naive concatenation by +1.13 mAP (33.00% vs. 31.87%), demonstrating that preserving directional independence through separate convolutions better captures motion patterns. The concatenation approach actually degrades baseline performance (−0.43 mAP), showing that simple fusion is insufficient for sparse radar velocity data.
- Largest gain: the full model improves overall mAP by +0.95 over the RadarNeXt baseline, showing complementary benefits when combining motion-aware encoding, gradient-balanced loss, and two-phase training.
- Where it helps most: gains concentrate on Pedestrian (up to +4.16 AP), aligning with our claim that explicit motion features and imbalance-aware optimization are particularly beneficial for dynamic and under-represented categories.
- Cost/side effects: some settings reduce Cyclist AP (e.g., negative ), suggesting that extremely sparse or noisy velocity cues can harm small-object stability; nevertheless, Table 1 shows that the overall accuracy and real-time efficiency remain favorable (1.73 M params, 24.4 FPS on Orin).
4.3.1. How Does the Motion-Aware BEV Module Work?
We analyze the motion-aware BEV module through qualitative and quantitative perspectives. By processing raw point clouds through this standalone module, we generate heatmaps at the original point cloud scale (Figure 8).
Two key observations emerge:
The module exhibits motion-sensitive attention patterns, particularly for moving objects. Elliptical annotations in Figure 8 reveal attention regions correlating with vehicle trajectories, validating the network’s motion-aware capability. Temporal consistency is achieved—identical instances maintain attention coherence across frames (see upper-right and lower-right vehicles in Figure 8), demonstrating non-random feature learning. Quantitatively, MA-BEV improves overall mAP by 0.70%, with Car AP increasing significantly (+2.17 percentage points). Heatmap distributions confirm velocity-aligned feature activations for moving targets, verifying motion–geometry coupled representation. The 1.86% Cyclist AP decline stems from estimation errors in non-rigid motion fields.
4.3.2. How Does the Improved Loss Function Guide Network Learning?
As shown in Table 2, our enhanced loss function addresses class imbalance through the following aspects:
- Gradient-aware weighting for minority classes (Pedestrian AP +2.60%).
- Task-specific regularization preventing overfitting to dominant categories.
This design mitigates the skewed learning caused by imbalanced labels (Figure 7), enabling balanced feature learning across categories.
4.3.3. Is Two-Phase Training Beneficial?
Compared to single-phase training vulnerable to sparse point clouds and class imbalance, our two-phase approach:
- Learns robust spatiotemporal features through multi-frame fusion (Pedestrian AP +3.16%).
- Stabilizes training via trajectory-based representation for static/slow-moving objects.
However, limitations exist: Limited guidance for fast-moving targets due to trajectory–position mismatch Diminished returns for under-represented classes (Truck AP −1.43%) The 9.3% Pedestrian AP improvement confirms the effectiveness of trajectory-based learning for dynamic targets while highlighting the need for adaptive motion modeling in future work.
4.4. Training Stability Analysis
To validate the reproducibility and robustness of our approach, we conducted multi-seed training experiments across five random initializations ([42, 123, 2048, 2025, 2026]). Figure 9 visualizes the training dynamics, and Table 3 summarizes the performance statistics.
Key observations: (1) Low variance across seeds (std < 0.32%) demonstrates stable training dynamics. (2) Our method converges ∼8 epochs faster (24 vs. 32 epochs), validating that the adaptive multi-task balancing loss (Section 3.3) effectively mitigates optimization conflicts. (3) Consistent Pedestrian AP improvement (+4.16 ± 0.21%) across all seeds confirms that motion-aware encoding provides genuine benefits rather than overfitting to specific initializations. As shown in Figure 9, both training loss and validation mAP curves exhibit smooth convergence without oscillations, further confirming the stability of our gradient-aware balancing mechanism.
5. Conclusions
This study proposes a velocity-aware BEV representation framework with gradient-coordinated learning for 4D radar perception, systematically addressing sparse point cloud detection and moving object tracking in dynamic environments. Through velocity vector decomposition and multi-task gradient-balancing mechanisms, our approach effectively addresses the representational limitations and optimization imbalance of conventional radar perception methods in dynamic scenarios. Experimental validation demonstrates stable moving target detection and trajectory prediction in complex traffic-flow scenarios while achieving real-time performance (12Hz) on embedded platforms through lightweight encoding strategies. Dynamic feature modeling: A speed-sensitive BEV coding architecture is proposed, which significantly improves the motion state estimation accuracy of dynamic obstacles through spatiotemporal feature fusion guided by Doppler information. Optimization stability enhancement: The gradient coordination loss function is designed to alleviate the optimization conflicts among multiple tasks such as target detection, velocity estimation and trajectory prediction, and the model convergence speed is increased by about 40%. Engineering feasibility verification: Achieving 12Hz real-time inference efficiency on an embedded platform provides a scalable radar processing paradigm for all-weather perception of autonomous driving systems. Future research will focus on expanding the heterogeneous feature fusion mechanism of multi-modal sensors (such as liDAR and camera) and exploring methods to enhance the robustness of radar representation under extreme weather conditions.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1Jin B. Cruz L. Gonçalves N. Pseudo RGB-D Face Recognition IEEE Sens. J.202222217802179410.1109/JSEN.2022.3197235 · doi ↗
- 2Jin B. Gonçalves N. Cruz L. Medvedev I. Yu Y. Wang J. Simulated multimodal deep facial diagnosis Expert Syst. Appl.202425212388110.1016/j.eswa.2024.123881 · doi ↗
- 3Jiang Z. Ma Y. Shi B. Lu X. Xing J. Gonçalves N. Jin B. Social NS Transformers: Low-Quality Pedestrian Trajectory Prediction IEEE Trans. Artif. Intell.202455575558810.1109/TAI.2024.3421175 · doi ↗
- 4Jiang Z. Qin C. Yang R. Shi B. Alsaadi F.E. Wang Z. Social Entropy Informer: A Multi-Scale Model-Data Dual-Driven Approach for Pedestrian Trajectory Prediction IEEE Trans. Intell. Transp. Syst.202526164381645310.1109/TITS.2025.3572254 · doi ↗
- 5Jiang Z. Yang R. Ma Y. Qin C. Chen X. Wang Z. Social Informer: Pedestrian Trajectory Prediction by Informer with Adaptive Trajectory Probability Region Optimization IEEE Trans. Cybern.202526152810.1109/TCYB.2025.361349841052188 · doi ↗ · pubmed ↗
- 6Yan Y. Mao Y. Li B. SECOND: Sparsely Embedded Convolutional Detection Sensors 201818333710.3390/s 1810333730301196 PMC 6210968 · doi ↗ · pubmed ↗
- 7Lang A.H. Vora S. Caesar H. Zhou L. Yang J. Beijbom O. Point Pillars: Fast Encoders for Object Detection From Point Clouds Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)Long Beach, CA, USA 15–20 June 2019126891269710.1109/CVPR.2019.01298 · doi ↗
- 8Yin T. Zhou X. Krähenbühl P. Center-based 3D Object Detection and Tracking Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)Nashville, TN, USA 20–25 June 20211178411793