An Interval Belief Rule Base Method with Attention Enhancement for Bearing Fault Diagnosis Under Variable Operating Conditions
Bing Chen, Jingying Li, Hongyu Li

TL;DR
This paper introduces a new method for diagnosing bearing faults in changing operating conditions using an enhanced rule-based model with attention and optimization.
Contribution
The novel IBRB-a model integrates expert knowledge with data-driven adaptation and attention mechanisms for improved fault diagnosis under variable conditions.
Findings
The proposed model effectively reduces interval uncertainty through a two-stage fusion strategy based on Evidential Reasoning.
Experimental results on benchmark datasets confirm the model's effectiveness and generalizability under variable operating conditions.
The use of P-CMA-ES optimization enhances the model's adaptability and performance in complex industrial systems.
Abstract
As bearings are critical mechanical components, their actual operating conditions exhibit notable dynamic complexity. Multiple factors—including rotational speed fluctuations, sudden load changes, and environmental disturbances—interact in a strongly coupled fashion. This imposes severe challenges on traditional fault diagnosis methods, such as limited interpretability, weak adaptive capacity, and elevated misjudgment rates. Therefore, this paper proposes an Interval Belief Rule Base model integrated with an attention mechanism (IBRB-a) under variable operating conditions. The proposed model combines expert knowledge’s ability to quantify uncertainty with a data-driven adaptation mechanism, thereby addressing the challenge of variable operating conditions in complex industrial systems. First, a novel interval rule construction method is incorporated into the traditional IBRB model, and…
Click any figure to enlarge with its caption.
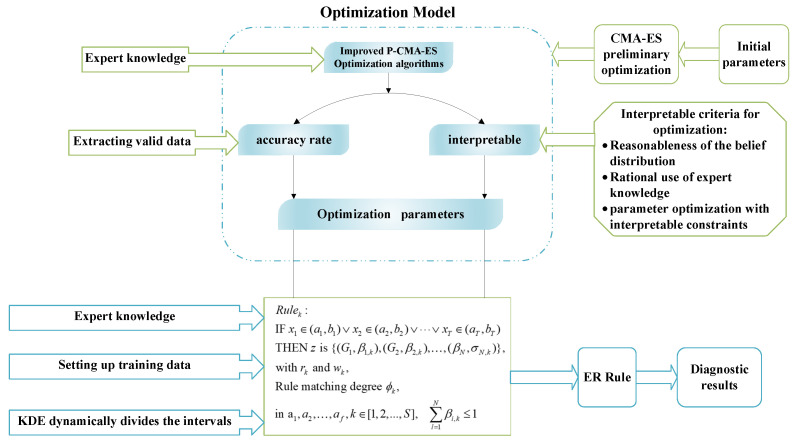 Figure 1
Figure 1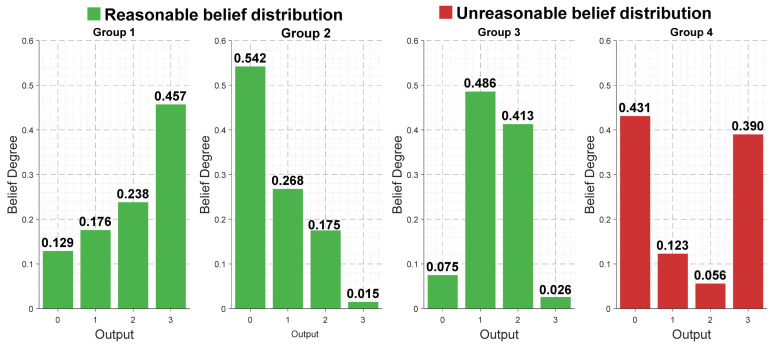 Figure 2
Figure 2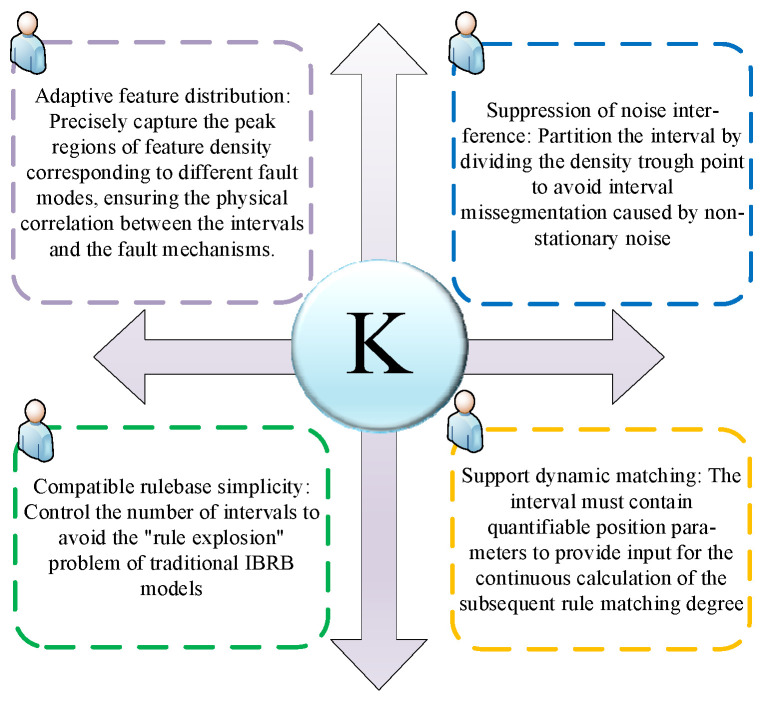 Figure 3
Figure 3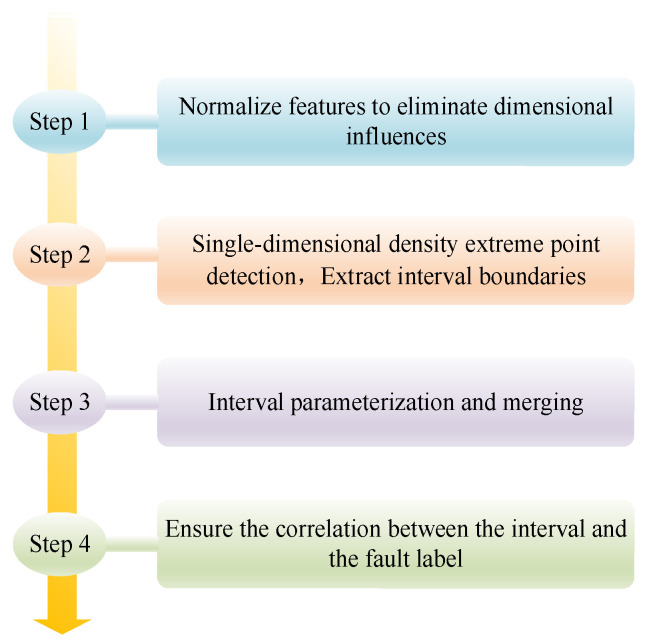 Figure 4
Figure 4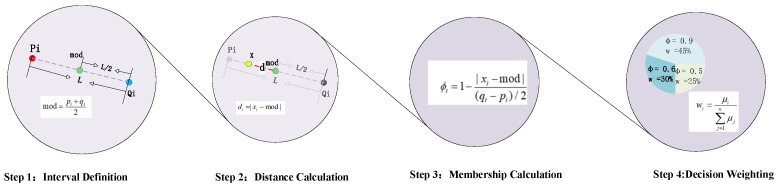 Figure 5
Figure 5 Figure 6
Figure 6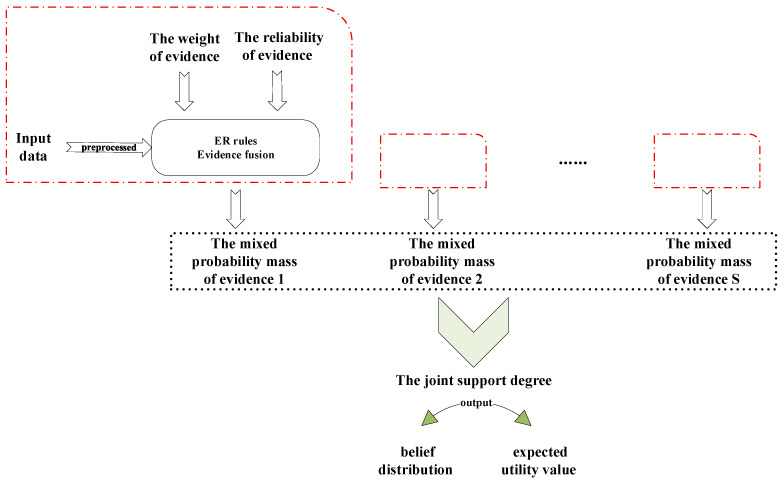 Figure 7
Figure 7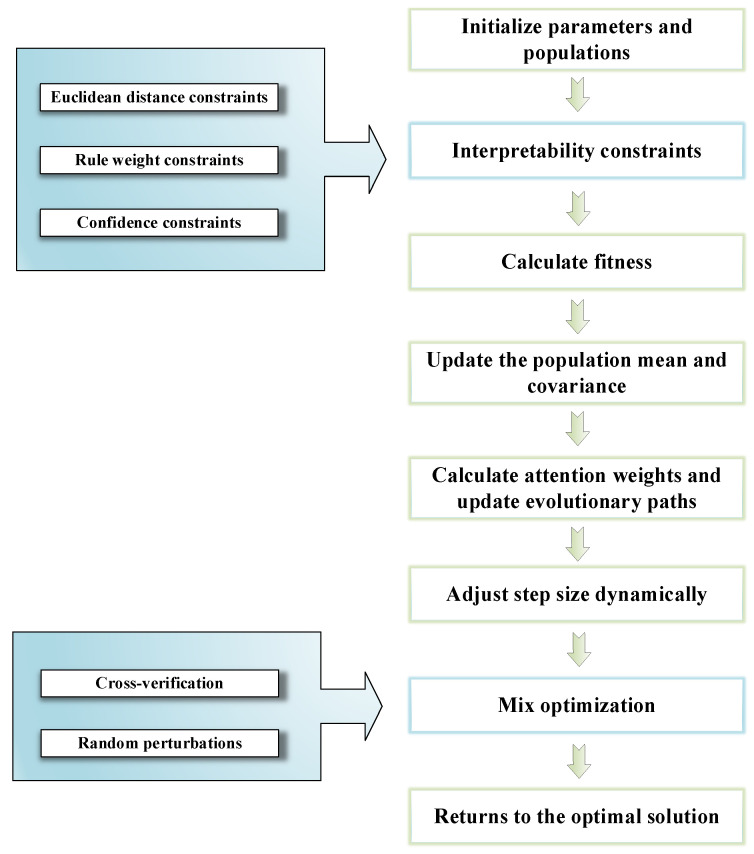 Figure 8
Figure 8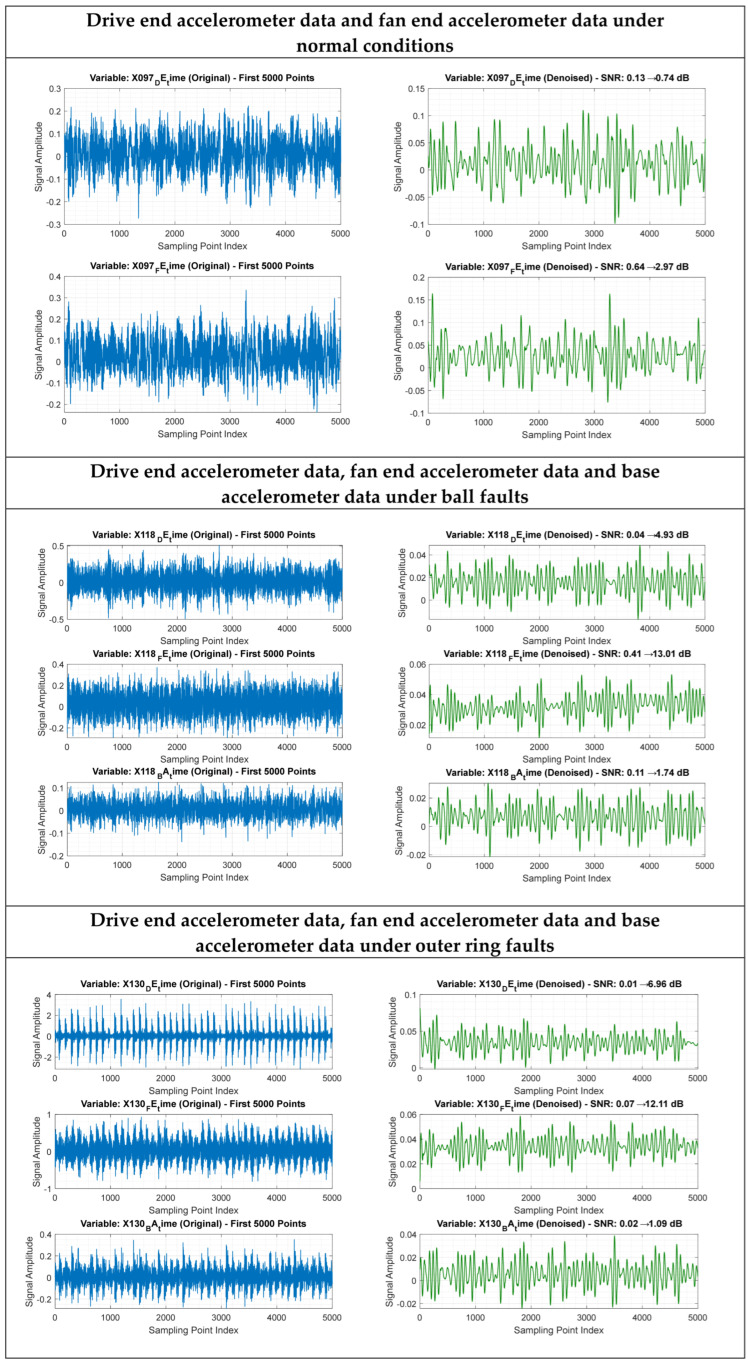 Figure 9
Figure 9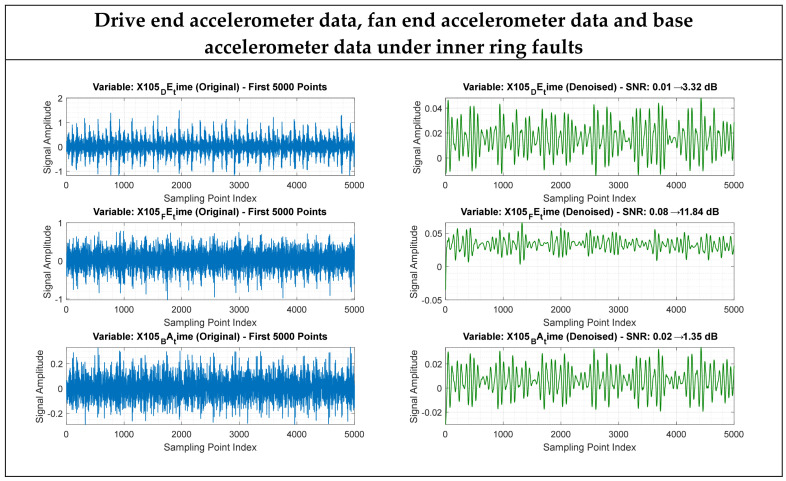 Figure 10
Figure 10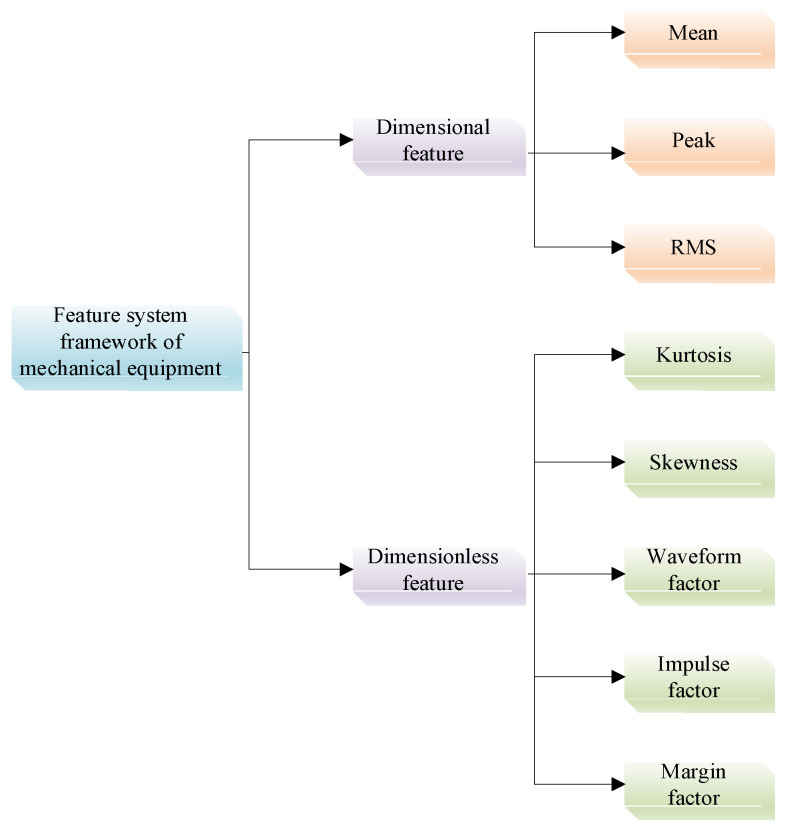 Figure 11
Figure 11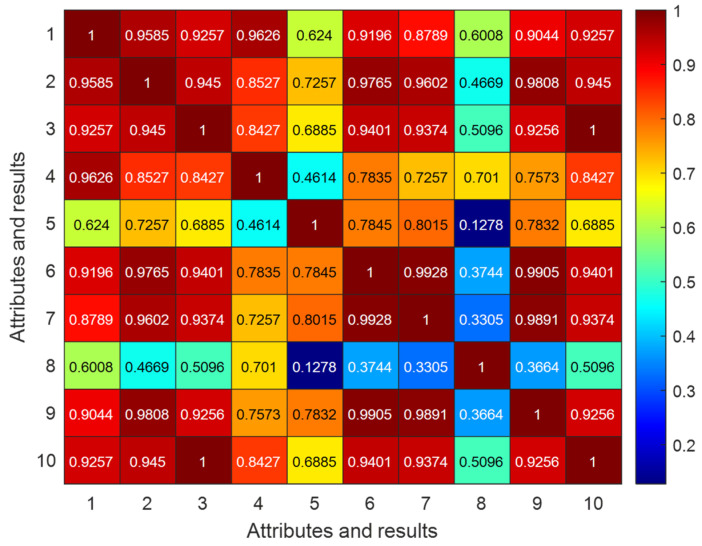 Figure 12
Figure 12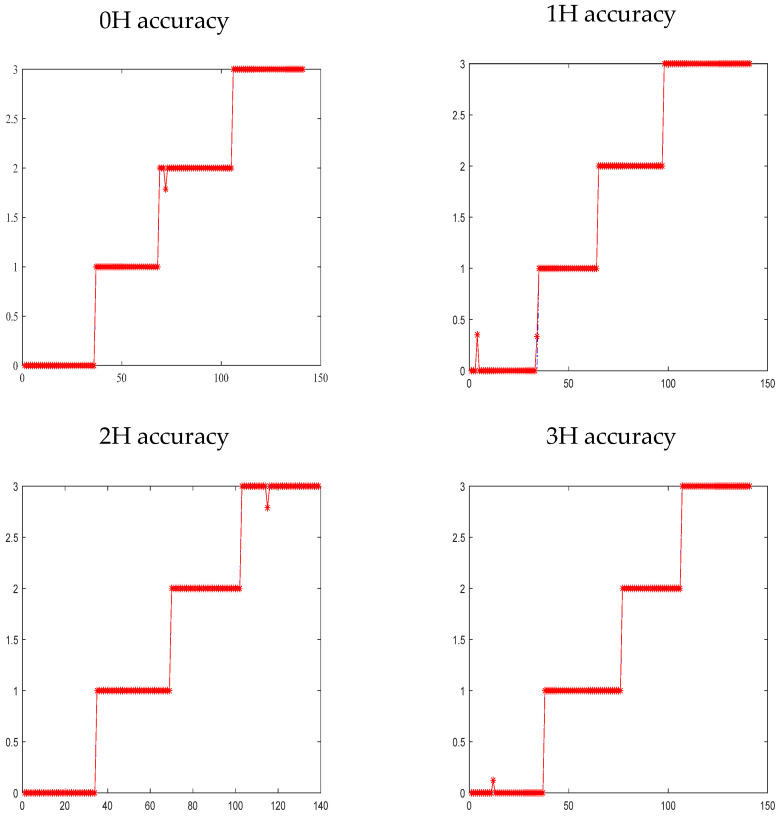 Figure 13
Figure 13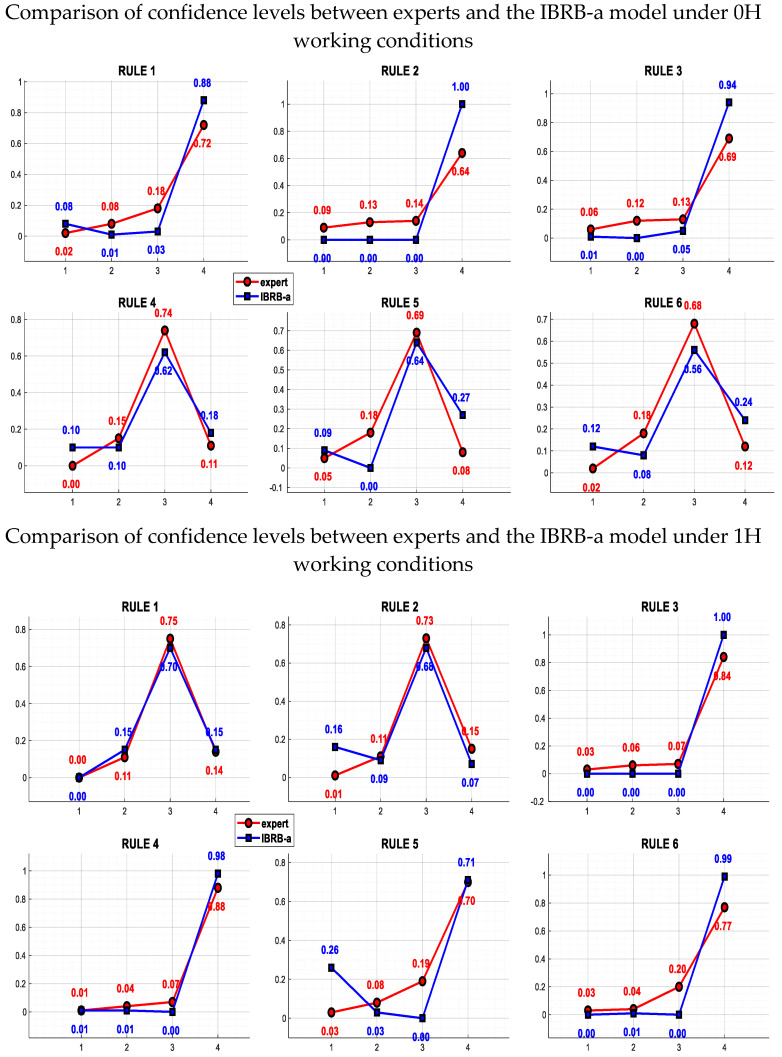 Figure 14
Figure 14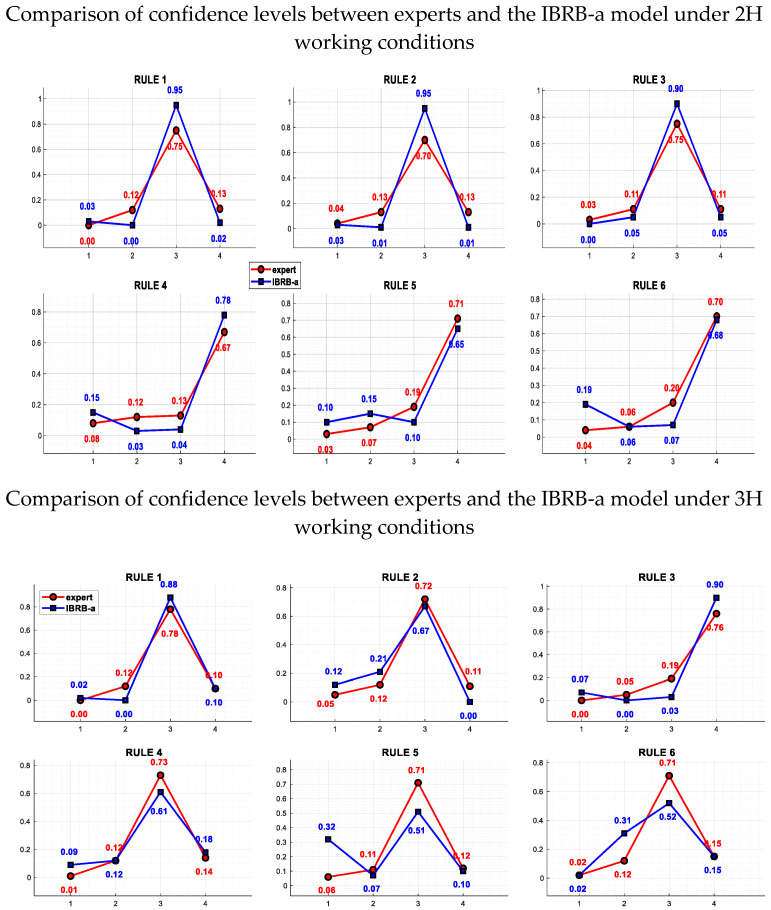 Figure 15
Figure 15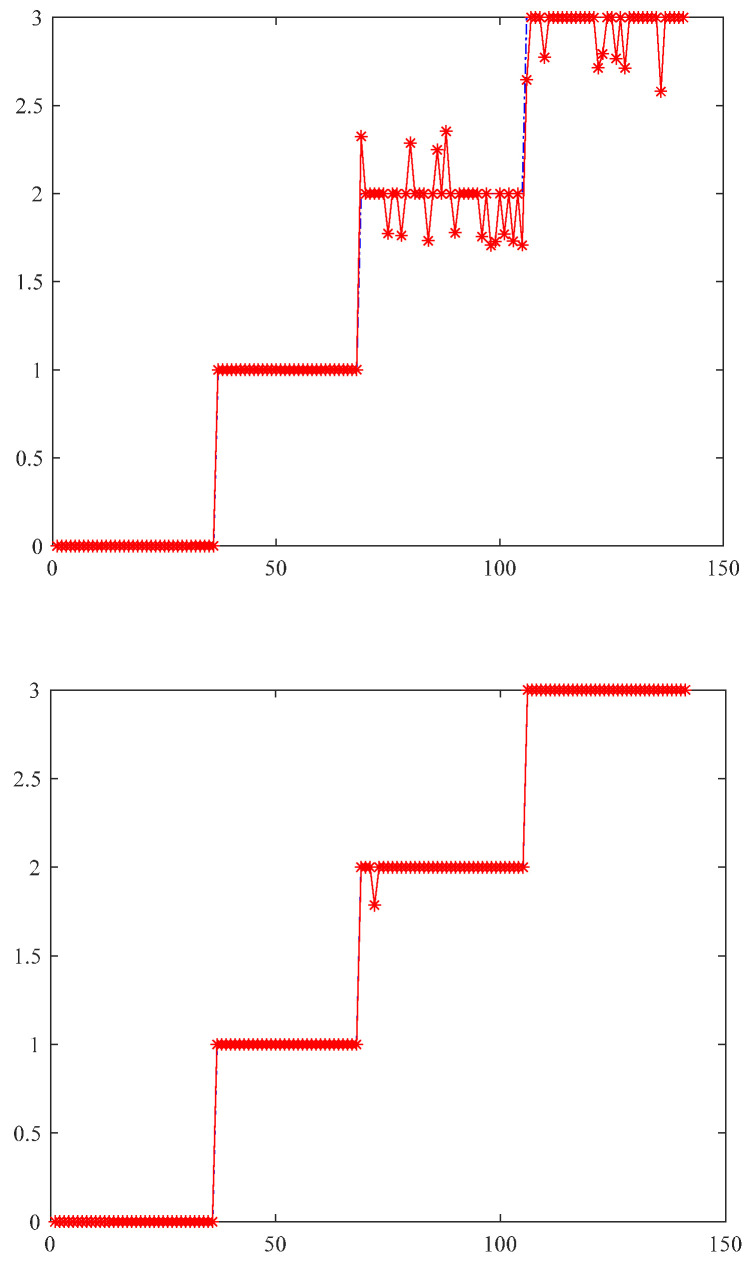 Figure 16
Figure 16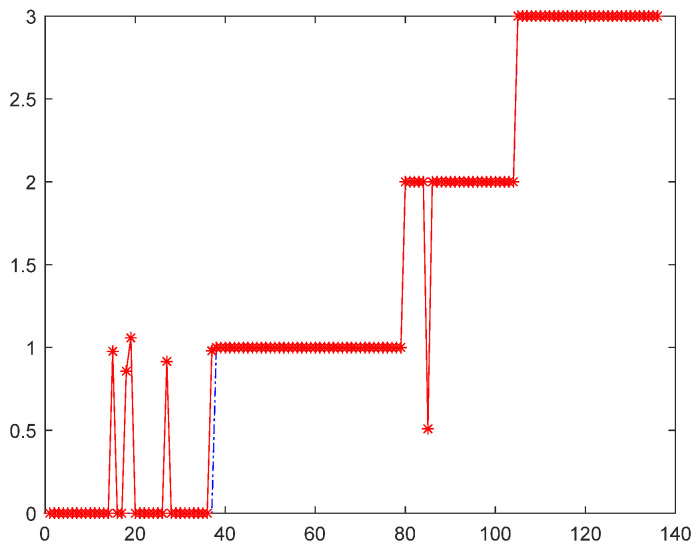 Figure 17
Figure 17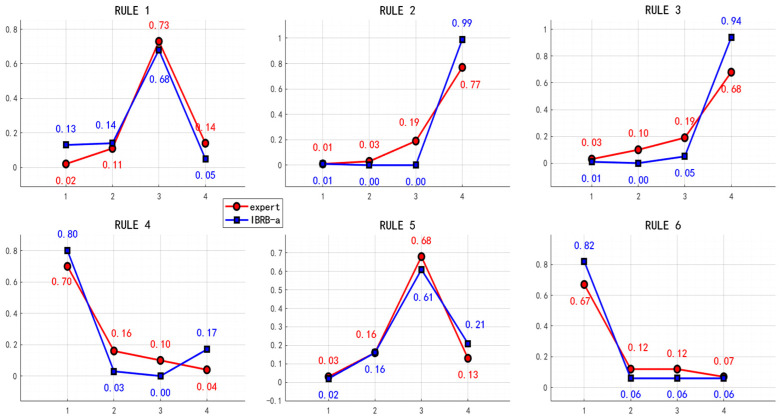 Figure 18
Figure 18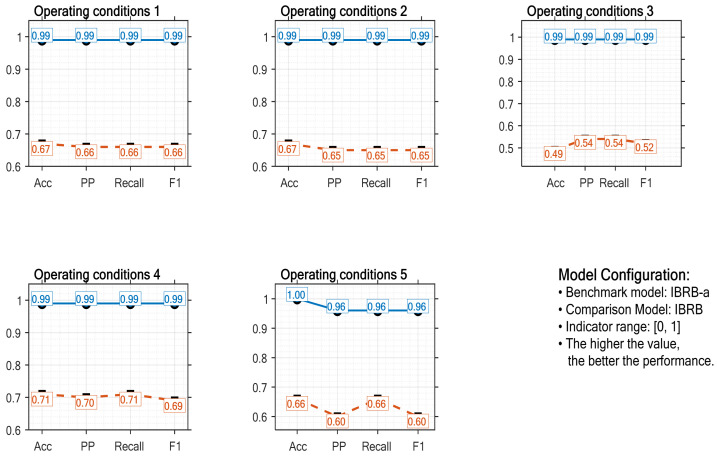 Figure 19
Figure 19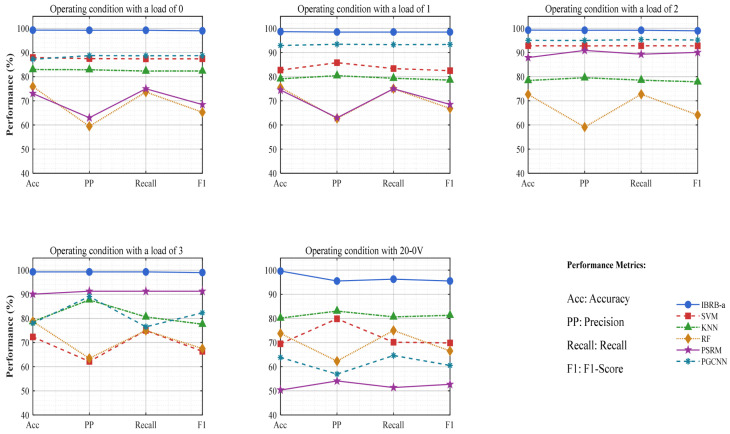 Figure 20
Figure 20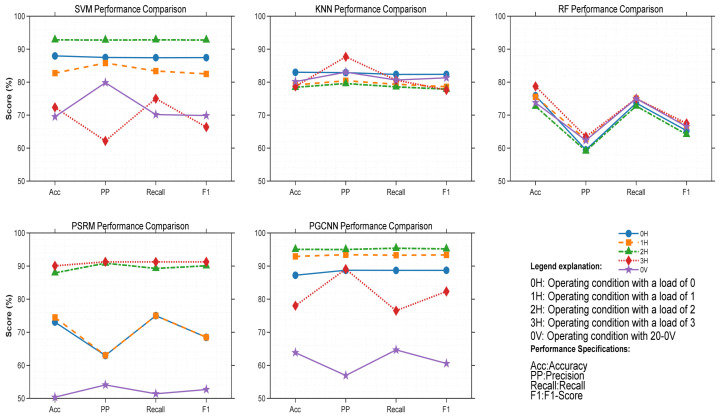 Figure 21
Figure 21- —Open Foundation of Key Laboratory of the Ministry of Education on Application of Artificial Intelligence in Equipment
- —Natural Science Foundation of Heilongjiang Province
- —Basic Research Support Program for Outstanding Young Teachers in Provincial Undergraduate Universities of Heilongjiang Province
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsMachine Fault Diagnosis Techniques · Fault Detection and Control Systems · Risk and Safety Analysis
1. Introduction
Bearing is one of the key rotating components of large-scale mechanical equipment [1,2,3]. Effective bearings fault diagnosis can avoid significant social and economic losses [4,5]. Therefore, the fault diagnosis of rolling bearing is of great significance in avoiding accidents, reducing the maintenance cost of machinery.
Presently, fault diagnosis methods can be classified into three main categories: knowledge-driven methods [6,7,8,9], data-driven methods [10,11,12,13,14,15,16,17], and hybrid-driven methods [18,19,20,21,22]:
(1) Knowledge-driven methods [23]. By leveraging expert experience and domain knowledge, these methods can effectively diagnose faults in systems: they make decisions via rules and reasoning to identify and resolve faults.
(2) Data-driven methods [24,25,26]. By utilizing historical data and real-time sensor data, these methods can effectively identify and predict system faults, while demonstrating notable advantages with regard to adaptability and automation level. However, traditional methods often face the challenge of “catastrophic forgetting” when addressing dynamically emerging fault categories. To this end, lifelong learning paradigms aimed at achieving continuous learning have attracted significant attention. For instance, a generalized lifelong learning framework based on an inverter has been proposed to balance model stability and plasticity [27]. Furthermore, targeting specific diagnostic scenarios such as low-speed bearings, this framework has been further refined and applied, with mechanisms such as dynamic learnable pruning introduced to enhance adaptability to incremental information regarding weak faults [28]. These works provide novel insights for the online updating and upgrading of data-driven models without the need for retraining.
(3) Hybrid-driven models [29,30]. By combining the combination of the advantages of data-driven and knowledge-driven approaches, hybrid-driven models either constrain data learning via physical models or optimize the parameters of knowledge models via data. The combination of these two approaches can enhance the generalizability and engineering applicability of the models.
Under variable operating conditions, bearing fault diagnosis faces significant challenges. While knowledge-based methods can leverage expert experience to address certain complex scenarios, they fundamentally rely on a fixed rule system. When confronted with frequent changes in operating conditions, their original rule base fails to rapidly incorporate fault patterns associated with new operating conditions—this leads to a disconnect between diagnostic rules and actual fault mechanisms, as well as a significant decline in adaptability. In contrast, data-driven methods focus on the laws governing data distribution and establish fault mapping models through large-scale sample training. However, variable operating conditions induce significant shifts in the data distribution, which in turn impairs the models’ generalizability. Furthermore, most data-driven models feature a “black-box” structure, resulting in poor interpretability. In contrast, hybrid-driven methods deeply integrate expert knowledge with data to construct a diagnostic framework more suited to variable operating conditions. On the one hand, they use knowledge-driven methods to decouple relationships from a physical perspective, thereby reducing reliance on large-scale labeled data. On the other hand, they employ data-driven approaches to optimize parameters in real-time, acclimate to operating condition fluctuations, and detect subtle fault features. Through this integration, the framework not only ensures the interpretability of diagnostic logic but also enhances the model’s adaptability, making it a promising approach for addressing the challenges posed by complex operating conditions.
Although the interval belief rule base (IBRB) has achieved some progress, it still has limitations when addressing bearing fault diagnosis in variable operating conditions. From a theoretical perspective, the core challenge of this problem lies in the mismatch between the data distribution and feature patterns. During equipment operation, operating condition parameters change dynamically according to production requirements, which directly alters bearing-related data, resulting in a nonlinear mapping relationship between fault features under different operating conditions. Moreover, random fluctuations in environmental factors introduce substantial non-stationary noise. This further degrades the signal-to-noise ratio (SNR) of the features, leading to feature ambiguity due to multi-source interference and significantly increasing the computational burden of the prediction process. Therefore, the specific problems faced are as follows:
(1) Traditional data-based sampling methods often fail to capture key feature regions accurately—due to their reliance on preset distribution assumptions, which makes it difficult to balance model efficiency and interpretability.
(2) Rules constructed under specific operating conditions fail to cover new operating scenarios, resulting in coverage gaps within the rule base. Furthermore, the “dynamic optimal solution drift” issue encountered during the parameter optimization process hinders the model from converging to a stable optimal solution. Ultimately, this approach fails to meet the requirements for interpretability and adaptability in industrial applications.
To overcome the limitations of traditional IBRB under varying operating conditions, this study introduces an attention mechanism as a core dynamic adjustment component. This design is grounded in a dual rationale. Theoretically, through dynamic re-weighting, attention enables the model to adaptively screen critical features and activate corresponding rules based on the current input. This transforms the fixed knowledge base into an inference system that flexibly adjusts to concept drift, directly addressing the challenge of “dynamic optimal solution drift.” Practically, the attention weights embedded within the interpretable rule structure possess clear physical meanings, rendering the focus of each decision traceable and explainable. Thus, the integration of the attention mechanism is not a mere augmentation but a deliberate design choice aimed at simultaneously enhancing the model’s adaptability to varying conditions and the transparency of the decision-making process, thereby meeting the dual industrial diagnostic requirements of robustness and credibility.
This is essentially different from existing methods: (1) Distinction from existing IBRB variants: Most mainstream studies focus on improving optimization algorithms to pursue static optimal parameters, while the IBRB-a introduces the attention mechanism as a dynamic modulator, enabling the model to adaptively adjust rule confidence based on current input features. This fundamentally alleviates the problem of “dynamic optimal solution drift”, transforming the optimization objective from searching for a fixed point to learning a conditionally optimal parameter space. (2) Distinction from conventional attention hybrid models: In the “deep learning + attention” framework, the attention module is usually a black box. In contrast, the IBRB-a explicitly embeds attention weights into the belief rule structure, with a clear physical meaning—it directly represents the support degree of different features for a specific rule under the current operating condition. Thus, while enhancing adaptive capability, the model strictly maintains interpretability. Therefore, the main contributions of this paper are as follows:
(1) A reference point selection approach based on kernel density estimation (KDE) is proposed. By examining the local density features of the data distribution, this method dynamically refines the sampling strategy and independently identifies key feature regions. This enhances the model’s operational efficiency and effectively safeguards the interpretability of the algorithm.
(2) An enhanced projection covariance matrix adaptation evolution strategy (P-CMA-ES) is utilized to optimize the model by integrating an attention mechanism with a dynamic step-size adjustment mechanism. This algorithm applies attention weights to impose interpretability constraints on the diagnostic decision-making process and accommodates dynamic variations in operating conditions through adaptive step-size adjustment, thereby markedly improving the model’s interpretability and applicability in industrial settings.
The structure of this paper is as follows: Section 2 defines the research problem and presents an overview of the IBRB-a model; Section 3 details the reasoning mechanisms and optimization procedures of the proposed model; Section 4 offers experimental validation results; and Section 5 draws conclusions and explores directions for future research.
2. Problem Description and Introduction to the IBRB-a Method
This section discusses the limitations of the IBRB method for bearing faults diagnosis under variable operating conditions and introduces the construction of the improved IBRB-a model.
2.1. Problem Description
Several issues remain to be addressed when the IBRB is used for fault diagnosis:
Problem 1: Existing data sampling methods have difficulty accurately capturing key fault features under variable operating conditions. This is primarily due to factors: dynamic changes in operating condition parameters induce nonlinear mapping of fault features; environmental factors introduce non-stationary noise, which impairs the reliable identification of key feature regions; and achieving a balance between model efficiency and interpretability is challenging. Therefore, the primary problem for the bearing fault diagnosis system is how to autonomously identify key features stably and efficiently and construct the model reference interval, as follows.
where represents the actual extracted fault feature, which is jointly affected by the nonlinear mapping and non-stationary noise . is the effective region where the key fault features should lie. is the preset high-reliability threshold.
Problem 2: When operating conditions change, the rules established on the basis of specific operating conditions fail to accommodate new fault modes and feature mapping relationships, resulting in the formation of “coverage blind areas”. The main reason is that variable operating conditions cause dynamic distortion of the mapping relationship, which prevents adaptation to match new operating conditions and thus leads to a loss of discriminative ability. This dynamic mismatch problem severely restricts the reliability and generalizability of the rule-based system. Therefore, overcoming dynamic changes and ensuring the effectiveness of the diagnostic system under variable operating conditions constitutes a key problem.
where is the input feature space and is the fault mode output space. denotes the initial operating condition identifier. is the new operating condition identifier. is the effective domain of the initial rule .
Problem 3: During parameter optimization, it is difficult to achieve convergence to a stable optimal solution, and interpretability is insufficient. Traditional optimization algorithms are designed based on the assumption of fixed extreme points in the objective function. Yet, under variable operating conditions, the objective function’s form changes continuously, leading to drift in the optimal solution and preventing stable convergence. Furthermore, the reasoning process fails to demonstrate the correlation between parameters and diagnostic results, resulting in a lack of interpretability. Consequently, the key problem is to ensure stable convergence to valid solutions and guarantee the transparency of optimization decisions under the condition of a continuously changing objective function.
where is the optimization parameter, is the optimal solution of the objective function that varies under variable operating conditions, is the parameter obtained by the algorithm, is the correlation degree between the parameters and diagnostic results, is the acceptable threshold, and is the interpretability threshold.
2.2. IBRB-a Methodology Definition
To address the three aforementioned problems in practical engineering operations, this paper develops a bearing fault diagnosis system founded on IBRB-a. In the novel bearing fault diagnosis system, there are a number of belief rules, and the k-th belief rule is formulated as follows:
where denotes a prerequisite attribute for the bearing failure characteristics to be used as input to the model, is the number of prerequisite attributes, and denotes the total number of rules. is the reference value interval, where , denotes the rule reliability. represents the rule weights. are interpretable constraints on the model. indicates the number of interpretable guidelines. is the rule matching degree factor. The modeling process of the developed bearing fault diagnosis system is shown in Figure 1. It displays the structure of the IBRB-a model and its three primary aspects: modeling, reasoning, and optimization. Therefore, the interpretability should also be balanced from these three aspects.
The description of the interpretability criteria pertaining to the IBRB model in Cao et al. [31]’s paper can be elaborated from three aspects: belief rule base construction, reasoning mechanism, and model optimization, as shown in Table 1. Under variable operating conditions, the bearing fault diagnosis model based on IBRB-a ensures interpretability and reliability in accordance with these criteria. Under such conditions, belief rules can offer explicit semantic descriptions for the input and output of the bearing fault diagnosis, which constitutes the primary expression of the IBRB-a model’s interpretability [32]. By introducing expert knowledge within the model through belief rules, if the optimized belief distribution remains generally consistent with the initial expert settings, the model’s reasoning logic can be considered consistent with domain common sense [33].
However, models often improve accuracy at the cost of reduced interpretability, which may lead to unrealistic confidence distributions in the final prediction results. For example, in bearing fault diagnosis, there are four health conditions: normal. A sample output prediction might be: {(Normal, 0.431), (Ball fault, 0.123), (Inner ring fault, 0.056), (Outer ring fault, 0.390)}. This indicates that the system assigns a confidence level of 0.431 to “Normal” and 0.390 to “Outer ring fault”. Such a belief distribution appears contradictory, as a logically consistent outcome should not simultaneously assign high confidence to conflicting conclusions. Therefore, an interpretable belief distribution ought to demonstrate convex or monotonic properties instead of a concave shape, as depicted in Figure 2.
3. Reasoning and Optimization of IBRB-a
The IBRB-a model establishes a variable operating condition bearing fault diagnosis framework with the core logic of “feature processing-rule matching-reasoning fusion-parameter optimization”. First, feature selection and KDE-based dynamic division are performed to determine the reference intervals, thereby establishing the foundation for features processing. Then, expert knowledge-based constraints are integrated, the interval belief rule base is initialized, the degree of agreement between samples and intervals is quantified through dynamic rule matching, and initial diagnostic results are produced in combination with the ER strategy. Finally, the improved P-CMA-ES with interpretability constraints is used to optimize the model parameters. Section 3.1, Section 3.2 and Section 3.3 detail the reference interval selection and matching, the model reasoning process, and the parameter optimization method, respectively.
To provide a clear and concise overview of the entire IBRB-a workflow, Algorithms A1 and A2 presents pseudocode for the key steps of feature processing, rule matching, reasoning fusion, and parameter optimization. This algorithmic representation complements the detailed theoretical explanations in Section 3.1, Section 3.2 and Section 3.3.
3.1. Dynamic Interval Division
Under variable operating conditions, the fault characteristics of bearings exhibit coupled features of nonlinear mapping and non-stationary noise. Traditional fixed interval division methods rely on preset distribution assumptions, which easily lead to under-segmentation of key fault characteristic regions or over-segmentation of redundant regions, making it difficult to balance model efficiency and interpretability. To address this issue, this section combines the multi-dimensional goals for dynamic interval division illustrated in Figure 3 (The symbol k shown in the figure is defined as “key”) and proposes a dynamic reference interval division method based on KDE. By analyzing the local density distribution of feature data, the method autonomously identifies interval boundaries, thereby providing a reliable foundation for calculating rule matching degrees.
On the basis of the filtered n-dimensional fault feature space, KDE is independently performed for each feature dimension, and its mathematical formulation is expressed as:
where is the probability density estimation function of the s-th input feature, which is used to describe the sample distribution density of this feature under different values; represents the total number of samples; is the bandwidth of the s-th feature; is the kernel function; and is the value of the k-th sample on the s-th feature, which is directly obtained from the feature extraction results of preprocessed vibration signals of bearings. Combined with the characteristics of bearing fault features, the dynamic interval is partitioned into four key steps as presented in Figure 4.
A Gaussian kernel function is adopted in this study, with its mathematical expression given by:
The Gaussian kernel is characterized by an infinite support set and is infinitely differentiable and smooth, enabling it to generate smooth density estimation curves. Compared to alternative kernels such as the Epanechnikov, triangular, and cosine kernels, the Gaussian kernel provides the optimal balance between capturing fine-grained features of the data distribution and maintaining estimation stability. The bandwidth is the most critical parameter in KDE, directly influencing the smoothness of the density estimate. This study employs Silverman’s adaptive rule as the baseline bandwidth:
where denotes the sample standard deviation. This rule is considered optimal when the data approximates a normal distribution. Considering that actual bearing fault features may exhibit multimodal distributions, an adaptive adjustment factor is introduced. The final bandwidth is determined by maximizing the log-likelihood function of leave-one-out cross-validation:
This strategy ensures adaptive smoothing for different feature distributions, avoiding the extremes of losing feature details or introducing excessive noise. The backend attention mechanism and rule optimization process of the IBRB-a model exhibit a degree of fault tolerance to minor variations in KDE parameters. Even if slight deviations exist in the interval division, the model can compensate through adaptive inference, which structurally guarantees the overall robustness of the method.
This dynamic interval is generated under the drive of KDE, which is consistent with fault mechanisms, adaptive to working condition fluctuations, and free from preset fixed ranges. Based on this, the IBRB-a model obtains adaptive reference intervals, and further establishes a dynamic rule matching degree calculation model to achieve accurate matching between samples and rules.
In actual industrial production, the operating conditions of bearings are subject to constant fluctuations. Data such as vibration signal frequency and noise characteristics, which serve as the core basis for bearing fault diagnosis, undergo significant changes, resulting in different manifestations of the same bearing fault under varying operating conditions. However, in the intervals of the traditional IBRB model, when a sample falls within an interval, the interval rules are activated indiscriminately, leading to low sensitivity to faults under different operating conditions. Therefore, this paper proposes a calculation method transitioning from undifferentiated activation to dynamic judgment of activation matching. Let the input sample values of each attribute be denoted as . After interval membership judgment, if the sample falls into the target reference interval, the preset rules within this interval are activated. Meanwhile, the rule matching degree of the sample data is dynamically calculated to quantify the degree of rule activation and the matching level between the sample rules and the interval rules. The corresponding calculation formula is expressed as follows:
where represents the matching degree of the sample data of the i-th attribute falling into a certain interval matched by the rule, represents the center of the reference interval, represents the interval boundary, and represents sample data that falling into this reference interval. This formula takes the midpoint of the interval as the reference benchmark. Through the difference operation and normalization process between the sample coordinates and the midpoint coordinates, it converts the position information of the sample within the interval into a matching degree index in the interval [0, 1]. The calculation result directly reflects the effectiveness of rule activation and the degree of consistency between rules. The central idea of this formula is that the closer the distance between the sample and the center of the reference interval is, the higher the matching degree, which indicates a better degree of agreement between the rule and the current operating condition. When the sample point is infinitely close to the center of the interval, the matching degree approaches the maximum value, and the rule then occupies a dominant position in the decision-making process; conversely, as the distance increases, the matching degree decreases monotonically, and the rule’s influence on the decision-making process gradually diminishes. The calculation process is mainly divided into four steps, as shown in Figure 5.
By calculating the rule matching coefficient within the interval, a method for calculating the weights of activated rules within the interval is designed. When the input sample is located within a specific interval, the method for determining the weights of the activated rules is given by Equation (10):
where denotes the activation weight of the i-th activated interval rule; denotes the rule weight; and denotes the minimum activation weight. The primary idea embodied in this formula is that the lower the interval rule matching degree is, the smaller the rule activation weight. is determined on the basis of expert knowledge and can be any constant within the interval [0, 1].
After the above two-step calculation, the interval rule achieves the following effect: When different data sample values fall within the same interval, the rule matching degrees differ, thereby resulting in different performances for different inputs. Therefore, when dividing intervals, the points with the densest distribution should be placed in the middle of the intervals; this allows the highest degree of rule matching to be obtained.
3.2. Inference Process of the Model
In complex industrial scenarios, the extensiveness of data and the diversity of expert knowledge are intertwined. To process various types of uncertain information efficiently, the ER inference rules are introduced into the IBRB-a model. The ER rules construct a framework that comprehensively considers the reliability of evidence that effectively describes, transforms, and integrates multisource information in an uncertain environment and ultimately reaches a consistent conclusion. This characteristic enables the IBRB-a model to perform accurate and efficient information processing in complex and dynamic scenarios, provides solid support for the decision-making process, and renders the decision-making basis output by the model more persuasive.
While ensuring model reliability and accuracy, the ER rules also prevent the model from falling into a “black-box” or “gray-box” system. During the inference process, as presented in Figure 6, the IBRB-a model achieves a rational transformation of the input and output information (Criterion 6). It not only preserves the informational characteristics of the original samples but also produces inference results that align more closely with real-world scenarios (Criterion 7). This reflects the model’s effective balance between interpretability and performance.
To comprehensively handle the uncertainties arising from multiple rules and diverse information sources, the proposed model employs a two-stage Evidential Reasoning (ER) fusion strategy. The fundamental principle of this strategy is hierarchical information aggregation, which emulates the human expert reasoning process of progressively narrowing down the diagnostic scope to reach a definitive conclusion:
Stage 1: Intra-rule fusion. For a single belief rule, the antecedent attributes may be matched to varying degrees. The objective of this stage is to aggregate these matching degrees across different attributes within the same rule to compute the joint belief degree of the rule being activated as a whole, along with its associated uncertainty.
Stage 2: Inter-rule fusion. After obtaining the joint belief degrees of all activated rules, the objective of this stage is to fuse the potentially conflicting diagnostic conclusions indicated by these different rules, outputting the final belief distribution and the corresponding expected utility value.
This two-stage design ensures the structural clarity of the inference process and the computational tractability. The procedure is visually illustrated in Figure 7 (The content contained in the dashed boxes of the figure is completely identical, and therefore not duplicated for representation). The detailed reasoning steps are elaborated as follows [32].
Step 1: Convert the bearing fault feature data into a belief distribution. The -th piece of evidence can be formulated as the subsequent belief distribution.
where denotes the frame of discernment; denotes the evaluation grades for bearing fault diagnosis results; denotes the number of evaluation grades; denotes the confidence level of the result; and denotes that the -th attribute in the frame of discernment is globally unknown.
Step 2: Combine the evidence weight and reliability , convert the belief degree into the basic probability mass, and consider normalization, where and .
where is the normalization factor and satisfies condition , where stands for the probability mass of the k-th piece of evidence at the specific evaluation grade .
Step 3: Through iterative aggregation, gradually merge the probability masses of different pieces of evidence, calculate the joint probability, perform normalization, and generate the joint belief degree. The joint support degree for independent pieces of evidence can be calculated as follows:
where ; denotes the joint support degree of independent pieces of evidence; and denotes the joint probability mass of pieces of evidence and satisfies two conditions: and . The confidence degree distribution of the relative results conforms to Equation (11).
Step 4: Calculate the weighted sum of the joint belief degree and the utility value in order to get the final diagnosis result. The calculation formula is shown below:
where is the final utility value, and is the utility score of .
3.3. Model Optimization
In the current study, the P-CMA-ES optimization algorithm, with its distinctive features, serves as an effective method for optimizing the IBRB prediction model [34]. Its key advantages include: (1) Efficient global search capability, which prevents the algorithm from falling into local optima; (2) simplification of the rule base, which reduces computational costs and avoids the “curse of dimensionality”; and (3) improved reliability through multi-objective balancing that enhances key features. Therefore, the P-CMA-ES is employed in this paper to optimize the IBRB-a model. However, it should be emphasized that increases in model accuracy come at the price of decreased interpretability [35]. To balance accuracy and interpretability, several interpretability constraints [36] are incorporated into the P-CMA-ES framework. The constraints of optimization parameters can be listed as [37].
Within the IBRB-a model, the difference between predicted and actual values is assessed using mean squared error (MSE). The formulation of the objective optimization function is given below [38]:
where is the total number of training sample data, is the model’s output value, and is the system’s label value. The optimization process of the improved P-CMA-ES is illustrated in Figure 8. The specific operation steps are as follows:
Step 1: Parameter input. In the IBRB-a model, the parameters to be optimized include confidence, rule reliability, and rule weight. The parameter set can be expressed as
where represents the initial parameter set.
Step 2: To enhance the diversity of the initial population and prevent the algorithm from falling into local optima, Gaussian random perturbations are introduced based on the initial point to generate individuals of the initial population:
where is the -th individual in the generation, is the disturbance coefficient, which governs the amplitude of the disturbance, is a random vector following the standard normal distribution, denotes the number of additional individuals in the initial population. The original initial points and perturbed points are merged to calculate the mean value of the initial population.
This mean value is employed as the initial search center of the P-CMA-ES algorithm.
Step 3: Add interpretability constraints.
(1) Euclidean distance constraint: Expert knowledge is among the core elements of interpretability, and the optimization process of local search needs to be anchored in expert judgment. To this end, expert knowledge can be integrated into the initial population, and further local optimization can be carried out with the help of the Euclidean distance [39]:
where denotes the population of the generation and EXP represents expert knowledge. To ensure that the optimized parameters maintain a reasonable distance from the initial values, a Euclidean distance constraint is imposed on the parameters, and its expression is as follows [32]:
where is the mean value of the current population; is the newly generated individual; and d is the maximum allowable distance set by experts. Through the distance threshold set by experts, the search range of the optimization algorithm can be effectively controlled, the risk of parameter solutions deviating from expert cognition can be reduced, and thus, the random oscillation phenomenon in the optimization process can be suppressed.
(2) Rule parameter constraint: For the inactive rule in the rule set, its parameter vector must satisfy:
where denotes the k-th candidate solution vector; represents the initial population vector; represents the index set of inactive rules; and denotes the index range of the parameters corresponding to the k-th rule in the vector.
(3) Attribute weight constraint: To ensure that the attribute weights are not lower than the minimum values set by experts, the following constraint is imposed.
where denotes the weight of the k-th attribute and where is the minimum threshold of the attribute weights.
(4) Confidence constraint: The confidence constraint is reflected in two main aspects. First, it is the constraint on the variation range of confidence: the variation range of the optimized confidence should not exceed the threshold, which satisfies the following formula [36].
where denotes the confidence value during the optimization process; represents the initial confidence value; and denotes the maximum threshold for confidence variation. Second, the normal-like distribution shape constraint: To ensure that the confidence variation conforms to a reasonable probability distribution pattern, the confidence vector of each evaluation grade must satisfy one of the following four monotonic patterns [40].
Monotonic increase: .
First increase then decrease: .
Unimodal distribution: .
Monotonic decrease: .
This constraint ensures that the confidence distribution conforms to the normal-like characteristics common in decision logic. If the optimization result does not satisfy the above patterns, the confidence should be adjusted to meet the constraint.
Step 4: Projection Constraint. The projection operator is used to ensure that the solution vector satisfies the following formula:
where is the equality constraint matrix; is the right-hand side vector of the equality constraint; and is the solution vector, which includes confidence, rule weights, and attribute weights. The projection algorithm’s specific steps are outlined below:
(1) Orthogonal projection onto a hyperplane: For each set of constraints , calculate the vertical distance between the current solution and the canonical hyperplane and project it onto the constraint plane along the normal vector direction, as in Equation (26):
where is the target value of the i-th constraint.
(2) Nonpositive repair: Set the nonpositive components to zero and uniformly compensate for the total sum of the nonpositive values to the positive components. This operation ensures while maintaining the constraint conditions of , and its expression is as follows:
where is the number of nonzero components in and where is the sum of deviations caused by the correction of negative components.
(3) Loop processing: Repeat the above process for each confidence distribution constraint until all the constraints satisfy the linear constraints and nonnegativity constraints.
Step 5: Optimal Solution Selection and Mean Update. Among the offspring generated in each generation, the top optimal individuals are selected through fitness ranking for weighted recombination, and the population mean is updated as follows:
where is the i-th optimal individual in the fitness ranking of the g-th generation. is the exponential decay weight; is the number of preferred individuals; is the number of offspring. In addition, attention weights are introduced to enhance the contribution of important individuals. The attention formula is as follow:
where is the fitness function; the negative exponential transformation ensures that individuals with higher fitness values obtain greater weights.
Step 6: The P-CMA-ES guides the search direction by adaptively updating the covariance matrix , and its update mechanism combines evolutionary path accumulation, multiparent information integration, and constraint handling techniques. The update formula as in Equation (30):
where is the covariance matrix, which determines the shape and direction of the search distribution; is the rank-one update learning rate; is the rank update learning rate; is the evolutionary path of the covariance matrix; is the heuristic indicator, which takes a value of 0 or 1; is the accumulation coefficient of the evolutionary path; is the attention weight of the i-th parent; is the standardized mutation vector [41], and satisfies Equation (31).
where is the “candidate solution” explored by the algorithm in the search space; is the mean vector of the population in the g-th generation; and is the step size of the g-th generation.
4. Experimental Validation
In this section, experiments are performed under variable load conditions using Case Western Reserve University (CWRU) and Southeast University (SEU) datasets, aiming to evaluate the accuracy, interpretability, and generalization of the proposed IBRB-a fault diagnosis model.
4.1. Evaluation Indicators
Under variable operating conditions of bearings, various parameters and external factors are subject to random variations. Accuracy is associated with the safety of equipment operation and production efficiency; interpretability enables technicians to verify and adopt the model’s diagnostic recommendations; and strong generalization capability enables the transfer of learned knowledge to new operating conditions and unseen fault types—this ultimately determines the model’s practical utility in real industrial environments.
To validate the model’s effectiveness in bearing fault diagnosis, we select four evaluation metrics for testing. The first metric is the overall accuracy (ACC) [42], can be described as follows:
where is the number of true positives for category ; denotes the count of true positives for category ; is the number of false positives for category ; and denotes the count of true negatives for category . The second evaluation indicator is the positive predictive value (PP) [43]:
is calculated separately for categories. where the PP_a_ for all categories are averaged to obtain the following:
The third indicator is the true positive rate (Recall) [44,45]:
is calculated separately for categories. where the recalls for all categories are averaged to obtain the values:
The fourth metric is the F1 score, which stands for the harmonic mean of accuracy and recall, and it is calculated via the following formula:
is calculated separately for categories. where the F1_a_ for all categories are averaged to obtain the values:
The F1 score spans from 0 to 1, with a value closer to 1 signifying superior fault diagnosis performance in terms of balancing precision and recall.
4.2. Data Introduction
4.2.1. CWRU Datasets
The dataset used for experimental validation incorporated four conditions: normal, ball faults, inner ring faults, and outer ring faults. The condition labels presented in Table 2. Vibration signals were collected with a sampling frequency of 12 kHz under different motor load conditions—0, 1, 2, and 3H—to capture behavioral characteristics under varying operational states.
In this experiment, a bearing with a radius of 0.007 mm was used as an example, and the data were divided into four groups for verification under the same rotational speed (1200 r·min^−1^) while different loads [46]. Detailed grouping information is presented in Table 3. Under 0H load, the first 121,265 data points were extracted from each fault type’s vibration signals and then separated into 118 sample groups. Each experiment included 472 samples (118 data points × 4 fault types). Of all samples, 70% were selected at random for model training, and the remaining 30% served for testing. Similarly, data extracted from the other three load groups also correspond to a four-class classification task.
4.2.2. SEU Bearing Data
In addition to the CWRU bearing dataset, SEU were also used for verification. This dataset was collected under the operating conditions of a rotational speed system load set to 20 Hz–0 V, encompassing 3 types of single-bearing fault states, 1 type of mixed fault state, and 1 type of healthy state. For the purpose of this paper, only data corresponding to 3 types of single faults and the healthy state were selected to verify the reliability and generalizability of the IBRB-a model. The grouping information is detailed in Table 4, and the label values of the fault states are presented in Table 2.
4.3. Data Preprocessing
Both datasets consist of bearing vibration signals actually collected from industrial test benches and are susceptible to interference from sensor noise, environmental vibration noise, and other sources. Such interference may obscure the fault characteristics of bearings, compromise the accuracy of feature extraction, and degrade the performance of subsequent diagnostic models. Thus, data preprocessing involving denoising and dimensionality reduction serves as a critical prerequisite for improving data quality and ensuring the reliability of diagnosis.
Wavelet threshold denoising is employed in the experiment to eliminate high-frequency noise from raw vibration signals, which exhibits superior performance in processing non-stationary signals such as bearing vibrations. Specifically, 5-level decomposition based on the db4 wavelet basis is adopted, combined with soft thresholding denoising using the square root logarithm (sqtwolog) adaptive threshold; after signal reconstruction, the length is calibrated to ensure consistency. Subsequently, time-frequency domain features are extracted, and dimensionality reduction is implemented via Principal Component Analysis (PCA) to simplify the model and enhance its generalization ability. As shown in Figure 9, the signal-to-noise ratio (SNR) of the denoised signal is significantly improved with clearer fault characteristics; after dimensionality reduction, the feature dimension is greatly reduced while the discriminative ability is retained. This preprocessing approach effectively improves data quality and lays a solid foundation for accurate fault diagnosis.
After noise reduction, a time-domain feature extraction method similar to that proposed in Reference [47] was adopted. After performing time-domain analysis on the bearing vibration signals, the resulting feature framework is illustrated in Figure 10. In-depth examination of these time-domain feature parameters enables accurate identification of fault types under different operating conditions, thereby contributing to the diagnostic method’s reliability and accuracy.
To reduce the interference of high-dimensional feature redundancy on model performance while retaining key information strongly correlated with fault modes, it is necessary to screen the original feature set. This set consists of eight time-domain feature parameters, as shown in Figure 10. The Pearson correlation coefficient was employed to analyze the correlation among all features. The visualization results under the 0H condition are presented in Figure 11, and the correlation coefficients between each feature and the fault label are detailed in Table 5. The four features with the highest absolute correlation coefficient values—peak, RMS, waveform factor and impulse factor—were selected as input variables. This approach reduces the input dimensionality of the model while ensuring the effective retention of core fault-related information.
4.4. CWRU Dataset Validation
4.4.1. Model Prediction and Validation
This section elaborates only on bearing fault diagnosis under the 0-load condition in detail, and the processing procedures for other loads are analogous. The k-th rule of the bearing fault diagnosis model based on IBRB-a as in Equation (39).
where represents four evaluation grades.
The model’s initial parameters are presented in Table 6. Among these, the constrains for rule reliability and rule weight were determined by domain experts on the basis of prior knowledge. First, the model parameters were initially optimized via the standard covariance matrix adaptation evolution strategy (CMA-ES) algorithm, and the optimized parameter configuration is shown in Table 7. The initially optimized parameters were subsequently input into the improved P-CMA-ES for further optimization. The final parameter values of the model are shown in Table 8. The initial parameter setting strategy of this optimization algorithm and the corresponding parameter values are provided in Table 9.
(1) Parameter setting: The constrained P-CMA-ES was employed to optimize the model. The optimization ranges of the rule weights and rule reliability were constrained to the interval [0.5, 1]. Moreover, the belief degrees corresponding to the consequence part of each rule were also constrained to vary within a specified range around their initial values. The optimized parameters are summarized in Table 6. All optimized values remain within the bounds defined by expert knowledge, ensuring that the resulting parameters of the IBRB-a model are both reasonable and suitable for practical application.
(2) Curve Fitting Results of the Model’s Predicted Diagnostic Outcomes and Actual Values: Under the four operating conditions, the fitting results between the model’s predicted values and actual values are shown in Figure 12, where the horizontal axis represents the sample number and the vertical axis denotes the classification number. This effect is attributed to the dynamic rule matching degree and the novel rule weight calculation method adopted by the model—these two elements endow the model with stronger adaptability, enabling it to smoothly cope with data fluctuations and nonlinear trends. As shown in the first subplot of Figure 12, the predicted values of the IBRB-a model exhibit an extremely high degree of fit with the actual labels. The accuracy reaches 99.29% under the 0-load condition. Table 8 clearly presents the IBRB-a fault diagnosis results under the 0H operating condition, which demonstrates high fault identification accuracy.
(3) Model interpretability: As shown in the first subplot of Figure 13, under the effect of the P-CMA-ES with expert constraints, the IBRB-a model retains parameter interpretability. This enables the belief distribution of its output results to be highly consistent with the initial expert-defined belief distribution. The study also reveals that even when complex algorithmic optimization is employed to increase model accuracy, the IBRB-a model continues to accurately reflect expert knowledge and judgments. This not only ensures the interpretability of the diagnostic results but also guarantees the transparency of the process and the reliability of the outcomes.
4.4.2. Results
The results of experimental show that the predicted values of the IBRB-a model show strong consistency with the actual labels in terms of fitting performance. The prediction accuracy is summarized in Figure 12. Under the four distinct load conditions, the model’s accuracy rates of 99.29%, 98.67%, 99.29%, and 99.29%. The overall variation in accuracy remains within a narrow range of 0.62%, indicating high stability under dynamic load changes. These results outperform those reported in comparable studies under similar variable operating conditions.
Analyze the IBRB-a model’s fault diagnosis results across the 0H, 1H, 2H, and 3H operating conditions. Table 10, Table 11, Table 12 and Table 13 show that the model maintains high fault identification accuracy across all operating conditions. Among these results, the positive predictive values (PPs) for most fault categories (e.g., G1, G2, and G4) under different operating conditions are close to or equal to 99%, while recall values remain consistently above 94%. These results systematically demonstrate the model’s ability to stably identify fault modes under different load conditions, providing a robust experimental foundation for its application in complex operational environments.
Further analysis of the dynamic behavior of performance indicators reveals that the influence of operational disturbances on diagnostic performance varies significantly across fault categories. Specifically, the G2 fault category demonstrates greater sensitivity to changes in operating conditions: its recall is 0.97 under the 0H condition, declines slightly to 0.94 under 1H operating condition, and recovers to 1.0 under 2H condition. Moreover, the positive predictive value (PP) of G2 decreases briefly to 0.94 under 1H operating condition but remains stable at 1.0 under all other conditions. These fluctuations reflect the complex coupling relationship between fault characteristics and operating parameters. The data indicate that the G2 fault mode is more susceptible to load variations. It is inferred that this behavior may be linked to nonlinear distortions in the vibration spectrum characteristics of this fault type within certain load ranges. These observations provide a basis for subsequent model refinement targeting specific fault modes.
Regarding interpretability, the IBRB-a model is underpinned by an optimization algorithm constrained by expert knowledge and an attention mechanism based on structured embedding. First, as elaborated in Section 3.3, the expert-constrained P-CMA-ES algorithm ensures that all rule parameters remain within intervals with clear physical meanings post-optimization, thereby preserving the semantic interpretability of the parameters at the source. Furthermore, as illustrated in Figure 13, the “feature-confidence” distribution generated by the model during inference is not a black-box output, and its decision-making logic is fully traceable: the distribution of attention weights directly reveals which features play a critical role in activating specific rules for a given input, while the confidence distribution of the rules yields the final diagnostic conclusion. This transparent inference chain—from input features to attention weights, followed by rule activation and conclusion fusion—endows each diagnostic decision with explicit mechanistic analyzability, mitigating the “black-box” effect inherent in complex models and establishing a solid foundation for the credible deployment and iterative optimization of the model in practical engineering applications.
Furthermore, the initialization random perturbation strategy proposed in this study not only enhances population diversity but also improves algorithm robustness. On the premise of preserving the core characteristics of expert knowledge, the optimization success rate is significantly improved by introducing random perturbations. Taking the 0H operating condition as an example, the accuracy rate is increased from 85.11% to 99.29%, as illustrated in Figure 14, where the horizontal axis represents the sample number and the vertical axis denotes the classification number. This reflects an effective balance between “respecting expert knowledge” and “enhancing algorithm robustness” in interpretable optimization. The results indicate that the method proposed in this study can adapt to the input of different initial expert knowledge in practical applications, thus providing stable and reliable technical support for the optimization of expert knowledge-based intelligent systems.
4.5. SEU Dataset Validation
To further test the generalization ability and reliability of the proposed method, a validation experiment was conducted using a distinct dataset. This dataset exhibits substantial differences in sample distribution compared to the first dataset and includes 473 fault samples covering four fault categories (G1–G4) under load operating conditions of 20 Hz–0 V. The experimental processing workflow strictly followed the standard paradigm of the first set of experiments: initial parameters were set on the basis of expert knowledge, followed by preliminary optimization via the conventional CMA-ES algorithm and subsequent iterative optimization via the P-CMA-ES. The experimental results are presented below.
(1) Parameter Optimization and Constraint Satisfaction: The initial parameters for the new dataset were set on the basis of experts’ prior knowledge of its fault characteristics. The constraint settings remained consistent with the first experiment: the optimization ranges for both rule weights and rule reliability were constrained to [0.5, 1], and the belief degrees were limited to vary within their initial value intervals. The parameter values after preliminary optimization via the conventional CMA-ES are provided in Table 14, while the final parameters optimized via the P-CMA-ES are detailed in Table 15.
The analysis indicates that all optimized parameters for the new dataset strictly fall within the expert-defined constraint boundaries. This result confirms that even under varying data distributions and fault characteristics, the P-CMA-ES maintains stable compliance with expert knowledge constraints, with no constraint violations observed. This finding verifies the method’s reliability during the parameter optimization process.
(2) Model diagnostic performance: On the new dataset, the agreement between the predicted values and true values of the IBRB-a model is presented in Figure 15. The results indicate that the model maintains high fitting accuracy on this dataset, accuracy reaches 95.59%. This indicates that the method retains stable performance even under completely different data distributions. As shown in Table 16, the fault identification accuracy under these operating conditions further verifies the applicability of the proposed method.
(3) To verify whether the model preserves knowledge interpretability on new datasets, we compared the optimized confidence distributions with the initial expert settings. As depicted in Figure 16, the optimized distributions exhibit a high degree of consistency with expert specifications regarding the confidence ranking of critical fault modes and their associated dominant features. For instance, rules initialized with high confidence by experts for “outer race faults” retained top rankings after optimization on new data, with no semantic deviation observed in their associated features. This indicates that the optimization process adapts to new data distributions while preserving the core framework and semantic structure of expert knowledge, without sacrificing interpretability for performance gains. Consequently, the model’s interpretability trait remains robust when generalized to new operating conditions.
(4) Robustness Analysis: The optimization algorithm maintains stable performance on new datasets, exhibiting strong cross-dataset generalization ability and anti-interference robustness, thus providing a reliability guarantee for its deployment in practical applications.
Verification results on the second dataset indicate that the proposed method maintains stable diagnostic accuracy, adherence to parameter constraints, and reliable parameter interpretability and robustness in industrial scenarios with different sample distributions. This further confirms the effectiveness and generalizability of the proposed method, providing more comprehensive experimental support for its engineering applications.
4.6. Comparison Experiments
The primary engineering contribution of this research is that it overcomes the limitations of the “stable operating condition assumption” in industrial fault diagnosis. This advancement allows for accurate equipment monitoring under complex operating states that better reflect real-world conditions. The findings demonstrate high reliability and interpretability, which can improve the understanding of bearing fault diagnosis in practical industrial settings and support targeted maintenance actions when faults are identified.
Therefore, three comparative experiments were performed to further evaluate the performance advantages of the IBRB-a model proposed in this study. The first set compares it with the traditional IBRB model; the second group assesses the contribution of each core component of the IBRB-a model through ablation experiments; the third set involves comparisons with other methods in the field of deep learning. All methods were evaluated on the same dataset using consistent evaluation metrics, as in previous sections, to ensure objective and fair comparisons.
(1) Comparative experiment with the traditional IBRB model: As a classical framework for interval-valued belief rule-based models, the traditional IBRB model has been widely validated in bearing fault diagnosis. In this experiment, the IBRB-a model was compared with the traditional IBRB model across multiple performance dimensions. Both models used the same rule initialization strategy and dataset partitioning ratio. To mitigate random errors, 10 independent repeated trials were conducted. According to the statistical results presented in Figure 17 (The blue curve represents the IBRB-a model), the IBRB-a model achieves significant improvement across all four core metrics: it attains an accuracy rate of over 98% under each operating condition, precision and F1 score both exceed 95%, and the recall rate remains above 96%. These values reflect an increase in more than 28 percentage points compared to the traditional IBRB model. The results demonstrate that, while retaining the advantages of the traditional IBRB framework, the IBRB-a model achieves comprehensive performance enhancement through structural improvements.
(2) To quantitatively evaluate the contribution of each core component in the IBRB-a framework, a systematic ablation experiment is designed herein. This experiment compares four ablation model variants, as introduced in Table 17, where each variant removes one core component, and all experiments are conducted under the same 10-fold cross-validation framework.
The systematic ablation experiment reveals the differential contributions of each core component to the performance of the IBRB-a model, with specific data comparisons shown in Table 18.
(3) To confirm the competitiveness of the IBRB-a model, this experiment selects five mainstream methods: Support Vector Machine (SVM), K-Nearest Neighbors (KNN), Random Forest (RF), probabilistic spiking response model (PSRM) and Physics Guided Convolutional Neural Network (PGCNN). Where SVM, KNN and RF are traditional machine learning methods, PSRM is a multilayer probabilistic spike response model [48], and PGCNN uses a rectangular input structure and rectangular convolution kernels guided by physical principles [49].
As shown in the line chart in Figure 18 and the detailed results in Table 19, the IBRB-a model performs consistently well across different operating conditions in all four evaluation metrics significantly outperforming all other compared methods. Taking Operating Condition 1 as an example, the table data show that the IBRB-a model achieves an accuracy of 99.29%, precision of 99.25%, recall of 99.25%, and F1 score of 99.00%—these values are far higher than those of SVM (87.94%, 87.47%, 87.41%, 87.42%), KNN (82.98%, 82.80%, 82.33%, 82.35%), RF (75.89%, 59.46%, 73.65%, 65.26%), PSRM (73.05%, 62.97%, 75.00%, 68.46%), and PGCNN (87.23%, 88.72%, 88.69%, 88.71%). A comparative analysis can also be conducted from another perspective via the line chart in Figure 19 and the specific data in Table 19. By observing the indicator changes in various methods under different operating conditions, it is found that all indicators of the IBRB-a model remain at a high level across different operating conditions, with minimal fluctuations. In terms of accuracy, the IBRB-a model demonstrated highly consistent performance across five evaluation scenarios, with recorded values of 99.29%, 98.67%, 99.29%, 99.29%, and 99.57%. In contrast, the indicators of the other methods fluctuate significantly under different operating conditions. As an example, the SVM achieved accuracy rates of 87.94%, 82.73%, 92.81%, 72.34%, and 69.5% across the five test scenarios.
Under the scenario of bearing fault diagnosis with variable operating conditions, traditional machine learning methods are relatively sensitive to changes in operating conditions because of their inherent algorithmic characteristics, leading to relatively low performance across all evaluation indicators. Although deep learning methods such as the PSRM and PGCNN can handle complex data patterns to some extent, they often exhibit underperformance when operating conditions shift, negatively affecting their generalization capability. In contrast, the IBRB-a model benefits from its specific structure and optimization strategy, enabling effective feature extraction under varying conditions and stronger adaptability to operational shifts. This leads to its stability in all evaluated metrics.
This section systematically verifies the performance of the IBRB-a model through three sets of progressive experiments: benchmark model comparison, internal strategy verification, and cross-domain method benchmarking.
In Experiment 1, compared to the baseline IBRB model, IBRB-a achieved significant improvements of 35.07%, 35.27%, 33.93%, and 35.83% in average accuracy, precision, recall, and F1 score, respectively. This improvement effectively validates the effectiveness of the optimized rule generation and evidential reasoning processes within the IBRB-a model. Specifically, by introducing adaptive rule generation, the IBRB-a model mitigates the problems of rule combination explosion and conflict; its optimized inference mechanism directly enhances computational efficiency and decision reliability. This demonstrates that the proposed method successfully integrates the transparency of belief rule-based systems with the capability to model complex data patterns.
In Experiment 2, The P-CMA-ES constrained optimization exerts the most critical impact—its removal leads to a sharp drop of 16.15% in average accuracy, and the performance degradation even reaches 27.86% under the 3H high-load operating condition, which highlights the decisive role of physical constraints in guiding the optimization direction and preventing the model from falling into local optima under high-load and complex conditions. The KDE-based interval division is crucial for the model’s adaptability to operating conditions; particularly under the 0 V variable speed operating condition, its absence results in a 13.10% decrease in accuracy, verifying its core value in adaptively capturing changes in data distribution and resisting feature drift. In contrast, although the attention weight module and dynamic rule matching mechanism have relatively moderate direct impacts on the average performance (decreasing by 3.50% and 3.07% respectively), a deeper analysis reveals their indispensable role in enabling adaptive and interpretable reasoning. The attention module acts as the dynamic core that translates the model’s static knowledge into context-aware decisions. Under variable operating conditions, it selectively focuses on the most relevant and discriminative features for each specific input, effectively filtering out noise and irrelevant variations induced by load or speed changes. This capability is crucial for maintaining robustness when feature distributions shift. More importantly, the generated attention weights provide a transparent, sample-level explanation for the diagnostic process by quantitatively showing how much each feature contributed to activating each rule. This directly operationalizes the model’s interpretability during inference, making the decision logic traceable and trustworthy. They jointly constitute the basic robustness framework of the model, ensuring the focus on key features and flexible adjustment of inference strategies under different operating conditions. In summary, the IBRB-a model proposed in this study exhibits significant comprehensive advantages in bearing fault diagnosis under varying operating conditions. Its core strengths lie in the fact that the rationality and convergence efficiency of model parameter learning are ensured through P-CMA-ES optimization integrated with physical constraints, and strong adaptability to changes in data distribution under complex operating conditions is endowed to the model via KDE-based adaptive interval division. Meanwhile, intelligent focus on discriminative features and dynamic adjustment of the inference process are achieved by the model through embedding the attention mechanism and dynamic rule matching. This series of innovative designs enables the IBRB-a to not only achieve high accuracy but also maintain high interpretability, thereby successfully resolving the inherent contradiction between high-performance “black-box” models and low-performance interpretable models. Consequently, the IBRB-a provides a highly reliable, adaptable, and decision-transparent intelligent diagnosis solution for the industrial field, with important theoretical significance and engineering application value.
In Experiment 3, The IBRB-a model outperforms state-of-the-art models—including SVM, KNN, RF, PSRM, and PGCNN—across all four core metrics, with improvements ranging from 13% to 37%. (1) Compared with traditional machine learning models such as SVM and KNN, IBRB-a achieves an average performance gain of approximately 18%, highlighting its inherent advantages in handling complex nonlinear patterns and uncertain information. SVM is sensitive to kernel functions and parameter settings, while KNN is prone to local fluctuations under varying operating conditions. In contrast, the fuzzy rule-based inference framework of IBRB-a naturally accommodates uncertainty, making it more robust to changes in data distribution. (2) The superior performance of IBRB-a over more complex models such as RF and PGCNN is particularly noteworthy. Although RF possesses strong fitting capability, its black-box nature may lead to unstable generalization under varying operating conditions. PGCNN can capture spatiotemporal features but relies heavily on large-scale labeled data and lacks interpretability. The performance of IBRB-a demonstrates that in the context of fault diagnosis under varying operating conditions, hybrid-driven models that integrate domain knowledge with data are often more adaptive and reliable than purely data-driven models. (3) The most distinctive advantage of IBRB-a lies in the unified achievement of interpretability and stability. All comparative models sacrifice interpretability to varying degrees to improve performance, whereas IBRB-a achieves excellent diagnostic performance while maintaining high interpretability.
In summary, the experimental analysis quantitatively validates the superiority of the IBRB-a model and elucidates the sources of its advantages from a mechanistic perspective. Through its innovative adaptive rule learning and optimization architecture, the IBRB-a model successfully addresses the efficiency and conflict issues of traditional belief rule-based systems in high-dimensional and complex scenarios, while circumventing the common limitations of mainstream data-driven models, such as sensitivity to data quality and poor interpretability. The high performance, stability, and interpretability demonstrated by the IBRB-a model endow it with unique engineering application value in the field of bearing fault diagnosis under varying operating conditions, where reliable and transparent decision-making is required.
4.7. Analysis of Algorithm Performance
To comprehensively evaluate the efficiency of the IBRB-a model framework, this section provides an in-depth analysis from two perspectives: theoretical complexity analysis and practical runtime performance.
(1) Complexity Analysis: The time complexity of the IBRB-a model is primarily correlated with the dimension of the optimization problem , the population size , and the number of iterations . Let L denote the size of the rule base, N the number of belief degrees per rule, and M the number of attribute weights in the system. The time complexity per generation can be expressed as , where satisfies the constraint , and the complexity of each individual evaluation is . For large values of , the computational cost is dominated by . Consequently, the total time complexity of the entire optimization process is . The spatial complexity is mainly determined by the storage requirements for the covariance matrix, the population, and auxiliary variables, which can be expressed as .
(2) Practical Runtime Statistics. Taking the 0 Hz operating condition as an example, the actual performance of the algorithm in the experimental environment (MATLAB R2024a) is summarized in Table 20. The time allocation analysis indicates that the computational load is relatively balanced between the two optimization stages. This validates the rationality of the hybrid framework design, effectively avoiding the bottleneck effect inherent in single-optimizer approaches.
The proposed optimization framework exhibits favorable scalability in its theoretical design. Its time complexity is dominated by , and the space complexity is , enabling it to handle computational demands of medium to large-scale problems. In terms of practical performance, through core designs such as the “global exploration-local tuning” two-stage synergy and domain knowledge-guided search, the algorithm achieves an effective balance between runtime efficiency and optimization accuracy. Experimental results demonstrate that the framework can generate high-precision, reliable, and structurally reasonable parameters for the belief rule base within a controllable timeframe. This verifies its practical value in complex system modeling and optimization tasks. These characteristics render the framework particularly suitable for complex optimization problems that demand high precision, strong constraints, and a certain degree of interpretability.
4.8. KDE Parameter Sensitivity Analysis
Prior to dynamic interval partitioning using KDE, a sensitivity analysis of KDE parameters was conducted to determine appropriate kernel functions and bandwidths.
(1) Kernel Function Sensitivity: Under a fixed bandwidth (determined by Silverman’s rule), four commonly used kernel functions were compared: Gaussian, Epanechnikov, triangular, and cosine. Table 21 presents the average diagnostic accuracy of the IBRB-a model under different kernel functions. As indicated in the table, the variations in average accuracy across different kernels are minimal. This suggests that model performance is insensitive to kernel selection when a reasonable bandwidth is applied. The Gaussian kernel was selected as the default due to its stable and marginally superior performance.
(2) Bandwidth Sensitivity: With the Gaussian kernel fixed, model performance was tested as the bandwidth coefficient varied within the range [0.7, 1.5]. Experimental results demonstrate that the model maintains an average accuracy plateau above 95% with a fluctuation range of less than ±1.21% as α varies across this wide interval. The performance curve exhibits a distinct “flat region,” verifying that the selected parameters lie within a robust zone. A significant performance degradation is only observed when the bandwidth is excessively small ( < 0.5, leading to overfitting noise) or excessively large ( > 1.8, resulting in the loss of feature details).
(3) Stability of Interval Reference Points: Beyond accuracy, the stability of the generated interval reference points under different KDE parameter settings was evaluated. Table 22 displays the interval partitioning results for feature F1 when the bandwidth coefficient α is set to 0.7, 1.0, and 1.3, respectively. As shown in Table 22, within the reasonable bandwidth range, the average offset rate of interval centers is less than 2%, indicating good stability of the KDE-based interval partitioning.
The aforementioned analysis indicates that the proposed KDE interval partitioning method offers threefold guarantees regarding parameter selection: a solid theoretical foundation; strong parameter robustness; and good structural fault tolerance. Consequently, the proposed method does not require tedious parameter tuning in practical engineering applications, demonstrating favorable utility and generalizability.
5. Conclusions
Based on the IBRB-r model, this study proposes a novel model named IBRB-a for bearing fault diagnosis under variable operating conditions. The model is designed to assist decision-makers in conducting clear, convenient, and efficient bearing fault prediction in practical industrial environments.
The IBRB-a model demonstrates practical utility in bearing fault diagnosis under variable operating conditions. It exhibits stable and superior diagnostic performance compared to the traditional IBRB model, as well as a range of machine learning and deep learning methods. The model is capable of adapting to dynamic industrial operating scenarios. It maintains interpretability through expert knowledge constraints, thereby avoiding the “black-box” problem, and enhances algorithm robustness via the introduction of random perturbation factors. This enables it to meet core industrial requirements for both reliability and interpretability in fault diagnosis. However, this study also objectively acknowledges the current limitations of the model: the adaptive capability of the model depends on the range of operating conditions covered by the training data, and its performance guarantee for completely unknown or extremely abrupt operating condition patterns requires further verification; the initialization of the model requires a certain amount of domain expert knowledge, which may affect its ability for rapid deployment in scenarios involving entirely new equipment or knowledge scarcity; despite the introduction of robustness designs, the foundation for rule matching and inference may still be challenged when facing extreme class imbalance or low-quality data.
Accordingly, future work will be deepened along the following paths: strategies combining meta-learning or online learning will be investigated to enable the model to achieve rapid self-update using a small number of new samples, thereby breaking through preset operating condition boundaries; methods integrating unsupervised feature learning with automated rule generation will be explored to reduce the model’s reliance on refined prior knowledge during construction; uncertainty quantification modules from evidence theory or hierarchical attention mechanisms will be introduced to enable the model not only to make diagnoses but also to evaluate the confidence of the diagnostic results, thereby making better decisions in the face of complex data.
This study not only proposes an effective bearing fault diagnosis model under varying operating conditions but also provides a theoretical basis and practical paradigm for constructing the next generation of data-intelligence integrated industrial health management systems.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1Li T. Zhao Z. Sun C. Cheng L. Chen X. Yan R. Gao R.X. Wavelet Kernel Net: An interpretable deep neural network for industrial intelligent diagnosis IEEE Trans. Syst. Man Cybern. Syst.2022522302231210.1109/TSMC.2020.3048950 · doi ↗
- 2Sun C. Ma M. Zhao Z. Tian S. Yan R. Chen X. Deep transfer learning based on sparse autoencoder for remaining useful life prediction of tool in manufacturing IEEE Trans. Ind. Inform.2019152416242510.1109/TII.2018.2881543 · doi ↗
- 3Lin J. Shao H. Zhou X. Cai B. Liu B. Generalized MAML for few-shot cross-domain fault diagnosis of bearing driven by heterogeneous signals Expert 202323012069610.1016/j.eswa.2023.120696 · doi ↗
- 4An B. Zhao Z. Wang S. Chen S. Chen X. Sparsity-assisted bearing fault diagnosis using multiscale period group lasso ISA Trans.20209833834810.1016/j.isatra.2019.08.04231515090 · doi ↗ · pubmed ↗
- 5Zhou D. Zhao Y. Wang Z. He X. Gao M. Review on diagnosis techniques for intermittent faults in dynamic systems IEEE Trans. Ind. Electron.2020672337234710.1109/TIE.2019.2907500 · doi ↗
- 6Yin T. Lu N. Guo G. Lei Y. Wang S. Guan X. Knowledge and data dual-driven transfer network for industrial robot fault diagnosis Mech. Syst. Signal Process.202318210959710.1016/j.ymssp.2022.109597 · doi ↗
- 7Li Y. Xie S. Wang J. Zhang J. Yan H. Sparse sampletrain axle bearing fault diagnosis: A semisupervised model based on prior knowledge embedding IEEE Trans. Instrum. Meas.202372353191110.1109/TIM.2023.3318686 · doi ↗
- 8Wang R. Huang W. Wang J. Shen C. Zhu Z. Multisource Domain Feature Adaptation Network for Bearing Fault Diagnosis under Time-Varying Working Conditions IEEE Trans. Instrum. Meas.202271351101010.1109/TIM.2022.3168903 · doi ↗