Hybrid Mamba–Graph Fusion with Multi-Stage Pseudo-Label Refinement for Semi-Supervised Hyperspectral–LiDAR Classification
Khanzada Muzammil Hussain, Keyun Zhao, Sachal Perviaz, Ying Li

TL;DR
This paper introduces a new deep learning framework that combines hyperspectral and LiDAR data using a hybrid model and pseudo-label refinement, achieving better classification accuracy with very few labeled examples.
Contribution
The novel HMGF-Net architecture integrates Mamba state-space modules and graph fusion with a multi-stage pseudo-label refinement pipeline for semi-supervised hyperspectral–LiDAR classification.
Findings
HMGF-Net achieves state-of-the-art classification accuracy on three benchmark datasets with up to 99% overall accuracy.
The hybrid model combining Mamba and graph-based fusion improves boundary delineation and reduces noise in classification maps.
Multi-stage pseudo-label refinement significantly enhances performance in low-label regimes with only ten labeled samples per class.
Abstract
What are the main findings? Novel Hybrid Architecture for HSI–LiDAR Fusion: We propose HMGF-Net, a unified multimodal network combining a spectral–spatial CNN (HSI) and a multi-scale CNN (LiDAR) with a Mamba state-space sequence module and a graph-based fusion layer to capture both local and long-range contextual features across modalities. Multi-Stage Pseudo-Label Refinement: We develop a three-stage semi-supervised training pipeline that progressively refines pseudolabels using confidence-based filtering, spatial–spectral smoothing via a KNN graph, and graph-consistency checks, effectively denoising labels and stabilizing training with very limited ground truth. What is the implication of the main findings? State-of-the-Art Performance with Limited Labels:The proposed approach achieves superior classification accuracy on three benchmark hyperspectral–LiDAR datasets (Houston2013,…
Click any figure to enlarge with its caption.
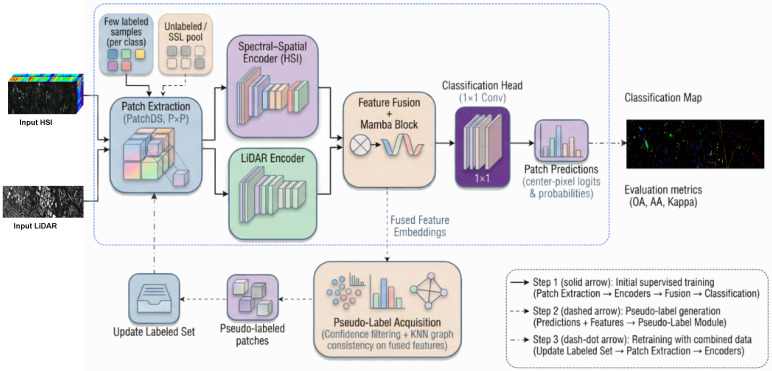 Figure 1
Figure 1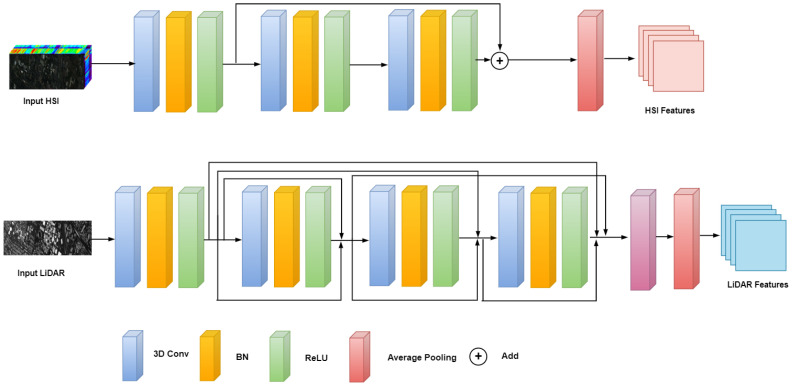 Figure 2
Figure 2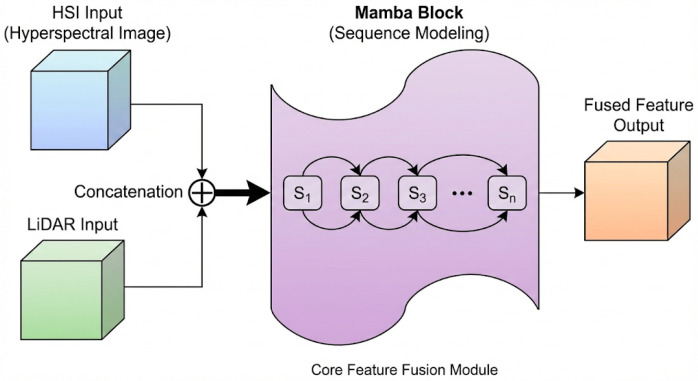 Figure 3
Figure 3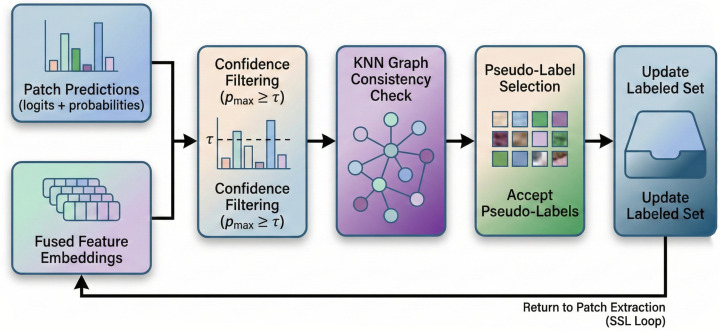 Figure 4
Figure 4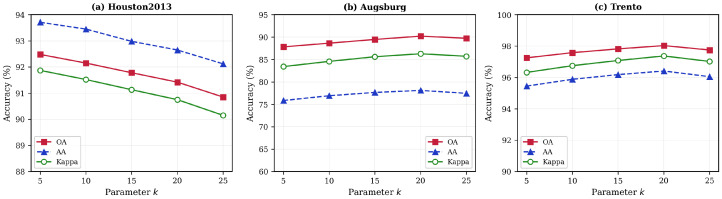 Figure 5
Figure 5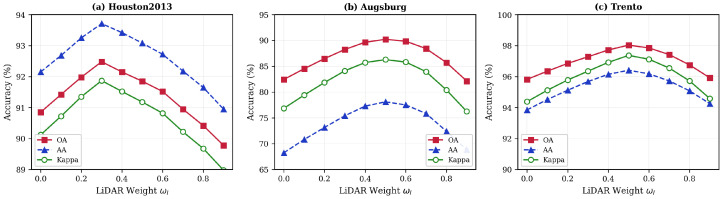 Figure 6
Figure 6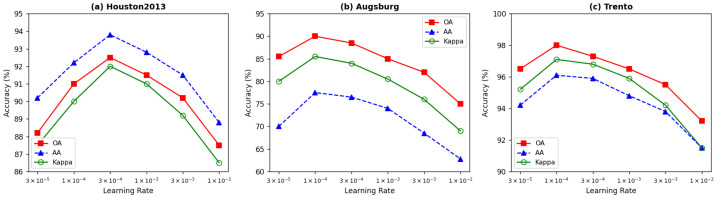 Figure 7
Figure 7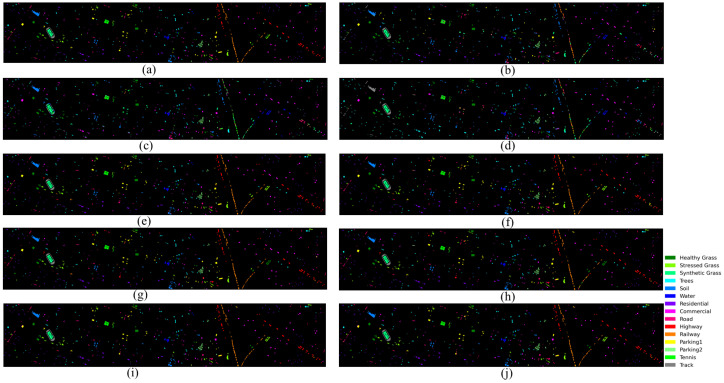 Figure 8
Figure 8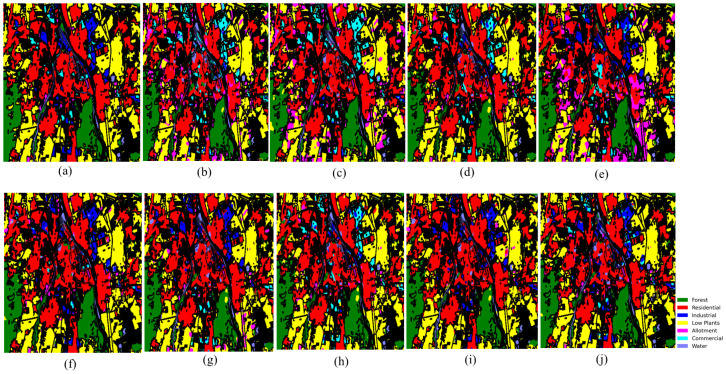 Figure 9
Figure 9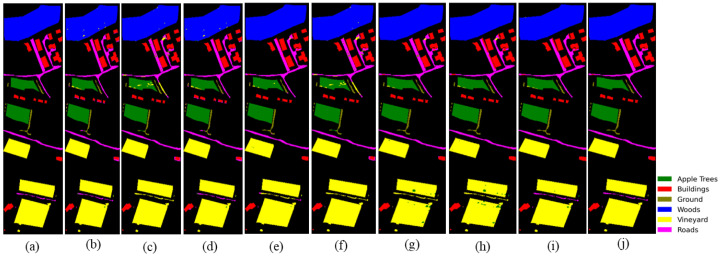 Figure 10
Figure 10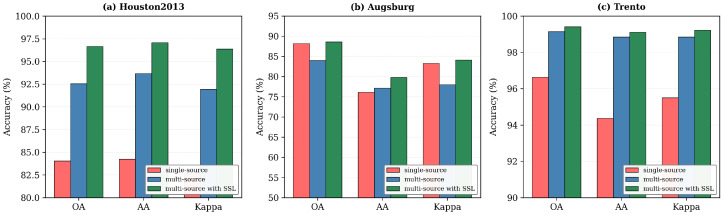 Figure 11
Figure 11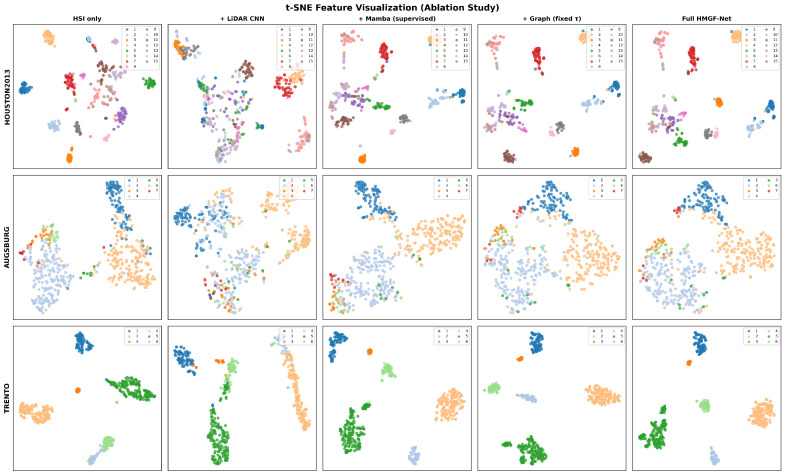 Figure 12
Figure 12| Dataset | OA | AA | Kappa |
|---|---|---|---|
| Houston2013 | 92.30 | 93.43 | 91.68 |
| Augsburg | 88.61 | 78.46 | 83.74 |
| Trento | 99.39 | 98.68 | 99.18 |
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsRemote-Sensing Image Classification · Advanced Image Fusion Techniques · Remote Sensing in Agriculture
1. Introduction
Hyperspectral Images (HSI) provide dense spectral information across hundreds of narrow bands, and have become indispensable for material identification and land cover analysis. However, issues such as spectral redundancy, nonlinear mixing, and high dimensionality continue to challenge robust spectral–spatial modeling, motivating the development of advanced learning strategies for high-dimensional remote sensing data [1,2]. Recent deep learning approaches have improved HSI classification through joint spatial–spectral feature extraction, hybrid CNN–attention architectures, and lightweight networks designed for small-sample settings [3,4,5].
To address the limitations of spectral information alone, complementary modalities such as Light Detection and Ranging (LiDAR) have been extensively integrated with HSI. LiDAR provides elevation and structural cues that enhance edge delineation and mitigate spectral ambiguity. Numerous studies have demonstrated that combining HSI and LiDAR significantly improves classification accuracy, particularly in heterogeneous or urban environments [6,7,8]. Recent advances include dual-branch transformers, hypergraph networks, and cross-attention fusion modules that model heterogeneous spectral–elevation interactions more effectively [9,10,11]. In addition to dual-modality setups, multisensor fusion frameworks now exploit combinations of hyperspectral, multispectral, radar, and LiDAR data to achieve more stable and generalizable scene understanding [12,13].
Despite this progress, multimodal HSI–LiDAR fusion remains difficult under limited supervision. HSI suffers from large intra-class spectral variance and sensitivity to noise, while LiDAR exhibits irregular sampling patterns and modality-specific distortions. Effective fusion requires bridging disparate feature spaces while preserving modality-specific advantages. Deep HSI classifiers based on random-patch learning, dense residual transfer, and spectral–spatial CNNs offer improved robustness [3,4,14], yet most multimodal fusion networks assume abundant labeled samples and degrade sharply when labels are scarce [15,16].
To address this, Semi-Supervised Learning (SSL) has gained importance in HSI classification. Modern SSL methods integrate unlabeled samples through consistency constraints, pseudolabel refinement, adversarial learning, and hybrid generative–discriminative models [17,18,19]. In addition, multiscale refinement strategies and cost-aware learning mechanisms have been shown to substantially improve label efficiency in low-annotation scenarios [15,20]. Nonetheless, applying SSL to multimodal fusion remains challenging, as pseudolabel noise can propagate between modalities, causing semantic drift unless cross-modal agreement and structural consistency are jointly enforced [21].
Meanwhile, long-range modeling advances have reshaped deep learning for remote sensing. Transformer-based architectures and graph neural networks have demonstrated strong spectral–spatial reasoning capabilities, but remain limited by computational complexity when applied to high-resolution hyperspectral cubes [2,16]. Recently, visual State-Space Models (SSMs), particularly Mamba-inspired architectures, have emerged as efficient alternatives that capture long-range dependencies with linear complexity. RS3Mamba and ConvMambaSR show excellent performance in segmentation and super-resolution tasks, highlighting the potential of SSMs for hyperspectral sequence modeling [22,23]. Additional work in SSM-driven remote sensing indicates improved efficiency, stability, and scalability compared to transformer-based models [24,25,26].
Despite these advances, existing state-space and graph-based approaches for remote sensing classification exhibit several limitations. Current Mamba-inspired architectures such as RS3Mamba [22] and ConvMambaSR [23] employ fixed scanning strategies over the spatial grid that do not adapt to irregular object boundaries in heterogeneous scenes, potentially overlooking critical cross-modal relationships at class transitions where spectral and elevation discontinuities do not align. While graph neural networks have shown promise for HSI classification through hypergraph convolutions [8] and cross-attention mechanisms [11], they face well-documented over-smoothing effects when stacked beyond two or three layers, and incur significant computational overhead when constructing dense pixel graphs over high-resolution hyperspectral cubes [2,16]. Most critically, neither paradigm alone addresses the challenge of pseudolabel noise propagation in semi-supervised multimodal learning. Erroneous predictions generated from one modality can corrupt feature representations through the fusion mechanism, leading to semantic drift during iterative self-training [21]. These limitations motivate the design of HMGF-Net, which combines efficient state-space sequence modeling with graph-based consistency verification specifically targeted at pseudolabel quality control. Motivated by these developments, we propose HMGF-Net. a Hybrid Mamba–Graph Fusion network for semi-supervised HSI–LiDAR classification. The proposed network integrates (i) spectral–spatial HSI encoding, (ii) multiscale LiDAR structural modeling, (iii) selective state-space sequence modeling for efficient long-range dependency capture, and (iv) graph-guided multimodal fusion. To mitigate pseudolabel noise in SSL, we introduce Multi-Stage Pseudo-Label Refinement (MS-PLR), a mechanism that applies confidence filtering, spatial–spectral smoothing, and graph-consistency propagation. Together, these components enable HMGF-Net to achieve robust and stable performance even under extremely limited labeled data.
These observations collectively motivate the design of a unified architecture capable of addressing the interconnected challenges of multimodal learning under limited labels. Existing methods rarely combine spectral–spatial HSI encoding, LiDAR structural modeling, efficient long-range sequence learning, graph reasoning, and systematic pseudolabel refinement into a single coherent framework. Moreover, multimodal SSL remains vulnerable to inconsistent pseudolabel predictions, which can propagate uncertainty and destabilize training. Additionally, high-dimensional hyperspectral sequences require an efficient long-range modeling approach that avoids the computational burden of transformers. These challenges form the foundation for our proposed methodology.
To address these intertwined challenges, we introduce HMGF-Net, a Hybrid Mamba–Graph Fusion Network equipped with an end-to-end Multi-Stage Pseudo-Label Refinement (MS-PLR) mechanism. In contrast to existing multimodal approaches, HMGF-Net integrates spectral–spatial representation learning for hyperspectral data, multiscale geometric modeling for LiDAR elevation cues, and efficient long-range dependency modeling through the Mamba selective state-space paradigm. These encoded features are subsequently processed within a graph-based fusion network that captures cross-modal relational structure and enhances contextual reasoning. Finally, the MS-PLR pipeline progressively refines pseudolabels through confidence filtering, spatial–spectral smoothing, and graph-consistency propagation, enabling the network to suppress noise, reinforce cross-modal stability, and achieve high classification accuracy even in demanding low-label conditions.
The main contributions of this work are summarized below:
- We present HMGF-Net, a unified multimodal architecture that integrates a 3D–2D spectral–spatial CNN encoder for hyperspectral data, a multiscale CNN for LiDAR elevation modeling, and Mamba-based selective state-space modeling for efficient long-range dependency learning. This design combines local spectral–spatial feature extraction with global sequence modeling, enabling a more expressive and computationally efficient multimodal representation than conventional CNN- or transformer-based approaches.
- We introduce a graph-guided multimodal fusion mechanism that aligns hyperspectral and LiDAR features using relational modeling based on spectral similarity, spatial proximity, and elevation-informed neighborhood structure. This graph-based fusion strategy promotes more coherent cross-modal interactions by preserving geometric continuity and spectral–spatial relationships, thereby enabling the network to integrate complementary modality information more effectively than concatenation, attention-only fusion, or shallow multimodal alignment methods.
- We develop a Multi-Stage Pseudo-Label Refinement (MS-PLR) framework designed to stabilize semi-supervised learning through progressive noise suppression. The refinement process incorporates confidence filtering, spatial–spectral neighborhood smoothing, and graph consistency propagation to reduce the influence of unreliable predictions. This enables more reliable pseudolabel supervision in low-label scenarios, preventing semantic drift and improving training stability by ensuring that refined labels remain structurally consistent with both spectral–spatial patterns and elevation cues.
2. Materials and Methods
Datasets
To assess the effectiveness of the proposed approach, three publicly accessible multisensor remote sensing image classification datasets are utilized as experimental datasets: the Houston2013, Trento, and Augsburg datasets. Comprehensive parameters are shown in Table 1.
Houston2013 dataset. The Houston2013 dataset was captured using the ITRES CASI-1500 (ITRES Research Limited, Calgary, AB, Canada) sensor over the University of Houston campus and its surrounding urban area in Houston, Texas, USA in 2012. This dataset includes both HSI and LiDAR DSM data. The spatial dimensions of the dataset are 349 × 1905, with a spatial resolution of approximately 2.5 m. The HSI data consist of 144 spectral bands, covering the wavelength range from 380 to 1050 nm. The LiDAR data provide elevation information for ground features. The land cover is categorized into fifteen types: Healthy Grass, Stressed Grass, Synthetic Grass, Trees, Soil, Water, Residential, Commercial, Road, Highway, Railway, Parking Lot 1, Parking Lot 2, Tennis Court, and Running Track.
Augsburg dataset. The Augsburg dataset consists of paired HSI and LiDAR DSM data; the HSI data were collected using the HySpex (Norsk Elektro Optikk AS, Skedsmokorset, Norway) sensor, while the LiDAR DSM data were obtained with the DLR-3K sensor (German Aerospace Center, Oberpfaffenhofen, Germany). This dataset was acquired over Augsburg, Germany, which is an urban environment. The spatial dimensions of the Augsburg dataset are 332 × 485, with a spatial resolution of approximately 30 m. The HSI data includes 180 spectral bands, spanning the wavelength range of 0.4 to 2.5 µm. The LiDAR DSM data provides 3D elevation information for surface features. The dataset comprises seven land cover categories with varying sample distributions.
Trento Dataset. The Trento dataset is an HSI–LiDAR pair dataset; the HSI data were collected by an AISA Eagle (Specim, Spectral Imaging Ltd., Oulu, Finland) sensor, while the LiDAR digital surface model (DSM) data were acquired by an Optech ALTM 3100EA (Teledyne Optech, Vaughan, ON, Canada) sensor. The dataset was captured over a rural area south of the city of Trento, Italy. The Trento dataset has a spatial dimension of 166 × 600 with a spatial resolution of approximately 1 m. The HSI data in the Trento dataset consist of 63 spectral bands, with wavelengths ranging from 420 to 990 nm. The LiDAR DSM data provide elevation information of ground features. The land cover is classified into six categories: Apple Trees, Buildings, Ground, Woods, Vineyard, and Roads.
3. Methods
To address the challenge of limited labeled samples in multi-source remote sensing image classification, we propose a Heterogeneous Multimodal Graph Fusion Network (HMGF-Net) trained with a Multi-Stage Progressive Learning Refinement (MS-PLR) strategy. The proposed framework consists of two complementary components: (1) the HMGF-Net architecture, which effectively integrates hyperspectral and LiDAR features through modality-specific encoders and a Mamba-based fusion module, and (2) the MS-PLR training strategy that leverages unlabeled data through graph-regularized pseudolabeling. The overall framework is illustrated in Figure 1, and the key notations used throughout this paper are summarized in Table 2.
3.1. Framework Overview
As shown in Figure 1, the proposed framework integrates the HMGF-Net architecture with the MS-PLR training strategy. The HMGF-Net architecture comprises three main components: (1) a dual-branch feature extraction module with modality-specific encoders, (2) a Mamba-based feature fusion module for cross-modal interaction, and (3) a classification head for land cover prediction. The MS-PLR training strategy employs a three-stage paradigm to maximize the utilization of both labeled and unlabeled samples:
Stage 1 (Supervised Pretraining): HMGF-Net is initially trained on the small labeled set using cross-entropy loss. The forward path consists of patch extraction, modality-specific encoders, Mamba-based feature fusion, and classification head. This stage establishes the initial feature representations.
Stage 2 (Pseudolabel Generation): Using the pretrained HMGF-Net, we generate predictions for all unlabeled samples in . High-confidence predictions are filtered through dynamic thresholding and validated via KNN graph consistency checking. Only samples that pass both criteria are accepted as pseudolabels.
Stage 3 (Semi-Supervised Refinement): HMGF-Net is fine-tuned on the augmented dataset , where denotes the validated pseudolabel set. A reduced learning rate prevents catastrophic forgetting of the knowledge learned in Stage 1.
3.2. HMGF-Net Architecture
The HMGF-Net architecture is designed for effective multimodal feature extraction and fusion. We describe each architectural component in detail below.
3.2.1. Dual-Branch Feature Extraction Module
For multi-source remote sensing data, we develop a dual-branch architecture with customized connectivity mechanisms specifically designed for the distinct characteristics of HSI and LiDAR data. Figure 2 illustrates the feature extraction module.
The HSI encoder employs 3D convolutions to jointly capture spectral correlations and spatial context. For an input patch , we apply three cascaded 3D convolutional layers with spectral kernel sizes of 7, 5, and 3, progressively reducing spectral dimensionality while extracting hierarchical features. Each layer incorporates batch normalization and ReLU activation to stabilize training and introduce non-linearity.
Considering the spectral–spatial complexity and potential noise in spatial dimensions, we enhance the standard 3D CNN with residual learning. The residual block incorporates skip connections that allow direct propagation of spectral features across layers, which helps preserve critical spectral information while alleviating gradient vanishing issues. It can be expressed as
where represents the input of the l-th layer and represents the mapping function. The 3D features are reduced via spectral average pooling and a 2D convolution to produce , where .
Because LiDAR data adopt the Digital Surface Model format, which has local correlations and sparsity, we use a dense connection method in which features of each layer are connected to all previous layers. This effectively leverages local correlations and enhances the re-usability and representational power of features:
where denotes concatenation of features from all preceding layers. The LiDAR encoder processes elevation information through three 2D convolutional layers with channel dimensions 1→32→64→64, producing .
3.2.2. Mamba-Based Feature Fusion Module
To capture long-range spatial dependencies and enable effective cross-modal interaction, we propose a Mamba-based state-space fusion module. Unlike attention mechanisms, which have complexity, the state-space model formulation enables linear-time sequence modeling while capturing long-range dependencies. The detailed structure is illustrated in Figure 3.
The modality-specific features are first concatenated along the channel dimension to form a unified representation
then the spatial feature map is reshaped into a sequence representation to model spatial positions as sequential tokens:
where is the sequence length and is the feature dimension. This transformation enables the application of sequential modeling to capture spatial relationships.
Our Mamba block is based on structured state-space sequence models (S4/Mamba), which map input sequences to output sequences through a latent state. The discretized state-space recurrence for each spatial position is
where is the latent state with dimension , is the discretized state transition matrix, and , are input-dependent projection matrices that enable content-aware sequence modeling. This selective mechanism allows the model to adaptively filter and retain relevant cross-modal information based on input content, which is crucial for fusing heterogeneous HSI spectral and LiDAR elevation features.
The complete Mamba block processes the input sequence through a gating mechanism:
where denotes the selective state-space operation, is the SiLU activation function, and ⊙ represents element-wise multiplication to provide a gating mechanism. The gating allows the network to control information flow, suppressing irrelevant features while enhancing discriminative ones.
3.2.3. Classification Head
The fused features are passed through a convolution to produce class logits. The center-pixel prediction is extracted and converted to class probabilities via softmax:
where K is the number of land cover classes. The center-pixel extraction strategy focuses on the most reliable prediction within each patch, reducing boundary effects.
3.3. Multi-Stage Progressive Learning Refinement (MS-PLR) Strategy
While the HMGF-Net architecture provides effective multimodal feature fusion, the limited availability of labeled samples in remote sensing applications motivates the development of a semi-supervised training strategy. The MS-PLR strategy leverages unlabeled data through graph-regularized pseudolabeling to progressively refine the model. This training strategy operates on top of the HMGF-Net architecture and consists of three stages, as outlined in Algorithm 1. Algorithm 1 HMGF-Net Training with MS-PLR StrategyRequire: HSI , LiDAR , labeled set , unlabeled set Ensure: Trained HMGF-Net model
- 1:Stage 1: Supervised Pretraining
- 2:Initialize HMGF-Net parameters
- 3:Train HMGF-Net on for epochs using
- 4:Stage 2: Pseudo-Label Generation
- 5:Compute predictions and confidences for using HMGF-Net
- 6:Compute dynamic threshold
- 7:Select candidates:
- 8:Build KNN graph on fused features and compute
- 9:Filter by agreement:
- 10:Stage 3: Semi-Supervised Refinement
- 11:Fine-tune HMGF-Net on for epochs with
- 12:return
3.3.1. Stage 1: Supervised Pretraining
HMGF-Net is first trained on labeled data using cross-entropy loss with label smoothing to prevent overconfident predictions:
where the smoothed label applies smoothing parameter . This stage establishes robust initial feature representations that form the foundation for subsequent pseudolabel generation.
3.3.2. Stage 2: Graph-Regularized Pseudolabel Acquisition
To leverage unlabeled data while avoiding error propagation from noisy pseudo-labels, we propose a graph-regularized acquisition strategy that combines confidence filtering with feature-space consistency verification. The pipeline is illustrated in Figure 4 and consists of two key components.
For each unlabeled sample , we compute the prediction confidence as . A fixed threshold ignores that different categories have varying learning difficulties, which makes difficult categories less likely to be selected when filtering pseudolabeled samples. Therefore, we employ a dynamic threshold that adapts to the confidence distribution:
where is the base threshold, is the blending coefficient, and denotes the positive part function. This adaptive threshold adjusts to the model’s overall confidence level, ensuring balanced selection across categories with different learning difficulties. Samples exceeding this threshold form the candidate set .
To verify pseudolabel quality through spatial–spectral consistency, we construct a k-nearest neighbor graph in the learned feature space. For each candidate sample, we extract the globally averaged fused feature and compute the cosine similarity to identify neighbors.
The neighborhood-aggregated prediction provides a smoothed estimate:
where denotes the k nearest neighbors and is the row-normalized adjacency weight. A pseudolabel is accepted only if the aggregated neighborhood prediction agrees with the sample’s own prediction:
This graph consistency check effectively filters out samples near class boundaries or in ambiguous regions, ensuring that only high-quality pseudolabels contribute to model training.
3.3.3. Stage 3: Semi-Supervised Refinement
After pseudolabel generation, HMGF-Net is fine-tuned on the augmented dataset . To account for potential noise in pseudolabels, we apply confidence-based sample reweighting, where labeled samples receive a weight of 1.0 and pseudolabeled samples receive a weight equal to their confidence score . Training proceeds with a reduced learning rate (where ) to prevent catastrophic forgetting of the knowledge learned in Stage 1.
4. Results
This section presents a comprehensive evaluation of the proposed HMGF-Net with MS-PLR across three benchmark datasets: Houston2013, Augsburg, and Trento. We first describe the evaluation protocol, then present quantitative results with detailed comparisons against state-of-the-art methods, followed by parameter sensitivity studies and visual assessment.
4.1. Evaluation Protocol
The baseline methods span diverse state-of-the-art paradigms published between 2021–2024, including CNN-based approaches (Res-CP [30], CCR-Net [31], SepDGConv [32]), few-shot and semi-supervised methods (DCFSL [33], S3Net [34]), dual-modality fusion architectures (DSCA-Net [35], Fusion_HCT [36]), and transformer-based multimodal fusion (MFT [37]). Notably, MFT [37] (2023) represents the current state-of-the-art in multimodal remote sensing transformers, while DSCA-Net [35] (2024) is among the most recent dual-stream adaptive networks. This selection ensures a comprehensive comparison, with seven of eight baselines published in 2022 or later.
All models operated under identical training conditions with the same hyperspectral and LiDAR input modalities. The proposed HMGF-Net employed its dual-branch encoder, Mamba-based fusion module, and MS-PLR training strategy as described in Section 3.
Table 3 reports the hyperparameter configurations for MS-PLR. The base threshold and KNN neighborhood size k were tuned per dataset via grid search, while the blending coefficient generalized well across all datasets without per-dataset adjustment. Houston2013 requires a higher (0.60) due to its fifteen-class complexity and finer inter-class boundaries, whereas Trento and Augsburg benefit from larger k (20) owing to their spatially homogeneous agricultural and urban parcels. The KNN graph is reconstructed at the start of each SSL round using updated fused features, ensuring that neighborhood relationships reflect the current model state.
4.2. Quantitative Results
4.2.1. Results on Houston2013
Table 4 presents the complete class-wise and overall results on Houston2013. The proposed HMGF-Net achieves the highest OA (92.30%), AA (93.43%), and Kappa (91.68), outperforming all comparison models. Notably, HMGF-Net demonstrates superior performance on challenging urban classes such as Commercial (94.72%), Residential (98.04%), and Road (91.51%), which exhibit high intra-class variability. The integration of Mamba-based long-range modeling with graph fusion provides stronger context propagation, while MS-PLR reduces pseudolabel noise near class boundaries.
4.2.2. Results on Augsburg
Table 5 reports results on the Augsburg dataset, which contains large-scale and highly heterogeneous urban–vegetation mixtures. HMGF-Net achieves an OA of 88.61%, AA of 78.46%, and Kappa of 83.74, outperforming competing approaches. The Augsburg dataset poses significant challenges due to the dominance of the Residential-Area and Low-Plants classes, which together comprise over 70% of the scene. HMGF-Net significantly improves on Low-Plants (95.36%) and maintains competitive performance across minority classes. The graph-based fusion mechanism effectively incorporates elevation discontinuities and spectral relationships, ensuring reliable pseudolabel propagation.
4.2.3. Results on Trento
Table 6 shows results on the Trento dataset. The proposed method achieves the highest OA (99.39%), AA (98.68%), and Kappa (99.18). Trento consists primarily of agricultural and semi-structured terrain where hyperspectral-LiDAR fusion plays a critical role in distinguishing vegetation types. HMGF-Net produces near-perfect accuracy for classes such as Apple Trees (99.70%), Woods (100.00%), Vineyard (99.98%), and Roads (96.97%). The Mamba state-space module effectively captures long-range spectral patterns, while the KNN graph consistency verification incorporates elevation and spatial continuity across agricultural parcels.
4.3. Comparative Analysis
Across all three datasets, HMGF-Net consistently surpasses existing models in OA, AA, and Kappa. Table 7 summarizes the performance comparison. The improvements arise from four key architectural and methodological strengths:
- Hybrid Encoder Design: The 3D–2D CNN with residual connections for HSI and dense connections for LiDAR effectively captures modality-specific characteristics while maintaining computational efficiency.
- Efficient Sequence Modeling: The Mamba block models long-range dependencies with complexity, offering advantages over standard CNNs (limited receptive field) and transformers ( complexity).
- Graph-Regularized Fusion: The KNN graph consistency verification aligns predictions semantically in the learned feature space, improving robustness against noisy pseudolabels.
- Progressive Refinement: The MS-PLR strategy progressively expands the training set with validated pseudolabels, enabling effective utilization of unlabeled data under extreme label scarcity.
4.4. Parameter Sensitivity Analysis
To investigate the robustness of HMGF-Net to hyperparameter selection, we conducted systematic sensitivity analysis on three critical parameters: KNN neighborhood size k, LiDAR fusion weight , and learning rate . For all experiments, the batch size and patch size were fixed at 32 and , respectively, with label smoothing .
4.4.1. Impact of KNN Neighborhood Size
The KNN neighborhood size k determines the scope of spatial–spectral consistency verification in the graph-regularized pseudolabel acquisition module. As illustrated in Figure 5, we evaluated classification performance with k values ranging from 5 to 25.
For Houston2013, optimal performance is achieved at (OA: 92.30%). This is attributed to its high spatial resolution (2.5 m), where neighboring pixels are more likely to belong to the same category within a compact neighborhood. In contrast, Augsburg and Trento achieve optimal results at , reflecting their larger homogeneous regions that benefit from broader neighborhood context. These results demonstrate that optimal k is dataset-dependent and should be tuned based on spatial characteristics.
4.4.2. Impact of LiDAR Fusion Weight
The fusion weight controls the relative contribution of LiDAR features, with HSI weight satisfying . Figure 6 shows classification performance as varies from 0 to 0.9.
For Houston2013, optimal performance occurs at , indicating that spectral information dominates for distinguishing diverse urban categories. For Augsburg and Trento, balanced fusion ( ) yields the best results, as elevation information provides crucial discriminative features for separating vegetation types and distinguishing buildings. Performance degradation at extreme weights ( or ) confirms the importance of multimodal fusion.
4.4.3. Impact of Learning Rate
Figure 7 evaluates six learning rates: . Houston2013 achieves optimal performance at , while Augsburg and Trento perform best at .
The larger optimal learning rate for Houston2013 may be attributed to its complex fifteen-class feature space requiring more aggressive parameter updates. Excessively large learning rates ( ) cause significant performance degradation across all datasets, particularly for Augsburg (OA drops to 75.82%) due to its severe class imbalance. We recommend learning rates in the range for similar HSI-LiDAR classification tasks.
4.5. Visual Assessment
Figure 8, Figure 9 and Figure 10 present visual classification maps for all three datasets. Compared to baseline methods, HMGF-Net produces smoother regions, cleaner class boundaries, and fewer isolated misclassifications.
On Houston2013, HMGF-Net exhibits improved discrimination along road networks and parking lot boundaries, where spectral confusion is prevalent. The Augsburg results show enhanced separation between residential and commercial areas, benefiting from the elevation-aware fusion mechanism. On Trento, the agricultural parcel boundaries are sharply delineated, demonstrating effective utilization of both spectral signatures and terrain structure.
4.6. Summary
The experimental results across the Houston2013, Augsburg, and Trento datasets confirm that HMGF-Net with MS-PLR offers substantial advantages in multimodal semi-supervised learning. Through its combination of spectral–spatial encoding, Mamba-based sequence modeling, graph-regularized fusion, and progressive pseudolabel refinement, the proposed framework delivers robust performance under limited annotation, consistently surpassing state-of-the-art methods across all datasets and evaluation metrics.
5. Discussion
5.1. Ablation Study
To comprehensively evaluate the contribution of each component in our proposed HMGF-Net framework, we conducted extensive ablation experiments on all three benchmark datasets. The ablation study is organized into four parts: (1) module-wise quantitative analysis, presented in Table 8; (2) semi-supervised learning effectiveness, illustrated in Figure 11; (3) feature representation visualization using t-SNE, shown in Figure 12; and (4) computational complexity comparison, reported in Table 9.
5.1.1. Module-Wise Ablation Analysis
To quantify the contribution of each component in our proposed framework, we conducted a comprehensive module-wise ablation study. The results are presented in Table 8. Starting from the HSI-only baseline, we progressively integrated each module and evaluate the resulting classification performance across all three datasets. The HSI-only baseline, which employs only the spectral–spatial encoder without any auxiliary information, achieves OA of 96.64%, 84.04%, and 88.18% on the Trento, Houston2013, and Augsburg datasets, respectively. In contrast, using LiDAR data alone yields significantly lower performance with OA of 90.24%, 61.45%, and 58.61%, confirming that spectral information from HSI provides more discriminative features than elevation information alone for land cover classification tasks.
Introduction of the Mamba-based fusion module, which integrates both HSI and LiDAR inputs through state-space sequence modeling, substantially improves the classification performance, achieving OA of 99.14%, 92.54%, and 83.96% on the three datasets. This improvement of 2.50%, 8.50%, and −4.22% over HSI-only baseline demonstrates the effectiveness of our cross-modal fusion strategy in capturing long-range spatial dependencies and complementary information between modalities. The temporary performance drop on the Augsburg dataset can be attributed to the introduction of noisy elevation features in heterogeneous urban regions, which is subsequently addressed by the graph-based refinement. Adding the graph-based consistency verification with a fixed threshold further enhances the results to 99.38%, 95.31%, and 88.46% OA, highlighting the importance of pseudolabel quality control through spatial–spectral neighborhood consistency checking.
The performance pattern on Augsburg (88.18% → 83.96% → 88.61%) warrants detailed analysis. The temporary drop after introducing the Mamba fusion module is caused by LiDAR noise at 30 m resolution inducing modality-fusion mismatch, rather than by oversmoothing from sequence modeling. Three observations support this conclusion: (1) LiDAR-only classification achieves only 58.61% OA on Augsburg, the lowest across all datasets, confirming limited discriminative power at coarse resolution; (2) Augsburg’s urban classes exhibit spectral homogeneity but elevation heterogeneity, causing noisy LiDAR features to dilute discriminative spectral information when fused; and (3) if oversmoothing were responsible, degradation would occur across all datasets, yet Houston2013 shows +8.50% improvement and Trento achieves 99.38% OA. The graph-consistency verification addresses this by rejecting pseudolabels where neighborhood predictions disagree, recovering OA from 83.96% to 88.46% (+4.50%).
Finally, the complete HMGF-Net with the proposed MS-PLR strategy achieves the best performance across all datasets: 99.41% OA on Trento (+2.77% over baseline), 96.65% OA on Houston2013 (+12.61% over baseline), and 88.61% OA on Augsburg (+0.43% over baseline). The most significant improvement is observed on the Houston2013 dataset, where the complex urban environment with fifteen diverse land cover categories benefits substantially from our multimodal fusion and semi-supervised learning approach. These ablation results validate that each proposed component contributes positively to the final classification performance and that their synergistic combination yields optimal results across diverse remote sensing scenarios.
5.1.2. Effectiveness of Semi-Supervised Learning
To further validate the effectiveness of our proposed semi-supervised learning strategy, we compared three representative configurations, as illustrated in Figure 11: single-source classification using only HSI data, multi-source fusion combining HSI and LiDAR through the Mamba-based module under fully supervised settings, and multi-source with SSL, representing the complete HMGF-Net framework with graph-regularized pseudolabel acquisition. The visualization clearly demonstrates the progressive performance improvement achieved by each enhancement. On the Houston2013 dataset, the multi-source configuration achieves OA of 92.54%, AA of 93.66%, and Kappa of 91.94%, representing substantial improvements of 8.50%, 9.42%, and 9.22% over the single-source baseline (OA = 84.04%, AA = 84.24%, Kappa = 82.72%). Incorporation of our semi-supervised learning strategy with MS-PLR further boosts the performance to OA of 96.65%, AA of 97.08%, and Kappa of 96.37%, demonstrating the significant benefit of leveraging abundant unlabeled samples through propagation of high-confidence pseudolabels.
Similar performance gains are observed for the Trento dataset, where the full HMGF-Net achieves 99.41% OA compared to 96.64% for single-source and 99.14% for multi-source without SSL. The consistent improvement across all three metrics confirms that the semi-supervised refinement effectively enhances the model’s generalization capability by exploiting the rich spatial structure in unlabeled data. For the Augsburg dataset, which presents more challenging scenarios with severe class imbalance and complex urban landscapes, multi-source fusion initially shows slightly lower OA (83.96%) than single-source (88.18%) due to the introduction of noisy elevation features in heterogeneous regions. However, the semi-supervised refinement stage effectively addresses this limitation by selectively incorporating reliable pseudolabels verified through graph-based spatial consistency, ultimately achieving 88.61% OA with notably improved AA (79.75% vs. 76.10%) and Kappa coefficient (84.13% vs. 83.27%). These experimental results confirm that our proposed MS-PLR strategy successfully exploits the complementary information from both modalities while leveraging unlabeled samples to enhance classification accuracy across diverse remote sensing scenarios.
5.1.3. Feature Representation Visualization
To provide intuitive insights into the discriminative capability of learned feature representations, we employ t-distributed Stochastic Neighbor Embedding (t-SNE) to visualize the high-dimensional features extracted by different ablation configurations, as shown in Figure 12. Each row corresponds to a specific dataset (Houston2013, Augsburg, and Trento, from top to bottom), while each column represents a progressive ablation variant from left to right: HSI only, + LiDAR CNN, + Mamba (supervised), + Graph (fixed ), and Full HMGF-Net.
For the Houston2013 dataset with fifteen land cover categories, the HSI-only baseline exhibits considerable overlap between semantically similar classes, particularly among different vegetation types and urban structures. The introduction of LiDAR features initially increases inter-class confusion due to the limited discriminative power of elevation information alone. However, the Mamba-based fusion module effectively integrates complementary cross-modal information, resulting in more compact intra-class clusters and clearer inter-class boundaries. The subsequent graph-based refinement and full HMGF-Net configuration progressively improve the cluster separation, with the final visualization showing well-defined, tightly grouped clusters for all fifteen categories with minimal overlap.
Similar progressive improvements are observed for the Augsburg dataset with seven classes. The initial HSI-only representation shows significant mixing between classes 1–2 (different forest types) and classes 3–4 (residential and industrial areas). The Mamba fusion and graph-based refinement stages gradually disentangle these confusing categories, with the full HMGF-Net producing the most separable feature space where each class forms a distinct and compact cluster. For the Trento dataset with six classes, the relatively simpler classification task results in well-separated clusters even with the baseline configuration. Nevertheless, the progressive integration of modules further enhances the compactness of intra-class distributions and increases the margins between different categories. The full HMGF-Net achieves the most discriminative feature representation with clearly defined boundaries and minimal intra-class variance, which directly translates to the superior classification accuracy of 99.41% OA reported in Table 8. These visualizations provide compelling qualitative evidence that each proposed component contributes to learning more discriminative and well-structured feature representations for HSI-LiDAR classification.
5.1.4. Computational Complexity Analysis
Table 9 compares the computational cost of all methods on Houston2013 in terms of trainable parameters, FLOPs, training time, and inference time. HMGF-Net contains only 227.63 K parameters, a reduction of 93.9% relative to DSCA-Net (3737.71 K) and 75.8% relative to MFT (940.79 K). The parameter efficiency arises from replacing quadratic self-attention ( ) with linear state-space recurrence ( ) in the Mamba block. Training requires 688.64 s owing to the iterative pseudolabel refinement stages; however, inference completes in 2.07 s for the full test set, comparable to lightweight baselines such as DCFSL (2.04 s) and Fusion_HCT (2.35 s). Despite this modest computational footprint, HMGF-Net attains the highest OA (92.30%), outperforming DSCA-Net by +1.50% while using only 6.1% of its parameters, demonstrating a favorable accuracy–efficiency tradeoff that is suitable for operational deployment.
Compared to the transformer-based MFT, HMGF-Net reduces parameters by 75.8% (227.63 K vs. 940.79 K) while achieving +6.36% higher OA (92.30% vs. 85.94%), confirming the efficiency advantage of linear-complexity state-space modeling over quadratic self-attention.
5.2. Cross-Dataset Generalization Analysis
To assess the portability of HMGF-Net across heterogeneous remote sensing scenarios, we examined performance variations for semantically equivalent classes appearing in multiple datasets.
The Water class exhibits the largest cross-dataset variation, with 100.00% on Houston2013 versus 66.12% on Augsburg. Three factors account for this discrepancy:
- Spatial Resolution: Houston2013 (2.5 m) resolves water bodies as spectrally pure pixels, whereas Augsburg (30 m) produces mixed pixels containing water, vegetation, and built-up materials along riverbanks and canals. Mixed pixels exhibit ambiguous spectral signatures that reduce classifier confidence.
- Spectral Range: Augsburg spans 0.4–2.5 µm, including Short-Wave Infra-Red (SWIR) bands where water absorption is strong but variable depending on turbidity, depth, and dissolved constituents. Houston2013 covers only 0.38–1.05 µm, where water reflectance is more stable and distinctive.
- Water Body Heterogeneity: Houston2013 contains relatively homogeneous urban water features (retention ponds, swimming pools), while Augsburg includes rivers, industrial waterways, and agricultural irrigation channels with diverse spectral characteristics.
Despite these challenges, HMGF-Net achieves the highest accuracy for the Water class on Augsburg among all compared methods (66.12% versus 65.99% for DSCA-Net and 41.78% for MFT), demonstrating robust generalization even under unfavorable imaging conditions. The consistent improvements across all three datasets, each with distinct sensors, resolutions, and land-cover distributions, confirm that the proposed architecture generalizes effectively without dataset-specific tuning. Future work may incorporate resolution-adaptive modules or domain adaptation techniques to further enhance cross-sensor transferability.
6. Conclusions
This work introduces HMGF-Net, a unified multimodal framework designed to address the challenges of semi-supervised hyperspectral–LiDAR classification under extremely limited labeled data. By combining a 3D–2D spectral–spatial encoder for hyperspectral imagery, a multi-scale CNN for LiDAR elevation modeling, and an efficient Mamba selective state-space module for long-range feature refinement, the network captures both local spectral–spatial structure and global contextual dependencies. A graph-based fusion mechanism further enhances cross-modal alignment by modeling relational consistency across spectral, spatial, and elevation domains. To ensure training stability in low-label scenarios, the proposed Multi-Stage Pseudo-Label Refinement (MS-PLR) framework progressively mitigates label noise through confidence filtering, spatial–spectral smoothing, and graph-consistency propagation.
Extensive experiments on the Houston2013, Augsburg, and Trento datasets demonstrate that HMGF-Net consistently outperforms state-of-the-art hyperspectral, multimodal, and semi-supervised learning approaches. The model achieves superior overall accuracy, average accuracy, and Kappa values across all datasets, with notable improvements in structurally complex or spectrally ambiguous classes. The results confirm that integrating selective state-space modeling with graph-guided fusion and progressive pseudolabel refinement offers a robust and efficient solution for multimodal classification under restricted supervision.
Future research may extend the framework toward large-scale scene understanding, real-time inference, and multimodal transformer–state-space hybrids. Moreover, the integration of physics-informed priors, domain generalization mechanisms, or additional modalities such as SAR and multispectral data may further broaden the applicability of the proposed approach in operational remote sensing environments.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1Datta D. Mallick P.K. Bhoi A.K. Ijaz M.F. Shafi J. Choi J. Hyperspectral image classification: Potentials, challenges, and future directions Comput. Intell. Neurosci.20222022385463510.1155/2022/385463535528334 PMC 9071975 · doi ↗ · pubmed ↗
- 2Ranjan P. Girdhar A. A comprehensive systematic review of deep learning methods for hyperspectral images classification Int. J. Remote Sens.2022436221630610.1080/01431161.2022.2133579 · doi ↗
- 3Uchaev D. Uchaev D. Small sample hyperspectral image classification based on the random patches network and recursive filtering Sensors 202323249910.3390/s 2305249936904702 PMC 10006866 · doi ↗ · pubmed ↗
- 4Liu H. Bi W. Mughees N. Enhanced hyperspectral image classification technique using PCA-2D-CNN algorithm and null spectrum hyperpixel features Sensors 202525579010.3390/s 2518579041013028 PMC 12473149 · doi ↗ · pubmed ↗
- 5Torrecillas C. Zarzuelo C. de la Fuente J. Jigena-Antelo B. Prates G. Evaluation and Modelling of the Coastal Geomorphological Changes of Deception Island since the 1970 Eruption and Its Involvement in Research Activity Remote Sens.20241651210.3390/rs 16030512 · doi ↗
- 6Wang Q. Zhou B. Zhang J. Xie J. Wang Y. Joint classification of hyperspectral images and lidar data based on dual-branch transformer Sensors 20242486710.3390/s 2403086738339584 PMC 10856822 · doi ↗ · pubmed ↗
- 7Guo H. Tian B. Liu W. CC Former: Cross-Modal Cross-Attention Transformer for Classification of Hyperspectral and Li DAR Data Sensors 202525569810.3390/s 2518569841012936 PMC 12473655 · doi ↗ · pubmed ↗
- 8Wang L. Deng S. Hypergraph Convolution Network Classification for Hyperspectral and Li DAR Data Sensors 202525309210.3390/s 2510309240431884 PMC 12115920 · doi ↗ · pubmed ↗