A Lightweight Radar–Camera Fusion Deep Learning Model for Human Activity Recognition
Minkyung Jeon, Sungmin Woo

TL;DR
This paper introduces a privacy-friendly model that combines radar and camera data to accurately recognize human activities in indoor settings.
Contribution
A novel lightweight radar–camera fusion model using Transformer encoders for efficient and accurate human activity recognition.
Findings
The fusion model achieves 98.74% classification accuracy across 15 activity classes.
The model requires only 11 million floating-point operations, suitable for edge devices.
The model outperforms single-modality radar and camera baselines significantly.
Abstract
Human activity recognition in privacy-sensitive indoor environments requires sensing modalities that remain robust under illumination variation and background clutter while preserving user anonymity. To this end, this study proposes a lightweight radar–camera fusion deep learning model that integrates motion signatures from FMCW radar with coarse spatial cues from ultra-low-resolution camera frames. The radar stream is processed as a Range–Doppler–Time cube, where each frame is flattened and sequentially encoded using a Transformer-based temporal model to capture fine-grained micro-Doppler patterns. The visual stream employs a privacy-preserving 4×5-pixel camera input, from which a temporal sequence of difference frames is extracted and modeled with a dedicated camera Transformer encoder. The two modality-specific feature vectors—each representing the temporal dynamics of motion—are…
Genes, proteins, chemicals, diseases, species, mutations and cell lines named across the full text — each resolved to its canonical identifier and authoritative record.
Click any figure to enlarge with its caption.
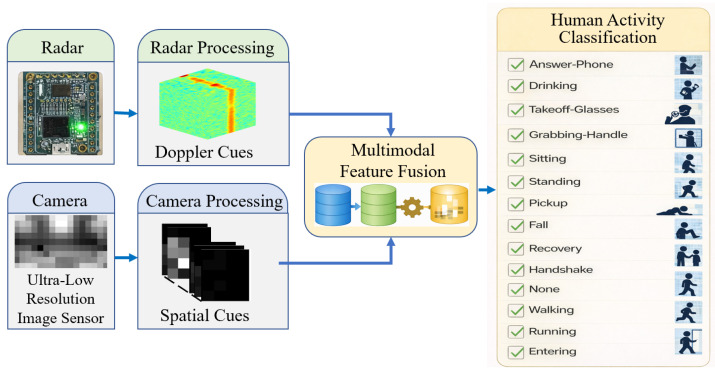 Figure 1
Figure 1 Figure 2
Figure 2 Figure 3
Figure 3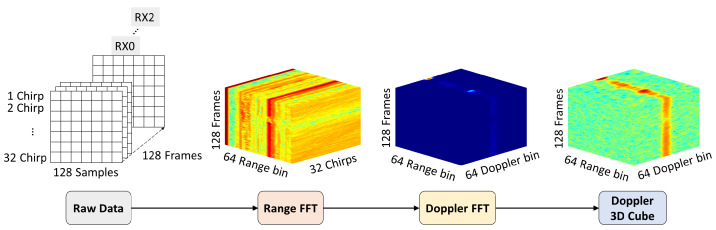 Figure 4
Figure 4 Figure 5
Figure 5 Figure 6
Figure 6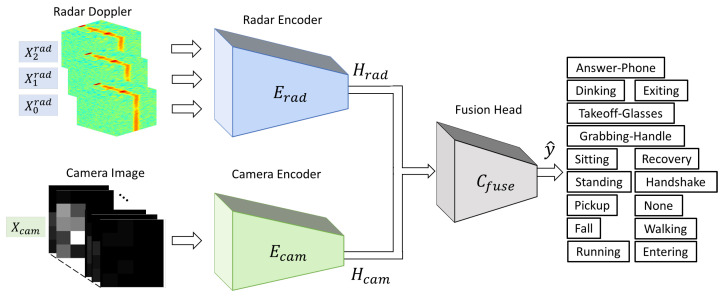 Figure 7
Figure 7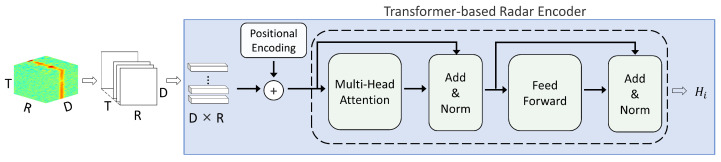 Figure 8
Figure 8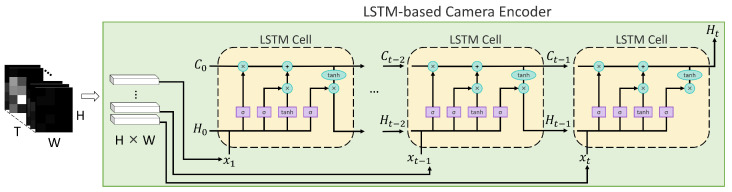 Figure 9
Figure 9 Figure 10
Figure 10- —Ministry of Education
- —Ministry of Education (MOE) and the Chungnam, Republic of Korea
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsAdvanced SAR Imaging Techniques · Non-Invasive Vital Sign Monitoring · Gait Recognition and Analysis
1. Introduction
Human Activity Recognition (HAR) aims to recognize and classify human activities from various sensing modalities using machine learning algorithms. HAR plays an important role in a wide range of applications including security, rehabilitation and patient monitoring, human–robot interaction, and daily-life behavior analysis such as hazardous activity detection and maintaining regular lifestyle routines [1,2,3,4,5,6,7,8,9].
Activity data can be broadly categorized into image-based data and non-image data. Image-based data include RGB, infrared (IR), and depth images, while non-image data include radar, gyroscopes, and accelerometers. Image-based HAR, which utilizes images captured by cameras, is a traditional and well-established approach [10,11,12]. Because it directly leverages visual information, it can capture fine-grained activity details such as subtle motion changes. However, prior studies have noted that vision-based approaches can raise privacy risks (e.g., potential identity leakage), particularly when high-resolution imagery is used [13]. Motivated by this issue, sensor-based HAR has attracted increasing attention as an alternative, and recent work reports a growing trend toward adopting wearable/sensor-based approaches [14]. Sensor-based HAR [15,16] can capture human motion with fewer privacy-related concerns, but it often exhibits limited discriminability for similar postures compared to image-based approaches.
Radar-based HAR using Frequency-Modulated Continuous Wave (FMCW) radar sensors [17,18,19] is largely robust to environmental factors such as illumination changes and enables contactless motion sensing. Nevertheless, radar signals alone may struggle to accurately discriminate fine-grained body movements or posture variations, which can lead to misclassification among visually similar activities.
As illustrated in Figure 1, this paper proposes a radar–camera fusion-based activity recognition model. Radar data provide range and velocity cues related to motion, while camera data provide complementary spatial cues. However, directly using high-resolution camera images still poses privacy risks due to the possibility of personal identification. Therefore, we assume a low-resolution camera stream and use only a region of interest; we then compute difference images between consecutive frames to retain only motion-change information. This preprocessing removes appearance and background details, enabling privacy-preserving activity recognition based solely on motion patterns. The proposed model adopts a lightweight architecture for real-time activity recognition and aims to achieve high accuracy without overly complex networks or a large number of parameters. Furthermore, we define 15 daily-life activity classes that cover both common and potentially hazardous behaviors, enhancing practical applicability in real-world environments.
Contributions. The main contributions of this work are summarized as follows:
- We propose a privacy-preserving radar–camera HAR framework in which we use only a camera stream and form temporal difference representations, retaining motion cues while removing identity-sensitive appearance information.
- We develop a lightweight multimodal fusion model that effectively integrates radar and privacy-preserving camera features, achieving high recognition accuracy with low computational complexity suitable for real-time deployment.
- We conduct comprehensive evaluations on 15 daily-life activity classes, including both static and dynamic motions, and provide detailed analyses (e.g., confusion matrices and modality-attention analysis) to demonstrate the complementary roles of radar and camera.
In this paper, Section 2 reviews the related work, Section 3 describes the proposed methods and presents the experimental results, and Section 4 provides further discussion. Section 5 discusses the limitations of the proposed approach, and Section 6 concludes the paper.
2. Related Work
HAR has evolved along two main axes: sensing modalities and model architectures. Sensor-based HAR leverages non-visual signals to enable activity recognition without directly capturing identifiable images, thereby mitigating privacy concerns. Among sensor modalities, FMCW radar has been widely adopted because it is robust to illumination changes and can capture human motion through characteristic signatures in the time, frequency, and range domains. Accordingly, radar-based HAR studies have explored diverse radar representations (e.g., range–Doppler, range–time, and time–frequency maps) together with spatiotemporal learning architectures.
Diraco et al. addressed privacy-sensitive environments by classifying 10 common bathroom activities using micro-Doppler signatures from a MIMO FMCW radar, employing a BiLSTM with multi-head attention to model temporal patterns [20]. Kim and Seo proposed the RD-CNN to learn time–frequency characteristics independently for each range bin [21], while Gianoglio et al. demonstrated real-time operation on embedded hardware using a lightweight CNN–LSTM architecture [22].
Recent research has increasingly focused on enhancing the discriminative power of radar signals through advanced attention mechanisms and efficient feature fusion while maintaining low computational complexity for edge deployment. Li et al. proposed MAEF-Net, which utilizes a multi-attention-enhanced fusion network to capture both local and global time–frequency characteristics from denoised TD maps, ensuring high accuracy with minimal overhead [23]. Similarly, Ding et al. introduced FML-ViT, a lightweight vision transformer that employs cascaded linear self-attention and context broadcasting to significantly reduce the computational complexity inherent in conventional attention-based models [24]. To further resolve ambiguities between similar motion profiles, Yuan et al. developed MFECNet, which fuses range–time (R–T) and Doppler–time (D–T) maps through a lightweight universal inverted bottleneck structure, effectively suppressing noise while enriching the feature representation [25].
Despite these advances in single-sensor processing, radar-only modalities often face inherent limitations in discriminating fine-grained activities with near-identical motion signatures. To overcome such ambiguity, the field has recently shifted towards sophisticated multimodal fusion approaches and the integration of foundation model-based architectures. Lately, the adoption of Multimodal Foundation Models (MFMs) has emerged as a dominant trend, enabling the interpretation of complex human contexts by aligning sensor data with language-based semantics [26,27,28]. These models leverage large-scale pre-training and self-supervised learning to achieve superior generalization across diverse environments.
Furthermore, new paradigms in data fusion and learning have been introduced to address data scarcity and privacy. Recent frameworks have pioneered the use of Federated Learning (FL) for multimodal HAR, integrating heterogeneous data while keeping sensitive information on-device [29]. Concurrently, Modality-Aware Contrastive Learning (MACL) has been investigated to extract robust features from unlabeled multimodal streams, further narrowing the gap between supervised and unsupervised recognition [30].
Multimodal fusion, particularly radar–camera fusion, continues to improve robustness by combining heterogeneous cues. Feng et al. utilized Low-Rank Multimodal Fusion (LMF) to integrate radar RVA maps and camera video sequences [31], and Zhou et al. demonstrated that fusing radar time–frequency spectrograms with high-resolution video significantly improves the discrimination of subtle inter-class differences [32].
Overall, prior work has progressed toward capturing fine-grained motion differences by combining informative radar representations with spatiotemporal models such as CNN–LSTM and Transformers. Multimodal fusion further enhances recognition by integrating radar’s non-visual sensing advantages with the spatial perception capability of cameras. However, many existing fusion approaches, including the latest foundation models, still rely on high-dimensional visual inputs and/or computationally demanding backbones, which can raise privacy concerns and hinder deployment on resource-limited devices. Motivated by these limitations, we propose a lightweight radar–camera fusion framework that emphasizes temporally compact motion representations from an ultra-low-resolution privacy-preserving camera stream while retaining radar’s robust motion sensing capability.
3. Proposed Methods
In this study, we propose a radar–camera-based deep learning model for recognizing 15 daily-life activities, including potentially hazardous behaviors. The proposed model improves recognition accuracy by fusing complementary radar and camera cues. To address privacy concerns in camera-based HAR, we use only an ultra-low-resolution camera stream in which personal identification is infeasible, and only motion-change information is preserved. To evaluate the proposed multimodal framework, we collected a dedicated dataset using a synchronized radar–camera sensing setup, as described in the following subsection.
3.1. Data Collection
Multimodal data were collected using an Infineon BGT60TR13C FMCW radar sensor (Infineon Technologies AG, Neubiberg, Germany) and a Sony ZV-1M2 camera (Sony Group Corporation, Minato, Tokyo, Japan), as illustrated in Figure 2. The BGT60TR13C operates at 60 GHz and was configured as summarized in Table 1. The camera captures video at 30 fps with a native resolution of 1280 × 720 pixels. For each recorded sample, approximately 3 s of synchronized radar and camera data were acquired.
All recordings were conducted indoors under normal lighting conditions without introducing artificial illumination changes. To incorporate environmental and viewpoint variability, data were collected from three different viewpoints and under multiple background configurations: (i) a background surface located at approximately 3.5 m from the sensors, (ii) a closer background surface at approximately 2 m, and (iii) a setup in which a doorway was visible to capture subjects entering and exiting the room. These configurations also introduced variation in the subject-to-sensor distance.
The dataset contains 15 daily activities. Detailed descriptions and representative examples of the 15 activities are provided below.
1.Answer-Phone: The subject stands in place and raises an arm to the ear, simulating answering a phone.2.Drinking: The subject stands in place and brings a bottle to the mouth, simulating drinking water.3.Takeoff-Glasses: The subject stands in place and removes glasses.4.Grabbing-Handle: The subject stands in place and grasps a door handle.5.Sitting: The subject transitions from a standing position to a seated position.6.Standing: The subject transitions from a seated position to a standing position.7.Pickup: The subject bends down to pick up an object from the floor and then stands up.8.Fall: The subject falls or collapses onto the floor.9.Recovery: The subject raises the upper body from a lying position on the floor.10.Handshake: The subject stands and raises one or both hands, waving them.11.None: The subject remains still in either a sitting or standing posture.12.Walking: The subject walks in various directions and at different speeds.13.Running: The subject runs in various directions and at different speeds.14.Entering: The subject enters the room from outside through the door.15.Exiting: The subject exits the room through the door.
For each activity, 450 scenes were recorded, resulting in a total of 6750 multimodal samples. The dataset includes recordings from two subjects, and both subjects appear in the training and test sets. To increase diversity in spatial conditions, we collected the dataset under multiple subject-to-sensor distances and viewing angles. Specifically, Answer-Phone, Drinking, Takeoff-Glasses, and Grabbing-Handle were recorded at two fixed distances (1.5 m and 2 m) with subjects positioned at predefined viewing angles, whereas the remaining activities (Sitting, Standing, Pickup, Handshake, None, Fall, Recovery, Walking, and Running) were recorded across three distance ranges (1.5–2 m, 2–2.5 m, and 2.5–3 m) and a broader set of viewing directions/angles. Table 2 summarizes the dataset acquisition settings.
Radar–camera synchronization was implemented in Python. Each sample contains 2.7 s of radar data (524,288 signal values) and a sequence of 41 camera frames.
Figure 3 presents five representative frames selected from the original 41-frame image sequence for each activity. These examples illustrate the spatiotemporal progression of each activity and highlight that the dataset captures realistic motion patterns and natural continuity of daily human behaviors.
3.2. Preprocessing
3.2.1. Radar Data
The raw radar data are FMCW-format floating-point values collected using the IfxRadar SDK, and 128 frames are stored to form a single scene. As shown in the Raw Data stage of Figure 4, each frame consists of 32 chirps, and each chirp contains 128 ADC samples. Consequently, the total data size for one scene comprises 524,288 signal values. At this stage, the raw signal is a floating-point value approximately in the range of to . This signal is converted into a 12-bit integer representation, i.e., within the range of 0 to 4095. As a result, a total of samples are generated per frame, and this process is repeated over 128 frames, yielding a total of 524,288 integer values. These data are stored as text files for each receiving antenna of the radar sensor, resulting in three separate radar data text files. In this study, the raw data acquired from the FMCW radar system are transformed into a sequence of Range–Doppler [31,32,33] maps, referred to as a Doppler cube, and used as input to the activity recognition model. The data preprocessing is performed on a per-frame basis following the steps described below.
1.Raw Data: The received frame data were reconstructed into a two-dimensional matrix of size . To improve signal processing accuracy, the mean value of each chirp was removed to compensate for DC offset. In addition, a recursive Moving Target Indicator (MTI) filter was applied to suppress strong clutter components originating from stationary background objects. The MTI filter isolates moving target signals by subtracting the clutter component estimated from the previous frame from the current radar frame. The MTI-filtered output is computed by removing the previous clutter estimate from the current frame as follows:
The clutter estimate is then updated using a weighted average of the current frame and the previous estimate :
where is the updated clutter estimate, and is the recursive coefficient controlling the update rate of the clutter model. In this study, was used, indicating that 80% of the clutter estimate is derived from the current frame while the remaining 20% is retained from the previous estimate. As the frame index progresses, the clutter estimate gradually converges, thereby effectively suppressing static components while preserving signals from dynamic targets.2.Range-FFT: A one-dimensional FFT was performed along the sample direction on the MTI-processed signal to extract range information. A Blackman–Harris window was applied to reduce sidelobes in the FFT spectrum. Half of the total samples, corresponding to range bins, were retained, and the result was reshaped to a size of . The cube obtained after the Range FFT corresponds to the Range FFT stage shown in Figure 4.3.Doppler-FFT: A one-dimensional FFT was performed along the chirp direction ( ) on the Range-FFT output to extract Doppler information. To improve Doppler resolution, zero padding with a length equal to was applied, expanding the matrix size to before performing the Doppler FFT. The resulting cube corresponds to the Doppler FFT stage shown in Figure 4.4.Doppler 3D Cube: After taking the magnitude of the final Range–Doppler map, the result was converted to the dB scale. To maintain consistency in the noise level, the converted values were clipped so that they did not fall below , i.e., . The Range–Doppler maps obtained from each frame were stacked over time to form the final Doppler cube with the size of . To reduce computational complexity and enable a lightweight model, the input to the radar network was further downsampled to .
3.2.2. Camera Data
The camera data were processed to retain coarse motion cues while reducing appearance and background information. Because a native ultra-low-resolution camera was not available, we captured frames at and immediately resized them to the intended resolution, after which all subsequent processing was performed only on the stream. The preprocessing pipeline then follows two steps: (1) motion-based region-of-interest (ROI) selection to focus on the most informative motion area, and (2) frame resizing and temporal differencing to generate a compact motion representations. This design supports effective activity recognition while reducing privacy risks by suppressing identity-revealing visual details in the representation used for learning and inference.
1.Motion-based ROI Cropping: To localize regions containing significant motion, temporal statistics were computed for each pixel location over an image sequence consisting of T frames *at the low-resolution input of *. The temporal mean and standard deviation of pixel intensities were defined as
Based on these statistics, a Standard Deviation–Mean ratio map (SM map) was defined as
where is a small constant introduced to prevent division by zero. The resulting SM map quantitatively captures relative temporal intensity variations, where higher values highlight regions of frequent inter-frame motion and lower values correspond to the static background. Specifically, the SM map is formulated as the ratio of the temporal standard deviation to the temporal mean ( ) over a window T. This coefficient of variation-based approach emphasizes relative temporal fluctuations rather than absolute intensity shifts. This characteristic provides inherent robustness to illumination changes. Sudden lighting variations typically impact the scene globally and simultaneously across most pixels. While such transitions may induce significant inter-frame differences at a specific time step, both the temporal mean ( ) and standard deviation ( ) tend to increase proportionally over the interval T. Consequently, since and in Equation (5) scale in a similar manner, the resulting SM values remain relatively stable. This mathematical property allows the system to effectively distinguish global illumination artifacts from localized, activity-induced motion signatures.To reduce noise, a mean filter was applied to the SM map, producing a smoothed map . Let denote a global threshold computed as twice the average value of the smoothed map. If , we set , so that regions exhibiting weak temporal variations are suppressed and the subsequent ROI search focuses on motion-dominant areas. An integral image was then computed from the filtered SM map to efficiently evaluate the sum of motion energy within candidate bounding boxes.Candidate bounding boxes were generated under the following constraints:
- The aspect ratio was fixed at H:W = 2:1 to reflect typical human body proportions.
- To avoid overly small or overly large boxes in the domain, the box height was restricted to pixels, and the width was set to .
- For each pair, candidate boxes were enumerated by sliding the window over the SM map with a stride of 1 pixel, ensuring dense spatial coverage. Among all candidates, the bounding box that maximized the integrated motion energy was selected as the optimal ROI. Consequently, each image sequence was cropped to the smallest region containing the most significant motion, effectively suppressing irrelevant background information while preserving motion-centric features. The selected ROI was shared across all frames within a sequence to ensure temporal consistency. Figure 5 illustrates the motion-based ROI cropping process for a Sitting activity. Regions with higher SM values correspond to areas with significant temporal variations, and the bounding box that maximizes the integrated motion energy is selected as the final ROI.2.Frame Resizing and Differencing: After ROI cropping, the extracted image sequence was resized to an ultra-low resolution of to further remove identity-related visual details while maintaining essential motion patterns. Subsequently, frame-to-frame differencing was applied between consecutive frames to generate a sequence of 40 difference images. Each pixel value in the difference images represents the intensity change between adjacent frames, resulting in large magnitudes in motion regions and near-zero values in static areas. To suppress noise caused by minor illumination variations or sensor artifacts, pixel values with absolute differences less than or equal to 5 were set to zero. Finally, the difference images were normalized based on their absolute values, producing a compact motion representation suitable for real-time processing and privacy-preserving activity recognition. Figure 6 compares an original camera frame with the final preprocessed output. While the original frame contains rich appearance and background information, the preprocessed result retains only coarse motion patterns at an ultra-low resolution, demonstrating effective suppression of identity-sensitive visual details.
Finally, to minimize temporal misalignment between radar and camera data, timestamps from the two sensors were synchronized. Samples exhibiting a time difference greater than 0.05 s were discarded, ensuring temporal consistency between the multimodal inputs.
The processed camera stream is extremely low resolution; nevertheless, it provides crucial cues for action recognition, especially for activities such as Answer-Phone, Drinking, and Takeoff-Glasses, which involve localized movements of specific body parts rather than global body motion.
3.3. Multimodal Fusion Framework
Figure 7 illustrates the proposed multimodal fusion framework, which consists of modality-specific encoders and a classification head. The radar encoder and camera encoder independently extract compact temporal representations from their respective inputs, and a classification head is attached depending on the evaluation setting: (i) single-modality baseline evaluation using a modality-specific head, or (ii) multimodal activity recognition using a fusion head.
Let and denote the preprocessed radar and camera inputs, respectively, where corresponds to the Doppler cube acquired from the i-th receiving antenna. Each radar input is independently processed by a shared radar encoder , and the resulting feature vectors are concatenated to form the aggregated radar representation:
Similarly, the camera input is processed by the camera encoder as
where and represent the radar and camera encoders, and and denote the extracted modality-specific feature vectors. To ensure a consistent fusion interface and fair architectural comparisons, all radar and camera encoder variants are configured to output 48-dimensional feature vectors, i.e., and .
For multimodal fusion, the two features are concatenated and classified by a fusion head:
where denotes feature concatenation and is the predicted activity distribution over the 15 classes. The fusion head is implemented as a lightweight multilayer perceptron (MLP) with nonlinear activation functions and dropout for improved generalization.
In the proposed fusion model, A transformer-based encoder utilizing self-attention is adopted for the radar modality to effectively capture sequential motion patterns. For the camera modality, an LSTM-based encoder is employed to model temporal dynamics in the ultra-low-resolution video stream. In addition, CNN-based encoders employing 3D convolutions are implemented as alternative backbone architectures for comparative analysis, rather than as part of the proposed fusion framework. The detailed architectures of radar and camera encoders are described in Section 3.4 and Section 3.5, and the classification heads are summarized in Section 3.6.
3.4. Radar Encoder
This subsection describes the radar encoder , which extracts a compact temporal feature vector from radar measurements. The radar input is represented as a Range–Doppler–Time spectrum with dimensions . Measurements from three receiving antennas are processed by three identical branches, and branch-wise features are aggregated via concatenation to produce the final radar feature vector .
To analyze the impact of different feature extraction strategies, three radar encoder backbones are considered: (i) a Transformer-based [34,35,36] encoder utilizing self-attention, (ii) an LSTM-based [37,38,39,40] encoder, and (iii) a CNN-based [41,42] encoder employing 3D convolutions. The layer-wise configurations and dimensional transformations of these variants are summarized in Table 3, Table 4 and Table 5.
3.4.1. Transformer-Based Radar Encoder
Transformers provide two key advantages over LSTMs: (i) self-attention can capture global dependencies and complex patterns over long sequences with less information degradation than sequential recurrence [43], and (ii) the architecture enables substantial parallelization, improving training efficiency and scalability on modern hardware [44]. Motivated by these strengths, we employ a Transformer-based radar encoder in the proposed method: the radar cube is rearranged into a temporal sequence, each time step is embedded into a low-dimensional token, and self-attention is applied to model global temporal dependencies. Radar cubes from the three receiving antennas are processed by three independent Transformer encoder branches with identical architectures but separate parameters, enabling branch-wise learning of antenna-specific temporal patterns. A classification (CLS) token and positional embeddings are used, and the CLS output is taken as the branch-wise global representation. The feature extracted from the i-th branch is denoted as ( ). The three branch features are then concatenated to form the radar feature representation . The detailed architecture and dimensional transformations are summarized in Table 3. Figure 8 illustrates the Transformer-based radar encoder for a single branch, and the corresponding layer-wise structure is summarized in Table 3. Note that the final fully connected (FC) layer shown in Table 3 corresponds to the radar-only classification head used in the single-modality baseline setting; in the fusion framework, the encoder output is taken before this classification layer.
3.4.2. LSTM-Based Radar Encoder
In the LSTM-based configuration, the two-dimensional Doppler spectrum at each time step is flattened and fed into a single-layer LSTM. At the beginning of the sequence, the initial cell state and hidden state are initialized to zero vectors, representing the absence of prior temporal information. The LSTM then iteratively updates its internal states by processing the input sequence , where denotes the flattened Doppler spectrum at time step t. The hidden state at the final time step is used as the representative feature for each antenna branch, and the three branch features are concatenated to form . The corresponding layer-wise structure is summarized in Table 4.
3.4.3. CNN-Based Radar Encoder
The CNN-based radar encoder employs 3D convolutions to preserve the spatiotemporal structure of the radar cube and capture localized motion patterns. Each radar branch produces a compact feature vector through global pooling, and the three branch features are concatenated to form . The layer-wise configuration and dimensional changes are summarized in Table 5.
3.5. Camera Encoder
This subsection describes the camera encoder , which extracts temporal motion features from privacy-preserving camera inputs. The camera input consists of a sequence of preprocessed ultra-low-resolution difference frames with dimensions , which retain motion cues while suppressing identity-sensitive appearance information. The camera encoder outputs a 48-dimensional feature vector .
To enable fair comparisons, three camera encoder backbones are considered: an LSTM-based encoder, a CNN-based encoder employing 3D convolutions, and a Transformer-based encoder utilizing self-attention. The detailed layer-wise configurations are summarized in Table 6, Table 7 and Table 8.
3.5.1. LSTM-Based Camera Encoder
In the LSTM-based configuration, each difference frame is flattened into a compact vector and processed by a single-layer LSTM to model temporal motion patterns across the sequence. At the beginning of the sequence, the initial cell state and hidden state are initialized to zero vectors, indicating the absence of prior temporal information. The LSTM sequentially updates its internal states by processing the input sequence , where denotes the flattened difference frame at time step t. The hidden state at the final time step serves as the global camera feature vector . Figure 9 illustrates the overall processing pipeline, and Table 6 summarizes the corresponding layer-wise structure. As in the radar case, the final FC layer in Table 6 corresponds to the camera-only classification head used in the single-modality baseline setting; for multimodal fusion, the encoder output is used prior to this classification layer.
Similarly, the final fully connected layer in Table 6 corresponds to the camera-only classification head used in the single-modality baseline setting; for multimodal fusion, the camera encoder output is used prior to this layer.
3.5.2. CNN-Based Camera Encoder
The CNN-based camera encoder uses 3D convolutions to capture localized spatiotemporal motion cues from the camera cube and compresses the input into a compact representation via global pooling. The resulting feature vector is used as , and the layer-wise architecture is summarized in Table 7.
3.5.3. Transformer-Based Camera Encoder
The Transformer-based camera encoder treats each frame as a temporal token and applies self-attention to model long-range temporal dependencies in motion patterns. With positional embeddings and a CLS token, the CLS output provides the global representation . The detailed architecture is summarized in Table 8.
3.6. Classification Heads
To decouple feature extraction from classification and to support both single-modality baselines and multimodal fusion within a unified framework, different classification heads are attached on top of the encoder outputs depending on the evaluation setting.
For single-modality baselines, a modality-specific head is applied to each encoder output:
where and are implemented as a lightweight fully connected layer.
For multimodal fusion, the fusion head takes the concatenated feature vector and performs nonlinear transformations via an MLP before producing the final class prediction. The detailed configurations are summarized in Table 9.
3.7. Training Environment
All experiments were conducted using PyTorch 2.5.1 with CUDA 12.4 on an NVIDIA GeForce RTX 4090 GPU. Model training was performed in a Python 3.11.5 environment, and both training and evaluation codes were executed on a Windows 11-based system.
The models were optimized using the Adam optimizer with an initial learning rate of and default momentum parameters . A cross-entropy loss function with label smoothing was employed to promote stable learning of decision boundaries between activity classes. The batch size was set to 32, and all models were trained for 1000 epochs. To improve optimization stability and convergence, a ReduceLROnPlateau learning rate scheduler was applied based on the validation loss. The learning rate was reduced by a factor of 0.3 if no improvement was observed for 50 consecutive epochs, with a minimum learning rate of .
To ensure reproducibility, all experiments were conducted with fixed random seeds for Python, NumPy, and PyTorch. Deterministic behavior was enforced by disabling cuDNN benchmarking and enabling deterministic computation. In addition, gradient clipping with a maximum norm of 2.0 was applied to prevent gradient explosion during recurrent model training. All models were trained using the same hyperparameter configuration to ensure fair comparisons across different modality combinations. Model selection was performed based on the highest validation accuracy, and the corresponding weights were saved for final evaluation on the test set. A summary of the training environment and key hyperparameters is provided in Table 10, and the evaluation results are reported using accuracy metrics and confusion matrix analyses in the following section.
3.8. Dataset Split and Evaluation Protocol
For each activity class, 450 independently recorded scenes were collected and randomly split into training and test sets with a ratio of 5:1. The train–test split was performed randomly; however, to prevent distance-related bias, the test set was constructed by maintaining an equal proportion of samples from each distance condition. The dataset includes recordings from two subjects, and both subjects are present in both the training and test sets. As a result, cross-subject or cross-session validation was not conducted in this study. Instead, the evaluation focuses on assessing the effectiveness of multimodal fusion under consistent subject conditions.
3.9. Quantitative Evaluation
To objectively evaluate the proposed approach, we measured classification accuracy as well as computational cost in terms of FLOPs and the number of trainable parameters (Params). These metrics enable an analysis of the trade-off between recognition performance and computational efficiency. Table 11 compares the accuracy, computational complexity, and parameter counts of the single-modality baselines and the multimodal fusion model.
As shown in Table 11, the proposed fusion model achieved a mean accuracy of 98.74% (98.74 ± 0.55%) across five random seeds, outperforming the radar-only and camera-only baselines by 3.48 and 3.11 percentage points, respectively. This improvement indicates that jointly leveraging radar and camera cues yields more discriminative representations than using a single sensor alone. As discussed later, the fusion model particularly enhances recognition of activities that are difficult to distinguish with radar alone due to subtle motion patterns (e.g., Answer-Phone, Drinking, and Takeoff-Glasses), while also improving performance on more dynamic activities such as Running and Entering. Moreover, the low standard deviation across runs demonstrates that the proposed method is not only accurate but also statistically stable.
In addition, the proposed fusion strategy is benchmarked against Zhou et al. [24]’s CNN–LSTM data-level fusion and Feng et al. [23]’s low-rank multimodal fusion (LMF) under the same dataset and preprocessing pipeline, so that only the network architectures differ across methods. For Zhou et al. [24], radar and camera streams are concatenated at the input, forming a four-channel tensor (three radar channels + one camera channel) for 2D CNN processing; the radar temporal length is aligned to the camera sequence and unified to 40 frames for the subsequent LSTM. For Feng et al. [23], the domain discriminator is removed to isolate the fusion mechanism, and max pooling in the camera branch is applied conservatively to preserve spatial information under the ultra-low-resolution input.
As summarized in Table 11, Zhou et al. [24] and Feng et al. [23] achieve higher accuracies (99.70% and 98.89%, respectively) than the proposed method (98.74%). However, the proposed fusion model requires only 11 MFLOPs and runs in 0.64 ms per inference (approximately 1563 FPS), whereas Zhou et al. [24] and Feng et al. [23] require 2464 and 25,856 MFLOPs, respectively (i.e., ∼224× and ∼2350× higher computational costs). Overall, these results highlight a competitive accuracy–efficiency trade-off suitable for lightweight real-time deployment.
3.10. Model Variants: Encoder Backbones and Radar Representations
In this subsection, we compare model variants to analyze the impact of encoder backbones and radar input representations on both single-modality baselines and multimodal fusion performance. Three encoder architectures are considered for both modalities: LSTM-, 3D-CNN-, and Transformer-based encoders. The 3D-CNN encoders apply 3D convolutions to capture localized spatiotemporal motion patterns, whereas Transformer encoders leverage self-attention to model global dependencies. LSTM encoders are well suited for sequential modeling by compressing temporal dependencies into compact feature representations.
We additionally evaluate two radar preprocessing strategies using the same raw radar recordings: a Doppler-cube representation and a Short-Time Fourier Transform (STFT)-based spectrogram representation [45,46]. Unlike the Doppler-based method in Section 3.2.1, the STFT-based approach first performs an FFT for each chirp to obtain range information and then applies STFT along the time axis, yielding a more continuous description of spectral evolution over time.
Table 12 reports the accuracy and computational costs (FLOPs and parameter counts) of the three encoder backbones for radar-only and camera-only settings under identical training conditions. While both radar representations can be used with temporal encoders, the STFT-based representation provides finer temporal continuity, which can benefit sequence models such as LSTMs; this tendency is reflected by the improved radar LSTM performance with STFT compared to the Doppler-based representation.
We further examine how the encoder choices for each modality affect multimodal fusion. Table 13 summarizes the fusion accuracy and computational costs for different combinations of radar and camera encoders under Doppler and STFT radar representations. Across all evaluated combinations, fusion models outperform their corresponding single-modality baselines, confirming that radar and camera provide complementary cues. The best-performing configuration reaches 99.41% accuracy using a Doppler-based radar CNN and a camera LSTM.
3.11. Confusion Matrix
We computed confusion matrices to analyze which activity classes benefit most from the proposed fusion approach compared to single-modality classification. We focus on the LSTM-based results for the radar-only, camera-only, and fusion models, where the benefits of fusion are most pronounced. Table 14, Table 15 and Table 16 report the confusion matrices on the test set for the radar-only, camera-only, and fusion models, respectively.
A clear trend is observed for activities dominated by localized or subtle body-part motion, such as Answer-Phone, Drinking, and Takeoff-Glasses. In the radar-only model (Table 14), these classes are frequently confused with one another: Answer-Phone is misclassified as Drinking 16 times and as Takeoff-Glasses 7 times (67/90 correct), while Drinking and Takeoff-Glasses also show noticeable cross-confusions (77/90 and 73/90 correct). This behavior is consistent with the fact that radar signatures of such actions often exhibit limited range displacement and similar micro-Doppler patterns. By contrast, the camera-only model (Table 15) provides stronger separation for these classes even under privacy-preserving inputs, achieving 85/90 for Answer-Phone and 89/90 for Takeoff-Glasses. When both modalities are fused (Table 16), the remaining ambiguity is further reduced, yielding 88/90, 84/90, and 90/90 for Answer-Phone, Drinking, and Takeoff-Glasses, respectively.
A second representative failure mode of the radar-only model appears in posture-transition activities, especially Standing and Pickup. Although both actions involve prominent motion, their dominant component is largely vertical and can produce similar range–velocity trends, leading to severe mutual confusion in Table 14: only 38/90 samples of Standing are correctly classified, with 20 misclassified as Sitting and 20 as Pickup. Likewise, Pickup achieves 56/90 correct, with errors distributed across Standing (11) and Handshake (14). In contrast, the camera-only model maintains high recognition for these classes (89/90 for Standing and 88/90 for Pickup), suggesting that even ultra-low-resolution motion cues preserve discriminative spatial–temporal changes during posture transitions. Importantly, fusing radar and camera features substantially resolves the radar-only ambiguities, improving Standing from 38/90 to 87/90 and maintaining Pickup at 88/90 with only a small residual confusion to Handshake (2 cases).
To further understand the radar-only failures, Table 17 breaks down misclassifications of Standing and Pickup by subject-to-sensor distance and viewing angle. The distribution of errors suggests a clearer dependence on distance than on viewing angle: for Standing, misclassifications are most frequent at 2–2.5 m (23 cases), compared to 1.5–2 m (16) and 2.5–3 m (13); for Pickup, a similar peak is observed at 2–2.5 m (19 cases), compared to 1.5–2 m (9) and 2.5–3 m (6). Overall, these results indicate that radar-only discrimination between posture-transition activities tends to be more challenging at intermediate distances in our setup, while angle-dependent degradation appears less consistent.
Overall, these confusion-matrix analyses confirm that the two modalities contribute complementary strengths: the camera branch is particularly effective for localized or posture-related cues (e.g., Answer-Phone, Takeoff-Glasses, Standing), while the radar branch remains reliable for large-scale dynamic motions (e.g., Running, Entering/Exiting). The proposed fusion model leverages this complementarity to reduce class-specific confusions and produce more stable separation across both subtle and dynamic activities.
4. Discussion
Class-WiseTransformer Attention Analysis for Modality Contribution
To analyze modality contributions in the radar–camera fusion framework, we design an attention-inspection model in which the fusion module is implemented as a Transformer. This design enables explicit visualization of attention weight maps over modality-specific tokens, allowing us to examine how the fusion module attends to radar and camera information for each activity class.
In the analysis model, both the radar and camera feature extractors are implemented using 3D convolutional encoders. Their outputs are tokenized and concatenated to form the Transformer input sequence, and the Transformer produces the final activity prediction. To isolate the behavior of the fusion module during attention analysis, the radar and camera encoders are initialized with pretrained weights obtained from the single-modality 3D-CNN variants trained in Section 3.10 and then kept fixed during the fusion training stage.
We visualize the attention weight maps within the Transformer encoder to investigate how the model distributes attention across radar and camera tokens. The Transformer input consists of a total of 16 tokens, where tokens 1–8 correspond to radar features and tokens 9–16 correspond to camera features, following the tokenization scheme induced by the 3D convolution-based encoders. As these tokens pass through the Transformer encoder, distinct attention distributions emerge depending on the activity class. Figure 10 shows representative attention maps for six activity classes.
In the attention maps, the y-axis denotes the query tokens and the x-axis denotes the key tokens. For example, a brighter 10th column indicates that many queries strongly attend to the 10th token, suggesting that the token is informative for classification. To clearly distinguish between modalities, a red boundary line is drawn between radar tokens (1–8) and camera tokens (9–16).
The attention maps indicate that for low-dynamics activities such as Answer-Phone, Drinking, and Takeoff-Glasses, the model tends to assign higher attention to camera tokens. This suggests that ultra-low-resolution difference frames still preserve discriminative cues for subtle arm and upper-body motions, even when overall translational movement is limited. In contrast, for activities involving large-scale motion (e.g., Running, Entering, and Exiting), attention is more concentrated on radar tokens, consistent with radar’s ability to encode time-varying range–Doppler patterns associated with rapid velocity changes and translational movements.
Table 18 reports the average attention ratio assigned to radar and camera tokens for each activity class. Among the 15 activities, Walking, Running, Entering, and Exiting involve stronger translational motion across space. Consistent with the qualitative attention maps, radar tokens receive higher attention weights for these dynamic activities, whereas camera tokens receive higher attention weights for many activities performed mostly in place. Walking exhibits a near-balanced attention ratio, suggesting that both modalities contribute comparably for this class.
5. Limitation and Future Work
Although the proposed method demonstrates that even ultra-compact spatial cues from an extremely low-resolution camera can complement neural features and improve action recognition, several considerations are necessary before deploying it in real-world applications. First, our experiments were conducted with only two participants in a single classroom environment. While we additionally collected data at multiple subject–sensor distances, recognition performance may still vary with user-dependent factors such as body size, appearance (e.g., clothing color), and distance to the sensors. Moreover, radar measurements can be affected by environmental factors and electromagnetic interference from nearby electronic devices, which may influence performance.
We also note potential failure cases related to the camera modality. Since the camera branch relies on motion-change cues derived from frame differencing, frequent or abrupt illumination changes (e.g., flickering lights or rapid sunlight variations) may introduce spurious intensity differences and degrade recognition performance. In future work, we plan to improve robustness under such conditions through illumination-robust preprocessing and data augmentation (e.g., brightness/contrast jitter) and by exploring alternative motion representations less sensitive to lighting variations.
More broadly, the generalizability of the proposed approach across different indoor environments, sensor placements, and user populations remains an open question: variations in room layout, furniture configuration, sensor mounting height, and user physical characteristics can alter both radar reflections and low-resolution camera representations. Therefore, expanding the dataset to include multiple environments and a more diverse participant pool is an important next step toward improving real-world applicability.
Finally, although the proposed camera preprocessing is intended to remove identifiable visual cues, this study does not include a quantitative privacy assessment (e.g., re-identification attacks or privacy metrics). Future work will incorporate such evaluations to measure identity leakage directly.
6. Conclusions
This study proposed a lightweight radar–camera fusion framework for privacy-preserving human activity recognition. FMCW radar robustly captures motion dynamics through range–Doppler–time signatures and remains effective under challenging visual conditions (e.g., illumination changes), while camera measurements provide complementary spatial motion cues that can help resolve ambiguities between similar activities. However, conventional camera-based HAR systems often rely on high-resolution imagery and thus raise privacy concerns, whereas radar-only HAR can struggle to reliably discriminate fine-grained activities with similar motion profiles.
To address these limitations, we used a ultra-low-resolution camera stream and applied frame-to-frame differencing, so that the representation retains primarily motion-change information while suppressing appearance and background details. Radar measurements were represented as Doppler-based 3D cubes and unfolded into temporal sequences, which were encoded using an Transformer-based radar encoder. The modality-specific feature vectors were then fused by concatenation and classified through lightweight fully connected layers, resulting in a simple yet effective fusion architecture.
Experimental results demonstrated that the proposed fusion model consistently outperformed the corresponding single-modality baselines and achieved 98.74% overall accuracy. The fusion model improved recognition for both low-dynamics activities and dynamic activities involving pronounced temporal variations (e.g., Running and Entering). Confusion-matrix results further indicated reduced class confusions among visually or kinematically similar activities that were frequently misclassified by single-sensor models.
In terms of efficiency, the proposed model requires only approximately 11 MFLOPs, supporting real-time deployment on resource-constrained edge devices. Overall, this work presents a practical HAR solution that jointly targets privacy preservation, high recognition performance, and low computational cost, with potential applications in smart homes, indoor monitoring, and healthcare.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1Vrigkas M. Nikou C. Kakadiaris I.A. A review of human activity recognition methods Front. Robot. AI 201522810.3389/frobt.2015.00028 · doi ↗
- 2Aggarwal J.K. Xia L. Human activity recognition from 3d data: A review Pattern Recognit. Lett.201448708010.1016/j.patrec.2014.04.011 · doi ↗
- 3Kim E. Helal S. Cook D. Human activity recognition and pattern discovery IEEE Pervasive Comput.20099485310.1109/MPRV.2010.7PMC 302345721258659 · doi ↗ · pubmed ↗
- 4Gu F. Chung M.H. Chignell M. Valaee S. Zhou B. Liu X. A survey on deep learning for human activity recognition ACM Comput. Surv. (CSUR)20215417710.1145/3472290 · doi ↗
- 5Ramasamy Ramamurthy S. Roy N. Recent trends in machine learning for human activity recognition—A survey Wiley Interdiscip. Rev. Data Min. Knowl. Discov.20188 e 125410.1002/widm.1254 · doi ↗
- 6Haresamudram H. Anderson D.V. Plötz T. On the role of features in human activity recognition Proceedings of the 2019 ACM International Symposium on Wearable Computers London, UK 9–13 September 20197888
- 7Dhiman C. Vishwakarma D.K. A review of state-of-the-art techniques for abnormal human activity recognition Eng. Appl. Artif. Intell.201977214510.1016/j.engappai.2018.08.014 · doi ↗
- 8Wang W. Liu A.X. Shahzad M. Ling K. Lu S. Understanding and modeling of wifi signal based human activity recognition Proceedings of the 21st annual international conference on mobile computing and networking Paris, France 7–11 September 20156576