Toward Realistic Autonomous Driving Dataset Augmentation: A Real–Virtual Fusion Approach with Inconsistency Mitigation
Sukwoo Jung, Myeongseop Kim, Jean Oh, Jonghwa Kim, Kyung-Taek Lee

TL;DR
This paper introduces a method to create realistic autonomous driving datasets by combining real and virtual data, reducing costs and risks.
Contribution
The novel real–virtual fusion framework with inconsistency mitigation techniques improves dataset realism and model generalization.
Findings
The real–virtual fusion approach significantly reduces the reality gap in autonomous driving datasets.
Incorporating virtual objects with illumination matching enhances visual consistency in augmented images.
Abstract
Autonomous driving systems rely on vast and diverse datasets for robust object recognition. However, acquiring real-world data, especially for rare and hazardous scenarios, is prohibitively expensive and risky. While purely synthetic data offers flexibility, it often suffers from a significant reality gap due to discrepancies in visual fidelity and physics. To address these challenges, this paper proposes a novel real–virtual fusion framework for efficiently generating highly realistic augmented image datasets for autonomous driving. Our methodology leverages real-world driving data from South Korea’s K-City, synchronizing it with a digital twin environment in Morai Sim (v24.R2) through a robust look-up table and fine-tuned localization approach. We then seamlessly inject diverse virtual objects (e.g., pedestrians, vehicles, traffic lights) into real image backgrounds. A critical…
Click any figure to enlarge with its caption.
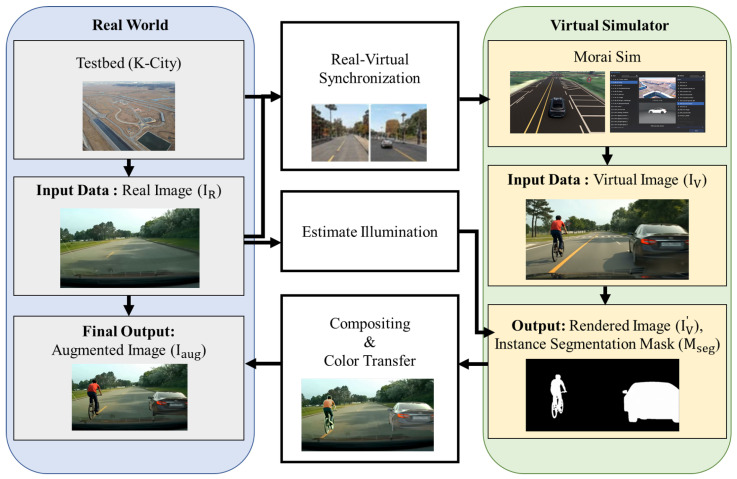 Figure 1
Figure 1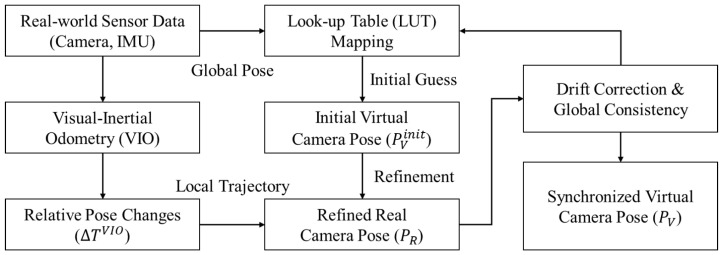 Figure 2
Figure 2 Figure 3
Figure 3 Figure 4
Figure 4- —Ministry of Trade, Industry and Energy (MOTIE)
- —Korea Institute of Advancement of Technology (KIAT)
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsAdvanced Neural Network Applications · Autonomous Vehicle Technology and Safety · Adversarial Robustness in Machine Learning
1. Introduction
The rapid advancement of autonomous driving technology promises innovative changes in transportation, enhancing safety, efficiency, and accessibility [1]. A cornerstone of reliable autonomous driving systems lies in their robust perception capabilities, particularly accurate and real-time object recognition from various sensors such as cameras, LiDAR, and IMUs [2,3,4,5]. Deep learning models, exemplified by architectures like YOLOv7 [6], YOLOv8 [7], YOLOv11 [8], and YOLOE [9], have shown remarkable success in object detection tasks, but their performance is critically dependent on the availability of vast, diverse, and high-quality training datasets [10].
However, the acquisition of such extensive datasets from real-world scenarios presents significant challenges. Collecting real data, especially for rare, extreme, or hazardous events (e.g., unexpected pedestrian behavior, complex traffic interactions at high speeds), is prohibitively expensive, time-consuming, and carries inherent safety risks [11,12,13,14,15]. These corner cases are precisely where autonomous driving systems need the most robust training and validation to ensure safety and reliability. Addressing this long-tail distribution—where critical scenarios appear infrequently—is essential for robust perception systems. Recent studies have highlighted data augmentation as a key strategy to resolve such class imbalance problems [16,17]. Consequently, researchers have increasingly turned to synthetic data generated from virtual environments, leveraging advanced simulators and digital twins [18,19,20,21,22,23,24,25,26].
Purely synthetic data, while offering unparalleled control over scenario generation and automatic ground truth labeling, often suffers from a significant reality gap. This discrepancy arises from differences in visual fidelity, material properties, lighting conditions, and sensor noise characteristics between simulated and real environments. Models trained solely on synthetic data frequently exhibit degraded performance when deployed in the real world, hindering their generalization capabilities. Efforts to bridge this gap often involve sophisticated domain adaptation techniques [10], but a more direct approach that maximizes the realism of synthetic data generation remains crucial.
To address these limitations, this paper proposes a novel framework for generating highly realistic augmented image datasets by fusing real-world backgrounds with injected virtual objects. Our core idea is to leverage the authentic visual context of real driving scenes while injecting synthetic elements that represent challenging or rare scenarios. Specifically, we utilize real driving data from South Korea’s K-City, a renowned autonomous driving test facility, and a sophisticated digital twin environment created in the Morai Sim simulator [27,28]. This fusion approach aims to combine the best of both worlds: the high fidelity of real backgrounds with the flexibility and safety of virtual object generation. Previous work by Jung et al. has demonstrated strong capabilities in moving object detection and 3D reconstruction using various sensor modalities and deep learning [2,3,4], forming a foundation for robust sensor data processing in real environments.
A critical aspect of our framework is the mitigation of inconsistencies that inevitably arise when superimposing virtual objects onto real images. Simple cut-and-paste methods often result in visual artifacts (e.g., unrealistic lighting, improper boundaries), which can mislead perception models. Our approach integrates several advanced techniques, including accurate real-to-virtual synchronization of camera poses and illumination estimation from real scenes to drive physically based rendering of virtual objects. Furthermore, we employ color transfer techniques [29] to harmonize the visual appearance of injected objects with the background. This meticulous attention to detail ensures that the injected virtual objects appear as naturally integrated as possible, thereby minimizing the reality gap for the generated augmented datasets.
The primary contributions of this paper are summarized as follows:
- We propose an efficient and novel real–virtual fusion framework that leverages real-world driving data from K-City and a digital twin in Morai Sim for autonomous driving dataset augmentation.
- We develop a robust real–virtual synchronization method, combining a look-up table for initial alignment with a fine-tuned localization algorithm, to accurately map real camera poses to the virtual environment.
- We implement an advanced virtual object injection pipeline focusing on inconsistency mitigation, incorporating illumination matching and color transfer to enhance the photorealism of augmented images.
- We demonstrate the effectiveness of our framework through two comprehensive experiments: quantitatively assessing the perceptual realism of the generated augmented images using a pre-trained YOLOv7 model, and evaluating the improved object recognition performance and robustness of a fine-tuned YOLOv7 model on a real-world dataset (BDD100k [30]).
The remainder of this paper is structured as follows. Section 2 reviews related work in autonomous driving datasets, simulation, and data augmentation. Section 3 details our proposed real–virtual fusion methodology. Section 4 presents the experimental setup, results, and qualitative analysis. Finally, Section 5 concludes the paper and outlines future work.
2. Related Works
This section reviews existing literature on autonomous driving datasets, simulation technologies, data augmentation strategies, and techniques for bridging the reality gap between synthetic and real-world data.
2.1. Autonomous Driving Datasets and Perception
High-quality and diverse datasets are essential for training and validating perception models in autonomous driving. Traditional datasets mainly consist of annotated real-world data, capturing various environmental conditions and traffic scenarios. Several studies have focused on improving object detection using camera and IMU sensors [2,3,4]. For instance, Jung et al. applied Mask R-CNN for instance segmentation to enhance detection performance [3]. Furthermore, multi-sensor fusion, such as combining LiDAR and camera data, has proven effective for robust 3D object detection, particularly in complex traffic environments [5,31]. In the field of 3D reconstruction, sensor fusion techniques like ToF-stereo fusion have been explored to generate detailed environmental maps [32].
2.2. Autonomous Driving Simulation and Digital Twins
Real-world data collection is costly, time-consuming, and often hazardous. Consequently, autonomous driving simulation has become a critical tool for development and testing [13,14,21]. Modern simulators provide customized environments and can generate diverse scenarios, including corner cases that are difficult to encounter in reality. Digital Twin technology, which creates virtual replicas of physical systems, plays a key role in these simulations [1,19,20]. These frameworks enable high-fidelity simulations and proactive safety validation [1,18]. Accurately modeling virtual sensors to mimic real-world outputs is crucial for testing perception algorithms’ reliability [19]. Additionally, Mixed Reality (MR) integrates virtual elements into real-world driving, allowing specific scenarios to be tested with real vehicles [12,25,26]. However, these approaches primarily focus on the system architecture for Hardware-in-the-Loop (HIL) or Vehicle-in-the-Loop (VIL) verification to test algorithms in real time. This evolution of simulation platforms aims to create more realistic and comprehensive virtual testing environments [15,21].
2.3. Data Augmentation and Reality Gap Mitigation
While synthetic data offers significant advantages, the reality gap between synthetic and real data remains a primary challenge. This gap often leads to poor generalization of models trained on synthetic data when applied to the real world [10]. Various strategies have been proposed to address this issue:
- Domain Adaptation: Techniques such as unsupervised domain adaptation reduce the discrepancy between source (synthetic) and target (real) domains. This enables models to perform well on real data without requiring extensive real-world annotations [10].
- Generative Models: Recent advances in generative AI, such as Neural Radiance Fields (NeRF), offer promising methods for generating high-fidelity synthetic data [23,24]. Generative AI-based simulations are also emerging to create immersive mixed-reality environments for vehicle testing [22].
- Rendering-Based Augmentation: Injecting synthetic objects into real-world scenes is a powerful data augmentation strategy. For example, LiDAR-Aug [33] composites virtual objects into real LiDAR scans for 3D detection. While effective for geometric data, this approach does not address the photometric inconsistencies inherent in camera sensors. Similar principles apply to camera data, but maintaining visual consistency is critical. Simple cut-and-paste methods often introduce artifacts due to mismatched lighting, shadows, or occlusions. Color transfer techniques, such as those by Reinhard et al. [29], provide a baseline for matching visual properties between different images. However, robust augmentation requires addressing both geometric and photometric inconsistencies to achieve seamless real–virtual fusion.
Building upon these works, our research focuses on a robust real–virtual fusion framework. Unlike prior works that often rely on simple overlays or geometric-only fusion, we aim to generate augmented datasets with high visual realism by minimizing the domain gap through our automated inconsistency mitigation pipeline. This effectively enhances the performance of autonomous driving perception models.
3. Proposed Methodology
This section details our proposed real–virtual fusion framework for generating highly realistic augmented image datasets. We aim to overcome the limitations of purely synthetic or real-world data by leveraging the authenticity of real backgrounds and the flexibility of virtual object generation. An overview of the entire pipeline is illustrated in Figure 1.
3.1. Real–Virtual Synchronization
Accurate synchronization between the real-world driving environment (K-City) and its digital twin in Morai Sim is fundamental for seamlessly injecting virtual objects. This process ensures that the virtual camera’s pose within the simulator precisely matches the real camera’s pose when the background image was captured. Given that real-time synchronization is not a strict requirement for offline dataset generation, our approach focuses on achieving high precision in pose estimation and alignment.
3.1.1. Initial Alignment via Look-Up Table
The first step involves establishing an initial correspondence between the global coordinate systems of K-City and the Morai Sim digital twin. We capture image and Inertial Measurement Unit (IMU) data using a ZED 2 stereo camera (which includes IMU functionality) in the K-City testbed. The Morai Sim digital twin of K-City is constructed with precise geographical information, including High-Definition (HD) maps. We create a Look-up Table (LUT) that maps specific real-world positions and vehicle orientations from the K-City environment to their corresponding locations and poses within the Morai Sim’s virtual map. This LUT serves as a coarse initial alignment. For a given real image captured at a specific timestamp t, with an associated global position and vehicle orientation, we query the LUT to retrieve the closest corresponding virtual pose in the Morai Sim environment. This provides a robust starting point for subsequent fine-tuning.
3.1.2. Fine-Tuned Localization Using Visual–Inertial Odometry
While the Look-up Table provides a good initial guess, minor discrepancies (e.g., due to GPS drift, map inaccuracies, or slight misalignments in digital twin construction) can exist. To achieve highly accurate camera pose synchronization, we employ a fine-tuned localization algorithm based on Simultaneous Localization and Mapping (SLAM) principles. From the real camera images, we extract visual features (ORB features) and track them across consecutive frames to estimate relative camera motion. Concurrently, the IMU data provides high-frequency angular velocity and linear acceleration measurements. These inputs are fused to obtain Visual–Inertial Odometry (VIO) based on the algorithm proposed in our previous work [34]. The system is implemented in-house using C++ and the OpenCV 4.10.0 library. By combining the strengths of visual odometry and inertial odometry, we estimate the precise relative pose changes of the real vehicle. These relative pose changes are then used to refine the initial pose obtained from the Look-up Table. Specifically, for each real camera image sequence, we perform a local optimization of the camera trajectory, ensuring consistency between the visual features and IMU measurements. This process effectively corrects for short-term drifts and significantly improves the local accuracy of the real camera’s pose. The refined real camera pose is then used to set the virtual camera’s pose within Morai Sim, aiming for .
The cumulative refined real camera pose at timestamp can be expressed as a composition of the initial pose and the subsequent relative transformations:
where is the initial pose obtained from the Look-up Table at the starting timestamp , represents the estimated relative pose transformation between consecutive timestamps and , and ∘ denotes the composition operation of rigid body transformations.
3.1.3. Drift Correction and Global Consistency
Long-term VIO or SLAM-based systems are prone to cumulative drift. To prevent this, our approach incorporates periodic drift correction to maintain global consistency. At regular intervals, the locally refined VIO poses are re-referenced against the LUT’s global initial alignments. This acts as a loop closure mechanism, effectively re-anchoring the local trajectory to a globally consistent frame and distributing any accumulated drift across the trajectory segment. This ensures that the virtual camera’s trajectory remains globally consistent with the real vehicle’s path, even over extended periods of data acquisition, minimizing discrepancies for subsequent virtual object injection. Figure 2 illustrates the overall flowchart of this real–virtual synchronization framework.
3.2. Virtual Object Injection and Augmented Image Generation
With accurate real–virtual synchronization, the next step is to realistically inject virtual objects into the real background images. This stage focuses on minimizing visual and geometric inconsistencies, a key challenge in mixed-reality data generation.
3.2.1. Virtual Object Placement and Scene Composition
Once the real camera’s pose is precisely transferred to the virtual camera in Morai Sim, virtual objects from our library (e.g., vehicles, pedestrians, traffic signs) are dynamically placed into the virtual scene. In this study, we intentionally utilized real background frames captured in K-City that are relatively free of dynamic foreground objects. This design choice provides a blank canvas, allowing for the unrestricted placement of virtual agents without the immediate need for complex occlusion handling between real and virtual dynamic objects. Leveraging this flexibility, virtual objects are strategically positioned to create diverse and challenging scenarios, including rare events and dangerous interactions, effectively enabling the infinite generation of training data. The Morai Sim environment, as a digital twin of K-City, ensures that this virtual object placement respects the underlying road network and physical constraints.
3.2.2. Illumination Estimation and Color Transfer
A major source of visual inconsistency is mismatched lighting between real backgrounds and virtual objects. To address this, we perform illumination estimation from the real background image . Simplified statistical models are employed to approximate the real-world lighting environment. The estimated illumination parameters are then used to adjust the virtual image rendered by Morai Sim. The final augmented image is generated by compositing the realistically rendered virtual objects onto the real background image. Since the chosen real backgrounds are free of foreground objects, the compositing process involves directly superimposing the virtual object pixels. Morai Sim provides a precise segmentation mask ( ) for each rendered virtual object. The augmented image is formed by replacing the corresponding pixels in the real background with the rendered virtual object pixels according to . It is important to note that corresponds strictly to the object’s geometry, excluding cast shadows. While shadows contribute to visual realism, including them in the mask implies that the generated bounding boxes would essentially encompass the shadows, leading to inaccurate ground truth labels for detection tasks. Therefore, we prioritized label precision by limiting the compositing region to the object itself. As a final harmonization step, we apply a color transfer technique [29] between the source (rendered virtual object region ) and target (corresponding real background region ) within the object’s mask. The compositing process for each pixel coordinate p can be formally defined as:
where is the real background image, is the rendered virtual object image after color transfer, and is a binary mask value which is 1 if pixel p belongs to the object geometry, and 0 otherwise.
3.3. Automated Ground Truth Labeling
A significant advantage of generating data from a virtual environment is the automated provision of precise, rich ground truth labels. For each injected virtual object, Morai Sim automatically generates a comprehensive set of labels, including 2D bounding box coordinates, instance segmentation masks, and class labels. These rich, accurate, and consistent labels are immediately available for training and evaluating perception models, eliminating the time-consuming and error-prone manual annotation process required for real-world data.
4. Experiments
To validate the effectiveness and realism of our proposed real–virtual fusion framework, we conducted a series of comprehensive experiments. This section details the experimental setup, the datasets generated, the evaluation metrics, and the results obtained from our experiments.
4.1. Experimental Setup
4.1.1. Datasets
Our experiments are based on a combination of real-world data, a digital twin simulator, and the augmented datasets generated by our framework.
Real-World Data (K-City): We collected several hours of driving data from the K-City testbed in Hwaseong, South Korea. This data includes high-resolution camera images (1920 × 1080, 30 fps) and time-synchronized IMU measurements, which are crucial for our real-virtual synchronization process described in Section 3.1.Virtual Environment (Morai Sim): A high-fidelity digital twin of the K-City environment was utilized, built within the Morai Sim simulator. This virtual environment provides virtual sensor data corresponding to real-world coordinates.Generated Datasets: We generated two distinct datasets for our experiments, both based on the 7 target classes (Person, Bicycle, Car, Motorcycle, Bus, Truck, and Traffic Light).
- : A large-scale training dataset of 4229 augmented images. This set was created by injecting the 7 classes of virtual objects into the real K-City backgrounds, with approximately 500 images per class, covering various challenging scenarios (e.g., varying distances, angles, and potential near-collision trajectories). This dataset was generated in two versions: one with our full pipeline including color transfer, and one without, for ablation studies.
- : A test dataset of 553 augmented images (approx. 80 images per class). This set was created for Experiment 1. Real-World Test Set ( ): We utilize the official BDD100k [30] object detection validation split for Experiment 2. This large-scale dataset, comprising 10,000 images, provides diverse, real-world driving scenarios and includes annotations for all 7 of our target classes, enabling a robust evaluation of real-world generalization performance.
4.1.2. Implementation Details
We employ YOLOv7 [6] as our primary baseline model due to its established performance in real-time autonomous driving scenarios and its representative anchor-based architecture. To further validate the generalization capability of our augmented data across different detector types, we also conduct experiments using YOLOv8 (a representative anchor-free model) and the recently released YOLOv11. All models were initialized with weights pre-trained on the MS COCO dataset. This model (YOLOv7_base) serves as our baseline for both Experiments 1 and 2. We fine-tuned the YOLOv7_base model on our dataset for 100 epochs with an initial learning rate of 0.001 and a batch size of 16. We utilized the Stochastic Gradient Descent (SGD) optimizer with a momentum of 0.937 and a weight decay of 0.0005. Additionally, a linear warm-up strategy was employed for the first 3 epochs to ensure stable convergence. We trained two variants to assess the impact of our inconsistency mitigation pipeline: YOLOv7_aug (fine-tuned on augmented data without color transfer) and YOLOv7_ours (fine-tuned on augmented data with color transfer [29], using the proposed method). All training and testing were conducted on a workstation equipped with an NVIDIA GeForce RTX 3090Ti GPU and 128 GB of RAM.
4.1.3. Evaluation Metrics
To provide a comprehensive evaluation, we adopt the standard metrics used in object detection.
Precision (P): The accuracy of positive predictions. It is defined as:
where is True Positives and is False Positives.Recall (R): The ability of the model to find all relevant ground truths. It is defined as:
where is False Negatives.F1-Score: The harmonic mean of Precision and Recall, providing a single score that balances both metrics.
[email protected]: The mean Average Precision (mAP) calculated at a fixed Intersection over Union (IoU) threshold of 0.5. AP for a single class is the area under the Precision-Recall curve:
mAP is the average of AP scores across all C classes (in our case, ).
4.2. Experiments and Results
We conducted two main experiments to thoroughly evaluate our proposed real-virtual fusion framework.
4.2.1. Experiment 1: Perceptual Realism Test
This experiment aims to quantitatively assess the perceptual fidelity of our generated augmented data. The hypothesis is that if our synthetic objects are perceptually realistic, an off-the-shelf object detection model (YOLOv7_base) that has never seen our synthetic data should still be able to detect them with high accuracy. This provides a strong quantitative indicator of how real our augmented objects appear to a model trained exclusively on real data. We evaluated the performance of the YOLOv7_base model on our dataset, which contains the 7 target object classes injected into real K-City backgrounds. Table 1 shows the detection results for each class.
The high [email protected] scores across all classes indicate that the YOLOv7_base model successfully recognized the injected virtual objects despite having no prior exposure to our synthetic data. Considering that the standard YOLOv7 achieves approximately 69.7% [email protected] on the MS COCO validation set [6], our result of 80.7% suggests a remarkably high level of realism in our augmented data. This provides strong evidence that our framework effectively bridges the reality gap of virtual object injection.
To further validate the perceptual realism without architectural bias, we additionally employed the YOLOE detector in a prompt-free zero-shot mode. Unlike YOLOv7, this model was used to infer the augmented images without any prior knowledge of our specific dataset. As presented in Table 2, the model successfully detected a significant number of injected objects.
Notably, classes with complex textures such as Person, Bus, and Truck achieved high average confidence scores (above 0.83), indicating effective texture harmonization. While statistical metrics like FID or KID could provide complementary insights regarding distribution distances, these task-based evaluation results strongly confirm that our proposed pipeline generates synthetic data with sufficient objectness and realism to be utilized by state-of-the-art detectors.
4.2.2. Experiment 2: Performance Improvement Test
This experiment evaluates the effectiveness of training object detection models with our augmented data to improve performance on a real-world dataset. We fine-tuned the baseline models on our dataset and evaluated them on the BDD100k validation split ( ).
To demonstrate the universality of our approach, we extended the evaluation beyond YOLOv7 to include YOLOv8 and YOLOv11. For each architecture, we compared the pre-trained baseline (Base) against the model fine-tuned on our augmented dataset (Ours). The comparative results across all architectures are presented in Table 3.
The results in Table 3 demonstrate that training with our augmented data significantly improves object detection performance on the real-world BDD100k dataset. The YOLOv7_ours model achieved an overall [email protected] of 56.4%, outperforming the baseline YOLOv7_base (45.7%) by 10.7%.
Furthermore, we conducted an ablation study to isolate the contribution of our inconsistency mitigation technique. Table 4 compares the performance of YOLOv7_aug (trained on data without color transfer) and YOLOv7_ours (trained on data with color transfer).
The results reveal the critical role of our color transfer technique. YOLOv7_ours consistently achieved higher mAP scores across all classes compared to YOLOv7_aug, with an overall improvement of +5.9%. This indicates that simply overlaying virtual objects is insufficient; harmonizing the visual properties (e.g., color tone, brightness) between virtual objects and real backgrounds is essential for maximizing the realism and utility of synthetic training data.
4.3. Qualitative Analysis
In addition to quantitative metrics, we provide a qualitative analysis to visually demonstrate the quality of our augmented data and the improved detection performance. Figure 3 illustrates examples of our generated augmented images, showcasing the seamless integration of virtual objects into diverse real backgrounds. Figure 4 presents detection results on challenging BDD100k images, comparing the baseline model with our YOLOv7_ours model. These examples highlight instances where the baseline model failed to detect or misclassified objects that our augmented-data-trained model successfully identified.
5. Conclusions
This paper proposed a real–virtual fusion framework to generate realistic augmented datasets for autonomous driving. Our approach effectively addresses the data scarcity problem by injecting virtual objects into real-world backgrounds. Experimental results validated the effectiveness of the proposed method. First, the perceptual realism assessment showed an 80.7% [email protected] on the augmented test set, confirming high visual fidelity. Second, fine-tuning the YOLOv7 model with our augmented dataset improved performance on the real-world BDD100k dataset by 10.7% mAP compared to the baseline. Notably, we observed significant performance gains in data-scarce classes such as ‘Motorcycle’ (+15.2%) and ‘Bicycle’ (+13.2%). The ablation study further confirmed that color transfer is a critical component for reducing the domain gap between real and virtual data.
The generation process currently relies on fixed real-world backgrounds, which limits the ability to simulate varying weather or lighting conditions without additional generative models. Consequently, we observed that while the relative performance gains were substantial, the absolute detection accuracy for classes heavily dependent on specific lighting conditions (e.g., traffic lights) remained lower than that of daytime-dominant classes. This suggests that while our pipeline is effective, increasing background diversity is essential for achieving broader generalization across all environmental conditions.
Scalability to an even larger diversity of virtual objects and complex dynamic scenarios remains an area for further exploration. Moreover, while our framework significantly improves detection, its impact on other perception tasks (e.g., segmentation, manufacturing sites) could be investigated. Furthermore, this study focused on the overall pipeline of injecting virtual objects into synchronized real-world coordinates. The specific impact of synchronization accuracy on training efficiency, and a comparative analysis between context-aware placement (via digital twin) and random placement strategies, remain open questions. Future work will explore these geometric aspects, along with adaptive color transfer methods and the integration of Generative Adversarial Networks (GANs) to further refine realism. Specifically, generating more diverse and challenging occlusion scenarios in synthetic environments—such as heavy traffic where objects are partially hidden—and developing robust methods to handle them is a critical issue for future research to further close the reality gap.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1Yu B. Yuan C. Wan Z. Tang J. Kurdahi F. Liu S. ADDT—A Digital Twin Framework for Proactive Safety Validation in Autonomous Driving Systemsar Xiv 20252504.09461
- 2Jung S. Cho Y. Kim D. Chang M. Moving object detection from moving camera image sequences using an inertial measurement unit sensor Appl. Sci.20191026810.3390/app 10010268 · doi ↗
- 3Jung S. Cho Y. Lee K. Chang M. Moving object detection with single moving camera and IMU sensor using mask R-CNN instance image segmentation Int. J. Precis. Eng. Manuf.2021221049105910.1007/s 12541-021-00527-9 · doi ↗
- 4Jung S. Park S. Lee K. Pose Tracking of Moving Sensor using Monocular Camera and IMU Sensor KSII Trans. Internet Inf. Syst.2021153011330210.3837/tiis.2021.08.017 · doi ↗
- 5Wang Z. Huang X. Hu Z. Attention-Based Li DAR–Camera Fusion for 3D Object Detection in Autonomous Driving World Electr. Veh. J.20251630610.3390/wevj 16060306 · doi ↗
- 6Wang C.Y. Bochkovskiy A. Liao H.Y.M. YOL Ov 7: Trainable bag-of-freebies sets new state-of-the-art for real-time object detectorsar Xiv 20222207.02696
- 7Jocher G. Chaurasia A. Qiu J. Ultralytics YOL Ov 8, 2023 Available online: https://docs.ultralytics.com/models/yolov 8/(accessed on 23 December 2025)
- 8Jocher G. Qiu J. Ultralytics YOLO 11, 2024 Available online: https://docs.ultralytics.com/models/yolo 11/(accessed on 23 December 2025)