Edge-Distilled and Local–Global Feature Selection Network for Hyperspectral Image Super-Resolution
Xinzhao Li, Mengzhe Fan, Xiaoqing Zheng, Jiandong Shang

TL;DR
This paper introduces a new network for improving the resolution of hyperspectral images by better capturing edge details and combining local and global features.
Contribution
The paper proposes a novel network combining edge distillation and a local–global feature selection mechanism for hyperspectral image super-resolution.
Findings
The proposed EDLGFS network outperforms existing methods in reconstructing hyperspectral images.
The edge-guided knowledge distillation improves the extraction of edge details in super-resolution.
The LGFS mechanism effectively captures both local and global features for better image reconstruction.
Abstract
In recent years, the methods based on convolutional neural networks have achieved significant progress in hyperspectral image super-resolution. However, existing methods still face two key challenges: (1) they fail to fully extract edge detail information from hyperspectral images; (2) they struggle to simultaneously capture local and global features. To address these issues, we propose an Edge-Distilled and Local–Global Feature Selection network (EDLGFS) for hyperspectral image super-resolution. This network aims to effectively leverage edge details and local–global features, thereby enhancing super-resolution reconstruction quality. Firstly, we design an edge-guided super-resolution network based on knowledge distillation. This network transfers edge knowledge to improve the reconstruction. Secondly, we propose a Local–Global Feature Selection mechanism (LGFS), which integrates…
Click any figure to enlarge with its caption.
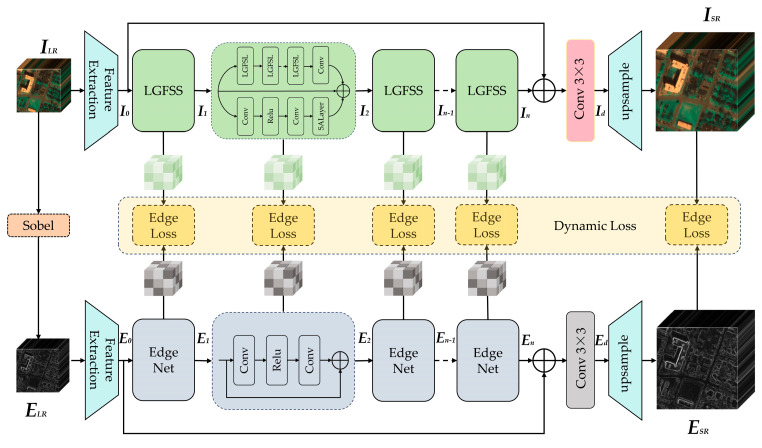 Figure 1
Figure 1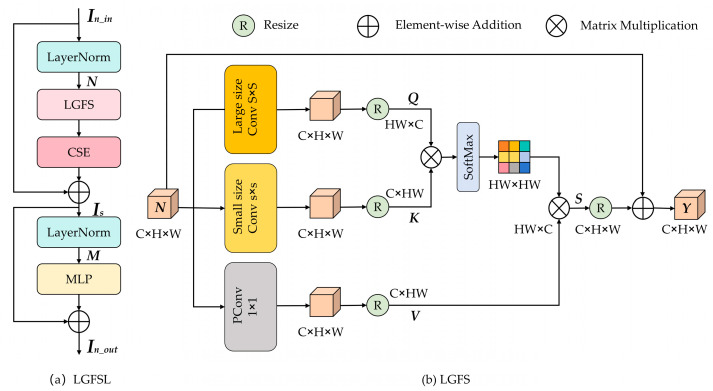 Figure 2
Figure 2 Figure 3
Figure 3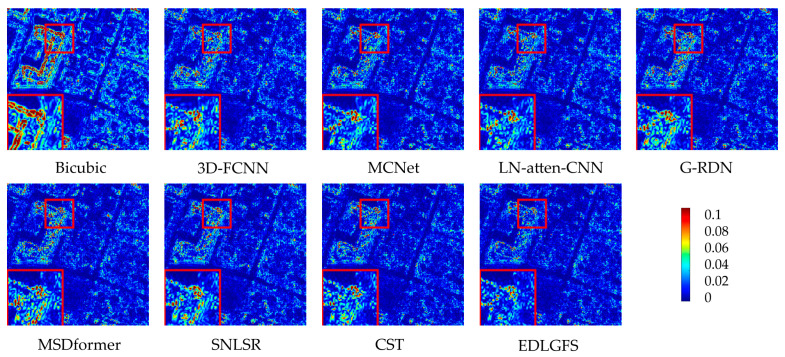 Figure 4
Figure 4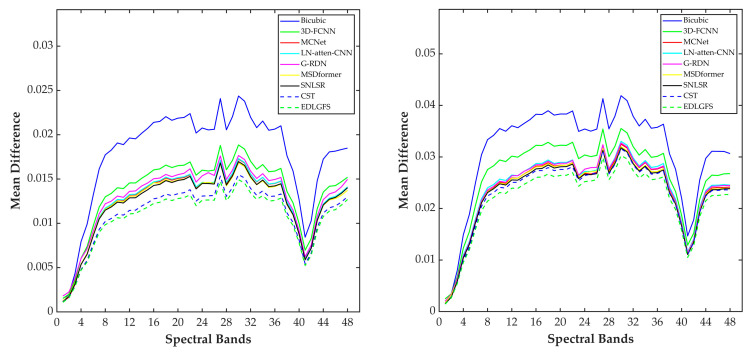 Figure 5
Figure 5 Figure 6
Figure 6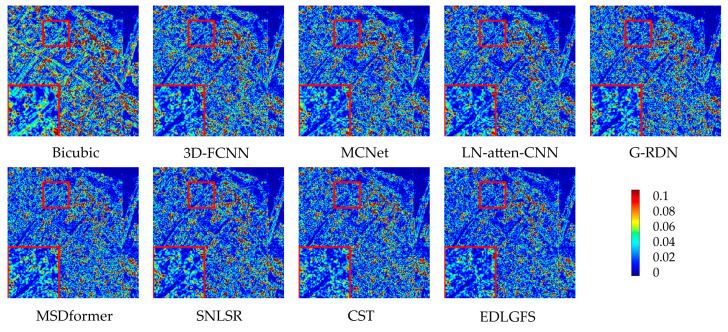 Figure 7
Figure 7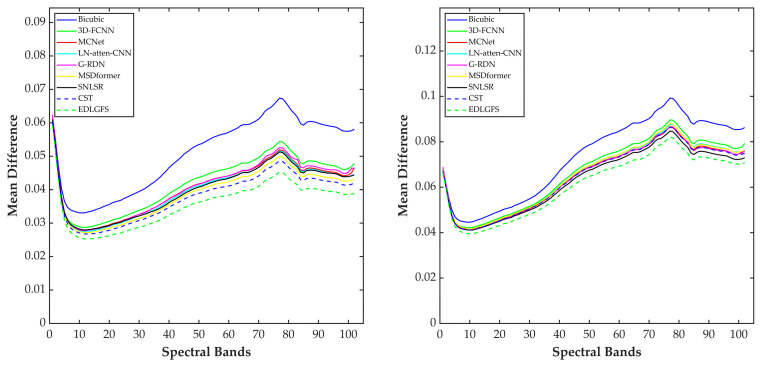 Figure 8
Figure 8 Figure 9
Figure 9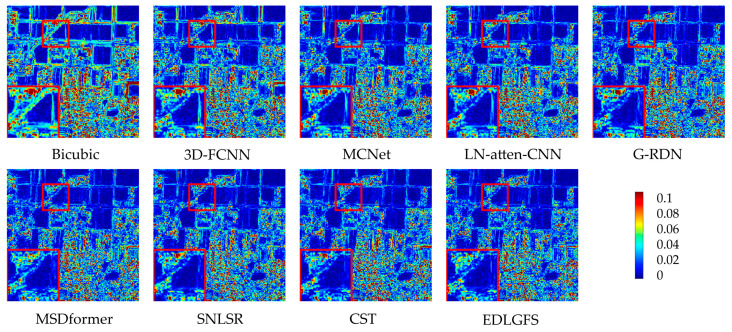 Figure 10
Figure 10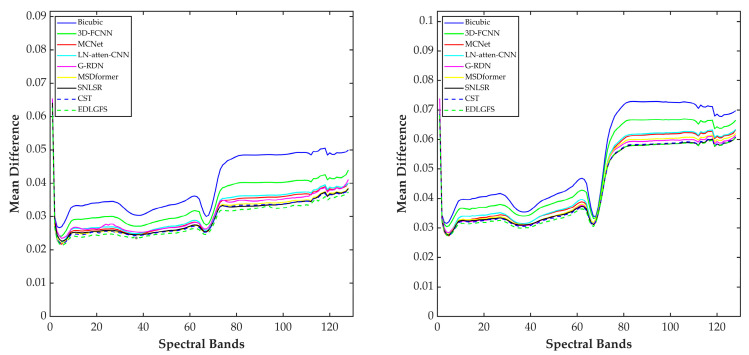 Figure 11
Figure 11- —Major Science and Technology Project of Henan Province, China
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsAdvanced Image Fusion Techniques · Advanced Image Processing Techniques · Remote-Sensing Image Classification
1. Introduction
Hyperspectral images (HSIs) are typically acquired by capturing tens to hundreds of continuous spectral bands within near-infrared, mid-infrared, visible light, and other bands of the electromagnetic spectrum [1]. Unlike traditional RGB or multispectral images, HSIs possess extremely high spectral resolution, enabling them to capture detailed spectral characteristics of target objects at every spatial location, which allows for precise material identification. Therefore, HSIs find extensive applications in various fields, such as target detection [2,3], mineral exploration [4], and medical diagnostics [5]. Furthermore, core hyperspectral analysis tasks including spectral unmixing and fine-grained land cover classification also heavily rely on high-quality HSIs. Recent advanced methods, such as spatial-channel multiscale Transformer networks for unmixing [6] and multi-scale memory networks for detection [7], further demonstrate the growing demand for precise spatial–spectral representations. However, due to fundamental imaging system constraints, achieving high spectral resolution often compromises spatial resolution. This limits the performance of the aforementioned applications [8]. Therefore, super-resolution (SR) techniques are required to enhance the spatial resolution of HSIs without hardware upgrades, thereby providing a superior data foundation for advanced computational models.
Recently, hyperspectral image super-resolution (HSISR) has become a vibrant research topic. Wang et al. [9] provided a systematic review of HSISR. This review categorizes HSISR techniques into fusion-based techniques [10,11] and single-image SR techniques [12,13], and highlights key challenges including spectral distortion and edge preservation. Fusion-based techniques typically integrate low-resolution (LR) HSIs with complementary high-resolution (HR) images, such as RGB or multispectral images. This produces results with enhanced spatial details while preserving spectral fidelity. However, these methods depend on HR auxiliary images and require complete registration with the HSIs. These requirements pose significant challenges in practical applications. Single-image SR does not depend on auxiliary images and only utilizes the LR HSIs to improve spatial resolution, making it more flexible in practical applications.
In the past, traditional single HSISR methods primarily relied on manually defined prior constraints and assumptions, such as sparse regularization [14] and three-dimensional total variation [15]. These prior constraints often fail to capture the complex features of HSIs, thereby limiting the models’ generalization ability. Recent surveys, such as Wang et al. [9], have also noted that prior constraints are often too simplistic to model complex real-world scenes. This has motivated a shift toward data-driven deep learning approaches.
Currently, convolutional neural networks (CNNs) have been extensively applied to natural image SR [16,17]. The core principle lies in extracting complex structural features in images through multiple convolutional layers and feature learning mechanisms [18,19,20]. Due to the outstanding performance of CNNs in image SR, researchers have extended their application to HSISR. The existing deep learning-based HSISR networks are mainly divided into 2D CNNs [21,22,23] and 3D CNNs [24,25,26,27]. Two-dimensional CNNs conduct independent convolution operations on each spectral band, which ignores spectral continuity. Three-dimensional CNNs can explore both spatial context and spectral correlations between adjacent bands. However, 3D CNNs fail to capture long-range spatial correlations and spectral similarities. Additionally, 3D convolutions introduce significant computational complexity.
To overcome these limitations, the Transformer architecture has been introduced into HSISR in recent studies [28,29]. As a deep learning model based on self-attention mechanisms, the Transformer excels at capturing global information and long-range dependencies. In contrast, CNNs efficiently extract fine local features due to their local receptive fields. Their complementary strengths in feature extraction have been applied to HSISR. For example, SwinIR [30] and SST [31] incorporate convolutional layers after multiple Transformer modules, combining the local inductive bias of CNNs with the global attention capability of the Transformer. Based on these complementary features, the DSSTSR network [32] designs the dual self-attention Swin Transformer, which utilizes spatial–spectral self-attention to minimize spectral distortion while extracting spatial features.
However, these methods typically suffer from two main limitations. First, they fail to fully utilize fine edge details. Second, they cannot model both local and global features simultaneously. These issues not only degrade visual quality but also impair the performance of downstream vision tasks that rely on precise spatial and spectral information [33], such as target detection, land cover classification, and fine-grained material identification. Therefore, it is crucial to develop an SR method that can effectively preserve edges and captures both local and global features.
Inspired by this, we propose an Edge-Distilled and Local–Global Feature Selection network (EDLGFS) for HSISR. This network adopts a parallel dual-path architecture. The main branch captures the complex local–global features and the auxiliary edge branch focuses on extracting and refining edge details. This separation treats edge information as explicit prior knowledge. It prevents edge details from being suppressed by other features, which is a common issue in single-stream designs. A core component of the network is the intermediate supervision strategy. We design a dynamic loss mechanism between the two branches. This guides the main branch to learn the edge details from the auxiliary branch instead of directly fusing features. During the intermediate feature extraction, we propose a Local–Global Feature Selection (LGFS) module. It combines convolutions of different sizes with self-attention to model spatial correlations among features of different receptive fields. This module achieves efficient feature selection, thereby capturing local–global features more effectively. Extensive experiments on three public datasets demonstrate that EDLGFS achieves superior SR reconstruction quality.
The core innovation of this paper lies in the integrated design of the overall architecture. It incorporates edge knowledge distillation, local–global feature selection, and a dynamic loss mechanism. In this study, our main contributions are summarized as follows:
- (1)We propose a super-resolution network using an edge distillation architecture. The auxiliary edge branch transfers knowledge only during training and is removed for inference. This guides the main branch to learn edge details without increasing computational complexity.
- (2)We design a Local–Global Feature Selection (LGFS) module. This module combines convolutions of different sizes with the self-attention. This fully captures local–global features through efficient feature selection.
- (3)We introduce a dynamic edge loss mechanism. By assigning learnable weights to different loss terms, it adaptively balances edge detail preservation and overall reconstruction. This method enhances training stability and improves the model’s reconstruction performance.
The structure of the remaining part of this article is as follows: Section 2 reviews existing SR methods for HSIs. Section 3 details the proposed EDLGFS method. Section 4 presents the datasets, experimental results and ablation studies. Finally, Section 5 concludes the paper.
2. Related Work
2.1. CNN-Based Single HSISR
Deep learning techniques have recently driven significant progress in single HSISR. Consequently, numerous convolutional neural networks (CNNs) have been developed for this task [12,21,23,24,34]. Li et al. [21] proposed an HSISR method combining a spatial constraint (SCT) strategy with a deep spectral difference CNN (SDCNN), which effectively enhances spatial resolution while preserving spectral integrity. Jia et al. [23] proposed a Spectral–Spatial Network (SSN) that divides the reconstruction task into a spatial section, enhanced by a maximum variance principle, and a spectral section optimized via a spectral angle error loss function to preserve spectral signatures. Yuan et al. [35] transferred knowledge from natural images to learn a low-to-high-resolution mapping for HSIs. They also used collaborative non-negative matrix factorization (CNMF) to preserve spectral characteristics. In order to capture the spectral continuity across adjacent bands in HSIs, Mei et al. [24] proposed a 3D full CNN (3D-FCNN) for HSISR. Li et al. [36] proposed a Mixed Convolution Network (MCNet) for HSISR. It combines 2D and 3D convolutions to better capture latent spatial features. Liu et al. [37] proposed a fully 3D U-Net (F3DUN) with skip connections for deep multi-scale feature extraction. Their work demonstrated the efficacy of pure 3D CNN for HSISR. Wang et al. [9] provided a comprehensive review of deep learning-based HSISR methods. They categorized techniques into single image, panchromatic image-assisted, and multispectral image-assisted approaches. Additionally, they summarized common datasets, metrics, and applications. Hu et al. [38] proposed a novel HSISR method named SNLSR, which recasts the SR task into the abundance domain. It utilizes a spatial-preserving decomposition network and spectral non-local attention to restore high-frequency details. Li et al. [39] proposed a Test-Time Training framework for HSISR that incorporates a novel self-training strategy and Spectral Mixup augmentation, effectively overcoming data scarcity to significantly enhance reconstruction performance across diverse re-al-world scenarios. However, these CNN-based methods primarily extract local features. They often fail to effectively model long-range spatial correlations and spectral similarities.
2.2. Transformer-Based Single HSISR
The Transformer possesses robust long-range dependency modeling capabilities and is widely applied in HSISR tasks. Liu et al. [40] proposed an innovative method to address HSISR by fusing a Transformer with 3D CNN. Their Interactformer model uses a dual-branch architecture. It effectively preserves spectral integrity while enhancing spatial details. Chen et al. [41] proposed a Multi-Scale Deformable Transformer (MSDformer). This method combines the local feature extraction strengths of CNNs with the global modeling capabilities of Transformers. It utilizes a Multi-Scale Spectral Attention Module to precisely extract local multi-scale features and employs a Deformation Convolution-based Transformation Module to effectively capture global long-range dependencies. Zhang et al. [42] proposed an efficient Transformer model named ESSAformer, which incorporates a linear complexity attention mechanism based on the spectral correlation coefficient (SCC). This approach not only reduces computational cost but also enhances reconstruction quality. Chen et al. [43] introduced a novel Cross-range Spatial–Spectral Transformer (CST). This method employs cross-attention mechanisms across spatial and spectral dimensions to capture long-range spatial–spectral dependencies. Zhang et al. [44] proposed a spatial–spectral aggregation Transformer that incorporates diffusion priors. It extracts prior features using a self-supervised diffusion model. By integrating an adaptive fusion module, it significantly improves reconstruction quality. However, these methods primarily focus on enhancing overall reconstruction quality. They often fail to fully exploit fine features like image edges.
2.3. Edge-Guided Single Image SR
Researchers have explored various edge-guided strategies to fully exploit edge details in HSIs. For example, Yang et al. [45] proposed a deep edge-guided recurrent residual network named DEGREE, which progressively restores high-frequency details using recurrent residuals and edge information. Zhao et al. [46] proposed G-RDN, which enhances image reconstruction quality by utilizing spatial gradients to highlight edges and textural details. Wang et al. [47] introduced the Edge-Guided Super-Resolution Network (EGSRN). This network employs an Edge Net module to explicitly extract edge features from LR images. It then integrates edge and image features through multi-layer Feature Extraction Modules and an Edge Information Fusion mechanism. However, these methods often fail to effectively capture local–global features, limiting the completeness of feature representation. This paper proposes an Edge-Distilled and Local–Global Feature Selection network (EDLGFS) to address these challenges. This network efficiently extracts fine edge features while simultaneously capturing local features and global contextual information.
3. Materials and Methods
3.1. Overall Network
Figure 1 depicts the overall framework of EDLGFS, which consists of two parallel branches. The main branch learns complex local–global features, while the auxiliary edge branch focuses on extracting and refining edge details. The auxiliary edge branch guides the main branch through knowledge distillation. We denote the input LR HSIs as , the original HR HSIs as , and the reconstructed HSIs as , where and represent height and width respectively. denotes the SR scaling factor, and denotes the number of spectra bands. We first extract edge maps from for each spectral band using the Sobel operator. This is expressed as follows:
where represents the Sobel edge extraction function. represents the edge image extracted from . The shallow features are extracted through a 3 × 3 convolution layer. This process can be represented as follows:
where and denote shallow feature extraction functions and and represent the corresponding shallow features. Subsequently, is processed through a series of Local–Global Feature Selection Stages (LGFSSs) to extract deep features. Meanwhile, is processed by a sequence of Edge Net modules to extract deep edge features.
The LGFSS comprises two parallel branches. The first branch employs a series of Local–Global Feature Selection layers (LGFSLs) followed by a 3 × 3 convolution. The second branch consists of two consecutive 3 × 3 convolutional layers and a spectral attention layer [43]. The features from both branches are adaptively fused via residual connections. The deep feature can be expressed as follows:
where represents the function of the n-th LGFSS, and represents the corresponding deep features extracted by the n-th LGFSS. In parallel, is processed by an equal number of Edge Net modules to extract hierarchical edge features. Each Edge Net module consists of two consecutive 3 × 3 convolutional layers and residual connections. Deep edge feature extraction is expressed as follows:
where denotes the n-th Edge Net function, and represents the deep edge features extracted by the n-th Edge Net. We employ an edge loss function ( ) to connect all levels of and separately, so that can learn the edge feature from . Then, the outputs from the last layer ( and ) are processed via skip connections and a convolutional layer. The final deep features are represented as follows:
where and represent the deep features. Finally, the image reconstruction layer processes the deep features to generate the SR image, which is represented as follows:
where and denote the upsampling operations via the PixelShuffle method. and represent the reconstructed HSI and edge map, respectively. Finally, learns image-level edge information from through an edge loss function ( ).
3.2. Local–Global Feature Selection (LGFS)
To fully capture the local–global features, we introduce the Local–Global Feature Selection layer (LGFSL), inspired by the Metaformer architecture [48]. Additionally, we incorporate the Cross-Scope Spectral Self-Attention module (CSE) [43] within LGFSL to extract cross-range spectral correlations in HSIs. As shown in Figure 2a, LGFSL consists of two LayerNorm layers, a Local–Global Feature Selection (LGFS) module, a CSE module, and a Feed-Forward Network (MLP). These modules are connected through two residual structures.
For the input feature , the whole process of LGFSL is represented as follows:
where denotes the output feature, denotes LayerNorm, denotes LGFSL, denotes CSE, and denotes the multi-layer perceptron module.
Due to the ability to capture long-range dependencies [49,50,51,52], self-attention mechanisms have been widely applied in many SR methods. However, these methods often fail to effectively capture local–global features. We propose the Local–Global Feature Selection (LGFS) module to address this issue. Its structure is shown in Figure 2b.
Given that denotes the input feature of LGFS, then, is projected into query ( ), key ( ), and value ( ) through a large kernel convolution, a small kernel convolution, and a point-wise convolution, respectively. It can be expressed as follows:
where , , and denote large kernel, small kernel, and point-wise convolutions, respectively. Large kernels have a larger receptive field, enabling them to capture broader contextual information and enhancing global modeling capabilities. Small kernels focus on local detailed features and refined spatial structures. By combining small and large kernels, the network can efficiently capture local–global features. Next, after transposing and flattening the spatial dimensions of , , and , they are reshaped into , , and . Then, we obtain the attention score by matrix multiplication:
where represents the similarity between all spatial positions, and the symbol represents matrix multiplication. Then, we apply the softmax function to obtain the attention weights, which is represented as follows:
where represents the attention weights. The softmax function is applied along the last dimension to ensure that the sum of weights at each position is 1. Then the feature is weighted and aggregated using the attention weight, which is represented as follows:
Finally, is transposed and reshaped into , which is added to the original input to realize the residual connection. It is expressed as follows:
where represents the module output. The residual connection facilitates gradient flow and stabilizes the training process. The LGFS module enables effective local–global feature selection, thereby enhancing SR reconstruction quality.
3.3. Dynamic Loss Mechanism
At present, many works have demonstrated that and loss functions have achieved good results in SR tasks [53]. The loss function encourages finding a reasonable pixel-level average, which may lead to too smooth results. The loss function can better balance the error distribution. Therefore, we employ the loss function for both assessing the quality of the SR reconstruction and guiding the main network to learn edge features. Additionally, we designed learnable dynamic weights to more effectively balance the contribution of each loss term.
Given represents the deep features obtained by the n-th LGFSS block of the main network, and represents the deep edge features obtained by the n-th Edge Net block of the auxiliary edge network. Then, the edge loss of the n-th deep feature and the total edge loss of all deep features can be expressed as follows:
where denotes the batch size, indicates the number of deep features in the network, denotes the n-th deep feature of the m-th image, represents the n-th deep edge feature of the m-th image, and represents the learnable parameters in our network.
In addition, for the reconstructed HSIs and the reconstructed edge image , we use the loss function to guide the network to learn the reconstructed edge features, which can be expressed as follows:
where denotes the batch size and and represent the m-th reconstructed HSIs and the m-th reconstructed edge image respectively.
In addition to the above edge loss, we also designed loss functions and for data monitoring. is to compare the reconstructed HSIs with the real HR HSIs, and is to compare the reconstructed edge image with the real edge image. and can be expressed as follows:
where is the number of inputs in the training batch, and , respectively, represent the m-th reconstructed HSIs and real HR HSIs, and represent the m-th reconstructed edge image and real HR edge image, respectively, and is extracted from by using Sobel operator.
We define the total loss function for the network as follows:
where and are the dynamic learnable weights we designed, aiming to balance the contribution of different loss terms.
4. Experiments and Results
4.1. Datasets
To evaluate our method, we conduct experiments on three public HSI datasets: Houston, Pavia Center, and Chikusei.
(1)Houston
The Houston 2018 dataset is a part of the 2018 IEEE GRSS Data Fusion Competition. It includes Multispectral-LiDAR point cloud data, hyperspectral data, and very-high-resolution RGB imagery. Hyperspectral data was obtained by the ITRES CASI 1500 spectral imaging instrument on the University of Houston campus in Houston, TX, USA. It covers a spectral range of 380–1050 nm with 48 bands and has a ground sampling distance (GSD) of 1 m. The spatial dimensions are 601 × 2384. After normalization, this data is used in this study.
(2)Pavia Center
The Pavia Center dataset was obtained by the Reflective Optical System Imaging Spectrometer (ROSIS) sensor. It was collected over central Pavia, Italy, in 2001. The dataset covers a wavelength range of 430 to 860 nm and contains 102 spectral bands. The spatial dimensions are 1096 × 1096 and the ground sampling distance is 1.3 m. After removing the low-quality areas and bands with low signal-to-noise ratio from the image, the final image size is 1096 × 715 × 102. After normalization, the image is used as the dataset for this study.
(3)Chikusei
Covering agricultural and urban regions in Chikusei, Ibaraki, Japan, the Chikusei dataset was captured using the Headwall Hyperspec-VNIR-C imaging sensor. The ground sampling distance of this dataset is 2.5 m. It consists of 128 spectral bands, and the spectral range covers 363 to 1018 nm. The original spatial dimensions are 2517 × 2335. After removing invalid edge areas, the final size of the Chikusei data is 2304 × 2048 × 128. After normalization, the image is used as the dataset for this study.
4.2. Evaluation Metrics and Training Details
We compare EDLGFS against eight advanced methods: the classical bicubic interpolation, 3D-FCNN [24], MCNet [36], LN-atten-CNN [34], G-RDN [46], MSDformer [41], SNLSR [38], and CST [43]. All hyperparameters are kept consistent with their original references as much as possible. However, some parameters were adjusted due to hardware constraints and dataset variations. For example, we have verified that PSNR saturates before 100 epochs for all methods. Therefore, we have uniformly set the epochs to 100. Specifically, due to the high computational cost of MCNet, its batch size was set to 8 for the Chikusei dataset. The parameter settings for the comparison methods are shown in Table 1. Three widely adopted metrics are employed for evaluation: Peak Signal-to-Noise Ratio (PSNR), Structural Similarity (SSIM) and Spectral Angle Mapper (SAM). Their ideal values are +∞ for PSNR, 1 for SSIM, and 0 for SAM.
In the proposed EDLGFS, we employ 3 × 3 kernels for standard convolutions and 1 × 1 kernels for pointwise convolutions. The input channels of the first 3 × 3 convolution correspond to number of bands in the input HSIs. We set the number of feature channels to 96. The numbers of LGFSS and LGFSL are both set to 4. In the LGFS module, the large and small kernel sizes are set to 5 × 5 and 3 × 3, respectively. We use a progressive upsampling strategy [54] to upscale LR HSIs (for example, when the scaling factor is 4, upsampling twice, and when the scaling factor is 8, upsampling three times). The learnable weights and in the loss function are initialized to 0.95 and 0.05, respectively. The network is trained for 100 epochs using the Adam optimizer with a learning rate of 10^−4^. The batch size is set to 32. All experiments were implemented in PyTorch 2.1.0 on the platform of the National Supercomputing Center in Zhengzhou.
4.3. Results of Houston Dataset
For the Houston 2018 dataset, we extract four non-overlapping 256 × 256 × 48 patches from the left region for testing. The remaining region serves as the training set. We augment this data by rotating the images by 90°, 180°, and 270°. Then, we crop the augmented images into 64 × 64 × 48 patches with a spatial overlap of 44 pixels. These patches serve as the reference HR HSIs. According to the Wald protocol [55,56], we generate corresponding LR image patches through band-wise Gaussian filtering. This process constructs the HR and LR image pairs. Specifically, we apply downsampling factors of 2, 4, and 8. This yields LR patches with spatial dimensions of 32 × 32, 16 × 16, and 8 × 8 pixels, respectively.
Table 2 presents the average metrics of all comparative algorithms on the Houston dataset. The best results are highlighted in bold, and the second-best are underlined. For scale factors ×2, ×4, and ×8, all deep learning-based methods consistently outperform the traditional bicubic interpolation method by a significant margin. The proposed EDLGFS achieves the best performance across all scale factors. In terms of PSNR and SSIM, EDLGFS significantly surpasses both traditional and advanced methods. This indicates that the proposed EDLGFS restores the spatial details and structural information more accurately. Additionally, EDLGFS achieves lower SAM values than competing methods. This suggests effective mitigation of spectral distortion and a better balance between spatial enhancement and spectral preservation. EDLGFS demonstrates greater robustness across increasing scale factors (from ×2 to ×8), exhibiting less performance degradation than other methods. Especially in the challenging scale factor ×8, it still maintains a significant advantage, demonstrating its adaptability to diverse resolution demands. Furthermore, we calculate the number of parameters and the computational cost (GFLOPs) during the inference process for a test image, as shown in Table 2. The computational cost of the proposed EDLGFS is significantly lower than that of 3D CNN-based methods. The results indicate that EDLGFS achieves a better balance between reconstruction accuracy and computational efficiency.
We present qualitative results on the Houston (scale factor ×4) in Figure 3, to visually illustrate the effectiveness of EDLGFS. Pseudo-R-G-B images are generated by combining the 16th, 32nd, and 40th spectral bands. From the results, the image reconstructed by the traditional Bicubic interpolation method is significantly blurred with substantial loss of structural details. Deep learning methods, such as 3D-FCNN, MSDformer, and CST among others, have achieved satisfactory reconstruction quality. However, there is still mild blurring at the building edges, insufficient contour sharpness, and discontinuous local details. In contrast, the proposed EDLGFS produces clearer edges and superior texture details. Through the enlarged picture in the red box, we can see our advantages more clearly. In addition, Figure 4 visualizes the mean error maps across all spectral bands to assess pixel-wise reconstruction accuracy. In the error map, blue and red indicate lower and higher reconstruction errors. As indicated by the enlarged area of the red box, EDLGFS exhibits lower reconstruction errors than other methods, indicating that EDLGFS has superior reconstruction quality. Finally, Figure 5 shows the average spectral difference curves (for scale factors ×4 and ×8) across the test images, which are used to evaluate the spectral reconstruction quality. A lower curve indicates higher spectral consistency with the Ground Truth (GT). These results confirm that EDLGFS achieves the best spectral fidelity across different scales.
4.4. Results on Pavia Center Dataset
For the Pavia Center dataset, four test images of size 256 × 256 × 102 are extracted from the left region without overlap. The remaining region is used for training. We first perform data augmentation on this remaining region by rotating it by 90°, 180°, and 270°. Then, we crop the augmented images into 64 × 64 × 102 patches with a spatial overlap of 52 pixels. These patches serve as the reference HR HSIs. We generate corresponding LR image patches from these reference HR image patches through band-wise Gaussian filtering. This process constructs the HR and LR image pairs. Specifically, two, four, and eight Gaussian kernels are used to downsample the HR image patches, yielding their corresponding LR image patches of sizes 32 × 32 × 102, 16 × 16 × 102, and 8 × 8× 102.
For scale factors ×2, ×4, and ×8 on the Pavia Center dataset, Table 3 lists the average performance metrics (PSNR, SSIM, SAM) of all comparison methods. The Pavia Center dataset, acquired in 2001, presents inherent challenges including lower native spatial resolution and a limited available training area. Consequently, the overall results for all methods are lower than those obtained on the Houston dataset. Despite these challenges, the proposed EDLGFS consistently outperforms other methods in terms of PSNR, SSIM, and SAM across all scales. This result further confirms that EDLGFS has stable performance in HSISR. Consistent with the results on the Houston dataset, the computational complexity of EDLGFS on the Pavia Center dataset is significantly lower than that of 3D CNN-based methods. This demonstrates a favorable trade-off between reconstruction accuracy and efficiency.
We present the qualitative visualization results of each method on the Pavia Center dataset at a scale factor of ×4 in Figure 6. We select the 96th, 30th, and 15th bands of the images and combine them into pseudo-R-G-B images for visual comparison. Visual inspection reveals that other methods exhibit blurred details. Specifically, building textures and edge contours lack sharpness. However, the proposed EDLGFS demonstrates superior visual fidelity. It achieves overall quality closer to the Ground Truth (GT) and accurately restores edge details and building textures. The enlarged area corresponding to the red box in the figure more intuitively highlights the significant advantage of the proposed EDLGFS in detail restoration. Figure 7 compares error distributions of each method for a scale factor ×4. In Figure 7, the proposed EDLGFS shows a smaller extent of red (high-error) regions, confirming its superior spatial reconstruction accuracy. Finally, the spectral fidelity is evaluated through average spectral difference curves for scale factors ×4 and ×8, as shown in Figure 8. The proposed EDLGFS achieves the lowest spectral difference curves at both scales, demonstrating that it better preserves spectral features.
4.5. Results on Chikusei Dataset
For the Chikusei dataset, eight test images of size 256 × 256 × 128 are extracted from the top region without overlap. The remaining region is used for training. We augment this data by rotating the images by 90°, 180°, and 270°. Then, we crop the augmented images into 64 × 64 × 128 patches with a spatial overlap of 24 pixels. These patches serve as the reference HR HSIs. We generate corresponding LR image patches from these reference HR image patches through band-wise Gaussian filtering. This process constructs the HR and LR image pairs. Specifically, two, four, and eight Gaussian kernels are used to downsample the HR image patches, yielding their corresponding LR image patches of sizes 32 × 32 × 128, 16 × 16 × 128, and 8 × 8× 128.
Table 4 lists the quantitative results (PSNR, SSIM, SAM) on the Chikusei dataset for scale factors ×2, ×4, and ×8. The best and second-best values are shown in bold and underlined, respectively. Across all scales, the proposed EDLGFS demonstrates superior performance, leading the comparison both in reconstruction fidelity (PSNR, SSIM) and spectral accuracy (SAM). These results demonstrate that the proposed EDLGFS excels at reconstructing spatial details while preserving spectral quality. This further validates the effectiveness of the edge distillation strategy and the Local–Global Feature Selection mechanism. The proposed EDLGFS has achieved optimal performance across all three test datasets. For the Chikusei dataset, the computational complexity of the proposed EDLGFS is still lower than that of 3D CNN-based methods. These consistent results across diverse datasets demonstrate the strong generalization capabilities of EDLGFS.
Figure 9 presents a qualitative comparison of the Chikusei dataset at a scale factor of 4. For visualization, we select the 70th, 100th, and 36th spectral bands to generate pseudo-R-G-B images. The visualization results reveal that other comparison methods often result in edge blurring. In contrast, the proposed EDLGFS excels at restoring sharp edge details, offering a distinct visual advantage. This can be intuitively verified through the local magnified area marked by the red box. Figure 10 displays the error distribution maps for each method at a scale factor of 4. From the result, EDLGFS exhibits the smallest red (high-error) regions. This indicates minimal deviation from the Ground Truth (GT) and higher reconstruction precision. The average spectral difference curves for scale factors ×4 and ×8 are shown in Figure 11. The proposed EDLGFS achieves the lowest spectral difference curves, demonstrating its ability to effectively enhance spatial resolution while preserving spectral features more accurately than other methods.
4.6. Ablation Study
To assess the contribution of each core module to the overall super-resolution performance, an ablation study is conducted in this section. All ablation models are trained and evaluated on the Houston dataset at a scale factor of ×4.
4.6.1. Ablation Study on the Number of LGFSSs
Our core feature reconstruction network consists of a series of LGFSSs. In this section, we investigate the impact of the number of LGFSSs (denoted as N) on the model’s reconstruction ability. As shown in Table 5, when N increases from 3 to 4, the number of model parameters increases from 6.00 M to 7.71 M, and the computational cost (GFLOPs) increases from 34.32 to 41.52. Concurrently, both PSNR and SSIM improve. At this point, PSNR (33.2695) and SSIM (0.9862) reach the optimal level in the table (indicated in bold). As N continues to increase to 5, the number of parameters further rises to 9.43 M, and computational cost increases to 48.71, but metrics such as PSNR and SSIM begin to decline. When N reaches 6, the model parameters quantity reaches 11.14 M, and the computational cost rises to 55.91. Meanwhile, the accuracy of the reconstruction indicators such as PSNR, SSIM, and SAM has significantly decreased. This result indicates that increasing the number of LGFSSs leads to a significant increase in model parameters and computational cost. However, the reconstruction performance of the model does not continuously improve as N increases. We attribute this to overfitting caused by increased depth. Deeper networks typically require larger training datasets to effectively learn feature mappings.
4.6.2. Break-Down Ablation
The proposed EDLGFS integrates three core designs: Edge Distillation, LGFS, and learnable loss weights. We conduct ablation studies on the Houston dataset (×4 and ×8 scaling), Pavia Center dataset (×4 scaling), and Chikusei dataset (×4 scaling) to evaluate the independent contributions of each design element. Each experiment has been independently run five times with five different random seeds. The results are reported as the mean ± standard deviation. Results are summarized in Table 6, Table 7 and Table 8 (best scores in bold). Experiments demonstrate that the proposed EDLGFS exhibits stable performance across all metrics with minimal standard deviation, indicating the model’s good stability. The following analysis is conducted from three aspects: removing the edge distillation branch, removing the LGFS module, and fixing learnable weights.
The design objective of the edge distillation strategy is to guide the model to focus on learning image edge details. When removing the edge branch, the edge-related loss term is disabled, and its corresponding weight is removed. Experiments demonstrate that removing the edge distillation branch leads to performance degradation across all datasets and scaling factors, particularly at higher scaling factors (such as ×8). For example, on the Houston dataset, after removing edge distillation, the PSNR decreases by approximately 0.16 dB and 0.43 dB at ×4 and ×8 scaling factors, respectively. On the Pavia Center and Chikusei datasets, the PSNR decreases by approximately 0.29 dB and 0.18 dB, respectively. This finding demonstrates that the edge distillation strategy effectively enhances the model’s ability to recover edge details. In addition, we only calculate the number of parameters and computational cost (GFLOPs) during the inference process for a test image, as shown in Table 6, Table 7 and Table 8. All parameters and computational costs are calculated using the “thop” library of PyTorch. Notably, the complete model imposes no additional parameters or computational cost during inference compared to the model without the edge branch. This is because the auxiliary edge network is utilized only during training and is discarded during inference. Thus, the strategy improves edge extraction without increasing inference overhead.
LGFS is designed to simultaneously capture both local spatial information and global long-range dependencies within images. The ablation experiment demonstrates that after removing this module, the model’s PSNR on the Houston dataset (×4 scaling) decreases by approximately 0.06 dB, and decreases by approximately 0.07 dB and 0.05 dB on the Pavia Center and Chikusei datasets, respectively. As shown in Table 6, Table 7 and Table 8, the parameters and computational costs significantly decrease after removing LGFS. This indicates that LGFS constitutes the primary component of computational cost in the proposed model. Nevertheless, LGFS significantly enhances the model’s ability to capture local–global features by integrating multi-scale convolution with a self-attention mechanism, thereby bringing stable improvements in multiple evaluation metrics.
The learnable weights in the loss function are designed to dynamically balance the contribution of each loss term. We have tested the impact of fixing the learnable weights to their initial values (0.95, 0.05). The experimental results show that on the Houston dataset (×4 scaling), the model’s PSNR decreases by approximately 0.03 dB. On Pavia Center and Chikusei datasets, the PSNR decreases by approximately 0.03 dB and 0.02 dB, respectively. Although the decrease is small, it still indicates that the learnable weights can adaptively balance the contributions of different loss terms, thereby optimizing the overall performance of the proposed model.
4.6.3. Ablation Study on the Different Convolution Kernel Sizes of LGFS
The proposed LGFS employs convolution with varying kernel sizes to capture features with different receptive fields. This section investigates the impact of different kernel size combinations on model performance. Table 9 presents quantitative comparison results for the Houston test dataset at a scale factor of ×4 (bold indicates optimal metrics). As shown in Table 9, when using the convolution kernel combination of (5 × 5, 3 × 3), the number of parameters size is 7.71 M and the computational cost is 41.52 GFLOPs, which is at a moderate level. Moreover, it simultaneously achieves the optimal level in PSNR, SSIM, and SAM. When using the combination of (3 × 3, 3 × 3) convolution kernels, although the number of parameters and computational cost are the lowest, the model is limited by a fixed receptive field and is difficult to effectively model cross-regional correlations (such as the overall object contours or distant context). For combinations such as (7 × 7, 3 × 3) and (7 × 7, 5 × 5) that involve larger-sized convolution kernels, the number of parameters and computational cost significantly increase. Furthermore, due to overly large receptive fields, the model tends to lose fine-grained local details during training, leading to performance degradation.
4.6.4. Ablation Study on the Different Initial Weights of Loss Function
This section investigates the impact of initial values for learnable weight parameters in the loss function. As shown in Table 10, the model achieves optimal reconstruction results when and , achieving optimal values for PSNR, SSIM, and SAM. As decreases and increases, the accuracy of reconstruction metrics such as PSNR, SSIM, and SAM shows a significant decline. The core cause of this trend is as follows: The loss term corresponding to directly restricts the global fitting degree between the model output and the real samples, which is the core constraint to ensure the overall accuracy of the reconstruction result. The loss term corresponding to focuses on edge details and belongs to an auxiliary constraint at the detail level. If the proportion of decreases and the proportion of increases, the model will overly focus on the matching of edge details, thereby weakening the core constraint on the overall reconstruction accuracy and ultimately leading to a decline in overall performance.
4.6.5. Robustness Analysis Against Degradations
Hyperspectral images are often affected by various degradations during imaging, such as noise, transmission errors, or sensor failures. Therefore, evaluating the robustness of super-resolution models against such data variations is crucial. In this section, we explore the reconstruction stability of the proposed EDLGFS under degraded conditions through robustness ablation experiments. To simulate noise effects and sensor failures during imaging, we introduced Gaussian noise and random value degradation into low-resolution image patches during data preparation. As shown in Table 11, the EDLGFS model demonstrates robust stability against both Gaussian noise and random value degradation. The slight degradation in performance is within an acceptable range, demonstrating the model’s adaptability and robustness to common data defects in real-world complex scenarios.
5. Conclusions
In this paper, a novel method named EDLGFS is proposed for HSISR. The proposed EDLGFS employs two parallel network branches. The main network learns the complex local–global features and the auxiliary edge network focuses on extracting and refining edge details. These two branches are connected through a knowledge distillation framework, where an edge loss function guides the main network to learn the edge details by the auxiliary edge network. Subsequently, we design a Local–Global Feature Selection mechanism (LGFS). This module first extracts feature representations with varying receptive fields through convolutional kernels of different sizes. Then, it employs the self-attention mechanism to model spatial dependencies between these features. By leveraging these spatial dependencies, it achieves an efficient feature selection mechanism that significantly enhances the ability to capture local–global feature. Additionally, we design a learnable dynamic loss mechanism, which assigns learnable weights to different loss terms, allowing the model to more effectively balance their contributions. Extensive experiments across multiple public datasets demonstrate that the proposed EDLGFS achieves superior reconstruction quality in HSISR.
Although the proposed EDLGFS demonstrates good performance in HSISR, it still has certain limitations. Firstly, the edge distillation branch relies on the Sobel operator for initial edge extraction. This method performs well in most cases, but it is sensitive to noise and complex textures, which may affect the stability of edge guidance in complex scenes. Future work could explore more robust edge detection algorithms or learnable edge extraction modules. Secondly, while the current loss function exhibits adaptability, it primarily optimizes pixel-level errors without sufficiently incorporating perceptual quality or spectral consistency constraints. Developing a more advanced loss function is expected to provide more effective guidance for edge restoration and spectral preservation. Importantly, these limitations do not undermine the validity of our core contributions but rather offer specific directions for future improvements.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1Bioucas-Dias J.M. Plaza A. Camps-Valls G. Scheunders P. Nasrabadi N. Chanussot J. Hyperspectral Remote Sensing Data Analysis and Future Challenges IEEE Geosci. Remote Sens. Mag.2013163610.1109/MGRS.2013.2244672 · doi ↗
- 2Yu H. Shang X. Song M. Hu J. Jiao T. Guo Q. Union of Class-Dependent Collaborative Representation Based on Maximum Margin Projection for Hyperspectral Imagery Classification IEEE J. Sel. Topics Appl. Earth Observ. Remote Sens.20211455356610.1109/JSTARS.2020.3038456 · doi ↗
- 3Xu Y. Zhang L. Du B. Zhang L. Hyperspectral Anomaly Detection Based on Machine Learning: An Overview IEEE J. Sel. Topics Appl. Earth Observ. Remote Sens.2022153351336410.1109/JSTARS.2022.3167830 · doi ↗
- 4Tan Y. Lu L. Bruzzone L. Guan R. Chang Z. Yang C. Hyperspectral band selection for lithologic discrimination and geological mapping IEEE J. Sel. Topics Appl. Earth Observ. Remote Sens.20201347148610.1109/JSTARS.2020.2964000 · doi ↗
- 5Lu G. Fei B. Medical hyperspectral imaging: A review J. Biomed. Opt.20141901090110.1117/1.JBO.19.1.01090124441941 PMC 3895860 · doi ↗ · pubmed ↗
- 6Sun H. Cao Q. Meng F. Xu J. Cheng M. Spatial-Channel Multiscale Transformer Network for Hyperspectral Unmixing Sensors 202525449310.3390/s 2514449340732622 PMC 12299682 · doi ↗ · pubmed ↗
- 7Huo Y. Dong Y. Wang C. Zhang M. Wang H. Multi-scale memory network with separation training for hyperspectral anomaly detection Inf. Process. Manag.20266310449410.1016/j.ipm.2025.104494 · doi ↗
- 8Landgrebe D.A. Serpico S.B. Crawford M.M. Singhroy V. Introduction to the special issue on analysis of hyperspectral image data IEEE Trans. Geosci. Remote Sens.2002391343134510.1109/TGRS.2001.934066 · doi ↗