Reinforcement Learning-Based Cloud-Aware HAPS Trajectory Optimization in Soft-Switching Hybrid FSO/RF Cooperative Transmission System
Beibei Cui, Shanyong Cai, Liqian Wang, Zhiguo Zhang, Feng Wang

TL;DR
This paper proposes a reinforcement learning framework to optimize HAPS trajectories in a hybrid FSO/RF system, improving connectivity by avoiding cloud interference.
Contribution
The novel integration of soft-switching with rateless codes and DRL for cloud-aware HAPS trajectory optimization is introduced.
Findings
RC-PPO achieves higher throughput compared to the HS-PPO baseline.
Trajectories optimized with RC-PPO are smoother and more cloud-aware.
The proposed framework effectively handles sparse feedback from rateless codes.
Abstract
Space–air–ground systems employing free-space optical (FSO) communication leverage high-altitude platform stations (HAPS) to deliver seamless and ubiquitous connectivity. Although FSO links offer high capacity, they are highly susceptible to cloud extinction, which severely degrades link availability. Hybrid FSO/radio-frequency (RF) transmission and cloud-aware HAPS trajectory optimization can enhance resilience. However, the conventional cloud-aware hybrid FSO/RF transmission system based on hard-switching (HS) between the FSO and RF links leads to frequent link transitions and unstable throughput. To address these challenges, we propose a joint optimization framework that integrates soft-switch between FSO and RF links with deep reinforcement learning (DRL) for HAPS trajectory optimization. Soft-switching based on rateless codes (RCs) enables simultaneous transmission over both links,…
Click any figure to enlarge with its caption.
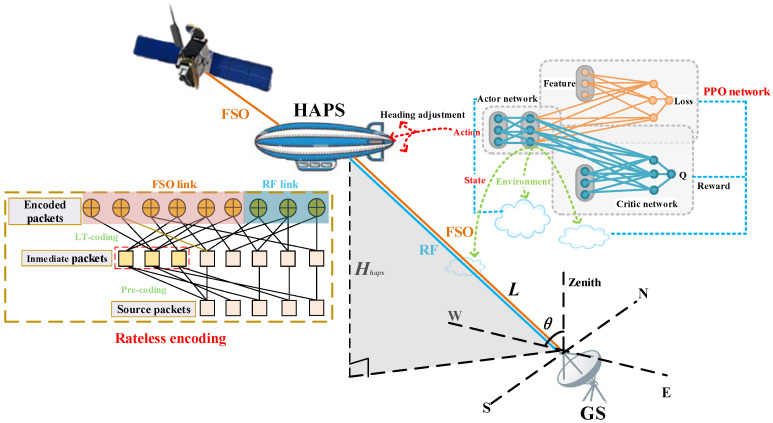 Figure 1
Figure 1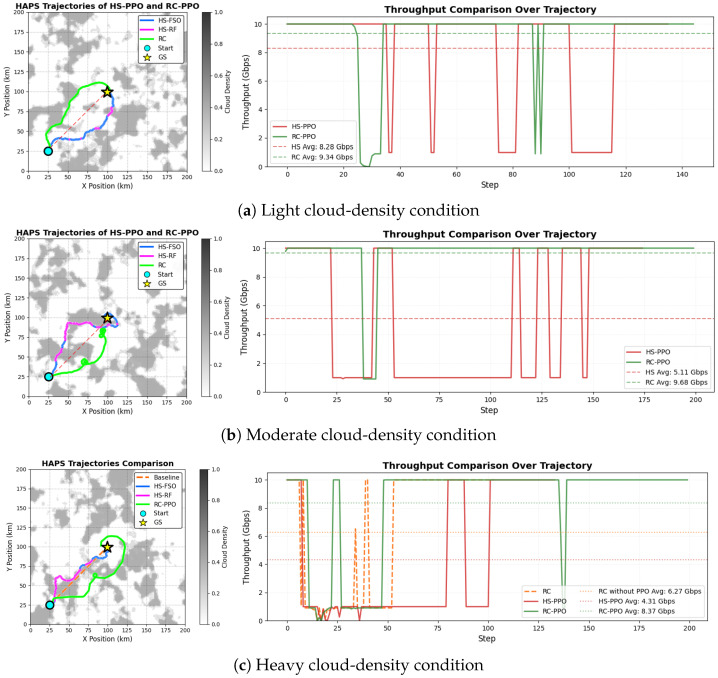 Figure 2
Figure 2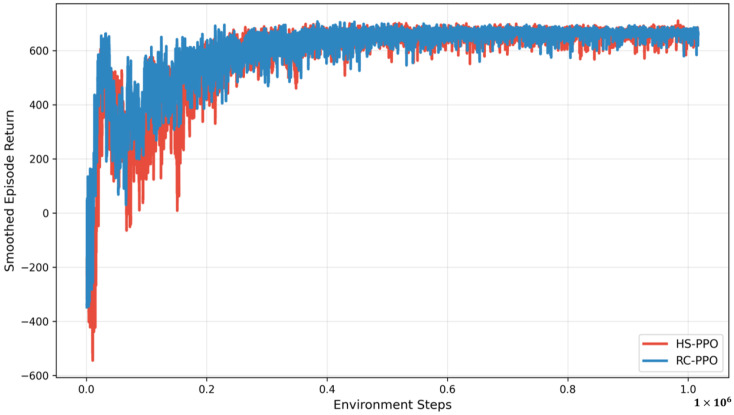 Figure 3
Figure 3- —National Natural Science Foundation of China
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsOptical Wireless Communication Technologies · UAV Applications and Optimization · Satellite Communication Systems
1. Introduction
The explosive growth of global data traffic has revealed the limitations of terrestrial networks in achieving ubiquitous connectivity [1]. Space–air–ground integrated networks (SAGINs) with free-space optical communication (FSO), using high-altitude platform stations (HAPS) to relay communications between satellites and ground stations, have emerged as a promising solution [2,3]. FSO links offer ultra-high bandwidth but suffer from low reliability due to atmospheric conditions such as clouds and atmospheric turbulence (AT) [4,5]. Hybrid FSO/RF transmission systems leverage RF backup to enhance reliability [6,7,8]. Such hybrid systems have been deployed in dual-hop relay links [9] and SAGIN scenarios to improve coverage and capacity [10]. Conventional hybrid FSO/RF systems employ hard-switching (HS) strategies that select links based on instantaneous SNR values [11], suffering from frequent transitions and unstable throughput. FSO/RF systems based on rateless code (RC), such as Raptor code [12], enable soft-switching by transmitting distinct encoded packets simultaneously over both the FSO and RF channels [13], thus eliminating switching overhead and improving reliability against burst disruptions. To avoid cloud cover, HAPS trajectory optimization is also an effective method to enhance link stability and throughput.
Deep reinforcement learning (DRL) offers a powerful framework for adaptive HAPS trajectory optimization in dynamic atmospheric environments [14]. For example, ref. [15] integrates 5G low-latency connectivity with a Deep Q-Network (DQN) for 3D trajectory optimization. Ref. [16] employs the deep deterministic policy gradient (DDPG) algorithm for coordinating HAPS coverage. However, these studies foucus on RF-only aerial communication networks. When extending DRL to hybrid FSO/RF systems, ref. [17] applies the A2C algorithm to optimize the HAPS trajectory in the HS FSO/RF transmission system, which relies on dense, per-step reward signals. This dense-reward strategy is fundamentally incompatible with the RC-based soft-switching FSO/RF system. For RC, a meaningful reward is available only upon successful block decoding, which introduces a critical challenge of reward sparsity. This sparse feedback (reward) severely complicates temporal credit assignment and hinders efficient exploration [18]. Ref. [19] successfully used Proximal Policy Optimization (PPO) with reward shaping to compensate for such reward sparsity when guiding UAVs to move to destinations. To the best of our knowledge, no existing work has investigated HAPS trajectory planning in an RC-based soft-switching hybrid FSO/RF system under stochastic cloud dynamics.
This paper proposes a joint optimization framework that integrates rateless-coded physical-layer transmission with PPO-based trajectory learning in a hybrid FSO/RF transmission system. Key contributions are as follows:
- The cloud-aware HAPS trajectory optimization problem in soft-switching hybrid FSO/RF systems is formulated and solved by a PPO-based DRL approach, under the stochastic moving occluding cloud (SMOC) model derived from the ERA5 dataset.
- A potential-based reward-shaping mechanism within the PPO framework is developed to mitigate sparse decoding feedback of RCs, delivering faster convergence and superior performance over threshold-based HS-PPO schemes.
The remainder of this paper is organized as follows. Section 2 presents the scheme of the trajectory-optimized HAPS–ground station (GS) hybrid FSO/RF link, FSO/RF channel models, and the throughput of HS and RC-based hybrid FSO/RF systems. Section 3 details the proposed RC-PPO algorithm and the HS-PPO algorithm as a reference and presents the corresponding Markov Decision Process (MDP) formulation and reward shaping strategy. Section 4 provides simulation results. Section 5 gives the conclusion.
2. System Model
This section presents the mathematical framework for the HAPS-assisted hybrid FSO/RF communication system. Firstly, a simplified three-tier SAGIN architecture is introduced. Subsequently, the channel model of FSO and RF links are presented. At last, the throughputs for hybrid FSO/RF systems with HS and RC are elaborated.
2.1. Space–Air–Ground Architecture
As illustrated in Figure 1, we consider a simplified three-tier Space–Air–Ground (SAG) system, which constitutes a fundamental building block of standard SAGINs. The LEO satellite operates at an orbital altitude of approximately 600 km and serves as the primary data source. The HAPS, positioned at km in the stratosphere, functions as an aerial relay node to bridge the satellite-to-ground communication gap. The satellite-to-HAPS link employs FSO communication to exploit its high bandwidth capacity, while the HAPS-to-GS link utilizes hybrid FSO/RF transmission to provide complementary link diversity.
A discrete-time model is adopted with time step index . The position of HAPS at time t is denoted as , where represents the horizontal coordinates and (the altitude of HAPS) remains constant. The GS is located at with . The instantaneous slant distance between HAPS and GS is given by:
And the elevation angle (Figure 1) is .
2.2. Channel Model
2.2.1. FSO Channel Model
The composite channel gain of the downlink FSO channel between HAPS and GS is expressed as:
where is the geometric loss due to the divergence of the beam on the slant path distance [20], follows the Gamma-Gamma distribution characterizing AT-induced fading [21], and represents the loss of cloud-induced attenuation. Among these factors, is critical for optimizing the HAPS trajectory due to its spatial heterogeneity. The cloud-induced attenuation follows the Beer–Lambert law [22]:
(km^−1^) is the attenuation coefficient [23], determined based on the visibility (V) (in km) and the wavelength (in nm) as
Here, is the optical wavelength, V is the visibility, and q is the size-distribution parameter of the scattering particles depending on V. The expression of V is given by:
where is the cloud-induced attenuation of the FSO link obtained by integration over the slant path:
Here, is the elevation angle and and are the cloud base and top altitudes. The extinction coefficient for the FSO link is given by [24]:
where g/cm^3^ is the water density, ( m) is the particle effective radius [24], and is the vertical profile of liquid water content (LWC) in g/m^3^. The three-dimensional (3D) distribution of LWC is modeled as a spatially correlated stochastic field, as detailed in Section 4.1.
The FSO link employs intensity modulation with direct detection (IM/DD) using on–off keying (OOK). The received optical power is , where denotes the transmit optical power and and , respectively, denote the transmitter and receiver telescope gains. The instantaneous electrical SNR is given by:
where R (A/W) is the photodetector responsivity, (A^2^/Hz) is the noise power spectral density, and (Hz) is the receiver bandwidth of the FSO link.
2.2.2. RF Channel Model
The RF channel provides complementary connectivity with enhanced reliability under cloud-obscured conditions. The RF channel gain incorporates free-space path loss (FSPL) and cloud-induced attenuation. The expression of FSPL is given by:
with RF carrier frequency and speed of light . The cloud attenuation coefficient (km^−1^) is computed similarly to (6) for FSO links by path-integrating the specific attenuation coefficient. The specific RF attenuation coefficient (km^−1^) is derived from Mie scattering theory and modeled as [25]:
where (km^−1^/(g·m^−3^)) is the mass extinction coefficient at RF frequency .
Similar to (8), the instantaneous SNR of RF link with QPSK modulation is given by:
where is the transmitting power, and are the transmitting and receiving antenna gains, (W/Hz) is the spectral density of RF noise power, and (Hz) is the receiver bandwidth of the RF link.
2.3. Hybrid FSO/RF Systems
This section describes the throughput of hybrid FSO/RF communication systems based on HS and RC. These two schemes differ fundamentally in how they exploit link diversity, which affects trajectory optimization.
2.3.1. Hard Switching
The HS scheme selects either the FSO or RF link at each time step based on instantaneous channel quality. The instantaneous throughput is given by:
where is the switching threshold, and are the transmitted data rates, and are the per-packet success reception probabilities accounting for forward error correction (FEC). The optimal threshold value maximizes the expected throughput:
For the hybrid FSO/RF system, the bit error rate (BER) for the FSO link with OOK modulation and the RF link with QPSK modulation depend on their respective signal-to-noise ratios (SNRs) at the receiver. The BER for each link can be uniformly expressed as:
where denotes the FSO or RF link, is the instantaneous SNR, and is the modulation-dependent efficiency factor, with for OOK and for QPSK. For a packet of bits in length, assuming FEC capable of correcting up to bit errors, the packet success probability is computed via the binomial sum:
2.3.2. Rateless Coding
RCs enable the generation of an arbitrary number of encoded packets until the receiver accumulates sufficient packets to decode the original source block [13]. Unlike traditional channel codes with fixed code rates, RCs automatically adjust the number of encoded packets required to be sent for successful decoding based on channel conditions. Raptor code, which represents the state of the art in RCs, consists of a high-code-rate precode (typically Low-Density Parity-Check (LDPC) code [26]) followed by a Luby Transform (LT) [27] outer code and is utilized in this paper.
Let denote the source symbol vector containing information symbols. The precode generates an intermediate symbol vector (Figure 1):
where is the precode generator matrix producing intermediate symbols. The LT encoder then produces output symbols via:
where is a random sparse row sampled according to a robust soliton degree distribution and ⊕ denotes XOR over . Each output symbol is formed by XORing a small subset of intermediate symbols, with the subset size and selection determined by the degree distribution.
In the RC scheme, both FSO and RF links transmit different encoded symbols simultaneously. Crucially, any correctly received symbol contributes to decoding, regardless of which link delivered it. This superposition property eliminates the need for link selection decisions and enables full utilization of both links under all channel conditions. The receiver can successfully decode the source data block once it accumulates approximately distinct encoded symbols, where is the average overhead required by the belief-propagation (BP) decoder. This overhead is typically – for well-designed Raptor codes [13]. The impact of dynamic SNR fluctuations on the hybrid link is captured through the packet success probabilities and in Equation (15), which determine the rate of correctly received symbols. Therefore, the expected effective throughput for RC is given by:
3. Trajectory Optimization
This section presents the trajectory optimization framework for hybrid FSO/RF communication schemes. Firstly, the PPO algorithm and MDP formulation are introduced as the foundation of DRL. Subsequently, the trajectory optimization strategies for the HS and RC schemes using PPO-based DRL are elaborated.
3.1. Proximal Policy Optimization
PPO is an on-policy actor-critic algorithm that uses a clipped surrogate objective to constrain policy updates, thereby preventing large deviations from the current policy and ensuring stable training. The objective of PPO, which is maximized at each iteration, is given by:
where denotes the empirical average over a finite batch of samples, denotes an entropy bonus, is the value function loss, and are weighting coefficients.
The clipped surrogate objective prevents excessively large policy updates by constraining the probability ratio between the current and old policies, given by:
where the function clip acts as a clipping operation that constrains the probability ratio to the interval . (typically 0.1–0.3) is a hyperparameter. The probability ratio at time step t is given by:
Moreover, the advantage estimator ( ) is formulated as a discounted sum of future temporal-difference (TD) residuals ( ), given by:
where is the discount factor, and the TD residual is defined as:
Here, is the immediate reward received from the environment, and is the state value, which can be used to evaluate the state under the current policy.
The value function loss ( ) minimizes the mean squared error (MSE) between predicted state values and empirical returns, given by:
where is the discounted sum of future rewards. The entropy term ( ) encourages exploration by preventing premature convergence to deterministic policies, given by
Network parameters are updated after collecting a trajectory of length T, using the collected batch to perform multiple epochs of minibatch gradient descent on the PPO objective. The pseudocode of the algorithm is shown in Algorithm 1. Algorithm 1 PPO for HAPS Trajectory Optimization Require: Policy and value network , hyperparameters 1:for each training iteration do2: Collect trajectory using 3: Compute returns 4: Compute TD residuals 5: Compute advantages 6: Normalize advantages: 7: Store old policy probabilities 8: for epoch do9: for mini-batch do10: Compute 11: Update via gradient ascent on 12: end for13: end for14:end for15:return Optimized policy
3.2. Trajectory Optimization with PPO-Based DRL
The HAPS trajectory optimization problem is formalized as a finite-horizon MDP defined by the tuple , where is the state space, is the action space, P is the transition probability, and R is the reward function. The control objective for both RC and HS schemes is to find an optimal policy maximizing the expected discounted return:
The state space, action space, and reward function differ significantly between the RC and HS schemes due to their distinct communication paradigms.
3.2.1. RC-PPO
The state space should contain all information needed for the RC-PPO agent to make decisions and preserve the Markovian property of the environment, given by:
where denote the current coordinates of the HAPS, is the heading angle measured clockwise from north, is the number of steps remaining, and contains cloud extinction coefficients sampled at probe points along prospective directions.
Since RC allows both links to transmit simultaneously without switching overhead, the action space contains only navigation decisions:
where is the discrete heading change with representing the maximum single-step turn angle.
State transitions decompose into deterministic kinematic evolution and stochastic cloud field dynamics. For simplicity, the speed of the HAPS is assumed constant of , and the effects of wind (atmospheric currents) are not considered in the kinematic model. The HAPS position evolves according to:
The decoding progress , defined as the fraction of successfully received packets to the total required, evolves according to:
where is the total number of source packets, is the redundancy overhead in the RCs, and is the aggregate packet-arrival rate from both links. Noted, in real-world deployment, the receiver provides feedback only upon successful decoding of complete data blocks, making unavailable for real-time decision-making by the HAPS. The aggregate rate:
where and are the transmitted symbol rates of the FSO and RF links, and denote the probability of successful symbol reception as a function of extinction loss of cloud, and are distance-dependent weight factors where is the distance from HAPS to the ith probe position and is a normalization constant, thereby assigning higher influence to nearer probes. At each time step, probe points are placed along candidate directions at varying distances from the current HAPS position to estimate future channel conditions.
In order to maximize the average capacity over the allowed T time steps, the reward function balances multiple objectives and is defined as:
where encourages high instantaneous throughput, provides dense feedback on decoding progress through potential-based reward shaping, discourages sharp heading changes to maintain flight stability, and with penalizes excessive distance from the GS to accelerate policy convergence speed and improve link quality. , , , , and q are weighting factors to balance the physical and task-driven scales of their corresponding terms.
The terminal reward indicates mission completion:
An episode terminates when either the mission succeeds ( ) or timeout occurs ( ).
The inclusion of in the reward function addresses the sparse feedback challenge inherent in RC. According to the potential-based shaping theorem [19], our shaping term corresponds to the potential function , which preserves the optimal policy while providing dense training signals.
Importantly, although is used during training to accelerate policy learning, the trained policy depends only on the observable state and requires no real-time decoding feedback at deployment.
3.2.2. HS-PPO
For HS-PPO, the state space omits decoding progress but includes the currently selected link represented by the binary indicator :
where denotes the currently active link. The action space includes both navigation and link selection decisions:
where denotes the currently active link (0 for FSO, 1 for RF). The instantaneous reward is defined as:
where penalizes frequent link switch, and is the data rate from the active link:
The terminal reward for HS-PPO is defined similar to that for RC-PPO, with episodes terminating upon mission completion or timeout.
4. Simulation and Results
This section presents the cloud field generation, training setup, and evaluation of the proposed HS-PPO and RC-PPO agents. Key parameters are summarized in Table 1.
4.1. Cloud Field Generation
The 3D LWC field is generated using the SMOC model [28], leveraging statistics of cloud cover and average integrated liquid water content (ILWC) from the ERA5. A log-normal distribution of the content of liquid cloud water (CLWC) over the given site is obtained based on the extracted information from the dataset. Spatially correlated 3D LWC fields are then synthesized by generating random Gaussian fields based on empirical spatial correlations from ERA5, ensuring realistic cloud structures. Finally, an analytical vertical profile is applied to modulate the altitude-dependent LWC distribution within each cloud column:
where W is the columnar ILWC (in kg/m^2^), is the cloud base altitude, denotes the gamma function, and , determine the shape of the clouds’ vertical profile, given by:
where C is the CLWC. The resulting 3D LWC field is used to compute the specific extinction coefficients of the cloud for the FSO and RF channels according to (7) and (10), respectively.
4.2. PPO Training Configuration
Both RC-PPO and HS-PPO agents employ identical neural network architectures, consisting of a three-layer MLP feature extractor with hidden dimensions [128, 64, 32] and ReLU activations. The feature extractor feeds into separate policy and value heads. The policy head was initialized using orthogonal initialization with a gain of 0.01 to reduce initial entropy. Each cycle collects 200 episodes to form a batch. This batch is reused for 10 update epochs with a mini-batch size of 64. Evaluation is performed with 200 deterministic test episodes employing the static cloud fields generated in Section 4.1. PPO training hyperparameters are detailed in Table 2.
Moreover, for the weighting parameter settings of the reward function (Equations (32) and (35)), an iterative behavior-driven tuning methodology is employed. Specifically, for the RC-PPO agent, is fixed as the baseline to reflect the primary objective of maximizing throughput; is selected via grid search to balance the decoding progress signal and throughput exploration; and serve as regularization terms to encourage smooth trajectories and movement toward the ground station, respectively. q is set to a large scalar to clearly signify task completion. The specific parameter values are summarized in Table 3.
4.3. Results and Discussion
Figure 2 shows representative HAPS trajectories and their corresponding instantaneous throughput achieved by the HS-PPO and RC-PPO agents under varied cloud conditions. To systematically assess the performance of both schemes, 100 random cloud distributions were first generated using the SMOC model. For each cloud distribution, the ILWC along the slant path was averaged over the starting point to the GS (indicated by the red dashed line in Figure 2). The mean values of ILWC were then ranked across 100 cloud distribution cases to approximately characterize the difficulty of trajectory optimization. For each typical HAPS mission duration (approximately 0.8–1.3 h for a 100 km flight at 75–120 km/h [29]), the cloud field can be regarded as slowly varying (with a temporal decorrelation scale of 15–29 h [30]). Hence, the use of a static cloud map in each episode is justified.
Representative cloud scenarios were selected at the 25th, 50th, and 75th among 100 cloud distributions of this ranked distribution, corresponding to light, moderate, and heavy cloud-density distributions. The horizontal position of the starting point is uniformly fixed at (25 km, 25 km), and the position of the GS is set at (100 km, 100 km).
The overall objective of HAPS trajectory optimization is to approach the GS while actively avoiding dense cloud regions, thereby minimizing signal attenuation and maximizing both throughput and communication coverage of the HAPS. Under light cloud-density conditions (Figure 2a), both HS-PPO and RC-PPO agents tend to advance directly toward the GS, achieving favorable throughput performance due to minimal cloud-induced extinction. As cloud density increases (Figure 2b,c), HS-PPO exhibits substantial throughput degradation attributed to severe FSO link attenuation in dense cloud regions, necessitating RF channel backup. In contrast, RC-PPO achieves higher effective hybrid throughput by dynamically leveraging transient FSO transmission windows while maintaining a reliable RF backup link. This strategy enables RC-PPO to reduce signal interruption durations and feedback latency compared to HS-PPO.
In terms of quantified throughput, under light cloud, the average throughput of RC-PPO is 9.34 Gbps, which is improved by 12.8% compared with the throughput of 8.28 Gbps for HS-PPO. As cloud density increases to a moderate level, RC-PPO reaches 9.68 Gbps, representing a significant 89.4% improvement compared to the throughput (5.11 Gbps) of HS-PPO. Under heavy cloud, the throughput of RC-PPO maintains 7.06 Gbps, yielding a 51.8% improvement over the 4.65 Gbps of HS-PPO. The results demonstrate that the RC-PPO system exhibits substantial throughput improvement under light, moderate, and heavy cloud conditions. RC-PPO demonstrates the most pronounced throughput advantage over HS-PPO under moderate cloud-density conditions. In addition, under heavy cloud-density conditions (Figure 2c), a non-RL scheme is also evaluated, which follows a straight-line path from the starting point directly to the GS without any adaptive cloud avoidance. Results show that RC-PPO achieves the highest average throughput, outperforming both the non-RL RC and HS-PPO schemes. It confirms that the performance gain stems not only from the use of RCs but from the predictive trajectory optimization enabled by DRL.
Figure 3 illustrates the training performance of the RC-PPO and HS-PPO agents. Although a direct quantitative comparison of their absolute return values is complicated for the differences in reward design, the resulting HAPS trajectories suggest that both schemes achieve effective policy learning. Notably, despite the inherently sparser feedback of the RCs (informative feedback is available only upon successful decoding of entire data blocks), the RC-PPO agent exhibits slightly more stable convergence performance. This improved stability is attributed to a shaped-reward mechanism specifically designed to provide incremental feedback on packet decoding progress. By incorporating denser reward signals, RC-PPO effectively mitigates variance in policy gradient estimates, thereby improving sample efficiency throughout training.
5. Conclusions
This paper presents an integrated framework that combines RCs with a PPO-based DRL algorithm for HAPS trajectory optimization in a hybrid FSO/RF SAG system. By embedding potential-based reward shaping around decoding progress, the proposed RC-PPO method addresses key limitations of conventional HS schemes, enabling more reliable exploitation of both FSO and RF channels under stochastic cloud obstruction. Simulations demonstrate that RC-PPO improves achievable capacity and transmission reliability. Under moderate cloud scenarios, the average throughput of the RC-PPO agent is 9.68 Gbps, achieving 89.4% improvement compared to that of HS-PPO (5.11 Gbps). Moreover, RC-PPO exhibits more stable training convergence compared to HS-PPO.
The proposed framework in this paper can be further extended to multi-HAPS/multi-GS systems by adopting multi-agent reinforcement learning (MARL) strategies, such as Multi-Agent PPO (MA-PPO), where multiple HAPSs coordinate their trajectories and transmission policies to optimize coverage and load balancing.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1Xu G. Xu M. Zhang Q. Song Z. Cooperative FSO/RF Space-Air-Ground Integrated Network System with Adaptive Combining: A Performance Analysis IEEE Trans. Wirel. Commun.2024231727917293
- 2Samy R. Yang H.C. Rakia T. Alouini M.S. Space-Air-Ground FSO Networks for High-Throughput Satellite Communications IEEE Commun. Mag.202260828710.1109/MCOM.002.2200018 · doi ↗
- 3Ata Y. Alouini M.S. HAPS Based FSO Links Performance Analysis and Improvement with Adaptive Optics Correction IEEE Trans. Wirel. Commun.20232249164929
- 4Zhu X. Kahn J. Free-space optical communication through atmospheric turbulence channels IEEE Trans. Commun.2002501293130010.1109/tcomm.2002.800829 · doi ↗
- 5Yu S. Ding J. Fu Y. Ma J. Tan L. Wang L. Novel approximate and asymptotic expressions of the outage probability and BER in gamma–gamma fading FSO links with generalized pointing errors Opt. Commun.201943528929610.1016/j.optcom.2018.11.021 · doi ↗
- 6Bag B. Das A. Ansari I.S. ProkešA. Bose C. Chandra A. Performance Analysis of Hybrid FSO Systems Using FSO/RF-FSO Link Adaptation Photo. J.2018107904417
- 7Sharma K. Kaur S. Singh H. Channel modelling and performance analysis of switching based hybrid FSO/RF communication system J. Opt.20251910.1007/s 12596-025-02811-7 · doi ↗
- 8Zhang Q. Yu J. Long J. Wang C. Chen J. Lu X. A Hybrid RF/FSO Transmission System Based on a Shared Transmitter Sensors 202525202110.3390/s 2507202140218534 PMC 11991323 · doi ↗ · pubmed ↗